Материалы по тегу: mlperf
|
12.09.2025 [23:07], Владимир Мироненко
Intel Arc Pro впервые поучаствовали в бенчмарках MLPerf Inference, но в лидерах предсказуемо осталась NVIDIAMLCommons объявил результаты набора бенчмарков MLPerf Inference v5.1. Последний раунд демонстрирует, насколько быстро развивается инференс и соответствующие бенчмарки, пишет ресурс HPCwire. В этом раунде было рекордное количество заявок — 27. Представлены результаты сразу пяти новых ускорителей: AMD Instinct MI355X, Intel Arc Pro B60 48GB Turbo, NVIDIA GB300, NVIDIA RTX 4000 Ada 20GB, NVIDIA RTX Pro 6000 Blackwell Server Edition. Всего же количество результатов MLPerf перевалило за 90 тыс. результатов. В текущем раунде были представлены три новых бенчмарка: тест рассуждений на основе модели DeepSeek-R1, тест преобразования речи в текст на основе Whisper Large v3 и небольшой тест LLM на основе Llama 3.1 8B. Как отметил ресурс IEEE Spectrum, бенчмарк на основе модели Deepseek R1 671B (671 млрд параметров), более чем в 1,5 раза превышает самый крупный бенчмарк предыдущего раунда на основе Llama 3.1 405B. В модели Deepseek R1, ориентированной на рассуждения, большая часть вычислений выполняется во время инференса, что делает этот бенчмарк ещё более сложным. Что касается самого маленького бенчмарка, основанного на Llama 3.1 8B, то, как поясняют в MLCommons, в отрасли растёт спрос на рассуждения с малой задержкой и высокой точностью. SLM отвечают этим требованиям и являются отличным выбором для таких задач, как реферирование текста или периферийные приложения. В свою очередь бенчмарк преобразования голоса в текст, основанный на Whisper Large v3, был разработан в ответ на растущее количество голосовых приложений, будь то смарт-устройства или голосовые ИИ-интерфейсы. 
Источник изображения: NVIDIA NVIDIA вновь возглавила рейтинг MLPerf Inference, на этот раз с архитектурой Blackwell Ultra, представленной платформой NVIDIA GB300 NVL72, которая установила рекорд, увеличив пропускную способность DeepSeek-R1 на 45 % по сравнению с предыдущими системами GB200 NVL72 (Blackwell). NVIDIA также продемонстрировала высокие результаты в бенчмарке Llama 3.1 405B, который имеет более жёсткие ограничения по задержке. NVIDIA применила дезагрегацию, разделив фазы работы с контекстом и собственно генерацию между разными ускорителями. Этот подход, поддерживаемый фреймворком Dynamo, обеспечил увеличение в 1,5 раза пропускной способности на один ускоритель по сравнению с традиционным обслуживанием на системах Blackwell и более чем в 5 раз по сравнению с системами на базе Hopper. 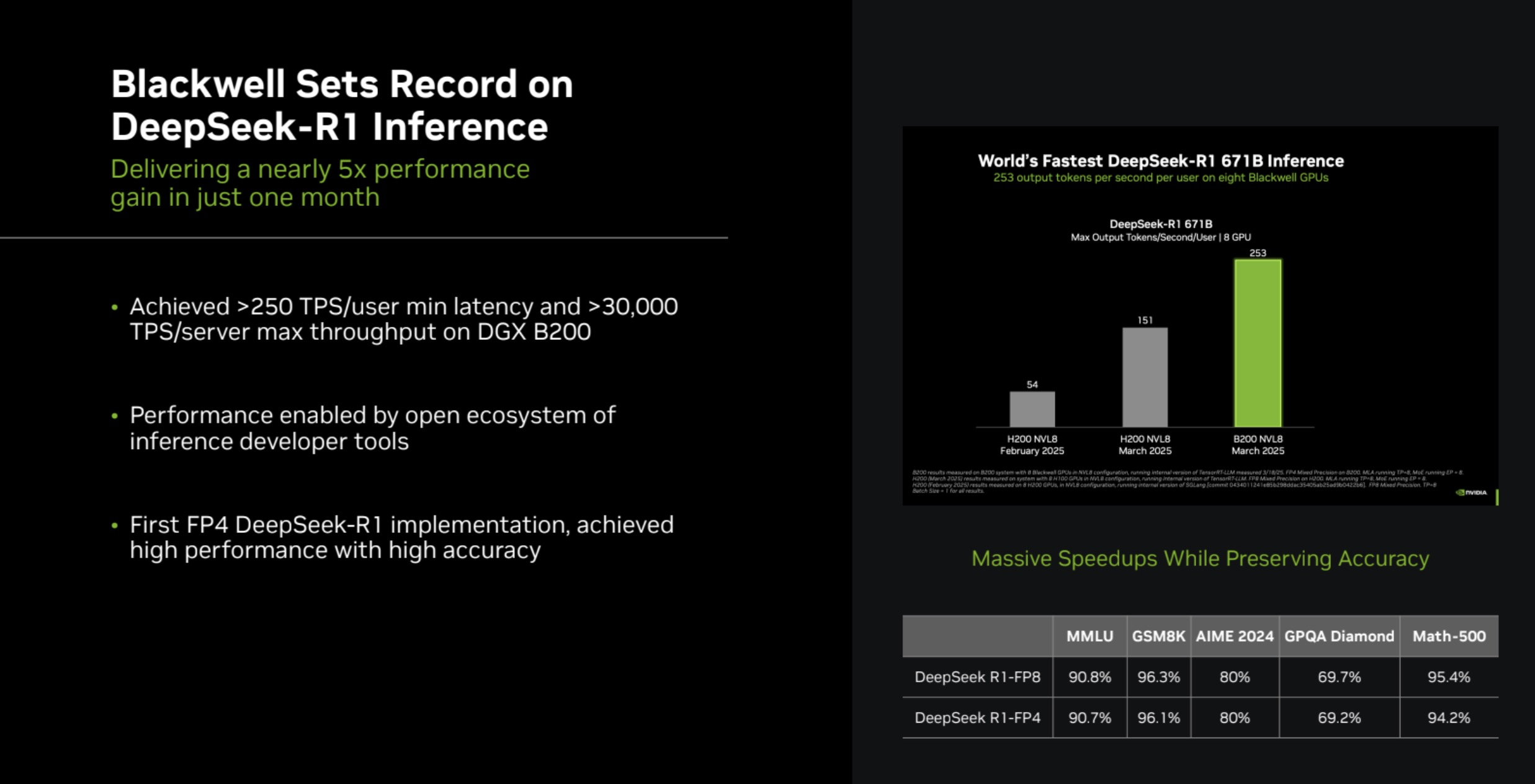
Источник изображения: NVIDIA NVIDIA назвала «дезагрегированное обслуживание» одним из ключевых факторов успеха, помимо аппаратных улучшений при переходе к Blackwell Ultra. Также свою роль сыграло использованием фирменного 4-бит формата NVFP4. «Мы можем обеспечить точность, сопоставимую с BF16», — сообщила компания, добавив, что при этом потребляется значительно меньше вычислительной мощности. Для работы с контекстом NVIDIA готовит соускоритель Rubin CPX. В более компактных бенчмарках решения NVIDIA также продемонстрировали рекордную пропускную способность. Компания сообщила о более чем 18 тыс. токенов/с на один ускоритель в бенчмарке Llama 3.1 8B в автономном режиме и 5667 токенов/с на один ускоритель в Whisper. Результаты были представлены в офлайн-, серверных и интерактивных сценариях, при этом NVIDIA сохранила лидерство в расчете на GPU во всех категориях. 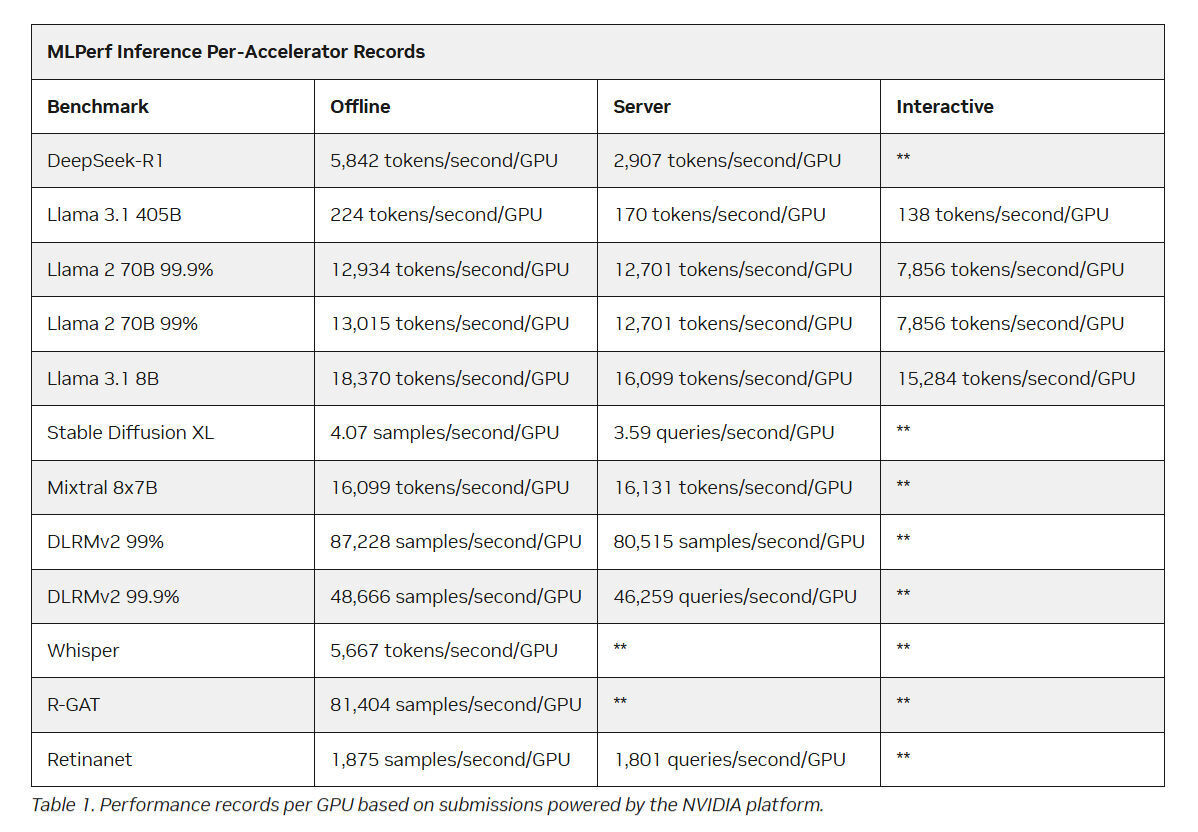
Источник изображения: NVIDIA/TechPowerUp AMD представила результаты AMD Instinct MI355X только в «открытой» категории, где разрешены программные модификации модели. Ускоритель MI355X превзошёл в бенчмарке Llama 2 70B ускоритель MI325X в 2,7 раза по количеству токенов/с. В этом раунде AMD также впервые обнародовала результаты нескольких новых рабочих нагрузок, включая Llama 2 70B Interactive, MoE-модель Mixtral-8x7B и генератор изображений Stable Diffusion XL. 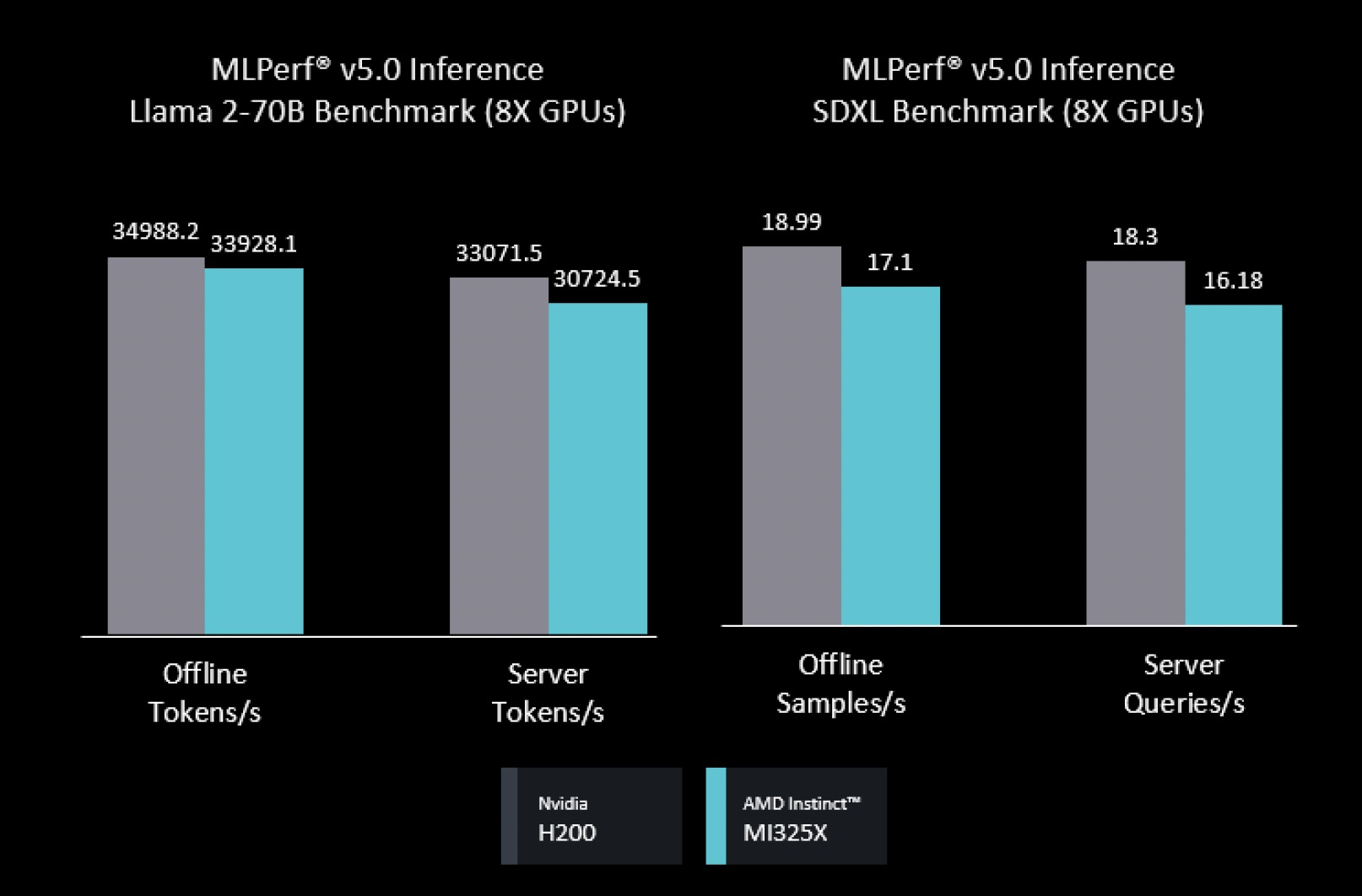
Источник изображения: AMD/ServeTheHome В число «закрытых» заявок AMD входили системы на базе ускорителей AMD MI300X и MI325X. Более продвинутый MI325X показал результаты, схожие с показателями систем на базе NVIDIA H200 на Llama 2 70b, в комбинированном тесте MoE и тестах генерации изображений. Кроме того, компанией была представлена первая гибридная заявка, в которой ускорители AMD MI300X и MI325X использовались для одной и той же задачи инференса — бенчмарка на базе Llama 2 70b. Возможность распределения нагрузки между различными типами ускорителей — важный шаг, отметил IEEE Spectrum. В этом раунде впервые был представлен и ускоритель Intel Arc Pro. Для бенчмарков использовалась видеокарта MaxSun Intel Arc Pro B60 Dual 48G Turbo, состоящая из двух GPU с 48 Гбайт памяти, в составе платформы Project Battlematrix, которая может включать до восьми таких ускорителей. Система показала результаты на уровне NVIDIA L40S в небольшом тесте LLM и уступила ему в тесте Llama 2 70b. 
