Материалы по тегу: интерконнект
|
19.06.2025 [09:27], Владимир Мироненко
ИИ — это не только GPU: Marvell проектирует полсотни кастомных чипов для ЦОДПоскольку провайдеры облачных сервисов, ИИ-стартапы и суверенные субъекты масштабируют свои ЦОД, Marvell видит растущий спрос не только на основное вычислительное оборудование, включая пользовательские CPU, GPU и ускорители, но и на широкий спектр вспомогательных полупроводниковых элементов, включая контроллеры сетевых интерфейсов, чипы управления питанием, устройства расширения памяти и т.д., пишет Converge Digest. В ходе мероприятия для инвесторов AI Investor Day 2025 гендиректор Мэтт Мерфи (Matt Murphy) обрисовал растущую роль компании в поддержке ИИ-инфраструктуры, отметив два ключевых события, формирующих рынок: рост числа новых разработчиков ИИ-инфраструктуры за пределами традиционных четырёх ведущих гиперскейлеров и быстрое появление компонентов XPU Attach как важной новой категории кастомных полупроводников. Мерфи отметил, что эти тенденции способствуют формированию гораздо более крупного и разнообразного общего целевого рынка, чем прогнозировалось ранее. 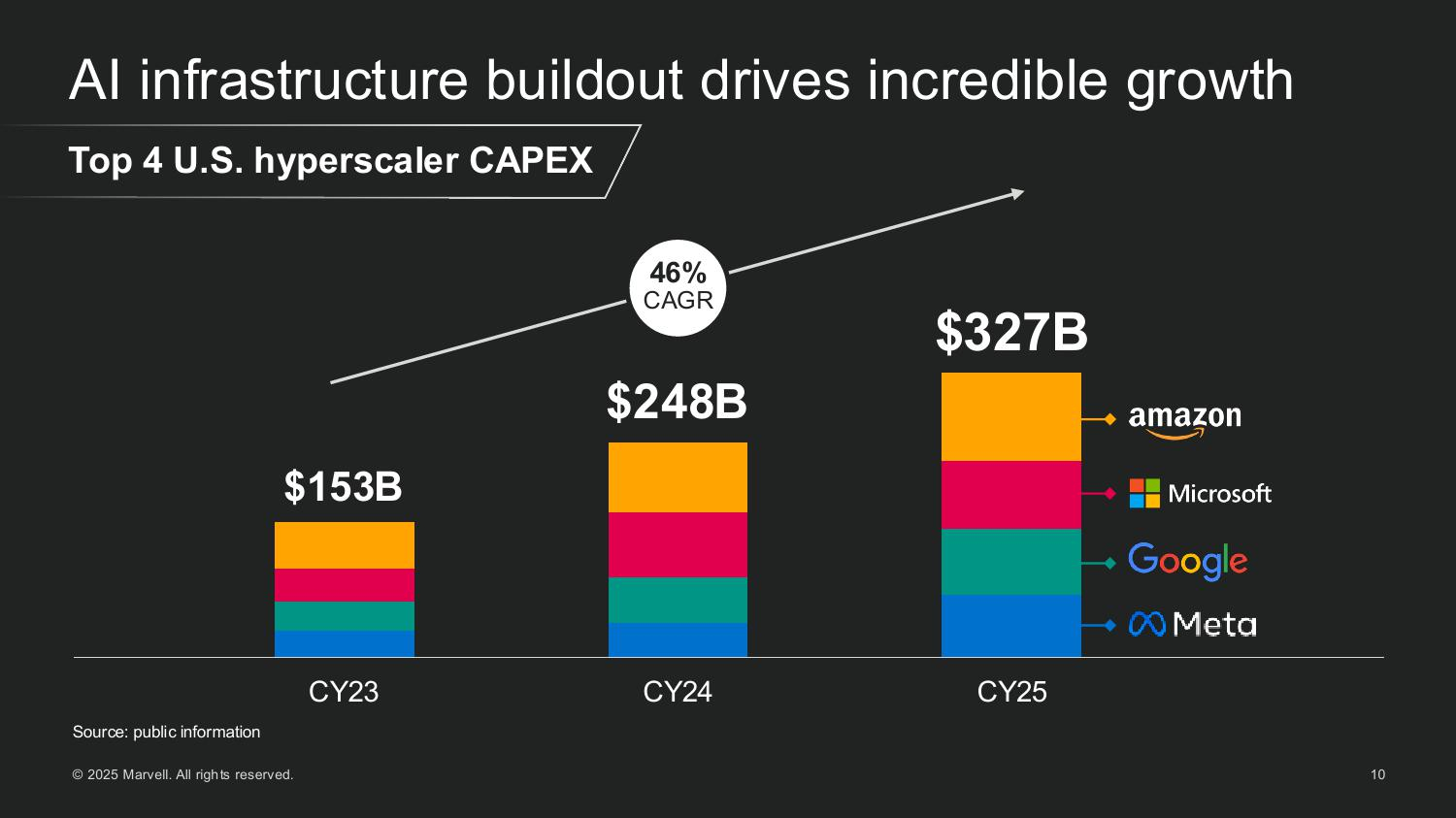
Источник изображений: Marvell Мерфи рассказал, как резко выросли глобальные капитальные затраты на ЦОД, обусловленные