Материалы по тегу: nvidia
|
23.10.2025 [00:40], Владимир Мироненко
Умение Альтмана играть на самолюбии руководителей позволило OpenAI заключить сделки на сотни миллиардов долларовГлава OpenAI Сэм Альтман (Sam Altman) оказался умелым стратегом. Чтобы обеспечить компанию чуть ли не бесконечными вычислительными мощностями, он организовал целую серию сделок на сотни миллиардов долларов, натравив друг на друга гигантов Кремниевой долины. Альтман сыграл на их самолюбии и желании нажиться на будущем росте OpenAI. Все они теперь делают ставку на успех стартапа, который пока невероятно далёк от прибыльности, пишет The Wall Street Journal. Но выйти из игры они уже не могут — OpenAI должна выжить любой ценой. А NVIDIA даже готова расплатиться по долгам OpenAI, если что-то пойдёт не так. За последние два месяца цены на акции Oracle, NVIDIA, AMD и Broadcom резко взлетали вверх после объявления о сделках, связанных с OpenAI. В общей сложности их рыночная стоимость выросла на $630 млрд в первый день торгов после этих объявлений. Каждый раз за этим следовал более масштабный рост акций технологических компаний, способствуя росту фондового рынка США до рекордных высот. «Самые успешные люди, которых я знаю, верят в себя почти до самообмана», — написал в 2019 году Альтман в блоге «Как достичь успеха», а затем добавил: «Одной веры в себя недостаточно — нужно ещё и уметь убеждать других в своей вере». В этом году OpenAI планирует получить выручку в размере $13 млрд, что несопоставимо со счетами на $650 млрд, которые компания получит только в рамках сделок с NVIDIA и Oracle, согласно подсчётам The Wall Street Journal. С учётом соглашений с AMD, Broadcom и другими провайдерами облачных услуг, такими как Microsoft, общая сумма затрат приближается к $1 трлн. Обязательства на такие объёмы поставок чипов и километровых ЦОД до того, как OpenAI сможет себе это позволить, вызывают опасения, что энтузиазм в отношении ИИ превращается в пузырь, зависящий от успеха всего одной компании. Некоторые партнёры даже помогают OpenAI оплачивать свои чипы, заключая циклические сделки. 
Источник изображения: Rain Bennett / Unsplash В прошлом году Альтман спросил гендиректора Microsoft Сатью Наделлу (Satya Nadella), готова ли его компания инвестировать не менее $100 млрд в создание новых ЦОД OpenAI в рамках будущего проекта Stargate. Тот ответил отказом. Такой же ответ он получил от TSMC. Последней он представил проект стоимостью $7 трлн по строительству новых заводов по производству микросхем по всему миру. Ситуация изменилась, когда Альтману удалось заручиться поддержкой гендиректора SoftBank Масаёси Сона (Masayoshi Son). Сон согласился возглавить проект стоимостью $500 млрд. После объявления Белого дома США о поддержке проекта Stargate, акции SoftBank подскочили на 11 %, как и акции других технологических партнёров, участвующих в проекте. Практически сразу NVIDIA предложила OpenAI организовать похожий проект и помочь с его финансированием, но без участия SoftBank. В последующие после анонса недели и месяцы OpenAI получила сотни предложений о потенциальных площадках для строительства, что подготовило почву для её следующих шагов. В свою очередь Microsoft расторгла договоры аренды некоторых ЦОД в США, ссылаясь на отказ от поддержки нагрузок OpenAI. Вместе с тем она, являясь на тот момент главным инвестором OpenAI, разрешила ей найти дополнительные вычислительные мощности у других поставщиков и сосредоточила усилия на привлечении клиентов. После этого OpenAI заключила контракт с Oracle на $300 млрд, что привело к рекордному за четверть века росту акций последней. Внутри Microsoft сделку раскритиковали — не было уверенности, что Oracle справится, поскольку строительство гигантских ЦОД обязывает OpenAI выплачивать в среднем $60 млрд/год, что более чем вчетверо превышает её текущую выручку. 
