Материалы по тегу: gb200
|
15.10.2025 [15:25], Руслан Авдеев
OpenAI и Oracle развернут 450 тыс. ускорителей NVIDIA в техасском дата-центре StargateПо словам председателя Oracle Ларри Эллисона (Larry Ellison), дата-центр проекта Stargate а Абилине (Abilene, Техас) вместит более 450 тыс. ускорителей на базе NVIDIA GB200, сообщает Datacenter Dynamics. Дата-центр Stargate получит 1,2 ГВт энергии — по словам Эллисона, энергии достаточно, чтобы обеспечить миллион домохозяйств в США. Как заявил миллиардер, «это довольно большой город». Питаться кампус будет как от энергосети штата, так и от газовых турбин. Информация подтверждает данные о том, что OpenAI и Oracle освоят всю ёмкость кампуса, застраиваемого Crusoe. Первые два строения уже функционируют, они введены в эксплуатацию в сентябре 2025 года. Строительство оставшихся шести зданий должны быть завершены к середине 2026 года. В марте 2025 года заявлялось, что площадка получит 64 тыс. ускорителей NVIDIA к концу 2026 года. С тех пор OpenAI подписала не имеющее обязательной силы письмо о намерении арендовать оборудование NVIDIA на 10 ГВт, которая в ответ пообещала инвестировать в OpenAI $100 млрд. 
Источник изображения: OpenAI О росте числа используемых Stargate ускорителей можно было догадаться после анонса Oracle облачного ИИ-суперкомпьютера Zettascale10, который должен заработать во II половине 2026 года. Он объединит до 800 тыс. ускорителей в нескольких близко расположенных ЦОД. В Oracle отмечали, что суперкомпьютер станет основой флагманского суперкластера, создаваемого при участии OpenAI в Абилине в рамках проекта Stargate.
13.10.2025 [00:30], Владимир Мироненко
Вложи $5 млн — получи $75 млн: NVIDIA похвасталась новыми рекордами в комплексном бенчмарке InferenceMAX v1
b200
gb200
hardware
nvidia
open source
semianalysis
бенчмарк
ии
инференс
рекорд
финансы
энергоэффективность
NVIDIA сообщила о результатах, показанных суперускорителем GB200 NVL72, в новом независимом ИИ-бенчмарке InferenceMAX v1 от SemiAnalysis. InferenceMAX оценивает реальные затраты на ИИ-вычисления, определяя совокупную стоимость владения (TCO) в долларах на миллион токенов для различных сценариев, включая покупку и владение GPU в сравнении с их арендой. InferenceMAX опирается на инференс популярных моделей на ведущих платформах, измеряя его производительность для широкого спектра вариантов использования, а