Материалы по тегу: интерконнект
|
09.10.2025 [11:42], Сергей Карасёв
Broadcom представила 102,4-Тбит/с СРО-коммутатор TH6-DavissonКомпания Broadcom анонсировала коммутационную систему платформу с интегрированной оптикой CPO (Co-Packaged Optics) третьего поколения Tomahawk 6 — Davisson (TH6-Davisson) для современных кластеров ИИ. Решение обеспечивает пропускную способность до 102,4 Тбит/с. В основу новинки положен чип-коммутатор Tomahawk 6. Утверждается, что TH6-Davisson устанавливает новый стандарт производительности для дата-центров, рассчитанных на наиболее ресурсоёмкие нагрузки. Поддерживаются оптические соединения с пропускной способностью 200 Гбит/с на линию. В случае вертикального масштабирования в один кластер могут быть объединены до 512 XPU. В двухуровневых горизонтально масштабируемых сетях количество XPU может превышать 100 тыс. Решение TH6-Davisson обеспечивает гибкие возможности в плане конфигурации портов. Возможны варианты 64 × 1,6 Тбит/с, 128 × 800 Гбит/с, 256 × 400 Гбит/с, 512 × 200 Гбит/с, 512 × 100 Гбит/с или 512 × 50 Гбит/с. Среди других преимуществ платформы названы возможность замены лазерных модулей ELSFP в полевых условиях и совместимость с DR-оптикой. 
Источник изображения: Broadcom При изготовлении TH6-Davisson задействована технология TSMC Compact Universal Photonic Engine (TSMC COUPE) вкупе с усовершенствованной многокристальной компоновкой на уровне подложки. Благодаря этому значительно снижаются потери, в результате чего энергопотребление оптического интерконнекта уменьшается на 70 % по сравнению с традиционными решениями. Таким образом, обеспечивается сокращение совокупной стоимости владения, что важно в случае масштабных инфраструктур, ориентированных на ИИ.
06.10.2025 [10:54], Владимир Мироненко
250 Тбит/с на чип: Ayar Labs, Alchip и TSMC предложили референс-дизайн для упаковки ASIC, памяти и оптических модулей в одном чипеКомпания Ayar Labs (США), занимающаяся разработкой интерконнекта на базе кремниевой фотоники, и тайваньский производитель ASIC-решений Alchip Technologies представили референсную платформу проектирования ИИ ASIC с несколькими оптическими IO-модулями на основе технологии кремниевой фотоники TSMC COUPE (Compact Universal Photonic Engine). В начале сентября компании объявили о стратегическом партнёрстве с целью ускорения масштабирования ИИ-инфраструктуры благодаря объединению технологии CPO компании Ayar Labs, экспертизы Alchip в области создания и упаковки кастомных ASIC, а также технологии упаковки и техпроцесса компании TSMC. Как сообщил технический директор Ayar Labs Владимир Стоянович (Vladimir Stojanovic) в интервью EE Times, платформа предназначена для устранения узких мест в передаче данных, замедляющих работу ИИ-инфраструктуры, путём эффективного сокращения времени простоя системы и создания крупных высокопроизводительных ИИ-кластеров нового поколения. Партнёры отметили, что по мере роста ИИ-моделей и размеров кластеров традиционные медные соединения достигают своих физических и энергетических пределов. Путём замены меди на интегрированную оптику (CPO) решение Alchip и Ayar Labs обеспечивает расширенную дальность связи, низкую задержку, энергоэффективность и высокий радикс, необходимые для масштабных развертываний ИИ-ускорителей. «Масштабируемые сети ИИ-кластеров ограничены расстоянием медных соединений. В то же время энергоэффективность сети ограничена плотностью мощности и возможностями систем охлаждения», — пояснил Эрез Шайзаф (Erez Shaizaf), технический директор Alchip, добавив, что CPO снимает эти ограничения. 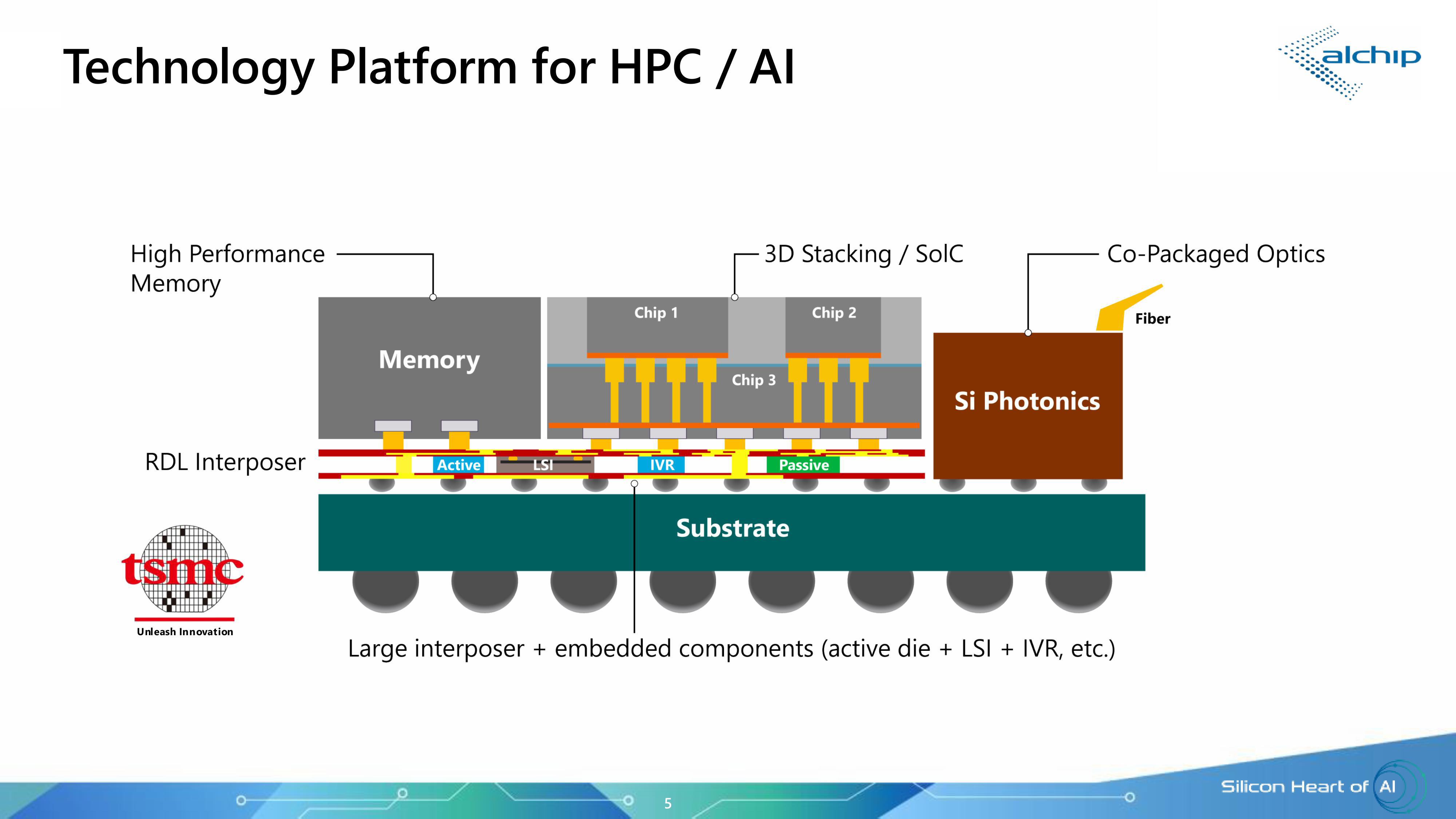
