Материалы по тегу: nvidia
|
14.10.2025 [20:58], Владимир Мироненко
Oracle анонсировала крупнейший в мире зеттафлопсный ИИ-кластер OCI Zettascale10: до 800 тыс. ускорителей NVIDIA в нескольких ЦОД
800gbe
ethernet
hardware
hpc
nvidia
oracle
oracle cloud infrastructure
stargate
ии
интерконнект
кластер
сша
цод
Oracle анонсировала облачный ИИ-кластер OCI Zettascale10 на базе сотен тысяч ускорителей NVIDIA, размещённых в нескольких ЦОД, который имеет пиковую ИИ-производительность 16 Зфлопс (точность вычислений не указана). OCI Zettascale10 — это инфраструктура, на которой базируется флагманский ИИ-суперкластер, созданный совместно с OpenAI в техасском Абилине (Abilene) в рамках проекта Stargate и основанный на сетевой архитектуре Oracle Acceleron RoCE нового поколения. OCI Zettascale10 использует NVIDIA Spectrum-X Ethernet — первую, по словам NVIDIA, Ethernet-платформу, которая обеспечивает высокую масштабируемость, чрезвычайно низкую задержку между ускорителями в кластере, лидирующее в отрасли соотношение цены и производительности, улучшенное использование кластера и надежность, необходимую для крупномасштабных ИИ-задач. Как отметила Oracle, OCI Zettascale10 является «мощным развитием» первого облачного ИИ-кластера Zettascale, который был представлен в сентябре 2024 года. Кластеры OCI Zettascale10 будут располагаться в больших кампусах ЦОД мощностью в гигаватты с высокоплотным размещением в радиусе двух километров, чтобы обеспечить наилучшую задержку между ускорителями для крупномасштабных задач ИИ-обучения. Именно такой подход выбран для кампуса Stargate в Техасе. Oracle отметила, что помимо возможности создавать, обучать и развёртывать крупнейшие ИИ-модели, потребляя меньше энергии на единицу производительности и обеспечивая высокую надёжность, клиенты получат свободу работы в распределённом облаке Oracle со строгим контролем над данными и суверенитетом ИИ. 
Источник изображения: OpenAI Изначально кластеры OCI Zettascale10 будут рассчитаны на развёртывание до 800 тыс. ускорителей NVIDIA, обеспечивая предсказуемую производительность и высокую экономическую эффективность, а также высокую пропускную способность между ними благодаря RoCEv2-интерконнекту Oracle Acceleron со сверхнизкой задержкой. Acceleron предлагает 400G/800G-подключение со сверхнизкой задержкой, двухуровневую топологию, множественное подключение одного NIC к нескольким коммутатором с физической и логической изоляцией сетевых потоков, поддержку LPO/LRO и гибкость конфигурации. DPU Pensando от AMD в Acceleron место тоже нашлось. 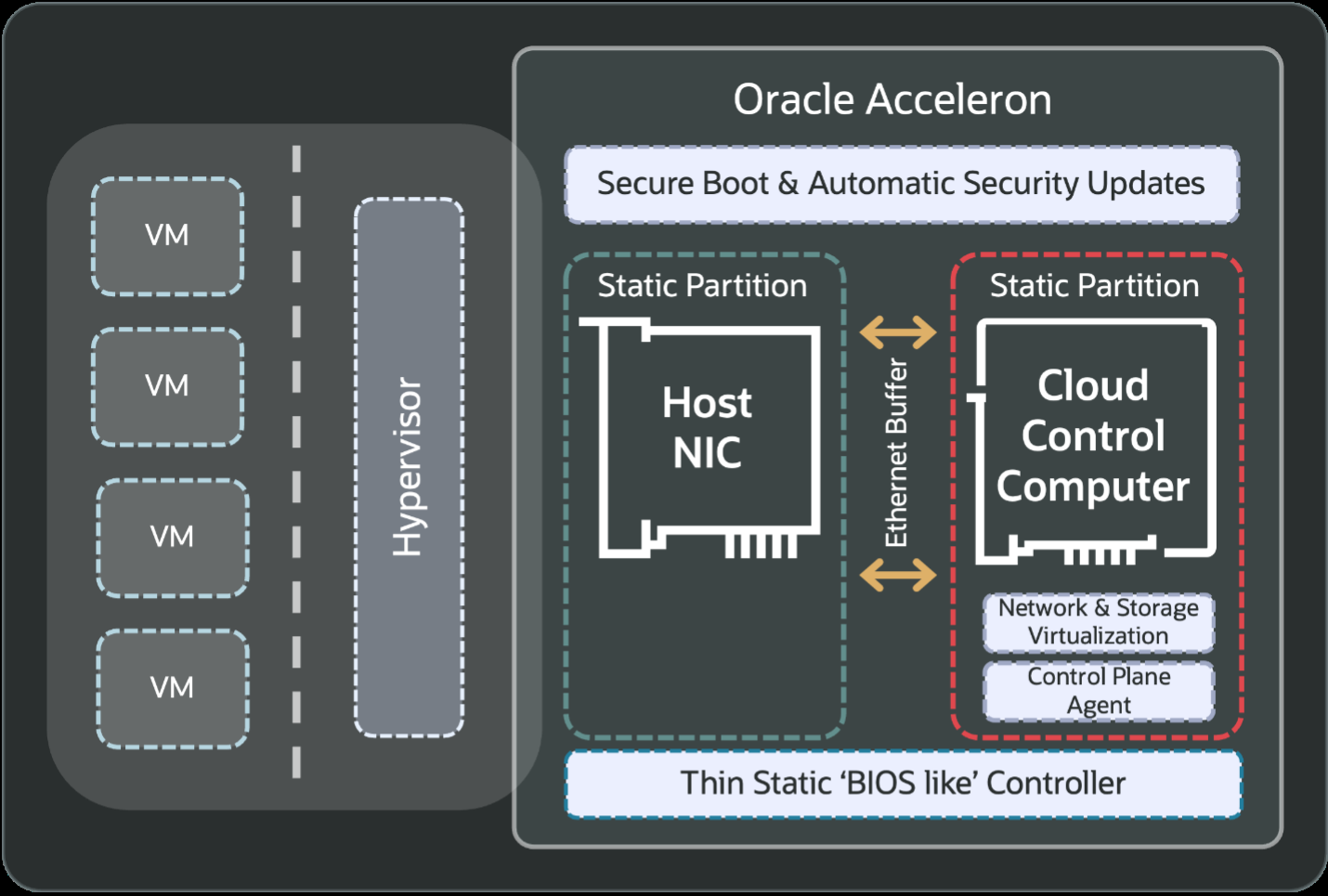
Источник изображения: Oracle OCI уже принимает заказы на OCI Zettascale10, который поступит в продажу во II половине следующего календарного года. В августе NVIDIA анонсировала решение Spectrum-XGS Ethernet для объединения нескольких ЦОД в одну ИИ-суперфабрику, которым, по-видимому, воспользуется не только Oracle, но и Meta✴.
