Материалы по тегу: grace
|
25.07.2024 [10:12], Владимир Мироненко
AMD показала превосходство чипов EPYC над Arm-процессорами NVIDIA Grace в серии бенчмарков, но не всё так простоAMD провела серию тестов, чтобы доказать преимущество своих нынешних процессоров AMD EPYC над Arm-процессорами NVIDIA Grace Superchip. Как отметила AMD, в связи с растущей востребованностью ЦОД некоторые компании начали предлагать альтернативные варианты процессоров, «часто обещающие преимущества по сравнению с обычными решениями x86». «Обычно их представляют с большой помпой и заявлениями о значительных преимуществах в производительности и энергоэффективности по сравнению с x86. Слишком часто эти утверждения довольно сложно воплотить в реальные сценарии конкурентной рабочей нагрузки — с использованием устаревших, недостаточно оптимизированных альтернатив или плохо документированных предположений», — отметила AMD. С помощью серии стандартных отраслевых тестов AMD, по её словам, продемонстрировала преимущество EPYC над решениями на базе Arm. «Благодаря проверенной архитектуре x86-64, впервые разработанной AMD, вы можете получить всё это без дорогостоящего портирования или изменений в архитектуре», — подчеркнула компания. Иными словами, тесты AMD могут быть просто попыткой развеять опасения, что архитектура x86 «выдыхается» и что Arm берёт верх. 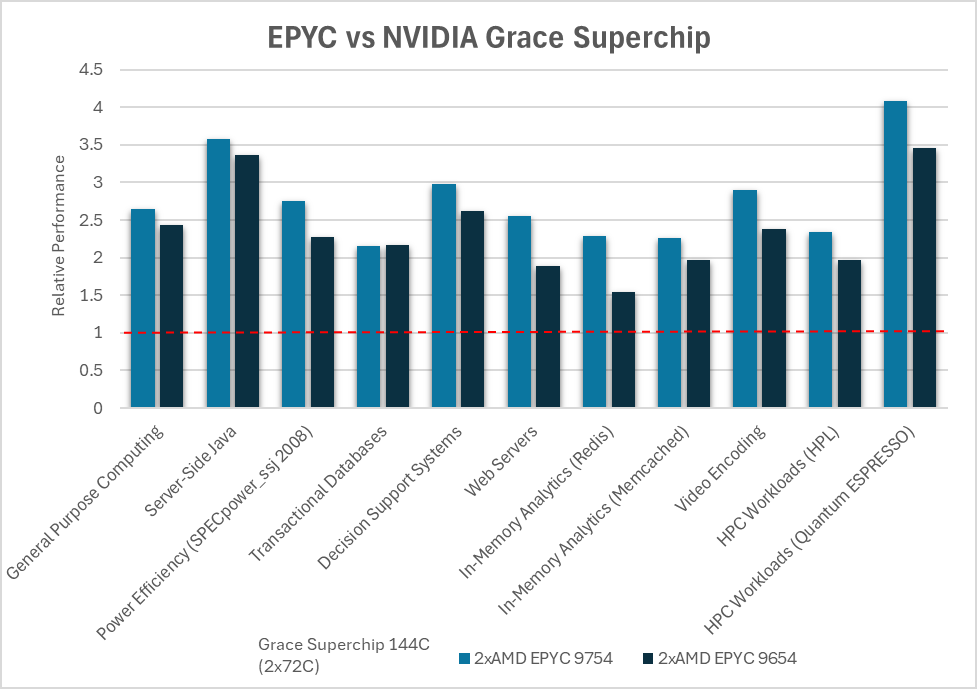
Источник изображений: AMD AMD сравнила производительность AMD EPYC и NVIDIA Grace CPU в десяти ключевых рабочих нагрузках, охватывающих вычисления общего назначения, Java, транзакционные базы данных, системы поддержки принятия решений, веб-серверы, аналитику, кодирование видео и нагрузки HPC. Согласно представленному выше графику, 128-ядерный процессор EPYC 9754 (Bergamo) и 96-ядерный EPYC 9654 (Genoa) более чем вдвое превзошли NVIDIA Grace CPU Superchip по производительности