Источник изображения: Ross Sneddon / Unsplash Между тем переговоры OpenAI и NVIDIA по их собственному проекту создания ИИ-инфраструктуры зашли в тупик. Всё изменилось в июне, когда стало известно о сделке между Google и OpenAI. А после появления сообщения о том, что OpenAI начала арендовать ускорители TPU у Google для поддержки ChatGPT, гендиректор NVIDIA Дженсен Хуанг (Jensen Huang) практически сразу позвонил Альтману, чтобы узнать, правда ли это, и дал понять, что готов возобновить переговоры. В итоге NVIDIA подписала соглашение о предоставлении в аренду OpenAI до 5 млн своих чипов, что по сегодняшним ценам обойдётся в $350 млрд. Также NVIDIA готова инвестировать до $100 млрд, чтобы помочь стартапу оплатить сделку. Более того, в рамках сделки NVIDIA также обсуждает предоставление гарантий по некоторым кредитам, которые OpenAI планирует взять на строительство собственных ЦОД, сообщили источники WSJ. Этим шагом NVIDIA может возложить на себя миллиардные долговые обязательства, если стартап не сможет вовремя погасить кредиты. Несмотря на заключённые с NVIDIA и другими компаниями контракты, OpenAI продолжала расширять свою вычислительную базу. Всего через несколько недель компания подписала с AMD контракт на 6 ГВт, в рамках которого может также получить до 10 % её акций. После объявления 6 октября о сделке с OpenAI акции AMD выросли на рекордные 24 %. Неделю спустя OpenAI официально представила проект по разработке ИИ-чипа совместно с Broadcom, над которым они работали с начала 2024 года. После объявления о сделке OpenAI с NVIDIA переговоры о заключении крупного соглашения ускорились. Сделка с Broadcom сопоставима по масштабу со сделкой с NVIDIA — до 10 ГВт вычислительной мощности для OpenAI к 2029 году.
22.10.2025 [17:09], Владимир Мироненко
