Материалы по тегу: amd
|
10.10.2025 [12:00], Сергей Карасёв
AMD представила Ethernet-адаптеры Solarflare X4 со сверхнизкой задержкойКомпания AMD анонсировала Ethernet-адаптеры Solarflare X4 для систем, в которых критическое значение имеет минимальная задержка. Это могут быть платформы для трейдинга, анализа финансовых данных в реальном времени и других задач, где, как подчеркивается, важна каждая наносекунда. В семейство Solarflare X4 вошли две модели — X4542 и X4522. По сравнению с изделиями Solarflare предыдущего поколения новинки, по заявлениям AMD, обеспечивают уменьшение задержки до 40 %. Производительность на системном уровне увеличилась на 200 % по отношению к адаптерам Solarflare X2. Обе новинки выполнены в виде низкопрофильных карт расширения половинной длины с интерфейсом PCIe 5.0 x8. В основу положена кастомизированная ASIC, обеспечивающая сверхнизкие задержки. AMD уверяет, что при использовании адаптеров в связке с процессорами EPYC 4005 Grado достигается снижение задержки до 12 % по сравнению с аналогичными по классу решениями конкурентов. 
Источник изображения: AMD Версия Solarflare X4542 оснащена двумя разъёмами QSFP с поддержкой двух портов 40/50/100GbE или четырёх портов 1/10/25GbE. Модификация Solarflare X4522, в свою очередь, получила два разъёма SFP с поддержкой пары портов 1/10/25/50GbE. Карты оснащены пассивным охлаждением. Энергопотребление составляет менее 25 Вт. Для адаптеров доступно фирменное ПО AMD Solarflare Onload, которое отвечает за повышение производительности при работе с ресурсоёмкими сетевыми приложениями, такими как резидентные базы данных, программные балансировщики нагрузки и веб-серверы. Solarflare Onload помогает поднять эффективность обработки огромных объёмов небольших пакетов данных — даже в периоды пиковой нагрузки. AMD отмечает, что 9 из 10 крупнейших мировых фондовых бирж используют решения Solarflare для обеспечения работы своих торговых платформ.
08.10.2025 [11:27], Сергей Карасёв
До 16 ядер Zen 5 в AM5: AMD представила чипы Ryzen Embedded 9000Компания AMD анонсировала процессоры серии Ryzen Embedded 9000, предназначенные для использования во встраиваемых устройствах, промышленных компьютерах, системах автоматизации, платформах машинного зрения и пр. Производитель обещает доступность чипов в течение семи лет. Изделия Ryzen Embedded 9000, выполненные на архитектуре Zen 5, совместимы с разъёмом AM5. При изготовлении применяется 4-нм технология. Показатель TDP варьируется от 65 до 170 Вт. Заявлена поддержка оперативной памяти DDR5 и интерфейса PCIe 5.0. 
Источник изображений: AMD На сегодняшний день в новое семейство процессоров входят семь моделей: Ryzen Embedded 9600X, 9700X, 9800X3D, 9900X, 9900X3D, 9950X и 9950X3D. Они насчитывают от 6 до 16 вычислительных ядер с поддержкой многопоточности. Базовая тактовая частота варьируется от 3,8 до 4,7 ГГц, максимальная частота — от 5,2 до 5,7 ГГц (см. характеристики ниже). Объём кеша L3 составляет от 32 до 128 Мбайт (решения с индексом 3D поддерживают технологию 3D V-Cache). 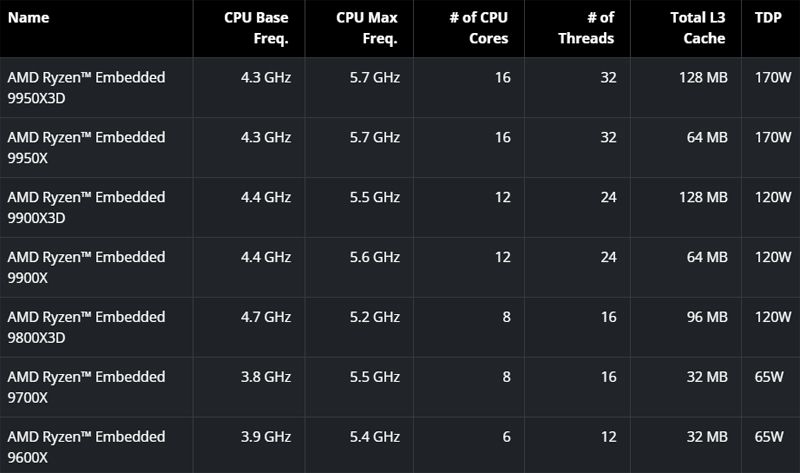 В состав чипов входит графический ускоритель на архитектуре AMD RDNA 2. Говорится о поддержке инструкций AVX-512, предназначенных для ускорения ресурсоёмких вычислений, таких как обработка больших массивов данных, задачи ИИ и пр. Компания AMD также сообщает, что в конце текущего года дебютируют новые процессоры семейства Ryzen Pro Embedded, поставлять которые планируется в течение десяти лет. Эти чипы получат расширенные функции обеспечения безопасности, включая инструмент AMD Platform Secure Boot и средства полного шифрования памяти AMD Memory Guard.
