Материалы по тегу: ocp
|
22.09.2025 [16:44], Сергей Карасёв
OpenYard представила российский GPU-сервер HN203I на базе Intel Xeon 6Российский разработчик и производитель серверного оборудования OpenYard сообщил о создании флагманской системы HN203I на аппаратной платформе Intel Xeon 6. Сервер выполнен в формате 2OU в соответствии со стандартом Open Rack v3.0 (опционально Open Rack v2.2). «HN203I — это технологический скачок для российской серверной индустрии. Мы создаём флагманскую платформу, которая сочетает в себе максимальную производительность, энергоэффективность и простоту эксплуатации», — говорит компания. Возможна установка двух процессоров Intel Xeon 6700E (Sierra Forest-SP) или Xeon 6500P/6700P (Granite Rapids-SP) с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5 с поддержкой изделий RDIMM ёмкостью до 128 Гбайт и 3DS RDIMM ёмкостью до 256 Гбайт. Таким образом, максимальный объём ОЗУ составляет 8 Тбайт. В оснащение входят восемь слотов PCIe 5.0 x16 MCIO и три слота PCIe 5.0 x4 MCIO, разъём OCP 3.0 (PCIe 5.0 x16), два коннектора M.2 M-Key (PCIe 5.0 x2 и PCIe 5.0 x4), а также разъём M.2 Key E (PCIe 5.0 x1). Допускается монтаж десяти SFF-накопителей (NVMe) с возможностью горячей замены и четырёх LFF-устройств с интерфейсом SATA/SAS. Кроме того, могут быть установлены до четырёх PCIe-ускорителей NVIDIA H100/L40/L40S/L4. 
Источник изображения: OpenYard Модель HN203I располагает контролером ASPEED AST2600, двумя сетевыми портами управления RJ45 (по одному спереди и сзади), двумя портами USB 3.0 Type-A, интерфейсом mini-DP. Применено воздушное охлаждение, а диапазон рабочих температур простирается от +10 до +40 °C. Максимальная мощность блоков питания — 5500 Вт. Габариты составляют 537 × 801,6 × 93 мм. Управление осуществляется через BIOS OpenYard и систему OYBMC. Сервер подходит для ИИ-нагрузок, облачных сервисов, телеком-задач и гиперскейл-инфраструктуры.
22.09.2025 [11:40], Сергей Карасёв
Arista проектирует коммутаторы с СЖО для ИИ ЦОДКомпания Arista, по сообщениям интернет-источников, поделилась планами по созданию оборудования для дата-центров. В разработке в числе прочего находятся коммутаторы и серверные стойки с жидкостным охлаждением. Как рассказал соучредитель Arista Андреас Бехтольшайм (Andreas Bechtolsheim), проектируемые коммутаторы будут на 100 % использовать СЖО. Это, как ожидается, обеспечит экономию электроэнергии на системном уровне от 5 % до 10 % в зависимости от температуры и повысит надёжность из-за отсутствия вибраций, вызываемых вентиляторами. NVIDIA уже анонсировала свои коммутаторы с СЖО. Кроме того, разрабатывается серверная стойка стандарта ORv3W, поддерживающая мощность до 120 кВт. Она сможет вместить до 16 2OU-коммутаторов, а также блоки управления, силовые полки и коммутационные панели. Стойка будет оснащена специальными фитингами для развёртывания СЖО и единой шиной питания. 
Источник изображений: Arista По словам Бехтольшайма, значительная часть разработок Arista связана с новыми системами охлаждения. Применение СЖО позволит создавать конфигурации с высокой плотностью размещения коммутаторов. Это важно в свете строительства ЦОД нового поколения, ориентированных на ресурсоёмкие задачи ИИ и НРС. 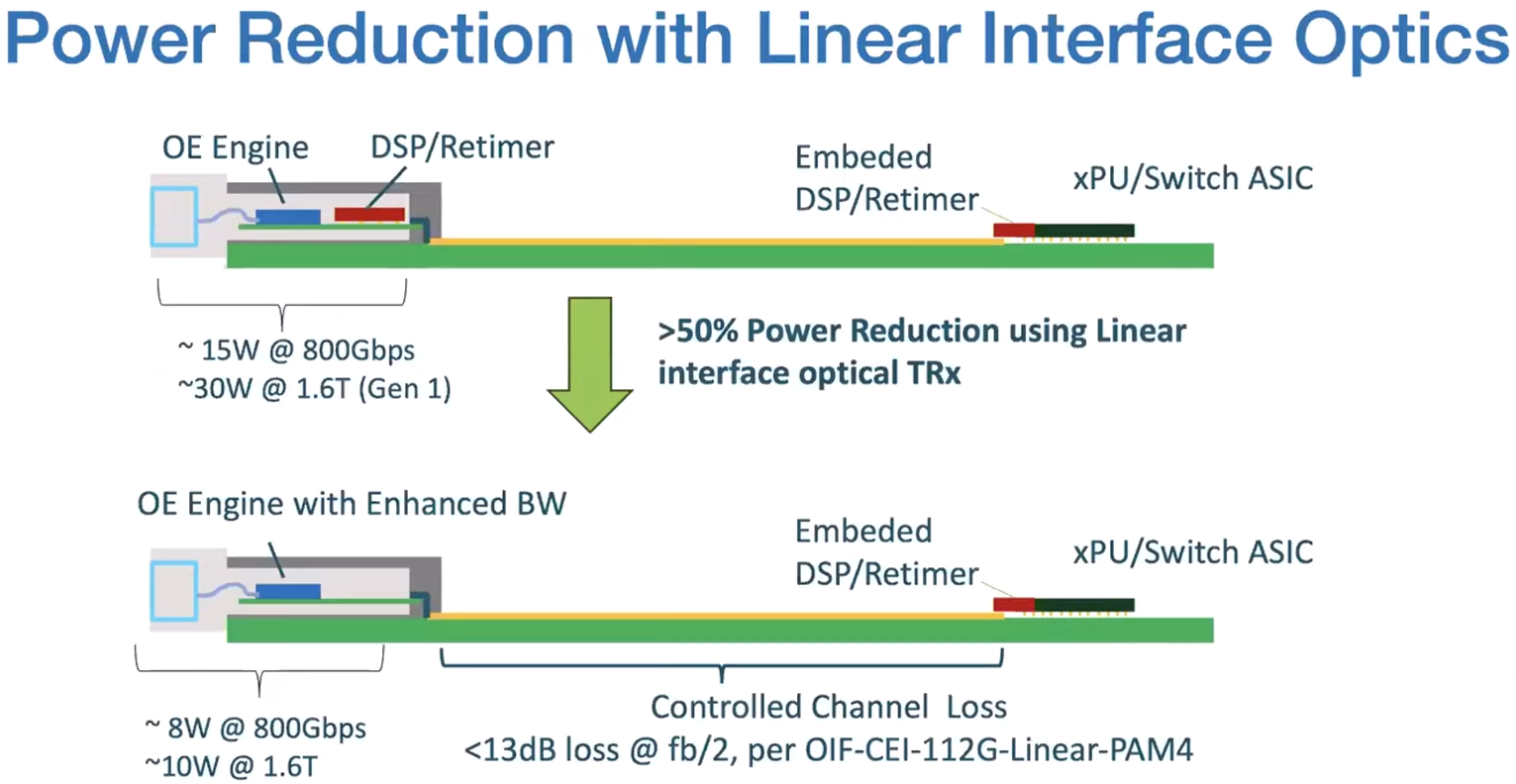 Соучредитель Arista также затронул тему LPO (Linear Pluggable Optics) — технологии, которая позволяет формировать прямые соединения между оптоволоконными модулями, устраняя необходимость в традиционных компонентах вроде цифровых сигнальных процессоров (DSP). Бехтольшайм отмечает, что LPO может обеспечить дополнительную экономию энергии на 20 % по сравнению с другими оптическими системами. По его мнению, в перспективе данная технология будет востребована в сетях, поддерживающих приложения ИИ.
