Материалы по тегу: asic
|
06.10.2025 [10:54], Владимир Мироненко
250 Тбит/с на чип: Ayar Labs, Alchip и TSMC предложили референс-дизайн для упаковки ASIC, памяти и оптических модулей в одном чипеКомпания Ayar Labs (США), занимающаяся разработкой интерконнекта на базе кремниевой фотоники, и тайваньский производитель ASIC-решений Alchip Technologies представили референсную платформу проектирования ИИ ASIC с несколькими оптическими IO-модулями на основе технологии кремниевой фотоники TSMC COUPE (Compact Universal Photonic Engine). В начале сентября компании объявили о стратегическом партнёрстве с целью ускорения масштабирования ИИ-инфраструктуры благодаря объединению технологии CPO компании Ayar Labs, экспертизы Alchip в области создания и упаковки кастомных ASIC, а также технологии упаковки и техпроцесса компании TSMC. Как сообщил технический директор Ayar Labs Владимир Стоянович (Vladimir Stojanovic) в интервью EE Times, платформа предназначена для устранения узких мест в передаче данных, замедляющих работу ИИ-инфраструктуры, путём эффективного сокращения времени простоя системы и создания крупных высокопроизводительных ИИ-кластеров нового поколения. Партнёры отметили, что по мере роста ИИ-моделей и размеров кластеров традиционные медные соединения достигают своих физических и энергетических пределов. Путём замены меди на интегрированную оптику (CPO) решение Alchip и Ayar Labs обеспечивает расширенную дальность связи, низкую задержку, энергоэффективность и высокий радикс, необходимые для масштабных развертываний ИИ-ускорителей. «Масштабируемые сети ИИ-кластеров ограничены расстоянием медных соединений. В то же время энергоэффективность сети ограничена плотностью мощности и возможностями систем охлаждения», — пояснил Эрез Шайзаф (Erez Shaizaf), технический директор Alchip, добавив, что CPO снимает эти ограничения. 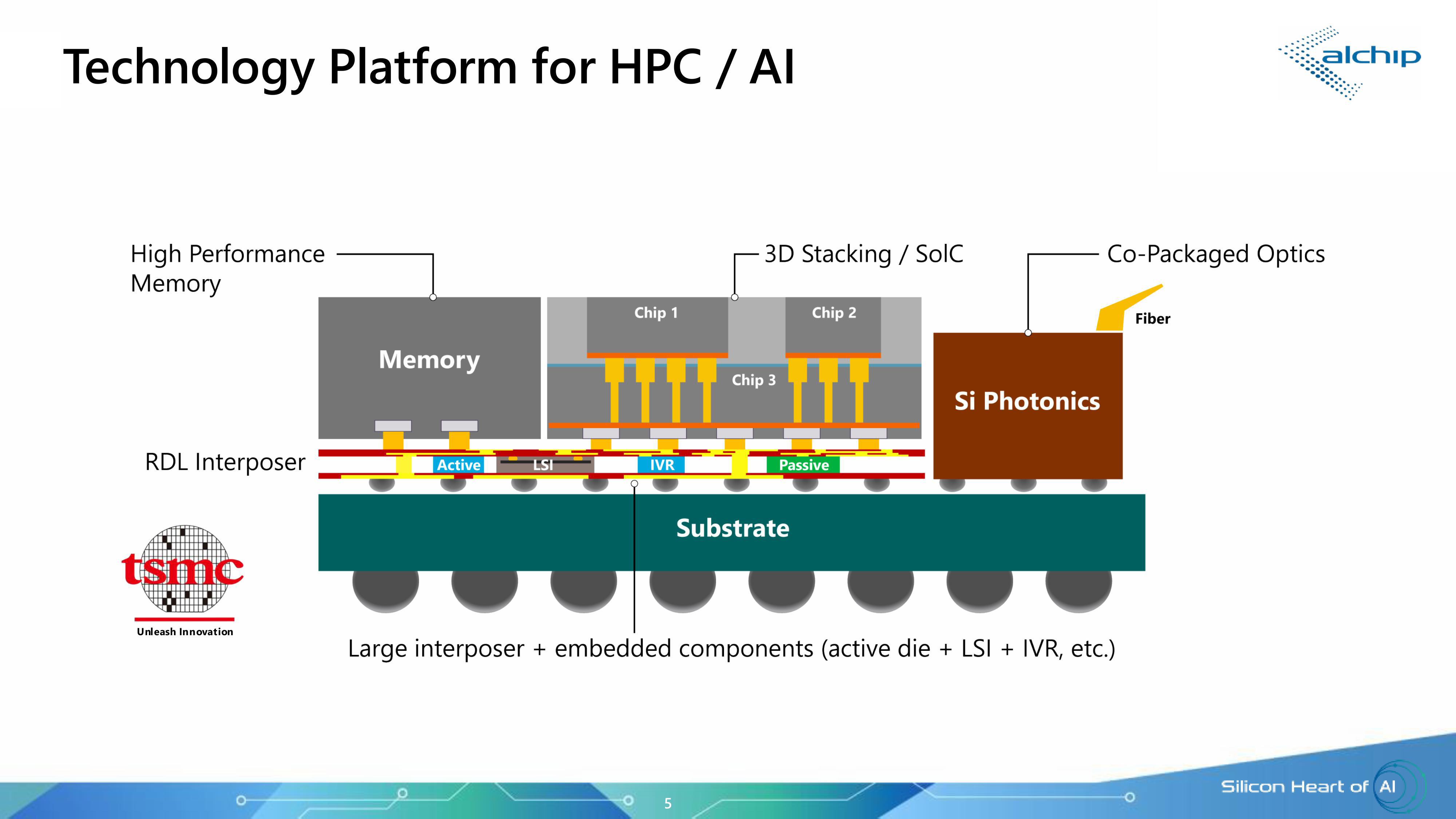
Источник изображений: Ayar Labs Новое совместное решение включает оптические модули Ayar Labs TeraPHY, размещённые вместе с решениями Alchip на общей подложке, обеспечивая прямой доступ ИИ-ускорителя к оптическому интерфейсу. Такая интеграция обеспечивает пропускную способность 100+ Тбит/с на каждый ускоритель и поддерживает более 256 оптических портов на устройство. TeraPHY не привязан к какому-либо протоколу и обеспечивает гибкую интеграцию с кастомными чиплетами. Референсный дизайн позволяет партнёрам «заложить основу» для быстрого создания подобной системы. Платформа референсного проекта включает два вычислительных кристалла с чиплетами HBM и другими чиплетами, в сочетании с восемью оптическими IO-модулями на базе чиплета TeraPHY. Такая конструкция обеспечит двустороннюю пропускную способность 200–250 Тбит/с для каждой сборки (SiP), что значительно превышает показатели современных крупных GPU, сообщил Стоянович. Это позволит масштабировать систему, а также значительно расширить объём памяти, имеющей пропускную способность, сопоставимую с HBM, добавил он. Оптический модуль Ayar Labs основан на чиплете TeraPHY PIC с двумя дополнительными слоями чиплетов, собранными с помощью TSMC COUPE. Два слоя электронных чиплетов собраны по технологии TSMC SoIC (System on Integrated Chips), которая использует вертикальное размещение нескольких кристаллов друг над другом, чтобы обеспечить более плотное соединение между ними, позволяя снизить энергопотребление, увеличить производительность и уменьшить задержки. По словам Стояновича, такой дизайн будет масштабироваться до уровня UCIe-A и выше как минимум в течение следующего десятилетия. 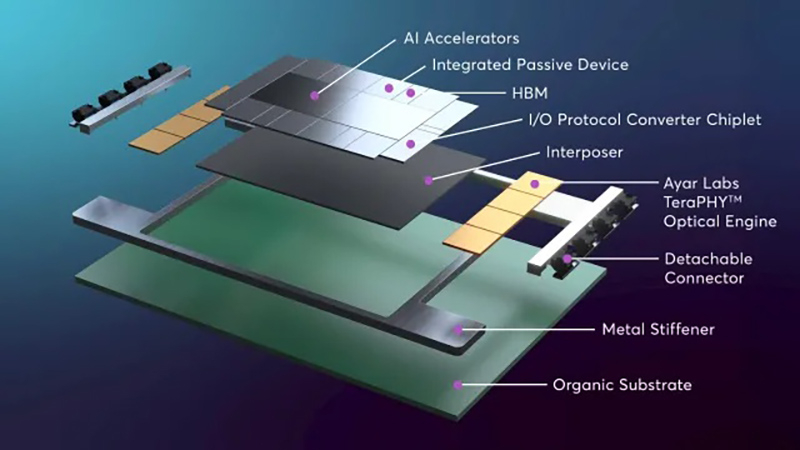 Совместное решение Alchip и Ayar Labs позволяет масштабировать многостоечную сетевую фабрику без потерь мощности и задержек, характерных для подключаемых оптических кабелей, за счёт минимизации длины электрических трасс и размещения оптических соединений вблизи вычислительного ядра. Благодаря поддержке UCIe для межкомпонентных соединений и гибкому размещению конечных точек на границе чипов, команды разработчиков могут интегрировать масштабируемое решение Alchip и Ayar Labs с существующими вычислительными блоками, стеками памяти и ускорителями, обеспечивая при этом соблюдение требований к производительности, целостности сигнала и температурному режиму на уровне всей сборки. Как сообщается, компании предоставят командам разработчиков дополнительные материалы, референсные архитектуры и варианты сборки. Платформа референсного дизайна включает в себя тестовые программы, позволяющие тестировать сборку и прошивку управления модулем, что облегчает его интеграцию в сборку. «Заказчику нужна поддержка, чтобы он понимал процессы оценки надёжности и испытаний, поэтому мы тесно сотрудничаем с Alchip, чтобы предоставить заказчику доступ ко всему этому пакету», — рассказал Стоянович.
