Материалы по тегу: hpc
|
10.03.2024 [22:13], Сергей Карасёв
Arm-процессор SiPearl Rhea2 для европейских суперкомпьютеров выйдет в 2025 годуКонсорциум European Processor Initiative (EPI) раскрыл планы по выпуску HPC-процессоров нового поколения с архитектурой Arm. Речь идёт о чипах Rhea2, которые, как ожидается, войдут в состав следующего европейского суперкомпьютера экзафлопсного уровня. Разработчиком изделий Rhea является французская компания SiPearl. Процессор первого поколения на базе Arm Neoverse V1 обладает высокой энергетической эффективностью. Он производится на предприятии TSMC с использованием 6-нм технологии N6. Чип станет основой одного из блоков экзафлопсного суперкомпьютера Jupiter, который в нынешнем году будет запущен в Юлихском исследовательском центре (FZJ) в Германии. О процессоре Rhea2 информации пока не слишком много. Известно, что он получит двухчиплетную компоновку. Ожидается, что будет реализована поддержка памяти HBM и DDR5. Разработчик переведёт Rhea2 на более «тонкий» по сравнению с чипом первого поколения техпроцесс. 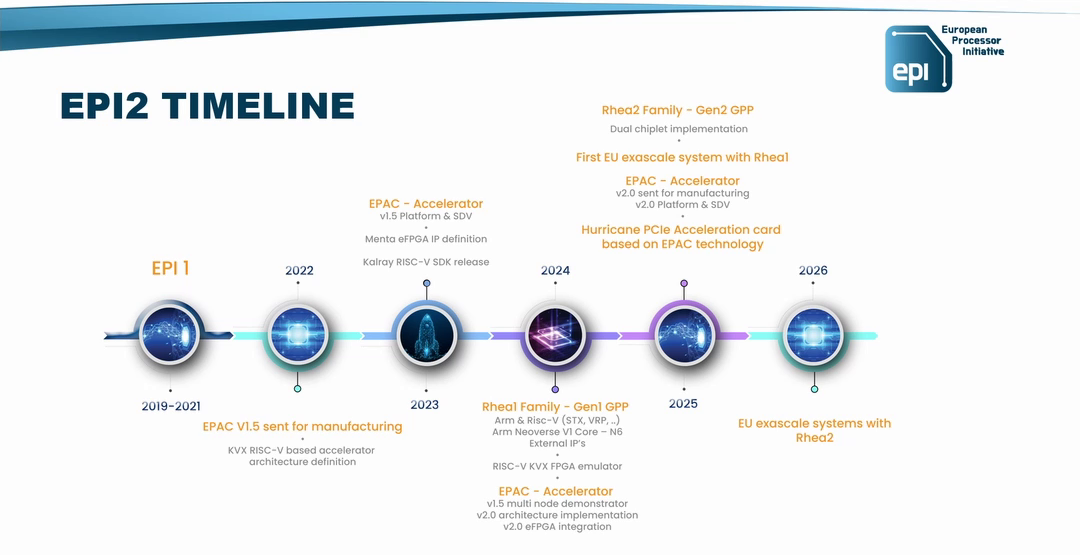
Источник изображения: EPI Сообщается, что Rhea2 дебютирует в 2025 году. Процессор будет задействован в новом европейском НРС-комплексе — вероятно, в системе «Жюль Верн» (Jules Vernes), которая расположится во Франции. Ввод этого суперкомпьютера в эксплуатацию запланирован на 2026 год. Создание машины финансируется Евросоюзом, Францией и Нидерландами, а её управление возьмёт на себя Французское национальное агентство по высокопроизводительным вычислениям (GENCI), которое на 49 % принадлежит французскому правительству. Генеральный директор SiPearl Филипп Ноттон (Philippe Notton) отметил, что разработка чипа Rhea2 проходит быстрее, поскольку компания многому научилась при создании изделия первого поколения и учла допущенные ошибки. Он добавил, что SiPearl сотрудничает со многими партнёрами, включая NVIDIA, AMD и Intel, но вдаваться в подробности о характеристиках Rhea2 не стал. Эксперты полагают, что Rhea2 будет использовать ядра Neoverse 3 (Poseidon).