06.10.2025 [16:45], Владимир Мироненко
AMD поставит OpenAI ИИ-ускорители на 6 ГВт, а OpenAI получит долю в AMDAMD и OpenAI объявили о заключении многолетнего соглашения о стратегическом партнёрстве, в рамках которого будет построена ИИ-инфраструктура на базе сотен тысяч ИИ-ускорителей AMD нескольких поколений общей мощностью 6 ГВт общей стоимостью, по предварительным оценкам, $60–$80 млрд. После объявления о сделке акции AMD выросли на 28 % до $211,18 в начале торгов, что само по себе тянет на рекорд, пишет Bloomberg. В рамках соглашения AMD предоставила OpenAI возможность покупки до 160 млн обыкновенных акций, которые будут переданы по мере достижения контрольных целей. Первый транш будет предоставлен после развёртывания инфраструктуры на 1 ГВт, которое начнется во II половине следующего года. ИИ-системы будут основаны на чипах AMD Instinct MI450. Последующие транши будут выделяться по мере развёртывания оборудования в ЦОД до итогового показателя мощности в 6 ГВт. Выпуск акций также привязан к достижению AMD целей по цене акций и достижению OpenAI технических и коммерческих целей. Исходя из текущего количества выпущенных акций AMD к завершению сделки у OpenAI будет 10 % её акций. 
Источник изображения: AMD «Мы рассматриваем эту сделку как безусловно преобразующую не только для AMD, но и для динамики всей отрасли», — заявил исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) агентству Reuters в воскресенье. В AMD также сообщили, что партнёрство с OpenAI принесет компании десятки миллиардов долларов дохода, значительно увеличит прибыль AMD на акцию и ускорит развитие инфраструктуры ИИ OpenAI. Для AMD эта сделка станет отправной точкой для более широкого внедрения её технологий, что может увеличить доход компании в этой области до более чем $100 млрд, заявили руководители компании, не уточняя конкретных сроков, пишет Bloomberg. Для OpenAI сотрудничество с AMD обеспечит более надёжную альтернативу решениям NVIDIA, на которые OpenAI и операторы ЦОД тратят значительную часть своих бюджетов. В прошлом месяце стало известно о соглашении OpenAI с NVIDIA, в рамках которого производитель чипов инвестирует в стартап до $100 млрд, включая поставку ускорителей общей мощностью не менее 10 ГВт. Ускорители AMD будут использоваться преимущественно для инференса, а NVIDIA — для обучения. Попутно OpenAI при поддержке Broadcom разрабатывает собственные ИИ-ускорители, которые должны появиться в 2026 году.
29.09.2025 [11:10], Руслан Авдеев