14.10.2025 [17:24], Руслан Авдеев
ABB поддержит NVIDIA во внедрении 800 В питания для мегаваттных ИИ-стоекКомпания ABB Group, специализирующаяся на электрификации и автоматизации, объявила об ускоренной разработке новых решений для дата-центров совместно с NVIDIA. В первую очередь речь идёт о создании и внедрении передовых энергетических решений, необходимых для эффективной и масштабируемой подачи энергии, сообщает пресс-служба ABB. ABB будет развивать платформу 800 В DC для мегаваттных серверных стоек. Прогнозируется, что мировой спрос на ЦОД вырастет с 80 ГВт в 2024 году до около 220 ГВт к 2030 году. Капитальные затраты, по мнению экспертов, превысят $1 трлн, сообщает Dell'Oro Group. На рабочие нагрузки ИИ придётся порядка 70 % этого роста. Чтобы эффективно обеспечивать мощность такого уровня, потребуются новые технологии и архитектура распределения электроэнергии. Будущие ЦОД получат комбинацию источника бесперебойного питания среднего напряжения (MV) и систему распределения постоянного тока в серверных с использованием твердотельных преобразователей, заменяющих классические трансформаторы и иные компоненты. 
Источник изображения: Frames For Your Heart/unsplash.com В ABB заявляют, что компания возглавляет разработку новых технологий распределения электричества, позволяющих создавать дата-центры нового поколения. Утверждается, что она одной из первых стала инвестировать в новые ИБП, DC-системы и твердотельные компоненты. Портфолио решений ABB для дата-центров включает интеллектуальные системы распределения электроэнергии, специальные решения для резервного питания ЦОД, средства цифрового мониторинга и прочие ключевые технологии, обеспечивающие бесперебойную работу оборудования и оптимизирующие использование энергии для ИИ-серверов. Около 40 % научных исследований ABB в сфере электроснабжения приходится на тематики, имеющие решающее значение для ЦОД нового поколения — это касается работ в области электрической архитектуры, систем защиты, распределения постоянного тока и охлаждения. В конце мая сообщалось, что Infineon Technologies объединит усилия с NVIDIA для разработки централизованной архитектуры высоковольтного питания постоянным током (HVDC) на 800 В для нужд ИИ ЦОД.
14.10.2025 [13:26], Руслан Авдеев
«Нервная система» ИИ-фабрик: Meta✴ и Oracle развернут сетевые платформы NVIDIA Spectrum-X Ethernet в своих ЦОДNVIDIA объявила, что Meta✴ и Oracle развернут в своих ИИ ЦОД Ethernet-платформы NVIDIA Spectrum-X. В NVIDIA подчёркивают, что модели на триллионы параметров трансформируют дата-центры в ИИ-фабрики гигаваттного уровня, а лидеры индустрии стандартизируют использование решений Spectrum-X Ethernet в качестве одного из драйверов промышленной революции. По словам компании, речь идёт не просто о быстром Ethernet, а о «нервной системе» ИИ-фабрик, позволяющей гиперскейлерам объединять миллионы ИИ-ускорителей в гигантские кластеры для обучения крупнейших за всю историю моделей. Oracle намерена строить ИИ-гигафабрики из ускорителей NVIDIA Vera Rubin с интерконнектами Spectrum-X Ethernet. В Oracle подчёркивают, что инфраструктура Oracle Cloud «с нуля» строится для ИИ-задач, и партнёрство с NVIDIA способствует лидерству Oracle в сфере ИИ. Использование Spectrum-X Ethernet позволит клиентам связывать миллионы ускорителей и быстрее обучать, внедрять и пользоваться благами генеративных и «рассуждающих» ИИ нового поколения. Meta✴ намерена интегрировать коммутаторы в свою сетевую инфраструктуру для программной платформы Facebook✴ Open Switching System (FBOSS), как раз разработанной для управления и контроля массивами сетевых коммутаторов. Интеграция решений ускорит масштабное внедрение для повышения эффективности ИИ-проектов. Интеграция NVIDIA Spectrum Ethernet в коммутатор Minipack3N и использование FBOSS позволит повысить эффективность и предсказуемость, необходимые для обучения крупнейших в истории ИИ-моделей и доступа к ИИ-приложениям миллионам людей. 
Источник изображения: NVIDIA Платформа NVIDIA Spectrum-X Ethernet включает как собственно коммутаторы Spectrum-X Ethernet, так и адаптеры Spectrum-X Ethernet SuperNIC. Spectrum-X Ethernet уже продемонстрировала рекордную эффективность, позволившую крупнейшему в мире суперкомпьютеру Colossus компании xAI добиться использования 95 % возможной полосы, тогда как обычные Ethernet-платформы обеспечивают лишь 60 %, утверждает NVIDIA. 
Источник изображения: Meta✴ В июне сообщалось, что продажи Ethernet-коммутаторов NVIDIA за год выросли на 760 % благодаря росту спроса на ИИ, а в последнем квартале рост составил +98 %. Акции Arista, одного из ключевых поставщиков коммутаторов для Meta✴, упали после анонса NVIDIA и объявления Meta✴, что коммутаторы Minipack3N теперь используют ASIC Spectrum-4 и производятся Accton.
14.10.2025 [09:54], Сергей Карасёв
Giga Computing представила ИИ-сервер TO86-SD1 на платформе NVIDIA HGX B200Компания Giga Computing, подразделение Gigabyte, анонсировала высокопроизводительный сервер TO86-SD1 для обучения ИИ-моделей, инференса и ресурсоёмких HPC-задач. Новинка выполнена в форм-факторе 8OU в соответствии со стандартом OCP ORv3. Возможна установка двух процессоров Intel Xeon 6500P/6700P (Granite Rapids-SP) с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5 (RDIMM 6400 или MRDIMM 8000). Во фронтальной части предусмотрены отсеки для восьми SFF-накопителей с интерфейсом PCIe 5.0 (NVMe); поддерживается горячая замена. Есть коннектор M.2 2280/22110 для SSD (PCIe 5.0 x4). Упомянута поддержка CXL 2.0. Сервер несёт на борту ИИ-ускорители NVIDIA HGX B200 поколения Blackwell в конфигурации 8 × SXM. Суммарный объём памяти HBM3E составляет 1,4 Тбайт. Доступны 12 слотов PCIe 5.0 x16 для карт расширения FHHL с доступом через лицевую панель корпуса. Говорится о совместимости с NVIDIA BlueField-3 DPU и NVIDIA ConnectX-7 NIC. 
Источник изображения: Giga Computing В оснащение входят контроллер ASPEED AST2600, два сетевых порта 10GbE на базе Intel X710-AT2, выделенный сетевой порт управления 1GbE, разъёмы USB 3.2 Gen1 Type-C, Micro-USB и Mini-DP. Применяется система воздушного охлаждения с четырьмя 92-мм вентиляторами в области материнской платы и двенадцатью 92-мм кулерами в GPU-секции. Диапазон рабочих температур — от +10 до +35 °C. Заявлена совместимость с Windows Server, RHEL, Ubuntu, Citrix, VMware ESXi.
