Материалы по тегу: hpc
|
17.09.2025 [11:04], Сергей Карасёв
В США появится ИИ-суперкомпьютер с Arm-процессорами AmpereOne M и ускорителями Qualcomm Cloud AIУниверситет штата Нью-Йорк в Стони-Бруке (SBU) объявил о получении гранта в размере $13,77 млн от Национального научного фонда США (NSF) на приобретение и эксплуатацию высокопроизводительного энергоэффективного суперкомпьютера для задач ИИ. Средства получит Институт передовых вычислительных наук (IACS) в составе SBU. В проекте также примет участие Университет штата Нью-Йорк в Буффало (UB). Деньги выделяются в рамках программы Sustainable Cyber-infrastructure for Expanding Participation (Устойчивая киберинфраструктура для расширенной совместной работы). В основу НРС-комплекса, который пока не получил определённого названия, лягут процессоры AmpereOne M, разработанные компанией Ampere Computing специально для ресурсоёмких ИИ-нагрузок в дата-центрах. Эти чипы насчитывают до 192 кастомизированных 64-бит ядер на базе Arm v8.6+ Реализована поддержка 12 каналов DDR5-5600 и 96 линий PCIe 5.0. Кроме того, в состав суперкомпьютера войдут ИИ-ускорители Qualcomm Cloud AI, которые несут на борту до 576 Мбайт SRAM и до 128 Гбайт памяти LPDDR4x с пропускной способностью до 548 Гбайт/с. Расчётные показатели быстродействия машины пока не раскрываются. 
Источник изображения: Ampere Ожидается, что комбинация AmpereOne M и Qualcomm Cloud AI обеспечит высокую энергоэффективность, а также значительную производительность, достаточную для работы с крупными ИИ-моделями. Доступ к ресурсам суперкомпьютера планируется предоставлять исследователям, студентам и преподавателям на всей территории США. Новый НРС-комплекс поможет ускорить открытия в области геномики, биоинформатики и в других областях. Кроме того, система будет применяться при реализации проектов в сферах машинного обучения и статистического анализа.
06.09.2025 [13:42], Сергей Карасёв
Состоялся официальный запуск первого в Европе экзафлопсного суперкомпьютера JUPITERВ Юлихском исследовательском центре (FZJ) в Германии официально введён в эксплуатацию суперкомпьютер JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) — первый в Европе вычислительный комплекс экзафлопсного класса. Система будет использоваться в том числе для исследований в области климата, нейробиологии и квантового моделирования. Контракт на создание JUPITER подписан между Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU) и консорциумом, в который входят Eviden (Atos) и ParTec. Суперкомпьютер состоит из блока Booster для решения ресурсоёмких задач и универсального блока cCuster. В основу Booster положена платформа BullSequana XH3000 с прямым жидкостным охлаждением. Используются около 6000 вычислительных узлов с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200 (4×200G на узел, DragonFly+). В общей сложности задействованы почти 24 тыс. суперчипов NVIDIA GH200 (Grace Hopper). В июньском рейтинге TOP500 блок JUPITER Booster располагался на четвёртом месте: на тот момент его FP64-производительность составляла 793,4 Пфлопс. Теперь показатель преодолел рубеж в 1 Эфлопс. При этом ИИ-производительность, как ожидается, будет находиться на уровне 90 Эфлопс. 