Источник изображений: Ayar Labs Новое совместное решение включает оптические модули Ayar Labs TeraPHY, размещённые вместе с решениями Alchip на общей подложке, обеспечивая прямой доступ ИИ-ускорителя к оптическому интерфейсу. Такая интеграция обеспечивает пропускную способность 100+ Тбит/с на каждый ускоритель и поддерживает более 256 оптических портов на устройство. TeraPHY не привязан к какому-либо протоколу и обеспечивает гибкую интеграцию с кастомными чиплетами. Референсный дизайн позволяет партнёрам «заложить основу» для быстрого создания подобной системы. Платформа референсного проекта включает два вычислительных кристалла с чиплетами HBM и другими чиплетами, в сочетании с восемью оптическими IO-модулями на базе чиплета TeraPHY. Такая конструкция обеспечит двустороннюю пропускную способность 200–250 Тбит/с для каждой сборки (SiP), что значительно превышает показатели современных крупных GPU, сообщил Стоянович. Это позволит масштабировать систему, а также значительно расширить объём памяти, имеющей пропускную способность, сопоставимую с HBM, добавил он. Оптический модуль Ayar Labs основан на чиплете TeraPHY PIC с двумя дополнительными слоями чиплетов, собранными с помощью TSMC COUPE. Два слоя электронных чиплетов собраны по технологии TSMC SoIC (System on Integrated Chips), которая использует вертикальное размещение нескольких кристаллов друг над другом, чтобы обеспечить более плотное соединение между ними, позволяя снизить энергопотребление, увеличить производительность и уменьшить задержки. По словам Стояновича, такой дизайн будет масштабироваться до уровня UCIe-A и выше как минимум в течение следующего десятилетия. 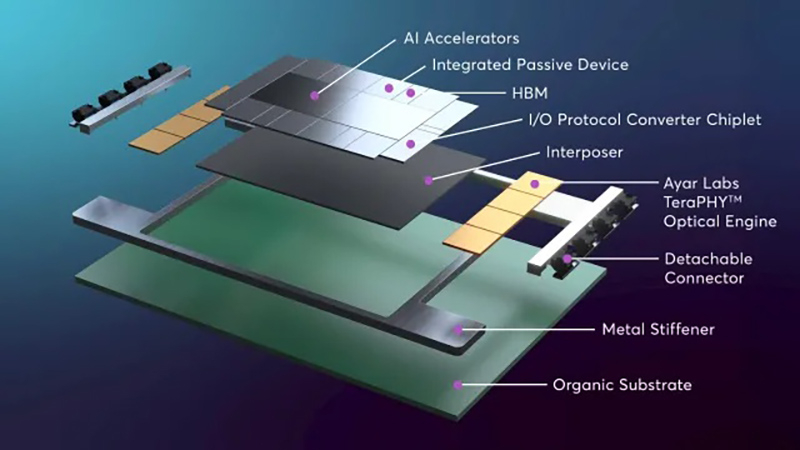 Совместное решение Alchip и Ayar Labs позволяет масштабировать многостоечную сетевую фабрику без потерь мощности и задержек, характерных для подключаемых оптических кабелей, за счёт минимизации длины электрических трасс и размещения оптических соединений вблизи вычислительного ядра. Благодаря поддержке UCIe для межкомпонентных соединений и гибкому размещению конечных точек на границе чипов, команды разработчиков могут интегрировать масштабируемое решение Alchip и Ayar Labs с существующими вычислительными блоками, стеками памяти и ускорителями, обеспечивая при этом соблюдение требований к производительности, целостности сигнала и температурному режиму на уровне всей сборки. Как сообщается, компании предоставят командам разработчиков дополнительные материалы, референсные архитектуры и варианты сборки. Платформа референсного дизайна включает в себя тестовые программы, позволяющие тестировать сборку и прошивку управления модулем, что облегчает его интеграцию в сборку. «Заказчику нужна поддержка, чтобы он понимал процессы оценки надёжности и испытаний, поэтому мы тесно сотрудничаем с Alchip, чтобы предоставить заказчику доступ ко всему этому пакету», — рассказал Стоянович.
