Материалы по тегу: grace
|
23.06.2025 [11:58], Сергей Карасёв
Подземный суперкомпьютер Olivia стал самым мощным в НорвегииВ Норвегии введён в эксплуатацию самый мощный в стране суперкомпьютер — система Olivia, созданная корпорацией HPE. Комплекс расположен в дата-центре Лефдаль (Lefdal Mine Datacenter, LMD) на базе бывшего рудника, а для его охлаждения используется холодная вода из близлежащего фьорда. Машина построена на платформе HPE Cray Supercomputing EX (EX254n). В её состав входят 252 узла, каждый из которых содержит два 128-ядерных процессора AMD EPYC 9745 (Turin). В сумме это даёт 64 512 CPU-ядер. Кроме того, задействован GPU-кластер с 76 узлами, оснащёнными четырьмя гибридными суперчипами NVIDIA GH200: таким образом, в общей сложности применены 304 ускорителя. Используется интерконнект HPE Slingshot 11. За хранение данных отвечает система HPE Cray ClusterStor E1000 вместимостью 5,3 Пбайт. В текущей конфигурации GPU-кластер Olivia обладает производительностью 13,2 Пфлопс (FP64) и пиковым быстродействием 16,8 Пфлопс. При этом энергопотребление составляет 219 кВт. Таким образом, машина демонстрирует производительность в 60,274 Гфлопс/Вт. В июньском рейтинге мощнейших суперкомпьютеров мира TOP500 GPU-комплекс Olivia располагается на 117-й позиции, тогда как в списке самых энергоэффективных суперкомпьютеров GREEN500 он занимает 22-ю строку. CPU-блок Olivia занимает 271-е место в рейтинге с фактической и пиковой FP64-производительностью 4,25 и 4,95 Пфлопс соответственно. 
Источник изображения: Sigma2 Olivia эксплуатируется государственной компанией Sigma2. Применять суперкомпьютер планируется для проведения исследований в различных областях, включая изменения климата, здравоохранение, ИИ и пр. Суперкомпьютер обладает возможностями для дальнейшего расширения. В частности, количество ядер CPU может быть увеличено до 119 808. Кроме того, могут быть добавлены ещё 224 ускорителя.
23.06.2025 [09:05], Сергей Карасёв
Половинка суперчипа: Arm-процессор NVIDIA Grace C1 набирает популярность в телеком-оборудовании, СХД и на периферииКомпания NVIDIA отметила рост популярности своего Arm-процессора Grace C1 среди ключевых ODM-партнёров. Изделие применяется в телекоммуникационном оборудовании, СХД, периферийных и облачных решениях, а также в других системах, где первостепенное значение имеет показатель производительности в расчёте на ватт затрачиваемой энергии. Архитектура NVIDIA Grace на сегодняшний день представлена в двух основных конфигурациях: это двухпроцессорный Grace Superchip и новый однопроцессорный Grace CPU C1. Последний содержит 72 ядра Arm Neoverse V2 (Armv9) с поддержкой векторных расширений SVE2. Объём кеша L2 составляет 1 Мбайт в расчёте на ядро. Кроме того, есть 114 Мбайт кеша L3. Тактовая частота достигает 3,1 ГГц. 