ростом гиперскейлеров и развитием суверенного ИИ. Ведущие американские гиперскейлеры — AWS, Microsoft, Google и Meta✴ — увеличили совокупные капитальные затраты со $150 млрд в 2023 году до более чем $300 млрд в 2025 году. По прогнозам, на глобальном уровне к 2028 году затраты превысят уже $1 трлн. Marvell считает, что значительная часть этих расходов будет направлена на кастомные полупроводниковые платформы. 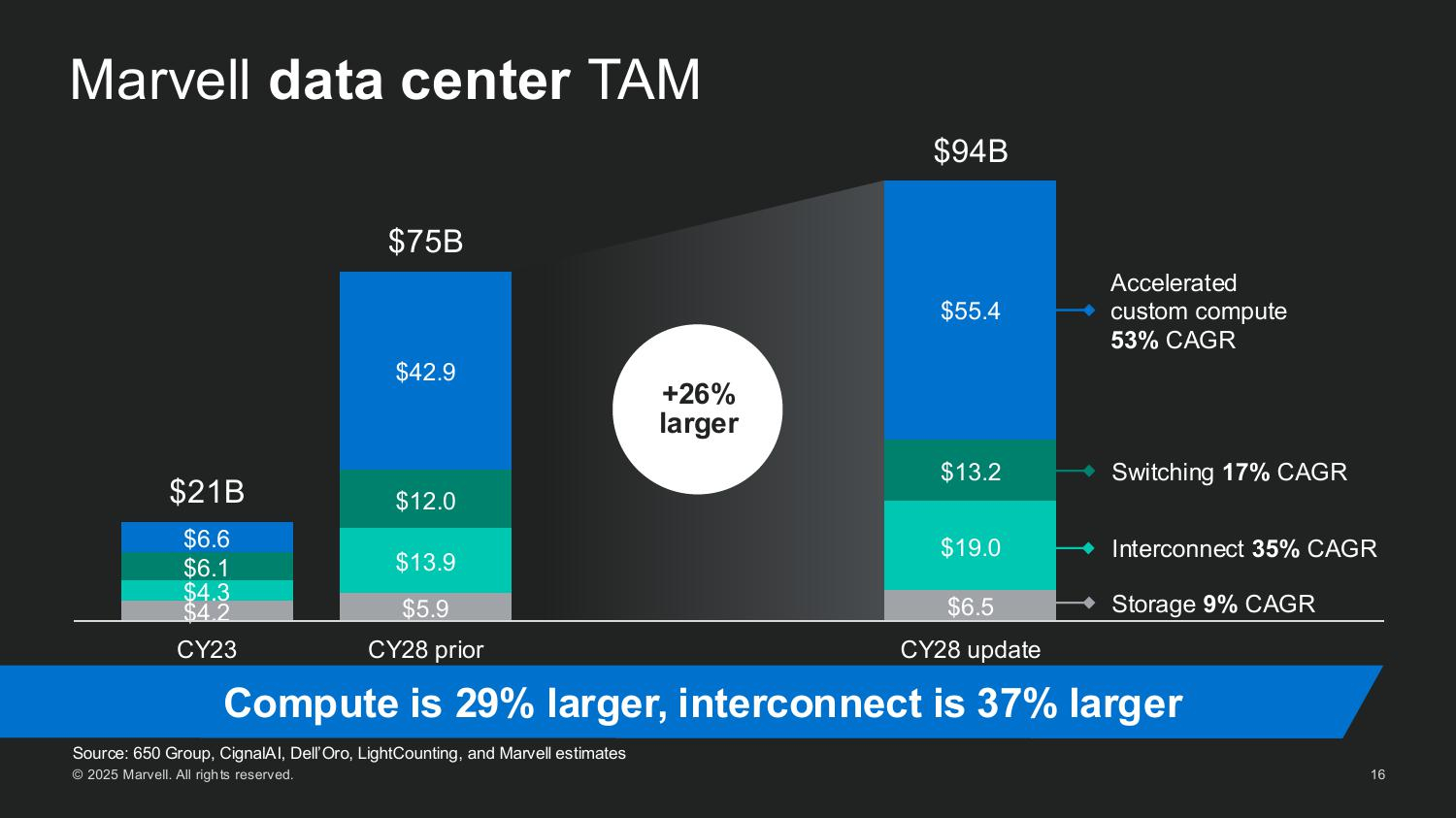 Marvell пересмотрела прогноз общего целевого рынка (TAM) в сторону увеличения до $94 млрд к 2028 году, что на 25 % больше её оценки в прошлом году. Эта сумма включает:
Мерфи подчеркнул, что XPU Attach — прорывная категория, отметив, что «вычислительные ИИ-платформы больше не определяются одним чипом. Это сложные системы с бурным ростом числа сокетов — каждый из которых представляет собой новую возможность [для компании]».  «В прошлом году у нас было три кастомных вычислительных чипа и TAM на $75 млрд. В этом году у нас 18 сокетов, TAM на $94 млрд и растущий поток из более чем 50 проектов. Рынок ИИ-инфраструктуры быстро развивается, и Marvell находится прямо в его центре», — подытожил Мерфи. 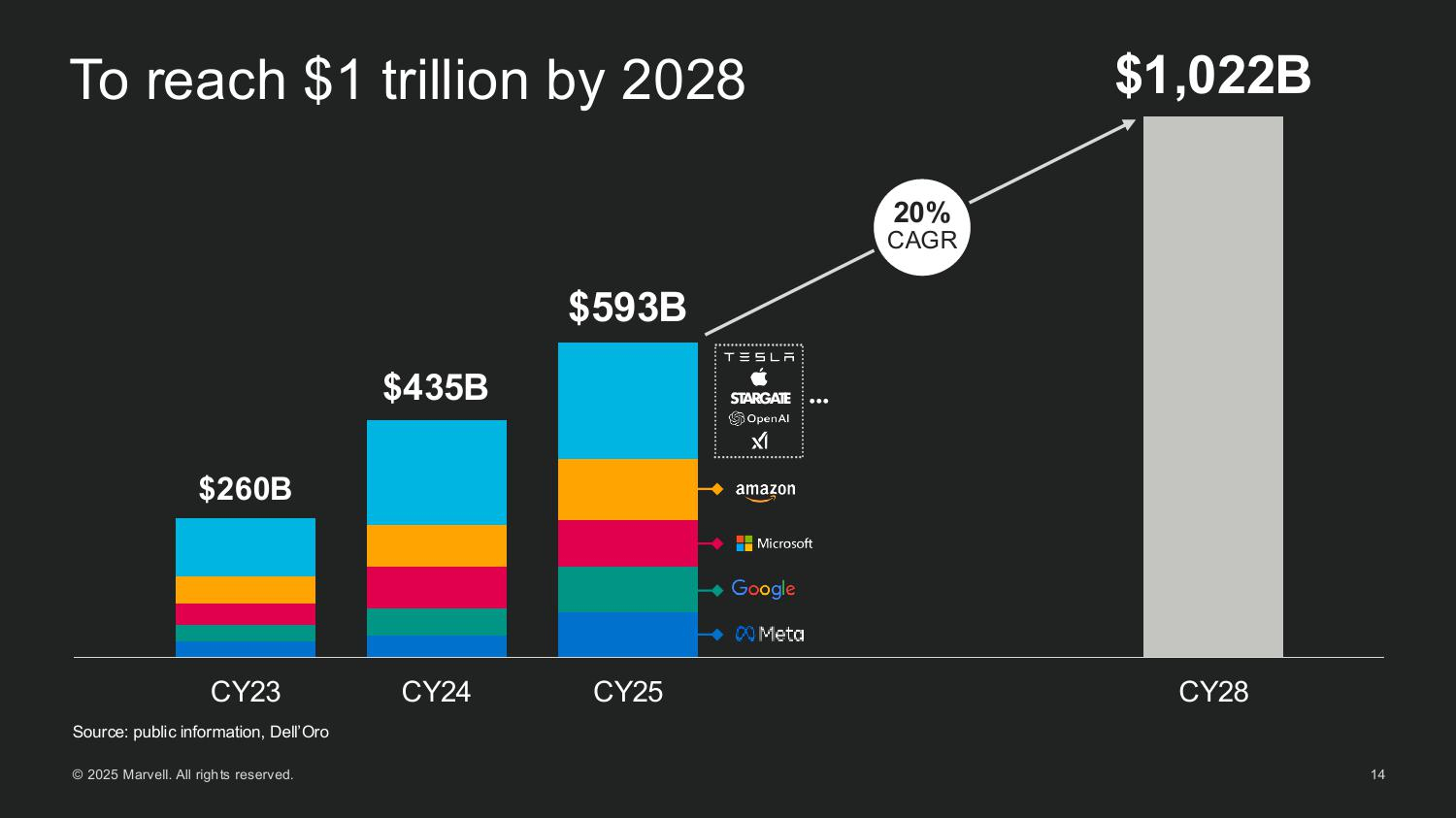 Marvell на сегодняшний день обеспечила разработку 18 кастомных чипов:
