Материалы по тегу: ускоритель
|
09.07.2025 [16:30], Руслан Авдеев
SambaManaged превратит почти любой ЦОД в ИИ ЦОД всего за три месяцаРазработчик ИИ-ускорителей SambaNova анонсировал решение SambaManaged на базе SN40L. Это первый в отрасли продукт, оптимизированный для инференса, внедрить который можно всего за 90 дней — намного быстрее, чем обычно требуется для систем такого уровня (18–24 мес.), говорит компания. Модульная платформа разработана специально для быстрого развёртывания и позволяет существующим дата-центрам почти немедленно организовать ИИ-инференс с минимальными модификациями инфраструктуры. По мере того, как стремительно растёт спрос на ИИ-задачи, связанные именно с инференсом, традиционные дата-центры сталкиваются с новыми проблемами — на внедрение систем, оптимизированных для таких задач, требуется от полутора до двух лет, много энергии, а также дорогостоящие обновления оборудования. Решение SambaManaged позволяет устранить эти барьеры, быстро развернув прибыльные инференс-сервисы, используя уже имеющуюся силовую и сетевую инфраструктуру. 
Источник изображений: SambaNova SambaManged формируется из стоек SambaRack SN40L-16, каждая из которых включает 16 ускорителей (RDU в терминологии SambaNova) SN40L с BF16-производительностью 10,2 Тфлопс. Платформа оснащена двумя 64-ядерными хост-процессорами, 2 Тбайт DDR4, четырьмя загрузочными 960-Гбайт SSD (RAID1 + два hot-spare) и шестью 7,6-Тбайт NVMe SSD в RAID10 для данных. Энергопотребление составляет всего 7–14,5 кВт (типовое 10 кВт). Стойка весит 485 кг. Рабочая температура — от +15 до +30 °C. Фактически это переименованная платформа DataScale SN40L, только теперь разработчик не говорит о возможности обучения моделей. Как подчёркивают в SambaNova, дата-центры сталкиваются с проблемами энергоснабжения и охлаждения, недостатком компетенций и др. на фоне роста спроса на ИИ. Система SambaManaged обеспечивает высокую ИИ-производительность при низком энергопотреблении и минимальных изменениях инфраструктуры. Преимуществами для ЦОД и облачных провайдеров называются рекордная производительность на каждый затраченный Вт, позволяющая снизить совокупную стоимость владения (TCO) и быстрее вернуть инвестиции. Систему можно внедрить всего за 90 дней. При этом обеспечивается невероятно быстрый инференс с ведущими open source моделями, что позволяет избежать привязки к конкретному вендору и гарантирует совместимость с будущими технологиями. Модульный дизайн позволяет быстро строить даже большие инференс-системы, включая т.н. Token Factory мощностью до 1 МВт (100 стоек). Систему можно масштабировать по мере изменения бизнес-потребностей. Можно выбрать полностью управляемое решение или взять на себя часть контроля за операциями.  SambaManaged уже внедряется крупной публичной компанией в США, потребляющей немало энергии. Платформа обеспечивает максимальную пропускную способность для моделей вроде DeepSeek и ей подобных, помогая клиентам увеличивать доход от инференса и оптимизировать энергоэффективность (PUE). В SambaNova заявляют, что SambaManaged меняет правила игры для организаций, желающих ускорить реализацию ИИ-проектов без ущерба скорости, масштабу или эффективности. Везде, где есть доступ к Сети и электроэнергии, можно обеспечить необходимую инфраструктуру в рекордные сроки. В конце июня 2025 года сообщалось, что SambaNova делает ставку на инференс и партнёрство с облачными провайдерами и госзаказчиками из США. Groq, ещё один поставщик решений для инференса, первым сменил бизнес-подход, отказавшись от продажи ускорителей в пользу формирования целых ИИ ЦОД. Cerebras совместно с партнёрами также создаёт крупные ИИ-суперкомпьютеры и кластеры.
06.07.2025 [00:44], Владимир Мироненко
Esperanto, создатель уникального тысячеядерного RISC-V-ускорителя, закрывается — всех инженеров переманили крупные компанииСтартап Esperanto, специализирующийся на разработке серверных ускорителей на базе архитектуры RISC-V, сворачивает свою деятельность, сообщил ресурс EE Times. В настоящее время компания, которую уже покинуло большинство сотрудников, ищет покупателя на свои технологии или заинтересованных в лицензировании её разработок. Компания известна созданием тысячеядерного ИИ-ускорителя ET-SoC-1. Генеральный директор Esperanto Арт Свифт (Art Swift) сообщил EE Times о закрытии дочерних предприятий в Европе — у неё была значительная инженерная команда в Испании и ещё одна небольшая в Сербии. В штаб-квартире Esperanto в Маунтин-Вью (Калифорния) численность персонала сократилась на 90 %. Свифт и еще несколько инженеров остались, чтобы продать или лицензировать разработки компании и содействовать любой потенциальной передаче технологий. По словам Свифта, компания подверглась атаке со стороны богатых конкурентов, которые предлагали зарплату «в два, три, даже в четыре раза выше», чем могла предложить небольшая Esperanto. «Они фактически уничтожили наши команды — очень жаль, но мы не смогли конкурировать с ними», — говорит Свифт, отмечая, что уже несколько компаний проявило интерес к приобретению технологии или её лицензированию на неисключительной основе. Он добавил, что у Esperanto был крупный клиент, которому есть что предложить, что добавляет оптимизма. Ранее компания, судя по всему, пыталась предложить свои чипы Meta✴. 
Источник изображения: Esperanto Technologies Интерес рынка к RISC-V для чипов ЦОД остаётся высоким, особенно в Европе, где инвестирует в новую экосистему чипов на основе RISC-V. Вместе с тем именно ключевое преимущество разработок Esperanto — энергоэффективность — оказалось труднореализуемым, говорит гендиректор: «При неограниченном бюджете на электроэнергию энергоэффективность на самом деле не имеет значения». Esperanto готовила к выпуску чиплет второго поколения, который должен был поступить в производство на мощностях Samsung по 4-нм техроцессу в 2026 году. Чиплет предложил бы до 16 Тфлопс в FP64-вычислениях или до 256 Тфлопс в FP8-расчётах при потреблении 15–60 Вт. В один чип можно объединить до восьми чиплетов. Третье поколение технологии удвоило бы вычислительную мощность чиплетов. «Компании действительно были заинтересованы в получении этой технологии, так что посмотрим», — говорит Свифт. В прошлом году Esperanto договорилась с корпорацией NEC о сотрудничестве в области НРС с целью создания программных и аппаратных решений следующего поколения с архитектурой RISC-V. Также сообщалось о разработке чипа ET-SoC-2 для НРС и ИИ-задач. На пике развития штат Esperanto составлял 140 человек. По словам Свифта, 95 % бывших сотрудников стартапа уже нашли новую работу. В аналогичной ситуации оказалась Codasip, объявившая о готовности продать свои активы, поскольку обострение конкуренции на рынке RISC-V и отсутствие достаточного запаса средств ограничивают возможности небольших компаний, которые зачастую не могут конкурировать с IT-гигантами. ИИ-стартап Untether AI тоже провалил тест на выживание, объявив о закрытии бизнеса после того, как AMD переманила ряд его ведущих специалистов.
29.06.2025 [00:20], Сергей Карасёв
Speedata представила ускоритель анализа данных и привлекла на развитие $44 млнСтартап Speedata, занимающийся разработкой специализированных чипов для ускорения аналитики данных, провёл раунд финансирования Series B, в ходе которого на развитие получено $44 млн. В общей сложности на сегодняшний день компания привлекла $114 млн. Speedata разработала аналитический сопроцессор (Analytics Processing Unit, APU) под названием Callisto. Утверждается, что в случае рабочих нагрузок Apache Spark это изделие способно обеспечить 100-кратный прирост производительности по сравнению с CPU. Если сравнивать с GPU, то разработчик обещает сокращение капитальных затрат на 91 %, экономию пространства на 94 % и уменьшение потребления электроэнергии на 86 %. Особенность Callisto — использование относительно новой архитектуры CGRA, в разработке которой принимали участие основатели Speedata. Подобно программируемым пользователем вентильным матрицам (FPGA) решения с архитектурой GCRA можно настроить на выполнение определённых задач с максимальной эффективностью. При этом в случае Callisto устранены ограничения с обработкой логики ветвления, с которыми могут сталкиваться GPU, говорит компания. Кроме того, Callisto содержит ряд других оптимизаций для повышения производительности при аналитике данных. 
Источник изображения: Speedata Чип Callisto является основой серверного ускорителя C200. Это решение выполнено в виде карты расширения с интерфейсом PCIe 5.0 х16. Новинка обеспечивает ускорение операций, связанных с аналитикой данных на аппаратном уровне, снижая нагрузку на CPU. Speedata обещает «революционное соотношение цены и производительности», а также возможность обработки огромных массивов информации в рекордно короткие сроки. В систему типоразмера 2U могут быть установлены две карты C200. В качестве примера возможностей новинки компания Speedata приводит обработку некой рабочей нагрузки в фармацевтической области. С использованием APU задача была выполнена за 19 минут по сравнению с 90 часами при применении неспециализированного процессора. Таким образом, обеспечено ускорение в 280 раз. В раунде финансирования Series B приняли участие Walden Catalyst Ventures, 83North, Koch Disruptive Technologies, Pitango First и Viola Ventures, а также ряд стратегических инвесторов, в число которых вошли генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) и соучредитель Mellanox Technologies Эяль Вальдман (Eyal Waldman). Деньги будут направлены на дальнейшее развитие технологии.
