Материалы по тегу: intel
|
20.10.2025 [16:00], Сергей Карасёв
Экономичный гибрид: Intel объединила ускорители Gaudi 3 и NVIDIA B200 в одной ИИ-платформеКорпорация Intel показала гибридную стоечную систему Устройство объединяет посредством Ethernet массивы ускорителей Gaudi3 и NVIDIA B200. Платформа Gaudi3 Rack Scale 64 содержит до 16 вычислительных узлов. Каждый из них оснащён двумя неназванными процессорами Intel Xeon, четырьмя OAM-ускорителями Intel Gaudi 3 (64 в одном домене), четырьмя 400GbE-адаптерами NVIDIA ConnectX-7 и одним DPU NVIDIA BlueField-3, отмечает SemiAnalysis. Суммарно доступно 8,2 Тбайт HBM2e, а агрегированная пропускная способность составляет 76,8 Тбайт/с. Мощность суперускорителя составляет 120 кВт. Кроме того, задействованы 12 коммутаторов на чипах Broadcom Tomahawk 5 (51,2 Тбит/с). Для масштабирования и связи с другими узлами, в том числе NVIDIA, используется именно Ethernet. В составе гибридной системы ускорители Intel Gaudi 3 используются на decode-стадии, т.е. для генерации токенов, где важен объём и пропускная способность памяти, тогда как чипы NVIDIA B200 отвечают за prefill-задачи инференса, т.е. за обработку контекста и заполнение KVCache, где важна скорость вычислений. NVIDIA сама стремится к этому же подходу и уже анонсировала соускорители Rubin CPX, которые как раз будут заниматься работой с контекстом в сверхбольших моделях и созданием KV-кеша. 
Источник изображений: Intel Intel утверждает, что гибридная конфигурация из Gaudi3 и B200 позволяет достичь 1,7-кратного прироста производительности в расчёте на доллар совокупной стоимости владения (TCO) по сравнению с платформами, использующими только B200. Однако, как отмечается, эти заявления пока не подтверждены независимыми тестами. К тому же, программная платформа Gaudi3 отстаёт от платформы NVIDIA и является закрытой. Кроме того, нынешняя архитектура Gaudi приближается к концу своего существования, что ставит под сомнение жизнеспособность предложенной платформы в долгосрочной перспективе.  Для Intel это, возможно, один из немногих шансов продать остатки Gaudi3. Между тем Intel недавно анонсировала GPU-ускоритель Crescent Island, разработанный специально для ИИ-инференса. Решение, в основу которого положена архитектура Xe3P, получит 160 Гбайт памяти LPDDR5X. Массовые поставки будет организованы не ранее 2027 года. Ранее компания отказалась от планов по выпуску Falcon Shores, сосредоточившись на Jaguar Shores. Сейчас же компания начала сворачивать поддержку ускорителей Ponte Vecchio (Intel Max) и Arctic Sound (Flex).
