Материалы по тегу: nvlink
|
04.10.2025 [12:56], Сергей Карасёв
Fujitsu и NVIDIA создадут вычислительную ИИ-инфраструктуру нового поколенияЯпонская корпорация Fujitsu объявила о расширении стратегического сотрудничества с NVIDIA с целью создания полнофункциональной инфраструктуры ИИ следующего поколения, в состав которой войдут ИИ-агенты. Предполагается, что инициатива поможет ускорить развитие таких отраслей, как здравоохранение, производство, робототехника и др. Партнёры намерены работать по ряду направлений. В частности, Fujitsu и NVIDIA займутся созданием передовой вычислительной инфраструктуры для задач ИИ. Речь идёт об объединении серверных процессоров Fujitsu Monaka на архитектуре Arm с высокопроизводительными GPU разработки NVIDIA. Для этого будет задействована технология NVLink Fusion, позволяющая применять скоростные интерконнекты NVLink со сторонними чипами. Конечной целью является предоставление комплексной экосистемы HPC-ИИ с интегрированным софтом Fujitsu для Arm-процессоров и NVIDIA CUDA. Кроме того, сотрудничество предусматривает создание «саморазвивающейся» платформы ИИ-агентов. Она, как ожидается, обеспечит высокую производительность и безопасность. Планируется внедрение механизма, который позволит агентам и моделям ИИ развиваться автономно с возможностью оптимизации под запросы конкретных отраслей. В конечном итоге, такие агенты будут предоставляться заказчикам в виде микросервисов NVIDIA NIM. 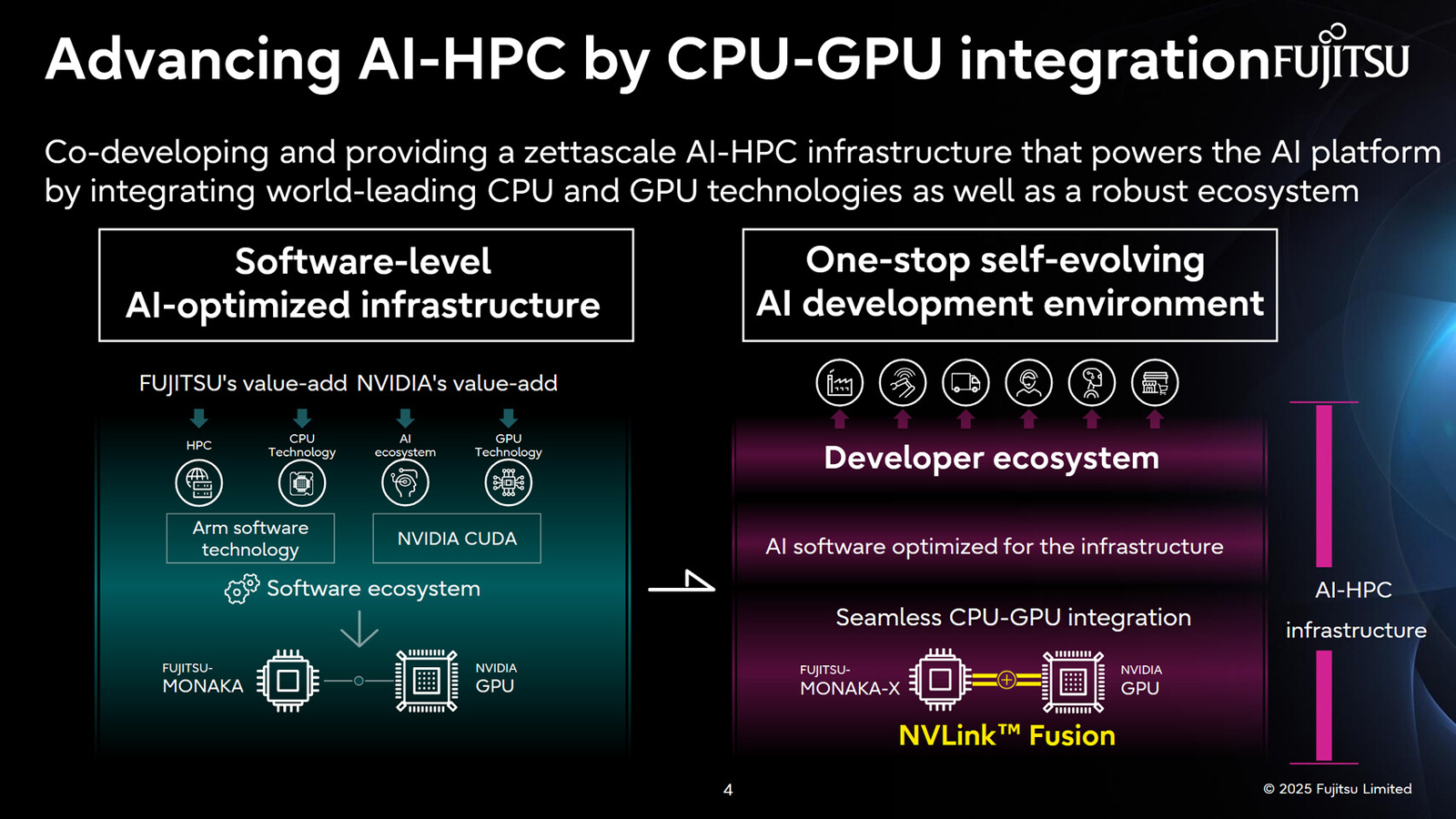
Источник изображений: Fujitsu Ещё одним направлением сотрудничества названо формирование партнёрской экосистемы для расширения использования агентов и моделей ИИ. Планируется также разработка передовых квантовых технологий, включая гибридные квантово-классические вычислительные системы на основе чипов Monaka и НРС-решений NVIDIA.  В целом, как отмечается, к 2030 году спрос на вычислительные мощности для ИИ в Японии вырастет в 320 раз по сравнению с 2020-м. На этом фоне местные компании, включая Fujitsu, SoftBank и KDDI, активно реализуют различные проекты, направленные на развитие рынка ИИ.
18.09.2025 [16:09], Владимир Мироненко
Intel разработает для NVIDIA кастомные CPU для серверов и ПК, а NVIDIA вложит в Intel $5 млрдNVIDIA и корпорация Intel заключили соглашение о сотрудничестве с целью совместной разработки специализированных чипов для ЦОД и ПК для использования гиперскейлерами, а также другими клиентами на корпоративном и потребительском рынках. Согласно пресс-релизу, компании намерены обеспечить бесшовное объединение архитектур NVIDIA и Intel с использованием NVIDIA NVLink, реализуя преимущества NVIDIA в области ИИ и ускоренных вычислений совместно с ведущими технологиями процессоров Intel и экосистемой x86 для предоставления передовых решений для клиентов. Ранее NVIDIA представила интерконнект NVLink Fusion, который как раз и позволяет объединять решения компании с чиплетами других вендоров. Одним из первых продуктов стал чип GB10, включающий GPU Blackwell и Arm-процессор MediaTek. В рамках партнёрства Intel разработает кастомные серверные x86-процессоры для ИИ-платформ NVIDIA. Для персональных компьютеров Intel разработает SoC с архитектурой x86 и GPU-чиплетами NVIDIA RTX. Новые SoC RTX на базе x86 будут использоваться в широком спектре ПК. У Intel уже был опыт интеграции GPU AMD в свои SoC, но не слишком удачный — Kaby Lake-G были заброшены через пару лет после выхода. 