результаты может перепроверить любой желающий, говорят авторы бенчмарка. Суперускоритель GB200 NVL72 победил во всех категориях бенчмарка InferenceMAX v1. Чипы NVIDIA Blackwell показали наилучшую окупаемость инвестиций — вложение в размере $5 млн приносят $75 млн дохода от токенов DeepSeek R1, обеспечивая 15-кратную окупаемость (год назад NVIDIA обещала ROI на уровне 700 %). Также ускорители поколения Blackwell отличаются самой низкой совокупной стоимостью владения. например, оптимизация ПО NVIDIA B200 позволила добиться стоимости всего в два цента на миллион токенов на OpenAI gpt-oss-120b, обеспечив пятикратное снижение стоимости одного токена всего за два месяца. NVIDIA B200 первенствовал и по пропускной способности и интерактивности, обеспечив 60 тыс. токенов в секунду на ускоритель и 1 тыс. токенов в секунду на пользователя в gpt-oss с новейшим стеком NVIDIA TensorRT-LLM. NVIDIA сообщила, что постоянно повышает производительность путём оптимизации аппаратного и программного стека. Первоначальная производительность gpt-oss-120b на системе NVIDIA DGX Blackwell B200 с библиотекой NVIDIA TensorRT LLM уже была лидирующей на рынке, но команды NVIDIA и сообщество разработчиков значительно оптимизировали TensorRT LLM для ускорения исполнения открытых больших языковых моделей (LLM). 
Источник изображений: NVIDIA Компания отметила, что выпуск TensorRT LLM v1.0 стал значительным прорывом в повышении скорости инференса LLM благодаря распараллеливанию и оптимизации IO-операций. А у недавно вышедшей модели gpt-oss-120b-Eagle3-v2 используется спекулятивное декодирование — интеллектуальный метод, позволяющий предсказывать несколько токенов одновременно. Это уменьшает задержку и обеспечивает получение ещё более быстрых результатов — пропускная способность выросла втрое, до 100 токенов в секунду на пользователя (TPS/пользователь), а общая производительность на ускоритель выросла с 6 до 30 тыс. токенов. 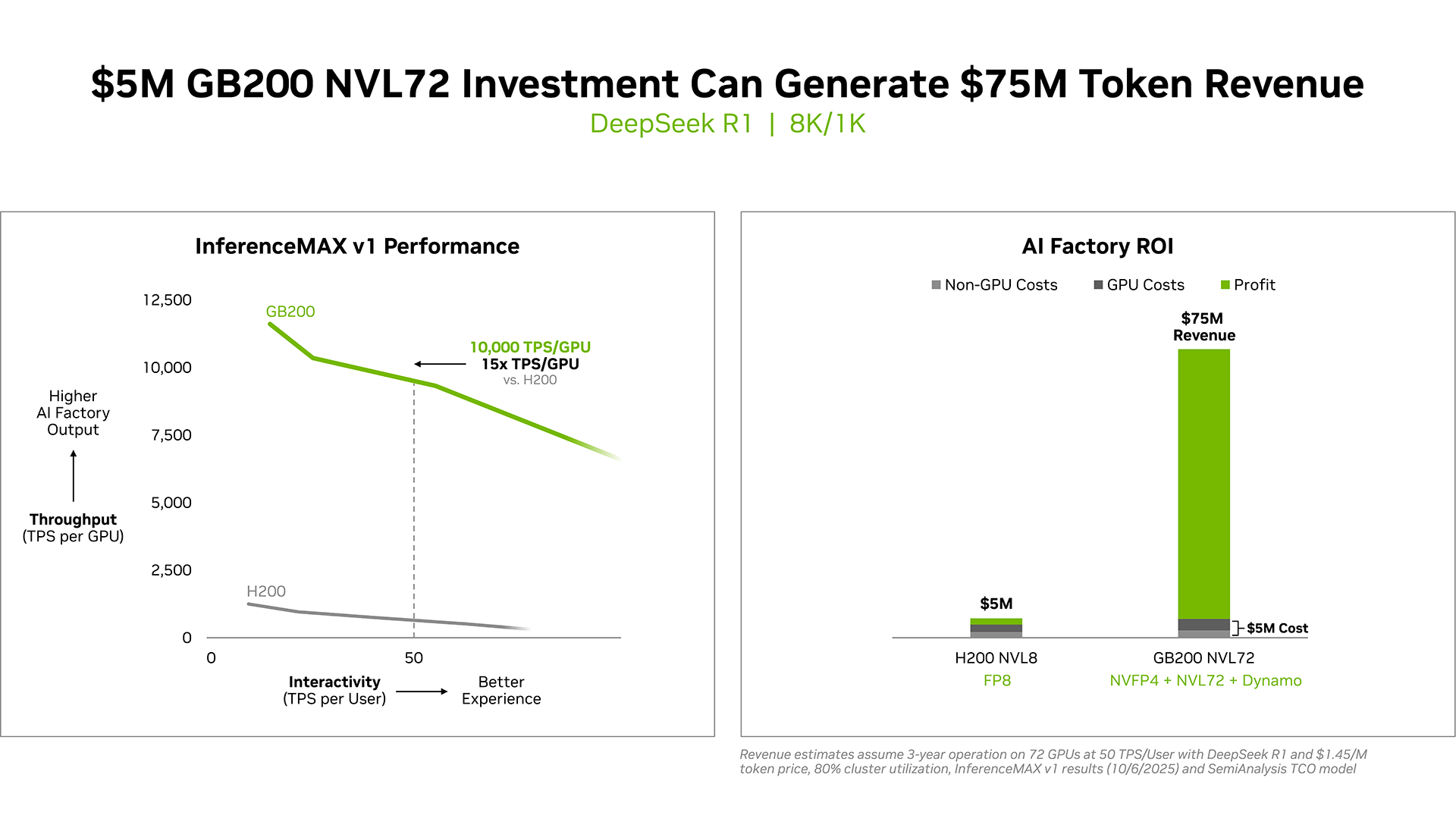 Для моделей с «плотной» архитектурой (Dense AI), таких как Llama 3.3 70b, которые требуют значительных вычислительных ресурсов из-за большого количества параметров и одновременного использования всех параметров в процессе инференса, NVIDIA Blackwell B200 достиг нового рубежа производительности в бенчмарке InferenceMAX v1, отметила NVIDIA. Суперускоритель показал более 10 тыс. токенов/с (TPS) на GPU при 50 TPS на пользователя, т.