Материалы по тегу: dpu
|
02.09.2025 [10:14], Владимир Мироненко
Intel анонсировала IPU E2200 — 400GbE DPU семейства Mount MorganIntel анонсировала DPU Intel IPU E2200 под кодовым названием Mount Morgan, представляющий собой обновление 200GbE IPU E2100 (Mount Evans), разработанного при участии Google для использования в ЦОД последней, причём не слишком удачного, как отмечают некоторые аналитики. Как сообщает ресурс ServeTheHome, Intel E2200 производится по 5-нм техпроцессу TSMC. Он базируется на той же архитектуре, что и предшественник, но предлагает более высокую производительность. Вычислительный блок включает до 24 ядер Arm Neoverse N2 с 32 Мбайт кеша, четырьмя каналами LPDDR5-6400 и выделенным сопроцессором безопасности. Сетевая часть представлена 400GbE-интерфейсом с RDMA, а хост-подключение — подсистемой PCIe 5.0 x32 со встроенным коммутатором PCIe. 
Источник изображений: Intel via ServeTheHome  Для обработки пакетов используется P4-программируемый процессор FXP — модуль обработки трафика с алгоритмом синхронизации и настраиваемыми параметрами разгрузки, что позволяет распределять задачи между сетевыми ускорителями и Arm-ядрами. 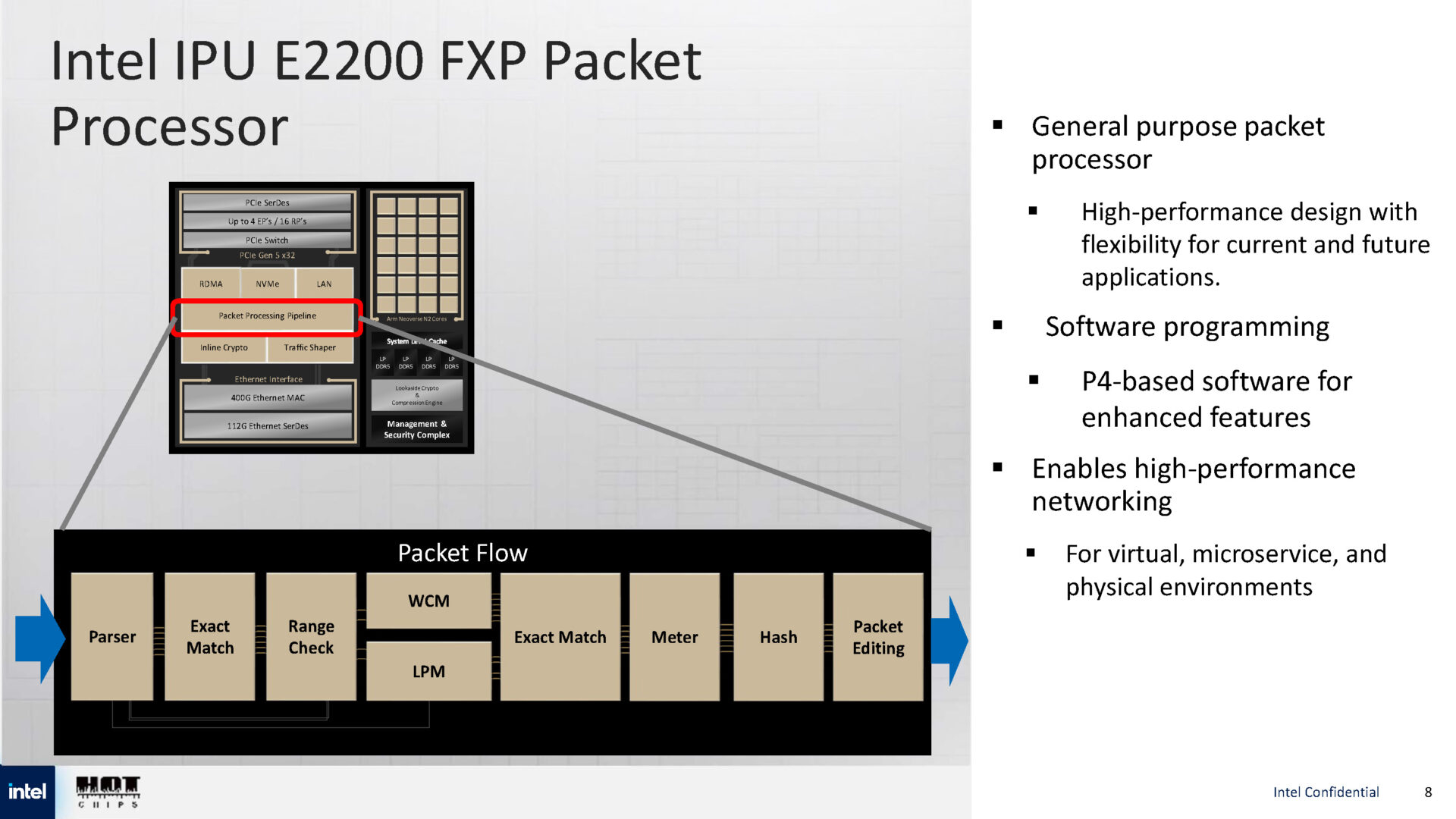 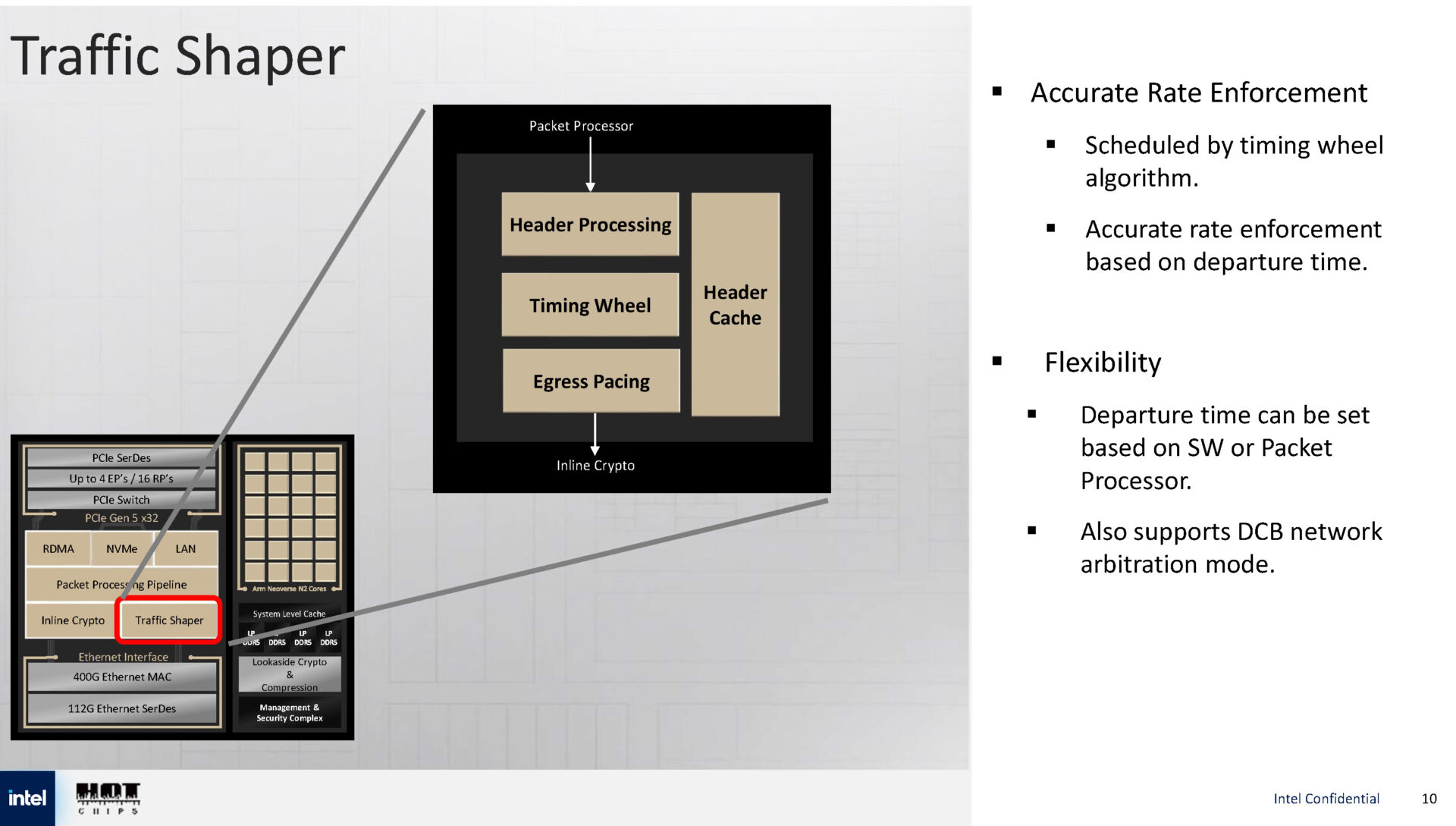 Также имеется встроенный криптографический модуль для шифрования на лету (inline) с поддержкой протоколов IPsec и PSP, настраиваемый для каждого потока. Для управления потоками данных используется модуль Traffic Shaper с поддержкой алгоритма Timing Wheel. 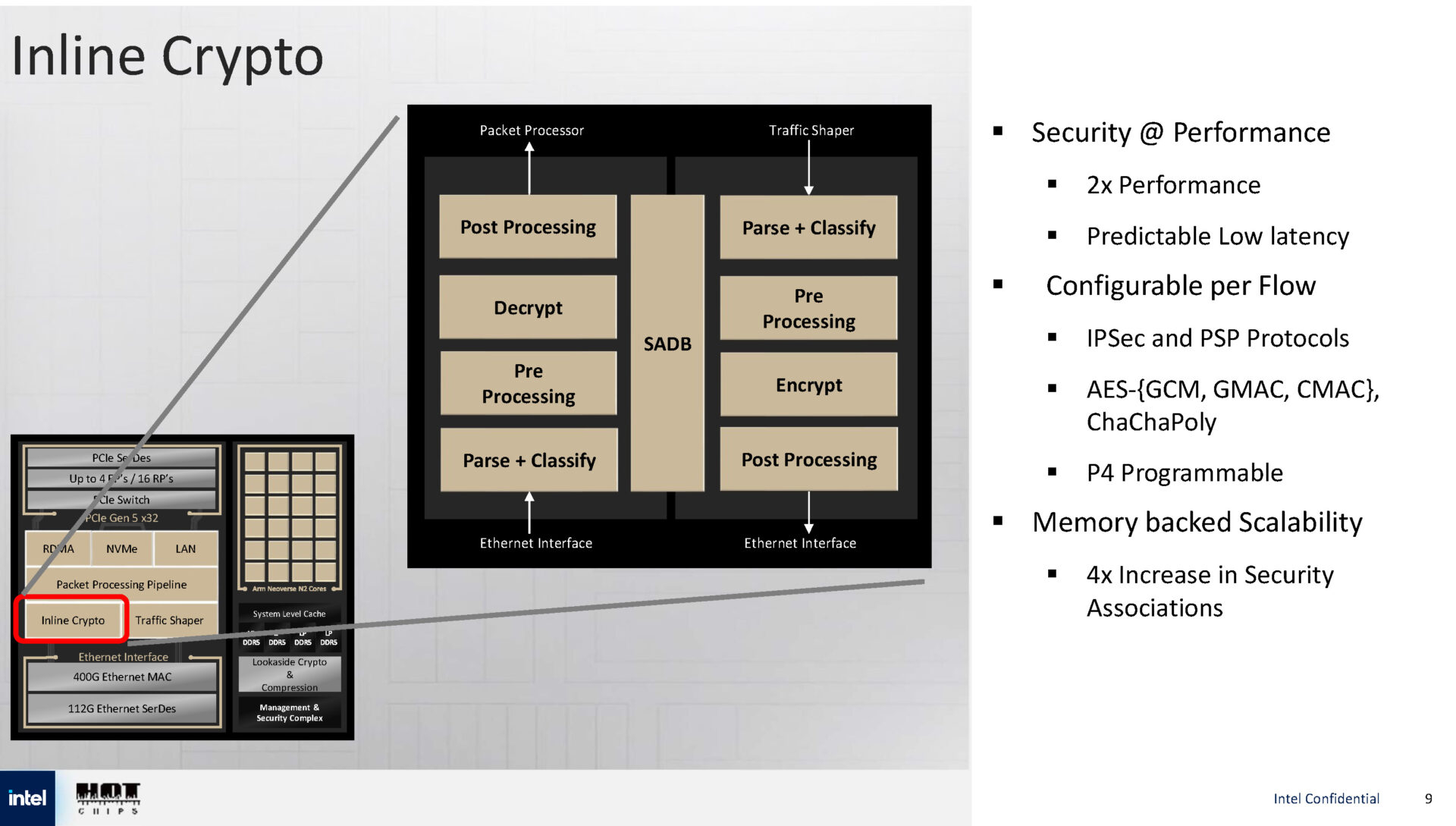  Кроме того, есть и Look-Aside-блок для компрессии и шифрования. Как и в IPU E2100, у IPU E2200 имеется выделенный модуль для независимого внешнего управления. Также поддерживаются программируемые параметры разгрузки с использованием различных ускорителей и IP-блоков.