Канадский рынок дата-центров вырастет почти на порядок — до 10,3 ГВтКанада готовится к новой фазе развития рынка дата-центров. В отчёте аналитического агентства DC Byte говорится, что общая ёмкость рынка ЦОД в обозримом будущем вырастет до 10,3 ГВт с нынешних введённых в эксплуатацию 1,4 ГВт. Проекты общей мощностью 8,9 ГВт находятся на разных этапах реализации, их них 6,9 ГВт — на ранних этапах без фактического начала строительства. Во многом будущий рост объясняется серией анонсов, состоявшихся во II полугодии 2024 года. В том числе речь идёт о проекте инвестора, бизнесмена и шоумена Кевином О’Лири (Kevin O’Leary) Wonder Valley в провинции Альберта. В своё время было заявлено, что речь идёт о строительстве 55 объектов мощностью 100 МВт каждый с питанием от природного газа. Это крупнейший проект, на который приходится 5,6 ГВт от общего плана (по другим данным — 7,5 ГВт). В DC Byte отмечают, что речь идёт о новом этапе роста, связанном с бумом ИИ и ориентированных на ускорители дата-центров. Тем не менее, они должны заработать не раньше 2027 года, а пока же рынок всё ещё ориентирован на «традиционные» дата-центры, где лидируют Vantage, Cologix и Compass. 93 % IT-нагрузок ЦОД страны приходится на Торонто, Монреаль и провинцию Альберту (столица Эдмонтон). При этом в Канаде 60 % местной генерации приходится на ГЭС, т.е. «зелёную» энергетику, что при соблюдении некоторых условий, не может не привлекать глобальных игроков. Впрочем, природного газа здесь тоже хватает, и на него тоже делают ставку. 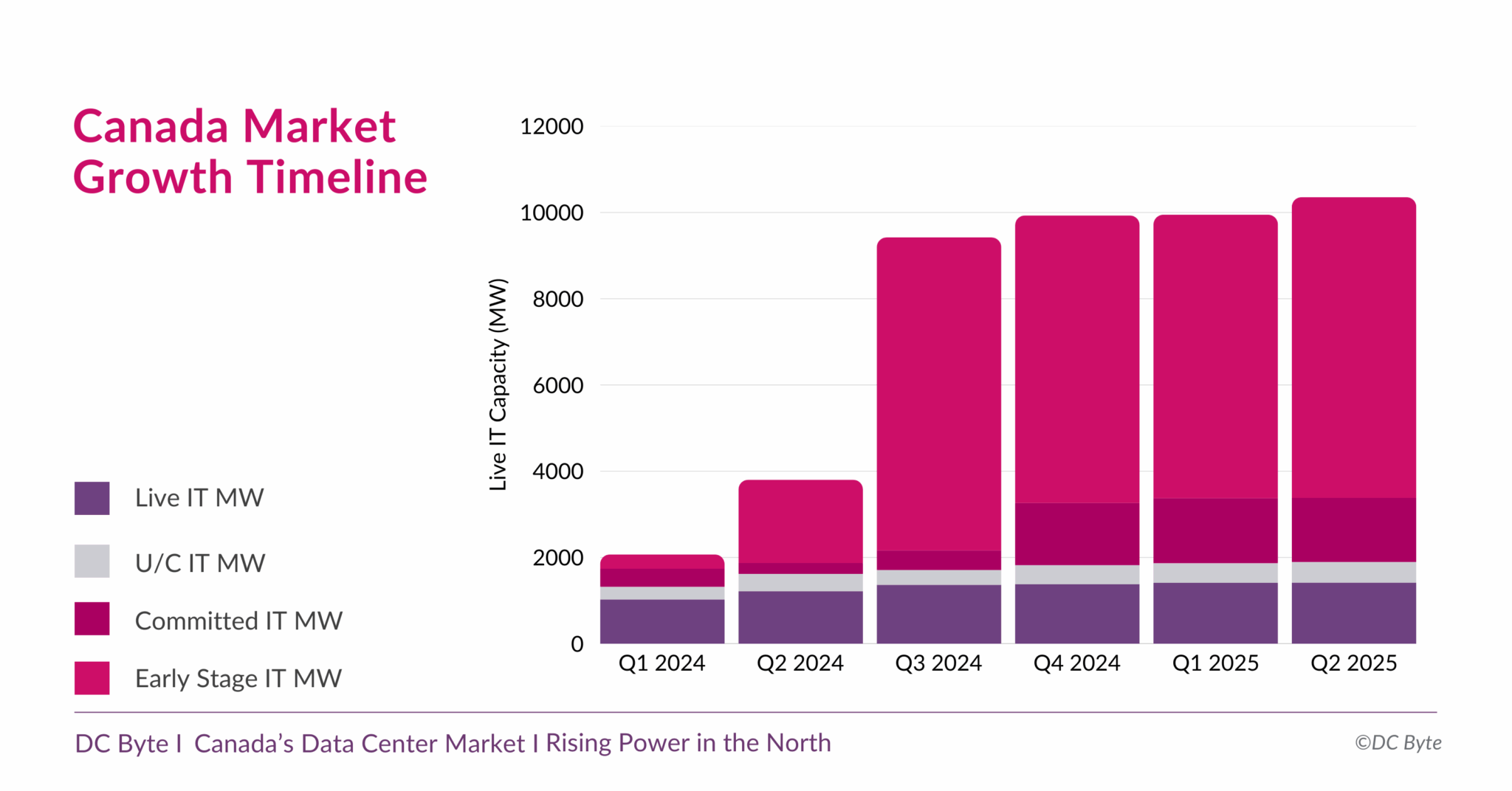
Источник изображения: DC Byte Пока же местные проекты отличает скромность. Так, совокупная мощность сети ИИ ЦОД Bell AI Fabric, планируемой Bell Canada и Telus, составит 500 МВт. Впрочем, на конференции All In Canada AI Ecosystem в Монреале Канада представила стратегию развития суверенного ИИ, подчеркнув важность цифрового суверенитета и экономической независимости, и анонсировала открытие первой ИИ-фабрики Telus, построенной при поддержке NVIDIA и HPE. Фабрика обеспечивает полный цикл работы с ИИ — от обучения моделей до инференса, с хранением данных внутри страны и питанием от возобновляемой энергии на 99 %. 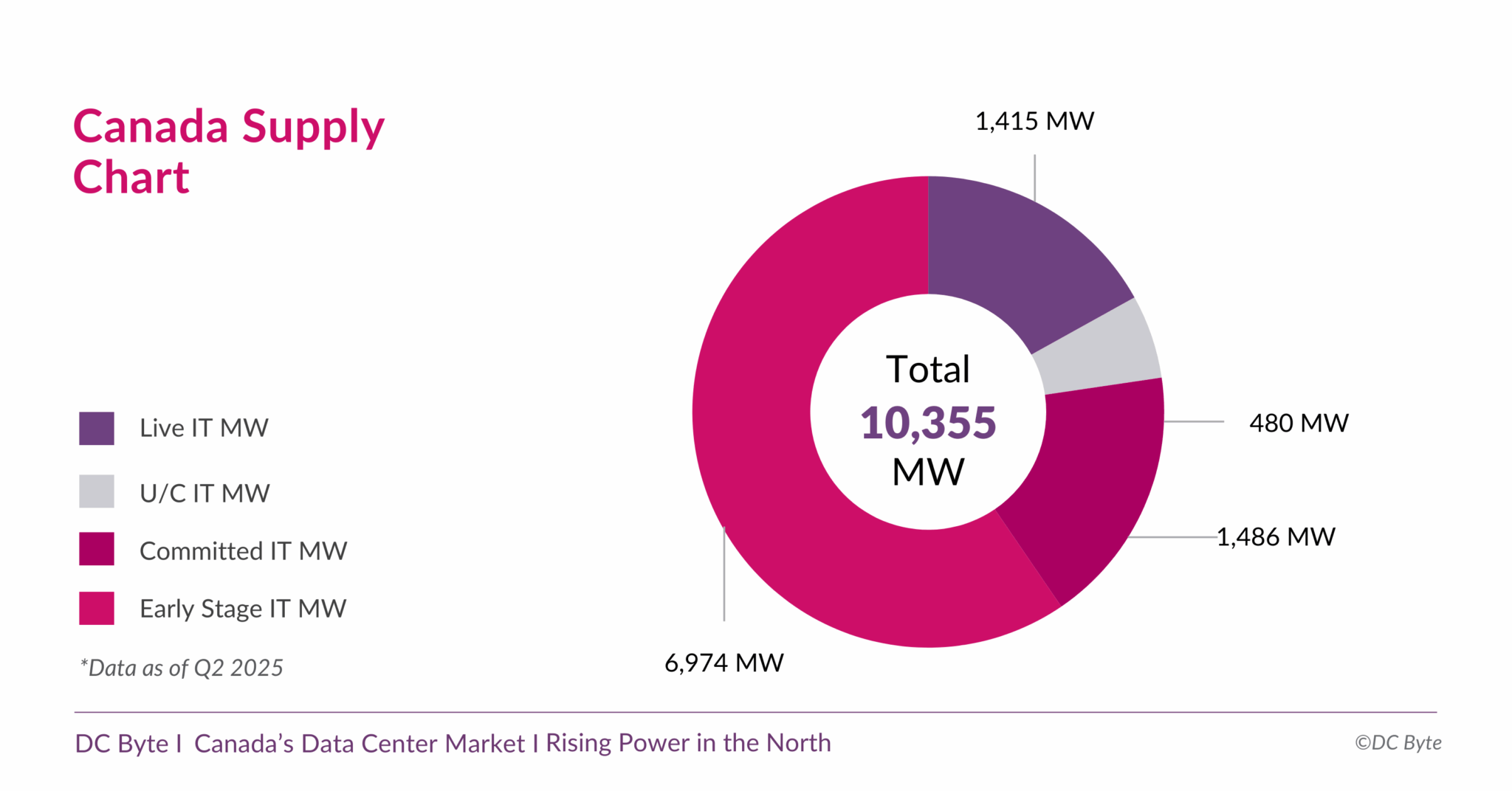
Источник изображения: DC Byte Тогда AMD и канадская Cohere объявили о расширении сотрудничества в сфере ИИ. В частности, ключевые «безопасные» решения последней, включая Command A, Vision, Translate и North, будут доступны на ИИ-инфраструктуре на базе ускорителей Instinct. Благодаря этому корпоративные и государственные клиенты, включая канадские проекты «суверенного ИИ», получат больше возможностей выбора ИИ-инструментов. AMD станет использовать платформу Cohere North для решения собственных инженерных и бизнес-задач.