AWS пожертвовала компактностью GB300 NVL72, лишь бы снизить зависимость от NVIDIAAmazon Web Services (AWS) нашла выход, как использовать собственные Nitro DPU K2v5/6 (EFA) в новейших стоечных системах NVIDIA GB300 NVL72, которые, как считает гиперскейлер, превосходит адаптеры NVIDIA ConnectX-7/8 по производительности. В связи с тем, что в стойках NVIDIA Oberon используются укороченные лотки высотой 1U, AWS размещает NIC в отдельной стойке JBOK, предназначенной только для сетевых карт, пишет SemiAnalysis. Причина кроется в невозможности установить в 1U сразу девять фирменных адаптеров (8 × EFA + 1 × ENA/EBS). Для серверных систем GB200 NVL предыдущего поколения AWS выбрала вариант NVL36×2, поскольку только в этом случае использовались 2U-узлы, где достаточно места для всех NIC. Однако сдвоенная конфигурация менее эффективна, чем нативная конструкция NVL72. NVIDIA сама была не очень довольна вариантами NVL36. Meta✴, например, и вовсе «растянула» NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждением. 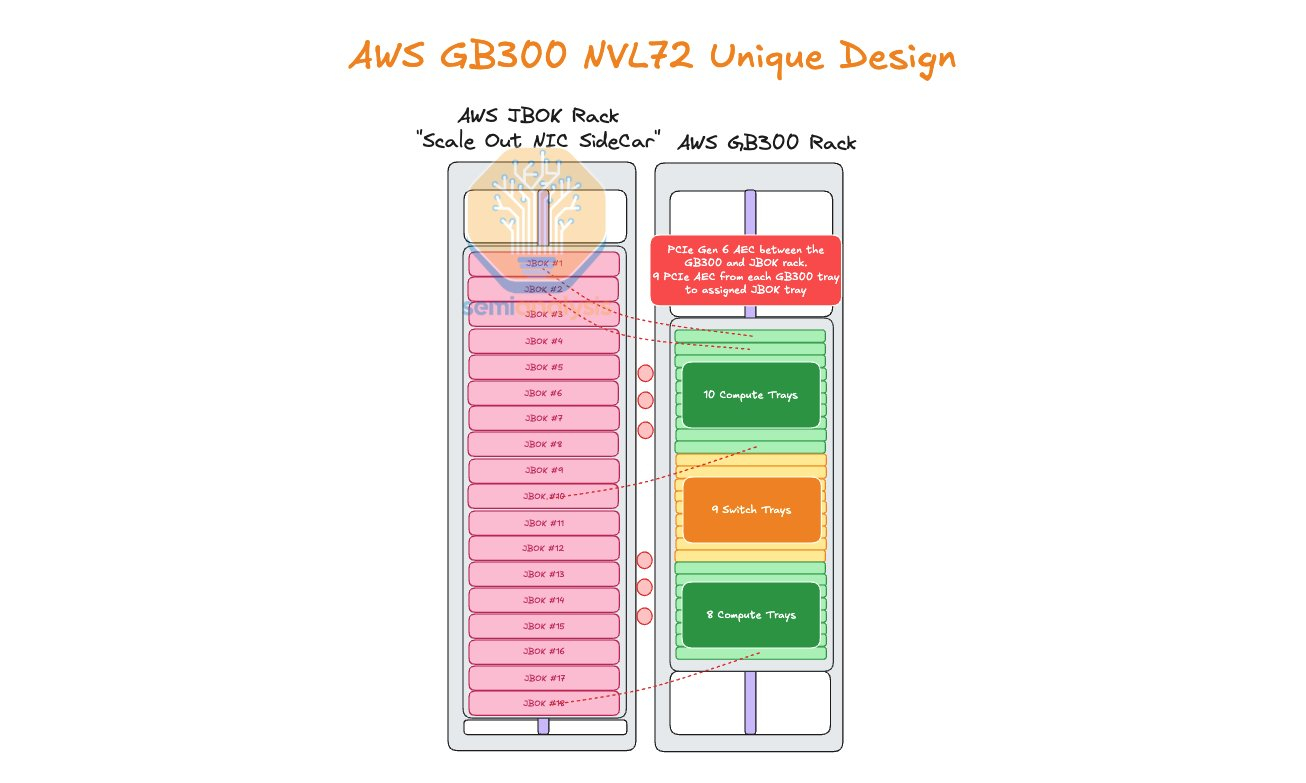
Источник изображения: SemiAnalysis AWS в случае Blackwell Ultra предпочла остановиться на NVL72-варианте, а DPU вынести в отдельную стойку — всего 18 узлов высотой 2U, по 9 NIC в каждом. С узлами NVIDIA они соединены активными электрическими кабелями (AEC) и портами OSFP-XD для передачи сигналов PCIe 6.0. По словам AWS, её адаптеры лучше справляются с нагрузками, чем ConnectX-8 (RoCEv2), что отчасти спорно. В любом случае таким образом компания снижается зависимость от NVIDIA. 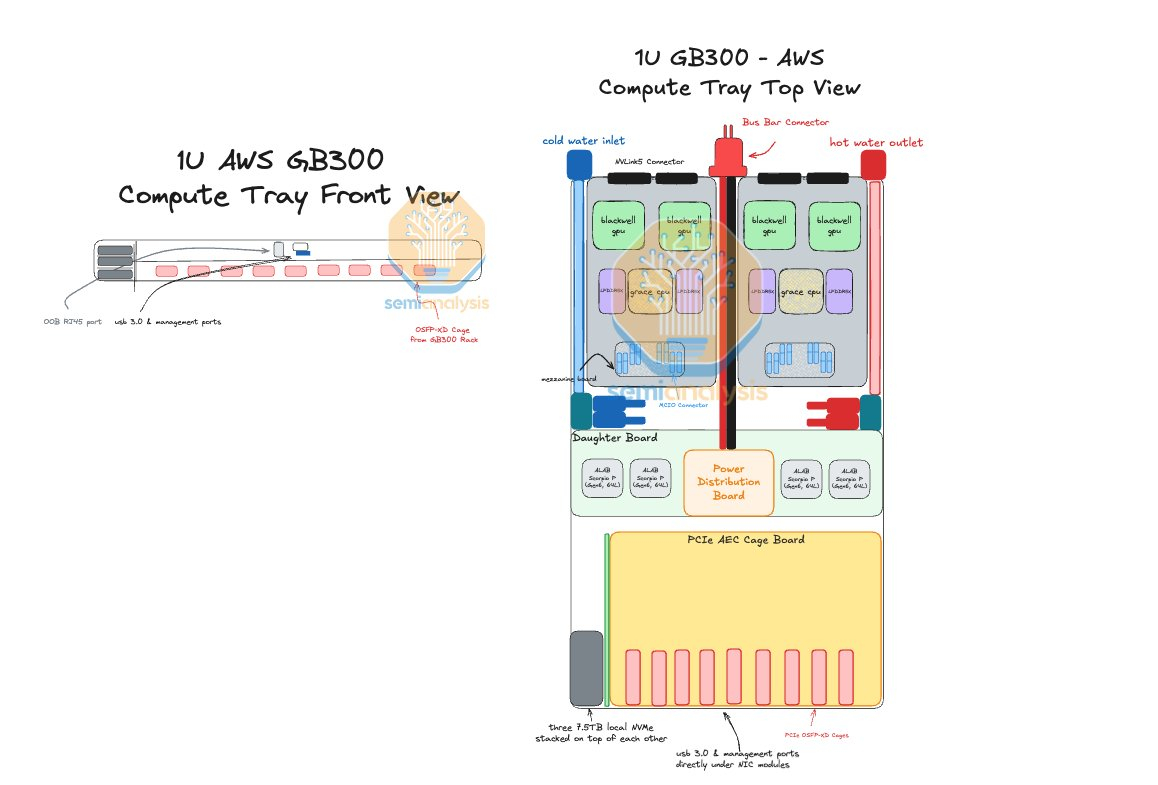
Источник изображения: SemiAnalysis С точки зрения SemiAnalysis, доработка GB300 в AWS помогает устранить единую точку отказа в референсной архитектуре NVIDIA, где каждый ускоритель взаимодействует только с одним сетевым адаптером ConnectX-8, тогда как в конфигурации AWS каждый ускоритель общается с двумя NIC. У AWS накоплен богатый опыт разработки собственного оборудования для ЦОД. Ранее компания в партнёрстве с Broadcom разрабатывала специализированные сетевые коммутаторы. Также недавно представленные ею EC2-инстансы P6-B200 и P6e-GB200 оснащены собственным сетевым стеком Elastic Fabric Adapter (EFAv4) на базе собственных контроллеров Nitro, который оптимизирует обработку сетевых пакетов и снижает задержки для высокопроизводительных приложений.