09.09.2025 [17:50], Сергей Карасёв
Бескабельные серверы и стойки Softbank помогут роботам вытеснить людей из ЦОДКорпорация SoftBank объявила о разработке новой стойки для серверов без кабелей. Это поможет в организации обслуживания ЦОД при помощи специализированных роботов. Стойка упрощает выполнение таких задач, как установка и демонтаж модулей, замена компонентов в случае неисправности и проведение автоматизированных проверок. В современных ЦОД большое количество кабелей внутри серверных стоек является серьёзным препятствием для выполнения тех или иных работ с использованием роботов. Из-за плотной кабельной сети затрудняется точное определение и управление целевым оборудованием в стойке, что негативно отражается на возможностях автоматизации обслуживания. Для решения данной проблемы SoftBank разработала серверную стойку с «бескабельной конструкцией». 
Источник изображений: SoftBank Новинка имеет ширину 19″: она выполнена в соответствии со стандартом OCP ORv3 (Open Rack v3). Говорится о совместимости с системами жидкостного охлаждения. Стойка рассчитана на монтаж серверов общего назначения. Питание подаётся по общей шине на задней стороне стойки. В системе охлаждения используется «слепой разъём», упрощающий соединение магистралей СЖО. Для передачи данных служит оптический интерфейс. Таким образом, при установке серверы могут просто задвигаться в стойку без необходимости подключения кабелей.  В настоящее время SoftBank готовится к тестированию стоек в реальных условиях с использованием специализированных роботов для обслуживания. Проект является частью программы SoftBank по внедрению автоматизации в дата-центре для задач ИИ на острове Хоккайдо, открытие которого запланировано на 2026 финансовый год. Нужно отметить, что робототехнические комплексы для выполнения рутинных задач в ЦОД тестируют и многие другие компании. В их число входят Google, Digital Edge, Digital Realty, Scala Data Centers и Oracle. Правда, пока речь идёт в основном о патрулировании и выполнении некоторых простейших с точки зрения человека операций.
01.09.2025 [23:40], Руслан Авдеев
Meta✴ «растянула» суперускорители NVIDIA GB200 NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждениемДля того, чтобы развернуть в традиционных ЦОД с воздушным охлаждением современные высокоплотные стойки с ИИ-ускорителями, приходится идти на ухищрения. Один из вариантов предложила Meta✴, передаёт Wccftech. Хотя у Meta✴ есть собственный полноценный вариант суперускорителя NVIDIA GB200 NVL72 на базе ORv3-стоек Catalina (до 140 кВт) со встроенными БП и ИБП, компания также разработала также вариант, схожий с конфигурацией NVL36×2, от производства которого NVIDIA отказалась, посчитав его недостаточно эффективным. Ускоритель NVL36×2 задумывался как компромиссный вариант для ЦОД с воздушным охлаждением — одна стойка (плата Bianca, 72 × B200 и 36 × Grace) «растянута» на две. 
