Материалы по тегу: b300
|
22.10.2025 [17:09], Владимир Мироненко
AWS пожертвовала компактностью GB300 NVL72, лишь бы снизить зависимость от NVIDIAAmazon Web Services (AWS) нашла выход, как использовать собственные Nitro DPU K2v5/6 (EFA) в новейших стоечных системах NVIDIA GB300 NVL72, которые, как считает гиперскейлер, превосходит адаптеры NVIDIA ConnectX-7/8 по производительности. В связи с тем, что в стойках NVIDIA Oberon используются укороченные лотки высотой 1U, AWS размещает NIC в отдельной стойке JBOK, предназначенной только для сетевых карт, пишет SemiAnalysis. Причина кроется в невозможности установить в 1U сразу девять фирменных адаптеров (8 × EFA + 1 × ENA/EBS). Для серверных систем GB200 NVL предыдущего поколения AWS выбрала вариант NVL36×2, поскольку только в этом случае использовались 2U-узлы, где достаточно места для всех NIC. Однако сдвоенная конфигурация менее эффективна, чем нативная конструкция NVL72. NVIDIA сама была не очень довольна вариантами NVL36. Meta✴, например, и вовсе «растянула» NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждением. 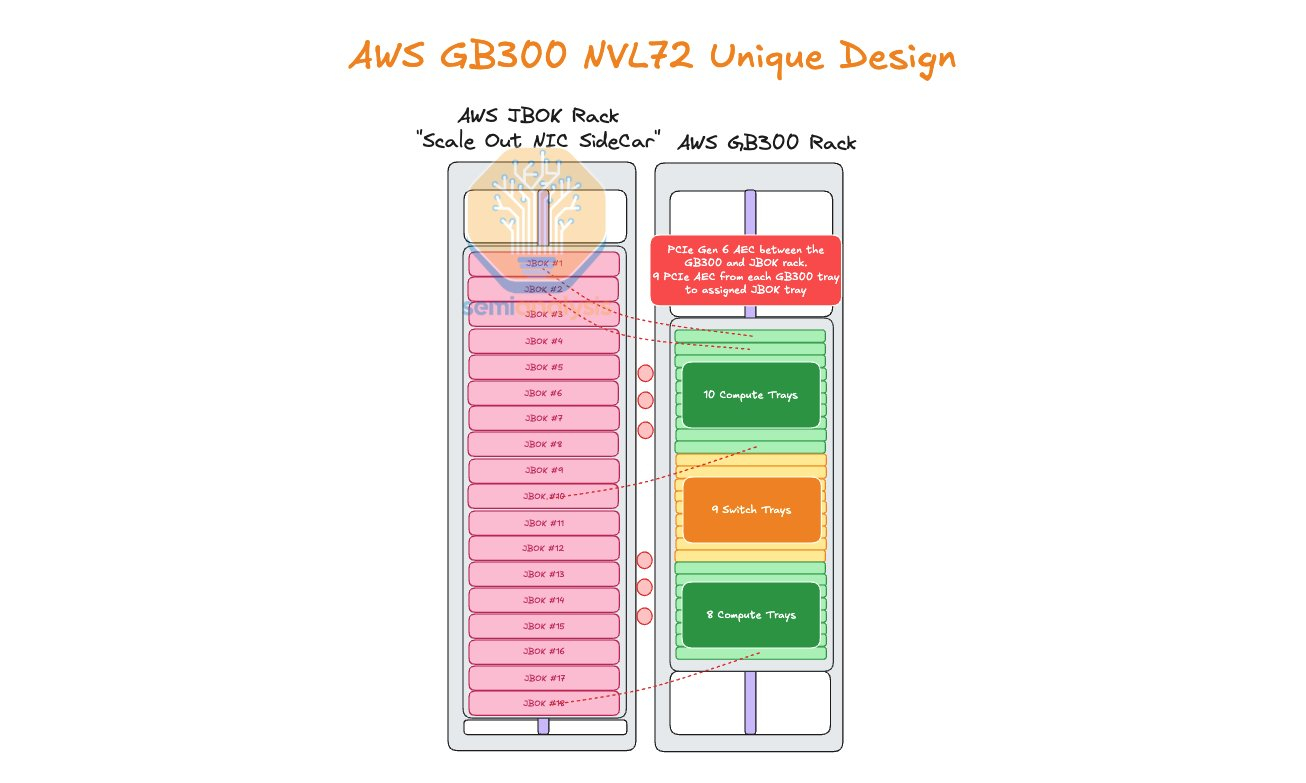