21.06.2025 [08:41], Руслан Авдеев
Через 10 лет ИИ-ускорители получат терабайты HBM и будут потреблять 15 кВт — это изменит подход к проектированию, питанию и охлаждению ЦОДИИ-чипы нового поколения не просто будут быстрее — они станут потреблять беспрецедентно много энергии и потребуют кардинально изменить инфраструктуру ЦОД. По данным учёных, к 2035 году энергопотребление ИИ-ускорителей может вырасти до порядка 15 кВт, из-за чего окажется под вопросом способность инфраструктуры современных ЦОД обслуживать их, сообщает Network World. Исследователи лаборатории TeraByte Interconnection and Package Laboratory (TeraLab), подведомственной Корейскому институту передовых технологий (KAIST), подсчитали, что переход к HBM4 состоится в 2026 году, а к 2038 году появится уже HBM8. Каждый этап развития обеспечит повышение производительности, но вместе с ней вырастут и требования к питанию и охлаждению. В лаборатории полагают, что мощность только одного GPU вырастет с 800 Вт до 1200 Вт к 2035 году. В сочетании с 32 стеками HBM, каждый из которых будет потреблять 180 Вт, общая мощность может увеличиться до 15 360 Вт (в таблице ниже дан расчёт для стеков HBM8, а не HBM7 — прим. ред.). Ожидается, что отдельные модули HBM8 обеспечат ёмкость до 240 Гбайт и пропускную способность памяти до 64 Тбайт/с. В рамках ускорителя можно суммарно получить порядка 5–6 Тбайт HBM с ПСП до 1 Пбайт/с. Это приведёт к изменению конструкции самого ускорителя. Ключевым элементом становятся стеки HBM — процессоры, контроллеры и ускорители будут интегрированы в единую подложку с HBM-модулями. Возможен переход к 3D-упаковке с использованием двусторонних интерпозеров-подложек или даже нескольких интерпозеров на разных «этажах» кристаллов. 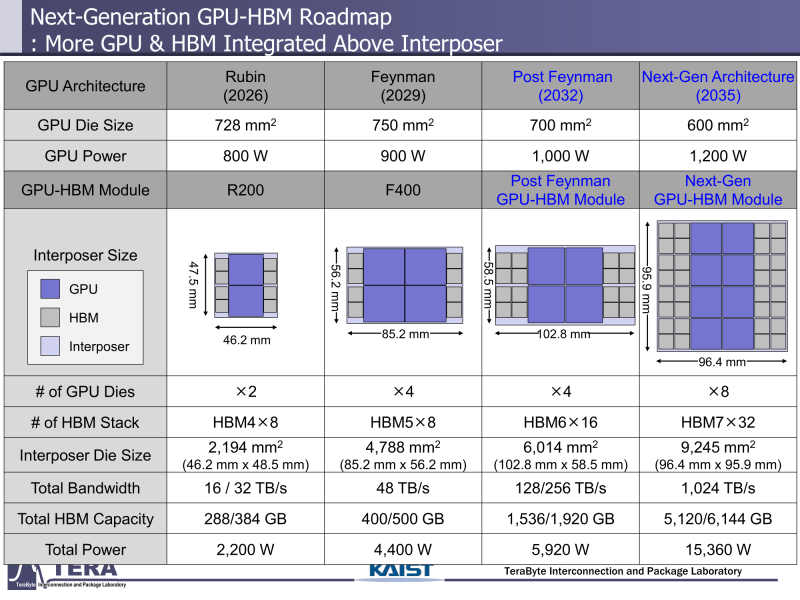
Источник изображений: KAIST Кроме того, для ускорителей придётся разработать и новые системы охлаждения. К уже традиционным прямому жидкостному охлаждению (DLC) и погружным СЖО, вероятно, придётся добавить системы теплоотвода, интегрированные непосредственно в корпуса чипов. Также будут использоваться «жидкостные сквозные соединения» (F-TSVs) для отвода тепла из многослойных чипов, «бесстыковые» соединения Cu–Cu, термодатчики в кристаллах и интеллектуальные системы управления, позволяющие чипам адаптироваться к температурным изменениям. 