Материалы по тегу: hpc
|
24.01.2024 [14:50], Сергей Карасёв
Европейский экзафлопсный суперкомпьютер Jupiter будет построен на базе модульного ЦОДЮлихский исследовательский центр (FZJ) в Германии раскрыл информацию о конфигурации дата-центра для первого европейского суперкомпьютера экзафлопсного класса — системы JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research). Напомним, Европейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) заключило контракт на создание JUPITER с консорциумом, в который входят Eviden (подразделение Atos) и ParTec, немецкая компания по производству суперкомпьютерного оборудования. Ввод суперкомпьютера в эксплуатацию запланирован на осень 2024 года. Сообщается, что JUPITER будет построен на базе модульного ЦОД, за создание которого отвечает Eviden. Этот дата-центр займёт площадь приблизительно 2300 м2. Модульная архитектура на основе контейнеров обеспечит ряд преимуществ: значительное сокращение времени планирования и монтажа, а также снижение затрат на строительство и эксплуатацию. Кроме того, в дальнейшем облегчится модернизация, тогда как инфраструктура электропитания и охлаждения может гибко адаптироваться к новым требованиям. Eviden заявляет, что благодаря модульности сроки поставки необходимых узлов сократятся на 50 %. 
Источник изображения: Eviden Конфигурация ЦОД включает около 50 взаимозаменяемых модулей, в том числе 20 IT-контейнеров, 15 контейнеров энергоснабжения, а также примерно 10 логистических контейнеров со складскими помещениями, инженерными комнатами и пр. В состав IT-модулей войдут по два контейнера, объединяющих 20 стоек платформы BullSequana XH3000 с прямым жидкостным охлаждением. Модули данных будут содержать четыре контейнера с накопителями. Модульный ЦОД финансируется Федеральным министерством образования и исследований (BMBF). При этом BMBF и Министерство культуры и науки земли Северный Рейн-Вестфалия (MKW NRW) обеспечат равное финансирование технического оборудования. В состав суперкомпьютера войдут модули NVIDIA Quad GH200, а также энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea. Быстродействие на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность «незначительно превысит 1 Эфлопс».
24.01.2024 [14:50], Руслан Авдеев
Обновлённый космический суперкомпьютер HPE Spaceborne-2 готов к отправке на МКСНа следующей неделе планируется запуск на Международную космическую станцию (МКС) обновлённого варианта специального вычислительного модуля HPE Spaceborne Computer-2. Как сообщает Национальная лаборатория МКС, это коммерческая версия суперкомпьютера из серийных компонентов, созданная на основе серверов семейств HPE EdgeLine и ProLiant. Организаторами запуска выступают NASA, Northrop Grumman и SpaceX. Старт должен состояться 29 января 2024 года в рамках миссии NG-20 — борту корабля Northrop Grumman Cygnus планируется доставить на станцию различные научные материалы, оборудование и компоненты. Одним из грузов будет и обновлённая версия Spaceborne-2, ранее отправленного на МКС в феврале 2021 года и вернувшегося на Землю 11 января 2023. Первый компьютер серии Spaceborne отправили на МКС 14 августа 2017 года, возвращение состоялось 4 июня 2019. 
Источник изображения: NASA По данным Datacenter Dynamics, в состав системы всё ещё входят x86-серверы HPE Edgeline EL4000 с одним GPU и HPE DL360 Gen10. Обновлённая система протестирована HPE и передана NASA. Всего по требованию NASA пришлось внести 516 корректировок. Например, HPE в сотрудничестве с KIOXIA оснастила систему дополнительным хранилищем. Суперкомпьютер поможет продолжающимся на МКС исследованиям, обеспечив более быструю обработку наблюдений со станции за Землёй и более эффективный мониторинг здоровья астронавтов.
