Материалы по тегу: 400gbe
|
16.12.2024 [11:19], Сергей Карасёв
Раскрыты характеристики сетевых устройств Eviden с технологией BXI v3В ноябре текущего года компания Eviden (дочерняя структура Atos) представила интерконнект третьего поколения BullSequana eXascale Interconnect (BXI v3) для рабочих нагрузок ИИ и HPC. Теперь, как сообщает ресурс Next Platform, раскрыты некоторые характеристики устройств с поддержкой данной технологии. BXI v3 в качестве базового протокола связи использует Ethernet. Технология BXI v3 ляжет в основу интеллектуального сетевого адаптера (Smart NIC) и соответствующего коммутатора. Говорится, что для изготовления чипов ASIC с поддержкой BXI v3 компания Eviden рассматривает возможность применения 3-нм или 4-нм методики TSMC. Коммутатор BXI v3 располагает 64 портами, работающими на скорости 800 Гбит/с. Их можно переконфигурировать в 128 портов с пропускной способностью 400 Гбит/с. В свою очередь, адаптер Smart NIC функционирует на скорости 400 Гбит/с. Он будет предлагаться в виде двухслотовой карты расширения PCIe или OCP-3 (с интерфейсом PCIe 5.0). Возможны варианты адаптеров с двумя портами 400 Гбит/с. Карта BXI v3 способна управлять пакетами объёмом до 9 Мбайт, что полезно в нагруженных инфраструктурах ИИ. 
Источник изображения: Eviden Платформа BXI v3 поддерживает топологии fat tree и dragonfly+, а также fat tree с оптимизацией маршрутов (используется при обучении больших языковых моделей). Для BXI v3 заявлена поддержка до 64 тыс. конечных точек, а задержка составляет менее 200 нс от порта к порту. Изделия с поддержкой BXI v3 поступит в продажу в 2025 году. Осенью 2027 года ожидается появление интерконнекта BXI v4, который предусматривает повышение пропускной способности портов на сетевых картах и коммутаторах до 1,6 Тбит/с. При этом сетевые адаптеры получат поддержку интерфейса PCIe 6.0. В 2029-м планируется переход на интерконнект BXI v5: он обеспечит скорость портов на коммутаторах до 3,2 Тбит/с, тогда как сетевые адаптеры продолжат работать на скоростях до 1,6 Тбит/с, но получат поддержку PCIe 7.0.
22.11.2024 [14:47], Руслан Авдеев
Nokia подписала пятилетнее соглашение по переводу ЦОД Microsoft Azure со 100GbE на 400GbEФинская Nokia расширила соглашение о поставке ЦОД Microsoft Azure маршрутизаторов и коммутаторов. По данным пресс-службы Nokia, соглашение будет действительно в течение пяти лет. Оборудование Nokia, по словам самой компании, повысит масштабируемость и надёжность ЦОД облака Azure по всему миру. Финансовые условия соглашения пока не разглашаются, но, по данным Nokia, благодаря сотрудничеству компаний финский вендор сможет расширить присутствие на рынках более чем на 30 стран и усилить свои позиции в качестве стратегического поставщика для облачной инфраструктуры Microsoft. На уже существующих объектах Azure будет поддерживаться миграция внутренних сетей со 100GbE на 400GbE. Вендор отмечает, что компании, как и ранее, сотрудничают в работе над open source ПО SONiC для маршрутизаторов и коммутаторов ЦОД. В Nokia заявили, что с февраля 2025 года начнёт внедрение платформы 7250 IXR-10e для поддержки многотерабитных сетей в дата-центров Microsoft. Маршрутизатор и коммутаторы, использующие платформу SONiC, будут внедряться на новых площадках ЦОД, что поможет Microsoft справиться с растущим требованиям к объёмам трафика в ближайшие годы. 