24.08.2025 [23:18], Сергей Карасёв
NeuReality готовит чип NR2 для оркестрации инференсаКомпания NeuReality раскрыла предварительную информацию об изделии NR2 — чипе второго поколения, предназначенном специально для оркестрации инференса. Изделие представляет собой более эффективную альтернативу связке CPU и NIC в высокопроизводительных системах ИИ. Чип первого поколения NR1 дебютировал в июне нынешнего года. Изделие может применяться в связке с любым GPU или ИИ-ускорителем. При этом, как утверждается, NR1 позволяет повысить эффективность использования GPU почти до 100 % по сравнению со средним показателем в 30–50 % при традиционном сочетании CPU и NIC в современных серверах. В состав NR1 входят четыре декодера видео/изображений, 16 DSP для аудио/речи, 16 векторных DSP общего назначения, два порта 10/25/50/100GbE и пр. Характеристики NR2 на данный момент полностью не раскрываются. Известно, что в основу решения положена платформа Arm Neoverse Compute Subsystems (CSS) V3. Чип может объединять до 128 ядер, оптимизированных для масштабных рабочих нагрузок обучения моделей ИИ и инференса. По сравнению с оригинальной версией в NR2 реализована более глубокая интеграция между CPU-блоком и NIC для координации ИИ-моделей в реальном времени, дезагрегации на основе микросервисов, потоковой передачи токенов, оптимизации KV-кеша и оркестровки. 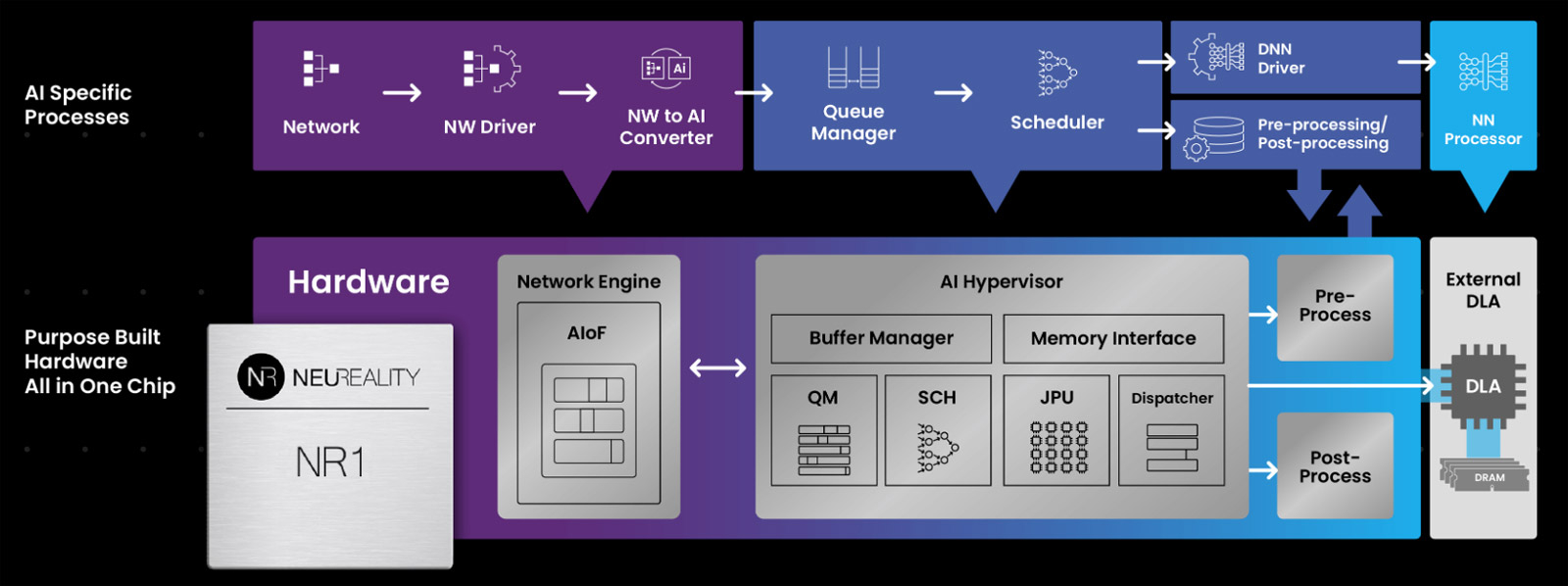
Источник изображения: NeuReality В целом, как отмечает NeuReality, чипы серии NR представляют собой качественно новый класс изделий, способных управлять рабочими нагрузками инференса с непревзойдённой эффективностью. Гипервизор ИИ в сочетании с ядрами Arm Neoverse обеспечивает оптимальную оркестровку и максимальную загрузку доступных ресурсов.
