Материалы по тегу: sc23
|
24.11.2023 [17:14], Сергей Карасёв
Лос-Аламосская национальная лаборатория внедрит обновлённые ИИ-системы SambaNovaЛос-Аламосская национальная лаборатория (LANL) Министерства энергетики США (DOE) заключила соглашение о сотрудничестве со стартапом SambaNova Systems, который специализируется на разработке ИИ-решений. Финансовые условия договора не раскрываются, но ранее стартап уже поставлял LANL свои решения. В рамках партнёрства LANL расширит применение программно-аппаратных комплексов SambaNova DataScale. Речь идёт о системе DataScale SN30, содержащей восемь ускорителей собственной разработки Cardinal SN30, суммарно имеющих 5 Гбайт SRAM и 8 Тбайт DRAM. Конфигурация комплекса может включать от одного до трёх узлов SN30. Кроме того, LANL внедрит решение SambaNova Suite для генеративного ИИ. Эта платформа предоставляет различные ИИ-модели, оптимизированные для корпоративных и государственных организаций. Они могут быть развёрнуты локально или в облаке с возможностью адаптации к собственному набору данных заказчика. 
Источник изображения: SambaNova Новое многолетнее соглашение между LANL и SambaNova является расширением действующего партнёрства между сторонами. Лаборатория будет использовать технологии SambaNova для решения широкого спектра задач, связанных с ИИ и большими языковыми моделями (LLM), в том числе в интересах национальной безопасности. Отмечается, что платформа SambaNova Suite предлагает быстрый и эффективный способ развёртывания генеративного ИИ для реализации самых сложных проектов.
23.11.2023 [20:38], Сергей Карасёв
1,5 кВт на чип: ZutaCore показала высокоэффективную систему прямого жидкостного охлаждения HyperCoolКомпания ZutaCore на конференции SC23 сообщила о том, что её система прямого жидкостного охлаждения HyperCool Direct-On-Chip вошла в состав серверов Dell и Pegatron на платформе Intel Xeon Sapphire Rapids. Двухфазная система HyperCool способна эффективно отводить тепло от самых мощных серверных процессоров — с показателем TDP 1500 Вт и более. Это комплексное решение с замкнутым контуром вместо воды использует специальную диэлектрическую жидкость, благодаря чему оборудование защищено от коррозии. Платформа HyperCool обладает хорошей масштабируемостью и может быть развёрнута в новых или модернизированных дата-центрах — cтандартизированный интегрированный 6U-модуль способен отводить 100 кВт и выше. Система обеспечивает коэффициент PUE меньше 1,02. Конструкция HyperCool позволяет повторно использовать выделяемое тепло — например, для обогрева зданий. СЖО подходит для применения в ЦОД, ориентированных на решение задач ИИ и НРС. Система позволяет снизить общее энергопотребление и сократить выбросы вредных газов в атмосферу. 
Источник изображения: ZutaCore Отмечается, что недавно технология HyperCool была сертифицирована для высокопроизводительных серверов ASUS. Кроме того, в экосистему ZutaCore входят AMD, Boston Limited, Dell, Equinix, Intel, World Wide Technologies (WWT) и другие. Утверждается, что по сравнению с традиционными системами охлаждения решение HyperCool обеспечивает сокращение совокупной стоимости владения на 50 %.
21.11.2023 [09:56], Сергей Карасёв
MSI представила GPU-серверы с жидкостным охлаждением на AMD EPYC Genoa и Intel Xeon Sapphire RapidsКомпания MSI на конференции по высокопроизводительным вычислениям SC23 представила новые серверы на процессорах AMD EPYC Genoa и Intel Xeon Sapphire Rapids. Устройства ориентированы на дата-центры и подходят для НРС-нагрузок, генеративного ИИ и других ресурсоёмких задач. Одна из новинок — платформа G4201, которая допускает установку двух чипов Xeon Sapphire Rapids и 32 модулей оперативной памяти DDR5. Этот сервер формата 4U располагает восемью слотами PCIe 5.0 x16 для ускорителей высотой в два слота, а также двумя PCIe 5.0 x16 для карт толщиной в один слот. Дебютировал также сервер G4101 типоразмера 4U. Он рассчитан на один чип EPYC Genoa (до 128 ядер; TDP до 500 Вт) и 12 модулей DDR5-4800. Возможно применение жидкостного охлаждения. Доступны четыре разъёма PCIe 5.0 х16 для трёхслотовых ускорителей и ещё два разъёма PCIe 5.0 x16. Во фронтальной части расположены отсеки для 12 накопителей U.2 NVMe или SAS/SATA (SFF). Кроме того, предусмотрены два коннектора M.2 M-Key (2280/22110, PCIe 3.0 x4/x2). Питание обеспечивают два блока мощностью 3000 Вт каждый. 