09.03.2024 [17:47], Сергей Карасёв
Индия потратит $1,2 млрд на суверенный ИИ-суперкомпьютер с 10 тыс. ускорителей и собственные LLMПравительство Индии, по сообщению ресурса The Register, утвердило программу развития национальной инфраструктуры ИИ. На эти цели будет выделено в общей сложности около $1,24 млрд. Одним из ключевых проектов в рамках данной инициативы является создание мощного суверенного суперкомпьютера для ИИ-задач и обработки больших языковых моделей (LLM). Информации о проекте новой НРС-системы на данный момент немного. Говорится, что в её состав войдут как минимум 10 тыс. ускорителей на базе GPU. Комплекс будет создаваться на основе государственно-частного партнёрства и станет частью вычислительной инфраструктуры IndiaAI Compute Capacity. Другим направлением комплексной программы является формирование центра инноваций в области ИИ — IndiaAI Innovation Centre. Он займётся разработкой и внедрением базовых ИИ-моделей. Ожидается, что особое внимание будет уделено LMM и моделям, специфичным для конкретных областей. Центр будет использовать периферийные и распределённые вычисления «для достижения оптимальной эффективности». 
Фото: Saurav Mahto / Unsplash Выделенные средства будут направлены ещё на несколько проектов. Это, в частности, финансирование индийских ИИ-стратапов IndiaAI Startup Financing, платформа наборов данных IndiaAI Datasets Platform для использования в сфере ИИ и инициатива IndiaAI FutureSkills, которая упростит доступ к различным ИИ-программам и поможет в формировании соответствующих лабораторий. В целом, Индия в рамках финансирования рассчитывает стимулировать технологическую независимость и демократизировать преимущества ИИ во всех слоях общества. Предполагается, что ИИ станет движущей силой цифровой экономики страны. Индия также разрабатывает собственные процессоры с архитектурой RISC-V, которые планируется применять в серверном оборудовании.
03.03.2024 [21:59], Сергей Карасёв
Киловаттный ускоритель NVIDIA B200 Blackwell появится в 2025 годуКомпания Dell во время конференции, посвящённой квартальному отчёту, подтвердила подготовку ускорителя нового поколения NVIDIA B200 семейства Blackwell для ресурсоёмких ИИ-задач и НРС-приложений, на что обратил внимание ресурс Videocardz. Ожидается, что это изделие появится в следующем году. Официальный анонс решений Blackwell состоится в этому году. Причём в NVIDIA прогнозируют, что ускорители окажутся в дефиците сразу после выхода. Объясняется это стремительным ростом рынка ИИ, в том числе быстрым развитием генеративных сервисов. Известно, что в семейство Blackwell войдут флагманское изделие B100 для ИИ и HPC-задач, модель B40 для корпоративных заказчиков, гибридное решение GB200, сочетающее чип B100 и Arm-процессор Grace, а также GB200 NVL для обработки больших языковых моделей (LLM). Теперь говорится, что также готовится ускоритель B200: отмечается, что это может быть название конечного продукта. 
Источник изображения: NVIDIA По данным Dell, показатель TDP в случае B200 может достигать 1000 Вт. Для сравнения: ускоритель NVIDIA H100 в форм-факторе SXM обладает TDP в 700 Вт. На подготовку B200 намекнул операционный директор Dell Джефф Кларк (Jeff Clarke). По его словам, инженерная команда компании будет готова к появлению продукта. Таким образом, можно предположить, что Dell уже проектирует серверы нового поколения, рассчитанные на установку ускорителей B200. Отмечается также, что акции Dell по состоянию на 1 марта 2024 года выросли в цене на 32 %, тогда как капитализация NVIDIA превысила $2 трлн. При этом Dell является одним из ключевых партнёров NVIDIA в сегменте дата-центров.
28.02.2024 [14:01], Сергей Карасёв
CERN открыла новый дата-центр во Франции для поддержания экспериментов БАКЕвропейская организация по ядерным исследованиям (CERN) объявила об открытии в Превессене во Франции нового ЦОД, который займётся обработкой информации, поступающей от Большого адронного коллайдера (БАК). Объект построен в рекордные сроки — менее чем за два года. Общая площадь дата-центра превышает 6000 м2. Предусмотрены шесть залов для размещения оборудования, каждый из которых рассчитан на мощность в 2 МВт и может вместить до 78 стоек. В ЦОД в основном будут размещены серверы на базе CPU для обработки данных экспериментов, а также небольшое количество систем и хранилищ для обеспечения непрерывности операций и аварийного восстановления. Ожидается, что на полное оснащение площадки оборудованием потребуется около десяти лет. 