Источник изображения: Intel Следует также отметить, что в этом раунде, как и в предыдущем, участвовала Nebius (ранее Yandex N.V.). Компания отметила, что результаты, полученные на односерверных инсталляциях, подтверждают, что Nebius AI Cloud обеспечивает «высочайшие» показатели производительности для инференса базовых моделей, таких как Llama 2 70B и Llama 3.1 405B. В частности, Nebius AI Cloud установила новый рекорд производительности для NVIDIA GB200 NVL72. По сравнению с лучшими результатами предыдущего раунда, её однохостовая инсталляция показала прирост производительности на 6,7 % и 14,2 % при работе с Llama 3.1 405B в автономном и серверном режимах соответственно. «Эти два показателя также обеспечивают Nebius первое место среди других разработчиков MLPerf Inference v5.1 для этой модели в системах GB200», — сообщила компания.
07.06.2025 [16:24], Владимир Мироненко
AMD впервые приняла участие в бенчмарке MLPerf Training, но до рекордов NVIDIA ей ещё очень далекоКонсорциум MLCommons объявил новые результаты бенчмарка MLPerf Training v5.0, отметив быстрый рост и эволюцию в области ИИ, а также рекордное количество общих заявок и увеличение заявок для большинства тестов по сравнению с бенчмарком v4.1. MLPerf Training v5.0 предложил новый бенчмарк предварительной подготовки большой языковой модели на основе Llama 3.1 405B, которая является самой большой ИИ-моделью в текущем наборе тестов обучения. Он заменил бенчмарк на основе gpt3 (gpt-3-175B), входивший в предыдущие версии MLPerf Training. Целевая группа MLPerf Training выбрала его, поскольку Llama 3.1 405B является конкурентоспособной моделью, представляющей современные LLM, включая последние обновления алгоритмов и обучение на большем количестве токенов. Llama 3.1 405B более чем в два раза больше gpt3 и использует в четыре раза большее контекстное окно. Несмотря на то, что бенчмарк на основе Llama 3.1 405B был представлен только недавно, на него уже подано больше заявок, чем на предшественника на основе gpt3 в предыдущих раундах, отметил консорциум. 
Источник изображения: NVIDIA MLCommons сообщил, что рабочая группа MLPerf Training регулярно добавляет новые рабочие нагрузки в набор тестов, чтобы гарантировать, что он отражает тенденции отрасли. Результаты бенчмарка Training 5.0 показывают заметный рост производительности для новых бенчмарков, что указывает на то, что отрасль отдаёт приоритет новым рабочим нагрузкам обучения, а не старым. Тест Stable Diffusion показал увеличение скорости в 2,28 раза для восьмичиповых систем по сравнению с версией 4.1, вышедшей шесть месяцев назад, а тест Llama 2.0 70B LoRA увеличил скорость в 2,10 раза по сравнению с версией 4.1; оба превзошли исторические ожидания роста производительности вычислений с течением времени в соответствии с законом Мура. Более старые тесты в наборе показали более скромные улучшения производительности. 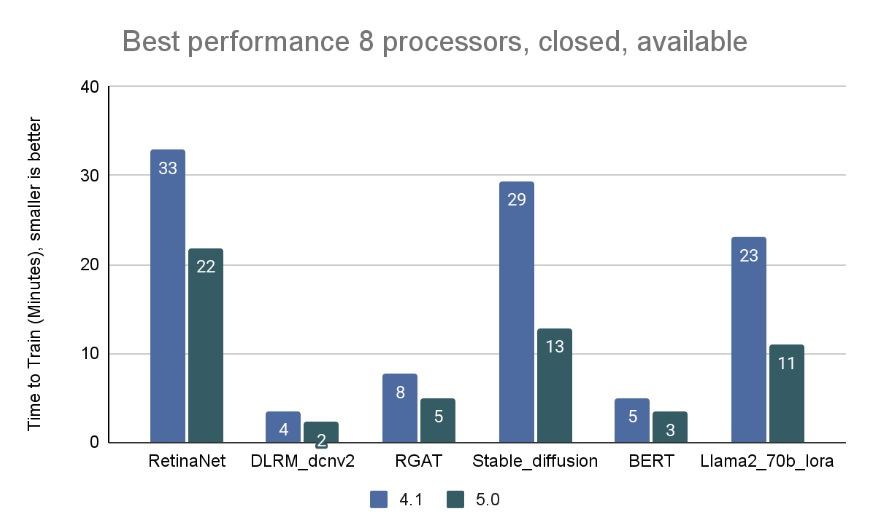
Источник изображений: MLCommons На многоузловых 64-чиповых системах тест RetinaNet показал ускорение в 1,43 раза по сравнению с предыдущим раундом тестирования v3.1 (самым последним, включающим сопоставимые масштабные системы), в то время как тест Stable Diffusion показал резкое увеличение в 3,68 раза. «Это признак надёжного цикла инноваций в технологиях и совместного проектирования: ИИ использует преимущества новых систем, но системы также развиваются для поддержки высокоприоритетных сценариев», — говорит Шрия Ришаб (Shriya Rishab), сопредседатель рабочей группы MLPerf Training. 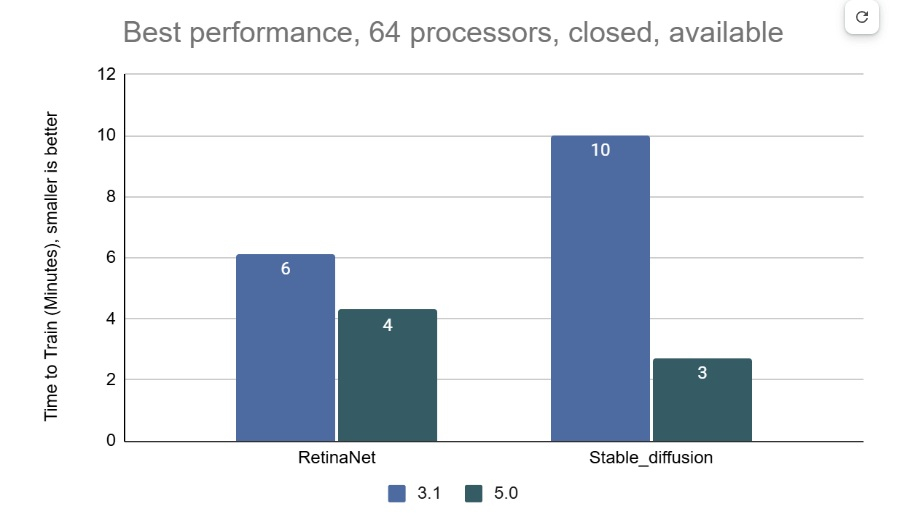 В заявках на MLPerf Training 5.0 использовалось 12 уникальных чиповых, все в категории коммерчески доступных. Пять из них стали общедоступными с момента выхода последней версии набора тестов MLPerf Training:
Заявки также включали три новых семейства процессоров:
Кроме того, количество представленных многоузловых систем увеличилось более чем в 1,8 раза по сравнению с версией бенчмарка 4.1. Хиуот Касса (Hiwot Kassa), сопредседатель рабочей группы MLPerf Training, отметил растущее число провайдеров облачных услуг, предлагающих доступ к крупномасштабным системам, что делает доступ к обучению LLM более демократичным. 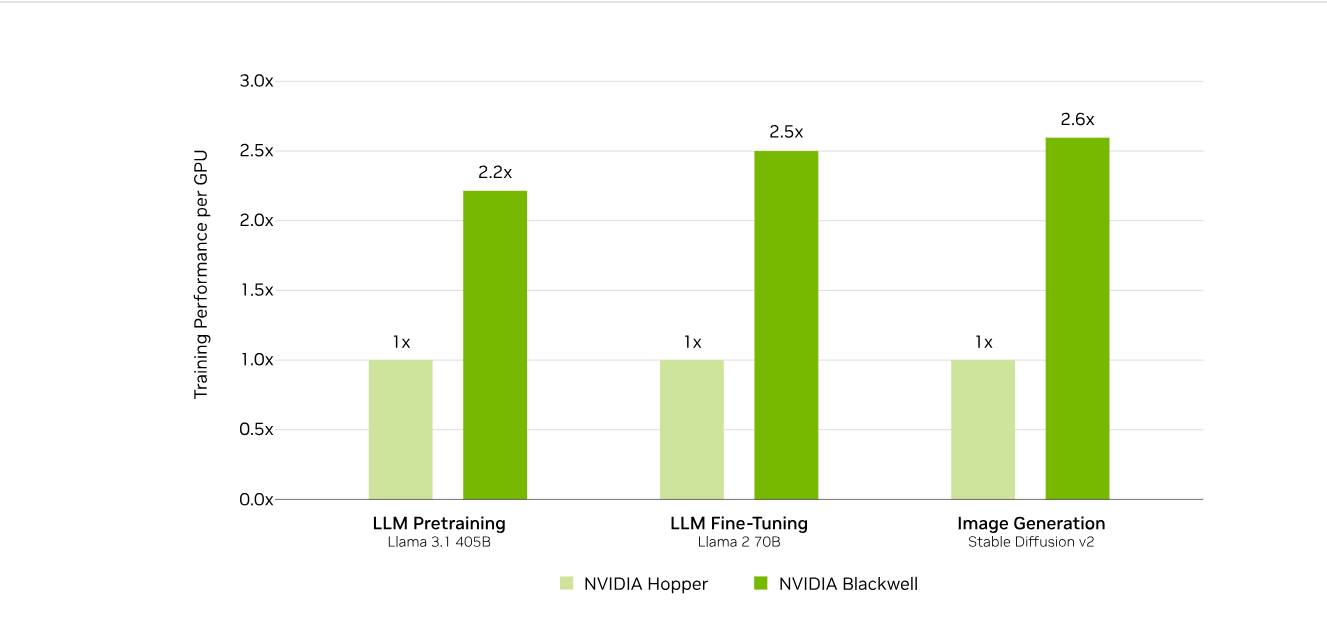
Источник изображений: NVIDIA Последние результаты MLPerf Training 5.0 от NVIDIA показывают, что её ускорители Blackwell GB200 демонстрируют рекордные результаты по времени обучения, демонстрируя, как стоечная конструкция «ИИ-фабрики» компании может быстрее, чем раньше, превращать «сырые» вычислительные мощности в развёртываемые модели, пишет ресурс HPCwire. Раунд MLPerf Training v5.0 включает 201 результат от 20 организаций-участников: AMD, ASUS, Cisco, CoreWeave, Dell, GigaComputing, Google Cloud, HPE, IBM, Krai, Lambda, Lenovo, MangoBoost, Nebius, NVIDIA, Oracle, QCT, SCITIX, Supermicro и TinyCorp. «Мы бы особенно хотели поприветствовать впервые подавших заявку на участие в MLPerf Training AMD, IBM, MangoBoost, Nebius и SCITIX, — сказал Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons. — Я также хотел бы выделить первый набор заявок Lenovo на результаты тестов энергопотребления в этом раунде — энергоэффективность в системе обучения ИИ-систем становится всё более важной проблемой, требующей точного измерения». 