06.10.2025 [09:19], Сергей Карасёв
Corning и GlobalFoundries создадут оптические коннекторы для кремниевой фотоникиАмериканский контрактный производитель полупроводниковых изделий GlobalFoundries и компания Corning, специализирующаяся на производстве стёкол, керамики и т.п., объявили о сотрудничестве. Совместными усилиями партнёры разработают разъёмные волоконно-оптические коннекторы для кремниевой фотоники. Речь идёт о решении GlassBridge для платформы GF Fotonix. Коннектор на основе стеклянного волновода совместим с V-образными канавками GF Fotonix. Система предназначена для удовлетворения растущих потребностей ИИ ЦОД в высокой пропускной способности каналов связи. Разрабатываются также другие механизмы соединения, включая вертикальное разъёмное решение типа Fibre-to-PIC (Photonic Integrated Circuit). Сотрудничество предусматривает использование передовых разработок Corning в области материалов, оптического волокна и средств связи. Это, в частности, стёкла специального состава, стеклянные подложки и методы лазерной обработки. Кроме того, будут применяться оптоволоконные массивы (Fibre Array Unit — FAU) с волокнами со сверхточным выравниванием сердцевины, благодаря которому минимизируются потери. 
Источник изображения: Corning В перспективе разъёмы нового типа помогут повысить удобство развёртывания и эксплуатации высокоскоростного интерконнекта на основе кремниевой фотоники в дата-центрах, ориентированных на ресурсоёмкие приложения ИИ и НРС. Не так давно GlobalFoundries объявила о том, что её платформа кремниевой фотоники выделена в отдельное продуктовое семейство. При этом компания увеличила объём инвестиции в соответствующей сфере в два раза.
23.09.2025 [15:49], Руслан Авдеев
За ИИ в дальнюю дорогу: Китай строит собственный децентрализованный вариант StargateКитай строит крупный кластер ЦОД на острове в городе Уху (Wuhu) на реке Янцзы в рамках проекта, который уже называют «китайским Stargate». Впрочем, по масштабам с оригинальным Stargate он пока не сопоставим, сообщает The Financial Times. Кластер в Уху — лишь часть более масштабного плана Пекина по укреплению своих позиций в качестве ИИ-сверхдержавы. Новый шаг сделан в ответ на усилия США по сохранению лидерства в сфере ИИ. По оценкам Epoch AI, на Америку сегодня приходится до ¾ мировых вычислительных мощностей, на Китай — пока лишь 15 %. В марте Пекин представил план, согласно которому в отдалённых от побережья западных регионах будут сосредоточены ЦОД, специализирующиеся на обучении ИИ-моделей — они не требуют столь малого времени отклика, как ЦОД для инференса, которые строятся ближе к ключевым населённым пунктам. Одним из примеров последних стал «остров данных» (Data Island) в Уху для четырёх ИИ ЦОД компаний Huawei, China Telecom, China Unicom и China Mobile, которые будут обслуживать богатые города в дельте Янцзы: Шанхай, Ханчжоу, Нанкин и Сучжоу. 
Источник изображения: Ryan Moulton/unsplash.com Всего в Уху построили ЦОД 15 компаний, общий объём инвестиций составил ¥270 млрд юаней ($37 млрд). Местное правительство предлагает субсидии, покрывающие до 30 % затрат на ИИ-чипы, в других регионах субсидии значительно скромнее. ЦОД в Уланчаб во Внутренней Монголии будет обслуживать Пекин и Тяньцзинь, ЦОД в Гуйчжоу будут обеспечивать сервисами Гуанчжоу, а Цинъян в Ганьсу будет обслуживать Чэнду и Чунцин. Оптимизация работы ЦОД призвана компенсировать невыгодное положение КНР в сравнении с США, на руку которым играет и жёсткий экспортный контроль, не позволяющий Китаю закупать передовые ИИ-ускорители и связанное оборудование. Китайским производителям вроде Huawei и Cambricon нелегко заполнить пустующую нишу, в том числе из-за ограниченных производственных мощностей в КНР. Китайским ЦОД приходится полагаться на менее производительные отечественные решения или закупать чипы на чёрном рынке — в КНР уже имеется сеть посредников, скрытно импортирующих решения NVIDIA. Один из поставщиков — базирующаяся в Уху компания Gate of the Era, закупающая партии серверов с ускорителями Blackwell для китайских ЦОД. Не так давно стало известно о гигантском ИИ ЦОД для 115 тыс. ускорителей NVIDIA, расположенном на окраине пустыни Гоби в Синьцзяне. В самой NVIDIA утверждают, что контрабанда ускорителей обречена на провал с технической и экономической точки зрения. 