Источник изображения: NVIDIA Процессор Grace CPU C1 функционирует в связке со 120, 240 или 480 Гбайт памяти LPDDR5X, пропускная способность которой достигает 512 Гбайт/с (384 Гбайт/с для варианта 480 Гбайт). Реализована поддержка четырёх массивов PCIe 5.0 x16, что даёт в общей сложности 64 линии (поддерживается бифуркация). Показатель TDP составляет до 250 Вт (вместе с памятью). 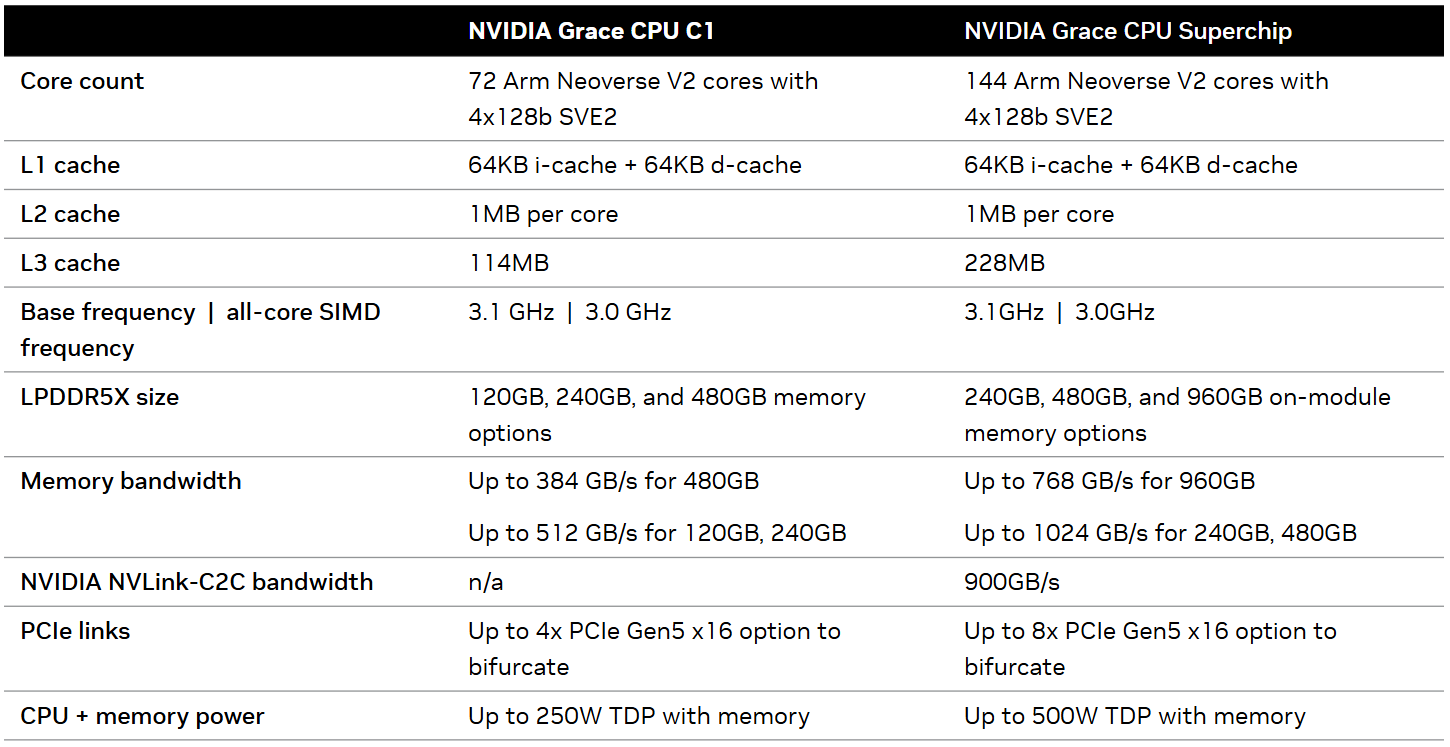
Источник изображения: NVIDIA По заявлениям NVIDIA, системы на базе Grace CPU C1 демонстрируют двукратное повышение производительности на ватт затрачиваемой энергии по сравнению с сопоставимыми по классу продуктами, построенными на чипах с архитектурой х86. Устройства на основе Grace CPU C1 проектируют такие компании, как Foxconn, Jabil, Lanner, MiTAC, Supermicro и QCT. В телекоммуникационной отрасли, как отмечается, востребован компьютер NVIDIA Compact Aerial RAN, объединяющий процессор Grace CPU C1 с ускорителем NVIDIA L4 и адаптером NVIDIA ConnectX-7 SmartNIC. Кроме того, Grace CPU C1 применяется в системах хранения WEKA и Supermicro.
01.04.2025 [14:53], Владимир Мироненко
Arm намерена занять 50 % рынка чипов для ЦОД к концу 2025 года — NVIDIA ей в этом поможетСогласно прогнозу Arm Holdings, к концу 2025 года доля процессоров с Arm-архитектурой на мировом рынке CPU для ЦОД вырастет до 50 % с 15 % в 2024 году. В интервью агентству Reuters Мохамед Авад (Mohamed Awad), руководитель подразделения инфраструктурных решений Arm, отметил, что благодаря более низкому энергопотреблению, чем у процессоров Intel и AMD, Arm-чипы становятся все более популярными среди компаний, занимающихся облачными вычислениями. Журналист ресурса The Register обратился в Arm Holdings с просьбой пояснить, благодаря чему компания рассчитывает добиться столь стремительного роста доли на рынке. Как сообщили в британской компании, принадлежащей японскому конгломерату Softbank, её прогноз в значительной степени основан на росте поставок ИИ-серверов. Мохамед Авад сообщил The Register, что в течение следующих нескольких лет, как ожидает компания, продажи ИИ-серверов вырастут на 300 %. «Для этого увеличения энергоэффективность больше не является конкурентным преимуществом — это базовое отраслевое требование. Именно здесь вычислительная платформа Arm Neoverse является явным лидером и предпочтительной платформой для ведущих партнёров отрасли, включая AWS, Google, Microsoft и NVIDIA», — заявил он. 