Источник изображения: NVIDIA В рамках соглашения о сотрудничестве NVIDIA инвестирует в Intel $5 млрд путём приобретения на эту сумму обыкновенных акций Intel по цене $23,28 за единицу. После этого объявления акции Intel подскочили на премаркете на 33 % до примерно $33 за единицу, сообщил ресурс CNBC. Ранее SoftBank потратила $2 млрд на покупку акций Intel по $23/шт. В конце августа власти США приобрели 9,9 % долю в Intel за $8,9 млрд, получив акции по $20,47 за бумагу. «Это историческое сотрудничество тесно связывает ИИ-технологии и ускоренные вычисления NVIDIA с CPU Intel и обширной экосистемой x86 — слиянием двух платформ мирового класса. Вместе мы расширим наши экосистемы и заложим основу для следующей эры вычислений», — отметил генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang). Как полагают аналитики CNBC, сотрудничество, по всей видимости, не включают производство чипов NVIDIA на производственных мощностях Intel.
22.08.2025 [16:33], Владимир Мироненко
Почти как у самой NVIDIA: NVLink Fusion позволит создавать кастомные ИИ-платформыТехнологии NVIDIA NVLink и NVLink Fusion позволят вывести производительность ИИ-инференса на новый уровень благодаря повышенной масштабируемости, гибкости и возможностям интеграции со сторонними чипами, которые в совокупности отвечает стремительному росту сложности ИИ-моделей, сообщается в блоге NVIDIA. С ростом сложности ИИ-моделей выросло количество их параметров — с миллионов до триллионов, что требует для обеспечения их работы значительных вычислительных ресурсов в виде кластеров ускорителей. Росту требований, предъявляемых к вычислительным ресурсам, также способствует внедрение архитектур со смешанным типом вычислений (MoE) и ИИ-алгоритмов