при обработке вышеуказанных нагрузок. Напомним, что Grace CPU Superchip содержит два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2, соединённых шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работает как единый 144-ядерный процессор. В свою очередь, ресурс The Register отметил, что речь идёт о версии с 480 Гбайт памяти LPDDR5x, а не с 960 Гбайт. 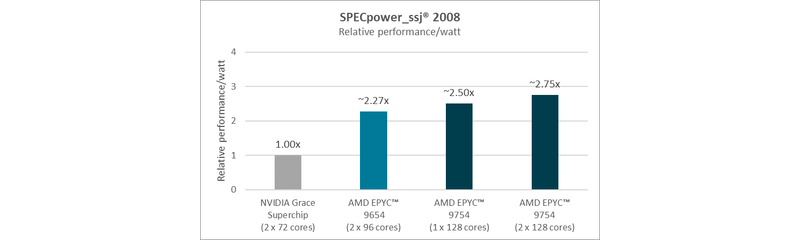 В тесте SPECpower-ssj2008, по данным AMD, одно- и двухсокетные системы на базе AMD EPYC 9754 превосходят систему NVIDIA Grace CPU Superchip по производительности на Вт примерно в 2,50 раза и 2,75 раза соответственно, а двухсокетная система AMD EPYC 9654 — примерно в 2,27 раза. Помимо производительности и эффективности, ещё одним важным фактором для операторов ЦОД является совместимость, сообщила AMD. По оценкам, во всем мире существуют триллионы строк программного кода, большая часть которого написана для архитектуры x86. EPYC основаны на архитектуре x86-64, впервые разработанной AMD, и эта архитектура является наиболее широко используемой и поддерживаемой в индустрии ЦОД, заявила компания, добавив, что изменения в архитектуре сложны, дороги и чреваты риском. AMD также отметила, что экосистема AMD EPYC включает более 250 различных конструкций серверов и поддерживает около 900 уникальных облачных инстансов. Также процессоры AMD EPYC установили более 300 мировых рекордов производительности и эффективности в широком спектре тестов. В то же время лишь немногие Arm-решения доказали свою эффективность. В свою очередь, ресурс The Register отметил, что ситуация не так проста, как AMD пытается всех убедить. В феврале сайт The Next Platform сообщил, что исследователи из университетов Стоуни-Брук и Буффало сравнили данные о производительности суперчипа NVIDIA Grace CPU Superchip и нескольких процессоров x86, предоставленные несколькими НИИ и разработчиком облачных решений. 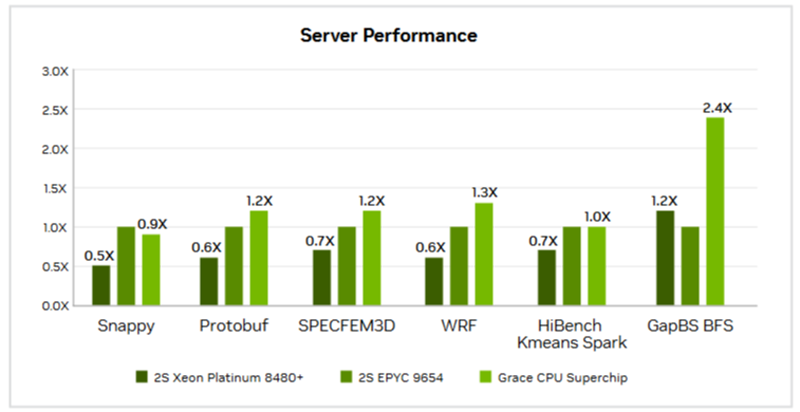