Источник изображения: Arm Holdings Как утверждает Arm Holdings, Arm-архитектура всё чаще используется гиперскейлерами AWS, Google, Microsoft в своих чипах. По оценкам Bernstein Research, в 2023 году почти 10 % серверов по всему миру содержат Arm-процессоры приложений в качестве «основных мозгов», и половина из них была развёрнута Amazon, сообщившей, что у нее в облаке используется более 2 млн чипов Graviton собственной разработки. В свою очередь, Google объявила в 2024 году о выпуске собственного процессора Axion на базе Neoverse V2 для своих ЦОД, а Microsoft сообщила в конце прошлого года об общедоступности в облаке Azure инстансов с использованием процессоров собственной разработки Cobalt 100. Расширение использования этими провайдерами облачных услуг Arm-процессоров может объяснить часть роста, который Авад прогнозирует на этот год, но продукты NVIDIA также, вероятно, составят значительную долю, полагает The Register. Например, система DGX GB200 NVL72 включает 36 процессора NVIDIA Grace и 72 ускорителя Blackwell B200, что составляет 2592 ядра Arm Neoverse V2, и они, вероятно, будут востребованы в этом году, отметил ресурс. Также не следует забывать о других решениях для ЦОД, которые имеют ядра на базе Arm-архитектуры, такие как SmartNIC и DPU — BlueField-3 от NVIDIA, а также карты Nitro в серверах AWS.
20.03.2025 [15:58], Сергей Карасёв
Supermicro анонсировала петабайтное 1U-хранилище All-Flash на базе Arm-суперчипа NVIDIA GraceКомпания Supermicro представила сервер ARS-121L-NE316R в форм-факторе 1U, на базе которого могут формироваться системы хранения данных петабайтной вместимости. В основу новинки положен суперчип NVIDIA Grace со 144 ядрами Arm Neoverse V2 и 960 Гбайт памяти LPDDR5x. Устройство оборудовано 16 фронтальными отсеками для NVMe-накопителей E3.S 1T. При использовании SSD ёмкостью 61,44 Тбайт суммарная вместимость может достигать 983 Тбайт. При этом до 40 серверов могут быть установлены в одну стойку, что обеспечит 39,3 Пбайт «сырой» ёмкости. Новинка располагает двумя внутренними посадочными местами для M.2 NVMe SSD и двумя слотами PCIe 5.0 x16 для карт типоразмера FHHL. Присутствуют сетевой порт управления 1GbE (RJ45), порт USB 3.0 Type-A и разъём mini-DP. Габариты сервера составляют 772,15 × 438,4 × 43,6 мм, масса — 19,8 кг без установленных накопителей. 
Источник изображения: Supermicro Питание обеспечивают два блока мощностью 1600 Вт с сертификатом 80 Plus Titanium. Применена система воздушного охлаждения с восемью съёмными вентиляторами диаметром 40 мм. Диапазон рабочих температур — от +10 до +35 °C. При необходимости сервер может быть оснащён двумя DPU NVIDIA BlueField-3 или двумя адаптерами ConnectX-8. Система подходит для поддержания рабочих нагрузок с интенсивным обменом данными, таких как ИИ-инференс, аналитика и пр. Отмечается, что при создании новинки Supermicro тесно сотрудничала с NVIDIA и WEKA (разработчик платформ хранения данных).