Источник изображения: Nuno Alberto/unsplash.сom Инициатива East Data, West Computing, которая предполагала строительство ЦОД в богатых энергоресурсами отдалённых провинциях вроде Ганьсу и Внутренней Монголии, оказалась не вполне успешной. Недостаток технических компетенций и локального спроса, а также дороговизна каналов связи до востока страны привли к тому, что эти ИИ ЦОД не используются на полную мощность, а то и вовсе проставивают. Во многих случаях закупка чипов субсидировалась местными властями, которые не горят желанием отдавать ускорители кому-то ещё. Поэтому Пекин рассчитывает использовать сетевые технологии China Telecom и Huawei для объединения мощностей разрозненных ускорителей на разных объектах, создав децентрализованный вычислительный кластер. Китайские телеком-гиганты применяют сетевое оборудование для «трансляции» вычислительных мощностей с запада на восток страны. Тем не менее, эксперты DC Byte считают, что использование множества небольших ЦОД менее эффективно, чем одного нового крупного дата-центра.
20.09.2025 [01:40], Владимир Мироненко
NVIDIA купила за $900 млн разработчика интерконнекта для ИИ-платформ EnfabricaСогласно публикациям CNBC и The Information, NVIDIA заключила сделку с разработчиком интерконнекта для ИИ-систем Enfabrica стоимостью $900 млн, чтобы лицензировать ряд его технологий, а также переманить его гендиректора и ключевых сотрудников. Оплата сделки, завершённой на прошлой неделе, производилась собственными средствами NVIDIA и её акциями. Глава Enfabrica Рочан Санкар (Rochan Sankar) уже присоединился к команде NVIDIA. Спрос на вычислительные мощности для поддержки генеративного ИИ со стороны таких компаний, как OpenAI, Anthropic, Mistral, AWS, Microsoft и Google, ставит перед NVIDIA сложную задачу: как создать унифицированный, отказоустойчивый GPU-кластер, способный справиться с такими огромными нагрузками. Решения Enfabrica, основанной в 2019 году, призваны решить эту задачу. Как пишет Network World со ссылкой на аналитиков, NVIDIA считает интеграцию технологий Enfabrica критически важной для повышения эффективности своих кластеров в обучении новейших ИИ-моделей. Во всяком случае, Enfabrica утверждает, что её технология позволяет бесшовно объединить более 100 тыс. ускорителей в единый кластер. Кроме того, к ускорителям можно добавить CXL-пулы DRAM/SSD. 
Источник изображений: Enfabrica «Используя SuperNIC и фабрику Enfabrica, NVIDIA может ускорить передачу данных в кластерах, обойти текущие ограничения масштабирования сетевых фабрик и снизить зависимость от дорогостоящей памяти HBM», — отметила Рачита Рао (Rachita Rao), старший аналитик Everest Group, имея в виду чип ACF-S, разработанный для обеспечения более высокой пропускной способности, большей отказоустойчивости, меньшей задержки и лучшего программного управления для операторов ЦОД, работающих с ресурсоёмкими ИИ-системами и HPC. Enfabrica утверждает, что ACF-S более отказоустойчив в сравнении с традиционным интерконнектом, поскольку заменяет двухточечные соединения GPU многопутевой архитектурой, которая снижает перегрузку, улучшает распределение данных и гарантирует, что сбои в работе GPU не приведут к остановке процесса вычислений. По мнению Чарли Дая (Charlie Dai), главного аналитика Forrester, для NVIDIA также представляет интерес технология EMFASYS, позволяющая дать ИИ-серверам доступ к внешним пулам памяти. По словам Дая, сочетание ACF-S и EMFASYS может помочь NVIDIA добиться более высокой загрузки GPU и снижения совокупной стоимости владения (TCO) — ключевых показателей для гиперскейлеров и разработчиков LLM. 