е. вчетверо более высокую пропускную способность на GPU по сравнению с NVIDIA H200. 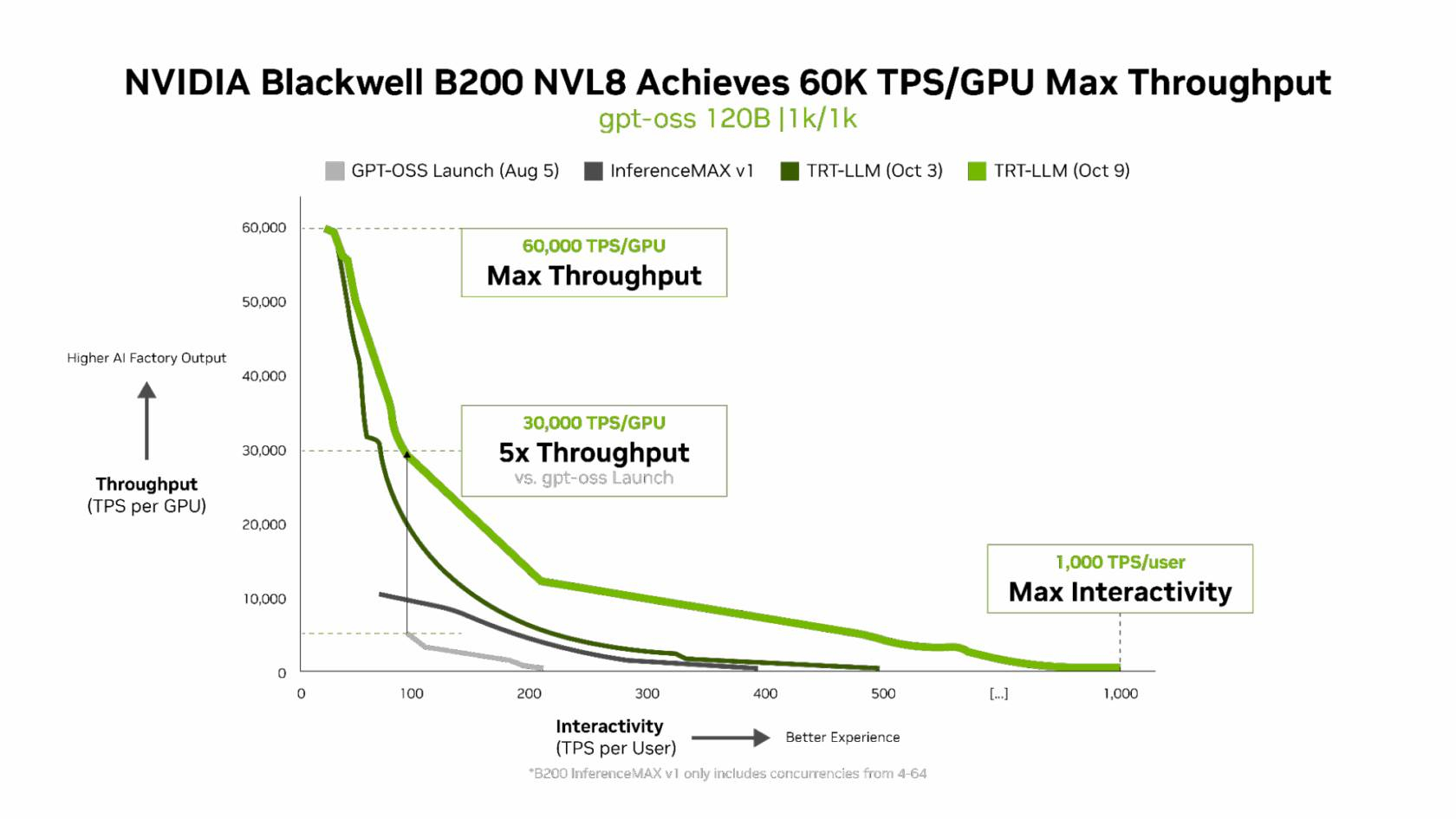 NVIDIA подчеркнула, что такие показатели, как количество токенов на Вт, стоимость на миллион токенов и TPS/пользователь не уступают по важности пропускной способности. Фактически, для ИИ-фабрик с ограниченной мощностью ускорители с архитектурой Blackwell обеспечивают до 10 раз лучшую производительность на МВт по сравнению с предыдущим поколением и позволяют получать более высокий доход от токенов. 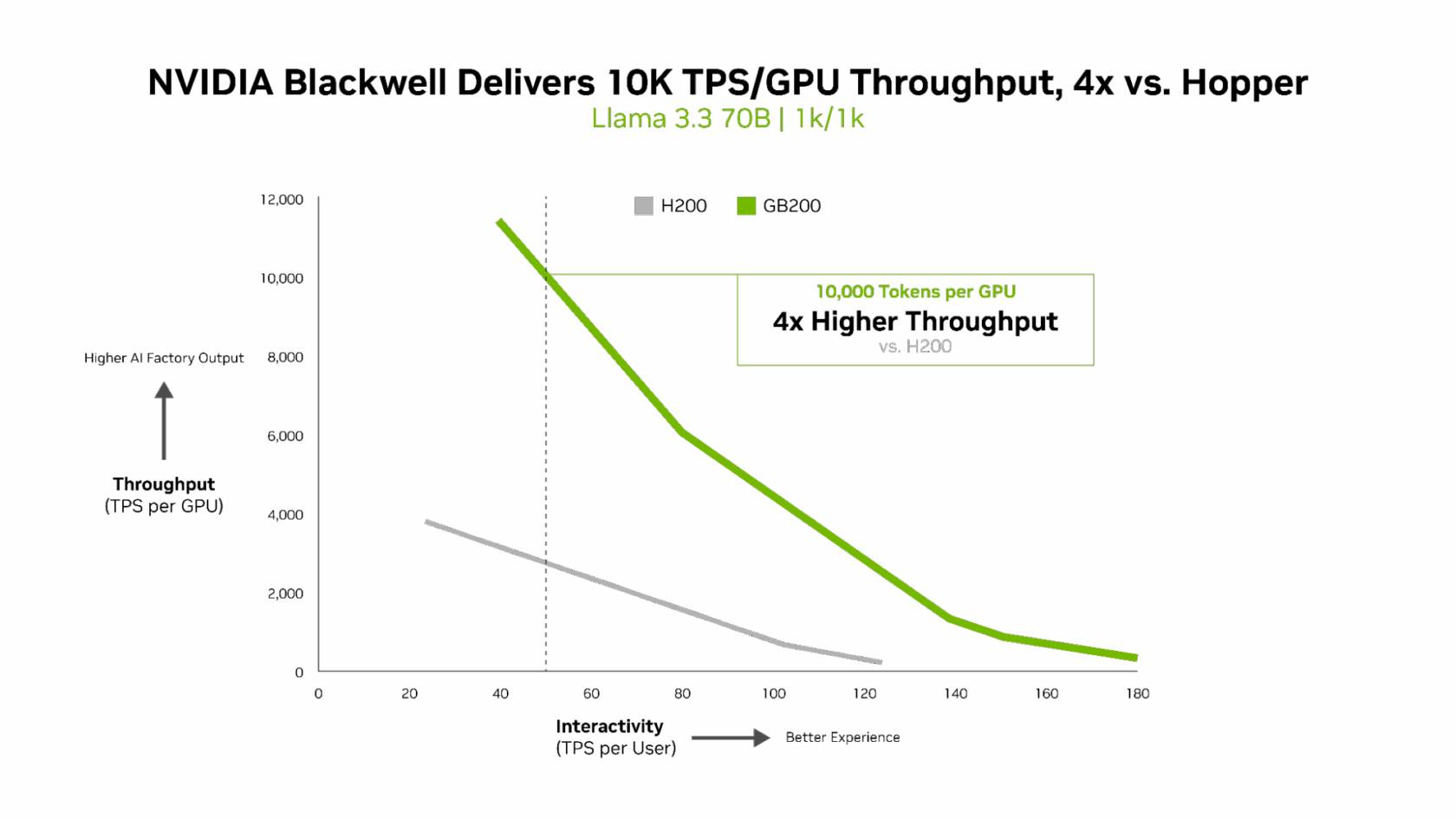 Компания отметила, что стоимость обработки одного токена (Cost per Token) имеет решающее значение для оценки эффективности ИИ-модели и напрямую влияет на эксплуатационные расходы. NVIDIA утверждает, что в целом архитектура NVIDIA Blackwell позволила снизить стоимость обработки миллиона токенов в 15 раз по сравнению с предыдущим поколением. 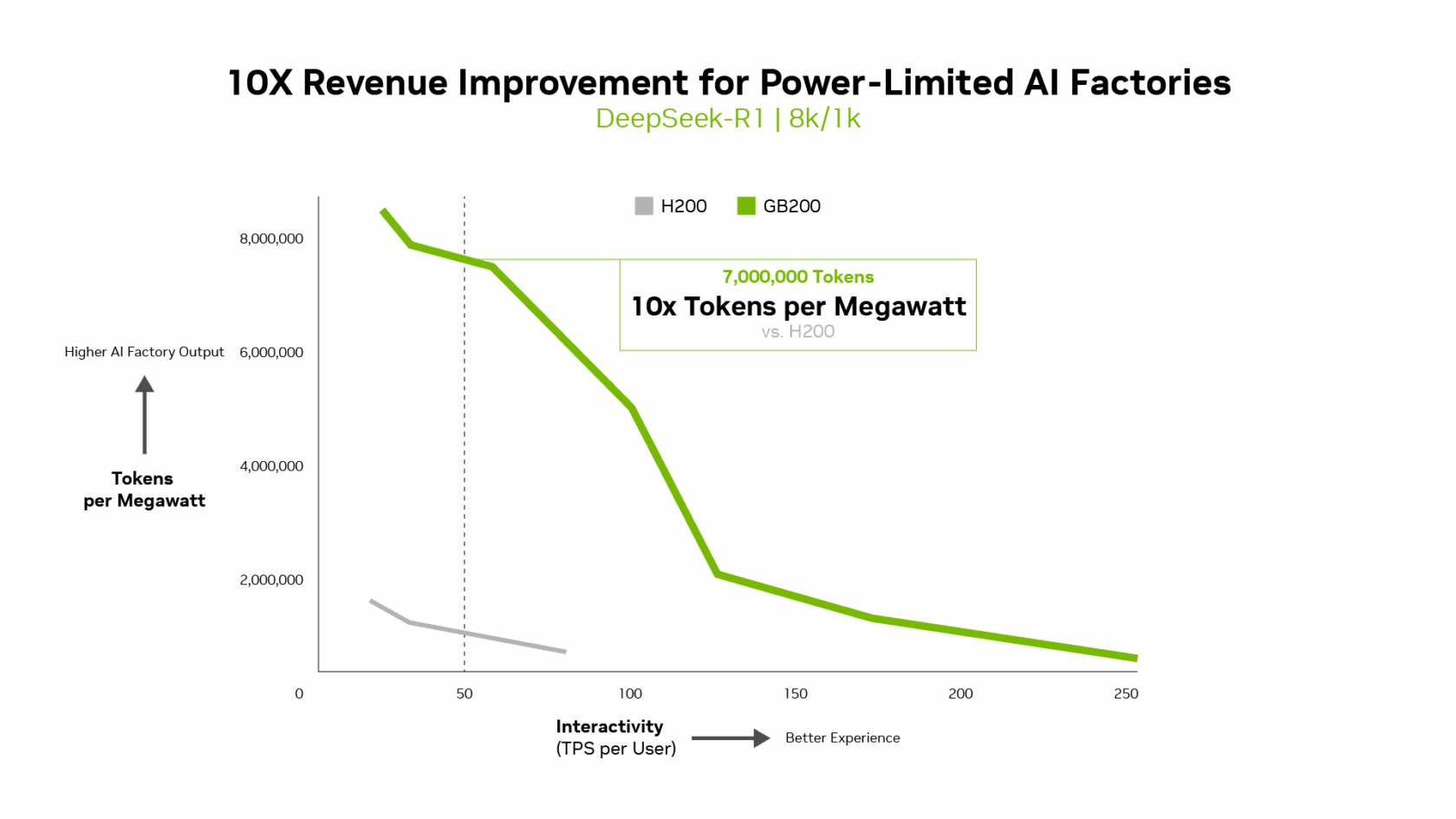 В InferenceMAX используется метод оценки эффективности Pareto front, определяющий наилучшее (компромиссное) сочетание различных факторов для оценки производительности ускорителя. Это показывает, насколько Blackwell лучше конкурентов справляется с балансом стоимости, энергоэффективности, пропускной способности и скорости отклика. Системы, оптимизированные только для одной метрики, могут демонстрировать пиковую производительность «в вакууме», но такая «экономика» не масштабируется в производственных средах. 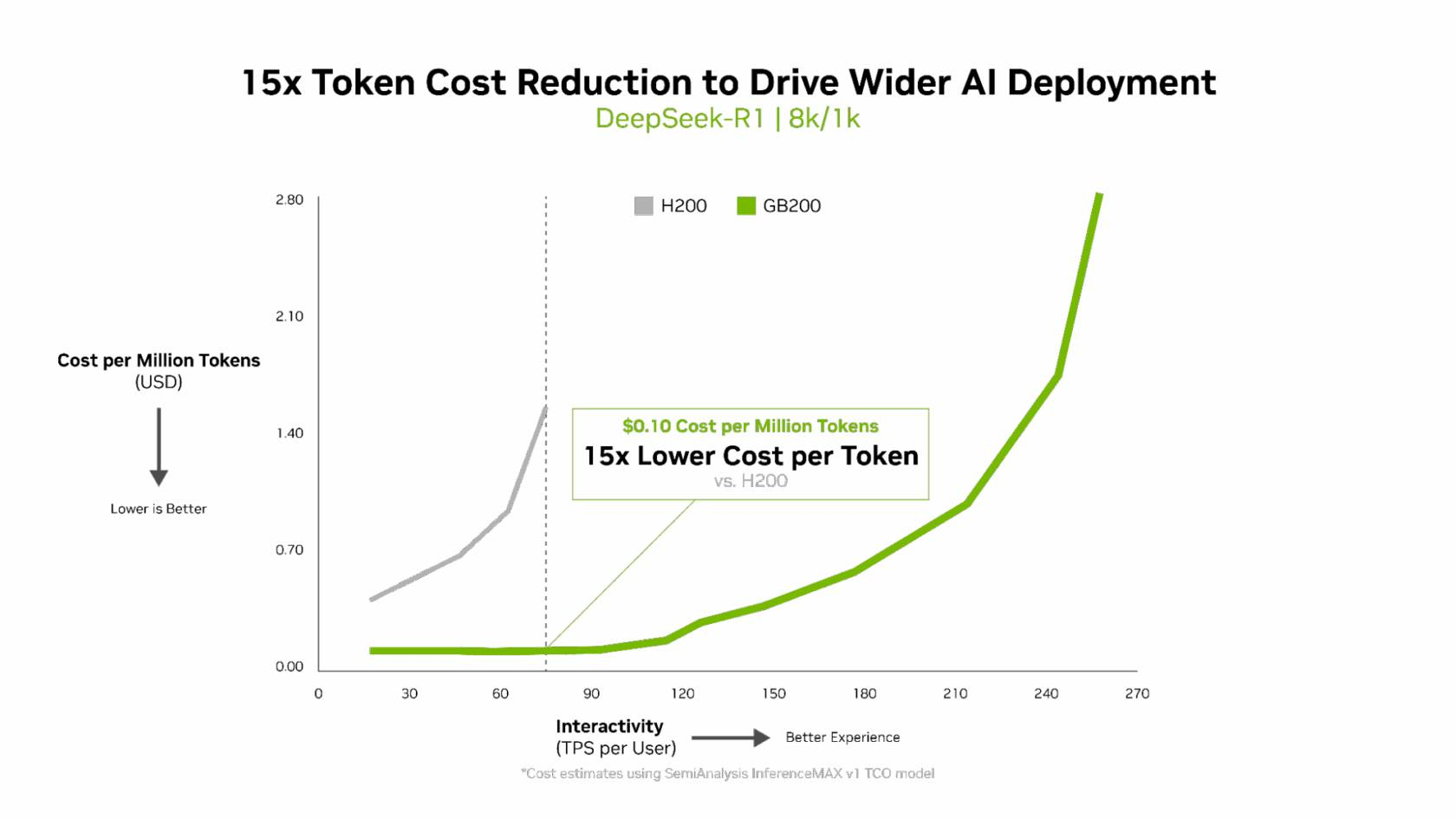 Компания отметила, что ИИ переходит от экспериментальных пилотных проектов к ИИ-фабрикам — инфраструктуре, которая производит интеллектуальные решения, преобразуя данные в токены и решения в режиме реального времени. Фреймворк NVIDIA Think SMART помогает предприятиям ориентироваться в этом переходе, демонстрируя, как полнофункциональная платформа инференса обеспечивает измеримую окупаемость инвестиций. Обещая 15-кратную окупаемость инвестиций и непрерывный рост производительности за счёт ПО, NVIDIA не просто лидирует в текущей гонке ИИ-технологий, но и задаёт правила для следующего этапа, где экономика будет определять победителей рынка, пишет The Tech Buzz. Для предприятий, делающих ставку на конкурирующие платформы в своих стратегиях по развёртыванию ИИ, результаты таких бенчмарков должны побудить к пересмотру выбора ИИ-инфраструктуры.