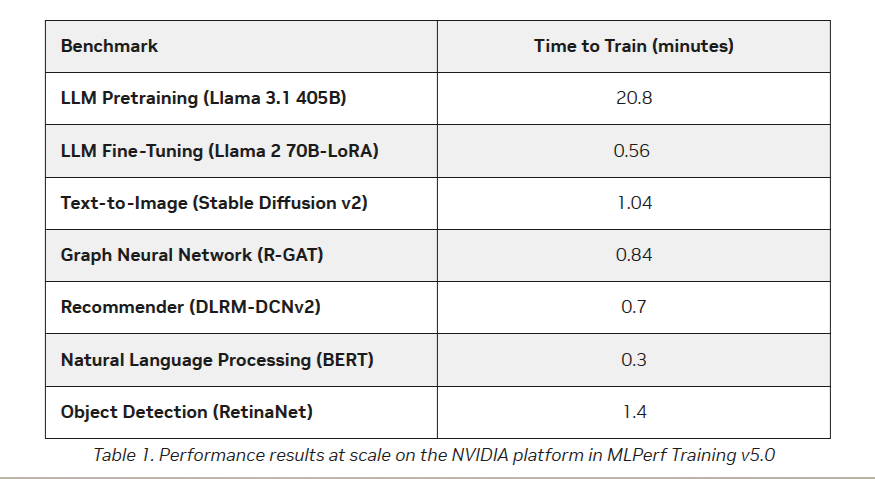 NVIDIA представила результаты кластера на основе систем GB200 NVL72, объединивших 2496 ускорителей. Работая с облачными партнерами CoreWeave и IBM, компания сообщила о 90-% эффективности масштабирования при расширении с 512 до 2496 ускорителей. Это отличный результат, поскольку линейное масштабирование редко достигается при увеличении количества ускорителей за пределами нескольких сотен. Эффективность масштабирования в диапазоне от 70 до 80 % уже считается солидным результатом, особенно при увеличении количества ускорителей в пять раз, пишет HPCwire. В семи рабочих нагрузках в MLPerf Training 5.0 ускорители Blackwell улучшили время сходимости «до 2,6x» при постоянном количестве ускорителей по сравнению с поколением Hopper (H100). Самый большой рост наблюдался при генерации изображений и предварительном обучении LLM, где количество параметров и нагрузка на память самые большие.  Хотя в бенчмарке проверялась скорость выполнения операций, NVIDIA подчеркнула, что более быстрое выполнение задач означает меньшее время аренды облачных инстансов и более скромные счета за электроэнергию для локальных развёртываний. Хотя компания не публиковала данные об энергоэффективности в этом бенчмарке, она позиционировала Blackwell как «более экономичное» решение на основе достигнутых показателей, предполагая, что усовершенствования дизайна тензорных ядер обеспечивают лучшую производительность на Ватт, чем у поколения Hopper. Также HPCwire отметил, что NVIDIA была единственным поставщиком, представившим результаты бенчмарка предварительной подготовки LLM на основе Llama 3.1 405B, установив начальную точку отсчёта для обучения с 405 млрд параметров. Это важно, поскольку некоторые компании уже выходят за рамки 70–80 млрд параметров для передовых ИИ-моделей. Демонстрация проверенного рецепта работы с 405 млрд параметров даёт компаниям более чёткое представление о том, что потребуется для создания ИИ-моделей следующего поколения. 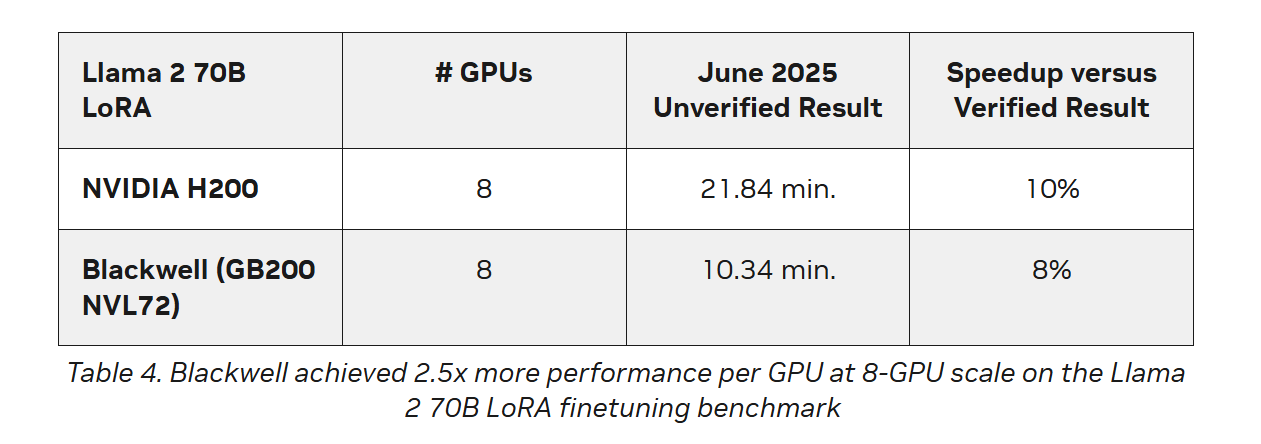 В ходе пресс-конференции Дэйв Сальватор (Dave Salvator), директор по ускоренным вычислительным продуктам в NVIDIA, ответил на распространенный вопрос: «Зачем фокусироваться на обучении, когда в отрасли в настоящее время все внимание сосредоточено на инференсе?». Он сообщил, что тонкая настройка (после предварительного обучения) остается ключевым условием для реальных LLM, особенно для предприятий, использующих собственные данные. Он обозначил обучение как «фазу инвестиций», которая приносит отдачу позже в развёртываниях с большим объёмом инференса. Этот подход соответствует более общей концепции «ИИ-фабрики» компании, в рамках которой ускорителям даются данные и питание для обучения моделей. А затем производятся токены для использования в реальных приложениях. К ним относятся новые «токены рассуждений» (reasoning tokens), используемые в агентских ИИ-системах. 
 NVIDIA также повторно представила результаты по Hopper, чтобы подчеркнуть, что H100 остаётся «единственной архитектурой, кроме Blackwell», которая показала лидерские показатели по всему набору MLPerf Training, хотя и уступила Blackwell. Поскольку инстансы на H100 широко доступны у провайдеров облачных сервисов, компания, похоже, стремится заверить клиентов, что существующие развёртывания по-прежнему имеют смысл. 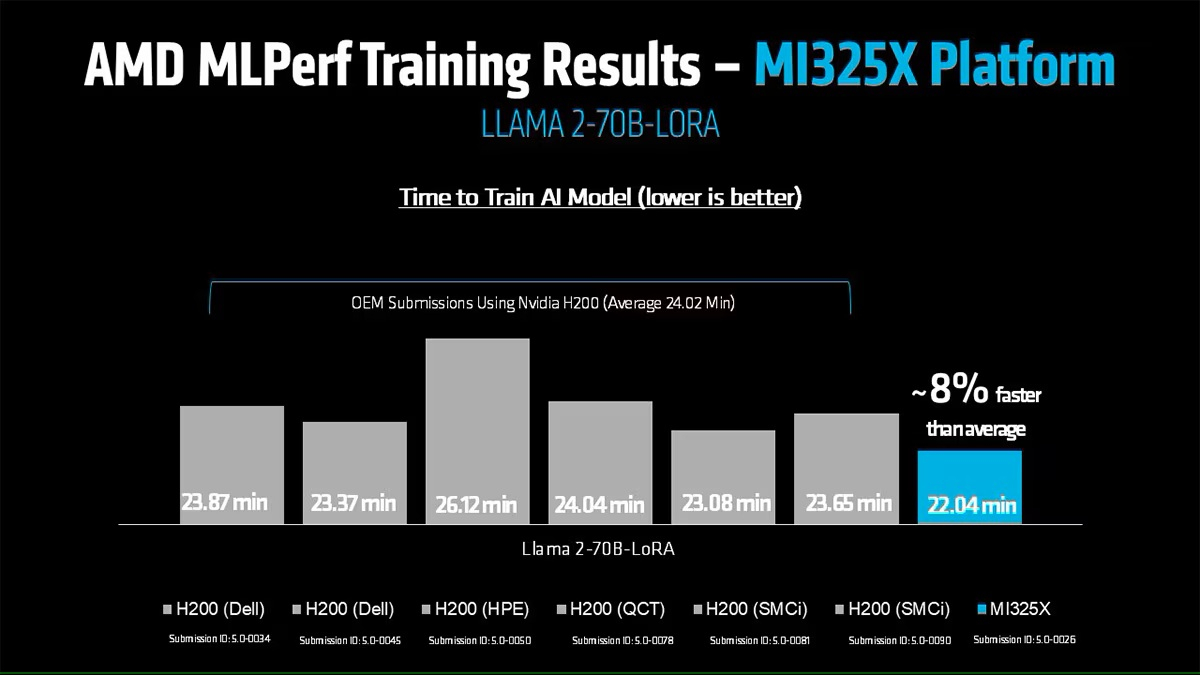
Источник изображений: AMD AMD, со своей стороны, продемонстрировала прирост производительности поколения чипов. В тесте Llama2 70B LoRA она показала 30-% прирост производительности AMD Instinct MI325X по сравнению с предшественником MI300X. Основное различие между ними заключается в том, что MI325X оснащён почти на треть более быстрой памятью.  В самом популярном тесте, тонкой настройке LLM, AMD продемонстрировала, что её новейший ускоритель Instinct MI325X показывает результаты наравне с NVIDIA H200. Это говорит о том, что AMD отстает от NVIDIA на одно поколение, отметил ресурс IEEE Spectrum. 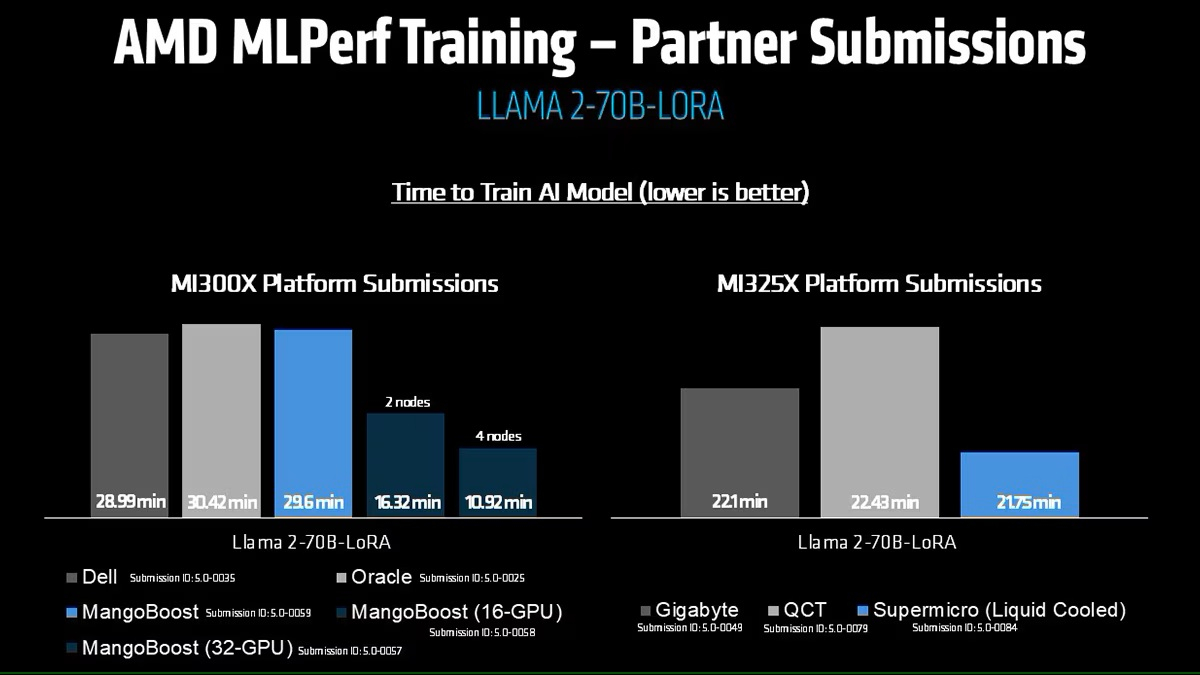 AMD впервые представила результаты MLPerf Training, хотя в предыдущие годы другие компании представляли результаты в этом тесте, используя ускорители AMD. В свою очередь, Google представила результаты лишь одного теста, задачи генерации изображений, с использованием Trillium TPU. Тест MLPerf также включает тест на энергопотребление, измеряющий, сколько энергии уходит на выполнение каждой задачи обучения. В этом раунде лишь Lenovo включила измерение этого показателя в свою заявку, что сделало невозможным сравнение между компаниями. Для тонкой настройки LLM на двух ускорителях Blackwell требуется 6,11 ГДж или 1698 КВт·ч — примерно столько энергии уходит на обогрев небольшого дома зимой.
