Материалы по тегу: tsmc
|
06.10.2025 [10:54], Владимир Мироненко
250 Тбит/с на чип: Ayar Labs, Alchip и TSMC предложили референс-дизайн для упаковки ASIC, памяти и оптических модулей в одном чипеКомпания Ayar Labs (США), занимающаяся разработкой интерконнекта на базе кремниевой фотоники, и тайваньский производитель ASIC-решений Alchip Technologies представили референсную платформу проектирования ИИ ASIC с несколькими оптическими IO-модулями на основе технологии кремниевой фотоники TSMC COUPE (Compact Universal Photonic Engine). В начале сентября компании объявили о стратегическом партнёрстве с целью ускорения масштабирования ИИ-инфраструктуры благодаря объединению технологии CPO компании Ayar Labs, экспертизы Alchip в области создания и упаковки кастомных ASIC, а также технологии упаковки и техпроцесса компании TSMC. Как сообщил технический директор Ayar Labs Владимир Стоянович (Vladimir Stojanovic) в интервью EE Times, платформа предназначена для устранения узких мест в передаче данных, замедляющих работу ИИ-инфраструктуры, путём эффективного сокращения времени простоя системы и создания крупных высокопроизводительных ИИ-кластеров нового поколения. Партнёры отметили, что по мере роста ИИ-моделей и размеров кластеров традиционные медные соединения достигают своих физических и энергетических пределов. Путём замены меди на интегрированную оптику (CPO) решение Alchip и Ayar Labs обеспечивает расширенную дальность связи, низкую задержку, энергоэффективность и высокий радикс, необходимые для масштабных развертываний ИИ-ускорителей. «Масштабируемые сети ИИ-кластеров ограничены расстоянием медных соединений. В то же время энергоэффективность сети ограничена плотностью мощности и возможностями систем охлаждения», — пояснил Эрез Шайзаф (Erez Shaizaf), технический директор Alchip, добавив, что CPO снимает эти ограничения. 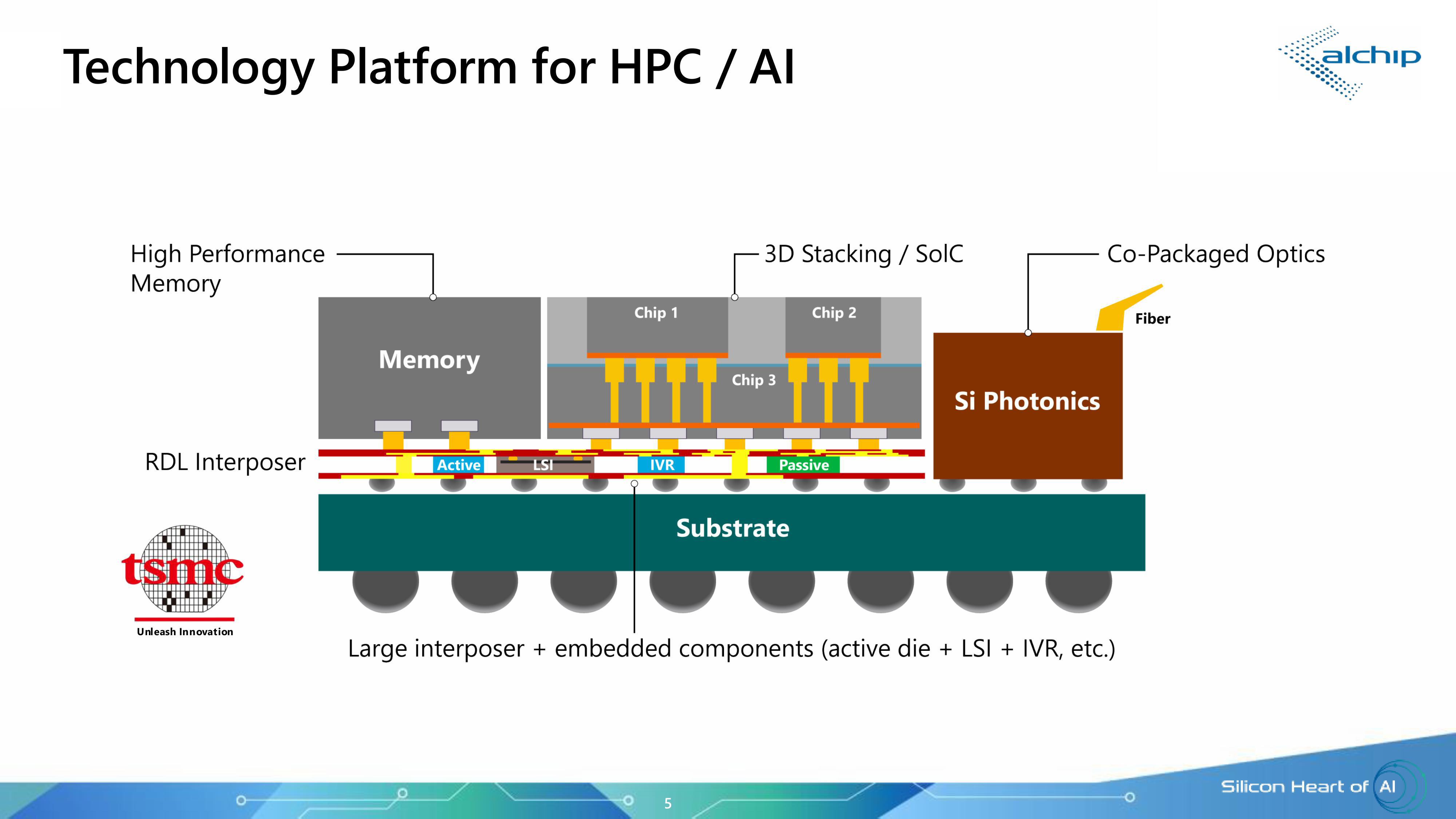
Источник изображений: Ayar Labs Новое совместное решение включает оптические модули Ayar Labs TeraPHY, размещённые вместе с решениями Alchip на общей подложке, обеспечивая прямой доступ ИИ-ускорителя к оптическому интерфейсу. Такая интеграция обеспечивает пропускную способность 100+ Тбит/с на каждый ускоритель и поддерживает более 256 оптических портов на устройство. TeraPHY не привязан к какому-либо протоколу и обеспечивает гибкую интеграцию с кастомными чиплетами. Референсный дизайн позволяет