05.08.2025 [10:39], Сергей Карасёв
HyperPort на 3,2 Тбит/с: Broadcom выпустила чип-коммутатор Jericho4 для распределённой ИИ-инфраструктурыКомпания Broadcom объявила о начале поставок коммутационного чипа Jericho4, специально разработанного для распределённой инфраструктуры ИИ. Изделие, как утверждается, позволяет объединять более миллиона ускорителей (GPU, TPU) в географически разнесённых дата-центрах, преодолевая традиционные ограничения масштабирования. Отмечается, что по мере роста размера и сложности моделей ИИ требования к инфраструктуре ЦОД повышаются: создаётся необходимость в объединении ресурсов нескольких площадок, каждая из которых обеспечивает мощность в десятки или сотни мегаватт. Для этого требуется оборудование нового поколения, оптимизированное для сверхширокополосной и безопасной передачи данных на значительные расстояния. Новинка позволяет решить проблему. Jericho4 обладает коммутационной способностью 51,2 Тбит/с. Благодаря глубокой буферизации и интеллектуальному управлению перегрузкой изделие обеспечивает поддержку RoCE без потерь на расстоянии более 100 км, что позволяет формировать распределённую инфраструктуру ИИ, говорит Broadcom. 
Источник изображений: Broadcom Могут быть задействованы интерфейсы 50GbE, 100GbE, 200GbE, 400GbE, 800GbE и 1.6TbE. Реализована технология HyperPort, которая объединяет четыре порта 800GbE в один канал с пропускной способность 3,2 Тбит/с, что упрощает проектирование и управление сетью. Единая инфраструктура на базе Jericho4 может масштабироваться до 36 тыс. портов HyperPort, каждый из которых работает со скоростью 3,2 Тбит/с. Jericho4 поддерживает шифрование MACsec на каждом порту на полной скорости для защиты передаваемой между ЦОД информации без ущерба для производительности — даже при самых высоких нагрузках. Новинка полностью соответствует спецификациям, разработанным консорциумом Ultra Ethernet (UEC): благодаря этому достигается бесшовная интеграция с широкой экосистемой сетевых карт, коммутаторов и программных стеков. 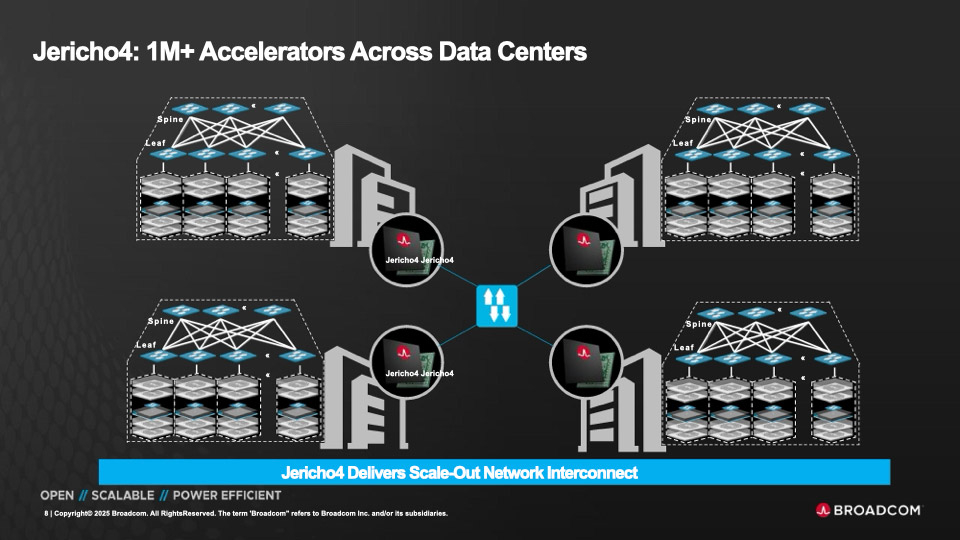 Чип Jericho4 производится по 3-нм технологии. Он оснащён модулями Broadcom PAM4 SerDes 200G. Это устраняет необходимость в дополнительных компонентах, таких как ретаймеры, что способствует снижению энергопотребления и повышению надёжности системы в целом. В частности, энергозатраты уменьшены на 40 % в расчёте на бит по сравнению с решениями предыдущего поколения. Это помогает организациям снижать эксплуатационные расходы и достигать целей устойчивого развития, говорит Broadcom.
16.07.2025 [11:44], Сергей Карасёв
Broadcom представила 51,2-Тбит/с чип-коммутатор Tomahawk Ultra — альтернативу NVIDIA InfiniBand и NVLinkКомпания Broadcom анонсировала чип-коммутатор Tomahawk Ultra, специально разработанный для кластеров НРС и платформ ИИ. Новинка, как ожидается, составит конкуренцию InfiniBand в традиционных суперкомпьютерах, NVLink в стоечных решениях вроде NVIDIA GB200 NVL72, а также Ultra Accelerator Link (UALink) в масштабируемых системах ИИ в дата-центрах. Решение Tomahawk Ultra разработано в рамках инициативы Broadcom Scaling Up Ethernet (SUE). Утверждается, что эта технология будет поддерживать масштабируемые системы с не менее чем 1024 ускорителями ИИ. Для сравнения, NVIDIA заявляет, что её коммутационная система NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене. Broadcom подчёркивает, что чип Tomahawk Ultra разработан с нуля специально для удовлетворения потребностей высоконагруженных НРС-сред и ИИ-кластеров. Новинка обеспечивает коммутационную способность 51,2 Тбит/с при размере пакетов 64 байта. Задержка составляет 250 нс, что значительно меньше, чем у коммутаторов с более высокой пропускной способностью. А общая задержка при общении XPU между собой составляет не более 400 нс. Поддерживается обработка до 77 млрд пакетов в секунду. 
Источник изображений: Broadcom Основная часть трафика, передаваемого через коммутаторы Ethernet, состоит из пакетов большего размера. Поэтому при проектировании сетевого оборудования внимание уделяется прежде всего увеличению размера пакетов для оптимизации пропускной способности. Вместе с тем обмен пакетами небольшого размера широко распространен в платформах НРС/ИИ: представленная новинка Broadcom нацелена именно на такие среды.
