Материалы по тегу: cpu
|
18.10.2025 [15:39], Сергей Карасёв
В Linux появилось упоминание загадочного x86-процессора от неизвестного ранее производителяВ списках рассылок Linux Kernel и GNU Binutils, по сообщению ресурса Phoronix, появилась информация о кодах операций (opcode), которые используются в процессорах с архитектурой х86, не имеющих отношения к изделиям AMD и Intel. О каком именно производителе чипов идёт речь, пока не ясно. О загадочных инструкциях сообщил Кристиан Ладлофф (Christian Ludloff), опытный эксперт по архитектуре x86. Он в течение многих лет работал в компаниях Google, AMD и Texas Instruments. Кроме того, Ладлофф является создателем сайта sandpile.org, на котором собрана различная техническая информация о чипах x86. Известно, что новые инструкции используются в продуктах некоего производителя изделий. То есть речь не идёт об исследовательской организации или каком-либо экспериментальном проекте. 
Источник изображения: Phoronix Высказываются предположения, что за новым x86-процессором может стоять китайская компания Zhaoxin. Минувшим летом она представила чип KH-50000 для серверов и ИИ-систем. Изделие выполнено на x86-совместимой архитектуре Zhaoxin Century Avenue, лицензия на которую ей досталась по наследству от Cyrix и VIA. В целом, китайские компании на фоне американских санкций активно развивают направление собственных серверных чипов. Так, компания Loongson недавно представила 64-ядерные процессоры 3C6000 на архитектуре LoongArch. Однако для Zhaoxin нет смысла секретничать, поскольку компания давно открыто и активно занимается разработкой, развивая открытые проекты, в том числе ядро Linux, библиотеки, компиляторы и т.д. В Китае также есть Hygon, которая, как ранее сообщалось, готовит 128-ядерного конкурента AMD EPYC с SMT4 и AVX-512. Ранее AMD и Hygon выпустили процессор Dhyana, который представлял собой чуть доработанный под местные требования первые EPYC Naples. Чем-то похожим занимается Montage Technology, выпускающая под брендом Jintide перелицованные Intel Xeon. Также известна тайваньская DM&P Electronics, которая выпускает 32-бит x86-процессоры Vortex86, которые корнями уходят к Rise Technology и SiS. Лицензии на современный набор инструкций у неё нет. Среди других предположений, высказанных в Сети, есть упоминание сделки Intel с NVIDIA по разработке кастомных CPU. Наконец, упоминаются эмуляторы, программные или с аппаратной поддержкой, т.е. не x86-процессоры. Это может быть интересно, например, Qualcomm. Кроме того, в российских процессорах «Эльбрус» есть двоичная трансляция x86-кода.
09.10.2025 [22:09], Владимир Мироненко
Intel анонсировала процессоры Xeon 6+ — Clearwater Forest с 288 E-ядрами DarkmontIntel раскрыла на мероприятии Intel Tech Tour Arizona новые подробности о следующем поколении серверных процессоров, выполненных по техпроцессу Intel 18A, которые получат название Xeon 6+ (Clearwater Forest) и будут иметь до 288 энергоэффективных ядер Darkmont E-Core, сообщил ресурс Phoronix. В максимальной конфигурации Xeon 6+ включает 12 чиплетов E-Core (Intel 18A с RibbonFET и PowerVia), 3 базовых тайла (Intel 3) и 2 чиплета I/O (Intel 7). 12 EMIB-тайлов объединяют все чиплеты в единую 2.5D-упаковку. Как сообщается, Xeon 6+ имеет в 1,9 раза более высокую пропускную способность памяти по сравнению с предыдущим поколением. Это связано с поддержкой 12 каналов памяти DDR5-8000 по сравнению с восемью каналами DDR5-6400 в процессорах Xeon 6700E (Sierra Forest-SP). Впрочем, у Xeon 6900E (Sierra Forest-AP) тоже поддерживает 12 каналов памяти, хотя и DDR5-6400 (а в 2DPC — 5200). Модули памяти MRDIMM новинки не поддерживают. 
Источник изображений: Intel/Wccftech.com Производительность Clearwater Forest также обеспечивается L3-кешем объёмом до 576 Мбайт (в 6700E было до 108 Мбайт, а 6900P — до 504 Мбайт), техпроцессом 18A и новой функцией Intel AET. Intel AET (Application Energy Telemetry) — технология телеметрии энергопотребления приложений, помогающая разработчикам/администраторам профилировать и масштабировать рабочие нагрузки на этих процессорах с большим количеством ядер.  Intel Xeon 6+ также позиционируется как процессор с улучшенной эффективностью до 23 % по всем видам нагрузок. На ещё одном слайде указано, что у Intel Xeon 6+ «в 1,9 раза более высокая производительность», чем у Xeon 6780E. Ресурс Phoronix вполне справедливо считает такое сравнение некорректным, учитывая удвоенное количество ядер, большее количество каналов памяти и более высокую скорость памяти, больший размер L3-кеша и т. д. Впрочем, есть надежда, что Intel вскоре опубликует более конкретные сравнительные показатели, а также таблицу с моделями Xeon 6+, чтобы получить точное представление о сравнении с серией Xeon 6700E.  Intel также подтвердила, что Xeon 6+ будет обладать максимальным TDP в диапазоне от 300 до 500 Вт и совместимостью с одно- и двухсокетными платформами. Также доступно до шести каналов UPI 2.0, до 96 линий PCIe 5.0 и до 64 линий CXL 2.0. Ускорители Intel QAT, DLB, DSA и IAA по-прежнему поддерживаются Xeon 6+, но Intel практически ничего не рассказала об этих блоках.