15.10.2025 [09:13], Сергей Карасёв
Intel представила GPU-ускоритель Crescent Island для ИИ-инференсаКорпорация Intel, как и ожидалось, представила на мероприятии OCP Global Summit в Сан-Хосе (Калифорния, США) графический процессор нового поколения для дата-центров. Изделие с кодовым названием Crescent Island специально оптимизировано для задач ИИ-инференса. В основу GPU положена архитектура Xe3P. Она представляет собой усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake для ноутбуков и компактных настольных ПК. Говорится об улучшенном показателе производительности в расчёте на 1 Вт затрачиваемой энергии. Ускоритель на базе Crescent Island получит 160 Гбайт памяти LPDDR5X. Как отмечает ресурс Tom's Hardware, максимальный объём чипов LPDDR5X составляет 8 Гбайт. При этом используются два 16-бит канала памяти, что в сумме даёт 32 бита. Таким образом, для обеспечения 160 Гбайт памяти требуются 20 чипов LPDDR5X. Это означает, что ускоритель получит либо один массивный GPU с 640-бит интерфейсом памяти для подключения всех 20 чипов LPDDR5X, либо два менее крупных процессора с 320-бит интерфейсом, каждый из которых будет обслуживать 10 чипов LPDDR5X. 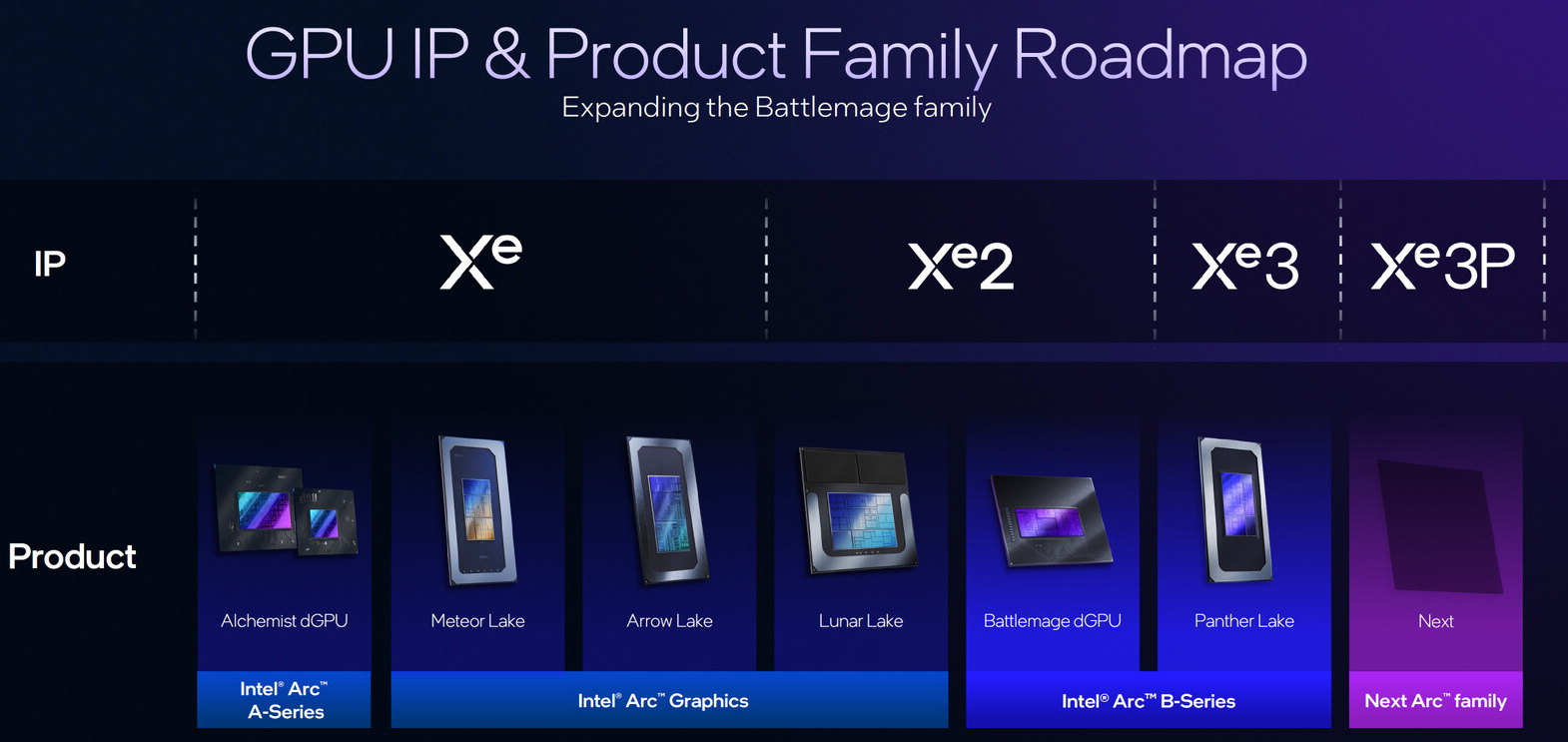
Источник изображения: Intel Прочие технические детали не раскрываются. При этом Intel отмечает, что изделие Crescent Island предназначено для использования в серверах с воздушным охлаждением. GPU поддерживает работу с широким спектром типов данных, благодаря чему может применяться в составе облачных платформ «токен как услуга» (tokens-as-a-service). 