Источник изображений: Forschungszentrum Jülich / Sascha Kreklau «С запуском первого в Европе эксафлопсного суперкомпьютера мы открываем новую главу в развитии науки, искусственного интеллекта и инноваций. JUPITER укрепляет цифровой суверенитет Европы и ускоряет научные исследования», — отмечает Екатерина Захариева (Ekaterina Zaharieva), еврокомиссар по стартапам, исследованиям и инновациям.  JUPITER планируется использовать для прогнозирования погоды и моделирования изменений климата, работы с европейскими большими языковыми моделями (LLM) и генеративным ИИ, разработки лекарственных препаратов и картирования человеческого мозга, моделирования молекулярной динамики и пр. Ожидается, что JUPITER сможет побить мировой рекорд по скорости обработки кубитов в квантовых вычислениях.  Между тем продолжается создание блока cCuster. В его состав войдут энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea1. Эти чипы содержат 80 ядер Neoverse V1 (Zeus), 64 Гбайт HBM2e и четыре интерфейса DDR5. Модуль cCuster будет оснащён двумя такими процессорами на каждый вычислительный узел, 512 Гбайт DDR5 (в отдельных узлах 1 Тбайт) и одним NDR200-подключением. Общее количество узлов составит около 1300. Ожидаемая FP64-производительность — 5 Пфлопс.  Хранилище суперкомпьютера включает быструю СХД ExaFLASH и ёмкую ExaSTORE. ExaFLASH включает 20 All-Flash СХД IBM Storage Scale 6000: 21 Пбайт («сырая» 29 Пбайт), запись до 2 Тбайт/с, чтение до 3 Тбайт/с. В ExaSTORE под хранение будет выделена «сырая» ёмкость 300 Пбайт, а для резервного копирования и архивов будет использоваться ленточная библиотека ёмкостью 700 Пбайт. 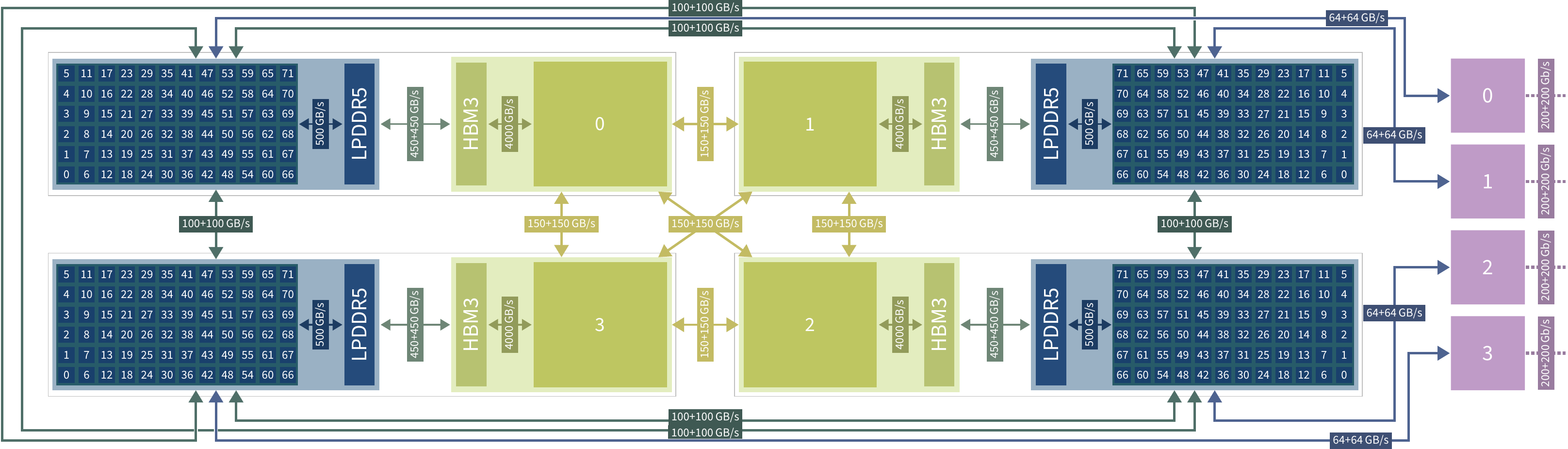
Узел Booster По оценкам, суммарные расходы на JUPITER и его эксплуатацию в течение шести лет достигнут примерно €500 млн. Половину от этой суммы предоставит EuroHPC, а остальную часть покроют Федеральное министерство образования и научных исследований Германии (BMBF) и Министерство культуры и науки земли Северный Рейн-Вестфалия (MKW NRW). Машина размещена в модульном ЦОД, что упростит дальнейшую модернизацию. Нужно отметить, что на сегодняшний день только три суперкомпьютера в мире официально преодолели планку в 1 Эфлопс. Это машины El Capitan, Frontier и Aurora: все они установлены в лабораториях Министерства энергетики США (DoE). Впрочем, Китай о своих HPC-комплексах публично практически не говорит уже несколько лет, так что реальный список экзафлопсных систем гораздо больше.
28.08.2025 [09:28], Владимир Мироненко
ASUS Cloud увеличит вычислительные мощности Тайваня на 50 %, построив 250-Пфлопс ИИ-суперкомпьютерASUS Cloud в партнёрстве с Taiwan AI Cloud (Taiwan Web Service Corp) и Национальным центром высокопроизводительных вычислений Тайваня (National Center for High-performance Computing, NCHC) в Тайнане (Тайвань) построит суперкомпьютер на ускорителях NVIDIA. Об этом сообщил гендиректор ASUS Cloud и Taiwan AI Cloud Питер Ву (Peter Wu, на фото ниже) в интервью газете South China Morning Post (SCMP). Питер Ву рассказал, что суперкомпьютер с начальной производительностью 80 Пфлопс (точность не уточняется) будет работать на 1700 ускорителях NVIDIA H200. Его запуск запланирован на декабрь, а со временем производительность новой системы вырастет до 250 Пфлопс. Ранее сообщалось, что NVIDIA также поставит два суперускорителя GB200 NVL72 и узлы HGX B300 для данной машины. По словам Ву, после запуска суперкомпьютера общая вычислительную мощность HPC-систем Тайваня вырастет минимум на 50 %. В феврале 2025 года Национальный совет по науке и технологиям Тайваня (NSTC) объявил о планах по увеличению общей вычислительной мощности систем страны примерно до 1200 Пфлопс к 2029 году с имеющихся 160 Пфлопс. 