рассуждений с масштабированием (Test-time scaling, TTS). NVIDIA представила интерконнект NVLink в 2016 году. Пятое поколение NVLink, вышедшее в 2024 году, позволяет объединить в одной стойке 72 ускорителя каналами шириной 1800 Гбайт/с (по 900 Гбайт/с в каждую сторону), обеспечивая суммарную пропускную способность 130 Тбайт/с — в 800 раз больше, чем у первого поколения.  Производительность NVLink зависит от аппаратных средств и коммуникационных библиотек, в частности, от библиотеки NVIDIA Collective Communication Library (NCCL) для ускорения взаимодействия между ускорителями в топологиях с одним и несколькими узлами. NCCL поддерживает вертикальное и горизонтальное масштабирование, а также включает в себя автоматическое распознавание топологии и оптимизацию передачи данных. 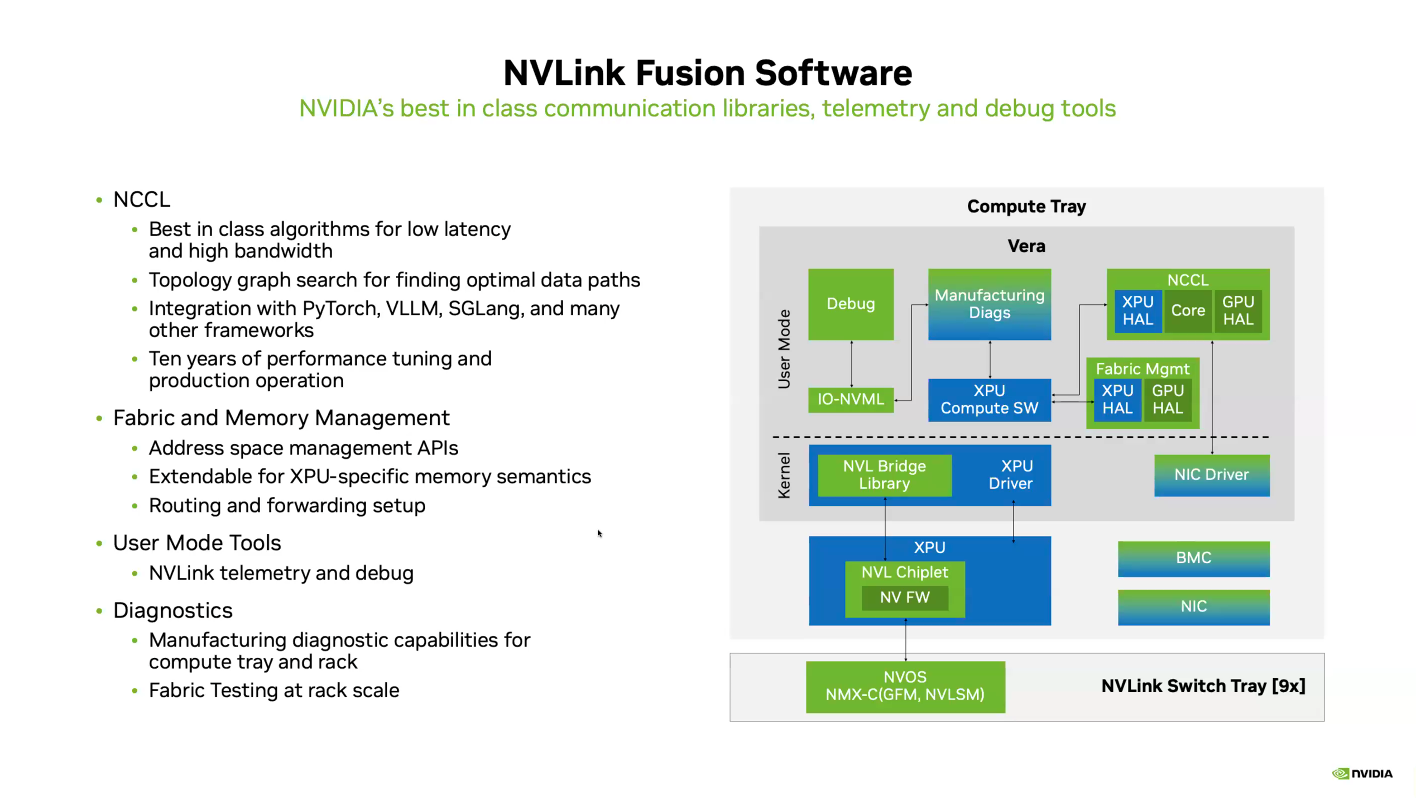 Технология NVLink Fusion призвана обеспечить гиперскейлерам доступ ко всем проверенным в производстве технологиям масштабирования NVLink. Она позволяет интегрировать кастомные микросхемы (CPU и XPU) с технологией вертикального и горизонтального масштабирования NVIDIA NVLink и стоечной архитектурой для развёртывания кастомных ИИ-инфраструктур. 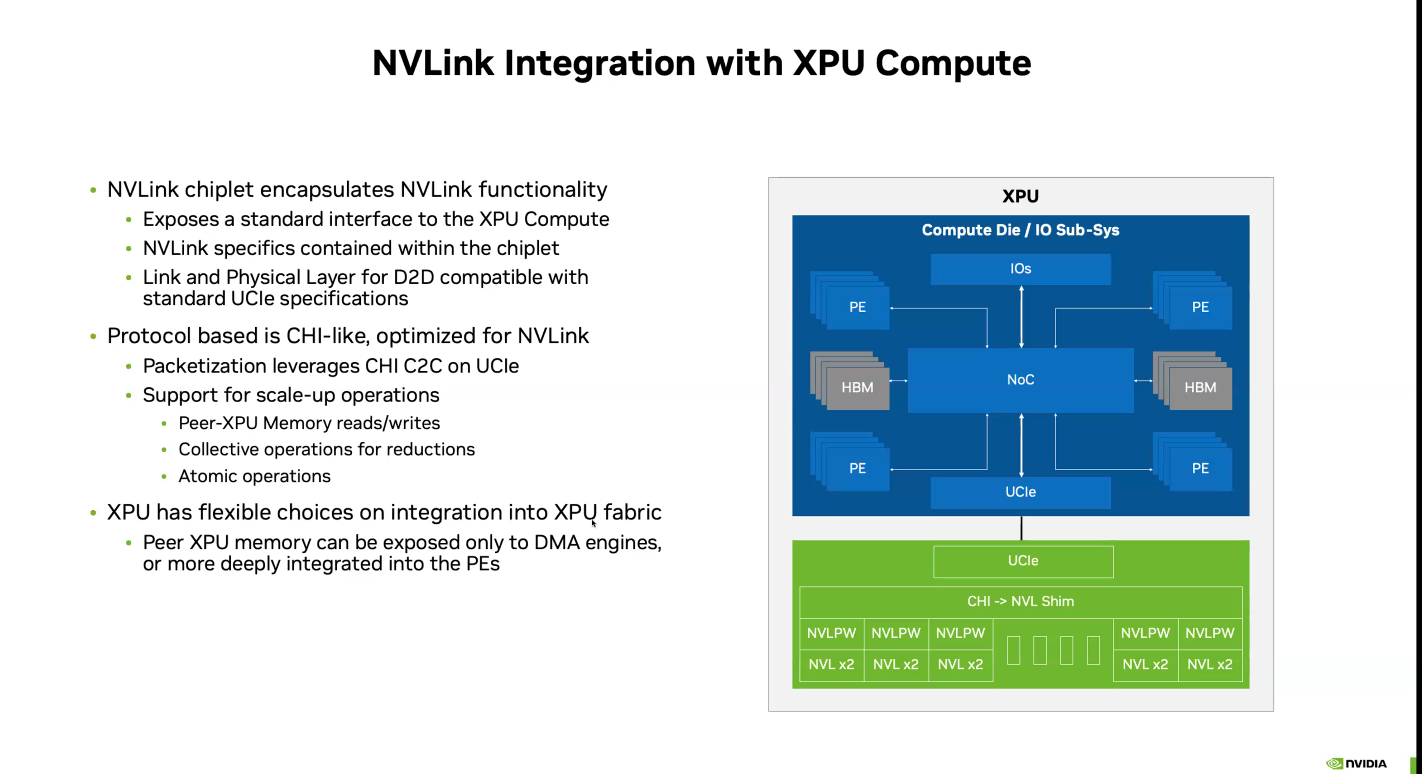 Технология охватывает NVLink SerDes, чиплеты, коммутаторы и стоечную архитектуру, предлагая универсальные решения для конфигураций кастомных CPU, кастомных XPU или комбинированных платформ. Модульное стоечное решение OCP MGX, позволяющее интегрировать NVLink Fusion с любым сетевым адаптером, DPU или коммутатором, обеспечивает заказчикам гибкость в построении необходимых решений, заявляет NVIDIA. 