Источник изображений: NVIDIA Большинство этих тестов были ориентированы на HPC, включая Linpack, HPCG, OpenFOAM и Gromacs. И хотя производительность системы Grace сильно различалась в разных тестах, в худшем случае она находилась где-то между Intel Skylake-SP и Ice Lake-SP, превосходя AMD Milan и находясь в пределах досягаемости от показателей Xeon Max. Данные результаты отражают тот факт, что самые мощные процессоры AMD EPYC Genoa и Bergamo могут превзойти первый процессор NVIDIA для ЦОД — при правильно выбранном тесте. 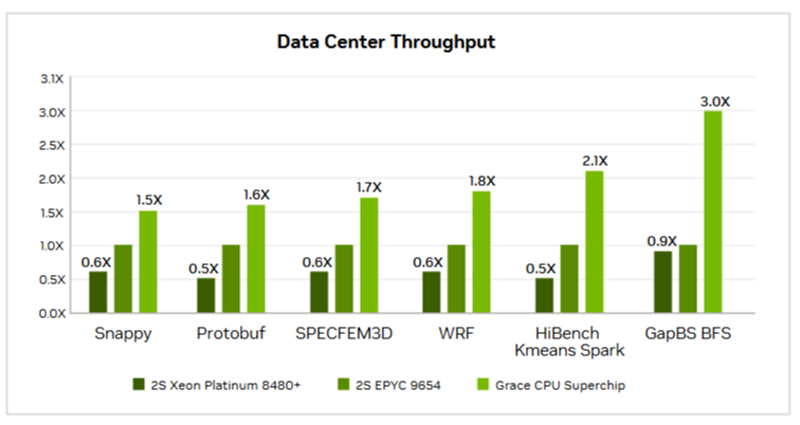 В техническом описании Grace CPU Superchip компания NVIDIA сообщает, что этот чип обеспечивает от 0,9- до 2,4-кратного увеличения производительности по сравнению с двумя 96-ядерными EPYC 9654 и предлагает до трёх раз большую пропускную способность в различных облачных и HPC-сервисах. NVIDIA отмечает, что Superchip предназначен для «обработки массивов для получения интеллектуальных данных с максимальной энергоэффективностью», говоря об ИИ, анализе данных, нагрузках облачных гиперскейлеров и приложениях HPC.
17.06.2024 [22:49], Илья Коваль
Три квантовых компьютера, NVIDIA DGX Quantum, немножко HPC и облако: в Израиле открыт уникальный центр квантовых вычислений IQCC
aws
gh200
grace
hardware
hpc
nvidia
quantum machines
израиль
квантовые вычисления
квантовый компьютер
облако
разработка
Стартап Quantum Machines, разработчик систем управления квантовыми компьютерами, открыл Израильский центр квантовых вычислений (Israeli Quantum Computing Center, IQCC). Площадка, создание которой было частично профинансировано правительством страны, располагается в Тель-Авивском университете. По словам основателей, это первый в мире центр, располагающий квантовыми компьютерами разных типов, которые интегрированы с системой NVIDIA DGX Quantum, HPC-инфраструктурой и облаком. 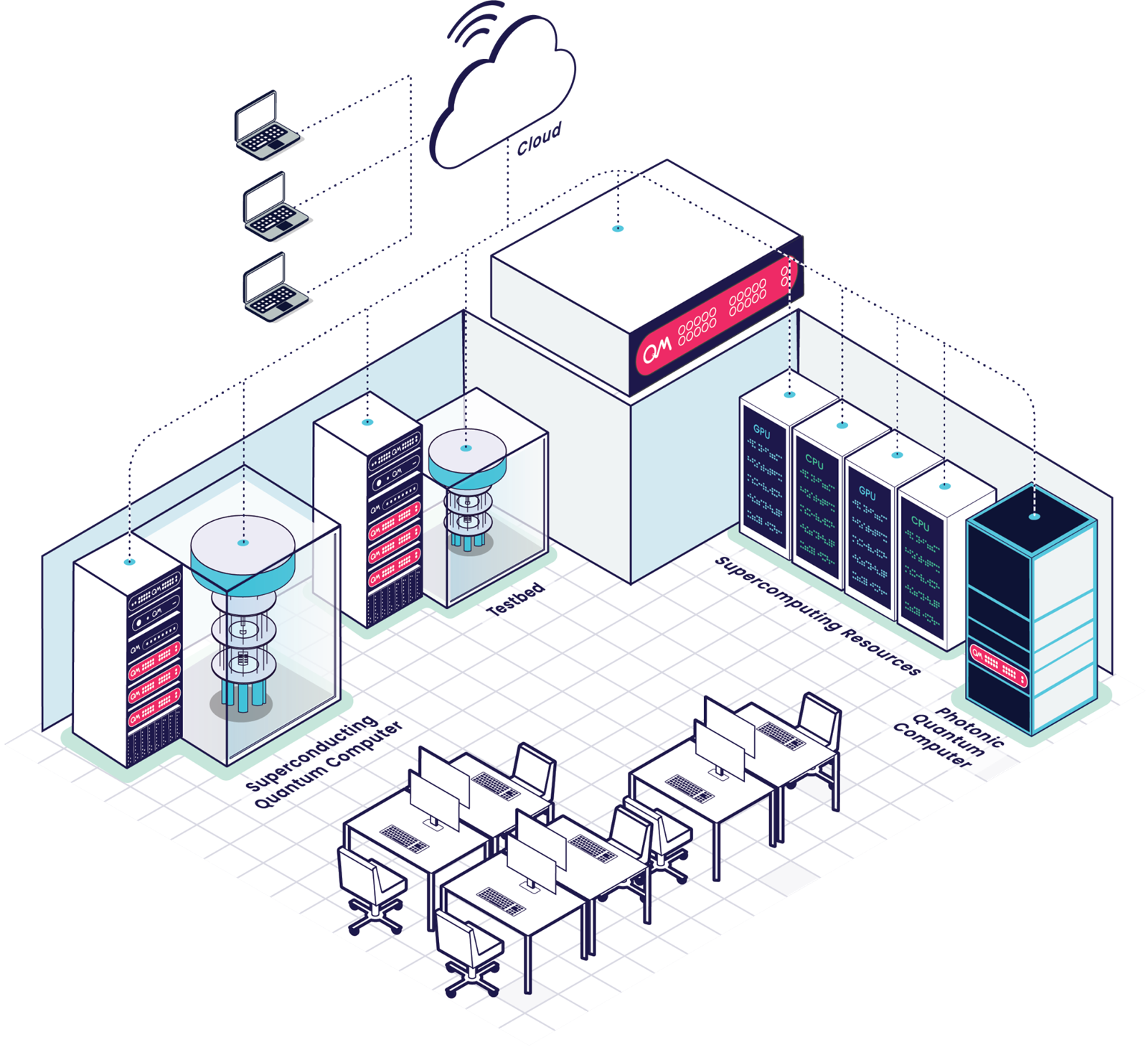
