Материалы по тегу: разработка
|
12.10.2025 [14:51], Сергей Карасёв
Graphcore, спасённая SoftBank, воспрянула духом — штат в Великобритании удвоится, а в разработку в Индии инвестируют $1 млрдБританский стартап Graphcore, занимающийся созданием специализированных ИИ-ускорителей, по сообщению Datacenter Dynamics, намерен инвестировать в Индии до $1 млрд в течение следующих 10 лет. При этом в Бангалоре на юге страны будет сформирован кампус для разработки ИИ-решений. Компания Graphcore, основанная в Бристоле в 2016 году, проектирует ускорители нового класса под названием Intelligence Processing Unit (IPU). Архитектура таких изделий основана на применении особых «тайлов» — это область кристалла, содержащая вычислительную логику и некоторое количество быстрой памяти. В июле прошлого года фирму Graphcore за неназванную сумму приобрела японская холдинговая корпорация SoftBank Group, которая активно развивает направление ИИ. Как отмечает Graphcore, на базе нового ИИ-кампуса в Индии будут сформированы около 500 новых рабочих мест. Планируется привлекать специалистов в области проектирования логических схем, дизайна, тестирования и пр. Инженеры Graphcore в Бангалоре займутся разработкой передовых ИИ-решений, которые в перспективе помогут в решении глобальных проблем в области общественного здравоохранения, экологической устойчивости и пр. 
Источник изображения: Graphcore Говорится, что с 2015 года SoftBank Group инвестировала в различные инициативы в Индии более $12 млрд. Создаваемая в Бангалоре площадка будет способствовать реализации комплексной стратегии SoftBank Group по трансформации в ведущего мирового поставщика ИИ-платформ. Напомним, японская корпорация участвует в масштабном проекте Stargate по развитию ИИ-инфраструктуры в США: предполагается, что суммарные затраты в рамках данной инициативы достигнут $500 млрд. Между тем Graphcore заявила о намерении увеличить численность персонала. Ожидается, что в ближайшие два года количество сотрудников в британском представительстве вырастет примерно вдвое, достигнув 750 человек. Речь идёт о привлечении разработчиков чипов и ПО, а также специалистов в сфере ИИ. При этом два года назад состояние компании было не лучшим. Из-за проблем с финансами она закрыла офис в Китае, свернула операции в Норвегии, Японии и Южной Корее, а также сократила пятую часть штата.
29.09.2025 [12:35], Сергей Карасёв
Databricks и OpenAI помогут клиентам в развёртывании приложений на базе передовых ИИ-моделейСтартап Databricks, специализирующийся на создании решений в сфере аналитики данных и ИИ, и компания OpenAI объявили о заключении многолетнего соглашения о сотрудничестве. Партнёры помогут клиентам в развёртывании агентов на базе передовых ИИ-моделей. В рамках соглашения модели OpenAI, включая GPT-5, будут тесно интегрированы со средой ИИ-разработки Databricks Agent Bricks. Заказчики получат возможность создавать готовые к использованию ИИ-приложения непосредственно на основе управляемых данных на платформе Databricks Data Intelligence. Цель сотрудничества Databricks и OpenAI в том, чтобы предоставить организациям единую инфраструктуру для разработки, оценки и масштабирования ИИ-агентов — систем, способных выполнять задачи автономно, практически без участия человека. Это могут быть агенты рассуждений для поддержки принятия решений в той или иной сфере, анализа финансовых рисков, проверки контрактов и планирования логистики. В качестве других примеров названы агенты повышения производительности для поддержки пользователей, а также агенты-разработчики для отладки систем, модернизации устаревших приложений и создания готового к использованию программного кода. 