13.10.2025 [00:30], Владимир Мироненко
Вложи $5 млн — получи $75 млн: NVIDIA похвасталась новыми рекордами в комплексном бенчмарке InferenceMAX v1
b200
gb200
hardware
nvidia
open source
semianalysis
бенчмарк
ии
инференс
рекорд
финансы
энергоэффективность
NVIDIA сообщила о результатах, показанных суперускорителем GB200 NVL72, в новом независимом ИИ-бенчмарке InferenceMAX v1 от SemiAnalysis. InferenceMAX оценивает реальные затраты на ИИ-вычисления, определяя совокупную стоимость владения (TCO) в долларах на миллион токенов для различных сценариев, включая покупку и владение GPU в сравнении с их арендой. InferenceMAX опирается на инференс популярных моделей на ведущих платформах, измеряя его производительность для широкого спектра вариантов использования, а результаты может перепроверить любой желающий, говорят авторы бенчмарка. Суперускоритель GB200 NVL72 победил во всех категориях бенчмарка InferenceMAX v1. Чипы NVIDIA Blackwell показали наилучшую окупаемость инвестиций — вложение в размере $5 млн приносят $75 млн дохода от токенов DeepSeek R1, обеспечивая 15-кратную окупаемость (год назад NVIDIA обещала ROI на уровне 700 %). Также ускорители поколения Blackwell отличаются самой низкой совокупной стоимостью владения. например, оптимизация ПО NVIDIA B200 позволила добиться стоимости всего в два цента на миллион токенов на OpenAI gpt-oss-120b, обеспечив пятикратное снижение стоимости одного токена всего за два месяца. NVIDIA B200 первенствовал и по пропускной способности и интерактивности, обеспечив 60 тыс. токенов в секунду на ускоритель и 1 тыс. токенов в секунду на пользователя в gpt-oss с новейшим стеком NVIDIA TensorRT-LLM. NVIDIA сообщила, что постоянно повышает производительность путём оптимизации аппаратного и программного стека. Первоначальная производительность gpt-oss-120b на системе NVIDIA DGX Blackwell B200 с библиотекой NVIDIA TensorRT LLM уже была лидирующей на рынке, но команды NVIDIA и сообщество разработчиков значительно оптимизировали TensorRT LLM для ускорения исполнения открытых больших языковых моделей (LLM). 
