Материалы по тегу: hpc
|
20.02.2024 [23:25], Сергей Карасёв
Поменьше и побольше: у NVIDIA оказалось сразу два ИИ-суперкомпьютера EOSНа днях NVIDIA снова официально представила суперкомпьютер EOS для решения ресурсоёмких задач в области ИИ. Издание The Register обратило внимание на нестыковки в публичных заявлениях компании относительно конфигурации и производительности машины. В итоге NVIDIA признала, что у неё есть две архитектурно похожих системы под одним и тем же именем. Впрочем, полной ясности это не внесло. НРС-комплекс EOS изначально был анонсирован почти два года назад — в марте 2022-го. Тогда речь шла о кластере, объединяющем 576 систем NVIDIA DGX H100, каждая из которых содержит восемь ускорителей H100 — в сумме 4608 шт. Суперкомпьютер, согласно заявлениям NVIDIA, обеспечивает ИИ-быстродействие на уровне 18,4 Эфлопс (FP8), тогда как производительность на операциях FP16 составляет 9 Эфлопс, а FP64 — 275 Пфлопс.  Вместе с тем в ноябре 2023 года NVIDIA объявила о том, что ИИ-суперкомпьютер EOS поставил ряд рекордов в бенчмарках MLPerf Training. Тогда говорилось, что комплекс содержит 10 752 ускорителя H100, а его FP8-производительность достигает 42,6 Эфлопс. Представители компании сообщили, что суперкомпьютер, использованный для MLPerf Training с 10 752 ускорителями H100, «представляет собой другую родственную систему, построенную на той же архитектуре DGX SuperPOD». Вместе с тем комплекс, занявший 9-е место в TOP500 от ноября 2023 года — это как раз версия EOS с 4608 ускорителями, представленная на днях в рамках официального анонса. Но... цифры всё не сходятся! В TOP500 FP64-производительность EOS составляет 121,4 Пфлопс при пиковом значении 188,7 Пфлопс. Сама NVIDIA, как уже было отмечено выше, называет цифру в 275 Пфлопс. Таким образом, суперкомпьютер, участвующий в рейтинге TOP500, мог содержать от 2816 до 3161 ускорителя H100 из 4608 заявленных. С чем связано такое несоответствие, не совсем ясно. Высказываются предположения, что у NVIDIA могли возникнуть сложности с обеспечением стабильности кластера на момент составления списка TOP500, поэтому система была включена в него в урезанной конфигурации.
19.02.2024 [15:30], Сергей Карасёв
Крупнейший на Дальнем Востоке ЦОД заработает до конца 2024 года — его мощность составит 100 МВтКомпания «Битривер-Б» (входит в группу BitRiver), резидент территории опережающего развития (ТОР) «Бурятия», намерена ввести в эксплуатацию крупнейший на Дальнем Востоке дата-центр во II половине 2024 года. Ресурсы ЦОД планируется использовать для высокопроизводительных энергоёмких вычислений, таких как майнинг, облачные сервисы и современные цифровые услуги. Проект реализуется в рамках соглашения с Корпорацией развития Дальнего Востока и Арктики (КРДВ). Строительство дата-центра началось в 2022 году, а объём инвестиций BitRiver на сегодняшний день превысил 1,4 млрд руб. Планируемая мощность ЦОД составляет 100 МВт. Отмечается, что ЦОД станет якорным предприятием, вокруг которого в Республике Бурятия будет формироваться IT-кластер в соответствии с целями развития цифровой экономики РФ. На площадке будут созданы рабочие места с комфортными условиями труда для 120 высококвалифицированных специалистов. В штат планируется принимать людей с ограниченными возможностями здоровья, а также выпускников местных учебных заведений. Кроме того, оператор ЦОД намерен сотрудничать с вузами и организовывать практику для студентов. 
Источник изображения: BitRiver Выбор ТОР «Бурятия» для строительства дата-центра, как сообщается, не случаен. Действующие здесь налоговые льготы (нулевые налоги на землю и имущество) и административные преференции создают комфортные условия для бизнеса, а также повышают экономическую эффективность проекта. Интерес к будущему ЦОД уже проявили крупные институциональные и частные заказчики из России, СНГ, стран Персидского залива, Китая и других государств БРИКС. «В настоящее время происходит взаимное проникновение двух сквозных технологий — блокчейна и ИИ. В этом смысле новые центры обработки данных для энергоёмких вычислений служат инфраструктурным заделом для выполнения задачи развития цифровой экономики и ИИ, в частности. Вся сфера высокопроизводительных и энергоёмких вычислений в России, особенно с учётом тенденции повсеместного использования ИИ, к 2035 году может потреблять до нескольких десятков ГВт», — отмечает «Битривер-Б».
