Материалы по тегу: llm
|
29.08.2025 [17:53], Руслан Авдеев
ИИ и IIoT помогли Aramco сократить время простоев на 40 % и снизить расходы на техобслуживание на 30 %Внедрение ИИ позволило нефтегазовой компании Aramco из Саудовской Аравии весьма эффективно оптимизировать бизнес, сообщает VAST Data. Благодаря комбинации алгоритмов машинного обучения с сетями IoT-датчиков в инфраструктуре компании — на буровых установках, трубопроводах предприятиях по нефтепереработке и т.д. — Aramco добилась сокращения времени незапланированных простоев на 40 % и снижении расходов на техническое обслуживание на 30 %. Системы компании позволяют выявлять признаки перегрузки оборудования задолго до того, как произойдёт серьёзный инцидент, своевременно предотвратив поломки и каскад аварий. Важен и экологический аспект. Сжигание попутного и «лишнего» газа всегда было неприятным пятном на репутации отрасли. Теперь ИИ Aramco использует более 18 тыс. датчиков для прогнозирования того, где и когда придётся сжигать газ и можно ли этого избежать. В результате с 2010 года сжигание сократилось более чем наполовину и уже более десяти лет сжигается менее 1 % от общего уровня добычи газа. На одном из крупнейших в мире месторождении Хурайс (Khurais) Aramco развёрнуто 40 тыс. датчиков на 500 нефтяных скважинах, потоки данных интегрируются в системы машинного обучения и роботизированные платформы. Фактически создан «живой» цифровой двойник месторождения с постоянным обновлением данных и возможностью моделирования процессов. 
Источник изображения: Zbynek Burival/unsplash.com Знаковой стала разработка первой в своём роде ИИ-модели Aramco METABRAIN c 7 млрд параметров, созданной из датасета на основе данных, накопленных компанией за 90 лет. В своём роде это всезнающий промышленный консультант. Модель обеспечивает предиктивную аналитику, оптимизирует рабочие процессы и поддерживает принятие тех или иных решений. Фактически речь идёт о банке памяти, объединённом с «рассуждающей» моделью, в том числе обрабатывается историческая информация для получения рекомендаций. Мегапроекты вроде реализуемого в Хурайсе, предусматривают использование не периодической отчётности, а данных от многочисленных сенсоров, поэтому стратегическое планирование поддерживается ИИ METABRAIN. С появлением ИИ роль руководителя проекта меняется от административного контроля к стратегической интерпретации. Контроль всё ещё важен, но теперь он тесно связан с непрерывным использованием ИИ-технологий, говорит компания. ИИ может порекомендовать перераспределить ресурсы или сообщить о вероятном сбое, но общение с другими людьми всё равно остаётся прерогативой человека. Aramco активно участвует в ИИ-проектах в Саудовской Аравии. Так, в сентябре 2024 года Aramco Digital объявила о партнёрстве с Cerebras, Groq и Qualcomm для развития ИИ и 5G IoT в стране. В феврале 2025 года Groq и Aramco Digital объявили об открытии крупнейшего в EMEA вычислительного ИИ-центра для инференса.
22.08.2025 [17:23], Руслан Авдеев
Google: медианный промпт Gemini потребляет 0,24 Вт·ч энергии и 0,26 мл водыКомпания Google опубликовала документ, в котором описывается методология измерения потребления энергии и воды, а также выбросов и воздействия на окружающую среду ИИ Gemini. Как утверждают в Google, «медианное» потребление энергии на одно текстовое сообщение в Gemini Apps составляет 0,24 Вт·ч, выбросы составляют 0,03 г эквивалента углекислого газа (CO2e), а воды расходуется 0,26 мл. В компании подчёркивают, что показатели намного ниже в сравнении со многими публичными оценками, а на каждый запрос тратится электричества столько же, сколько при просмотре телевизора в течение девяти секунд. Google на основе данных о сокращении выбросов в ЦОД и декарбонизации энергопоставок полагает, что за последние 12 месяцев энергопотребление и общий углеродный след сократились в 33 и 44 раза соответственно. В компании надеются, что исследование внесёт вклад в усилия по разработке эффективного ИИ для общего блага. Методологии расчёта энергопотребления учитывает энергию, потребляемую активными ИИ-ускорителями (TPU), CPU, RAM, а также затраты простаивающих машин и общие расходы ЦОД. При этом из расчёта исключаются затраты на передачу данных по внешней сети, энергия устройств конечных пользователей, расходы на обучение моделей и хранение данных. 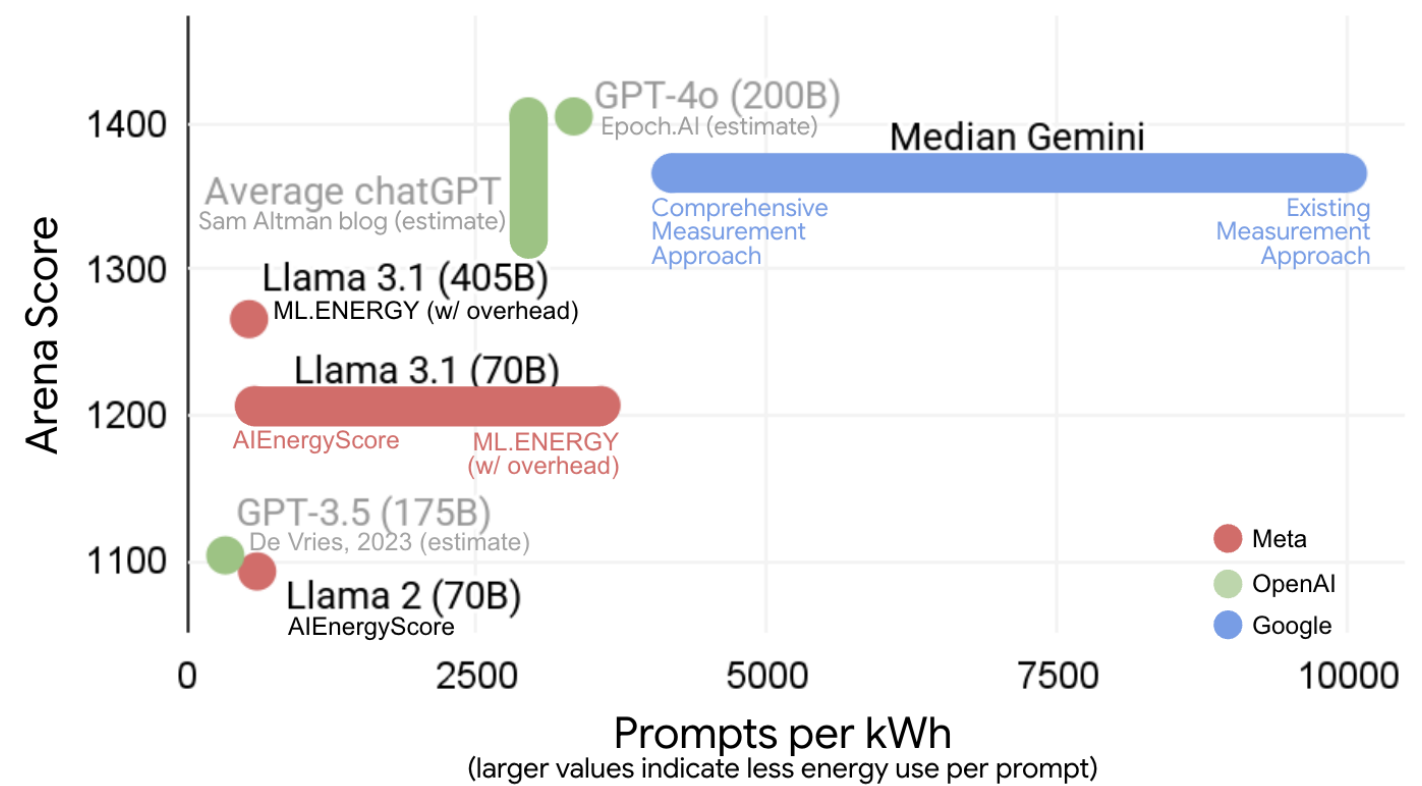
