Материалы по тегу: risc-v
|
02.10.2025 [13:10], Руслан Авдеев
Meta✴ приобрела Rivos, разработчика RISC-V-ускорителей, совместимых с CUDAMeta✴ Platforms приобрела занимающийся разработкой ИИ-чипов на базе RISC-V стартап Rivos. Это должно ускорить разработку собственных полупроводников и снизить зависимость от сторонних поставщиков, сообщает Silicon Angle. Условия покупки пока неизвестны, но ключевой инвестор стартапа, Walden Catalyst, с гордостью сообщил о сделке, а нынешний генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan), имевший прямое отношение к созданию и развитию стартапа, поздравил команду. Стартап был основан в 2021 году, а в 2023-м к нему присоединились около полусотни бывших инженеров Apple. Meta✴ будет использовать опыт Rivos для расширения работ над семейством собственных ИИ-ускорителей Meta✴ Training and Inference Accelerator (MTIA). Впрочем, Rivos использовала комплексный подход, разрабатывая CPU и GPUGPU-чипы с кеш-когерентностью и унифицированным доступом к памяти (DDR и HBM), дополненные интегрированным 800G-интерконнектом на базе Ultra Ethernet. Это похоже на подход NVIDIA при создании суперускорителей. В 2025 году Rivos выпустила на TSMC тестовый чип, работающий на частоте 3,1 ГГц и программный стек, совместимый с NVIDIA CUDA. Изначальная стратегия предполагала создание энергоэффективного ИИ-ускорителя с частотой до 3,5 ГГц, совместимого с существующей экосистемой, который планировалось продавать гиперскейлерам (хотя бы одному). Первую коммерческую платформу компания собиралась выпустить в следующем году, она позволила бы перекомпилировать, а не переписывать с нуля приложения, созданные для платформ NVIDIA. Компания также принимала участие в создании RISC-V RVA23 Profile. 
Источник изображения: Rivos Хотя Meta✴ не раскрыла стоимость сделки, вероятно, речь идёт о миллиардных тратах. В августе сообщалось, что стартап вёл переговоры с инвесторами о возможном раунде финансирования в объёме $300–$400 млн, а то и $500 млн, что повысило бы оценку стоимости компании до более чем $2 млрд. ИИ-проекты Meta✴ полагаются преимущественно на сторонние аппаратные решения. Компания потратила миллиарды долларов на покупку ускорителей, в основном NVIDIA, и потратит ещё миллиарды на аренду ИИ-инфраструктуры у сторонних игроков. В частности, буквально на днях она подписала новую сделку с CoreWeave на $14,2 млрд. В этом году капзатраты могут достигнуть $72 млрд, а выпуск собственных чипов позволил бы компании сэкономить миллиарды долларов, снизив зависимость от NVIDIA и облачных операторов. 