Источник изображения: ASUS Как отметил DataCenter Dynamics, ASUS ранее сотрудничала с NVIDIA в развёртывании суперкомпьютеров на Тайване, включая 9-Плфопс машину Taiwania 2. В 2022 году ASUS и NVIDIA построили на Тайване суперкомпьютер для медицинских исследований. Taiwan AI Cloud уже реализовала аналогичные нынешнему проекты по созданию ИИ-инфраструктуры в других странах. Среди них — ЦОД в Сингапуре, а также объект во Вьетнаме с 200 ускорителями NVIDIA, который строят для государственного оператора Viettel. Этот проект стартовал в начале 2025 года после того, как правительство США одобрило поставку чипов NVIDIA. Ву отметил рост популярности агентного ИИ. Министерство цифровых технологий острова (MODA) «рекомендовало нам предоставить открытую архитектуру с фреймворком агентного ИИ», чтобы помочь местным компаниям использовать или модернизировать свои существующие приложения, сказал он. Говоря о материковом Китае, Питер Ву заявил, что компании будет «непросто» реализовывать там аналогичные проекты «из-за ситуации с поставками GPU». Китайский подход, заключающийся в «стекировании и кластеризации» малопроизводительных чипов для достижения производительности, аналогичной системам с передовыми ИИ-ускорителями, может быть осуществим с точки зрения инференса. Ву отметил, что запуск DeepSeek «рассуждающей» модели R1 в январе спровоцировал рост спроса на инференс, поскольку эта модель превосходно справляется с такими задачами. «Если рабочая нагрузка аналогична [инференсу], будет легче внедрить альтернативную технологическую схему с существующими [чипами]», — сказал Ву, добавив, что разработчики «могут столкнуться с проблемами в выборе GPU», если проект предполагает обучение или тонкую настройку ИИ-систем. Говоря о будущем, Ву сообщил, что ожидает дальнейшего развития трёх сегментов ИИ в будущем: вычислительной геномики, квантовых вычислений и так называемых цифровых двойников. «Приложение-убийца [для цифровых двойников] может появиться в сфере ухода за пожилыми людьми, помогая им получать лекарства, еду или принимать душ», — прогнозирует Ву.
26.08.2025 [22:13], Руслан Авдеев
IBM и AMD займутся разработкой новых вычислительных архитектур на стыке квантовых и классических подходовAMD и IBM анонсировали разработку нового поколения вычислительных архитектур, в основе которых лежат квантовые компьютеры и HPC-системы. Речь идёт о т.н. «квантово-центричных супервычислениях», сообщает пресс-служба AMD. Команды намерены продемонстрировать первые результаты до конца текущего года. Компании сотрудничают над разработкой масштабируемых, open source платформ, способствующих переосмыслению будущего вычислений с использованием лидерства IBM в сфере квантовых компьютеров и ПО для них, а также ведущей роли AMD в сфере HPC и ИИ-ускорителей. По словам главы IBM Арвинда Кришны (Arvind Krishna), квантовые вычисления со временем позволят «симулировать» реальный мир и представлять информацию принципиально новым способом. Комбинация технологий IBM и AMD позволят построить мощную гибридную модель, оставляющую позади традиционные вычисления. В новой архитектуре квантовые компьютеры будут работать в тандеме с HPC-кластерами и ИИ-инфраструктурой с использованием CPU, ИИ-ускорителей и прочих вычислительных модулей. При таком гибридном подходе различные части задачи решаются оптимальным для них типом оборудования. Например, в будущем квантовые компьютеры смогут моделировать поведение атомов и молекул, а классические ИИ-суперкомпьютеры — анализировать большие массивы данных. Вместе эти технологии смогут решать реальные задачи в беспрецедентном масштабе и с беспрецедентной скоростью, говорят компании. 
Источник изображения: Yue WU/unsplash.com Компании изучают способы интеграции CPU, FPGA и ИИ-ускорителей AMD с квантовыми компьютерами IBM для совместного ускорения выполнения принципиально новых алгоритмов. Ключевым планом сотрудничества является разработка систем коррекции ошибок, что является важнейшим шагом на пути к созданию отказоустойчивых квантовых компьютеров, которые IBM планирует выпустить к 2030 году. Также компании планируют изучить, как именно open source решения вроде Qiskit могли бы выступить катализаторами развития и внедрения новых алгоритмов, использующих квантово-центричные супервычисления. IBM уже начала работать в направлении интеграции квантовых и традиционных систем. Недавно она заключила соглашение с японским НИИ RIKEN о подключении своего модульного квантового компьютера IBM Quantum System Two к одному из самых быстрых суперкомпьютеров мира Fugaku. Суперкомпьютеры Frontier в Ок-Риджской национальной лаборатории (ORNL) и El Capitan в Ливерморской национальной лаборатории (LLNL) полагаются на CPU и ускорители AMD. Другими словами, на чипах AMD работают два из быстрейших суперкомпьютеров из мирового рейтинга TOP500.