04.04.2025 [10:26], Владимир Мироненко
Бенчмарк MLPerf Inference 5.0 показал, что ускорители AMD Instinct MI325X не уступают NVIDIA H200Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Inference 5.0, о чём сообщил ресурс IEEE Spectrum. Он отметил, что ускорители NVIDIA с архитектурой Blackwell превзошли все остальные чипы, но последняя версия ускорителей Instinct от AMD — Instinct MI325X — оказалась на уровне конкурирующего решения NVIDIA H200. Сопоставимые результаты были получены в основном в тестах одной из маломасштабных больших языковых моделей (LLM) — Llama2 70B. Чтобы лучше отражать особенности развития ИИ, консорциум добавил три новых теста MLPerf — всего доступно 11 бенчмарков. Добавлены два теста для LLM. Популярная и относительно компактная Llama2 70B уже является устоявшимся эталоном MLPerf, но консорциум решил включить тест, имитирующий скорость реагирования, ожидаемую пользователями от чат-ботов. Поэтому был добавлен новый эталон Llama2-70B Interactive, который ужесточает требования к оборудованию: системы должны выдавать не менее 25 токенов в секунду при задержке на ответ не более 450 мс. С учётом роста популярности «агентного ИИ» в MLPerf решили добавить тестирование LLM с характеристиками, необходимыми для таких задач. В итоге была выбрана Llama3.1 405B. Эта модель имеет широкое контекстное окно — 128 тыс. токенов, что в 30 раз больше, чем у Llama2 70B. Третий новый бенчмарк — RGAT — представляет собой графовую сеть. Он классифицирует информацию в сети. Например, набор данных для тестирования RGAT состоит из научных статей, связанных между собой авторами, учреждениями и областями исследований, что составляет 2 Тбайт данных. RGAT должен классифицировать статьи по почти 3000 темам. 
Источник изображения: IEEE Spectrum В этом раунде тестов поступили заявки от NVIDIA и 15 компаний-партнёров, включая Dell, Google и Supermicro. Оба ускорителя NVIDIA с архитектурой Hopper первого и второго поколения — H100 и H200 — показали хорошие результаты. «Мы смогли добавить ещё 60 % производительности за последний год, — у Hopper, которая была запущена в производство в 2022 году, сообщил Дэйв Сальватор (Dave Salvator), один из директоров NVIDIA. — У неё всё ещё есть некоторый запас производительности». Лидером же оказался B200 с архитектурой Blackwell. B200 содержит на 36 % больше памяти HBM, чем у H200, но, что ещё важнее, он может выполнять ключевые математические операции, используя FP4 вместо FP8 у Hopper. В тесте Llama3.1 405B система от Supermicro с восемью B200 выдала почти в четыре раза больше токенов в секунду, чем система с восемью H200 от Cisco. И та же система Supermicro была в три раза быстрее самого быстрого сервера на H200 в интерактивной версии Llama2 70B. NVIDIA использовала суперчип GB200 — сочетание ускорителей Blackwell и процессоров Grace — чтобы продемонстрировать эффективность интерконнекта NVLink, который позволяет работать множеству узлов как один ускоритель. В непроверенном результате, которым компания поделилась с журналистами, стойка GB200 NVL72 выдавала 869 200 токенов в секунду в Llama2 70B. Самая быстрая система текущего раунда MLPerf Inference — сервер NVIDIA B200 — показала 98 443 токена в секунду. Ускоритель Instinct MI325X позиционируется AMD как конкурент H200. Он имеет ту же архитектуру, что и предшественник MI300, но оснащён увеличенным объёмом памяти HBM с более высокой пропускной способностью — 256 Гбайт и 6 Тбайт/с (рост на 33 % и 13 % соответственно). AMD оптимизировала ПО, что позволило увеличить скорость инференса DeepSeek-R1 в 8 раз. В тесте Llama2 70B компьютеры с восемью MI325X отставали от аналогичных систем на базе H200 всего на 3–7 %. В задачах генерации изображений система MI325X показала отличия в пределах 10 % от системы на H200. Также сообщается, что партнёр AMD, компания Mangoboost, продемонстрировала почти четырёхкратное увеличение производительности в тесте Llama2 70B, запустив вычисления на четырёх узлах. 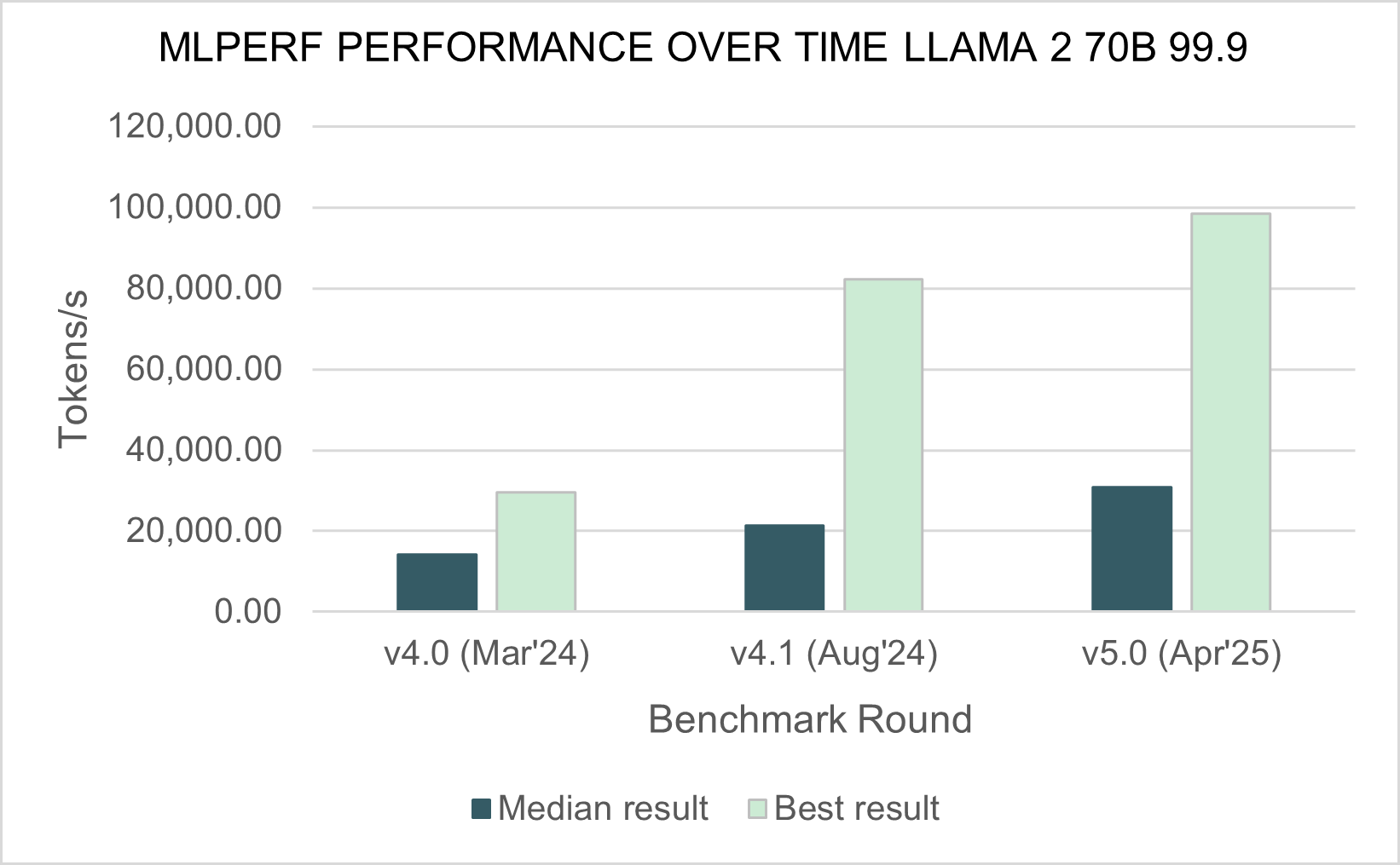
Источник изображения: ML Commons Intel традиционно использует в тестах только процессорные системы, чтобы показать, что для некоторых рабочих нагрузок GPU не требуются. В этот раз были представлены первые данные по чипам Intel Xeon 6900P и 6700P (Granite Rapids), выпускаемым по техпроцессу Intel 3. Компьютер с двумя Xeon 6 показал результат в 40 285 семплов в секунду в тесте распознавания изображений, что составляет около одной трети производительности системы Cisco с двумя NVIDIA H100. По сравнению с результатами Xeon 5 в октябре 2024 года новый процессор демонстрирует прирост в 80 % в данном тесте и ещё большее ускорение в задачах обнаружения объектов и медицинской визуализации. С 2021 года, когда Intel начала представлять результаты Xeon, её процессоры достигли 11-кратного прироста производительности в тесте ResNet. Intel отказалась от участия в категории ускорителей: её конкурент для H100 — Gaudi 3 — не появился ни в текущих результатах MLPerf, ни в версии 4.1, выпущенной в октябре 2024 года. Чип Google TPU v6e также продемонстрировал свои возможности, хотя результаты были ограничены задачей генерации изображений. При 5,48 запроса в секунду система с четырьмя TPU показала прирост в 2,5 раза по сравнению с аналогичным компьютером, использующим TPU v5e, в результатах за октябрь 2024 года. Тем не менее 5,48 запроса в секунду — это примерно те же показатели, что и у аналогичного по размеру компьютера Lenovo с NVIDIA H100.
14.11.2024 [23:07], Владимир Мироненко
Google и NVIDIA показали первые результаты TPU v6 и B200 в ИИ-бенчмарке MLPerf TrainingУскорители Blackwell компании NVIDIA опередили в бенчмарках MLPerf Training 4.1 чипы H100 более чем в 2,2 раза, сообщил The Register. По словам NVIDIA, более высокая пропускная способность памяти в Blackwell также сыграла свою роль. Тесты были проведены с использование собственного суперкомпьютера NVIDIA Nyx на базе DGX B200. Новые ускорители имеют примерно в 2,27 раза более высокую пиковую производительность в вычисления FP8, FP16, BF16 и TF32, чем системы H100 последнего поколения. B200 показал в 2,2 раза более высокую производительность при тюнинге модели Llama 2 70B и в два раза большую производительность при предварительном обучении (Pre-training) модели GPT-3 175B. Для рекомендательных систем и генерации изображений прирост составил 64 % и 62 % соответственно. Компания также отметила преимущества используемой в B200 памяти HBM3e, благодаря которой бенчмарк GPT-3 успешно отработал всего на 64 ускорителях Blackwell без ущерба для производительности каждого GPU, тогда как для достижения такого же результата понадобилось бы 256 ускорителей H100. Впрочем, про Hopper компания тоже не забывает — в новом раунде компания смогла масштабировать тест GPT-3 175B до 11 616 ускорителей H100. 