24.01.2024 [13:55], Сергей Карасёв
Итальянская нефтегазовая компания Eni получит 600-Пфлопс суперкомпьютер HPC6 на базе AMD Instinct MI250XИтальянская нефтегазовая компания Eni, по сообщению ресурса Inside HPC, заказала суперкомпьютер HPE Cray EX4000 на аппаратной платформе AMD. Быстродействие этой машины, как ожидается, составит около 600 Пфлопс. Известно, что в состав системы, получившей название HPC6, войдут 3472 узла, каждый из которых получит 64-ядерный процессор AMD EPYC и четыре ускорителя AMD Instinct MI250X. Таким образом, общее количество ускорителей составит 13 888. Судя по всему, компания смогла достаточно полно адаптировать своё ПО для работы на современных ускорителях AMD, эксперименты с которыми она начала ещё несколько лет назад. Комплекс будет использовать хранилище HPE Cray ClusterStor E1000 с интерконнектом HPE Slingshot. Узлы суперкомпьютера будут организованы в 28 стоек. Предусмотрено применение технологии прямого жидкостного охлаждения, которая, по заявлениям Eni, рассеивает 96 % вырабатываемого тепла. Максимальная потребляемая мощность — 10,17 МВт. 
Источник изображения: AMD Новый суперкомпьютер разместится в ЦОД Eni Green Data Center в Феррера-Эрбоньоне, который, как утверждается, является одним из самых энергоэффективных и экологически чистых вычислительных центров в Европе. По производительности HPC6 значительно превзойдёт комплексы HPC4 и HPC5, совокупная вычислительная мощность которых составляет 70 Пфлопс. При производительности 600 Пфлопс система HPC6 займёт второе место в текущем списке TOP500 самых мощных суперкомпьютеров мира.
17.01.2024 [08:08], Владимир Мироненко
300 кВт на стойку: Aligned представила СЖО DeltaFlow~ для своих дата-центровКомпания Aligned представила новую систему жидкостного охлаждения DeltaFlow~, которая позволяет увеличить плотность размщения вычислительных мощностей 300 кВт на стойку, сообщил ресур Datacenter Dynamics. DeltaFlow~ — это готовое решение, поддерживающее текущие и будущие технологии жидкостного охлаждения, включая прямое охлаждение direct-to-chip с CDU, охлаждение с использованием теплообменника на задней дверце (Rear-door Heat Exchanger, RDHx) и иммерсионное охлаждение. Решение опирается на систему с замкнутым контуром без использования наружного воздуха или воды. По словам Alidned, новая СЖО позволяет клиентам по-максимуму использовать современные чипы и ускорителя, сокращая время выхода на рынок, затраты и риски. 
Фото: Aligned DeltaFlow~ также интегрируется с технологией воздушного охлаждения Delta3 (Delta Cube) без изменений в подаче электроэнергии или существующей температуры в машинных залах. Delta3 вместо традиционного холодного коридора использует вентиляторы и теплообменники, расположенные непосредственно за стойками и подключённые к водяному контуру, уходящему к чиллерам. Delta3 позволяет добиться плотности до 50 кВт на стойку. Aligned стала одной из последних компаний, анонсировавшей платформу для оборудования высокой плотности, основанное на жидкостном охлаждении. Ранее в этом месяце Stack представила решение с использованием погружного охлаждения, которое позволяет поддерживать мощность 300 кВт или выше на стойку. Летом прошлого года CyrusOne анонсировала новую архитектуру ЦОД для ИИ-нагрузок, где тоже используется погружное охлаждение и тоже можно получить 300 кВт на стойку. Тогда же Digital Realty запустила услугу колокации с поддержкой размещений до 70 кВт на стойку, а в декабре Equinix объявила о планах по расширению поддержки передовых технологий СЖО в значительной части своих ЦОД, хотя и не указала предельную плотность. DataBank также переработала конструкцию машинных залов для поддержки размещений высокой плотностью с использованием жидкостного охлаждения.
16.01.2024 [22:51], Руслан Авдеев
Заброшенные шахты могут стать хранилищами «мусорного» тепла эдинбургского суперкомпьютераМеждународная группа учёных намеревается выяснить, можно ли сохранить «мусорное» тепло суперкомпьютера Эдинбургского университета в старых шахтах для того, чтобы впоследствии направить его на отопление местных домов. По словам учёных, в шахтах много воды, поэтому они способны стать идеальным хранилищем тепла. При этом для более чем 800 тыс. шотландских домохозяйств отопление является дорогим удовольствием, так что дешёвый источник тепла им не помешает. Исследование обойдётся в £2,6 млн ($3,3 млн), сообщает Datacenter Dynamics. Эдинбургский университет выделит £500 тыс. ($633 тыс). из собственно фонда, связанного со снижением вредных выбросов, а правительство Шотландии предоставило грант на сумму £1 млн ($1,27 млн). Подключатся и другие структуры, включая даже Министерство энергетики США с грантом $1 млн. 
