Материалы по тегу: blackwell
|
10.10.2025 [14:50], Руслан Авдеев
Не для себя стараемся: Microsoft развернула для OpenAI первый в мире ИИ-кластер на базе суперускорителей NVIDIA GB300 NVL72Microsoft представила первый в мире ИИ-кластер, использующий более 4,6 тыс. NVIDIA Blackwell Ultra в составе суперускорителей NVIDIA GB300 NVL72, объединённых интерконнектом Quantum-X800 InfiniBand. Этот кластер — лишь первый из многих. Компания развернёт сотни тысяч ускорителей Blackwell Ultra в ИИ ЦОД по всему миру. Благодаря им Microsoft намерена стать первой, поддерживающей обучение для моделей с сотнями триллионов параметров. Как сообщают в Microsoft, запуск в Microsoft Azure суперкластера NVIDIA GB300 NVL72 стал важным шагом в развитии передовых ИИ-технологий. Разработанная совместно с NVIDIA система представляет собой первый в мире масштабируемый ИИ-кластер на основе GB300, обеспечивающий вычислительные мощности, необходимые OpenAI для обслуживания моделей с триллионами параметров. Речь идёт о новом стандарте ускоренных вычислений, говорят компании. Новые инстансы Azure ND GB300 v6 оптимизированы для рассуждающих моделей, агентных систем и мультимодального генеративного ИИ. Каждая стойка GB300 NVL72 обслуживает 18 виртуальных машин, а сам суперускоритель с производительностью до 1,44 Эфлопс (FP4 Tensor Core) включает:

Источник изображения: Microsoft Создание передовой инфраструктуры требует переосмысления всех уровней системы, включая вычисления, память, системы охлаждения и питания, ЦОД в целом как единой структуры. Новая архитектура стоек обеспечивает высокую пропускную способность инференса при меньших задержках на крупных моделях, это позволяет агентным и мультимодальным ИИ-системам быть более масштабируемыми и эффективными, чем когда-либо, говорит компания. Для масштабирования за пределы стойки используется NVIDIA Quantum-X800 InfiniBand, что гарантирует обучения сверхбольших моделей с применением десятков тысяч ИИ-ускорителей с минимальными накладными расходами на их синхронизацию, что дополнительно повышает производительность. 
Источник изображения: Microsoft Передовые системы охлаждения Azure используют автономные теплообменники, чтобы свести к минимуму расход воды и поддерживать температурную стабильность для высокоплотных кластеров. Также продолжается разработка и внедрение новых моделей распределения питания, обеспечивающих высокую энергетическую плотность и динамический баланс нагрузок. Дополнительную помощь в оптимизации работы оказывает и модернизированное программное обеспечение. Ранее Microsoft обладала эксклюзивными правами на предоставление облачных сервисов компании OpenAI, но в январе 2025 года появилась новость, что ИИ-стартапу разрешили пользоваться и облаками других провайдеров, если у Microsoft не хватит собственных мощностей. Разногласия между компаниями продолжают нарастать. Формально первенство по создание кластера на базе GB300 NVL72 принадлежит CoreWeave, имеющей тесные отношения с NVIDIA и обслуживающей OpenAI — как напрямую, так и при посредничестве Microsoft.
03.09.2025 [09:47], Владимир Мироненко
Гибридный суперчип NVIDIA GB10 оказался технически самым совершенным в семействе BlackwellNVIDIA поделилась подробностями о суперчипе GB10 (Grace Blackwell), который ляжет в основу рабочих станций DGX Spark (ранее DIGITS) для ИИ-задач, пишет ресурс ServeTheHome. 