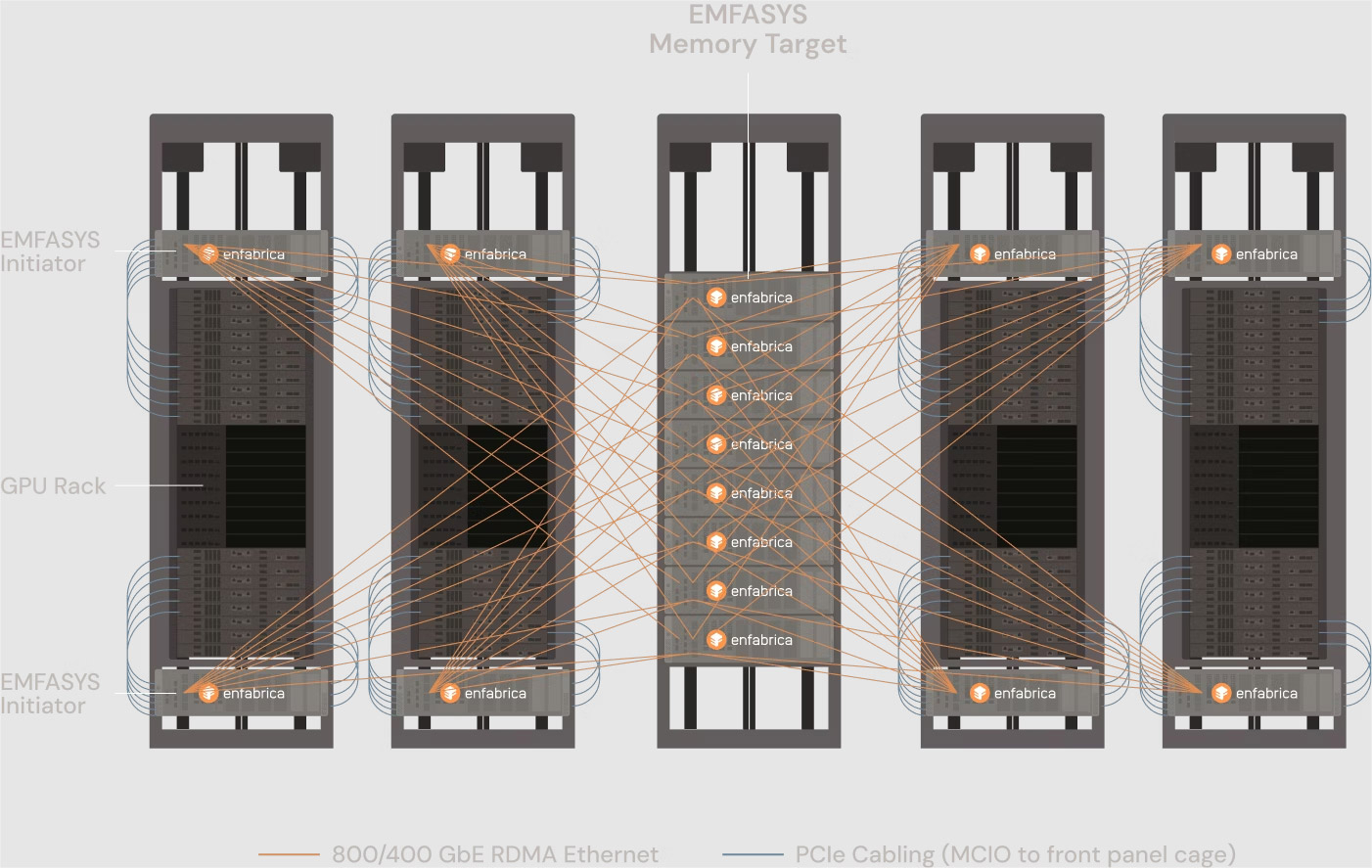 Как сообщает Blocks & Files, Enfabrica привлекла в общей сложности $290 млн венчурного финансирования: $50 млн в раунде A в размере $50 млн в 2022 году при оценке в $50 млн; $125 млн в раунде B в 2023 году с оценкой в размере $250 млн; $115 млн в раунде C в 2024 году. По данным Pitchbook, оценочная стоимость компании сейчас составляет около $600 млн. NVIDIA инвестировала в компанию в раунде B. На этой неделе NVIDIA также объявила об инвестициях в Intel в размере $5 млрд в рамках совместной разработки специализированных чипов для ЦОД и ПК. Квазислияния получили широкое распространение в Кремниевой долине, поскольку позволяют обойти препоны регуляторов. В начале этого года Meta✴ приобрела за $14,3 млрд 49 % акций Scale AI, переманив его основателя Александра Ванга (Alexandr Wang) вместе с ключевыми сотрудниками. Месяц спустя Google объявила о похожем соглашении с ИИ-стартапом Windsurf, в рамках которого его соучредитель и гендиректор Варун Мохан (Varun Mohan) перешёл вместе с рядом сотрудников в подразделение Google DeepMind. Аналогичные сделки были в прошлом году у Google с Character.AI, Microsoft с Inflection AI и у Amazon с Adept.
19.09.2025 [11:45], Сергей Карасёв
Обнародована предварительная спецификация PCIe 8.0Некоммерческая организация PCI Special Interest Group (PCI-SIG) сообщила о выходе спецификации PCI Express (PCIe) 8.0 версии 0.3. Документ, как отмечается, получил одобрение со стороны участников соответствующей рабочей группы и теперь доступен членам организации. Стандарт PCIe 8.0 предполагает, что «сырая» скорость передачи данных составит до 256 ГТ/с на линию. При этом пропускная способность в двустороннем режиме x16 будет достигать 1 Тбайт/с против 512 Гбайт/с у интерфейса предыдущего поколения. Для PCIe 8.0 предусмотрено обеспечение обратной совместимости с более ранними версиями PCIe. Организация PCI-SIG намерена выпустить полную версию спецификации PCIe 8.0 к 2028 году. Стандарт разрабатывается с прицелом на системы ИИ, высокоскоростные сети, периферийные вычисления, квантовые платформы и другие приложения, которым требуется высокая пропускная способность. 
Источник изображения: PCI-SIG Модель членства PCI-SIG подразумевает, что каждая компания-участник может внести свой вклад в процесс разработки спецификаций. В случае PCIe 8.0 внимание в числе прочего уделяется повышению энергетической эффективности и общим улучшениям на уровне протокола. Ещё одним направлением работ названо достижение целевых показателей надёжности. Эл Янес (Al Yanes), президент и председатель PCI-SIG, отмечает, что выход спецификации PCIe 8.0 в 2028 году отражает тенденцию удвоения пропускной способности данного интерфейса каждые три года. По его словам, новый стандарт обеспечит экономичный и скоростной интерконнект с низкими задержками для удовлетворения растущих потребностей отрасли.