Источник изображений: Google Впрочем, по мнению некоторых экспертов, данные вводят в заблуждение, поскольку часть информации не учитывается. Так, не принимается в расчёт «косвенное» использование воды, поскольку считается только вода, которую ЦОД применяют для охлаждения, хотя значительная часть водопотребления приходится на генерирующие мощности, а не на их потребителей. Кроме того, при учёте углеродных выбросов должны приниматься во внимание не купленные «зелёные сертификаты», а реальное загрязняющее действие ЦОД в конкретной локации с учётом использования «чистой» и «обычной» энергии в местной электросети. 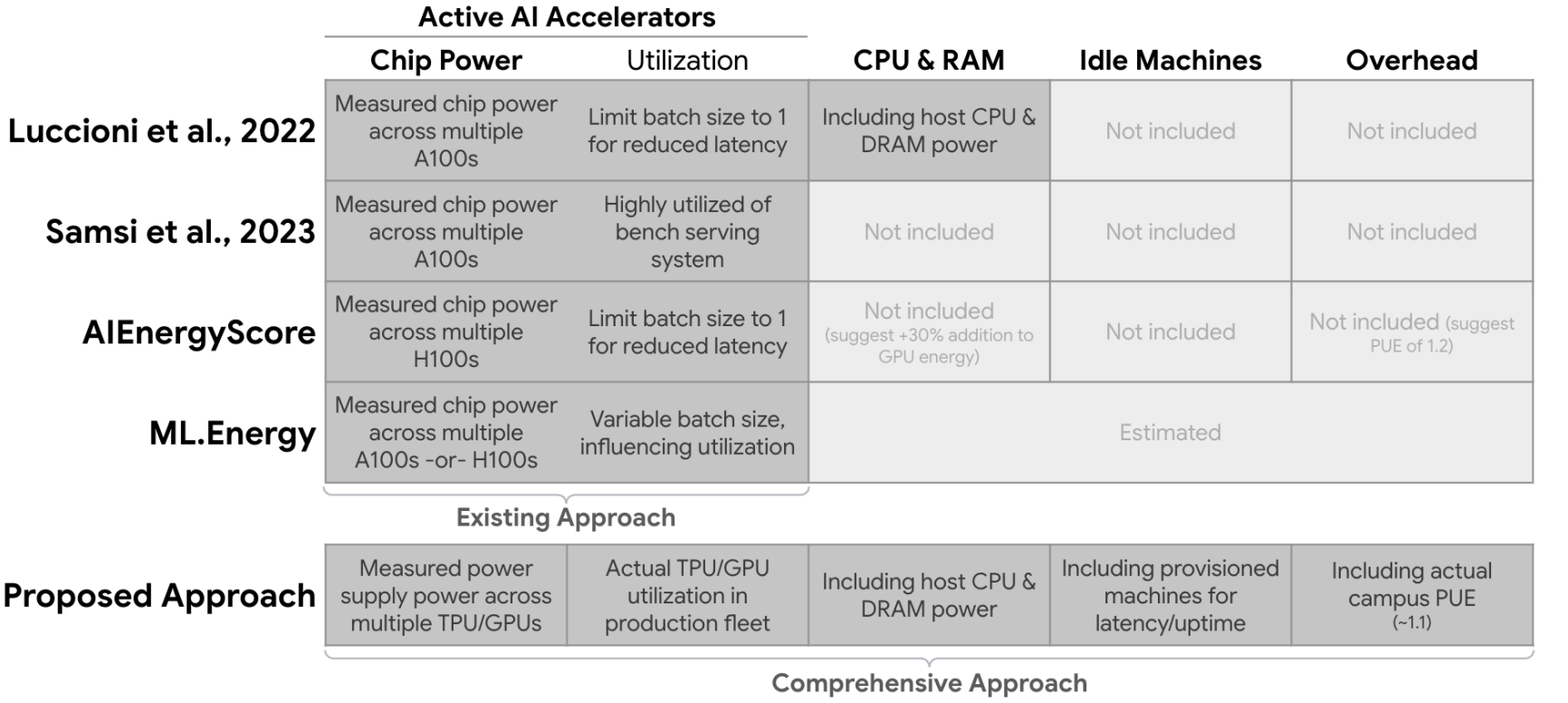 OpenAI также недавно оказалась в центре внимания экспертов и общественности, поскольку появилась информация, что её новейшая модель GPT-5 потребляет более 18 Вт·ч электроэнергии, до 40 Вт·ч на ответ средней длины. Сам глава компании Сэм Альтман (Sam Altman) объявил, что в среднем на выполнение запроса тратится около 0,34 Вт∙ч и около 0,32 мл воды. Это несколько больше, чем заявленные показатели Google Gemini, однако, согласно расчётам исследователей, эти цифры, скорее всего, актуальны для GPT-4o.
14.08.2025 [17:29], Руслан Авдеев
Умнее, но прожорливее: GPT-5 потребляет до 20 раз больше энергии, чем предыдущие моделиНедавно представленной модели OpenAI GPT-5 в сравнении с ChatGPT образца середины 2023 года для обработки идентичного запроса потребуется до 20 раз больше энергии, сообщает The Guardian. Официальную информацию об энергопотреблении OpenAI, как и большинство её конкурентов, не публикует. В июне 2025 года глава компании Сэм Альтман (Sam Altman) сообщил, что речь идёт о 0,34 Вт∙ч и 0,00032176 л на запрос, но о какой именно модели идёт речь, не сообщалось. Документальные подтверждения этих данных тоже отсутствуют. По словам представителя Университета штата Иллинойс (University of Illinois), GPT-5 будет потреблять намного больше энергии в сравнении с моделями-предшественницами как при обучении, так и при инференсе. Более того, в день премьеры GPT-5 исследователи из Университета Род-Айленда (University of Rhode Island) выяснили, что модель может потреблять до 40 Вт∙ч для генерации ответа средней длины из приблизительно 1 тыс. токенов. Для сравнения, в 2023 году на обработку одного запроса уходило порядка 2 Вт∙ч. Сейчас среднее потребление GPT-5 составляет чуть более 18 Вт∙ч на запрос, что выше, чем у любых других сравнивавшихся учёными моделей, за исключением апрельской версии «рассуждающей» o3 и DeepSeek R1. Предыдущая модель GPT-4o потребляет значительно меньше. 18 Вт∙ч эквивалентны 18 минутам работы лампочки накаливания. С учётом того, что ChatGPT обрабатывает около 2,5 млрд запросов ежедневно, за сутки тратится энергии, достаточной для снабжения 1,5 млн домохозяйств в США. 
Источник изображения: Dean Brierley / Unsplash В целом учёные не удивлены, поскольку GPT-5 в разы производительнее своих предшественниц. Летом 2025 года ИИ-стартап Mistral опубликовал данные, в которых выявлена «сильная корреляция» между масштабом модели и её энергопотреблением. По её данным, GPT-5 использует на порядок больше ресурсов, чем GPT-3. При этом многие предполагают, что даже GPT-4 в 10 раз больше GPT-3. Впрочем, есть и дополнительные факторы, влияющие на потребление ресурсов. Так, GPT-5 использует более эффективное оборудование и новую, более экономичную экспертную архитектуру с оптимизацией расхода ресурсов на ответы, что в совокупности должно снизить энергопотребление. С другой стороны, в случае с GPT-5 речь идёт о «рассуждающей» модели, способной работать с видео и изображениями, поэтому реальное потребление ресурсов, вероятно, будет очень высоким. Особенно в случае длительных рассуждений. 