Источник изображений: NVIDIA Компания отметила, что выпуск TensorRT LLM v1.0 стал значительным прорывом в повышении скорости инференса LLM благодаря распараллеливанию и оптимизации IO-операций. А у недавно вышедшей модели gpt-oss-120b-Eagle3-v2 используется спекулятивное декодирование — интеллектуальный метод, позволяющий предсказывать несколько токенов одновременно. Это уменьшает задержку и обеспечивает получение ещё более быстрых результатов — пропускная способность выросла втрое, до 100 токенов в секунду на пользователя (TPS/пользователь), а общая производительность на ускоритель выросла с 6 до 30 тыс. токенов. 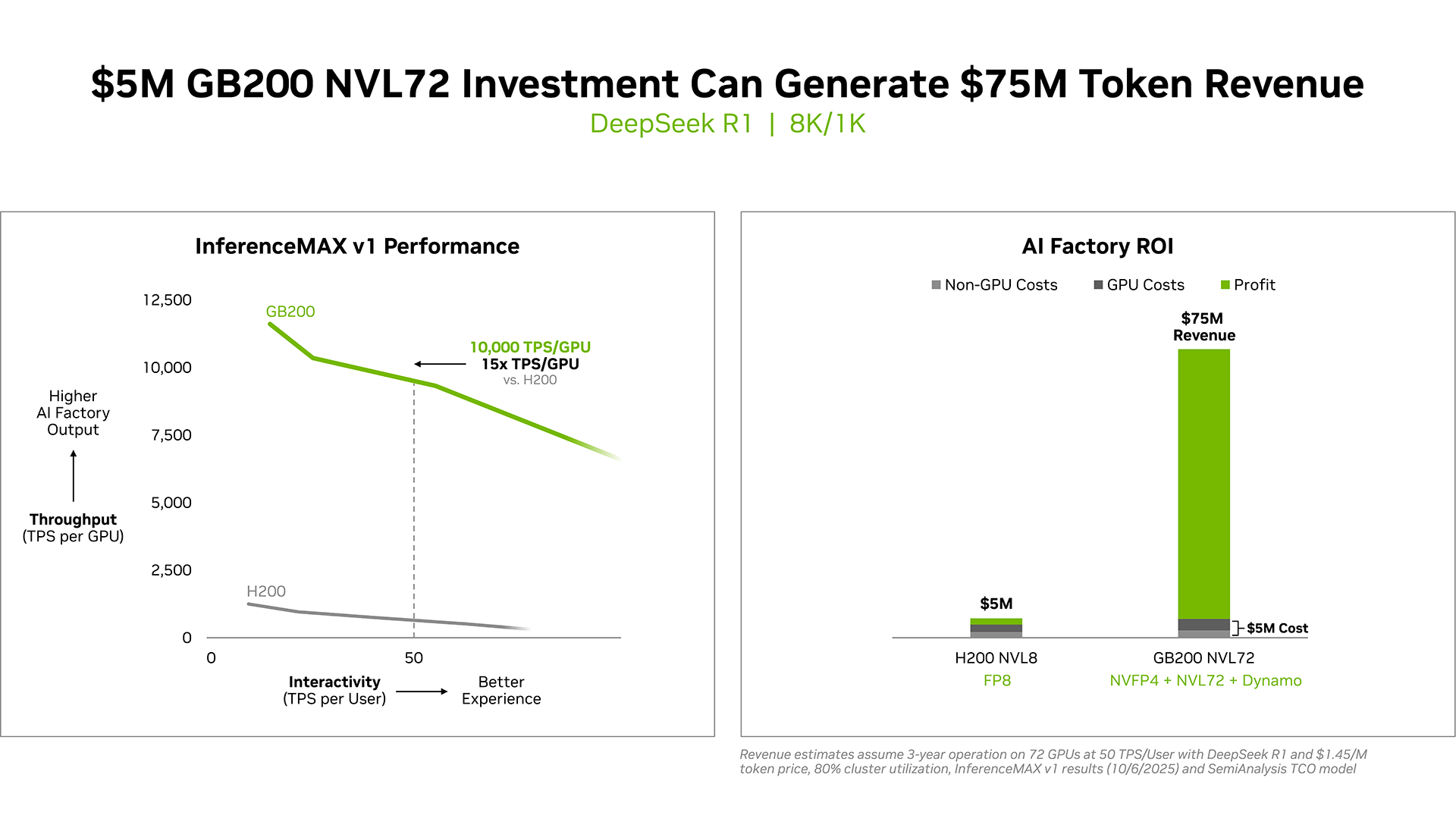 Для моделей с «плотной» архитектурой (Dense AI), таких как Llama 3.3 70b, которые требуют значительных вычислительных ресурсов из-за большого количества параметров и одновременного использования всех параметров в процессе инференса, NVIDIA Blackwell B200 достиг нового рубежа производительности в бенчмарке InferenceMAX v1, отметила NVIDIA. Суперускоритель показал более 10 тыс. токенов/с (TPS) на GPU при 50 TPS на пользователя, т.е. вчетверо более высокую пропускную способность на GPU по сравнению с NVIDIA H200. 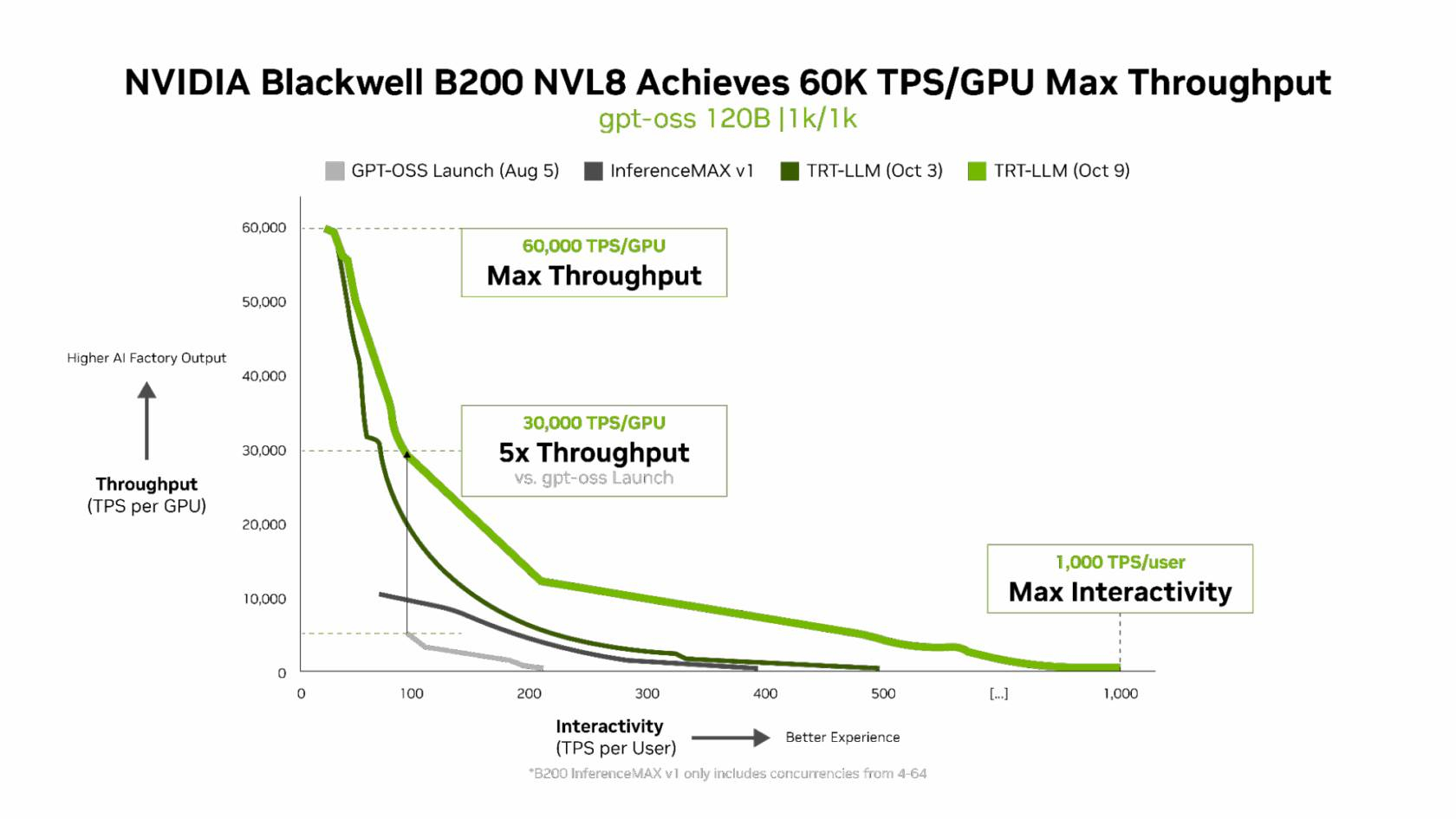 NVIDIA подчеркнула, что такие показатели, как количество токенов на Вт, стоимость на миллион токенов и TPS/пользователь не уступают по важности пропускной способности. Фактически, для ИИ-фабрик с ограниченной мощностью ускорители с архитектурой Blackwell обеспечивают до 10 раз лучшую производительность на МВт по сравнению с предыдущим поколением и позволяют получать более высокий доход от токенов. 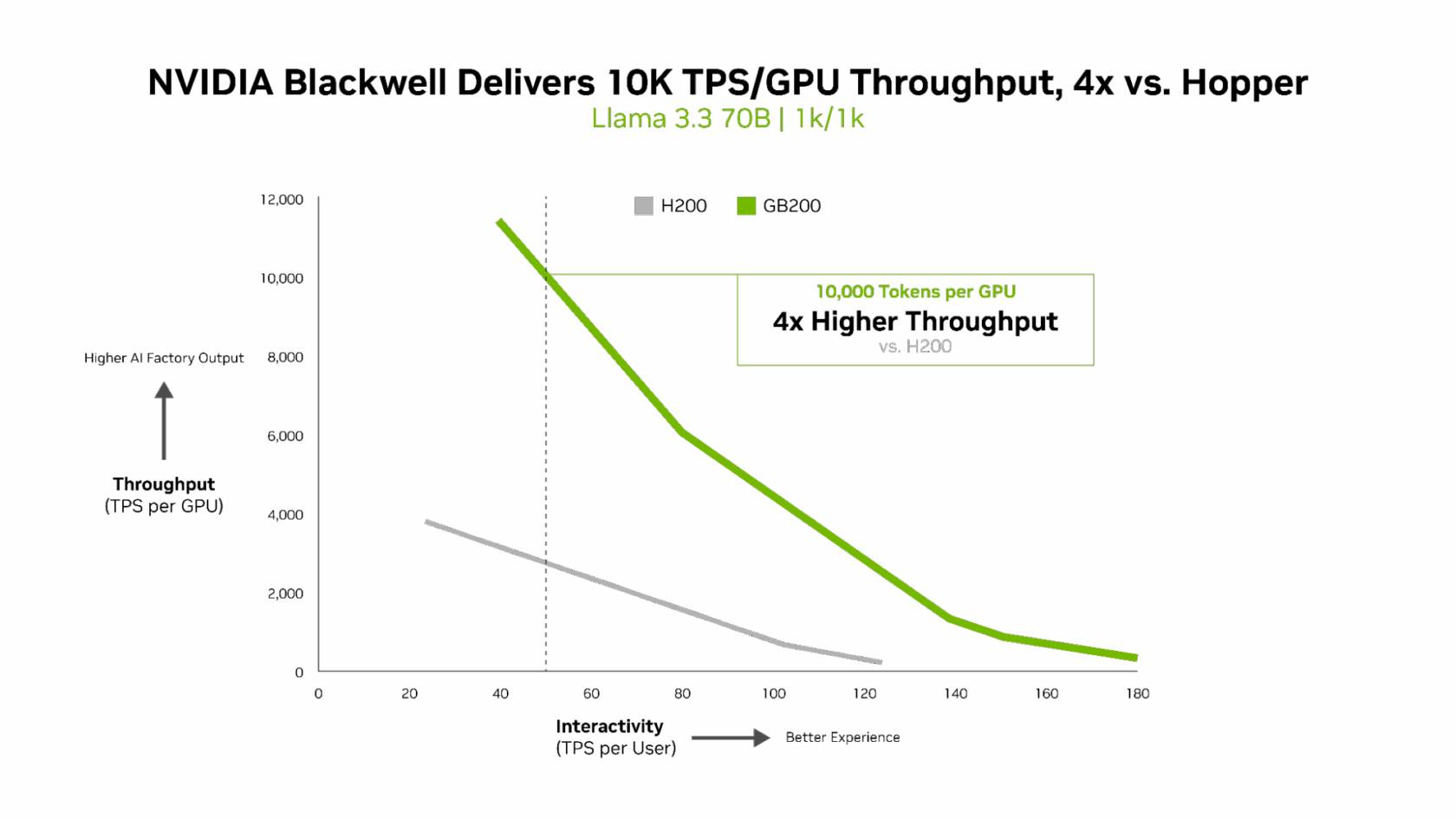 Компания отметила, что стоимость обработки одного токена (Cost per Token) имеет решающее значение для оценки эффективности ИИ-модели и напрямую влияет на эксплуатационные расходы. NVIDIA утверждает, что в целом архитектура NVIDIA Blackwell позволила снизить стоимость обработки миллиона токенов в 15 раз по сравнению с предыдущим поколением. 