21.09.2025 [13:23], Сергей Карасёв
В Германии запущена квантово-классическая система с суперчипами NVIDIA GH200Компании Quantum Machines и Arque Systems развернули в Юлихском суперкомпьютерном центре в Германии (Jülich Supercomputing Centre, JSC) гибридную квантово-классическую вычислительную систему на платформе NVIDIA DGX Quantum. Это первый подобный проект, реализованный на базе крупной НРС-площадки в Европе. Новая система сочетает суперчипы NVIDIA GH200, 5-кубитный квантовый процессор Arque Systems и гибридный квантово-классический контроллер Quantum Machines OPX1000. Использованная архитектура, как утверждается, обеспечивает возможность квантовой коррекции ошибок (QEC), что является критически важным требованием при организации практических квантовых вычислений. Контроллер OPX1000, как отмечается, обеспечивает бесшовное взаимодействие между классическими и квантовыми вычислительными ресурсами. Достигается двусторонняя передача данных с задержкой менее 4 мкс, что в 1000 раз лучше, чем в предыдущих подобных реализациях. 
Источник изображения: Arque Systems Ключевыми задачами проекта названы ускорение процедур калибровки кубитов и тестирование производительности квантовой коррекции ошибок. Кроме того, на базе комплекса планируется осуществлять разработку гибридных квантово-классических вычислительных алгоритмов. Одним из главных преимуществ платформы названа возможность запуска нейронных сетей и моделей машинного обучения на высокопроизводительных GPU с сохранением взаимодействия с квантовой подсистемой с низкой задержкой. Такой уровень интеграции, как подчёркивается, недоступен ни в одной другой современной системе квантовых вычислений. «Объединяя квантовые и классические вычислительные ресурсы на базе ведущего европейского суперкомпьютерного центра, мы открываем новые возможности для исследователей в плане изучения гибридных квантово-классических алгоритмов», — говорит доктор Кристель Михильсен (Kristel Michielsen), директор JSC. Нужно отметить, что JSC является оператором первого в Европе экзафлопсного суперкомпьютера — машины JUPITER, которая была официально запущена в эксплуатацию в сентябре 2025 года. Система использует примерно 6000 вычислительных узлов с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200 (4×200G на узел, DragonFly+): в общей сложности задействованы почти 24 тыс. NVIDIA GH200.