Источник изображения: Nokia В Nokia заявляют, что новая фаза сотрудничества повысит масштабируемость и надёжность дата-центров Microsoft Azure по всему миру. По словам представителя Microsoft, в последние шесть лет компания сотрудничала с инженерами Nokia для разработки маршрутизаторов на базе SONiC для содействия экспансии гиперскейлера. В последние месяцы Nokia заявила о наличии амбиций в индустрии ЦОД. В прошлом месяце глава компании Пекка Лундмарк (Pekka Lundmark) заявил, что вендор видит «важную возможность» расширить присутствие на рынке дата-центров. Также в минувшем сентябре Nokia анонсировала запуск платформы автоматизации ЦОД — Event-Driven Automation (EDA).
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 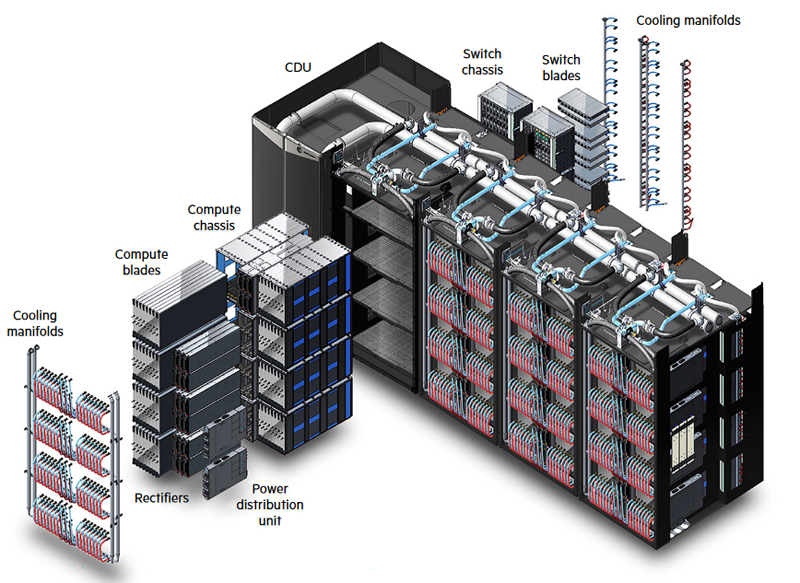 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
21.10.2024 [13:21], Сергей Карасёв
Xsight Labs представила 400GbE DPU серии E1Компания Xsight Labs анонсировала, как утверждается, самую производительную на рынке программно-определяемую «систему на чипе» (SoC), предназначенную для создания DPU с поддержкой RoCEv2 и UET (Ultra Ethernet Transport). Изделие под названием E1 станет доступно заказчикам для тестирования во II квартале 2025 года. Чип будет предлагаться в модификациях E1-32 и E1-64. Первая содержит 32 ядра Arm Neoverse N2 v9.0-A, имеет 16 Мбайт кеша и использует конфигурацию памяти 2 × DDR5-5200. Показатель TDP равен 65 Вт. У второго варианта количество ядер составляет 64, размер конфигурируемого кеша/буфера — 32 Мбайт. Конфигурация памяти — 4 × DDR5-5200, величина TDP — 90 Вт. В обоих случаях используется полное шифрование памяти на лету (AES-XTS). Новинка использует до восьми блоков SerDes, обеспечивая сетевую пропускную способность до 800 Гбит/с. Возможны следующие конфигурации портов: 2 × 400GbE, 4 × 200GbE и 8 × 100/50/25/10GbE. Заявлена производительность на уровне 200 Mpps и 20 млн подключений в секунду. Также есть пара 1GbE-портов для внешнего управления. Доступны программируемые DMA-движки (до 3 Тбит/с) и разгрузка типовых операций, включая шифрование AES-GCM (для IPSec) и AES-XTS (для СХД) на лету. 