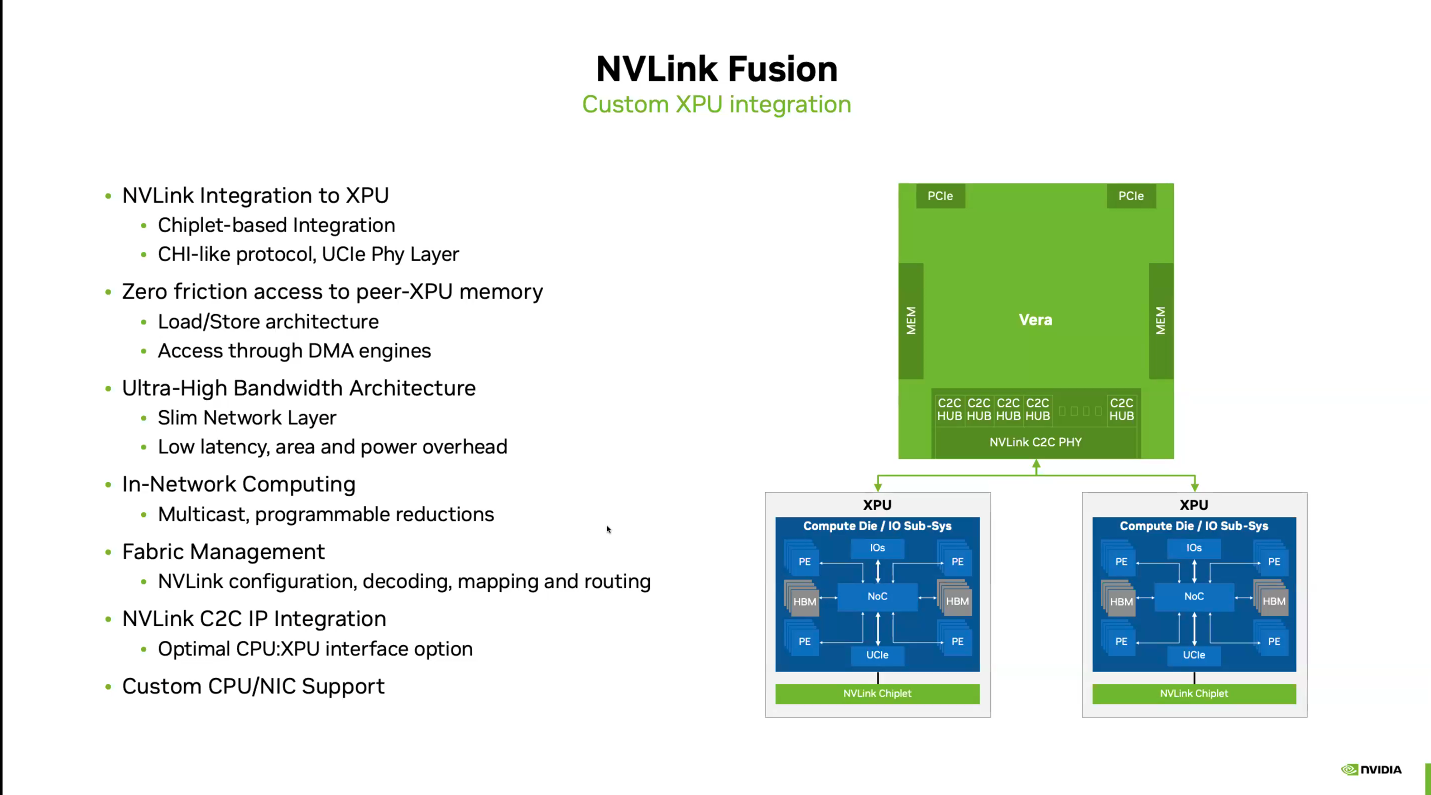 NVLink Fusion поддерживает конфигурации с кастомными CPU и XPU с использованием IP-блоков и интерфейса UCIe, предоставляя заказчикам гибкость в реализации интеграции XPU на разных платформах. Для конфигураций с кастомными CPU рекомендуется интеграция с IP NVLink-C2C для оптимального подключения и производительности GPU. При этом предлагаются различные модели доступа к памяти и DMA. 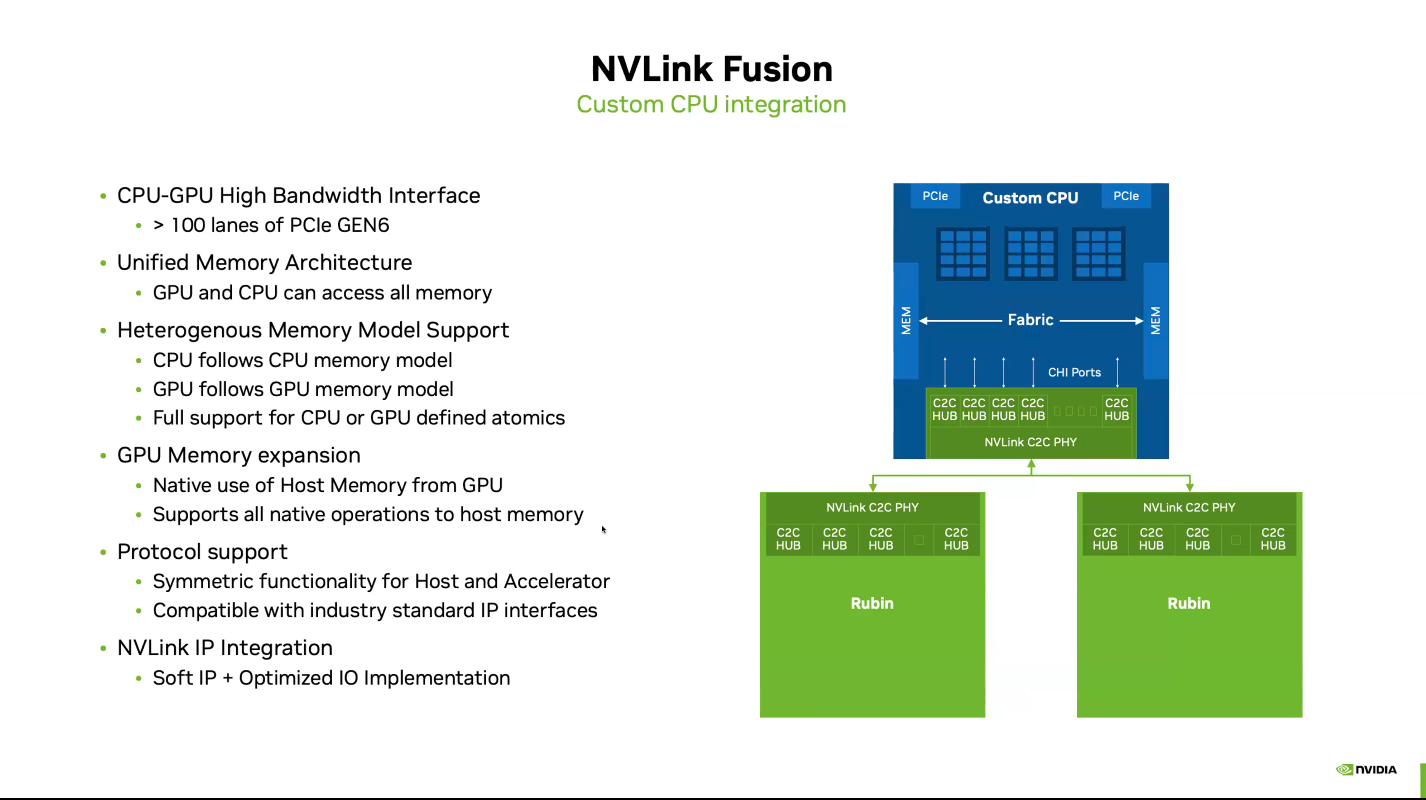 NVLink Fusion использует преимущества обширной экосистемы кремниевых чипов, в том числе от партнёров по разработке кастомных полупроводников, CPU и IP-блоков, что обеспечивает широкую поддержку и быструю разработку новых решений. Основанная на десятилетнем опыте использования технологии NVLink и открытых стандартах архитектуры OCP MGX, платформа NVLink Fusion предоставляет гиперскейлерам исключительную производительность и гибкость при создании ИИ-инфраструктур, подытожила NVIDIA.  При этом основным применением NVLink Fusion с точки зрения NVIDIA, по-видимому, должно стать объединение сторонних чипов с её собственными, а не «чужих» чипов между собой. Более открытой альтернативой NVLink должен стать UALink с дальнейшим масштабированием посредством Ultra Ethernet.
22.08.2025 [13:30], Алексей Разин
NVIDIA поможет японцам создать один из мощнейших суперкомпьютеров мира FugakuNEXTВ начале этого десятилетия созданный в Японии суперкомпьютер Fugaku пару лет удерживался на верхней строчке в рейтинге мощнейших систем мира TOP500, он и сейчас занимает в нём седьмое место. В попытке технологического реванша японский исследовательский институт RIKEN доверился компании NVIDIA, которая поможет Fujitsu создать суперкомпьютер Fugaku NEXT. Помимо Arm-процессоров Fujitsu MONAKA-X, в основу нового японского суперкомпьютера лягут и ускорители NVIDIA, хотя