Marvell сопровождает более 50 активных кастомных полупроводниковых проектов — сочетание XPU и Attach — с более чем 10 клиентами. Среди них облачные гиперскейлеры, новые ИИ-стартапы и национальные ИИ-инициативы. По оценкам компании, эти проекты принесут $75 млрд потенциального дохода за весь срок их реализации, и это без учёта 18 уже готовых проектов. 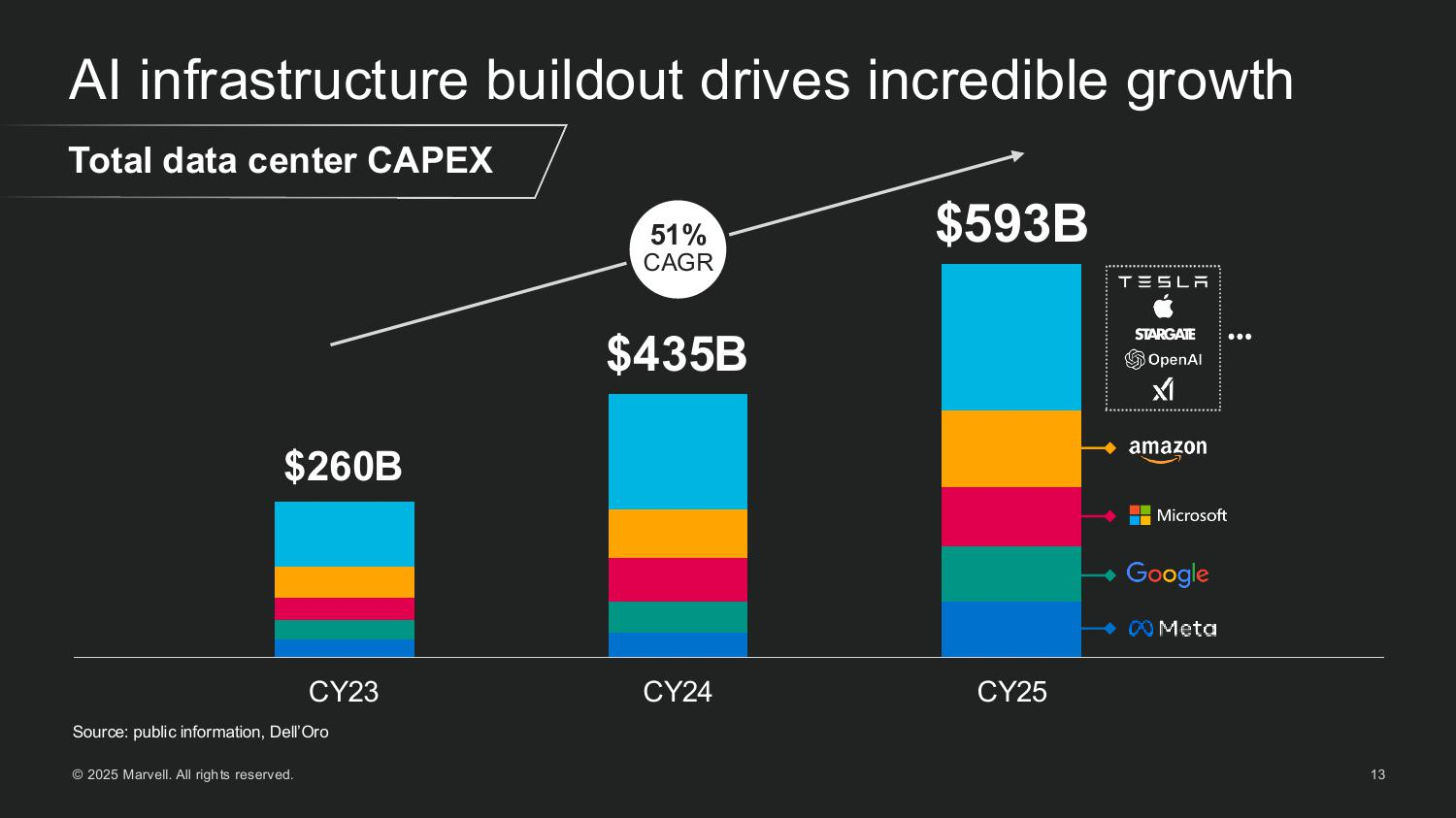 Мерфи подчеркнул, что на этом рынке больше не доминирует несколько «мегасокетов». «Ещё в 2023 году на один сокет приходилось 75 % TAM. К 2028 году ни один сокет не будет превышать 10–15 %. Это огромная диверсификация — и она отлично подходит для нас», — сообщил глава Marvell.