22.08.2025 [13:30], Алексей Разин
NVIDIA поможет японцам создать один из мощнейших суперкомпьютеров мира FugakuNEXTВ начале этого десятилетия созданный в Японии суперкомпьютер Fugaku пару лет удерживался на верхней строчке в рейтинге мощнейших систем мира TOP500, он и сейчас занимает в нём седьмое место. В попытке технологического реванша японский исследовательский институт RIKEN доверился компании NVIDIA, которая поможет Fujitsu создать суперкомпьютер Fugaku NEXT. Помимо Arm-процессоров Fujitsu MONAKA-X, в основу нового японского суперкомпьютера лягут и ускорители NVIDIA, хотя изначально планировалось обойтись без них. NVIDIA будет принимать непосредственное участие в интеграции своих компонентов в суперкомпьютерную систему, создаваемую японскими партнёрами. По меньшей мере, скоростные интерфейсы, которыми располагает NVIDIA, пригодятся для обеспечения быстрого канала передачи информации между CPU и ускорителями. Сама NVIDIA обтекаемо говорит, что для этого можно задействовать шину NVLink Fusion. С ускорителями AMD, по-видимому, эти процессоры будут общаться более традиционно, т.е. по шине PCIe. 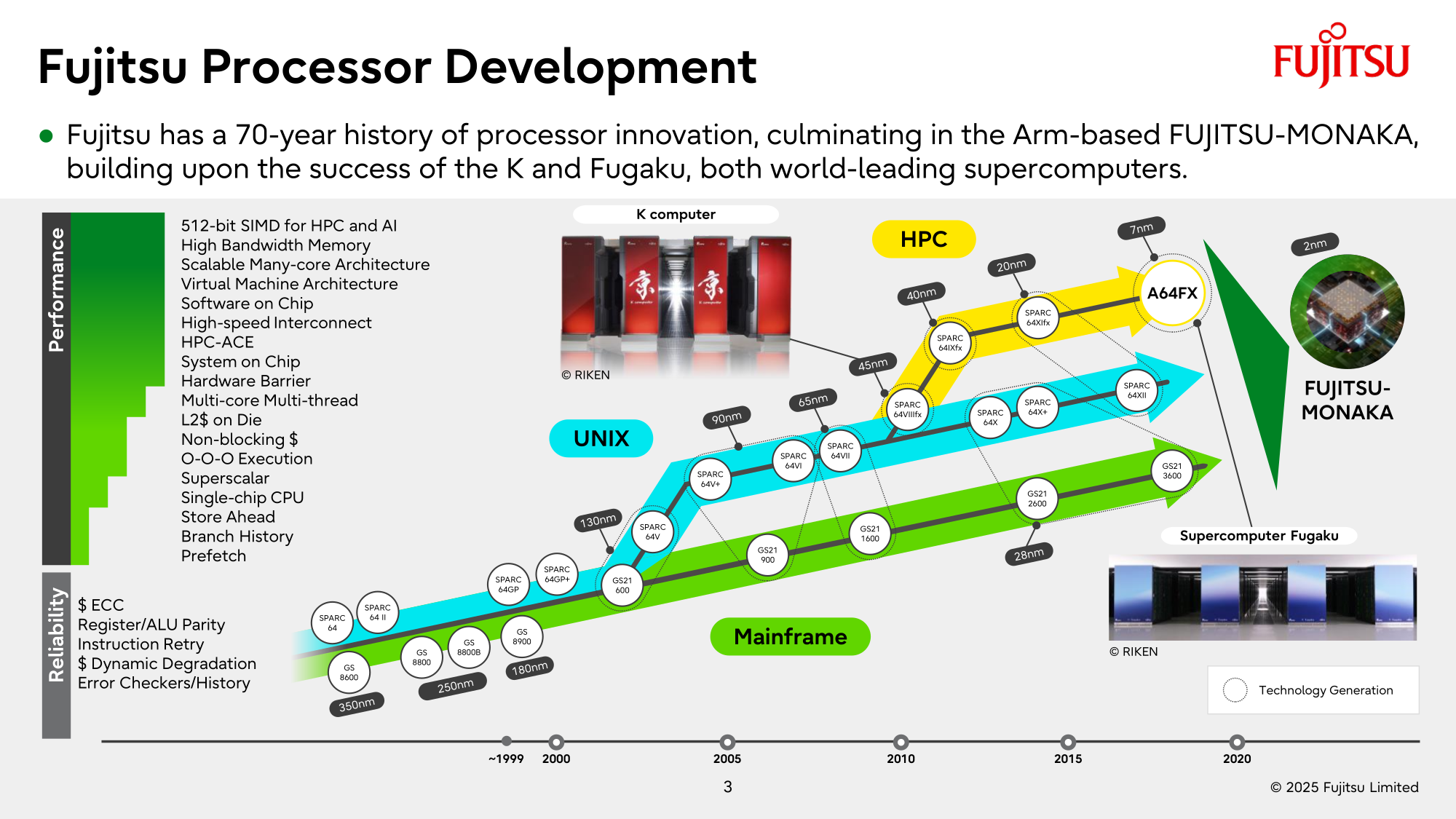
Источник изображений: Fujitsu Кроме того, NVIDIA собирается применить в составе данной системы передовые типы памяти. Применяемые при создании FugakuNEXT решения, по мнению представителей NVIDIA, смогут стать типовыми для всей отрасли в дальнейшем. Подчёркивается, что будущая платформа станет не просто техническим апгрейдом, а инвестицией в будущее страны. 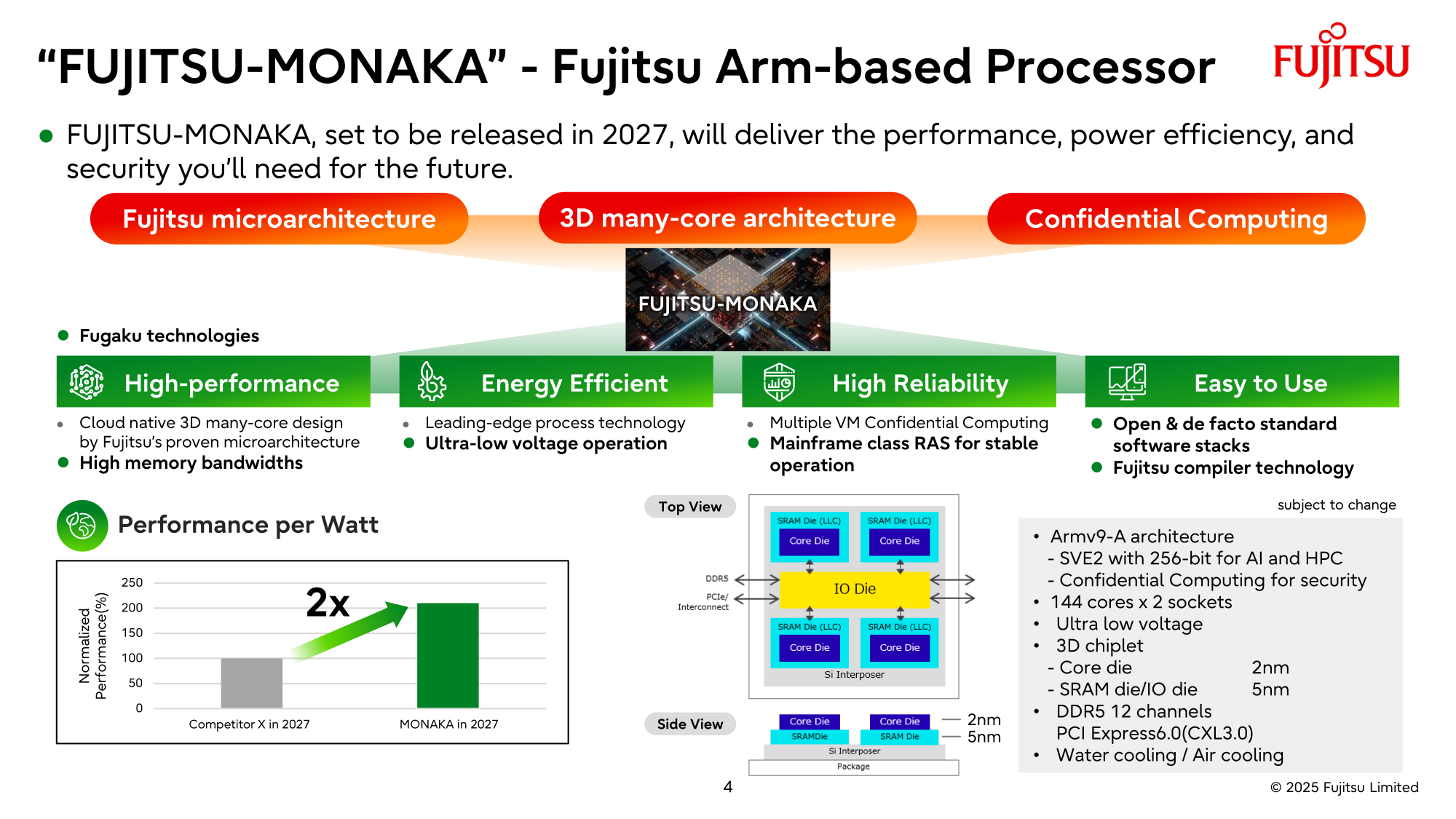 Сама архитектура системы не уточняется, поэтому сложно судить, насколько активно японские разработчики будут использовать ускорители NVIDIA, и к какому поколению они будут относиться. Создатели ставят перед собой амбициозные цели — FugakuNEXT должна стать первой системой «зетта-масштаба». Своего предшественника она должна превзойти более чем в пять раз, обеспечив быстродействие на уровне 600 Эфлопс (FP8). 