Источник изображений: NVIDIA via Wccftech Ранее сообщалось, что GB10 был создан NVIDIA в сотрудничестве MediaTek. GB10 объединяет чиплет CPU от MediaTek (S-Dielet) с ускорителем Blackwell (G-Dielet) с помощью 2.5D-упаковки. Оба кристалла изготавливаются по 3-нм техпроцессу TSMC. Как отметил ServeTheHome, GB10 технически является самым передовым продуктом на архитектуре Blackwell на сегодняшний день.  CPU включает 20 ядер на базе архитектуры Armv9.2, которые разбиты на два кластера по десять ядер (Cortex-X925 и Cortex-A725). На каждый кластер приходится 16 Мбайт кеш-памяти L3. Унифицированная оперативная память LPDDR5X-9400 ёмкостью 128 Гбайт подключена напрямую к CPU через 256-бит интерфейс с пропускной способностью 301 Гбайт/с. Объёма памяти достаточно для работы с моделями с 200 млрд параметров.  На кристалле CPU также находятся контроллеры HSIO для PCIe, USB и Ethernet. Для адаптера ConnectX-7 с поддержкой RDMA и GPUDirect выделено всего восемь линий PCIe 5.0, что не позволит работать обоим имеющимся портам в режиме 200GbE. Именно этот адаптер позволяет объединить две системы DGX Spark в пару для работы с ещё более крупными моделями.  G-Die имеет ту же архитектуру, что и B100. Ускоритель оснащён тензорными ядрами пятого поколения и RT-ядрами четвёртого поколения и обеспечивает производительность 31 Тфлопс в FP32-вычислениях. ИИ-производительность в формате NVFP4 составляет 1000 TOPS. Ускоритель подключён к CPU через шину NVLink C2C с пропускной способностью 600 Гбайт/с. G-Die оснащён 24 Мбайт кеш-памяти L2, которая также доступна ядрам CPU в качестве кеша L4, что обеспечивает когерентность памяти между CPU и GPU на аппаратном уровне. 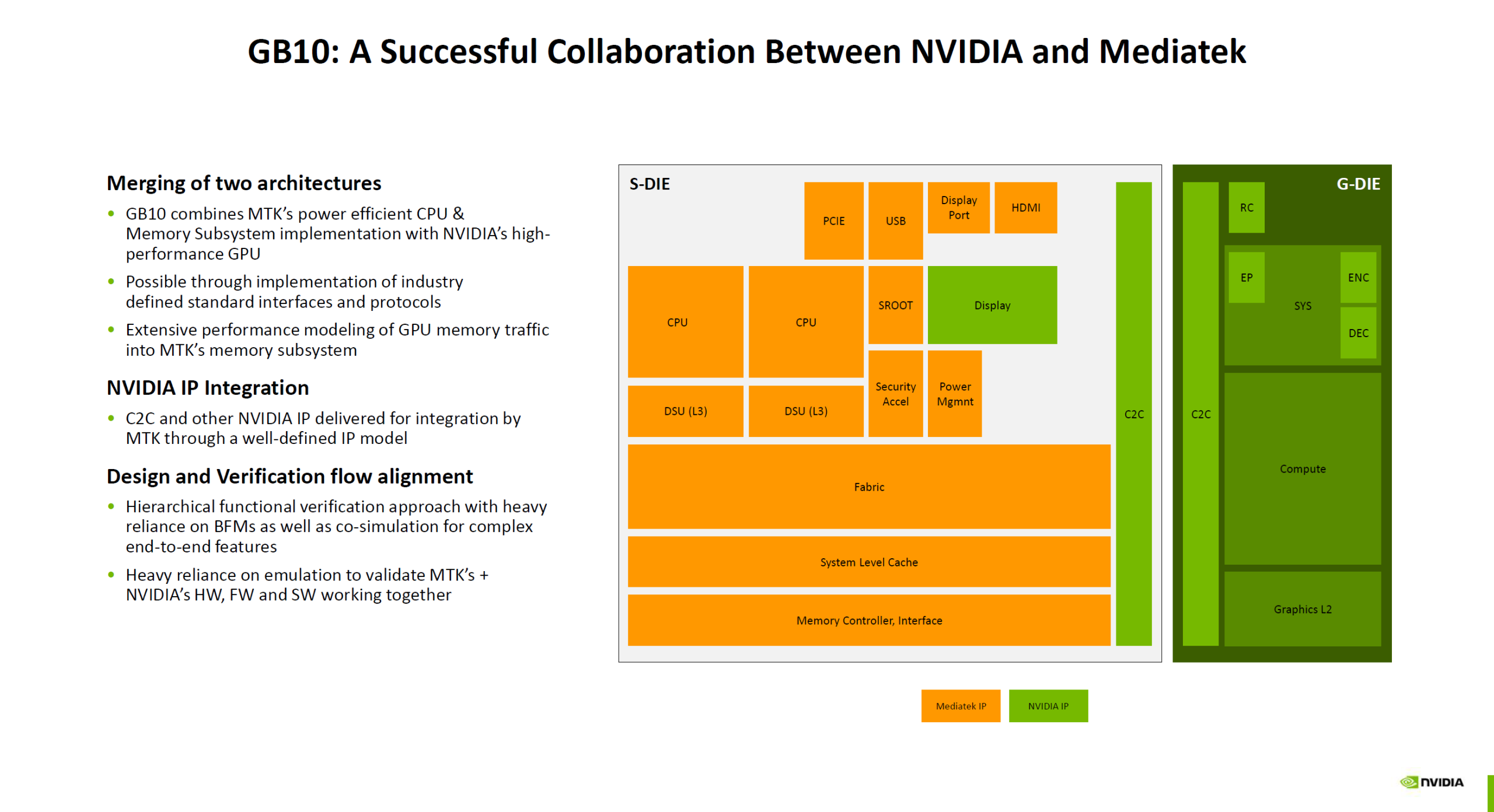 Поддерживается технология SR-IOV, интегрированы движки NVDEC и NVENC. Возможно подключение до четырёх дисплеев: три DisplayPort Alt-mode (4K@120 Гц) и один HDMI 2.1a (8K@120 Гц). Что касается безопасности, есть выделенные процессоры SROOT и OSROOT, а также поддержка fTPM и дискретного TPM (по данным Wccftech). TDP GB10 составляет 140 Вт.