партнёрам «заложить основу» для быстрого создания подобной системы. Платформа референсного проекта включает два вычислительных кристалла с чиплетами HBM и другими чиплетами, в сочетании с восемью оптическими IO-модулями на базе чиплета TeraPHY. Такая конструкция обеспечит двустороннюю пропускную способность 200–250 Тбит/с для каждой сборки (SiP), что значительно превышает показатели современных крупных GPU, сообщил Стоянович. Это позволит масштабировать систему, а также значительно расширить объём памяти, имеющей пропускную способность, сопоставимую с HBM, добавил он. Оптический модуль Ayar Labs основан на чиплете TeraPHY PIC с двумя дополнительными слоями чиплетов, собранными с помощью TSMC COUPE. Два слоя электронных чиплетов собраны по технологии TSMC SoIC (System on Integrated Chips), которая использует вертикальное размещение нескольких кристаллов друг над другом, чтобы обеспечить более плотное соединение между ними, позволяя снизить энергопотребление, увеличить производительность и уменьшить задержки. По словам Стояновича, такой дизайн будет масштабироваться до уровня UCIe-A и выше как минимум в течение следующего десятилетия. 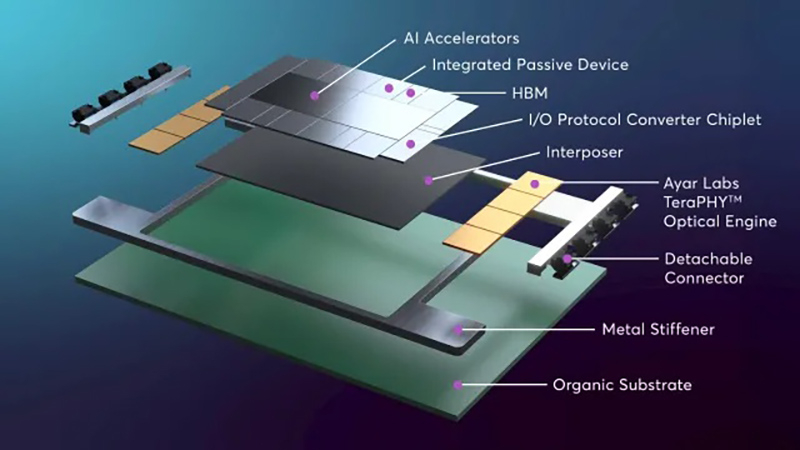 Совместное решение Alchip и Ayar Labs позволяет масштабировать многостоечную сетевую фабрику без потерь мощности и задержек, характерных для подключаемых оптических кабелей, за счёт минимизации длины электрических трасс и размещения оптических соединений вблизи вычислительного ядра. Благодаря поддержке UCIe для межкомпонентных соединений и гибкому размещению конечных точек на границе чипов, команды разработчиков могут интегрировать масштабируемое решение Alchip и Ayar Labs с существующими вычислительными блоками, стеками памяти и ускорителями, обеспечивая при этом соблюдение требований к производительности, целостности сигнала и температурному режиму на уровне всей сборки. Как сообщается, компании предоставят командам разработчиков дополнительные материалы, референсные архитектуры и варианты сборки. Платформа референсного дизайна включает в себя тестовые программы, позволяющие тестировать сборку и прошивку управления модулем, что облегчает его интеграцию в сборку. «Заказчику нужна поддержка, чтобы он понимал процессы оценки надёжности и испытаний, поэтому мы тесно сотрудничаем с Alchip, чтобы предоставить заказчику доступ ко всему этому пакету», — рассказал Стоянович.