29.07.2025 [16:38], Сергей Карасёв
MaxLinear представила DPU Panther V с пропускной способностью 450 Гбит/сКомпания MaxLinear анонсировала ускоритель обработки данных Panther V, предназначенный для использования в дата-центрах и инфраструктурах гиперскейлеров. Решение берёт на себя выполнение таких ресурсоёмких операций с данными, как сжатие, дедупликация, шифрование и проверка в реальном времени. В результате, снижается нагрузка на CPU, уменьшаются задержки, повышаются общая производительность и энергоэффективность, а также сокращаются капитальные и эксплуатационные затраты. Новинка выполнена на той же архитектуре, которая лежит в основе DPU Panther III. При этом вместо интерфейса PCIe 4.0 используется PCIe 5.0 (x16). Пропускная способность увеличена более чем в два раза — с 200 до 450 Гбит/с. Устройство оптимизировано для НРС-задач, гипермасштабируемых и гиперконвергентных архитектур, рабочих нагрузок ИИ и машинного обучения. 
Источник изображения: MaxLinear Упомянут механизм дедупликации структурированных данных MaxHash вплоть до 15:1 (в сочетании с алгоритмами глубокого сжатия). Это значительно повышает эффективную вместимость и увеличивает срок службы NVMe SSD. Реализованы различные средства обеспечения безопасности, включая сквозную защиту данных, ЕСС и пр. Говорится о развитой программной экосистеме: это SDK с унифицированными API, а также интеллектуальный балансировщик нагрузки для бесшовной интеграции в средах Linux и FreeBSD. Возможно объединение в системе нескольких ускорителей Panther V с суммарной пропускной способностью свыше 3,2 Тбит/с.
23.07.2025 [09:37], Владимир Мироненко
SSD не нужны: OFP обещает на порядок повысить плотность All-Flash СХД и наполовину снизить расходы на инфраструктуруИнициатива Open Flash Platform (OFP) призвана полностью пересмотреть работу с флеш-памятью в ИИ ЦОД. Участники OFP — Hammerspace, Linux Foundation, Лос-Аламосская национальная лаборатория (LANL), ScaleFlux, SK hynix и Xsight Systems — намерены отказаться от традиционных All-Flash хранилищ и контроллеров. Вместо них предложено использовать флеш-картриджи с минимумом аппаратной начинки, а доступ к таким массивам предоставлять посредством DPU и pNFS. Как отмечено в пресс-релизе, OFP отвечает многим фундаментальным требованиям, возникающим в связи со следующим этапом развития СХД для ИИ. Для ИИ требуются поистине огромные массивы данных, но вместе с тем ЦОД сталкиваются с дефицитом энергии, повышением температуры и недостатком свободного места. Именно поэтому в OFP решили, что инфраструктуры хранения для ИИ лучше разработать с чистого листа. Если 10 лет назад технология NVMe вывела флеш-память на новый уровень производительности благодаря отказу от устаревших шин данных и контроллеров, то теперь OFP обещает раскрыть возможности флеш-памяти, исключив посредников в виде серверов хранения и проприетарных программных стеков. OFP же опирается на открытые стандарты и open source решения, в частности, Parallel NFS (pNFS) и стандартный Linux, для размещения флеш-памяти непосредственно в SAN. А отказ от традиционных СХД обеспечит на порядок большую плотность размещения данных, существенную экономию энергии и значительно более низкую совокупную стоимость владения. 
Источник изображения: openflashplatform.org OFP отметила, что существующие решения изначально привязаны к модели сервера хранения, которая требует чрезмерных ресурсов для повышения производительности и возможностей. Конструкции всех современных поставщиков AFA не оптимизированы для достижения максимальной плотности размещения флеш-памяти и привязаны к сроку службы CPU (обычно пять лет), тогда как срок службы флеш-памяти в среднем составляет восемь лет. Эти серверы хранения также предлагают проприетарные структуры и уровни хранения данных, что приводит к увеличению количества копий данных и добавлению расходов на лицензирование для каждого узла. Комментируя инициативу, ресурс Blocks & Files отметил, что Pure Storage и другие поставщики AFA уже предлагают оптимизированные схемы лицензирования и подписки, в том числе с обновлением контроллеров и дисковых полок. Та же Pure Storage предлагает более высокую плотность хранения, чем многие другие поставщики, хотя и использует проприетарные решения. Поддержкой DPU тоже удивить нельзя. Например, VAST Data уже поддерживает работу своего ПО на NVIDIA BlueField-3. А большинство поставщиков флеш-массивов и так поддерживают RDMA и GPUDirect. OFP выступает за открытый, основанный на стандартах подход, включающий несколько основных элементов:
Благодаря использованию открытых архитектур и компонентов, соответствующих отраслевым стандартам, реализация OFP приведёт к значительному повышению эффективности хранения данных, утверждают основатели инициативы. Так, обещано десятикратное увеличение плотности размещения данных, что позволит «упаковать» в одну стойку 1 Эбайт, попутно снизив энергопотребление на 90 %, увеличив срок службы флеш-памяти на 60 % и уменьшив совокупную стоимость владения (TCO) на 60 % по сравнению со стандартными массивами хранения. По мнению Blocks & Files, в текущем виде OFP выглядит скорее как маркетинговая инициатива, от которой в первую очеред выиграют её участники. Концепция же «сетевых» SSD сама по себе не нова. Весной Kioxia показала SSD с «оптикой». Да, тут речь идёт скорее о блочном доступе и NVMe-oF, но, например, Nimbus Data в прошлом году представила ExaDrive EN с поддержкой NFS.
07.07.2025 [10:15], Руслан Авдеев
DPU-революция так и не состоялась, но развитие ИИ может изменить ситуациюВ 2013 году AWS представила инстансы EC2 C3, вскользь упомянув о расширенных сетевых возможностях благодаря появлению Intel Virtual Function. Позже компания пояснила, что кастомные сетевые адаптеры позволили перенести на них часть нагрузок вроде межсетевого экрана, что высвободило ресурсы серверов. Данное решение оставалось нишевым, но развитие ИИ может всё изменить, сообщает The Register. Решение нашло отклик и у других гиперскейлеров. Они начали создавать собственные SmartNIC или DPU. Mellanox в 2017 году представила DPU BlueField, изначально предназначенный для ускорения перемещения данных All-Flash хранилищ. Чуть позже VMware начала адаптацию своего гипервизора для работы со SmartNIC, предусматривающую запуск сетевых функций на DPU. Потенциал разработки оценила и NVIDIA, которая и приобрела Mellanox, а позже — ещё и Nebulon. В 2021 году Intel вместе с Google разработала Infrastructure Processing Unit (IPU), а годом позже AMD купила разработчика DPU Pensando. В 2022 году VMware представила vSphere Distributed Services Engine, предназначенный для управления SmartNIC и реализации на них распределённого файрвола. Хотя за SmartNIC стояли ключевые игроки IT-отрасли вроде VMware, Intel, AMD и NVIDIA, у каждой из которых было немало клиентов из сферы дата-центров, никакой революции с массовым применением DPU не произошло. VMware признала, что Distributed Services Engine не получил всеобщего признания, а эксперты отрасли подчеркнули, что основными потребителями DPU являются AWS и Microsoft Azure, сдающие мощности конечным заказчикам. ⅔ развёртываний DPU и SmartNIC приходится именно на этих двух гиперскейлеров, а за пределами облачного сегмента особенного прогресса нет. 