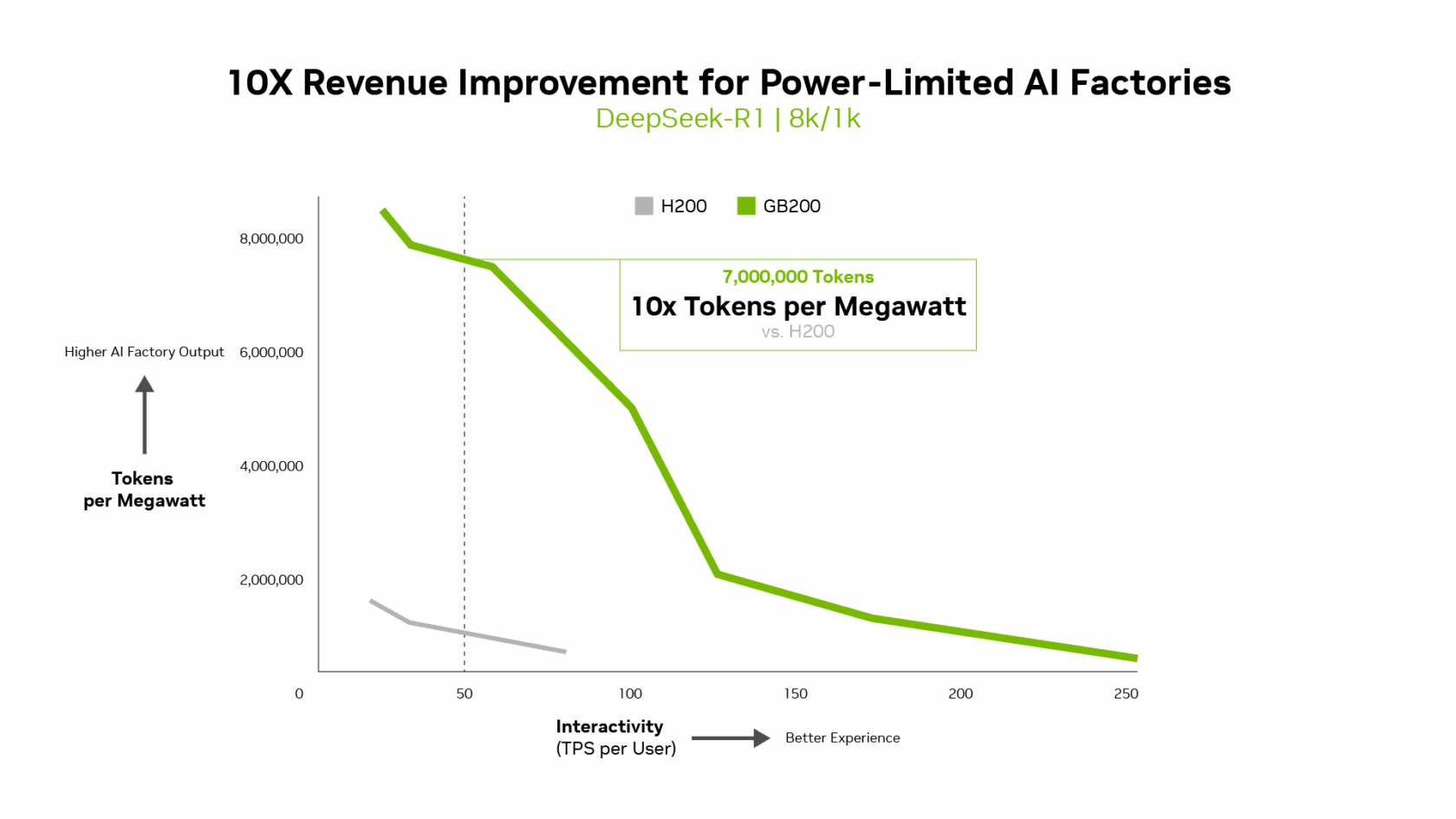 В InferenceMAX используется метод оценки эффективности Pareto front, определяющий наилучшее (компромиссное) сочетание различных факторов для оценки производительности ускорителя. Это показывает, насколько Blackwell лучше конкурентов справляется с балансом стоимости, энергоэффективности, пропускной способности и скорости отклика. Системы, оптимизированные только для одной метрики, могут демонстрировать пиковую производительность «в вакууме», но такая «экономика» не масштабируется в производственных средах. 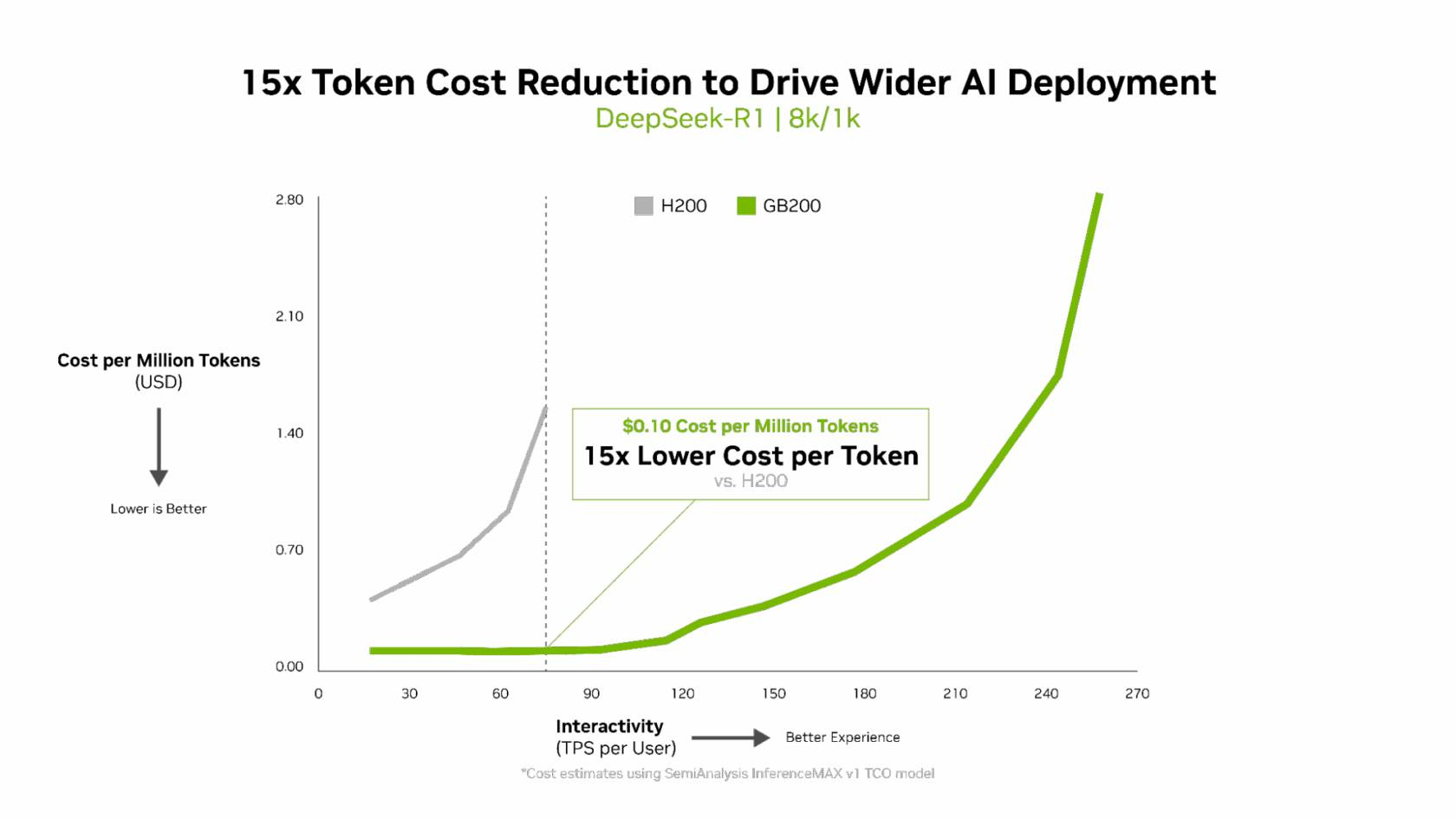 Компания отметила, что ИИ переходит от экспериментальных пилотных проектов к ИИ-фабрикам — инфраструктуре, которая производит интеллектуальные решения, преобразуя данные в токены и решения в режиме реального времени. Фреймворк NVIDIA Think SMART помогает предприятиям ориентироваться в этом переходе, демонстрируя, как полнофункциональная платформа инференса обеспечивает измеримую окупаемость инвестиций. Обещая 15-кратную окупаемость инвестиций и непрерывный рост производительности за счёт ПО, NVIDIA не просто лидирует в текущей гонке ИИ-технологий, но и задаёт правила для следующего этапа, где экономика будет определять победителей рынка, пишет The Tech Buzz. Для предприятий, делающих ставку на конкурирующие платформы в своих стратегиях по развёртыванию ИИ, результаты таких бенчмарков должны побудить к пересмотру выбора ИИ-инфраструктуры.
10.10.2025 [15:25], Владимир Мироненко
Бизнес Oracle по сдаче в аренду ИИ-мощностей оказался не таким прибыльным, как ожидалосьБизнес Oracle по сдаче в аренду ИИ-серверов оказался гораздо менее прибыльным, чем ранее прогнозировали фондовые аналитики, сообщил ресурс The Information после ознакомления со внутренними документами компании, о чём пишет DataCenter Dynamics. Средняя валовая рентабельность Oracle по сделкам с такими компаниями, как OpenAI, составила всего лишь 16 %, хотя выручка за последний год утроилась. Что