Источник изображений: Quantum Machines Приоритетный доступ со скидкой получат исследовательские организации Израиля, но в целом центр будет открыт для компаний со всего света. Как говорят создатели, IQCC — это лучший в мире полигон для создания новых технологий в области квантовых вычислений, а открытая архитектура площадки позволяет регулярно проводить обновления и упрощает дальнейшее масштабирование возможностей и вычислительных мощностей. Сейчас в IQCC установлены 21-кубитный компьютер Galilee от Quantware на сверхпроводящих кубитах (ещё один такой же используется в качестве тестовой платформы) и фотонный компьютер Negev от ORCA (8 кумод). Системы управляются контроллерами OPX1000 от самой Quantum Machines. HPC-инфраструктура представлена DGX A100, четырьмя GH200 и 128 vCPU на базе AMD EPYC 9334 (Genoa). Дополнительные ресурсы можно арендовать в облаке AWS.  Для Galilee и Negev доступна интеграция с DGX Quantum, платформой для гибридных квантово-классических вычислений, которая была создана NVIDIA и Quantum Machines и впервые в мире развёрнута именно в IQCC. Управлять компьютерами и разрабатывать ПО можно с использованием Qiskit, QUA, OpenQASM3, QBridge, а также Classiq. К системе организован облачный доступ. В ближайшие месяцы в IQCC будут развёрнуты ещё несколько квантовых компьютеров и QPU.
09.06.2024 [12:36], Сергей Карасёв
ASUS представила ИИ-систему ESC AI POD на базе NVIDIA GB200 NVL72Компания ASUS анонсировала мощный вычислительный комплекс ESC AI POD, предназначенный для решения ресурсоёмких задач в области ИИ и НРС. В основу новинки положена платформа NVIDIA GB200 NVL72 на архитектуре Blackwell. Решение ESC NM2N721-E1 использует 72 ускорителя NVIDIA Blackwell и 36 процессоров NVIDIA Grace, объединённых интерконнекта NVIDIA NVLink 5. 