Источник изображения: SemiAnalysis AWS в случае Blackwell Ultra предпочла остановиться на NVL72-варианте, а DPU вынести в отдельную стойку — всего 18 узлов высотой 2U, по 9 NIC в каждом. С узлами NVIDIA они соединены активными электрическими кабелями (AEC) и портами OSFP-XD для передачи сигналов PCIe 6.0. По словам AWS, её адаптеры лучше справляются с нагрузками, чем ConnectX-8 (RoCEv2), что отчасти спорно. В любом случае таким образом компания снижается зависимость от NVIDIA. 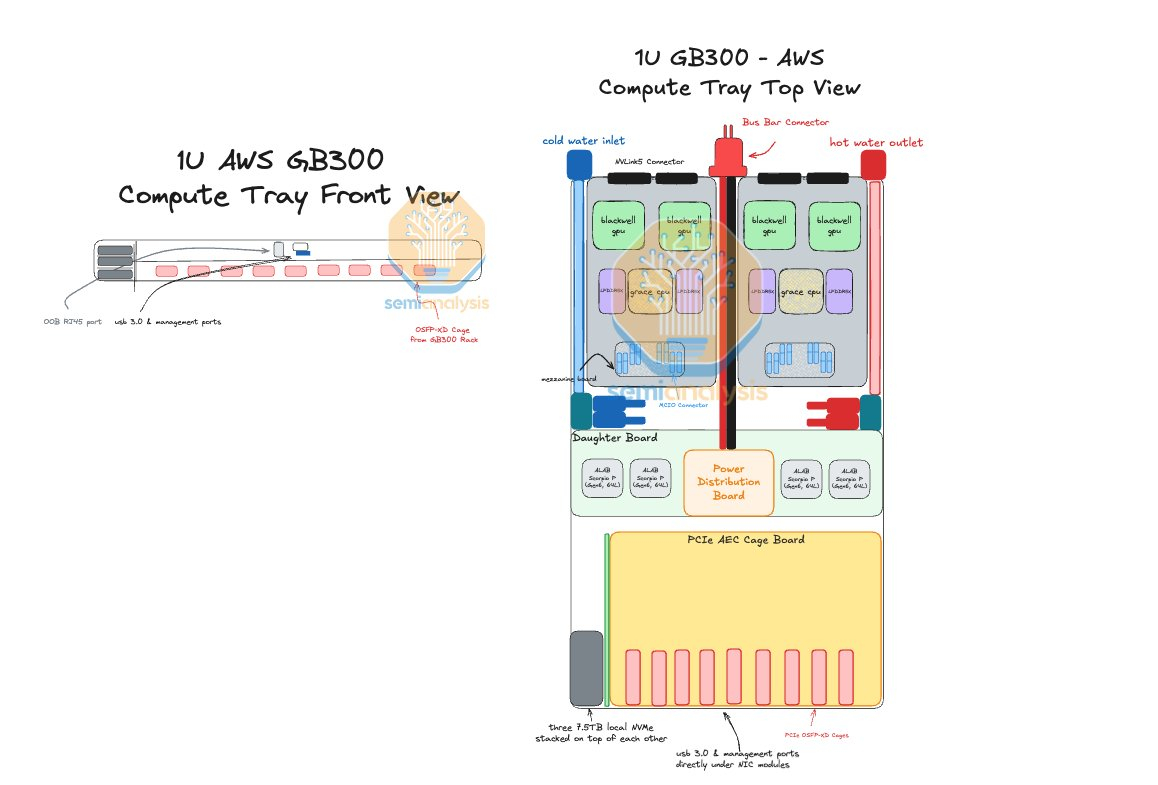
Источник изображения: SemiAnalysis С точки зрения SemiAnalysis, доработка GB300 в AWS помогает устранить единую точку отказа в референсной архитектуре NVIDIA, где каждый ускоритель взаимодействует только с одним сетевым адаптером ConnectX-8, тогда как в конфигурации AWS каждый ускоритель общается с двумя NIC. У AWS накоплен богатый опыт разработки собственного оборудования для ЦОД. Ранее компания в партнёрстве с Broadcom разрабатывала специализированные сетевые коммутаторы. Также недавно представленные ею EC2-инстансы P6-B200 и P6e-GB200 оснащены собственным сетевым стеком Elastic Fabric Adapter (EFAv4) на базе собственных контроллеров Nitro, который оптимизирует обработку сетевых пакетов и снижает задержки для высокопроизводительных приложений.