Чип-коммутатор Tomahawk Ultra (семейство BCM78920) поддерживают 64 порта 800GbE, 128 портов 400GbE или 256 портов 200GbE. Изделие использует блоки Peregrine 106.25G PAM4 SerDes. Решение совместимо по выводам с Broadcom Tomahawk 5 (TH5). Поддерживаются функции, предназначенные для масштабируемых нагрузок ИИ и HPC, включая Link Layer Retry (LLR), Credit-based Flow Control (CBFC) и AI Fabric Headers (AFH). Кроме того, непосредственно в ASIC реализована поддержка коллективных операций вроде AllReduce and AllGather. Используются измененные заголовки Ethernet, размер которых уменьшен с 46 до 10 байт: это позволяет оптимизировать общее соотношение размера заголовка к полезной нагрузке. Упомянута совместимость с современными топологиями сетей HPC, такими как Mesh, Torus и Dragonfly. Кроме того, заявлена совместимость с Ultra Ethernet (UEC). Поставки Tomahawk Ultra уже начались.
04.06.2025 [01:00], Владимир Мироненко
Broadcom представила самые быстрые в мире Ethernet-коммутаторы Tomahawk 6: 102,4 Тбит/с на чип и 1,6 Тбит/с на портКомпания Broadcom объявила о старте поставок серии чипов-коммутаторов Tomahawk 6 (BCM78910), первых Ethernet-коммутаторов, обеспечивающий коммутационную способность 102,4 Тбит/с, что вдвое выше возможностей Ethernet-коммутаторов, доступных на рынке. Сообщается, что благодаря невероятной возможности масштабирования, энергоэффективности и оптимизированным для ИИ функциям Tomahawk 6 нацелен на использование в крупных ИИ-кластерах. В случае вертикального масштабирования (scale-up) новинка позволяет объединить до 512 XPU в один кластер. В двухуровневых горизонтально масштабируемых (scale-out) сетях Tomahawk 6 может объединить более 100 тыс. XPU со скоростью 200GbE на каждое подключение. В целом же решение позволяет объединить до 1 млн XPU. Tomahawk 6 предлагает SerDes-блоки 100G/200G PAM с поддержкой «дальнобойных» пассивных медных подключений. Есть и вариант с интегрированными оптическими интерфейсами (CPO), который обеспечивает более высокую энергоэффективность, более низкий уровень задержки, а также повышенную стабильность работы. 
Источник изображений: Broadcom Встроенная технология Cognitive Routing 2.0 автоматически выявляет перегрузки и перенаправляет потоки данных по альтернативным маршрутам, что помогает избежать узких мест в производительности. Cognitive Routing 2.0 в Tomahawk 6 включает расширенную телеметрию, динамический контроль перегрузки, быстрое обнаружение сбоев и обрезку пакетов, что обеспечивает глобальную балансировку нагрузки и адаптивное управление потоком. Эти возможности адаптированы для современных рабочих ИИ-нагрузок, включая MoE-модели, тонкую настройку, обучение с подкреплением и рассуждающие модели.  «Tomahawk 6 — это не просто обновление, это прорыв, — заявил Рам Велага (Ram Velaga), старший вице-президент и генеральный менеджер подразделения Core Switching Group компании Broadcom. — Он знаменует собой поворотный момент в проектировании ИИ-инфраструктуры, объединяя самую высокую пропускную способность, энергоэффективность и адаптивные функции маршрутизации для scale-up и scale-out сетей в одной платформе». Tomahawk 6 поддерживает как стандартные топологии, например, сеть Клоза или тор, так и сети на базе фреймворка Broadcom Scale-Up Ethernet (SUE). 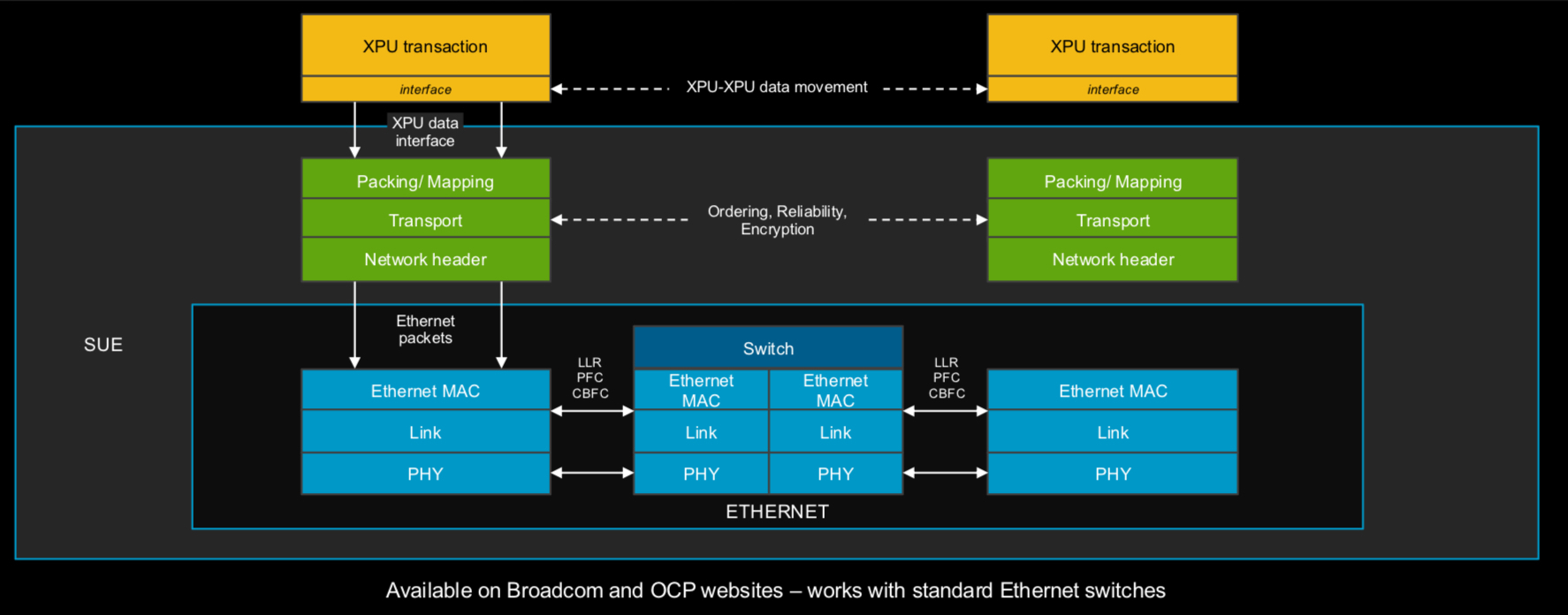 Компания отметила, что благодаря использованию 200G SerDes коммутатор обеспечивает самую большую дальность для пассивного медного соединения, что позволяет проектировать высокоэффективную систему с малой задержкой, высочайшей надежностью и самой низкой совокупной стоимостью владения (TCO). Возможные конфигурации портов: 64 × 1.6TbE, 128 × 800GbE, 256 × 400GbE, 512 × 200GbE. Но Tomahawk 6 предлагает и конфигурацию 1024 × 100GbE, т.е. высокоплотный и экономичный интерконнект на основе Ethernet. А поддержка CPO не просто избавляет от множества трансиверов, но и существенно сокращает связанные с ними перебои, что крайне важно для гиперскейлеров. 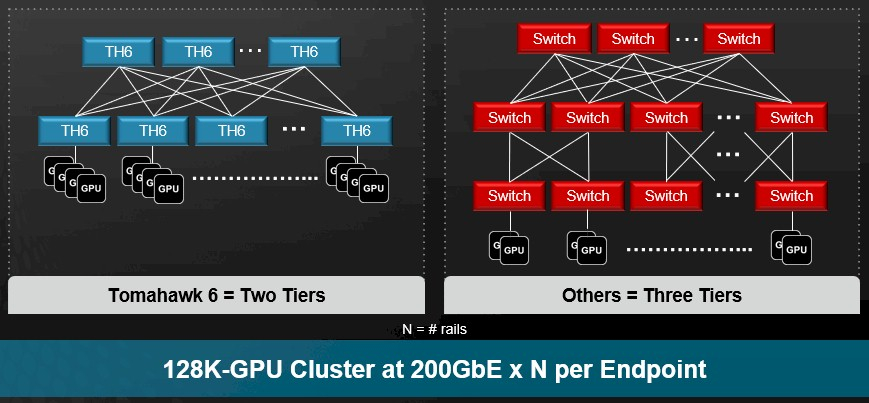 Использование Ethernet предоставляет операторам сетей значительные преимущества, позволяя им использовать единый технологический стек и согласованные инструменты во всей ИИ-инфраструктуре. Это также позволяет использовать взаимозаменяемые интерфейсы, с помощью которых облачные операторы могут динамически формировать кластеры XPU для различных рабочих нагрузок клиентов. Кроме того, Tomahawk 6 также соответствует требованиям Ultra Ethernet Consortium.