Источник изображения: Rivos По словам Constellation Research, Meta✴ является единственным крупным ИИ-предприятием, почти полностью зависящим от инфраструктурных решений NVIDIA. Имеются данные, что компания уже взаимодействовала с Rivos некоторое время, поэтому и решила приобрести стартап целиком. Если инициатива увенчается успехом, это поможет Meta✴ снизить расходы как на обучение, так и на инференс. Также сообщается, что Meta✴ работает с TSMC над выпуском своего нового чипа, и уже отправила на производство необходимую документацию для выпуска пробных образцов для оценки их эффективности.
09.09.2025 [17:00], Владимир Мироненко
Быстрее и «умнее»: SiFive представила второе поколени RISC-V-ядер IntelligentSiFive представила семейство ядер Intelligent второго поколения с архитектурой RISC-V, включающее новые ядра X160 Gen 2 и X180 Gen 2, а также обновлённые решения X280 Gen 2, X390 Gen 2 и XM Gen 2. Новые решения разработаны для расширения возможностей скалярной, векторной и, в случае серии XM, матричной обработки данных, адаптированных для современных задач в сфере ИИ. Как отметил ресурс EE Times, анонсируя новую линейку продуктов, SiFive стремится воспользоваться быстрорастущим спросом на решения для обработки ИИ-нагрузок, который, по прогнозам Deloitte, вырастет как минимум на 20 % во всех технологических средах, включая впечатляющий скачок на 78 % в сфере периферийных вычислений с использованием ИИ. Ядра SiFive второго поколения позволяют решать критически важные задачи в области внедрения ИИ, в частности, в области управления памятью и ускорения нелинейных функций. Ключевым нововведением в процессорах серии X является их способность функционировать в качестве блока управления ускорителем (ACU). Это позволяет ядрам SiFive обеспечивать основные функции управления и поддержки для ускорителя заказчика через интерфейсы SiFive Scalar Coprocessor Interface (SSCI) и Vector Coprocessor Interface eXtension (VCIX). Данная архитектура позволяет заказчикам сосредоточиться на инновациях в обработке данных на уровне платформы, оптимизируя программный стек. 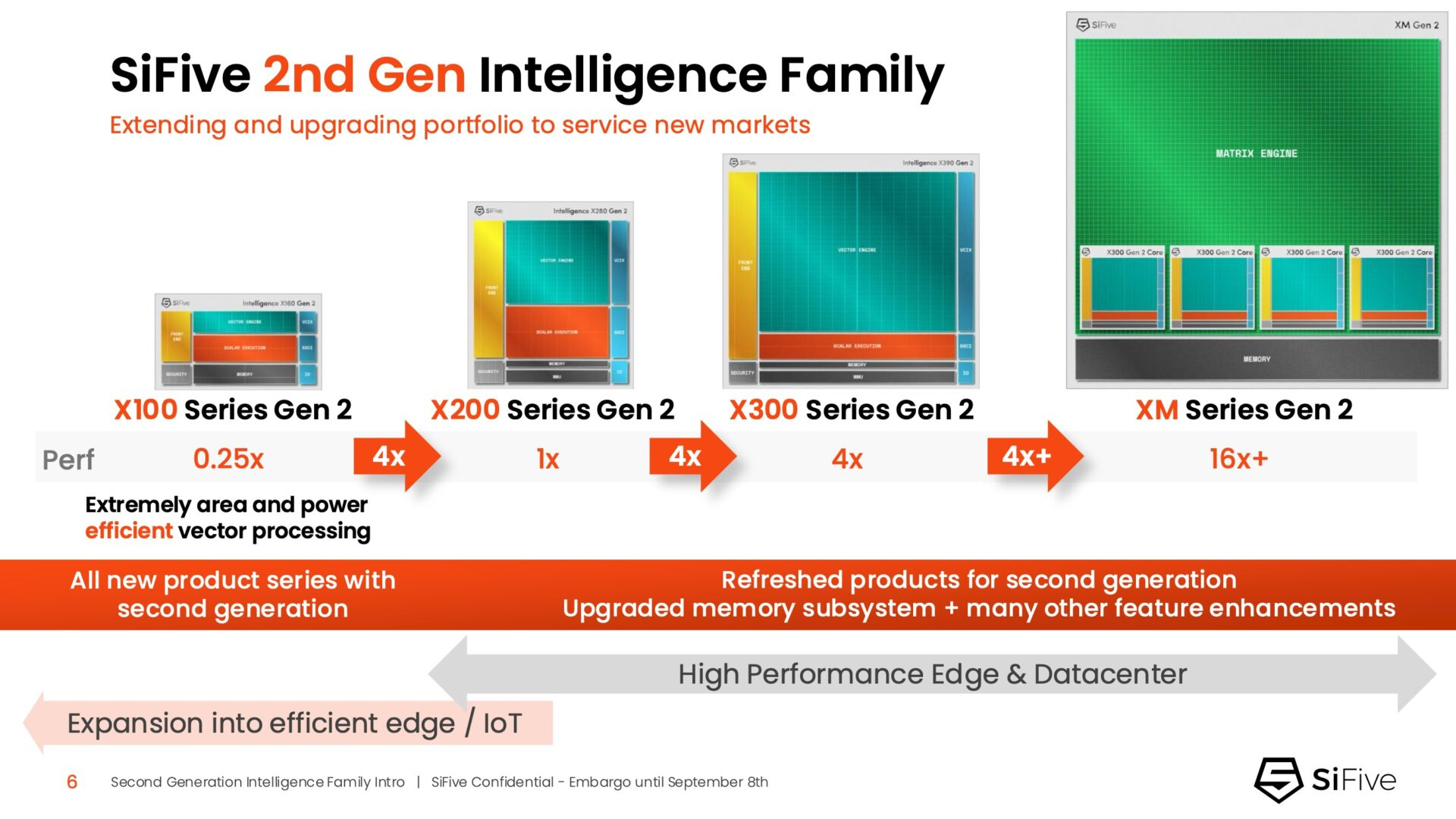
Источник изображений: SiFive/ServeTheHome Джон Симпсон (John Simpson), главный архитектор SiFive, сообщил ресурсу EE Times, что интеллектуальные ядра SiFive обеспечивают гибкость, сокращают трафик системной шины за счёт локальной обработки на чипе ускорителя и обеспечивают более тесную связь для задач пред- и постобработки. Он рассказал, что SiFive представила два важных усовершенствования в архитектуре, которые напрямую устраняют узкие места производительности: устойчивость к задержкам памяти и более эффективную подсистему памяти. 