Источник изображений: NVIDIA Компания отметила, что платформа NVIDIA Blackwell обеспечивает значительный скачок производительности по сравнению с платформой Hopper, особенно при работе с LLM. В то же время чипы поколения Hopper по-прежнему остаются актуальными благодаря непрерывным оптимизациям ПО, порой кратно повышающим производительность в некоторых задач. Интрига в том, что в этот раз NVIDIA решила не показывать результаты GB200, хотя такие системы есть и у неё, и у партнёров.  В свою очередь, Google представила первые результаты тестирования 6-го поколения TPU под названием Trillium, о доступности которого было объявлено в прошлом месяце, и второй раунд результатов ускорителей 5-го поколения TPU v5p. Ранее Google тестировала только TPU v5e. По сравнению с последним вариантом, Trillium обеспечивает прирост производительности в 3,8 раза в задаче обучения GPT-3, отмечает IEEE Spectrum.  Если же сравнивать результаты с показателями NVIDIA, то всё выглядит не так оптимистично. Система из 6144 TPU v5p достигла контрольной точки обучения GPT-3 за 11,77 мин, отстав от системы с 11 616 H100, которая выполнила задачу примерно за 3,44 мин. При одинаковом же количестве ускорителей решения Google почти вдвое отстают от решений NVIDIA, а разница между v5p и v6e составляет менее 10 %. 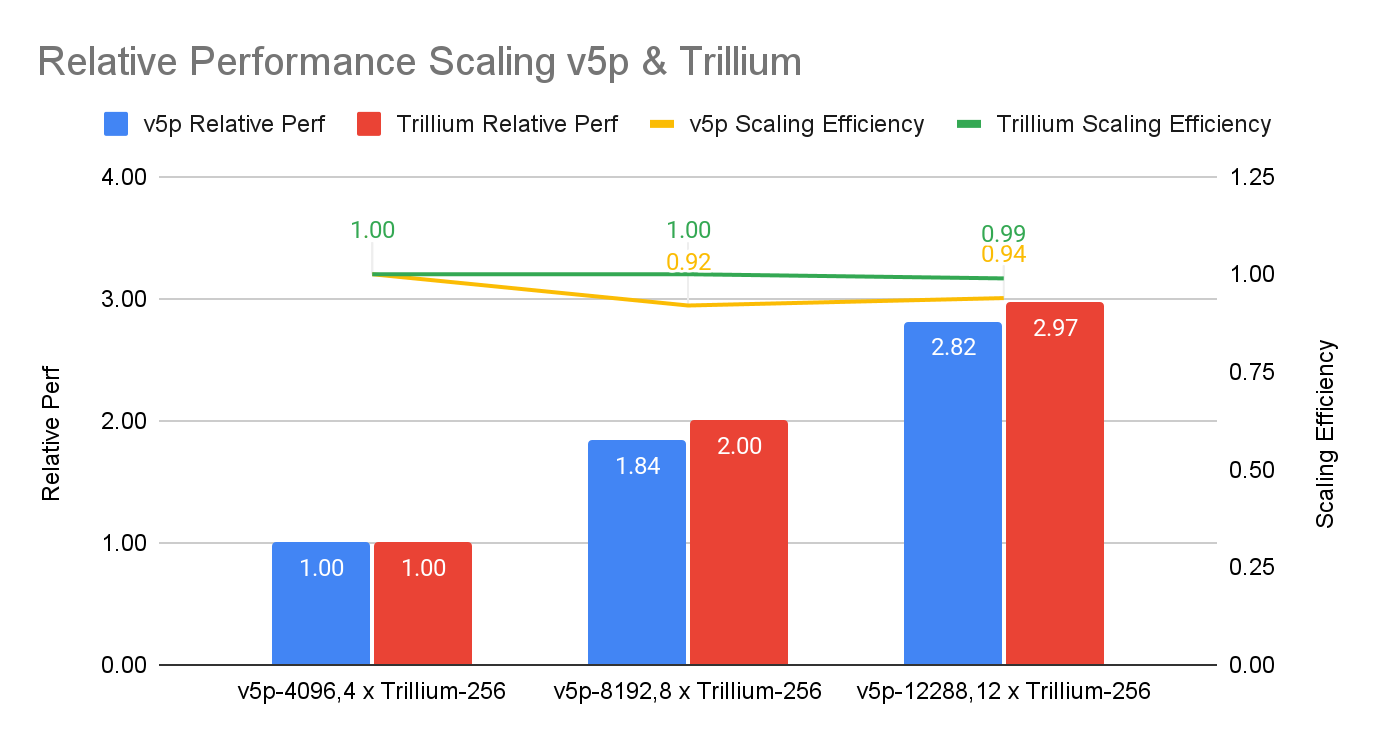
Источник изображения: Google В тесте Stable Diffusion система из 1024 TPU v5p заняла второе место, завершив работу за 2,44 мин, тогда как система того же размера на основе NVIDIA H100 справилась с задачей за 1,37 мин. В остальных тестах на кластерах меньшего масштаба разрыв остаётся примерно полуторакратным. Впрочем, Google упирает на масштабируемость и лучшее соотношение цены и производительности в сравнении как с решениями конкурентов, так и с собственными ускорителями прошлых поколений. Также в новом раунде MLPerf появился единственный результат измерения энергопотребления во время проведения бенчмарка. Система из восьми серверов Dell XE9680, каждый из которых включал восемь ускорителей NVIDIA H100 и два процессора Intel Xeon Platinum 8480+ (Sapphire Rapids), в задаче тюнинга Llama2 70B потребила 16,38 мДж энергии, потратив на работу 5,05 мин. — средняя мощность составила 54,07 кВт.
29.08.2024 [01:00], Владимир Мироненко
NVIDIA вновь показала лидирующие результаты в ИИ-бенчмарке MLPerf InferenceNVIDIA сообщила, что её платформы показали самые высокие результаты во всех тестах производительности уровня ЦОД в бенчмарке MLPerf Inference v4.1, где впервые дебютировал ускоритель семейства Blackwell. Ускоритель NVIDIA B200 (SXM, 180 Гбайт HBM) оказался вчетверо производительнее H100 на крупнейшей рабочей нагрузке среди больших языковых моделей (LLM) MLPerf — Llama 2 70B — благодаря использованию механизма Transformer Engine второго поколения и FP4-инференсу на Tensor-ядрах. Впрочем, именно B200 заказчики могут и не дождаться. Ускоритель NVIDIA H200, который стал доступен в облаке CoreWeave, а также в системах ASUS, Dell, HPE, QTC и Supermicro, показал лучшие результаты во всех тестах в категории ЦОД, включая последнее дополнение к бенчмарку, LLM Mixtral 8x7B с общим количеством параметров 46,7 млрд и 12,9 млрд активных параметров на токен, использующую архитектуру Mixture of Experts (MoE, набор экспертов). 
Источник изображения: NVIDIA Как отметила NVIDIA, MoE приобрела популярность как способ привнести большую универсальность в LLM, поскольку позволяет отвечать на широкий спектр вопросов и выполнять более разнообразные задачи в рамках одного развёртывания. Архитектура также более эффективна, поскольку активируются только несколько экспертов на инференс — это означает, что такие модели выдают результаты намного быстрее, чем высокоплотные (Dense) модели аналогичного размера. Также NVIDIA отмечает, что с ростом размера моделей для снижения времени отклика при инференсе объединение нескольких ускорителей становится обязательными. По словам компании, NVLink и NVSwitch уже в поколении NVIDIA Hopper предоставляют значительные преимущества для экономичного инференса LLM в реальном времени. А платформа Blackwell ещё больше расширит возможности NVLink, позволив объединить до 72 ускорителей. 
Источник изображения: NVIDIA Заодно компания в очередной раз напомнила о важности программной экосистемы. Так, в последнем раунде MLPerf Inference все основные платформы NVIDIA продемонстрировали резкий рост производительности. Например, ускорители NVIDIA H200 показали на 27 % большую производительность инференса генеративного ИИ по сравнению с предыдущим раундом. А Triton Inference Server продемонстрировал почти такую же производительность, как и у bare-metal платформ. Наконец, благодаря программным оптимизациям в этом раунде MLPerf платформа NVIDIA Jetson AGX Orin достигла более чем 6,2-кратного улучшения пропускной способности и 2,5-кратного улучшения задержки по сравнению с предыдущим раундом на рабочей нагрузке GPT-J LLM. По словам NVIDIA, Jetson способен локально обрабатывать любую модель-трансформер, включая LLM, модели класса Vision Transformer и, например, Stable Diffusion. А вместо разработки узкоспециализированных моделей теперь можно применять универсальную GPT-J-6B модель для обработки естественного языка на периферии.
23.06.2024 [11:45], Сергей Карасёв
AMD отказывается от публичного тестирования ускорителей Instinct MI300X в бенчмарках MLPerfКомпания AMD, по сообщению ресурса Wccftech, отклонила просьбу стартапа Tiny Corp о сравнительном испытании ИИ-ускорителей Instinct MI300X в бенчмарке MLPerf, который предлагает тесты для множества разных сценариев, в том числе для задач машинного зрения, обработки языка, рекомендательных систем и обучения с подкреплением. Tiny Corp является разработчиком фреймворка Tinygrad для нейросетей. Кроме того, стартап проектирует компактные компьютеры Tinybox, ориентированные на выполнение ИИ-задач. В зависимости от типа используемых ускорителей (AMD или NVIDIA) производительность достигает 738 или 991 Тфлопс (FP16). Цена — $15 тыс. и $25 тыс. соответственно. Не так давно Tiny Corp предложила AMD предоставить ускорители Instinct MI300X для нового этапа тестов в MLPerf. Однако разработчик чипов по каким-то причинам отказался это сделать, дав крайне уклончивый ответ. «Наше предложение было отклонено. Они [компания AMD] не говорят чётко "нет", используя вместо этого не несущие смысловой нагрузки слова вроде "партнёрство" и "сотрудничество"», — отмечается в сообщении Tiny Corp. 
Источник изображения: AMD Высказываются предположения, что нежелание AMD участвовать в тестах MLPerf может быть связано с заявлениями компании о превосходстве ускорителей Instinct MI300X над изделиями конкурентов. Фактическая оценка производительности в MLPerf может подорвать эти утверждения. Впрочем, в тестах MLPerf отказываются участвовать и другие игроки рынка, например, Groq. Так или иначе, на сегодняшний день чипы NVIDIA остаются безоговорочными лидерами в бенчмарке MLPerf. Вместе с тем единственным конкурентом для них в этом тесте выступают изделия Intel Gaudi. Изделия Intel не дотягивают по производительности до решений NVIDIA, но компания делает упор на стоимость своих продуктов и даже публично назвала цены на ускорители Gaudi, что для данной индустрии случай крайне редкий.
12.06.2024 [18:00], Владимир Мироненко
Уже рутина: NVIDIA снова улучшила результаты в ИИ-бенчмарке MLPerf TrainingВычислительные платформы NVIDIA снова продемонстрировали высокую производительность, на этот раз в свежих тестах MLPerf Training v4.0. Так, суперкомпьютер NVIDIA EOS-DFW более чем утроил свою производительность в LLM-тесте на базе GPT-3 175B по сравнению с прошлогодним результатом. Как сообщается, 11 616 ускорителей NVIDIA H100, объединённых 400G-интерконнектом NVIDIA Quantum-2 InfiniBand, позволили суперкомпьютеру EOS достичь столь значительного результата благодаря более масштабному и комплексному подходу к проектированию системы. А это позволяет более эффективно обучать и запускать крупные модели, экономя время и ресурсы, говорит компания. А более современный ускоритель H200 с улучшенной подсистемой памяти в MLPerf Training быстрее H100 на 14 %, а в GNN-тестах (RGAT) узлы с H200 оказались быстрее узлов с H100 сразу на 47 %. 