Источник изображения: Intel Пробные поставки новинки планируется начать во II половине 2026 года, тогда как широкая доступность ожидается не ранее 2027-го. Решениям на основе Crescent Island предстоит конкурировать с ИИ-ускорителями AMD и NVIDIA следующего поколения, такими как Rubin CPX.
14.10.2025 [16:15], Сергей Карасёв
Intel подготовила 200GbE-адаптеры серии E835 для дата-центровВ начале текущего года корпорация Intel анонсировала сетевые контроллеры и адаптеры семейства Ethernet E830 с поддержкой стандарта 200GbE для корпоративных, облачных и периферийных развёртываний. А теперь появилась информация об изделиях серии Ethernet E835 с улучшенными характеристиками. 
Источник изображений: Intel Новые адаптеры ориентированы на дата-центры и телекоммуникационные инфраструктуры. Заявлена поддержка хост-интерфейсов PCIe 5.0 х8 и PCIe 4.0 х16. Intel предложит варианты в конфигурациях с портами 1 × 200GbE, 2 × 100GbE, 2 × 25GbE, 4 × 25GbE и 8 × 25GbE.  Реализована поддержка протоколов управления OS2BMC и OCP NIC 3.0, средств безопасности Secure Boot, SPDM (Security Protocol and Data Model), MCTP Type 6 и Root of Trust (на аппаратном уровне), а также стандартов FIPS 140-3 Level 1 и NIST SP800-193. Как и в случае с решениями Ethernet E830, имеется поддержка PTM (Precision Time Measurement), 1588 PTP и SyncE.  Судя по представленному изображению, устройства серии Ethernet E835 оборудованы пассивным охлаждением на основе крупного радиатора. Среди прочего говорится о совместимости с RDMA iWARP и RoCE v2. Сетевые адаптеры оптимизированы для использования в системах с процессорами Xeon 6. От решений Ethernet E830 унаследованы такие технологии, как Virtual Machine Device Queues (VMDq), Flexible Port Partitioning (FPP), Intel Data Direct I/O и др.
14.10.2025 [15:45], Руслан Авдеев
Intel продала компании Graid технологию VROC: будут временные перебои с продажами и техподдержкойТехнология Intel VROC (Virtual RAID on CPU) со времён Xeon Skylake-SP позволяет создавать программно-аппаратные RAID-массивы из NVMe-накопителей в серверных системах без необходимости приобретать RAID-контроллеры сторонних производителей. С выходом Xeon Sapphire Rapids компания намеревалась прекратить поддержку VROC, но столкнулась с возмущением клиентов — многие компании всё ещё использовали старые, но стабильные системы. В результате Intel продолжила поддержку, но приняла решение продать бизнес на сторону. Новым владельцем стала Graid Technology. Это может вызвать ряд технических проблем до