26.03.2025 [01:00], Владимир Мироненко
NVIDIA поделится с MediaTek фирменным интерконнектом NVLink для создания кастомных ASICMediaTek объявила о планах расширить сотрудничество с NVIDIA, интегрировав NVLink в разрабатываемые ей ASIC, сообщил ресурс DigiTimes. В свою очередь, ресурс smbom.com пишет, что партнёры намерены совместно разрабатывать передовые решения с использованием NVLink и 224G SerDes. Аналитики предполагают, что выход NVIDIA в сектор ASIC позволит ей ускорить дальнейшее продвижение на рынке с использованием опыта MediaTek и при этом решать имеющиеся проблемы. Как ожидают аналитики, по мере развития сотрудничества двух компаний всё больше провайдеров облачных услуг будет проявлять интерес к работе с MediaTek. Внедрение NVLink в ASIC MediaTek может значительно повысить привлекательность сетевых решений NVIDIA. Объединив усилия, NVIDIA и MediaTek смогут предложить комплексную разработку кастомных ASIC, которая будет включать поддержку HBM4e, обширную библиотеку IP-блоков, передовые процессы производства и упаковки. MediaTek отдельно подчеркнула, что её SerDes-блоки является ключевым преимуществом при разработке ASIC. 
Источник изображения: MediaTek Компании расширяют сотрудничество с ведущими мировыми производствами полупроводников, ориентируясь на передовые техпроцессы. Применяя технологию совместной оптимизации проектирования (DTCO), они стремятся достичь оптимального соотношения между производительностью, энергопотреблением и площадью (PPA). Сообщается, что несколько облачных провайдеров уже изучают объединённое IP-портфолио NVIDIA и MediaTek. 
Источник изображения: MediaTek По неофициальным данным, Google уже прибегла к услугам MediaTek при разработке 3-нм TPU седьмого поколения, которое поступит в массовое производство к III кварталу 2026 года. Ожидается, что переход на 3-нм процесс принесет MediaTek более $2 млрд дополнительных поступлений. По данным источников в цепочке поставок, восьмое поколение TPU перейдёт на 2-нм процесс TSMC, что вновь укрепит позиции MediaTek. Также прогнозируется, что предстоящий выход чипа GB10 совместной разработки NVIDIA и MediaTek, и долгожданного чипа N1x, значительно улучшат бизнес-операции MediaTek и ещё больше укрепят позиции компании в полупроводниковой отрасли. Эксперты отрасли считают, что MediaTek имеет все возможности для того, что стать ключевым бенефициаром роста спроса на ИИ-технологии, особенно для малых и средних предприятий.
28.01.2025 [00:14], Владимир Мироненко
Дороговизна и высокое энергопотребление ИИ-ускорителей NVIDIA открыли новые горизонты для Marvell и BroadcomВзрывной рост популярности ChatGPT и других решений на базе генеративного ИИ вызвал беспрецедентный спрос на вычислительные мощности, что привело к дефициту ИИ-ускорителей, пишет DIGITIMES. NVIDIA занимает львиную долю рынка ИИ-чипов, а ведущие поставщики облачных услуг, такие как Google, Amazon и Microsoft, активно занимаются проектами по разработке собственных ускорителей, стремясь снизить свою зависимость от внешних поставок. Всё большей популярностью у крупных облачных провайдеров пользуются ASIC, поскольку они стремятся оптимизировать чипы под свои конкретные требования, отметил DIGITIMES. ASIC обеспечивают высокую производительность и энергоэффективность в узком спектре задач, что делает их альтернативой универсальным ускорителям NVIDIA. Несмотря на доминирование NVIDIA на рынке, высокое энергопотребление её чипов в сочетании с высокой стоимостью позволило ASIC занять конкурентоспособную нишу. Особенно хорошо ASIC подходят для обучения и инференса ИИ-моделей, предлагая значительно более высокие показатели производительности в пересчёте на 1 Вт по сравнению с GPU общего назначения. Также ASIC предоставляют заказчикам больший контроль над своим технологическим стеком. На рынке разработки ASIC основными конкурентами являются Broadcom и Marvell, которые используют разные технологии и стратегические подходы. 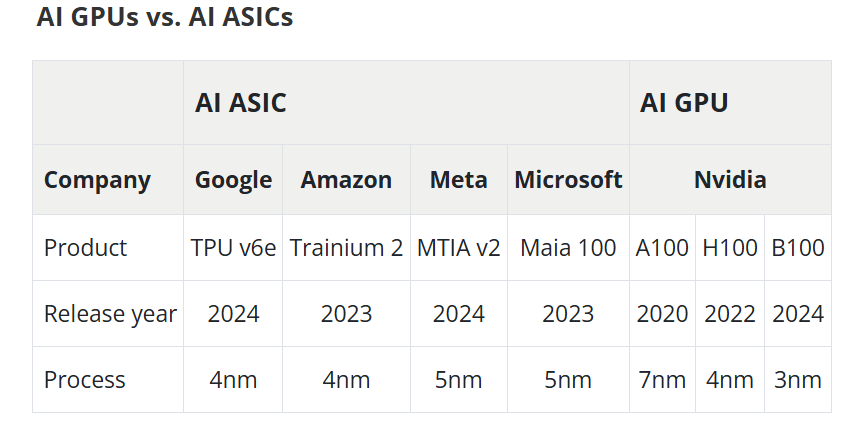
Источник изображений: DIGITIMES Marvell укрепила свои позиции на рынке, в частности, благодаря партнёрству с Google в разработке серверных Arm-чипов, расширив при этом стратегическое сотрудничество со своим основным клиентом — Amazon. TPU v6e от Google представляет собой самую передовую ASIC ИИ среди чипов, разработанных четырьмя ведущими облачными провайдерам, приближаясь по производительности к H100. Однако она всё ещё отстает от ускорителей NVIDIA примерно на два года, утверждает DIGITIMES. Созданный Marvell и Amazon ускоритель Trainium 2 по производительности находится между NVIDIA A100 и H100. В ходе последнего отчёта о финансовых результатах Marvell поделилась прогнозом значительного роста выручки от ASIC, начиная с 2024 года (2025 финансовый год), обусловленного Trainium 2 и Google Axion. В частности, совместный с Amazon проект Marvell Inferential ASIC предполагается запустить в массовое производство в 2025 году (2026 финансовый год), в то время как Microsoft Maia, как ожидается, начнет приносить доход с 2026 года (2027 финансовый год).  Как утверждают в Morgan Stanley, хотя бизнес Marvell по производству кастомных чипов является ключевым драйвером роста его подразделения по разработке решений для ЦОД, он также несёт в себе значительную неопределённость. Краткосрочные прогнозы Morgan Stanley для продуктов Marvell/Trainium положительны, что подтверждается возросшими мощностями TSMC по упаковке чипов методом CoWoS, планами Amazon по расширению производства и уверенностью Marvell в рыночном спросе. Однако в долгосрочной перспективе конкурентная среда создает проблемы. Появление компаний вроде WorldChip Electronics в секторе вычислительных чипов может заставить Marvell переориентироваться на сетевые решения. Кроме того, потенциальное снижение прибыли от Trainium после 2026 года означает, что Marvell нужно будет обеспечить запуск новых проектов для поддержания динамики роста, говорят аналитики. Broadcom и Marvell являют собой примеры разных стратегий развития в секторе ASIC, отмечает DIGITIMES. Broadcom отдаёт приоритет крупномасштабной интеграции и проектированию платформ, подкрепляя свой подход значительными инвестициями в НИОКР и сложной технологической интеграцией. В свою очередь, Marvell развивается за счёт стратегических приобретений, например, Cavium, Avera и Innovium, благодаря чему расширяет своё портфолио технологий.
