Материалы по тегу: ускоритель
|
29.07.2025 [16:38], Сергей Карасёв
MaxLinear представила DPU Panther V с пропускной способностью 450 Гбит/сКомпания MaxLinear анонсировала ускоритель обработки данных Panther V, предназначенный для использования в дата-центрах и инфраструктурах гиперскейлеров. Решение берёт на себя выполнение таких ресурсоёмких операций с данными, как сжатие, дедупликация, шифрование и проверка в реальном времени. В результате, снижается нагрузка на CPU, уменьшаются задержки, повышаются общая производительность и энергоэффективность, а также сокращаются капитальные и эксплуатационные затраты. Новинка выполнена на той же архитектуре, которая лежит в основе DPU Panther III. При этом вместо интерфейса PCIe 4.0 используется PCIe 5.0 (x16). Пропускная способность увеличена более чем в два раза — с 200 до 450 Гбит/с. Устройство оптимизировано для НРС-задач, гипермасштабируемых и гиперконвергентных архитектур, рабочих нагрузок ИИ и машинного обучения. 
Источник изображения: MaxLinear Упомянут механизм дедупликации структурированных данных MaxHash вплоть до 15:1 (в сочетании с алгоритмами глубокого сжатия). Это значительно повышает эффективную вместимость и увеличивает срок службы NVMe SSD. Реализованы различные средства обеспечения безопасности, включая сквозную защиту данных, ЕСС и пр. Говорится о развитой программной экосистеме: это SDK с унифицированными API, а также интеллектуальный балансировщик нагрузки для бесшовной интеграции в средах Linux и FreeBSD. Возможно объединение в системе нескольких ускорителей Panther V с суммарной пропускной способностью свыше 3,2 Тбит/с.
28.07.2025 [13:35], Сергей Карасёв
Huawei представила ИИ-систему CloudMatrix 384 — конкурента NVIDIA GB200 NVL72Компания Huawei, по сообщению Reuters, представила на Всемирной конференции по искусственному интеллекту (WAIC) в Шанхае (Китай) систему CloudMatrix 384 для ресурсоёмких ИИ-нагрузок. Участники ранка рассматривают эту платформу в качестве прямого конкурента NVIDIA GB200 NVL72. Информация о характеристиках CloudMatrix 384 появилась в апреле нынешнего года: система объединяет 384 ускорителя Huawei Ascend 910C. Для сравнения: NVIDIA GB200 NVL72 содержит в одной стойке 18 узлов 1U, каждый из которых включает два ускорителя GB200 — в сумме это даёт 72 чипа B200 и 36 процессоров Grace. Быстродействие CloudMatrix 384 достигает 300 Пфлопс (BF16) против 180 Пфлопс у NVIDIA GB200 NVL72. Кроме того, решение Huawei в 3,6 раза превосходит конкурирующую платформу по объёму памяти HBM и в 2,1 раза по пропускной способности памяти. Однако для достижения таких показателей потребовалось в пять с лишним раз больше ускорителей. Таким образом, по производительности и энергоэффективности отдельные карты Ascend 910C существенно уступают изделиям NVIDIA GB200. 
Источник изображения: MyDrivers По данным сетевых источников, на коммерческий рынок система CloudMatrix 384 может поступить под именем Atlas 900 A3 SuperPoD. Компания Huawei, не вдаваясь в подробности, отмечает, что машина использует архитектуру «суперузлов», которая позволяет ИИ-ускорителям взаимодействовать на сверхвысоких скоростях. Обещаны ультранизкие задержки. Выход системы призван укрепить позиции Китая в сфере ИИ на фоне американских санкций. Власти США наложили запрет на поставки в КНР передовых решений в сфере ИИ. Тем не менее, за три месяца действия новых правил по ужесточению контроля над экспортом таких ускорителей в Китай всё равно попали изделия NVIDIA на сумму не менее $1 млрд. А сама компания NVIDIA между тем рассчитывает возобновить отгрузки ИИ-ускорителей H20 китайским заказчикам.