Источник изображения: Tim King / Unsplash Чтобы посчитать энергопотребление, группа из Университета Род-Айленда умножила среднее время, необходимое модели для ответа на запрос на среднюю мощность, потребляемую моделью в ходе работы. Важно отметить, что это только примерные оценки, поскольку достоверную информацию об использовании моделями конкретных чипов и распределении запросов найти очень трудно. Озвученная Альтманом цифра в 0,34 Вт∙ч практически совпадает с данными, рассчитанными для GPT-4o. Учёные подчёркивают необходимость большей прозрачности со стороны ИИ-бизнесов по мере выпуска всё более производительных моделей. В университете считают, что OpenAI и её конкуренты должны публично раскрыть информацию о воздействии GPT-5 на окружающую среду. Ещё в 2023 году сообщалось, что на обучение модели уровня GPT-3 требуется около 700 тыс. л воды, а на диалог из 20-50 вопросов в ChatGPT уходило около 500 мл. В 2024 году сообщалось, что на генерацию ста слов у GPT-4 уходит до трёх бутылок воды.
12.07.2025 [01:00], Руслан Авдеев
NVIDIA, Cisco и Indosat помогут Индонезии встать на ИИ-рельсы
cisco
indosat ooredoo hutchison
llm
nvidia
software
ии
индонезия
информационная безопасность
конфиденциальность
обучение
разработка
Индонезия сделала важный шаг к созданию суверенного ИИ, объявив о создании «Центра передового опыта в сфере ИИ» (AI Center of Excellence, CoE). Проект реализуется под руководством Министерства цифровых коммуникаций и информации (Komdigi) и при поддержке NVIDIA, Cisco и телеком-оператора Indosat Ooredoo Hutchison (IOH). Центр станет частью национальной инициативы «Золотое видение 2045» (Golden 2045 Vision), направленной на цифровую трансформацию экономики и развитие инноваций. В задачи CoE входят развитие локальной ИИ-инфраструктуры, подготовка кадров и поддержка стартапов. Частью CoE станет NVIDIA AI Technology Center, который обеспечит поддержку исследований в области ИИ, предоставит доступ к программе NVIDIA Inception для стартапов и предложит обучение в экосистеме NVIDIA Deep Learning Institute. Также CoE получит типовую суверенную ИИ-фабрику с новейшими ускорителями Blackwell. Дополнительно курируемый государством форум разработает надёжные ИИ-фреймворки для создания решений, соответствующих местным ценностям. Важное внимание уделяется вопросам кибербезопасности. На базе центра заработает система Sovereign Security Operations Center Cloud Platform, разработанная Cisco, сочетающая ИИ-распознавание угроз, локальное управление данными и управляемые сервисы обеспечения безопасности. Проект строится на четырёх стратегических столпах:

Источник изображения: Jeremy Bishop/unspalsh.com Уже сейчас около 30 независимых разработчиков и стартапов используют ИИ-инфраструктуру IOH на базе NVIDIA. С учётом того, что Indosat покрывает связью весь индонезийский архипелаг, компания может обслуживать сотни миллионов носителей индонезийского языка (Bahasa Indonesia) с помощью приложений на основе специальных LLM, таких как Indosat Sahabat-AI. В будущем Indosat и NVIDIA намерены внедрять технологии AI-RAN, позволяющие охватывать ещё более широкий круг людей, которые смогут пользоваться ИИ с помощью беспроводных сетей. Индонезия давно стала весьма привлекательным рынком для инвесторов. Так, Microsoft намерена в течение четырёх лет инвестировать в облачную инфраструктуру и ИИ-проекты Индонезии $1,7 млрд. А NVIDIA и Indosat Ooredoo Hutchison планируют построить ИИ-центр стоимостью $200 млн в Центральной Яве, $500 млн намерена инвестировать Tencent. Даже «Яндекс» имеет там собственные интересы.
15.06.2025 [23:29], Владимир Мироненко
Большая жатва: AMD назначила вице-президентом по ИИ гендиректора ИИ-стартапа Lamini, в который сама же и вложиласьAMD продолжает укреплять команду специалистов в сфере ИИ за счёт привлечения талантливых разработчиков, а также поглощения ИИ-стартапов. На минувшей неделе Шарон Чжоу (Sharon Zhou, вторая справа на фото ниже), соучредитель и гендиректор ИИ-стартапа Lamini (PowerML Inc.) сообщила в соцсети X, что она и несколько сотрудников присоединяются к AMD. Комментируя переход, представитель AMD сообщил ресурсу CRN, что это было наймом специалистов, а не приобретением команды, как это было в случае с разработчиком ИИ-чипов Untether AI, который фактически прекратил существование после сделки. В настоящее время неизвестно, какой будет дальнейшая судьба Lamini, которую в прошлом году покинул Грег Диамос (Greg Diamos), бывший архитектор ПО NVIDIA CUDA, основавший компанию вместе с Чжоу в 2022 году. До основания Lamini Чжоу работала менеджером по ML-продуктам в Google, менеджером по продуктам в ИИ-стартапах Kensho Technologies и Tamr, а также занимала должность внештатного преподавателя компьютерных наук в Стэнфордском университете, где она получила докторскую степень по этой же специальности. В AMD её назначили на должность вице-президента по ИИ. 
Источник изображения: Sharon Zhou/X Платформа Lamini позволяет компаниям настраивать и кастомизировать большие языковые модели (LLM) с использованием собственных данных. В частности, Lamini предложила новый подход под названием Mixture of Memory Experts (MoME), направленный на повышение производительности LLM и фактической точности путем радикального снижения частоты галлюцинаций с 50 % до 5 %. Утверждается, что этот подход позволяет значительно сократить объём вычислительных ресурсов для обучения LLM, а также продолжительность этого процесса. В 2023 году AMD представила Lamini как одного из первых независимых поставщиков ПО, поддержавших её ускорители Instinct. В сентябре того же года Lamini сообщила, что использует более чем 100 ускорителей серии Instinct MI200 и что платформа AMD ROCm «достигла программного паритета» с NVIDIA CUDA. До определённого момента ИИ-платформа Lamini была единственной коммерческой платформой, целиком и полностью работающей на базе AMD Instinct.  В прошлом году стартап привлек финансирование в размере $25 млн от нескольких инвесторов, включая венчурное подразделение AMD, Эндрю Ына (Andrew Ng), гендиректора Dropbox Дрю Хьюстона (Drew Houston), и Лип-Бу Тана (Lip-Bu Tan), который в начале этого года стал гендиректором Intel. Помимо команды Untether AI, AMD приобрела в течение последних нескольких неделе разработчика систем кремниевой фотоники Enosemi и стартапа Brium, специализирующегося на инструментах оптимизации ИИ ПО для различной аппаратной инфраструктуры.