Источник изображения: Xsight Labs Есть восемь двухрежимных контроллеров и 40 (32+8) линий PCIe 5.0, а также поддержка P2P-коммутации PCIe. Упомянуты поддержка до четырёх хостов/устройств, SR-IOV (64K PF/VF), а также программная эмуляция и пространства MMIO. Реализована поддержка интерфейсов I2C/I3C/SMBus, SPI/QSPI, SMI, UART, GPIO, 1588 RTC, JTAG. Говорится о высоком уровне обеспечения безопасности: возможно создание изолированных и защищённых сред, которые аутентифицируют каждого клиента. Поддерживается функция безопасной загрузки UEFI Secure Boot with Arm Trusted Firmware (TF-A). Заявлена возможность работы «из коробки» в Debian, Ubuntu, SONiC и Lightbits Labs LightOS, а также совместимость с Netdev, VirtIO, XNA/XDP и DPDK/SPDK. В частности, возможна эмуляция NVMe-, RDMA- и сетевых устройств. Изделие E1 производится по 5-нм технологии TSMC. Оно, как утверждает Xsight Labs, обеспечивает беспрецедентную энергоэффективность и вычислительные возможности, устанавливая новый стандарт производительности для DPU SoC. Новинка ориентирована на облачные платформы и периферийные дата-центры, поддерживающие интенсивные ИИ-нагрузки. DPU позволяет создавать SDN/SDS-решения, брандмауэры, NVMe-oF СХД, вычислительные хранилища, CDN-платформы, балансировщики и т.п.
11.10.2024 [11:55], Сергей Карасёв
DPU + UEC: AMD представила 400G-адаптеры Pensando Salina и PollaraКомпания AMD анонсировала сетевой сопроцессор (DPU) третьего поколения Pensando Salina 400, а также сетевую карту Pensando Pollara 400, ориентированную на применение в составе ИИ-систем. Образцы изделий станут доступны заказчикам в текущем квартале, тогда как массовые продажи начнутся в I половине 2025 года. Решение Pensando Salina 400, рассчитанное на сетевые кластеры гиперскейлеров, обеспечивает пропускную способность до 400 Гбит/с. Утверждается, что по сравнению с DPU предыдущего поколения производительность увеличилась в два раза. Устройство Pensando Salina 400 выполнено в виде карты PCIe 5.0 с двумя портами 400GbE. Задействованы 16 ядер Arm Neoverse-N1 и 232 ядра P4 MPU. Объём памяти DDR5 достигает 128 Гбайт, её пропускная способность — 102 Гбайт/с. Новинка будет применяться в том числе в интеллектуальных коммутаторах, предназначенных для решения различных задач во внешней зоне: это может быть распределение данных, балансировка нагрузки, обеспечение безопасности, шифрование и пр. 
Источник изображений: AMD В свою очередь, Pensando Pollara 400 представляет собой интеллектуальный сетевой адаптер с одним портом 400 Гбит/с. Изделие выполнено на том же чипе, что и Pensando Salina 400. Компания AMD называет Pensando Pollara 400 первой в мире сетевой картой для приложений ИИ, соответствующей стандартам, которые определяет консорциум Ultra Ethernet (UEC). Примечательно, что первые спецификации консорциум намерен представить не раньше конца текущего года.  Цель UEC — разработка основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Благодаря программируемой архитектуре P4 адаптер можно настраивать с учётом конкретных требований. В целом, как утверждается, новинка является мощным решением для повышения производительности рабочих нагрузок ИИ и улучшения надёжности сети.
02.07.2024 [23:55], Алексей Степин
15 тыс. ускорителей на один ЦОД: Alibaba Cloud рассказала о сетевой фабрике, используемой для обучения ИИAlibaba Cloud раскрыла ряд сведений технического характера, касающихся сетевой инфраструктуры и устройства своих дата-центров, занятых обработкой ИИ-нагрузок, в частности, обслуживанием LLM. Один из ведущих инженеров компании, Эньнань Чжай (Ennan Zhai), опубликовал доклад «Alibaba HPN: A Data Center Network for Large Language Model Training», который будет представлен на конференции SIGCOMM в августе этого года. В качестве основы для сетевой фабрики Alibaba Cloud выбрала Ethernet, а не, например, InfiniBand. Новая платформа используется при обучении масштабных LLM уже в течение восьми месяцев. Выбор обусловлен открытостью и универсальностью стека технологий Ethernet, что позволяет не привязываться к конкретному вендору. Кроме того, меньше шансы пострадать от очередных санкций США. Отмечается, что традиционный облачный трафик состоит из множества относительно небыстрых потоков (к примеру, менее 10 Гбит/с), тогда как трафик при обучении LLM включает относительно немного потоков, имеющих периодический характер со всплесками скорости до очень высоких значений (400 Гбит/с). При такой картине требуются новые подходы к управлению трафиком, поскольку традиционные алгоритмы балансировки склонны к перегрузке отдельных участков сети. 