19.09.2025 [01:45], Владимир Мироненко
Microsoft вот-вот достроит «самый передовой» ИИ ЦОД в мире Fairwater и потратит $4 млрд на ещё один такой жеMicrosoft заявила, что находится на завершающей стадии строительства дата-центра Fairwater в Маунт-Плезант (Mount Pleasant) в Висконсине (США) стоимостью $3,3 млрд, который она называет самым передовым ИИ ЦОД в мире, пишет газета The Wall Street Journal. Ранее сообщалось, что Microsoft приостановила вторую фазу проекта, чтобы провести переоценку планов. Вице-председатель и президент Microsoft Брэд Смит (Brad Smith) сообщил, что объект будет запущен в эксплуатацию в начале 2026 года и первоначально будет использоваться для обучения моделей компании OpenAI, к которой затем могут присоединиться и другие арендаторы, включая саму Microsoft. Неподалёку будет построен ещё один ИИ ЦОД таких же масштабов, на который компания выделит в течение следующих трёх лет $4 млрд. Третий ЦОД семейства Fairwater появится в Джорджии. По словам Смита, сочетание вычислительной мощности ускорителей NVIDIA с сетевыми и системными решениями сделает проекты «поистине передовыми», что позволит обучать продвинутые как никогда ИИ-модели. 
Источник изображений: Microsoft ЦОД в Висконсине занимает площадь в 127,5 Га и включает три двухэтажных здания (это упростит развёртывание сети) общей площадью 111,5 тыс. м 2. Для его строительства потребовалось 74,6 км свай фундамента глубокого заложения, 112 тыс. т металлоконструкций, 190 км подземного кабеля среднего напряжения и 112,6 км трубопроводов. Впрочем, признаёт компания, им повезло, что хоть какая-то базовая инфраструктура на участке уже была создана усилиями бывшего владельца кампуса — Foxconn.  Microsoft сообщила, что в ЦОД будут размещены сотни тысяч ускорителей NVIDIA GB200, соединённых оптоволокном (800G InfiniBand/Ethernet), которого хватило бы, чтобы «обернуть планету четыре раза». Производительность ЦОД будет в десять раз выше, чем у самых быстрых современных суперкомпьютеров, утверждает компания, не предоставляя дополнительных подробностей.  ЦОД отличается передовой системой охлаждения. Более 90 % оборудования объекта будет обслуживаться замкнутой системой СЖО, которая будет заполнена на этапе строительства и, по словам компании, не потребует дозаправки. Остальная часть серверного оборудования будет использовать охлаждение наружным воздухом, а вода будет потребляться лишь в самые жаркие дни. В результате общее годовое потребление воды одним ЦОД на территории кампуса будет примерно эквивалентно расходу воды обычного ресторана за этот же период.  Для питания ЦОД будут заключены соглашения о закупках электроэнергии (PPA) из возобновляемых источников. Microsoft также финансирует новый проект солнечной электростанции мощностью 250 МВт, строительство которой в настоящее время ведётся в округе Портидж (Portage). Ожидается, что в первом ЦОД штат составит около 500 сотрудников, а после завершения строительства второго дата-центра их количество вырастет до 800.
01.09.2025 [23:40], Руслан Авдеев