29.07.2025 [11:10], Руслан Авдеев
NVIDIA заказала у TSMC производство 300 тыс. ИИ-ускорителей H20 в ответ на высокий спрос в КитаеНа прошлой неделе NVIDIA обратилась к тайваньской TSMC с заказом на выпуск 300 тыс. ИИ-ускорителей H20. Причиной тому — большой спрос на специально ослабленные чипы в Китае, сообщает Reuters со ссылкой на осведомлённые источники. Один из них подчеркнул, что высокий спрос в Поднебесной фактически заставил NVIDIA не полагаться на существующие запасы, а сделать новый заказ. Дело в том, что в июле администрация президента США Дональда Трампа (Donald Trump) вновь позволила продавать ухудшенные ускорители H20 в Китай — в апреле их поставки в страну были запрещены полностью. В своё время NVIDIA разрабатывала H20 специально для китайского рынка — после очередных экспортных ограничений, введённых США на поставку в Китай в конце 2023 года. H20 далеко не так хорош, как модели вроде NVIDIA H100 и, тем более, NVIDIA Blackwell, которые свободно поставляются в некоторые, «дружественные» США страны. По данным источников, новые заказы у TSMC дополнят уже имеющиеся запасы в 600-700 тыс. ускорителей H20, которые находятся на складах NVIDIA. Для сравнения, по данным экспертов SemiAnalysis, в 2024 году NVIDIA продала около 1 млн чипов H20. В ходе поездки в Пекин в текущем месяце глава NVIDIA Дженсен Хуанг заявил, что возобновление производства H20 будет зависеть от объёмов новых заказов на эти ускорители. При этом он добавил, что на «перезапуск» цепочки поставок потребуется девять месяцев. После визита Хуанга СМИ сообщали, что NVIDIA имеет ограниченные запасы H20 на складах и пока не имеет немедленных планов на возобновление производства полупроводниковых пластин для них. 
Источник изображения: NVIDIA Для поставок H20 разработчику потребуется получать экспортные лицензии у американских властей. В середине июля компания якобы получила заверения в том, что они скоро будут выданы. Правда, Министерство торговли США всё ещё должно одобрить выдачу лицензий. В понедельник NVIDIA отказалась комментировать новые заказы или статус своих заявок на получение экспортных лицензий. Министерство торговли пока воздерживается от комментариев. По некоторым данным, NVIDIA запросила у китайских компаний, заинтересованных в закупках ускорителей H20, представить новую документацию, в том числе прогнозируемые объёмы закупок. По данным представителя администрации Трампа, возобновление продаж H20 в Китай стало одним из результатов переговоров о закупке в КНР редкоземельных магнитов, необходимых во многих отраслях. В своё время Пекин ограничил их экспорт в разгар американо-китайской торговой войны. Решение возобновить экспорт H20 в КНР вызвало осуждение ряда американских политиков, как демократов, так и республиканцев. Те считают, что это помешает США сохранить лидерство в сфере ИИ-технологий. Тем не менее, Дженсен Хуанг не так давно раскритиковал запрет на продажу чипов в Китай, заявив, что это только ускоряет технический прогресс в Поднебесной. Многие политики из США считают, что сохранение экспорта помешает Китаю полностью перейти на собственные решения, такие как продукция Huawei. До апрельского запрета китайские технологические гиганты, включая Tencent, ByteDance и Alibaba, увеличили закупки H20, внедряя относительно недорогие и эффективные ИИ-модели DeepSeek китайской разработки, а также собственные модели. Популярность продуктов NVIDIA в Китае трудно переоценить — их активно ремонтируют в КНР и ввозят контрабандой в страну. После запрета на продажи Р20 в апреле, NVIDIA предупредила, что должна буквально «списать» запасы на $5,5 млрд, а Хуанг заявил в одном из интервью, что компания потеряет от отказа от потенциальных продаж ещё $15 млрд.