Источник здесь и далее: Alibaba Cloud Разработанная Alibaba Cloud альтернатива носит название High Performance Network (HPN). Она учитывает многие аспекты работы именно с LLM. Например, при обучении важна синхронизация работы многих ускорителей, что делает сетевую инфраструктуру уязвимой даже к единичным точкам отказа, особенно на уровне внутристоечных коммутаторов. Alibaba Cloud использует для решения этой проблемы парные коммутаторы, но не в стековой конфигурации, рекомендуемой производителями. 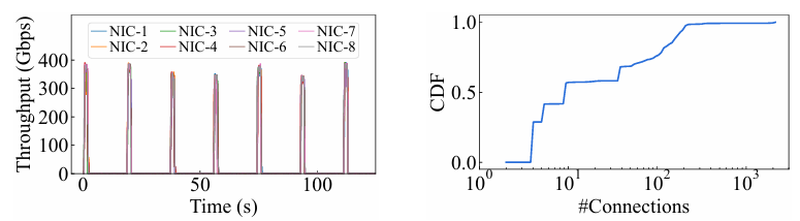
Характер трафика при обучении LLM Каждый хост содержит восемь ИИ-ускорителей и девять сетевых адаптеров. Каждый из NIC имеет по паре портов 200GbE. Девятый адаптер нужен для служебной сети. Между собой внутри хоста ускорители общаются посредством NVLink на скорости 400–900 Гбайт/с, а для общения с внешним миром каждому из них полагается свой 400GbE-канал с поддержкой RDMA. При этом порты сетевых адаптеров подключены к разным коммутаторам из «стоечной пары», что серьёзно уменьшает вероятность отказа. 