Источник изображений: Meta✴ via Wccftech Meta✴ пошла несколько иным путём. Она точно так же использует две стойки, одна конфигурация узлов другая. Если в версии NVIDIA в состав одно узла входят один процессор Grace и два ускорителя B200, то у Meta✴ соотношение CPU к GPU уже 1:1. Все вместе они точно так же образуют один домен с 72 ускорителями, но объём памяти LPDDR5 в два раза больше — 34,6 Тбайт вместо 17,3 Тбайт. Эту пару «обрамляют» четыре стойки — по две с каждый стороны. Для охлаждения CPU и GPU по-прежнему используется СЖО, теплообменники которой находятся в боковых стойках и продуваются холодным воздухом ЦОД. 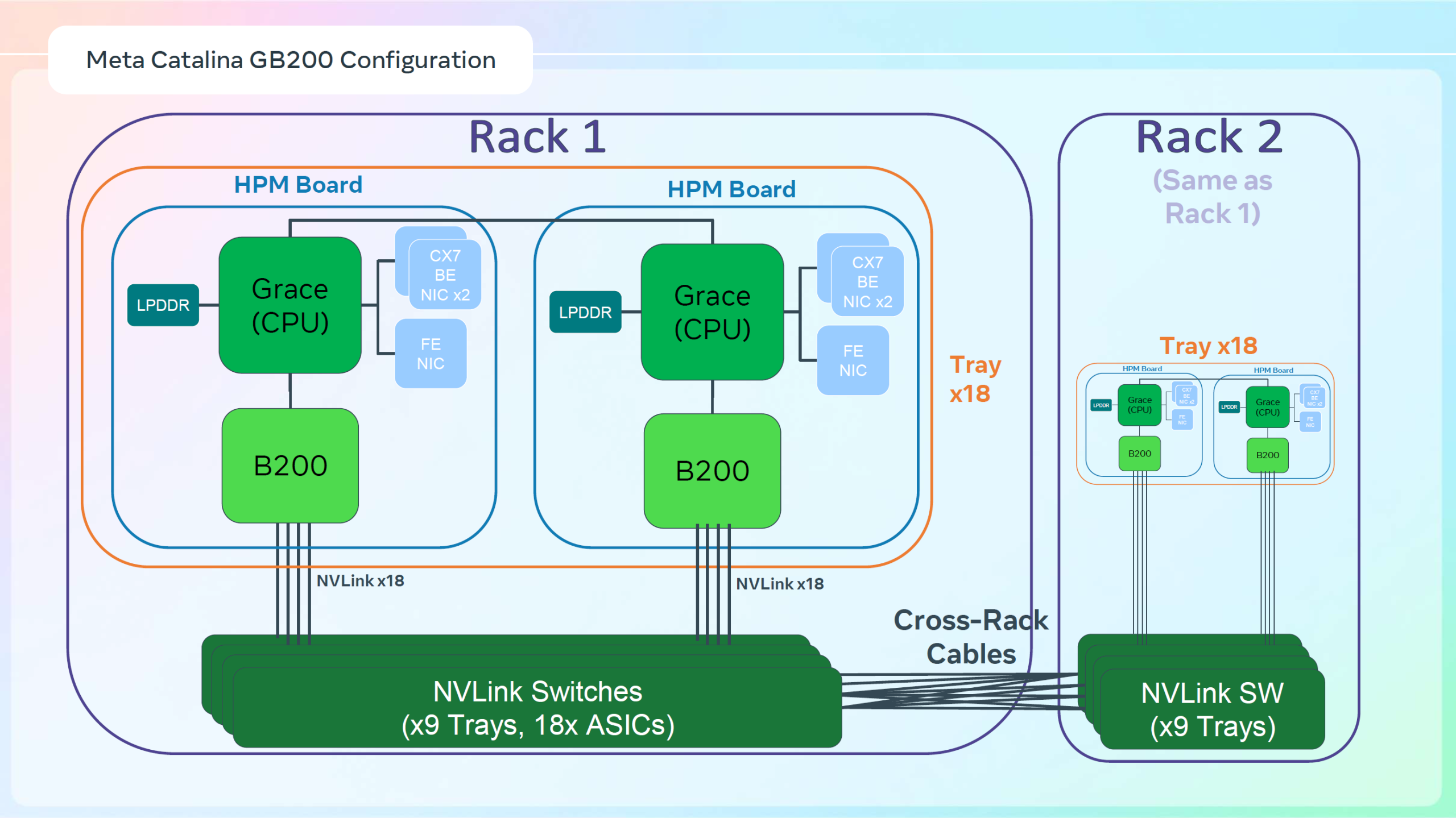 Это далеко не самая эффективная с точки зрения занимаемой площади конструкция, но в случае гиперскейлеров оплата в арендуемых дата-центрах нередко идёт за потребляемую энергию, а не пространство. В случае невозможности быстро переделать собственные ЦОД или получить площадку, поддерживающую высокоплотную энергоёмкую компоновоку стоек и готовую к использованию СЖО, это не самый плохой вариант. В конце 2022 года Meta✴ приостановила строительство около дюжины дата-центров для пересмотра их архитектуры и внедрения поддержки ИИ-стоек и СЖО. Первые ЦОД Meta✴, построенные по новому проекту, должны заработать в 2026 году, передаёт DataCenter Dynamics. 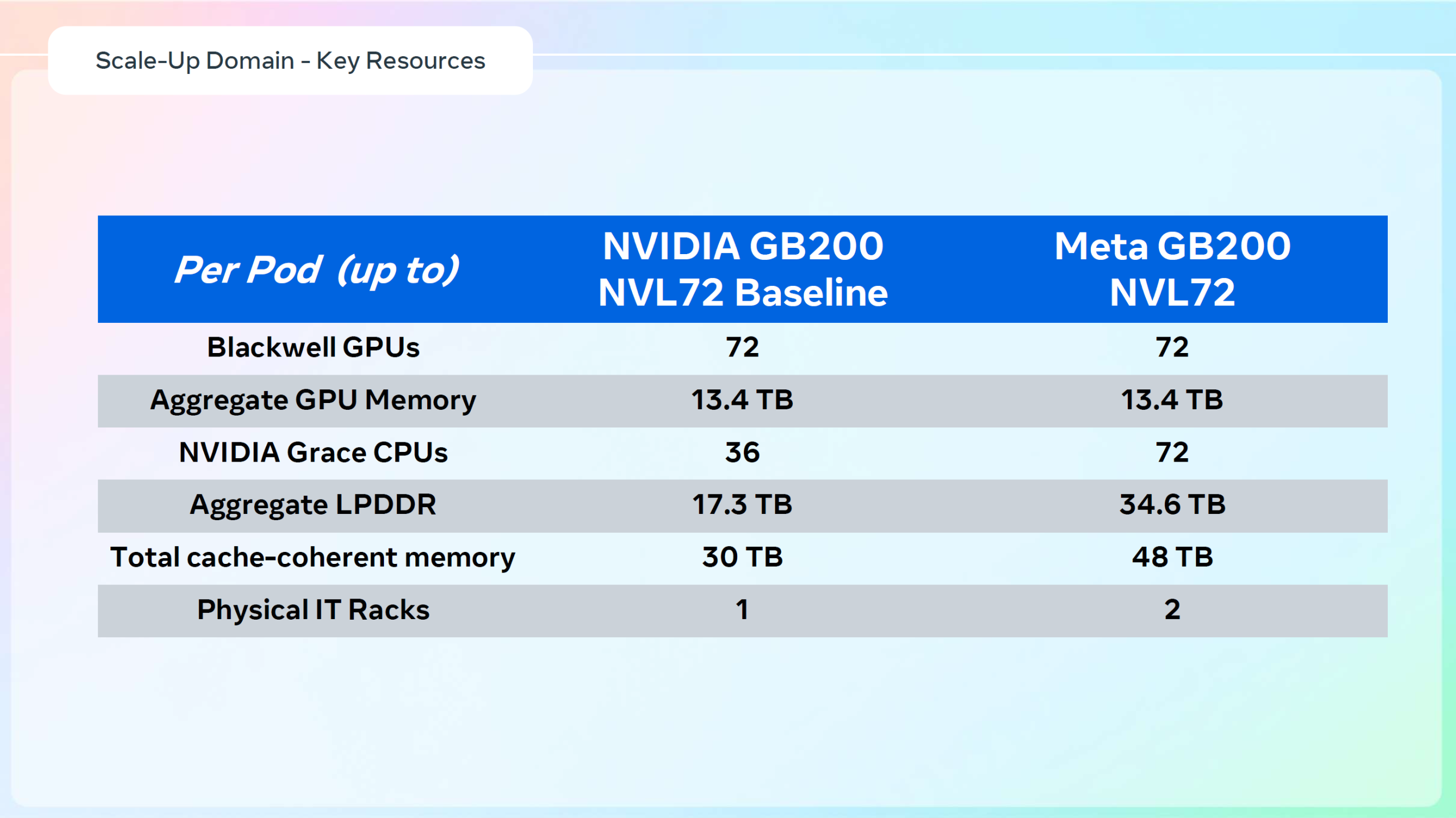 На сегодня у Meta✴ около 30 действующих или строящихся кампусов ЦОД, большей частью на территории США. Планируются ещё несколько кампусов, включая гигаваттные. Также компания выступает крупным арендатором дата-центров, а сейчас в пылу гонки ИИ и вовсе переключилась на быстровозводимые тенты вместо капитальных зданий, лишённые резервного питания и традиционных систем охлаждения.  Собственные версии GB200 NVL72 есть у Google, Microsoft и AWS. Причём все они отличаются от эталонного варианта, который среди крупных игроков, похоже, использует только Oracle. Так, AWS решила разработать собственную СЖО, в том числе из-за того, что ей жизненно необходимо использовать собственные DPU Nitro. Google ради собственного OCS-интерконнекта «пристроила» к суперускорителю ещё одну стойку с собственным оборудованием. Microsoft же аналогично Meta✴ добавила ещё одну стойку с теплообменниками и вентиляторами.