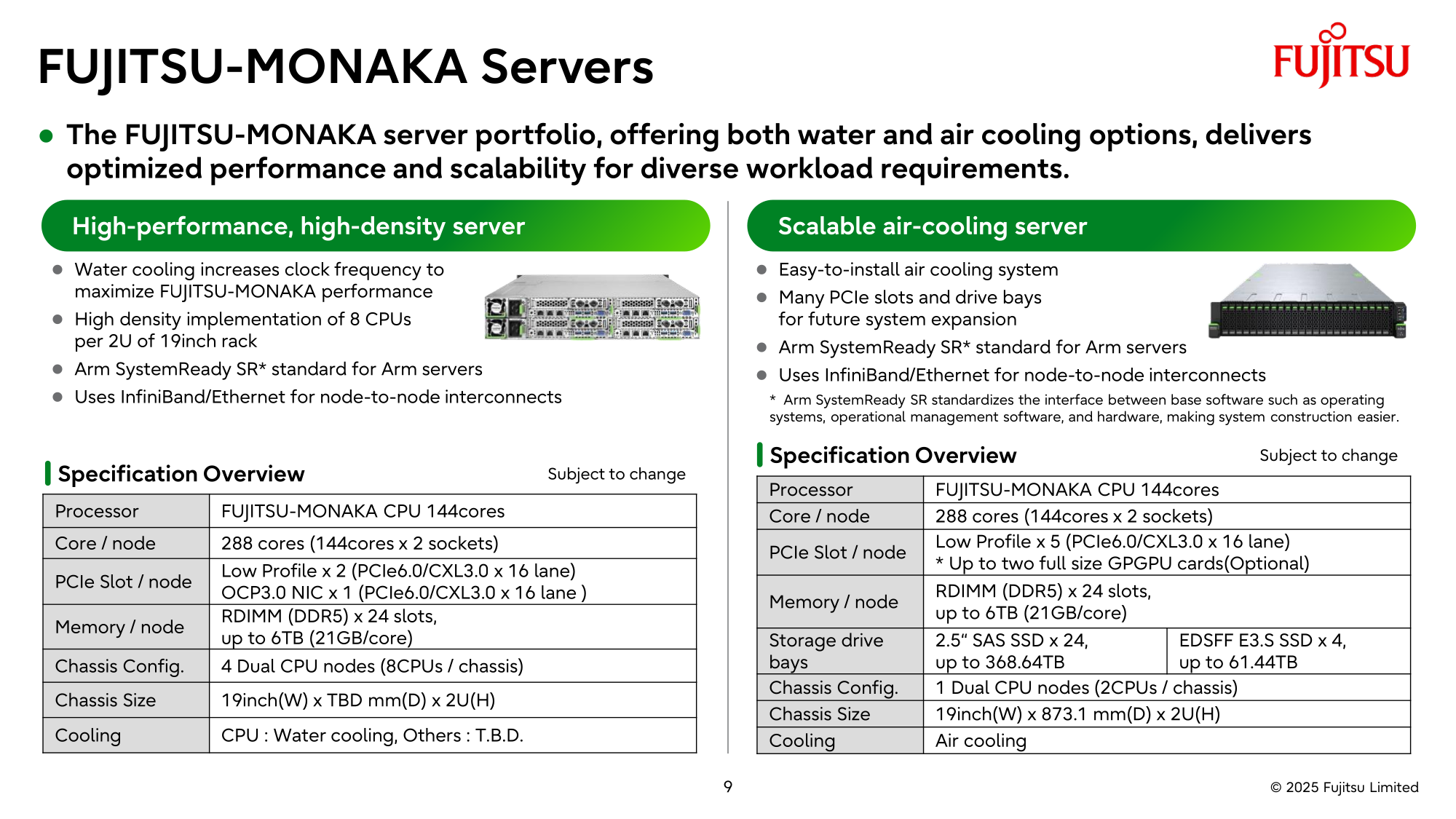 На уровне приложений прирос быстродействия может быть стократным, отмечают создатели. Новый суперкомпьютер сможет применяться для обучения больших языковых моделей. Впрочем, в строй он будет введён лишь к 2030 году, а Fujitsu ещё только предстоит выпустить свои процессоры MONAKA-X для этой системы.
17.08.2025 [14:15], Сергей Карасёв
Inspur разработала СЖО для мегаваттных стоек с 3-кВт ИИ-ускорителямиКитайская компания Inspur Information представила передовую систему двухфазного жидкостного охлаждения для ИИ-платформ следующего поколения, таких как суперускоритель Metabrain SD200. Решение может использоваться для отвода тепла от серверных стоек мегаваттного класса. Inspur отмечает, что из-за стремительного развития ИИ наблюдается тенденция к повышению плотности вычислений. Это приводит к быстрому увеличению энергопотребления стоек с серверным оборудованием. Различные компании, такие как Aligned, JetCool и CyrusOne, разрабатывают решения для стоек мощностью 300 кВт, тогда как крупные ЦОД-операторы и гиперскейлеры готовятся к появлению мегаваттных установок. В таких условиях возможностей стандартных систем охлаждения становится недостаточно. 
Источник изображения: Inspur Двухфазная СЖО Inspur способна охлаждать кристаллы мощностью более 3000 Вт, тогда как показатель теплосъёма превышает 250 Вт на квадратный 1 см2. Благодаря изоляции хладагента предотвращается коррозия, что сводит к минимуму риск коротких замыканий, снижает износ и отказы компонентов, говорит компания. Ключевыми преимуществами новой СЖО названы надёжность и долговечность, отсутствие утечек, простота эксплуатации, безопасная работа IT-оборудования, а также уменьшение общей стоимости владения по сравнению с другими аналогичными решениями. При разработке системы специалистам Inspur Information удалось преодолеть