21.08.2025 [10:03], Сергей Карасёв
NVIDIA представила ИИ-платформу Jetson AGX Thor Developer Kit с GPU BlackwellКомпания NVIDIA анонсировала вычислительные модули Jetson T5000 и T4000, а также комплект для разработчиков Jetson AGX Thor Developer Kit. Изделия предназначены для создания роботов, периферийных ИИ-систем, обработки данных от камер и сенсоров и других задач. Решение Jetson T5000 объединяет CPU с 14 вычислительными 64-бит ядрами Arm Neoverse-V3AE с максимальной тактовой частотой 2,6 ГГц, а также 2560-ядерный GPU на архитектуре Blackwell с частотой до 1,57 ГГц (задействованы 96 тензорных ядер пятого поколения). Объём памяти LPDDR5X с пропускной способностью 273 Гбайт/с составляет 128 Гбайт. Заявленная производительность достигает 2070 Тфлопс (FP4—Sparse). Реализована поддержка четырёх интерфейсов 25GbE. 
Источник изображений: NVIDIA В свою очередь, модель Jetson T4000 содержит CPU с 12 ядрами Arm Neoverse-V3AE (до 2,6 ГГц) и 1536-ядерный GPU на архитектуре Blackwell (до 1,57 ГГц; 64 тензорных ядра пятого поколения). Объём памяти LPDDR5X равен 64 Гбайт (273 Гбайт/с). У этого решения быстродействие составляет до 1200 Тфлопс (FP4—Sparse). Упомянуты три интерфейса 25GbE. Обе новинки обеспечивают возможность кодирования видео в многопоточных режимах: 6 × 4Kp60 (H.265), 12 × 4Kp30 (H.265), 24 × 1080p60 (H.265), 50 × 1080p30 (H.265), 48 × 1080p30 (H.264) или 6 × 4Kp60 (H.264). Декодирование возможно в следующих форматах: 4 × 8Kp30 (H.265), 10 × 4Kp60 (H.265), 22 × 4Kp30 (H.265), 46 × 1080p60 (H.265), 92 × 1080p30 (H.265), 82 × 1080p30 (H.264) и 4 × 4Kp60 (H.264). Допускается подключение до 20 камер посредством HSB, до 6 камер через 16 линий MIPI CSI-2 или до 32 камер через виртуальные каналы.  Среди прочего упомянута поддержка восьми линий PCIe 5.0, интерфейсов USB 3.2 (×3) и USB 2.0 (×4), HDMI 2.1 и DisplayPort 1.4a, I2S/2x (×5), DMIS (×2), UART (×4), SPI (×3), I2C (×13), PWM (×6). Габариты модулей составляют 100 × 87 мм. Решение Jetson AGX Thor Developer Kit построено на основе Jetson T5000. Система несёт на борту накопитель M.2 NVMe SSD вместимостью 1 Тбайт и комбинированный адаптер Wi-Fi 6E / Bluetooth (M.2 Key-E). Реализованы порты HDMI 2.0b и DisplayPort 1.4a, 5GbE RJ45 и QSFP28 (4 × 25 GbE), по два разъёма USB 3.2 Type-A и USB 3.1 Type-C. Размеры устройства составляют 243,19 × 112,4 × 56,88 мм. Комплект доступен для заказа по ориентировочной цене $3500.
19.08.2025 [23:10], Руслан Авдеев
NVIDIA готовит для Китая урезанный ИИ-ускоритель на архитектуре BlackwellNVIDIA работает над новым ИИ-ускорителем, предназначенным специально для китайского рынка. Модель на основе новейшей архитектуры Blackwell будет мощнее модели H20, допущенной для продаж в КНР, сообщает Reuters со ссылкой на осведомлённые источники. Как сообщают источники, новый чип, предварительно названный B30A, будет представлять собой однокристальную систему, которая, вероятно, обеспечит половину чистой вычислительной мощности флагманской модели NVIDIA B300 на двух кристаллах. Новый чип получит высокоскоростную память и поддержку технологии NVIDIA NVLink. Впрочем, эти функции имеются и в H20, основанном на устаревшей архитектуре Hopper. Источники сообщают, что окончательные характеристики чипа не определены, но NVIDIA рассчитывает предоставить китайским клиентам образцы для тестирования уже в следующем месяце. Компания подчёркивает, что рассматривает выпуск различных продуктов в той мере, в какой это позволяет американское правительство. Всё, что предлагается, одобрено компетентными органами и предназначено исключительно для коммерческого использования. В прошлом году на долю Китая пришлось 13 % выручки NVIDIA, поэтому глава компании Дженсен Хуанг (Jensen Huang) жёстко раскритиковал американские запреты. Ускоритель H20 был разработан специально для КНР ещё в 2023 году, но в апреле 2025 года он попал под санкции. AMD также разработала для Китая ослабленные ускорители MI308, которые тоже попали под санкции. Теперь уже сам Китай говорит, что H20 может представлять опасность для национальной безопасности и призывает отказаться от использования этих чипов. 