08.10.2025 [11:27], Сергей Карасёв
До 16 ядер Zen 5 в AM5: AMD представила чипы Ryzen Embedded 9000Компания AMD анонсировала процессоры серии Ryzen Embedded 9000, предназначенные для использования во встраиваемых устройствах, промышленных компьютерах, системах автоматизации, платформах машинного зрения и пр. Производитель обещает доступность чипов в течение семи лет. Изделия Ryzen Embedded 9000, выполненные на архитектуре Zen 5, совместимы с разъёмом AM5. При изготовлении применяется 4-нм технология. Показатель TDP варьируется от 65 до 170 Вт. Заявлена поддержка оперативной памяти DDR5 и интерфейса PCIe 5.0. 
Источник изображений: AMD На сегодняшний день в новое семейство процессоров входят семь моделей: Ryzen Embedded 9600X, 9700X, 9800X3D, 9900X, 9900X3D, 9950X и 9950X3D. Они насчитывают от 6 до 16 вычислительных ядер с поддержкой многопоточности. Базовая тактовая частота варьируется от 3,8 до 4,7 ГГц, максимальная частота — от 5,2 до 5,7 ГГц (см. характеристики ниже). Объём кеша L3 составляет от 32 до 128 Мбайт (решения с индексом 3D поддерживают технологию 3D V-Cache). 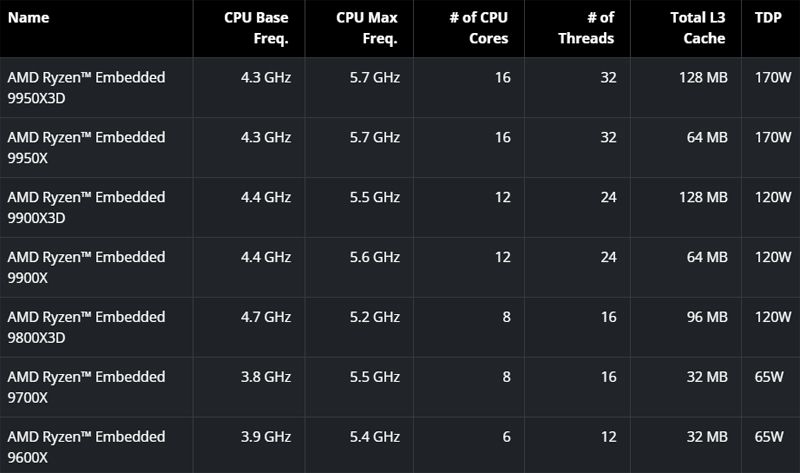 В состав чипов входит графический ускоритель на архитектуре AMD RDNA 2. Говорится о поддержке инструкций AVX-512, предназначенных для ускорения ресурсоёмких вычислений, таких как обработка больших массивов данных, задачи ИИ и пр. Компания AMD также сообщает, что в конце текущего года дебютируют новые процессоры семейства Ryzen Pro Embedded, поставлять которые планируется в течение десяти лет. Эти чипы получат расширенные функции обеспечения безопасности, включая инструмент AMD Platform Secure Boot и средства полного шифрования памяти AMD Memory Guard.
03.10.2025 [11:46], Владимир Мироненко
CPU двойного назначения: SiPearl анонсировала 80-ядерный Arm-процессор Athena1Французский разработчик серверных Arm-процессоров SiPearl, не имеющий собственных производственных мощностей, объявил о выпуске процессора Athena1 для приложений двойного назначения. Как сообщается в пресс-релизе, созданный на основе опыта, полученного при разработке процессора Rhea1, который будут использоваться в первом европейском экзафлопсном суперкомпьютере JUPITER, новый чип будет предлагать функции, специально разработанные для рабочих нагрузок государственных, оборонных и аэрокосмических приложений, включая такие направления, как защищенная связь и разведка, криптография и шифрование, обработка разведывательных данных, тактические сети, электронное обнаружение и локальная обработка данных на транспортных средствах. В дополнение к вычислительной мощности, Athena1 будет отличаться безопасностью и целостностью данных. Семейство Athena1 будет предлагаться в вариантах с 16, 32, 48, 64 или 80 ядрами Arm Neoverse V1 (Zeus), в зависимости от требуемой мощности для каждого приложения, ограничений по нагреву и других факторов. Подробные технические характеристики будут раскрыты позже. 
Источник изображения: SiPearl Производством кристаллов Athena1 займётся TSMC. Предполагается, что первоначально упаковка будет осуществляться на Тайване с последующим переносом в Европу, чтобы способствовать развитию европейской промышленной экосистемы. Коммерческий выпуск Athena1 запланирован на II половину 2027 года. Филипп Ноттон (Philippe Notton), генеральный директор и основатель SiPearl отметил, что при разработке новой версии первого процессора компании, «идеально отвечающей требованиям двойного назначения», был использован опыт, накопленный её научно-исследовательскими и опытно-конструкторскими группами в области высокопроизводительных вычислений. «В рамках программы, порученной нам Европой по содействию возвращению высокопроизводительных процессорных технологий на континент, Athena1 является идеальным дополнением к Rhea1, помогая утвердить стратегическую независимость Европы», — подчеркнул Ноттон.