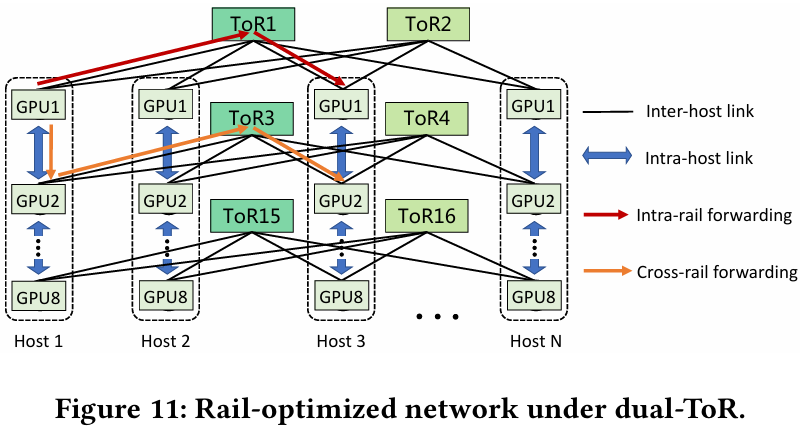 В докладе говорится, что Alibaba Cloud использует современные одночиповые коммутаторы с пропускной способностью 51,2 Тбит/с. Этим условиям отвечают либо устройства на базе Broadcom Tomahawk 5 (март 2023 года), либо Cisco Silicon One G200 (июнь того же года). Судя по использованию выражения «начало 2023 года», речь идёт именно об ASIC Broadcom.  Своё предпочтение именно одночиповых коммутаторов компания объясняет просто: хотя многочиповые решения с большей пропускной способностью существуют, в долгосрочной перспективе они менее надёжны и стабильны в работе. Статистика показывает, что аппаратные проблемы у подобных коммутаторов возникают в 3,77 раза чаще, нежели у одночиповых. 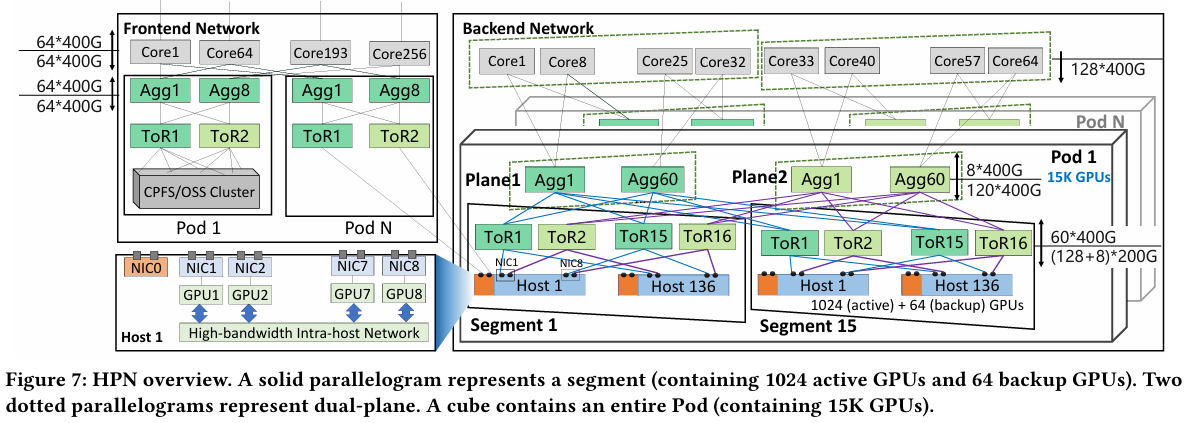 Одночиповые решения класса 51,2 Тбит/с выделяют много тепла, но ни один поставщик оборудования не смог предложить Alibaba Cloud готовые решения, способные удерживать температуру ASIC в пределах 105 °C. Выше этого порога срабатывает автоматическая защита. Поэтому для охлаждения коммутаторов Alibaba Cloud создала собственное решение на базе испарительных камер. 