21.10.2025 [21:50], Владимир Мироненко
Nebius запустила первый в Израиле ИИ ЦОД с NVIDIA HGX B200Компания Nebius объявила о доступности платформы Nebius AI Cloud в своем новом ЦОД в Израиле, запущенном на площадке в Модиине (Modiin). Сообщается, что это один из крупнейших в стране ИИ-кластеров и первый на архитектуре NVIDIA Blackwell. Кластер включает 4 тыс. ускорителей в составе HGX B200, объединённых интерконнектом NVIDIA Quantum InfiniBand, и предоставляет доступ к стеку NVIDIA AI Enterprise, в том числе к микросервисам NVIDIA NIM и инструментам управления ИИ-агентами NeMo. Запуск в Израиле последовал за аналогичными развёртываниями Nebius в Европе и США. Новая площадка объединяет передовую аппаратную и программную инфраструктуру, включая усовершенствованные системы охлаждения, системы управления энергопотреблением и механизмы управления данными, разработанные для интенсивных рабочих ИИ-нагрузок. Nebius — партнёр NVIDIA по облачным технологиям (NCP). «Запуск Nebius крупнейшего в Израиле облака ИИ на базе Blackwell знаменует собой начало развития инфраструктуры ИИ в стране», — сообщил директор представительства NVIDIA в Израиле, отметив, что благодаря суверенному доступу к передовым вычислительным, сетевым технологиям и ПО, израильские компании и разработчики смогут внедрять инновации, развёртывать и масштабировать следующее поколение агентного и физического ИИ. 
Источник изображения: Nebius Nebius входит в число первых партнёров NCP, получивших сертификат Exemplar Cloud для учебных рабочих нагрузок на базе NVIDIA H100, продемонстрировав производительность в пределах 95 % от референсной архитектуры NVIDIA. Платформа Nebius AI Cloud получила сертификацию SOC2 Type II, включая HIPAA, и обеспечивает сквозное шифрование, а также полное соответствие стандартам защиты данных GDPR и CCPA.