22.08.2025 [16:33], Владимир Мироненко
Почти как у самой NVIDIA: NVLink Fusion позволит создавать кастомные ИИ-платформыТехнологии NVIDIA NVLink и NVLink Fusion позволят вывести производительность ИИ-инференса на новый уровень благодаря повышенной масштабируемости, гибкости и возможностям интеграции со сторонними чипами, которые в совокупности отвечает стремительному росту сложности ИИ-моделей, сообщается в блоге NVIDIA. С ростом сложности ИИ-моделей выросло количество их параметров — с миллионов до триллионов, что требует для обеспечения их работы значительных вычислительных ресурсов в виде кластеров ускорителей. Росту требований, предъявляемых к вычислительным ресурсам, также способствует внедрение архитектур со смешанным типом вычислений (MoE) и ИИ-алгоритмов рассуждений с масштабированием (Test-time scaling, TTS). NVIDIA представила интерконнект NVLink в 2016 году. Пятое поколение NVLink, вышедшее в 2024 году, позволяет объединить в одной стойке 72 ускорителя каналами шириной 1800 Гбайт/с (по 900 Гбайт/с в каждую сторону), обеспечивая суммарную пропускную способность 130 Тбайт/с — в 800 раз больше, чем у первого поколения.  Производительность NVLink зависит от аппаратных средств и коммуникационных библиотек, в частности, от библиотеки NVIDIA Collective Communication Library (NCCL) для ускорения взаимодействия между ускорителями в топологиях с одним и несколькими узлами. NCCL поддерживает вертикальное и горизонтальное масштабирование, а также включает в себя автоматическое распознавание топологии и оптимизацию передачи данных. 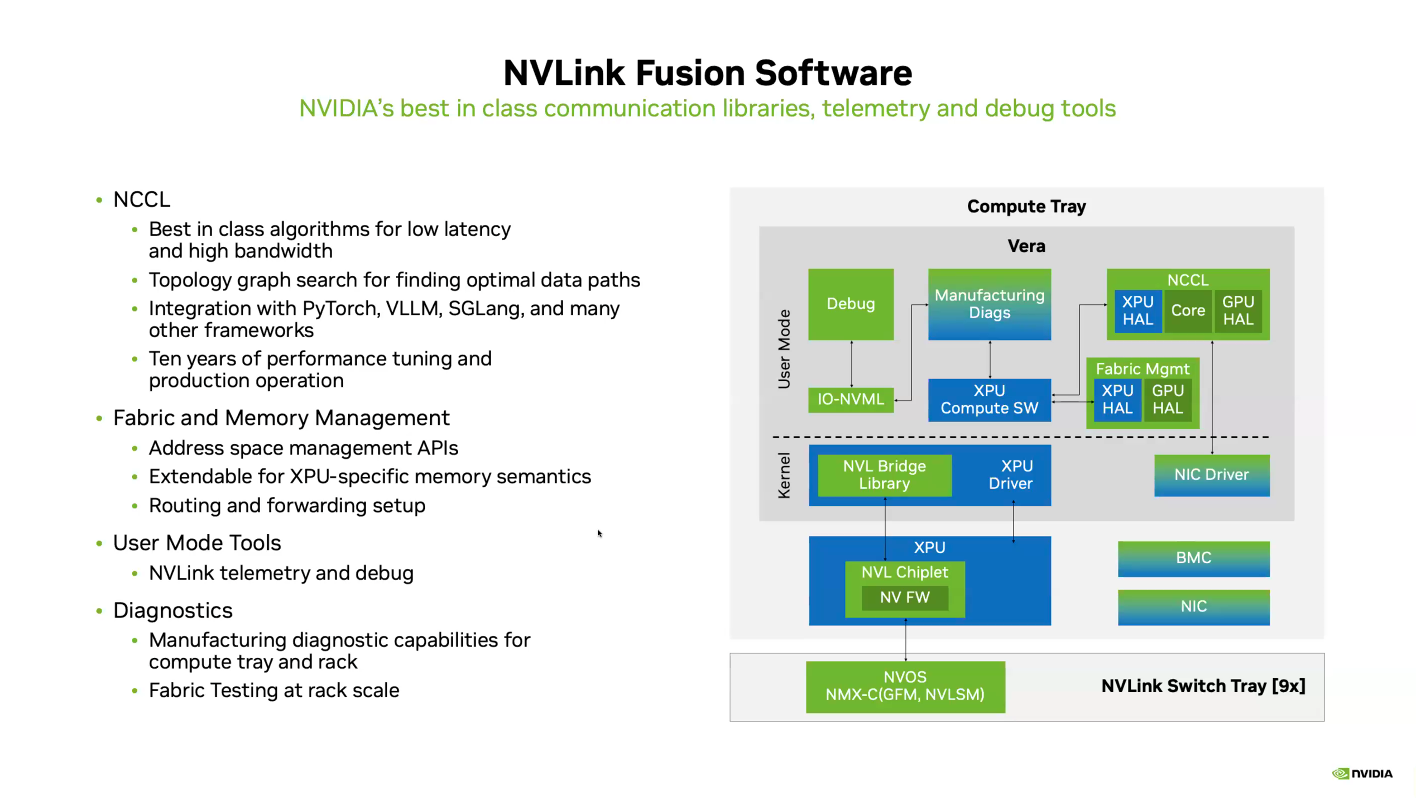 Технология NVLink Fusion призвана обеспечить гиперскейлерам доступ ко всем проверенным в производстве технологиям масштабирования NVLink. Она позволяет интегрировать кастомные микросхемы (CPU и XPU) с технологией вертикального и горизонтального масштабирования NVIDIA NVLink и стоечной архитектурой для развёртывания кастомных ИИ-инфраструктур. 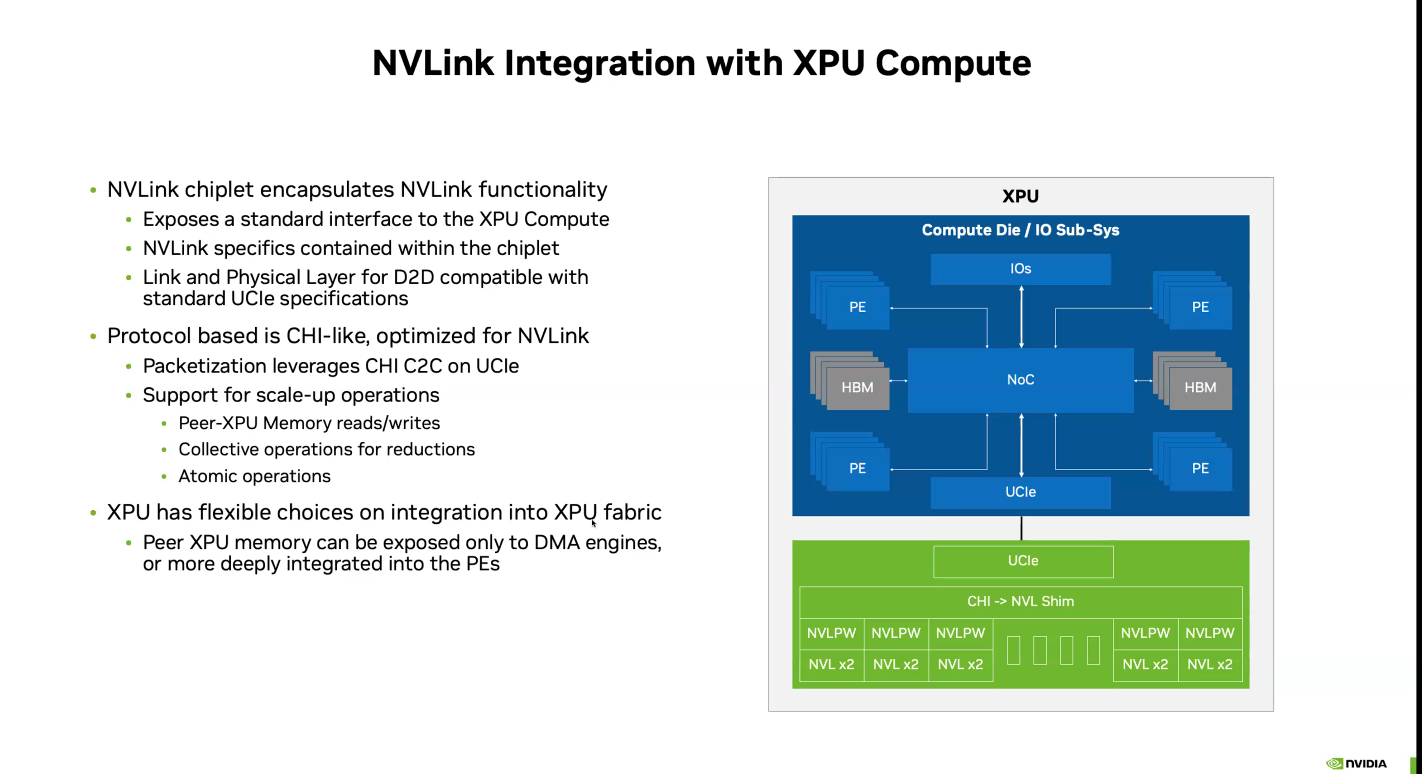 Технология охватывает NVLink SerDes, чиплеты, коммутаторы и стоечную архитектуру, предлагая универсальные решения для конфигураций кастомных CPU, кастомных XPU или комбинированных платформ. Модульное стоечное решение OCP MGX, позволяющее интегрировать NVLink Fusion с любым сетевым адаптером, DPU или коммутатором, обеспечивает заказчикам гибкость в построении необходимых решений, заявляет NVIDIA. 