24.07.2025 [11:37], Сергей Карасёв
QNAP выпустила ИИ-ускорители для NAS: QAI-M100 и QAI-U100Компания QNAP Systems анонсировала ИИ-ускорители QAI-M100 и QAI-U100, предназначенные для решения различных задач на периферии: это может быть распознавание лиц и объектов, анализ данных в режиме реального времени и пр. Новинки могут использоваться с сетевыми хранилищами QNAP. Изделие QAI-M100 выполнено в форм-факторе M.2 2280 (M+B key) с интерфейсом PCIe 2.0 x1. Задействован процессор Rockchip RK1808 с двумя вычислительными ядрами Arm Cortex-A35, работающими на частоте до 1,6 ГГц. Интегрированный нейропроцессорный блок с поддержкой TensorFlow, Caffe и ONNX обеспечивает производительность до 3 TOPS на операциях INT8. Модуль VPU способен декодировать видеоматериалы H.264 в формате 1080p60 и кодировать 1080p30. Говорится о поддержки памяти LPDDR2/LPDDR3/DDR3/DDR3L/DDR4-800 (в оснащение ускорителя входит 1 Гбайт). В комплект поставки включён тонкий радиатор для рассеяния тепла. В свою очередь, вариант QAI-U100 представляет собой внешний ускоритель в виде USB-брелока с интерфейсом USB 3.2 Gen1. Размеры составляют 92,5 × 29 × 11 мм. Прочие технические характеристики аналогичны устройству типоразмера М.2. 
Источник изображений: QNAP Для работы с новинками требуется NAS под управлением QTS 5.2.1.2930 build 20241025 (или более поздней версией) или QuTS hero h5.2.1.2929 build 20241025 (или выше). Обеспечивается совместимость с софтом QNAP AI Core v3.5.0 (и выше), Multimedia Console v2.7.0 (или более поздними версиями) и QuMagie v1.5.1 (и выше).  Модель QAI-M100 может устанавливать в такие сетевые хранилища QNAP, как TS-435XeU, TS-473A, TS-673A, TS-h765eU и TS-873A. Модификация QAI-U100 может подключаться к различным NAS с количеством отсеков от трёх до 16, включая ТС-332Х, TS-432PXU, TS-432PXU-RP, TS-432X, TS-432XU, TS-432XU-RP, TS-435XeU, TS-473A, TS-632X, TS-673A, TS-h765eU, TS-832PX, TS-832PXU, TS-832PXU-RP, TS-832X, TS-832XU, TS-932PX, TS-932X, TS-h973AX, TS-1232PXU-RP, TS-1232XU, TS-1673AU-RP и др.
23.07.2025 [12:51], Сергей Карасёв
Ускоритель Hailo-10H обеспечивает поддержку генеративного ИИ на периферииКомпания Hailo сообщила о коммерческой доступности изделия Hailo-10H — ИИ-ускорителя второго поколения, ориентированного на работу с генеративными приложениями на периферии. Новинка доступна в виде интегрируемого чипа COB (Chip On Board), а также в виде модулей формата M.2 Key M 2242/2280. По словам компании. при энергопотреблении всего 2,5 Вт новинка способна выдавать более 10 токенов в секунду на моделях с 2 млрд параметров, при этом на отдачу первого токена уходит менее одной секунды. Также чип позволяет детектировать объекты в режиме реального времени в видеопотоке 4K. По заявлениям разработчика, Hailo-10H позволяет использовать большие языковые модели (LLM), визуально-языковые модели (VLM) и другие модели генеративного ИИ локально — без необходимости подключения к облаку. Это выводит ИИ-возможности периферийных устройств на новый уровень. Кроме того, обеспечивается ряд других преимуществ по сравнению с обработкой информации в облаке. В частности, достигается высокий уровень конфиденциальности, поскольку персональные данные не пересылаются на сторонние серверы, а остаются на устройстве. Отпадает также необходимость оплаты облачных вычислительных ресурсов. 