20.10.2025 [16:00], Сергей Карасёв
Экономичный гибрид: Intel объединила ускорители Gaudi 3 и NVIDIA B200 в одной ИИ-платформеКорпорация Intel показала гибридную стоечную систему Устройство объединяет посредством Ethernet массивы ускорителей Gaudi3 и NVIDIA B200. Платформа Gaudi3 Rack Scale 64 содержит до 16 вычислительных узлов. Каждый из них оснащён двумя неназванными процессорами Intel Xeon, четырьмя OAM-ускорителями Intel Gaudi 3 (64 в одном домене), четырьмя 400GbE-адаптерами NVIDIA ConnectX-7 и одним DPU NVIDIA BlueField-3, отмечает SemiAnalysis. Суммарно доступно 8,2 Тбайт HBM2e, а агрегированная пропускная способность составляет 76,8 Тбайт/с. Мощность суперускорителя составляет 120 кВт. Кроме того, задействованы 12 коммутаторов на чипах Broadcom Tomahawk 5 (51,2 Тбит/с). Для масштабирования и связи с другими узлами, в том числе NVIDIA, используется именно Ethernet. В составе гибридной системы ускорители Intel Gaudi 3 используются на decode-стадии, т.е. для генерации токенов, где важен объём и пропускная способность памяти, тогда как чипы NVIDIA B200 отвечают за prefill-задачи инференса, т.е. за обработку контекста и заполнение KVCache, где важна скорость вычислений. NVIDIA сама стремится к этому же подходу и уже анонсировала соускорители Rubin CPX, которые как раз будут заниматься работой с контекстом в сверхбольших моделях и созданием KV-кеша. 
Источник изображений: Intel Intel утверждает, что гибридная конфигурация из Gaudi3 и B200 позволяет достичь 1,7-кратного прироста производительности в расчёте на доллар совокупной стоимости владения (TCO) по сравнению с платформами, использующими только B200. Однако, как отмечается, эти заявления пока не подтверждены независимыми тестами. К тому же, программная платформа Gaudi3 отстаёт от платформы NVIDIA и является закрытой. Кроме того, нынешняя архитектура Gaudi приближается к концу своего существования, что ставит под сомнение жизнеспособность предложенной платформы в долгосрочной перспективе.  Для Intel это, возможно, один из немногих шансов продать остатки Gaudi3. Между тем Intel недавно анонсировала GPU-ускоритель Crescent Island, разработанный специально для ИИ-инференса. Решение, в основу которого положена архитектура Xe3P, получит 160 Гбайт памяти LPDDR5X. Массовые поставки будет организованы не ранее 2027 года. Ранее компания отказалась от планов по выпуску Falcon Shores, сосредоточившись на Jaguar Shores. Сейчас же компания начала сворачивать поддержку ускорителей Ponte Vecchio (Intel Max) и Arctic Sound (Flex).
20.10.2025 [09:11], Сергей Карасёв
Pegatron представила ИИ-систему RA4802-72N2 на базе NVIDIA GB300 NVL72Компания Pegatron представила систему RA4802-72N2, предназначенную для наиболее ресурсоёмких ИИ-нагрузок, включая обучение больших языковых моделей (LLM) в масштабе и инференс. В основу положена платформа NVIDIA GB300 NVL72. Изделие GB300 содержит Arm-процессор Grace с 72 ядрами Neoverse V2 (Demeter) и два чипа Blackwell Ultra. В составе RA4802-72N2 объединены 18 вычислительных лотков, каждый из которых несёт на борту два Grace и четыре Blackwell Ultra. В сумме это даёт 36 процессоров Grace и 72 чипа Blackwell Ultra. Каждый из вычислительных узлов располагает 960 Гбайт памяти LPDDR5X и 1152 Гбайт памяти HBM3e. Таким образом, в общей сложности система оперирует примерно 17 Тбайт LPDDR5X и 20 Тбайт HBM3e. ИИ-производительность достигает 720 Пфлопс на операциях FP8/FP6. 