Источник изображений: NVIDIA По словам компании, поставщики услуг LLM могут всего за четыре года, инвестировав $1, получить $7, используя модель Llama 3 70B на серверах на базе NVIDIA HGX H200, если исходить из того, что обслуживание обходится в $0,60 за миллион токенов, а пропускная способность HGX H200 составляет 24 тыс. токенов в секунду. 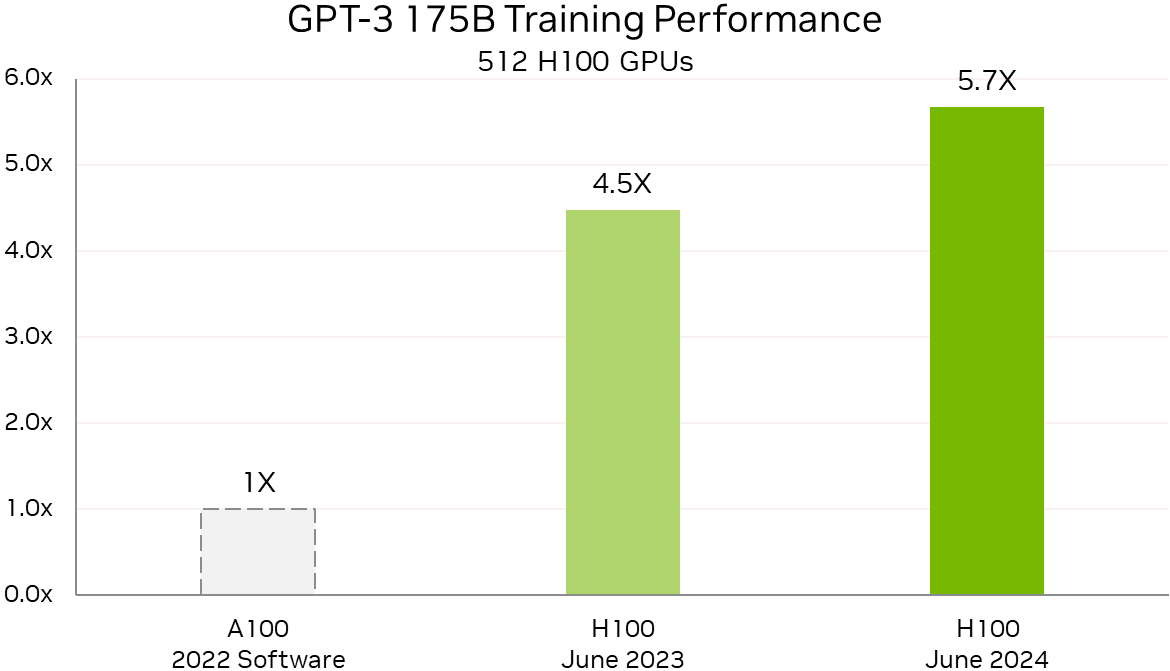 Росту производительности также способствовало совершенствование и оптимизация ПО. Так, кластер из 512 чипов H100 за год стал на 27 % быстрее, а рост производительности с увеличением количества ускорителей теперь более линеен. В новом тесте MLPerf Training по тюнингу LLM (LoRA применительно к Meta✴ Llama 2 70B) системы NVIDIA показали эффективное масштабирование при количестве ускорителей от 8 до 1024. NVIDIA также увеличила производительность обучения Stable Diffusion v2 почти на 80 % при тех же масштабах систем, что были представлены в прошлом тестировании. 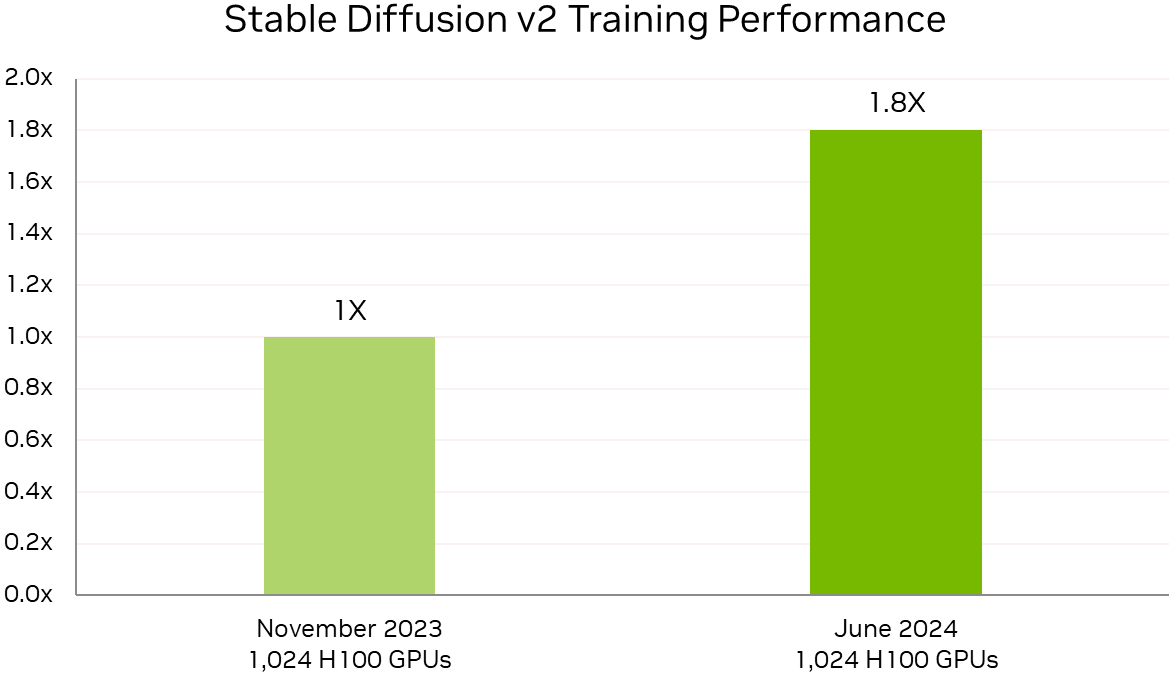 NVIDIA отметила, что для компаний, запускающих приложения на базе LLM, высокая производительность имеет большое значение. Возможность обучать и настраивать более мощные модели — и быстрее их развёртывать и запускать — позволит получить лучшие результаты и более высокий доход. А с выходом платформы NVIDIA Blackwell скоро появится возможность как обучения, так и инференса моделей генеративного ИИ с триллионом параметров.
28.03.2024 [14:31], Сергей Карасёв
Intel Gaudi2 остаётся единственным конкурентом NVIDIA H100 в бенчмарке MLPerf InferenceКорпорация Intel сообщила о том, что её ИИ-ускоритель Habana Gaudi2 остаётся единственной альтернативой NVIDIA H100, протестированной в бенчмарке MLPerf Inference 4.0. При этом, как утверждается, Gaudi2 обеспечивает высокое быстродействие в расчёте на доллар, хотя именно чипы NVIDIA являются безоговорочными лидерами. Отмечается, что для платформы Gaudi2 компания Intel продолжает расширять поддержку популярных больших языковых моделей (LLM) и мультимодальных моделей. В частности, для MLPerf Inference v4.0 корпорация представила результаты для Stable Diffusion XL и Llama v2-70B. Согласно результатам тестов, в случае Stable Diffusion XL ускоритель H100 превосходит по производительности Gaudi2 в 2,1 раза в оффлайн-режиме и в 2,16 раза в серверном режиме. При обработке Llama v2-70B выигрыш оказывается более значительным — в 2,76 раза и 3,35 раза соответственно. Однако на большинстве этих задач (кроме серверного режима Llama v2-70B) решение Gaudi2 выигрывает у H100 по показателю быстродействия в расчёте на доллар. 
Источник изображений: Intel В целом, ИИ-ускоритель Gaudi2 в Stable Diffusion XL показал результат в 6,26 и 6,25 выборок в секунду для оффлайн-режима и серверного режима соответственно. В случае Llama v2-70B достигнут показатель в 8035,0 и 6287,5 токенов в секунду соответственно. 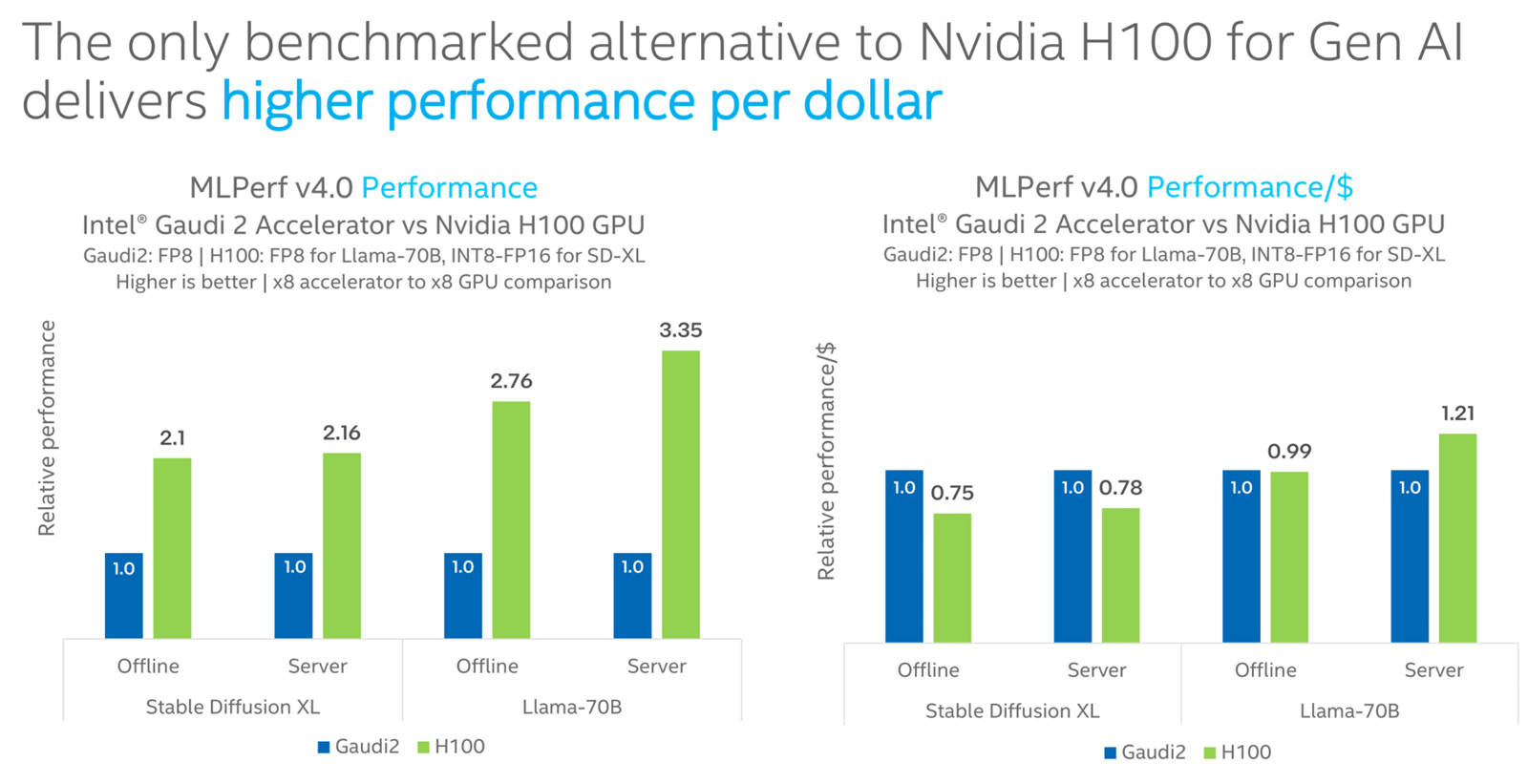 Говорится также, что серверные процессоры Intel Xeon Emerald Rapids благодаря улучшениям аппаратной и программной составляющих в бенчмарке MLPerf Inference v3.1 демонстрируют в среднем в 1,42 раза более высокие значения по сравнению с чипами Xeon Sapphire Rapids. Например, для GPT-J с программной оптимизацией и для DLRMv2 зафиксирован рост быстродействия примерно в 1,8 раза.
27.03.2024 [22:29], Алексей Степин
Новый бенчмарк — новый рекорд: NVIDIA подтвердила лидерские позиции в MLPerf InferenceКомпания NVIDIA опубликовала новые, ещё более впечатляющие результаты в области работы с большими языковыми моделями (LLM) в бенчмарке MLPerf Inference 4.0. За прошедшие полгода и без того высокие результаты, демонстрируемые архитектурой Hopper в инференс-сценариях, удалось улучшить практически втрое. Столь внушительный результат достигнут благодаря как аппаратным улучшениям в ускорителях H200, так и программным оптимизациям. Генеративный ИИ буквально взорвал индустрию: за последние десять лет вычислительная мощность, затрачиваемая на обучение нейросетей, выросла на шесть порядков, а LLM с триллионом параметров уже не являются чем-то необычным. Однако и инференс подобных моделей тоже является непростой задачей, к которой NVIDIA подходит комплексно, используя, по её же собственным словам, «многомерную оптимизацию». 