21.06.2025 [01:43], Анжелла Марина
Основатель SoftBank предложил создать в США хаб Crystal Land стоимостью $1 трлн для развития ИИ и роботовОснователь SoftBank, японский миллиардер Масаёси Сон (Masayoshi Son), предложил создать в штате Аризона масштабный индустриальный комплекс стоимостью до $1 трлн для развития ИИ и робототехники. Проект получил внутреннее название Crystal Lan. Он может стать одним из самых амбициозных проектов бизнесмена за всю его карьеру. Как пишет Bloomberg, Сон мечтает создать в США аналог крупного китайского технопарка в Шэньчжэне, где сосредоточены мощности по выпуску электроники. В состав комплекса могут войти линии по производству промышленных роботов на основе ИИ. При этом детали участия ключевых игроков, таких как тайваньского производителя чипов TSMC, остаются неясными. Хотя SoftBank стремится вовлечь эту компанию в проект, её представитель подчеркнул, что планы TSMC в Аризоне никак не связаны с Crystal Land. Тем не менее, суммарные инвестиции TSMC в США уже оцениваются в $165 млрд. Сейчас SoftBank ведёт переговоры с американскими властями, включая министра торговли США Говарда Лютника (Howard Lutnick), чтобы получить налоговые льготы и другие преференции для компаний, которые решат строить свои заводы в новом парке. Помимо этого, Сон лично обсуждает возможность участия Samsung Electronics. Примечательно, что на фоне этих новостей акции SoftBank выросли на 2,7 %, бумаги TSMC прибавили 1,9 %, а Samsung на 0,5 %. Официальных комментариев от компаний пока не последовало. 
Источник изображения: SoftBank Как отмечает Bloomberg, реализация Crystal Land зависит от множества факторов. Например, от интереса крупных технологических корпораций к этому проекту, наличия спроса и долгосрочного финансирования. При этом, по замыслу Сона, в будущем такие центры могут появиться не только в Аризоне, но и в других регионах США. В числе потенциальных участников также рассматриваются портфельные компании SoftBank Vision Fund, включая стартап Agile Robots SE, занимающийся автоматизацией. При этом у SoftBank есть и другие масштабные планы. В частности, компания намерена вложить до $40 млрд в OpenAI, купить за $6,5 млрд Ampere Computing и участвовать в проекте Stargate вместе с Oracle и MGX из ОАЭ. Для реализации всех инициатив SoftBank рассчитывает на внешние инвестиции, используя модель проектного финансирования, как это делают, например, при строительстве трубопроводов или других масштабных объектов.
15.04.2025 [23:38], Владимир Мироненко
AMD начнёт размещать заказы на производство чипов в СШАAMD впервые в своей новейшей истории начнёт размещать заказы на производство своих чипов в США — на заводе TSMC в Аризоне. Об этом заявила 15 апреля генеральный директор AMD Лиза Су (Lisa Su) в ходе своего визита на Тайвань, где провела встречу с руководством TSMC, а также с другими партнёрами, пишет Reuters. Лиза Су сообщила, что совместно с TSMC был достигнут ряд важных вех, включая успешный пробный выпуск 2-нм чипа. Она также продемонстрировала совместно с генеральным директором TSMC Си-Си Вэем (C.C. Wei) кремниевую пластину с образцами чиплета CCD для серверных процессоров EPYC Venice на архитектуре Zen 6, который будет производиться с использованием 2-нм техпроцесса TSMC N2 — это первый в отрасли продукт для HPC-систем, который будет выпускаться по столь тонкой технологии со следующего года, говорит AMD. AMD также объявила об успешном запуске и валидации AMD EPYC Turin на новой фабрике TSMC в Аризоне. «Наш новый EPYC пятого поколения показал себя очень хорошо, поэтому мы готовы начать производство», — заявила журналистам в Тайбэе Лиза Су. Выпуск чипа начнётся в 2026 году. Правда, самые передовые техпроцессы, включая 2-нм, эта фабрика получит только через несколько лет. Как сообщают ресурсы Anue и TechNews, Лиза Су также заявила, что хотя Тайвань является ключевым регионом в цепочкк поставок AMD, компания наращивает своё присутствие в США. Су отметила, что приобретение ZT Systems за $4,9 млрд стало ключевым шагом для увеличения производства ИИ-серверов на чипах AMD в США: «Мы хотим иметь очень устойчивую цепочку поставок, поэтому Тайвань продолжает оставаться очень важной частью этой цепочки поставок, но Соединённые Штаты также будут важны, и мы расширяем нашу работу там, включая нашу работу с TSMC и другими ключевыми партнёрами». 