изначально планировалось обойтись без них. NVIDIA будет принимать непосредственное участие в интеграции своих компонентов в суперкомпьютерную систему, создаваемую японскими партнёрами. По меньшей мере, скоростные интерфейсы, которыми располагает NVIDIA, пригодятся для обеспечения быстрого канала передачи информации между CPU и ускорителями. Сама NVIDIA обтекаемо говорит, что для этого можно задействовать шину NVLink Fusion. С ускорителями AMD, по-видимому, эти процессоры будут общаться более традиционно, т.е. по шине PCIe. 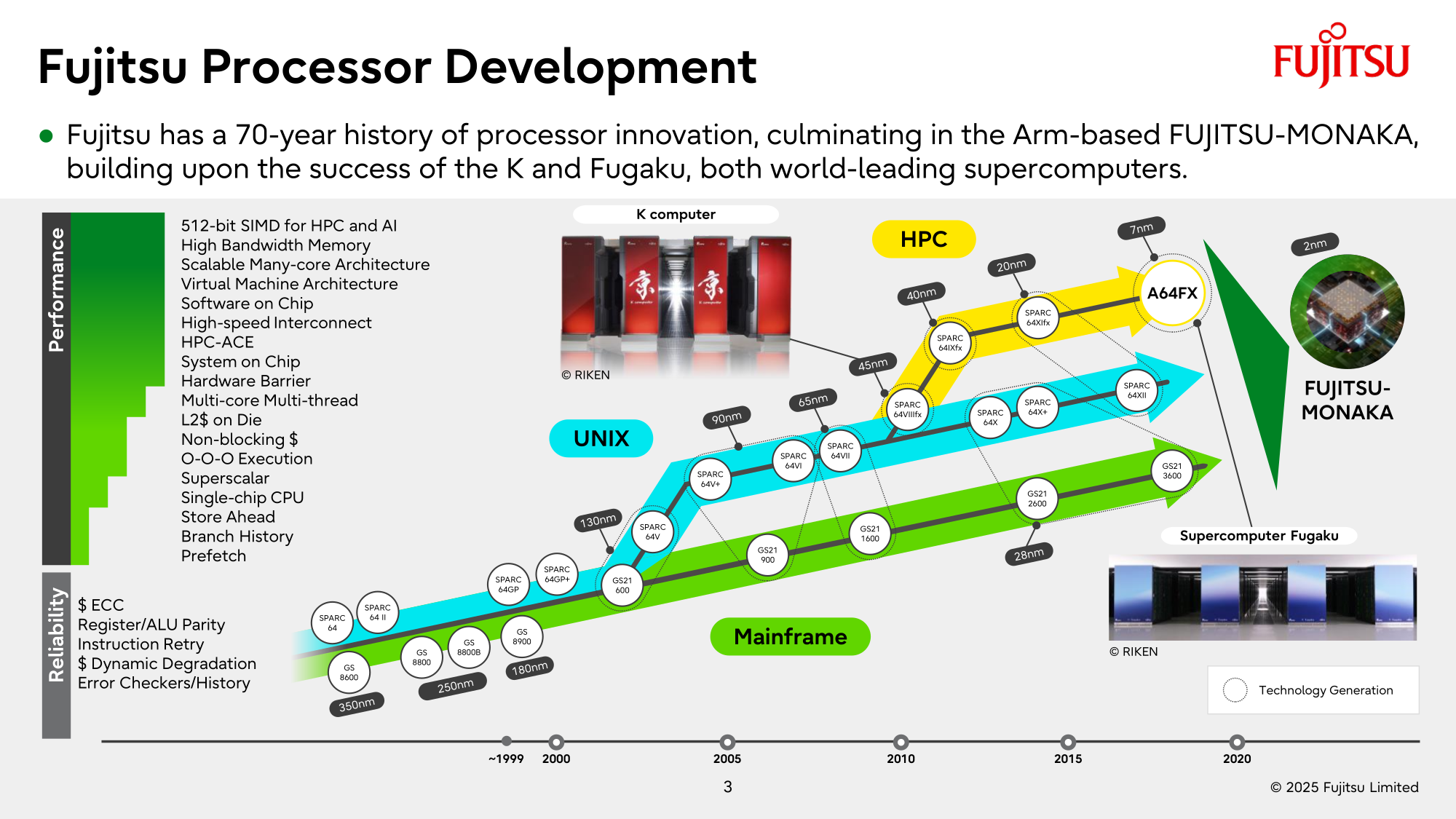
Источник изображений: Fujitsu Кроме того, NVIDIA собирается применить в составе данной системы передовые типы памяти. Применяемые при создании FugakuNEXT решения, по мнению представителей NVIDIA, смогут стать типовыми для всей отрасли в дальнейшем. Подчёркивается, что будущая платформа станет не просто техническим апгрейдом, а инвестицией в будущее страны. 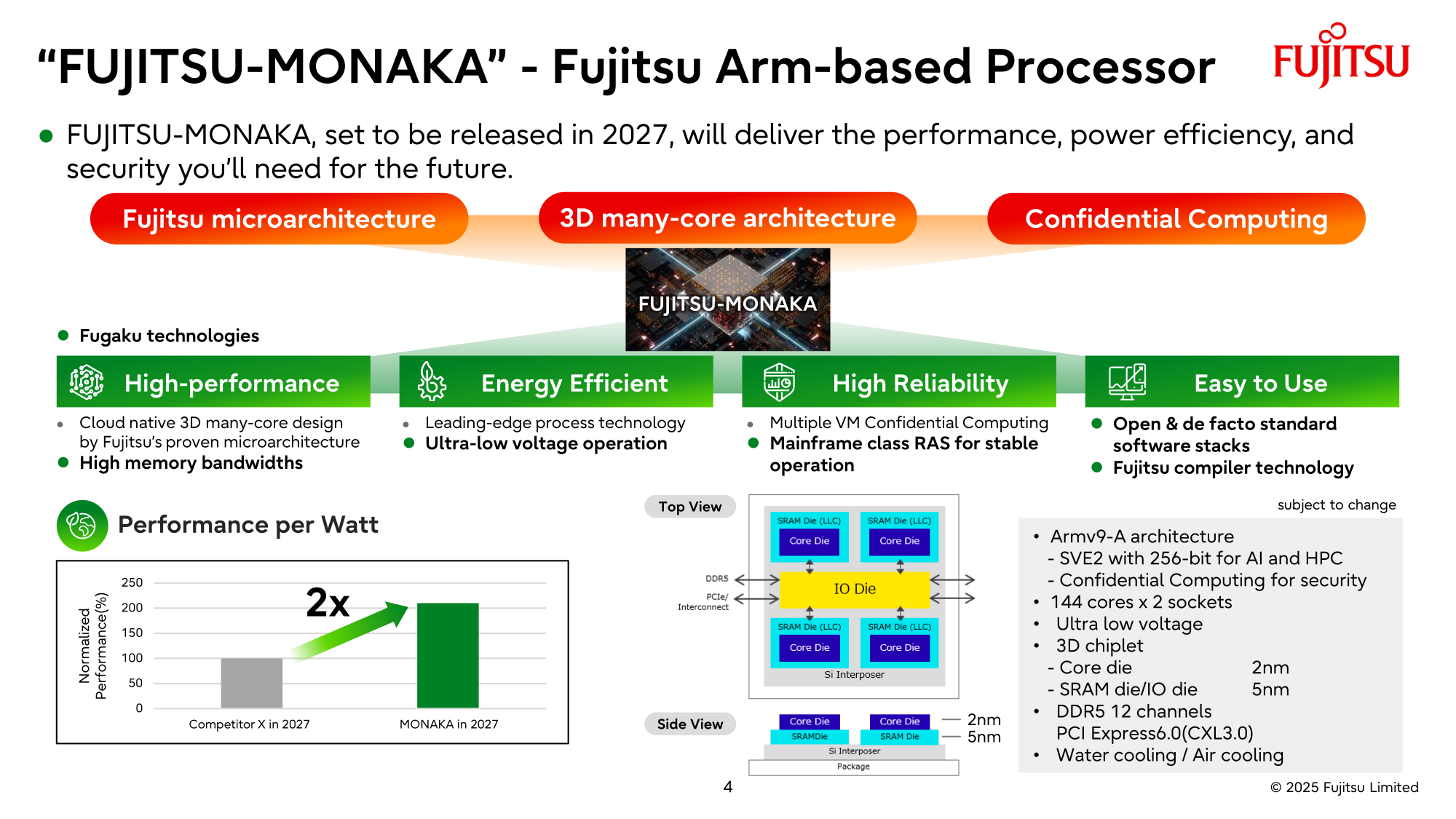 Сама архитектура системы не уточняется, поэтому сложно судить, насколько активно японские разработчики будут использовать ускорители NVIDIA, и к какому поколению они будут относиться. Создатели ставят перед собой амбициозные цели — FugakuNEXT должна стать первой системой «зетта-масштаба». Своего предшественника она должна превзойти более чем в пять раз, обеспечив быстродействие на уровне 600 Эфлопс (FP8). 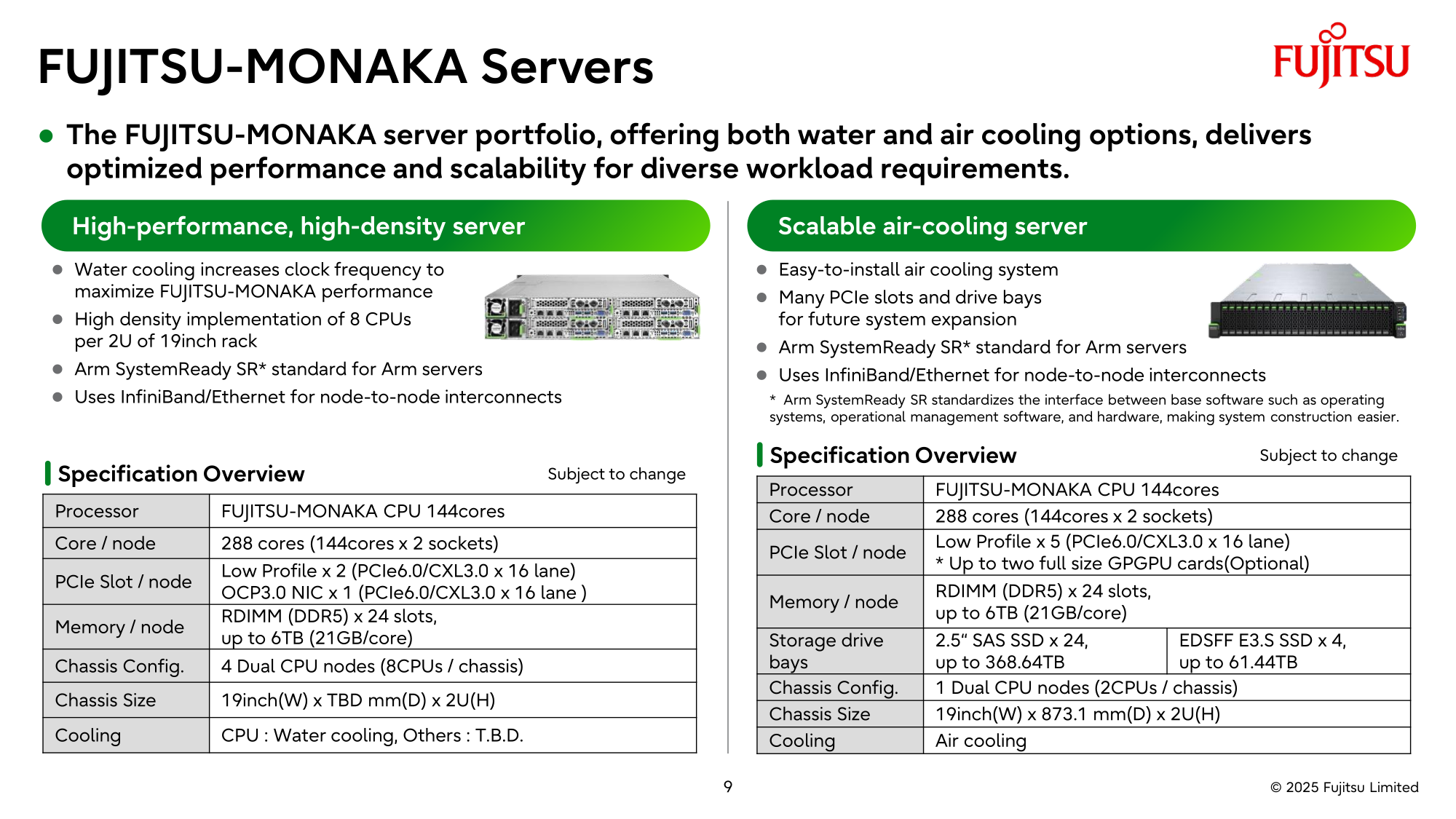 На уровне приложений прирос быстродействия может быть стократным, отмечают создатели. Новый суперкомпьютер сможет применяться для обучения больших языковых моделей. Впрочем, в строй он будет введён лишь к 2030 году, а Fujitsu ещё только предстоит выпустить свои процессоры MONAKA-X для этой системы.