конца ноября, сообщает портал Serve The Home. Graid, которая сама занимается созданием программно-аппаратных NVMe RAID с GPU-ускорением, продолжит поддержку Intel VROC. В октябре и ноябре 2025 года будут периоды, во время которых заказы новых ключей и техническая поддержка будут недоступны, но этот период продлится не очень долго, после чего GRAID сама будет отвечать за связанный бизнес. 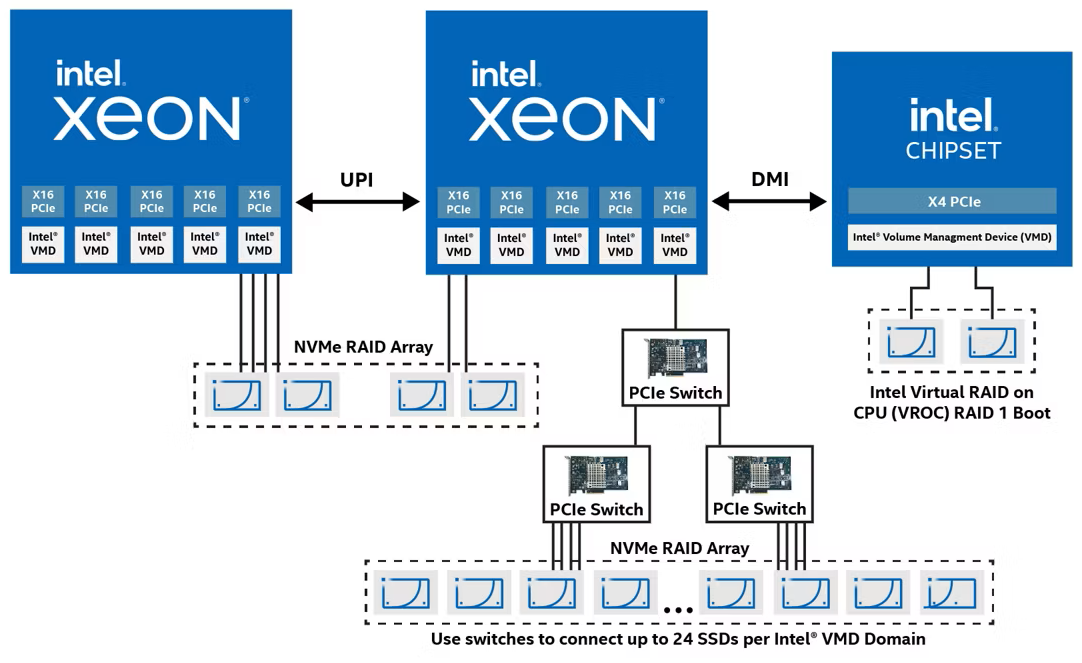
Источник изображения: Intel 23 октября — последний день подачи заявки на получение нового аппаратного ключа VROC в рамках RMA в случае поломки. 30 октября — последний день, чтобы отправить сломанный ключ в компанию. До 30 ноября можно будет заказать аппаратные ключи самой Intel (про ключи OEM-партнёров ничего не говорится). С 8 по 23 ноября планируется полная остановка продаж новых ключей и гарантийного обслуживания, только с 24 ноября Graid приступит к обслуживанию старых клиентов Intel и собственных новых клиентов. Поскольку бизнес передаётся независимой компании, вполне вероятно, что она может поменять ценовую политику. Впрчоем, для клиентов Intel даже такой сценарий может оказаться очень выигрышным, поскольку это — лучшая альтернатива полному отключению. Многие клиенты всё ещё используют VROC в старых платформах. Graid тоже должна выиграть, поскольку получит список активных клиентов, которым можно продать собственные, более современные решения. Для Intel же это повод избавиться от устаревших активов.
14.10.2025 [09:54], Сергей Карасёв
Giga Computing представила ИИ-сервер TO86-SD1 на платформе NVIDIA HGX B200Компания Giga Computing, подразделение Gigabyte, анонсировала высокопроизводительный сервер TO86-SD1 для обучения ИИ-моделей, инференса и ресурсоёмких HPC-задач. Новинка выполнена в форм-факторе 8OU в соответствии со стандартом OCP ORv3. Возможна установка двух процессоров Intel Xeon 6500P/6700P (Granite Rapids-SP) с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5 (RDIMM 6400 или MRDIMM 8000). Во фронтальной части предусмотрены отсеки для восьми SFF-накопителей с интерфейсом PCIe 5.0 (NVMe); поддерживается горячая замена. Есть коннектор M.2 2280/22110 для SSD (PCIe 5.0 x4). Упомянута поддержка CXL 2.0. Сервер несёт на борту ИИ-ускорители NVIDIA HGX B200 поколения Blackwell в конфигурации 8 × SXM. Суммарный объём памяти HBM3E составляет 1,4 Тбайт. Доступны 12 слотов PCIe 5.0 x16 для карт расширения FHHL с доступом через лицевую панель корпуса. Говорится о совместимости с NVIDIA BlueField-3 DPU и NVIDIA ConnectX-7 NIC. 