Источник изображения: Microsoft Впрочем, намечаются и новые сценарии применения DPU, например — в Ethernet-коммутаторах или даже в качестве замены CPU. Потенциально это поможет расширить клиентскую базу. Например, Cisco применяет DPU в «защитных» продуктах Hypershield и смарт-коммутаторах N9300, а первыми DPU в свои коммутаторы CX 1000 внедрила Aruba ещё в 2021 году. Но такие продукты массовыми так и не стали. Ситуацию может изменить стремительное развитие ИИ-технологий. Недавно аналитики Gartner представили «эталонную» архитектуру для работы с ИИ на периферии и в Kubernetes-средах. В обоих случаях рекомендуется использовать DPU. Аналогичный подход в архитектуре для ИИ-облаков поддерживает и NVIDIA. Red Hat тоже поддержала идею использования DPU для виртуальных коммутаторов, балансировщиков, межсетевых экранов, для оптимизации работы баз данных или аналитических нагрузок за счёт прямого взаимодействия с NVMe и даже для инференса. Так, в OpenShift скоро появится DPU Operator. Пять лет назад Fungible объявила, что DPU должны стать «третьим сокетом» наравне с CPU и GPU, а через два года она была куплена Microsoft. И ей ещё повезло, потому что, например, Kalray оказалась вынуждена продать часть своего бизнеса. Возможно, в жизни этой компании и других стартапов наступит светлая полоса — революция в сфере ИИ может привести и к революционному развитию DPU.
21.06.2025 [23:32], Сергей Карасёв
Xsight Labs выпустила DPU E1 с 64 ядрами Arm Neoverse N2 и 40 линиями PCIe 5.0Компания Xsight Labs объявила о доступности программно-определяемых «систем на чипе» (SoC) серии E1, предназначенных для создания DPU. Такие изделия могут применяться в облачных и периферийных дата-центрах, рассчитанных в том числе на ИИ-нагрузки. О подготовке решений E1 сообщалось в конце прошлого года. Для чипа предусмотрены варианты E1-32 и E1-64, конфигурация которых включает соответственно 32 и 64 ядра Arm Neoverse N2. Младшая версия имеет 16 Мбайт кеша и использует конфигурацию памяти 2 × DDR5-5200, старшая — 32 Мбайт и 4 × DDR5-5200. Доступны 40 (32+8) линий PCIe 5.0. Сетевые порты могут иметь конфигурацию 2 × 400GbE, 4 × 200GbE и 8 × 100/50/25/10GbE. 
Источник изображений: Xsight Labs На базе E1 могут создаваться карты расширения различной конфигурации. Благодаря наличию 32 программируемых линий PCIe 5.0 и восьми двухрежимных контроллеров 16 линий могут быть выделены для хост-подключения, а другие 16 линий — для подключения внешних устройств. В качестве примера приводится конфигурация с двумя портами 400GbE или возможностью подсоединения четырёх SSD с интерфейсом PCIe 5.0 х4 каждый.  Кроме того, компания Xsight Labs представила 1U-систему E1-Server в форм-факторе на основе E1. Эта платформа подходит для решения таких задач, как CDN, веб-сервер, VPN, шлюз для защиты от DDoS-атак и пр. Устройство располагает четырьмя слотами для модулей памяти DDR5-5200 суммарным объёмом до 512 Гбайт и коннекторомв для SSD формата M.2. Возможна установка двух карт расширения типоразмера FHFL/FHHL/HHHL. Диапазон рабочих температур — от 0 до +35 °C.