узкие места управления температурой и давлением фазового перехода, а также решить проблемы дисбаланса потока и перегрева во время скачков нагрузки: утверждается, что в конфигурации с 200 чипами отклонение распределения потока составляет менее 10 %, а разница температур — менее 2 °C. Применяется специально разработанный хладагент низкого давления, который безопасен для окружающей среды. Несмотря на отсутствие риска утечки, рабочее давление системы составляет менее 1 МПа.
08.08.2025 [11:50], Руслан Авдеев
Tesla отказалась от развития ИИ-суперкомпьютеров DojoTesla распускает команду, стоявшую за суперкомпьютером Dojo, сообщает TechCrunch со ссылкой на Bloomberg. Как сообщают анонимные источники, глава проекта Питер Бэннон (Peter Bannon) покидает компанию, а оставшихся участников команды переведут на работу с другими вычислительными проектами Tesla. О закрытии Dojo стало известно после ухода из Tesla порядка 20 сотрудников, основавших собственный ИИ-стартап DensityAI, который займётся разработкой чипов, аппаратного и программного обеспечения для ИИ ЦОД, связанных с робототехникой, ИИ-агентами и автомобильными приложениями. DensityAI основана бывшим руководителем Dojo Ганешем Венкатарамананом (Ganesh Venkataramanan), причём в не самый удачный для Tesla момент, поскольку глава компании Илон Маск (Elon Musk) ранее настоял на том, чтобы акционеры рассматривали компанию как бизнес, занимающийся ИИ и робототехникой. Решение о закрытии Dojo стало значительным изменением стратегии. Ранее Маск утверждал, что суперкомпьютер станет краеугольным камнем для удовлетворения амбиций компании в сфере ИИ и основная цель — добиться полной автономии машин благодаря способности Dojo обрабатывать огромные массивы видеоданных. В 2023 году Morgan Stanley посчитал, что Dojo может поднять капитализацию Tesla на $500 млрд за счёт новых источников дохода — проектов роботакси и программных сервисов. 