Источник изображения: CERN Отмечается, что новый объект соответствует строгим техническим требованиям, обеспечивающим экологическую устойчивость. Развёрнута эффективная система рекуперации тепла, которое будет использоваться для отопления зданий на территории Превессена. Целевой коэффициент PUE составляет 1,1, а показатель эффективности использования воды (WUE) — 0,379 л/кВт·ч. Система охлаждения будет автоматически включаться, когда наружная температура достигнет 20 °C. При этом температура в самих помещениях дата-центра ни при каких условиях не должна превышать 32 °C. БАК в настоящее время генерирует около 45 Пбайт информации в неделю, но ожидается, что этот объём удвоится после модернизации комплекса. Данные экспериментов передаются в глобальную вычислительную сеть Worldwide LHC Computing Grid (WLCG), объединяющую около 170 дата-центров, расположенных в более чем 40 странах. Общая ёмкость хранилищ составляет примерно 3 Эбайт, а для обработки данных задействован примерно 1 млн процессорных ядер. Существующий дата-центр CERN на площадке в Мерене (Швейцария) по-прежнему является основным для организации.
26.02.2024 [13:44], Сергей Карасёв
В России официально представлен суперкомпьютер «Сергей Годунов» производительностью 54,4 ТфлопсВ Институте математики имени С. Л. Соболева Сибирского отделения Российской академии наук (ИМ СО РАН) официально представлен вычислительный комплекс «Сергей Годунов», названный в честь известного советского и российского математика. Монтажом и тестированием системы занимались специалисты группы компаний РСК. Суперкомпьютер создан на базе высокоплотной и энергоэффективной платформы «РСК Торнадо» с жидкостным охлаждением. Каждый из узлов в составе системы оснащён двумя процессорами Intel Xeon Ice Lake-SP с 38 ядрами, работающими на базовой частоте 2,4 ГГц. Производительность кластера на момент запуска составляет 54,4 Тфлопс. Предполагается, что HPC-комплекс поможет повысить эффективность научных исследований и будет способствовать развитию новых технологий. Среди сфер применения суперкомпьютера названы: медицинская электроакустическая томография; моделирование эпидемиологических, экологических, экономических и социальных процессов; вычислительная аэрогидродинамика и задачи оптимизации турбулентных течений; моделирование и построение сценариев развития системы биосфера-экономика-социум с учётом безуглеродного и устойчивого развития и изменения климата; решение обратных задач геофизики прямым методом на основе подхода Гельфанда-Левитана-Крейна». 
Источник изображений: РСК Отмечается, что монтажные и пуско-наладочные работы в рамках проекта произведены в сжатые сроки — за 3,5 недели. В перспективе возможности системы будут расширяться. В частности, в 2024 году планируется осуществить модернизацию, которая позволит более чем вдвое нарастить производительность — до 120,4 Тфлопс.  «У нас появилась возможность решать мультидисциплинарные задачи, моделировать объёмные процессы и предсказывать поведение сложных математических систем. На суперкомпьютере проводятся вычисления по критически важным проблемам и задачам, стоящим перед РФ», — отмечает исполняющий обязанности директора ИМ СО РАН Андрей Миронов. В целом, запущенный комплекс является основным инструментом для проведения исследований и прикладных разработок в академгородке Новосибирска и создания технологической платформы под эгидой Научного совета Отделения математических наук РАН по математическому моделированию распространения эпидемий с учётом социальных, экономических и экологических процессов.