Источник изображений: Hailo Ускоритель Hailo-10H может использоваться в системах с CPU на архитектурах x86 и Arm. Энергопотребление находится на уровне 2,5 Вт. Говорится о совместимости с Linux, Windows и Android, а также с фреймворками TensorFlow, TensorFlow Lite, Keras, PyTorch и ONNX. Изделия в виде модулей М.2 используют интерфейс PCIe 3.0 x4. Объём встроенной памяти LPDDR4/4X составляет 4 или 8 Гбайт. Предусмотрены индустриальный и автомобильный варианты исполнения: в первом случае диапазон рабочих температур простирается от -40 до +85 °C, во втором — от -40 до +105 °C.  Производительность Hailo-10H достигает 40 TOPS в режиме INT4 и 20 TOPS в режиме INT8. Ускоритель полностью совместим с программным стеком Hailo. Среди ключевых сфер применения новинки названы автомобилестроение, телекоммуникации, розничная торговля, информационная безопасность, персональные компьютеры и пр.
21.07.2025 [18:58], Владимир Мироненко
xAI ищет разработчиков кастомных чипов для ИИ-системИИ-стартап xAI Илона Маска (Elon Musk) разместил вакансии для разработчиков кастомных полупроводников, сообщил ресурс DataCenter Dynamics (DCD). Стартап ищет сотрудников для «создания ИИ-систем нового поколения, охватывающих весь спектр, от полупроводниковых чипов до компиляторов и моделей». Круг должностных обязанностей специалистов включает «разработку и доработку новых аппаратных архитектур для расширения границ вычислительной эффективности», а также использование ИИ в процессе проектирования оборудования. От кандидатов на должность ожидается знание инструментов для создания чипов, таких как Chisel, а также VHDL и Verilog. В идеале претенденты должны иметь опыт «симуляции обучающих рабочих нагрузок на новых аппаратных ИИ-архитектурах». Соответствующий требованиям сотрудник присоединится к команде xAI, работающей над «созданием ИИ-систем нового поколения, которые обеспечат революционную эффективность и масштабируемость на новом оборудовании, компиляторах и моделях». 
Источник изображения: xAI Как полагает DCD, команду, о которой идёт речь, возглавляет Сяо Сан (Xiao Sun), ранее работавший в Meta✴, а до этого занимавшийся разработкой аппаратного обеспечения и алгоритмов машинного обучения, а также CMOS-устройств в IBM. DCD отметил, что на данный момент неясно, сотрудничает ли xAI с другой компанией в разработке полупроводниковых чипов, как, например, Google и OpenAI, которые работают с Broadcom над созданием семейства TPU и ИИ-чипа соответственно. Компания Tesla, в которой Маск является крупнейшим акционером, также разработала собственный чип — Dojo D1, ориентированный на обработку видеоданных для обучения полуавтономных автомобилей. Однако большая часть команды, стоящей за чипом Dojo D1, покинула Tesla, и его будущее туманно. Илон Маска показал систему в 2024 году. Годом ранее Маск заявил, что чип используется из-за нехватки ускорителей NVIDIA: «Честно говоря, я не знаю, смогут ли они поставить нам достаточно графических процессоров — возможно, Dojo нам и не нужен, — но они не смогут». Как и Tesla, xAI использует значительное количество ускорителей NVIDIA для своих вычислительных задач, более 200 тыс. из них входят в состав суперкомпьютера Colossus в Мемфисе (США). Маск надеется расширить Colossus до миллиона ускорителей. В свою очередь, xAI приобрела участок под второй дата-центр в Мемфисе.