Источник изображения: hangela/pixabay.com Дата-центр Advanced Computing Facility (ACF) на территории Эдинбургского университета уже обслуживает один суперкомпьютер, а в 2025 году к нему присоединится машина экзафлопсного уровня, первый суперкомпьютер такого класса в Великобритании. В рамках исследования Edinburgh Geobattery, проводимого специалистами в области геотермальной энергетики TownRock Energy совместно с представителями науки и промышленности, будет оцениваться, возможно и целесообразно ли хранить тёплую воду (+40 °C) в заброшенных шахтах до того, как передать её на нужды городского отопления. Предполагается, что тепло ACF поможет обогреть не менее 5 тыс. домохозяйств, если тесты подтвердят теоретические выкладки. ACF выделяет до 70 ГВт·ч тепла ежегодно, но после запуска нового суперкомпьютера этот показатель увеличится до 272 ГВт·ч. Новая машина, оснащённая СЖО, будет построена в специально возведённом крыле ACF, которое само по себе обойдётся в £31 млн ($39,24 млн). 
Фото: EPCC ACF / Keith Hunter Использование тепла ЦОД обычно считается довольно эффективным методом дополнительной эксплуатации дата-центров. Тем не менее, такая технология имеет серьёзный недостаток, поскольку передавать тепло туда, где оно востребовано, не всегда целесообразно. Некоторые европейские системы располагаются в «шаговой» доступности от систем районного отопления, а другие представляют собой небольшие вычислительные модули, которые предлагается размещать непосредственно в зданиях. Есть и проекты централизованного управления передачей тепла ЦОД. В непосредственной близости от Эдинбурга находятся заброшенные угольные, сланцевые и другие шахты, частично затопленные подземными водами. Проект предусматривает передачу тепла ЦОД естественными потоками грунтовых вод, с последующим использованием теплонасосов для обогрева зданий. Более того, в университете утверждают, что четверть британских домов расположена над бывшими шахтами, поэтому гипотетически получить тепло таким способом могут до 7 млн домохозяйств.
05.01.2024 [01:08], Владимир Мироненко
Варяг на княжение: Intel назначила вице-президентом группы DCAI Джастина Хотарда из HPEКорпорация Intel объявила о назначении с 1 февраля исполнительным вице-президентом и генеральным менеджером подразделения Data Center and AI Group (DCAI) Джастина Хотарда (Justin Hotard), до этого занимавшего должность исполнительного вице-президента и генерального менеджера по высокопроизводительным вычислениям (HPC), ИИ и лабораториям в Hewlett Packard Enterprise (HPE). До прихода в HPE в 2015 году Хотард занимал пост президента NCR Small Business, а также работал в компаниях Symbol Technologies и Motorola Inc., где занимался корпоративным развитием и операционной деятельностью. Хотард получил степень бакалавра наук в области электротехники в Университете Иллинойса в Урбана-Шампейне и степень магистра делового администрирования в Школе менеджмента Слоуна при Массачусетском технологическом институте. 
Источник изображения: Intel Джастин Хотард сменит на посту Сандру Риверу (Sandra Rivera), которая 1 января стала главным исполнительным директором Programmable Solutions Group (PSG), самостоятельного подразделения Intel. Аналогичная судьба постигла и Аруна Субраманьяна (Arun Subramaniyan), теперь уже бывшего вице-президента и генерального менеджера DCAI, который был переведён в формально независимую компанию Articul8, ответственную за программную ИИ-платформу для корпоративных заказчиков. Сам по себе приход на столь высокую должность человека, который ранее не работал в Intel, для корпорации несколько необычен. Хотард будет подчиняться непосредственно главе корпорации Пэту Гелсингеру (Patrick Gelsinger). Он будет отвечать за набор продуктов Intel для ЦОД, охватывающий корпоративные и облачные технологии, включая процессоры Xeon, GPU и ускорители. Он также будет заниматься внедрением и развитием технологий ИИ.