14.06.2025 [17:04], Владимир Мироненко
Scale AI получила от Meta✴ более $14 млрд, но потеряла гендиректора и рискует лишиться крупных контрактов с Gooogle, Microsoft, OpenAI и xAIИИ-стартап Scale AI, занимающийся подготовкой, оценкой и разметкой данных для обучения ИИ-моделей, объявил о крупной инвестиционной сделке с Meta✴, по результатм которой его рыночная стоимость превысила $29 млрд. Сделка существенно расширит коммерческие отношения Scale и Meta✴. Также её условиями предусмотрен переход гендиректора Scale AI Александра Ванга (Alexandr Wang) и ещё ряда сотрудников в Meta✴. Вместо Ванга, который останется в совете директоров стартапа, временно исполняющим обязанности гендиректора Scale AI назначен Джейсон Дроги (Jason Droege), директор по стратегии, имеющий «20-летний опыт создания и руководства знаковыми технологическими компаниями, включая Uber Eats и Axon». Представитель Scale AI уточнил в интервью ресурсу CNBC, что Meta✴ вложит в компанию $14,3 млрд, в результате чего получит в ней 49-% долю акций, но без права голоса. «Мы углубим совместную работу по созданию данных для ИИ-моделей, а Александр Ванг присоединится к Meta✴ для работы над нашими усилиями по созданию суперинтеллекта», — рассказал представитель Meta✴. Переманивая Ванга, который не имея опыта в R&D, сумел с нуля создать крупный бизнес в сфере ИИ, гендиректор Meta✴ Марк Цукерберг (Mark Zuckerberg) делает ставку на его организаторские способности, полагая, что укрепить позиции Meta✴ в сфере ИИ под силу опытному бизнес-лидеру, больше похожему на Сэма Альтмана (Sam Altman), чем на учёных, стоящих у руля большинства конкурирующих ИИ-лабораторий, пишет Reuters. 
Источник изображения: Scale AI Инвестиции в Scale AI станут вторыми по величине в истории Meta✴ после приобретения WhatsApp за $19 млрд. Однако сделка может оказаться не совсем выгодной для Scale AI, предупреждает Reuters, поскольку многие компании, являющиеся клиентами Scale AI, могут отказаться от дальнейшего сотрудничества из-за опасений по поводу того, что Ванг, оставаясь в совете директоров стартапа, будет предоставлять Meta✴ внутреннюю информацию о приоритетах конкурентов. Представитель Scale AI заверил, что инвестиции Meta✴ и переход Ванга не повлияют на клиентов стартапа, и что Meta✴ не будет иметь доступа к его какой-либо деловой информации или данным. Тем не менее, по словам источников Reuters, Google, один их крупнейших клиентов Scale AI, планирует разорвать отношения со стартапом. Источники сообщили, что Google планировала потратить $200 млн только в этом году на услуги Scale AI по подгтовке и разметке данных людьми. После объявления о сделке поисковый гигант уже провёл переговоры с несколькими конкурентами Scale AI. Scale AI получила в 2024 году размере $870 млн, из них около около $150 млн от Google, утверждают источники. По их словам, другие крупные клиенты, включая Microsoft, OpenAI и xAI, тоже планируют отказаться от услуг Scale AI. Официальных подтверждений этой информации пока не поступало. А финансовый директор OpenAI заявил в пятницу, что компания, которой источники тоже приписывают намерение отказаться от услуг Scale AI, продолжит работать со стартапом, как с одним из своих многочисленных поставщиков данных.
07.06.2025 [16:24], Владимир Мироненко
AMD впервые приняла участие в бенчмарке MLPerf Training, но до рекордов NVIDIA ей ещё очень далекоКонсорциум MLCommons объявил новые результаты бенчмарка MLPerf Training v5.0, отметив быстрый рост и эволюцию в области ИИ, а также рекордное количество общих заявок и увеличение заявок для большинства тестов по сравнению с бенчмарком v4.1. MLPerf Training v5.0 предложил новый бенчмарк предварительной подготовки большой языковой модели на основе Llama 3.1 405B, которая является самой большой ИИ-моделью в текущем наборе тестов обучения. Он заменил бенчмарк на основе gpt3 (gpt-3-175B), входивший в предыдущие версии MLPerf Training. Целевая группа MLPerf Training выбрала его, поскольку Llama 3.1 405B является конкурентоспособной моделью, представляющей современные LLM, включая последние обновления алгоритмов и обучение на большем количестве токенов. Llama 3.1 405B более чем в два раза больше gpt3 и использует в четыре раза большее контекстное окно. Несмотря на то, что бенчмарк на основе Llama 3.1 405B был представлен только недавно, на него уже подано больше заявок, чем на предшественника на основе gpt3 в предыдущих раундах, отметил консорциум. 