13.02.2024 [18:03], Владимир Мироненко
В Казахстане построят суперкомпьютер при участии компании Presight AI из ОАЭМинистерство цифрового развития, инновации и аэрокосмической промышленности Республики Казахстан (МЦРИАП РК), АО «Фонд национального благосостояния «Самрук-Қазына» и компания Presight AI Ltd. из ОАЭ подписали соглашение о создании суперкомпьютера в Казахстане и строительства ЦОД для его размещения, сообщается на сайте МЦРИАП РК. Проект будет выполнен в два этапа. В ходе первого этапа будут установлены вычислительные мощности в существующем ЦОД АО «НИТ» (оператор ИКТ электронного правительства), а на втором этапе будет построен новый ЦОД со значительными вычислительными мощностями. 
Источник изображения: МЦРИАП РК Как сообщается в пресс-релизе, со стороны рынка, высших учебных заведений, научного сообщества и государственных органов имеется потребность в создании технологической инфраструктуры (суперкомпьютер) для успешного развития инструментов ИИ. В стране появился ряд стартапов и зрелых компаний, занимающихся внедрением ИИ, такие как Cerebra, ForUS.Data, GoatChat.AI, Higgsfield AI, AI Labs, Sergek Group и др. Также отмечено, что запуск технологической HPC-инфраструктуры определит лидерство Казахстана в Центральной Азии в сфере развития ИИ, который предоставит возможность аренды вычислительных мощностей для сопредельных стран. Ранее МЦРИАП РК сообщило о расширении сотрудничества с Объединёнными Арабскими Эмиратами (ОАЭ) с целью реализации проектов в области дата-центров и ИИ.
12.02.2024 [21:16], Сергей Карасёв
У нас просто нет столько энергии: Швейцария намерена размещать свои крупные ЦОД в Северной ЕвропеШвейцария не планирует разворачивать на своей территории крупные дата-центры из-за ограниченности ресурсов. Об этом, как сообщает Swissinfo, заявил глава Швейцарского национального суперкомпьютерного центра (CSCS) Томас Шультесс (Thomas Schulthess). По его словам, Северная Европа является подходящим регионом для аутсорсинга вычислительных мощностей. В частности, Финляндия, Норвегия и Швеция имеют значительные ресурсы в плане гидроэлектроэнергии вдали от городов: эти мощности используются для снабжения электричеством добывающих предприятий, бумажных заводов и пр. «Мы никогда не будем управлять в Швейцарии дата-центрами мощностью в несколько сотен мегаватт, как у ведущих технологических компаний, таких как Microsoft или Google», — заявил господин Шультесс. 
Суперкомпьютер Alps в Швейцарском национальном суперкомпьютерном центре. Источник изображения: Keystone/gaetan Bally Глава CSCS полагает, что Швейцария должна помочь Северной Европе адаптировать электроэнергетическую инфраструктуру для научных вычислений. Например, уже создан консорциум LUMI (Large Unified Modern Infrastructure), в который входят десять стран: Финляндия, Бельгия, Чехия, Дания, Эстония, Исландия, Норвегия, Польша, Швеция и Швейцария. В рамках инициативы на территории бывшей финской бумажной фабрики запущен суперкомпьютер предэкзафлопсного класса. Как отмечает Шультесс, этот ЦОД имеет удобное и экономически выгодное расположение, поскольку само здание и сопутствующая энергетическая инфраструктура уже были построены для поддержания работы завода. Поиск подобных площадок, по словам Шультесса, важен в свете стремительного развития ИИ, НРС-платформ, а также в связи с развитием электрифицированных и роботизированных автомобилей. «Для нас это означает, что мы должны подумать о том, как решить проблемы, связанные с растущим спросом на электроэнергию», — заключил глава CSCS.
12.02.2024 [08:54], Сергей Карасёв
EuroHPC развернёт в Европе специализированные индустриальные суперкомпьютерыЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о начале приёма заявок от заинтересованных площадок для размещения специализированных суперкомпьютеров промышленного уровня. Речь идёт о вычислительных комплексах не ниже среднего класса, специально разработанных с учётом норм безопасности, конфиденциальности и целостности данных в индустриальном сегменте. К таким системам обычно предъявляются более высокие требования, нежели к суперкомпьютерам для решения научных задач. 