27.09.2025 [15:32], Сергей Карасёв
Майнинговая компания Iren увеличила мощность ИИ-облака, закупив тысячи ускорителей NVIDIA и AMD за $674 млнКриптомайнинговая компания Iren (ранее известная как Iris Energy), по сообщению Datacenter Dynamics, увеличила количество ИИ-ускорителей в своём облаке примерно в два раза. Стоимость приобретённого оборудования оценивается в $674 млн. Компании прочат статус серьёзного игрока на рынке неооблаков. Компания находится в процессе перехода от майнинга криптовалют к облачному бизнесу на базе ИИ. В частности, закуплены 7100 ускорителей NVIDIA B300 и 4200 изделий NVIDIA B200, а также 1100 AMD Instinct MI350X. В результате, общее количество ускорителей в составе платформы Iren достигло приблизительно 23 тыс. Новое оборудование в ближайшие месяцы будет развёрнуто в кампусе Iren в городе Принс-Джордже (Prince George) в северной части провинции Британская Колумбия в Канаде. В настоящее время на этой площадке ведётся строительство вычислительного комплекса с жидкостным охлаждением мощностью 10 МВт (ИТ-нагрузка), который сможет поддерживать более 4500 суперускорителей NVIDIA GB300. В конце августа нынешнего года Iren сообщила о приобретении 1200 ускорителей NVIDIA B300 для серверов с воздушным охлаждением и 1200 изделий NVIDIA GB300 для систем с жидкостным охлаждением: стоимость данной партии составила примерно $168 млн. Эти чипы также предназначены для ЦОД в Принс-Джордже. Тогда говорилось, что Iren привлекла финансирование в размере около $96 млн для покупки GB300: средства получены по схеме лизинга сроком на два года. 
Источник изображения: Iren В настоящее время Iren управляет пятью кампусами ЦОД общей мощностью 810 МВт, расположенными в Северной Америке: два в Техасе (США) и три в Британской Колумбии (Канада). Ещё 2,1 ГВт находятся в стадии строительства, причём 2 ГВт из них приходится на новый кампус в Техасе. Как отмечает Дэниел Робертс (Daniel Roberts), соучредитель и содиректор Iren, удвоение парка GPU позволит удовлетворить растущие потребности клиентов в масштабируемых вычислительных мощностях.
25.09.2025 [11:37], Сергей Карасёв
Edgecore Networks представила ИИ-сервер AGS8600 на базе AMD EPYC Turin и Instinct MI325XКомпания Edgecore Networks анонсировала сервер AGS8600 формата 8U, построенный на аппаратной платформе AMD. Устройство, уже доступное для заказа, предназначено для решения ресурсоёмких задач в сферах ИИ, машинного обучения, НРС, научных исследований и пр. Система несёт на борту два 64-ядерных процессора EPYC 9575F поколения Turin с показателем TDP в 400 Вт. Доступны 24 слота для модулей оперативной памяти DDR5. Во фронтальной части расположены восемь отсеков для SFF-накопителей U.2 (NVMe): базовая конфигурация включает шесть SSD вместимостью 7,68 Тбайт каждый и два SSD на 1,92 Тбайт. Сервер укомплектован восемью GPU-ускорителями Instinct MI325X с 256 Гбайт памяти HBM3e и производительностью до 2,6 Пфлопс в режиме FP8. Задействованы семь линий Infinity Fabric в расчёте на GPU. В оснащение включены восемь однопортовых сетевых адаптеров BCM957608-P1400GDF00 400G QSFP112-DD PCIe Ethernet NIC. Кроме того, присутствуют два двухпортовых адаптера BCM957608-P2200GQF00 200GbE QSFP112 PCIe Ethernet NIC, выделенный сетевой порт управления 1GbE, контроллер ASPEED AST2600, два порта USB 3.0 и интерфейс D-Sub. 
Источник изображения: Edgecore Networks За возможности расширения отвечают восемь слотов PCIe 5.0 x16 для карт половинной высоты и четыре разъёма PCIe 5.0 x16 для карт полной высоты. Питание обеспечивают шесть блоков мощностью 3300 Вт с сертификатом 80 Plus Titanium. Применена система воздушного охлаждения с 15 вентиляторами, допускающими горячую замену. Габариты составляют 448 × 850 × 351 мм. Диапазон рабочих температур — от +10 до +35 °C. На сервере используется ОС с ядром Linux. Среди поддерживаемого ПО упомянуты ROCm 6.2.4, RCCL 2.20.5, PyTorch 2.3/2.2/2.1/2.0/1.13, TensorFlow 2.16.1/2.15.1/2.14.1, JAX 0.4.26 и ONNX Runtime 1.17.3.