30.09.2025 [20:43], Владимир Мироненко
Zhaoxin представила серверный x86-процессор KH-50000: 96 ядер без SMT и 12 каналов DDR5-5200Китайская компания Zhaoxin объявила о выходе серверного процессора нового поколения KH-50000 на x86-совместимой архитектуре Zhaoxin Century Avenue, анонсированного в июле этого года. Новинка предназначена для обеспечения выполнения широкого круга задач, включая обработку ИИ-нагрузок, облачные вычисления и Big Data. KH-50000 представлен в двух вариантах: с 72 и 96 ядрами. Чип имеет размеры 72 × 76 мм. Используется чиплетная компоновка с массивным IO-кристаллом и четырьмя вычислительными кластерами, содержащими по три чиплета каждый. Каждый чиплет содержит до 8 ядер и 32 Мбайт кеша L3 — итого 96 ядер и 384 Мбайт кеша L3. KH-50000 поддерживает 32- и 64-бит инструкции x86, включая SSE4.2, AVX и AVX2. Также реализована поддержка виртуализации, но нет поддержки SMT. 
Источник изображений: Zhaoxin/Tom's Hardware 96-ядерный вариант KH-50000 поддерживает тактовую частоту 2,2 ГГц и 3,0 ГГц в режиме Boost. У 72-ядерного чипа базовая тактовая частота составляет 2,6 ГГц и 3,0 ГГц в режиме Boost. Данных о TDP нет. KH-50000 поддерживает масштабирование 2S и 4S, что позволяет увеличить количество ядер до 384 на сервер. Для межчипового взаимодействия используется интерфейс ZPI 5.0 (Zhaoxin Processor Interconnect) собственной разработки.  Процессор поддерживает до 12 каналов DDR5-5200 ECC RDIMM, что позволяет использовать в общей сложности до 3 Тбайт памяти, в отличие от 2 Тбайт DDR4-3200 у предшественника KH-40000. Также сообщается о наличии 128 линий PCIe 5.0 совместимых с ZPI/CXL и 16 линий PCIe 4.0 по сравнению со 128 линиями PCIe 3.0 в KH-40000. Количество портов SATA и USB несколько уменьшилось по сравнению с KH-4000, но теперь реализована поддержка спецификации USB 3.2 Gen2 (четыре порта). Также указана поддержка 12 портов SATA III. Как отметил ресурс Tom's Hardware, в соответствии с требованиями безопасности Китая KH-5000 поддерживает фирменные стандарты шифрования SM2, SM3 и SM4. В частности, Zhaoxin интегрировала в KH-50000 чип четвёртого поколения от National Technology (вероятно, NS350). Этот чип соответствует требованиям безопасности китайского стандарта криптографических модулей GM/T 0012-2020 и международному стандарту TPM 2.0 (SPEC 1.59).
18.09.2025 [16:09], Владимир Мироненко
Intel разработает для NVIDIA кастомные CPU для серверов и ПК, а NVIDIA вложит в Intel $5 млрдNVIDIA и корпорация Intel заключили соглашение о сотрудничестве с целью совместной разработки специализированных чипов для ЦОД и ПК для использования гиперскейлерами, а также другими клиентами на корпоративном и потребительском рынках. Согласно пресс-релизу, компании намерены обеспечить бесшовное объединение архитектур NVIDIA и Intel с использованием NVIDIA NVLink, реализуя преимущества NVIDIA в области ИИ и ускоренных вычислений совместно с ведущими технологиями процессоров Intel и экосистемой x86 для предоставления передовых решений для клиентов. Ранее NVIDIA представила интерконнект NVLink Fusion, который как раз и позволяет объединять решения компании с чиплетами других вендоров. Одним из первых продуктов стал чип GB10, включающий GPU Blackwell и Arm-процессор MediaTek. В рамках партнёрства Intel разработает кастомные серверные x86-процессоры для ИИ-платформ NVIDIA. Для персональных компьютеров Intel разработает SoC с архитектурой x86 и GPU-чиплетами NVIDIA RTX. Новые SoC RTX на базе x86 будут использоваться в широком спектре ПК. У Intel уже был опыт интеграции GPU AMD в свои SoC, но не слишком удачный — Kaby Lake-G были заброшены через пару лет после выхода. 
Источник изображения: NVIDIA В рамках соглашения о сотрудничестве NVIDIA инвестирует в Intel $5 млрд путём приобретения на эту сумму обыкновенных акций Intel по цене $23,28 за единицу. После этого объявления акции Intel подскочили на премаркете на 33 % до примерно $33 за единицу, сообщил ресурс CNBC. Ранее SoftBank потратила $2 млрд на покупку акций Intel по $23/шт. В конце августа власти США приобрели 9,9 % долю в Intel за $8,9 млрд, получив акции по $20,47 за бумагу. «Это историческое сотрудничество тесно связывает ИИ-технологии и ускоренные вычисления NVIDIA с CPU Intel и обширной экосистемой x86 — слиянием двух платформ мирового класса. Вместе мы расширим наши экосистемы и заложим основу для следующей эры вычислений», — отметил генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang). Как полагают аналитики CNBC, сотрудничество, по всей видимости, не включают производство чипов NVIDIA на производственных мощностях Intel.