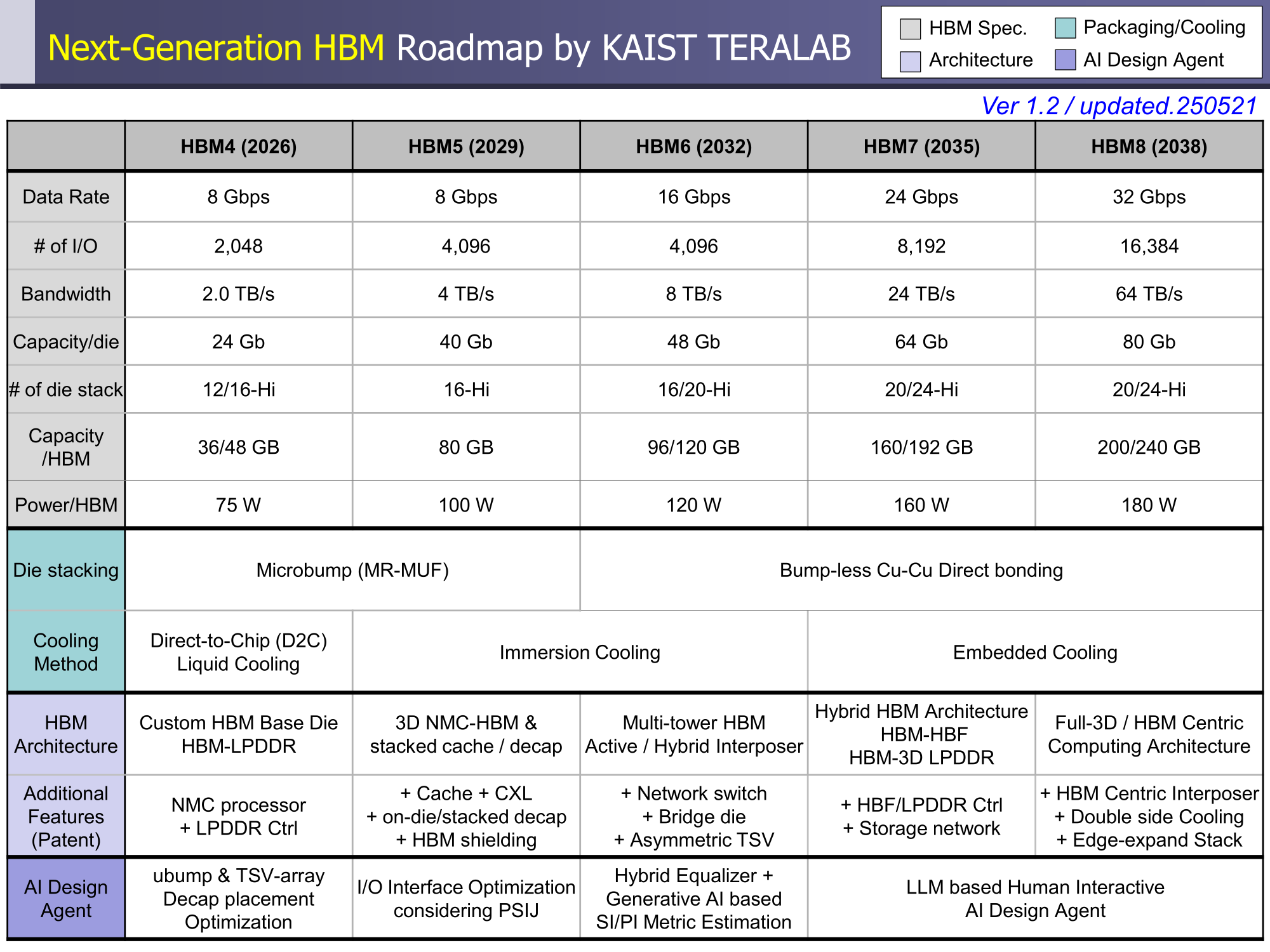 На уровне ЦОД изменится и контур охлаждения, и температурное зонирование всего объекта. В KAIST подчёркивают, что высокую плотность размещения мощностей объекты в большинстве регионов попросту не смогут поддерживать. Пока гиперскейлеры резервируют гигаватты на десятилетия вперёд, региональным коммунальным службам потребуется 7–15 лет на модернизацию ЛЭП. А где-то этого может и не произойти. Так, в Дублине (Ирландия) по-прежнему действует мораторий на строительство новых ЦОД, во Франкфурте-на-Майне похожий запрет действует до 2030 года, а в Сингапуре сегодня доступно всего лишь 7,2 МВт. 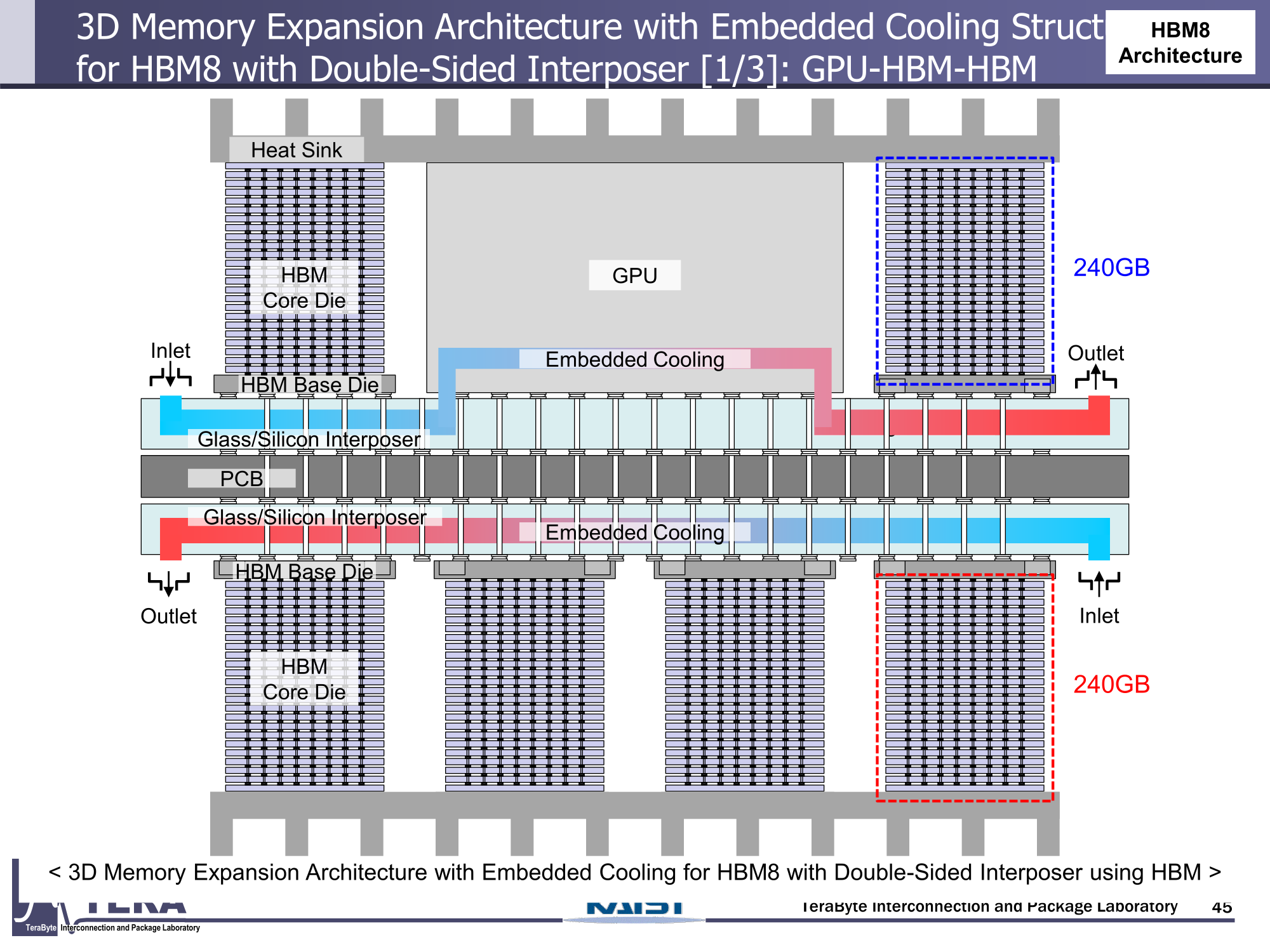 Как считают эксперты, электричество превратилось из одной из статей расходов в определяющий фактор — от его доступности будет зависеть сама возможность реализации ИИ-проектов. На электричество приходится 40-60 % операционных расходов в современной инфраструктуре ИИ, облачной и локальной. Как отмечают в TechInsights, один 15-кВт ускоритель при круглосуточной работе может «съедать» энергии на $20 тыс./год, и это без учёта стоимости охлаждения. 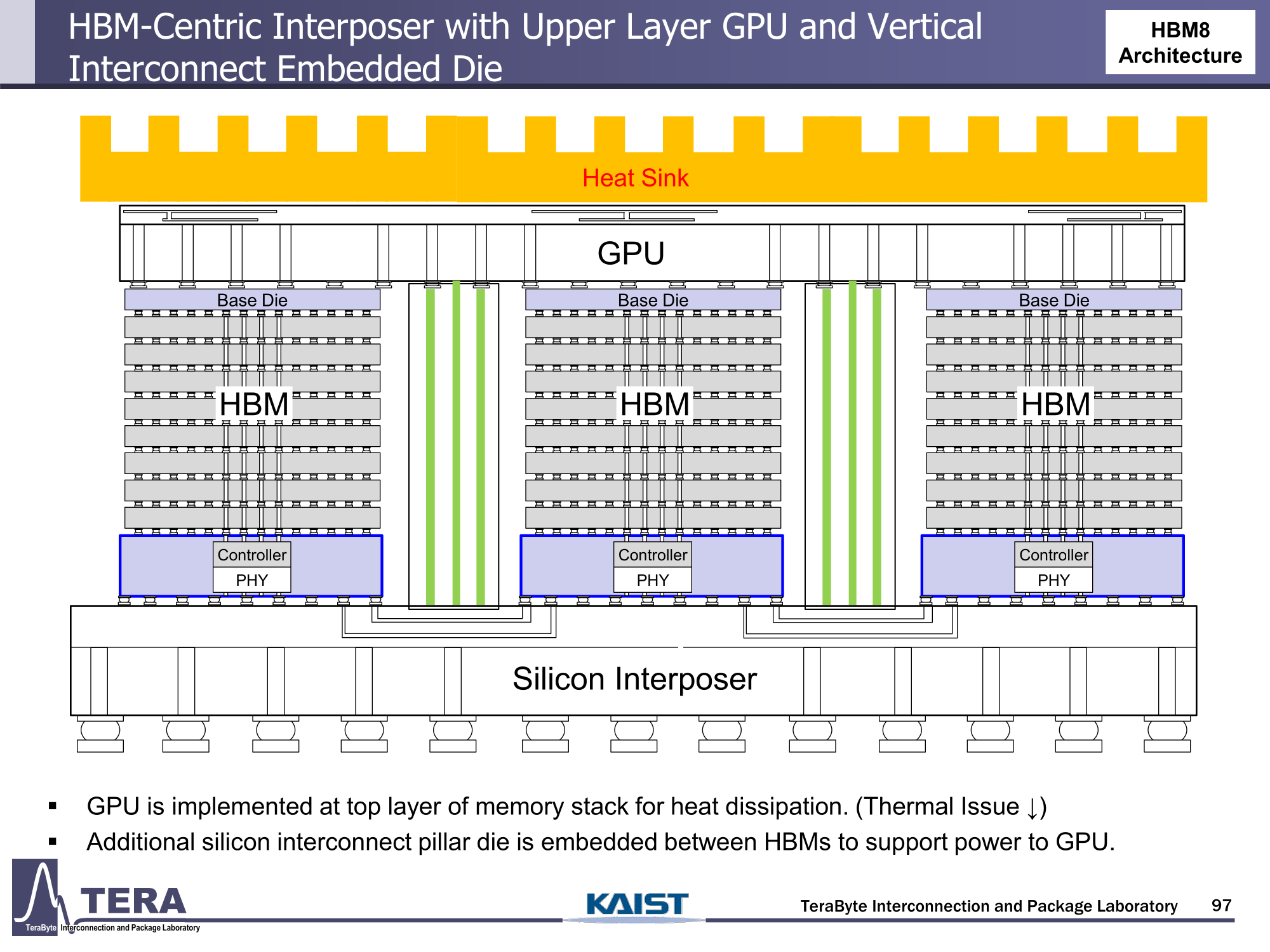 Компании уже вынуждены пересматривать стратегии развёртывания инфраструктуры, учитывая соответствие регуляторным требованиям, региональные тарифы на электроэнергию и др. Гиперскейлеры получают дополнительное преимущество благодаря более низкому PUE, доступу к возобновляемой энергии и оптимизированным схемам закупки энергии. В новой реальности производительность измеряется не только в долларах или флопсах, но и киловаттах. 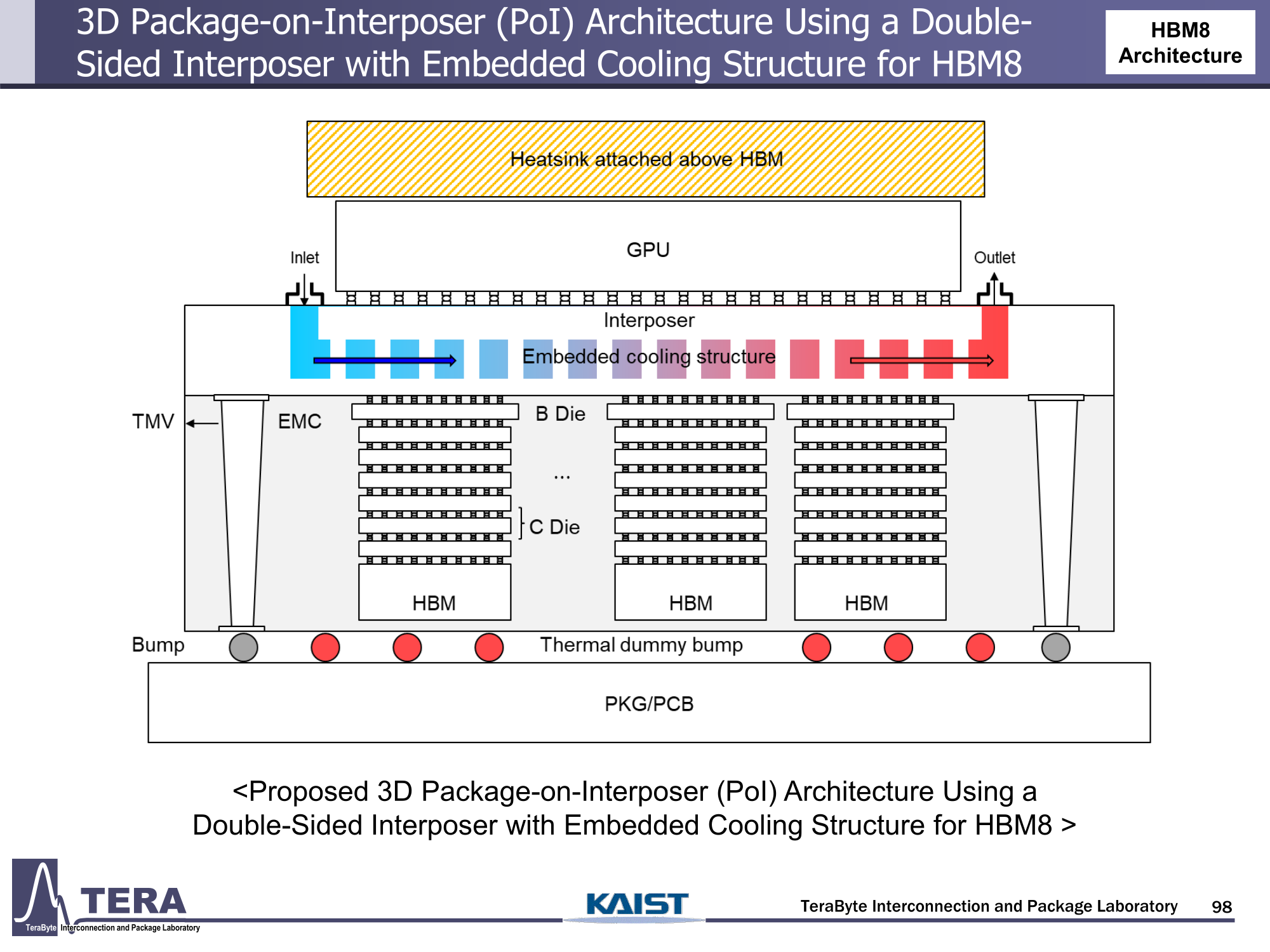 Более того, меняется география рынка ЦОД. Богатые энергией регионы вроде США, Скандинавии или стран Персидского залива привлекают всё больше инвестиций для строительства дата-центров, а регионы со слабыми энергосистемами рискуют превратиться в «ИИ-пустыни», в которых масштабировать мощности невозможно. 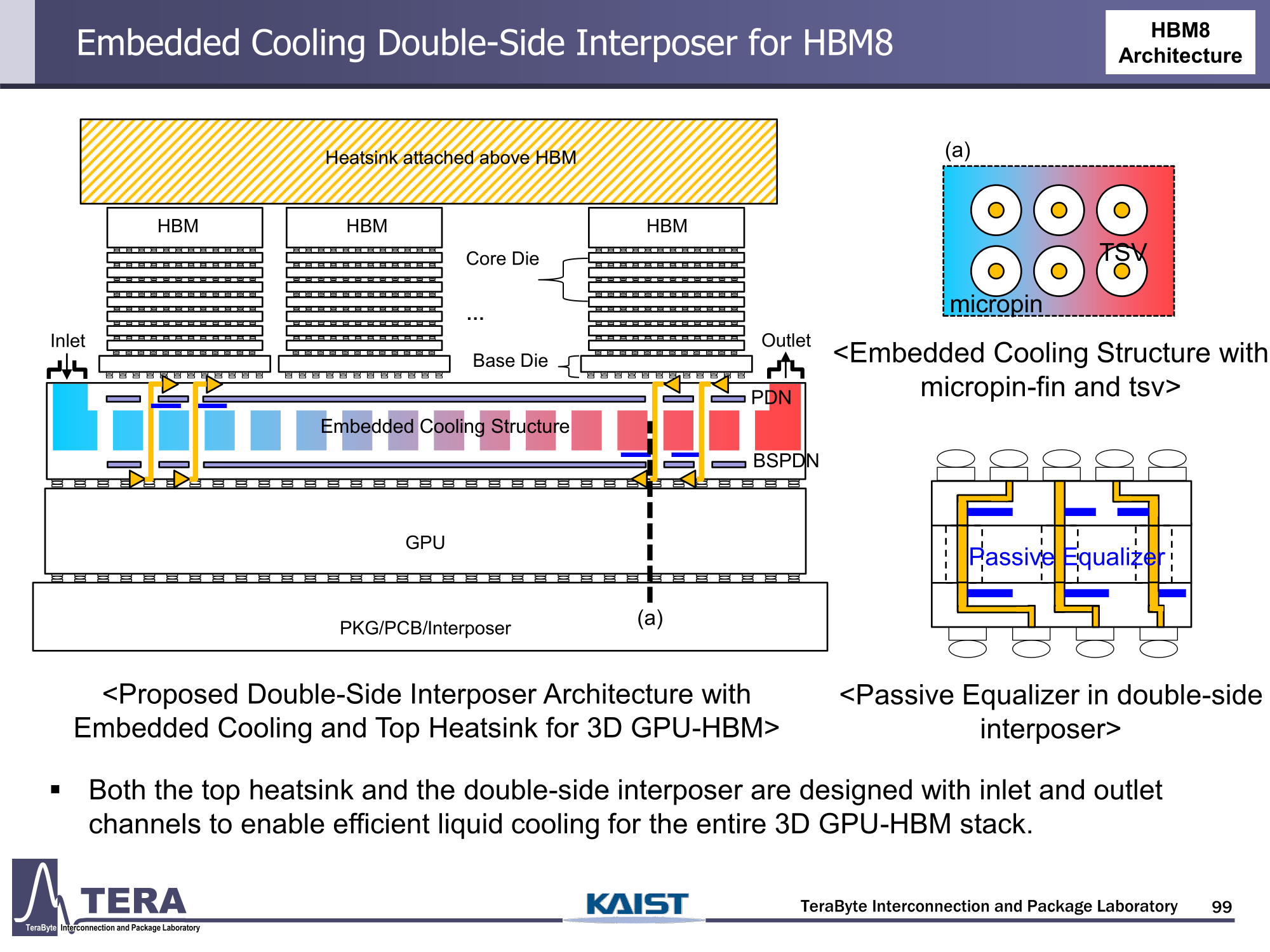 Строителям ИИ-инфраструктуры теперь придётся уделять очень много внимания вопросам энергетики: расходами на электричество, наличие источников энергии, прозрачностью выбросов, близостью ЦОД к электросетям и др. Буквально на днях американский регулятор NERC, отвечающий за надзор за электросетями и сопутствующей инфраструктурой в США, заявил, что подключение к сетям ЦОД в настоящее время весьма рискованно из-за непредсказуемости ЦОД.