17.09.2025 [10:57], Сергей Карасёв
AMD представила процессоры EPYC Embedded 4005 для периферийного оборудованияКомпания AMD анонсировала процессоры серии EPYC Embedded 4005, предназначенные для использования в индустриальных серверах начального уровня, а также в различном периферийном оборудовании, включая межсетевые экраны следующего поколения (NGFW). Изделия, выполненные на архитектуре AMD Zen 5, рассчитаны на установку в разъём AM5. Применена чиплетная компоновка, а при производстве задействована 4-нм технология. Новые CPU содержат до 128 Мбайт кеша L3 (у модели EPYC Embedded 4585PX с технологией 3D V-Cache). Говорится о поддержке оперативной памяти DDR5-5600 ECC, 28 линий PCIe 5.0 и инструкций AVX-512. Фактически новинки развивают серию EPYC 4005 Grado, которая сама по себе является развитием Ryzen 9000. 
Источник изображения: AMD Все CPU поддерживают технологию многопоточности и имеют конфигурируемый показатель TDP, благодаря чему может достигаться оптимальный баланс между производительностью и энергоэффективностью для конкретных задач. В семейство EPYC Embedded 4005 на сегодняшний день входят шесть моделей:
В процессорах реализованы функции безопасности AMD Infinity Guard, которые призваны обеспечить защиту конфиденциальных данных от сложных кибератак. Производить чипы EPYC Embedded 4005 компания AMD намерена в течение семи лет.
12.09.2025 [23:07], Владимир Мироненко
Intel Arc Pro впервые поучаствовали в бенчмарках MLPerf Inference, но в лидерах предсказуемо осталась NVIDIAMLCommons объявил результаты набора бенчмарков MLPerf Inference v5.1. Последний раунд демонстрирует, насколько быстро развивается инференс и соответствующие бенчмарки, пишет ресурс HPCwire. В этом раунде было рекордное количество заявок — 27. Представлены результаты сразу пяти новых ускорителей: AMD Instinct MI355X, Intel Arc Pro B60 48GB Turbo, NVIDIA GB300, NVIDIA RTX 4000 Ada 20GB, NVIDIA RTX Pro 6000 Blackwell Server Edition. Всего же количество результатов MLPerf перевалило за 90 тыс. результатов. В текущем раунде были представлены три новых бенчмарка: тест рассуждений на основе модели DeepSeek-R1, тест