17.09.2025 [10:57], Сергей Карасёв
AMD представила процессоры EPYC Embedded 4005 для периферийного оборудованияКомпания AMD анонсировала процессоры серии EPYC Embedded 4005, предназначенные для использования в индустриальных серверах начального уровня, а также в различном периферийном оборудовании, включая межсетевые экраны следующего поколения (NGFW). Изделия, выполненные на архитектуре AMD Zen 5, рассчитаны на установку в разъём AM5. Применена чиплетная компоновка, а при производстве задействована 4-нм технология. Новые CPU содержат до 128 Мбайт кеша L3 (у модели EPYC Embedded 4585PX с технологией 3D V-Cache). Говорится о поддержке оперативной памяти DDR5-5600 ECC, 28 линий PCIe 5.0 и инструкций AVX-512. Фактически новинки развивают серию EPYC 4005 Grado, которая сама по себе является развитием Ryzen 9000. 
Источник изображения: AMD Все CPU поддерживают технологию многопоточности и имеют конфигурируемый показатель TDP, благодаря чему может достигаться оптимальный баланс между производительностью и энергоэффективностью для конкретных задач. В семейство EPYC Embedded 4005 на сегодняшний день входят шесть моделей:
В процессорах реализованы функции безопасности AMD Infinity Guard, которые призваны обеспечить защиту конфиденциальных данных от сложных кибератак. Производить чипы EPYC Embedded 4005 компания AMD намерена в течение семи лет.
12.09.2025 [23:30], Владимир Мироненко
Благодаря NVIDIA доля Arm на рынке серверных процессоров достигла 25 %Стремительный рост вычислительных мощностей ЦОД на фоне бума ИИ-технологий способствовал росту доходов не только производителей ускорителей и серверных CPU, но и компании Arm, чью архитектуру они используют в своих чипах, передаёт The Register. В январе Arm заявила о намерении занять 50 % рынка чипов для ЦОД к концу 2025 года Согласно исследованию Dell’Oro Group, во II квартале доля Arm-чипов на рынке серверных CPU составила 25 %, тогда как годом ранее она равнялась 15 %. Движущей силой роста стало внедрение суперускорителей NVIDIA GB200 NVL72 и GB300 NVL72, которые включают 36 Arm-процессоров Grace на базе архитектуры Neoverse V2 (Demeter) с интерфейсом NVLink-C2C. Заказы на поставку чипов NVIDIA расписаны на месяцы вперёд, что обеспечивает гарантированный источник доходов Arm наряду с ростом доли на рынке. Аналитик Dell’Oro Барон Фунг (Baron Fung) сообщил The Register, что ещё год назад рост Arm на рынке серверных процессоров обеспечивался практически исключительно за счёт кастомных CPU, таких как AWS Graviton. Но теперь выручка от продаж Grace сопоставима с доходами от облачных GPU. AWS использует кастомные процессоры на архитектуре Arm с 2018 года. А Microsoft и Google лишь в последние несколько лет начали всерьёз развивать свои Arm-процессорах Cobalt и Axion соответственно, отметил The Register. 
Источник изображения: Arm Рост доли Arm на рынке зависит от того, насколько больше разработчиков чипов выведет свои чипы на рынок серверных процессоров. NVIDIA сейчас работает над новым процессором на базе Arm с использованием кастомных ядер Vera. Qualcomm и Fujitsu также работают над серверными чипами. А появление NVIDIA NVLink Fusion может привести к созданию новых гибридных чипов. По данным Dell’Oro, рост рынка ИИ-технологий также привёл к росту рынка компонентов для серверов и СХД, составившему во II квартале 44 % в годовом исчислении. Продажи SmartNIC и DPU, которые зачастую тоже используют Arm-ядра, примерно удвоились по сравнению с прошлым годом на фоне перехода на Ethernet для вычислительных ИИ-кластеров. Поставки ASIC для обработки ИИ-нагрузок сейчас сопоставимы с объёмами поставок GPU, хотя GPU по-прежнему приносят большую часть доходов.
12.09.2025 [00:44], Владимир Мироненко
Intel покидает уже второй по счёту главный архитектор Xeon в этом годуРесурсу CRN стало известно о предстоящем уходе из Intel в конце этого месяца Ронака Сингхала (Ronak Singhal), который стал уже вторым главным архитектором процессоров Xeon, покинувшим компанию за последние восемь месяцев после ухода в январе Сайлеша Коттапалли (Sailesh Kottapalli) в Qualcomm. Intel подтвердила CRN, что Сингхал покидает компанию. Уход Сингхала ресурс связывает с назначением Кеворка Кечичяна (Kevork Kechichian) главой Группы ЦОД (DCG) в рамках реорганизации компании, проводимой гендиректором Лип-Бу Таном (Lip-Bu Tan). В последнее время Сингхал руководил реализацией технологической стратегии и управлением продуктами в разрезе серверных процессоров Xeon. Ответственность Сингхалпа также распространялась на разработку платформ и множества сопутствующих технологий, касающихся памяти, безопасности и ИИ в Xeon. Ранее Сингхал руководил разработкой серверной архитектуры Haswell и Broadwell, последний из которых, по его словам, стал первым 14-нм серверным чипом компании. Он также возглавлял разработку IP-блоков для процессоров Xeon, Core и Atom. 
Источник изображения: Intel В конце июля Тан сообщил сотрудникам, что компания «сосредоточена на восстановлении» доли рынка серверных процессоров, наращивая выпуск чипов Granite Rapids, а также «расширяя возможности для нагрузок гиперскейлеров». Как отметил финансовый директор Дэвид Цинснер (David Zinsner), линейка серверных продуктов Diamond Rapids, запуск которой запланирован на следующий год, «не даёт желаемого результата». По его словам, следующее поколение — Coral Rapids — является «реальной возможностью», которая позволит Intel «сделать действительно большой шаг вперёд».