11.06.2025 [23:59], Игорь Осколков
Представлена финальная спецификация PCI Express 7.0Консорциум PCI-SIG официально объявил о релизе спецификаций PCI Express 7.0 версии 1.0. Базовые характеристики интерфейса изменений не претерпели: «сырая» скорость 128 ГТ/с на линию, которая конвертируется в 512 Гбайт/с в двустороннем режиме в конфигурации x16; кодирование PAM4; поддержка Flit-режима; универсальность и обратная совместимость с предыдущими версиями PCIe; повышенная энергоэффективность; расширенная коррекция ошибок и т.д. Новый стандарт ориентирован на решения с интенсивным обменом данными, которым требуются низкая задержка, высокая скорость и повышенная надёжность: ИИ-платформы, 800G-сети, облака гиперскейлеров, квантовые системы и т.п. Впрочем, как и стандарты прошлого поколения, PCIe 7.0 сохранит гибкость, предоставляя 11 различных профилей, которые охватывают весь спектр возможных применений интерфейса, от мобильных платформ до HPC-систем. Консорциум придерживается выбранного темпа выпуска спецификаций — каждые три года появляется новый стандарт, который, по мнению PCI-SIG, всегда чуть опережает текущие потребности индустрии. Здесь есть два важных момента. Во-первых, PCI-SIG не пытается добиться максимально возможной скорости (за NVLink уже не угнаться), а старается дать максимум скорости по приемлемой цене. Во-вторых, уже сейчас разработчики IP говорят о возможных проблемах насыщения данными даже одной линии PCIe 7.0 в некоторых приложениях и сложностях физической и логической реализации нового интерфейса. 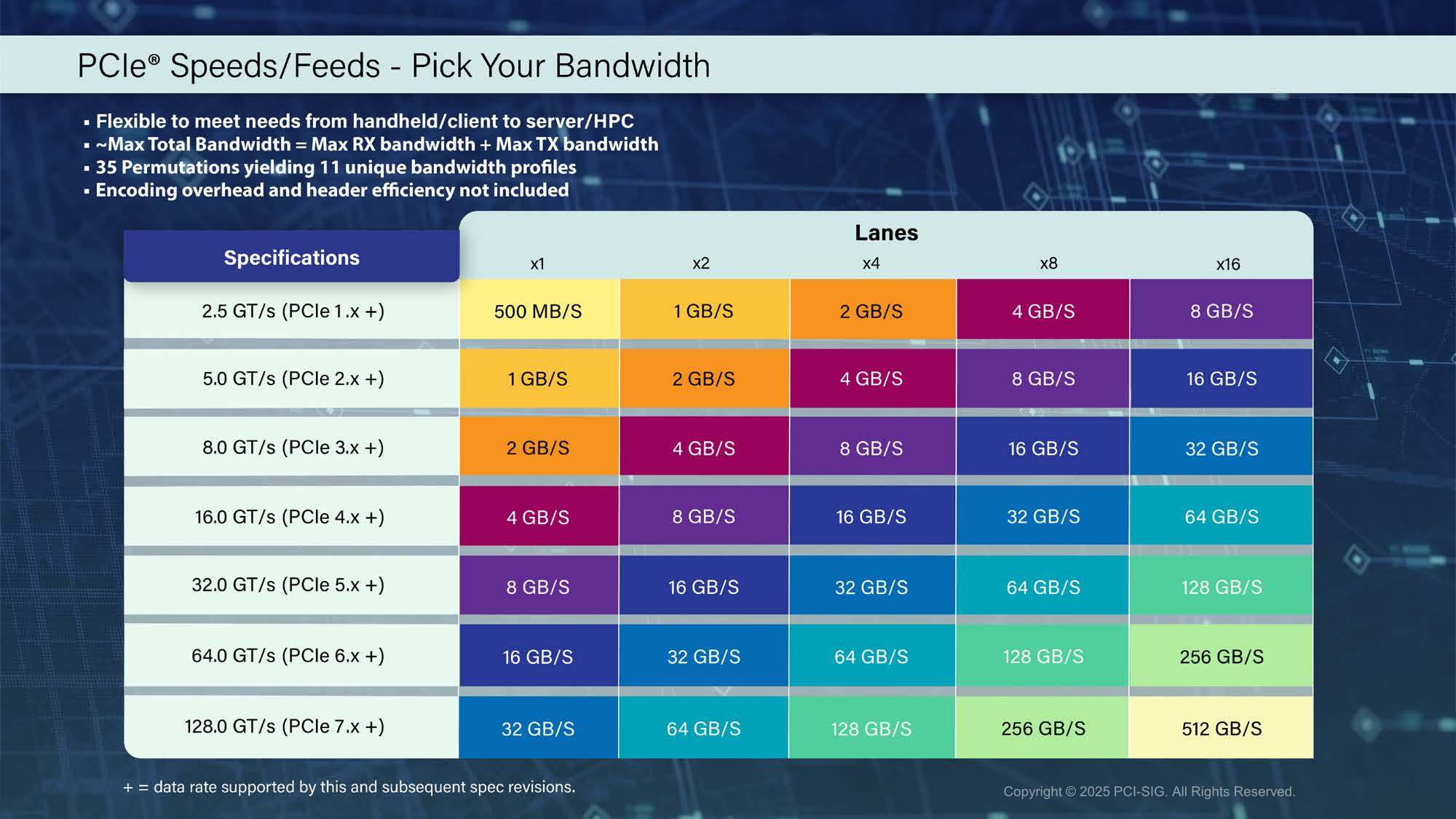