Источник изображений: AMD Впоследствии Су также подтвердила намерение «найти стратегического партнёра для [продажи] производственных активов компании ZT Systems». Она не стала вдаваться в подробности, но по данным Bloomberg, Compal Electronics, Wiwynn (Wistron) и Jabil собираются представить предложения по покупке производственных мощностей ZT Systems. Ранее демонстрировавшие интерес к покупке Inventec, которая в итоге продала AMD свою долю в ZT Systems, и Pegatron отказались от дальнейшего участия в борьбе за этот актив, сообщили источники Bloomberg. Сейчас самое подходящее время для AMD для продажи производственных мощностей в США, поскольку многие тайваньские OEM/ODM-вендоры спешат начать строительство заводов в США, чтобы избежать текущих или будущих пошлин, отметил Bloomberg. AMD намерена завершить продажу к концу II квартала. Стоимость сделки оценивается в $3–4 млрд.  В свою очередь, NVIDIA объявила в понедельник о планах в течение четырёх следующих лет выпустить в США с помощью производственных партнёров ИИ-платформы на $500 млрд. Сейчас компания строит заводы совместно с Foxconn в Хьюстоне и с Wistron в Далласе. Тайваньские фирмы, включая Foxconn (Hon Hai Precision Industry Co.), полагаются на Мексику как на ключевой центр сборки и производства компонентов ИИ-серверов. После президентских выборов в США в прошлом году Foxconn приобрела землю под новое производствj и пообещала, что вскоре объявит о дополнительных инвестициях в экономику США. А тайваньская Quanta Computer одобрила увеличение уставного капитала своего американского подразделения на $230 млн.
14.04.2025 [19:28], Алексей Степин
NVIDIA будет производить часть ИИ-ускорителей и платформ в СШАNVIDIA заявила, что не собирается ограничиваться исключительно тайваньскими производственными мощностями. Выпуск чипов Blackwell уже стартовал на площадке TSMC в Фениксе, штат Аризона. Здесь же в сотрудничестве с Amkor и SPIL будут налажены упаковка и тестирование новых GPU. Техасу отводится роль производителя суперкомпьютеров и платформ: NVIDIA строит соответствующие заводы совместно с Foxconn в Хьюстоне и с Wistron в Далласе. Всего компания застолбила почти 93 тыс. м2 производственных площадей в Аризоне и Техасе. Ожидается, что вышеупомянутые заводы выйдут на проектную мощность уже в течение ближайших 12–15 месяцев, а в течение четырёх следующих лет компания планирует произвести в США ИИ-платформ на $500 млрд. Как отмечает глава NVIDIA, Дженсен Хуанг (Jensen Huang), размещение производственных мощностей в США позволит компании лучше справляться с растущим спросом на ИИ-решения и суперкомпьютеры, укрепит её цепочки поставок и в целом поспособствует большей гибкости в решениях. Описываемое заявление NVIDIA сделала практически сразу после того, как ей удалось избежать экспортных ограничений на чип H20, наиболее производительный ИИ-ускоритель, разрешённый к экспорту в Китай. Согласно изданию NPR, этому помогло обещание крупных капиталовложений в ИИ-инфраструктуру США со стороны руководства компании. Многие другие разработчики и производители в сфере ИИ также вынуждены соглашаться с политикой текущей администрации США, дабы избежать огромных пошлин. 
Источник изображения: NVIDIA Хотя NVIDIA и заявляет, что инициатива с размещением производства чипов в США создаст сотни тысяч рабочих мест и увеличит активность экономики на триллионы долларов, всё не так просто, как может показаться. Реализации данных планов не способствуют ограничения, наложенные на торговлю с КНР и могущие помешать поставкам исходных материалов для производства микрочипов. Также упоминается нехватка квалифицированной рабочей силы. Меж тем, усилия администрации текущего президента США по отмене «закона о чипах» (CHIPS and Science Act), принятого в 2022 году и включающего в себя серьёзные субсидии иностранным высокотехнологичным компаниям, могут отпугнуть потенциальных инвесторов в лице полупроводниковых гигантов.