09.09.2025 [17:00], Владимир Мироненко
Быстрее и «умнее»: SiFive представила второе поколени RISC-V-ядер IntelligentSiFive представила семейство ядер Intelligent второго поколения с архитектурой RISC-V, включающее новые ядра X160 Gen 2 и X180 Gen 2, а также обновлённые решения X280 Gen 2, X390 Gen 2 и XM Gen 2. Новые решения разработаны для расширения возможностей скалярной, векторной и, в случае серии XM, матричной обработки данных, адаптированных для современных задач в сфере ИИ. Как отметил ресурс EE Times, анонсируя новую линейку продуктов, SiFive стремится воспользоваться быстрорастущим спросом на решения для обработки ИИ-нагрузок, который, по прогнозам Deloitte, вырастет как минимум на 20 % во всех технологических средах, включая впечатляющий скачок на 78 % в сфере периферийных вычислений с использованием ИИ. Ядра SiFive второго поколения позволяют решать критически важные задачи в области внедрения ИИ, в частности, в области управления памятью и ускорения нелинейных функций. Ключевым нововведением в процессорах серии X является их способность функционировать в качестве блока управления ускорителем (ACU). Это позволяет ядрам SiFive обеспечивать основные функции управления и поддержки для ускорителя заказчика через интерфейсы SiFive Scalar Coprocessor Interface (SSCI) и Vector Coprocessor Interface eXtension (VCIX). Данная архитектура позволяет заказчикам сосредоточиться на инновациях в обработке данных на уровне платформы, оптимизируя программный стек. 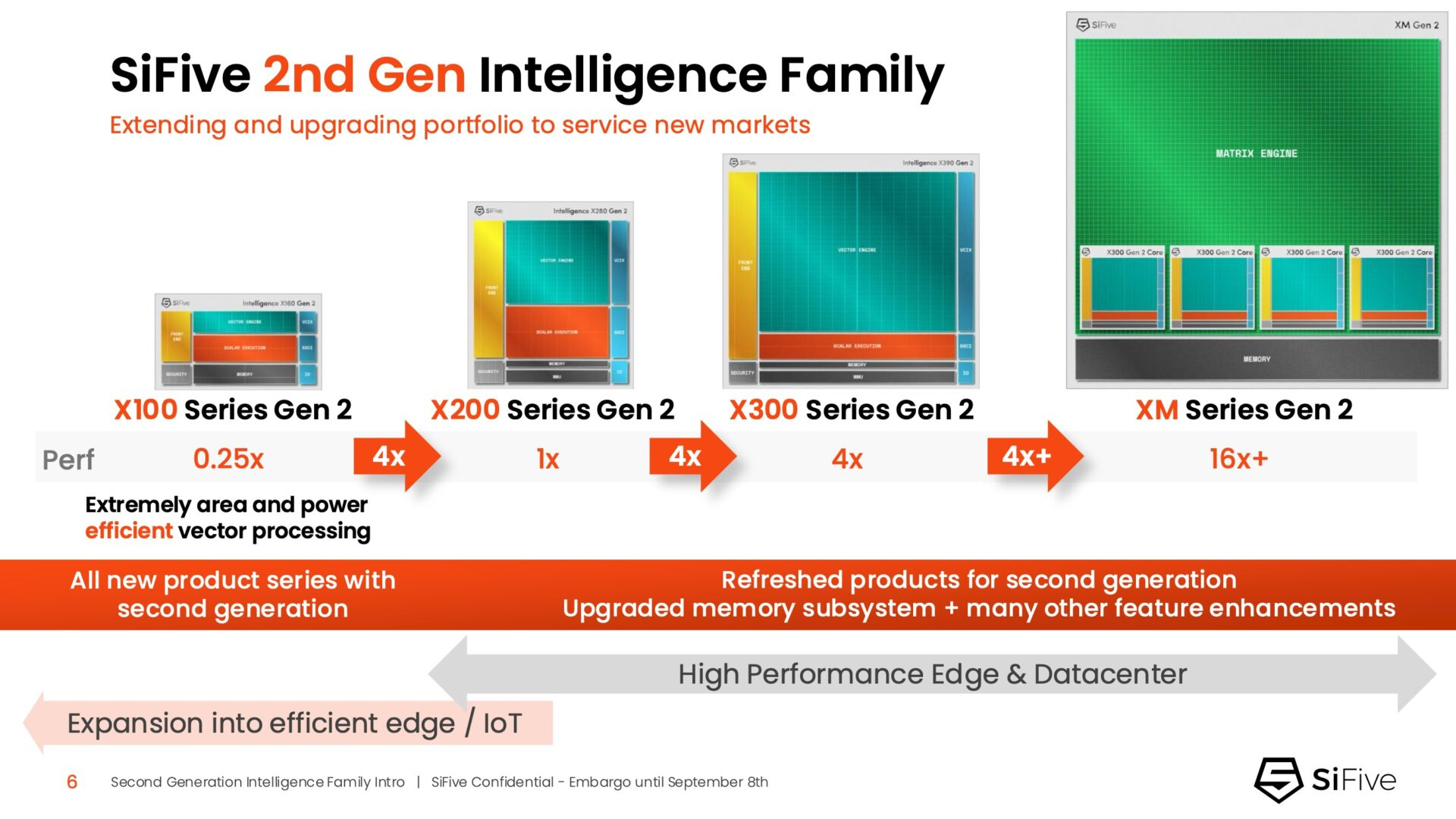