Источник изображения: Pegatron В состав RA4802-72N2 также входят девять коммутационных лотков. Общая пропускная способность интерконнекта NVLink составляет 130 Тбайт/с. В расчёте на вычислительный узел используются два адаптера NVIDIA ConnectX-8 и один DPU NVIDIA BlueField-3. Прочие характеристики включают контроллер Aspeed AST2600, модуль TPM 2.0, восемь отсеков для накопителей E1.S NVMe, коннектор M.2 2280/22110 NVMe. Система выполнена в форм-факторе 48U MGX с габаритами 600 × 2296 × 1200 мм. Применяется полностью жидкостное охлаждение. Полка питания оснащена шестью 1U-модулями мощностью 33 кВт. Поставки машины RA4802-72N2 уже начались.
20.10.2025 [01:23], Владимир Мироненко
Ускорителей хватит на всех — Alibaba Aegaeon оптимизировал обработку ИИ-нагрузок, снизив использование дефицитных NVIDIA H20 на 82 %Alibaba Cloud представила Aegaeon, систему пулинга вычислений, позволяющую сократить количество ускорителей NVIDIA, необходимых для обслуживания ИИ-моделей, на 82 %, пишет ресурс SCMP. По словам разработчиков, благодаря Aegaeon количество ускорителей NVIDIA H20, необходимых для обслуживания десятков моделей с 72 млрд параметров, удалось сократить с 1192 до 213 единиц. «Aegaeon — это первое решение на рынке, которое выявило чрезмерные затраты, связанные с обслуживанием параллельных рабочих нагрузок LLM», — сообщили исследователи из Пекинского университета и Alibaba Cloud. Провайдеры облачных сервисов, такие как Alibaba Cloud и ByteDance Volcano Engine, предоставляют пользователям одновременно тысячи ИИ-моделей — множество вызовов API обрабатывается одновременно. Однако на практике для инференса чаще всего используются лишь несколько моделей, таких как Qwen и DeepSeek, а большинство других моделей применяются лишь эпизодически. Это приводит к неэффективному использованию вычислительных ресурсов: исследователи обнаружили, что 17,7 % ускорителей выделяется на обслуживание лишь 1,35 % запросов в Alibaba Cloud. Aegaeon выполняет «автоматическое масштабирование» на уровне токенов, обеспечивая переключение ускорителей между обслуживанием различных моделей в процессе генерации. В рамках системы один ускоритель поддерживает обработку до семи моделей по сравнению с двумя-тремя моделями в альтернативных системах. При этом задержка, связанная с переключением между моделями, снижена на 97 %, заявили исследователи. Alibaba Cloud сообщила, что решение уже используется на её торговой площадке моделей Bailian. 
Источник изображения: Alibaba Глава NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что из-за экспортных ограничений доля компании на рынке передовых чипов в Китае сократилась с 95 % до нуля. Этому также способствовала стратегия Пекина, направленная на самообеспечение местного рынка. В связи с этим планы NVIDIA возобновить отгрузки ИИ-ускорителей H20, на которые ранее были установлены ограничения правительством США, встретили в Китае довольно прохладно. Более того, в Китае вынесли запрет местным компаниям на покупку разработанного специально для местного рынка ускорителя NVIDIA RTX Pro 6000D, поскольку пришли к выводу, что китайские ИИ-чипы не уступают продукции NVIDIA, разрешённой к экспорту в Китай.
17.10.2025 [17:18], Руслан Авдеев
Poolside и CoreWeave построят в Техасе 2-ГВт кампус ИИ ЦОД, работающий на газе из Пермского бассейнаИИ-стартап Poolside объединился с CoreWeave для строительства кампуса ЦОД Project Horizon мощностью 2 ГВт на площади 230 га на территории ранчо Longfellow в Западном Техасе. Для электроснабжения планируется использовать природный газ, добываемый в местном Пермском бассейне, сообщает Datacenter Dynamics. ЦОД построят с использованием «гибридного модульного подхода», предполагающего «параллельное, а не последовательное строительство», которое будет завершено в I квартале 2027 года. CoreWeave станет ключевым арендатором первой фазы проекта, которая должна обеспечить мощность 250 МВт в соответствии с договором аренды на 15 лет. В будущем допускается увеличение арендуемых мощностей до 500 МВт. Также соглашение компаний предусматривает, что с декабря CoreWeave предоставит Poolside кластер NVIDIA GB300 NVL72 с более чем 40 тыс. чипов. По словам Poolside, партнёрство с CoreWeave обеспечит немедленный доступ к ускорителям новейшего поколения, что позволит обучать модели с триллионами параметров. Poolside основана в 2023 году. Стартап разрабатывает ПО для автоматизации написания программного кода с высокими корректностью и безопасностью, достаточных для того, чтобы его можно было использовать в государственных учреждениях. По данным Bloomberg, в 2024 году компания выпустила ИИ-агента для разработчиков государственного и оборонного секторов. Также ведутся работы и в области создания «общего искусственного интеллекта» (AGI). 