Meta✴ «растянула» суперускорители NVIDIA GB200 NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждениемДля того, чтобы развернуть в традиционных ЦОД с воздушным охлаждением современные высокоплотные стойки с ИИ-ускорителями, приходится идти на ухищрения. Один из вариантов предложила Meta✴, передаёт Wccftech. Хотя у Meta✴ есть собственный полноценный вариант суперускорителя NVIDIA GB200 NVL72 на базе ORv3-стоек Catalina (до 140 кВт) со встроенными БП и ИБП, компания также разработала также вариант, схожий с конфигурацией NVL36×2, от производства которого NVIDIA отказалась, посчитав его недостаточно эффективным. Ускоритель NVL36×2 задумывался как компромиссный вариант для ЦОД с воздушным охлаждением — одна стойка (плата Bianca, 72 × B200 и 36 × Grace) «растянута» на две. 
Источник изображений: Meta✴ via Wccftech Meta✴ пошла несколько иным путём. Она точно так же использует две стойки, одна конфигурация узлов другая. Если в версии NVIDIA в состав одно узла входят один процессор Grace и два ускорителя B200, то у Meta✴ соотношение CPU к GPU уже 1:1. Все вместе они точно так же образуют один домен с 72 ускорителями, но объём памяти LPDDR5 в два раза больше — 34,6 Тбайт вместо 17,3 Тбайт. Эту пару «обрамляют» четыре стойки — по две с каждый стороны. Для охлаждения CPU и GPU по-прежнему используется СЖО, теплообменники которой находятся в боковых стойках и продуваются холодным воздухом ЦОД. 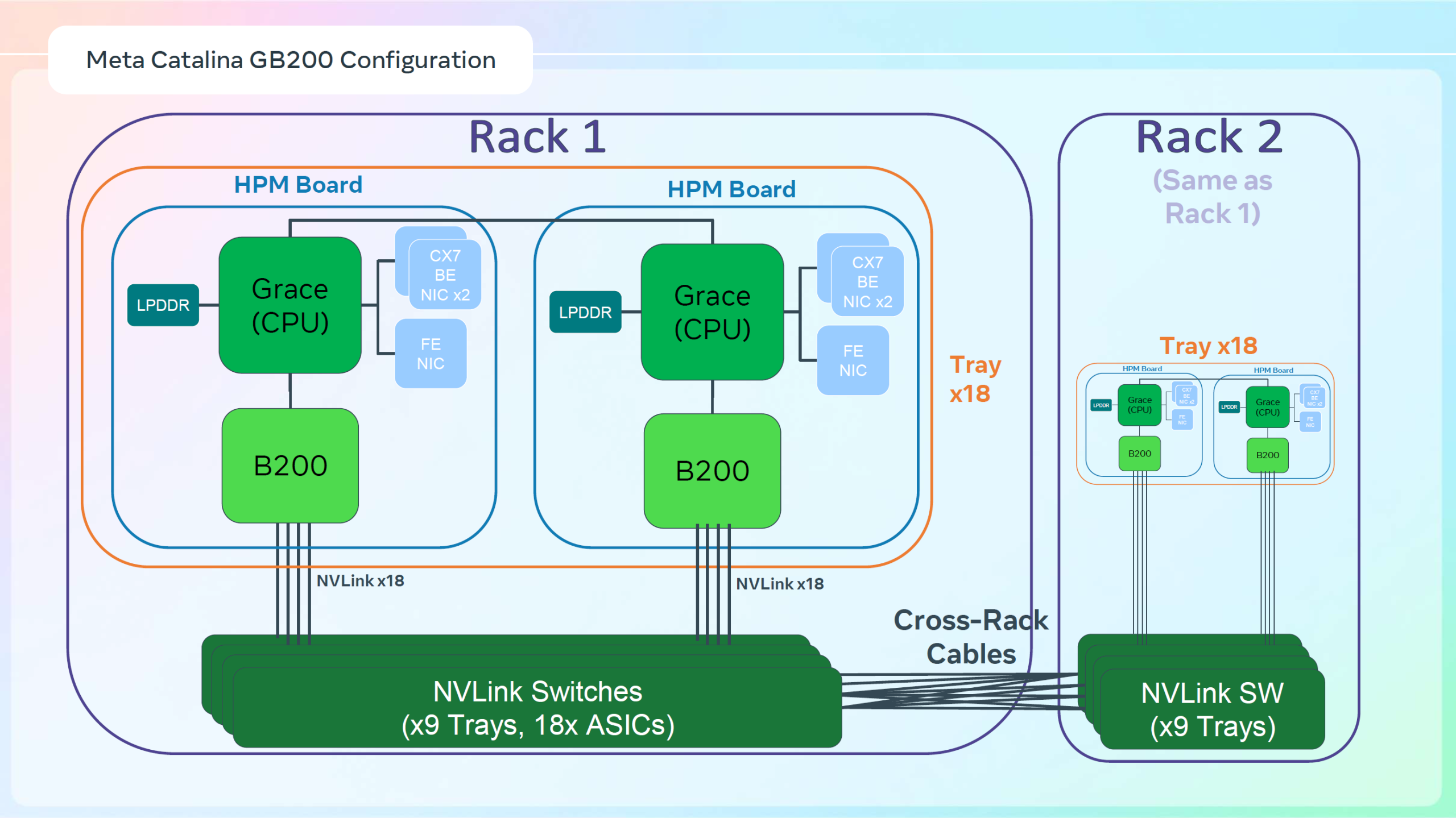 Это далеко не самая эффективная с точки зрения занимаемой площади конструкция, но в случае гиперскейлеров оплата в арендуемых дата-центрах нередко идёт за потребляемую энергию, а не пространство. В случае невозможности быстро переделать собственные ЦОД или получить площадку, поддерживающую высокоплотную энергоёмкую компоновоку стоек и готовую к использованию СЖО, это не самый плохой вариант. В конце 2022 года Meta✴ приостановила строительство около дюжины дата-центров для пересмотра их архитектуры и внедрения поддержки ИИ-стоек и СЖО. Первые ЦОД Meta✴, построенные по новому проекту, должны заработать в 2026 году, передаёт DataCenter Dynamics. 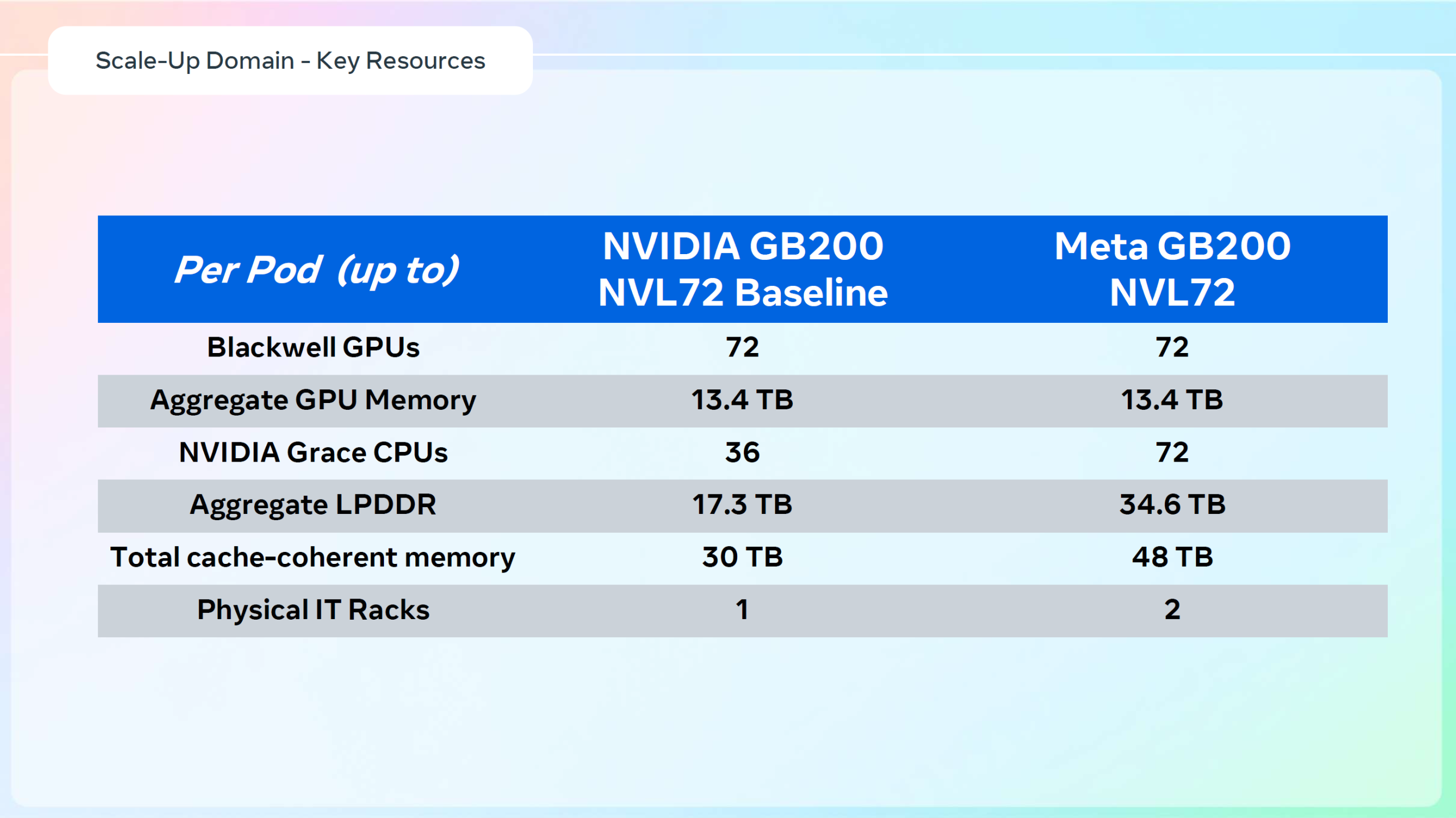 На сегодня у Meta✴ около 30 действующих или строящихся кампусов ЦОД, большей частью на территории США. Планируются ещё несколько кампусов, включая гигаваттные. Также компания выступает крупным арендатором дата-центров, а сейчас в пылу гонки ИИ и вовсе переключилась на быстровозводимые тенты вместо капитальных зданий, лишённые резервного питания и традиционных систем охлаждения.  Собственные версии GB200 NVL72 есть у Google, Microsoft и AWS. Причём все они отличаются от эталонного варианта, который среди крупных игроков, похоже, использует только Oracle. Так, AWS решила разработать собственную СЖО, в том числе из-за того, что ей жизненно необходимо использовать собственные DPU Nitro. Google ради собственного OCS-интерконнекта «пристроила» к суперускорителю ещё одну стойку с собственным оборудованием. Microsoft же аналогично Meta✴ добавила ещё одну стойку с теплообменниками и вентиляторами.