24.02.2024 [19:46], Сергей Карасёв
ИИ-ускорители NVIDIA Blackwell сразу будут в дефицитеКомпания NVIDIA, по сообщению ресурса Seeking Alpha, прогнозирует высокий спрос на ИИ-ускорители следующего поколения Blackwell. Поэтому сразу после выхода на рынок эти изделия окажутся в дефиците, и их поставки будут ограничены. «На все новые продукты спрос превышает предложение — такова их природа. Но мы работаем так быстро, как только можем, чтобы удовлетворить потребности заказчиков», — говорит глава NVIDIA Дженсен Хуанг (Jensen Huang). Из-за стремительного развития генеративного ИИ на рынке сформировалась нехватка нынешних ускорителей NVIDIA H100 поколения Hopper. Срок выполнения заказов на серверы с этими изделиями достигает 52 недель. Аналогичная ситуация, вероятно, сложится и с ускорителями Blackwell, анонс которых ожидается в течение нынешнего года. «Полагаем, что отгрузки наших продуктов следующего поколения будут ограниченными, поскольку спрос намного превышает предложение», — сказала Колетт Кресс (Colette Kress), финансовый директор NVIDIA. Главный вопрос заключается в том, насколько быстро NVIDIA сможет организовать массовое производство Blackwell B100, а также серверов DGX на их основе. Дело в том, что это совершенно новые продукты, в которых используются другие компоненты. По имеющейся информации, Blackwell станет первой архитектурой NVIDIA, предусматривающей чиплетную компоновку. Это может упростить производство ускорителей на уровне кремния, но в то же время усложнит процесс упаковки. 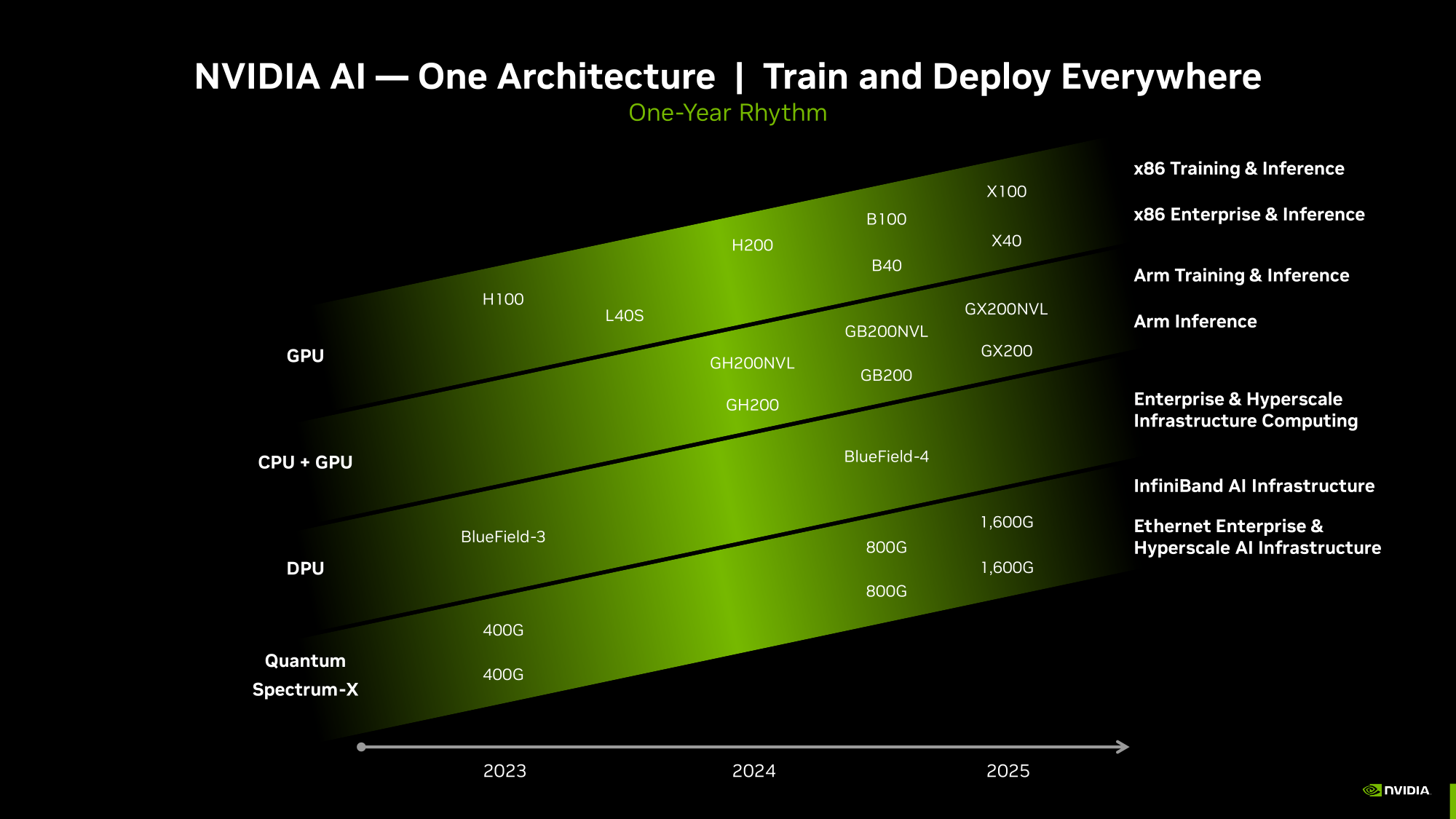
Источник изображения: NVIDIA В дополнение к флагманскому чипу B100 для ИИ и HPC-задач компания готовит решение B40 для корпоративных заказчиков, гибридный ускоритель GB200, сочетающий ускоритель B100 и Arm-процессор Grace, а также GB200 NVL для обработки больших языковых моделей.
