Материалы по тегу: arm
|
12.09.2025 [23:30], Владимир Мироненко
Благодаря NVIDIA доля Arm на рынке серверных процессоров достигла 25 %Стремительный рост вычислительных мощностей ЦОД на фоне бума ИИ-технологий способствовал росту доходов не только производителей ускорителей и серверных CPU, но и компании Arm, чью архитектуру они используют в своих чипах, передаёт The Register. В январе Arm заявила о намерении занять 50 % рынка чипов для ЦОД к концу 2025 года Согласно исследованию Dell’Oro Group, во II квартале доля Arm-чипов на рынке серверных CPU составила 25 %, тогда как годом ранее она равнялась 15 %. Движущей силой роста стало внедрение суперускорителей NVIDIA GB200 NVL72 и GB300 NVL72, которые включают 36 Arm-процессоров Grace на базе архитектуры Neoverse V2 (Demeter) с интерфейсом NVLink-C2C. Заказы на поставку чипов NVIDIA расписаны на месяцы вперёд, что обеспечивает гарантированный источник доходов Arm наряду с ростом доли на рынке. Аналитик Dell’Oro Барон Фунг (Baron Fung) сообщил The Register, что ещё год назад рост Arm на рынке серверных процессоров обеспечивался практически исключительно за счёт кастомных CPU, таких как AWS Graviton. Но теперь выручка от продаж Grace сопоставима с доходами от облачных GPU. AWS использует кастомные процессоры на архитектуре Arm с 2018 года. А Microsoft и Google лишь в последние несколько лет начали всерьёз развивать свои Arm-процессорах Cobalt и Axion соответственно, отметил The Register. 
Источник изображения: Arm Рост доли Arm на рынке зависит от того, насколько больше разработчиков чипов выведет свои чипы на рынок серверных процессоров. NVIDIA сейчас работает над новым процессором на базе Arm с использованием кастомных ядер Vera. Qualcomm и Fujitsu также работают над серверными чипами. А появление NVIDIA NVLink Fusion может привести к созданию новых гибридных чипов. По данным Dell’Oro, рост рынка ИИ-технологий также привёл к росту рынка компонентов для серверов и СХД, составившему во II квартале 44 % в годовом исчислении. Продажи SmartNIC и DPU, которые зачастую тоже используют Arm-ядра, примерно удвоились по сравнению с прошлым годом на фоне перехода на Ethernet для вычислительных ИИ-кластеров. Поставки ASIC для обработки ИИ-нагрузок сейчас сопоставимы с объёмами поставок GPU, хотя GPU по-прежнему приносят большую часть доходов.
04.09.2025 [11:35], Сергей Карасёв
Sipeed представила NanoKVM Pro — IP-KVM с поддержкой 4K в настольной и встраиваемой версияхКомпания Sipeed анонсировала решение NanoKVM Pro, предназначенное для организации удалённого управления IP-KVM (Keyboard, Video, Mouse). Изделие предлагается в двух вариантах — в «настольном» исполнении, а также в виде мини-платы для установки внутрь корпуса рабочей станции или сервера. В основу новинки положен процессор Axera Tech AX630C. Он содержит два ядра Arm Cortex-A53 с тактовой частотой до 1,2 ГГц и NPU для ускорения ИИ-операций с производительностью до 3,2 TOPS в режиме INT8. Говорится о возможности работы с видеоматериалами в формате 4K. 
Источник изображения: Sipeed Обе модификации NanoKVM Pro оснащены 1 Гбайт оперативной памяти LPDDR4X и флеш-чипом eMMC вместимостью 32 Гбайт. Есть сетевой порт 1GbE с опциональной поддержкой PoE, а также три разъёма USB Type-C, один из которых служит для подачи питания. Дополнительно может быть установлен адаптер Wi-Fi 6 с коннектором для антенны. Через HDMI-вход возможен захват 4K-видео (45 к/с); кроме того, имеется HDMI-выход. Поддерживается удалённое управление питанием. «Настольная» модификация выполнена в корпусе с размерами 65 × 65 × 28 мм. Во фронтальной части располагается сенсорный информационный дисплей с диагональю 1,47″ и разрешением 320 × 172 точки. Рядом с экраном находится колесико управления. Приём заказов на NanoKVM Pro уже начался. Версия в виде платы для установки внутрь корпуса предлагается по цене от $69 до $85 в зависимости конфигурации (наличие Wi-Fi 6 и/или PoE). «Настольный» вариант стоит от $79 до $95.
03.09.2025 [09:47], Владимир Мироненко
Гибридный суперчип NVIDIA GB10 оказался технически самым совершенным в семействе BlackwellNVIDIA поделилась подробностями о суперчипе GB10 (Grace Blackwell), который ляжет в основу рабочих станций DGX Spark (ранее DIGITS) для ИИ-задач, пишет ресурс ServeTheHome. 