Источник изображения: Giga Computing В оснащение входят контроллер ASPEED AST2600, два сетевых порта 10GbE на базе Intel X710-AT2, выделенный сетевой порт управления 1GbE, разъёмы USB 3.2 Gen1 Type-C, Micro-USB и Mini-DP. Применяется система воздушного охлаждения с четырьмя 92-мм вентиляторами в области материнской платы и двенадцатью 92-мм кулерами в GPU-секции. Диапазон рабочих температур — от +10 до +35 °C. Заявлена совместимость с Windows Server, RHEL, Ubuntu, Citrix, VMware ESXi.
10.10.2025 [10:11], Сергей Карасёв
Intel готовит новый GPU-ускоритель, оптимизированный для инференсаКорпорация Intel в ходе мероприятия Intel Tech Tour Arizona сообщила о подготовке новых ИИ-ускорителей на базе GPU. Речь идёт об изделиях, специально оптимизированных для задач инференса. Кроме того, компания поделилась планами по развитию ИИ-продуктов в целом. Ранее предполагалось, что в 2025 году Intel выведет на рынок ускорители Falcon Shores. Изначально планировалось, что это будут гибридные решения, содержащие блоки CPU и GPU. Однако впоследствии Intel сделала выбор в пользу конфигурации исключительно на основе GPU. А затем корпорация и вовсе заявила, что на коммерческом рынке изделия Falcon Shores не появятся. Вместо этого Intel решила сфокусировать внимание на выпуске ускорителей Jaguar Shores. Войдёт ли готовящийся к выпуску GPU для инференса в семейство Jaguar Shores, пока не ясно. Подробности о новинке Intel обещает раскрыть в ходе предстоящего мероприятия 2025 OCP Global Summit, которое пройдёт с 13 по 16 октября в Сан-Хосе (Калифорния, США). На сегодняшний день известно, что устройство получит улучшенную память с высокой пропускной способностью. Изделие будет ориентировано на корпоративный сектор. 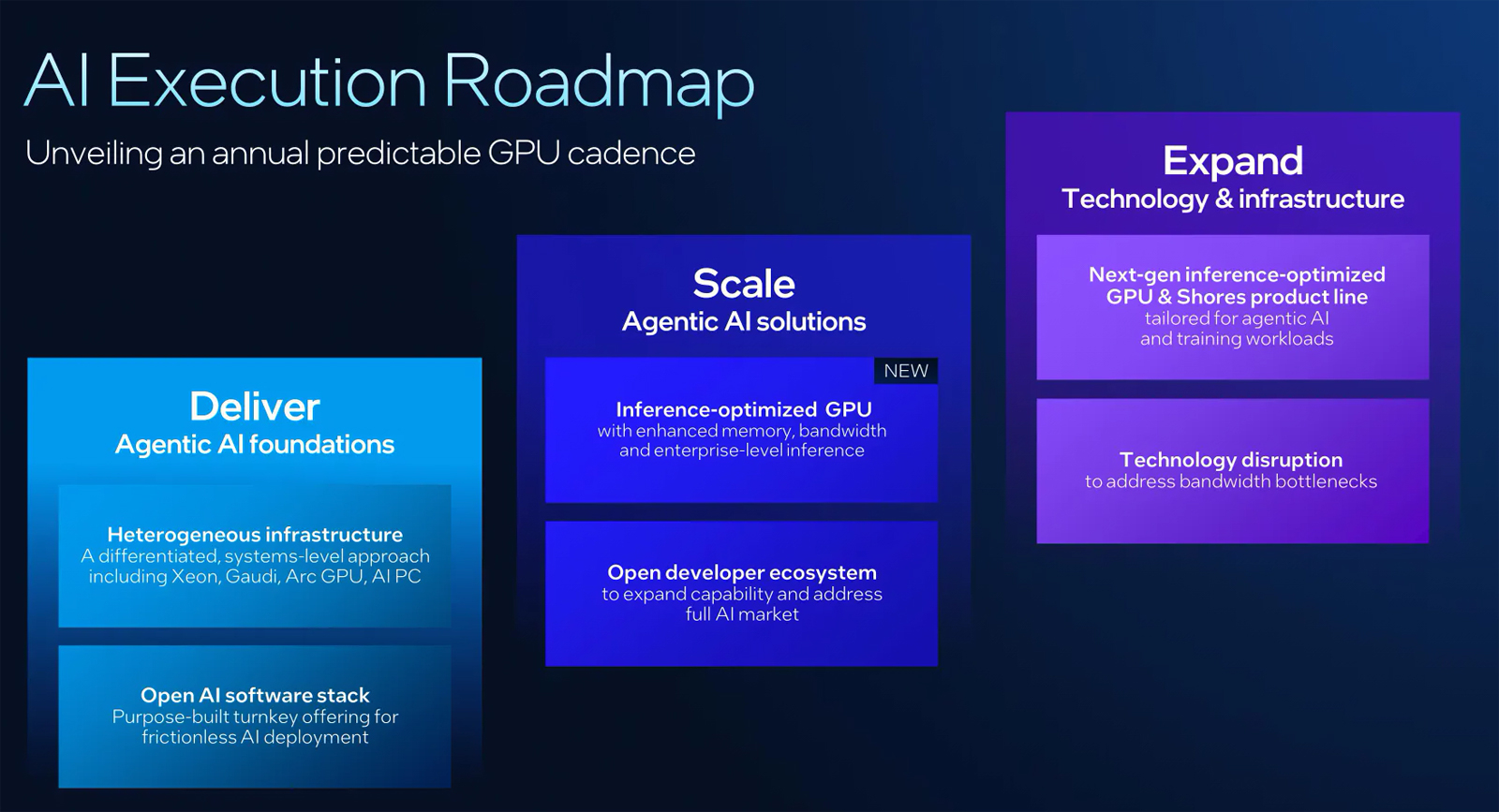