Источник изображений: PCI-SIG  Впрочем, до появления первых реальных продуктов с поддержкой PCIe 7.0 ещё долго. На 2027 год запланирован старт предварительного «тестирования на соответствие» (FYI, First Year Inventory Compliance Program), так что внедрение нового стандарта начнётся не раньше 2028 года. Внедрение PCIe 6.0, представленного ещё в январе 2022 года, тоже только-только начинается и займёт ещё год-два.   Анонсированная почти два года назад оптическая версия PCIe продолжает разрабатываться. В PCIe 7.0 и PCIe 6.4 впервые были добавлены спецификации ретаймеров, которые позволят передавать сигнал PCIe по оптоволокну. Это позволит сделать интерконнект на базе PCIe значительно компактнее, чем при использовании традиционных медных соединений, а также позволит эффективно вывести PCIe за пределы узла. Впрочем, пока что речь идёт скорее о масштабах стойки или нескольких, а не целого ЦОД.
04.06.2025 [22:00], Владимир Мироненко
Лучше, чем InfiniBand и Ethernet: Cornelis Networks представила 400G-интерконнект Omni-Path CN5000Поставщик сетевых решений Cornelis Networks объявил о выходе 400G-интерконнекта CN5000, «самого производительного в отрасли сквозного (end-to-end) сетевого решения, специально созданного для максимизации производительности ИИ и HPC». Это первая крупная платформа Cornelis Networks после выделения из Intel в 2021 году, призванная конкурировать с Ethernet и InfiniBand. Лиза Спелман (Lisa Spelman), генеральный директор Cornelis Networks, отметила, что сети должны не только быстро перемещать данные, но и раскрывать весь потенциал каждого вычислительного цикла. «Если вы посмотрите на текущие ИИ-кластеры или кластеры HPC, вы увидите, что использование вычислений в некоторых случаях составляет менее 30 %, а… в лучших архитектурах и лучших случаях оно достигает (лишь) 50 %», — сообщила Спелман в интервью Network World. 