19.06.2025 [09:27], Владимир Мироненко
ИИ — это не только GPU: Marvell проектирует полсотни кастомных чипов для ЦОДПоскольку провайдеры облачных сервисов, ИИ-стартапы и суверенные субъекты масштабируют свои ЦОД, Marvell видит растущий спрос не только на основное вычислительное оборудование, включая пользовательские CPU, GPU и ускорители, но и на широкий спектр вспомогательных полупроводниковых элементов, включая контроллеры сетевых интерфейсов, чипы управления питанием, устройства расширения памяти и т.д., пишет Converge Digest. В ходе мероприятия для инвесторов AI Investor Day 2025 гендиректор Мэтт Мерфи (Matt Murphy) обрисовал растущую роль компании в поддержке ИИ-инфраструктуры, отметив два ключевых события, формирующих рынок: рост числа новых разработчиков ИИ-инфраструктуры за пределами традиционных четырёх ведущих гиперскейлеров и быстрое появление компонентов XPU Attach как важной новой категории кастомных полупроводников. Мерфи отметил, что эти тенденции способствуют формированию гораздо более крупного и разнообразного общего целевого рынка, чем прогнозировалось ранее. 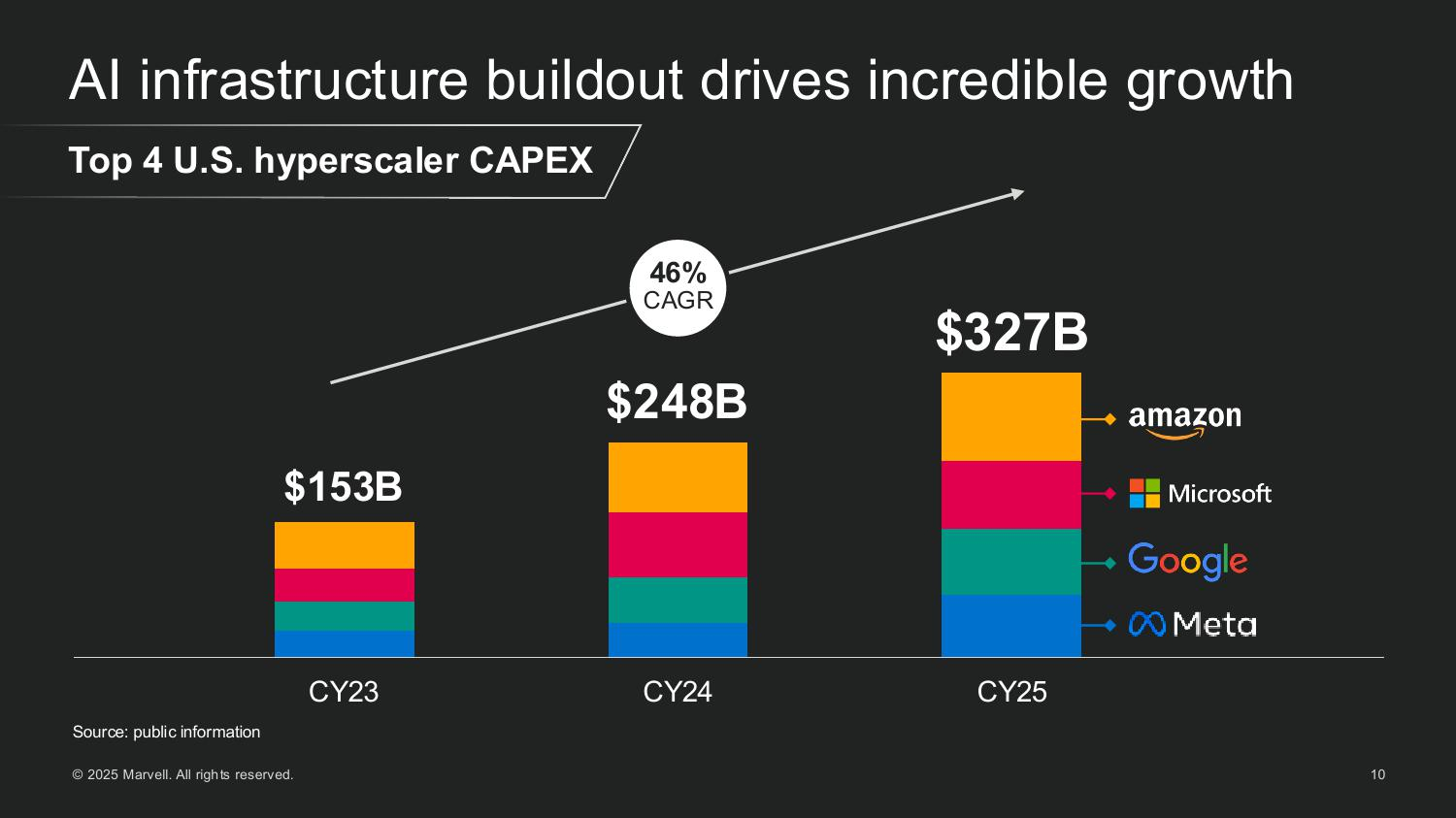
Источник изображений: Marvell Мерфи рассказал, как резко выросли глобальные капитальные затраты на ЦОД, обусловленные ростом гиперскейлеров и развитием суверенного ИИ. Ведущие американские гиперскейлеры — AWS, Microsoft, Google и Meta✴ — увеличили совокупные капитальные затраты со $150 млрд в 2023 году до более чем $300 млрд в 2025 году. По прогнозам, на глобальном уровне к 2028 году затраты превысят уже $1 трлн. Marvell считает, что значительная часть этих расходов будет направлена на кастомные полупроводниковые платформы. 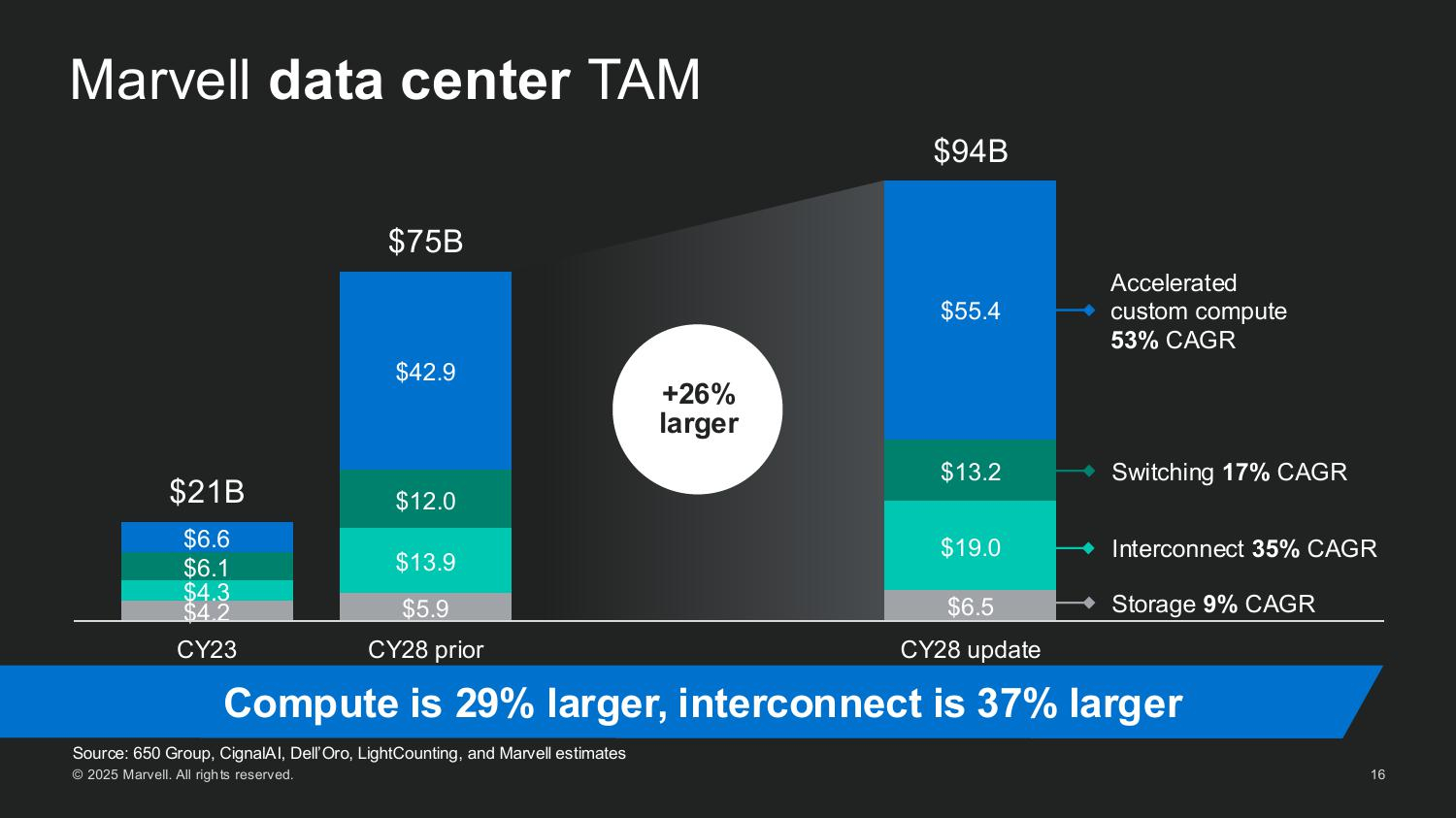 Marvell пересмотрела прогноз общего целевого рынка (TAM) в сторону увеличения до $94 млрд к 2028 году, что на 25 % больше её оценки в прошлом году. Эта сумма включает:
Мерфи подчеркнул, что XPU Attach — прорывная категория, отметив, что «вычислительные ИИ-платформы больше не определяются одним чипом. Это сложные системы с бурным ростом числа сокетов — каждый из которых представляет собой новую возможность [для компании]».  «В прошлом году у нас было три кастомных вычислительных чипа и TAM на $75 млрд. В этом году у нас 18 сокетов, TAM на $94 млрд и растущий поток из более чем 50 проектов. Рынок ИИ-инфраструктуры быстро развивается, и Marvell находится прямо в его центре», — подытожил Мерфи. 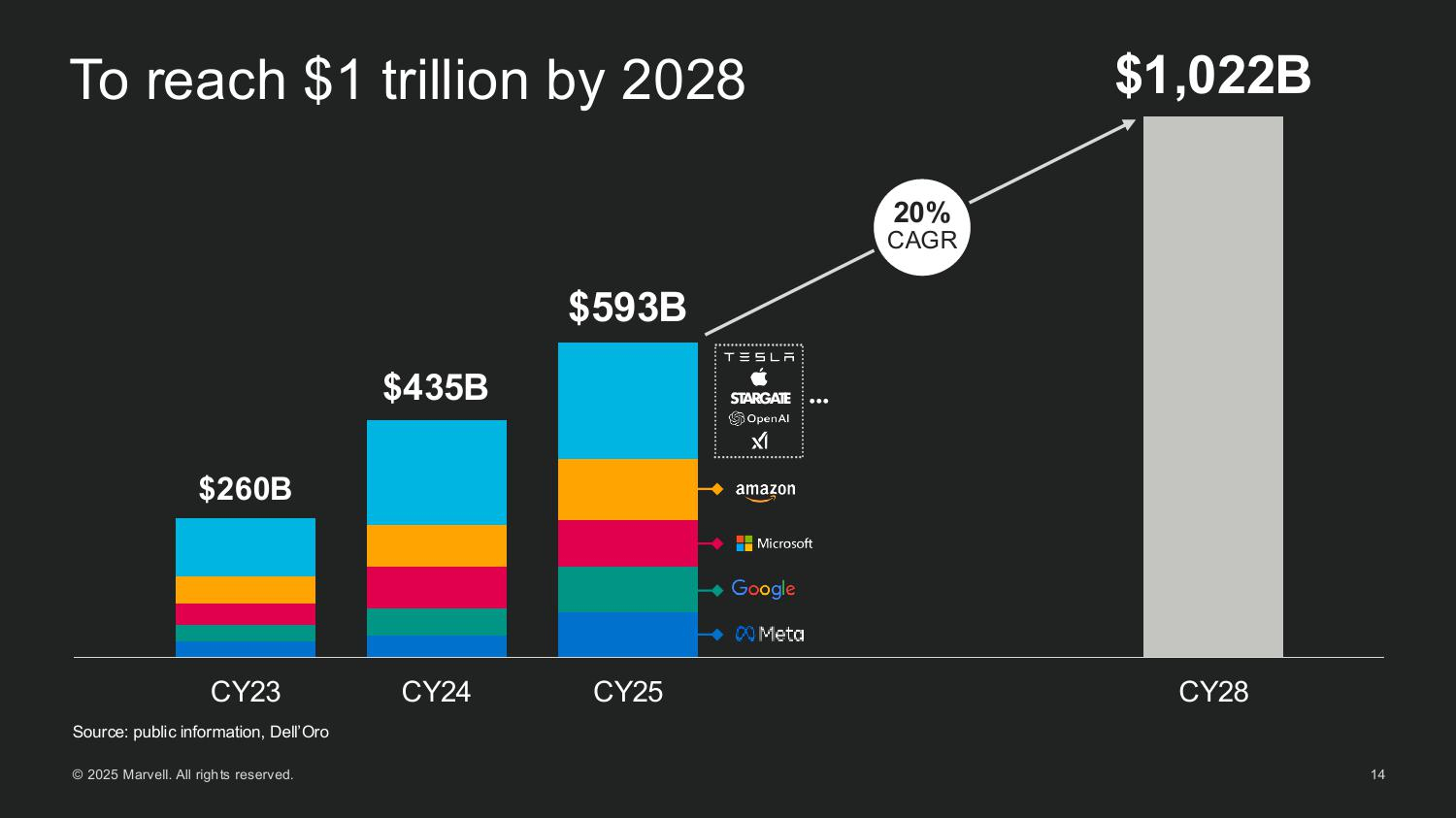 Marvell на сегодняшний день обеспечила разработку 18 кастомных чипов:
Marvell сопровождает более 50 активных кастомных полупроводниковых проектов — сочетание XPU и Attach — с более чем 10 клиентами. Среди них облачные гиперскейлеры, новые ИИ-стартапы и национальные ИИ-инициативы. По оценкам компании, эти проекты принесут $75 млрд потенциального дохода за весь срок их реализации, и это без учёта 18 уже готовых проектов. 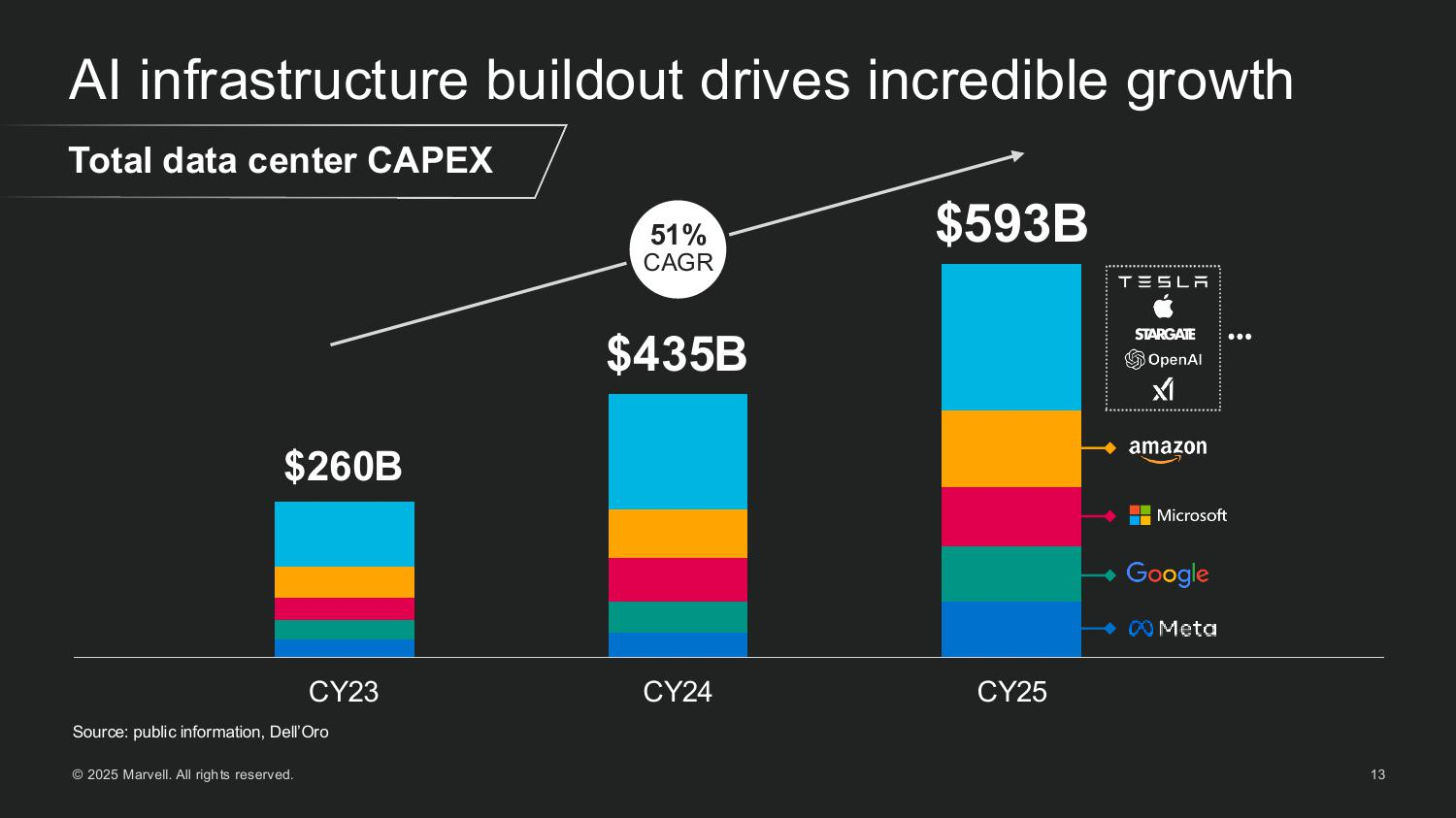 Мерфи подчеркнул, что на этом рынке больше не доминирует несколько «мегасокетов». «Ещё в 2023 году на один сокет приходилось 75 % TAM. К 2028 году ни один сокет не будет превышать 10–15 %. Это огромная диверсификация — и она отлично подходит для нас», — сообщил глава Marvell.