касается новейших ускорителей NVIDIA, то компания терпит убытки, составившие почти $100 млн от сдачи в аренду чипов Blackwell за I квартал 2026 финансового года, закончившийся в августе. По данным The Information, за последний квартал Oracle выручила $900 млн от сдачи в аренду ИИ-серверов, получив валовую прибыль в размере $125 млн, или 14 центов на каждый доллар продаж. Компания не раскрывает финансовые показатели по использованию ИИ-серверов. На рентабельность влияют различные факторы, включая зарплату, стоимость электроэнергии и другие эксплуатационные расходы ЦОД Oracle, а также амортизационные расходы на оборудование. Кроме того, существует разрыв во времени между покупкой чипов и началом их использования клиентами. 
Источник изображения: Alice Pasqual / Unsplash Oracle сообщила, что на конец I квартала 2026 финансового года благодаря подписанию многомиллиардных контрактов с тремя клиентами объём оставшихся обязательств по контрактам (RPO) составил более $455 млн. Позже выяснилось, что был заключён контракт с OpenAI на $300 млрд. Аналитики полагают, что для финансирования этой сделки Oracle может потребоваться привлечь до $100 млрд заёмных средств в течение следующих четырёх лет для наращивания мощностей. В прошлом месяце Oracle продала серию облигаций инвестиционного уровня на сумму $18 млрд для расширения бизнеса и строительства ИИ-инфраструктуры. Следует отметить, что речь идёт лишь о части бизнес-предложения Oracle. Как полагает The Information, если доля аренды ИИ-серверов в общем объёме бизнеса Oracle продолжит расти, общая валовая рентабельность снизится с нынешних 70 %. Ресурс предупредил, что это затронет всех основных провайдеров облачных услуг, поскольку ИИ-серверы на чипах NVIDIA значительно дороже традиционных серверов и их использование требует дополнительных расходов, в том числе на специализированное сетевое оборудование и электроэнергию. Чтобы привлечь клиентов, поставщики облачных услуг предлагают скидки, что также отражается на прибыльности бизнеса. 