23.02.2024 [19:07], Сергей Карасёв
Австралийский суперкомпьютерный центр внедрит суперчипы NVIDIA Grace Hopper для квантовых исследованийАвстралийский суперкомпьютерный центр Pawsey начнёт использовать решение NVIDIA CUDA Quantum — открытую платформу для интеграции и программирования CPU, GPU и квантовых компьютеров (QPU). Ожидается, что это поможет ускорить развитие перспективного направления квантовых вычислений. Pawsey развернёт в своём Национальном центре инноваций в области суперкомпьютеров и квантовых вычислений восемь узлов с суперчипами NVIDIA GH200. Эти изделия содержат 72-ядерный Arm-процессор Grace и ускоритель H100 с 96 Гбайт HBM3. Объём общей для обоих кристаллов памяти составляет 576 Гбайт (480 Гбайт LPDDR5x). Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с. Сообщается, что узлы проектируемой системы будут использовать модульную архитектуру NVIDIA MGX, которая предназначена для построения HPC-систем и комплексов ИИ. Предполагается, что высокопроизводительная гибридная платформа с CPU, GPU и QPU позволит выполнять высокоточные и гибко масштабируемые квантовые симуляции. В рамках проекта будет применяться специализированное ПО NVIDIA cuQuantum для разработки квантовых решений. 
Источник изображения: NVIDIA Национальное научное агентство Австралии (CSIRO) оценивает размер внутреннего рынка квантовых вычислений в $2,5 млрд в год с потенциалом создания до 10 тыс. новых рабочих мест к 2040-му. Для достижения таких показателей необходимо внедрение квантовых вычислений в различных областях, включая астрономию, науки о жизни, медицину, финансы и пр.
22.02.2024 [18:45], Руслан Авдеев
Австралийское Минобороны представило мощный суперкомпьютер Taingiwilta, не сказав о нём практически ни словаАвстралийский суперкомпьютер Taingiwilta для нужд Минобороны Австралии должен заработать уже в этом году, но военное ведомство отказывается сообщать хоть какие-то детали о его характеристиках и возможностях. The Register сообщает, что и ответственная за создание машины Defence Science Technology Group отказалась давать комментарии относительно спецификаций системы. Впрочем, представитель разработчика суперкомпьютера всё-таки сообщил, что часть ПО для машины создано в рамках проекта Министерства обороны США Computational Research and Engineering Acquisition Tools and Environments (CREATE). В частности, суперкомпьютер будет использоваться для вычислительной гидродинамики. Потребуются и сложные средства разграничения доступа, поскольку суперкомпьютер будет выполнять как секретные, так и не особенно секретные задачи. 
Фото: Australian Army / SGT Tristan Kennedy Taingiwilta расположен на территории специально построенного объекта Mukarntu. Министерство обороны Австралии впервые анонсировало систему в августе 2022 года, но и тогда представители местных властей отказались раскрывать детали проекта. При этом они заявляли, что Taingiwilta входит в 50 наиболее производительных вычислительных систем мира, поэтому можно предположить, что речь идёт о как минимум 10 Пфлопс — если ориентироваться на актуальный рейтинг TOP500. Профессор Ченнупати Джагадиш (Chennupati Jagadish), президент Австралийской академии наук, говорит, что отсутствие внятной HPC-стратегии ставит под вопрос процветание и безопасность Австралии. В документе «Будущие вычислительные потребности австралийского научного сектора» подчёркивается, что сейчас страна имеет умеренные возможности для высокопроизводительных вычислений, а уже имеющиеся мощности требуют частых и значительных обновлений и имеют ограниченный жизненный цикл.