16.01.2025 [16:16], Руслан Авдеев
США вводят очередные ограничения на выпуск и экспорт современных чиповМинистерство торговли США вводит новый пакет экспортных ограничений, призванных помешать Китаю и другим странам закупать передовые чипы, сообщает Silicon Angle. В частности, ограничения коснутся предприятий, выпускающих микросхемы, а также работающих по заказу других организаций. Так, новые меры коснутся TSMC и Samsung Electronics, а также упаковщиков чипов, включая ту же TSMC. Новые правила предусматривают получение производителями чипов и упаковщиками полупроводников лицензий на экспорт «определённых передовых чипов» в ряд регионов. Власти откажутся от подобных требований, если производитель чипов получит технические аттестации от доверенных участников цепочек поставок. Так, разработчики чипов могут получить от американских властей статус «одобренных» или «авторизованных». Если разработчик подтверждает, что его чипы не достигают по своим характеристикам установленных США порогов производительности, лицензионные требования к ним отменяются. То же касается фабрик и компаний-упаковщиков. Если характеристики производимых чипов не превышают определённого порога, новые экспортные ограничения не применяются. 
Источник изображения: CHUTTERSNAP/unsplash.com Объявлено и о ряде других нормативных изменений. В частности, запускается процесс утверждения компаний в перечне одобренных дизайн-центров и поставщиков чипов и услуг OSAT (Outsourced Semiconductor Assembly and Test). Также оптимизированы процедуры раскрытия информации в случаях, если производитель принимает заказ клиента, потенциально способного перенаправить продукцию в Китай. В связи с новыми правилами в чёрный список Entity List отправятся 16 новых организаций, включая некоторые ИИ-компании, поддерживающие развитие производства передовых чипов в Китае. Одной из таких компаний стала Sophgo — в прошлом году выяснилось, что она якобы передала выпущенную для неё продукцию компании Huawei, давно пребывающей в американском чёрном списке, после чего TSMC прекратила выполнение её заказов и поставки. Министерство торговли вводит новые правила всего через несколько дней после того, как администрация уходящего президента США ввела глобальные ограничения на поставки ИИ-чипов и передовых моделей ИИ. Ранее американские власти уже вводили санкции, ограничивающие возможности китайской полупроводниковой индустрии. Речь идёт о закупках чипов NVIDIA, памяти HBM и других компонентов. Не щадят и союзников. Нидерландской ASML запрещено поставлять в КНР оборудование для DUV-литографии, на котором можно изготавливать 5- и 7-нм полупроводники.
11.11.2024 [11:29], Сергей Карасёв
США запретили TSMC выпускать передовые чипы для китайских ИИ-компанийTSMC, по сообщению The Register, полностью прекратит выпуск передовых изделий для китайских заказчиков, которые занимаются разработкой аппаратных ИИ-решений, включая ускорители на базе GPU. Данная мера, как утверждается, продиктована необходимостью соблюдения экспортных требований США. Власти США последовательно вводят различные санкции, призванные ограничить возможности китайской полупроводниковой индустрии. Речь идёт о закупках чипов NVIDIA, памяти HBM и других компонентов. А нидерландской компании ASML запрещено поставлять в Китай оборудование для DUV-литографии, на котором можно изготавливать 5- и 7-нм продукцию. Теперь новые ограничительные меры в отношении клиентов из КНР вводит TSMC. Этот контрактный производитель объявил о том, что с 11 ноября 2024 года прекращает отгружать чипы, произведённые по 7-нм и более совершенным технологиям, китайским заказчикам, которые занимаются разработкой ИИ-устройств и GPU. Напомним, что в октябре TSMC уведомила американские власти о том, что некий китайский клиент, по всей видимости, пытается обойти экспортный контроль в отношении Huawei, размещая заказы на изделия, схожие с ИИ-ускорителем Ascend 910B. Это продукт был разработан Huawei в качестве альтернативы NVIDIA A100. Решение Ascend 910B представляет собой следующее поколение 7-нм чипа Ascend 910. По имеющейся информации, TSMC, следуя экспортным ограничения США, прекратила все поставки изделий этому неназванному клиенту. 