Источник изображения: unsplash.com / Rolf van Root Клиенты Databricks смогут запускать большие языковые модели (LLM) на основе собственных корпоративных данных, доступных через SQL-запросы или API, и безопасно развёртывать их в нужном масштабе с помощью встроенных средств управления и мониторинга. Сотрудничество также охватывает каталог Databricks Unity Catalog, который используется для управления данными и моделями ИИ. По заявлениям Databricks, он помогает отслеживать происхождение данных, контролировать доступ и обеспечивать соблюдение нормативных требований. В целом, партнёрство направлено на ускорение внедрения ИИ в корпоративном секторе. Ожидается, что в рамках сотрудничества Databricks и OpenAI получат более $100 млн выручки. В марте нынешнего года Databricks заключила аналогичное соглашение с компанией Anthropic PBC (разработчик LLM семейства Claude), которая была основана в 2021 году выходцами из OpenAI.
11.09.2025 [08:48], Руслан Авдеев
NVIDIA работает над эталонным дизайном гигаваттных ИИ-фабрикNVIDIA анонсировала разработку эталонного дизайна дата-центров гигаваттного уровня с использованием технологии цифровых двойников. Эталонные проекты ИИ ЦОД будут доступны компаниям-партнёрам по всему миру. В разработке нового решения компании помогают Schneider Electric, Siemens, Vertiv, Cadence, emeraldai, E Tech Group, phaidra.ai, PTC и Vertech. Для создания высокопроизводительной ИИ-инфраструктуры будет предложена технология цифровых двойников Omniverse Blueprint, позволяющая создавать высокопроизводительную и энергоэффективную ИИ-инфраструктуру. Технология позволяет заказчикам объединять все данные, связанные с созданием дата-центра, в единую универсальную модель, отражающую как можно больше деталей виртуального и физического строения объектов. Благодаря этому можно проектировать и моделировать оборудование с высокой энергетической и вычислительной плотностью. Модели ИИ-фабрики можно подключить к более масштабным системам: энергосетям, системам водоснабжения и транспортным артериям, что требует координации и моделирования на протяжении всего жизненного цикла кампусов ЦОД. В модель включаются локальные генерирующие мощности, энергохранилища, технологии охлаждения и даже ИИ-агенты для управления работой ЦОД. В компании заявляют, что только одновременное проектирование инфраструктуры и технологического стека обеспечивает настоящую оптимизацию, при которой питание, охлаждение, ускорители и ПО рассматриваются как единое целое. 
Источник изображения: NVIDIA В марте 2024 года сообщалось, что NVIDIA и Siemens внедрят ИИ в промышленное проектирование и производство с помощью интеграции NVIDIA Omniverse Cloud API в платформу Xcelerator. Тогда же Schneider Electric и NVIDIA объявили о разработке эталонных проектов инфраструктур ИИ ЦОД. В рамках объявленного сотрудничества AVEVA, дочерняя компания Schneider Electric, должна была подключить свою платформу цифровых двойников к NVIDIA Omniverse, создав единую среду для виртуального моделирования и совместной работы.
19.08.2025 [11:03], Руслан Авдеев
Tencent похвасталась, что накопила достаточно ускорителей для обучения новых и обновления существующих ИИ-моделейВ ходе отчёта о работе во II квартале 2025 года президент китайской Tencent Holdings Мартин Лау (Martin Lau) объявил, что компании не нужны дополнительные ИИ-ускорители. Их уже достаточно для обучения систем искусственного интеллекта и обновления готовых моделей, сообщает Datacenter Dynamics. Отвечая на вопрос о продолжающихся переговоров Китая и США об импорте ИИ-чипов в КНР и их влияния на Tencent, представитель компании ответил, что однозначного ответа о ситуации с импортом пока нет. По словам Лау, правительства ведут активные дискуссии, а бизнес ждёт, чем всё закончится. Но пока у компании достаточно чипов для обучения и обновления моделей. Также имеется много вариантов покупки чипов для инференса. По словам Лау, новые ускорители для этой цели могут и не понадобиться — компания вносит многочисленные изменения в ПО, чтобы поднять эффективность инференса. В марте Tencent заявила, что сосредоточилась на повышении эффективности использования доступных ускорителей после триумфа DeepSeek. США давно ограничили продажу ИИ-ускорителей китайским компаниям, и постоянно ужесточали политику. В августе 2025 года NVIDIA и AMD договорились платить США по 15 % от выручки от продаж ускорителей в Китай — в обмен на получение экспортных лицензий на «ослабленные» модели NVIDIA H20 и AMD MI308. Тем временем власти КНР настоятельно рекомендуют местным бизнесам отказаться от покупки американских чипов по соображениям безопасности. 