Источник изображения: Oracle The Information назвал такую ситуацию плохой новостью для Oracle, но не все эксперты разделяют это мнение. По мнению ряда аналитиков, рентабельность вполне соответствует ожиданиям. Например, согласно отчёту Investor's Business Daily, аналитик Stifel Брэд Рибак (Brad Reback) ранее прогнозировал валовую рентабельность облачного бизнеса Oracle примерно в 16 %. Он также указал в аналитической записке для инвесторов, что «по мере масштабирования этого сегмента OCI валовая рентабельность должна существенно вырасти». Аналитик Guggenheim Джон ДиФуччи (John DiFucci) тоже считает, что вышеупомянутый разрыв между вводом мощностей в эксплуатацию и оплатой клиентами не следует воспринимать как дурное предзнаменование. «Мы не удивимся, если увидим более низкую валовую рентабельность в начале сделки по обучению ИИ до начала получения дохода, но мы считаем разумным ожидать, что любая сделка будет обеспечивать не менее 25 % валовой рентабельности в течение всего срока её действия — иначе Oracle её не подпишет», — заявил ДиФуччи. Следует также учесть мнение NVIDIA по этому поводу, генеральный директор которой Дженсен Хуанг (Jensen Huang) отверг критику финансового положения Oracle, заявив, что компания «будет невероятно успешна». «Когда вы только начинаете внедрять новую технологию, вполне вероятно, что поначалу вы можете не заработать, но со временем система станет невероятно прибыльной», — сказал Хуанг.
10.10.2025 [14:50], Руслан Авдеев
Не для себя стараемся: Microsoft развернула для OpenAI первый в мире ИИ-кластер на базе суперускорителей NVIDIA GB300 NVL72Microsoft представила первый в мире ИИ-кластер, использующий более 4,6 тыс. NVIDIA Blackwell Ultra в составе суперускорителей NVIDIA GB300 NVL72, объединённых интерконнектом Quantum-X800 InfiniBand. Этот кластер — лишь первый из многих. Компания развернёт сотни тысяч ускорителей Blackwell Ultra в ИИ ЦОД по всему миру. Благодаря им Microsoft намерена стать первой, поддерживающей обучение для моделей с сотнями триллионов параметров. Как сообщают в Microsoft, запуск в Microsoft Azure суперкластера NVIDIA GB300 NVL72 стал важным шагом в развитии передовых ИИ-технологий. Разработанная совместно с NVIDIA система представляет собой первый в мире масштабируемый ИИ-кластер на основе GB300, обеспечивающий вычислительные мощности, необходимые OpenAI для обслуживания моделей с триллионами параметров. Речь идёт о новом стандарте ускоренных вычислений, говорят компании. Новые инстансы Azure ND GB300 v6 оптимизированы для рассуждающих моделей, агентных систем и мультимодального генеративного ИИ. Каждая стойка GB300 NVL72 обслуживает 18 виртуальных машин, а сам суперускоритель с производительностью до 1,44 Эфлопс (FP4 Tensor Core) включает:

Источник изображения: Microsoft Создание передовой инфраструктуры требует переосмысления всех уровней системы, включая вычисления, память, системы охлаждения и питания, ЦОД в целом как единой структуры. Новая архитектура стоек обеспечивает высокую пропускную способность инференса при меньших задержках на крупных моделях, это позволяет агентным и мультимодальным ИИ-системам быть более масштабируемыми и эффективными, чем когда-либо, говорит компания. Для масштабирования за пределы стойки используется NVIDIA Quantum-X800 InfiniBand, что гарантирует обучения сверхбольших моделей с применением десятков тысяч ИИ-ускорителей с минимальными накладными расходами на их синхронизацию, что дополнительно повышает производительность. 
Источник изображения: Microsoft Передовые системы охлаждения Azure используют автономные теплообменники, чтобы свести к минимуму расход воды и поддерживать температурную стабильность для высокоплотных кластеров. Также продолжается разработка и внедрение новых моделей распределения питания, обеспечивающих высокую энергетическую плотность и динамический баланс нагрузок. Дополнительную помощь в оптимизации работы оказывает и модернизированное программное обеспечение. Ранее Microsoft обладала эксклюзивными правами на предоставление облачных сервисов компании OpenAI, но в январе 2025 года появилась новость, что ИИ-стартапу разрешили пользоваться и облаками других провайдеров, если у Microsoft не хватит собственных мощностей. Разногласия между компаниями продолжают нарастать. Формально первенство по создание кластера на базе GB300 NVL72 принадлежит CoreWeave, имеющей тесные отношения с NVIDIA и обслуживающей OpenAI — как напрямую, так и при посредничестве Microsoft.
09.10.2025 [13:10], Руслан Авдеев
Huawei попыталась продать свои ИИ-чипы Ascend в ОАЭ, пока США тянули с поставками ускорителей NVIDIA на Ближний ВостокВласти США, наконец, одобрили экспорт ИИ-чипов NVIDIA в Объединённые Арабские Эмираты (ОАЭ) на сумму в несколько миллиардов долларов. Это первый шаг на пути реализации двухсторонней сделки, которую американские чиновники могут взять за образец при организации экспорта ИИ-технологий в другие страны, сообщает Bloomberg. По словам источников издания, Министерство торговли США недавно выдало экспортные лицензии NVIDIA в соответствии с двусторонним соглашением по ИИ, анонсированным США и ОАЭ в мае. Разрешение на экспорт получено после того, как ОАЭ объявили о конкретных планах инвестиций на территории США. Речь идёт об ощутимом прогрессе в реализации соглашения, о котором было объявлено около пяти месяцев назад — оно касалось строительства кампуса ЦОД на 5 ГВт в ОАЭ, одним из арендаторов которого должна стать OpenAI. Некоторые политические фигуры в Вашингтоне усомнились в целесообразности реализации столь крупного ИИ-проекта за пределами США, особенно в регионе, имеющего тесные связи с Пекином. Получение разрешений на покупку чипов является одним из приоритетов для ОАЭ, многие чиновники страны недовольны темпами одобрения американского экспорта. Развитие ИИ является одним из ключевых интересов ближневосточной страны, вкладывающей огромные средства в инфраструктуру как на своей территории, так и за рубежом. По данным Bloomberg, в основе сделки — обещание ОАЭ инвестировать $1,4 трлн в США в следующие десять лет. Тем временем Вашингтон планировал ежегодно одобрять поставки в ОАЭ до 500 тыс. американских ИИ-ускорителей, каждый пятый из которых предназначался для ЦОД гиганта G42 из Абу-Даби. Правда, источники утверждают, что первая партия для G42, имеющей партнёрские отношения с OpenAI, не предназначена. 