Источник изображения: Tesla В 2024 году Маск сообщил, что команда Tesla, занятая искусственным интеллектом, «удвоит ставку» на Dojo перед презентацией роботакси. Тем не менее разговоры о Dojo уже в августе того же года постепенно сошли на нет, когда Маск начал продвигать ИИ-кластер Cortex (на базе ускорителей NVIDIA) при штаб-квартире Tesla в Остине (Техас). Проект Dojo включал в себя как суперкомпьютер, так и предполагал собственное производство ИИ-ускорителей. Ещё в 2021 году Tesla во время официального анонса Dojo представила чип D1, который должен был бы использоваться совместно с ускорителями NVIDIA для обеспечения работы Dojo. Также сообщалось, что ведутся работы над чипом D2, в котором будут устранены недостатки предшественника. По данным источников Bloomberg, теперь Tesla намерена сделать ставку преимущественно на NVIDIA, а также других сторонних партнёров вроде AMD, а Samsung будет выпускать чипы на заказ. В прошлом месяце с Samsung подписан контракт на выпуск инференс-чипов AI6, которые будут работать как с автопилотами Tesla, так и использоваться в роботах Optimus и дата-центрах. Ранее Маск намекнул, что в случае с Dojo 3 (D3) и инференс-чипом AI6, речь, возможно, будет идти о едином чипе. Недавно совет директоров Tesla предложил Маску пакет акций на $29 млрд, чтобы тот оставался в Tesla и продвигал ИИ-разработки компании, вместо того чтобы отвлекаться на другие бизнесы.
05.08.2025 [11:16], Сергей Карасёв
Европейские чипы Cinco Ranch на базе RISC-V близки к началу массового производстваУчастники проекта Barcelona Zettascale Laboratory (BZL), координируемого Барселонским суперкомпьютерным центром (BSC) в Испании, по сообщению ресурса EETimes, достигли фазы Tape-out в рамках разработки европейских процессоров Cinco Ranch на открытой архитектуре RISC-V. Tape-out — это финальная стадия проектирования интегральных схем или печатных плат перед их отправкой в производство. Данный процесс предполагает перенос цифрового макета чипа на фотошаблон для последующего изготовления. Производством изделий займётся предприятие Intel Foundry с применением техпроцесса Intel 3. Cinco Ranch представляет собой пятое поколение чипов серии Lagarto. По сути, это «система на кристалле» (SoC) промышленного класса с высокой энергетической эффективностью. Конструкция чипа включает три отдельных специализированных ядра, каждое из которых оптимизировано под определённые вычислительные задачи. В частности, присутствует ядро Sargantana (RV64G) с однопоточным выполнением инструкций по порядку. Кроме того, имеется двухпоточное ядро Lagarto Ka с внеочередным исполнением машинных инструкций. Довершает картину высокопроизводительное 6-поточное ядро Lagarto Ox (RV64GC) с внеочередным исполнением инструкций. Нужное ядро выбирается в момент загрузки системы. 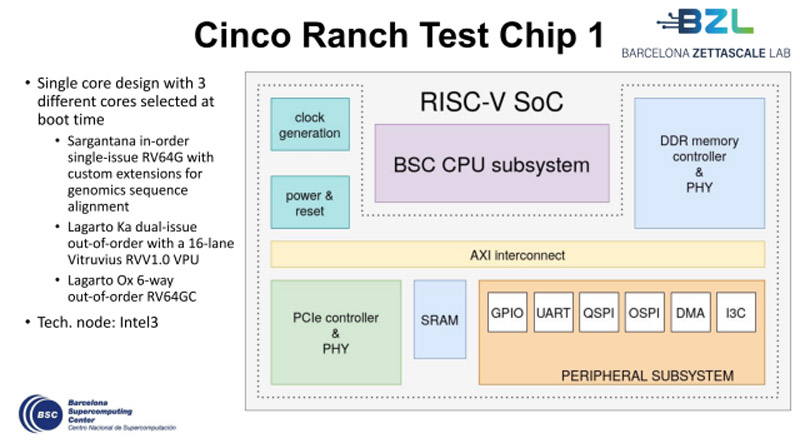
Источник изображения: BSC Решение Cinco Ranch содержит 16-канальный векторный блок Vitruvius++ VPU и трёхуровневую систему кеша. Реализована поддержка памяти DDR5 и интерфейса PCIe 3.0. Площадь чипа составляет 16 мм2. Главной целью проекта BZL является разработка суверенных суперкомпьютерных технологий в Европе. Предполагается, что создаваемые чипы найдут применение в различных областях, включая НРС-платформы, автономные транспортные средства, системы ИИ и пр. После всестороннего тестирования чипов Cinco Ranch будет освоено их массовое производство.