Источник изображений: ASUS Утверждается, что ESC AI POD поддерживает работу с большими языковыми моделями (LLM), насчитывающими до триллиона параметров. В состав системы входят вычислительные узлы, коммутаторы, а также полки питания 1U мощностью 33 кВт. Возможно развёртывание воздушно-жидкостного или полностью жидкостного охлаждения. Кроме того, ASUS продемонстрировала в рамках Computex 2024 другие новинки. В их числе — системы, выполненные на модульной архитектуре NVIDIA MGX. Это, в частности, сервер ESC NM1-E1 типоразмера 2U, комплектующийся суперчипом NVIDIA Grace Hoppe GH200. Он использует технологию NVIDIA NVLink-C2C и поддерживает воздушное охлаждение. Кроме того, показаны серверы ESC NM2-E1 и ESR1-511N-M1 (стандарта 1U).
Среди других решений упоминаются серверы ESC N8 на платформе Intel Xeon Emerald Rapids и ESC N8A на базе AMD EPYC 9004 (Genoa). Эти системы несут на борту ускорители NVIDIA Blackwell. Кроме того, ASUS готовит новые ИИ-решения, оснащённые сетевым ускорителем NVIDIA BlueField-3 SuperNIC.
02.06.2024 [16:20], Сергей Карасёв
NVIDIA представила ускорители GB200 NVL2, платформы HGX B100/B200 и анонсировала экосистему следуюшего поколения Vera RubinNVIDIA сообщила о широкой отраслевой поддержке своей архитектуры нового поколения Blackwell. Эти ускорители, а также чипы Grace легли в основу многочисленных систем для ИИ-фабрик и дата-центров, которые, как ожидается, будут способствовать «следующей промышленной революции». 
Источник изображений: NVIDIA Генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) объявил о том, что серверы на базе Blackwell выпустят ASRock Rack, ASUS, Gigabyte, Ingrasys, Inventec, Pegatron, QCT, Supermicro, Wistron и Wiwynn. Речь идёт об устройствах разного уровня, рассчитанных на облачные платформы, периферийные вычисления и ЦОД клиентов. «Началась очередная промышленная революция. Компании и целые страны сотрудничают с NVIDIA, чтобы трансформировать традиционные дата-центры общей стоимостью в триллионы долларов в платформы нового типа — фабрики ИИ», — говорит Хуанг. 
NVIDIA HGX B200 
NVIDIA HGX B100 Для решения ИИ-задач и поддержания других ресурсоёмких приложений будут выпущены серверы с CPU на архитектурах х86 и Arm (изделия Grace) с воздушным и жидкостным охлаждением. Заказчикам будут доступны модели с одним и несколькими ускорителями. В частности, сама NVIDIA предлагает DGX-системы Blackwell, а для сторонних производителей доступны готовые платформы HGX B100 и HGX B200.   Кроме того, компания представила ускоритель GB200 NVL2, т.е. сборку из двух GB200, объединённых NVLink 5. NVIDIA также сообщила о том, что модульная архитектура NVIDIA MGX отныне поддерживает Blackwell, включая и GB200 NVL2. В целом, NVIDIA MGX предлагает свыше 100 различных конфигураций. На сегодняшний день на базе MGX выпущены или находятся в разработке более 90 серверов от более чем 25 партнёров NVIDIA по сравнению с 14 системами от шести партнёров в 2023 году. В составе MGX, в частности, впервые будут использоваться изделия AMD EPYC Turin и чипы Intel Xeon 6 (ранее — Granite Rapids).  Отмечается, что глобальная партнёрская экосистема NVIDIA включает TSMC, а также поставщиков различных компонентов, включая серверные стойки, системы электропитания, решения для охлаждения и пр. В число поставщиков такой продукции входят Amphenol, Asia Vital Components (AVC), Cooler Master, Colder Products Company (CPC), Danfoss, Delta Electronics и Liteon. Серверы нового поколения готовят Dell Technologies, Hewlett Packard Enterprise (HPE) и Lenovo.  В скором времени NVIDIA представит улучшенные ускорители Blackwell Ultra, которые получат более современную HBM3e-память. А уже в следующем году компания покажет решения на архитектуре следующего поколения: ускорители Rubin, процессоры Vera, NVLink 6 с удвоенной пропускной способностью (3,6 Тбайт/с), коммутаторы X1600 и DPU SuperNIC CX9 для сетей 1,6 Тбит/с.