23.07.2025 [15:46], Руслан Авдеев
Илон Маск объявил, что ИИ-суперкомпьютер xAI Colossus 2 запустят в ближайшие неделиОснователь ИИ-стартапа xAI Илон Маск (Elon Musk) поделился в социальной сети X информацией о будущем второго кампуса ЦОД в Мемфисе (Теннесси). В числе прочего он объявил намерении запустить в эксплуатацию суперкомпьютер Colossus 2 в ближайшие недели, сообщает Commercial Appeal. По его словам, Colossus 2 получит 550 тыс. ИИ-ускорителей. Компания располагает в городе двумя кампусами — Colossus 1 и Colossus 2. Первый расположен на территории бывшего завода Electrolux и включает 230 тыс. укорителей, в том числе 30 тыс. NVIDIA GB200. Система используется только для обучения, инференс осуществляется в облаках партнёров xAI. Второй кампус, Colossus 2 на площадке Тулейн-роуд (Tulane Road), на первом этапе получит 110 тыс. GB200 и GB300, что потребует 170 МВт энергии. Он должен начать работу в течение нескольких недель. Сроки развёртывания оставшихся 440 тыс. ускорителей не определены, поскольку поставки NVIDIA GB300 задерживаются. В феврале дочерняя структура xAI, компания CTC Property, купила более 75 га вдоль Тулейн-роуд за $70,9 млн. С тех пор, как xAI объявил о планах довести количество ускорителей Colossus до 1 млн, всё чаще возникает вопрос, как именно компания намерена снабжать свой проект энергией. В мае Маск объявил, что Colossus 2 станет первым гигаваттным ИИ-кластером. 15 июля в xAI подтвердили, что компания работает с Memphis Light, Gas and Water (MLGW) и Tennessee Valley Authority (TVA) над обеспечением объекта питанием. MLGW подтвердила, что у неё есть договор на поставку 500 кВт объекту xAI на Тулейн-роуд. 
Источник изображения: X/@elonmusk А 16 июля MXZ Tech LLC, дочерняя компания xAI, приобрела территорию бывшей электростанции Duke Energy (46 га) неподалёку от кампуса Colossus 2. Этот объект сохранил подключение к энергосети TVA. Кроме того, кампус Colossus 2 уже получил 168 модулей Tesla Megapacks. По-видимому, этот кампус тоже не обойдётся без газовых турбин, и использование которых для питания Colossus 1 вызвало недовольство местных экоактививстов NAACP и SELC. Впрочем, пока непонятно, состоится ли серьёзное разбирательство. 
Источник изображения: X/@elonmusk Совсем недавно Илон Маск сообщил о намерении ввести в эксплуатацию эквивалент 50 млн NVIDIA H100 в течение пяти лет — это ответ на недавнее заявление OpenAI о намерении освоить более 1 млн ускорителей к концу текущего года, а в будущем получить в своё распоряжение 100 млн ускорителей. Сейчас xAI намерена найти ещё $12 млрд на закупку ускорителей.
20.07.2025 [14:26], Сергей Карасёв
NVIDIA приступила к производству ИИ-ускорителей GB300Компания NVIDIA, по сообщению DigiTimes, приступила к ограниченному производству суперчипов Grace Blackwell GB300 для ресурсоёмких ИИ-нагрузок. Ожидается, что поставки изделия будут организованы в сентябре с постепенным наращиванием объёмов выпуска. Решение GB300 представляет собой связку из Arm-процессора Grace с 72 ядрами Neoverse V2 и двух чипов Blackwell Ultra. В оснащение входят 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Ускоритель GB300 является основой стоечной системы GB300 NVL72, которая насчитывает 36 чипов Grace и 72 процессора Blackwell Ultra. ИИ-производительность такого комплекса достигает 720 Пфлопс на операциях FP8/FP6. «На данном этапе серьёзных проблем с GB300 нет. Поставки должны идти гладко со II половины года», — подчеркнули представители одного из ODM-производителей. 
Источник изображения: NVIDIA Вместе с тем, как отмечается, сохраняется высокий спрос на ускорители GB200. Заказчики продолжают закупать эти изделия, несмотря на сложности с охлаждением. Огромная вычислительная мощность и повышенная плотность компоновки серверов обусловили необходимость применения жидкостных систем отвода тепла. Однако при этом возникли проблемы протечек. Оказалось, что во многих случаях это связано с быстроразъёмными соединениями, которые не всегда удовлетворяют нужным требованиям — даже после стресс-тестирования на заводе. ODM-производители отмечают, что реальные условия эксплуатации сильно различаются по давлению воды и конструкции трубопроводов, что затрудняет полное исключение протечек. Послепродажное обслуживание требует значительных временных и финансовых затрат. В случае GB200 основные сложности были обусловлены переходом от архитектуры Hopper к Blackwell, что привело к комплексным изменениям на уровне платформы. С другой стороны, GB300 использует существующую инфраструктуру, а поэтому, как ожидается, серьёзных проблем при выпуске и поставках этих изделий не возникнет. ODM-производители, которые в настоящее время активно тестируют GB300, говорят об обнадёживающих результатах. Предполагается, что переход пройдёт гладко: массовые поставки запланированы на III квартал с увеличением объёмов выпуска в последней четверти текущего года. Новые вызовы может создать появление ускорителей следующего поколения семейства Rubin, которые придут на смену Blackwell Ultra во II половине 2026 года. Эта платформа предполагает использование чиплетов и полностью новой стойки Kyber (для VR300 NVL 576), которая заменит нынешнюю конструкцию Oberon. Плотность компоновки возрастёт до 600 кВт на стойку, что потребует ещё более надёжных систем охлаждения. Отмечается, что применение СЖО станет обязательным для суперускорителей Rubin. Вместе с тем с восстановлением производства ослабленных ускорителей H20, которые США вновь разрешили поставлять в Китай, возможны проблемы. Как передаёт Reuters со ссылкой на The Information, TSMC успела переключить производственные линии, которые использовались для H20, на выпуск других продуктов. Полное восстановление производства H20 может занять девять месяцев.
16.07.2025 [08:58], Руслан Авдеев
Разработка AWS собственной СЖО для NVIDIA GB200 NVL72 привела к падению акций VertivГиперскейлер Amazon Web Services (AWS) разработал собственную систему охлаждения для последнего поколения ускорителей NVIDIA. Ранее в этом месяце облачный гигант начал внедрение систем UltraServer на основе NVIDIA GB200 NVL72, поэтому переход на жидкостное охлаждение стал необходим, сообщает Datacenter Dynamics. Вице-президент AWS Дэвид Браун (David Brown) заявил, что для поддержки «невероятных вычислительных мощностей» стойкам GB200 NVL72 пришлось перейти на СЖО. По его словам, ранее компания обходилась воздушным охлаждением, речь идёт о первом масштабном внедрении жидкостных систем в AWS. При этом AWS рассматривала возможность обратиться к сторонним разработчикам СЖО, но решила отказаться от идеи, поскольку она потребовала бы строительства полностью новых ЦОД, рассчитанных на такие системы охлаждения. Это привело бы к задержкам внедрения на несколько лет. 