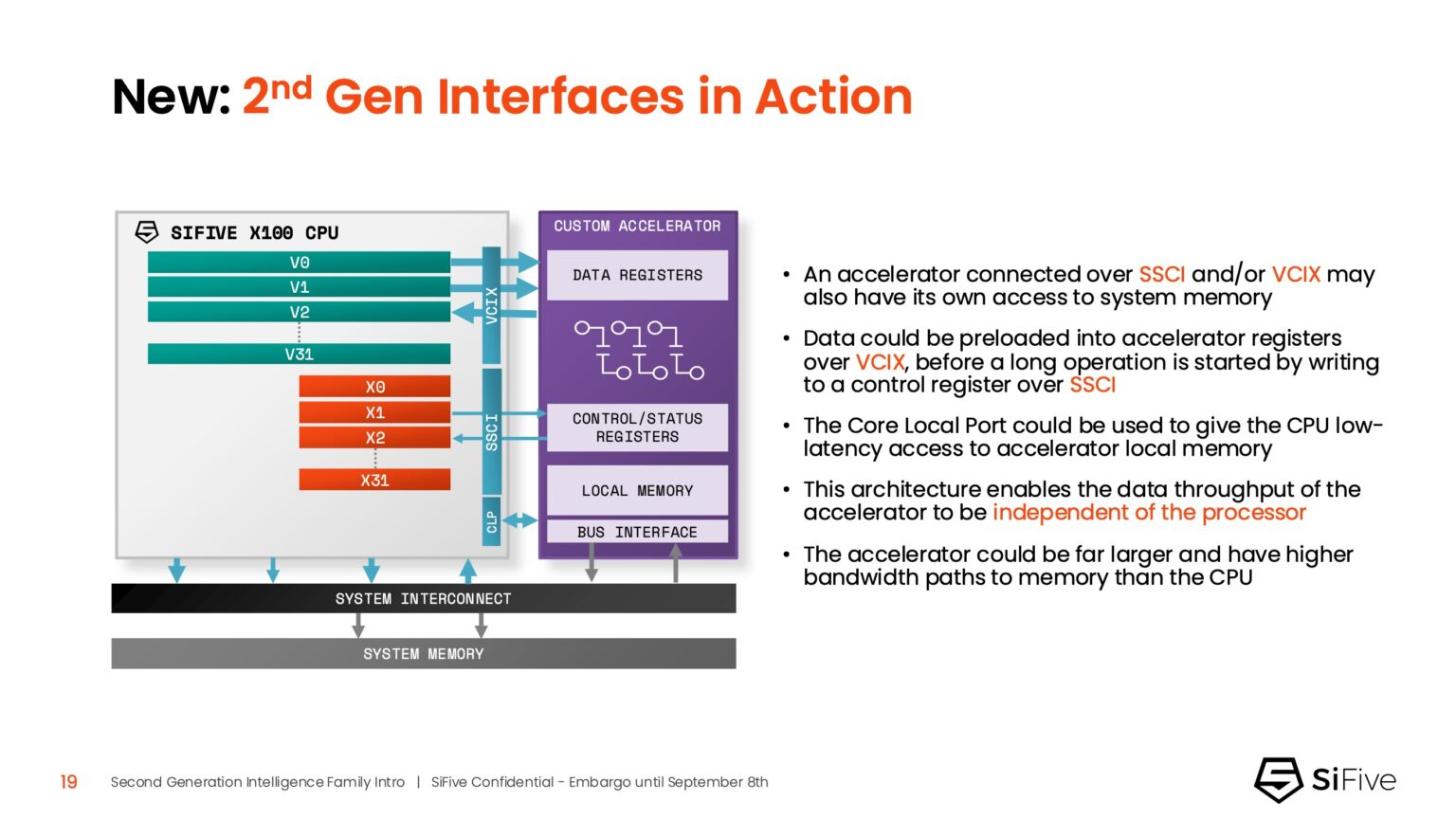 Функцию Memory Latency Tolerance позволяет снизить задержку загрузки. Симпсон рассказал, что блок скалярных вычислений, обрабатывающий все инструкции, отправляет векторные инструкции в очередь векторных команд (VCQ). При обнаружении такого инструкции одновременно отправляется запрос в подсистему памяти (кеш L2 или выше). Ранняя отправка запросов, отделённая от исполнения, позволяет быстрее получить ответ от памяти и поместить его в переупорядочиваемую настраиваемую очередь загрузки векторных данных (VLDQ). Это гарантирует готовность данных к моменту, когда инструкция в конечном итоге покинет VCQ, что приводит к «загрузке вектора в течение одного цикла». 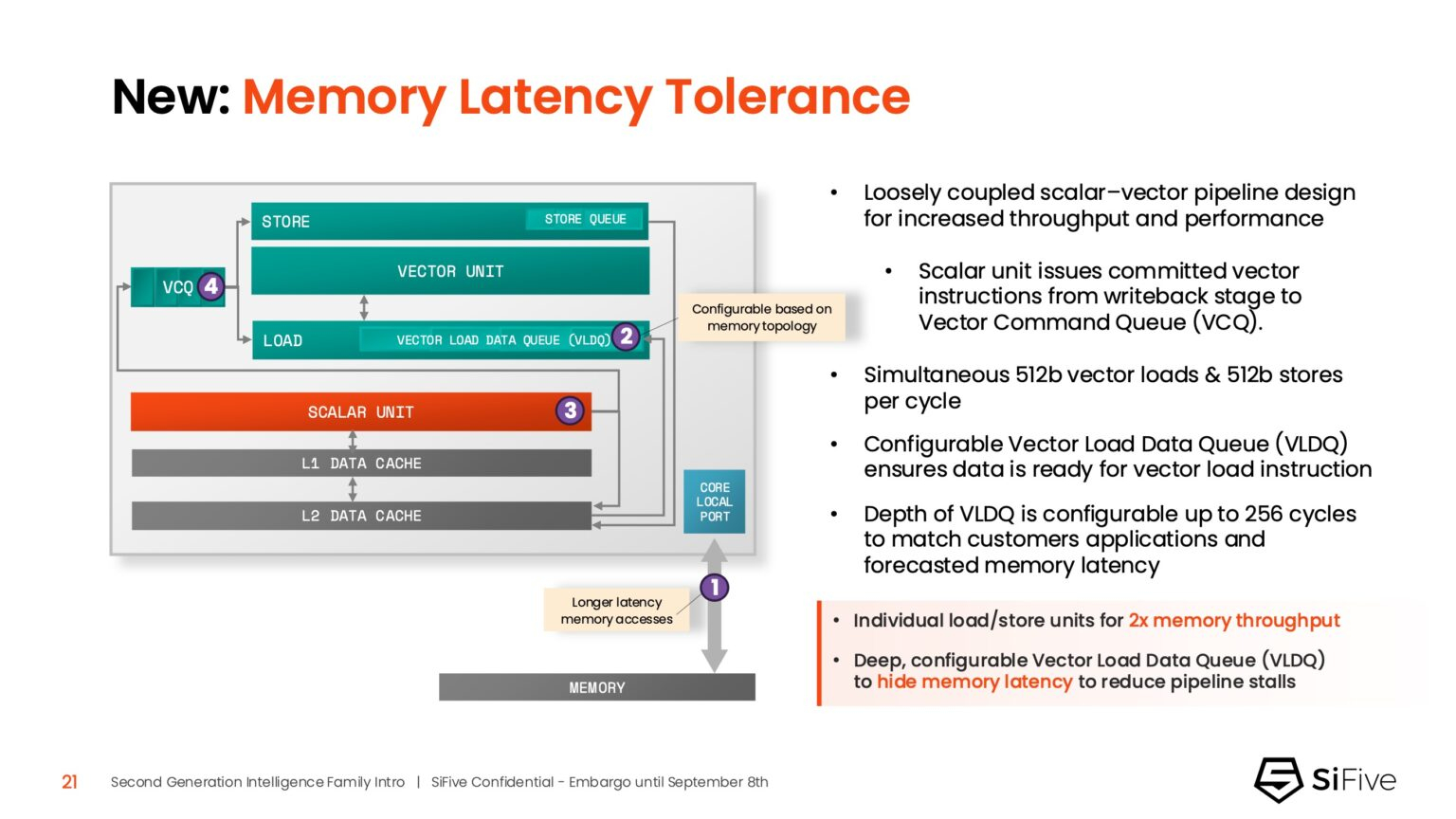 Симпсон подчеркнул конкурентное преимущество решения, отметив: «Xeon, представленный на Hot Chips, может обслуживать 128 невыполненных запросов, и это топовый показатель для Xeon, а в нашем четырёхъядерном процессоре этот показатель составляет 1024». Эта «прекрасная технология» обеспечивает непрерывную обработку данных, эффективно предотвращая простои конвейера.  Более эффективная подсистема памяти, которая представляет собой ещё одно существенное обновление, основана на переходе от инклюзивной к неинклюзивной иерархии кешей. В инклюзивной системе кеширования предыдущего поколения данные из общего кеша L3 реплицировались в частные кеши L1/L2, что компания посчитала неэффективным расходом «кремния». Конструкция ядер второго поколения исключает копирование, что, по словам Симпсона, даёт «в 1,5 раза большую производительность по сравнению с первым поколением» при меньшей занимаемой площади на кристалле. 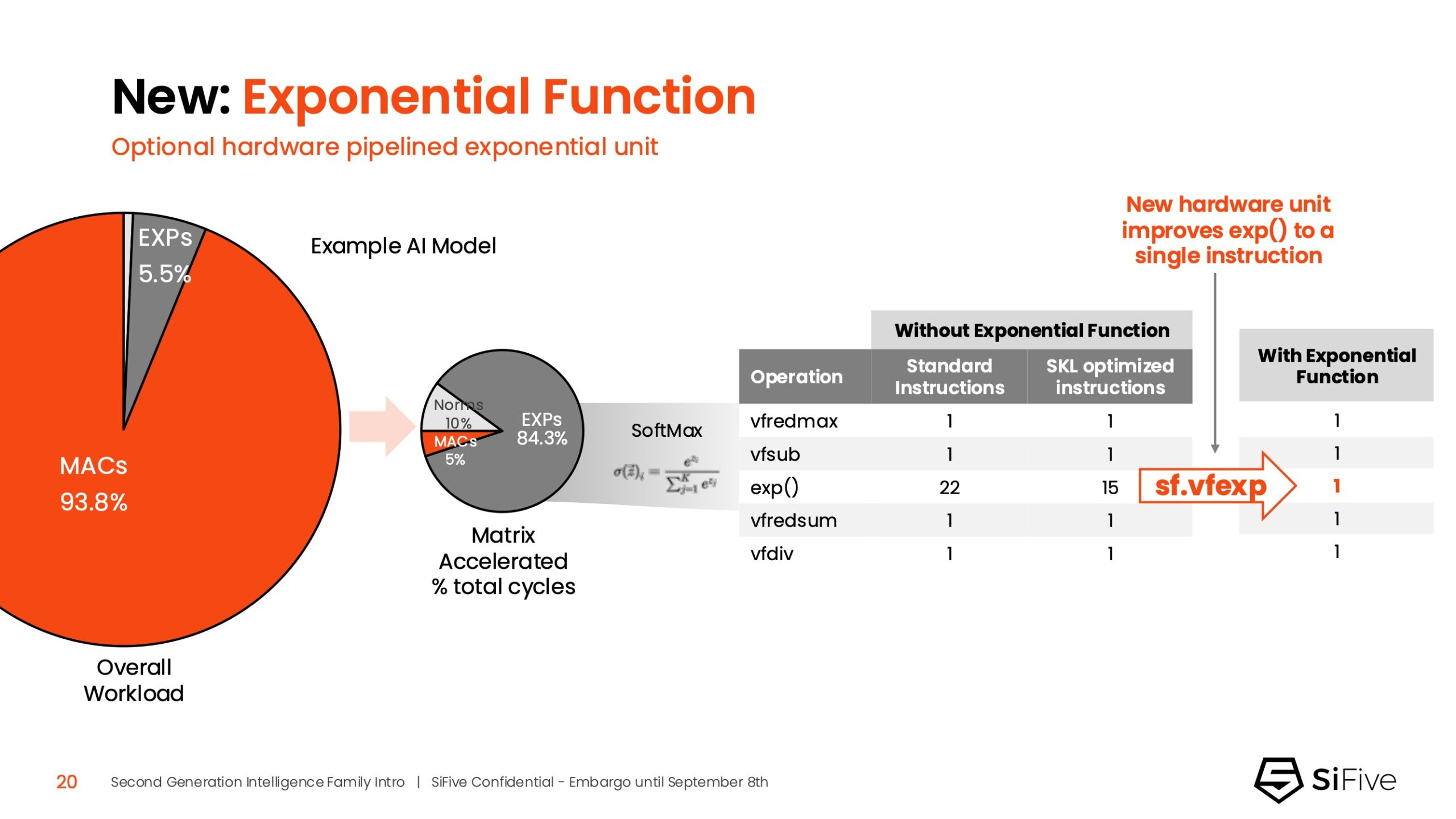 SiFive также интегрировала новый аппаратный конвейерный экспоненциальный блок. В то время как MAC-операции доминируют в рабочих ИИ-нагрузках, возведение в степень становится следующим серьёзным узким местом. Например, в BERT LLM, ускоренных матричным движком, операции softmax, включающие возведение в степень, занимают более 50 % оставшихся циклов. Программными оптимизациями SiFive сократила выполнение функции возведения в степень с 22 до 15 циклов, а новый аппаратный блок сокращает её до одной инструкции, уменьшая общее время выполнения функции до пяти циклов. Программный стек для семейства Intelligence второго поколения поддерживает масштабируемость. В серии XM среда выполнения машинного обучения уже распределяет рабочие нагрузки между несколькими кластерами XM на одном кристалле. Впрочем, пока масштабирование за пределы одного кристалла требует дальнейшей разработки библиотеки межпроцессорного взаимодействия (IPC).  Флагманские решения X160 Gen 2 и X180 Gen 2 могут быть настроены для работы под управлением операционной системы реального времени, пишет SiliconANGLE. 32-бит IP-ядро Intelligence X160 разработано для оптимизации энергоэффективности и приложений с жесткими ограничениями по площади кристалла, в то время как 64-бит IP-ядро Intelligence X180 обеспечивает более высокую производительность и лучшую интеграцию с более крупными подсистемами памяти, сообщил ресурс CNX-Software.  