13.05.2024 [09:00], Сергей Карасёв
Более 200 Эфлопс для ИИ: NVIDIA представила новые НРС-системы на суперчипах Grace HopperКомпания NVIDIA рассказала о новых высокопроизводительных комплексах на основе суперчипов Grace Hopper для задач ИИ и НРС. Отмечается, что суммарная производительность этих систем превышает 200 Эфлопс. Суперкомпьютеры предназначены для решения самых разных задач — от исследований в области изменений климата до сложных научных проектов. Одним из таких НРС-комплексов является EXA1 — HE, который является совместным проектом Eviden (дочерняя структура Atos) и Комиссариата по атомной и альтернативным видам энергии Франции (СЕА). Система использует 477 вычислительных узлов на базе Grace Hopper, а пиковое быстродействие достигает 104 Пфлопс. Ещё одной системой стал суперкомпьютер Alps в Швейцарском национальном компьютерном центре (CSCS). Он использует в общей сложности 10 тыс. суперчипов Grace Hopper. Заявленная производительность на операциях ИИ достигает 10 Эфлопс, и это самый быстрый ИИ-суперкомпьбтер в Европе. Утверждается, что по энергоэффективности Alps в 10 раз превосходит систему предыдущего поколения Piz Daint. 
Источник изображений: NVIDIA В свою очередь, комплекс Helios, созданный компанией НРЕ для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша), содержит 440 суперчипов NVIDIA GH200 Grace Hopper. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс.  В список систем на платформе Grace Hopper также входит Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Комплекс расположится в Юлихском исследовательском центре (FZJ) в Германии. Кроме того, в список вошёл комплекс DeltaAI на основе GH200 Grace Hopper, созданием которого занимается Национальный центр суперкомпьютерных приложений (NCSA) при Университете Иллинойса в Урбане-Шампейне (США).  В числе прочих систем названы суперкомпьютер Miyabi в Объединённом центре передовых высокопроизводительных вычислений в Японии (JCAHPC), Isambard-AI в Бристольском университете в Великобритании (5280 × GH200), а также суперкомпьютер в Техасском центре передовых вычислений при Техасском университете в Остине (США), комплекс Venado в Лос-Аламосской национальной лаборатории США (LANL) и суперкомпьютер Recursion BioHive-2 (504 × H100).
10.05.2024 [23:47], Сергей Карасёв
Eviden представила семейство ИИ-серверов BullSequana AIКомпания Eviden (дочерняя структура Atos) анонсировала серверы серии BullSequana AI, предназначенные для решения ИИ-задач. В зависимости от модификации и уровня производительности устройства подходят для различных сценариев использования — от НРС-платформ до периферийных вычислений. Наиболее производительными серверами семейства являются решения BullSequana AI 1200H. Они могут применяться в составе облачных и гибридных инфраструктур, а также в дата-центрах заказчиков. По сути, это суперкомпьютер корпоративного уровня, специально разработанный для ресурсоёмких задач, таких как точная настройка ИИ-систем или обучение больших языковых моделей (LLM). Конфигурация BullSequana AI 1200H включает суперчипы NVIDIA Grace Hopper, а также интерконнект NVIDIA Quantum-2 InfiniBand. Задействовано программное обеспечение Eviden Jarvice XE, Eviden Smart Energy Management Suite, Eviden Smart Management Center и NVIDIA AI Enterprise. 
Источник изображения: Eviden Серверы BullSequana AI 1200H, насчитывающие в общей сложности 1456 ускорителей NVIDIA H100, выбраны для модернизации французского суперкомпьютера Jean Zay. Производительность этого НРС-комплекса увеличится более чем в три раза — с 36,85 до 125,9 Пфлопс. Кроме того, в новое семейство серверов вошли производительные устройства BullSequana AI 800, системы BullSequana AI 600 с воздушным и гибридным охлаждением, модели BullSequana AI 200 для частных и гибридных облачных сред, а также BullSequana AI 100 для периферийных вычислений. 