19.06.2025 [11:21], Сергей Карасёв
AWS готовит чип Graviton и ускоритель Trainium следующего поколенияОблачная платформа Amazon Web Services (AWS), по сообщению ресурса CNBC, готовит обновлённую модификацию своего серверного процессора Graviton4, а также ускоритель Trainium следующего поколения, предназначенный для ресурсоёмких приложений ИИ. Оригинальная версия Graviton4 дебютировала в конце 2023 года. Изделие, разработанное подразделением Annapurna Labs в составе AWS, содержит 96 ядер Neoverse V2 Demeter с 2 Мбайт кеша L2 в расчёте на ядро. Используются 12 каналов памяти DDR5-5600. В общей сложности чип насчитывает 73 млрд транзисторов и изготавливается по 4-нм техпроцессу TSMC. По имеющейся информации, у инстансов на базе обновлённой версии Graviton4 пропускная способность сетевой подсистемы увеличится в 12 раз — с нынешних 50 Гбит/с до 600 Гбит/с. Прочие технические характеристики готовящегося изделия не раскрываются, но известно, что информацию о сроках его доступности AWS раскроет до конца текущего месяца. 
Источник изображения: AWS Сообщается также, что ускоритель Trainium следующего поколения выйдет до конца текущего года. Нынешнее решение Trainium2, основанное на ядрах NeuronCore-V3, было представлено в ноябре 2023-го. Его производительность достигает 1,29 Пфлопс в режиме FP8. Утверждается, что быстродействие Trainium3 увеличится в два раза, то есть будет составлять до 2,58 Пфлопс (FP8). Ранее появлялась информация, что энергопотребление Trainium3 может достигать 1000 Вт. Теперь говорится, что в плане энергетической эффективности ИИ-ускоритель нового поколения на 50 % превзойдёт предшественника. Возможно, имеется в виду быстродействие в расчёте на 1 Вт затрачиваемой энергии.
19.06.2025 [09:27], Владимир Мироненко
ИИ — это не только GPU: Marvell проектирует полсотни кастомных чипов для ЦОДПоскольку провайдеры облачных сервисов, ИИ-стартапы и суверенные субъекты масштабируют свои ЦОД, Marvell видит растущий спрос не только на основное вычислительное оборудование, включая пользовательские CPU, GPU и ускорители, но и на широкий спектр вспомогательных полупроводниковых элементов, включая контроллеры сетевых интерфейсов, чипы управления питанием, устройства расширения памяти и т.