04.01.2024 [00:31], Владимир Мироненко
Китай построил 500-Пфлопс публичную ИИ-платформу Shangzhuang, которая вскоре станет втрое мощнееКитай запустил облачную ИИ-платформу, управляемую окологосударственным холдингом Beijing Energy Holding (BEH). «Пекинская публичная вычислительная платформа» (Beijing AI Public Computing Platform), также известная как проект Shangzhuang, поможет смягчить «острую нехватку вычислительных мощностей» в стране, необходимых для развития технологий ИИ. Платформа доступна для использования образовательными учреждениями, исследовательскими центрами, а также малыми и средними предприятиями. Её первая фаза с вычислительной мощностью 500 Пфлопс (FP16) была официально запущена в самом конце 2023 года. В I квартале 2024 года планируется завершить вторую фазу строительства, доведя производительность Shangzhuang до 1,5 Эфлопс. А в будущем остаётся возможность построить ещё 2 Эфлопс мощностей. 
Фото: BEH BEH заявил о своём стремлении сделать проект максимально экологически дружественным, выразив намерение в будущем полностью обеспечивать платформу чистой энергией. С этой целью BEH подписал соглашения о стратегическом сотрудничестве с Alibaba Cloud Computing, Sugon Information Industry и стартапом Zhipu AI для совместной работы в области зелёной энергетики, публичного облака и инфраструктуры интеллектуальных вычислений.
23.12.2023 [02:11], Владимир Мироненко
В Испании официально запустили 314-Пфлопс суперкомпьютер MareNostrum 5, который вскоре объединится с двумя квантовыми компьютерами21 декабря в Суперкомпьютерном центре Барселоны — Centro Nacional de Supercomputación (BSC-CNS) — в торжественной обстановке официально запустили европейский суперкомпьютер MareNostrum 5 производительностью 314 Пфлопс. В церемонии, посвящённой машине, созданной в рамках проекта European High Performance Computing Joint Undertaking (EuroHPC JU), принял участие председатель правительства Испании. MareNostrum 5 представляет собой крупнейшую инвестицию, когда-либо сделанную Европой в научную инфраструктуру Испании — суммарно €202 млн, из которых €151,4 млн ушло на приобретение суперкомпьютера. Финансирование было проведено EuroHPC JU через Фонд ЕС «Соединение Европы» и программу исследований и инноваций «Горизонт 2020», а также государствами-участниками: Испанией (через Министерство науки, инноваций и университетов и правительство Каталонии), Турцией и Португалией. С запуском MareNostrum 5 заметно укрепились позиции BSC в качестве одного из ведущих суперкомпьютерных центров мира с более чем 900 сотрудниками, занимающимися исследования в области информатики, наук о жизни и о Земле, а также вычислительных систем для науки и техники. Обладая максимальной общей производительностью 314 Пфлопс, MareNostrum 5 присоединяется к двум другим системам EuroHPC: Lumi (Финляндия) и Leonardo (Италия), тоже являющихся суперкомпьютерами предэкзафлопсного класса, единственными системами такого уровня в Европе. 