Источник изображения: Eviden В целом, как отмечается, каждая модель BullSequana AI предлагает различные уровни производительности, масштабируемости и гибкости. Таким образом, заказчики могут подобрать наиболее подходящий для себя вариант в зависимости от конкретного варианта использования, бюджета и размера бизнеса.
26.04.2024 [11:46], Сергей Карасёв
HPE построила самый мощный в Польше суперкомпьютер Helios производительностью 35 ПфлопсКомпания HPE сообщила о создании нового суперкомпьютера под названием Helios для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша). Вычислительный комплекс будет использоваться для решения ресурсоёмких задач, связанных с ИИ. На сегодняшний день Helios — самая высокопроизводительная система в Польше. Она обеспечивает теоретическую пиковую производительность на уровне 35 Пфлопс, что более чем в четыре раза превосходит показатель предыдущего флагманского суперкомпьютера Cyfronet. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс. В основу Helios положены узлы HPE Cray EX. Комплекс состоит из трёх сегментов. Один из них предназначен для традиционных вычислений, еще один — для рабочих нагрузок, связанных с обработкой больших данных. Третий сегмент оптимизирован для ИИ-задач: он использует суперчипы NVIDIA. Суперкомпьютер планируется применять при реализации проектов в области химии, медицины, создания передовых материалов, астрономии и защиты окружающей среды. Раздел общего назначения использует процессоры AMD EPYC поколения Genoa. Общее количество вычислительных ядер Zen 4 составляет 75 264, объём оперативной памяти DDR5 — 200 Тбайт. Сегмент для работы с большими данными основан на платформе HPE Cray Supercomputing XD665 с чипами EPYC Genoa, памятью DDR5-4800, быстрыми накопителями NVMe и ускорителями NVIDIA H100, суммарное количество которых равно 24. 
Источник изображения: HPE Наконец, ИИ-раздел объединяет 440 суперчипов NVIDIA GH200 Grace Hopper для компьютерного моделирования с интенсивным использованием графики, поддержки приложений на основе генеративного ИИ и пр. Все компоненты вычислительного комплекса связаны друг с другом посредством 200G-интерконнекта HPE Slingshot. Комплекс Helios оснащён Lustre-хранилищем общей вместимостью 17,5 Пбайт на базе HPE Cray ClusterStor E1000.
18.04.2024 [13:23], Сергей Карасёв
Eviden и CEA анонсировали второй суперкомпьютер EXA1 — HE на базе Arm-суперчипов NVIDIA Grace HopperКомпания Eviden (дочерняя структура Atos) и Комиссариат по атомной и альтернативным видам энергии Франции (СЕА) объявили о реализации второй фазы суперкомпьютерной программы EXA1. Она предусматривает ввод в эксплуатацию НРС-комплекса EXA1 HE (High Efficiency) на платформе Eviden BullSequana XH3000. Первая очередь системы — EXA1 HF (High-Frequency) — была запущена в 2021 году. Основой послужила платформа BullSequana XH2000. Изначально машина включала 12 960 процессоров AMD EPYC 7763 (64C/128T, 2,45 ГГц), а её производительность на момент анонса составляла 23,2 Пфлопс. Комплекс EXA1 HE использует 477 вычислительных узлов на базе суперчипов NVIDIA Grace Hopper. Применяется жидкостное охлаждение тёплой водой. Заявленная производительность в тесте Linpack составляет приблизительно 60 Пфлопс, а пиковое быстродействие достигает 104 Пфлопс. Задействован фирменный интерконнект BXI (BullSequana eXascale Interconnect). Сеть основана на топологии DragonFly и состоит из 156 коммутаторов. Отмечается, что суперкомпьютер EXA1 соответствует требованиям оборонных программ, реализуемых военным отделом CEA. 
Источник изображения: Eviden Отметим, что в марте нынешнего года компания Eviden заключила соглашение о модернизации французского НРС-комплекса Jean Zay. Суперкомпьютер получит 1456 ускорителей NVIDIA H100 в дополнение к 416 картам NVIDIA A100 и 1832 ускорителям NVIDIA V100, которые задействованы в настоящее время. В результате, пиковая производительность Jean Zay поднимется с нынешних 36,85 до 125,9 Пфлопс.