22.02.2024 [13:34], Сергей Карасёв
HBM мало не бывает: суперкомпьютер OSC Cardinal получил чипы Intel Xeon Max и ускорители NVIDIA H100Суперкомпьютерный центр Огайо (OSC) анонсировал проект Cardinal по созданию нового кластера для задач HPC и ИИ. Гетерогенная система, построенная на серверах Dell PowerEdge с процессорами Intel, будет введена в эксплуатацию во II половине 2024 года. В состав кластера войдут узлы, оборудованные процессорами Xeon Max 9470 семейства Sapphire Rapids. Эти чипы содержат 52 ядра (104 потока) с максимальной тактовой частотой 3,5 ГГц и 128 Гбайт памяти HBM2e. В общей сложности будут задействованы 756 таких процессоров. Каждый узел получит 512 Гбайт DDR5 и NVMe SSD вместимостью 400 Гбайт. Узлы входят в состав серверов Dell PowerEdge C6620. Компанию им составят 16 узлов Dell PowerEdge R660, тоже с двумя Xeon Max 9470, но с 2 Тбайт DDR5 и 12,8 Тбайт NVMe SSD. Все эти узлы объединит 200G-интерконнект Infiniband. Кроме того, будут задействован 32 узла Dell PowerEdge XE9640 с двумя чипами Xeon 8470 Platinum (52C/104T; до 3,8 ГГц), четырьмя ускорителями NVIDIA H100 с 96 Гбайт памяти HBM3 и 1 Тбайт DDR5. Говорится о применении четырёх соединений NVLink и 400G-платформы Quantum-2 InfiniBand. Заявленная пиковая ИИ-производительность (FP8) — около 500 Пфлопс. 
Фото: Ohio Supercomputer Center via The Next Platform Суперкомпьютер обеспечит общую FP64-производительность на уровне 10,5 Пфлопс. Таким образом, по быстродействию кластер приблизительно на 40 % превзойдёт три нынешние машины OSC вместе взятые. При этом Cardinal занимает всего девять стоек и требует пару CDU для работы СЖО. Отмечается, что Cardinal — это результат сотрудничества OSC, Dell Technologies, Intel и NVIDIA. Новый суперкомпьютер придёт на смену системе Owens, которая используется в OSC с 2016 года.