Источник изображения: Donald Wu/unsplash.com Впрочем, операционные капитальные затраты за II квартал составили ¥17,9 млрд ($2,49 млрд), увеличившись на 149 % в сравнении с аналогичным периодом 2024 года. Такой рост обусловлен в том числе и увеличением инвестиций в ИИ-ускорители и серверы для расширения возможностей компании в сфере искусственного интеллекта. Общие капитальные затраты — ¥19,1 млрд. В 2024 году капитальные затраты Tencent составили $10,6 млрд, более чем втрое больше, чем годом ранее. В отчёте о доходах за IV квартал 2024 года компания заявила, что в 2025 году капитальные затраты составят только несколько десятков процентов от выручки. По словам Лау, годовые целевые показатели затрат пока не пересмотрены, но «амортизационные» отчисления на ИИ продолжают расти. В то же время компания продолжает пользоваться плодами вложений в искусственный интеллект. Финансовые результаты Tencent, связанные с облачными сервисами, не раскрываются. Общая выручка компании за II квартал составила 184,5 млрд юаней ($25,7 млрд), увеличившись на 15 % год к году, валовая прибыль — 105 млрд юаней ($14,62 млрд), на 22 % выше год к году. В ходе конференции, посвящённой квартальным результатам, было отмечено, что рост «облачных» доходов ускорился в сравнении с предыдущими кварталами — выросли доходы от предоставления в аренду ускорителей и API-токенов.
21.07.2025 [18:58], Владимир Мироненко
xAI ищет разработчиков кастомных чипов для ИИ-системИИ-стартап xAI Илона Маска (Elon Musk) разместил вакансии для разработчиков кастомных полупроводников, сообщил ресурс DataCenter Dynamics (DCD). Стартап ищет сотрудников для «создания ИИ-систем нового поколения, охватывающих весь спектр, от полупроводниковых чипов до компиляторов и моделей». Круг должностных обязанностей специалистов включает «разработку и доработку новых аппаратных архитектур для расширения границ вычислительной эффективности», а также использование ИИ в процессе проектирования оборудования. От кандидатов на должность ожидается знание инструментов для создания чипов, таких как Chisel, а также VHDL и Verilog. В идеале претенденты должны иметь опыт «симуляции обучающих рабочих нагрузок на новых аппаратных ИИ-архитектурах». Соответствующий требованиям сотрудник присоединится к команде xAI, работающей над «созданием ИИ-систем нового поколения, которые обеспечат революционную эффективность и масштабируемость на новом оборудовании, компиляторах и моделях». 
Источник изображения: xAI Как полагает DCD, команду, о которой идёт речь, возглавляет Сяо Сан (Xiao Sun), ранее работавший в Meta✴, а до этого занимавшийся разработкой аппаратного обеспечения и алгоритмов машинного обучения, а также CMOS-устройств в IBM. DCD отметил, что на данный момент неясно, сотрудничает ли xAI с другой компанией в разработке полупроводниковых чипов, как, например, Google и OpenAI, которые работают с Broadcom над созданием семейства TPU и ИИ-чипа соответственно. Компания Tesla, в которой Маск является крупнейшим акционером, также разработала собственный чип — Dojo D1, ориентированный на обработку видеоданных для обучения полуавтономных автомобилей. Однако большая часть команды, стоящей за чипом Dojo D1, покинула Tesla, и его будущее туманно. Илон Маска показал систему в 2024 году. Годом ранее Маск заявил, что чип используется из-за нехватки ускорителей NVIDIA: «Честно говоря, я не знаю, смогут ли они поставить нам достаточно графических процессоров — возможно, Dojo нам и не нужен, — но они не смогут». Как и Tesla, xAI использует значительное количество ускорителей NVIDIA для своих вычислительных задач, более 200 тыс. из них входят в состав суперкомпьютера Colossus в Мемфисе (США). Маск надеется расширить Colossus до миллиона ускорителей. В свою очередь, xAI приобрела участок под второй дата-центр в Мемфисе.