X160 поставляется с кеш-памятью объёмом до 200 КиБ и памятью объёмом 2 МиБ. Помимо промышленного оборудования, ядро может найти применение в потребительских устройствах, таких как фитнес-трекеры. Кроме того, X160 можно установить в системах с несколькими ИИ-ускорителями для управления чипами и предотвращения изменения прошивки. Благодаря двум встроенным кешам общей ёмкостью более 4 МиБ ядро позволяет работать с большим объёмом данных. По данным SiFive, X160 подходит для обучения ИИ-моделей и использования в оборудовании ЦОД.  В свою очередь, ядро X280 ориентировано на потребительские устройства, такие как гарнитуры дополненной реальности, а X390 также может использоваться в автомобилях и инфраструктурных системах. Последнее ядро выполняет векторную обработку в четыре раза быстрее, чем X280.  Все пять продуктов Intelligence Gen 2 уже доступны для лицензирования, а появление первых чипов на их основе ожидается во II квартале 2026 года. SiFive сообщила, что два ведущих американских производителя полупроводников лицензировали новую серию X100 ещё до её публичного анонса. Они используют IP-ядро X100 в двух различных сценариях: одна компания задействует сочетание скалярного векторного ядра SiFive с матричным движком, выступающим в качестве блока управления ускорителем, а вторая использует векторный движок в качестве автономного ИИ-ускорителя.
08.09.2025 [19:09], Сергей Карасёв
Axelera AI представила ускоритель Metis M.2 Max для ИИ-задач на периферииСтартап Axelera AI B.V. из Нидерландов анонсировал ускоритель Metis M.2 Max, предназначенный для ИИ-инференса на периферии. Новинка может использоваться, в частности, для работы с большими языковыми моделями (LLM) и визуально-языковыми моделями (VLM). Metis M.2 Max представляет собой улучшенную версию изделия Metis M.2, дебютировавшего в 2023 году. В основу положен чип Axelera Metis AIPU, содержащий четыре ядра с открытой архитектурой RISC-V: ИИ-производительность достигает 214 TOPS на операциях INT8. Ускорители выполнены в форм-факторе M.2 2280, а для обмена данными служит интерфейс PCIe 3.0 x4. У модели Metis M.2 Max по сравнению с оригинальной версией в два раза повысилась пропускная способность памяти (точные значения не приводятся). Её объём в зависимости от модификации составляет 1, 4, 8 или 16 Гбайт. Реализованы расширенные средства обеспечения безопасности, включая защиту целостности прошивки. Новинка будет предлагаться в вариантах со стандартным и расширенным диапазоном рабочих температур: в первом случае он простирается от -20 до +70 °C, во втором — от -40 до +85 °C. Благодаря этому, как утверждается, Metis M.2 Max подходит для применения в самых разных областях, в том числе в промышленном секторе, розничной торговле, в сферах здравоохранения и общественной безопасности и пр. 