Источник изображения: NVIDIA MLCommons сообщил, что рабочая группа MLPerf Training регулярно добавляет новые рабочие нагрузки в набор тестов, чтобы гарантировать, что он отражает тенденции отрасли. Результаты бенчмарка Training 5.0 показывают заметный рост производительности для новых бенчмарков, что указывает на то, что отрасль отдаёт приоритет новым рабочим нагрузкам обучения, а не старым. Тест Stable Diffusion показал увеличение скорости в 2,28 раза для восьмичиповых систем по сравнению с версией 4.1, вышедшей шесть месяцев назад, а тест Llama 2.0 70B LoRA увеличил скорость в 2,10 раза по сравнению с версией 4.1; оба превзошли исторические ожидания роста производительности вычислений с течением времени в соответствии с законом Мура. Более старые тесты в наборе показали более скромные улучшения производительности. 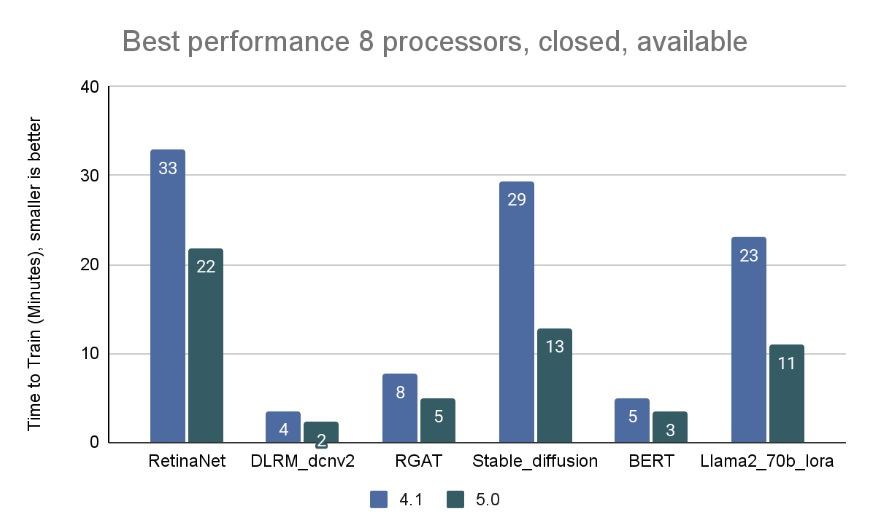
Источник изображений: MLCommons На многоузловых 64-чиповых системах тест RetinaNet показал ускорение в 1,43 раза по сравнению с предыдущим раундом тестирования v3.1 (самым последним, включающим сопоставимые масштабные системы), в то время как тест Stable Diffusion показал резкое увеличение в 3,68 раза. «Это признак надёжного цикла инноваций в технологиях и совместного проектирования: ИИ использует преимущества новых систем, но системы также развиваются для поддержки высокоприоритетных сценариев», — говорит Шрия Ришаб (Shriya Rishab), сопредседатель рабочей группы MLPerf Training. 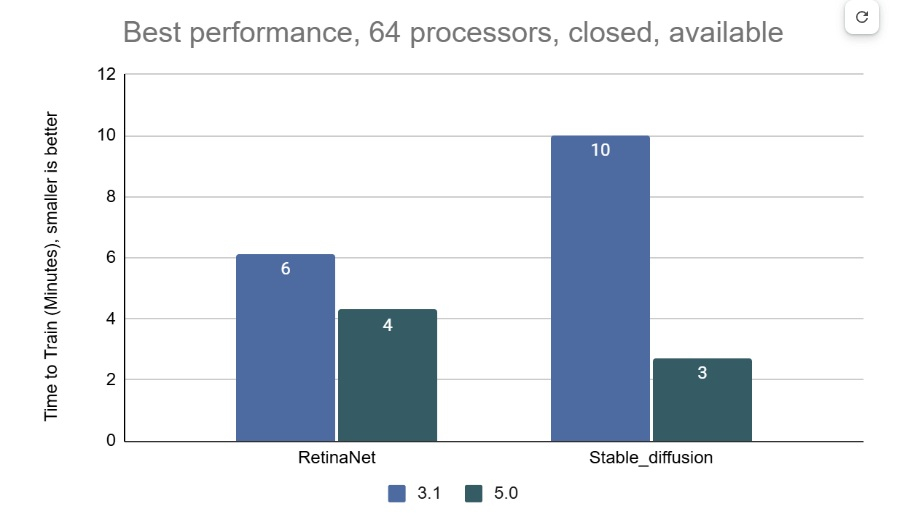 В заявках на MLPerf Training 5.0 использовалось 12 уникальных чиповых, все в категории коммерчески доступных. Пять из них стали общедоступными с момента выхода последней версии набора тестов MLPerf Training:
Заявки также включали три новых семейства процессоров:
Кроме того, количество представленных многоузловых систем увеличилось более чем в 1,8 раза по сравнению с версией бенчмарка 4.1. Хиуот Касса (Hiwot Kassa), сопредседатель рабочей группы MLPerf Training, отметил растущее число провайдеров облачных услуг, предлагающих доступ к крупномасштабным системам, что делает доступ к обучению LLM более демократичным. 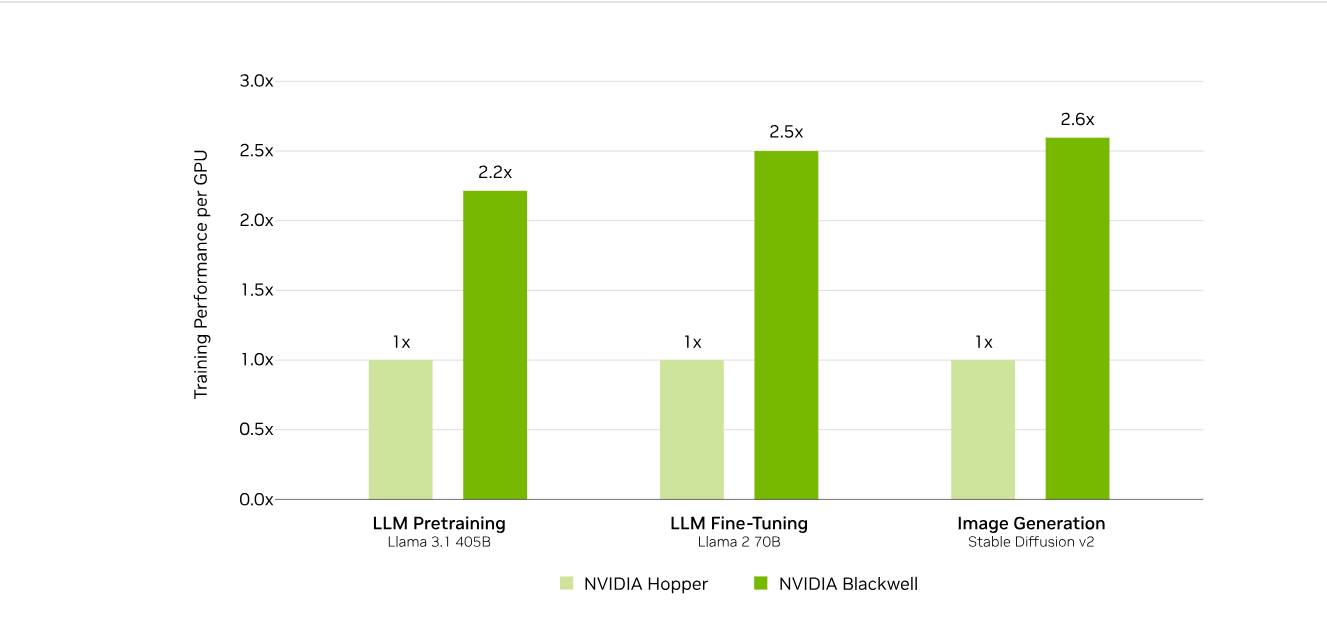
Источник изображений: NVIDIA Последние результаты MLPerf Training 5.0 от NVIDIA показывают, что её ускорители Blackwell GB200 демонстрируют рекордные результаты по времени обучения, демонстрируя, как стоечная конструкция «ИИ-фабрики» компании может быстрее, чем раньше, превращать «сырые» вычислительные мощности в развёртываемые модели, пишет ресурс HPCwire. Раунд MLPerf Training v5.0 включает 201 результат от 20 организаций-участников: AMD, ASUS, Cisco, CoreWeave, Dell, GigaComputing, Google Cloud, HPE, IBM, Krai, Lambda, Lenovo, MangoBoost, Nebius, NVIDIA, Oracle, QCT, SCITIX, Supermicro и TinyCorp. «Мы бы особенно хотели поприветствовать впервые подавших заявку на участие в MLPerf Training AMD, IBM, MangoBoost, Nebius и SCITIX, — сказал Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons. — Я также хотел бы выделить первый набор заявок Lenovo на результаты тестов энергопотребления в этом раунде — энергоэффективность в системе обучения ИИ-систем становится всё более важной проблемой, требующей точного измерения». 