Источник изображений: NVIDIA via Wccftech Ранее сообщалось, что GB10 был создан NVIDIA в сотрудничестве MediaTek. GB10 объединяет чиплет CPU от MediaTek (S-Dielet) с ускорителем Blackwell (G-Dielet) с помощью 2.5D-упаковки. Оба кристалла изготавливаются по 3-нм техпроцессу TSMC. Как отметил ServeTheHome, GB10 технически является самым передовым продуктом на архитектуре Blackwell на сегодняшний день.  CPU включает 20 ядер на базе архитектуры Armv9.2, которые разбиты на два кластера по десять ядер (Cortex-X925 и Cortex-A725). На каждый кластер приходится 16 Мбайт кеш-памяти L3. Унифицированная оперативная память LPDDR5X-9400 ёмкостью 128 Гбайт подключена напрямую к CPU через 256-бит интерфейс с пропускной способностью 301 Гбайт/с. Объёма памяти достаточно для работы с моделями с 200 млрд параметров.  На кристалле CPU также находятся контроллеры HSIO для PCIe, USB и Ethernet. Для адаптера ConnectX-7 с поддержкой RDMA и GPUDirect выделено всего восемь линий PCIe 5.0, что не позволит работать обоим имеющимся портам в режиме 200GbE. Именно этот адаптер позволяет объединить две системы DGX Spark в пару для работы с ещё более крупными моделями.  G-Die имеет ту же архитектуру, что и B100. Ускоритель оснащён тензорными ядрами пятого поколения и RT-ядрами четвёртого поколения и обеспечивает производительность 31 Тфлопс в FP32-вычислениях. ИИ-производительность в формате NVFP4 составляет 1000 TOPS. Ускоритель подключён к CPU через шину NVLink C2C с пропускной способностью 600 Гбайт/с. G-Die оснащён 24 Мбайт кеш-памяти L2, которая также доступна ядрам CPU в качестве кеша L4, что обеспечивает когерентность памяти между CPU и GPU на аппаратном уровне. 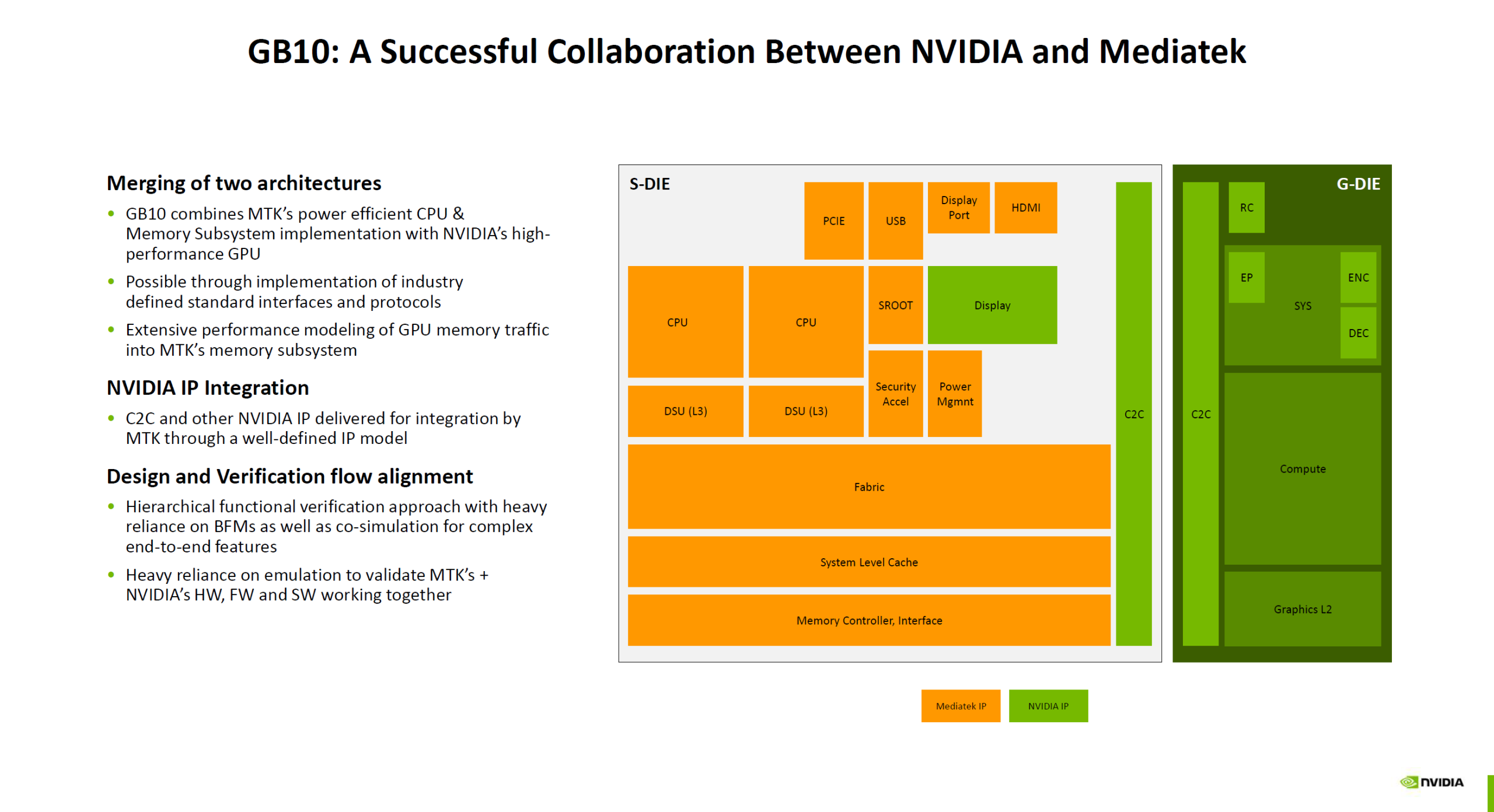 Поддерживается технология SR-IOV, интегрированы движки NVDEC и NVENC. Возможно подключение до четырёх дисплеев: три DisplayPort Alt-mode (4K@120 Гц) и один HDMI 2.1a (8K@120 Гц). Что касается безопасности, есть выделенные процессоры SROOT и OSROOT, а также поддержка fTPM и дискретного TPM (по данным Wccftech). TDP GB10 составляет 140 Вт.
02.09.2025 [21:29], Сергей Карасёв
VMware с осторожностью подходит к масштабной поддержке архитектуры ArmКомпания VMware, по сообщению ресурса DigiTimes, не подтверждает и не опровергает информацию об обеспечении широкомасштабной поддержки архитектуры Arm в своих облачных решениях. Между тем количество заказчиков, использующих в дата-центрах Arm-чипы, увеличилось с 2021-го по 2025 год в 14 раз, достигнув 70 тыс. Учитывая рост популярности Arm-изделий в сегменте ЦОД, VMware в настоящее время предоставляет техническую поддержку для отдельных продуктов, таких как VMware Cloud Foundation (VCF) и Tanzu. При этом компания заявляет, что планов по внедрению комплексной поддержки Arm на текущий момент нет. VMware отслеживает рыночные тенденции и запросы клиентов, чтобы «сформировать стратегию на будущее». 
Источник изображения: VMware Руководители Broadcom, включая глобального директора по ИИ Криса Вульфа (Chris Wolf) и генерального директора подразделения VCF Криша Прасада (Krish Prasad), подчеркивают, что текущие взаимоотношения VMware с экосистемой Arm ограничивается отдельными заказчиками. Каких-либо массовых запросов на внедрение поддержки Arm со стороны типичных клиентов виртуального облака пока нет. Это свидетельствует о том, что архитектура x86 продолжает доминировать в соответствующем рыночном сегменте. В частности, Прасад заявляет, что рынок ИИ-серверов по-прежнему ориентирован на повышение вычислительной мощности ускорителей, тогда как улучшенная энергоэффективность, присущая изделиям Arm, играет «ограниченную роль в принятии стратегических решений». Ведущие мировые облачные провайдеры, включая AWS, Google и Microsoft, уже ведут разработку собственных Arm-чипов для дата-центров. Однако, как отмечает DigiTimes, дальнейший успех архитектуры Arm на рынке облачных решений для ИИ во многом зависит от её более широкого внедрения в других областях, связанных с ЦОД. Речь идёт, в частности, о динамике спроса на Arm-решения со стороны покупателей серверов общего назначения. Повышение требований к вычислительным ресурсам в свете стремительного развития ИИ может снизить конкурентное преимущество чипов x86 — в том числе в секторе частных облаков. Небольшие предприятия с ограниченным бюджетом, как ожидается, начнут более активно присматриваться к процессорам Arm в связи с их высокой энергоэффективностью. В целом, отраслевые обозреватели сходятся во мнении, что осторожная позиция VMware в отношении Arm, вероятно, временная. Компания может изменить стратегию в случае повышения спроса со стороны клиентов.
02.09.2025 [10:14], Владимир Мироненко
Intel анонсировала IPU E2200 — 400GbE DPU семейства Mount MorganIntel анонсировала DPU Intel IPU E2200 под кодовым названием Mount Morgan, представляющий собой обновление 200GbE IPU E2100 (Mount Evans), разработанного при участии Google для использования в ЦОД последней, причём не слишком удачного, как отмечают некоторые аналитики. Как сообщает ресурс ServeTheHome, Intel E2200 производится по 5-нм техпроцессу TSMC. Он базируется на той же архитектуре, что и предшественник, но предлагает более высокую производительность. Вычислительный блок включает до 24 ядер Arm Neoverse N2 с 32 Мбайт кеша, четырьмя каналами LPDDR5-6400 и выделенным сопроцессором безопасности. Сетевая часть представлена 400GbE-интерфейсом с RDMA, а хост-подключение — подсистемой PCIe 5.0 x32 со встроенным коммутатором PCIe. 