Источник изображений: SiFive/ServeTheHome Джон Симпсон (John Simpson), главный архитектор SiFive, сообщил ресурсу EE Times, что интеллектуальные ядра SiFive обеспечивают гибкость, сокращают трафик системной шины за счёт локальной обработки на чипе ускорителя и обеспечивают более тесную связь для задач пред- и постобработки. Он рассказал, что SiFive представила два важных усовершенствования в архитектуре, которые напрямую устраняют узкие места производительности: устойчивость к задержкам памяти и более эффективную подсистему памяти. 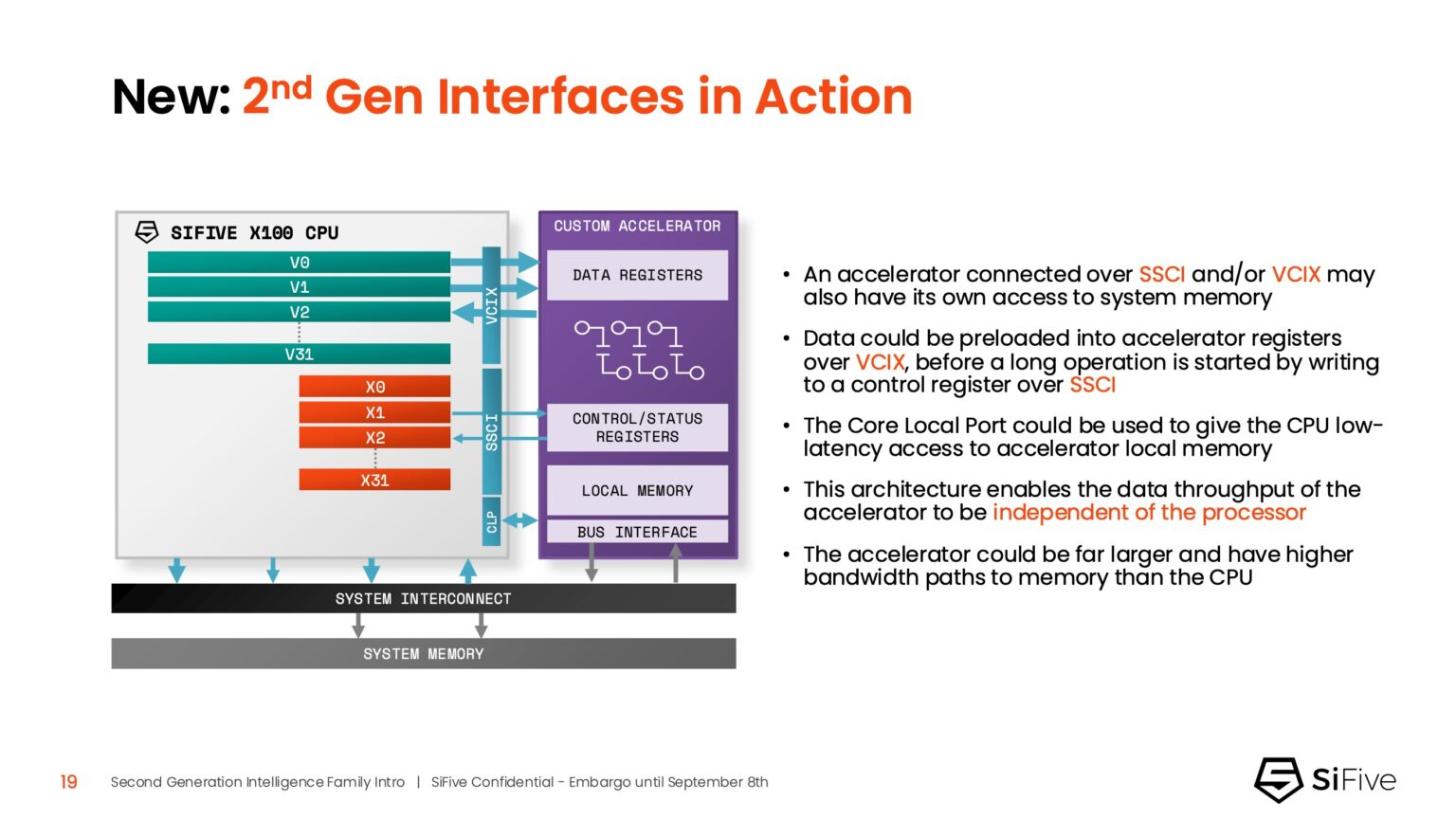 Функцию Memory Latency Tolerance позволяет снизить задержку загрузки. Симпсон рассказал, что блок скалярных вычислений, обрабатывающий все инструкции, отправляет векторные инструкции в очередь векторных команд (VCQ). При обнаружении такого инструкции одновременно отправляется запрос в подсистему памяти (кеш L2 или выше). Ранняя отправка запросов, отделённая от исполнения, позволяет быстрее получить ответ от памяти и поместить его в переупорядочиваемую настраиваемую очередь загрузки векторных данных (VLDQ). Это гарантирует готовность данных к моменту, когда инструкция в конечном итоге покинет VCQ, что приводит к «загрузке вектора в течение одного цикла». 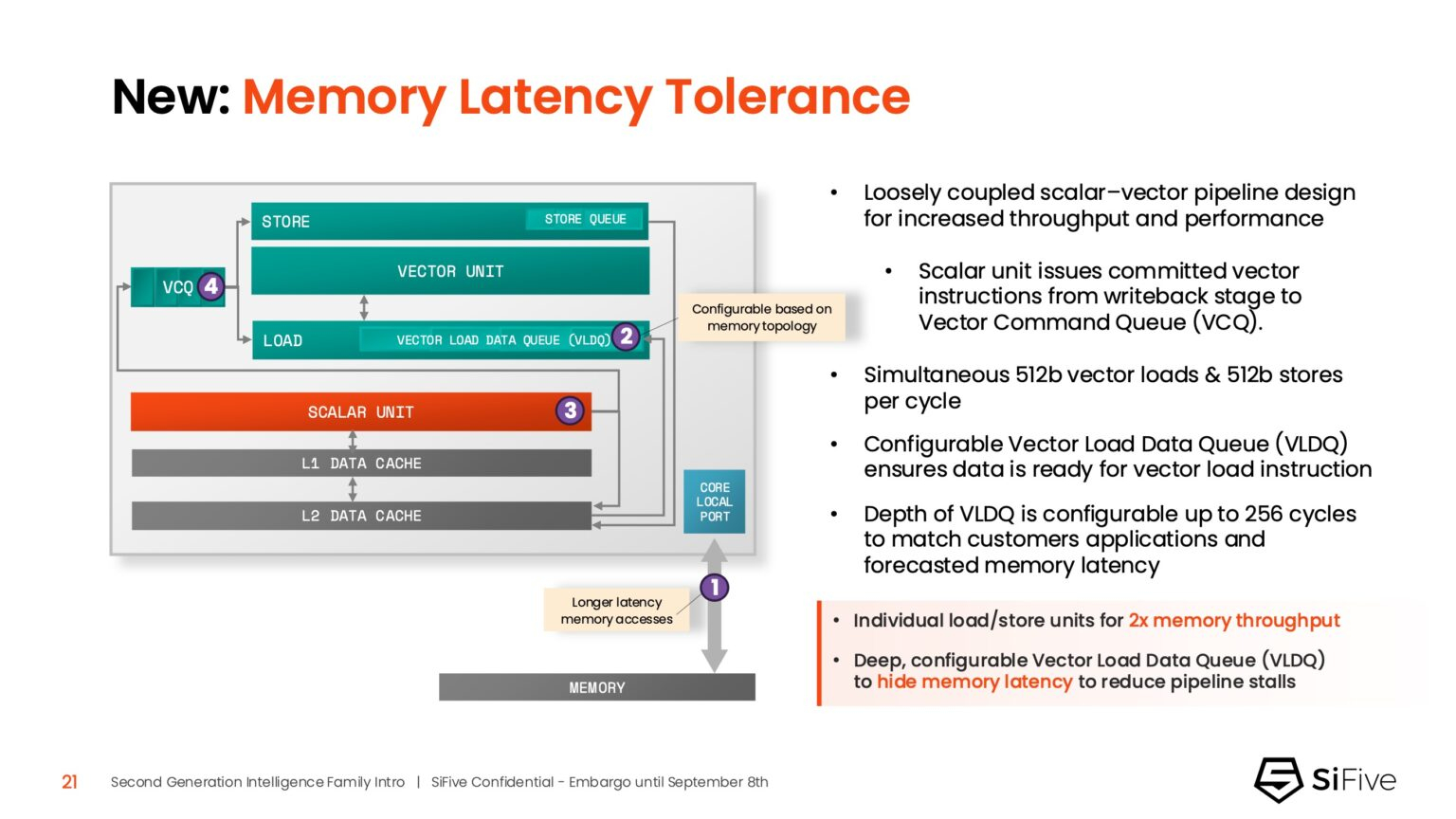 Симпсон подчеркнул конкурентное преимущество решения, отметив: «Xeon, представленный на Hot Chips, может обслуживать 128 невыполненных запросов, и это топовый показатель для Xeon, а в нашем четырёхъядерном процессоре этот показатель составляет 1024». Эта «прекрасная технология» обеспечивает непрерывную обработку данных, эффективно предотвращая простои конвейера.  