07.01.2025 [16:10], Владимир Мироненко
NVIDIA представила «персональный ИИ-суперкомпьютер» Project DIGITS на базе гибридного ускорителя GB10Компания NVIDIA представила «персональный ИИ-суперкомпьютер» Project DIGITS — это самая компактная аппаратная платформа на базе суперчипов Grace Blackwell. Разработанная для исследователей ИИ, специалистов по данным и студентов система поставляется с полным набором ПО для создания, тюнинга и инференса ИИ-моделей. Это позволяет локально создавать и дорабатывать модели, а затем разворачивать их в облаке или ЦОД. Project DIGITS будет доступен в мае по цене от $3000. Project DIGITS оснащён чипом GB10 с FP4-производительностью до 1 Пфлопс, разработанным в партнёрстве с MediaTek. GB10 включает ускоритель Blackwell, подключённый посредством NVLink-C2C к 20-ядерному Arm-процессору Grace, 128 Гбайт унифицированной когерентной памяти LPDDR5x и 4-Тбайт NVMe SSD. В оснащение также входит адаптеры Wi-Fi, Bluetooth и Ethernet (RJ45). На задней стенке есть видеовыход HDMI и четыре разъёма USB-C. По словам компании, Project DIGITS позволит запускать модели размером до 200 млрд параметров, а при объединении двух таких систем посредством NIC ConnectX (два порта SFP28) возможен запуск моделей с 405 млрд параметров. 
Источник изображений: NVIDIA Работает новинка под управлением NVIDIA DGX OS — специализированной сборки Ubuntu Linux, оптимизированной для работы с ИИ-нагрузками. Пользователи Project DIGITS получат доступ к обширной библиотеке ПО NVIDIA AI, включая комплекты для разработки ПО, инструменты оркестрации, фреймворки и модели, доступные в каталоге NVIDIA NGC и на портале NVIDIA Developer. Разработчики смогут настраивать модели с помощью фреймворка NVIDIA NeMo, использовать в работе с данными библиотеки NVIDIA RAPIDS и задействовать популярные программные платформы, включая PyTorch, Python и Jupyter notebooks. 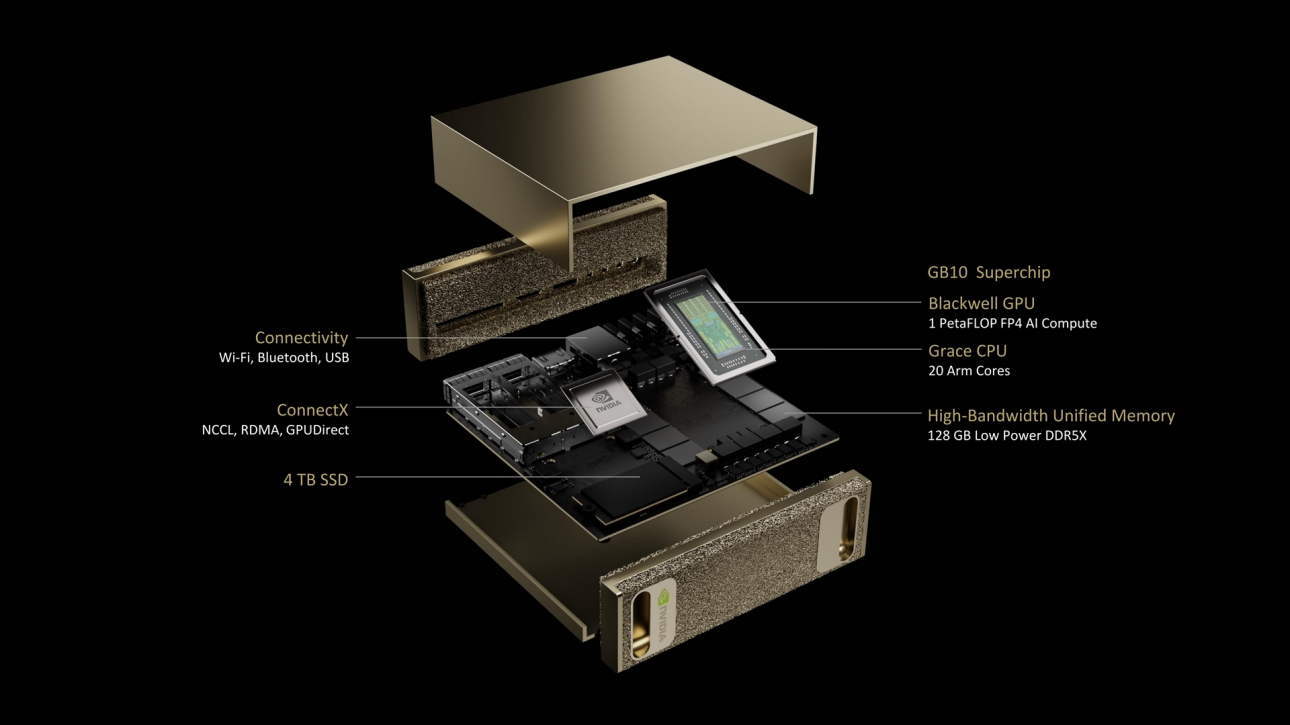 Для создания агентских приложений AI можно будет использовать NVIDIA Blueprints и микросервисы NVIDIA NIM, доступные для исследований, разработки и тестирования в рамках программы NVIDIA Developer Program. Благодаря единой архитектуре Grace Blackwell предприятия и индивидуальные исследователи смогут прототипировать, настраивать и тестировать ИИ-модели на локальных системах Project DIGITS с последующим развёртыванием в NVIDIA DGX Cloud, облачных инстансах или собственной инфраструктуре ЦОД.