Источник изображений: Intel via ServeTheHome  Для обработки пакетов используется P4-программируемый процессор FXP — модуль обработки трафика с алгоритмом синхронизации и настраиваемыми параметрами разгрузки, что позволяет распределять задачи между сетевыми ускорителями и Arm-ядрами. 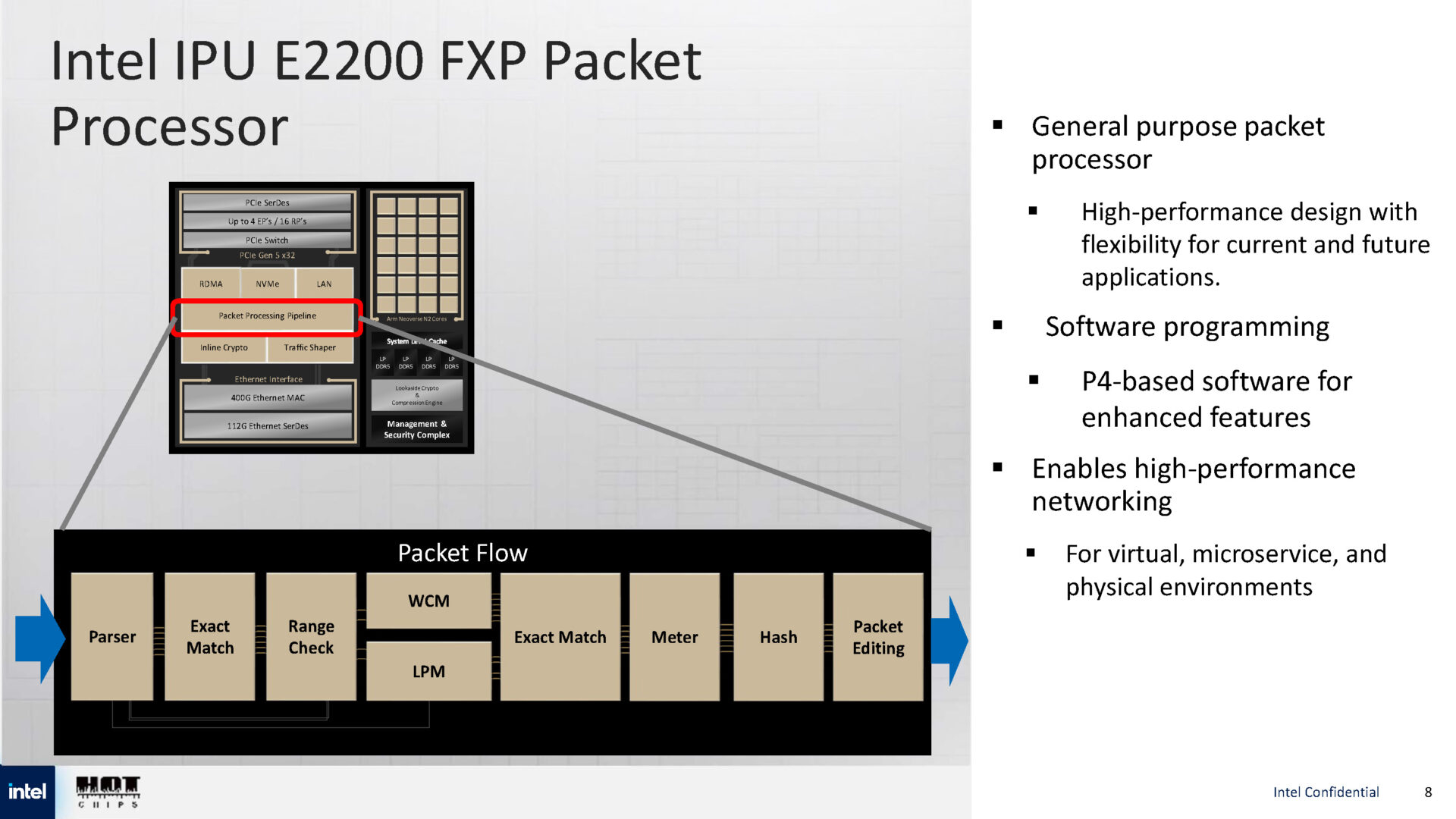 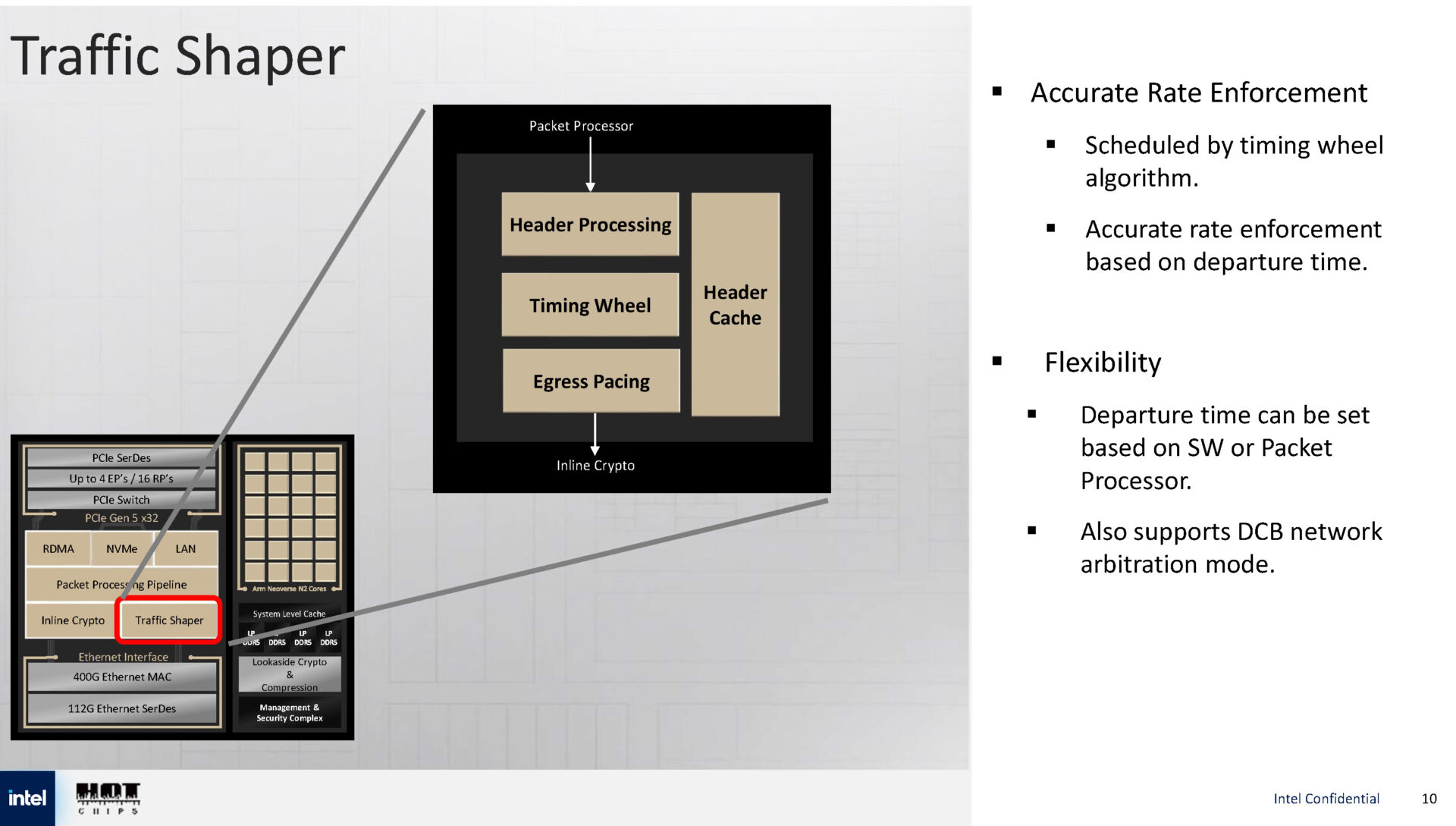 Также имеется встроенный криптографический модуль для шифрования на лету (inline) с поддержкой протоколов IPsec и PSP, настраиваемый для каждого потока. Для управления потоками данных используется модуль Traffic Shaper с поддержкой алгоритма Timing Wheel. 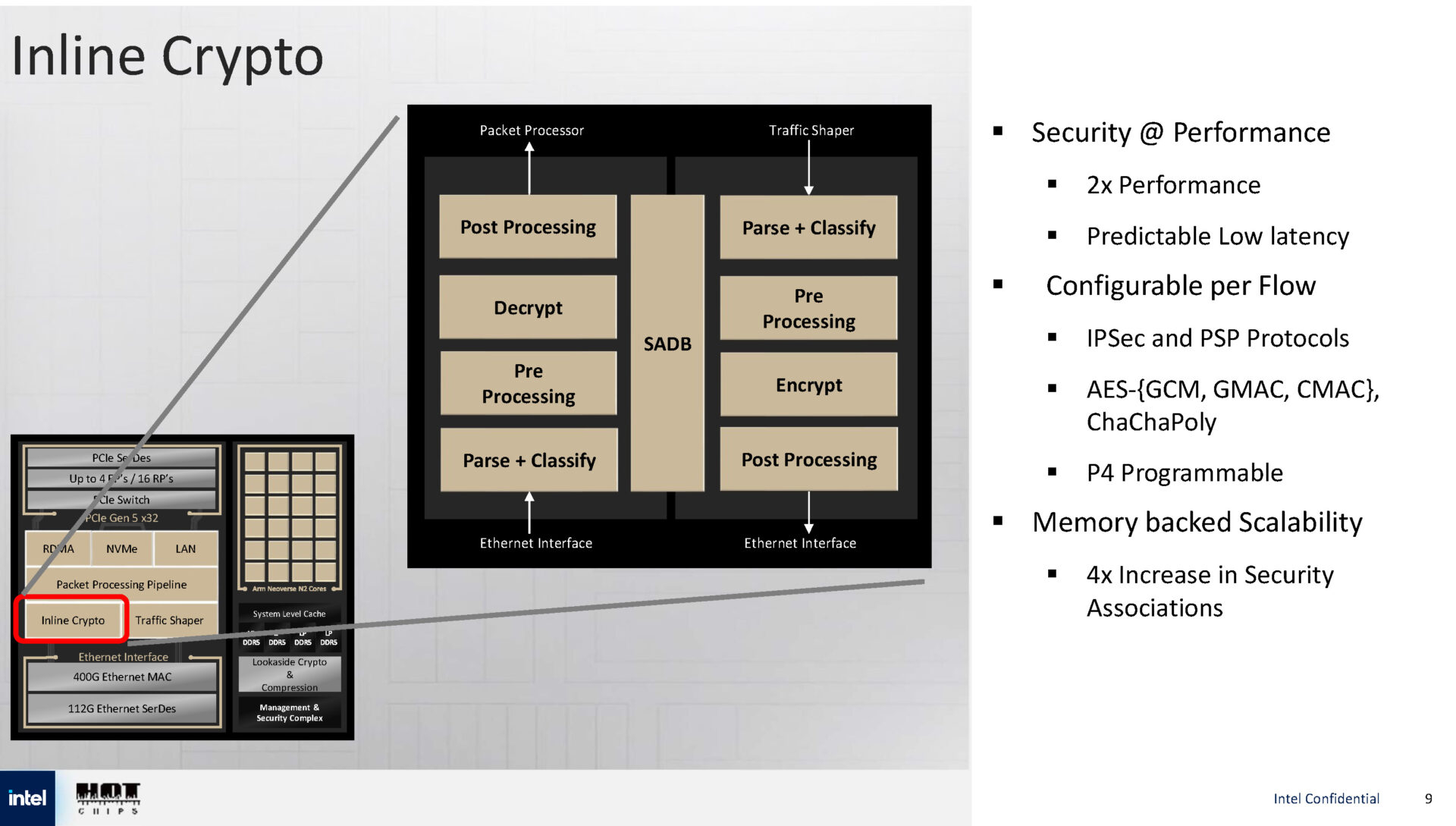  Кроме того, есть и Look-Aside-блок для компрессии и шифрования. Как и в IPU E2100, у IPU E2200 имеется выделенный модуль для независимого внешнего управления. Также поддерживаются программируемые параметры разгрузки с использованием различных ускорителей и IP-блоков.