20.07.2025 [14:26], Сергей Карасёв
NVIDIA приступила к производству ИИ-ускорителей GB300Компания NVIDIA, по сообщению DigiTimes, приступила к ограниченному производству суперчипов Grace Blackwell GB300 для ресурсоёмких ИИ-нагрузок. Ожидается, что поставки изделия будут организованы в сентябре с постепенным наращиванием объёмов выпуска. Решение GB300 представляет собой связку из Arm-процессора Grace с 72 ядрами Neoverse V2 и двух чипов Blackwell Ultra. В оснащение входят 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Ускоритель GB300 является основой стоечной системы GB300 NVL72, которая насчитывает 36 чипов Grace и 72 процессора Blackwell Ultra. ИИ-производительность такого комплекса достигает 720 Пфлопс на операциях FP8/FP6. «На данном этапе серьёзных проблем с GB300 нет. Поставки должны идти гладко со II половины года», — подчеркнули представители одного из ODM-производителей. 
Источник изображения: NVIDIA Вместе с тем, как отмечается, сохраняется высокий спрос на ускорители GB200. Заказчики продолжают закупать эти изделия, несмотря на сложности с охлаждением. Огромная вычислительная мощность и повышенная плотность компоновки серверов обусловили необходимость применения жидкостных систем отвода тепла. Однако при этом возникли проблемы протечек. Оказалось, что во многих случаях это связано с быстроразъёмными соединениями, которые не всегда удовлетворяют нужным требованиям — даже после стресс-тестирования на заводе. ODM-производители отмечают, что реальные условия эксплуатации сильно различаются по давлению воды и конструкции трубопроводов, что затрудняет полное исключение протечек. Послепродажное обслуживание требует значительных временных и финансовых затрат. В случае GB200 основные сложности были обусловлены переходом от архитектуры Hopper к Blackwell, что привело к комплексным изменениям на уровне платформы. С другой стороны, GB300 использует существующую инфраструктуру, а поэтому, как ожидается, серьёзных проблем при выпуске и поставках этих изделий не возникнет. ODM-производители, которые в настоящее время активно тестируют GB300, говорят об обнадёживающих результатах. Предполагается, что переход пройдёт гладко: массовые поставки запланированы на III квартал с увеличением объёмов выпуска в последней четверти текущего года. Новые вызовы может создать появление ускорителей следующего поколения семейства Rubin, которые придут на смену Blackwell Ultra во II половине 2026 года. Эта платформа предполагает использование чиплетов и полностью новой стойки Kyber (для VR300 NVL 576), которая заменит нынешнюю конструкцию Oberon. Плотность компоновки возрастёт до 600 кВт на стойку, что потребует ещё более надёжных систем охлаждения. Отмечается, что применение СЖО станет обязательным для суперускорителей Rubin. Вместе с тем с восстановлением производства ослабленных ускорителей H20, которые США вновь разрешили поставлять в Китай, возможны проблемы. Как передаёт Reuters со ссылкой на The Information, TSMC успела переключить производственные линии, которые использовались для H20, на выпуск других продуктов. Полное восстановление производства H20 может занять девять месяцев.
19.07.2025 [13:46], Сергей Карасёв
Rockchip анонсировала ИИ-ускоритель RK182X с архитектурой RISC-VКомпания Rockchip, по сообщению ресурса CNX Software, представила в Китае ИИ-ускоритель RK182X, предназначенный для работы с большими языковыми моделями (LLM) и визуально-языковыми моделями (VLM) на периферии. Новинка ориентирована на совместное использование с другими SoC Rockchip. Изделие получило многоядерную архитектуру RISC-V (точное количество ядер пока не раскрывается). В зависимости от модификации задействованы 2,5 или 5 Гбайт памяти DRAM со «сверхвысокой пропускной способностью» (ПСП тоже не раскрывается). Реализована поддержка интерфейсов PCIe 2.0, USB 3.0 и Ethernet. По заявлениям Rockchip, ИИ-ускоритель RK182X способен обрабатывать LLM/VLM, насчитывающие до 7 млрд параметров. В частности, таким моделям требуется примерно 3,5 Гбайт памяти при использовании режимов INT4/FP4. Говорится о совместимости с фреймворками PyTorch, ONNX и TensorFlow, а также форматом HuggingFace GGUF (GPT-Generated Unified Format). 