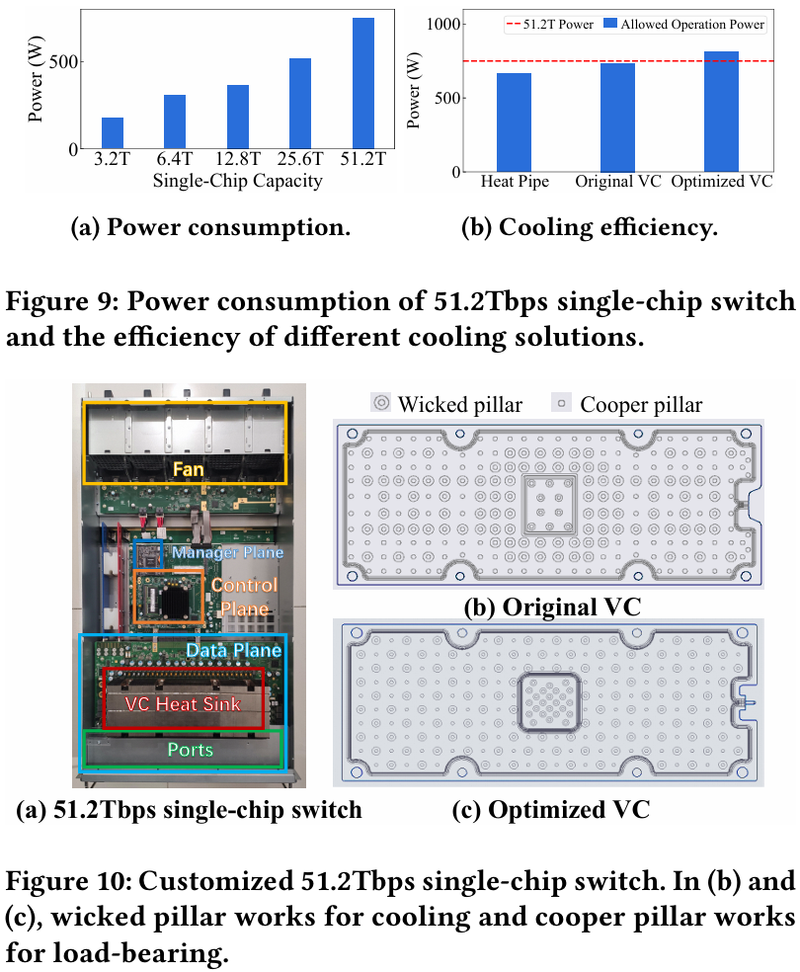 Сетевая фабрика позволяет создавать кластеры, каждый из которых содержит 15360 ускорителей и располагается в отдельном здании ЦОД. Такое высокоплотное размещение позволяет использовать оптические кабели длиной менее 100 м и более дешёвые многомодовые трансиверы, которые дешевле одномодовых примерно на 70 %. Ёмкость такого дата-центра составляет около 18 МВт. 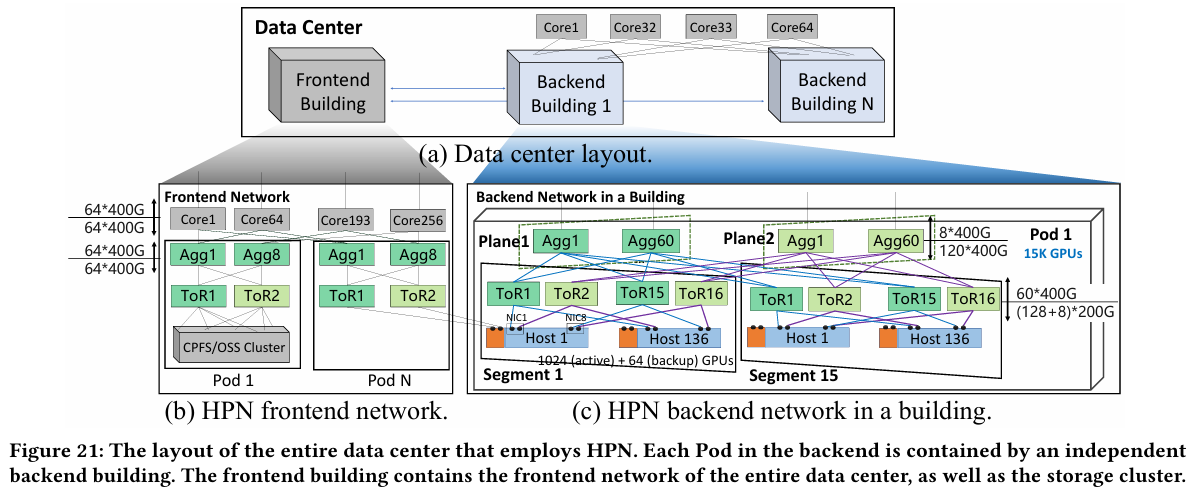 Но есть у HPN и недостаток: использование топологии с двумя внутристоечными коммутаторами и другие особенности архитектуры усложняют кабельную подсистему, поэтому инженеры поначалу столкнулись с ростом ошибок при подключении сетевых интерфейсов. В настоящее время активно используются тесты, позволяющие проверить каждое подключение на соответствие идентификаторов портов и коммутаторов рабочим схемам. Отмечается, что параметры Ethernet-коммутаторов удваиваются каждые два года, поэтому компания уже разрабатывает сетевую архитектуру следующего поколения, рассчитанную на применение будущих ASIC 102,4 Тбит/с. По словам Alibaba Cloud, обучение LLM с сотнями миллиардов параметров потребует огромного распределённого кластера, количество ускорителей в котором исчисляется миллионами. И ему требуется соответствующая сетевая инфраструктура.