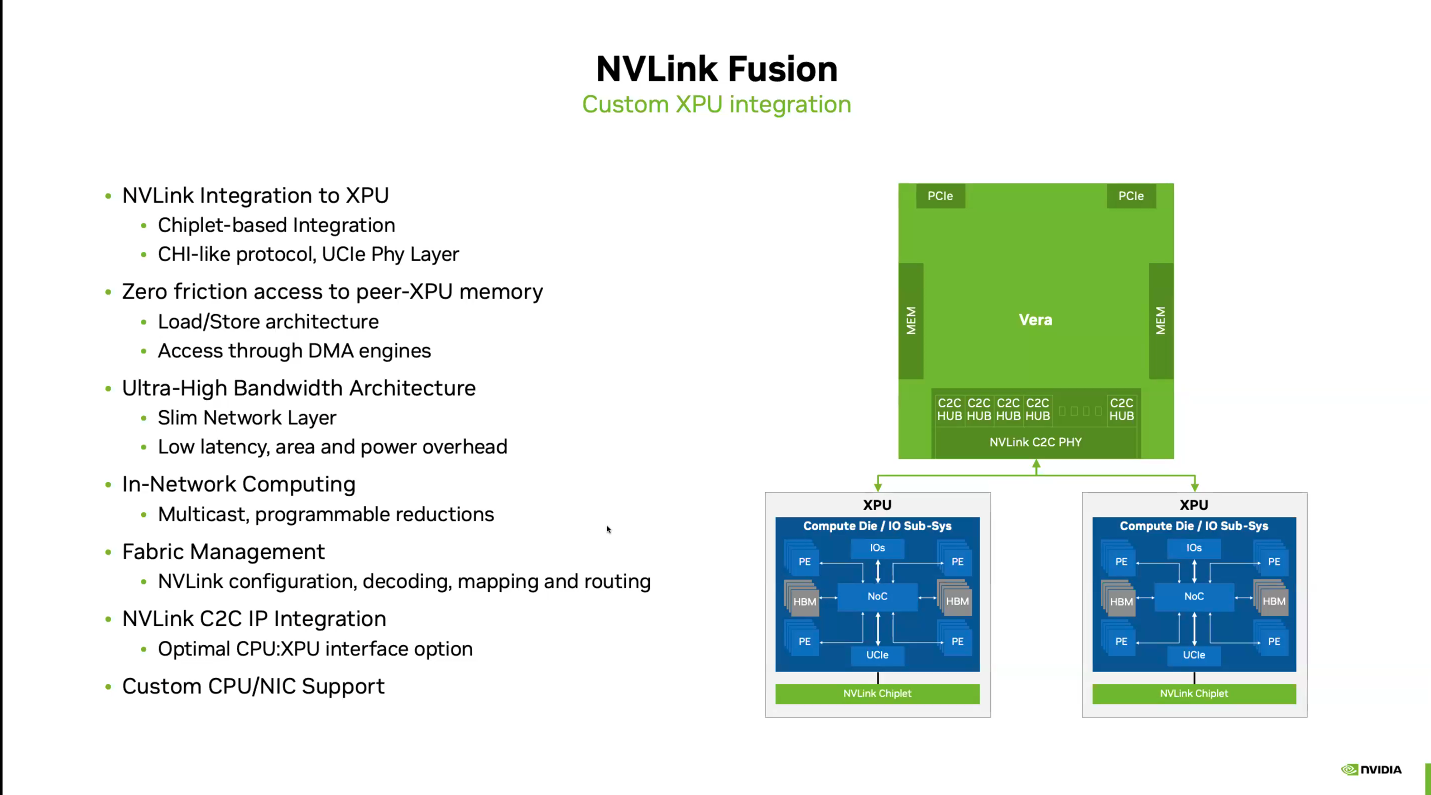 NVLink Fusion поддерживает конфигурации с кастомными CPU и XPU с использованием IP-блоков и интерфейса UCIe, предоставляя заказчикам гибкость в реализации интеграции XPU на разных платформах. Для конфигураций с кастомными CPU рекомендуется интеграция с IP NVLink-C2C для оптимального подключения и производительности GPU. При этом предлагаются различные модели доступа к памяти и DMA. 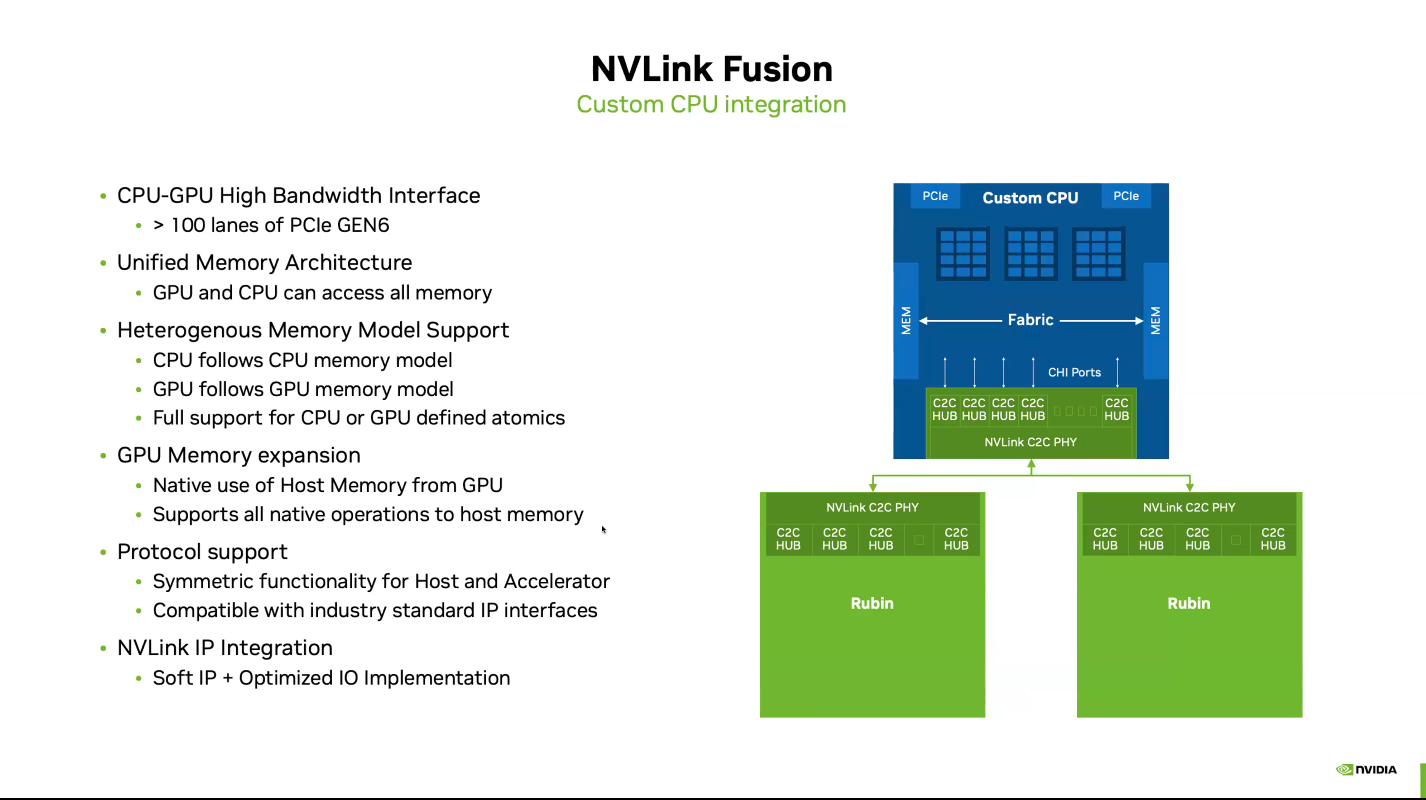 NVLink Fusion использует преимущества обширной экосистемы кремниевых чипов, в том числе от партнёров по разработке кастомных полупроводников, CPU и IP-блоков, что обеспечивает широкую поддержку и быструю разработку новых решений. Основанная на десятилетнем опыте использования технологии NVLink и открытых стандартах архитектуры OCP MGX, платформа NVLink Fusion предоставляет гиперскейлерам исключительную производительность и гибкость при создании ИИ-инфраструктур, подытожила NVIDIA.  При этом основным применением NVLink Fusion с точки зрения NVIDIA, по-видимому, должно стать объединение сторонних чипов с её собственными, а не «чужих» чипов между собой. Более открытой альтернативой NVLink должен стать UALink с дальнейшим масштабированием посредством Ultra Ethernet.
06.08.2025 [15:23], Руслан Авдеев
Meta✴ заказала ИИ-серверы Santa Barbara с кастомными ASICMeta✴ разместила заказ на поставку ИИ-серверов нового поколения на базе ASIC-модулей у тайваньского производителя Quanta Computer. Компания заказала до 6 тыс. стоек и намерена начать развёртывание серверов Santa Barbara к концу 2025 года, сообщает Datacenter Dynamics. Новые серверы заменят существующие решения Minerva. В отчёте также указано, что серверы нового поколения будут иметь TDP более 180 кВт и потребуют тщательно кастомизированных корпусов, систем водяного охлаждения и других компонентов. Все компоненты будут поставляться компанией SynMing Electronics. По данным отчёта, поставкой ASIC займётся Broadcom, а сборкой серверов — Quanta Computer. Окончательный дизайн будет утверждён в текущем квартале, а пробное производство начнётся в IV квартале 2025 года. Как сообщают «источники в цепочке поставок», IT-гигант завершил разработки проектных решений для двух–трёх новых серверов с кастомными ИИ-ускорителями. Хотя прямо ASIC не упоминается, Meta✴ давно работает над собственными ИИ-чипами Meta✴ Training and Inference Accelerator (MTIA), которые разрабатываются с 2023 года. Компания рассчитывает внедрить чипы в собственные дата-центры, чтобы снизить зависимость от NVIDIA. 