Источник изображений: NVIDIA Одним из ключевых инструментов является TensorRT-LLM, включающий в себя компилятор и прочие средства разработки, учитывающие архитектуру ускорителей компании. Благодаря ему удалось почти втрое повысить производительность инференса GPT-J на ускорителях H100 всего за полгода. Такой прирост достигнут благодаря оптимизации очередей на лету (inflight sequence batching), применению страничного KV-кеша (paged KV cache), тензорному параллелизма (распределение весов по ускорителям), FP8-квантизации и использованию нового ядра XQA (XQA kernel). 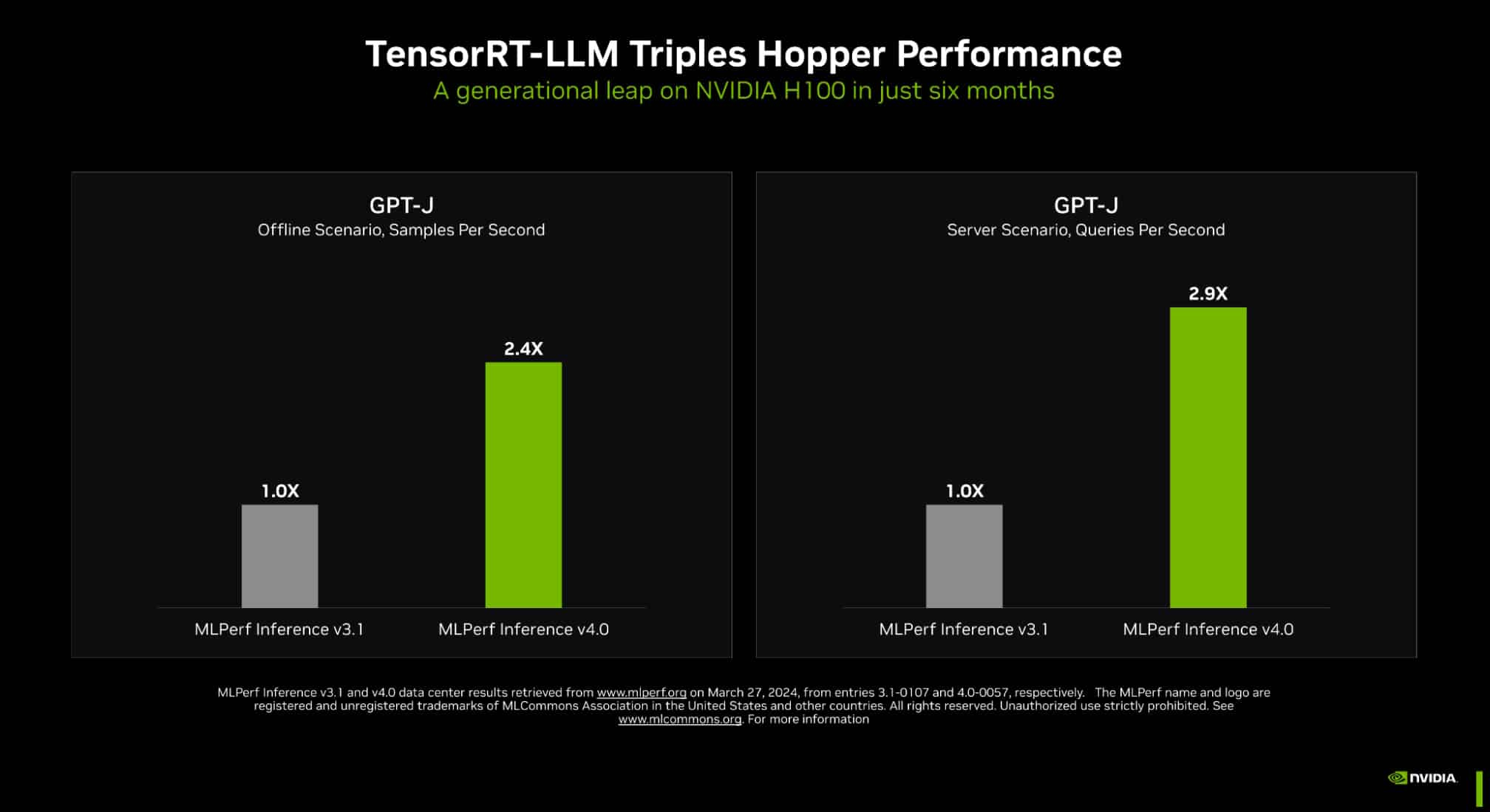 В случае ускорителей H200, использующих ту же архитектуру Hopper, что и H100, важную роль играет память: 141 Гбайт HBM3e (4,8 Тбайт/с) против 80 Гбайт HBM3 (3,35 Тбайт/с). Такой объём позволяет разместить модель уровня Llama 2 70B целиком в локальной памяти. В тесте MLPerf Llama 2 70B ускорители H200 на 28 % производительнее H100 при том же теплопакете 700 Вт, а увеличение теплопакета до 1000 Вт (так делают некоторые вендоры в своих MGX-платформах) даёт ещё 11–14 % прироста, а итоговая разница с H100 в этом тесте может доходить до 45 %. 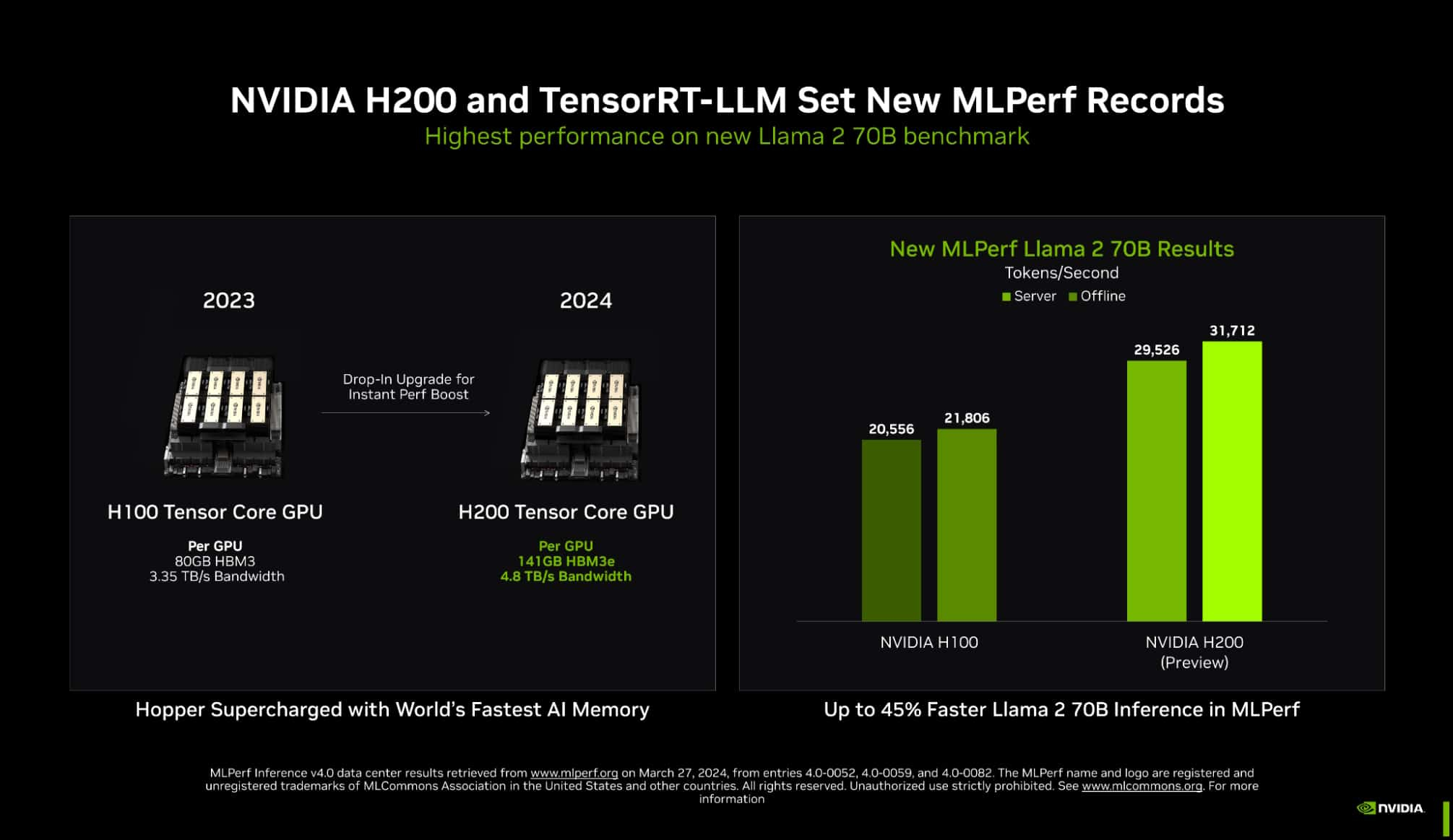 В специальном разделе новой версии MLPerf NVIDIA продемонстрировала несколько любопытных техник дальнейшей оптимизации: «структурированную разреженность» (structured sparsity), позволяющую поднять производительность в тесте Llama 2 на 33 %, «обрезку» (pruning), упрощающую ИИ-модель и позволяющую повысить скорость инференса ещё на 40 %, а также DeepCache, упрощающую вычисления для Stable Diffusion XL и дающую до 74 % прироста производительности. На сегодня платформа на базе модулей H200, по словам NVIDIA, является самой быстрой инференс-платформой среди доступных. Результатами GH200 компания похвасталась ещё в прошлом раунде, а вот показатели ускорителей Blackwell она не предоставила. Впрочем, не все считают результаты MLPerf показательными. Например, Groq принципиально не участвует в этом бенчмарке.
14.11.2023 [03:20], Алексей Степин
Intel показала результаты тестов ускорителя Max 1550 и рассказала о будущих чипах Gaudi3 и Falcon ShoresВ рамках SC23 корпорация Intel продемонстрировала ряд любопытных слайдов. На них присутствуют результаты тестирования ускорителя Max 1550 с архитектурой Xe, а также планы относительно следующего поколения ИИ-ускорителей Gaudi. 
Изображение: Intel При этом компания применила иной подход, нежели обычно — вместо демонстрации результатов, полученных в стенах самой Intel, слово было предоставлено Аргоннской национальной лаборатории Министерства энергетики США, где летом этого года было завершён монтаж суперкомпьютера экза-класса Aurora, занимающего нынче второе место в TOP500.  В этом HPC-кластере применены OAM-модули Max 1550 (Ponte Vecchio) с теплопакетом 600 Вт. Они содержат в своём составе 128 ядер Xe и 128 Гбайт памяти HBM2E. Интерфейс Xe Link позволяет общаться напрямую восьми таким модулям, что обеспечивает более эффективную масштабируемость. 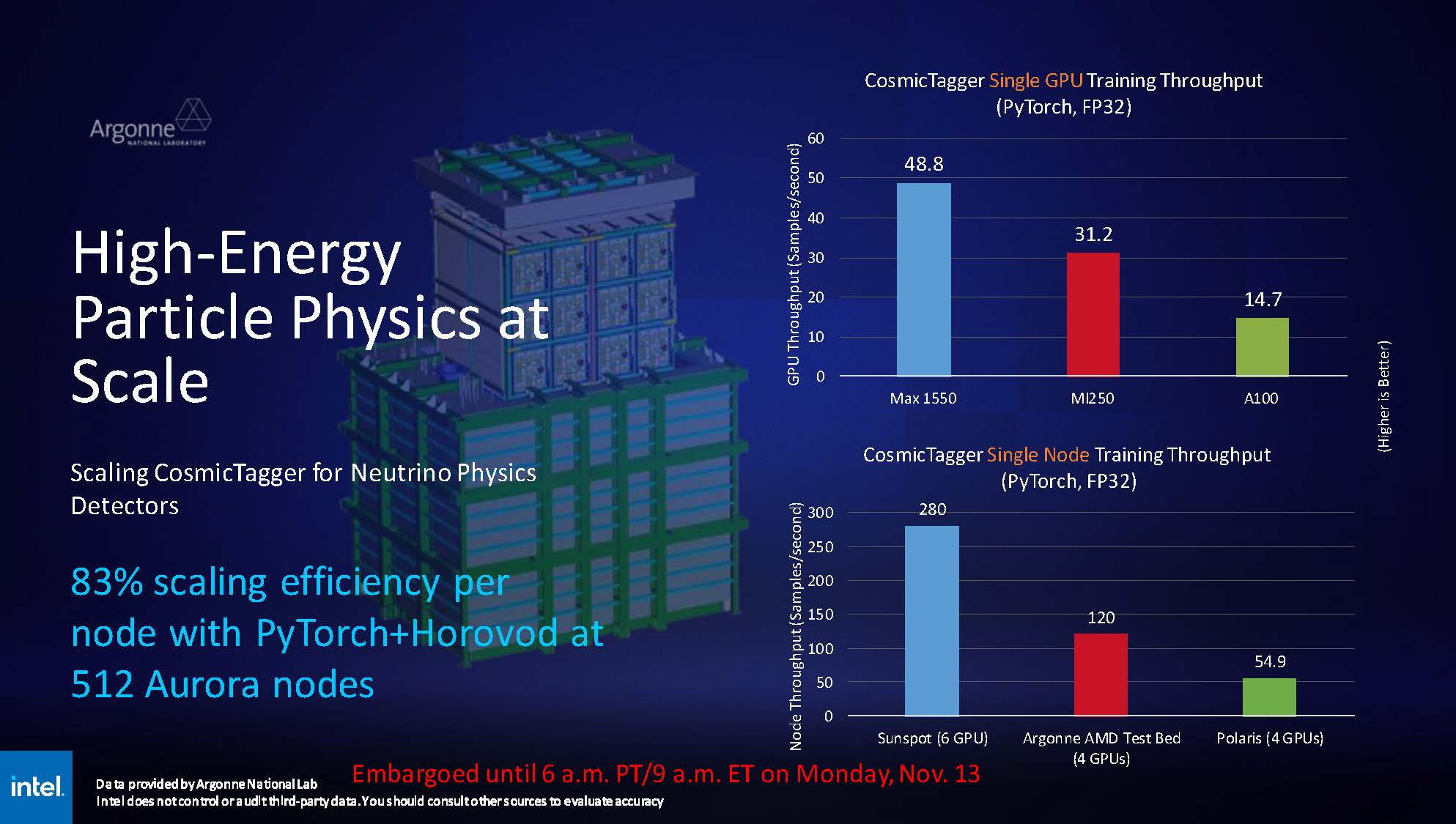