20.10.2025 [09:11], Сергей Карасёв
Pegatron представила ИИ-систему RA4802-72N2 на базе NVIDIA GB300 NVL72Компания Pegatron представила систему RA4802-72N2, предназначенную для наиболее ресурсоёмких ИИ-нагрузок, включая обучение больших языковых моделей (LLM) в масштабе и инференс. В основу положена платформа NVIDIA GB300 NVL72. Изделие GB300 содержит Arm-процессор Grace с 72 ядрами Neoverse V2 (Demeter) и два чипа Blackwell Ultra. В составе RA4802-72N2 объединены 18 вычислительных лотков, каждый из которых несёт на борту два Grace и четыре Blackwell Ultra. В сумме это даёт 36 процессоров Grace и 72 чипа Blackwell Ultra. Каждый из вычислительных узлов располагает 960 Гбайт памяти LPDDR5X и 1152 Гбайт памяти HBM3e. Таким образом, в общей сложности система оперирует примерно 17 Тбайт LPDDR5X и 20 Тбайт HBM3e. ИИ-производительность достигает 720 Пфлопс на операциях FP8/FP6. 
Источник изображения: Pegatron В состав RA4802-72N2 также входят девять коммутационных лотков. Общая пропускная способность интерконнекта NVLink составляет 130 Тбайт/с. В расчёте на вычислительный узел используются два адаптера NVIDIA ConnectX-8 и один DPU NVIDIA BlueField-3. Прочие характеристики включают контроллер Aspeed AST2600, модуль TPM 2.0, восемь отсеков для накопителей E1.S NVMe, коннектор M.2 2280/22110 NVMe. Система выполнена в форм-факторе 48U MGX с габаритами 600 × 2296 × 1200 мм. Применяется полностью жидкостное охлаждение. Полка питания оснащена шестью 1U-модулями мощностью 33 кВт. Поставки машины RA4802-72N2 уже начались.
17.10.2025 [17:18], Руслан Авдеев
Poolside и CoreWeave построят в Техасе 2-ГВт кампус ИИ ЦОД, работающий на газе из Пермского бассейнаИИ-стартап Poolside объединился с CoreWeave для строительства кампуса ЦОД Project Horizon мощностью 2 ГВт на площади 230 га на территории ранчо Longfellow в Западном Техасе. Для электроснабжения планируется использовать природный газ, добываемый в местном Пермском бассейне, сообщает Datacenter Dynamics. ЦОД построят с использованием «гибридного модульного подхода», предполагающего «параллельное, а не последовательное строительство», которое будет завершено в I квартале 2027 года. CoreWeave станет ключевым арендатором первой фазы проекта, которая должна обеспечить мощность 250 МВт в соответствии с договором аренды на 15 лет. В будущем допускается увеличение арендуемых мощностей до 500 МВт. Также соглашение компаний предусматривает, что с декабря CoreWeave предоставит Poolside кластер NVIDIA GB300 NVL72 с более чем 40 тыс. чипов. По словам Poolside, партнёрство с CoreWeave обеспечит немедленный доступ к ускорителям новейшего поколения, что позволит обучать модели с триллионами параметров. Poolside основана в 2023 году. Стартап разрабатывает ПО для автоматизации написания программного кода с высокими корректностью и безопасностью, достаточных для того, чтобы его можно было использовать в государственных учреждениях. По данным Bloomberg, в 2024 году компания выпустила ИИ-агента для разработчиков государственного и оборонного секторов. Также ведутся работы и в области создания «общего искусственного интеллекта» (AGI). 