15.09.2025 [09:24], Владимир Мироненко
Считавшаяся неудачной сделка по покупке Sun в итоге сделала Oracle облачным гигантом
exadata
hardware
oracle
oracle cloud infrastructure
sun
гиперскейлер
ии
интерконнект
облако
сделка
цод
Когда в апреле 2009 года Oracle, считавшаяся на тот момент третьей в мире по величине софтверной компанией, объявила о покупке Sun Microsystems, все расценили сделку как неудачную. Покупка обошлась в $7,4 млрд ($5,6 млрд с учётом собственных средств и долгов Sun), а решение главы Oracle Ларри Эллисона (Larry Ellison) вызвало лишь один вопрос: зачем компании, занимающейся СУБД и корпоративным ПО, покупать пришедшего в упадок производителя серверов и ПО, принимая на себя бремя расходов по ведению аппаратного бизнеса? На то, чтобы ответ на него стал очевидным, ушло почти 15 лет, приводит SiliconANGLE слова аналитика Тони Баера (Tony Baer). Многие считали, что покупка Sun подорвёт финансовое положение Oracle. Основополагающий бизнес Sun по выпуску SPARC-серверов с ОС Solaris был ослаблен из-за Linux и x86 — мало кто хотел платить за наследника UNIX и дорогое «железо», так что на момент сделки Sun ежемесячно теряла $100 млн. В действительности же всё оказалось не так уж плохо. В следующем после закрытия сделки финансовом году общая выручка Oracle (по GAAP) выросла на 33 %, в основном за счёт ПО, в то время как выручка от аппаратного бизнеса снизилась всего лишь на 6 %. Вместе с тем количество развёрнутых ПАК Oracle Exadata (Oracle Database Machine) по всему миру превысило 1 тыс. Предположительно, выручка от Exadata была учтена в разделе ПО. Если ранее Exadata использовала оборудование HP, то после приобретения Sun компания больше не зависела от сторонних производителей и вскоре её слоганом для Exadata стало «инженерные системы». 
Источник изображений: Oracle Распространённое мнение сводилось к тому, что, купив Sun, Oracle выходит на серверный рынок. На самом деле, приобретение Sun привнесло в Oracle системный подход, который стал ключом не только к её растущему бизнесу по выпуску ПАК Exadata, но и к будущему облачному бизнесу, о котором компания даже не помышляла в 2009 году, отметил SiliconANGLE. Мало кто мог предсказать, что Oracle со временем станет крупным облачным провайдером. Даже сам Эллисон поначалу воспринимал эту идею скептически, назвав в 2008 году облачный бизнес «бессмыслицей». Тем не менее, в 2016 году компания запустила Oracle Cloud Infrastructure (OCI) и… всего через два года решила полностью поменять облачную архитектуру, поняв, что текущая ничем не отличается от AWS, Microsoft Azure или Google Cloud. В частности, для повышения безопасности была обеспечена полная изоляция кода и данных клиентов, а для повышения производительности и масштабируемости была упрощена топология и внедрена поддержка RDMA. Кроме того, Oracle не только опиралась на опыт Sun, но и агрессивно переманивала специалистов AWS и Azure. И хотя сейчас практически каждый гиперскейлер использует ускорители NVIDIA, только OCI может объединить их в суперкластеры из 131 тыс. чипов, а с недавних пор и ускорители AMD. Облачный сервис Oracle Exadata также выиграл: учитывая спрос клиентов и тот факт, что ни один гиперскейлер не может повторить оптимизацию RDMA-интерконнекта, которую сделала Oracle, инфраструктура Exadata теперь размещена как нативный сервис у всех трёх гиперскейлеров в их же ЦОД. За последний год выручка от баз данных MultiCloud выросла более чем в 15 раз.  10 сентября акции Oracle показали рекордный за 26 лет рост, и не столько из-за увеличения выручки, которая оказалась ниже ожиданий Уолл-стрит, сколько благодаря развитию её облачной инфраструктуры. Объём оставшихся обязательств по контрактам (RPO) компании вырос год к году на 359 % до $455 млрд. В тот же день было объявлено о сделке с Open AI на сумму в $300 млрд, вместе с которой Oracle участвует в проекте Stargate. И хотя RPO Oracle намного выше показателей её конкурентов среди гиперскейлеров, она значительно уступает им по размерам дохода, поскольку компании приходится направлять значительно большую часть средств на капитальные вложения. Существуют опасения, что ажиотаж вокруг ИИ может повторить ситуацию с пузырём доткомов. Oracle хеджирует свои риски, не покупая здания или недвижимость для облачных регионов OCI. Оборудование и инфраструктура закупаются только по факту поступления заказов, но большая ставка на одного клиента — Open AI — ставит под сомнение устойчивость её позиций, пишет SiliconANGLE. Кроме того, есть вероятность, что и заказы остальных клиентов будут реализованы в полном объёме. Тем не менее, 15 лет назад вряд ли кто бы подумал, что приобретение Sun Microsystems преобразит Oracle. Хотя в то время серверный бизнес Sun переживал упадок, у неё был системный опыт, который изменил ход событий. И в долгосрочной перспективе именно опыт Sun запустил перемены в основном бизнесе Oracle, превратив поставщика корпоративного ПО в успешного провайдера облачной инфраструктуры.