Источник изображения: UX Indonesia/unspalsh.com С началом бума генеративного ИИ Meta✴ стремится расширить серверную ИИ-инфраструктуру и самостоятельно разрабатывать ASIC. В феврале 2024 года компания, похоже, искала специалистов по ASIC-решениям, размещая объявления о поиске соответствующих сотрудников в Индии и Калифорнии. В марте 2025 года южнокорейская FuriosaAI, занимающийся разработкой микросхем, отклонила предложение Meta✴ о покупке бизнеса за $800 млн. На прошлой неделе были опубликованы результаты за II квартал 2025 года, согласно которым выручка составила $47,5 млрд, что на 22 % больше по сравнению с аналогичным периодом прошлого года. Прибыль компании выросла на 36 %, составив $18,3 млрд за три месяца, заканчивающиеся 30 июня, но расходы Meta✴ также увеличились на 12 %, до $27 млрд, что связано с ростом затрат на дата-центры, серверы и исследователей в области ИИ. На пресс-конференции, посвящённой финансовым результатам компании, было объявлено, что наибольшая часть капитальных затрат в будущем будет направлена на серверы. Также было заявлено, что компания всё ещё решает, когда будут развёртываться новые мощности.
26.07.2025 [15:54], Сергей Карасёв
OCP запустила проект OCS по развитию оптической коммутации в ИИ ЦОДНекоммерческая организация Open Compute Project Foundation (OCP) анонсировала проект Optical Circuit Switching (OCS), направленный на ускорение внедрения технологий фотонной (оптической) коммутации в ИИ ЦОД. Цель инициативы — повышение пропускной способности, снижение задержек и улучшение энергоэффективности инфраструктур с интенсивным обменом данными. Проект возглавляют iPronics и Lumentum, а в число его участников входят Coherent, Google, Lumotive, Microsoft, nEye, NVIDIA, Oriole Networks и Polatis (Huber+Suhner). Нужно отметить, что разработкой фотонных решений для высоконагруженных платформ ИИ и дата-центров занимаются многие компании. В их число входят DustPhotonics, Oriole Networks, Lightmatter, Celestial AI, Xscape Photonics, Ayar Labs и пр. 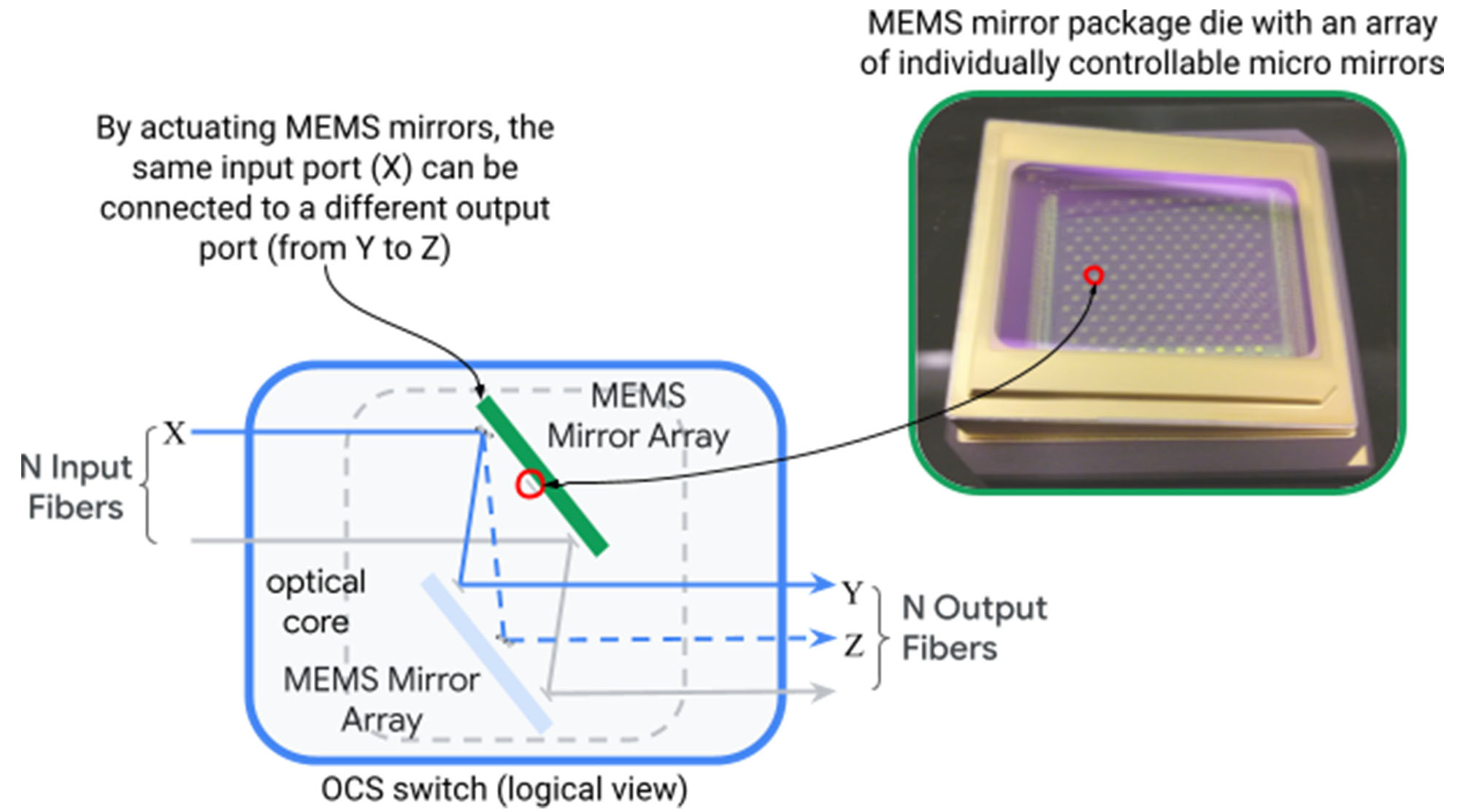
Источник изображений: Google В отличие от традиционной электрической коммутации, решение OCS базируется на оптической маршрутизации данных. Новый интерконнект планируется использовать в кластерах ИИ, поддерживающих ресурсоёмкие нагрузки, включая генеративные сервисы и большие языковые модели (LLM). Предполагается, что проект OCS позволит создать масштабируемое и надёжное решение для обработки больших объёмов данных, поддерживающее бесшовную интеграцию с различными сетевыми протоколами. Упомянута совместимость с такими программными фреймворками, как gNMI, gNOI, gNSI и OpenConfig. 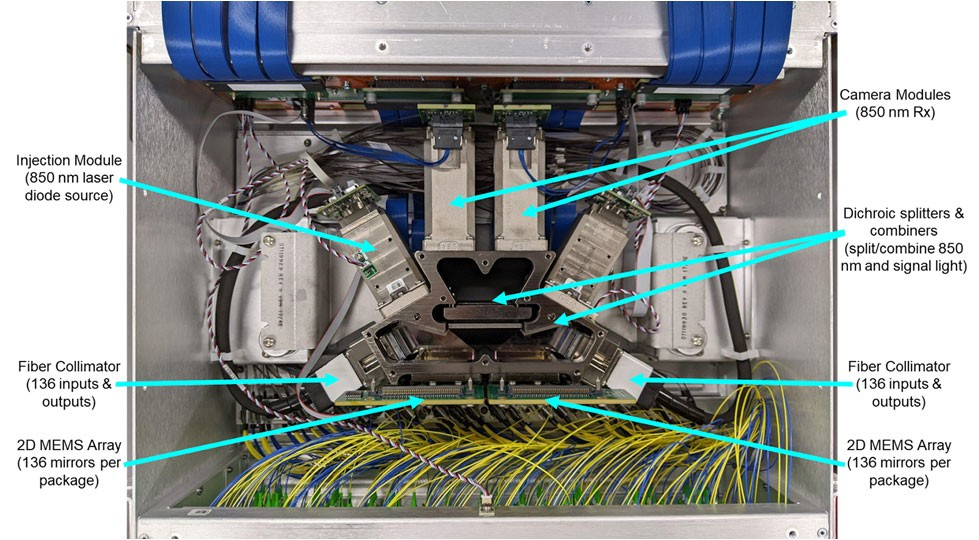 В заявлении OCP говорится, что инициатива OCS будет способствовать сотрудничеству между ведущими игроками отрасли, гиперскейлерами и поставщиками для создания совместимых открытых продуктов, которые помогут стимулировать инновации в области оптических сетей. В частности, планируется выпуск компактных и гибко настраиваемых оптических коммутаторов для ИИ ЦОД. На практике оптическую коммутацию массово использует, по-видимому, только Google. В 2022 году компания рассказала об OCS Apollo, которые используют MEMS-переключатели для перенаправления лучей света. Эти коммутаторы обслуживают кластеры TPU.