д., пишет Converge Digest. В ходе мероприятия для инвесторов AI Investor Day 2025 гендиректор Мэтт Мерфи (Matt Murphy) обрисовал растущую роль компании в поддержке ИИ-инфраструктуры, отметив два ключевых события, формирующих рынок: рост числа новых разработчиков ИИ-инфраструктуры за пределами традиционных четырёх ведущих гиперскейлеров и быстрое появление компонентов XPU Attach как важной новой категории кастомных полупроводников. Мерфи отметил, что эти тенденции способствуют формированию гораздо более крупного и разнообразного общего целевого рынка, чем прогнозировалось ранее. 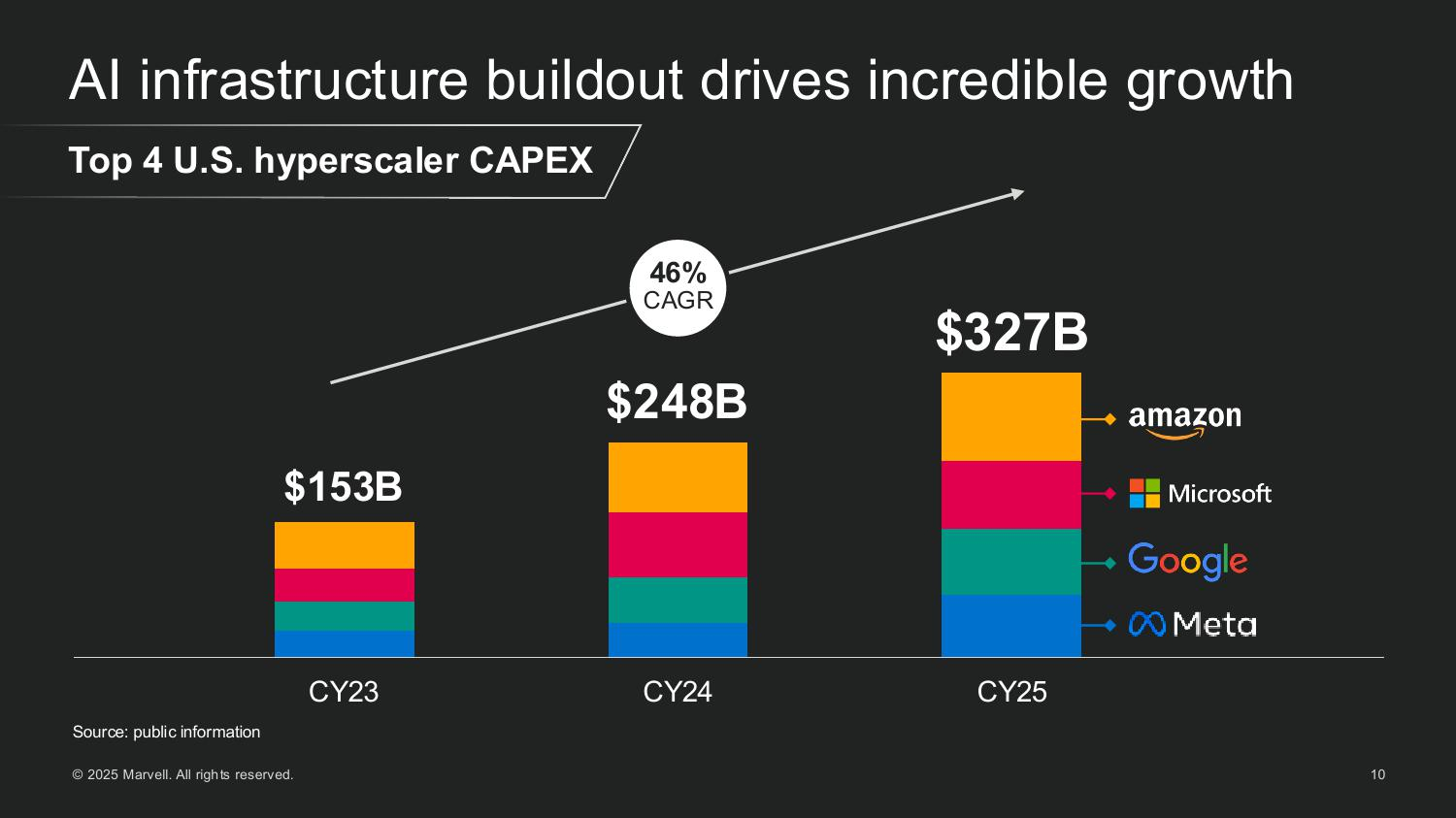
Источник изображений: Marvell Мерфи рассказал, как резко выросли глобальные капитальные затраты на ЦОД, обусловленные ростом гиперскейлеров и развитием суверенного ИИ. Ведущие американские гиперскейлеры — AWS, Microsoft, Google и Meta✴ — увеличили совокупные капитальные затраты со $150 млрд в 2023 году до более чем $300 млрд в 2025 году. По прогнозам, на глобальном уровне к 2028 году затраты превысят уже $1 трлн. Marvell считает, что значительная часть этих расходов будет направлена на кастомные полупроводниковые платформы. 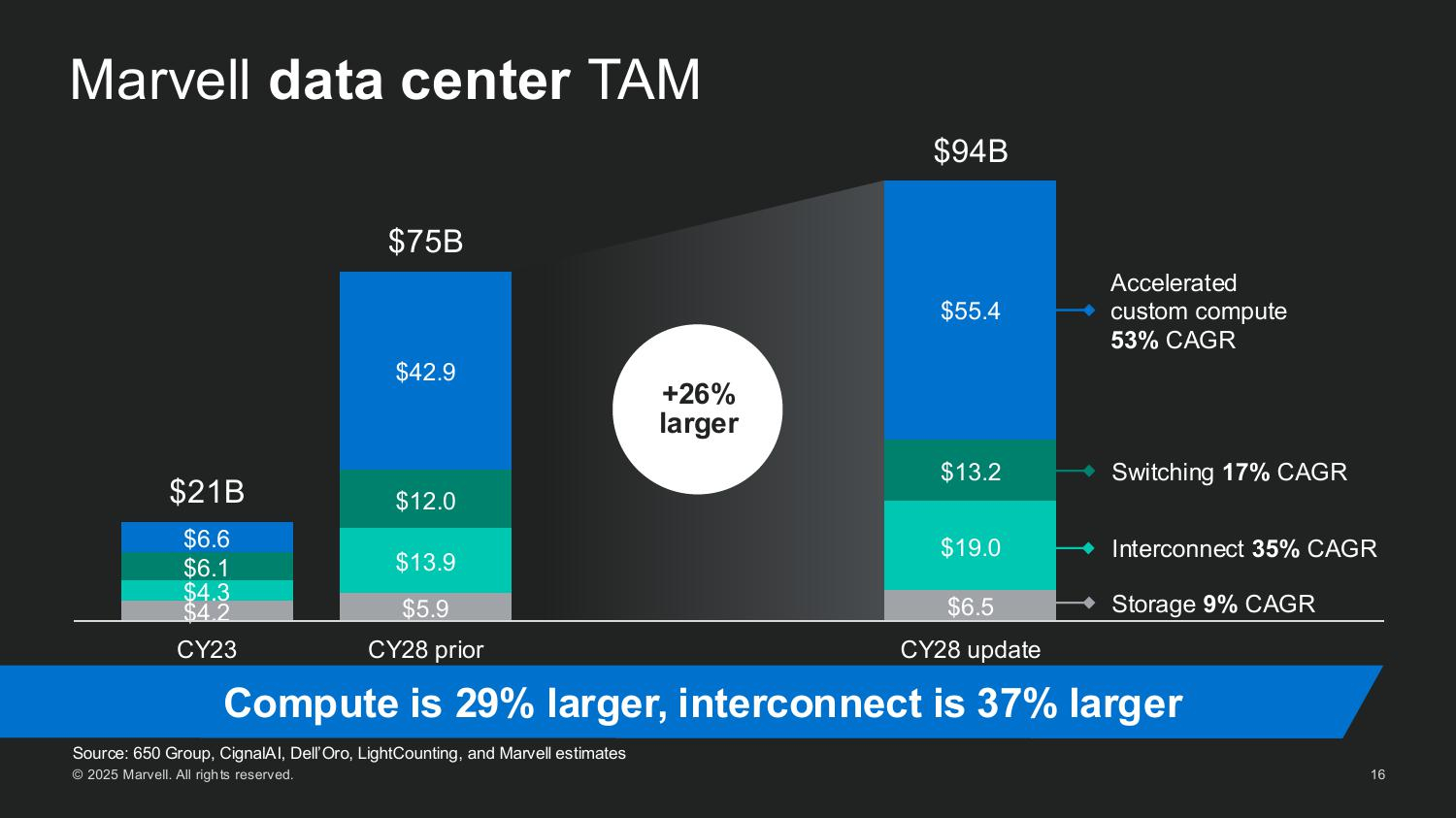 Marvell пересмотрела прогноз общего целевого рынка (TAM) в сторону увеличения до $94 млрд к 2028 году, что на 25 % больше её оценки в прошлом году. Эта сумма включает:
Мерфи подчеркнул, что XPU Attach — прорывная категория, отметив, что «вычислительные ИИ-платформы больше не определяются одним чипом. Это сложные системы с бурным ростом числа сокетов — каждый из которых представляет собой новую возможность [для компании]».  «В прошлом году у нас было три кастомных вычислительных чипа и TAM на $75 млрд. В этом году у нас 18 сокетов, TAM на $94 млрд и растущий поток из более чем 50 проектов. Рынок ИИ-инфраструктуры быстро развивается, и Marvell находится прямо в его центре», — подытожил Мерфи. 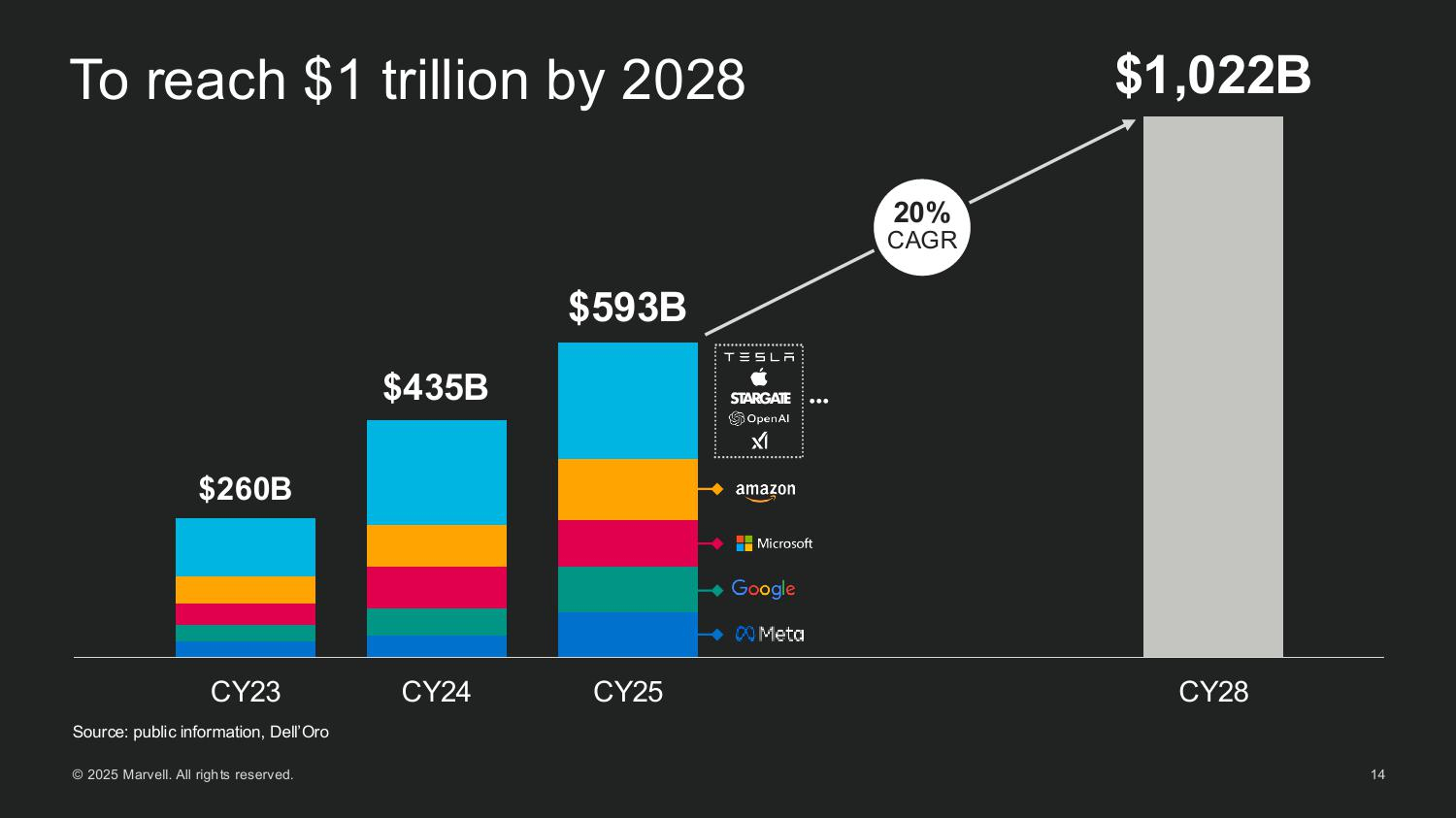 Marvell на сегодняшний день обеспечила разработку 18 кастомных чипов:
Marvell сопровождает более 50 активных кастомных полупроводниковых проектов — сочетание XPU и Attach — с более чем 10 клиентами. Среди них облачные гиперскейлеры, новые ИИ-стартапы и национальные ИИ-инициативы. По оценкам компании, эти проекты принесут $75 млрд потенциального дохода за весь срок их реализации, и это без учёта 18 уже готовых проектов. 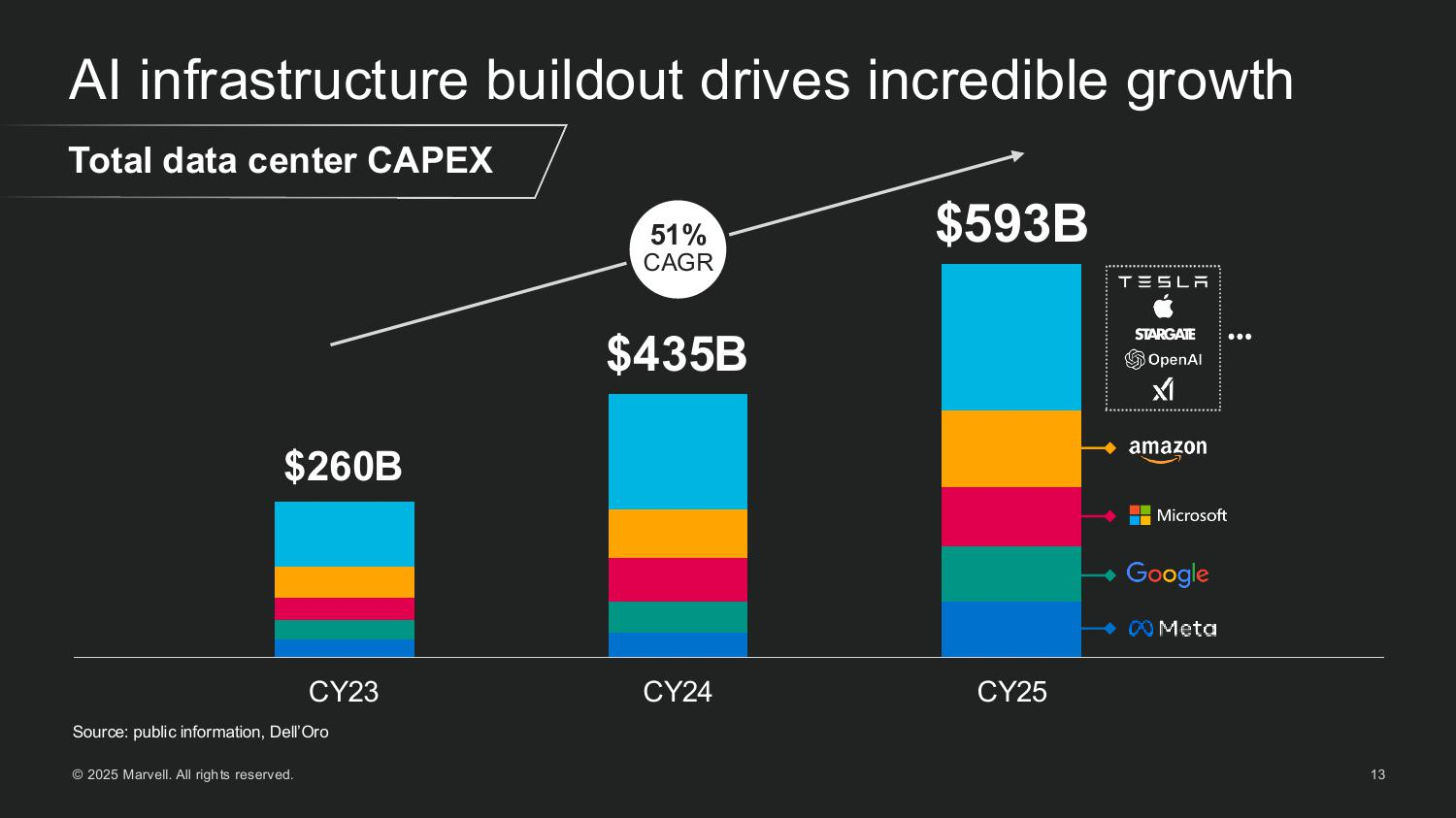 Мерфи подчеркнул, что на этом рынке больше не доминирует несколько «мегасокетов». «Ещё в 2023 году на один сокет приходилось 75 % TAM. К 2028 году ни один сокет не будет превышать 10–15 %. Это огромная диверсификация — и она отлично подходит для нас», — сообщил глава Marvell.