Источник изображений: BSC Eviden (Atos) была выбрана в качестве основного поставщика, но в создании машины приняли участие Lenovo, IBM, Intel и NVIDIA, а также Partec. Как отмечено в пресс-релизе, уникальная архитектура MareNostrum 5 была создана для того, чтобы предоставить исследователям лучшие из доступных технологий. Это гетерогенная машина, сочетающая в себе две отдельные системы: раздел общего назначения (GPP), предназначенный для классических вычислений, и GPU-раздел (ACC), ориентированный на ИИ. Обе системы по отдельности входят в первую двадцатку TOP500, занимая 19-е и 8-е места соответственно. Раздел общего назначения (GPP) является крупнейшим в мире x86-кластером на базе Intel Xeon Sapphire Rapids. Эта часть суперкомпьютера имеет пиковую производительность 45,9 Пфлопс. Система, произведённая Lenovo, специально разработана для решения сложных научных задач с разделением ресурсов, что обеспечивает большую гибкость и повышает эффективность системы, поскольку разные пользователи или проекты могут использовать её одновременно. GPP имеет 6408 стандарных узлов следующей конфигурации:
Дополнительно система имеет 72 узла с двумя 56-ядерными Xeon Max (1,7 ГГц) и набортной памятью HBM2e объёмом 128 Гбайт.  GPU-раздел (ACC) производства Eviden является третьим по мощности в Европе и восьмым в мире по версии TOP500, с пиковой производительностью 260 Пфлопс. Он основан на 4480 ускорителях NVIDIA H100. Раздел имеет 1120 узлов, каждый из которых включает:
Общая ёмкость хранилища MareNostrum 5 составляет 650 Пбайт, из которых, 402 Пбайт приходятся на LTO, 248 Пбайт — на HDD, а остальное — на NVMe SSD. Задействована ФС IBM Spectrum Scale. Машина использует интерконнект InfiniBand NDR200, объединяющий более 8000 узлов. Можно заметить, что NVIDIA предоставила BSC не совсем стандартные решения. В будущем ожидается появление ещё одного GPP-раздела на базе NVIDIA Grace, а вот расширение ACC узлами с Xeon Emerald Rapids и Rialto Bridge не состоится. 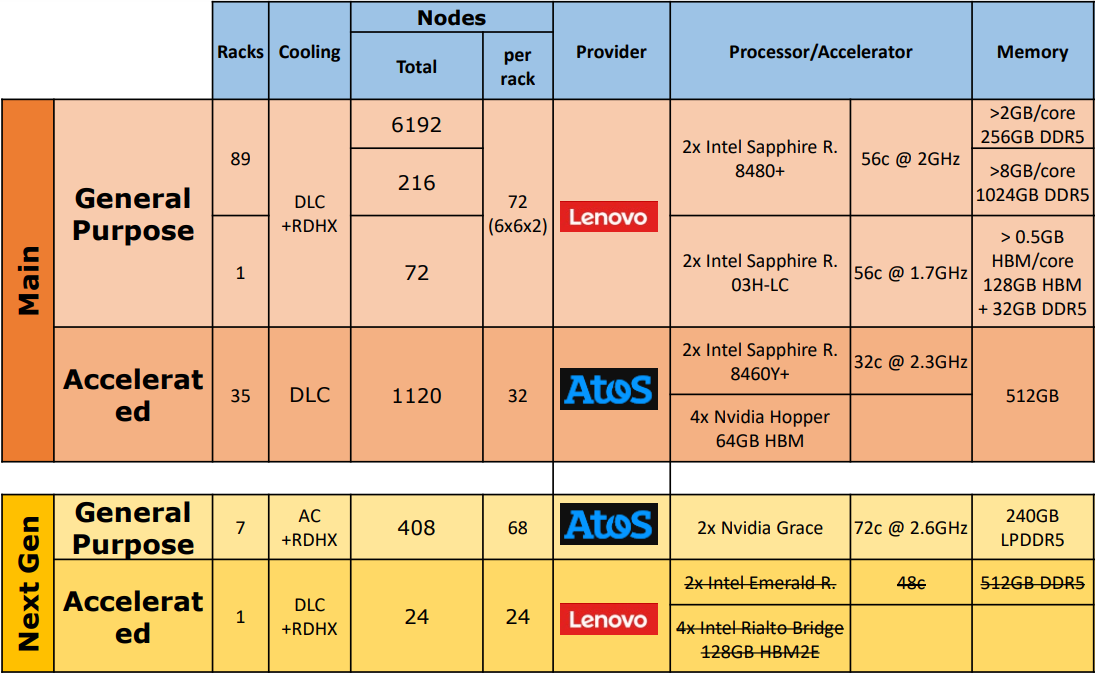 Благодаря увеличенной вычислительной мощности MareNostrum 5 позволяет решать всё более сложные задачи. Например, климатические модели получат более высокое разрешение, что сделает прогнозы гораздо более точными и надёжными. Также появится возможность решать гораздо более сложные проблемы в области ИИ и Big Data. Отдельное внимание уделено поддержке европейских медицинских исследований в области создания новых лекарств, разработки вакцин и моделирования распространения вирусов. Суперкомпьютер также станет важнейшим инструментом для материаловедения и инженерии, включая проектирование и оптимизацию самолётов, развитие более безопасной, экологически чистой и эффективной авиации. Аналогичным образом, машина будет использоваться для моделирования процессов энергогенерации, включая ядерный синтез. В ближайшие месяцы MareNostrum 5 объединится с двумя квантовыми компьютерами: первой системой испанской суперкомпьютерной сети (RES), которая является частью инициативы Quantum Spain, и одним из первых европейских квантовых компьютеров EuroHPC JU. Оба квантовых компьютера будут одними из первых, которых запустили в Южной Европе.