19.05.2025 [16:07], Руслан Авдеев
NVLink Fusion: NVIDIA открыла фирменный интерконнект NVLink сторонним разработчикам чиповNVIDIA представила технологию NVLink Fusion, позволяющую применять скоростные интерконнекты NVLink с «полукастомными» ускорителями, включая ASIC-модули. Благодаря этому NVLink можно использовать даже с ускорителями, разработанными сторонними компаниями, сообщает The Register. NVLink 5 поколения сегодня обеспечивает пропускную способность на уровне 1,8 Тбайт/с (900 Гбайт/с в каждом направлении) на каждый ускоритель с возможностью объединения до 72 ускорителей. Ранее поддержка интерконнектов компании ограничивалась ускорителями и процессорами NVIDIA, хотя сообщалось и о сотрудничестве с MediaTek. 
Источник изображений: NVIDIA Как сообщают в NVIDIA, технологию будут предлагать в двух конфигурациях — первая предназначена для связи кастомных CPU с ускорителями NVIDIA (CPU-to-GPU), в 14 раз быстрее в сравнении с PCIe 5.0 (128 Гбайт/с). Второй, более необычный вариант предусматривает связь CPU Crace и Vera с ускорителями, разработанными не NVIDIA. Этого можно добиться, используя либо IP-блок NVLink, либо отдельный чиплет. 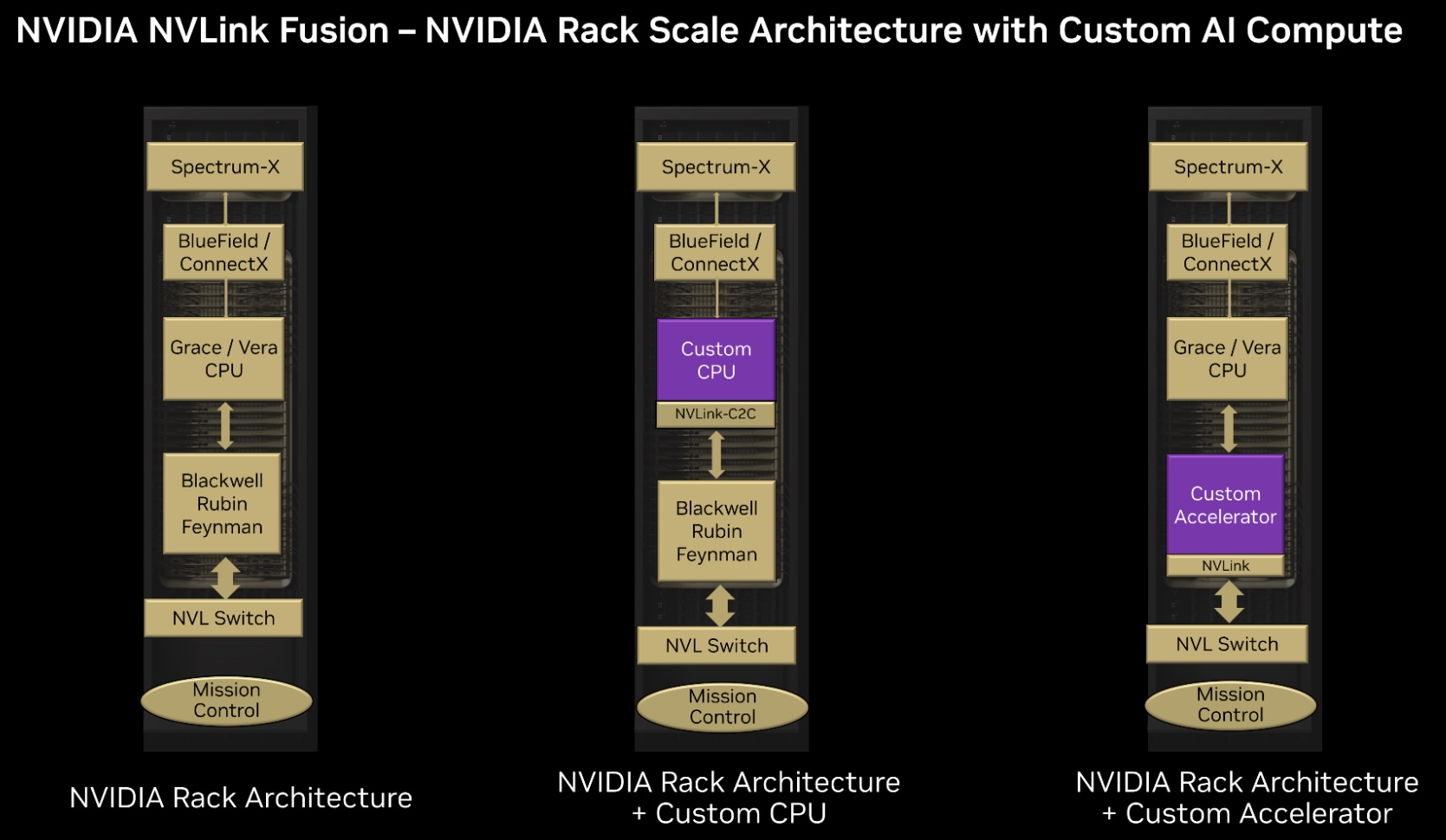 В теории это откроет возможность создания кластеров-«суперчипов» с любыми комбинациями CPU и GPU NVIDIA, AMD, Intel и др., но только с участием продуктов NVIDIA. Другими словами, объединить, например, только процессоры и ускорители Intel с помощью NVLink Fusion не выйдет. Кроме того, NVIDIA не открывает свой стандарт полностью. Как сообщает пресс-служба NVIDIA, поддержку интерконнекта уже обещали добавить MediaTek, Marvell, AIchip, Astera Labs, Synopsys и Cadence, а Fujitsu и Qualcomm планируют добавить объединить свои CPU с ускорителями NVIDIA посредством NVLink Fuison. При этом ни AMD, ни Intel в списке партнёров пока нет и, возможно, они там не появятся. Обе компании сделали ставку на Ultra Accelerator Link — открытую альтернативу NVLink. UALink первой версии предлагает всего лишь 200 Гбит/с на линию (до 800 Гбит/с на ускоритель), но позволяет объединить до 1024 ускорителей. Стандарт во много основан на AMD Infinity Fabric. Год назад AMD также приоткрыла Infinity Fabric, но в PCIe-версии, представив AFL (Accelerated Fabric Link). Intel же изначально сделала ставку на Ethernet для связи ускорителей внутри и вне узла.