21.02.2024 [21:18], Руслан Авдеев
Итальянские военные захотели создать группировку спутников-суперкомпьютеровМинистерство обороны Италии изучает возможность формирования «военно-космического облака» и поручила поддерживаемому государством подрядчику Leonardo проверить концепцию. По данным The Register, проект Military Space Cloud Architecture (MILSCA) предполагает формирование архитектуры, обеспечивающей правительство и вооружённые силы высокопроизводительными вычислениями и хранилищами данных в космосе. План предусматривает создание группировки спутников, каждый с FP32-производительностью 250 Тфлопс и хранилищем ёмкостью не менее 100 Тбайт данных. Ещё 100 Тбайт будет зарезервировано на Земле. Все ресурсы будут связаны друг с другом для поддержки выполнения задач, касающихся ИИ и анализа данных. Фактически речь идёт о гигантском, разнесённом в пространстве суперкомпьютерном кластере. Для сравнения — в состав кластера HPE Spaceborne-2 на МКС входит ускоритель NVIDIA T4 с FP32-производительностью 8 Тфлопс. 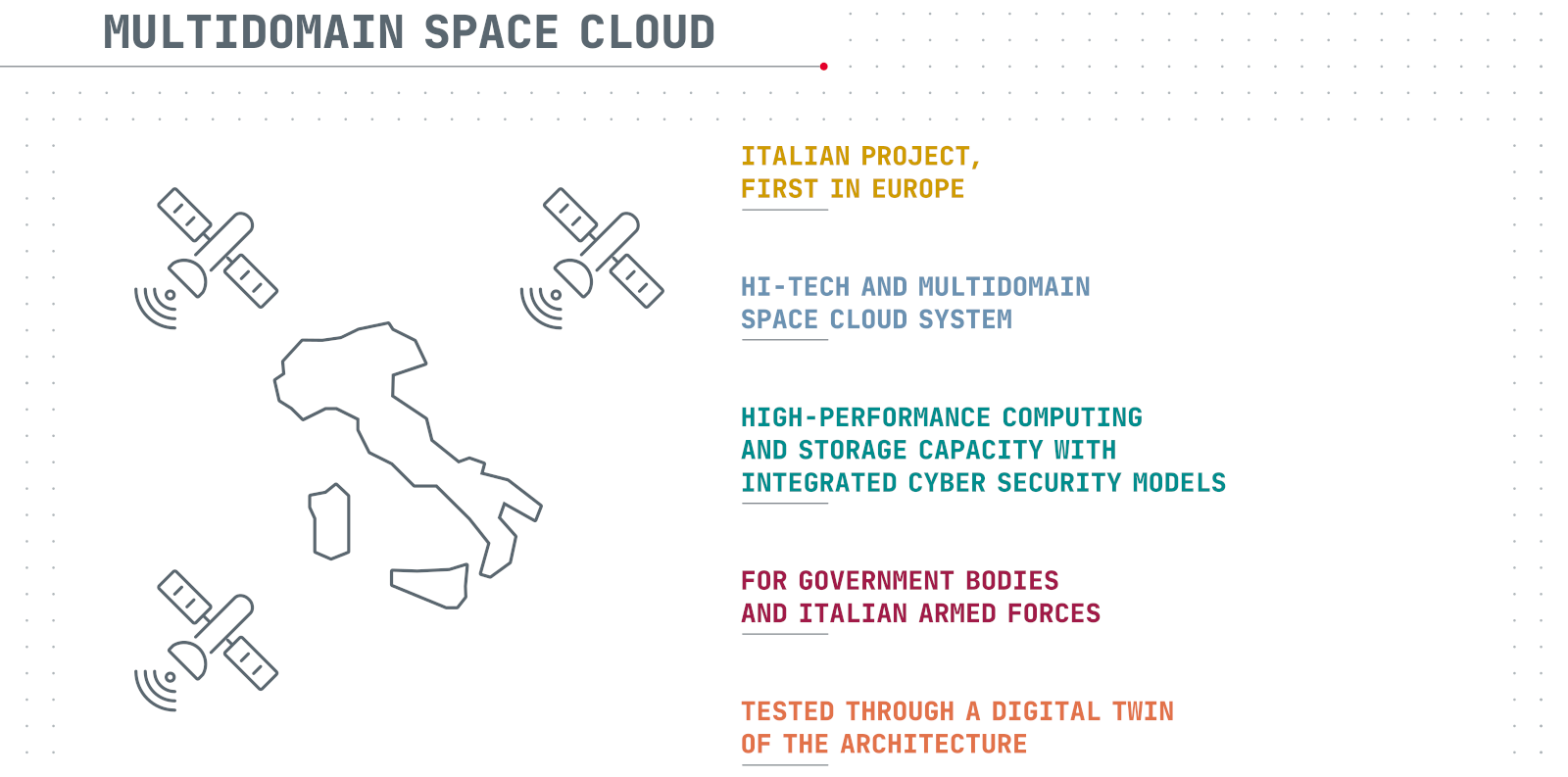
Источник изображения: Leonardo В Leonardo обещают быструю обработку данных на орбите и утверждают, что коммуникации будут менее уязвимы, чем наземные. Пользователи получат гарантированный доступ к телеком-услугам, данным наблюдения за Землёй, а также навигационным сведениям в любое время в любой части планеты. Кроме того, группировка послужит важным «бэкапом» для