28.12.2024 [01:55], Владимир Мироненко
Дороже, но втрое эффективнее: NVIDIA готовит ускорители GB300 с 288 Гбайт HBM3E и TDP 1,4 кВтNVIDIA выпустила новые ускорители GB300 и B300 всего через шесть месяцев после выхода GB200 и B200. И это не минорное обновление, как может показаться на первый взгляд — появление (G)B300 приведёт к серьёзной трансформации отрасли, особенно с учётом значительных улучшений в инференсе «размышляющих» моделей и обучении, пишет SemiAnalysis. При этом с переходом на B300 вся цепочка поставок меняется, и от этого кто-то выиграет, а кто-то проиграет. Конструкция вычислительного кристалла B300 (ранее известного как Blackwell Ultra), изготавливаемого с использованием кастомного техпроцесса TSMC 4NP. Благодаря этому он обеспечивает на 50 % больше Флопс (FP4) по сравнению с B200 на уровне продукта в целом. Часть прироста производительности будет получена за счёт увеличения TDP, достигающим 1,4 кВт и 1,2 кВт для GB300 и B300 HGX соответственно (по сравнению с 1,2 кВт и 1 кВт для GB200 и B200). Остальное повышение производительности связано с архитектурными улучшениями и оптимизациями на уровне системы, такими как динамическое распределение мощности между CPU и GPU. Кроме того, в B300 применяется память HBM3E 12-Hi, а не 8-Hi, ёмкость которой выросла до 288 Гбайт. Однако скорость на контакт осталась прежней, так что суммарная пропускная способность памяти (ПСП) по-прежнему составляет 8 Тбайт/с. В качестве системной памяти будут применяться модули LPCAMM. Разница в производительности и экономичности из-за увеличения объёма HBM намного больше, чем кажется. Усовершенствования памяти имеют решающее значение для обучения и инференса больших языковых моделей (LLM) в стиле OpenAI O3, поскольку более длинные последовательности токенов негативно влияют на скорость обработки и задержку. 
Источник изображения: NVIDIA На примере обновления H100 до H200 хорошо видно, как память влияет на производительность ускорителя. Более высокая ПСП (H200 — 4,8 Тбайт/с, H100 — 3,35 Тбайт/с) в целом улучшила интерактивность в инференсе на 43 %. А большая ёмкость памяти снизила объём перемещаемых данных и увеличила допустимый размер KVCache, что увеличило количество генерируемых токенов в секунду втрое. Это положительно сказывается на пользовательском опыте, что особенно важно для всё более сложных и «умных» моделей, которые могут приносить больше дохода с каждого ускорителя. Валовая прибыль от использования передовых моделей превышает 70 %, тогда как для отстающих моделей в конкурентной open source среде она составляет менее 20 %. 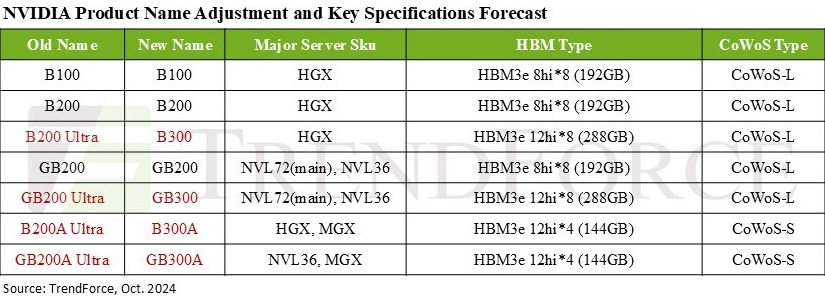
Источник изображения: TrendForce Однако одного наращивания скорости и памяти, как это делает AMD в Instinct MI300X (192 Гбайт), MI325X и MI355X (256 Гбайт и 288 Гбайт соответственно), мало. И дело не в том, что забагованное ПО компании не позволяет раскрыть потенциал ускорителей, а в особенности общения ускорителей между собой. Только NVIDIA может предложить коммутируемое соединение «все ко всем» посредством NVLink. В GB200 NVL72 все 72 ускорителя могут совместно работать над одной и той же задачей, что повышает интерактивность, снижая задержку для каждой цепочки размышлений и в то же время увеличивая их максимальную длину. На практике NVL72 — единственный способ увеличить длину инференса до более чем 100 тыс. токенов и при этом экономически эффективный, говорит SemiAnalysis. По оценкам, GB300 NVL72 обойдётся заказчиками минимум в $7,5 млн, тогда как GB200 NVL72 стоил порядка $3 млн.