24.08.2025 [23:18], Сергей Карасёв
NeuReality готовит чип NR2 для оркестрации инференсаКомпания NeuReality раскрыла предварительную информацию об изделии NR2 — чипе второго поколения, предназначенном специально для оркестрации инференса. Изделие представляет собой более эффективную альтернативу связке CPU и NIC в высокопроизводительных системах ИИ. Чип первого поколения NR1 дебютировал в июне нынешнего года. Изделие может применяться в связке с любым GPU или ИИ-ускорителем. При этом, как утверждается, NR1 позволяет повысить эффективность использования GPU почти до 100 % по сравнению со средним показателем в 30–50 % при традиционном сочетании CPU и NIC в современных серверах. В состав NR1 входят четыре декодера видео/изображений, 16 DSP для аудио/речи, 16 векторных DSP общего назначения, два порта 10/25/50/100GbE и пр. Характеристики NR2 на данный момент полностью не раскрываются. Известно, что в основу решения положена платформа Arm Neoverse Compute Subsystems (CSS) V3. Чип может объединять до 128 ядер, оптимизированных для масштабных рабочих нагрузок обучения моделей ИИ и инференса. По сравнению с оригинальной версией в NR2 реализована более глубокая интеграция между CPU-блоком и NIC для координации ИИ-моделей в реальном времени, дезагрегации на основе микросервисов, потоковой передачи токенов, оптимизации KV-кеша и оркестровки. 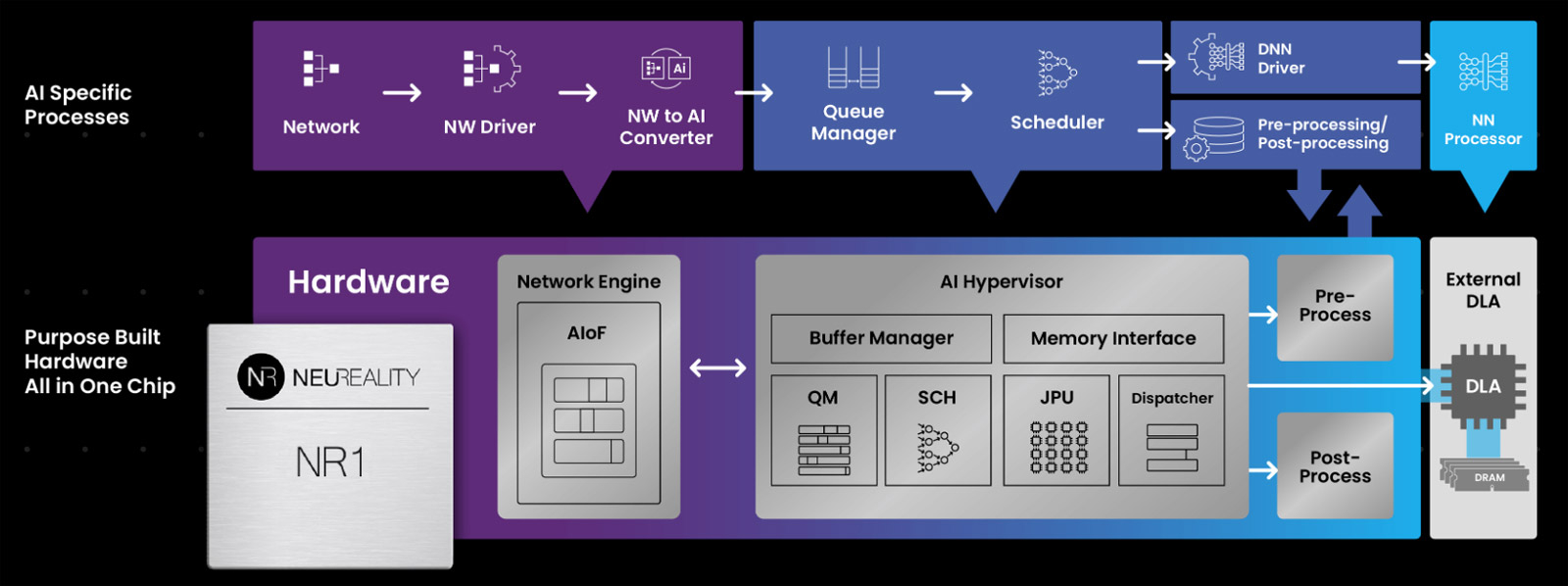
Источник изображения: NeuReality В целом, как отмечает NeuReality, чипы серии NR представляют собой качественно новый класс изделий, способных управлять рабочими нагрузками инференса с непревзойдённой эффективностью. Гипервизор ИИ в сочетании с ядрами Arm Neoverse обеспечивает оптимальную оркестровку и максимальную загрузку доступных ресурсов.