преобразования речи в текст на основе Whisper Large v3 и небольшой тест LLM на основе Llama 3.1 8B. Как отметил ресурс IEEE Spectrum, бенчмарк на основе модели Deepseek R1 671B (671 млрд параметров), более чем в 1,5 раза превышает самый крупный бенчмарк предыдущего раунда на основе Llama 3.1 405B. В модели Deepseek R1, ориентированной на рассуждения, большая часть вычислений выполняется во время инференса, что делает этот бенчмарк ещё более сложным. Что касается самого маленького бенчмарка, основанного на Llama 3.1 8B, то, как поясняют в MLCommons, в отрасли растёт спрос на рассуждения с малой задержкой и высокой точностью. SLM отвечают этим требованиям и являются отличным выбором для таких задач, как реферирование текста или периферийные приложения. В свою очередь бенчмарк преобразования голоса в текст, основанный на Whisper Large v3, был разработан в ответ на растущее количество голосовых приложений, будь то смарт-устройства или голосовые ИИ-интерфейсы. 
Источник изображения: NVIDIA NVIDIA вновь возглавила рейтинг MLPerf Inference, на этот раз с архитектурой Blackwell Ultra, представленной платформой NVIDIA GB300 NVL72, которая установила рекорд, увеличив пропускную способность DeepSeek-R1 на 45 % по сравнению с предыдущими системами GB200 NVL72 (Blackwell). NVIDIA также продемонстрировала высокие результаты в бенчмарке Llama 3.1 405B, который имеет более жёсткие ограничения по задержке. NVIDIA применила дезагрегацию, разделив фазы работы с контекстом и собственно генерацию между разными ускорителями. Этот подход, поддерживаемый фреймворком Dynamo, обеспечил увеличение в 1,5 раза пропускной способности на один ускоритель по сравнению с традиционным обслуживанием на системах Blackwell и более чем в 5 раз по сравнению с системами на базе Hopper. 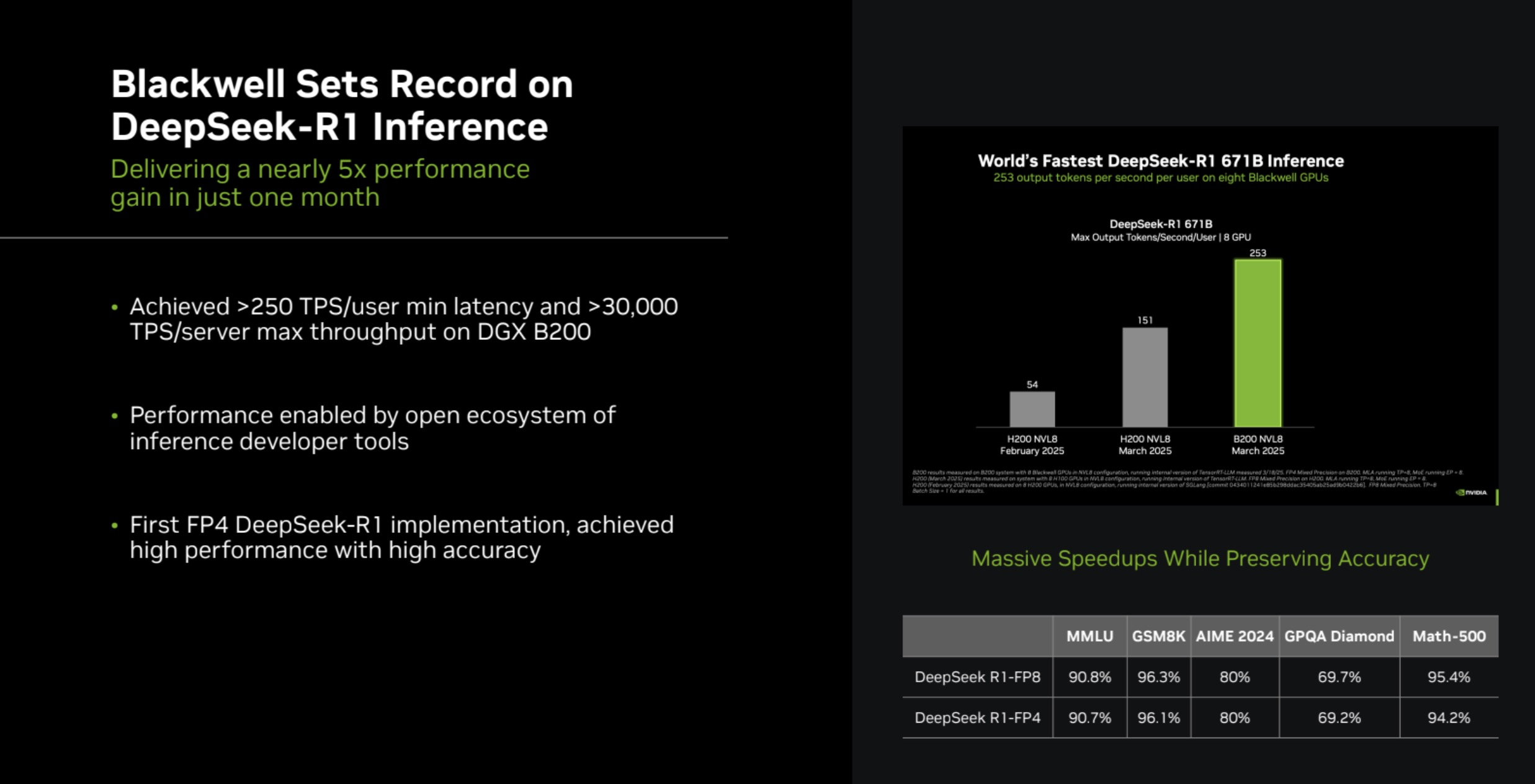