01.06.2025 [02:06], Сергей Карасёв
Петабайтные E2 SSD готовы со временем потеснить HDD в ЦОДОрганизации Storage Networking Industry Association (SNIA) и Open Compute Project (OCP), по сообщению ресурса StorageReview, разработали новый форм-фактор твердотельных накопителей, получивший обозначение E2. Устройства данного типа будут обладать большой вместимостью, достигающей 1 Пбайт. Для сравнения, Seagate поставила себе цель довести ёмкость HDD до 100 Тбайт к 2030 году, тогда как Pure Storage уже подготовила 150-Тбайт SSD. Стандарт E2 создаётся для «тёплого» хранения данных. Устройства нового формата займут промежуточное положение между HDD большой ёмкости и традиционными корпоративными SSD. Предполагается, что изделия E2 обеспечат оптимальный баланс производительности, плотности и стоимости при развёртывании крупномасштабных озёр данных для приложений ИИ, аналитики и других задач, которым требуются огромные массивы информации. Добиться этого планируется путём использования большого количества чипов QLC NAND в одном накопителе. 
Источник изображения: OCP / Micron Физические размеры накопителей E2 составляют 200 мм в длину, 76 мм в высоту и 9,5 мм в толщину. Применяется коннектор EDSFF, который также используется в устройствах E1 и E3. Отмечается, что по высоте SSD и расположению разъёма (27,7 мм от нижней части) формат E2 соответствуют стандарту E3, тогда как размещение светодиодного индикатора идентично E1. 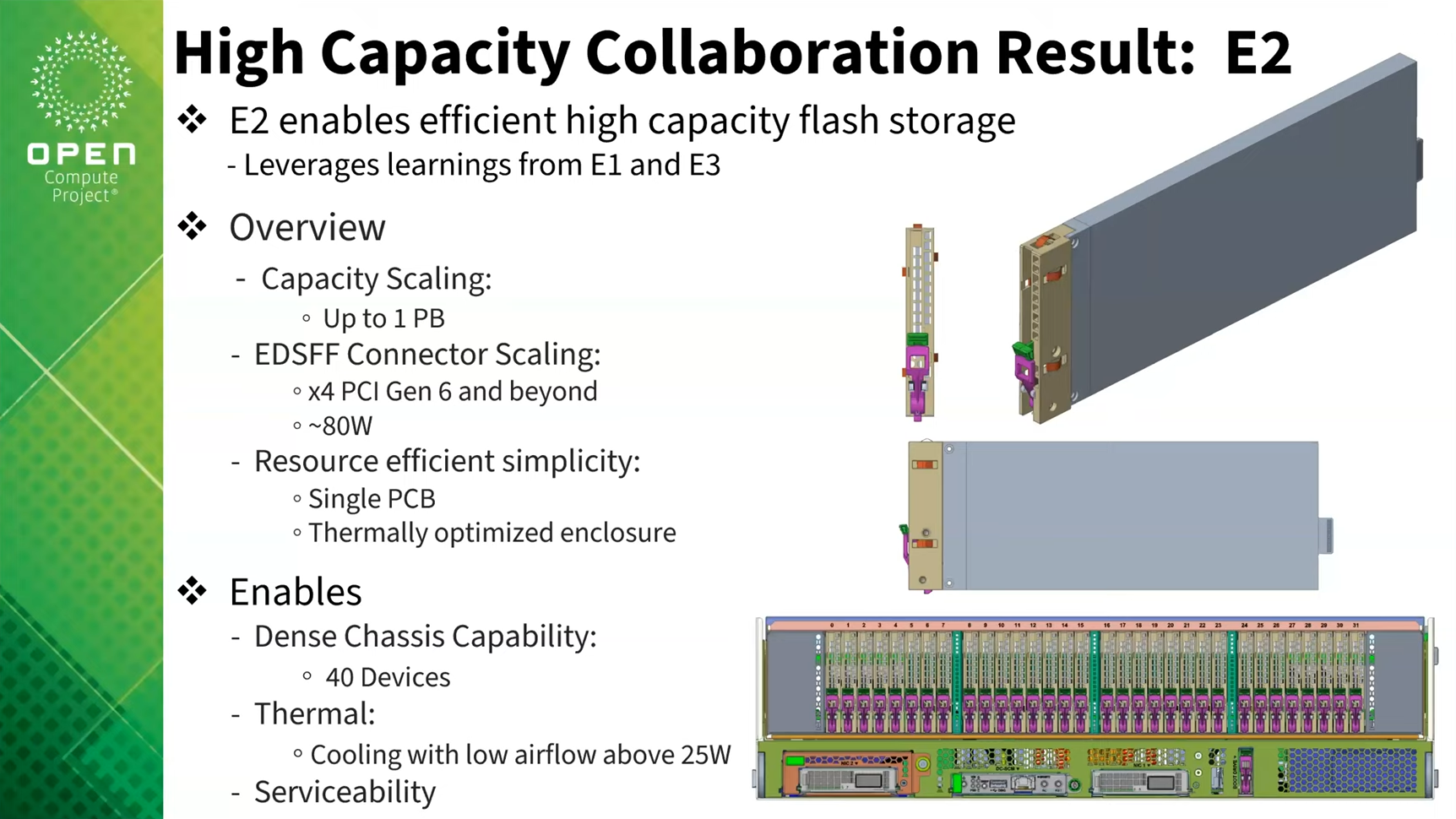
Источник изображения: OCP / Meta✴ Изделия нового типа предназначены прежде всего для установки в серверы с высокой плотностью компоновки. В этом случае система типоразмера 2U сможет нести на борту до 40 устройств E2, что в сумме даст до 40 Пбайт пространства для хранения данных. Новый стандарт предусматривает подключение посредством интерфейса PCIe 6.0 или выше с четырьмя линиями. 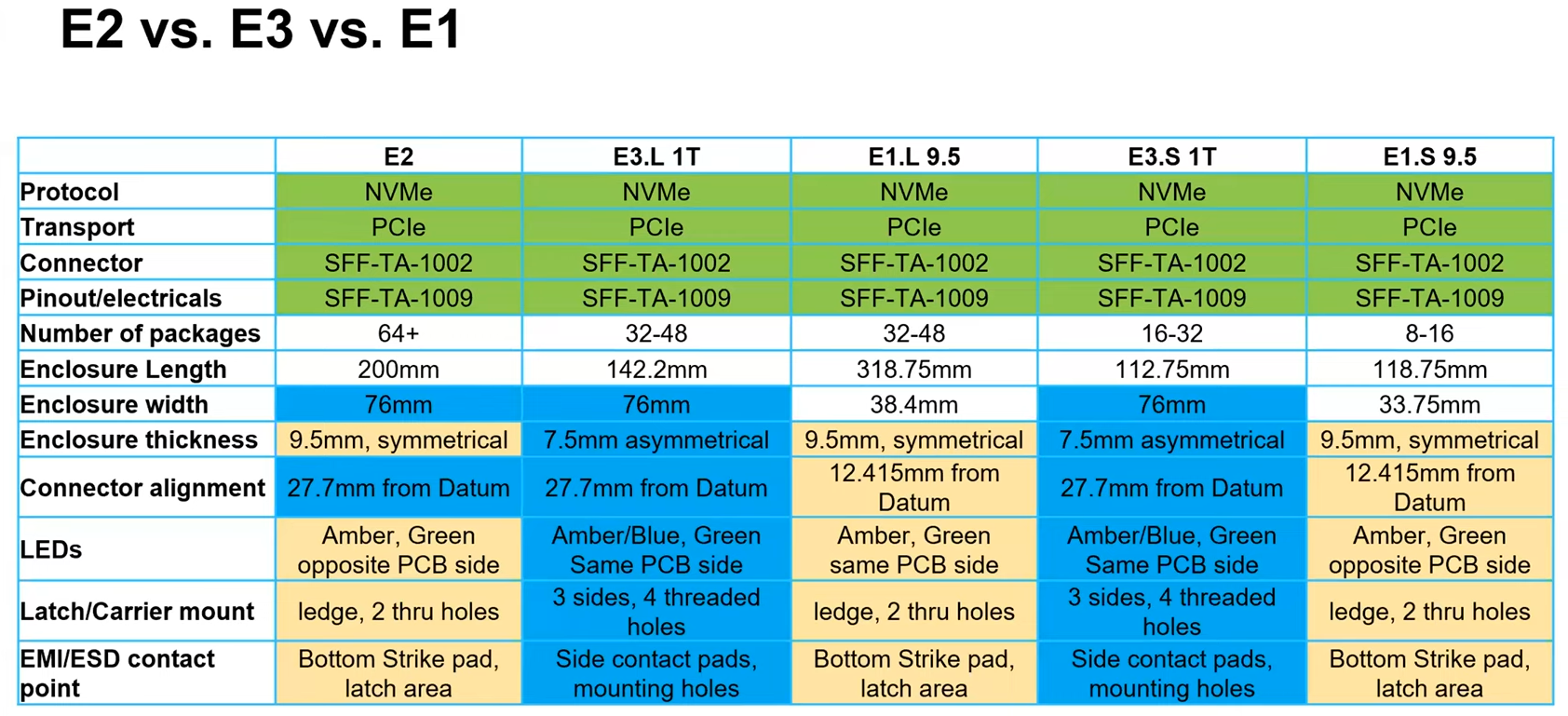
Источник изображения: OCP / Pure Storage Заявленная скорость передачи информации может достигать 10 000 Мбайт/с в расчёте на один накопитель. Энергопотребление — до 80 Вт: это означает, что в сервере с 40 такими накопителями только для подсистемы хранения данных потребуется мощность до 3,2 кВт. Таким образом, понадобится эффективное охлаждение — по всей видимости, на основе жидкостных систем. Первая версия спецификации E2 будет готова летом нынешнего года. Значительный вклад в разработку стандарта вносит Micron, которая будет использовать его в своих будущих SSD. Pure Storage и Micron представили прототипы E2 в ходе мероприятия OCP Storage Tech Talk. Проприетарные SSD-модули, отчасти напоминающие E2, уже начали медленно и выборочно вытеснять HDD из дата-центров Meta✴. На подходе и другие гиперскейлеры.
02.05.2025 [13:55], Сергей Карасёв
MSI представила многоузловые OCP-серверы на базе AMD EPYC 9005 TurinКомпания MSI анонсировала многоузловые серверы высокой плотности, выполненные в соответствии со стандартом OCP ORv3 (Open Rack v3). Дебютировали модели Open Compute CD281-S4051-X2 и Core Compute CD270-S4051-X4 на аппаратной платформе AMD EPYC 9005 Turin. Решение Open Compute CD281-S4051-X2, выполненное в форм-факторе 2OU, представляет собой двухузловой сервер для инфраструктур гиперскейлеров. Каждый узел может оснащаться одним процессором EPYC 9005 с показателем TDP до 500 Вт и 12 модулями DDR5. Доступны до 12 посадочных мест для накопителей E3.S с интерфейсом PCIe 5.0 (NVMe). Говорится о поддержке CPU-радиаторов Extended Volume Air Cooling (EVAC) и 48-вольтной архитектуры питания ORv3 (48VDC). 