Источник изображения: Boudewijn Huysmans/unsplash.com На прошлой неделе США допустили возможность продажи в Китай урезанных чипов нового поколения. Информация появилась после сделки, в результате которой NVIDIA и AMD будут отдавать правительству США 15 % выручки от продаж ИИ-ускорителей в Китае. По данным CNBC, Трамп заявлял, что сначала он рассчитывал на 20 %, но позже согласился и на меньшее. Тем не менее, американские парламентарии обеспокоены продажей даже ослабленных чипов в Китай. Предполагается, что это помешает США добиться мирового лидерства в сфере ИИ. NVIDIA и другие компании уверены, что интерес Китая к американской продукции необходимо сохранить, иначе бизнесы из Поднебесной перейдут на продукцию местных конкурентов. Ранее сообщалось, что NVIDIA готовит для Китая чипы на архитектуре Blackwell, предназначенные для инференса. В мае Reuters сообщало, что ускоритель на базе RTX6000D (возможно, B30/B40) будет дешевле H20. Он разработан с учётом ограничений, введённых американскими властями, и использует обычную память GDDR с пропускной способностью 1398 Гбайт/сек, т.е. чуть ниже установленного регуляторами «экспортного» порога в 1,4 Тбайт/с — якобы именно из-за этого H20 и попал под запрет. Один из источников сообщает, что поставки небольших партий в Китай NVIDIA намеревается начать уже в сентябре 2025 года.
12.08.2025 [14:51], Владимир Мироненко
NVIDIA анонсировала компактные ускорители RTX PRO 4000 Blackwell SFF Edition и RTX PRO 2000 BlackwellNVIDIA объявила о предстоящем выходе GPU NVIDIA RTX PRO 4000 Blackwell SFF Edition и NVIDIA RTX PRO 2000 Blackwell, «воплощающих мощь архитектуры NVIDIA Blackwell в компактном и энергоэффективном форм-факторе», которые «обеспечат ИИ-ускорение для профессиональных рабочих процессов в различных отраслях». Новинки отличаются вдвое меньшими размерами по сравнению с традиционными GPU, и при этом оснащены RT-ядрами четвёртого поколения и тензорными ядрами пятого поколения с пониженным энергопотреблением. Как сообщает NVIDIA, новые ускорители разработаны для обеспечения производительности нового поколения для различных профессиональных рабочих процессов, обеспечивая «невероятное» ускорение процессов проектирования, дизайна, создания контента, ИИ и 3D-визуализации. По сравнению с ускорителем предыдущего поколения RTX A4000 SFF, модель RTX PRO 4000 SFF обеспечивает до 2,5 раза более высокую производительность в обработке ИИ-нагрузок и в 1,5 раза более высокую пропускную способность памяти, обеспечивая большую эффективность при том же максимальном энергопотреблении 70 Вт. 
Источник изображений: NVIDIA Ускоритель включает 8960 ядер NVIDIA CUDA, 24 Гбайт памяти GDDR7 ECC со 192-бит шиной и пропускной способностью 432 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 770 TOPS, RT-ядер — 73 TOPS, в формате FP32 — 24 TOPS. Доступно 2 движка NVENC девятого поколения и 2 движка NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. Оптимизированная для массового проектирования и рабочих ИИ-процессов, RTX PRO 2000 обеспечивает до 1,6 раза более быстрое 3D-моделирование, в 1,4 раза более высокую производительность систем автоматизированного проектирования (САПР) и в 1,6 раза более высокую скорость рендеринга по сравнению с предыдущим поколением. Компания отметила, что инженеры САПР, продуктовые инженеры и специалисты творческих профессий по достоинству оценят 1,4-кратный прирост производительности RTX PRO 2000 при генерации изображений и 2,3-кратный прирост производительности при генерации текста, что обеспечивает более быструю итерацию, быстрое прототипирование и бесперебойную совместную работу.  RTX PRO 2000 оснащена 4352 ядрами NVIDIA CUDA, 16 Гбайт памяти GDDR7 ECC со 128-бит шиной и пропускной способностью 288 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 545 TOPS, RT-ядер — 54 TOPS, в формате FP32 — 17 TOPS. Доступно по одному движку NVENC девятого поколения и NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. NVIDIA сообщила, что ускорители NVIDIA RTX PRO 2000 Blackwell и NVIDIA RTX PRO 4000 Blackwell SFF Edition поступят в продажу позже в этом году, не указав конкретные сроки.