Источник изображения: Bailey Alexander/unsplash.com Пока Poolside проводит раунд привлечения $2 млрд инвестиций, оценка стоимости компании по его итогам должна составить $14 млрд. Большую часть средств направят на приобретение 40 тыс. ускорителей NVIDIA. В 2024 года стартап уже привлёк $500 млн, получив оценку в $3 млрд. Компания является известным клиентом Fluidstack, а также арендовала некоторое количество NVIDIA H100 у Iris Energy. Благодаря большим запасам природного газа и относительно доступной электроэнергии в целом Техас стал весьма привлекательным местом для строителей дата-центров. По информации CBRE, сегодня это второй по величине рынок ЦОД в США. В штате реализуется первый проект в рамках инициативы Stargate, Meta✴ инициировала строительство ЦОД на 1 ГВт в Эль-Пасо, а Fermi America, будучи новичком на рынке дата-центров, заранее договорилась о подключение к газопроводу своего будущего 11-ГВт кампуса в Амарилло (Amarillo).
15.10.2025 [23:05], Владимир Мироненко
Microsoft арендует у Nscale ещё 116 тыс. ускорителей NVIDIA GB300Nscale и Microsoft заключили расширенное соглашение о предоставлении гиперскейлеру ИИ-инфраструктуры в США и Европе — 116,6 тыс. ускорителей на базе платформы NVIDIA GB300, сообщил Data Center Dynamics. Microsoft, как и другие крупные технологические компании, нуждается в увеличении вычислительных мощностей для удовлетворения растущего спроса на ИИ-технологии. С учётом более ранних контрактов Microsoft получит от Nscale почти 200 тыс. ускорителей. Nscale развернёт в течение следующих 12–18 мес. около 104 тыс. ускорителей в ЦОД Cedarvale в Барстоу (Barstow, шт. Техас), который она арендует у биткоин-майнера Ionic Digital в рамках десятилетнего соглашения стоимостью $2 млрд. На начальном этапе мощность инфраструктуры составит 240 МВт (хотя в пресс-релизе Ionic указано 234 МВт), а поэтапное предоставление её услуг Microsoft начнётся в III квартале 2026 года, сообщила Nscale. Nscale планирует в дальнейшем постепенно увеличить мощность объекта до 1,2 ГВт, при этом у Microsoft есть опцион на вторую фазу мощностью 700 МВт, начиная с конца 2027 года. В рамках соглашения Nscale также предоставит Microsoft для использования вычислительные мощности на базе до 12,6 тыс. ускорителей в кампусе Start Campus в Синише (Sines, Португалия). Монтаж оборудования здесь начнётся в I квартале 2026 года. На данный момент в эксплуатации находится один дата-центр кампуса, введённый в строй в январе 2025 года — SIN01. Сейчас ведётся строительство объекта SIN02 мощностью 180 МВт. Суммарно кампус будет включать шесть ЦОД. 
Источник изображения: Start Campus Nscale и Microsoft не назвали точную стоимость последних сделок, но исходя из аналогичной стоимости контракта на один ускоритель, их общая стоимость составляет до $14 млрд, сообщил ресурс The Financial Times. Ранее крупнейший среди неооблаков контракт был подписан между Microfoft и CoreWeave в интересах OpenAI, которая после разлада с Microsoft теперь напрямую закупает мощности у CoreWeave. В этом году Microsoft уже подписала сделки на аренду ИИ-мощностей с Nebius, Lambda и Nscale на общую сумму порядка $33 млрд. Новые сделки Nscale с Microsoft расширяют контракт стоимостью $6,2 млрд, в рамках которого Microsoft арендует вычислительные мощности на базе 52 тыс. ускорителей NVIDIA на объекте Nscale в Норвегии. Nscale и Microsoft также заняты реализацией крупного проекта в Великобритании. В прошлом месяце компании объявили о планах строительства самого мощного британского ИИ-суперкомпьютера в будущем ЦОД Nscale в Лоутоне (Loughton, граф. Эссекс), который, как ожидается, будет оснащён не менее 23 тыс. чипов Grace Blackwell Ultra. Но и от строительства собственных ИИ ЦОД Microsoft не отказывается.