Источник изображения: Intel «Мы активно работаем над оптимизированным для инференса GPU, о котором подробнее расскажем на конференции OCP», — сообщил технический директор Intel Сачин Катти (Sachin Katti). Кроме того, Intel объявила о намерении перейти на ежегодный график выпуска ИИ-продуктов следующего поколения. Предполагается, что это поможет укрепить позиции на глобальном рынке ИИ, на котором корпорация уступила позиции NVIDIA. При этом Intel подчёркивает, что на ближайшую перспективу Jaguar Shores является основным приоритетом в области развития высокопроизводительных решений для ИИ-инфраструктуры.
09.10.2025 [22:09], Владимир Мироненко
Intel анонсировала процессоры Xeon 6+ — Clearwater Forest с 288 E-ядрами DarkmontIntel раскрыла на мероприятии Intel Tech Tour Arizona новые подробности о следующем поколении серверных процессоров, выполненных по техпроцессу Intel 18A, которые получат название Xeon 6+ (Clearwater Forest) и будут иметь до 288 энергоэффективных ядер Darkmont E-Core, сообщил ресурс Phoronix. В максимальной конфигурации Xeon 6+ включает 12 чиплетов E-Core (Intel 18A с RibbonFET и PowerVia), 3 базовых тайла (Intel 3) и 2 чиплета I/O (Intel 7). 12 EMIB-тайлов объединяют все чиплеты в единую 2.5D-упаковку. Как сообщается, Xeon 6+ имеет в 1,9 раза более высокую пропускную способность памяти по сравнению с предыдущим поколением. Это связано с поддержкой 12 каналов памяти DDR5-8000 по сравнению с восемью каналами DDR5-6400 в процессорах Xeon 6700E (Sierra Forest-SP). Впрочем, у Xeon 6900E (Sierra Forest-AP) тоже поддерживает 12 каналов памяти, хотя и DDR5-6400 (а в 2DPC — 5200). Модули памяти MRDIMM новинки не поддерживают. 