20.01.2025 [07:53], Владимир Мироненко
SRAM, да и только: d-Matrix готовит ИИ-ускоритель CorsairСтартап d-Matrix создал ИИ-ускоритель Corsair, оптимизированный для быстрого пакетного инференса больших языковых моделей (LLM). Архитектура ускорителя основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости порядка 150 Тбайт/с. Новинка, по словам компании, отличается производительностью и энергоэффективностью, пишет EE Times. Массовое производство Corsair начнётся во II квартале. Среди инвесторов d-Matrix — Microsoft, Nautilus Venture Partners, Entrada Ventures и SK hynix. d-Matrix фокусируется на пакетном инференсе с низкой задержкой. В случае Llama3-8B сервер d-Matrix (16 четырёхчиплетных ускорителей в составе восьми карт) может производить 60 тыс. токенов/с с задержкой 1 мс/токен. Для Llama3-70B стойка d-Matrix (128 чипов) может производить 30 тыс. токенов в секунду с задержкой 2 мс/токен. Клиенты d-Matrix могут рассчитывать на достижение этих показателей для размеров пакетов порядка 48–64 (в зависимости от длины контекста), сообщила EE Times руководитель отдела продуктов d-Matrix Шри Ганесан (Sree Ganesan). 
Источник изображений: d-Matrix Производительность оптимизирована для исполнения моделей в расчёте до 100 млрд параметров на одну стойку. По словам Ганесан, это реалистичный сценарий использования LLM. В таких сценариях решение d-Matrix обеспечивает 10-кратное преимущество в интерактивности (время до получения токена) по сравнению с решениями на базе традиционных ускорителей, таких как NVIDIA H100. Corsair ориентирован на модели размером менее 70 млрд параметров, подходящих для генерации кода, интерактивной генерации видео или агентского ИИ, которые требуют высокой интерактивности в сочетании с пропускной способностью, энергоэффективностью и низкой стоимостью.  Ранние версии архитектуры d-Matrix использовали MAC-блоки на базе SRAM-ячеек, дополненных большим количеством транзисторов для операций умножения. Сложение же выполнялось в аналоговом виде с использованием разрядных линий, измерения тока и аналого-цифрового преобразования. В 2020 году компания выпустила чиплетную платформу Nighthawk на основе этой архитектуры. «[Nighthawk] продемонстрировал, что мы можем значительно повысить точность по сравнению с традиционными аналоговыми решениями, но мы всё ещё отстаем на пару процентных пунктов от традиционных решений типа GPU», — сказал EE Times генеральный директор d-Matrix Сид Шет (Sid Sheth). 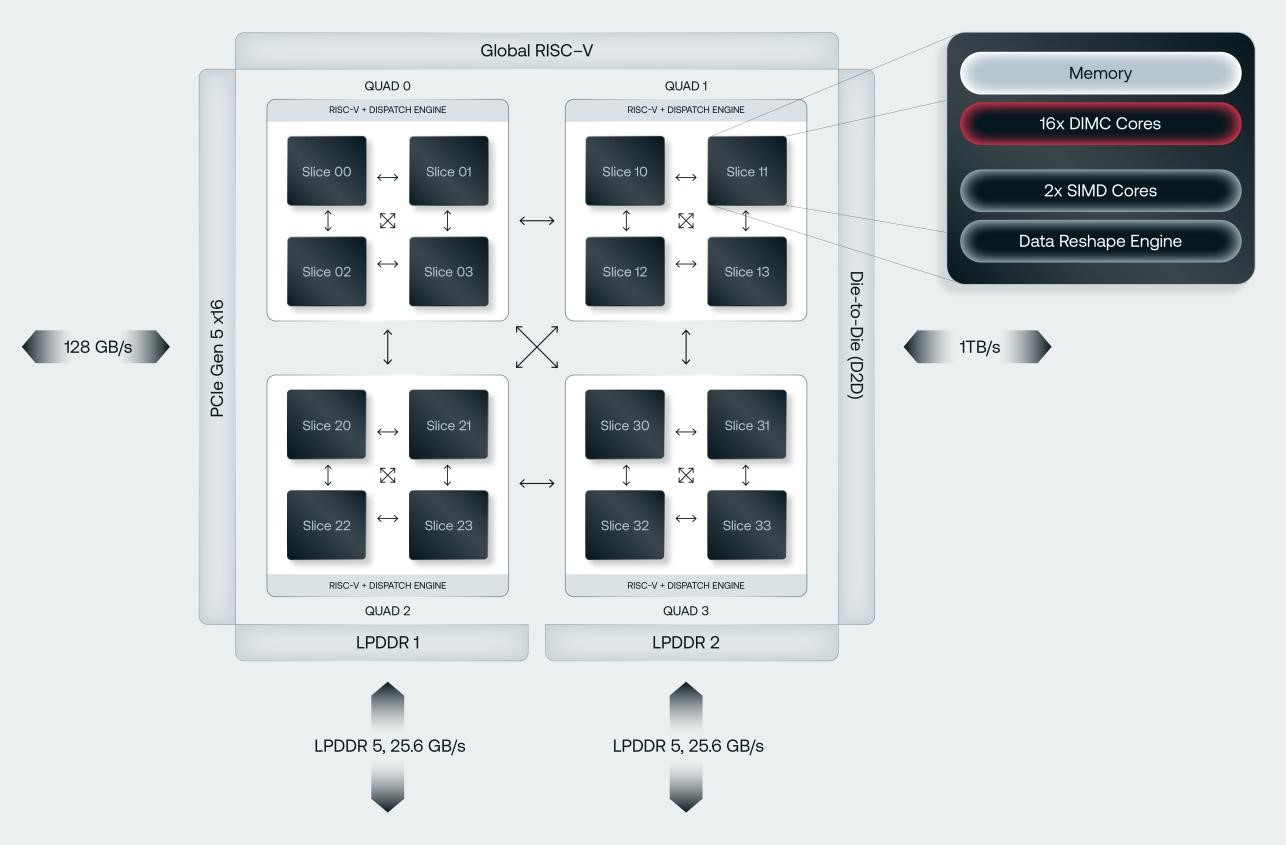 Однако потенциальным клиентам не понравилось, что при таком подходе возможно снижение точности, так что в Corsair компания вынужденно сделала выбор в пользу полностью цифрового сумматора. ASIC d-Matrix включает четыре чиплета, каждый из которых содержит по четыре вычислительных блока, объединённых посредством DMX Link по схеме каждый-с-каждым, и по одному планировщику и RISC-V ядру. Внутри каждого вычислительного блока есть 16 DIMC-ядер, состоящих из наборов SRAM-ячеек (64×64), а также два SIMD-ядра и движок преобразования данных. Суммарно доступен 1 Гбайт SRAM с пропускной способностью 150 Тбайт/с. 