16.06.2025 [09:20], Владимир Мироненко
x86 не нужен: «недопроцессор» NeuReality NR1 кратно ускоряет инференс на любых GPUNeuReality объявила о выходе чипа NR1, специально созданного для оркестрации инференса, передаёт HPCwire. Он сочетается с любым GPU или ИИ-ускорителем, позволяя повысить эффективность использование GPU почти до 100 % по сравнению со средним показателем в 30–50 % при традиционном сочетании классического процессора и сетевого адаптера в современных серверах. Чип NR1 призван заменить традиционные CPU и NIC, которые являются узким местом для ИИ-нагрузок, предлагая вместе с тем шестикратное увеличение вычислительной мощности для обеспечения максимальной пропускной способности ускорителей и масштабного ИИ-инференса, утверждает разработчик. Как отметила компания, в течение многих лет разработчики развивали GPU, чтобы соответствовать требованиям ИИ, делая их быстрее и мощнее. Но традиционные CPU, разработанные для эпохи интернета, а не эпохи ИИ, в основном не менялись, становясь узким местом, поскольку ИИ-модели становятся всё более сложными, а запросы ИИ-нагрузок растут в объёме. 
Источник изображений: NeuReality NR1 включает все базовые функции CPU, необходимые для работы с ИИ-задачами, выделенные обработчики мультимедиа и данных, аппаратный гипервизор и комплексные сетевые IP-блоки, что обеспечивает значительно более высокую производительность, более низкое энергопотребление и окупаемость инвестиций. В тестах самой компании исполнение одной и той же модели на базе генеративного ИИ на одном и том же ИИ-ускорителе её чип NR1 позволяет получить в 6,5 раза больше токенов, чем x86-сервер при той же стоимости и энергопотреблении. 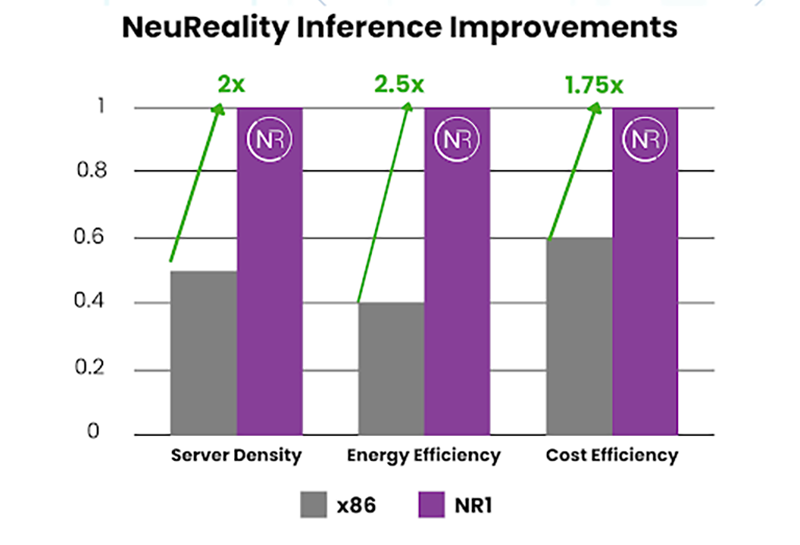 В соответствии с текущей тенденцией на разделение ресурсов хранения и вычислений, дезагрегация ИИ-ресурсов обеспечивает оптимизированную изоляцию ИИ-вычислений, отметила NeuReality. Такое разделение особенно важно в ЦОД и облаках. Традиционные программно-управляемые платформы, ориентированные на CPU, сталкиваются с такими проблемами, как высокая стоимость, энергопотребление и узкие места в системе при обработке задач ИИ-инференса. Сложность современной инфраструктуры и высокая стоимость часто ограничивают использование всех возможностей инференса, утверждает NeuReality. 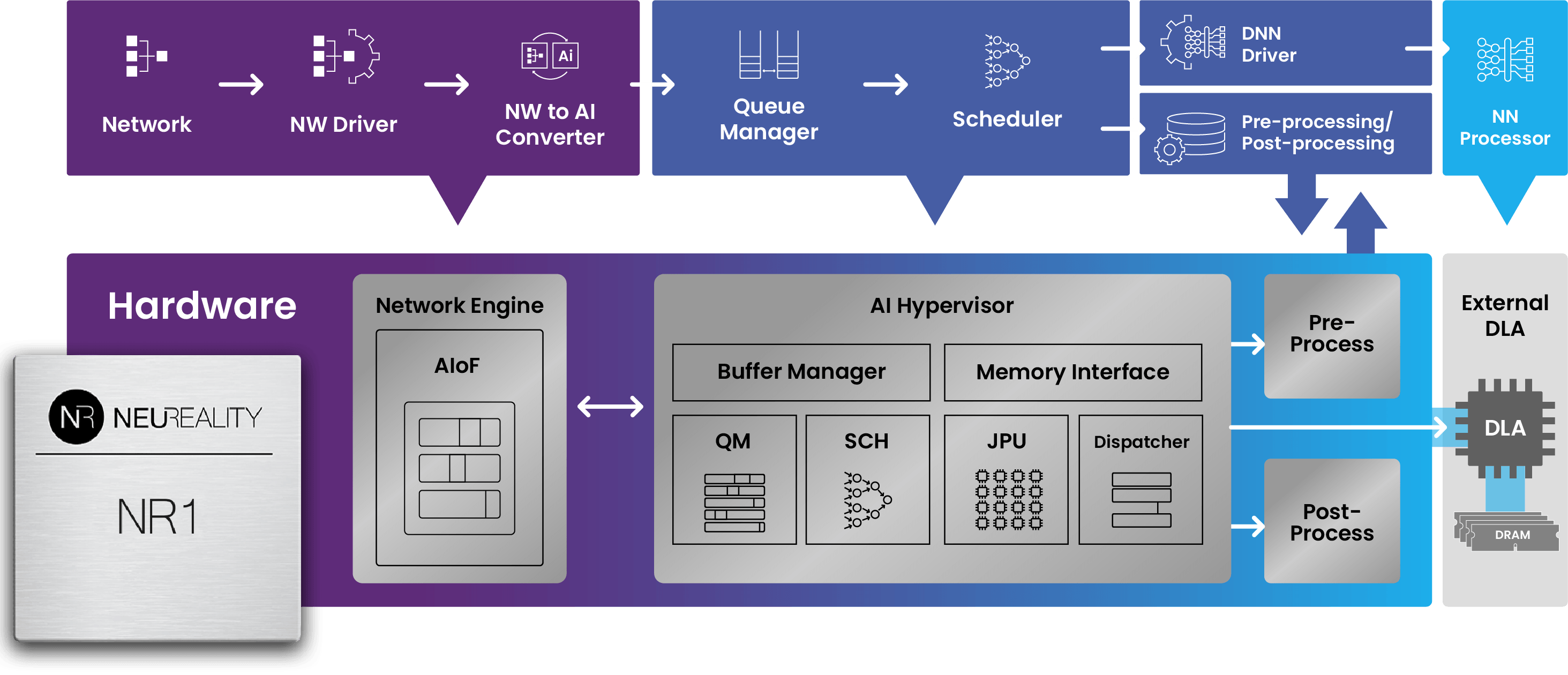 NR1 ориентирован на комплексную разгрузку ИИ-конвейера. Аппаратный ИИ-гипервизор отвечает за обработку путей данных и планирование заданий, охватывая механизмы пред- и постобработки данных, а также сетевой движок AI-over-Fabric. Благодаря этому достигнуто оптимальное соотношение цены и производительности и самые низкие эксплуатационные расходы, характеризующиеся низким энергопотреблением, минимальной задержкой и линейной масштабируемостью, говорит компания. Для DevOps и MLOps компания предоставляет полный SDK и сервисный слой на основе Kubernetes. Новый чип предлагается использовать для решения задач в сфере финансов и страхования, здравоохранении и фармацевтике, госуслугах и образовании, телекоммуникации, ретейле и электронной коммерции, для нагрузок генеративного и агентного ИИ, компьютерного зрения и т.д. NeuReality NR1 включает:
13.06.2025 [02:20], Владимир Мироненко
AMD готовит ИИ-стойки Helios AI двойной ширины с Instinct MI400, AMD EPYC Venice и 800GbE DPU Pensando VulcanoВместе с анонсом ускорителей MI350X и MI355X также рассказала о планах на ближайшее будущее, включая выпуск ускорителей серий MI400 (Altair) в 2026 году и MI500 (Altair+) в 2027 году, а также решений UALink, Ultra Ethernet, DPU Pensando и стоечных архитектур, которые послужат основой ИИ-кластеров. Так, AMD анонсировала новую архитектуру Helios AI с стойками двойной ширины, которая объединит процессоры AMD EPYC Venice с ядрами Zen 6, ускорители Instinct MI400 и DPU Vulcano. Благодаря приобретению ZT Systems компания смогла существенно ускорить разработку и интеграцию решений уровня стойки — Helios AI появятся уже в 2026 году. Как сообщает DataCenter Dynamics, Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер AMD по ЦОД рассказал перед мероприятием, что решение об увеличении ширины стойки было принято в сотрудничестве с «ключевыми партнёрами» AMD, поскольку предложение должно соответствовать «правильной точке проектирования между сложностью, надёжностью и предоставлением преимуществ производительности». По словам AMD, это позволит объединить тысячи чипов таким образом, чтобы их можно было использовать как единую систему «стоечного масштаба». «Впервые мы спроектировали каждую часть стойки как единую систему», — заявила генеральный директор AMD Лиза Су (Lisa Su) на мероприятии, пишет CNBC. 