09.09.2025 [15:46], Сергей Карасёв
d-Matrix представила 400GbE-адаптер JetStream для объединения своих ИИ-ускорителейСтартап d-Matrix анонсировал специализированную IO-карту JetStream, предназначенную для распределения нагрузок ИИ-инференса между серверами в дата-центре. Устройство ориентировано на использование в связке с ускорителями d-Matrix Corsair, архитектура которых основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC). JetStream использует стандарт Ethernet, благодаря чему обладает совместимостью с уже существующими коммутаторами. Новинка выполнена в виде платы расширения с интерфейсом PCIe 5.0 х16. Используются корзины QSFP-DD. Могут быть задействованы два 200GbE-порта со скоростью 200 Гбит/с или один 400GbE-порт. Архитектура серверов d-Matrix для ИИ-инференса предполагает установку ускорителей Corsair с DMX-мостом между каждыми двумя такими картами для обеспечения высокой пропускной способности без использования PCIe. Затем пары ускорителей объединяются посредством коммутатора PCIe. В эталонном дизайне один NIC JetStream обслуживает до четырёх экземпляров Corsair. d-Matrix утверждает, что сетевую задержку в такой конфигурации удалось сократить до 2 мкс. 
Источник изображений: d-Matrix По заявлениям d-Matrix, карты JetStream могут применяться в существующих ЦОД без необходимости замены дорогостоящих инфраструктурных компонентов. В связке с ИИ-ускорителями Corsair и ПО d-Matrix Aviator решения JetStream способны справляться с ИИ-моделями, насчитывающими более 100 млрд параметров. При этом, как утверждает разработчик, обеспечивается в 10 раз более высокая производительность, в три раза лучшая экономическая эффективность и втрое большая энергоэффективность по сравнению с решениями на базе GPU. 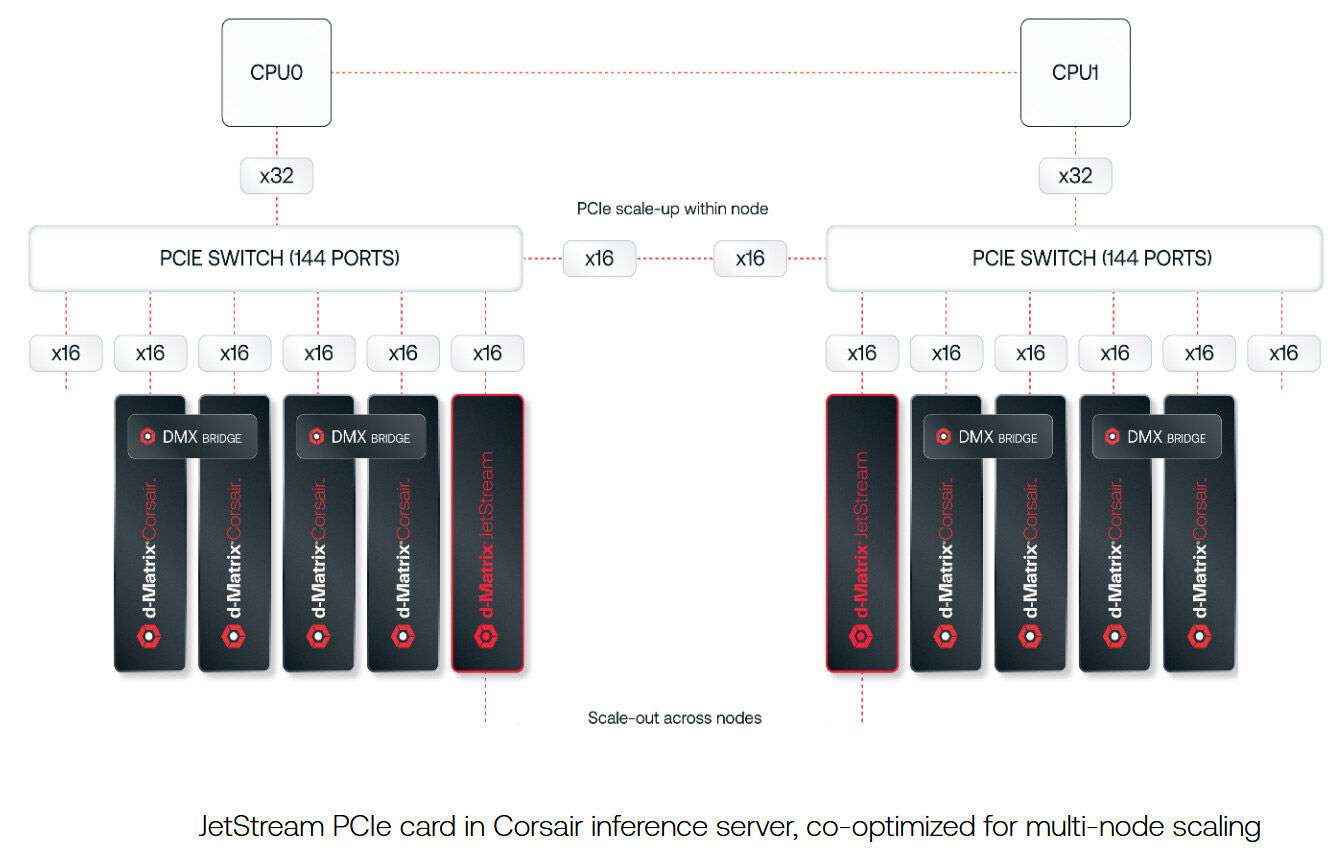 Энергопотребление JetStream составляет около 150 Вт. Адаптер оснащён системой охлаждения с радиатором и тепловыми трубками, которые охватывают зону QSFP-DD. Пробные поставки новинки уже начались, а массовое производство запланировано на конец текущего года.