09.06.2024 [12:46], Сергей Карасёв
Arista представила сетевые ИИ-решения Etherlink с прицелом на крупные кластерыКомпания Arista Networks анонсировала сетевые платформы Etherlink AI, созданные, как утверждается, для обеспечения оптимальной производительности при выполнении наиболее требовательных рабочих нагрузок ИИ, включая обучение больших языковых моделей (LLM) и их инференс. Решения Arista Etherlink AI поддерживают кластеры ИИ, насчитывающие от тысяч до сотен тысяч xPU. Используются эффективные одно- и двухуровневые сетевые топологии для обеспечения оптимальной производительности. Все коммутаторы Etherlink поддерживают новые стандарты Ultra Ethernet Consortium (UEC), которые, как ожидается, в перспективе дадут дополнительные преимущества в плане производительности. В семейство Arista Etherlink AI входят коммутаторы 7060X6 AI Leaf, построенные на базе ASIC Tomahawk 5 разработки Broadcom. Это изделие способно осуществлять коммутацию на скоростях до 51,2 Тбит/с. Новые устройства поддерживают до 60 портов 800GbE или до 128 портов 400GbE. 
Источник изображения: Arista В семействе сетевых платформ также представлены модульные системы Arista 7800R4 AI Spine 4-го поколения. В них применяются чипы-коммутаторы Broadcom Jericho3-AI, ориентированные специально на ИИ-задачи. Устройства Arista 7800R4 AI Spine поддерживают пропускную способность до 460 Тбит/с в одном шасси: 576 портов 800GbE или 1152 портов 400GbE. Наконец, дебютировали коммутаторы 7700R4 AI Distributed Etherlink Switch (DES), рассчитанные на наиболее крупные кластеры ИИ. Используя архитектуру Jericho3-AI, они обеспечивают распределение трафика без перегрузок. Это первые решения в новой серии сверхмасштабируемых интеллектуальных распределенных систем, которые способны поддерживать высочайшую пропускную способность для самых ресурсоёмких ИИ-задач, говорит компания.
24.05.2024 [10:30], Сергей Карасёв
Broadcom представила 400GbE-адаптеры P1400GD и N1400GDКорпорация Broadcom анонсировала высокопроизводительные Ethernet-адаптеры 400G, которые, как утверждается, призваны революционизировать экосистему дата-центров в эру ИИ. Изделия помогут устранить узкие места в системах коммутации на фоне стремительного роста объёмов передаваемых данных. По заявлениям Broadcom, дебютировавшие устройства — это первые на рынке адаптеры Ethernet, в основу которых положен контроллер (BCM57608), изготовленный по 5-нм технологии. В качестве ключевых сфер применения названы облачные и корпоративные среды, HPC-платформы, серверы хранения данных, приложения ИИ и машинного обучения. 
Источник изображения: Broadcom В семейство вошли модели P1400GD и N1400GD, выполненные в виде карт PCIe и OCP 3.0 соответственно. Используется интерфейс PCIe 5.0 x16. Адаптеры соответствуют стандарту 400GbE, кроме того, поддерживаются режимы 200/100/50/25GbE. В обоих случаях присутствует коннектор QSFP112-DD. Реализована поддержка RDMA over Converged Ethernet (RoCEv2). Упомянуты технологии TruFlow (ускорение сетевых операций) и TruManage (управление серверами). На аппаратном уровне реализованы инструменты обеспечения безопасности Root-of-Trust (RoT). Средства Multi-host позволяют сразу нескольким CPU обращаться к одному Ethernet-адаптеру. Говорится о совместимости с Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu, DPDK.
01.12.2023 [23:19], Алексей Степин
Broadcom представила первый сетевой коммутатор со встроенным ИИ-движкомКомпания Broadcom представила Trident 5-X12 — первый сетевой коммутатор, снабжённый ИИ-движком, который поможет избавиться от сетевых заторов и ускорить обучение ИИ. Новый сетевой процессор относится к семейству StrataXGS и имеет маркировку BCM78800. Он предназначен в первую очередь для компактных ToR-коммутаторов нового поколения. Это первый сетевой ASIC, дополненный инференс-движком NetGNT (Networking General-purpose Neural-network Traffic-analyzer). NetGNT может быть «натаскан» на распознавание ситуации, потенциально ведущей к сетевому затору. К примеру, в сценариях, характерных для обучения нейросетей, часто встречается ситуация, когда множество потоков пакетов прибывает одновременно на один порт, что и вызывает затор. Но движок Broadcom способен предсказать и заранее предотвратить такое развитие событий. 