Источник изображения: Sebastian/unsplash.com Источники не сообщают, когда будут выданы дополнительные экспортные лицензии, отчасти это будет зависеть от реальных инвестиций ОАЭ. Страна предполагает вкладывать в экономику США ту же сумму, на которую США разрешать поставлять чипы (будут оплачиваться отдельно). На днях сообщалось, что задержки с одобрение поставок ускорителей в Объединённые Арабские Эмираты «расстраивают» NVIDIA и реализация сделки между странами фактически заморожена. В Персидском заливе большой спрос на ИИ и достаточно средств на их оплату, что делает регион одним из важнейших рынков для соответствующих технологий в перспективе для гигантов вроде NVIDIA и OpenAI. ОАЭ и Саудовская Аравия с 2023 года страдают от введённых США ограничений на поставку им ИИ-ускорителей. Вашингтон опасается, что технологии могут быть перенаправлены в Китай, экспорт в который строго ограничен. Ранее американские власти практически остановили утверждение экспортных лицензий, ограничив экспорт, в числе прочего, и в ОАЭ. Новая администрация уже меняет ситуацию. По некоторым данным, к концу прошлого года США выдали несколько лицензий для Эмиратов, а G42 заключила партнёрство с Microsoft, во многом основанное на обещание эмиратской компании разорвать связи с Huawei. ЦОД в Абу-Даби будет лишь одним из проектов, в ходе реализации которых планируется вытеснить Китай, также располагающий ИИ-технологиями, с Ближнего Востока. 
Источник изображения: ZQ Lee/unspalsh.com В июле сообщалось, что Huawei пыталась привлечь клиентов в ОАЭ, предложив потенциальным покупателям тысячи ИИ-ускорителей Ascend 910B и удалённый доступ к более современным моделям, размещённым на территории КНР. Правда, усилия китайского бизнеса не увенчались успехом. Некоторые чиновники из США считают, что столь скромное предложение свидетельствует об ограниченных возможностях Китая для соперничества. До поездки Трампа на Ближний Восток ранее в этом году США планировали ежегодно одобрять поставку в регион около 100 тыс. ускорителей в год, но теперь речь идёт о 500 тыс. Некоторые чиновники считают, что майское соглашение не содержало подробно прописанного механизма обеспечения безопасности поставок ИИ-чипов в регионы, связанные с Пекином. Впрочем, администрация США заявляет, что подавляющее большинство передовых чипов в ОАЭ будет принадлежать американским компаниям и управляться ими же, местная G42 получит лишь 20 % от общего объёма поставок. Впрочем, когда именно эта и другие компании смогут покупать ускорители и на каких условиях, ещё неизвестно. В своё время министр торговли США Говард Лютник (Hovard Lutnik) заявлял, что союзники смогут покупать чипы при условии, что те будут использоваться аккредитованным американским оператором ЦОД, а облако, подключенное к этому дата-центру, будет также принадлежать аккредитованному американскому оператору.
08.10.2025 [23:55], Владимир Мироненко
xAI привлёк $20 млрд на покупку ускорителей NVIDIA для Colossus 2 — $2 млрд инвестировала сама NVIDIAxAI, ИИ-стартап Илона Маска (Elon Musk) проводит раунд финансирования, в рамках которого ему удалось привлечь гораздо больше средств, чем изначально планировалось — около $20 млрд, сообщил Bloomberg со ссылкой на информированные источники. В раунде также приняла участие NVIDIA, инвестировавшая $2 млрд в виде акций. Полученные инвестиции в виде акционерного капитала примерно на $7,5 млрд и заёмных средств на $12,5 млрд будут использованы на приобретение ускорителей NVIDIA для строящегося кластера Colossus 2. Для сделки по приобретению будет создана специализированная фирма, которая предоставит купленные чипы стартапу xAI в аренду на пять лет. Такая форма сделки позволяет институциональным инвесторам возмещать свои инвестиции за счёт аренды чипов, при этом долг будет обеспечен в виде залога ускорителями, а не более широкими активами xAI. Аналогичную схему использует и CoreWeave. 
Источник изображения: xAI По данным источников, в привлечении заёмных средств участвуют Apollo Global Management и Diameter Capital Partners, а Valor Capital возглавляет часть сделки, посвящённую привлечению акционерного капитала. Ранее Bloomberg сообщал о планах xAI привлечь около $10 млрд инвестиций. Ресурс не исключает, что стартапу удастся получить даже больше, чем $20 млрд, поскольку сбор средств продолжается. В NVIDIA заявили, что будут использовать растущую финансовую мощь компании для ускорения внедрения ИИ в отрасли. В сентябре финансовый директор NVIDIA Колетт Кресс (Colette Kress) сообщила на конференции Goldman Sachs, что компания будет и дальше совершать стратегические приобретения и выкупать акции, но приоритетом останется использование денежных средств, чтобы помочь другим компаниям быстрее внедрять ИИ.
07.10.2025 [14:43], Владимир Мироненко
xAI потратит $18 млрд на ускорители NVIDIA для ИИ-кластера Colossus 2Появились новые подробности о ЦОД Colossus 2, строительство которого невдалеке от Мемфиса xAI начала в марте этого года. Согласно данным Wall Street Journal, для обеспечения его функционирования xAI приобретет у NVIDIA 300 тыс. ускорителей на сумму как минимум $18 млрд без учёта расходов на сопутствующее оборудование (серверы и т.д.). В июле основатель xAI Илон Маск (Elon Musk) заявил, что Colossus 2 будет включать 550 тыс. чипов, а также дал понять, что в конечном итоге их количество может быть увеличено до 1 млн. В прошлом году компания открыла свой первый ИИ-кластер Colossus 1 в Мемфисе на месте бывшего завода бытовой техники Electrolux. Для обеспечения ЦОД Colossus 2 площадью 92,9 тыс. м2 электроэнергией xAI построит новую электростанцию в Миссисипи мощностью более 1 ГВт, использующую газовые турбины. Этого объёма достаточно для обеспечения почти 1 млн домохозяйств. Как сообщает WSJ, Colossus 1 и Colossus 2 будут потреблять электроэнергии больше, чем всё население Мемфиса. Согласно нормативным документам, копии которых имеются у WSJ, компания планирует проложить линии электропередачи от электростанции к кампусу Colossus 2. Это подразумевает, что в рамках проекта xAI также построит подстанции. 
Источник изображения: X/@elonmusk Сообщается, что системам охлаждения ЦОД потребуются тысячи кубометров питьевой воды ежедневно. В феврале xAI объявила о планах строительства очистных сооружений в рамках мер по снижению воздействия объекта на окружающую среду. Установка стоимостью $80 млн позволит компании повторно использовать около 49,2 тыс. м3 сточных вод в день. Для финансирования расширения инфраструктуры компании, видимо, понадобятся дополнительные средства. xAI недавно сообщила кредиторам, что в этом году ожидает убытки в размере $13 млрд. В июле появились слухи о том, что компания планирует привлечь дополнительный капитал при оценке её рыночной стоимости в пределах от $170 до $200 млрд. |
|