10.10.2025 [14:50], Руслан Авдеев
Не для себя стараемся: Microsoft развернула для OpenAI первый в мире ИИ-кластер на базе суперускорителей NVIDIA GB300 NVL72Microsoft представила первый в мире ИИ-кластер, использующий более 4,6 тыс. NVIDIA Blackwell Ultra в составе суперускорителей NVIDIA GB300 NVL72, объединённых интерконнектом Quantum-X800 InfiniBand. Этот кластер — лишь первый из многих. Компания развернёт сотни тысяч ускорителей Blackwell Ultra в ИИ ЦОД по всему миру. Благодаря им Microsoft намерена стать первой, поддерживающей обучение для моделей с сотнями триллионов параметров. Как сообщают в Microsoft, запуск в Microsoft Azure суперкластера NVIDIA GB300 NVL72 стал важным шагом в развитии передовых ИИ-технологий. Разработанная совместно с NVIDIA система представляет собой первый в мире масштабируемый ИИ-кластер на основе GB300, обеспечивающий вычислительные мощности, необходимые OpenAI для обслуживания моделей с триллионами параметров. Речь идёт о новом стандарте ускоренных вычислений, говорят компании. Новые инстансы Azure ND GB300 v6 оптимизированы для рассуждающих моделей, агентных систем и мультимодального генеративного ИИ. Каждая стойка GB300 NVL72 обслуживает 18 виртуальных машин, а сам суперускоритель с производительностью до 1,44 Эфлопс (FP4 Tensor Core) включает:

Источник изображения: Microsoft Создание передовой инфраструктуры требует переосмысления всех уровней системы, включая вычисления, память, системы охлаждения и питания, ЦОД в целом как единой структуры. Новая архитектура стоек обеспечивает высокую пропускную способность инференса при меньших задержках на крупных моделях, это позволяет агентным и мультимодальным ИИ-системам быть более масштабируемыми и эффективными, чем когда-либо, говорит компания. Для масштабирования за пределы стойки используется NVIDIA Quantum-X800 InfiniBand, что гарантирует обучения сверхбольших моделей с применением десятков тысяч ИИ-ускорителей с минимальными накладными расходами на их синхронизацию, что дополнительно повышает производительность. 
Источник изображения: Microsoft Передовые системы охлаждения Azure используют автономные теплообменники, чтобы свести к минимуму расход воды и поддерживать температурную стабильность для высокоплотных кластеров. Также продолжается разработка и внедрение новых моделей распределения питания, обеспечивающих высокую энергетическую плотность и динамический баланс нагрузок. Дополнительную помощь в оптимизации работы оказывает и модернизированное программное обеспечение. Ранее Microsoft обладала эксклюзивными правами на предоставление облачных сервисов компании OpenAI, но в январе 2025 года появилась новость, что ИИ-стартапу разрешили пользоваться и облаками других провайдеров, если у Microsoft не хватит собственных мощностей. Разногласия между компаниями продолжают нарастать. Формально первенство по создание кластера на базе GB300 NVL72 принадлежит CoreWeave, имеющей тесные отношения с NVIDIA и обслуживающей OpenAI — как напрямую, так и при посредничестве Microsoft.