02.06.2025 [22:50], Руслан Авдеев
NVIDIA якобы разрабатывает для Китая «антисанкционный» ИИ-ускоритель B30 с возможностью объединения в кластерыПосле запрета США на экспорт в Китай ИИ-ускорителей H20 NVIDIA занялась разработкой альтернативного продукта на базе Blackwell. Ранее уже появилась информация о имеется модели B40 на основе видеокарты RTX Pro 6000D. Тогда же упоминалось, что компания ведёт разработку ещё одного чипа. Теперь источники The Information сообщили о модели B30, причём с возможностью объединения в кластеры. По имеющимся данным, модель будет использовать память GDDR7 и GB20x — те же, что лежат в основе игровых видеокарт серии RTX 5000. Хотя многие предполагают, что B30 получат поддержку NVLink, в потребительских продуктах последнего поколения поддержка этого интерконнекта не предусмотрена. С другой стороны, у компании теперь есть серверы на основе RTX Pro Blackwell, которые объединяют до восьми GPU посредством платы с адаптерами ConnectX-8 SuperNIC со встроенными коммутаторами PCIe 6.0 для связи между ускорителями. Аналогичная конфигурация применяется для связи систем DGX Spark. В своё время глава NVIDIA Дженсен Хуанг (Jensen Huang) прямо заявил, что возможности архитектуры Hopper в плане её ослабления исчерпаны, и компания больше не будет использовать её для выпуска ослабленных ускорителей для Китая. При этом американские власти своими санкциями специально нацелились на снижение пропускной способности памяти и интерконнектов чипов для КНР.  Хотя NVIDIA соблюдает санкционные требования, компания давно находится в оппозиции к американским регуляторам — сам Хуанг недавно раскритиковал экспортные ограничения, заявив, что те только помогают Китаю нарастить собственные компетенции в сфере ИИ. NVIDIA уже потеряла $4,6 млрд из-за запрета на экспорт H20 в Китай, а в перспективе потеряет более $15 млрд. AMD после запрета на экспорт чипов MI308 сообщила о вероятных потерях $800 млн. По словам Хуанга, США, вводя новые меры, США рискуют потерять конкурентные преимущества в сфере ИИ, если китайские конкуренты вроде Huawei будут вынуждены форсировать инновации из-за отсутствия доступа к передовому оборудованию. В результате новые китайские продукты, возможно, не только смогут конкурировать с продукцией NVIDIA, но и начнут задавать будущие мировые стандарты в сфере ИИ-полупроводников.
26.05.2025 [14:38], Руслан Авдеев
NVIDIA выпустит для Китая дешёвый ускоритель семейства BlackwellNVIDIA намерена выпустить новый ИИ-ускоритель для Китая, который будет значительно дешевле недавно запрещённой к продаже в КНР модели H20. По данным источников Reuters, начало массового производства запланировано на июнь. Новинка войдёт в серию Blackwell и будет стоить $6,5–$8 тыс., т.е. намного меньше, чем H20, которые продавались по $10–$12 тыс. Вероятное название новинки — B40. Ускоритель предположительно получит чип от NVIDIA RTX Pro 6000D, будет использовать память GDDR7 вместо HBM и лишится поддержки NVLink. Кроме того, модель не будет использовать передовую технологию упаковки TSMC CoWoS (Chip-on-Wafer-on-Substrate). Представитель NVIDIA заявил, что компания всё ещё оценивает урезанные варианты ускорители — до того, как компания утвердит новый дизайн продукта и получит одобрение американских регуляторов, она фактически изолирована от китайского рынка объёмом $50 млрд. В TSMC слухи не комментируют. Китай долго оставался огромным рынком для NVIDIA, на который пришлось 13 % всех продаж за прошлый финансовый год. Уже в третий раз NVIDIA вынуждена ухудшать свои ИИ-ускорители из-за американских санкций, пытающихся замедлить технологическое развитие КНР (ранее пришлось выпустить A800, H800, H20 и др.). Запрет на продажи H20 фактически заставил NVIDIA списать $5,5 млрд и упустить $15 млрд потенциальных продаж. При этом дальнейшее ухудшение характеристик H20 невозможно. 
Источник изображения: NVIDIA Новый ускоритель хотя и намного слабее H20, должен помочь сохранить конкурентоспособность NVIDIA на китайском рынке, несмотря на значительные потери выручки из-за торговых ограничений со стороны США. Основным конкурентом компании является Huawei, выпускающая чипы Ascend. По словам экспертов Oak Capital Partners, производительность китайских ускорителей достигнет показателей ослабленных моделей NVIDIA в течение года-двух, но NVIDIA сохранит преимущество благодаря программной экосистеме CUDA, сопоставимых альтернатив которой у Huawei пока нет. До 2022 года, т.е до ввода серьёзных экспортных ограничений со стороны США, доля NVIDIA на китайском рынке ускорителей составляла 95 %, а сейчас она упала до 50 % — об этом сообщил глава компании Дженсен Хуанг (Jensen Huang). Он также предупредил об неэффективности санкций и заявил, что продолжение ограничений приведёт к тому, что чипов Huawei будут покупать всё больше, а вместо того, чтобы замедлить развитие ИИ-индустрии Китая, американские власти способствуют её прогрессу. Новейшие экспортные ограничения в очередной раз коснулись пропускной способности памяти и интерконнекта, этот показатель чрезвычайно важен для ИИ-чипов. По оценкам инвестиционного банка Jefferies новые правила ограничивают пропускную способность на уровне 1,7–1,8 Тбайт/с. H20 обеспечивает 4 Тбайт/с. GF Securities прогнозирует, что GDDR7 позволит получить допустимые 1,7 Тбайт/с. По словам двух источников Reuters, NVIDIA создаёт ещё один чип на архитектуре Blackwell для Китая, производство которого должно начаться в сентябре, но его характеристики пока неизвестны.