22.08.2025 [13:30], Алексей Разин
NVIDIA поможет японцам создать один из мощнейших суперкомпьютеров мира FugakuNEXTВ начале этого десятилетия созданный в Японии суперкомпьютер Fugaku пару лет удерживался на верхней строчке в рейтинге мощнейших систем мира TOP500, он и сейчас занимает в нём седьмое место. В попытке технологического реванша японский исследовательский институт RIKEN доверился компании NVIDIA, которая поможет Fujitsu создать суперкомпьютер Fugaku NEXT. Помимо Arm-процессоров Fujitsu MONAKA-X, в основу нового японского суперкомпьютера лягут и ускорители NVIDIA, хотя изначально планировалось обойтись без них. NVIDIA будет принимать непосредственное участие в интеграции своих компонентов в суперкомпьютерную систему, создаваемую японскими партнёрами. По меньшей мере, скоростные интерфейсы, которыми располагает NVIDIA, пригодятся для обеспечения быстрого канала передачи информации между CPU и ускорителями. Сама NVIDIA обтекаемо говорит, что для этого можно задействовать шину NVLink Fusion. С ускорителями AMD, по-видимому, эти процессоры будут общаться более традиционно, т.е. по шине PCIe. 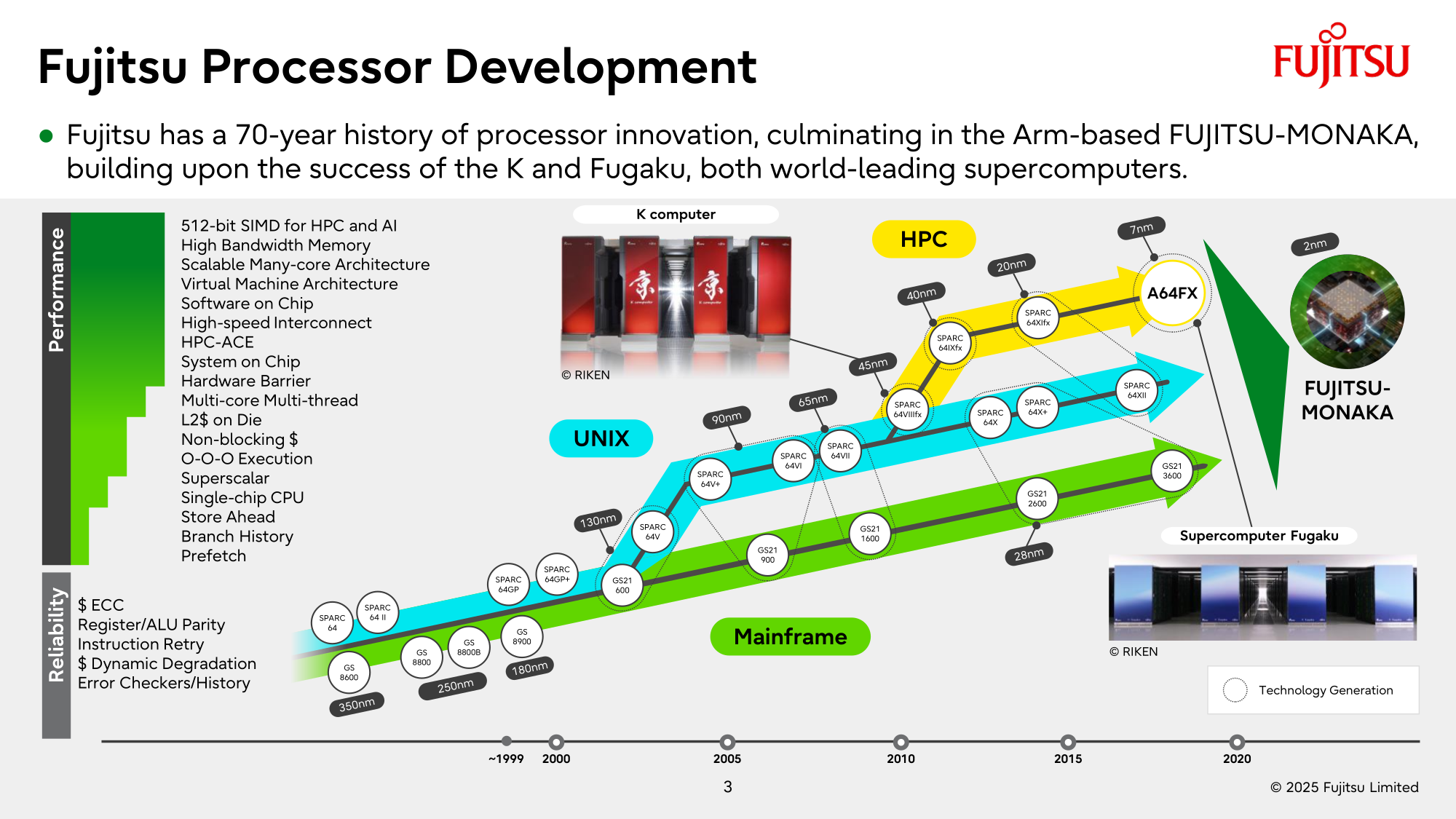
Источник изображений: Fujitsu Кроме того, NVIDIA собирается применить в составе данной системы передовые типы памяти. Применяемые при создании FugakuNEXT решения, по мнению представителей NVIDIA, смогут стать типовыми для всей отрасли в дальнейшем. Подчёркивается, что будущая платформа станет не просто техническим апгрейдом, а инвестицией в будущее страны. 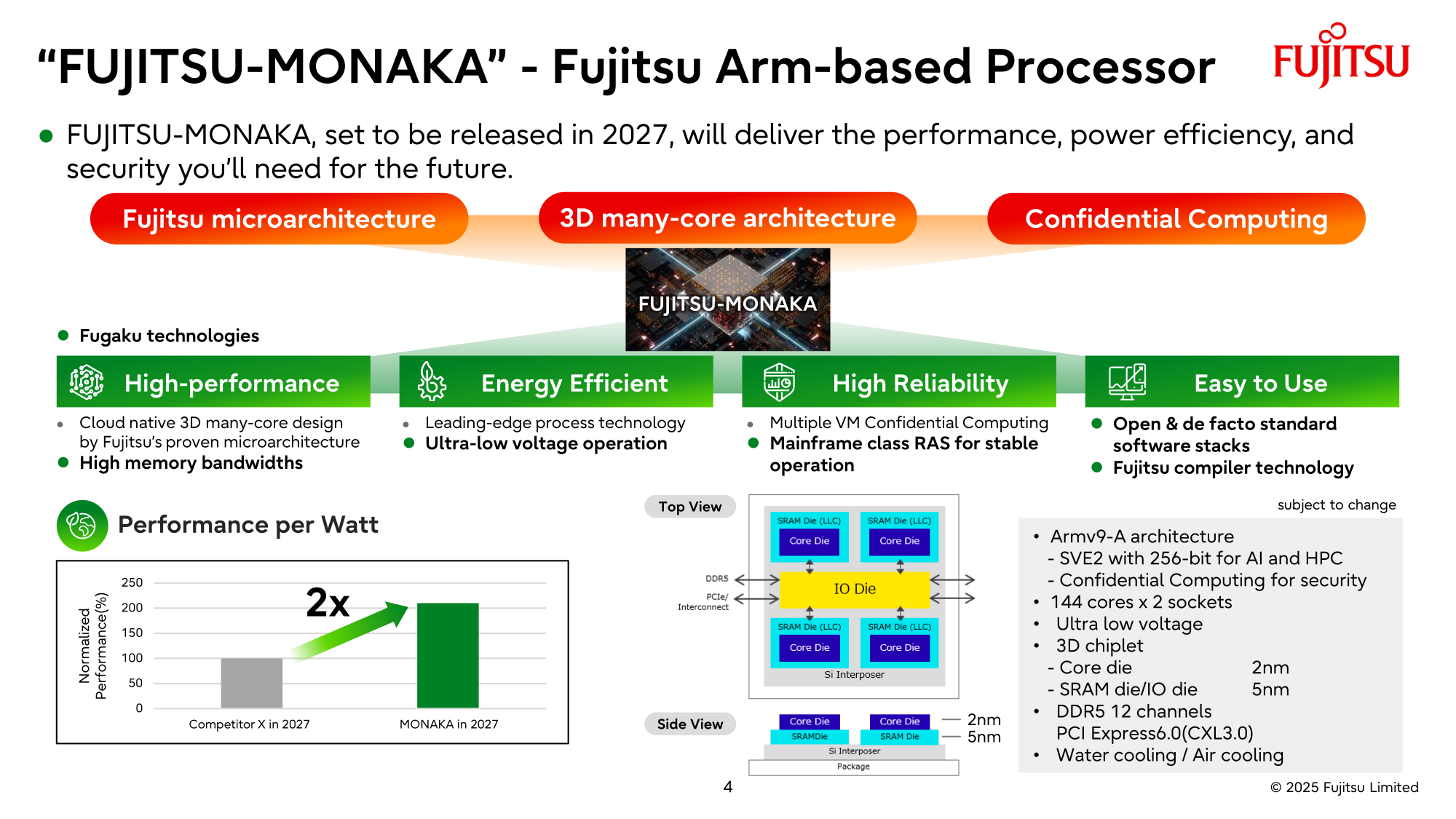 Сама архитектура системы не уточняется, поэтому сложно судить, насколько активно японские разработчики будут использовать ускорители NVIDIA, и к какому поколению они будут относиться. Создатели ставят перед собой амбициозные цели — FugakuNEXT должна стать первой системой «зетта-масштаба». Своего предшественника она должна превзойти более чем в пять раз, обеспечив быстродействие на уровне 600 Эфлопс (FP8). 