16.04.2024 [16:20], Сергей Карасёв
Завершено строительство Arm-суперкомпьютера Venado на базе суперчипов NVIDIA Grace HopperЛос-Аламосская национальная лаборатория (LANL) Министерства энергетики США объявила о завершении сборки НРС-комплекса Venado, предназначенного для решения сложных ресурсоёмких задач в области ИИ. В создании системы приняли участие компании HPE и NVIDIA. Проект Venado был анонсирован в мае 2022 года. Система смонтирована в Центре моделирования и симуляции Николаса К. Метрополиса (Nicholas C. Metropolis) в составе LANL. В церемонии открытия комплекса приняли участие представители Министерства энергетики США, Администрации по национальной ядерной безопасности США и других организаций. Venado — первый в США суперкомпьютер, построенный на суперчипах NVIDIA Grace и Grace Hopper с ядрами Arm. Суперкомпьютер построен на платформе HPE Cray EX. В общей сложности задействованы 2560 гибридных суперчипов Grace Hopper с прямым жидкостным охлаждением: эти изделия объединяют ядра Arm v9 и ускорители на архитектуре Hopper. Кроме того, в состав НРС-системы входят 920 суперчипов Grace. Узлы объединены интерконнектом HPE Slingshot 11. 
Источник изображений: LANL На суперкомпьютере используется специализированное ПО HPE Cray, которое, как утверждается, позволяет оптимизировать рабочие нагрузки по моделированию и симуляции. Систему планируется использовать в таких областях, как материаловедение, возобновляемые источники энергии, астрофизика и пр. ИИ-производительность системы (FP8) составит около 10 Эфлопс. Машина также получит Lustre-хранилище.  «Являясь первым в США суперкомпьютером на базе NVIDIA Grace Hopper, система Venado обеспечивает революционную производительность и энергоэффективность для ускорения научных открытий», — говорит Ян Бак (Ian Buck), вице-президент HPC-подразделения NVIDIA. При этом Venado относится к классу экспериментальных суперкомпьютеров и будет использоваться для переноса и оптимизации имеющихся кодов, а также для создания нового ПО и проверки различных концепций.
19.03.2024 [22:37], Сергей Карасёв
HPE выпустила локальный суперкомпьютер для генеративного ИИКомпания HPE сообщила о доступности модульной суперкомпьютерной системы для генеративного ИИ. Платформа, предназначенная для локального размещения в инфраструктуре заказчика, построена на суперчипах NVIDIA GH200 Grace Hopper. О подготовке системы HPE заявила в ноябре 2023 года. В её основу положены серверы ProLiant DL380a Gen11. В общей сложности могут быть задействованы до 168 суперчипов GH200. Кроме того, применяются Ethernet-платформа NVIDIA Spectrum-X и DPU NVIDIA BlueField-3. Решение дополнено платформой машинного обучения и аналитическим программным обеспечением HPE, платформой для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая включает микросервисы на базе загружаемых программных контейнеров, а также сервисом NVIDIA NeMo Retriever и другими библиотеками для обработки данных и ИИ. Суперкомпьютерная система ориентирована на крупные предприятия, исследовательские институты и правительственные учреждения. 
Источник изображения: HPE Утверждается, что в конфигурации с 16 узлами комплекс может оптимизировать модель Llama 2 с 70 млрд параметров всего за 6 минут. Высокая производительность позволяет клиентам повысить продуктивность бизнеса с помощью приложений генеративного ИИ, таких как виртуальные помощники, умные чат-боты и средства корпоративного поиска. При этом софт HPE Machine Learning Inference позволит предприятиям быстро и безопасно развертывать масштабные модели машинного обучения. Компания HPE также сообщила о намерении выпустить продукты следующего поколения, использующие аппаратные решения NVIDIA на базе архитектуры Blackwell. Речь идёт о гибридных суперчипах GB200, а также изделиях HGX B200 и HGXB100. Подробности о новых системах будут раскрыты позднее. |
|