Источник изображения: Bailey Alexander/unsplash.com Пока Poolside проводит раунд привлечения $2 млрд инвестиций, оценка стоимости компании по его итогам должна составить $14 млрд. Большую часть средств направят на приобретение 40 тыс. ускорителей NVIDIA. В 2024 года стартап уже привлёк $500 млн, получив оценку в $3 млрд. Компания является известным клиентом Fluidstack, а также арендовала некоторое количество NVIDIA H100 у Iris Energy. Благодаря большим запасам природного газа и относительно доступной электроэнергии в целом Техас стал весьма привлекательным местом для строителей дата-центров. По информации CBRE, сегодня это второй по величине рынок ЦОД в США. В штате реализуется первый проект в рамках инициативы Stargate, Meta✴ инициировала строительство ЦОД на 1 ГВт в Эль-Пасо, а Fermi America, будучи новичком на рынке дата-центров, заранее договорилась о подключение к газопроводу своего будущего 11-ГВт кампуса в Амарилло (Amarillo).
16.10.2025 [15:53], Руслан Авдеев
NVIDIA поможет Starcloud отправить в космос первый ИИ-спутник с H100Появление массовых космических дата-центров уже не за горами. В скором времени вывести на орбиту ИИ-спутник намерен стартап Starcloud (ранее Lumen Orbit), участвующий в грантовой программе NVIDIA Inception. В Starcloud заявляют, что в космосе доступна практически неограниченная возобновляемая энергия, которая даже с учётом расходов на запуск на порядок дешевле, чем на Земле. При этом постоянное нахождение Солнца в «пределах прямой видимости» позволяет отказаться от мощных резервных источников питания. Затраты ожидаются в основном до вывода в космос, а после предполагается десятикратная «экономия» углеродных выбросов в течение всего жизненного цикла в сравнении с ЦОД на Земле. Охлаждение в космосе тоже практически «бесплатное» и «безлимитное». Запуск спутника запланирован на ноябрь 2025 года. Речь идёт о дебютном использовании ИИ-ускорителей NVIDIA H100 в космосе. 60-килограммовый спутник Starcloud-1 размером с небольшой холодильник должен обеспечить в 100 раз более эффективные вычисления, чем любой предыдущий космический проект аналогичного назначения. 
Источник изображения: Starcloud На начальном этапе космические дата-центры будут применяться для анализа данных наблюдений за земной поверхностью. Обработка данных в режиме реального времени в космосе обеспечивает огромные преимущества в критических ситуациях — при распознавании лесных пожаров, получении сигналов о бедствии и др. Инференс в космосе, т.е. там же, где будут собираться данные, позволяет выдавать результаты практически немедленно, снижая задержки с часов до минут. Методы наблюдения за Землёй включают съёмки камерами в нескольких диапазонах и радарами с синтезированной апертурой (SAR) для создания трёхмерных карт с высоким разрешением. SAR, в частности, генерируют около 10 Гбайт данных в секунду, поэтому обрабатывать информацию на месте намного выгоднее, чем отправлять её на Землю. 
Источник изображения: Starcloud В Starcloud подчёркивают необходимость быть конкурентоспособными на фоне наземных ЦОД, поэтому компания выбрала ИИ-ускорители NVIDIA. Вместе с тем Starcloud — недавний «выпускник» программы Google for Startups Cloud AI Accelerator, поэтому для тестов будет использоваться LLM Gemma. Что касается будущих запусков, в перспективе Starcloud рассчитывает перейти на платформу NVIDIA Blackwell. Ещё осенью 2024 года сообщалось, что Lumen Orbit проектирует на орбите гигантские гигаваттные дата центры. Идея популярна — основатель Amazon Джефф Безос (Jeff Bezos) в начале октября заявлял, что в космосе скоро появится множество ЦОД гигаваттного масштаба.