26.03.2025 [01:00], Владимир Мироненко
NVIDIA поделится с MediaTek фирменным интерконнектом NVLink для создания кастомных ASICMediaTek объявила о планах расширить сотрудничество с NVIDIA, интегрировав NVLink в разрабатываемые ей ASIC, сообщил ресурс DigiTimes. В свою очередь, ресурс smbom.com пишет, что партнёры намерены совместно разрабатывать передовые решения с использованием NVLink и 224G SerDes. Аналитики предполагают, что выход NVIDIA в сектор ASIC позволит ей ускорить дальнейшее продвижение на рынке с использованием опыта MediaTek и при этом решать имеющиеся проблемы. Как ожидают аналитики, по мере развития сотрудничества двух компаний всё больше провайдеров облачных услуг будет проявлять интерес к работе с MediaTek. Внедрение NVLink в ASIC MediaTek может значительно повысить привлекательность сетевых решений NVIDIA. Объединив усилия, NVIDIA и MediaTek смогут предложить комплексную разработку кастомных ASIC, которая будет включать поддержку HBM4e, обширную библиотеку IP-блоков, передовые процессы производства и упаковки. MediaTek отдельно подчеркнула, что её SerDes-блоки является ключевым преимуществом при разработке ASIC. 
Источник изображения: MediaTek Компании расширяют сотрудничество с ведущими мировыми производствами полупроводников, ориентируясь на передовые техпроцессы. Применяя технологию совместной оптимизации проектирования (DTCO), они стремятся достичь оптимального соотношения между производительностью, энергопотреблением и площадью (PPA). Сообщается, что несколько облачных провайдеров уже изучают объединённое IP-портфолио NVIDIA и MediaTek. 