02.10.2025 [21:02], Владимир Мироненко
Microsoft потратит $33 млрд на доступ к 100+ тыс. NVIDIA GB300 в неооблаках, но со временем хочет перейти на свои ИИ-ускорителиВ Сети появились новые подробности о сделке стоимостью до $19,4 млрд, заключённой Microsoft с Nebius Group NV в начале сентября. Как сообщает Bloomberg со ссылкой на информированные источники, Microsoft получит пятилетний доступ к выделенной инфраструктуре на базе более чем 100 тыс. суперускорителей NVIDIA GB300. Ранее сообщалось, что речь идёт о мощностях нового ЦОД Nebius в Вайнленде (Нью-Джерси, США). Как пишет Forbes, Nebius отличается от многих облачных провайдеров тем, что фокусируется только на рабочих нагрузках ИИ и МО, что позволяет лучше оптимизировать архитектуру ЦОД в отличие от гиперскейлеров, которые занимаются решением множества задач. Кроме того, Nebius отличается от других неооблаков, таких как CoreWeave, тем, что предоставляет инструменты и сервисы для разработчиков, которые позволяют совершенствовать ИИ-модели, выполнять инференс и разрабатывать кастомные решения, а не просто фокусируется на «чистой» вычислительной мощности. При этом Nebius начала наращивать вычислительные мощности ещё до того, как возник спрос на эти ресурсы, отметил Forbes. Подобные контракты Microsoft заключила с ещё несколькими неооблаками (neocloud), включая CoreWeave, Nscale и Lambda, на общую сумму в $33 млрд, и они обеспечивают её большую выгоду. Вместо того, чтобы тратить огромные ресурсы на строительство собственных ЦОД, Microsoft обращается к проверенному поставщику ИИ-инфраструктуры, благодаря чему может быстрее совершенствовать свою ИИ-инфраструктуру с меньшими первоначальными затратами, используя высвободившиеся мощности для предоставления клиентам прибыльных услуг на базе ИИ. Вдобавок такой подход позволяет Microsoft быстрее менять стратегию, чем при использовании собственных дата-центров. В начале бума ИИ Microsoft арендовала мощности даже у Oracle, своего прямого конкурента, для поддержки ИИ-функций в поиске Bing. 
Источник изображения: Nebius/Bloomberg Эти сделки также устраняют для Microsoft значительную часть финансовых рисков, связанных со строительством собственных ЦОД. Она не только сразу получает необходимые мощности для своих ИИ-сервисов, вместо того чтобы тратить годы на строительство ЦОД, но и перекладывает на других вопросы строительства, финансирования и управление этими ЦОД, что даёт компании большую финансовую гибкость. Так, Microsoft может отнести некоторые затраты к операционным, а не капитальным, что, по словам аналитика Bernstein Марка Мёрдлера (Mark Moerdler), даёт потенциальные преимущества для денежного потока, налогообложения и способа представления прибыли в финотчётах. Компания использует серверы неооблаков не только для обучения ИИ-моделей, но и для сложного инференса. Сделки с неооблаками становятся популярными и у конкурентов Microsoft, хотя им далеко до её масштабов. В мае 2025 года OpenAI расширила с конкурирующей с Nebius компанией CoreWeave контракт стоимостью $11,9 млрд на $4 млрд, после чего заключила ещё одно соглашение на $6,5 млрд, увеличив общую сумму соглашений до $22,4 млрд. Ещё один технологический гигант Meta✴ подписал сделку с CoreWeave на сумму в $14,2 млрд, обеспечив себе доступ к её облачным ИИ-сервисов на период до 2031 года. Вместе с тем в долгосрочной перспективе Microsoft намерена переключиться на ИИ-ускорители собственной разработки, которые обеспечивают лучший показатель TCO, передаёт CNBC. Два года назад компания представила первые ИИ-чипы Maia 100. Следующее поколение этих чипов, как ожидается, появится в 2026 году. При этом компания сосредоточится не на чипах в отдельности, а будет использовать более системный подход, учитывающий вопросы охлаждения, интерконнекта и т.д. Пока что, признаёт Microsoft, в течение многих лет решения NVIDIA обеспечивали лучшее соотношение цены к производительности.