Источник изображений: CNX Software ИИ-ускоритель спроектирован для применения в связке с такими процессорами Rockchip, как RK3576/RK3588 и другими, вероятно, включая решения RK3668 и RK3688, которые были также представлены вчера. Эти чипы содержат собственный интегрированный NPU-модуль с производительностью 6 TOPS или более для обработки ИИ-нагрузок. 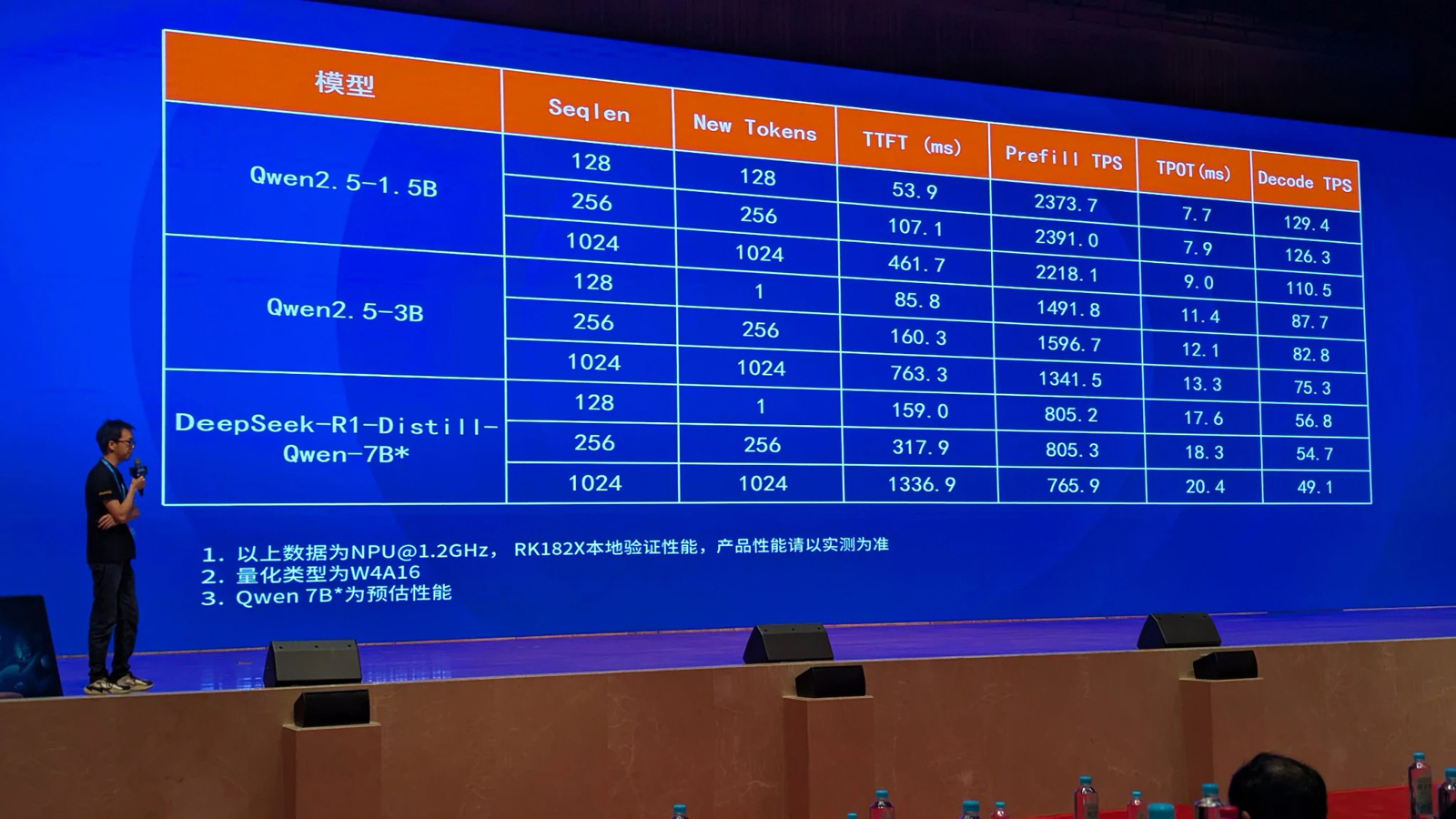 Однако благодаря применению отдельного ускорителя ИИ-быстродействие на определённых задачах может быть повышено в 8–10 раз. Rockchip, в частности, обнародовала скоростные показатели RK182X для таких популярных моделей, как DeepSeek-R1-Distill-Qwen-7B, Qwen2.5-1.5B и Qwen2.5-3B.