21.07.2025 [16:42], Сергей Карасёв
Запущен самый мощный в Великобритании ИИ-суперкомпьютер — комплекс Isambard-AIВ Великобритании официально введён в эксплуатацию суперкомпьютер Isambard-AI: это самый мощный в стране вычислительный комплекс, ориентированный на задачи ИИ. В июньском рейтинге TOP500 машина занимает 11-е место, а в списке наиболее энергоэффективных систем Green500 — четвёртую позицию. Суперкомпьютер назван в честь британского инженера Изамбарда Кингдома Брюнеля (Isambard Kingdom Brunel), внёсшего значимый вклад в Промышленную революцию. Проект реализован при участии компаний NVIDIA и HPE, Бристольского университета (University of Bristol) и других организаций. Создание Isambard-AI обошлось примерно в £225 млн ($302 млн). В основу комплекса положена платформа HPE Cray EX с интерконнектом Slingshot 11. Задействованы 5448 суперчипов NVIDIA GH200 Grace Hopper, которые объединяют 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. Применена СХД Cray ClusterStor E1000 вместимостью 25 Пбайт. Питание полностью обеспечивается от источников энергии с нулевыми выбросами углерода. Избыточное тепло может использоваться для обогрева близлежащих зданий. Развёрнута система прямого жидкостного охлаждения HPE. 
Источник изображений: NVIDIA В тесте Linpack комплекс Isambard-AI демонстрирует FP64-быстродействие на уровне 216,5 Пфлопс, тогда как теоретический пиковый показатель составляет 278,58 Пфлопс. Производительность при решении ИИ-задач достигает 21 Эфлопс (FP8). Как отмечается, Isambard-AI более чем в 10 раз превосходит по скорости второй по быстродействию суперкомпьютер в Великобритании и предоставляет больше вычислительной мощности, чем все остальные НРС-машины страны вместе взятые.  Новый комплекс будет применяться для решения наиболее сложных и ресурсоёмких задач, таких как разработка передовых лекарственных препаратов, моделирование климата, материаловедение, большие языковые модели (LLM) и др. Доступ к ресурсам Isambard-AI регулируется Министерством науки, инноваций и технологий и Департаментом исследований и инноваций Великобритании.
21.07.2025 [09:27], Сергей Карасёв
10 долгих лет: состоялся официальный запуск экзафлопсного суперкомпьютера AuroraВ Аргоннской национальной лаборатории (ANL) Министерства энергетики США (DOE) в Иллинойсе состоялась церемония торжественного разрезания ленты в честь официального запуска суперкомпьютера Aurora экзафлопсного класса. В мероприятии приняли участие руководители и исследователи Intel, HPE и DOE. Церемония была скорее формальностью, поскольку Aurora стала доступна исследователям со всего мира в начале текущего года. Aurora является одним из трёх суперкомпьютеров DOE с производительностью более 1 Эфлопс. Наряду с El Capitan в Ливерморской национальной лаборатории имени Лоуренса (LLNL) и Frontier в Национальной лаборатории Оук-Ридж (ORNL) эти НРС-комплексы занимают первые три места как в списке TOP500 самых быстрых суперкомпьютеров мира, так и в бенчмарке HPL-MxP для оценки производительности ИИ. У суперкомпьютера непростая судьба. Анонс машины состоялся в 2015 году — система с FP64-производительностью на уровне 180 Пфлопс по плану должна была заработать в 2018 году. Однако планы неоднократно корректировались, а проект в конце концов был кардинально пересмотрен. Первые тестовые кластеры системы заработали более двух лет назад, а частично запущенная система попала в TOP500 в конце 2023 года. Целиком она заработала в 2024 году. 
Источник изображения: ANL / Intel В проекте по созданию Aurora принимали участие Intel и HPE. Машина построена на платформе HPE Cray EX — Intel Exascale Compute Blade: задействованы процессоры Intel Xeon CPU Max и ускорители Intel Data Center GPU Max, объединённые интерконнектом HPE Slingshot. В общей сложности применяются 63 744 ускорителей, что делает Aurora одним из крупнейших в мире суперкомпьютеров на базе GPU. 
Источник изображения: ANL / Intel Установлена ОС SUSE Linux Enterprise Server 15 SP4. Производительность в тесте Linpack составляет 1,012 Эфлопс, а теоретический пиковый показатель достигает 1,980 Эфлопс. НРС-комплекс занимает площадь около 930 м2. Развёрнута современная инфраструктура жидкостного охлаждения. Общая протяжённость соединений превышает 480 км, а количество конечных точек сети достигает 85 тыс.  Aurora останется по-своему уникальным суперкомпьютером: CPU с HBM на борту больше не планируются, от Ponte Vecchio компания отказалась в пользу Habana Gaudi и Falcon Shores. Но и последние на рынок не попадут, а будут использоваться для внутренних тестов и обкатки технологий. На смену им должны прийти Jaguar Shores, но точных дат Intel не называет.  Вычислительные мощности Aurora, как отмечается, помогают в решении сложнейших задач в самых разных областях. В биологии и медицине исследователи используют ИИ-возможности суперкомпьютера для прогнозирования эволюции вирусов, улучшения методов лечения рака и картирования нейронных связей в мозге. В аэрокосмической сфере Aurora используется для создания двигательных установок нового поколения и моделирования аэродинамических процессов. Комплекс играет важную роль в развитии технологий термоядерной энергетики, квантовых вычислений и пр. |
|