28.09.2025 [12:30], Сергей Карасёв
«Зелёная» энергия для «зелёных» ускорителей: Lambda и ECL впервые запитали NVIDIA GB300 NVL72 от водородаОблачный провайдер Lambda и стартап ECL объявили о развёртывании первых в отрасли систем NVIDIA GB300 NVL72 с питанием от водорода. Высокопроизводительная платформа предназначена для обучения базовых ИИ-моделей, инференса и других ресурсоёмких задач. ECL специализируется на создании автономных модульных дата-центров с питанием от водорода, при возведении которых применяются технологии 3D-печати. Первым ЦОД компании стал объект MV1 мощностью 1 МВт на площадке в Маунтин-Вью (Калифорния, США). Кроме того, ECL заявила о намерении построить ИИ ЦОД TerraSite-TX1 мощностью 1 ГВт к востоку от Хьюстона (Техас, США). Как сообщается, системы NVIDIA GB300 NVL72 компании Lambda смонтированы на базе модульного дата-центра MV1. Эта площадка отличается нулевым потреблением воды и нулевым уровнем выбросов вредных газов в атмосферу. Питание обеспечивается исключительно от водородных топливных элементов. Развёрнутые устройства GB300 NVL72 разработаны компанией Supermicro. Они обладают мощностью 142 кВт. Для отвода тепла применяется система прямого жидкостного охлаждения, вода для которой поступает от водородных топливных элементов, на которых вырабатывается в качество побочного продукта при генерации электричества. Задействованы централизованные блоки распределения охлаждающей жидкости (CDU). Утверждается, что это первое в отрасли подобное сочетание инфраструктуры на базе ускорителей NVIDIA с водородным источником «зеленой» энергии. 
Источник изображения: Lambda Отмечается, что развёртывание систем NVIDIA GB300 NVL72, масса которых составляет примерно 1800 кг, сопряжено с серьёзными трудностями. Лишь немногие дата-центры способны справиться с требованиями к плотности мощности и охлаждению. Водородные топливные элементы рассматриваются в качестве одного из наиболее перспективных способов решение проблемы питания таких объектов. При этом становится возможным устойчивое развитие облачных ИИ-платформ.
27.09.2025 [15:32], Сергей Карасёв
Майнинговая компания Iren увеличила мощность ИИ-облака, закупив тысячи ускорителей NVIDIA и AMD за $674 млнКриптомайнинговая компания Iren (ранее известная как Iris Energy), по сообщению Datacenter Dynamics, увеличила количество ИИ-ускорителей в своём облаке примерно в два раза. Стоимость приобретённого оборудования оценивается в $674 млн. Компании прочат статус серьёзного игрока на рынке неооблаков. Компания находится в процессе перехода от майнинга криптовалют к облачному бизнесу на базе ИИ. В частности, закуплены 7100 ускорителей NVIDIA B300 и 4200 изделий NVIDIA B200, а также 1100 AMD Instinct MI350X. В результате, общее количество ускорителей в составе платформы Iren достигло приблизительно 23 тыс. Новое оборудование в ближайшие месяцы будет развёрнуто в кампусе Iren в городе Принс-Джордже (Prince George) в северной части провинции Британская Колумбия в Канаде. В настоящее время на этой площадке ведётся строительство вычислительного комплекса с жидкостным охлаждением мощностью 10 МВт (ИТ-нагрузка), который сможет поддерживать более 4500 суперускорителей NVIDIA GB300. В конце августа нынешнего года Iren сообщила о приобретении 1200 ускорителей NVIDIA B300 для серверов с воздушным охлаждением и 1200 изделий NVIDIA GB300 для систем с жидкостным охлаждением: стоимость данной партии составила примерно $168 млн. Эти чипы также предназначены для ЦОД в Принс-Джордже. Тогда говорилось, что Iren привлекла финансирование в размере около $96 млн для покупки GB300: средства получены по схеме лизинга сроком на два года. 
Источник изображения: Iren В настоящее время Iren управляет пятью кампусами ЦОД общей мощностью 810 МВт, расположенными в Северной Америке: два в Техасе (США) и три в Британской Колумбии (Канада). Ещё 2,1 ГВт находятся в стадии строительства, причём 2 ГВт из них приходится на новый кампус в Техасе. Как отмечает Дэниел Робертс (Daniel Roberts), соучредитель и содиректор Iren, удвоение парка GPU позволит удовлетворить растущие потребности клиентов в масштабируемых вычислительных мощностях.