Источник изображений здесь и далее: Intel via ServeTheHome Хотя настройка вычислительного комплекса Aurora ещё продолжается, уже имеются данные о производительности Max 1550 в сравнении с AMD Instinct MI250 и NVIDIA A100. В тесте физики высоких частиц, использующих сочетание PyTorch+Horovod (точность вычислений FP32), ускорители Intel уверенно заняли первое место, а также показали 83% эффективность масштабирования на 512 узлах Aurora.  В тесте, симулирующем поведение комплекса кремниевых наночастиц, ускорители Max 1550, также оказались первыми как в абсолютном выражении, так и в пересчёте на 128-узловой тест в сравнении с системами Polaris (четыре A100 на узел) и Frontier (четыре MI250 на узел). Написанный с использованием Fortran и OpenMP код доказал работоспособность и при масштабировании до более чем 500 вычислительных узлов Aurora. 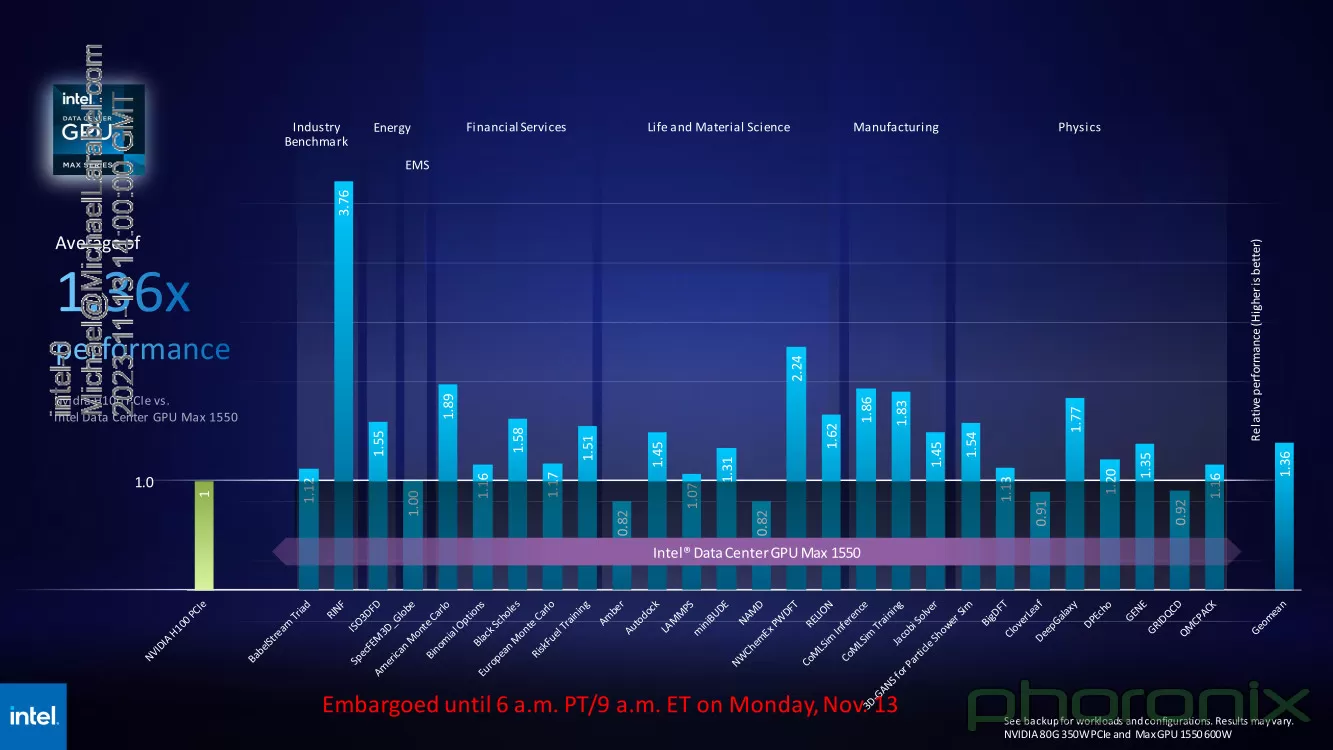
Источник изображения: Intel via Phoronix В целом, ускорители Intel Max 1550 демонстрируют хорошие результаты и не уступают NVIDIA H100: в некоторых задачах их относительная эффективность составляет не менее 0,82, но в большинстве других тестов этот показатель варьируется от 1,0 до 3,76. Очевидно, что у H100 появился достойный соперник, который, к тому же, имеет меньшую стоимость и большую доступность. Но сама NVIDIA уже представила чипы (G)H200, а AMD готовит Instinct MI300.  Системы на базе Intel Max доступны в различном виде: как в облаке Intel Developer Cloud, так и в составе OEM-решений. Supermicro предлагает сервер с восемью модулями OAM, а Dell и Lenovo — решения с четырьями ускорителями в этом же формате. PCIe-вариант Max 1100 доступен от вышеуказанных производителей, а также у HPE. 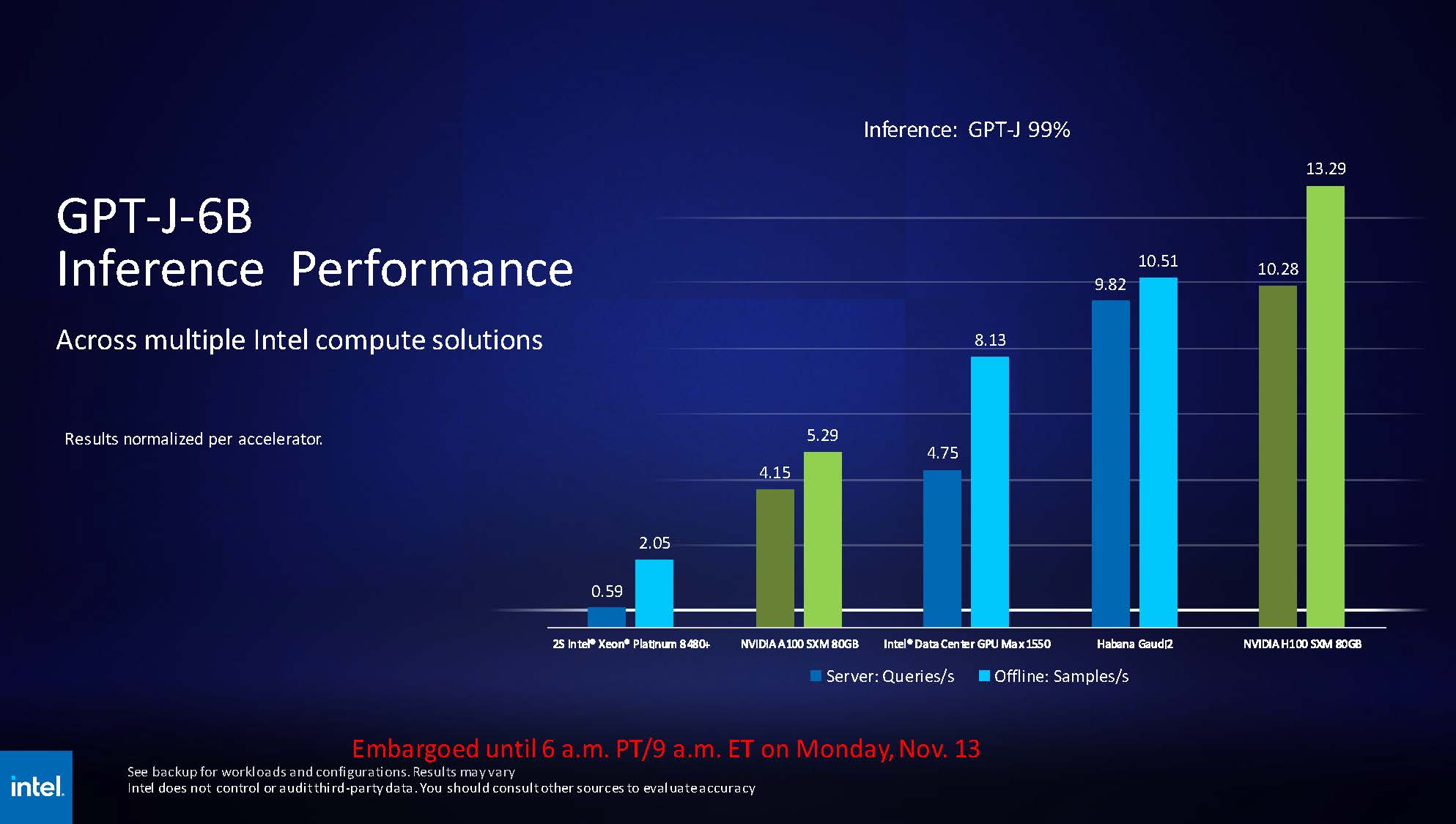 Помимо ускорителей Max, Intel привела и новые данные о производительности ИИ-сопроцессоров Gaudi2. Компания продолжает активно совершенствовать и оптимизировать программную экосистему Gaudi. В результате, в инференс-системе на базе модели GPT-J-6B результаты ускорителей Gaudi2 уже сопоставимы с NVIDIA H100 (SXM 80 Гбайт), а A100 существенно уступает как Gaudi2, так и Max 1550.  Но самое интересное — это сведения о планах относительно следующего поколения Gaudi. Теперь известно, что Gaudi3 будет производиться с использованием 5-нм техпроцесса. Новый чип будет в четыре раза быстрее в вычислениях BF16, а также получит вдвое более мощную подсистему памяти и в 1,5 раза больше памяти HBM. Увидеть свет он должен в 2024 году. 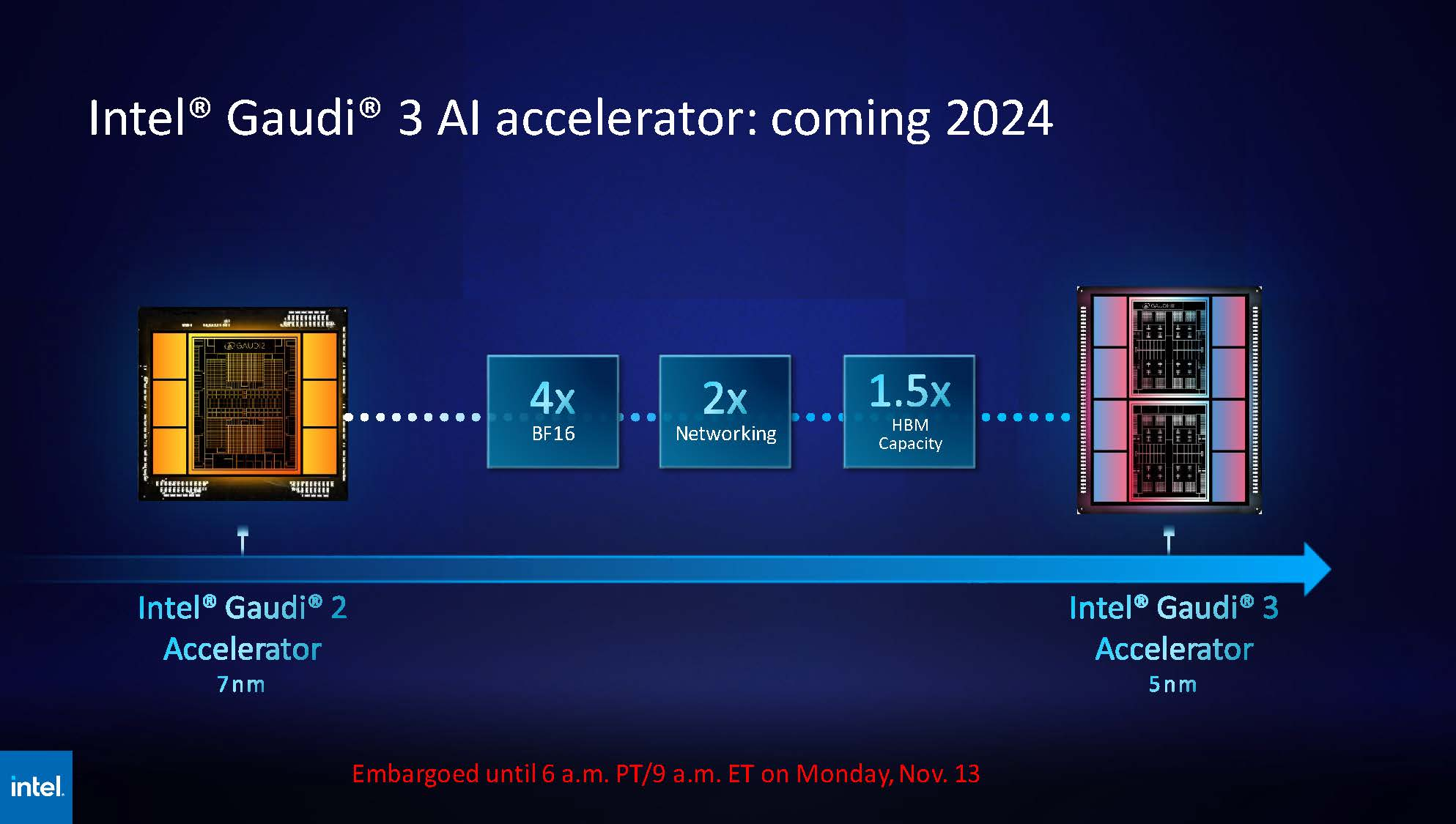 Заодно компания напомнила, что процессоры Xeon Emerald Rapids будут представлены ровно через месяц, а Granite Rapids появятся в 2024 году. В 2025 появится чип Falcon Shores, который теперь должен по задумке Intel сочетать в себе GPU и ИИ-сопроцессор. Он объединит архитектуры Habana и Xe в единое решение с тайловой компоновкой, памятью HBM3 и полной поддержкой CXL. 
Источник изображения: Intel via Phoronix Следует отметить, что такая унификация вполне реальна: Intel весьма активно развивает универсальный, гибкий и открытый стек технологий в рамках проекта oneAPI. В него входят все необходимые инструменты — от компиляторов и системных библиотек до средств интеграции с популярными движками аналитики данных, моделями и библиотеками искусственного интеллекта. |
|