Суперкомпьютер Leonardo. Источник изображения: EuroHPC JU / Cineca EuroHPC JU планирует закупить новые вычислительные комплексы совместно с консорциумом частных партнёров. С выбранными площадками будут заключены соглашения о размещении и эксплуатации оборудования. EuroHPC JU приобретёт как минимум один промышленный суперкомпьютер в 2024 году. Подробности о проекте не раскрываются, но известно, что общий вклад ЕС в его реализацию составит €12,2 млн. Новые промышленные суперкомпьютеры будут совместно финансироваться из бюджета EuroHPC JU, полученного в рамках Программы «Цифровая Европа» (DEP), а также за счёт взносов государств-участников организации. При этом EuroHPC JU покроет до 35 % затрат на приобретение вычислительных комплексов. Развёртывание этих систем поможет удовлетворить растущий спрос на вычислительные ресурсы со стороны индустриальных заказчиков. В целом, инициатива должна способствовать «повышению инновационного потенциала предприятий в Европе».
06.02.2024 [20:32], Руслан Авдеев
Министерство энергетики США превратило бывшие лаборатории ускорителя NSLS в научный дата-центрРасположенная в Нью-Йорке Брукхейвенская национальная лаборатория (Brookhaven National Laboratory) Министерства энергетики США перепрофилировала помещения, относившиеся к ускорителю частиц, в дата-центр для научных исследований. Datacenter Dynamics сообщает, что после реновации объект вошёл в состав научно-вычислительного центра (SDDC) при лаборатории. Проект обошёлся в $74,85 млн, средства были получены в рамках программы Science Laboratories Infrastructure Министерства энергетики. Новый ЦОД занимает площадь 5481 м2. Ранее комплекс обслуживал источник синхротронного излучения NSLS, который работал с 1982 по 2014 год. В 2015 году его заменил проект NSLS-II. Благодаря NSLS были получены две Нобелевские премии по химии. 
Источник изображения: Brookhaven National Laboratory Строительство ЦОД началось в III квартале 2021 года, а функционировать он начала ещё в IV квартале 2021. Однако переходный период не завершился до сих пор. К концу 2022 года в дата-центре имелись 54 серверных стойки, в том числе обслуживающие NSLS-II. Ожидалось, что к концу 2023 года число стоек увеличится до 106. Из 135 стоек старого ЦОД только 20 перенесли в здание NSLS, остальные утилизировали или заменили. В 2024–2027 гг. никаких крупных переездов более не планируется. 
Источник изображения: Brookhaven National Laboratory Кампус соответствует уровню Tier III, а также отвечает требованиям к надёжности и доступности. Дата-центр может длительное время работать без магистрального электричества и охлаждённой воды извне. Уровень PUE равен 1.2, а суммарная ёмкость составляет 9,6 МВт. Инфраструктура отдельные помещения для ленточной библиотеки, сетевое оборудования и основного машинного зала. Последний который разбит на две секции: для HTC- и HPC-вычислений. 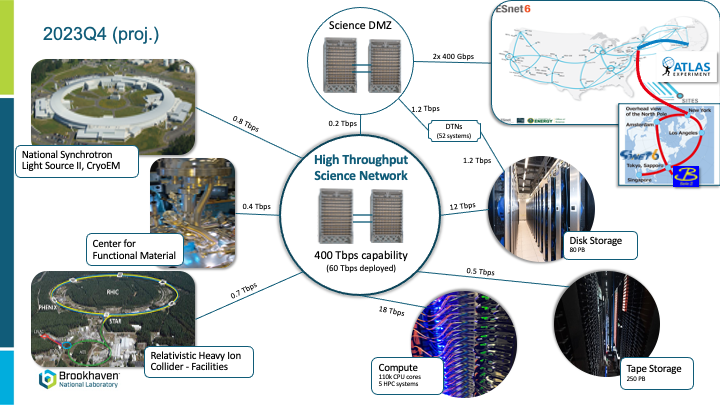
Источник изображения: Brookhaven National Laboratory Доступ к мощностям нового объекта получают учёные-физики, биологи, климатологи и, конечно, специалисты по энергетике. В частности, обрабатываются данные, полученные ускорителем NSLS-II, а также другая информация. Дополнительно ЦОД поддерживает международные исследования, проводимые экспертами Большого адронного коллайдера и ускорителя SuperKEKB в Японии.