Источник изображений: MSI Ещё одна новинка — модель G3101, получившая исполнение 3U. Она допускает установку одного процессора EPYC 7002/7003 с 64 ядрами (до 300 Вт) и восьми модулей DDR4-3200. Поддерживается развёртывание СЖО. Есть шесть отсеков для SFF-накопителей с интерфейсом SATA-3 и четыре слота PCIe 4.0 x16 для карт FHFL. Предусмотрены два сетевых порта 10GbE на базе Intel X710AT2. В оснащение включены два блока питания на 1600 Вт.  Кроме того, MSI анонсировала два сервера с поддержкой Compute Express Link (CXL) — модели S1301 и S2302, оптимизированные для задач с интенсивным использованием данных. Характеристики версии S1301 формата 1U таковы: два процессора EPYC 9004 (Genoa) с 32 ядрами и TDP до 210 Вт, 24 слота для модулей DDR5-4800, два разъёма PCIe 5.0 x16 для ускорителей HHHL, 10 отсеков для накопителей E3.S CXL, два коннектора M.2 M-Key 2280 (PCIe 3.0 x2) и два блока питания мощностью 1600 Вт.  В свою очередь, сервер S2302 стандарта 2U поддерживает два чипа Xeon Sapphire Rapids (до 60 ядер; 350 Вт), 32 модуля DDR5-4800, три ускорителя PCIe 5.0 x16 FHFL и две карты PCIe 5.0 x16 HHHL. Накопители могут устанавливаться по схеме 8 × E3.S CXL и 2 × E3.S PCIe 5.0 SSD или 10 × E3.S PCIe 5.0 SSD. Применены два блока питания на 1600 Вт.
19.11.2023 [23:59], Владимир Мироненко
Fujitsu Adaptive GPU Allocator позволит эффективнее использовать дефицитные ИИ-ускорителиКомпания Fujitsu представила технологии Adaptive GPU Allocator и Interactive HPC, позволяющие оптимизировать использования ускорителей и HPC-кластеров. Эти технологии будут использоваться в некоторых из её собственных облачных HPC-продуктов. Компания утверждает, что новые решения призваны помочь решить проблему глобальной нехватки ускорителей в связи с большим спросом на генеративный ИИ, позволяя клиентам оптимизировать использование своих вычислительных ресурсов. По словам Fujitsu, Adaptive GPU Allocator способна динамически определять программы, для работы которых действительно требуется ускоритель, и программы, которым фактически достаточно CPU, и соответствующим образом распределять ресурсы. Технология основана на оценке уровня возможного ускорения при использовании GPU для каждой конкретной программы и выделении ресурсов ускорителей так, чтобы минимизировать общее время обработки всеми программами. 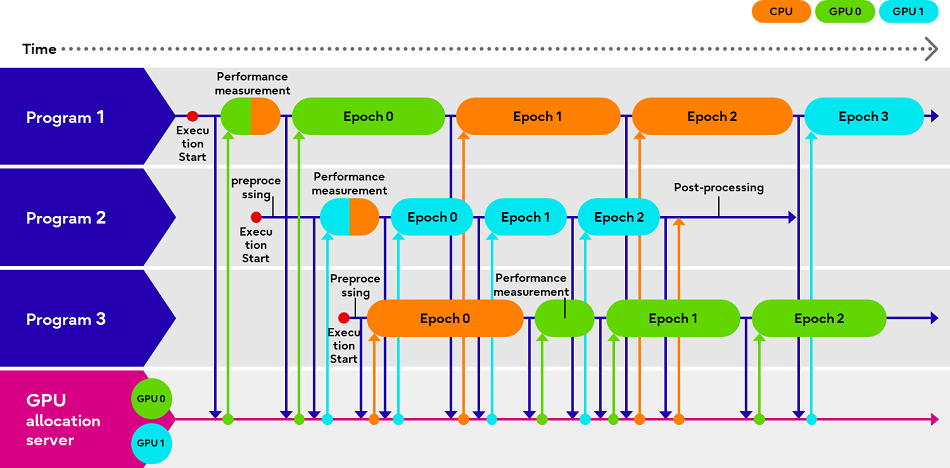