14.04.2025 [19:28], Алексей Степин
NVIDIA будет производить часть ИИ-ускорителей и платформ в СШАNVIDIA заявила, что не собирается ограничиваться исключительно тайваньскими производственными мощностями. Выпуск чипов Blackwell уже стартовал на площадке TSMC в Фениксе, штат Аризона. Здесь же в сотрудничестве с Amkor и SPIL будут налажены упаковка и тестирование новых GPU. Техасу отводится роль производителя суперкомпьютеров и платформ: NVIDIA строит соответствующие заводы совместно с Foxconn в Хьюстоне и с Wistron в Далласе. Всего компания застолбила почти 93 тыс. м2 производственных площадей в Аризоне и Техасе. Ожидается, что вышеупомянутые заводы выйдут на проектную мощность уже в течение ближайших 12–15 месяцев, а в течение четырёх следующих лет компания планирует произвести в США ИИ-платформ на $500 млрд. Как отмечает глава NVIDIA, Дженсен Хуанг (Jensen Huang), размещение производственных мощностей в США позволит компании лучше справляться с растущим спросом на ИИ-решения и суперкомпьютеры, укрепит её цепочки поставок и в целом поспособствует большей гибкости в решениях. Описываемое заявление NVIDIA сделала практически сразу после того, как ей удалось избежать экспортных ограничений на чип H20, наиболее производительный ИИ-ускоритель, разрешённый к экспорту в Китай. Согласно изданию NPR, этому помогло обещание крупных капиталовложений в ИИ-инфраструктуру США со стороны руководства компании. Многие другие разработчики и производители в сфере ИИ также вынуждены соглашаться с политикой текущей администрации США, дабы избежать огромных пошлин. 
Источник изображения: NVIDIA Хотя NVIDIA и заявляет, что инициатива с размещением производства чипов в США создаст сотни тысяч рабочих мест и увеличит активность экономики на триллионы долларов, всё не так просто, как может показаться. Реализации данных планов не способствуют ограничения, наложенные на торговлю с КНР и могущие помешать поставкам исходных материалов для производства микрочипов. Также упоминается нехватка квалифицированной рабочей силы. Меж тем, усилия администрации текущего президента США по отмене «закона о чипах» (CHIPS and Science Act), принятого в 2022 году и включающего в себя серьёзные субсидии иностранным высокотехнологичным компаниям, могут отпугнуть потенциальных инвесторов в лице полупроводниковых гигантов.
19.03.2025 [08:28], Сергей Карасёв
NVIDIA представила ускоритель RTX Pro 6000 Blackwell Server Edition с 96 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 6000 Blackwell Server Edition для требовательных приложений ИИ и рендеринга высококачественной графики. Ожидается, что новинка будет востребована среди заказчиков из различных отраслей, включая архитектуру, автомобилестроение, облачные платформы, финансовые услуги, здравоохранение, производство, игры и развлечения, розничную торговлю и пр. Как отражено в названии, в основу решения положена архитектура Blackwell. Задействован чип GB202: конфигурация включает 24 064 ядра CUDA, 752 тензорных ядра пятого поколения и 188 ядер RT четвёртого поколения. Устройство несёт на борту 96 Гбайт памяти GDDR7 (ECC) с пропускной способностью до 1,6 Тбайт/с. Ускоритель RTX Pro 6000 Blackwell Server Edition использует интерфейс PCIe 5.0 x16. Энергопотребление может настраиваться в диапазоне от 400 до 600 Вт. Реализована поддержка DisplayPort 2.1 с возможностью вывода изображения в форматах 8K / 240 Гц и 16K / 60 Гц. Аппаратный движок NVIDIA NVENC девятого поколения значительно повышает скорость кодирования видео (упомянута поддержка 4:2:2 H.264 и HEVC). Всего доступно по четыре движка NVENC/NVDEC. 
Источник изображения: NVIDIA По заявлениям NVIDIA, по сравнению с ускорителем предыдущего поколения L40S Ada Lovelace модель RTX PRO 6000 Blackwell Server Edition обеспечивает многократное увеличение производительности в широком спектре рабочих нагрузок. В частности, скорость инференса больших языковых моделей (LLM) повышается в пять раз для приложений агентного ИИ. Геномное секвенирование ускоряется практически в семь раз, а быстродействие в задачах генерации видео на основе текстового описания увеличивается в 3,3 раза. Достигается также двукратный прирост скорости рендеринга и примерно такое же повышение скорости инференса рекомендательных систем. Ускоритель RTX PRO 6000 Blackwell Server Edition может использоваться в качестве четырёх полностью изолированных экземпляров (MIG) с 24 Гбайт памяти GDDR7 каждый. Это обеспечивает возможность одновременного запуска различных рабочих нагрузок — например, ИИ-задач и обработки графики. Упомянута поддержка TEE.