Более эффективная подсистема памяти, которая представляет собой ещё одно существенное обновление, основана на переходе от инклюзивной к неинклюзивной иерархии кешей. В инклюзивной системе кеширования предыдущего поколения данные из общего кеша L3 реплицировались в частные кеши L1/L2, что компания посчитала неэффективным расходом «кремния». Конструкция ядер второго поколения исключает копирование, что, по словам Симпсона, даёт «в 1,5 раза большую производительность по сравнению с первым поколением» при меньшей занимаемой площади на кристалле. 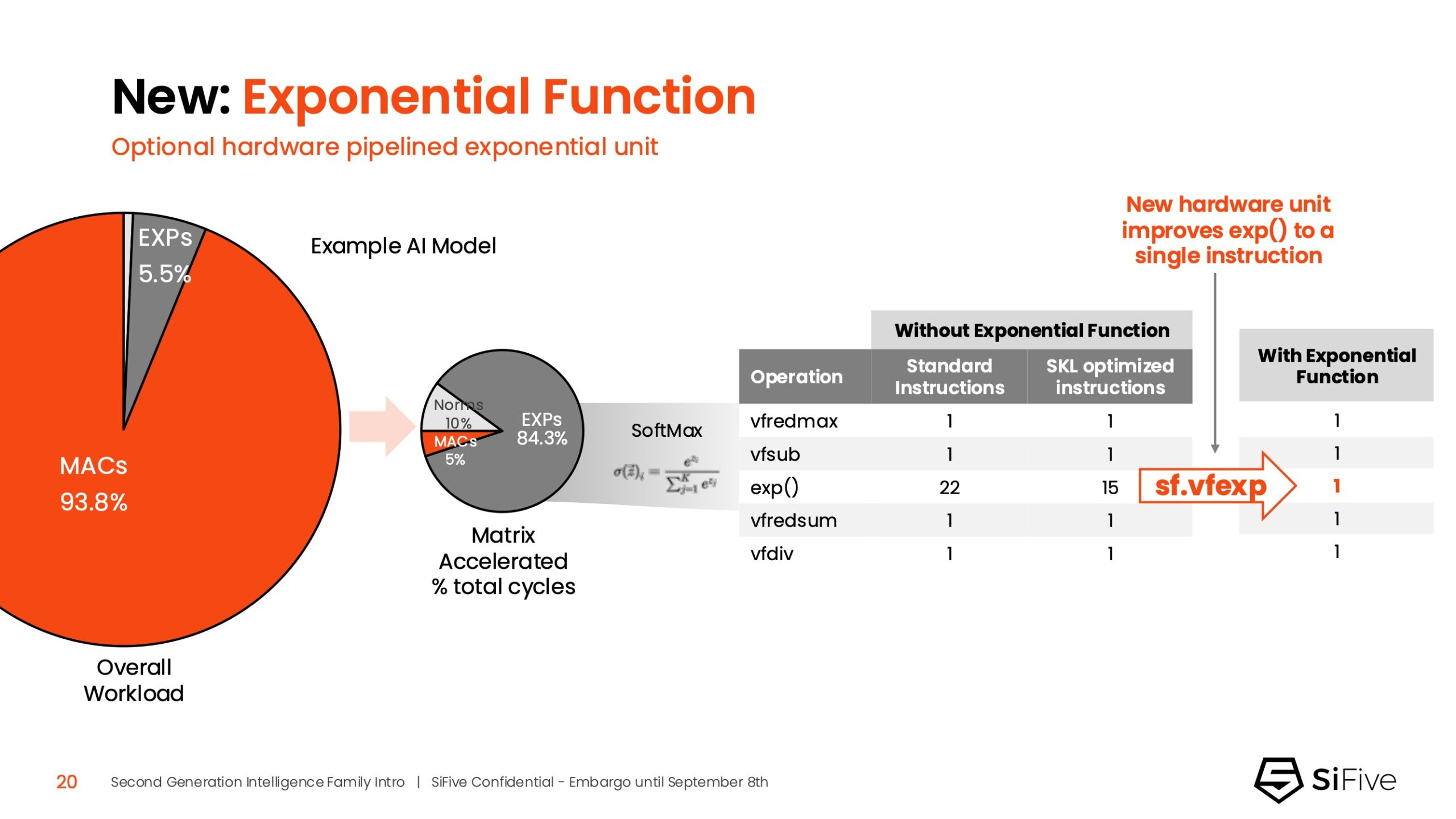 SiFive также интегрировала новый аппаратный конвейерный экспоненциальный блок. В то время как MAC-операции доминируют в рабочих ИИ-нагрузках, возведение в степень становится следующим серьёзным узким местом. Например, в BERT LLM, ускоренных матричным движком, операции softmax, включающие возведение в степень, занимают более 50 % оставшихся циклов. Программными оптимизациями SiFive сократила выполнение функции возведения в степень с 22 до 15 циклов, а новый аппаратный блок сокращает её до одной инструкции, уменьшая общее время выполнения функции до пяти циклов. Программный стек для семейства Intelligence второго поколения поддерживает масштабируемость. В серии XM среда выполнения машинного обучения уже распределяет рабочие нагрузки между несколькими кластерами XM на одном кристалле. Впрочем, пока масштабирование за пределы одного кристалла требует дальнейшей разработки библиотеки межпроцессорного взаимодействия (IPC).  Флагманские решения X160 Gen 2 и X180 Gen 2 могут быть настроены для работы под управлением операционной системы реального времени, пишет SiliconANGLE. 