Источник изображения: NVIDIA NVIDIA назвала «дезагрегированное обслуживание» одним из ключевых факторов успеха, помимо аппаратных улучшений при переходе к Blackwell Ultra. Также свою роль сыграло использованием фирменного 4-бит формата NVFP4. «Мы можем обеспечить точность, сопоставимую с BF16», — сообщила компания, добавив, что при этом потребляется значительно меньше вычислительной мощности. Для работы с контекстом NVIDIA готовит соускоритель Rubin CPX. В более компактных бенчмарках решения NVIDIA также продемонстрировали рекордную пропускную способность. Компания сообщила о более чем 18 тыс. токенов/с на один ускоритель в бенчмарке Llama 3.1 8B в автономном режиме и 5667 токенов/с на один ускоритель в Whisper. Результаты были представлены в офлайн-, серверных и интерактивных сценариях, при этом NVIDIA сохранила лидерство в расчете на GPU во всех категориях. 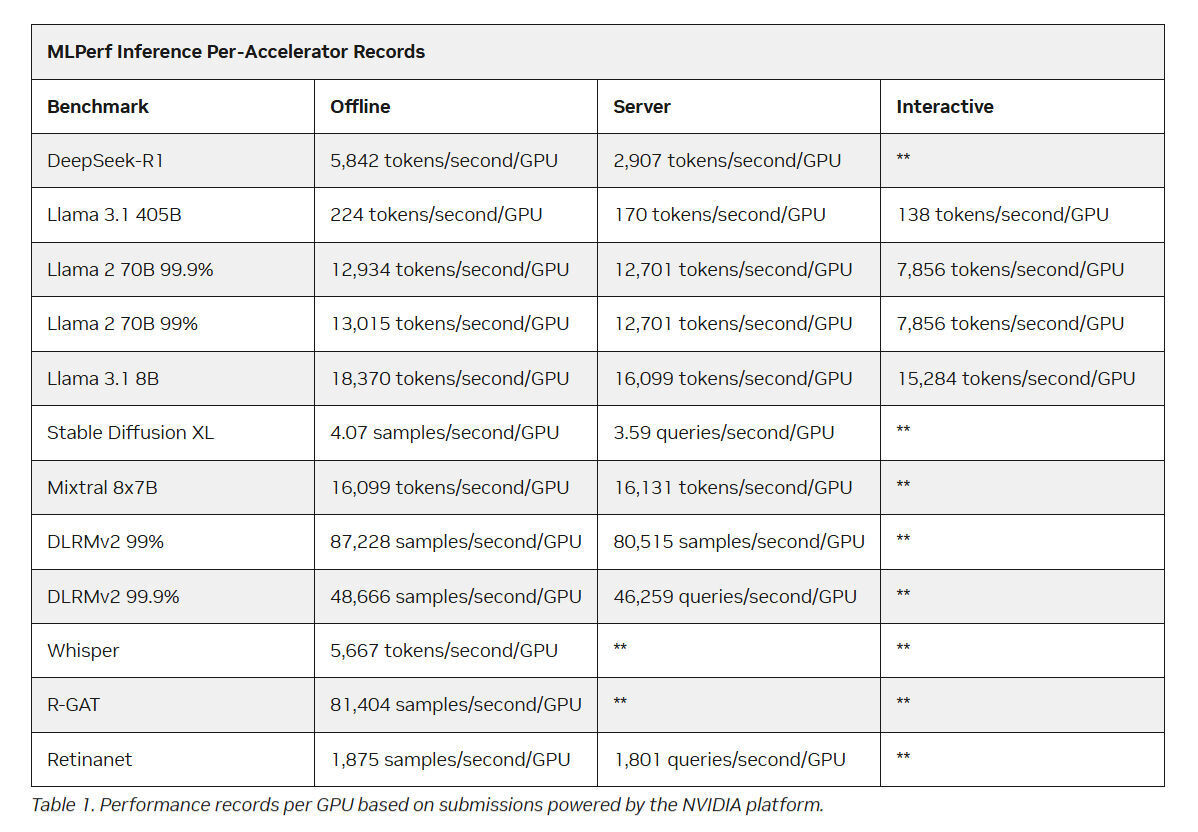
Источник изображения: NVIDIA/TechPowerUp AMD представила результаты AMD Instinct MI355X только в «открытой» категории, где разрешены программные модификации модели. Ускоритель MI355X превзошёл в бенчмарке Llama 2 70B ускоритель MI325X в 2,7 раза по количеству токенов/с. В этом раунде AMD также впервые обнародовала результаты нескольких новых рабочих нагрузок, включая Llama 2 70B Interactive, MoE-модель Mixtral-8x7B и генератор изображений Stable Diffusion XL. 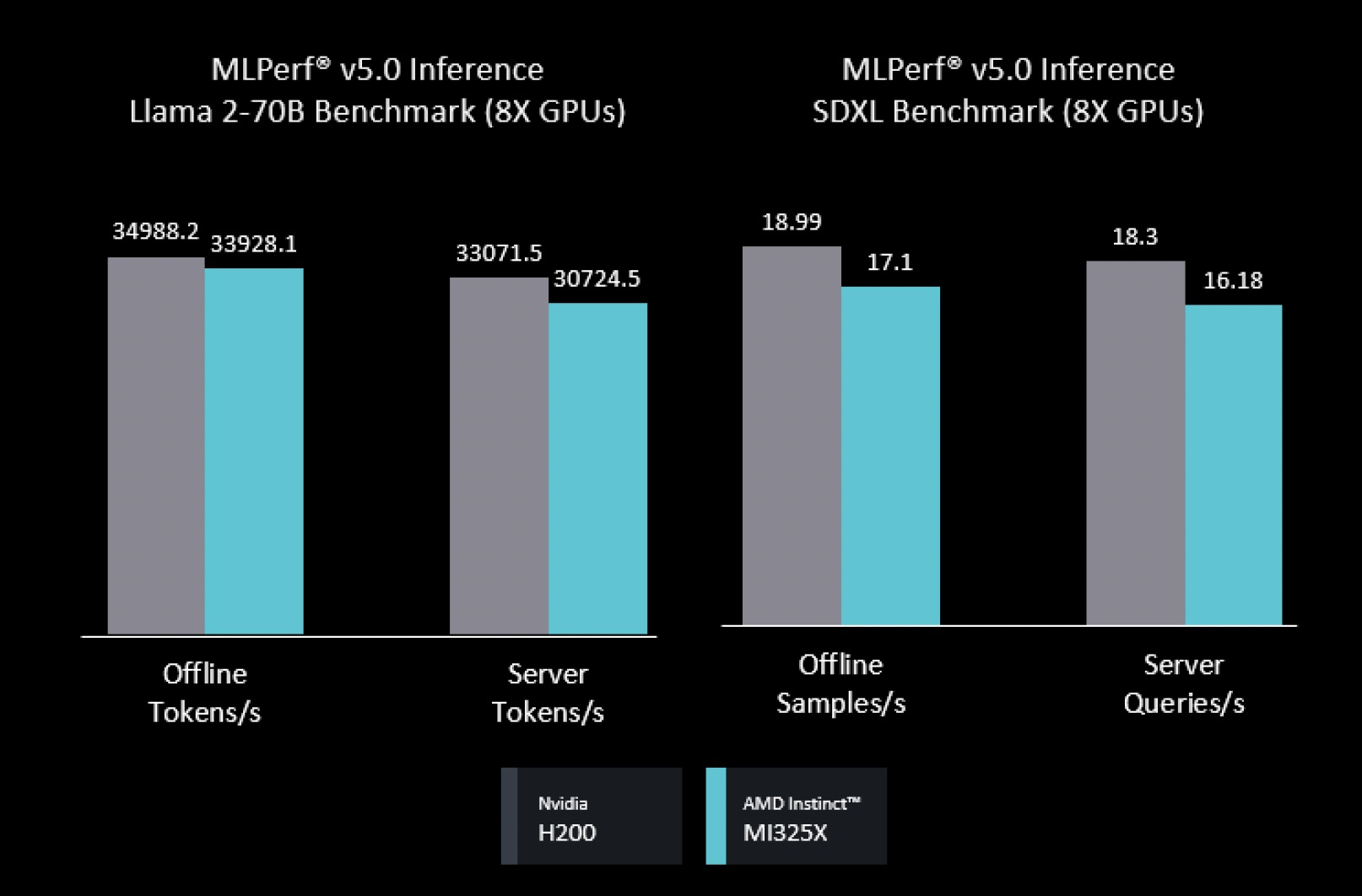
Источник изображения: AMD/ServeTheHome В число «закрытых» заявок AMD входили системы на базе ускорителей AMD MI300X и MI325X. Более продвинутый MI325X показал результаты, схожие с показателями систем на базе NVIDIA H200 на Llama 2 70b, в комбинированном тесте MoE и тестах генерации изображений. Кроме того, компанией была представлена первая гибридная заявка, в которой ускорители AMD MI300X и MI325X использовались для одной и той же задачи инференса — бенчмарка на базе Llama 2 70b. Возможность распределения нагрузки между различными типами ускорителей — важный шаг, отметил IEEE Spectrum. В этом раунде впервые был представлен и ускоритель Intel Arc Pro. Для бенчмарков использовалась видеокарта MaxSun Intel Arc Pro B60 Dual 48G Turbo, состоящая из двух GPU с 48 Гбайт памяти, в составе платформы Project Battlematrix, которая может включать до восьми таких ускорителей. Система показала результаты на уровне NVIDIA L40S в небольшом тесте LLM и уступила ему в тесте Llama 2 70b. 