19.07.2025 [15:58], Владимир Мироненко
Intel прекратила поддержку фирменного дистрибутива Clear Linux OSIntel объявила о прекращении поддержки оптимизированного для производительности дистрибутива Clear Linux OS. «Начиная с этого момента, Intel больше не будет предоставлять исправления безопасности, обновления или техническое обслуживание Clear Linux OS, а репозиторий Clear Linux OS на GitHub будет заархивирован и доступен в режиме только для чтения», — указано в заявлении компании на странице Clear Linux Project. Всем, кто в настоящее время использует Clear Linux OS, компания рекомендовала запланировать переход на другой активно поддерживаемый дистрибутив. Intel также отметила, что по-прежнему инвестирует в экосистему Linux, активно поддерживая различные проекты и дистрибутивы Linux с открытым исходным кодом и внося свой вклад в их оптимизацию для аппаратного обеспечения. Clear Linux был известен глубокой оптимизацией для x86-64, причём в производительности от этого выигрывали не только платформы Intel, но и AMD. Тем не менее, дистрибутив оставался достаточно нишевым. 
Источник изображения: clearlinux.org Как сообщил ранее ресурс Phoronix, в этом месяце Intel покинул Кирилл Шутемов (Kirill Shutemov) после 14 лет работы в компании, который внёс значительный вклад в развитие основных компонентов Intel для ядра Linux. Сообщается, что в последнее время Шутемов работал над аспектами управления памятью в ядре, а также принимал участие в реализации TDX в Intel. Согласно данным Phoronix, последний раунд увольнений Intel сильнее повлиял на разработку ПО, чем некоторые из предыдущих. В этот раз компанию покинули сразу несколько разработчиков Linux.
12.07.2025 [01:00], Руслан Авдеев
NVIDIA, Cisco и Indosat помогут Индонезии встать на ИИ-рельсы
cisco
indosat ooredoo hutchison
llm
nvidia
software
ии
индонезия
информационная безопасность
конфиденциальность
обучение
разработка
Индонезия сделала важный шаг к созданию суверенного ИИ, объявив о создании «Центра передового опыта в сфере ИИ» (AI Center of Excellence, CoE). Проект реализуется под руководством Министерства цифровых коммуникаций и информации (Komdigi) и при поддержке NVIDIA, Cisco и телеком-оператора Indosat Ooredoo Hutchison (IOH). Центр станет частью национальной инициативы «Золотое видение 2045» (Golden 2045 Vision), направленной на цифровую трансформацию экономики и развитие инноваций. В задачи CoE входят развитие локальной ИИ-инфраструктуры, подготовка кадров и поддержка стартапов. Частью CoE станет NVIDIA AI Technology Center, который обеспечит поддержку исследований в области ИИ, предоставит доступ к программе NVIDIA Inception для стартапов и предложит обучение в экосистеме NVIDIA Deep Learning Institute. Также CoE получит типовую суверенную ИИ-фабрику с новейшими ускорителями Blackwell. Дополнительно курируемый государством форум разработает надёжные ИИ-фреймворки для создания решений, соответствующих местным ценностям. Важное внимание уделяется вопросам кибербезопасности. На базе центра заработает система Sovereign Security Operations Center Cloud Platform, разработанная Cisco, сочетающая ИИ-распознавание угроз, локальное управление данными и управляемые сервисы обеспечения безопасности. Проект строится на четырёх стратегических столпах:

Источник изображения: Jeremy Bishop/unspalsh.com Уже сейчас около 30 независимых разработчиков и стартапов используют ИИ-инфраструктуру IOH на базе NVIDIA. С учётом того, что Indosat покрывает связью весь индонезийский архипелаг, компания может обслуживать сотни миллионов носителей индонезийского языка (Bahasa Indonesia) с помощью приложений на основе специальных LLM, таких как Indosat Sahabat-AI. В будущем Indosat и NVIDIA намерены внедрять технологии AI-RAN, позволяющие охватывать ещё более широкий круг людей, которые смогут пользоваться ИИ с помощью беспроводных сетей. Индонезия давно стала весьма привлекательным рынком для инвесторов. Так, Microsoft намерена в течение четырёх лет инвестировать в облачную инфраструктуру и ИИ-проекты Индонезии $1,7 млрд. А NVIDIA и Indosat Ooredoo Hutchison планируют построить ИИ-центр стоимостью $200 млн в Центральной Яве, $500 млн намерена инвестировать Tencent. Даже «Яндекс» имеет там собственные интересы.
11.07.2025 [08:53], Руслан Авдеев
Агентство по охране окружающей среды США посетовало на непрекращающиеся попытки бездумного внедрения ИИПо словам Агентства по охране окружающей среды (EPA) США, стартапы очень часто бездумно обращаются к ИИ без чёткого плана действий и проверенных данных. В результате предприниматели терпят неудачи и удивляются, почему ничего не сработало, передаёт The Register, отмечая, что на практике ставка на ИИ окупается лишь в четверти случаев. Глава информационной службы EPA заявил, что ИИ — не панацея от всех проблем, как считают многие. ИИ необходимо внедрять в бизнес с учётом конкретных сценариев использования, но некоторые видят, как ИИ внедряется в других организациях, и стремятся к тому же, «не задавая правильных вопросов». По словам чиновника, часто для решения задачи вовсе не нужен ИИ, а попытка угнаться за модой может замедлить рост компании, а не ускорить его. Примечательно, что в последнее время доходность инвестиций в ИИ оказалась довольно низкой. 
Источник изображения: Jud Mackrill/unsplash.com EPA вторит и компания Maximus, ответственная за разработку IT-решений для госслужб США. Компания сообщила о жалобах на большое количество ботов «на службе» у государственных учреждений. В Maximus разработали процесс оценки решения задач — оказалось, что в некоторых случаях ИИ действительно вовсе не нужен. По словам EPA, простое делегирование текущих задач искусственному интеллекту не всегда позволяет добиться нужного эффекта. Например, в гипотетической ситуации, когда компания перекладывает заполнение некой формы, являющееся частью бизнес-процесса, на ИИ без изучения логики бизнес-процесса может оказаться, что задачу передали машине без особой необходимости и с затратой лишних ресурсов. Тщательный анализ процесса поможет ответить на действительно важный вопрос: нужно ли вообще выполнение конкретной задачи с помощью ИИ, если её обработка вручную будет в несколько раз дешевле? Другими словами, любой ИИ-проект настолько хорош, насколько хороши данные, использованные при его планировании. Сейчас EPA среды ведёт реестр ИИ-приложений для поиска «наилучших вариантов использования ИИ». При этом крупный IT-бизнес, наоборот, заинтересован в повсеместном внедрении ИИ. Так, Microsoft планомерно укрепляет лидерство в сфере ИИ, предлагая клиентам почти 2 тыс. моделей, в том числе от конкурентов.И это далеко не единственная платформа такого рода на рынке.