05.12.2024 [16:14], Сергей Карасёв
Запущен британский Arm-суперкомпьютер Isambard 3 с суперчипами NVIDIA GraceВ Великобритании введён в эксплуатацию суперкомпьютер Isambard 3, предназначенный для ресурсоёмких приложений ИИ и задач НРС. Реализация проекта обошлась приблизительно в £10 млн, или примерно $12,7 млн. Машина пришла на смену комплексу Isambard 2, который отправился на покой в сентябре нынешнего года. Система Isambard 3 создана в рамках сотрудничества между исследовательским консорциумом GW4 Alliance, в который входят университеты Бата, Бристоля, Кардиффа и Эксетера, а также компаниями HPE, NVIDIA и Arm. Суперкомпьютер назван в честь британского инженера Изамбарда Кингдома Брюнеля, внесшего значимый вклад в Промышленную революцию. Полностью технические характеристики Isambard 3 не раскрываются. Известно, что в основу машины положены 384 суперпроцессорами NVIDIA Grace со 144 ядрами (2 × 72) Arm Neoverse V2 (Demeter), общее количество которых превышает 55 тыс. Задействована высокопроизводительная СХД HPE, которая обеспечивает расширенные IO-возможности с интеллектуальным распределением данных по нескольким уровням. Благодаря этому достигается эффективная обработка задач с интенсивным использованием информации, таких как обучение моделей ИИ. Известно также, что в составе комплекса применяется фирменный интерконнект HPE Slingshot, а в качестве внутреннего интерконнекта служит технология NVLink-C2C, которая в семь раз быстрее PCIe 5.0. Каждый узел суперкомпьютера содержит один суперчип Grace и сетевой адаптер Cassini с пропускной способностью до 200 Гбит/с. Объём системной памяти составляет 2 × 120 Гбайт (240 Гбайт). 
Источник изображения: GW4 Отмечается, что Isambard 3 демонстрирует в шесть раз более высокую производительность и в шесть раз лучшую энергоэффективность по сравнению с Isambard 2. Пиковое быстродействие FP64 у Isambard 3 достигает 2,7 Пфлопс при энергопотреблении менее 270 кВт. Применять новый суперкомпьютер планируется для таких задач, как проектирование оптимальной конфигурации ветряных электростанций на суше и воде, моделирование термоядерных реакторов, исследования в сфере здравоохранения и пр. Суперкомпьютер расположен в автономном дата-центре с системой самоохлаждения HPE Performance Optimized Data Center (POD) в Национальном центре композитов в Научном парке Бристоля и Бата. Там же ведётся монтаж ИИ-комплекса Isambard-AI стоимостью £225 млн ($286 млн), который должен стать самым быстрым и мощным суперкомпьютером в Великобритании. Проект Isambard-AI реализуется в несколько этапов. Первая фаза предполагает монтаж 42 узлов, каждый из которых несёт на борту четыре суперчипа NVIDIA GH200 Grace Hopper и 4 × 120 Гбайт памяти для CPU (доступно 460 Гбайт — по 115 Гбайт на CPU), а также 4 × 96 Гбайт памяти для GPU (H100). В ходе второй фазы будут добавлены 1320 узлов, насчитывающих в сумме 5280 суперчипов NVIDIA GH200 Grace Hopper. Кроме того, в состав Isambard 3 входит экспериментальный x86-модуль MACS (Multi-Architecture Comparison System), включающий сразу восемь разновидностей узлов на базе процессоров AMD EPYC и Intel Xeon нескольких поколений, часть из них также имеет ускорители AMD Instinct MI100 и NVIDIA H100/A100. Все они объединены 200G-интерконнектом HPE Slingshot.