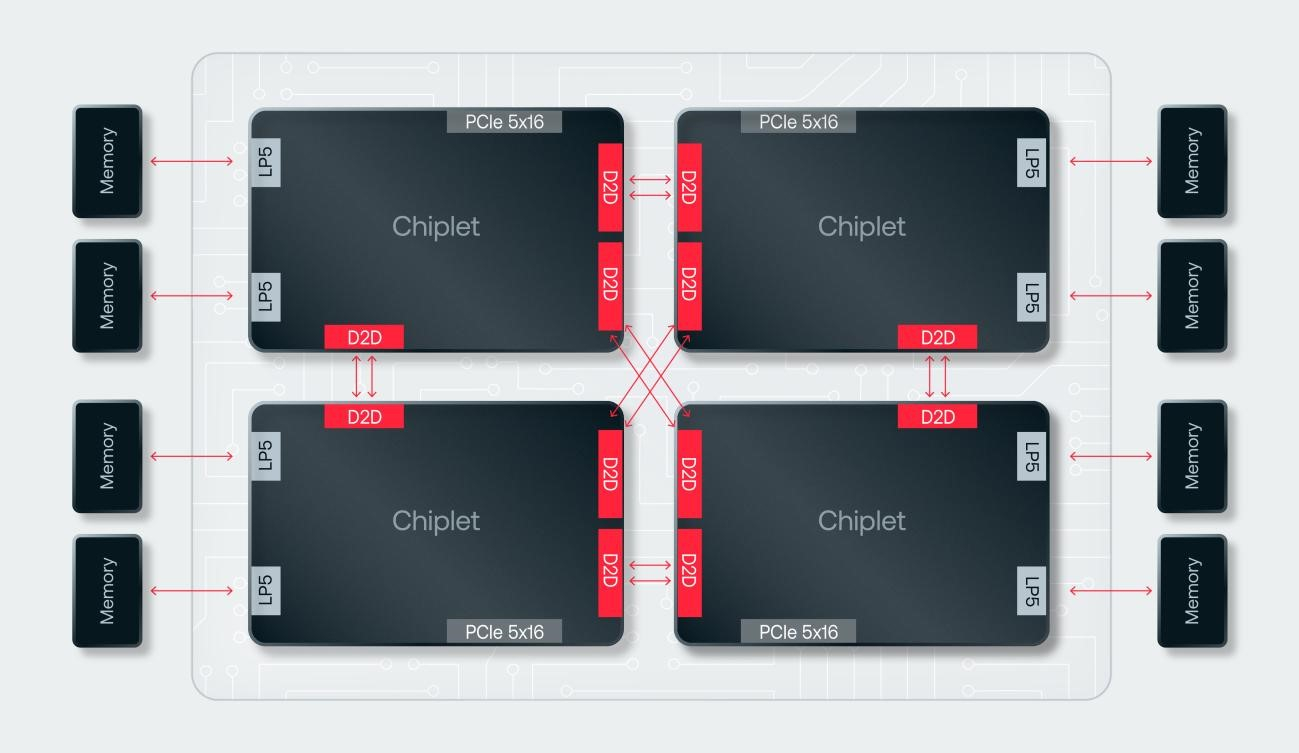 ASIC объединён со 128 Гбайт LPDDR5 (до 400 Гбайт/с) посредством органической подложки (без дорогостоящего кремниевого интерпозера). Хотя текущее поколение ASIC включает только четыре чиплета именно из-за ограничений подложки, в будущем их количество увеличится. Внешние интерфейсы ASIC представлены стандартным PCIe 5.0 x16 (128 Гбайт/с) и фирменным интерконнектом DMX Link (1 Тбайт/с) для объединения чиплетов. 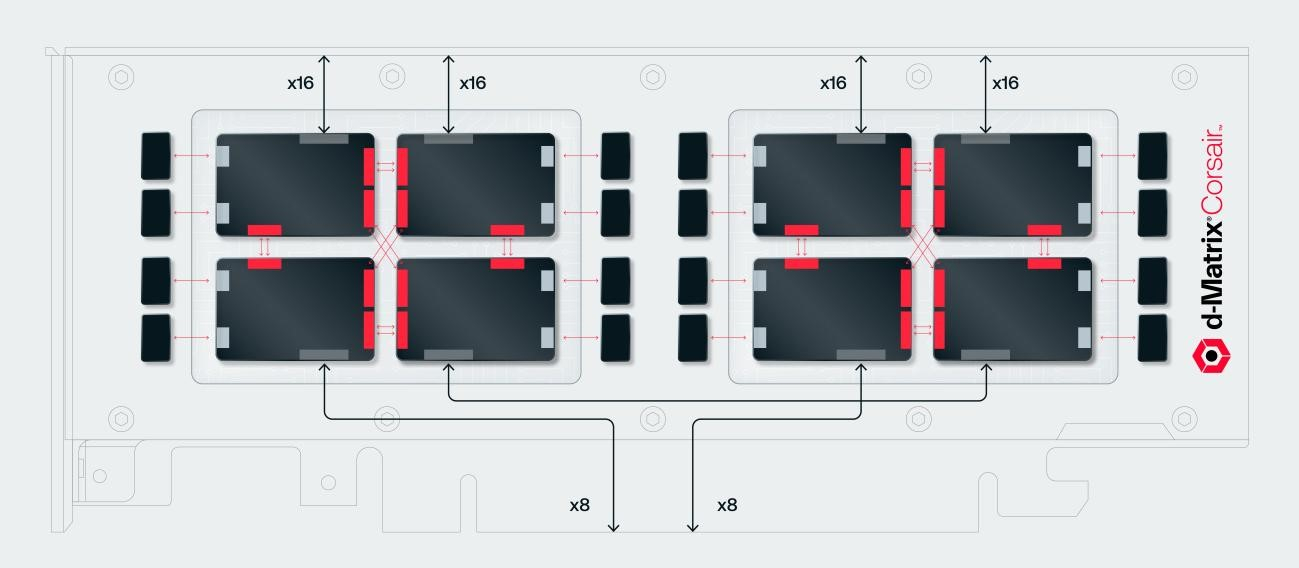 FHFL-карта Corsair включает два ASIC d-Matrix (т.е. всего восемь чиплетов) и имеет TDP на уровне 600 Вт. Ускоритель работает с форматами данных OCP MX (Microscaling Formats) и обеспечивает до 2400 Тфлопс в MXINT8-вычислениях или 9600 Тфолпс в случае MXINT4. Две карты Corsair можно объединить посредством 512-Гбайт/с мостика DMX Bridge. Их, по словам компании, достаточно для задействования тензорного параллелизма. Дальнейшее масштабирование возможно посредством PCIe-коммутации. Именно поэтому d-Matrix работает с GigaIO и Liqid. В одно шасси можно поместить восемь карт Corsair, а в стойку, которая будет потреблять порядка 6–7 кВт — 64 карты. 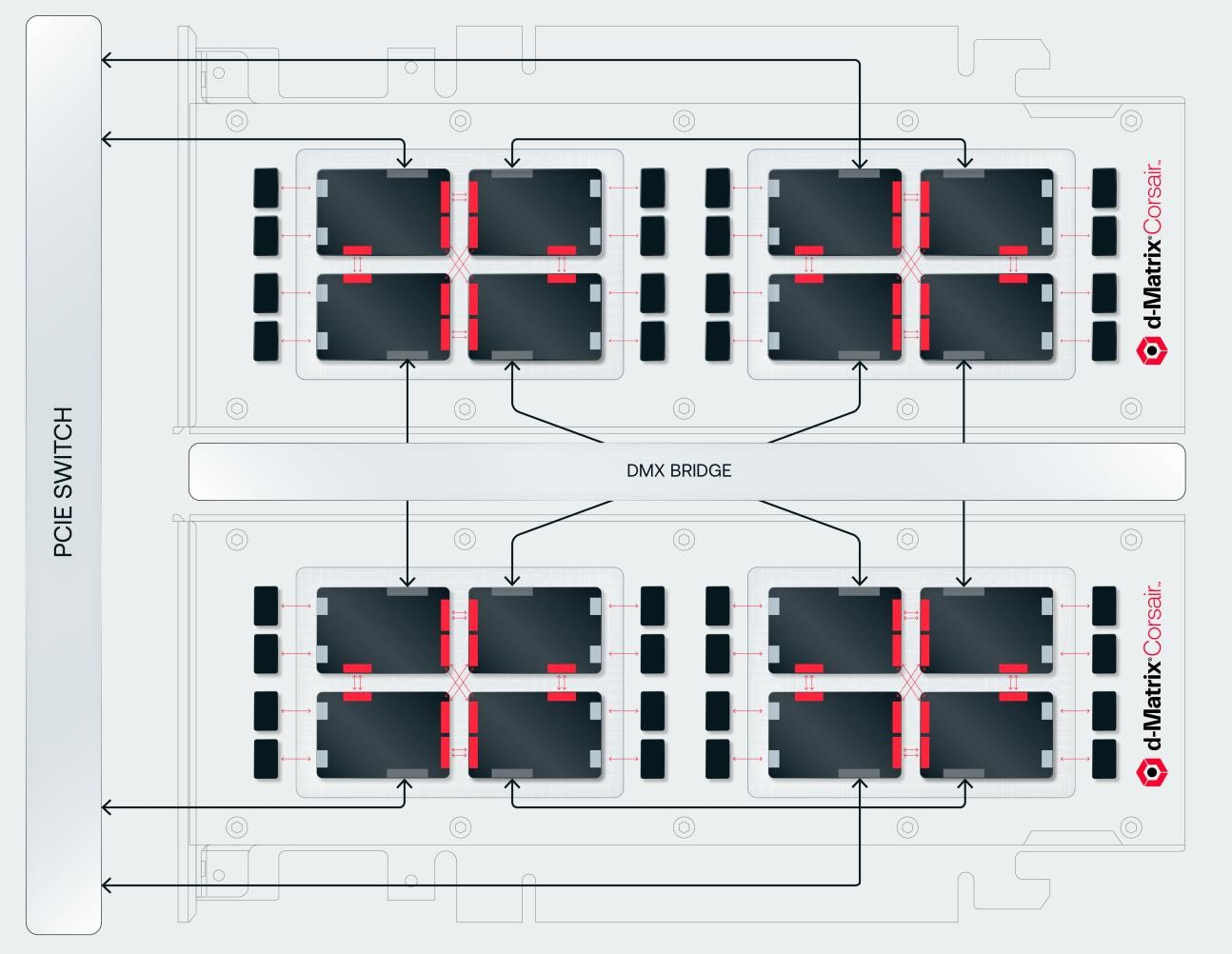 d-Matrix уже разрабатывает ASIC следующего поколения Raptor, который должен выйти в 2026 году. Raptor будет ориентирован на «думающие» модели и получит ещё больше памяти за счёт размещения DRAM непосредственно поверх вычислительных чиплетов. SRAM-чиплеты Raptor также перейдут с 6-нм техпроцесса TSMC, который используется при изготовлении Corsair, к 4 нм без существенных изменений микроархитектуры. По словам компании, она потратила два года на работу с TSMC, чтобы создать 3D-упаковку для нового поколения ASIC. 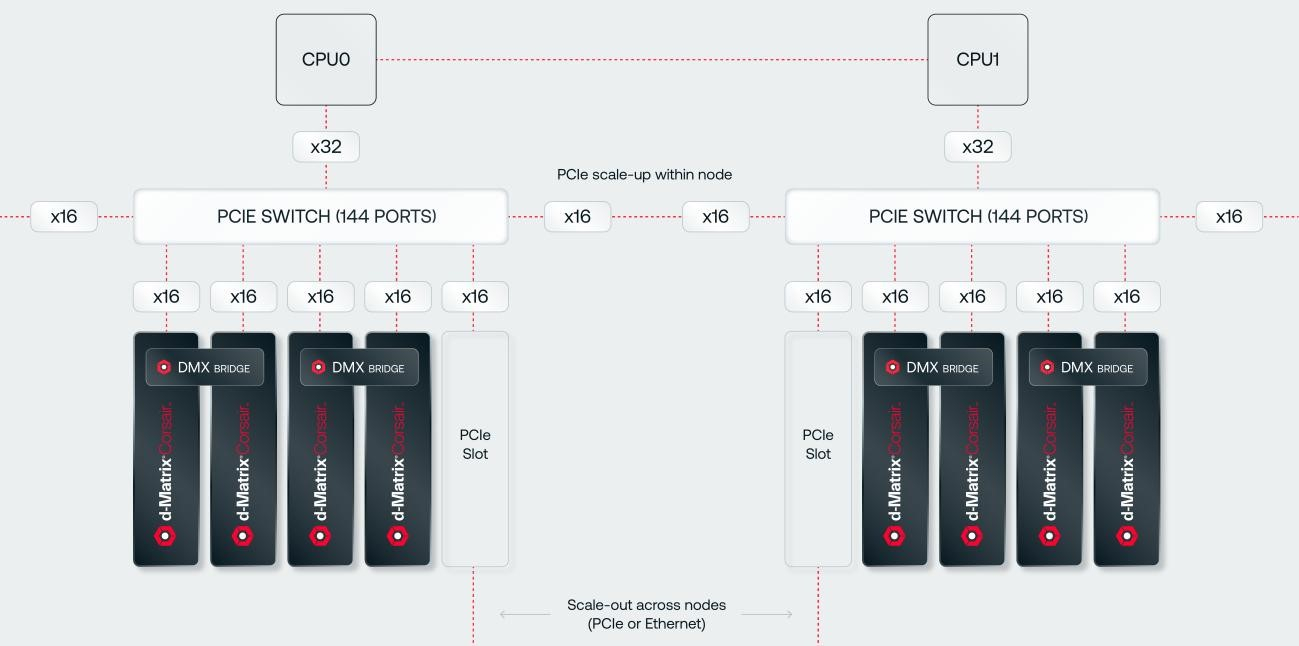 Как отмечает EETimes, команда разработчиков ПО d-Matrix в два раза больше команды разработчиков оборудования (120 против 60). Стратегия компании в области ПО заключается в максимальном использовании open source экосистемы, включая PyTorch, OpenAI Triton, MLIR, OpenBMC и т.д. Вместе они образуют программный стек Aviator, который отвечает за конвертацию моделей в числовые форматы d-Matrix, применяет к ним фирменные методы разрежения, компилирует их, распределяет нагрузку по картам и серверам, а также управляет исполнением моделей, включая обслуживание большого количества запросов.
06.01.2025 [15:39], Владимир Мироненко
NVIDIA начала переманивать тайваньских специалистов для будущего центра по разработке ASICТайваньскому изданию Commercial Times стало известно о планах NVIDIA создать подразделение для разработки специализированных ASIC. В публикации газеты сообщается, что американская компания выбрала Тайвань в качестве базы для своего центра исследований и разработок, и сейчас она активно переманивает квалифицированные кадры из крупных местных компаний по проектированию интегральных схем (ИС), что вызвало опасения у руководства отрасли по поводу потенциальной утечки мозгов. По данным источников Commercial Times, в тайваньских фирмах