21.12.2023 [14:51], Сергей Карасёв
Германия построит суперкомпьютер Herder экзафлопсного уровняЦентр высокопроизводительных вычислений HLRS в Штутгарте (Германия) объявил о заключении соглашения с компанией HPE по созданию двух новых суперкомпьютеров — систем Hunter и Herder. Они, как утверждается, предоставят «инфраструктуру мирового класса» для моделирования, ИИ, анализа данных и других ресурсоёмких задач в различных областях. Hunter заменит нынешний флагманский суперкомпьютер HLRS под названием Hawk. В основу Hunter ляжет платформа HPE Cray EX4000: в общей сложности планируется задействовать 136 таких узлов, каждый из которых будет оснащён четырьмя адаптерами HPE Slingshot. Архитектура Hunter предусматривает применение СХД нового поколения Cray ClusterStor, специально разработанной с учётом жёстких требований к вводу/выводу. Кроме того, будет задействована среда HPE Cray Programming Environment, которая предоставляет полный набор инструментов для разработки, портирования, отладки и настройки приложений. 
Источник изображения: HLRS Суперкомпьютер Hunter получит ускорители AMD Instinct MI300A. Утверждается, что это позволит сократить энергопотребление по сравнению с Hawk примерно на 80 % при пиковой производительности. Быстродействие Hunter составит около 39 Пфлопс против 26 Пфлопс у Hawk. Систему планируется ввести в эксплуатацию в 2025 году. Суперкомпьютер экзафлопсного класса Herder заработает не ранее 2027 года. Архитектура предусматривает применение ускорителей, но окончательная конфигурация комплекса будет определена только к концу 2025-го. 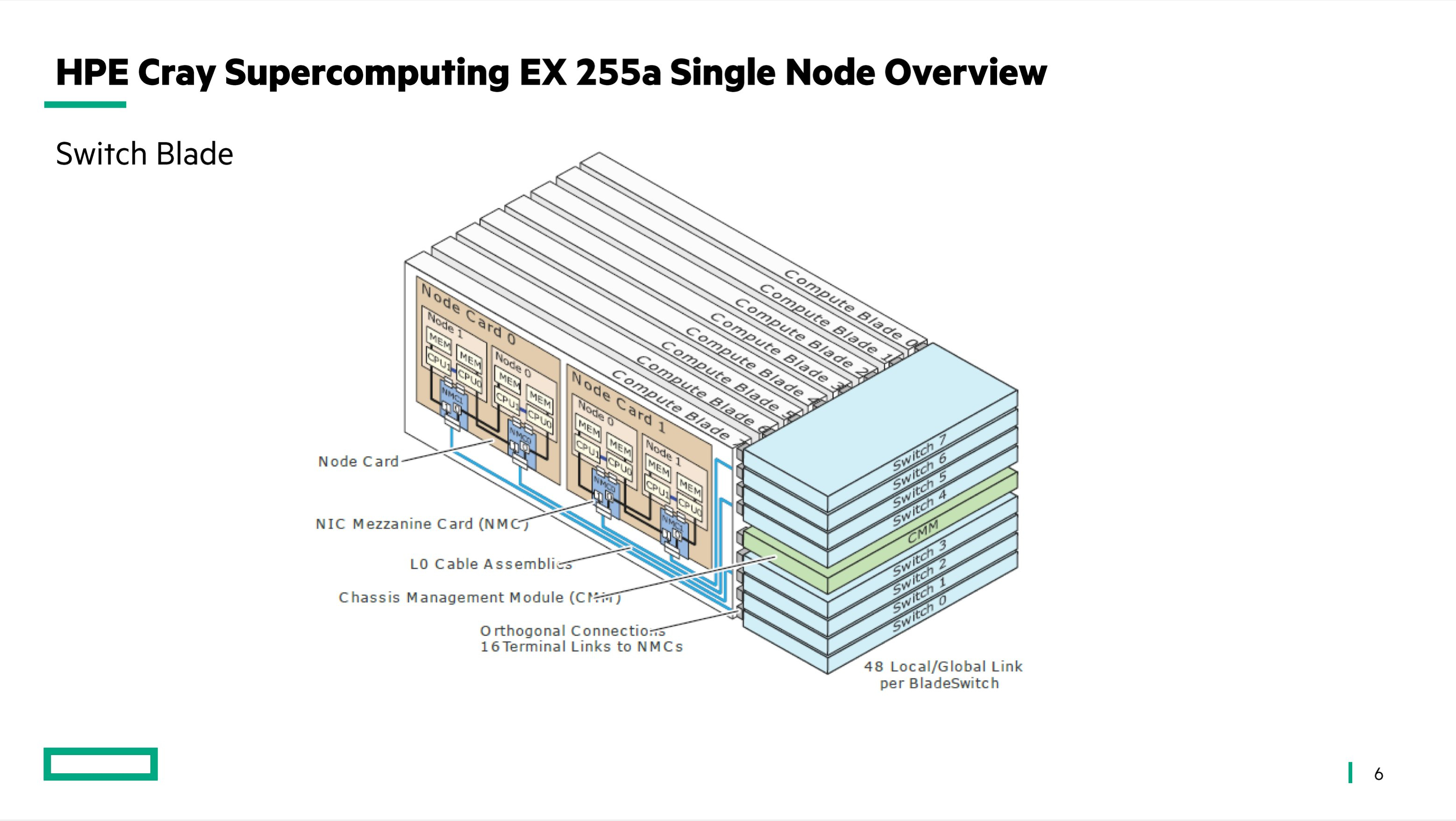
Источник изображения: HPE Общая стоимость Hunter и Herder оценивается в €115 млн. Финансирование будет осуществляться через Центр суперкомпьютеров Гаусса (GCS), альянс трёх национальных суперкомпьютерных центров Германии. Половину средств предоставит Федеральное министерство образования и исследований Германии (BMBF), оставшуюся часть — Министерство науки, исследований и искусств земли Баден-Вюртемберг. Нужно отметить, что в 2024 году в Юлихском исследовательском центре (FZJ) в Германии заработает вычислительный комплекс Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Кроме того, систему такого уровня намерена создать Великобритания.