Источник изображения: Intel Следует также отметить, что в этом раунде, как и в предыдущем, участвовала Nebius (ранее Yandex N.V.). Компания отметила, что результаты, полученные на односерверных инсталляциях, подтверждают, что Nebius AI Cloud обеспечивает «высочайшие» показатели производительности для инференса базовых моделей, таких как Llama 2 70B и Llama 3.1 405B. В частности, Nebius AI Cloud установила новый рекорд производительности для NVIDIA GB200 NVL72. По сравнению с лучшими результатами предыдущего раунда, её однохостовая инсталляция показала прирост производительности на 6,7 % и 14,2 % при работе с Llama 3.1 405B в автономном и серверном режимах соответственно. «Эти два показателя также обеспечивают Nebius первое место среди других разработчиков MLPerf Inference v5.1 для этой модели в системах GB200», — сообщила компания.
12.09.2025 [11:35], Сергей Карасёв
150 кВт на стойку для тестов: Digital Realty открыла лабораторию DRIL для ускорения внедрения ИИ и гибридного облакаОператор дата-центров Digital Realty объявил об открытии лаборатории инноваций DRIL (Digital Realty Innovation Lab) — специализированной тестовой площадки, призванной ускорить внедрение ИИ и гибридного облака. Партнёрами в рамках данного проекта являются Lenovo, AMD, Cisco и CommScope, которые предоставляют различные аппаратные и инфраструктурные решения. Отмечается, что ИИ оказывает преобразующее влияние на самые разные отрасли. Однако при его масштабном развёртывании предъявляются высокие требования к инфраструктуре ЦОД в плане обеспечения необходимой производительности при одновременной оптимизации энергопотребления. Площадка DRIL призвана помочь компаниям в создании сложных архитектур, ориентированных на ресурсоёмкие задачи ИИ. DRIL предоставляет партнёрам и клиентам полностью поддерживаемую реальную тестовую среду для апробации ИИ-развёртываний и гибридных облачных сред перед их масштабированием. Компании могут запускать собственные рабочие нагрузки с целью проверки эффективности и оптимизации. 
Источник изображения: Digital Realty Лаборатория DRIL сформирована на базе кампуса Digital Realty в Северной Вирджинии. На площадке, оснащённой серверами с процессорами AMD EPYC и ускорителями AMD Instinct, могут тестироваться рабочие нагрузки ИИ и HPC. Говорится о высокоплотном размещением оборудования — свыше 150 кВт на серверную стойку. Задействована технология прямого жидкостного охлаждения (DLC) Lenovo Neptune. Лаборатория DRIL, как подчёркивается, позволяет компаниям раскрыть весь потенциал ИИ и корпоративных рабочих нагрузок, даже если у них нет собственного дата-центра с современным оборудованием. Используя DRIL, клиенты могут снизить риски, оптимизировать конфигурацию своих систем и ускорить переход от этапа проверки концепции к фактическому внедрению. Предприятия могут тестировать различные сценарии задержек в разных локациях, оценивать требования к питанию, охлаждению и GPU-ресурсам, а также управлять ИИ-нагрузками.
10.09.2025 [12:44], Сергей Карасёв
В облаке Vultr по всему миру стали доступны ускорители AMD Instinct MI355XЧастный облачный провайдер Vultr объявил о том, что в его глобальной инфраструктуре стали доступны ускорители AMD Instinct MI355X, официально представленные в июне нынешнего года. Утверждается, что эти изделия устанавливают новый стандарт соотношения цены и производительности для ресурсоёмких ИИ-задач, в частности, инференса. Решение Instinct MI355X построено на архитектуре AMD CDNA 4-го поколения. Устройство располагает 288 Гбайт памяти HBM3E, пропускная способность которой достигает 8 Тбайт/с. Применяется жидкостное охлаждение. Упомянута поддержка программного стека AMD ROCm. На сайте Vultr говорится, что теоретическая производительность ИИ при использовании в конфигурации 8 × Instinct MI355X OAM достигает 20,1 Пфлопс в режиме FP16, 40,3 Пфлопс на операциях INT8/FP8 и 80,5 Пфлопс в режиме FP4. 
Источник изображения: Vultr При развёртывании ускорителей Instinct MI355X в своём облаке Vultr тесно сотрудничала с AMD и Supermicro. Благодаря 32 облачным регионам на шести континентах Vultr гарантирует низкую задержку и высокую доступность вычислительных мощностей. Стоимость услуг, как утверждается, ниже по сравнению с аналогичными предложениями гиперскейлеров. Ускорители Instinct MI355X подходят не только для инференса и обучения ИИ-моделей, но и для других нагрузок HPC, таких как симуляции, сложное моделирование или обработка больших массивов данных. |
|