Источник изображений: MSI В свою очередь, Core Compute CD270-S4051-X4 (S4051D270RAU3-X4) — это четырёхузловой сервер стандарта Data Center Modular Hardware Systems (DC-MHS). Устройство имеет типоразмер 2U. Оно подходит для облачных вычислений, CDN-сетей, ИИ-инференса и машинного обучения, виртуализации сетевых функций, телеком-приложений и пр.  Каждый узел новинки рассчитан на один чип EPYC 9005 с TDP до 400 Вт. Есть 12 слотов для модулей DDR5-6000 RDIMM/RIMM-3DS суммарным объёмом до 3 Тбайт, три фронтальных отсека для накопителей U.2 с интерфейсом PCIe 5.0 x4 (NVMe), два внутренних коннектора M.2 2280/22110 для SSD с интерфейсом PCIe 3.0 x2 (NVMe), а также слот PCIe 5.0 x16 OCP 3.0. Кроме того, каждый узел располагает контроллером ASPEED AST2600, сетевым портом управления 1GbE, разъёмами USB 2.0 Type-A и Mini DisplayPort, последовательным портом (USB Type-A). Вся система Core Compute CD270-S4051-X4 оборудована двумя блоками питания мощностью 2700 Вт с сертификатом 80 PLUS Titanium. Установлены четыре вентилятора охлаждения с возможностью горячей замены. Диапазон рабочих температур — от 0 до +35 °C. Габариты составляют 448 × 87 × 747 мм.
02.05.2025 [13:50], Сергей Карасёв
MiTAC анонсировала OCP-серверы на основе AMD EPYC Turin с воздушным и жидкостным охлаждением, а также edge-сервер на базе Intel Xeon Sapphire RapidsКомпания MiTAC Computing Technology представила OCP-серверы нового поколения C2810Z5 и C2820Z5, предназначенные для приложений ИИ и НРС. Устройства выполнены на аппаратной платформе AMD EPYC 9005 Turin. Решение C2810Z5 типоразмера 2OU имеет двухузловую конструкцию. Каждый узел допускает установку одного процессора и 12 модулей оперативной памяти DDR5-6400. Доступны шесть отсеков для накопителей U.2 и два посадочных места для SSD стандарта E1.S. Предусмотрены слоты PCIe 5.0 x16 для карт FHHL, HHHL и OCP NIC 3.0. Устройство оснащено воздушным охлаждением. Данная модель подходит для развёртывания микросервисов в облачных средах. В свою очередь, вариант C2820Z5 — это четырёхузловая система 2OU с технологией прямого жидкостного охлаждения. Каждый узел поддерживает два процессора EPYC 9005 Turin и 24 модуля памяти DDR5. Сервер подходит для высокопроизводительных вычислений. Кроме того, MiTAC анонсировала семейство серверов Whitestone 2 (WS2): это, как утверждается, компактная, но мощная платформа, специально оптимизированная для сетей Open RAN и периферийных задач. Система выполнена в корпусе небольшой глубины формата 1U. Задействован процессор Intel Xeon поколения Sapphire Rapids. 
Источник изображения: MiTAC Предусмотрены восемь слотов для модулей DDR5. Во фронтальной части находятся четыре порта 25GbE SFP28 и восемь портов 10GbE SFP+. Говорится о поддержке IEEE 1588 v2, Sync-E и GPS для синхронизации. В тыльной части располагаются вентиляторы охлаждения в виде девяти сдвоенных блоков. |
|