09.07.2025 [17:37], Владимир Мироненко
Apple подумывала о запуске облака на собственных чипах, но решение так и не принялаКомпания Apple ранее рассматривала возможность запуска собственных облачных сервисов в качестве альтернативы AWS, Microsoft Azure и Google Cloud, но, по всей видимости, отказалась от этой идеи, сообщил ресурс The Information. Проект был известен как Project ACDC (Apple Chips in Data Centers, чипы Apple в дата-центрах). В рамках ACDC компания намеревалась представлять разработчикам доступ к своим фирменным чипам серии Apple M. Сообщается, что Apple планировала предложить более дешевую и эффективную альтернативу традиционным облачным платформам, использующим серверы Intel или решения других вендоров, заменив их собственными чипами серии M, которые известны своей вычислительной эффективностью и мощными возможностями инференса. 
Источник изображения: Apple Apple использует эти чипы не только для устройств Mac и iPad, но начала их тестирование своих чипов в ЦОД, запустив систему Private Cloud Compute (PCC) для безопасной обработки в облаке ИИ-запросов сервиса Apple Intelligence. Другие сервисы Apple, такие, как Siri, Photos и Music, также используют возможности чипов серии Apple M для повышения скорости обработки данных, в том числе ускорения поиска. Проект ACDC был бы в значительной степени ориентирован на собственные разработки Apple, позволяя разработчикам создавать приложения для iOS и macOS непосредственно на чипах Apple и снижая тем самым зависимость от дорогостоящих ускорителей сторонних вендоров, отметил ресурс TechRadar. Компания не планировала сформировать новый отдел продаж для ACDC. И хотя глава Project ACDC Майкл Эбботт (Michael Abbott) покинул компанию в 2023 году, обсуждение этих возможностей продолжалось как минимум до начала 2024 года, сообщают источники. Вместе с тем будущее проекта на данный момент остаётся неопределённым. По данным Apple Insider, компания ежегодно тратит порядка $7 млрд на сторонние облачные сервисы.
17.06.2025 [23:55], Владимир Мироненко
AMD анонсировала платформу ROCm 7.0, облако для разработчиков AMD Developer Cloud и программу Radeon Test DriveAMD вместе с ускорителями Instinct MI350X/MI355X представила 7-ю версию своего открытого программного стека ROCm (Radeon open compute). Как сообщает компания, ROCm 7.0 предназначен для удовлетворения растущих потребностей рабочих нагрузок генеративного ИИ и HPC, одновременно расширяя возможности разработчиков за счёт доступности, эффективности и активного сотрудничества сообщества. По данным AMD, платформа ROCm 7 предлагает более чем в 3,5 раза большую производительность инференса, чем ROCm 6, и в 3 раза большую эффективность обучения. Это стало возможным благодаря улучшениям производительности и поддержке типов данных с меньшей точностью, таких как FP4 и FP6. Дальнейшие улучшения в коммуникационных стеках позволили оптимизировать использование ускорителя и перемещение данных. ROCm 7 поддерживает распределённый инференс, а также фреймворки SGLang, vLLM и llm-d. Платформа ROCm 7 создавалась совместно с этими партнёрами, включая разработку общих интерфейсов и примитивов для обеспечения эффективного распределённого инференса на платформах AMD. 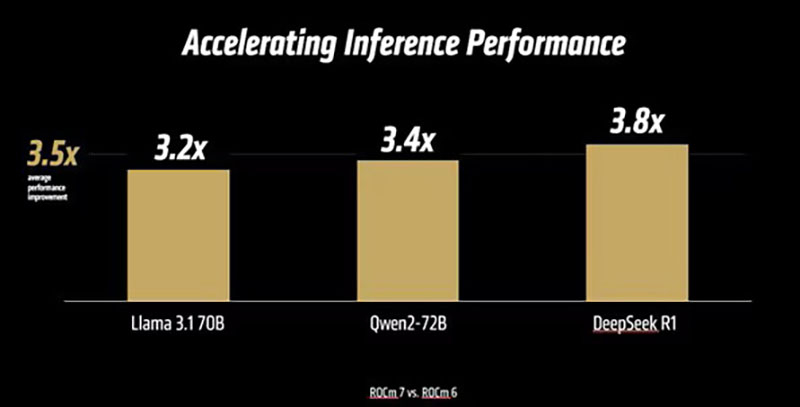