Источник изображения: MediaTek По неофициальным данным, Google уже прибегла к услугам MediaTek при разработке 3-нм TPU седьмого поколения, которое поступит в массовое производство к III кварталу 2026 года. Ожидается, что переход на 3-нм процесс принесет MediaTek более $2 млрд дополнительных поступлений. По данным источников в цепочке поставок, восьмое поколение TPU перейдёт на 2-нм процесс TSMC, что вновь укрепит позиции MediaTek. Также прогнозируется, что предстоящий выход чипа GB10 совместной разработки NVIDIA и MediaTek, и долгожданного чипа N1x, значительно улучшат бизнес-операции MediaTek и ещё больше укрепят позиции компании в полупроводниковой отрасли. Эксперты отрасли считают, что MediaTek имеет все возможности для того, что стать ключевым бенефициаром роста спроса на ИИ-технологии, особенно для малых и средних предприятий.
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 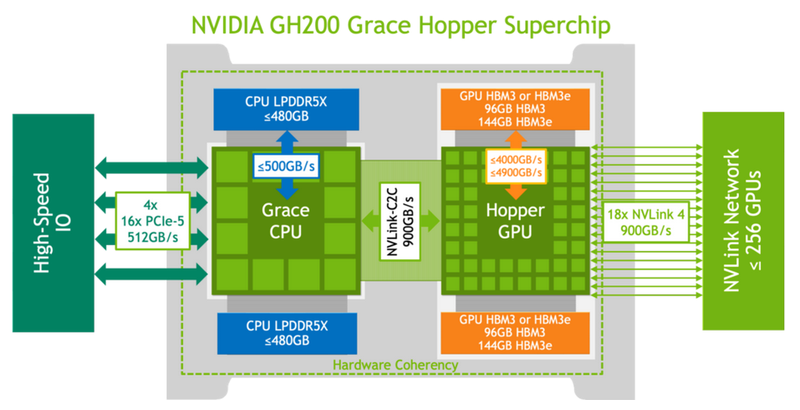
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 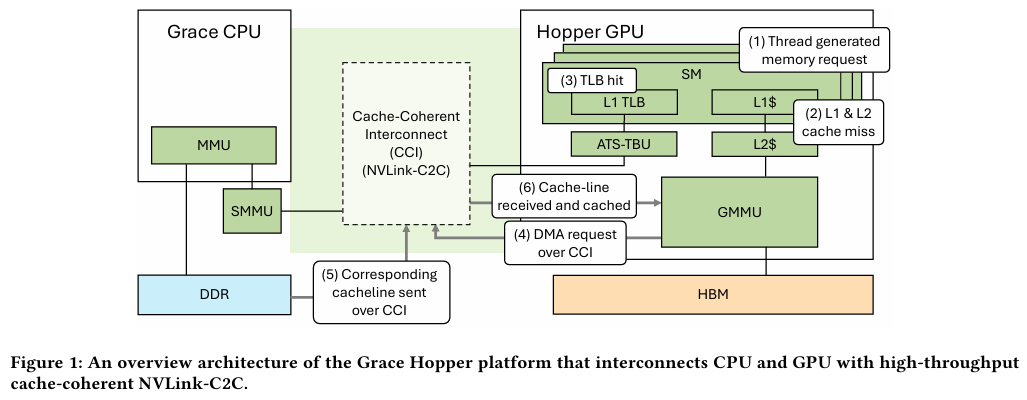
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 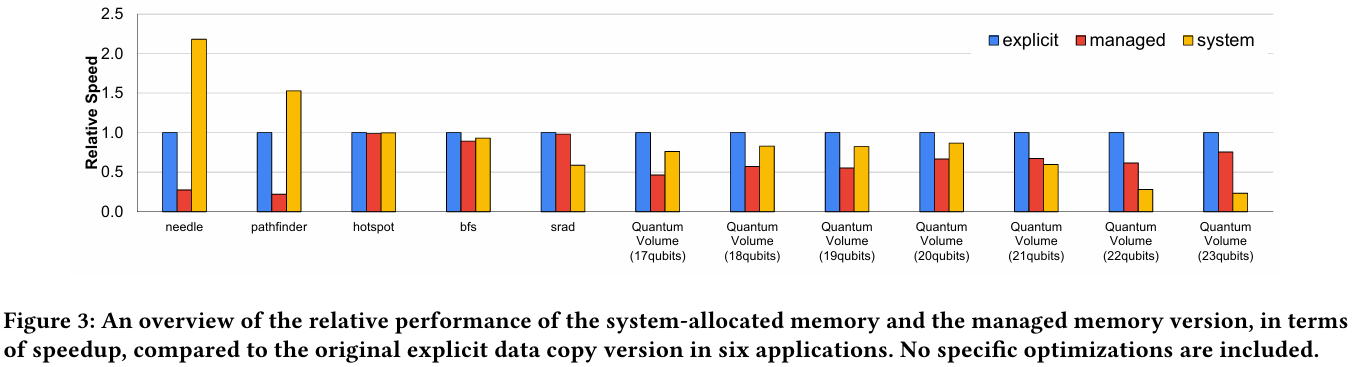
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 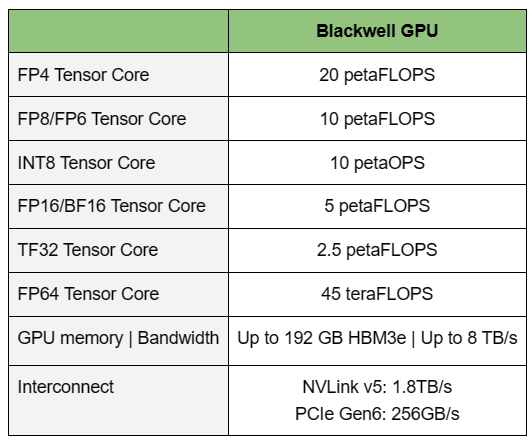 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений.  Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 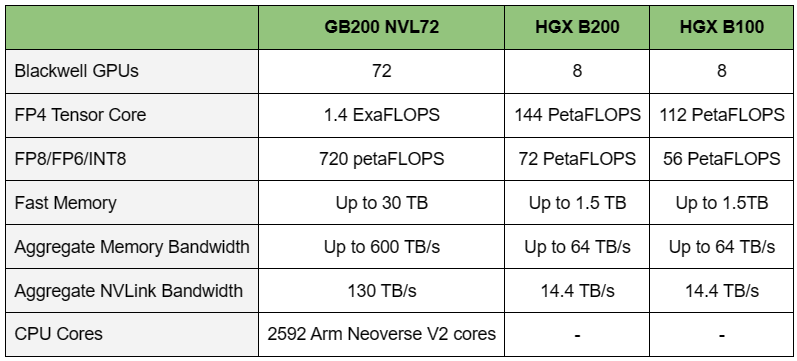 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку, оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла. 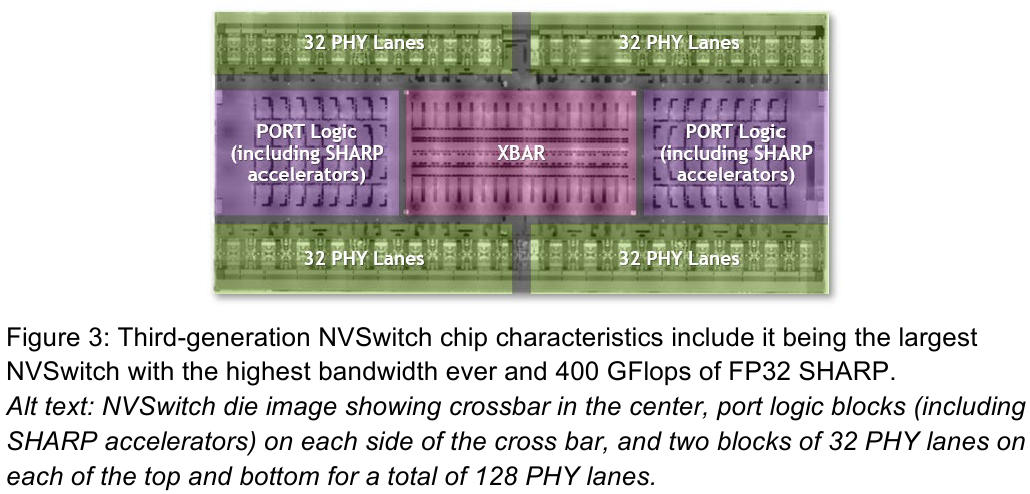 Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с). 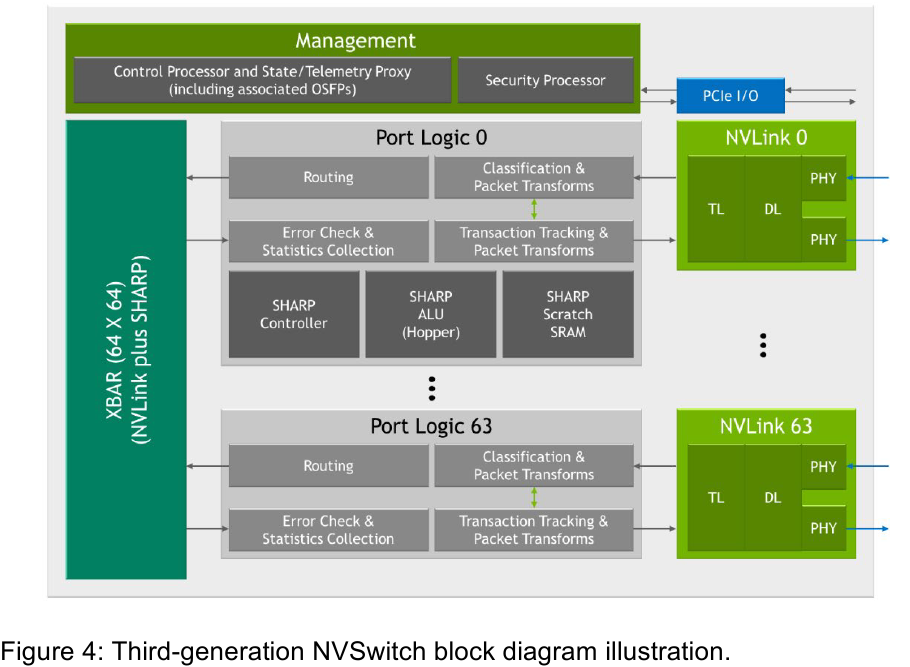 При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 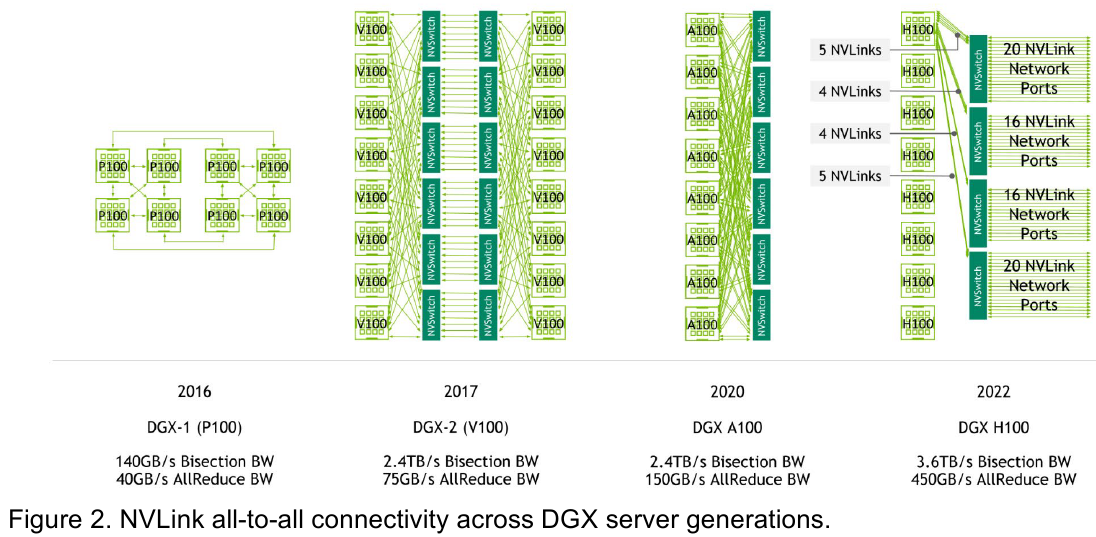 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 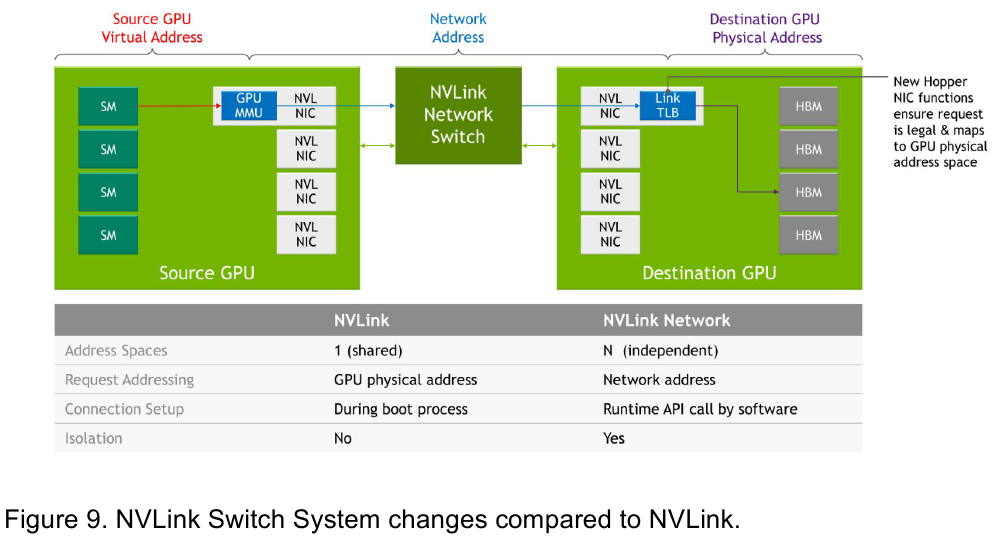 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым. |
|