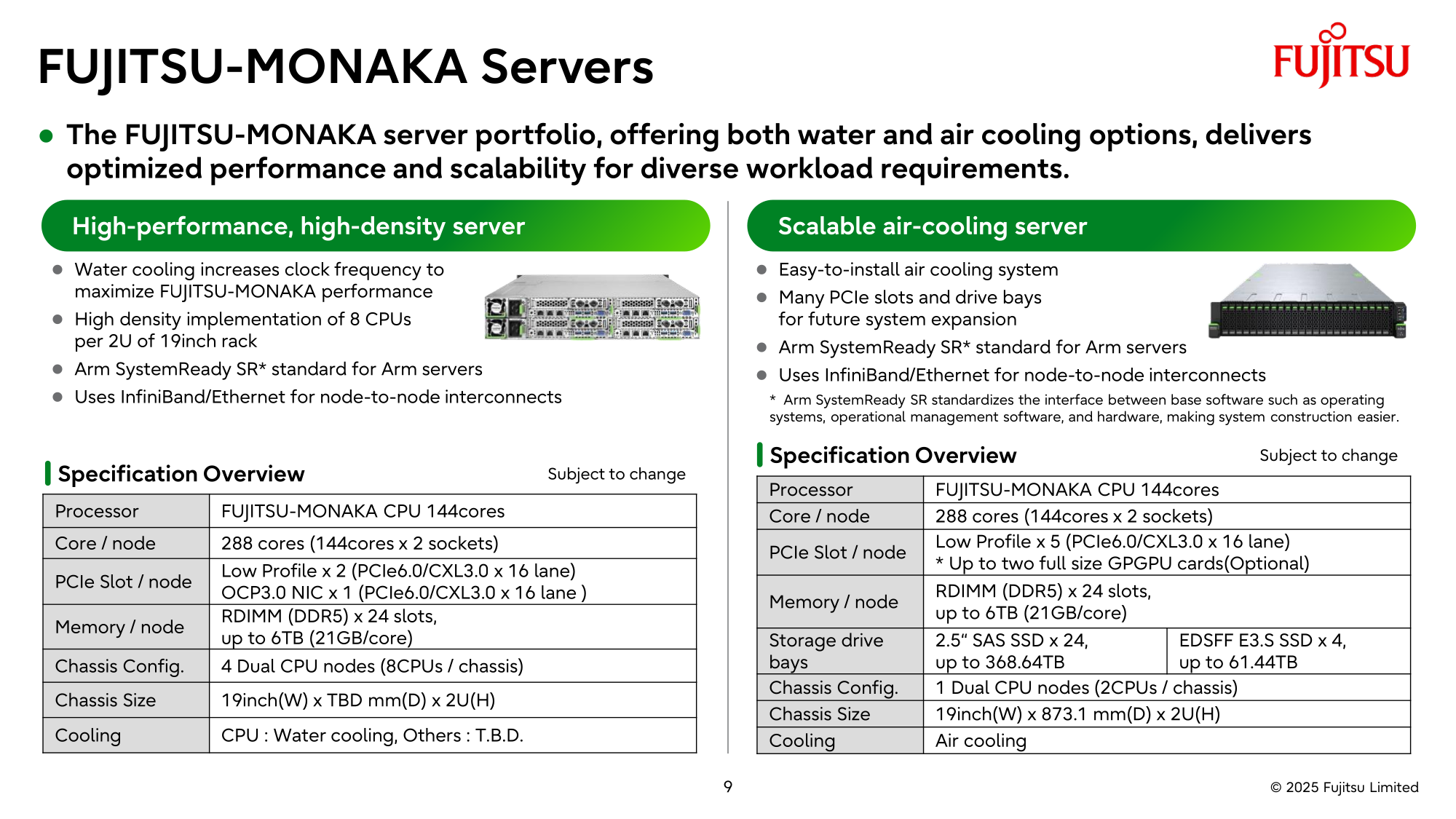 На уровне приложений прирос быстродействия может быть стократным, отмечают создатели. Новый суперкомпьютер сможет применяться для обучения больших языковых моделей. Впрочем, в строй он будет введён лишь к 2030 году, а Fujitsu ещё только предстоит выпустить свои процессоры MONAKA-X для этой системы.
01.08.2025 [14:26], Владимир Мироненко
Arm второй квартал подряд получила выручку больше миллиарда долларовАкции Arm Holdings упали на 9 % после публикации результатов компании за первый квартал 2026 финансового года, завершившегося 30 июня. Инвесторов не устроила более низкая выручка по сравнению с аналогичным кварталом годом ранее на фоне роста затрат на разработку, а также слабый прогноз на текущий квартал, оказавшийся ниже ожиданий Уолл-стрит, сообщил The Wall Street Journal. В свою очередь компания отметила, что второй квартал подряд её выручка превышает $1 млрд, составив $1,05 млрд, что на 12 % больше, чем выручка годом ранее в размере $906 млн, и на 15 % меньше показателя в предыдущем квартале. Консенсус-прогноз аналитиков, опрошенных LSEG, равен $1,06 млрд. 
Источник изображений: Arm Рост выручки обусловлен 25-% ростом роялти до $585 млн, что связано с ростом использования чипов на базе архитектуры Arm в ЦОД. Компания сообщила, что 70 тыс. предприятий для обработки рабочих ИИ-нагрузок в ЦОД использовали чипы с ядрами Arm Neoverse, что на 40 % больше, чем годом ранее. 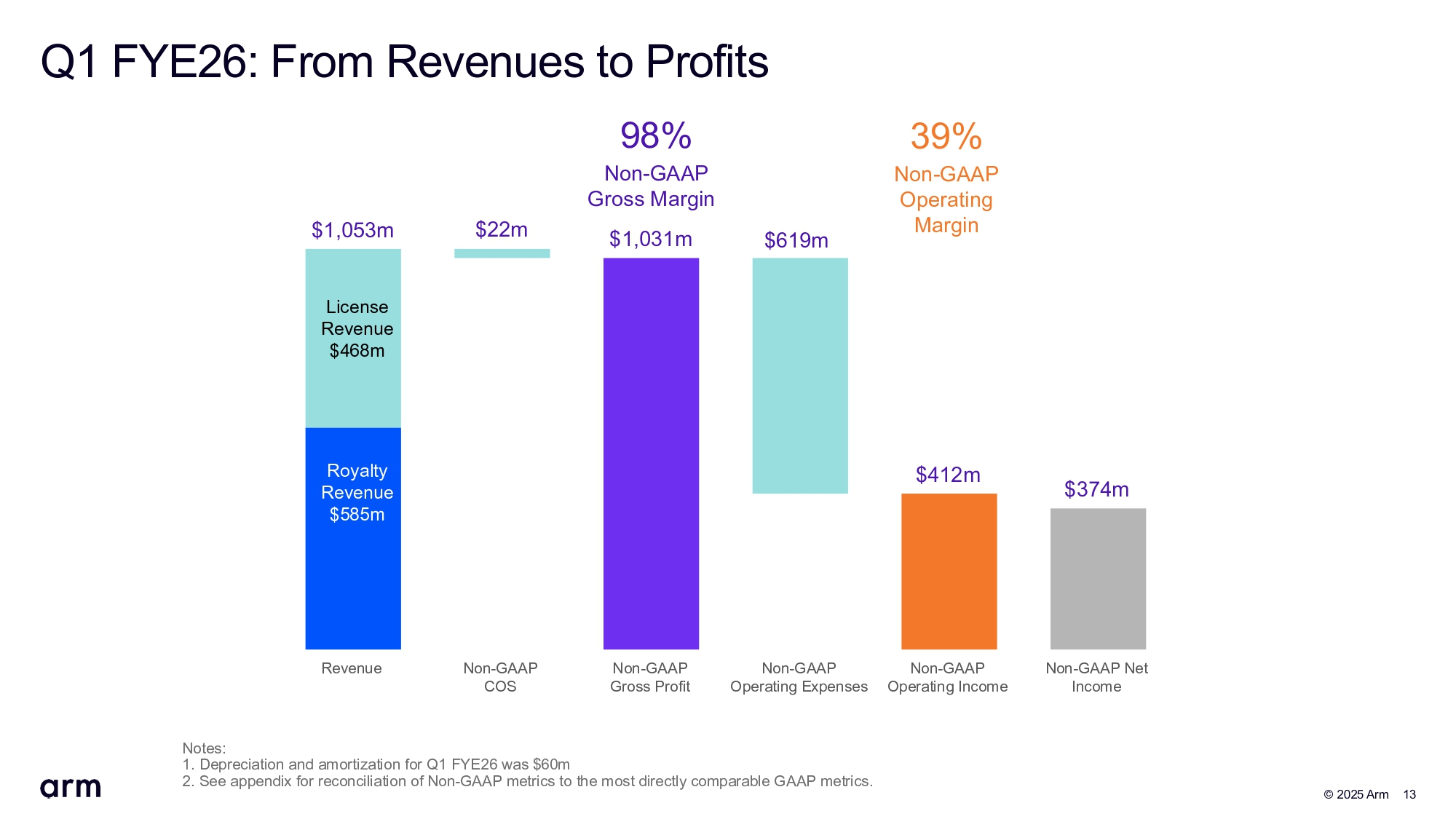 Выручка от лицензирования снизилась год к году на 1 % до $468 млн. Как пишет ресурс More Than Moore, компания объясняет падение «нормальными колебаниями сроков и объёмов многочисленных дорогостоящих лицензионных соглашений, а также влиянием невыполненных заказов», что является обычной позицией Arm. В отчётном квартале была продана 1 новая лицензия Arm Total Access, в результате чего общее число активных клиентов лицензионного плана достигло 45. Тем временем компания потеряла одного из своих лицензиатов Arm Flexible Access, ориентированного на НИОКР, в результате чего общее количество лицензий сократилось до 313. 