Изображения: Fujitsu Технических деталей о работе этой системы компания не предоставила. Сообщается лишь то, что при запросе программой доступа к ускорителю проводится замер скорости обработки одного и того же кусочка данных на CPU и GPU, на основании чего и принимается решение о дальнейшей обработке на CPU или GPU. Система может измерять производительность кода по мере его выполнения. Как уточняет The Register, что для работы Adaptive GPU Allocator программы должны задействовать фреймворк Fujitsu, который использует TensorFlow и PyTorch. 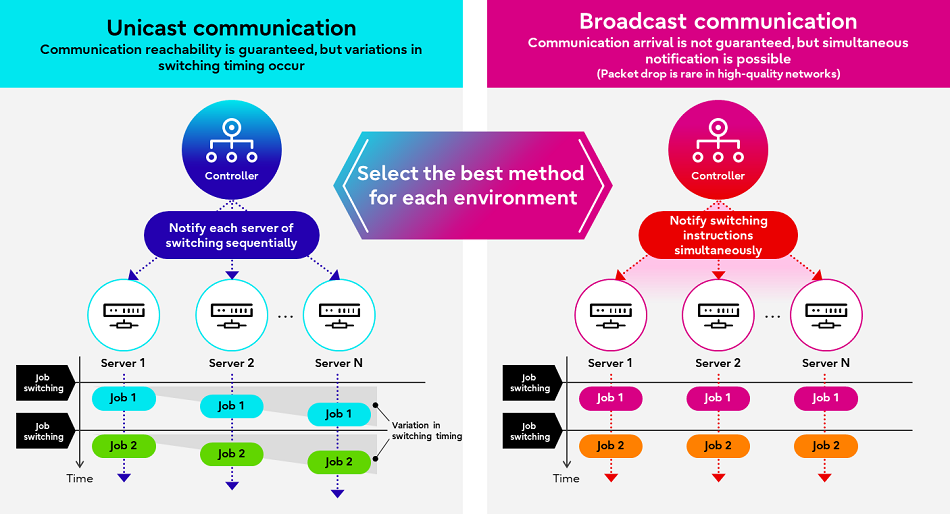 Adaptive GPU Allocator станет частью ИИ-платформы Fujitsu Kozuchi, выход которой ожидается после II половины 2024 финансового года, заканчивающегося 31 марта 2025 года. Чуть раньше появится технология Interactive HPC, которая позволит переключаться между несколькими задачами в HPC-кластерах в режиме реального времени, тогда как, по словам Fujitsu, традиционный подход предполагает отправку узлам команд на переключение по очереди. Деталей компания снова не сообщила, отметив лишь то, что в кластере из 256 узлов Interactive HPC позволила сократить время переключения с одной задачи на другую с нескольких секунд до 100 мс.
19.11.2023 [22:42], Сергей Карасёв
16 ускорителей на один сервер: Liqid и Dell представили платформу UltraStack L40SКомпания Liqid в партнёрстве с Dell Technologies анонсировала эталонную архитектуру UltraStack L40S для формирования систем с высокой плотностью компоновки GPU и иных ускорителей — до 16 шт. на один сервер. Такие платформы могут использоваться для ИИ-приложений, работы с большими языковыми моделями (LLM), задач НРС и пр. Новинка доступна в конфигурациях UltraStack x8 и UltraStack x16. В качестве хост-сервера в составе решения выступает Dell PowerEdge R760xa на базе Intel Xeon Sapphire Rapids: применены два процессора Xeon Gold 6430 (32 ядра; 64 потока; 1,9 ГГц). Объём оперативной памяти в первом случае составляет 1 Тбайт, во втором — 2 Тбайт. К серверу подключаются модули Liqid PCIe Chassis. Версия UltraStack x8 использует два таких модуля: задействованы восемь ускорителей NVIDIA L40S с 48 Гбайт памяти GDDR6 и SSD-хранилище вместимостью 30 Тбайт (NVMe). Вариант UltraStack x16 комплектуется тремя модулями Liqid PCIe Chassis: объединены 16 карт NVIDIA L40S, а ёмкость хранилища составляет 60 Тбайт. 