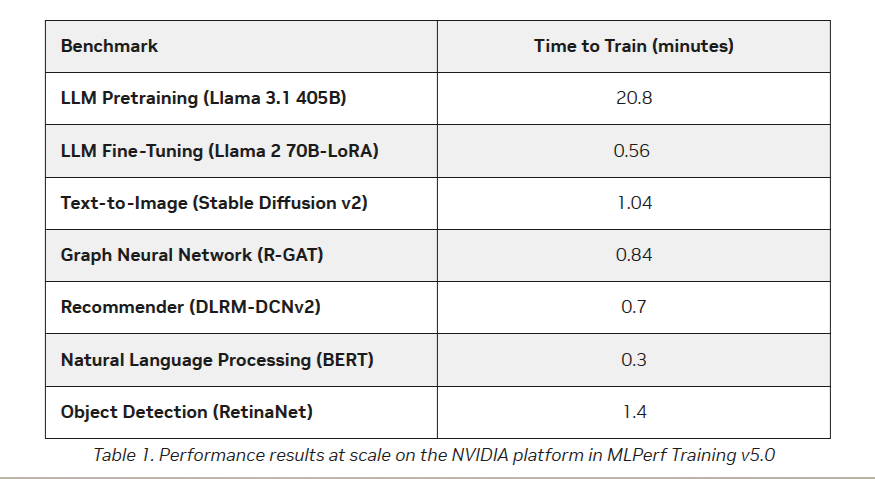 NVIDIA представила результаты кластера на основе систем GB200 NVL72, объединивших 2496 ускорителей. Работая с облачными партнерами CoreWeave и IBM, компания сообщила о 90-% эффективности масштабирования при расширении с 512 до 2496 ускорителей. Это отличный результат, поскольку линейное масштабирование редко достигается при увеличении количества ускорителей за пределами нескольких сотен. Эффективность масштабирования в диапазоне от 70 до 80 % уже считается солидным результатом, особенно при увеличении количества ускорителей в пять раз, пишет HPCwire. В семи рабочих нагрузках в MLPerf Training 5.0 ускорители Blackwell улучшили время сходимости «до 2,6x» при постоянном количестве ускорителей по сравнению с поколением Hopper (H100). Самый большой рост наблюдался при генерации изображений и предварительном обучении LLM, где количество параметров и нагрузка на память самые большие.  Хотя в бенчмарке проверялась скорость выполнения операций, NVIDIA подчеркнула, что более быстрое выполнение задач означает меньшее время аренды облачных инстансов и более скромные счета за электроэнергию для локальных развёртываний. Хотя компания не публиковала данные об энергоэффективности в этом бенчмарке, она позиционировала Blackwell как «более экономичное» решение на основе достигнутых показателей, предполагая, что усовершенствования дизайна тензорных ядер обеспечивают лучшую производительность на Ватт, чем у поколения Hopper. Также HPCwire отметил, что NVIDIA была единственным поставщиком, представившим результаты бенчмарка предварительной подготовки LLM на основе Llama 3.1 405B, установив начальную точку отсчёта для обучения с 405 млрд параметров. Это важно, поскольку некоторые компании уже выходят за рамки 70–80 млрд параметров для передовых ИИ-моделей. Демонстрация проверенного рецепта работы с 405 млрд параметров даёт компаниям более чёткое представление о том, что потребуется для создания ИИ-моделей следующего поколения. 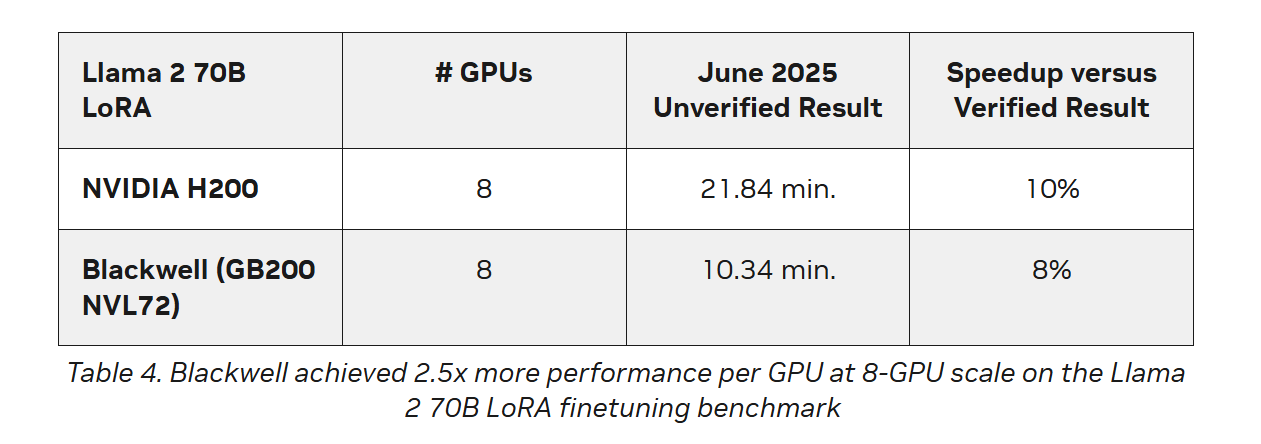 В ходе пресс-конференции Дэйв Сальватор (Dave Salvator), директор по ускоренным вычислительным продуктам в NVIDIA, ответил на распространенный вопрос: «Зачем фокусироваться на обучении, когда в отрасли в настоящее время все внимание сосредоточено на инференсе?». Он сообщил, что тонкая настройка (после предварительного обучения) остается ключевым условием для реальных LLM, особенно для предприятий, использующих собственные данные. Он обозначил обучение как «фазу инвестиций», которая приносит отдачу позже в развёртываниях с большим объёмом инференса. Этот подход соответствует более общей концепции «ИИ-фабрики» компании, в рамках которой ускорителям даются данные и питание для обучения моделей. А затем производятся токены для использования в реальных приложениях. К ним относятся новые «токены рассуждений» (reasoning tokens), используемые в агентских ИИ-системах. 
 NVIDIA также повторно представила результаты по Hopper, чтобы подчеркнуть, что H100 остаётся «единственной архитектурой, кроме Blackwell», которая показала лидерские показатели по всему набору MLPerf Training, хотя и уступила Blackwell. Поскольку инстансы на H100 широко доступны у провайдеров облачных сервисов, компания, похоже, стремится заверить клиентов, что существующие развёртывания по-прежнему имеют смысл. 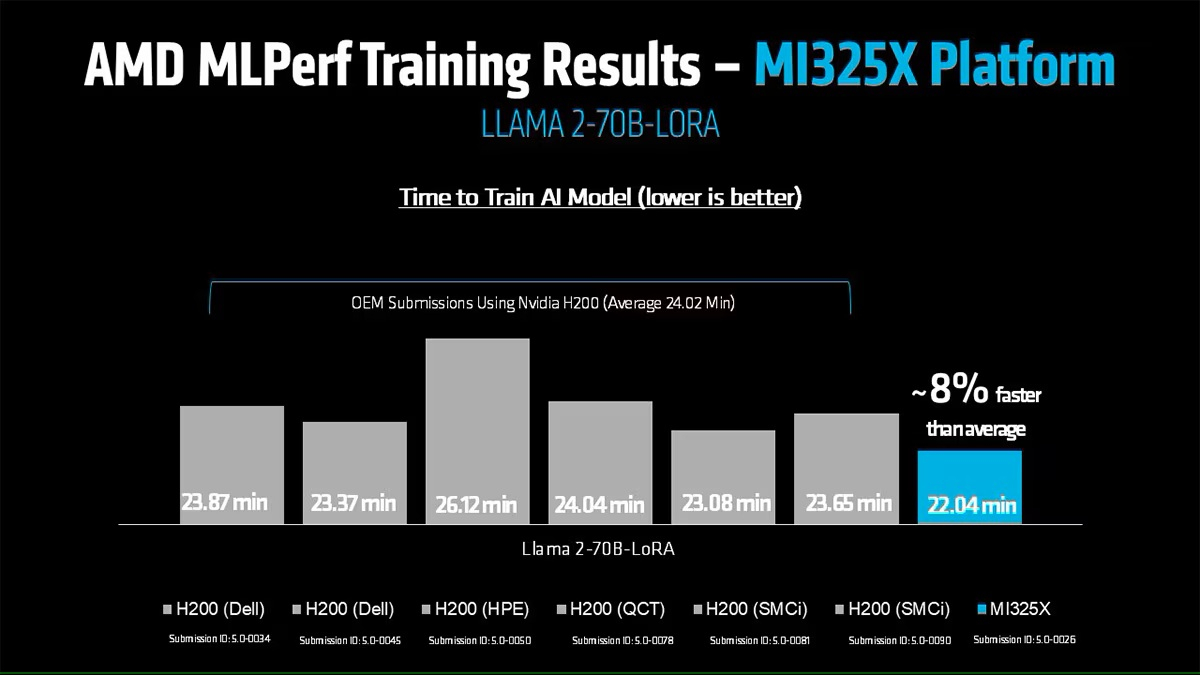
Источник изображений: AMD AMD, со своей стороны, продемонстрировала прирост производительности поколения чипов. В тесте Llama2 70B LoRA она показала 30-% прирост производительности AMD Instinct MI325X по сравнению с предшественником MI300X. Основное различие между ними заключается в том, что MI325X оснащён почти на треть более быстрой памятью.  В самом популярном тесте, тонкой настройке LLM, AMD продемонстрировала, что её новейший ускоритель Instinct MI325X показывает результаты наравне с NVIDIA H200. Это говорит о том, что AMD отстает от NVIDIA на одно поколение, отметил ресурс IEEE Spectrum. 