18.11.2024 [21:30], Сергей Карасёв
Счетверённые H200 NVL и 5,5-кВт GB200 NVL4: NVIDIA представила новые ИИ-ускорителиКомпания NVIDIA анонсировала ускоритель H200 NVL, выполненный в виде двухслотовой карты расширения PCIe. Изделие, как утверждается, ориентировано на гибко конфигурируемые корпоративные системы с воздушным охлаждением для задач ИИ и НРС. Как и SXM-вариант NVIDIA H200, представленный ускоритель получил 141 Гбайт памяти HBM3e с пропускной способностью 4,8 Тбайт/с. При этом максимальный показатель TDP снижен с 700 до 600 Вт. Четыре карты могут быть объединены интерконнкетом NVIDIA NVLink с пропускной способностью до 900 Гбайт/с в расчёте на GPU. При этом к хост-системе ускорители подключаются посредством PCIe 5.0 x16. В один сервер можно установить две такие связки, что в сумме даст восемь ускорителей H200 NVL и 1126 Гбайт памяти HBM3e, что весьма существенно для рабочих нагрузок инференса. Заявленная производительность FP8 у карты H200 NVL достигает 3,34 Пфлопс против примерно 4 Пфлопс у SXM-версии. Быстродействие FP32 и FP64 равно соответственно 60 и 30 Тфлопс. Производительность INT8 — до 3,34 Пфлопс. Вместе с картами в комплект входит лицензия на программную платформа NVIDIA AI Enterprise. 
Источник изображения: NVIDIA Кроме того, NVIDIA анонсировала ускорители GB200 NVL4 с жидкостным охлаждением. Они включает два суперчипа Grace-Backwell, что даёт два 72-ядерных процессора Grace и четыре ускорителя B100. Объём памяти LPDDR5X ECC составляет 960 Гбайт, памяти HBM3e — 768 Гбайт. Задействован интерконнект NVlink-C2C с пропускной способностью до 900 Гбайт/с, при этом всем шесть чипов CPU-GPU находятся в одном домене. 
Источник изображения: NVIDIA Система GB200 NVL4 наделена двумя коннекторами M.2 22110/2280 для SSD с интерфейсом PCIe 5.0, восемью слотами для NVMe-накопителей E1.S (PCIe 5.0), шестью интерфейсами для карт FHFL PCIe 5.0 x16, портом USB, сетевым разъёмом RJ45 (IPMI) и интерфейсом Mini-DisplayPort. Устройство выполнено в форм-факторе 2U с размерами 440 × 88 × 900 мм, а его масса составляет 45 кг. TDP настраиваемый — от 2,75 кВт до 5,5 кВт.
10.09.2024 [14:55], Сергей Карасёв
TACC ввёл в эксплуатацию Arm-суперкомпьютер Vista на базе NVIDIA GH200 для ИИ-задачТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) объявил о том, что мощности нового НРС-комплекса Vista полностью доступны открытому научному сообществу. Суперкомпьютер предназначен для решения ресурсоёмких задач, связанных с ИИ. Формальный анонс машины Vista состоялся в ноябре 2023 года. Тогда говорилось, что Vista станет связующим звеном между существующим суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Vista состоит из двух ключевых частей. Одна из них — кластер из 600 узлов на гибридных суперчипах NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель H100/H200. Обеспечивается производительность на уровне 20,4 Пфлопс (FP64) и 40,8 Пфлопс на тензорных ядрах. Каждый узел содержит локальный накопитель вместимостью 512 Гбайт, 96 Гбайт памяти HBM3 и 120 Гбайт памяти LPDDR5. Интероконнект — Quantum 2 InfiniBand (400G). Второй раздел суперкомпьютера объединяет 256 узлов с процессорами NVIDIA Grace CPU Superchip, содержащими два кристалла Grace в одном модуле (144 ядра). Узлы укомплектованы 240 Гбайт памяти LPDDR5 и накопителем на 512 Гбайт. Интерконнект — Quantum 2 InfiniBand (200G). Узлы произведены Gigabyte, а за интеграцию всей системы отвечала Dell. 
Источник изображения: TACC Общее CPU-быстродействие Vista находится на отметке 4,1 Пфлопс. В состав комплекса входит NFS-хранилише VAST Data вместимостью 30 Пбайт. Суперкомпьютер будет использоваться для разработки и применения решений на основе генеративного ИИ в различных секторах, включая биологические науки и здравоохранение.