05.02.2024 [16:21], Сергей Карасёв
Cadence представила суперкомпьютер Millennium M1 для вычислительной гидродинамики с ИИКомпания Cadence анонсировала систему Millennium Enterprise Multiphysics Platform: это, как утверждается, первое в отрасли программно-аппаратное решение для проектирования и анализа мультифизических систем. Суперкомпьютер, получивший название Cadence Millennium M1 CFD, ориентирован на решение задач в области вычислительной гидродинамики (CFD). Отмечается, что CFD используется для сокращения длительных циклов проектирования и уменьшения количества дорогостоящих экспериментов. Такие решения востребованы в аэрокосмической, оборонной, автомобильной, электронной и других отраслях. 
Источник изображения: Cadence Суперкомпьютер Millennium M1 использует узлы с традиционными CPU, дополненные ускорителями на базе GPU — до 32 ускорителей на стойку и с возможностью масштабирования до 5 тыс. GPU на кластер и более. Задействован высокоскоростной интерконнект. При этом Cadence пока не раскрывает точные характеристики системы, но говорит, что она в 20 раз энергоэффективнее традиционных CPU-кластеров. Кроме того, машина позволяет создавать цифровых двойников с функцией визуализации. 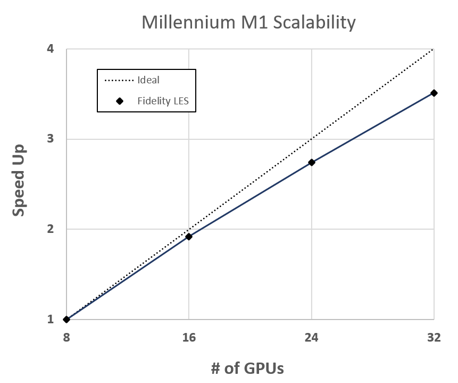
Источник изображения: Cadence Отмечается, что ключевой особенностью Millennium M1 является специализированное ПО. Оно может использоваться для решения задач моделирования турбулентных течений — Large Eddy Simulation (LES). Быстрое генерирование высококачественных синтетических данных позволяет ИИ-алгоритмам находить оптимальные решения без ущерба для точности. В целом, как утверждается, суперкомпьютер Millennium M1 расширяет возможности LES в аэрокосмической, автомобильной, энергетической и других отраслях благодаря сокращению времени выполнения расчётов с дней до часов. Система доступна в двух вариантах — облачном (минимум 8 ускорителей) и локальном (минимум 32 ускорителя). В первом случае машина размещается на платформе Cadence и масштабируется по мере необходимости. Во втором случае система размещается локально в IT-инфраструктуре заказчика.
02.02.2024 [13:29], Сергей Карасёв
Lenovo построит в Германии энергоэффективный суперкомпьютер на базе AMD EPYC Genoa и NVIDIA H100
amd
epyc
genoa
h100
hardware
hpc
lenovo
nvidia
германия
отопление
суперкомпьютер
энергоэффективность
Компания Lenovo объявила о заключении контракта с Падерборнским университетом в Германии (University of Paderborn) на создание нового НРС-комплекса, мощности которого будут использоваться для обеспечения исследований в рамках Национальной программы высокопроизводительных вычислений (NHR). В основу суперкомпьютера лягут двухузловые серверы ThinkSystem SD665 V3. Конфигурация каждого узла включает два процессора AMD EPYC Genoa и до 24 модулей оперативной памяти DDR5-4800. Применена технология прямого жидкостного охлаждения Lenovo Neptune Direct Water Cooling (DWC). Кроме того, НРС-комплекс будет использовать GPU-серверы ThinkSystem SD665-N V3, несущие на борту четыре ускорителя NVIDIA H100, связанные между собой посредством NVLink. Общее количество ядер составит более 136 тыс. Для подсистемы хранения выбрана платформа IBM ESS 3500, обеспечивающая возможности гибкого использования SSD (NVMe) и HDD. Новый суперкомпьютер расположится в Падерборнском центре параллельных вычислений (PC2). Монтаж оборудования планируется произвести во II половине текущего года. За интеграцию будет отвечать pro-com DATENSYSTEME GmbH. Ожидается, что по сравнению с нынешней системой центра Noctua 2 (на изображении), построенной Atos, готовящийся суперкомпьютер будет обладать примерно вдвое более высокой производительностью. Быстродействие Noctua 2 составляет до 4,19 Пфлопс (Linpack) для CPU-ядер и до 1,7 Пфлопс (Linpack) для GPU-блоков. 