Источник изображения: Axelera AI Разработчикам компания Axelera AI предлагает комплект Voyager SDK, который позволяет полностью раскрыть потенциал чипа Metis AIPU и упрощает развёртывание коммерческих приложений. Продажи ИИ-ускорителя Metis M.2 Max начнутся в IV квартале текущего года. Устройство будет поставляться отдельно и в комплекте с опциональным низкопрофильным радиатором охлаждения.
15.08.2025 [17:41], Сергей Карасёв
ИИ-стартап Rivos, успевший посудиться с Apple, ищет $500 млн, чтобы побороться с NVIDIAАмериканский стартап Rivos, по сообщению ресурса The Information, намерен получить финансирование в объеме до $500 млн, что увеличит его рыночную стоимость до $2 млрд. Средства в случае их привлечения помогут ускорить вывод на рынок ИИ-ускорителей нового типа, которые, как ожидается, смогут составить конкуренцию изделиям NVIDIA. Фирма Rivos, базирующаяся в Санта-Кларе (Калифорния, США), основана в 2021 году. Она занимается проектированием чипов на открытой архитектуре RISC-V: отсюда и название стартапа — RISC-V Open Source. Создаваемые изделия предназначены для приложений ИИ и больших языковых моделей (LLM). Штат Rivos насчитывает приблизительно 450 сотрудников. 
Источник изображения: unsplash.com / Steve Johnson Компания уже завершила разработку первого RISC-V-ускорителя: чип передан в опытное производство на предприятие TSMC. Осведомлённые источники утверждают, что массовый выпуск новинки может быть организован в 2026-м. Rivos якобы планирует сотрудничать с некой «крупной публичной компанией по созданию микрочипов» для разработки будущих ускорителей. Кроме того, стартап близок к заключению сделки по поставкам своей продукции неназванному партнёру. На сегодняшний день компания привлекла около $370 млн финансирования. В частности, $250 млн было получено в апреле 2024 года в ходе инвестиционного раунда Series-A3, в котором приняли участие Matrix Capital Management, Intel Capital, Dell Technologies Capital, MediaTek и др. В 2022-м Rivos столкнулся с судебным иском со стороны Apple. Компания из Купертино обвинила стартап в том, что он нанял на работу ряд бывших инженеров Apple, а затем использовал полученную от них конфиденциальную информацию для разработки собственных изделий. Rivos отвергла обвинения и подала встречный иск. Однако, как сообщалось, в ходе разбирательства компания уволила около 6 % своих сотрудников и отложила раунд финансирования Series A. Стороны окончательно урегулировали претензии в феврале 2024 года.
08.08.2025 [10:44], Сергей Карасёв
Стартап Xcena представил вычислительную память MX1 с поддержкой PCIe 6.0 и CXL 3.2Южнокорейский стартап Xcena анонсировал свой первый продукт — вычислительную память MX1. Избранные партнёры начнут получать образцы изделий с октября, тогда как массовое производство запланировано на 2026 год. Решение MX1 обладает поддержкой PCIe 6.0 и CXL 3.2. Новинка позволяет расширить основную память системы, добавив до 1 Тбайт в виде четырёх модулей DDR5 DIMM ёмкостью 256 Гбайт каждый. Реализована технология NDP (Near Data Processing), которая сводит к минимуму задержку при перемещении данных между интерфейсами и значительно снижает совокупную стоимость владения для приложений, требующих обработки больших объемов информации. Для выполнения вычислений в оперативной памяти используются «тысячи ядер» на открытой архитектуре RISC-V. Изделия MX1 позволяют существенно ускорить выполнение таких задач, как операции с векторными и графовыми базами данных, анализ информации и пр. При этом снижается нагрузка на CPU. Прототип на базе FPGA продемонстрировал сокращение времени обработки запросов при работе с базами данных на 46 % по сравнению с серверными CPU. Теоретически выигрыш может достигать 95 % при реализации в виде ASIC. 
Источник изображения: Xcena Чип задействует 4-нм техпроцесс Samsung Foundry. Упомянута поддержка ECC. Компания Xcena предоставляет полностью интегрированный комплект для разработчиков (SDK), состоящий из низкоуровневых драйверов, библиотек среды выполнения и вспомогательных инструментов, которые помогают создавать прототипы и развертывать MX1 с минимальными усилиями по интеграции.
05.08.2025 [11:16], Сергей Карасёв
Европейские чипы Cinco Ranch на базе RISC-V близки к началу массового производстваУчастники проекта Barcelona Zettascale Laboratory (BZL), координируемого Барселонским суперкомпьютерным центром (BSC) в Испании, по сообщению ресурса EETimes, достигли фазы Tape-out в рамках разработки европейских процессоров Cinco Ranch на открытой архитектуре RISC-V. Tape-out — это финальная стадия проектирования интегральных схем или печатных плат перед их отправкой в производство. Данный процесс предполагает перенос цифрового макета чипа на фотошаблон для последующего изготовления. Производством изделий займётся предприятие Intel Foundry с применением техпроцесса Intel 3. Cinco Ranch представляет собой пятое поколение чипов серии Lagarto. По сути, это «система на кристалле» (SoC) промышленного класса с высокой энергетической эффективностью. Конструкция чипа включает три отдельных специализированных ядра, каждое из которых оптимизировано под определённые вычислительные задачи. В частности, присутствует ядро Sargantana (RV64G) с однопоточным выполнением инструкций по порядку. Кроме того, имеется двухпоточное ядро Lagarto Ka с внеочередным исполнением машинных инструкций. Довершает картину высокопроизводительное 6-поточное ядро Lagarto Ox (RV64GC) с внеочередным исполнением инструкций. Нужное ядро выбирается в момент загрузки системы. 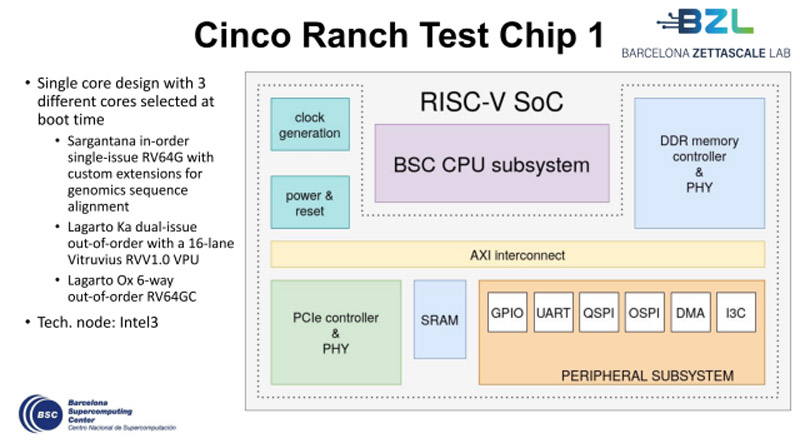
Источник изображения: BSC Решение Cinco Ranch содержит 16-канальный векторный блок Vitruvius++ VPU и трёхуровневую систему кеша. Реализована поддержка памяти DDR5 и интерфейса PCIe 3.0. Площадь чипа составляет 16 мм2. Главной целью проекта BZL является разработка суверенных суперкомпьютерных технологий в Европе. Предполагается, что создаваемые чипы найдут применение в различных областях, включая НРС-платформы, автономные транспортные средства, системы ИИ и пр. После всестороннего тестирования чипов Cinco Ranch будет освоено их массовое производство.