Источник изображений: AMD Вместе с ROCm 7 компания представила MLOps-платформу ROCm Enterprise AI для бесперебойных ИИ-операций в корпоративном сегменте. Платформа предлагает инструменты для тонкой настройки модели и интеграции как со структурированными, так и неструктурированными рабочими процессами. AMD заявила, что работает с партнёрами по экосистеме над созданием эталонных реализаций для таких приложений, как чат-боты и обобщение документов. 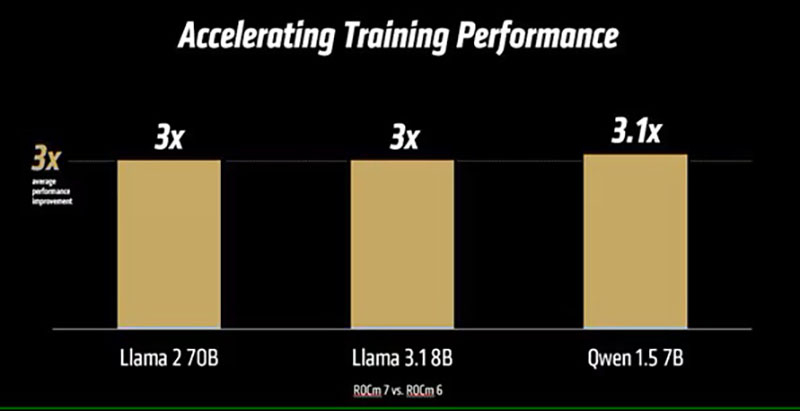 AMD отметила, что тесное партнёрство гарантирует разработчикам доступ к лучшим в своем классе инструментам, постоянному улучшению производительности и открытой среде для быстрой итерации и развёртывания. Также AMD представила партнёров экосистемы ROCm, которые используют преимущества данной платформы:
Кроме того, AMD представила «простую в использовании платформу для разработчиков» AMD Developer Cloud, обеспечивающую быстрый доступ к AMD Instinct с возможностью масштабирования от одного (192 Гбайт памяти) до восьми AMD Instinct MI300X (1536 Гбайт памяти). Сообщается, что конфигурации с одним ускорителем в основном используются для рабочих нагрузок инференса на «лёгких» моделях, тогда как максимальная конфигурация обеспечивает распределённое обучение, тонкую настройку и высокопроизводительный инференс для крупномасштабных моделей.  AMD сообщила, что платформа AMD Developer Cloud была разработана с учётом четырёх основных целей:
По словам компании, AMD Developer Cloud предполагает различные варианты использования. Решение идеально подходит для независимых разработчиков AI/ML, работающих над низкоуровневым программированием, разработкой ядер (kernel) или корпоративных приложений и проектов, нацеленных на нативную поддержку AMD. Также платформу можно использовать для мероприятий и хакатонов, обеспечивая масштабируемую поддержку образовательных и практических мероприятий с предоставлением кредитов на использование ускорителей во время семинаров, хакатонов, конкурсов и демонстраций.  Также с выходом ROCm 7 появилась поддержка ноутбуков и рабочих станциях на Windows с видеокартами Radeon и процессорами Ryzen AI. С этим связан ещё один важный анонс — компания представила программу ROCm on Radeon Test Drive, которая будет запущена этим летом партнёрстве с различными поставщиками оборудования (первыми стали Colfax и System76), чтобы упростить разработчикам возможность опробовать ROCm на GPU Radeon, передаёт Phoronix. В рамках Radeon Test Drive предоставляется возможность удалённо протестировать GPU Radeon (PRO). |
|