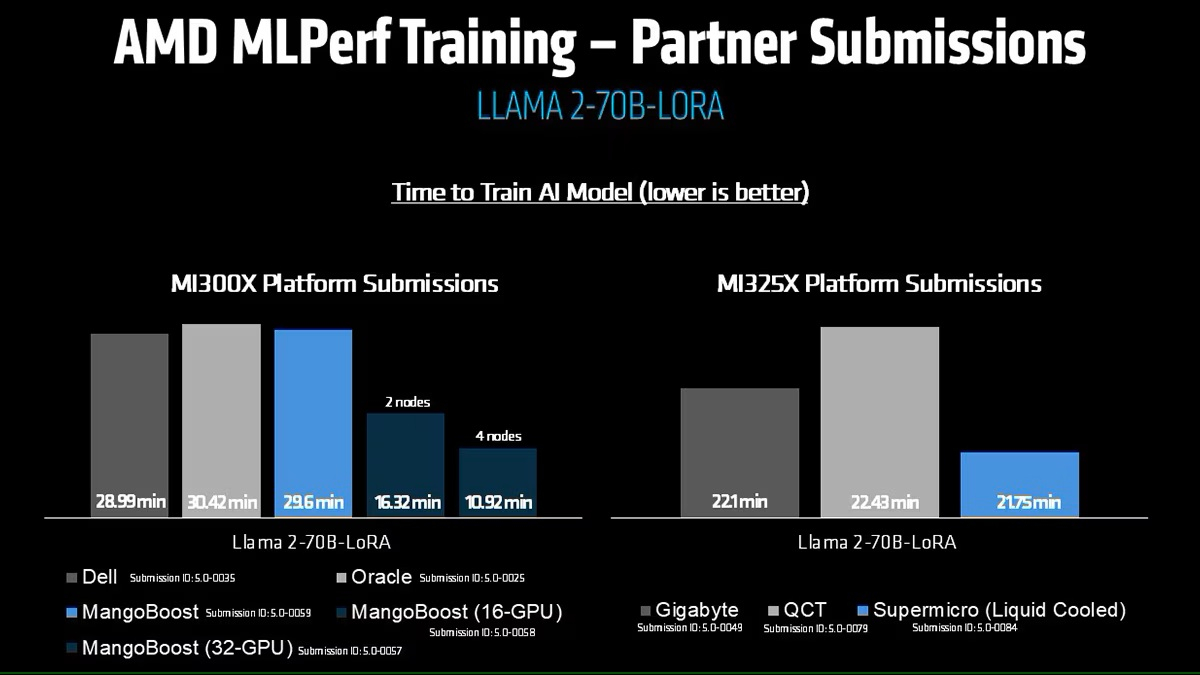 AMD впервые представила результаты MLPerf Training, хотя в предыдущие годы другие компании представляли результаты в этом тесте, используя ускорители AMD. В свою очередь, Google представила результаты лишь одного теста, задачи генерации изображений, с использованием Trillium TPU. Тест MLPerf также включает тест на энергопотребление, измеряющий, сколько энергии уходит на выполнение каждой задачи обучения. В этом раунде лишь Lenovo включила измерение этого показателя в свою заявку, что сделало невозможным сравнение между компаниями. Для тонкой настройки LLM на двух ускорителях Blackwell требуется 6,11 ГДж или 1698 КВт·ч — примерно столько энергии уходит на обогрев небольшого дома зимой.
30.05.2025 [09:34], Руслан Авдеев
Microsoft закрепляет лидерство в сфере ИИ, предлагая клиентам почти 2 тыс. моделей, в том числе от конкурентовКомпания Microsoft сделала серьёзную заявку на мировое лидерство в сфере искусственного интеллекта, в своё время инвестировав $13 млрд в стартап OpenAI. Позже компания использовала GPT-модели OpenAI в качестве основы для собственного бота Copilot AI, интегрировав его во многие свои продукты, а теперь вышла на новый уровень, сообщает Computer World. Компания запустила хостинг LLM и ИИ-сервисов крупнейших в мире ИИ-компаний и стартапов, включая собственных конкурентов — всего более 1900 моделей, от Llama AI (Meta✴) до разработок xAI и европейских стартапов Mistral и Black Forest Labs, а также китайского DeepSeek и др. Другими словами, даже если Copilot не оправдает ожиданий Microsoft в полной мере, она в какой-то степени разделит и успехи своих конкурентов и, вероятно, останется крупнейшей в мире ИИ-компанией. ЦОД Microsoft стали залогом её успеха на рынке искусственного интеллекта. Благодаря сделке с OpenAI сама Microsoft получает отчисления от каждого подписчика OpenAI. Для монетизации ИИ-решений в 2023 году Microsoft запустила сервис Azure OpenAI, позволяющий клиентам Azure создавать приложения с использованием моделей OpenAI. По некоторым данным, в сервисе зарегистрировано около 60 тыс. клиентов. 
Источник изображения: Craig Sybert/unsplash.com Бизнес компании растёт и благодаря договорённостями с другими ИИ-разработчиками. В середине мая Microsoft объявила о размещении моделей Grok в сервисе Azure AI Foundry. Кроме того, в облаке Microsoft размещены и другие популярные модели. Таким образом, Microsoft получает больше денег даже в том случае, когда конкуренты добиваются новых успехов. Недавно компания подробно рассказала о видении того, каким образом компании смогут создавать ИИ-агентов для выполнения широкого спектра задач. В центре внимания — Azure AI Foundry, позволяющий клиентам создавать ИИ-агентов, использую любую из почти 2 тыс. моделей и объединяя их возможности, в том числе, например, для работы на GutHub. Другими словами, заказчикам не придётся подписываться на использование моделей у каждой из компаний по отдельности. 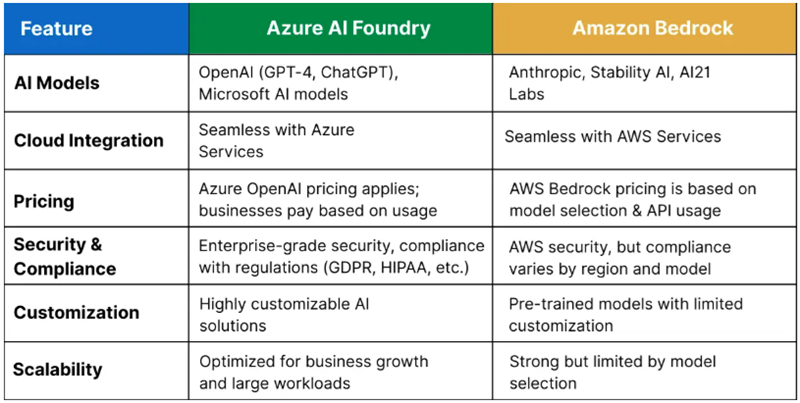
Источник изображения: Q Service Хотя крупнейшим облачным оператором в мире является Amazon (AWS), Microsoft постепенно сокращает разрыв, а подобные площадки для работы с разными ИИ-моделями обеспечивают ей большую фору. Amazon с аналогом Azure AI Foundry — Amazon Bedrock пыталась повторить нечто подобное, но ИИ-моделей у неё гораздо меньше. Высока вероятность, что в этой схватке первенство останется за Microsoft. По расчётам экспертов Q Services, предложение Bedrock лучше подходит разве что для стартапов и компаний, занимающихся разработкой, а Microsoft доминирует на более широком рынке, в том числе сотрудничая с крупными корпорациями. Большое преимущество компании — в использовании всех продуктов, от Microsoft 365 до Azure для продажи существующим клиентам сервисов Azure AI Foundry. У Amazon такая уникальная возможность отсутствует.