16.10.2025 [12:12], Руслан Авдеев
Группа инвесторов, включающая NVIDIA, под руководством Macquarie Asset Management купит Aligned Data Centers за $40 млрд — это одна из крупнейших сделок на рынке ЦОДГруппа AI Infrastructure Partnership (AIP), фонд MGX из ОАЭ и Global Infrastructure Partners (GIP) под руководством Macquarie Asset Management намерены приобрести техасского оператора ЦОД Aligned Data Centers за $40 млрд. Сделка заключена в рамках более широкого проекта по развитию ИИ-инфраструктуры, сообщает пресс-служба Macquaire, и станет одной из крупнейших на рынке ЦОД. Ожидается, что сделка будет закрыта в I полугодии 2026 года. AIP включает NVIDIA, BlackRock, Microsoft, xAI, Global Infrastructure Partners (GIP, принадлежит BlackRock) и государственную инвесткомпанию (создана при участии Mubadala и G42) из ОАЭ. AI Infrastructure Partnership была сформирована в 2024 году с целью ускорения инвестиций в ИИ-инфраструктуру нового поколения. По словам BlackRock, благодаря инвестициям в Aligned будет обеспечено создание инфраструктуры, необходимой для будущих ИИ-проектов. Aligned располагает 50 дата-центрами и 5 ГВт доступной мощности. Помимо США Aligned имеет серьёзный бизнес в Латинской Америке — компания приобрела OData, владеющей объектами в Бразилии, Чили, Колумбии и Мексике в мае 2023 года. Также она является инвестором канадского оператора ЦОД QScale SEC. 
Источник изображения: Aligned Data Centers Как сообщает Datacenter Knowledge, в последние месяцы IT-гиганты тратили миллиарды долларов на создание достаточной для удовлетворения спроса инфраструктуры ЦОД на фоне нарастающего интереса бизнеса к ИИ. В UBS утверждают, что мировые инвестиции в искусственный интеллект могут составить в 2025 году $375 млрд, а к 2026 году — $500 млрд. Руководство Aligned Data Centers заявило, что новое партнёрство будет способствовать ускоренному выполнению миссии по созданию инфраструктуры, обеспечивающей будущее цифровой экономики. Компания утверждает, что готова к более активному масштабированию, дальнейшим инновациям и переосмыслению возможностей устойчивой инфраструктуры ЦОД. Руководителем Aligned останется Эндрю Шаап (Andrew Schaap), а компания сохранит штаб-квартиру в Далласе (Техас).
15.10.2025 [15:25], Руслан Авдеев
OpenAI и Oracle развернут 450 тыс. ускорителей NVIDIA в техасском дата-центре StargateПо словам председателя Oracle Ларри Эллисона (Larry Ellison), дата-центр проекта Stargate а Абилине (Abilene, Техас) вместит более 450 тыс. ускорителей на базе NVIDIA GB200, сообщает Datacenter Dynamics. Дата-центр Stargate получит 1,2 ГВт энергии — по словам Эллисона, энергии достаточно, чтобы обеспечить миллион домохозяйств в США. Как заявил миллиардер, «это довольно большой город». Питаться кампус будет как от энергосети штата, так и от газовых турбин. Информация подтверждает данные о том, что OpenAI и Oracle освоят всю ёмкость кампуса, застраиваемого Crusoe. Первые два строения уже функционируют, они введены в эксплуатацию в сентябре 2025 года. Строительство оставшихся шести зданий должны быть завершены к середине 2026 года. В марте 2025 года заявлялось, что площадка получит 64 тыс. ускорителей NVIDIA к концу 2026 года. С тех пор OpenAI подписала не имеющее обязательной силы письмо о намерении арендовать оборудование NVIDIA на 10 ГВт, которая в ответ пообещала инвестировать в OpenAI $100 млрд. 
Источник изображения: OpenAI О росте числа используемых Stargate ускорителей можно было догадаться после анонса Oracle облачного ИИ-суперкомпьютера Zettascale10, который должен заработать во II половине 2026 года. Он объединит до 800 тыс. ускорителей в нескольких близко расположенных ЦОД. В Oracle отмечали, что суперкомпьютер станет основой флагманского суперкластера, создаваемого при участии OpenAI в Абилине в рамках проекта Stargate. |
|