Источник изображений: Intel/Wccftech.com Производительность Clearwater Forest также обеспечивается L3-кешем объёмом до 576 Мбайт (в 6700E было до 108 Мбайт, а 6900P — до 504 Мбайт), техпроцессом 18A и новой функцией Intel AET. Intel AET (Application Energy Telemetry) — технология телеметрии энергопотребления приложений, помогающая разработчикам/администраторам профилировать и масштабировать рабочие нагрузки на этих процессорах с большим количеством ядер.  Intel Xeon 6+ также позиционируется как процессор с улучшенной эффективностью до 23 % по всем видам нагрузок. На ещё одном слайде указано, что у Intel Xeon 6+ «в 1,9 раза более высокая производительность», чем у Xeon 6780E. Ресурс Phoronix вполне справедливо считает такое сравнение некорректным, учитывая удвоенное количество ядер, большее количество каналов памяти и более высокую скорость памяти, больший размер L3-кеша и т. д. Впрочем, есть надежда, что Intel вскоре опубликует более конкретные сравнительные показатели, а также таблицу с моделями Xeon 6+, чтобы получить точное представление о сравнении с серией Xeon 6700E.  Intel также подтвердила, что Xeon 6+ будет обладать максимальным TDP в диапазоне от 300 до 500 Вт и совместимостью с одно- и двухсокетными платформами. Также доступно до шести каналов UPI 2.0, до 96 линий PCIe 5.0 и до 64 линий CXL 2.0. Ускорители Intel QAT, DLB, DSA и IAA по-прежнему поддерживаются Xeon 6+, но Intel практически ничего не рассказала об этих блоках.
02.10.2025 [12:25], Сергей Карасёв
Dell представила сервер PowerEdge XR8720t для инфраструктур Cloud RANКомпания Dell анонсировала сервер PowerEdge XR8720t, ориентированный на заказчиков из телекоммуникационного сектора. Устройство, выполненное на аппаратной платформе Intel, предназначено для применения в составе инфраструктур Cloud RAN. По заявлениям Dell, PowerEdge XR8720t — это первое односерверное решение Cloud RAN. Отмечается, что обычно для таких задач требуются несколько серверов, что объясняется фундаментальными архитектурными ограничениями. Уникальная многосекционная архитектура Dell позволяет обойти эти сложности, используя единственный сервер в корпусе типоразмера 2U, в котором блоки располагаются бок о бок. 
Источник изображений: Dell Утверждается, что модель PowerEdge XR8720t специально разработана для периферийных и телекоммуникационных рабочих нагрузок, где задержка, отказоустойчивость и адаптивность имеют первостепенное значение. Полностью характеристики новинки не раскрываются. Известно, что сервер оснащается процессорами Xeon 6, насчитывающими от 32 до 72 вычислительных ядер. Это первый сервер с сетевым адаптером Intel OCP 3.0 E830-XXVDA8. Разъёмы для подключения сетевых кабелей располагаются во фронтальной части.  Устройство заключено в корпус глубиной 433 мм. Питание обеспечивают два блока мощностью 1400 Вт. Диапазон рабочих температур простирается от -5 до +55 °C. Говорится о соответствии стандартам NEBS Level 3 и GR-3108 Class 1. Сервер рассчитан на эксплуатацию в неблагоприятных условиях. Ещё одним преимуществом решения названа модульная архитектура, благодаря которой клиенты смогут расширять мощности или добавлять новые узлы без необходимости перепроектирования всей инфраструктуры.
29.09.2025 [12:28], Сергей Карасёв
Одноплатный компьютер AAEON GENE-ARH6 на базе Intel Arrow Lake обладает ИИ-производительностью до 96 TOPSКомпания AAEON расширила ассортимент одноплатных компьютеров, анонсировав модель GENE-ARH6 на аппаратной платформе Intel Arrow Lake. Новинка предназначена для создания индустриальных роботов, периферийных систем с ИИ-функциями, встраиваемых устройств, платформ мониторинга безопасности и пр. Изделие выполнено в 3,5" форм-факторе с размерами 146 × 101,7 мм. Максимальная конфигурация включает процессор Core Ultra 7 255H (6P + 8E + 2LPE) с частотой до 5,1 ГГц. Чип содержит графический ускоритель Intel Arc 140T GPU и нейропроцессорный блок Intel AI Boost. Общая ИИ-производительность достигает 96 TOPS на операциях INT8. Предусмотрены два слота для модулей DDR5-6400 SO-DIMM суммарным объёмом до 96 Гбайт. 