Источник изображений: AMD Дикманн заявил, что Helios предложит на 50 % больше пропускной способности памяти и на 50 % больше горизонтальной пропускной способности (по сравнению с NVIDIA Vera Rubin), поэтому «компромисс [за счёт увеличения ширины стойки] был признан приемлемым, поскольку крупные ЦОД, как правило, ограничены не квадратными метрами, а мегаваттами». 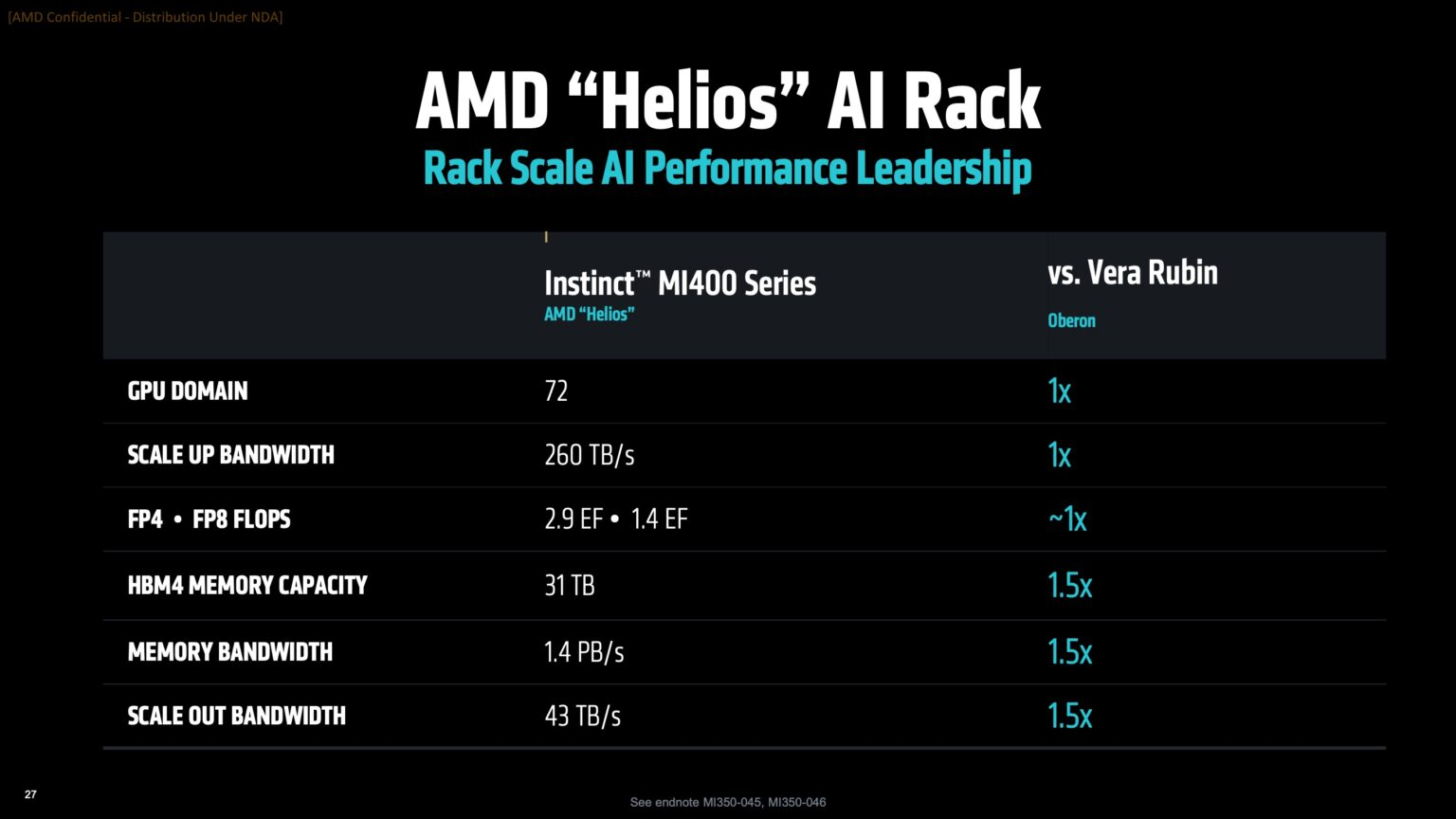 Как указано в блоге компании, «Helios создана для обеспечения вычислительной плотности, пропускной способности памяти, производительности и горизонтального масштабирования, необходимых для самых требовательных рабочих ИИ-нагрузок, в готовом к развёртыванию решении, которое ускоряет время выхода на рынок».  Helios представляет собой сочетание технологий AMD следующего поколения, включая:
 AMD отказалась сообщить стоимость анонсированных чипов, но, по словам Дикманна, ИИ-ускорители компании будут дешевле и в эксплуатации, и в приобретении в сравнении с чипами NVIDIA. «В целом, есть существенная разница в стоимости приобретения, которую мы затем накладываем на наше конкурентное преимущество в производительности, поэтому выходит значительная, исчисляемая двузначными процентами экономия», — сказал он.  AMD ожидает, что общий рынок ИИ-чипов превысит к 2028 году $500 млрд. Компания не указала, на какую долю общего пирога она будет претендовать — по оценкам аналитиков, в настоящее время у NVIDIA более 90 % рынка. Обе компании взяли на себя обязательство выпускать новые ИИ-чипы ежегодно, а не раз в два года, что говорит о том, насколько жёстче стала конкуренция и насколько важны передовые ИИ-технологии для гиперскейлеров. 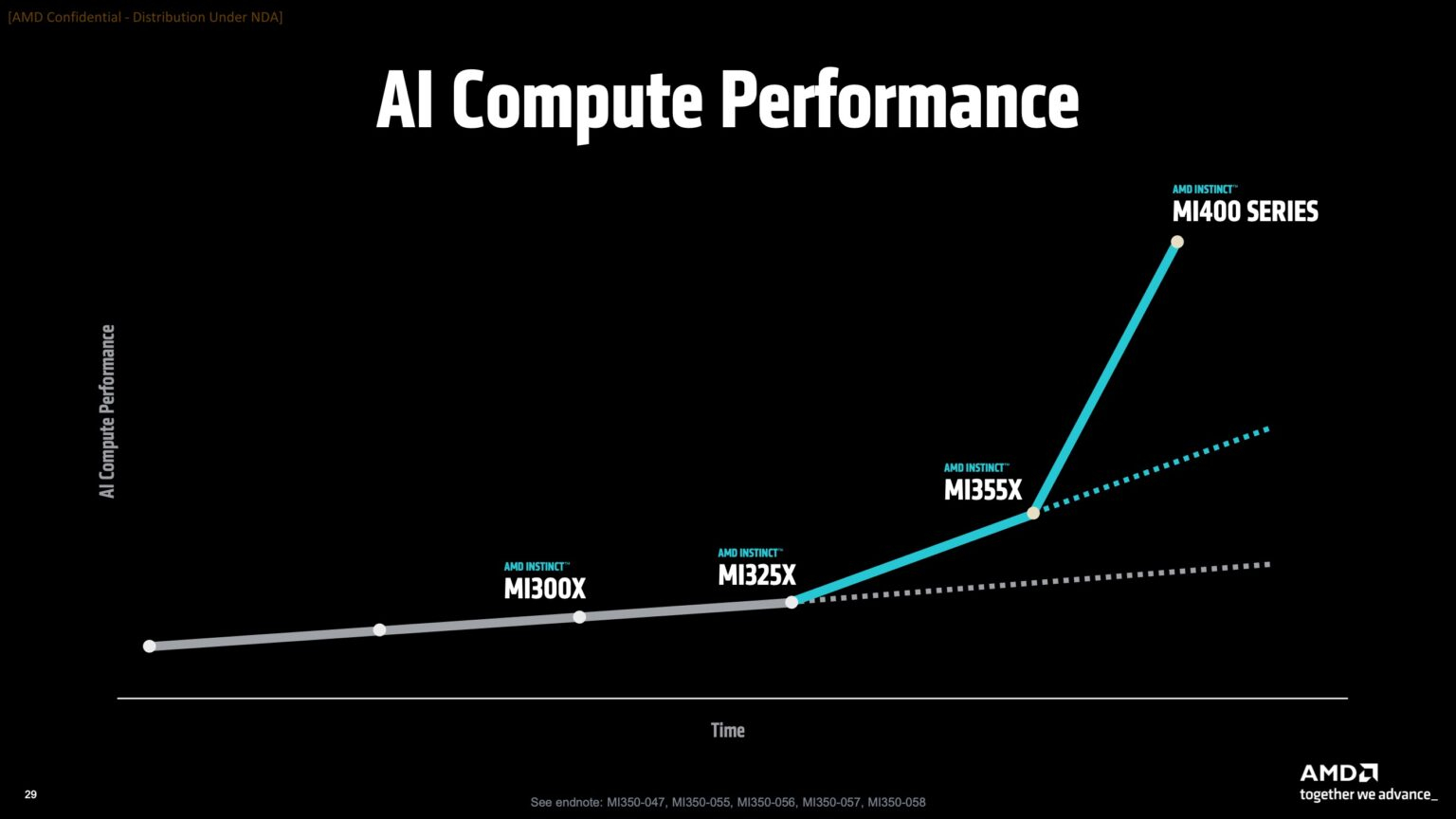 AMD сообщила, что её чипы Instinct используются семью из десяти крупнейших игроков ИИ-рынка, включая OpenAI, Tesla, xAI и Cohere. По словам AMD, Oracle планирует предложить своим клиентам кластеры с более чем 131 тыс. ускорителей MI355X. Meta✴ сообщила, что уже использует AMD-кластеры для инференса Llama и что она планирует купить серверы с чипами AMD следующего поколения. В свою очередь, представитель Microsoft сказал, что компания использует чипы AMD для обслуживания ИИ-функций чат-бота Copilot.
13.06.2025 [00:15], Владимир Мироненко
Ускорители AMD Instinct MI355X с архитектурой CDNA 4 потребляют 1400 ВтAMD представила ускоритель Instinct MI355X для ИИ- и HPC-нагрузок, демонстрирующий значительный рост производительности в задачах инференса, но вместе с тем почти удвоенное энергопотребление по сравнению с MI300X 2023 года выпуска, сообщил ресурс ComputerBase. Есть и чуть более простая версия MI350X, менее требовательная к питанию и охлаждению. AMD Instinct MI350X (Antares+) основан на оптимизированной архитектуре CDNA 4, отличающейся эффективной поддержкой новых форматов вычислений, в чём AMD ранее не была сильна. В дополнение к FP16 новый ускоритель поддерживает не только FP8, но также FP6 и FP4, которые актуальны для ИИ-нагрузок, особенно инференса. AMD во многом позиционирует Instinct MI350X как ускоритель для инференса, что имеет смысл, поскольку масштабирование MI350X по-прежнему ограничено лишь восемью ускорителями (UBB8), что снижает их конкурентоспособность по сравнению с ускорителями NVIDIA. Впрочем, для т.н. думающих моделей масштабирование тоже важно, что уже сказалось на продажах MI325X. 