Источник изображения: Liqid Платформа UltraStack L40S предполагает применение восьми двухпортовых сетевых адаптеров NVIDIA ConnectX-7 (16 × 200 Гбит/с), DPU BlueField-3, двух хост-адаптеров Liqid Gen 4.0 x16 HBA, а также коммутатора PCIe 4.0 на 24/48 портов. Среднее энергопотребление UltraStack x8 заявлено на уровне 4,5 кВт, UltraStack x16 — 7,5 кВт. Система базируется на ПО Liqid Matrix. Компания Liqid утверждает, что по сравнению с четырьмя серверами формата 2U, каждый из которых содержит четыре ускорителя NVIDIA L40S, её система UltraStack с 16 такими картами обеспечивает на 35 % более высокую производительность, сокращение энергопотребления на 35 % и снижение общей стоимости владения на 25 %.
19.11.2023 [00:03], Сергей Карасёв
DDN представила масштабируемую All-Flash СХД Infinia для НРС и ИИКомпания DataDirect Networks (DDN), специализирующаяся на платформах хранения данных для НРС-задач, анонсировала масштабируемую СХД Infinia, разработанную в сотрудничестве с Сандийскими национальными лабораториями (SNL) Министерства энергетики США. Infinia — программно-определяемое многопротокольное решение с горизонтальным масштабированием, которое подходит для различных сценариев использования. Это могут быть сложные научные задачи, приложения ИИ, большие языковые модели и пр. Узлами системы могут быть любые серверы с процессорами Intel, Arm или AMD. Говорится, что платформа Infinia может масштабироваться до сотен петабайт. Среди ключевых преимуществ решения разработчик называет простоту управления, высокую производительность и безопасность. 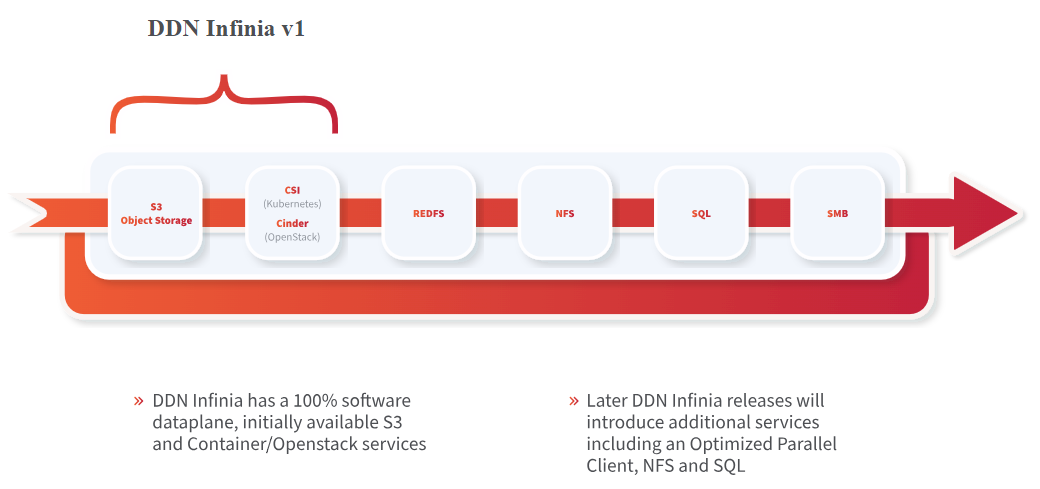
Источник изображения: DDN Референсная аппаратная платформа представляет собой 1U-узел с 24-ядерным процессором AMD EPYC Genoa. Во фронтальной части предусмотрены отсеки для 12 накопителей SFF формата U.2 (NVMe) с возможностью горячей замены. Предусмотрены два сетевых порта 10GbE и порт 1GbE (все с разъёмами RJ-45), а также слота PCIe 5.0 x16 для HHHL-адаптеров, которые могут предложить до четырёх 200G-портов. 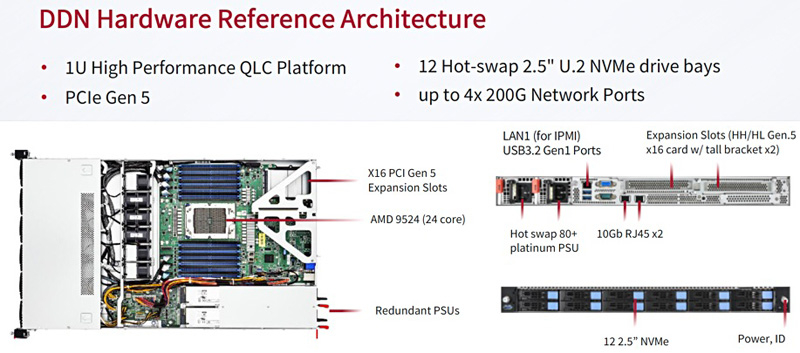
Источник изображения: DDN / StorageNewsletter Шасси имеет габариты 680 × 450 × 44 мм и весит 22,9 кг. СХД оборудована двумя блоками питания мощностью 850 Вт с сертификатом 80 Plus Platinum. В системе воздушного охлаждения применяются шесть вентиляторов. Диапазон рабочих температур — от +10 до +35 °C.