27.02.2025 [16:27], Владимир Мироненко
NVIDIA увеличила выручку, но снизила валовую прибыль — продукты стали сложнее и дороже, а спрос на Blackwell потрясающийNVIDIA объявила финансовые результаты за IV квартал и 2025 финансовый год, завершившийся 26 января 2025 года. Выручка компании в IV квартале составила $39,3 млрд, что на 12 % выше результата предыдущего квартала и на 78 % больше год к году при консенсус-прогнозе аналитиков, опрошенных LSEG, в размере $38,05 млрд. Вместе с тем компания сообщила о снижении валовой прибыли в отчётном квартале на 3 п.п. в годовом исчислении 73 %, объяснив это выходом новых продуктов для ЦОД, которые стали сложнее и дороже. Чистая прибыль (GAAP) выросла год к году на 80 % до $22,09 млрд. Чистая прибыль на разводнённую акцию (GAAP) составила $0,89, что на 14 % больше, чем в предыдущем квартале и на 82 % больше год к году. Скорректированная чистая прибыль на разводнённую акцию (Non-GAAP) составила $0,89, что на 10 % больше, чем в предыдущем квартале и на 71% больше, чем годом ранее, а также больше консенсус-прогноза аналитиков Уолл-стрит согласно опросу LSEG в размере $0,84. 
Источник изображений: NVIDIA Выручка компании в 2025 финансовом году выросла на 114 % до $130,5 млрд. Чистая прибыль (GAAP) увеличилась на 145 % с $29,76 млрд или $1,19 на разводнённую акцию в предыдущем финансовом году до $72,88 млрд или $2,94 на акцию в отчётном. Скорректированная чистая прибыль (Non-GAAP) выросла за год на 130 % до $2,99 на разводнённую акцию. В сегменте решений для ЦОД выручка за IV квартал составила $35,6 млрд, увеличившись на 93 % в годовом исчислении и опередив прогноз Уолл-стрит в $33,65 млрд. За год выручка этого сегмента увеличилась на 142 % до $115,2 млрд. Как отметил ресурс SiliconANGLE, на данный сегмент пришлось 91 % от общего дохода компании за IV квартал, по сравнению с 83 % год назад и всего 60 % в аналогичном квартале 2023 финансового года. Доход компании от продуктов для ЦОД вырос за последние два года почти в десять раз. Вместе с тем выручка от продаж сетевого оборудование упала за квартал на 9 % до $3 млрд, но компания наверняка увеличит продажи, т.к. решениями Spectrum-X буду оснащатсья первые ЦОД ИИ-мегапроекта Stargate. 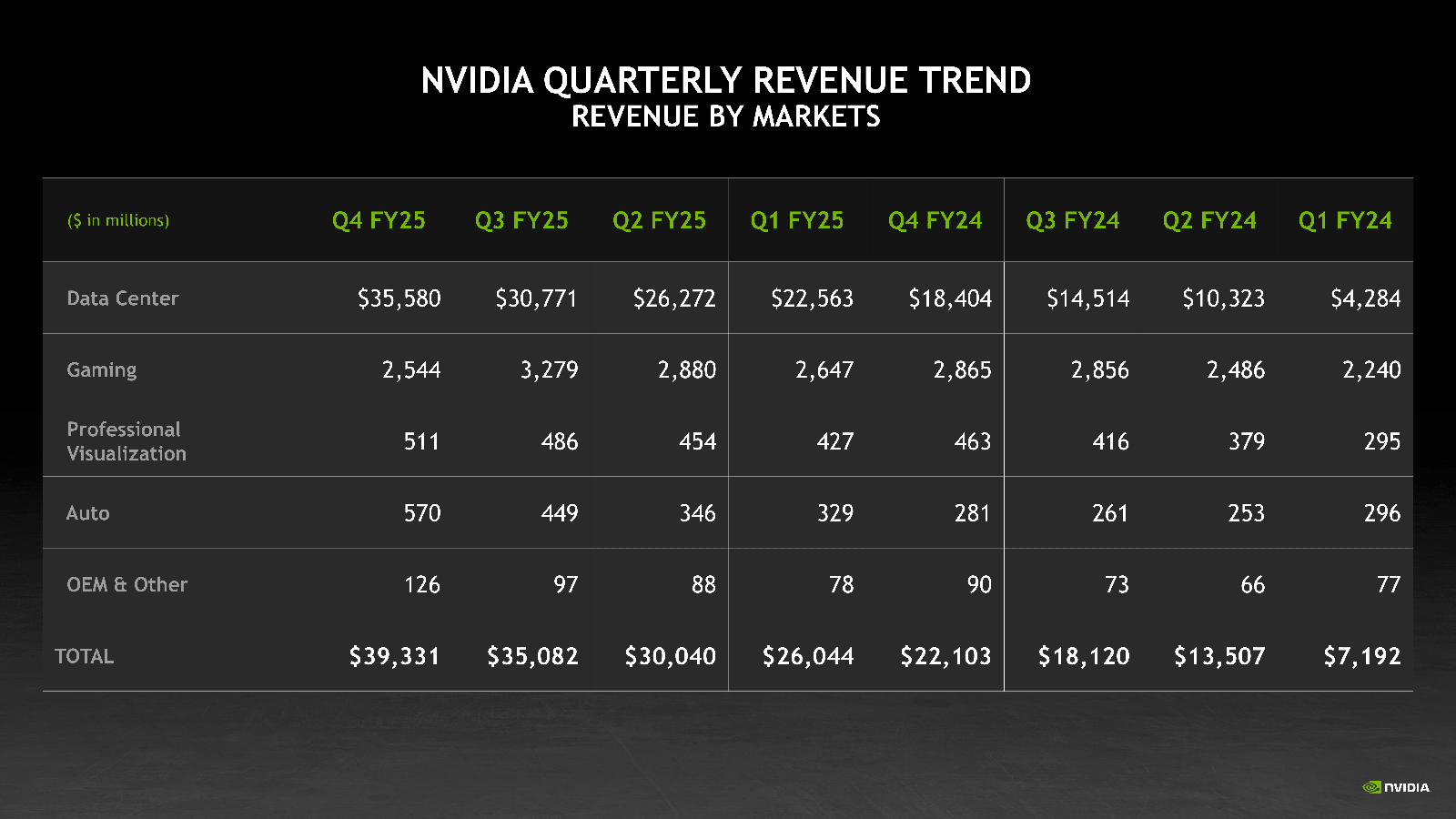 NVIDIA сообщила, что доход от продаж чипов с архитектурой Blackwell составил за квартал $11 млрд, что является «самым быстрым ростом продукта» в её истории. «Спрос на Blackwell потрясающий», — цитирует Bloomberg заявление гендиректора NVIDIA Дженсена Хуанга (Jensen Huang). Финансовый директор NVIDIA Колетт Кресс (Colette Kress) сообщила, что чипы Blackwell были лидерами по продажам для дата-центров и принесли порядка 50 % всего дохода сегмента ЦОД. В ходе телефонной конференции