21.12.2023 [12:09], Сергей Карасёв
В 2024 году EuroHPC запустит как минимум два новых квантовых компьютераЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило конкурс по выбору организаций, которым предстоит заняться интеграцией и эксплуатацией новых квантовых компьютеров. Заявки принимаются до 31 марта 2024 года. Сообщается, что в наступающем году EuroHPC JU планирует ввести в эксплуатацию как минимум две новые квантовые системы — комплексы EuroQCS-Poland и Euro-Q-Exa. Европейский союз выделит на эти проекты €20 млн, а дополнительное финансирование поступит от государств-участников EuroHPC JU. 
Источник изображения: pixabay.com EuroQCS-Poland — квантовый компьютер на основе ловушек ионов. Система будет размещена в Познаньском суперкомпьютерном и сетевом центре (PSNC) в Польше и интегрирована в местную НРС-инфраструктуру. Комплекс будет доступен широкому кругу европейских пользователей — от научного сообщества до промышленности и государственного сектора. Общая стоимость проекта оценивается в €15,5 млн. В свою очередь, Euro-Q-Exa будет представлять собой квантовый компьютер, основанный на сверхпроводящих кубитах. На первом этапе конфигурация предусматривает использование 50 физических кубитов с последующим расширением до 100 кубитов или более. Система будет смонтирована в Суперкомпьютерном центре Лейбница (LRZ) в Германии. Затраты на проект составят приблизительно €42,71 млн. В 2022 году, напомним, предприятие EuroHPC JU приняло решение о размещении первых квантовых компьютеров в Чехии, Германии, Испании, Франции, Италии и Польше. А в октябре 2023-го был объявлен тендер на создание платформы для бесшовного объединения всех европейских суперкомпьютеров и квантовых систем, а также инфраструктуры хранения данных. |
|