наземных центров, если с теми что-то случится. Leonardo и её совместные предприятия Telespazio и Thales Alenia Space изучат в ближайшие пару лет целесообразность создания такой группировки. В ходе первой фазы исследований участники проекта определятся с архитектурой всей системы, а в ходе второй попытаются провести симуляцию группировки с помощью «цифрового двойника» на суперкомпьютере Davinci-1. Она поможет заранее выявить потенциальные проблемы и оценить зоны покрытия. 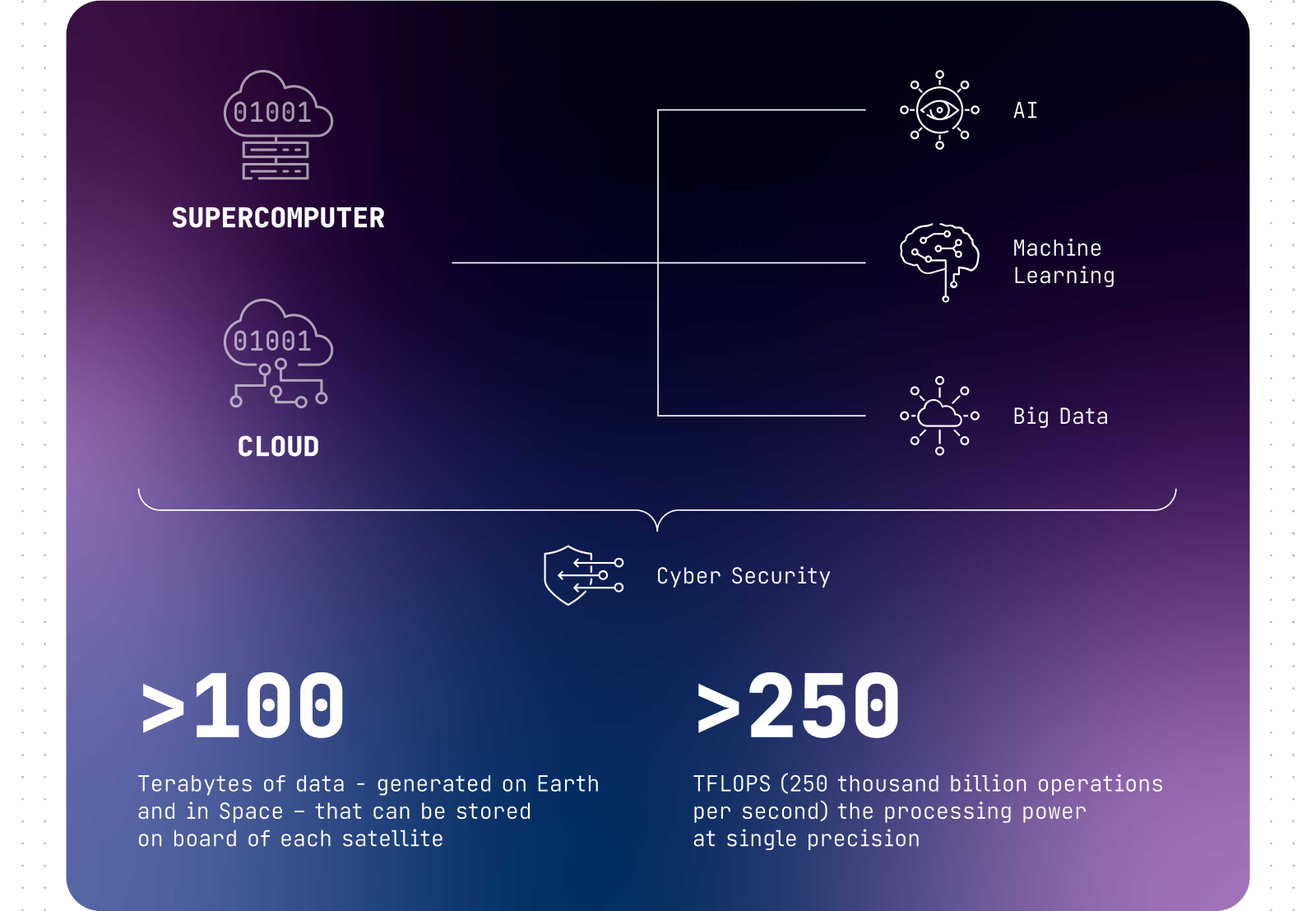
Источник изображения: Leonardo Оборудование потребует специальной защиты от космической радиации. Также предстоит решить вопросы энергоснабжения и терморегулирования. Кроме того, придётся по возможности минимизировать массу оборудования, доставляемого в космос. Дело осложняется тем, что для получения заданных характеристик придётся использовать достаточно горячие чипы, выполненные по тонким техпроцессам. Leonardo не впервые просят оценить перспективы космических вычислений. В 2022 году совместное предприятие Thales Alenia Space, созданное Leonardo и французской Thales, наняли для оценки перспектив космических ЦОД в рамках исследовательской программы Horizon Europe. Правда, на тот момент речь шла об экопроекте, а не группировке военного назначения. Недавно компания Axiom Space также заявила, что построит и выведет на орбиту ЦОД для поддержки миссий своей коммерческой космической станции. Компания намеревалась снизить зависимость от наземных сервисов. Blue Ring тоже планирует предоставлять вычисления в космосе. Наконец, Lonestar Data Holdings привлекает средства для постройки ЦОД на Луне. |
|