32-бит IP-ядро Intelligence X160 разработано для оптимизации энергоэффективности и приложений с жесткими ограничениями по площади кристалла, в то время как 64-бит IP-ядро Intelligence X180 обеспечивает более высокую производительность и лучшую интеграцию с более крупными подсистемами памяти, сообщил ресурс CNX-Software.  X160 поставляется с кеш-памятью объёмом до 200 КиБ и памятью объёмом 2 МиБ. Помимо промышленного оборудования, ядро может найти применение в потребительских устройствах, таких как фитнес-трекеры. Кроме того, X160 можно установить в системах с несколькими ИИ-ускорителями для управления чипами и предотвращения изменения прошивки. Благодаря двум встроенным кешам общей ёмкостью более 4 МиБ ядро позволяет работать с большим объёмом данных. По данным SiFive, X160 подходит для обучения ИИ-моделей и использования в оборудовании ЦОД.  В свою очередь, ядро X280 ориентировано на потребительские устройства, такие как гарнитуры дополненной реальности, а X390 также может использоваться в автомобилях и инфраструктурных системах. Последнее ядро выполняет векторную обработку в четыре раза быстрее, чем X280.  Все пять продуктов Intelligence Gen 2 уже доступны для лицензирования, а появление первых чипов на их основе ожидается во II квартале 2026 года. SiFive сообщила, что два ведущих американских производителя полупроводников лицензировали новую серию X100 ещё до её публичного анонса. Они используют IP-ядро X100 в двух различных сценариях: одна компания задействует сочетание скалярного векторного ядра SiFive с матричным движком, выступающим в качестве блока управления ускорителем, а вторая использует векторный движок в качестве автономного ИИ-ускорителя. |
|