Источник изображения: TSMC Решение TSMC ограничит возможности китайских компаний по использованию технологий с нормами 7-нм и менее при создании ИИ-устройств. Вместе с тем, подчёркивается, что правила не распространяются на китайских клиентов, которые заказывают у TSMC 7-нм чипы для других приложений, таких как мобильные устройства и системы связи. Как отмечает TrendForce, решение TSMC «отражает осторожную позицию гиганта контрактного производства в глобальной цепочке поставок полупроводников на фоне разгорающейся войны в сфере микрочипов между двумя мировыми сверхдержавами».
30.10.2024 [11:49], Сергей Карасёв
OpenAI разрабатывает собственные ИИ-чипы совместно с Broadcom и TSMC, а пока задействует AMD Instinct MI300XКомпания OpenAI, по информации Reuters, разрабатывает собственные чипы для обработки ИИ-задач. Партнёром в рамках данного проекта выступает Broadcom, а организовать производство изделий планируется на мощностях TSMC ориентировочно в 2026 году. Слухи о том, что OpenAI обсуждает с Broadcom возможность создания собственного ИИ-ускорителя, появились минувшим летом. Тогда говорилось, что эта инициатива является частью более масштабной программы OpenAI по увеличению вычислительных мощностей компании для разработки ИИ, преодолению дефицита ускорителей и снижению зависимости от NVIDIA. Как теперь стало известно, OpenAI уже несколько месяцев работает с Broadcom над своим первым чипом ИИ, ориентированным на задачи инференса. Соответствующая команда разработчиков насчитывает около 20 человек, включая специалистов, которые ранее принимали участие в проектировании ускорителей TPU в Google, в том числе Томаса Норри (Thomas Norrie) и Ричарда Хо (Richard Ho). Подробности о проекте не раскрываются. Reuters, ссылаясь на собственные источники, также сообщает, что OpenAI в дополнение к ИИ-ускорителям NVIDIA намерена взять на вооружение решения AMD, что позволит диверсифицировать поставки оборудования. Речь идёт о применении изделий Instinct MI300X, ресурсы которых будут использоваться через облачную платформу Microsoft Azure. 
Источник изображения: Unsplash Это позволит увеличить вычислительные мощности: компания OpenAI только в 2024 году намерена потратить на обучение ИИ-моделей и задачи инференса около $7 млрд. Вместе с тем, как отмечается, OpenAI пока отказалась от амбициозных планов по созданию собственного производства ИИ-чипов. Связано это с большими финансовыми и временными затратами, необходимыми для строительства предприятий.
08.08.2024 [00:48], Сергей Карасёв
NVIDIA задержит выпуск ускорителей GB200, отложит B100/B200, а на замену предложит B200AКомпания NVIDIA, по сообщению ресурса The Information, вынуждена повременить с началом массового выпуска ИИ-ускорителей следующего поколения на архитектуре Blackwell, сохранив высокие темпы производства Hopper. Проблема, как утверждается, связана с технологией упаковки Chip on Wafer on Substrate (CoWoS) от TSMC. Отмечается, что NVIDIA недавно проинформировала Microsoft о задержках, затрагивающих наиболее продвинутые решения семейства Blackwell. Речь, в частности, идёт об изделиях Blackwell B200. Серийное производство этих ускорителей может быть отложено как минимум на три месяца — в лучшем случае до I квартала 2025 года. Это может повлиять на планы Microsoft, Meta✴ и других операторов дата-центров по расширению мощностей для задач ИИ и НРС. По данным исследовательской фирмы SemiAnalysis, задержка связана с физическим дизайном изделий Blackwell. Это первые массовые ускорители, в которых используется технология упаковки TSMC CoWoS-L. Это сложная и высокоточная методика, предусматривающая применение органического интерпозера — лимит возможностей технологии предыдущего поколения CoWoS-S был достигнут в AMD Instinct MI300X. Кремниевый интерпорзер, подходящий для B200, оказался бы слишком хрупок. Однако органический интерпозер имеет не лучшие электрические характеристики, поэтому для связи используются кремниевые мостики. В используемых материалах как раз и кроется основная проблема — из-за разности коэффициента теплового расширения различных компонентов появляются изгибы, которые разрушают контакты и сами чиплеты. При этом точность и аккуратность соединений крайне важна для работы внутреннего интерконнекта NV-HBI, который объединяет два вычислительных тайла на скорости 10 Тбайт/с. Поэтому сейчас NVIDIA с TSMC заняты переработкой мостиков и, по слухам, нескольких слоёв металлизации самих тайлов.  