24.03.2025 [11:59], Руслан Авдеев
OpenAI и Meta✴ ведут переговоры с индийской Reliance Jio о сотрудничестве в сфере ИИMeta✴ и OpenAI по отдельности ведут переговоры с индийской Reliance Industries о потенциальном сотрудничестве для расширения ИИ-сервисов, сообщает The Information. Так, OpenAI хотела бы при помощи Reliance Jio расширить использование ChatGPT в Индии — об этом изданию сообщили два независимых источника, знакомых с вопросом. Более того, OpenAI обсуждала с сотрудниками сокращение стоимости подписок на платный вариант ChatGPT с $20/мес. до всего нескольких долларов. Пока неизвестно, велись ли разговоры об этом в ходе переговоров с Reliance. С последней, как утверждается, обсуждали продажу ИИ-моделей OpenAI корпоративным клиентам (через API). Также индийская компания заинтересована в локальном хостинге моделей OpenAI, чтобы данные местных клиентов будут храниться в пределах Индии. По имеющимся данным, с OpenAI и Meta✴ велись переговоры о запуске ИИ-моделей компаний в 3-ГВт ЦОД, который Reliance пока только планирует построить. Утверждается, что это будет «крупнейший дата-центр в мире» — его возведут в Джамнагаре (штат Гуджарат). Стоит отметить, что Reliance Industries является одним из крупнейших конгломератов Индии, имеющих интересы как в нефтегазовой отрасли, так и в IT и смежных отраслях, а также в сфере «зелёной» энергетики. 
Источник изображения: Shivam Mistry/unsplash.com Индия в целом считается очень перспективной страной для развития инвестиций в ИИ. Например, в конце прошлого года глава NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что страна должна стать одним из лидеров в области ИИ и создать собственную инфраструктуру. Тогда сообщалось, что Индия на государственном уровне обсуждает с NVIDIA совместную разработку чипов для ИИ-проектов, адаптированных к местным задачам. Также страна осваивает связанные с ИИ технологии — например, она затратит $1,2 млрд на суверенный ИИ-суперкомпьютер с 10 тыс. ускорителей и собственные LLM, а также готова покупать много ускорителей, включая ослабленные варианты, которые не достались Китаю после ужесточения американских санкций. И это далеко не все проекты, находящиеся сейчас на стадии разработки и реализации.
24.03.2025 [08:30], Владимир Мироненко
NVIDIA представила проект AI-Q Blueprint Platform для создания продвинутых ИИ-агентовПризнавая, что одних моделей, включая свежие Llama Nemotron с регулируемым «уровнем интеллекта», недостаточно для развёртывания ИИ на предприятии, NVIDIA анонсировала проект AI-Q Blueprint, представляющий собой фреймворк с открытым исходным кодом, позволяющий разработчикам подключать базы знаний к ИИ-агентам, которые могут действовать автономно. Blueprint был создан с помощью микросервисов NVIDIA NIM и интегрируется с NVIDIA NeMo Retriever, что упрощает для ИИ-агентов извлечение мультимодальных данных в различных форматах. С помощью AI-Q агенты суммируют большие наборы данных, генерируя токены в 5 раз быстрее и поглощая данные петабайтного масштаба в 15 раз быстрее с лучшей семантической точностью. Проект основан на новом наборе инструментов NVIDIA AgentIQ для бесшовного, гетерогенного соединения между агентами, инструментами и данными, опубликованном на GitHub. Он представляет собой программную библиотеку с открытым исходным кодом для подключения, профилирования и оптимизации команд агентов ИИ, работающих на основе корпоративных данных для создания многоагентных комплексных (end-to-end) систем. Его можно легко интегрировать с существующими многоагентными системами — как по частям, так и в качестве комплексного решения — с помощью простого процесса адаптации, который обеспечивает полную поддержку. 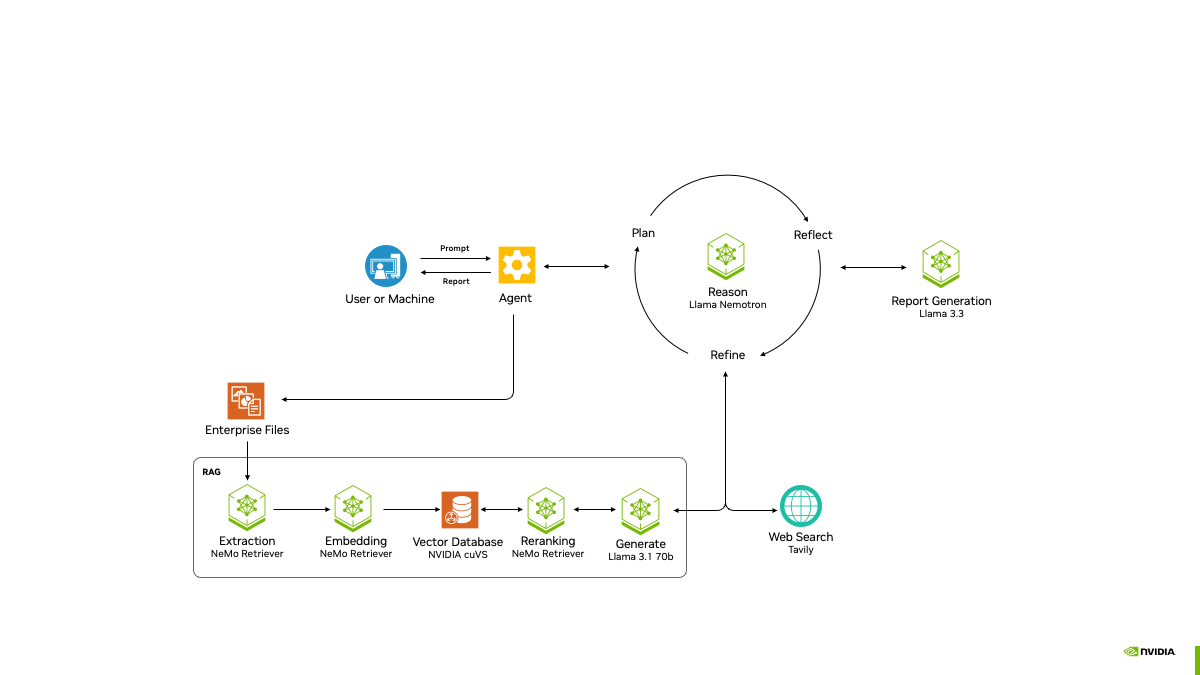 Набор инструментов AgentIQ также повышает прозрачность с полной отслеживаемостью и профилированием системы, что позволяет организациям контролировать производительность, выявлять неэффективность и иметь детальное представление о том, как генерируется бизнес-аналитика. Эти данные профилирования можно использовать с NVIDIA NIM и библиотекой с открытым исходным кодом NVIDIA Dynamo для оптимизации производительности агентских систем. Благодаря этим инструментам предприятиям будет проще объединять команды ИИ-агентов в таких решениях, как Agentforce от Salesforce, поиск Atlassian Rovo в Confluence и Jira, а также ИИ-платформа ServiceNow для трансформации бизнеса, чтобы устранить разрозненность, оптимизировать задачи и сократить время ответа с дней до часов. AgentIQ также интегрируется с такими фреймворками и инструментами, как CrewAI, LangGraph, Llama Stack, Microsoft Azure AI Agent Service и Letta, позволяя разработчикам работать в своей предпочтительной среде. Azure AI Agent Service интегрирован с AgentIQ для обеспечения более эффективных агентов ИИ и оркестровки многоагентных фреймворков с использованием семантического ядра, которое полностью поддерживается в AgentIQ. Возможности ИИ-агентов уже широко используются в различных отраслях. Например, платёжная система Visa использует ИИ-агентов для оптимизации кибербезопасности, автоматизируя анализ фишинговых писем в масштабе. Используя функцию профилирования AI-Q, Visa может оптимизировать производительность и затраты агентов, максимально увеличивая роль ИИ в эффективном реагировании на угрозы, сообщила NVIDIA. |
|