18.11.2023 [23:57], Сергей Карасёв
ИИ-суперкомпьютер «под ключ»: HPE и NVIDIA представили HPC-платформу на базе гибридных суперчипов Grace HopperКомпании HPE и NVIDIA анонсировали модульную суперкомпьютерную систему для генеративного ИИ и обучения моделей на основе частных массивов данных. Комплекс ориентирован на крупные предприятия, исследовательские организации и государственные структуры. В основу решения положена аппаратная платформа Cray EX2500. В состав входят суперчипы NVIDIA GH200 Grace Hopper, содержащие 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. Каждый узел системы использует четыре таких суперчипа. Узлы соединены друг с другом при помощи интерконнекта Slingshot. Говорится, что реализованная архитектура позволяет осуществлять масштабирование до тысяч ускорителей. При этом все мощности могут выделяться для решения одной задачи ИИ, что обеспечивает максимальную эффективность использования ресурсов. По сути, новое решение представляет собой мини-версию ИИ-суперкомпьютера Isambard-AI, который разместится в Бристольском университете (Великобритания). HPE и NVIDIA будут предлагать систему в качестве решения «под ключ» с услугами по установке и настройке. 
Источник изображения: HPE Кроме того, предусмотрен стек ПО для решения различных ИИ-задач: это среда HPE Machine Learning Development Environment, набор инструментов HPE Cray Programming Environment, а также пакет NVIDIA AI Enterprise. В целом, как отмечается, новая система предлагает заказчикам производительность и масштабируемость, которые позволяют решать наиболее сложные ИИ-задачи, включая обучение больших языковых моделей (LLM) и создание рекомендательных систем.
17.11.2023 [21:46], Алексей Степин