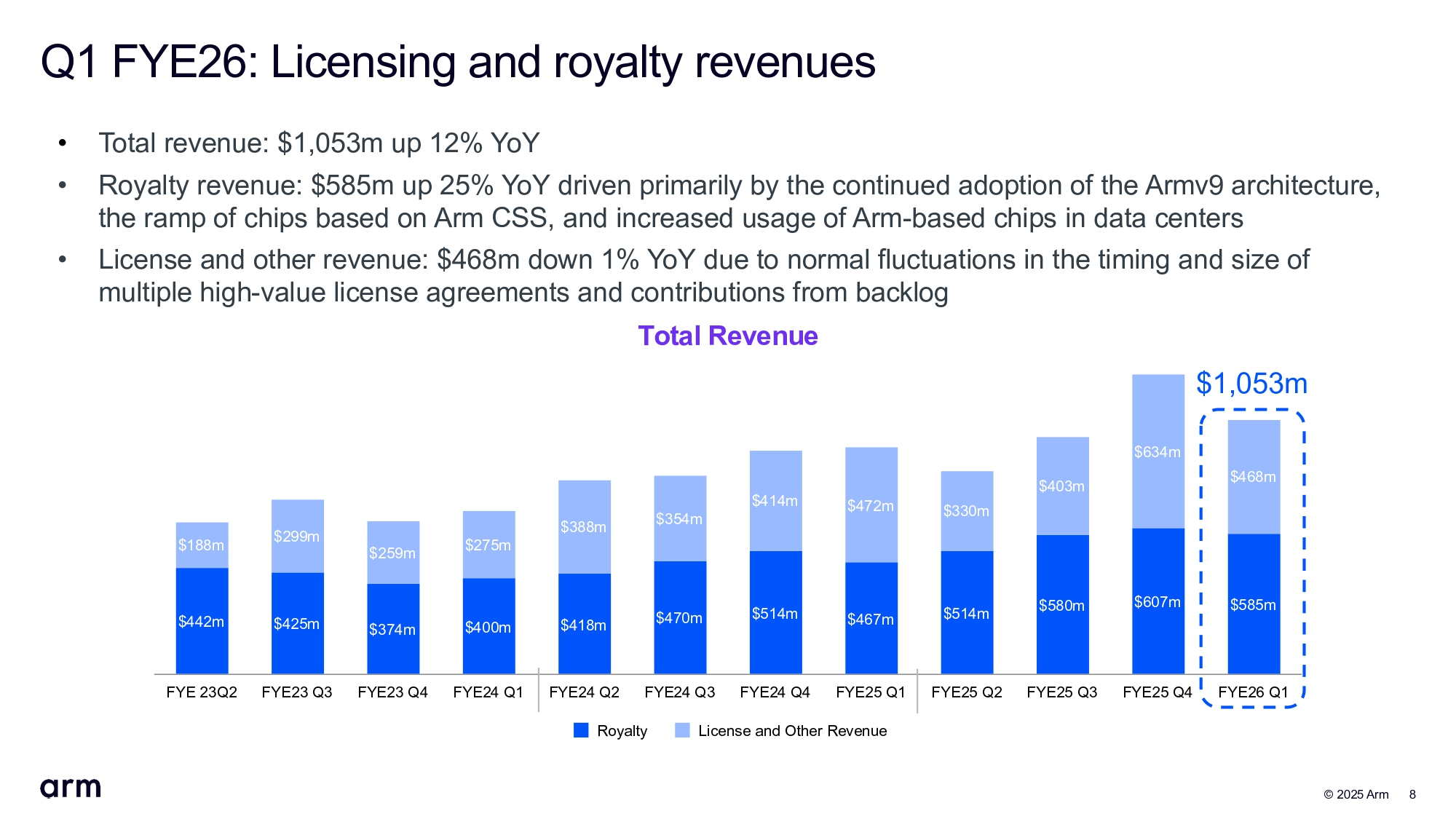 Чистая прибыль (GAAP) Arm составила $130 млн, что на 42 % меньше год к году. Скорректированная прибыль на акцию (Non-GAAP) равна $0,35, что соответствует прогнозу аналитиков, опрошенных LSEG. Во II финансовом квартале Arm прогнозирует выручку в пределах от $1,01 до $1,11 млрд, что соответствует прогнозу аналитиков от LSEG, равному $1,05 млрд. Скорректированная прибыль на акцию, как ожидает компания, составит 29–37 центов, что ниже среднего прогноза аналитиков в 36 центов на акцию, согласно данным LSEG. «Результаты и прогноз оказались слабыми и ниже ожиданий», — заявил агентству Reuters аналитик Summit Insights Киннгай Чан (Kinngai Chan). Выпускаемые сейчас смартфоны в основном полагаются на чипы на базе архитектуры Arm. Аналитики Morningstar ожидают, что Arm сохранит лидирующие позиции на рынке процессоров для смартфонов, где её доля составляет 99 %. Вместе с тем неопределённость, вызванная изменениями пошлин со стороны США и продолжающимися макроэкономическими проблемами, привела к снижению спроса на рынке: по данным International Data Corporation, мировые поставки смартфонов выросли всего на 1 % в период с апреля по июнь. И сдержанный прогноз подчёркивает неустойчивость рынка. 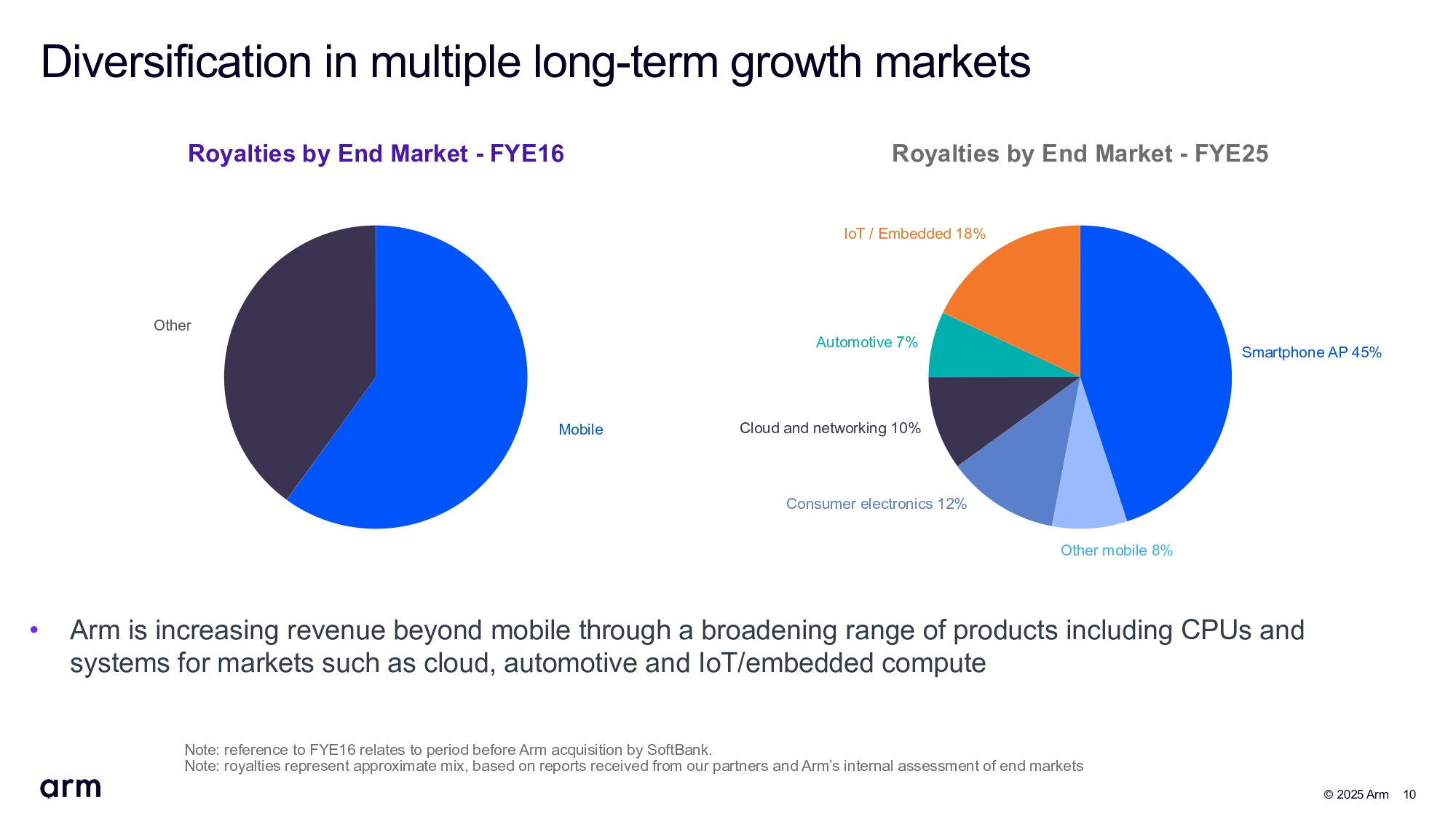 Генеральный директор Arm Рене Хаас (Rene Haas) заявил в интервью агентству Reuters, что компания «сознательно решила инвестировать больше» в технологии, выходящие за рамки разработки, подтвердив, что компания рассматривает возможность разработки собственных процессоров. Как отметил один из экспертов, Arm уже продаёт технологии практически всем ведущим разработчикам микросхем, и выпуск собственных готовых чиплетов или полупроводников может превратить её клиентов в конкурентов.