21.09.2025 [13:40], Сергей Карасёв
Schneider Electric готовит стойки NVIDIA GB300 NVL72 мощностью 142 кВтКомпания Schneider Electric анонсировала две эталонные платформы, призванные ускорить построение инфраструктур для дата-центров, ориентированных на ресурсоёмкие нагрузки ИИ и НРС. Разработка систем ведётся в партнёрстве с NVIDIA. Один из проектов предусматривает создание референсных стоек для суперускорителей NVIDIA GB300 NVL72. Такие стойки смогут обеспечивать мощность до 142 кВт. Предусмотрено использование жидкостного охлаждения. В одном машинном зале могут быть расположены три кластера GB300 NVL72, насчитывающих в общей сложности до 1152 ускорителей. Отмечается, что в основу решения положены наработки и опыт, полученные в ходе реализации аналогичного проекта для NVIDIA GB200 NVL72. Клиентам будет доступна специальная среда моделирования на базе вычислительной гидродинамики (CFD): могут применяться цифровые двойники для оценки различных конфигураций электропитания и охлаждения с целью оптимизации платформ под определённые нужды. 
Источник изображения: Schneider Electric Второй эталонный проект, как утверждается, представляет собой первую и единственную в отрасли платформу, предполагающую интеграцию систем управления питанием и жидкостным охлаждением, включая решения Motivair (контрольный пакет акций этой фирмы Schneider Electric приобрела в конце 2024 года). Для новой платформы заявлена совместимость с NVIDIA Mission Control — программным обеспечением NVIDIA для контроля производственных процессов и оркестрации работы ИИ-систем, включая управление кластерами и рабочими нагрузками. В таких системах могут применяться суперускорители GB300 NVL72 и GB200 NVL72. Подчёркивается, что новые эталонные решения являются результатом продолжающегося сотрудничества Schneider Electric и NVIDIA, которое направлено на удовлетворение растущих потребностей операторов дата-центров в области ИИ.
18.09.2025 [15:25], Сергей Карасёв
Giga Computing представила флагманский ИИ-сервер на базе NVIDIA HGX B300Компания Giga Computing, подразделение Gigabyte, анонсировала сервер G894-SD3-AAX7 — флагманскую систему, предназначенную для решения сложных HPC-задач, обучения больших языковых моделей (LLM), инференса и других ресурсоёмких ИИ-нагрузок. В основу новинки положены процессорры Intel Xeon Granite Rapids и ускорители NVIDIA Blackwell Ultra. 
Источник изображений: Giga Computing Сервер выполнен в форм-факторе 8U. Возможна установка двух процессоров Xeon 6500P/6700P с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5 RDIMM-6400 или MRDIMM-8000. Во фронтальной части расположены восемь посадочных мест для SFF-накопителей с интерфейсом PCIe 5.0 (NVMe) и поддержкой горячей замены. Кроме того, есть два внутренних коннектора для SSD типоразмера M.2 2280/22110 (PCIe 5.0 x4 и PCIe 5.0 x2).  Система, построенная на платформе NVIDIA HGX B300, имеет восемь SXM-ускорителей Blackwell Ultra. Могут быть реализованы восемь портов 800G OSFP InfiniBand или 16 портов 400GbE посредством адаптеров NVIDIA ConnectX-8 SuperNIC. Говорится о поддержке DPU NVIDIA BlueField-3 и о наличии четырёх слотов PCIe 5.0 x16 для карт FHHL.  Сервер оснащён двумя портами 10GbE на базе Intel X710-AT2, выделенным сетевым портом управления 1GbE, контроллером ASPEED AST2600, двумя портами USB 3.2 Gen1 Type-A и интерфейсом D-Sub. Применяется воздушное охлаждение. За питание отвечают 12 блоков мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Диапазон рабочих температур — от +10 до +30 °C. |
|