PCI-SIG выпустила предварительные спецификации PCIe 7.0 и анонсировала кабели CopprLinkОрганизация PCI Special Interest Group (PCI-SIG) рассказала о последних планах по развитию интерфейса PCI Express. В числе прочего были опубликованы сведения о новом стандарте кабелей и разъёмов CopprLink для подключений PCIe 5.0/6.0. Основанная в 1992 году организация PCI-SIG опубликовала первые спецификации PCI Express в 2003 году, а сегодня без этого интерфейса невозможно представить себе ни одну мало-мальски мощную вычислительную систему. В PCI-SIG на данный момент входит свыше 950 участников. Планы по развитию PCI Express, простирающиеся до 2028 года, показывают, что разработка новых, более производительных версий шины идёт темпами, позволяющими удовлетворить требования к скорости IO-подсистем, удваивающиеся примерно каждые 3 года. В версии PCIe 7.0 планируется довести этот показатель для x16-подключений до 512 Гбайт/с. Предварительная версия стандарта (релиз 0.3) была сформирована совсем недавно. 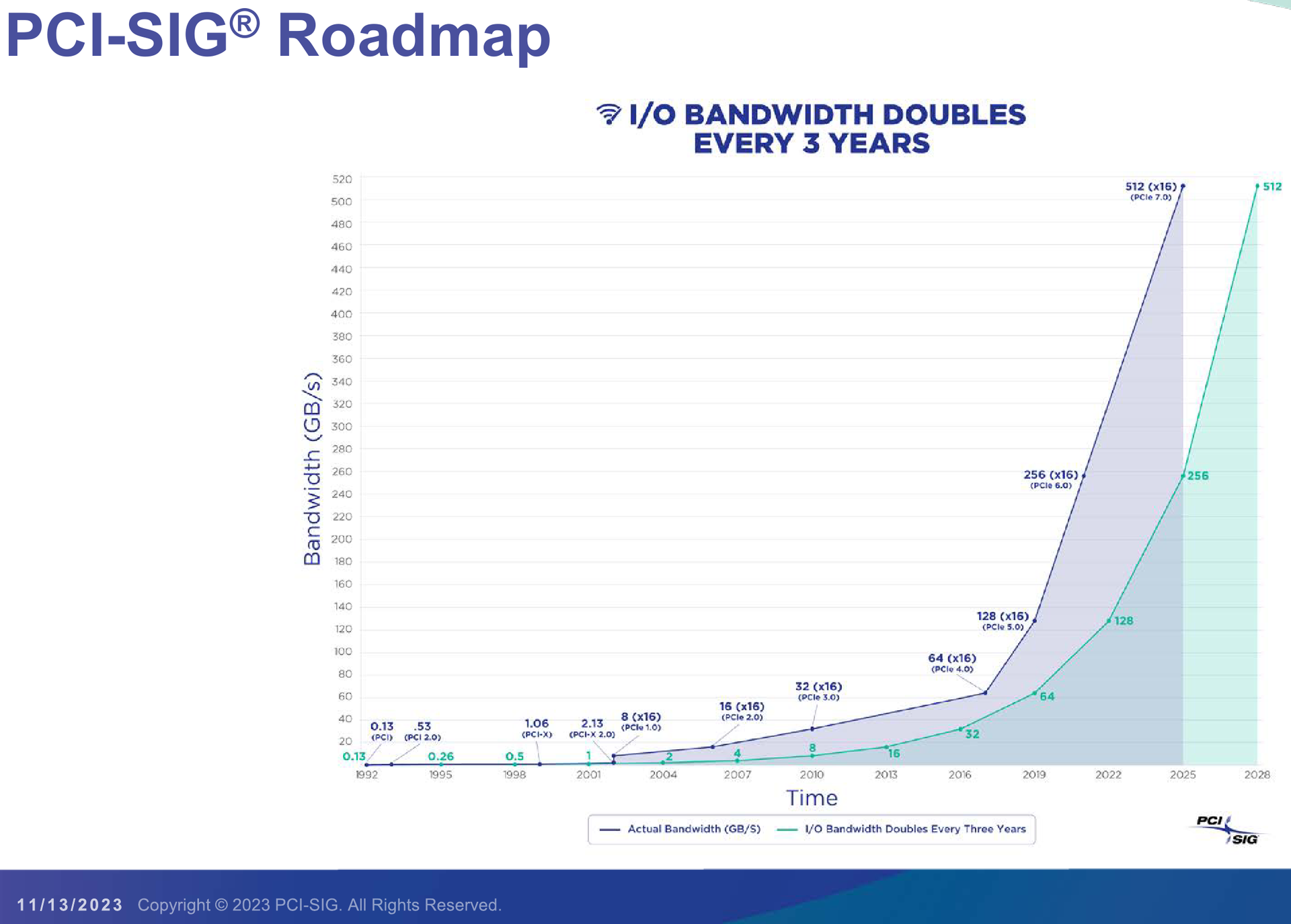
Источник изображений здесь и далее: PCI-SIG На данный момент релиз спецификаций PCI Express 7.0 ожидается в 2025 году, а массовое появление новых продуктов на их основе запланировано на 2028 год. Впрочем, первые продукты наверняка появятся чуть раньше. Во II квартале 2024 года ожидается появление первых решений с PCIe 6.0, а массовый характер программа тестирования таких устройств на соответствие стандарту примет лишь в 2025.  В августе этого года была сформирована новая рабочая группа PCI-SIG Optical Workgroup, ответственная за разработку оптического интерконнекта на базе PCI Express и взаимодействие с производителями в этой области. Задача заключается в адаптации стека технологий PCIe к оптической среде передачи данных с минимальными изменениями. Новые кабели позволят организовать соединения между стойками в пределах ЦОД в случаях, когда требуется минимальная латентность.  