по производству ИС, в середине 2024 года был отмечен резкий рост предложений с целью переманивания талантов. Поскольку NVIDIA запускает центр исследований и разработок ASIC, она может усилить попытки по переманиванию квалифицированных кадров, что вынуждает крупные компании, включая MediaTek, Alchip Technologies и дочернюю компанию TSMC GUC, принимать ответные меры в рамках подготовки к предстоящему противостоянию. Источник изображения: NVIDIA Как отметил ресурс TrendForce, технологические гиганты активно занимаются разработкой альтернатив ускорителям NVIDIA, чтобы ослабить свою зависимость от неё. В июле 2024 года Apple сообщила, что ее ИИ-модели для Apple Intelligence были обучены на Google TPU. А в декабре старший директор Apple по машинному обучению и искусственному интеллекту Бенуа Дюпен (Benoit Dupin) сообщил, что компания будет также использовать для обучения ИИ чипы Amazon Trainium2. А сейчас Apple совместно с Broadcom работает над созданием собственного серверного ИИ-ускорителя. Реагируя на этот тренд, NVIDIA создаёт собственный центр ASIC, расширяя спектр своих услуг, пишет Commercial Times. Согласно её публикации, компания планирует нанять на Тайване более тысячи специалистов в таких областях, как проектирование микросхем, разработка ПО, а также исследования и разработки в сфере ИИ. С учётом того, что тайваньские компании по выпуску ASIC сыграли важную роль в разработке Microsoft Cobalt и Maia, Google TPU и кастомных чипов AWS, это делает их специалистов идеальными целями для привлечения, отметила Commercial Times.
31.10.2024 [14:56], Владимир Мироненко
DIGITIMES Research: в 2024 году Google увеличит долю на рынке кастомных ИИ ASIC до 74 %Согласно отчету DIGITIMES Research, в 2024 году глобальные поставки ИИ ASIC собственной разработки для ЦОД, как ожидается, достигнут 3,45 млн единиц, а доля рынка Google вырастет до 74 %. Как сообщают аналитики Research, до конца года Google начнёт массовое производство нового поколения ИИ-ускорителей TPU v6 (Trillium), что ещё больше увеличит её присутствие на рынке. В 2023 году доля Google на рынке ИИ ASIC собственной разработки для ЦОД оценивалась в 71 %. В отчёте отмечено, что помимо самой высокой доли рынка, Google также является первым из трёх крупнейших сервис-провайдеров в мире, кто разработал собственные ИИ-ускорители. Первый TPU компания представила в 2016 году. Ожидается, что TPU v6 будет изготавливаться с применением 5-нм процесса TSMC, в основном с использованием 8-слойных чипов памяти HBM3 от Samsung. Также в отчёте сообщается, что Google интегрировала собственную архитектуру оптического интерконнекта в кластеры TPU v6, позиционируя себя в качестве лидера среди конкурирующих провайдеров облачных сервисов с точки зрения внедрения технологий и масштаба развёртывания. Google заменила традиционные spine-коммутаторы на полностью оптические коммутаторы Jupiter собственной разработки, которые позволяют значительно снизить энергопотребление и стоимость обслуживания ИИ-кластеров TPU POD по сравнению с решениями Broadcom или Mellanox. 