16.06.2025 [09:20], Владимир Мироненко
x86 не нужен: «недопроцессор» NeuReality NR1 кратно ускоряет инференс на любых GPUNeuReality объявила о выходе чипа NR1, специально созданного для оркестрации инференса, передаёт HPCwire. Он сочетается с любым GPU или ИИ-ускорителем, позволяя повысить эффективность использование GPU почти до 100 % по сравнению со средним показателем в 30–50 % при традиционном сочетании классического процессора и сетевого адаптера в современных серверах. Чип NR1 призван заменить традиционные CPU и NIC, которые являются узким местом для ИИ-нагрузок, предлагая вместе с тем шестикратное увеличение вычислительной мощности для обеспечения максимальной пропускной способности ускорителей и масштабного ИИ-инференса, утверждает разработчик. Как отметила компания, в течение многих лет разработчики развивали GPU, чтобы соответствовать требованиям ИИ, делая их быстрее и мощнее. Но традиционные CPU, разработанные для эпохи интернета, а не эпохи ИИ, в основном не менялись, становясь узким местом, поскольку ИИ-модели становятся всё более сложными, а запросы ИИ-нагрузок растут в объёме. 
Источник изображений: NeuReality NR1 включает все базовые функции CPU, необходимые для работы с ИИ-задачами, выделенные обработчики мультимедиа и данных, аппаратный гипервизор и комплексные сетевые IP-блоки, что обеспечивает значительно более высокую производительность, более низкое энергопотребление и окупаемость инвестиций. В тестах самой компании исполнение одной и той же модели на базе генеративного ИИ на одном и том же ИИ-ускорителе её чип NR1 позволяет получить в 6,5 раза больше токенов, чем x86-сервер при той же стоимости и энергопотреблении. 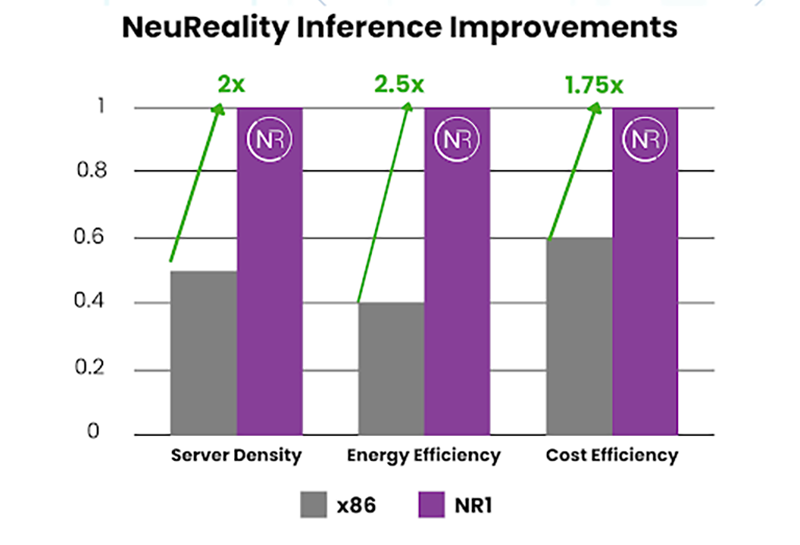 В соответствии с текущей тенденцией на разделение ресурсов хранения и вычислений, дезагрегация ИИ-ресурсов обеспечивает оптимизированную изоляцию ИИ-вычислений, отметила NeuReality. Такое разделение особенно важно в ЦОД и облаках. Традиционные программно-управляемые платформы, ориентированные на CPU, сталкиваются с такими проблемами, как высокая стоимость, энергопотребление и узкие места в системе при обработке задач ИИ-инференса. Сложность современной инфраструктуры и высокая стоимость часто ограничивают использование всех возможностей инференса, утверждает NeuReality. 