Вместе с тем у TSMC наблюдается нехватка мощностей по упаковке CoWoS. Компания в течение последних двух лет наращивала мощности CoWoS-S, в основном для удовлетворения потребностей NVIDIA, но теперь последняя переводит свои продукты на CoWoS-L. Поэтому TSMC строит фабрику AP6 под новую технологию упаковки, а также переведёт уже имеющиеся мощности AP3 на CoWoS-L. При этом конкуренты TSMC не могут и вряд ли смогут в ближайшее время предоставить хоть какую-то альтернативную технологию упаковки, которая подойдёт NVIDIA. Таким образом, как сообщается, NVIDIA предстоит определиться с тем, как использовать доступные производственные мощности TSMC. По мнению SemiAnalysis, компания почти полностью сосредоточена на стоечных суперускорителях GB200 NVL36/72, которые достанутся гиперскейлерам и небольшому числу других игроков, тогда как HGX-решения B100 и B200 «сейчас фактически отменяются», хотя малые партии последних всё же должны попасть на рынок. Однако у NVIDIA есть и запасной план. План заключается в выпуске упрощённых монолитных чипов B200A на базе одного кристалла B102, который также станет основой для ускорителя B20, ориентированного на Китай. B200A получит всего четыре стека HBM3e (144 Гбайт, 4 Тбайт/с), а его TDP составит 700 или 1000 Вт. Важным преимуществом в данном случае является возможность использования упаковки CoWoS-S. Чипы B200A как раз и попадут в массовые HGX-системы вместо изначально планировавшихся B100/B200.  На смену B200A придут B200A Ultra, у которых производительность повысится, но вот апгрейда памяти не будет. Они тоже попадут в HGX-платформы, но главное не это. На их основе NVIDIA предложит компромиссные суперускорители MGX GB200A Ultra NVL36. Они получат восемь 2U-узлов, в каждом из которых будет по одному процессору Grace и четыре 700-Вт B200A Ultra. Ускорители по-прежнему будут полноценно объединены шиной NVLink5 (одночиповые 1U-коммутаторы), но вот внутри узла всё общение с CPU будет завязано на PCIe-коммутаторы в двух адаптерах ConnectX-8. Главным преимуществом GX GB200A Ultra NVL36 станет воздушное охлаждение из-за относительно невысокой мощности — всего 40 кВт на стойку. Это немало, но всё равно позволит разместить новинки во многих ЦОД без их кардинального переоборудования пусть и ценой потери плотности размещения (например, пропуская ряды). По мнению SemiAnalysis, эти суперускорители в случае нехватки «полноценных» GB200 NVL72/36 будут покупать и гиперскейлеры.
11.03.2024 [13:39], Сергей Карасёв
Marvell представила 2-нм платформу для создания кастомизированных ЦОД-решенийКомпания Marvell Technology объявила о расширении сотрудничества с TSMC с целью создания первой в отрасли технологической платформы, ориентированной на производство кастомизированных изделий для дата-центров по нормам 2 нм. Речь, в частности, идёт об оптимизированных для облака ускорителях, коммутаторах Ethernet и цифровых сигнальных процессорах. Отмечается, что разработка специализированных решений для ЦОД представляет собой трудоёмкую задачу. Дополнительные сложности создаёт необходимость адаптации под «тонкий» техпроцесс — в данном случае 2-нм методику TSMC. Новая платформа как раз и призвана решить проблемы. 
Источник изображения: Marvell В основу платформы положен обширный пакет интеллектуальной собственности Marvell, охватывающий полный спектр инфраструктурных компонентов. Это высокопроизводительные решения SerDes со скоростью свыше 200 Гбит/с, процессорные подсистемы, механизмы шифрования, межкристальные структуры, элементы интерконнекта, а также различные интерфейсы физического уровня с высокой пропускной способностью для вычислительных модулей, памяти, сетевых узлов и подсистем хранения данных. Перечисленные компоненты, по сути, становятся строительными блоками для кластеров ИИ, облачных дата-центров и других инфраструктур, которые применяются для рабочих нагрузок ИИ и задач НРС. Благодаря использованию новой платформы Marvell разработчики смогут ускорить вывод на рынок передовых изделий и многочиповых решений, устраняющих существующие узкие места в ЦОД и поддерживающих самые сложные приложения. |
|