Однако полная замена медных кабелей не планируется — оптика дополнит медь там, где нужна большая длина соединения. Поэтому PCI-SIG ведёт разработку нового стандарта электрических кабелей под общим названием CopprLink, который должен будет заменить существующие кабели OCuLink. Возможностей последних для организации внутрисистемного интерконнекта в современных условиях уже не всегда достаточно.  Новые серверы и СХД требуют более высокой пропускной способности и гибкости топологии, что учитывается при разработке CopprLink. Эти кабели позволят как обеспечивать высокоскоростные подключения в пределах самих систем, так и соединять между собой шасси в пределах стойки. Разрабатываются и варианты для межстоечного соединения.  Вопреки непроверенным слухам, CopprLink не поддерживает передачу сколько-нибудь мощного питания и не является заменой стандарту 12VHPWR. В настоящее время спецификации CopprLink, обеспечивающего работу на скоростях PCIe 5.0/6.0, уже достигли версии 0.9. Полноценный анонс технологии должен состояться в начале 2024 года. 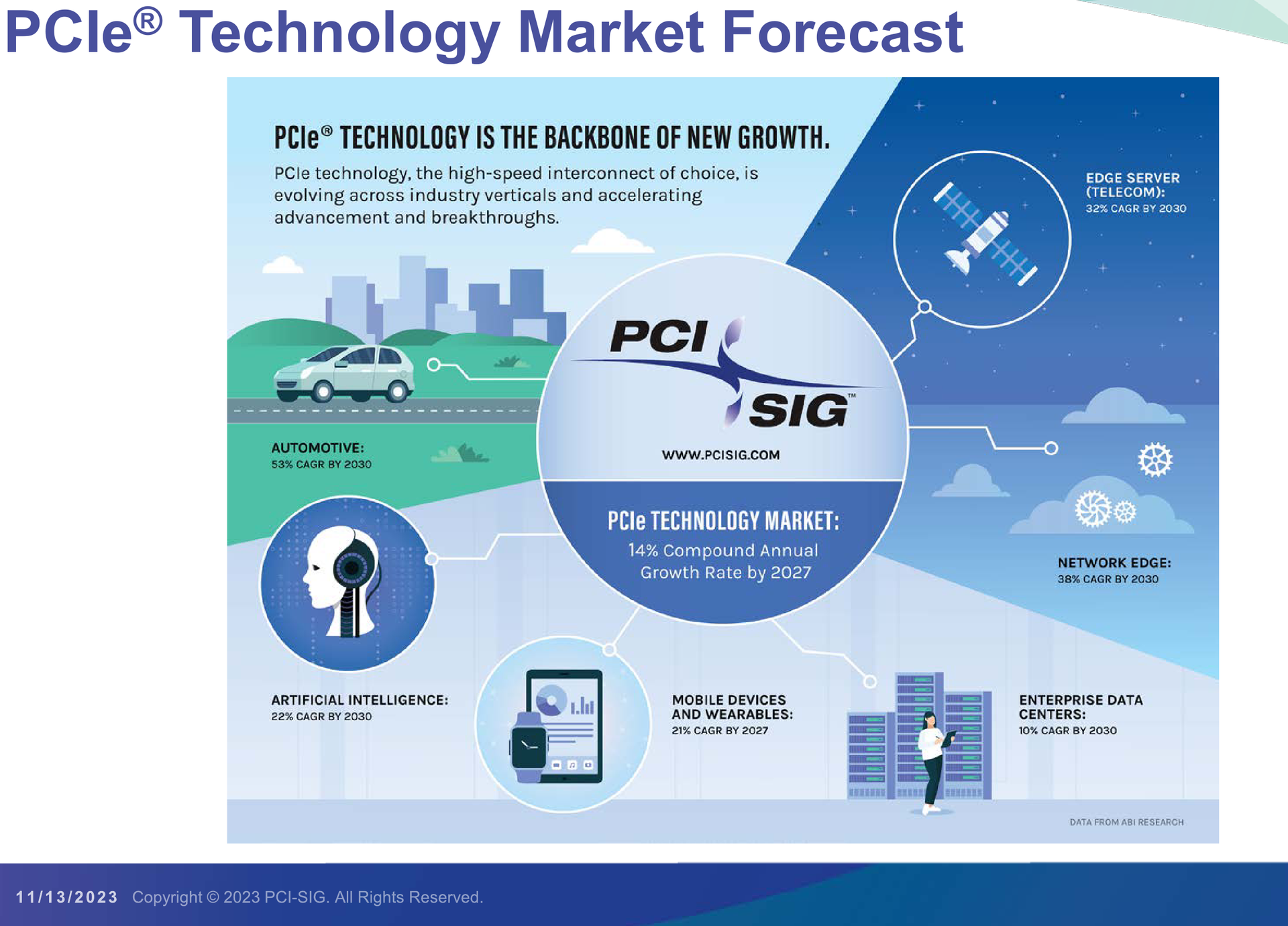 Технология PCI Express востребована во многих сегментах, от традиционных серверов и ПК до крупных ЦОД, телеком-платформ, ИИ-кластеров, умного транспорта и даже в мобильных и носимых устройствах. Ожидается, что в период до 2027 показатель CAGR для рынка PCIe-решений составит 14 %, а к концу периода он достинет объёма $10 млрд. Быстрее всего развитие будет идти в секторе автомобильных решений (CAGR 53 % до 2030 года), периферийных сетевых (38 %) и телекоммуникационных (32 %) платформ.