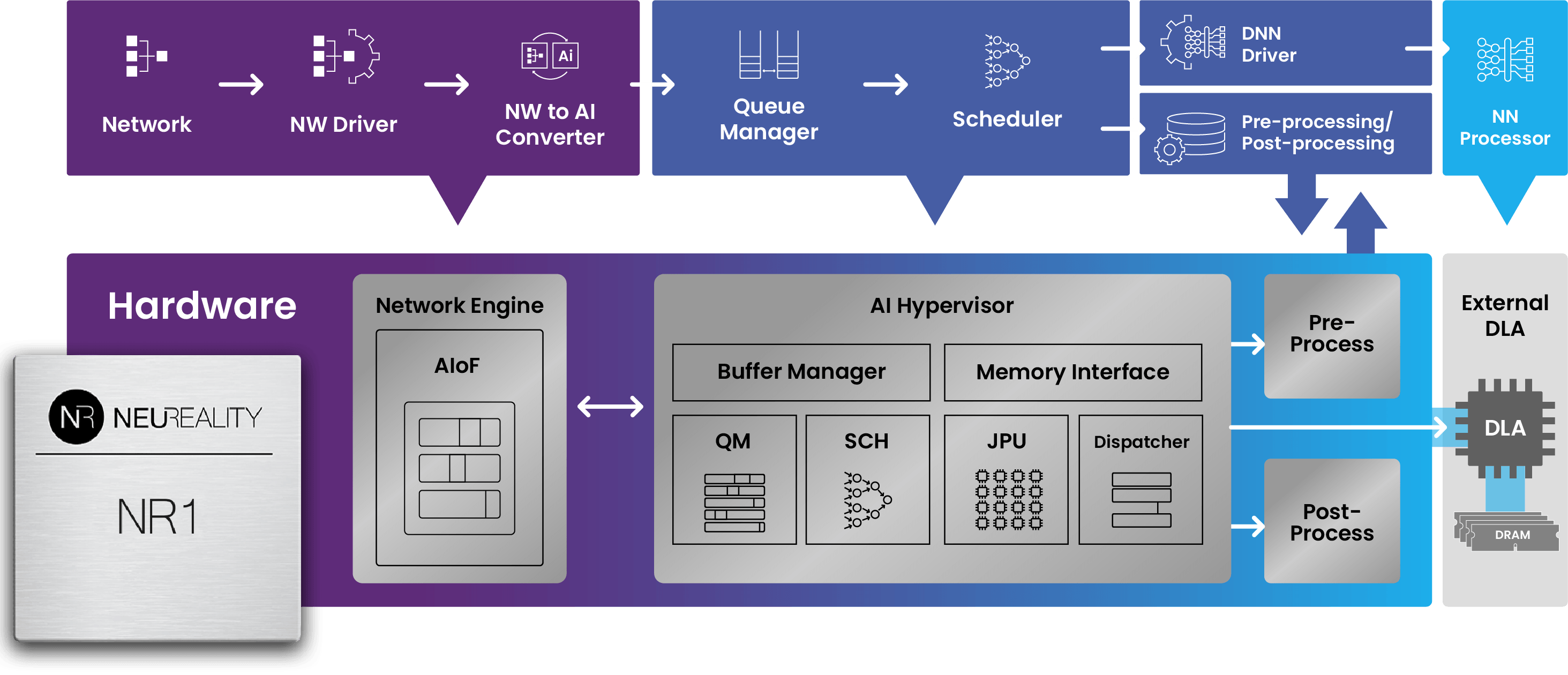 NR1 ориентирован на комплексную разгрузку ИИ-конвейера. Аппаратный ИИ-гипервизор отвечает за обработку путей данных и планирование заданий, охватывая механизмы пред- и постобработки данных, а также сетевой движок AI-over-Fabric. Благодаря этому достигнуто оптимальное соотношение цены и производительности и самые низкие эксплуатационные расходы, характеризующиеся низким энергопотреблением, минимальной задержкой и линейной масштабируемостью, говорит компания. Для DevOps и MLOps компания предоставляет полный SDK и сервисный слой на основе Kubernetes. Новый чип предлагается использовать для решения задач в сфере финансов и страхования, здравоохранении и фармацевтике, госуслугах и образовании, телекоммуникации, ретейле и электронной коммерции, для нагрузок генеративного и агентного ИИ, компьютерного зрения и т.д. NeuReality NR1 включает:
13.06.2025 [02:20], Владимир Мироненко
AMD готовит ИИ-стойки Helios AI двойной ширины с Instinct MI400, AMD EPYC Venice и 800GbE DPU Pensando VulcanoВместе с анонсом ускорителей MI350X и MI355X также рассказала о планах на ближайшее будущее, включая выпуск ускорителей серий MI400 (Altair) в 2026 году и MI500 (Altair+) в 2027 году, а также решений UALink, Ultra Ethernet, DPU Pensando и стоечных архитектур, которые послужат основой ИИ-кластеров. Так, AMD анонсировала новую архитектуру Helios AI с стойками двойной ширины, которая объединит процессоры AMD EPYC Venice с ядрами Zen 6, ускорители Instinct MI400 и DPU Vulcano. Благодаря приобретению ZT Systems компания смогла существенно ускорить разработку и интеграцию решений уровня стойки — Helios AI появятся уже в 2026 году. Как сообщает DataCenter Dynamics, Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер AMD по ЦОД рассказал перед мероприятием, что решение об увеличении ширины стойки было принято в сотрудничестве с «ключевыми партнёрами» AMD, поскольку предложение должно соответствовать «правильной точке проектирования между сложностью, надёжностью и предоставлением преимуществ производительности». По словам AMD, это позволит объединить тысячи чипов таким образом, чтобы их можно было использовать как единую систему «стоечного масштаба». «Впервые мы спроектировали каждую часть стойки как единую систему», — заявила генеральный директор AMD Лиза Су (Lisa Su) на мероприятии, пишет CNBC. 
Источник изображений: AMD Дикманн заявил, что Helios предложит на 50 % больше пропускной способности памяти и на 50 % больше горизонтальной пропускной способности (по сравнению с NVIDIA Vera Rubin), поэтому «компромисс [за счёт увеличения ширины стойки] был признан приемлемым, поскольку крупные ЦОД, как правило, ограничены не квадратными метрами, а мегаваттами». 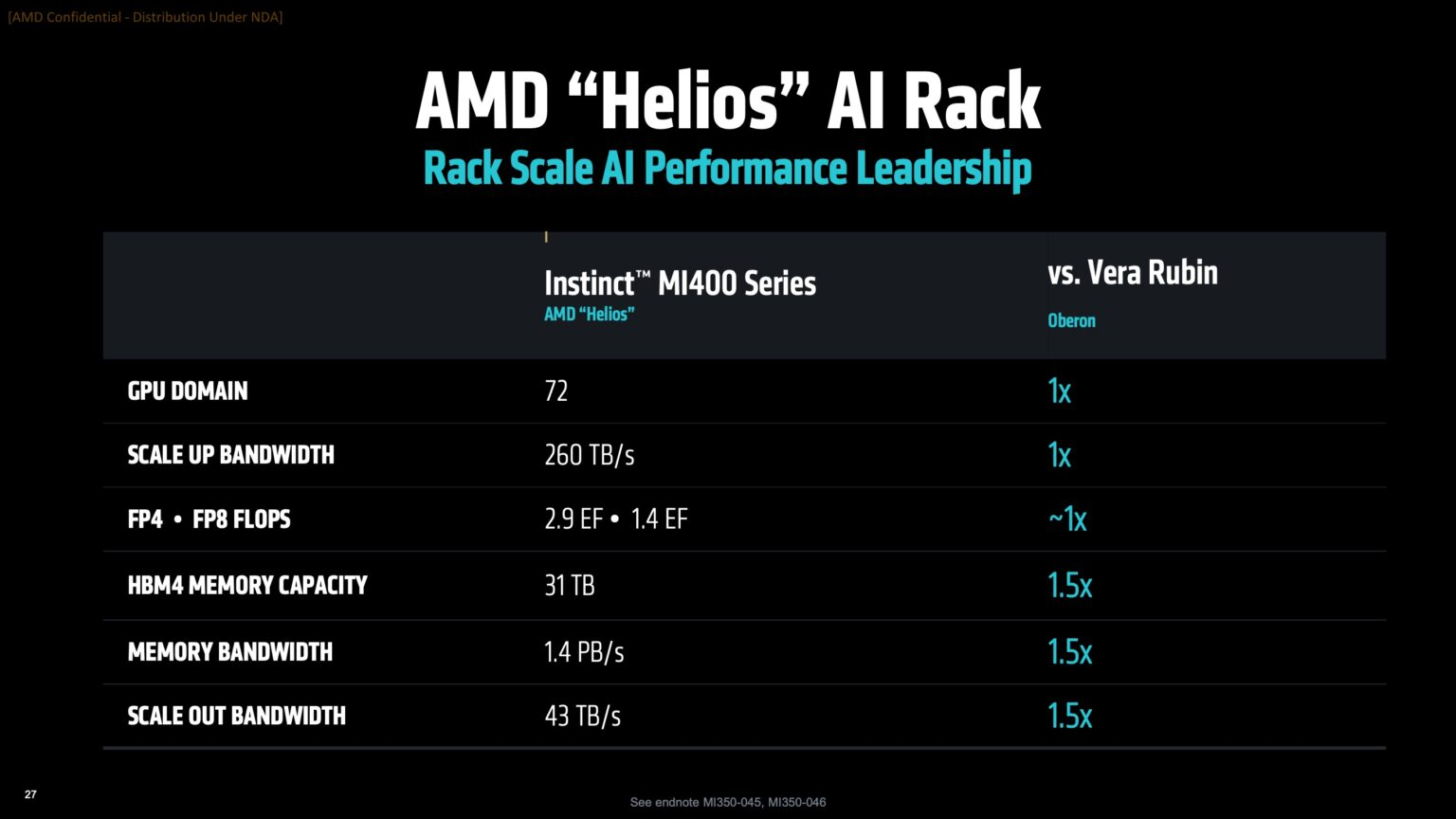 Как указано в блоге компании, «Helios создана для обеспечения вычислительной плотности, пропускной способности памяти, производительности и горизонтального масштабирования, необходимых для самых требовательных рабочих ИИ-нагрузок, в готовом к развёртыванию решении, которое ускоряет время выхода на рынок».  Helios представляет собой сочетание технологий AMD следующего поколения, включая:
 AMD отказалась сообщить стоимость анонсированных чипов, но, по словам Дикманна, ИИ-ускорители компании будут дешевле и в эксплуатации, и в приобретении в сравнении с чипами NVIDIA. «В целом, есть существенная разница в стоимости приобретения, которую мы затем накладываем на наше конкурентное преимущество в производительности, поэтому выходит значительная, исчисляемая двузначными процентами экономия», — сказал он.  AMD ожидает, что общий рынок ИИ-чипов превысит к 2028 году $500 млрд. Компания не указала, на какую долю общего пирога она будет претендовать — по оценкам аналитиков, в настоящее время у NVIDIA более 90 % рынка. Обе компании взяли на себя обязательство выпускать новые ИИ-чипы ежегодно, а не раз в два года, что говорит о том, насколько жёстче стала конкуренция и насколько важны передовые ИИ-технологии для гиперскейлеров. 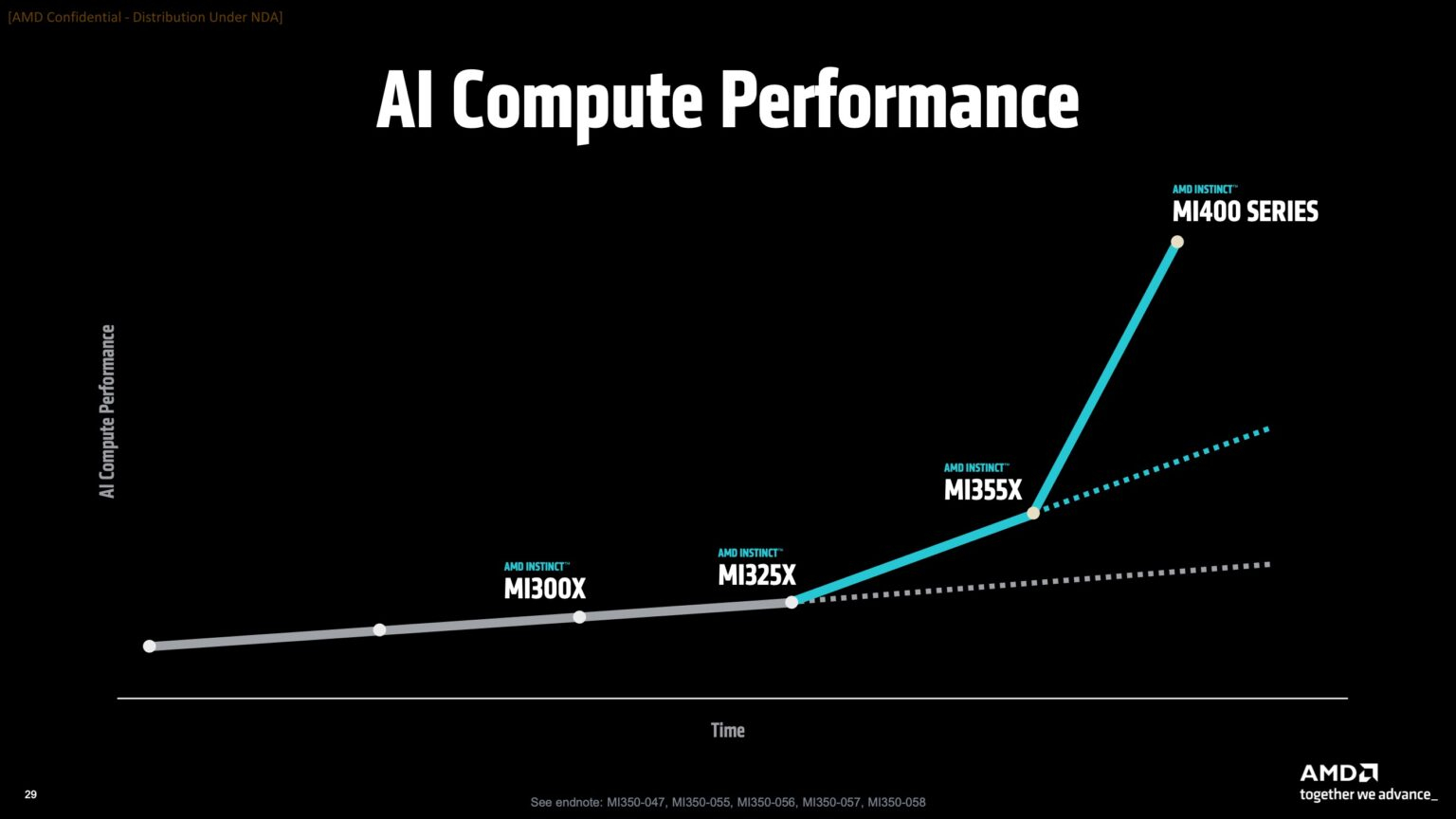 AMD сообщила, что её чипы Instinct используются семью из десяти крупнейших игроков ИИ-рынка, включая OpenAI, Tesla, xAI и Cohere. По словам AMD, Oracle планирует предложить своим клиентам кластеры с более чем 131 тыс. ускорителей MI355X. Meta✴ сообщила, что уже использует AMD-кластеры для инференса Llama и что она планирует купить серверы с чипами AMD следующего поколения. В свою очередь, представитель Microsoft сказал, что компания использует чипы AMD для обслуживания ИИ-функций чат-бота Copilot.
18.04.2025 [12:18], Сергей Карасёв
AMD выпустила DPU Pensando Pollara 400 для ИИ-инфраструктур с поддержкой Ultra EthernetКомпания AMD объявила о доступности DPU Pensando Pollara 400 AI NIC, первая информация о котором появилась в октябре прошлого года. Решение предназначено для построения высокопроизводительной ЦОД-инфраструктуры, ориентированной на рабочие нагрузки ИИ и машинного обучения. По заявлениям AMD, Pensando Pollara 400 — это первая в отрасли полностью программируемая сетевая карта AI NIC, разработанная с учетом стандартов консорциума Ultra Ethernet (UEC). Это обеспечивает максимальную гибкость, включая возможность добавления дополнительных функций. Новинка выполнена в виде низкопрофильной карты расширения половинной длины (HHHL) с интерфейсом PCIe 5.0 x16. Предусмотрен один порт QSFP112 400GbE с возможностью использования в режимах 25/50/100/200GbE. Заявлена поддержка RoCEv2, UEC RDMA, MCTP/SMBus, SPDM over MCTP, MCTP over PCIe VDM, а также шифрования AES-GCM 128/256. 
Источник изображения: AMD Реализованы различные функции, отвечающие за повышение быстродействия и эффективности. В частности, выборочная повторная передача помогает поднять производительность сети благодаря переотправке только потерянных или повреждённых пакетов. Контроль перегрузки с учётом пути даёт возможность оптимизировать производительность с помощью интеллектуальной балансировки нагрузки и автоматического обхода перегруженных маршрутов. Упомянуты также средства быстрого обнаружения неисправностей, инструменты обработки неупорядоченных пакетов и упорядоченной доставки сообщений. В целом, как подчёркивает AMD, благодаря совместимости с открытой экосистемой Pensando Pollara 400 помогает сократить капитальные затраты, не жертвуя при этом производительностью. Заказчики получают богатый набор функций и возможность программирования. |
|