Источник изображения: cloud.google.com Кроме того, трансиверы Google получил ряд усовершенствований, значительно нарастив пропускную способность. Если в 2017 году речь шла о полнодуплексном 200G-решении, то в этом году речь идёт уже о 800G-решениях с возможностью модернизации до 1,6T. Скорость одного канала также существенно выросла — с 50G PAM4 в 2017 году до 200G PAM4 в 2024 году.
26.06.2024 [01:00], Игорь Осколков
Etched Sohu — самый быстрый в мире ИИ-ускоритель, но только для трансформеровСтартап Etched, основанный в 2022 году выпускниками Гарварда, анонсировал самый быстрый, по его словам, ИИ-ускоритель Sohu. Секрет высокой производительности очень прост — Sohu представляет собой узкоспециализированный 4-нм ASIC, который умеет работать только с моделями-трансформерами. При этом в длинном анонсе новинки обещана чуть ли не революция в мире ИИ. Etched прямо говорит, что делает ставку на трансформеры, и надеется, что не прогадает. Данная архитектура ИИ-моделей была создана в недрах Google в 2017 году, но сама Google распознать её потенциал, по-видимому, вовремя не смогла. Сейчас же, по словам Etched, практически все массовые ИИ-модели являются именно трансформерами, а стремительно набирать популярность этот подход начал всего полтора года назад с выходом ChatGPT, хотя в Etched «предугадали» важность трансформеров ещё до выхода детища OpenAI. 
Источник изображений: Etched Etched в целом справедливо отмечает, что подавляющее большинство ИИ-ускорителей умышленно создаётся так, чтобы быть достаточно универсальными и уметь работать с различными типами и архитектурами ИИ-моделей. Это ведёт к взрывному росту транзисторного бюджета и уменьшению общей эффективности. Так, по словам Etched, загрузка ускорителя на базе GPU работой на практике составляет около 30 %, а у Sohu она будет на уровне 90 %.  Тут есть некоторое лукавство, потому что Etched в основном говорит о «больших» ускорителях, ориентированных и на обучение тоже, тогда как Sohu предназначен исключительно для инференса. На практике же бывают и гибридные подходы. Например, у AWS есть не только Trainium, но Inferentia. Meta✴ использует чипы NVIDIA для обучения, но для инференса разрабатывает собственные ускорители MTIA. Cerebras практически отказалась от инференса, а Groq — от обучения моделей. Корректнее было бы сравнить именно инференс-ускорители, пусть даже никто из упомянутых Etched конкурентов не ориентирован исключительно на трансформеры. 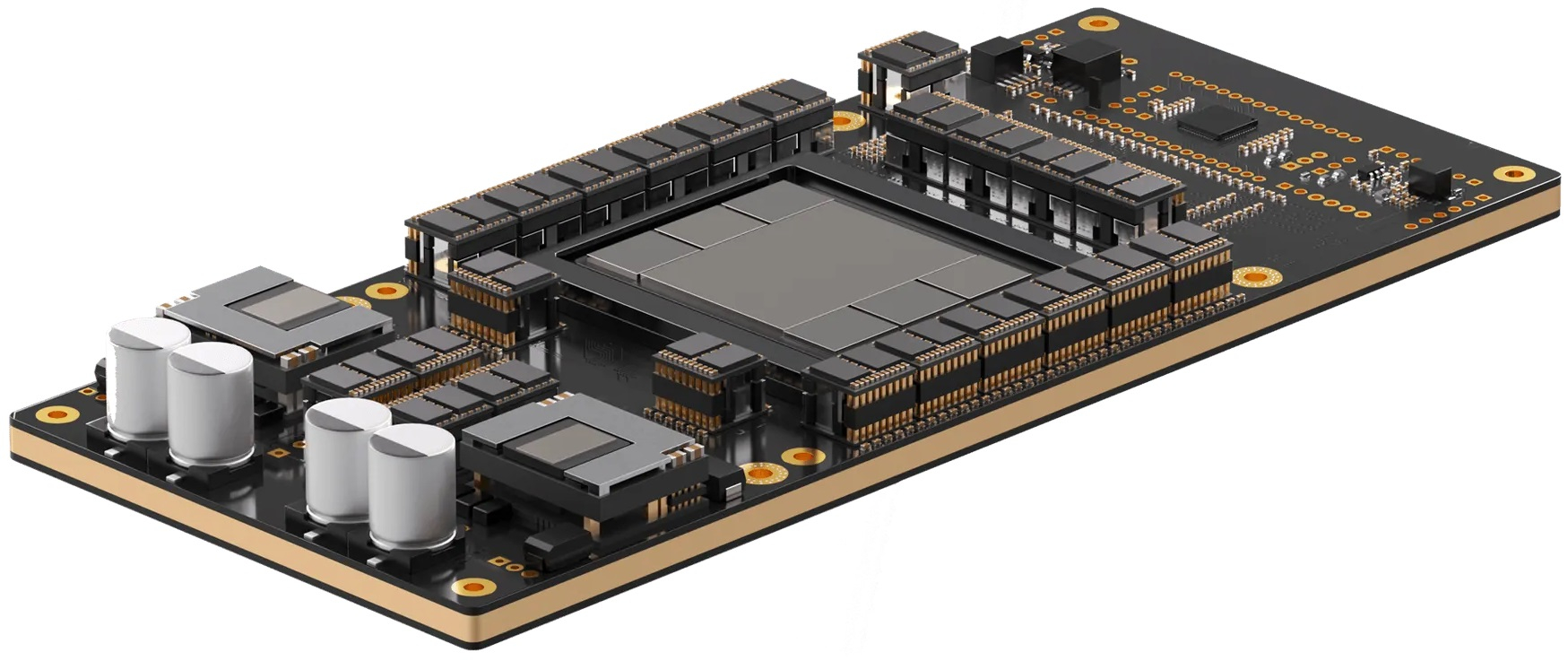 Также стартап критикует громоздкую программную экосистему для современного генеративного ИИ, к тому же не всегда открытую. Важность оптимизации ПО хороша видна на примере NVIDIA TensorRT-LLM. Но крупным компаниям этого мало, они готовы вкладывать немало средств в глубокую оптимизацию, чтобы ещё чуть-чуть повысить производительность. Дело доходит до выяснения того, у какого регистра задержка меньше при работе с каким тензорным ядром, говорит Etched. Стартап обещает, что его заказчикам не придётся заниматься такими изысканиями — весь программный стек будет open source. Впрочем, на примере AMD ROCm видно, что открытость ещё не означает мгновенный успех у пользователей. 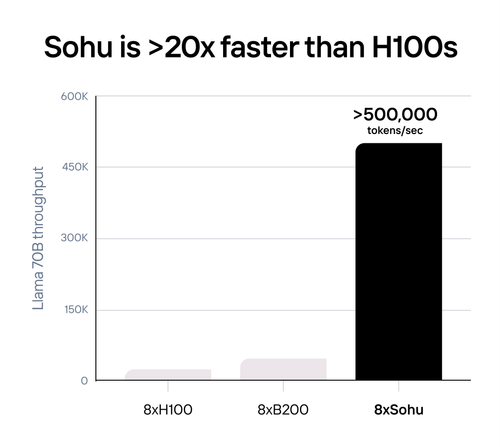 Технические характеристики Sohu не раскрываются. Явно говорится лишь о наличии 144 Гбайт HBM3e. Обещанная производительность сервера с восемью ускорителями Sohu составляет 500 тыс. токенов в секунду для Llama 70B: FP8 без разреженности, параллелизм на уровне модели, 2048 токенов на входе и 128 токенов на выходе. Иными словами, один такой сервер Sohu заменяет сразу 160 ускорителей NVIDA H100, говорит Etched. А вот про масштабируемость своих платформ компания пока ничего не говорит. Зато хвастается, что первые заказчики уже зарезервировали Sohu на десятки миллионов долларов. |
|