15.11.2023 [22:36], Владимир Мироненко
Hitachi Vantara и Quobyte предложат доступные, надёжные и масштабируемые хранилища для HPCHitachi Vantara, «дочка» Hitachi Ltd., специализирующаяся на СХД, управлении данными и цифровых решениях, объявила на конференции SC23 о партнёрстве с Quobyte, занимающейся разработкой высокопроизводительных программно определяемых хранилищ. Цель альянса — создание долговечных масштабируемых решений для хранения данных с доступной ценой. Партнёрство включает и стратегическое сотрудничество в области маркетинга и взаимодействия с клиентами. Как отмечено в пресс-релизе, интеграция интеллектуальной платформы данных Hitachi Vantara и передовой платформы хранения данных Quobyte «откроет новую эру управления данными, соответствующую меняющимся потребностям современных предприятий и сред HPC». «Объединяя наше мастерство управления данными с возможностями Quobyte в области хранения данных, мы не просто решаем проблемы управления данными, но и поднимаем операционную эффективность на новый уровень», — заявил представитель Hitachi Vantara. 
Изображение: Quobyte Сообщается, что благодаря партнёрству клиентам компаний будут предложены:
15.11.2023 [20:25], Алексей Степин
Cornelis Networks анонсировала семейство продуктов CN5000 для экосистемы Omni-Path 400GКак известно, уроненное Intel знамя Omni-Path подхватила компания Cornelis Networks, которая достаточно успешно и уверенно продолжает совершенствовать эту систему интерконнекта. Буквально на днях состоялся официальный анонс CN5000 — серии решений для экосистемы Omni-Path второго поколения, способных работать на скорости 400 Гбит/с. 
Источник изображений здесь и далее: Cornelis Networks О планах Cornelis Networks относительно CN5000 и следующих за ним поколений Omni-Path уже рассказывалось ранее. Во втором поколении разработчики отказались от Performance Scale Messaging и целиком перешли на открытый стек OFI (libfabric). По всей видимости, дела у Cornelis идут хорошо, поскольку анонс состоялся уже сейчас, хотя ранее выход CN5000 был запланирован на 2024 год. Никаких данных о сроках начала массовых поставок и ценах компания-разработчик пока не приводит, но потенциальным заказчикам уже предлагает связаться с отделом продаж.  Компания назвала главные достоинства новой технологии. Среди них высокая инфраструктурная эффективность, отличное соотношение цены и качеству, высокая защищённость соединений, реализация QoS, а также лучшая в своём классе латентность (менее 1 мкс), что особенно важно для рынков ИИ и HPC.  В основе инфраструктуры Omni-Path CN5000 лежат три ключевых продукта: хост-адаптеры PCIe 5.0, непосредственно устанавливаемые в узлы, 48-портовые 1U-коммутаторы и 576-портовые 17U-директоры. Для всех трёх доступно как воздушное, так и жидкостное охлаждение. Фабрика на базе CN5000 может содержать до 330 тыс. узлов, чего достаточно для построения крупномасштабных HPC-систем. |
|