Источник изображений: AMD via ServeTheHome Серия ускорителей AMD Instinct MI350X включает две модели: стандартный ускоритель Instinct MI350X мощностью 1000 Вт, который всё ещё можно использовать с системами воздушного охлаждения, а также более производительный Instinct MI355X до 1400 Вт, рассчитанный исключительно на работу с СЖО. Впрочем, AMD считает, что некоторые из её клиентов смогут использовать воздушное охлаждение для MI355X, пишет Tom's Hardware. В случае СЖО в одну стойку можно упаковать до 16 узлов (128 ускорителей MI355X), а в случае воздушного охлаждения — до 8 узлов (64 ускорителя MI350X). Для вертикального масштабирования предполагается использование UALink, для горизонтального — Ultra Ethernet.  Оба ускорителя будут поставляться с 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Сообщается, что ускоритель MI350X обладает максимальной производительностью в операциях FP4/FP6 в размере 18,45 Пфлопс, тогда как MI355X — до 20,1 Пфлопс. То есть обе модели серии Instinct MI350X превосходят ускоритель NVIDIA B300 (Blackwell Ultra), который с производительностью 15 FP4 Пфлопс. Что интересно, для векторных FP64-вычислений AMD сохранила тот же уровень производительности, что был у MI300X, а матричные FP64-вычисления стали почти вдвое медленнее. Тем не менее, это всё равно лучше, чем почти 30-кратное снижение скорости FP64-расчётов при переходе от B200 к B300. 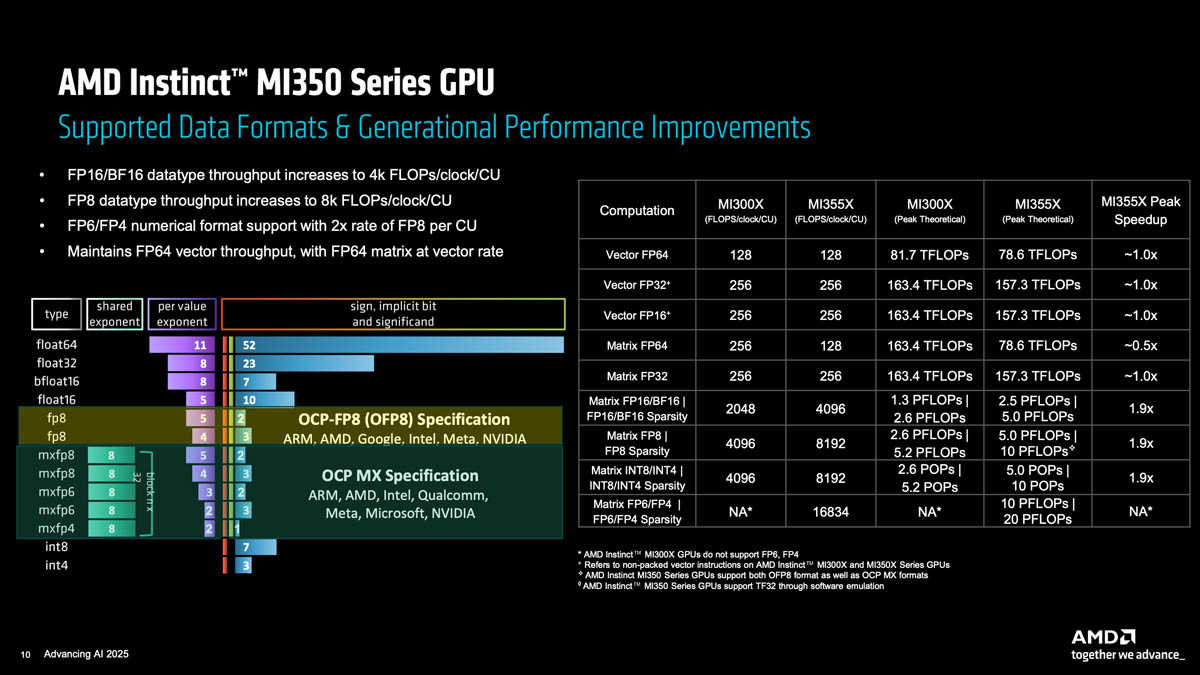 Если сравнивать производительность новых чипов с предшественником, то производительность MI350X в вычислениях с точностью FP8 составляет около 9,3 Пфлопс, в то время как у MI355X, как сообщается, этот показатель составляет 10,1 Пфлопс, что значительно выше, чем 5,22 Пфлопс у Instinct MI325X (во всех случаях речь идёт о разреженных вычислениях). MI355X также превосходит NVIDIA B300 на 0,1 Пфлопс в вычислениях FP8. Формально разница между MI350X и MI355X не так велика, но на практике она может достигать почти 20 % из-за возможности более долго поддерживать частоты при наличии СЖО. В целом, по словам AMD, в ИИ-тестах MI350X/MI355X быстрее MI300X в 2,6–4,2 раза в зависимости от задачи и до 1,3 раз быстрее (G)B200, но при этом значительно дешевле последних.  Компоновка MI350X/MI355X напоминает компоновку MI300X. Есть восемь 3-нм (TSMC N3P) XCD-чиплетов, лежащих поверх двух 6-нм (N6) IO-тайлов (IOD) и обрамлённых восемью стеками HBM3E. Переход к двум IOD повлиял и на NUMA-домены, поскольку теперь память можно поделить только пополам. А вот вычислительных инстансов может быть до восьми.  Используется комбинированная 3D- и 2.5D-компоновка чиплетов, причём для связи IOD, т.е. двух половинок всего чипа, используется шина Infinity Fabric AP с пропускной способностью 5,5 Тбайт/с. Каждый XCD содержит 36 CU, из которых активно только 32 (для повышения процента годных чипов), и общий L2-кеш объёмом 4 Мбайт. Все XCD подключены к Infinity Cache объёмом 256 Мбайт. Для связи с внешним миром есть один интерфейс PCIe 5.0 x16 (128 Гбайт/с) и семь линий Infinity Fabric (1075 Гбайт/с), которые как раз и позволяют объединить восемь ускорителей по схеме каждый-с-каждым.  Технический директор AMD Марк Пейпермастер (Mark Papermaster) заявил, что отрасль продолжит разрабатывать всё более мощные процессоры и ускорители для суперкомпьютеров, чтобы достичь производительности зеттафлопсного уровня примерно через десятилетие. Однако этот рост будет достигаться ценой резкого увеличения энергопотребления, поэтому суперкомпьютер с производительностью такого уровня будет потреблять примерно 500 МВт — половину того, что вырабатывает средний реактор АЭС.  Для поддержания роста производительности пропускная способность памяти и масштабирование мощности тоже должны расти. Согласно расчётам AMD, пропускная способность памяти ускорителя должна более чем удваиваться каждые два года, чтобы сохранить соотношение ПСП к Флопс. Это потребует увеличения количества стеков HBM на один ускоритель, что приведёт к появлению более крупных и более энергоёмких ускорителей и модулей.  Instinct MI300X имел пиковую мощность 750 Вт, Instinct MI355X имеет пиковую мощность 1400 Вт, в 2026–2027 гг., по словам Пейпермастера, нас ждут ускорители мощностью 1600 Вт, а в конце десятилетия — уже 2000 Вт. У чипов NVIDIA энергопотребление ещё выше — ожидается, что у ускорителей Rubin Ultra с четырьмя вычислительными чиплетами энергопотребление составит до 3600 Вт. На фоне растущего энергопотребления суперкомпьютеры и ускорители также быстро набирают производительность. Согласно презентации AMD на ISC 2025, эффективность производительности увеличилась с примерно 3,2 ГФлопс/Вт в 2010 году до примерно 52 Гфлопс/Вт к моменту появления экзафлопсных систем, таких как Frontier.  Поддержание такого темпа роста производительности потребует удвоения энергоэффективности каждые 2,2 года, пишет Tom's Hardware. Прогнозируемая система зетта-класса потребует эффективность на уровне 2140 Гфлопс/Вт, т.е. в 41 раз выше, чем сейчас. AMD считает, что для значительного повышения производительности суперкомпьютеров через десятилетие потребуется не только ряд прорывов в архитектуре чипов, но и прорыв в области памяти и интерконнектов.
09.06.2025 [14:02], Руслан Авдеев
Перегрев, плохое ПО и сила привычки: китайские компании не горят желанием закупать ИИ-ускорители HuaweiНесмотря на дефицит передовых ИИ-ускорителей на китайском рынке, китайская компания Huawei, выпустившая модель Ascend 910C, может столкнуться с проблемами при её продвижении. Она рассчитывала помочь китайскому бизнесу в преодолении санкций на передовые полупроводники, но перспективы нового ускорителя остаются под вопросом, сообщает The Information. Китайские гиганты вроде ByteDance, Alibaba и Tencent всё ещё не разместили крупных заказов на новые ускорители. Основная причина в том, что экосистема NVIDIA доминирует во всём мире (в частности, речь идёт о программной платформе CUDA), а решения Huawei недостаточно развиты. В результате компания продвигает продажи государственным структурам (при поддержке самих властей КНР) — это косвенно свидетельствует о сложности выхода на массовый рынок. Китайский бизнес годами инвестировал в NVIDIA CUDA для ИИ- и HPC-задач. Соответствующий инструментарий, библиотеки и сообщество разработчиков — настолько развитая экосистема, что альтернатива в лице Huawei CANN (Compute Architecture for Neural Networks) на её фоне выглядит весьма слабо. У многих компаний всё ещё хранятся огромные запасы ускорителей NVIDIA, накопленные в преддверии очередного раунда антикитайских санкций, поэтому у их владельцев нет стимула переходить на новые и незнакомые решения. Они скорее предпочтут оптимизировать программный стек, как это сделала DeepSeek, чтобы повысить утилизацию имеющегося «железа». Если бы, например, та же DeepSeek перешла на ускорители Huawei, это подтолкнуло бы к переходу и других разработчиков, но пока этого не происходит. Кроме того, некоторые компании вроде Tencent и Alibaba не желают поддерживать продукты конкурентов, что усложняет Huawei продвижение её ускорителей. 
Источник изображения: Huawei Есть и технические проблемы. Самый передовой ускоритель Huawei Ascend 910C периодически перегревается, поэтому возникла проблема доверия к продукции. Поскольку сбои во время длительного обучения модели обходятся весьма дорого. Кроме того, он не поддерживает ключевой для эффективного обучения ИИ формат FP8. Ascend 910С представляет собой сборку из двух чипов 910B. Он обеспечивает производительность на уровне 800 Тфлопс (FP16) и пропускную способность памяти 3,2 Тбайт/с, что сопоставимо с параметрами NVIDIA H100. Также Huawei представила кластер CloudMatrix 384. Наконец, проблема в собственно американских санкциях. В мае 2025 года Министерство торговли США предупредило, что использование чипов Huawei без специального разрешения может расцениваться, как нарушение экспортных ограничений — якобы в продуктах Huawei незаконно используются американские технологии. Такие ограничения особенно важны для компаний, ведущих международный бизнес — даже если они китайского происхождения. Хотя NVIDIA ограничили продажи в Китае, она по-прежнему демонстрирует рекордные показатели. По данным экспертов UBS, у компании есть перспективные проекты суммарной мощностью «десятки гигаватт» — при этом, каждый гигаватт ИИ-инфраструктуры, по заявлениям NVIDIA, приносит ей $40–50 млрд. Если взять вероятную очередь проектов на 20 ГВт с периодом реализации два-три года, то только сегмент ЦОД может обеспечить NVIDIA около $400 млрд годовой выручки. Это подчеркивает доминирующее положение компании на рынке аппаратного обеспечения для ИИ. |
|