08.09.2025 [09:29], Сергей Карасёв
DE-CIX запустила первую в мире платформу обмена ИИ-трафикомОператор точек обмена трафиком DE-CIX объявил о запуске первой в мире специализированной платформы, призванной обеспечить высокоскоростное и надёжное взаимодействие между агентами, сетями и приложениями на базе ИИ. Инфраструктура сформирована в рамках первой фазы проекта AI Internet Exchange (AI-IX). К платформе уже подключены более 50 сетей, ориентированных на задачи ИИ. Это, в частности, провайдеры инференс-услуг и GPUaaS, а также поставщики облачных сервисов. AI-IX, как утверждается, обеспечивает отказоустойчивое и высокозащищённое соединение с низкими задержками, специально предназначенное для сценариев использования ИИ в режиме реального времени. Это могут быть мультимодальные агенты, робототехнические устройства, системы автономного вождения и пр. Платформа использует проприетарную масштабируемую систему маршрутизации. Вторая фаза проекта AI-IX предполагает поддержку Ultra Ethernet для формирования географически распределённой среды обучения ИИ. Задачей консорциума Ultra Ethernet, созданного в июле 2023 года, является разработка ИИ/HPC-интерконнекта на базе Ethernet. DE-CIX отмечает, что с появлением Ultra Ethernet меняется подход к проектированию инфраструктуры для ресурсоёмких вычислений. Становится возможным объединение географически распределённых узлов, что предоставляет компаниям новые возможности в плане создания отказоустойчивой и более экономичной частной инфраструктуры ИИ. 
Источник изображения: DE-CIX В целом, как подчёркивает DE-CIX, пиринговые сети ИИ предлагают ряд преимуществ как для задач инференса, так и для обучения моделей. Среди них — снижение затрат, повышение безопасности, увеличение производительности и повышение гибкости.
03.09.2025 [16:32], Владимир Мироненко
GlobalFoundries объявила о готовности к массовому развёртыванию решений в сфере кремниевой фотоникиАмериканский контрактный производитель полупроводников GlobalFoundries вывел свою платформу кремниевой фотоники в отдельную линейку продуктов и удвоил инвестиции в её развитие, сообщил Кевин Соукуп (Kevin Soukup), старший вице-президент. Он сравнил текущее состояние внедрения технологии с «режимом запуска» Tesla, характеризующимся готовностью к ускоренному массовому развёртыванию, пишет Converge! Network Digest. По словам Соукупа спрос на кремниевую фотонику в ЦОД определяют три взаимосвязанных фактора: взрывной рост объёмов данных, развитие ИИ и LLM с триллионами параметров, а также стремительное увеличение энергопотребления. По его оценкам, к 2030 году глобальное энергопотребление ЦОД может удвоиться, и только в США на ИИ ЦОД будет приходиться 10–15 % всего потребления электроэнергии страны. При этом многие ASIC простаивают до 75 % времени в связи с низкой скоростью передачи данных между чипами. «Кремниевая фотоника снижает энергопотребление и задержку, обеспечивая при этом возможность масштабирования архитектур как в горизонтальном, так и в вертикальном направлении для GPU и ASIC», — сказал он. 
Источник изображения: GlobalFoundries GlobalFoundries опубликовала программу развития, охватывающую три ключевых подхода к оптической связи. В категории подключаемой оптики традиционные оптические модули с пропускной способностью 200 Гбит/с на линию, подключаемые к сетевым коммутаторам, широко используются в ЦОД уже сейчас. Модули с поддержкой 400 Гбит/с на линию пройдут тестирование к концу 2025 года. Выпуск прототипов намечен на 2026 год, запуск массового производства — на 2027 год. В категории линейной оптики (LPO) — оптических решений, в которых цифровая обработка сигнала перенесена с оптического модуля на хост-схему ASIC, что снижает энергопотребление и задержку, GlobalFoundries планирует развёртывания в ближайшей перспективе с партнерами по экосистеме. В категории интегрированной фотоники (CPO) основное внимание уделяется передовым корпусам, многоволоконным соединениям, отсоединяемым (detachable) оптическим интерфейсам и стекированию фотонных и электронных схем. Соукуп сообщил, что компанией была создана серьёзная экосистема для развитя фотоники, включая новый Центр упаковки передовых фотонных модулей (APPC) в Мальте (штат Нью-Йорк) для производства оптических модулей в стране. Intel и Broadcom также активно продвигают LPO- и CPO-решения, а Marvell инвестирует в подключаемые решения на базе DSP. Отрасль вступает в критическую фазу, когда гиперскейлеры должны выбирать оптическую архитектуру, которая обеспечивает баланс между масштабируемостью, эффективностью и рисками развёртывания, отметил Converge! Network Digest. |
|