21.07.2025 [14:05], Сергей Карасёв
NVIDIA CUDA обзавелась поддержкой RISC-VКомпания NVIDIA в ходе саммита RISC-V 2025 в Китае объявила о том, что ее платформа параллельных вычислений CUDA обзавелась поддержкой открытой архитектуры RISC-V. Это событие отражает растущий интерес к чипам RISC-V в сегменте дата-центров. Представленное решение предполагает использование типичной конфигурации: графический ускоритель обрабатывает параллельные рабочие нагрузки, тогда как CPU на основе RISC-V отвечает за функционирование системных драйверов, логики приложений и операционной системы. Такая модель позволяет CPU полностью координировать GPU-вычисления в среде CUDA. 
Источник изображения: RISC-V International (X/@risc_v) Кроме того, в дополнение к CPU с архитектурой RISC-V и ускорителю NVIDIA может быть задействован специализированный сопроцессор для обработки данных (DPU). Таким образом, могут формироваться гетерогенные вычислительные среды, в которых процессор RISC-V играет ключевую роль в управлении рабочими нагрузками. Предполагается, что чипы RISC-V будут использоваться на периферийных устройствах с поддержкой CUDA, включая решения с модулями NVIDIA Jetson. Поддержка RISC-V расширяет возможности CUDA в системах, где предпочтение отдаётся открытым наборам команд или где требуются специально оптимизированные чипы. По сути, NVIDIA создаёт мост между проприетарным стеком CUDA и открытой архитектурой RISC-V, которая активно развивается по всему миру, в том числе в Китае. 
Источник изображения: NVIDIA Ранее ряд китайских компаний, включая T-Head (принадлежит гиганту Alibaba Group Holding), Shanghai Shiqing Technology, Juquan Optoelectronics, Xinsiyuan Microelectronics и StarFive, сформировали патентный альянс в сфере RISC-V. Разработкой RISC-V-процессоров занимается научно-исследовательский институт Damo Academy (подразделение Alibaba Group Holding), Китайская академия наук, а также ряд других участников местного рынка. Не имея возможности поставлять флагманские ИИ-ускорители в Китай из-за американских санкций, NVIDIA вынуждена искать другие способы развития экосистемы CUDA в КНР.
19.07.2025 [13:46], Сергей Карасёв
Rockchip анонсировала ИИ-ускоритель RK182X с архитектурой RISC-VКомпания Rockchip, по сообщению ресурса CNX Software, представила в Китае ИИ-ускоритель RK182X, предназначенный для работы с большими языковыми моделями (LLM) и визуально-языковыми моделями (VLM) на периферии. Новинка ориентирована на совместное использование с другими SoC Rockchip. Изделие получило многоядерную архитектуру RISC-V (точное количество ядер пока не раскрывается). В зависимости от модификации задействованы 2,5 или 5 Гбайт памяти DRAM со «сверхвысокой пропускной способностью» (ПСП тоже не раскрывается). Реализована поддержка интерфейсов PCIe 2.0, USB 3.0 и Ethernet. По заявлениям Rockchip, ИИ-ускоритель RK182X способен обрабатывать LLM/VLM, насчитывающие до 7 млрд параметров. В частности, таким моделям требуется примерно 3,5 Гбайт памяти при использовании режимов INT4/FP4. Говорится о совместимости с фреймворками PyTorch, ONNX и TensorFlow, а также форматом HuggingFace GGUF (GPT-Generated Unified Format). 
Источник изображений: CNX Software ИИ-ускоритель спроектирован для применения в связке с такими процессорами Rockchip, как RK3576/RK3588 и другими, вероятно, включая решения RK3668 и RK3688, которые были также представлены вчера. Эти чипы содержат собственный интегрированный NPU-модуль с производительностью 6 TOPS или более для обработки ИИ-нагрузок. 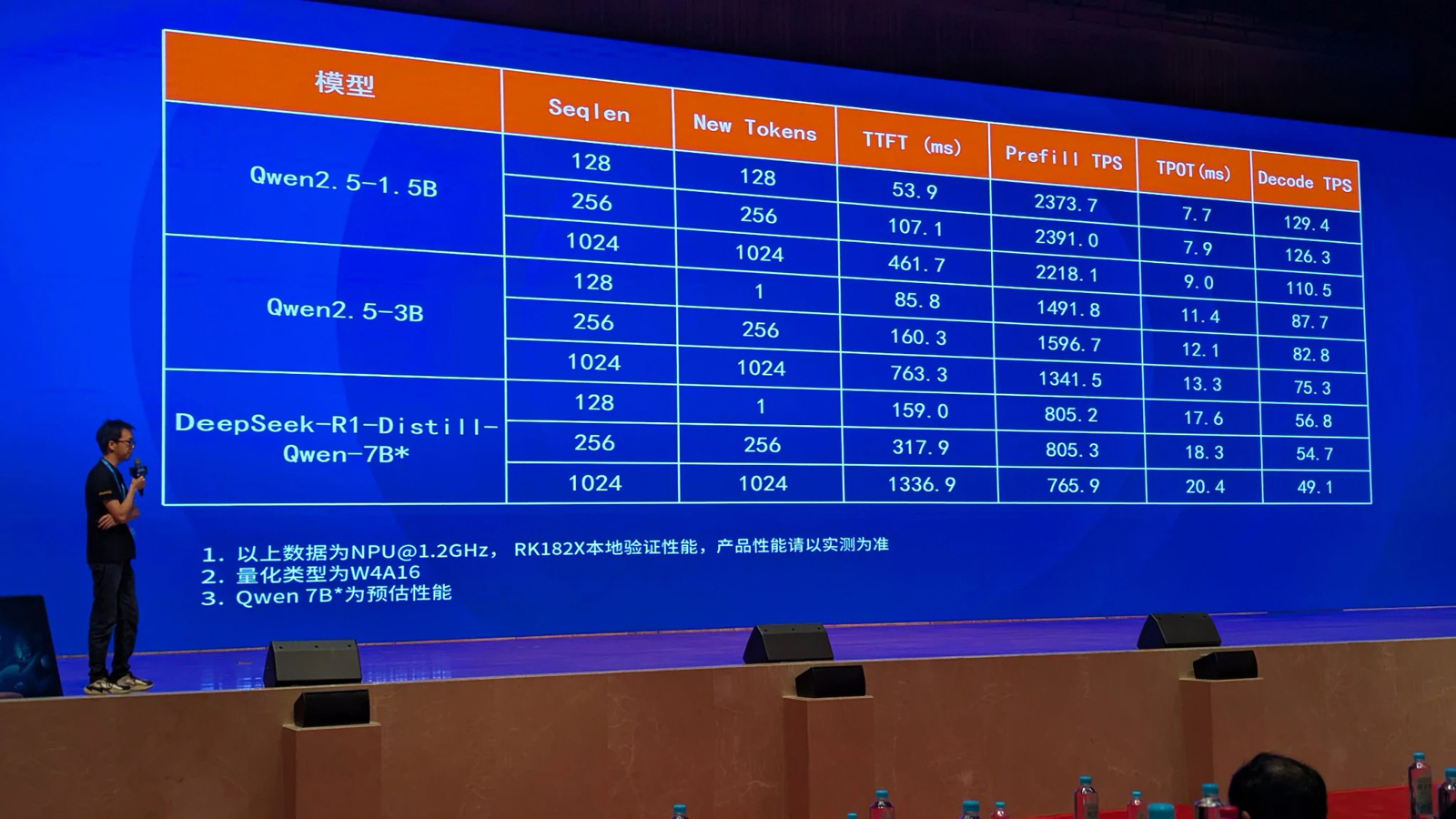 Однако благодаря применению отдельного ускорителя ИИ-быстродействие на определённых задачах может быть повышено в 8–10 раз. Rockchip, в частности, обнародовала скоростные показатели RK182X для таких популярных моделей, как DeepSeek-R1-Distill-Qwen-7B, Qwen2.5-1.5B и Qwen2.5-3B.
06.07.2025 [00:44], Владимир Мироненко