Хуанг сообщил, что предыдущие поколения чипов компании в основном использовались для обучения моделей ИИ, а новые чипы Blackwell в основном применяются для инференса. Некоторые инвесторы высказывали опасения, что спрос на самые мощные чипы NVIDIA может упасть из-за прогресса китайской DeepSeek, чья недорогая модель со способностью к рассуждениям DeepSeek R1 произвела фурор в отрасли, хотя на её разработку якобы ушло всего несколько миллионов долларов.  В ответ на это Кресс сообщила, что новые модели, разработанные для более тщательного «обдумывания» своих ответов, вероятно, потребуют гораздо больше вычислительной мощности по сравнению с более ранними моделями генеративного ИИ. «Для продолжительно думающего, рассуждающего ИИ может потребоваться в 100 раз больше вычислений на задачу по сравнению с однократными инференсами», — сказала она. Хуанг поддержал её, заявив, что «подавляющее большинство вычислений сегодня на самом деле относится к инференсу». Он выразил мнение, что в ближайшие годы ИИ-модели нового поколения могут потребовать «в миллионы раз» больше вычислительных мощностей, чем доступно сейчас. Опасения инвесторов также вызывает то, что AWS, Google и Microsoft, разрабатывающие собственные, кастомизированные ускорители, могут создать сильную конкуренцию NVIDIA. В ответ Хуанг заявил, что этим конкурентам ещё предстоит пройти долгий путь, и то, что чип разработан вовсе не означает, что он будет выпускаться.  Что касается результатов остальных подразделений компании, то игровой бизнес компании, включающий графические процессоры для 3D-игр, принёс ей $2,5 млрд, что меньше год к году на 11 %, а также меньше прогноза StreetAccount в размере $3,04 млрд. В сегменте профессиональной визуализации продажи за квартал составили $511 млн, что на 10 % больше год к году. За весь год выручка подразделения увеличилась на 21 % до $1,9 млрд. В автомобильном секторе выручка компании за отчётный квартал увеличилась в годовом исчислении на 103 % до $570 млн. За год выручка составила $1,7 млрд (рост — 55 %). Прогноз NVIDIA на I квартал 2026 финансового года по выручке равен $43 млрд ± 2 %, против $41,78 млрд, ожидаемых по оценкам LSEG. Это означает рост примерно на 65 % год к году, что является замедлением темпов роста компании по сравнению с ростом на 262 % за тот же период годом ранее. Компания также предупредила, что валовая прибыль будет меньше, чем ожидалось, поскольку она спешит выпустить новый дизайн чипа с архитектурой Blackwell. И также есть риск, что введение пошлин на импорт Соединёнными Штатами повлияет на результаты её работы. Акции NVIDIA выросли чуть более чем на 1 % в ходе расширенных торгов, что добавилось к росту более чем на 3 % в ходе обычной торговой сессии, отметил Bloomberg. |
|