16.07.2025 [12:44], Владимир Мироненко
AMD сообщила о грядущем возобновлении поставок MI308 в КитайAMD объявила о планах возобновить поставки ускорителей Instinct MI308 в Китай, разработанных с учётом ограничений США специально для этой страны, после чего акции компании выросли почти на 7 %. «Министерство торговли США недавно сообщило нам, что заявки на получение лицензий на экспорт продукции MI308 в Китай будут переданы на рассмотрение», — сообщили в AMD изданию The Register. «Мы планируем возобновить поставки по мере одобрения лицензий. Мы приветствуем прогресс, достигнутый администрацией Трампа в продвижении торговых переговоров, и её приверженность лидерству США в области ИИ», — подчеркнули в компании. Днём ранее стало известно, что власти США подтвердили готовность дать добро NVIDIA на возобновление отгрузок ускорителей H20 в Китай. Они тоже были созданы с учётом экспортных ограничений Министерства торговли США для этого рынка, но после очередного витка роста напряжённости между Вашингтоном и Пекином администрация США установила запрет на их поставку. Сейчас компания подаёт заявки на получение необходимых экспортных лицензий, которые гарантированно будут одобрены, после чего вновь начнёт поставки. 
Источник изображения: AMD По данным NVIDIA, из-за экспортных ограничений на поставки H20 в Китай, лишние расходы в I квартале 2026 финансового года составили $4,5 млрд. Также было недополучено $2,5 млрд выручки, хотя ранее ожидалось, что потери составят $5,5 млрд. В свою очередь, AMD сообщила в апреле, что из-за ограничений США её потери в 2024 финансовом году составят около $800 млн из-за складских расходов, закупочных обязательств и связанных с ними созданными резервами. Послабления для NVIDIA были предоставлены после встречи на прошлой неделе основателя и гендиректора NVIDIA Дженсена Хуанга (Jensen Huang) с Дональдом Трампом и американскими политиками, в ходе которой ему удалось их убедить в отсутствии угрозы для США поставок этих чипов. Возобновление поставок ускорителей в Китай является отступлением от курса администрации, которая неоднократно утверждала, что ограничения на поставки чипов не подлежат обсуждению, сообщил Bloomberg.
13.07.2025 [11:21], Сергей Карасёв
Французский разработчик фотонных ИИ-чипов Arago получил на развитие $26 млнСтартап Arago, занимающийся созданием фотонных чипов, по сообщению Datacenter Dynamics, провёл «посевной» раунд финансирования на сумму в $26 млн. Полученные средства компания намерена использовать для ускорения разработки и коммерциализации продуктов, а также для расширения штата. Arago базируется в Париже (Франция). Стартап был основан в 2024 году Николасом Мюллером (Nicolas Muller), Элиоттом Сарреем (Eliott Sarrey) и Амбруазом Мюллером (Ambroise Muller). Компания создаёт фотонный ускоритель под названием JEF для ресурсоёмких нагрузок ИИ. Arago заявляет, что в настоящее время развитие ИИ сдерживается возможностями современного оборудования на основе кремния. По мнению стартапа, повышение эффективности и производительности ИИ-систем подразумевает выход за рамки традиционных транзисторных технологий. Предполагается, что изделие JEF на основе фотоники поможет решить существующие проблемы, обеспечив значительное повышение быстродействия в расчёте на 1 Вт и $1 по сравнению с доступными на рынке решениями. 