Esperanto, создатель уникального тысячеядерного RISC-V-ускорителя, закрывается — всех инженеров переманили крупные компанииСтартап Esperanto, специализирующийся на разработке серверных ускорителей на базе архитектуры RISC-V, сворачивает свою деятельность, сообщил ресурс EE Times. В настоящее время компания, которую уже покинуло большинство сотрудников, ищет покупателя на свои технологии или заинтересованных в лицензировании её разработок. Компания известна созданием тысячеядерного ИИ-ускорителя ET-SoC-1. Генеральный директор Esperanto Арт Свифт (Art Swift) сообщил EE Times о закрытии дочерних предприятий в Европе — у неё была значительная инженерная команда в Испании и ещё одна небольшая в Сербии. В штаб-квартире Esperanto в Маунтин-Вью (Калифорния) численность персонала сократилась на 90 %. Свифт и еще несколько инженеров остались, чтобы продать или лицензировать разработки компании и содействовать любой потенциальной передаче технологий. По словам Свифта, компания подверглась атаке со стороны богатых конкурентов, которые предлагали зарплату «в два, три, даже в четыре раза выше», чем могла предложить небольшая Esperanto. «Они фактически уничтожили наши команды — очень жаль, но мы не смогли конкурировать с ними», — говорит Свифт, отмечая, что уже несколько компаний проявило интерес к приобретению технологии или её лицензированию на неисключительной основе. Он добавил, что у Esperanto был крупный клиент, которому есть что предложить, что добавляет оптимизма. Ранее компания, судя по всему, пыталась предложить свои чипы Meta✴. 
Источник изображения: Esperanto Technologies Интерес рынка к RISC-V для чипов ЦОД остаётся высоким, особенно в Европе, где инвестирует в новую экосистему чипов на основе RISC-V. Вместе с тем именно ключевое преимущество разработок Esperanto — энергоэффективность — оказалось труднореализуемым, говорит гендиректор: «При неограниченном бюджете на электроэнергию энергоэффективность на самом деле не имеет значения». Esperanto готовила к выпуску чиплет второго поколения, который должен был поступить в производство на мощностях Samsung по 4-нм техроцессу в 2026 году. Чиплет предложил бы до 16 Тфлопс в FP64-вычислениях или до 256 Тфлопс в FP8-расчётах при потреблении 15–60 Вт. В один чип можно объединить до восьми чиплетов. Третье поколение технологии удвоило бы вычислительную мощность чиплетов. «Компании действительно были заинтересованы в получении этой технологии, так что посмотрим», — говорит Свифт. В прошлом году Esperanto договорилась с корпорацией NEC о сотрудничестве в области НРС с целью создания программных и аппаратных решений следующего поколения с архитектурой RISC-V. Также сообщалось о разработке чипа ET-SoC-2 для НРС и ИИ-задач. На пике развития штат Esperanto составлял 140 человек. По словам Свифта, 95 % бывших сотрудников стартапа уже нашли новую работу. В аналогичной ситуации оказалась Codasip, объявившая о готовности продать свои активы, поскольку обострение конкуренции на рынке RISC-V и отсутствие достаточного запаса средств ограничивают возможности небольших компаний, которые зачастую не могут конкурировать с IT-гигантами. ИИ-стартап Untether AI тоже провалил тест на выживание, объявив о закрытии бизнеса после того, как AMD переманила ряд его ведущих специалистов.
04.07.2025 [19:50], Владимир Мироненко
Разработчик RISC-V-чипов Codasip готов продаться — целиком или по частямРазработчик чипов с архитектурой RISC-V и инструментов проектирования из Мюнхена Codasip объявил о готовности продать свои активы, сославшись на проявление к ним интереса со стороны компаний во время недавнего раунда финансирования. Компания сообщила, что процесс приёма заявок на покупку, начавшийся 1 июля, продлится три месяца, что, по мнению ресурса The Register, может указывать на уже поступившие предложения. Ландшафт открытой архитектуры RISC-V превращается из экосистемы сотрудничества в высококонкурентную коммерческую среду, отметил ресурс EE Times. На фоне этого один из основных поставщиков EDA-инструментов Synopsys запустил полный набор основных IP-блоков RISC-V. Попутно крупные игроки рынка полупроводников, такие как Bosch, Infineon, NXP, Qualcomm и Nordic Semiconductor, сформировали консорциум Quintauris для разработки собственных процессорных решений для автомобильного сектора. В связи с этим Codasip попала в сложное положение, оказавшись между гигантами, предлагающими интегрированные решения, и крупными вертикальными игроками, разрабатывающими собственные продукты на базе RISC-V, что потенциально может сократить её целевой рынок. Codasip сообщила, что у неё есть несколько бизнес-подразделений, нацеленных на четыре ключевых направления продуктов, с «отделимыми» R&D-командами, намекая таким образом, что можно купить отдельные группы, а не компанию целиком. 