29.07.2025 [14:30], Владимир Мироненко
Стартап SpiNNcloud поставит Лейпцигскому университету «нейроморфный» суперкомпьютер для создания новых лекарств in silicoСтартап SpiNNcloud Systems из Дрездена (Германия) сообщил о заключении сделки на поставку Лейпцигскому университету нейроморфного суперкомпьютера, основанного на принципах функционирования человеческого мозга и предназначенного для разработки новых лекарственных препаратов. Суперкомпьютер будет использоваться учёными для моделирования сворачивания белков в рамках исследований в области персонализированной медицины, объединяющей достижения геномики, ИИ, робототехники и новейших диагностических технологий. Стоимость сделки не разглашается. В суперкомпьютере применена высокопараллельная архитектура с 48 чипами SpiNNaker2 на серверной плате, каждый из которых содержит 152 Arm-ядра со специализированными ускорителями и потребляет 0,8–2,5 Вт. Вся система, оснащённая 4320 чипами с 656 640 ядрами, помещается в одну стойку, но университет решил развернуть её в двух стойках, сообщил Гектор Гонсалес (Hector Gonzalez), соучредитель и генеральный директор SpiNNcloud, отметив, что общий энергетический бюджет системы составляет 25 кВт. 
Источник изображений: SpiNNcloud Новый подход к разработке лекарств использует исключительную параллельность и масштабируемость суперкомпьютера для развёртывания миллионов небольших моделей, которым поручено находить соответствия между молекулами и профилями пациентов. Эта конструкция обеспечивает эффективные, событийно-ориентированные вычисления, позволяя выполнять сложное моделирование и разрабатывать новые персонализированные препараты с более высокой скоростью сходимости и при более низком энергопотреблении по сравнению с традиционными системами на базе GPU. «Точное и детализированное управление процессорами позволяет использовать очень разреженный маршрут, не задействуя все ядра, — поясняет Гонсалес. — Это один из фундаментальных аспектов, который очень сложно реализовать на GPU, поскольку GPU устроен как каскад вычислительных блоков, которые необходимо задействовать максимально полно, чтобы добиться синхронной эффективности». «Архитектура SpiNNcloud делает возможным скрининг миллиардов молекул in silico (виртуальное клиническое исследование)», — сообщил Кристиан Майр (Christian Mayr), соучредитель SpiNNcloud. По его словам, изначально разработанная для моделирования биологических нейронных сетей серверная система SpiNNcloud адаптирована для массивно-параллельного выполнения небольших гетерогенных задач. Прототип нейронной сети позволяет провести скрининг 20 млрд молекул менее чем за час — это на два порядка быстрее, чем на 1000 CPU-ядер.  Гонсалес сообщил ресурсу EE Times, что индивидуальный подход к разработке лекарств, используемый в персонализированной медицине, хорошо вписывается в архитектуру SpiNNcloud. «Это множество небольших моделей, которые взаимодействуют друг с другом через чрезвычайно быструю сеть», — пояснил он. «Наша вычислительная архитектура <…> уникально подходит для развёртывания эффективных алгоритмов, требующих динамической разреженности и экстремального параллелизма», — добавил глава SpiNNcloud. «Экстремальный параллелизм SpiNNcloud делает их идеально подходящими для задач, связанных со сворачиванием белков, например, для поиска низкомолекулярных лекарственных препаратов, — отметил Йенс Майлер (Jens Meiler), профессор Института Александра фон Гумбольдта по Интернету и обществу и директор Института поиска лекарственных препаратов Лейпцигского университета. — «Фолдинг белков можно рассматривать как задачу оптимизации, в которой белок стремится найти своё наименьшее энергетическое состояние. Суперкомпьютеры SpiNNcloud хорошо справляются с такими задачами».  Самая крупная система, развёрнутая SpiNNcloud на данный момент, включает 30 тыс. чипов (более 5 млрд вычислительных элементов) в Дрезденском университете. «Максимально возможная система, которую мы можем спроектировать, – это 16 стоек, — говорит Гонсалес. — При более чем 16 стойках будет сложно поддерживать достаточную связанность между моделями». По его словам, можно было бы развернуть в Лейпциге и более крупный суперкомпьютер с большим числом ядер, но компании пришлось учитывать финансовые ограничения университета. Как сообщает EE Times, SpiNNcloud также тестирует своё оборудование в новых исследовательских направлениях, основанных на классических методах глубокого обучения, в частности, в работе с MoE-моделями. По словам Гонсалеса, архитектура SpiNNcloud хорошо подходит для таких задач. Разработчик выразил надежду, что архитектуры, вдохновлённые принципами работы мозга, такие как SpiNNcloud, позволят создавать новые типы моделей, невозможные для реализации на массовом оборудовании.
19.07.2025 [13:39], Сергей Карасёв
Rockchip представила 10-ядерный Arm-процессор RK3668 с ИИ-модулемКомпания Rockchip, как сообщает ресурс CNX Software, процессор RK3668 на архитектуре Arm, предназначенный для создания одноплатных компьютеров и других устройств с ИИ-функциями. Изделие насчитывает 10 вычислительных ядер в конфигурации 4 × Arm Cortex-A730 и 6 × Arm Cortex-A530 (Armv9.3). Причём на сегодняшний день эти ядра официально не представлены. В состав чипа входят графический процессор Arm Magni с производительностью до 1–1,5 Тфлопс и блок VPU с возможностью декодирования материалов в формате 8K (60 к/с). Новинка располагает интегрированным нейропроцессорным модулем (NPU) с быстродействием до 16 TOPS для ускорения ИИ-операций. Процессор изображений (ISP) с ИИ-функциями поддерживает работу с видео 8K (30 к/с). Реализованы четыре канала оперативной памяти LPDDR5/5x/6 с пропускной способностью до 100 Гбайт/с. Возможно использование флеш-накопителей UFS 4.0. Поддерживаются интерфейсы HDMI 2.1 (до 8K / 60 к/с), MIPI DSI, PCIe, UCIe. Производственные нормы — 5–6 нм. 
Источник изображений: CNX Software Кроме того, Rockchip раскрыла дополнительную информацию о чипе RK3688, первые упоминания которого появились в октябре 2024 года. Это изделие объединяет 12 вычислительных ядер в конфигурации 8 × Arm Cortex-A730 и 4 × Arm Cortex-A530. Пропускная способность памяти LPDDR6 достигает 200 Гбайт/с. Возможно декодирование видеоматериалов 16Kp30 и кодирование 8Kp60. Производительность встроенного NPU-блока повышена до 32 TOPS. Этот процессор будет изготавливаться по технологии 4–5 нм.  Одной из первых компаний, которая возьмёт на вооружение новые чипы, станет Radxa: она, в частности, готовит одноплатный компьютер Rock 6 на основе RK3668. |
|