Источник изображений здесь и далее: Broadcom Trident 5-X12 также имеет расширенную систему телеметрии и располагает объёмными FIB с гибким распределением. Реализованы множественные механизмы распределения нагрузки и предотвращения заторов. Новинка относится к программируемым решениям (NPL), причём готовые сценарии предлагает и сама Broadcom. В рамках API сохранена совместимость с предыдущими решениями компании. Возможно использование SONiC. 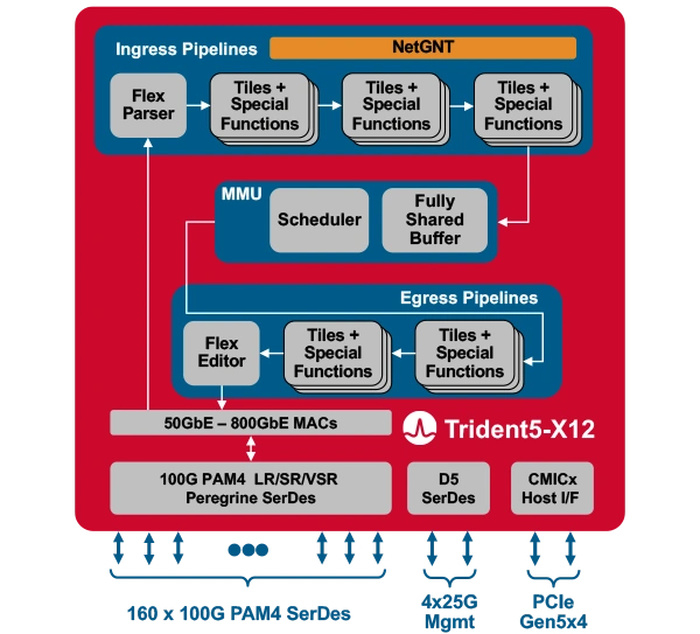 Чип оснащён 160 100G-блоками SerDes (PAM-4) и позволяет среди прочего реализовывать смешанные конфигурации — например, с 24 портами 400G и 8 портами 800G в 1U-шасси. При этом совокупная пропускная способность составляет 16 Тбит/с, однако благодаря 5-нм техпроцессу энергопотребление у новинки в пересчёте на порт на четверть ниже, нежели у Trident 4-X9.
22.11.2023 [11:18], Сергей Карасёв
NVIDIA представила сетевой ускоритель SuperNIC для гипермасштабируемых ИИ-нагрузокКомпания NVIDIA анонсировала аппаратное решение SuperNIC — это сетевой ускоритель нового типа, предназначенный для масштабных рабочих нагрузок ИИ в системах на базе Ethernet. Устройство обеспечивает скорость передачи данных до 400 Гбит/с с использованием RDMA (RoCE). Новинка выполнена на основе DPU BlueField-3: это часть сетевой 400G/800G-платформы Spectrum-X, которая предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с). Отмечается, что сообща BlueField-3 SuperNIC и Spectrum-4 составляют основу вычислительной системы, специально разработанной для ускорения ИИ-нагрузок. При этом платформа Spectrum-X обеспечивает высокую эффективность сети, превосходя по производительности традиционные среды Ethernet. По заявления NVIDIA, DPU предоставляет множество расширенных функций, таких как высокая пропускная способность, подключение с небольшой задержкой и пр. 
Источник изображения: NVIDIA Среди ключевых особенностей SuperNIC называются: высокоскоростное переупорядочение пакетов; расширенный контроль перегрузок с использованием данных в реальном времени и специализированных сетевых алгоритмов; возможность программирования ввода-вывода (I/O); энергоэффективный низкопрофильный дизайн; полная оптимизация для ИИ (включая вычисления, сети, хранилище, системное ПО, коммуникационные библиотеки). В одной системе могут быть задействованы до восьми SuperNIC, что позволяет добиться соотношения 1:1 с GPU. А это даёт возможность максимизировать производительность при выполнении сложных задач ИИ. |
|