Источник изображения: University of Paderborn Особое внимание при строительстве суперкомпьютера будет уделяться энергетической эффективности. Благодаря использованию источников питания с жидкостным охлаждением и полностью изолированных стоек более 97 % вырабатываемого тепла может быть передано непосредственно в систему циркуляции тёплой воды. Применение теплообменников и блоков распределения охлаждающей жидкости (CDU) обеспечивает температуру носителя в обратном контуре выше 45 °C, что позволяет повторно использовать генерируемое тепло.
28.01.2024 [20:59], Сергей Карасёв
Intel и ITRI открыли на Тайване лабораторию по сертификации СЖО для НРС-системТайваньское подразделение корпорации Intel и Научно-исследовательский институт промышленных технологий Тайваня (ITRI) сообщили об открытии совместной лаборатории по сертификации систем охлаждения для HPC-платформ. Новая структура получила название ITRI-Intel. О планах по запуску лаборатории стороны объявили в конце 2023 года. Тогда говорилось, что Intel расширяет сотрудничество с тайваньскими партнёрами с целью разработки и вывода на рынок передовых систем охлаждения для дата-центров, включая ЦОД, ориентированные на задачи ИИ. По данным Международного энергетического агентства (IEA), в 2022 году потребление энергии дата-центрами по всему миру колебалось от 0,9 % до 1,3 % от общих энергозатрат. При этом выбросы углекислого газа в сегменте ЦОД составили 0,3 % от глобального объёма. Ожидается, что внедрение новых технологий, включая системы иммерсионного (погружного) охлаждения, поможет поднять энергоэффективность дата-центров и сократить выбросы СО2 в соответствующем сегменте на 45 %. 
Источник изображения: ITRI-Intel Лаборатория ITRI-Intel будет предлагать комплексные услуги по сертификации технологий охлаждения НРС-систем на соответствие международным стандартам. Это, в частности, тестирование свойств материалов, оценка совместимости с серверными компонентами и анализ жизненного цикла. Отмечается также, что ITRI разрабатывает однофазную технологию погружного охлаждения с очень низким энергопотреблением. При этом не используются фторированные растворители (PFAS), которые, как считается, могут оказывать негативное влияние на здоровье людей.
25.01.2024 [14:41], Сергей Карасёв
Для звёзд — Xeon, для гравитации — EPYC: Lenovo обновила HPC-кластер Кардиффского университетаКомпания Lenovo поставила в Кардиффский университет в Великобритании 90 серверов ThinkSystem, которые позволили поднять производительность кластера Hawk HPC приблизительно в два раза. Система применяется для решения сложных задач в таких областях, как астрофизика и наука о жизни. 
Источник изображения: Lenovo Lenovo и британский поставщик IT-решений Logicalis предоставили HPC-ресурсы для двух исследовательских групп в Кардиффском университете. Одна из них — научная коллаборация, участвующая в проекте лазерно-интерферометрической гравитационно-волновой обсерватории (LIGO). Эта инициатива нацелена на обнаружение гравитационных волн. Сообщается, что для проекта LIGO компания Lenovo предоставила 75 серверов ThinkSystem SR645, оснащённых процессорами AMD EPYC Genoa. Эти системы поддерживают до 6 Тбайт оперативной памяти DDR5-4800 в виде 24 модулей и до трёх ускорителей PCIe (2 × PCIe 5.0 и 1 × PCIe 4.0). Отмечается, что установка серверов позволила удвоить вычислительные мощности, доступные исследователям. Вторая исследовательская группа в Кардиффском университете, изучающая процессы звёздообразования, получила 15 серверов Lenovo ThinkSystem SR630 на платформе Intel Xeon Sapphire Rapids и два сервера хранения ThinkSystem SR650 с возможностью установки 20 накопителей LFF или 40 накопителей SFF. Группа сосредоточена на анализе спиральных галактик, таких как наш Млечный Путь. Приобретённые серверы помогут в выполнении сложных задач моделирования. |
|