Источник изображения: Arago В основу чипа положена проприетарная фотонная технология Arago, которая, по утверждениям самой компании, даёт возможность «обойти технические барьеры», традиционно ограничивавшие производительность фотонных процессоров. Стартап подчёркивает, что JEF способен обеспечить десятикратное снижение энергопотребления по сравнению с передовыми ИИ-ускорителями на базе GPU при сопоставимых производительности и стоимости. Говорится о полной совместимости с существующей экосистемой ИИ, вычислительной инфраструктурой и технологическими процессами производства микросхем. Программный стек Arago Carlota может взаимодействовать с фреймворком PyTorch, позволяя разработчикам развёртывать и масштабировать модели ИИ без изменения имеющейся кодовой базы. В раунде финансирования на $26 млн приняли участие Earlybird, Protagonist, Visionaries Tomorrow, Generative IQ и C4 Ventures, а также бывший вице-президент Apple Бертран Серле (Bertrand Serlet), главный управляющий Arm Кристоф Фрей (Christophe Frey) и соучредитель Hugging Face Томас Вольф (Thomas Wolf). На сегодняшний день разработкой фотонных решений для ИИ-систем и дата-центров занимаются и многие другие компании. В их число входят DustPhotonics, Oriole Networks, Lightmatter, Celestial AI, Xscape Photonics, Ayar Labs и пр.
10.07.2025 [13:27], Руслан Авдеев
Количество заказчиков Arm из сферы ЦОД выросло в 14 раз с 2021 годаПо словам Arm, с 2021 года количество заказчиков, использующих в дата-центрах Arm-чипы, выросло в 14 раз до 70 тыс. Под руководством генерального директора компании Рене Хааса (Rene Haas) разработчик полупроводниковых технологий расширяет бизнес работал над продвижением своих решений на рынке ПК и существенно нарастив продажи на рынке чипов для ЦОД, сообщает Reuters. По словам IDC, Arm-чипы постепенно захватывают рынок, но до доминирования на рынке ЦОД им ещё далеко. Как и другие полупроводниковые компании, Arm немало выиграла от ИИ-бума — значительная доля роста в сегменте решений для ЦОД связана именно с ИИ. Компания заявила, что число стартапов, использующих Arm-архитектуру для чипов с 2021 года выросло в 12 раз. Это помогает компании, поскольку сегменты ПК и мобильных решений развиваются весьма медленно. Компания отказалась предоставить годовой финансовый прогноз при публикации последнего отчёта, сославшись на неопределенность на рынках. 
Источник изображения: Arm Ранее рынок ЦОД считался довольно сложным для проникновения на него Arm-технологий, но не так давно AWS, Google и Microsoft занялись разработкой собственных чипов для дата-центров на Arm-архитектуре. Amazon уже представила несколько поколений классических серверных CPU для дата-центров с 2018 года, а также варианты для ИИ-задач — с тех пор она добавила миллионы чипов на базе Arm для обслуживания своей облачной платформы. Пользователи некоторых сервисов могут даже не знать, что их задачи обрабатываются Arm-процессорами Amazon. Для успеха компании, создающей полупроводниковые технологии, необходимо, чтоб их поддерживали разработчики приложений по всему миру. По данным Arm, компания с 2021 года добилась приблизительного удвоения числа приложений, работающих на Arm-процессорах — приблизительно до 9 млн. Количество разработчиков, работающих с вычислительной архитектурой Arm, увеличилось с 2021 года в 1,5 раза до 22 млн человек. |
|