Источник изображения: AWS Альтернативой были полностью готовые решения для жидкостного охлаждения, но они не подходили из-за проблем с масштабируемостью: занимали слишком много места в ЦОД, требовали значительных переделок инфраструктуры или значительно увеличивали расход воды. Вместо этого компания разработала собственный теплообменник In Row Heat Exchanger (IRHX), который можно использовать без серьёзных изменений существующей инфраструктуры. IRHX состоит из блока распределения теплоносителя, насосного блока и теплообменников с вентиляторами. Охлаждающая жидкость к водоблокам, совместно разработанным AWS и NVIDIA. IRHX легко масштабируется, позволяя по необходимости убирать или добавлять внутренние теплообменники. 
Источник изображения: AWS Ранее AWS похвасталась, что у неё ушло четыре месяца на переход от набросков к первому прототипу прототипам и ещё 11 месяцев — на переход к массовому производству. AWS не впервые разрабатывает собственное оборудование. Компания имеет собственные чипы семейств Graviton, Tranium и Inferentia, а в прошлом году она представила серию решений для дата-центров для обеспечения выполнения связанных с ИИ задач нового поколения. После новости об использовании AWS собственных решений, акции Vertiv, поставляющей различные системы охлаждения для ЦОД, упали в цене. По данным Bloomberg Intelligence, разработки Amazon могут негативно сказаться на перспективах роста бизнеса Vertiv, поскольку она является крупным клиентом компании. Около 10 % всех продаж Vertiv связаны с жидкостным охлаждением.
11.07.2025 [09:09], Сергей Карасёв
В облаке AWS появились инстансы EC2 P6e-GB200 UltraServer на базе ИИ-суперускорителей NVIDIA GB200 NVL72Облачная платформа AWS объявила о доступности высокопроизводительных инстансов EC2 P6e-GB200 UltraServer, рассчитанных на наиболее ресурсоёмкие нагрузки ИИ. В основу экземпляров положены суперускорители NVIDIA GB200 NVL72. Система GB200 NVL72 объединяет в одной стойке 18 узлов 1U, каждый из которых содержит два ускорителя GB200, что даёт в общей сложности 72 чипа B200 и 36 процессоров Grace. Задействована шина NVLink 5. Инстансы u-p6e-gb200-x72 предоставляют доступ к 72 чипам поколения Blackwell в одном домене NVLink, включая примерно 13,4 Тбайт памяти HBM3e. Производительность в режиме FP8 достигает 360 Пфлопс. Количество vCPU составляет до 2592, объём памяти — до 17 280 ГиБ. Кроме того, предоставляется до 405 Тбайт пространства для хранения данных. Используются адаптеры AWS Elastic Fabric Adapter (EFAv4) с низкой задержкой, агрегированной скоростью передачи данных 28,8 Тбит/с и поддержкой NVIDIA GPUDirect RDMA. Пропускная способность EBS достигает 1080 Гбит/с. Также доступны u-p6e-gb200-x36 с вдвое меньшими характеристиками. 
Источник изображений: AWS Применяется система AWS Nitro, которая переносит функции виртуализации, хранения и сетевые операции на выделенное оборудование и ПО для повышения производительности и улучшения безопасности. Инстансы EC2 P6e-GB200 UltraServer объединяются в кластеры EC2 UltraCluster, что обеспечивает возможность безопасного и надёжного масштабирования до десятков тысяч ускорителей. 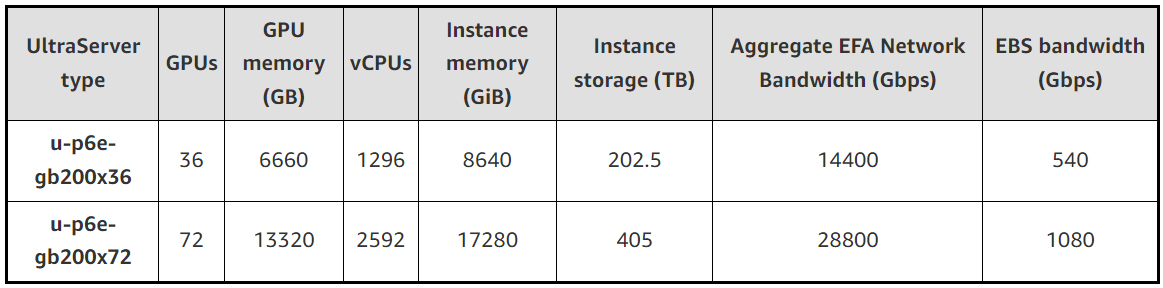 AWS отмечает, что новые экземпляры подходят для работы с передовыми ИИ-моделями, насчитывающими триллионы параметров. При этом может использоваться сочетание экспертных и рассуждающих моделей. После резервирования ёмкости стоимость за инстанс списывается авансом, и цена не меняется после оплаты.
02.07.2025 [08:35], Руслан Авдеев
Arm-чипы захватывают рынок, но до доминирования в ЦОД им пока далекоСерверы на базе Arm-чипов стремительно набирают популярность — в 2025 году их поставки должны вырасти на 70 %. Тем не менее, этого не хвататит, чтобы к концу года добиться планируемого Arm Holdings охвата рынка в 50 %, сообщает The Register. Аналитики IDC утверждают, что Arm-серверы пользуются массовым спросом в основном благодаря стоечным системам вроде NVIDIA GB200 NVL72. В новейшем отчёте Worldwide Quarterly Server Tracker эксперты IDC подсчитали, что в текущем году на Arm-серверы придётся 21,1 % от общего объёма мировых поставок. Ожидается, что поставки серверов с хотя бы одним ИИ-ускорителем вырастут на 46,7 %, на них придётся в текущем году около половины рыночной стоимости. Всего за три года, по оценкам IDC, рынок серверов должен вырасти втрое благодаря гиперскейлерам и облачным провайдерам. В целом рынок серверов достиг в I квартале 2025 года $95,2 млрд, увеличившись год к году на 134,1 %. В результате IDC повысила прогноз на год до $366 млрд, на 44,6 % выше год к году — исторический максимум для данного сегмента. При этом поставки «стандартных» x86-серверов должны вырасти в 2025 году на 39,9 % до $283,9 млрд. При этом доля AMD непрерывно растёт. Сегмент альтернативных систем вырастет на 63,7 % год к году, а их общий прогнозируемый объём составит $82 млрд. 
Источник изображения: NVIDIA / CoreWeave По прогнозам IDC, наибольший рост, на 59,7 % год к году ожидается в США. К концу 2025 года на данный рынок будет приходиться почти 62 % общей выручки от продаж серверов. Ещё одной точкой роста является Китай. IDC прогнозирует рост на 39,5 % — более 21 % квартального дохода во всём мире. Регионы EMEA и Латинская Америка могут рассчитывать на 7 % и 0,7 % соответственно, а Канаду, вероятно, ожидает спад на 9,6 % из-за некой «очень крупной сделки» 2024 года. В IDC подчёркивают, что спрос на большие вычислительные мощности для ИИ, вероятно, сохранится — эволюция от старых чат-ботов к рассуждающим моделям и агентному ИИ потребует роста производительности на несколько порядков, особенно для инференса. |
|