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 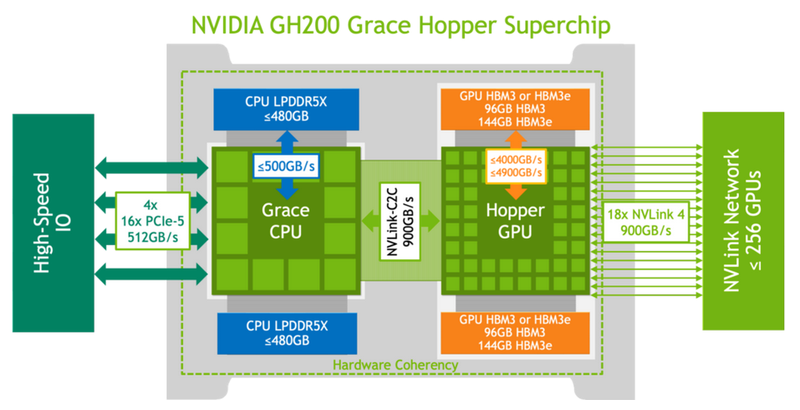
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 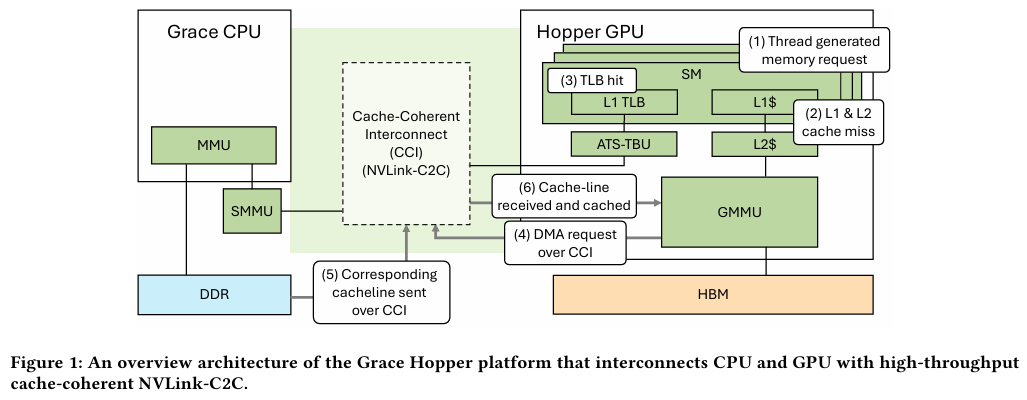
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 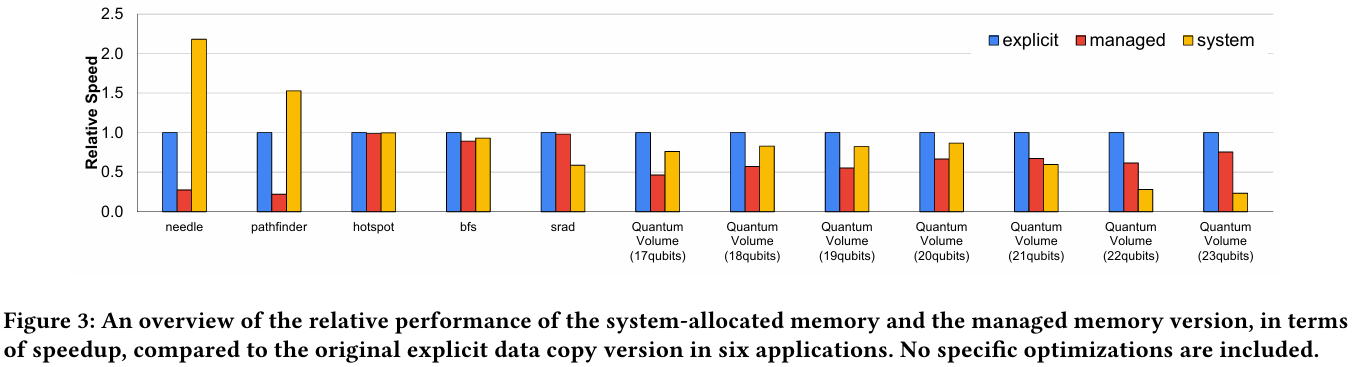
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования. |
|