Источник изображений: Codasip Как пишет The Register, у Codasip предполагаемая годовая выручка составляет $88,7 млн, что делает её одним из крупнейших разработчиков микросхем в экосистеме RISC-V. У Ventana Micro Systems предполагаемая выручка составляет $37,4 млн за год, а SiFive ожидала получить около $60 млн в прошлом году. Хотя RISC-V вызывает определённый интерес, предлагая открытый набор инструкций, лёгких путей для построения успешного бизнеса здесь не обещают — SiFive ранее уволила 20 % штата, Intel отказалась от программы Pathfinder for RISC-V, а Imagination Technologies отказалась от RISC-V, сосредоточившись на продуктах GPU и ИИ. У Codasip есть портфолио решений для прикладных и встраиваемых процессоров и портфолио процессоров с архитектурой безопасности CHERI с аппаратной защитой памяти, а также сопутствующее ПО. Отдельно разрабатываются высокопроизводительные прикладные процессоры в рамках проекта Евросоюза Digital Autonomy with RISC-V in Europe (DARE). Наконец, у компании есть и собственные EDA-инструменты для разработки и кастомизации чипов. Немалую часть средств компании приносят гранты от различных органов ЕС, многочисленных общеевропейских и национальных проектов, включая DARE, TRISTAN и NEUROKIT2E — более €119 млн ($140 млн). Однако большая часть этих денег пока не получена компанией. На следующих этапах грантовой поддержки компания может получить ещё €210 млн ($248 млн). Codasip также утверждает, что является частью новых консорциумов и проектов, которые могут принести ей финансирование в размере €51 млн ($60) или больше. По словам компании, эти средства могут быть переданы покупателю на разумных условиях.  «В первую очередь, быть разработчиком CPU — это дорогостоящий бизнес, поэтому долгосрочное финансирование имеет важное значение — если рыночное признание низкое, доходы не появятся немедленно», — отметил Эндрю Басс (Andrew Buss), старший директор по исследованиям IDC в регионе EMEA. По оценкам EE Times, потенциальные приобретатели Codasip делятся на три категории. Первая включает гигантов в сфере EDA и интеллектуальной собственности (IP), таких как Synopsys, для которой приобретение Codasip означает возможность консолидации рынка благодаря получению уникального набора инструментов Codasip Studio, расширению портфеля интеллектуальной собственности и устранению значительного конкурента. Вторая категория состоит из вертикальных интеграторов, в основном американских технологических титанов, таких как Intel, Qualcomm и Broadcom. Intel уже предлагала в 2021 году более $2 млрд за SiFive, но сделка не состоялась. Приобретение Codasip даст Intel зрелый портфель интеллектуальной собственности для клиентов Intel Foundry Services (IFS), а также надёжную, отличающуюся от x86 архитектуру для собственных продуктов. 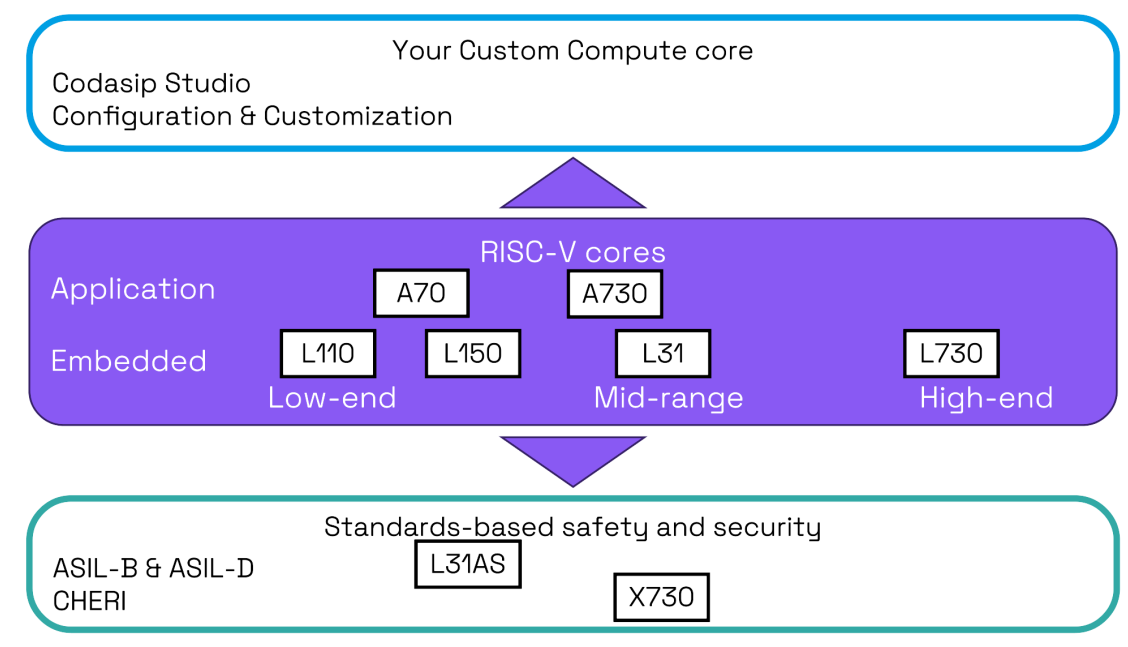 Для Qualcomm, судящейся с Arm, сделка означала бы снижение зависимости от архитектуры Arm. Сертифицированные IP-блоки для автомобильных решений Codasip идеально соответствует роли Qualcomm в качестве соучредителя в Quintauris, пишет EE Times. Broadcom может быть интересен набор Codasip Custom Compute, который она могла бы использовать для внутренних ядер контроллеров в SoC. Хотя вероятность заявки от Broadcom довольно низкая. И, наконец, третья категория — организации ЕС, которые могли бы купить Codasip для потенциального европейского консорциума. Европейский союз сделал технологический суверенитет центральной политической целью, что очевидно на примере таких инициатив, как «Европейский закон о чипах» (European Chips Act). Для Евросоюза покупка является стратегической: не допустить приобретения неевропейской организацией критически важного европейского технологического актива, в значительной степени субсидируемого за счет средств ЕС. Покупатель из страны, не входящей в ЕС, должен будет предоставить твёрдые, юридически обязывающие обязательства по поддержанию и развитию европейских центров НИОКР Codasip, обеспечению постоянного участия в стратегических проектах ЕС и в целом соответствию технологической повестке ЕС, подчеркнул EE Times. |
|