Источник изображения: AAEON Накопитель может быть подключён к порту SATA-3. Есть коннектор M.2 2280 M-Key (PCIe 4.0 x4 / SATA) для SSD, разъём M.2 3052 B-Key (PCIe 3.0 x1 + USB 3.2 / PCIe 3.0 x2; слот Nano-SIM) для сотового модема и коннектор M.2 2230 E-Key (PCIe 3.0 x1 + USB 2.0) для контроллера Wi-Fi. В оснащение входят сетевые адаптеры Intel I219 (один порт 1GbE) и Intel I226 (два порта 2.5GbE), а также звуковой кодек Realtek ALC897. Возможен вывод изображения одновременно на четыре дисплея через интерфейсы HDMI 2.1 (до 8K × 4K; 60 Гц), DP 2.0 (до 7680 × 4320 пикселей; 60 Гц), LVDS (1920 × 1080 точек) и eDP 1.4b (до 3840 × 2160 пикселей; 60 Гц). Доступны три гнезда RJ45 для сетевых кабелей и два порта USB 3.2 Gen2. Через разъёмы на плате могут быть задействованы четыре порта USB 2.0 и четыре последовательных порта (2 × RS-232/422/485 и 2 × RS-232). Питание подаётся через 2-контактный коннектор Phoenix. Диапазон рабочих температур — от 0 до +60 °C. Заявлена совместимость с Windows 10/11 и Ubuntu 24.04.2. Упомянут встроенный модуль TPM 2.0 для обеспечения безопасности.
26.09.2025 [09:53], Сергей Карасёв
Сервер хранения AIC SB407-VA допускает установку 60 накопителей LFF SATA/SASКомпания AIC представила сервер хранения данных SB407-VA, выполненный в форм-факторе 4U на аппаратной платформе Intel. Новинка допускает установку в общей сложности 70 накопителей разных типов, что позволяет сформировать массив большой ёмкости для таких задач, как аналитика данных, периферийные ИИ-приложения и пр. Сервер может комплектоваться двумя процессорами Xeon Sapphire Rapids или Emerald Rapids. Доступны 16 слотов для модулей DDR5-5600/4800 суммарным объёмом до 4 Тбайт (3DS RDIMM). Предусмотрены четыре слота расширения PCIe x16 и один разъём PCIe x8: во всех случаях могут монтироваться карты формата FHHL. 
Источник изображений: AIC Предусмотрены посадочные места для 60 накопителей LFF с интерфейсом SATA/SAS и возможностью горячей замены. Кроме того, могут быть установлены восемь SFF-устройств в конфигурации 6 × NMVe (PCIe 4.0) и 2 × SATA с поддержкой горячей замены. Плюс к этому есть два коннектора M.2 M Key 2280 для SSD с интерфейсом PCIe 4.0.  Модель AIC SB407-VA наделена контроллером Aspeed AST2600. Реализованы два сетевых порта 1GbE на базе Broadcom BCM5720 и выделенный сетевой порт управления 1GbE на основе Realtek RTL8211FS. Во фронтальной части расположен один порт USB3.0 Type-A, в тыльной — три гнезда RJ45 для сетевых кабелей, два разъёма USB 3.1 Gen1 Type-A и коннектор D-Sub. Габариты составляют 434 × 853 × 176 мм. Питание обеспечивают четыре блока мощностью 800 Вт с сертификатом 80 Plus Platinum/Titanium. Задействовано воздушное охлаждение, а диапазон рабочих температур простирается от 0 до +35 °C. |
|