Источник изображений: Cornelis Networks Согласно пресс-релизу, CN5000 позволяет ИИ- и HPC-приложениям достигать более быстрого и предсказуемого времени выполнения задач и большей вычислительной эффективности за счёт минимизации перегрузок и поддержания максимальной пропускной способности под нагрузкой. В HPC-нагрузках CN5000 обеспечивает по сравнению с InfiniBand NDR до двух раз более высокую скорость отправки сообщений, на 35 % меньшую задержку и на 30 % выше производительность в таких задачах как вычислительная гидродинамика (CFD), моделирование климата и сейсмическое моделирование. CN5000 также показывает более высокую устоявшуюся пропускную способность в реальных условиях. 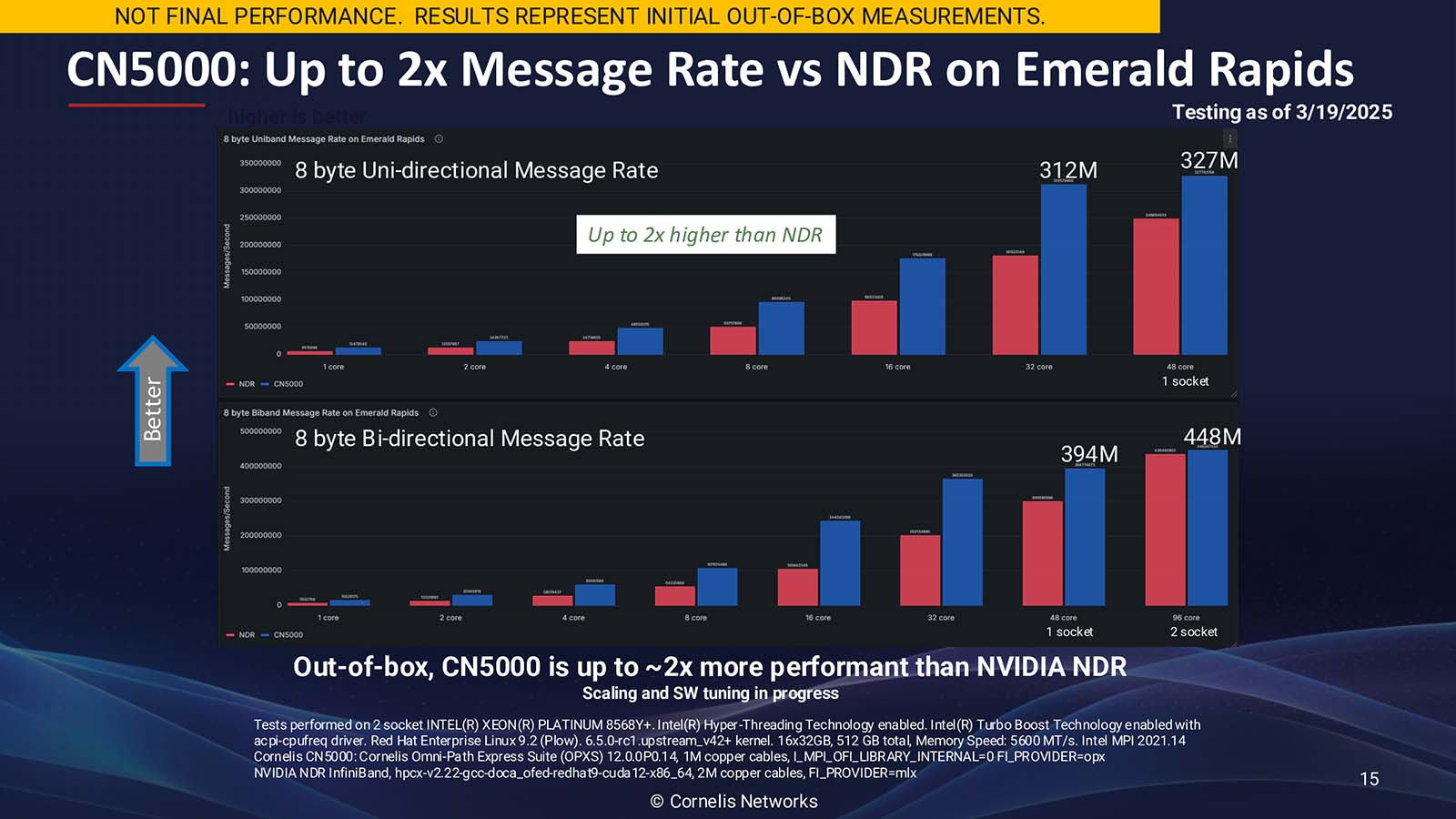 Для ИИ-приложений CN5000 предлагает в шесть раз более высокую производительность коллективных операций по сравнению RoCE. Коллективные операции, такие как all-reduce, представляют собой критические узкие места в распределённом обучении, где тысячи узлов должны эффективно синхронизировать обновления градиента. Сообщается, что CN5000 обеспечивает почти линейное масштабирование производительности обучения для больших языковых моделей (LLM) и более эффективный инференс с расширенной логикой. CN5000 является универсальным продуктом — интерконнект без проблем взаимодействует с CPU и GPU от AMD, Intel, NVIDIA и других производителей. Используется полностью открытый программный стек OpenFabrics, чтобы сделать переход от InfiniBand или Ethernet к Omni-Path «невероятно простым» для любого клиента, пояснила Спелман. Кроме того, OpenFabrics принят консорциумом Ultra Ethernet в качестве базового компонента. 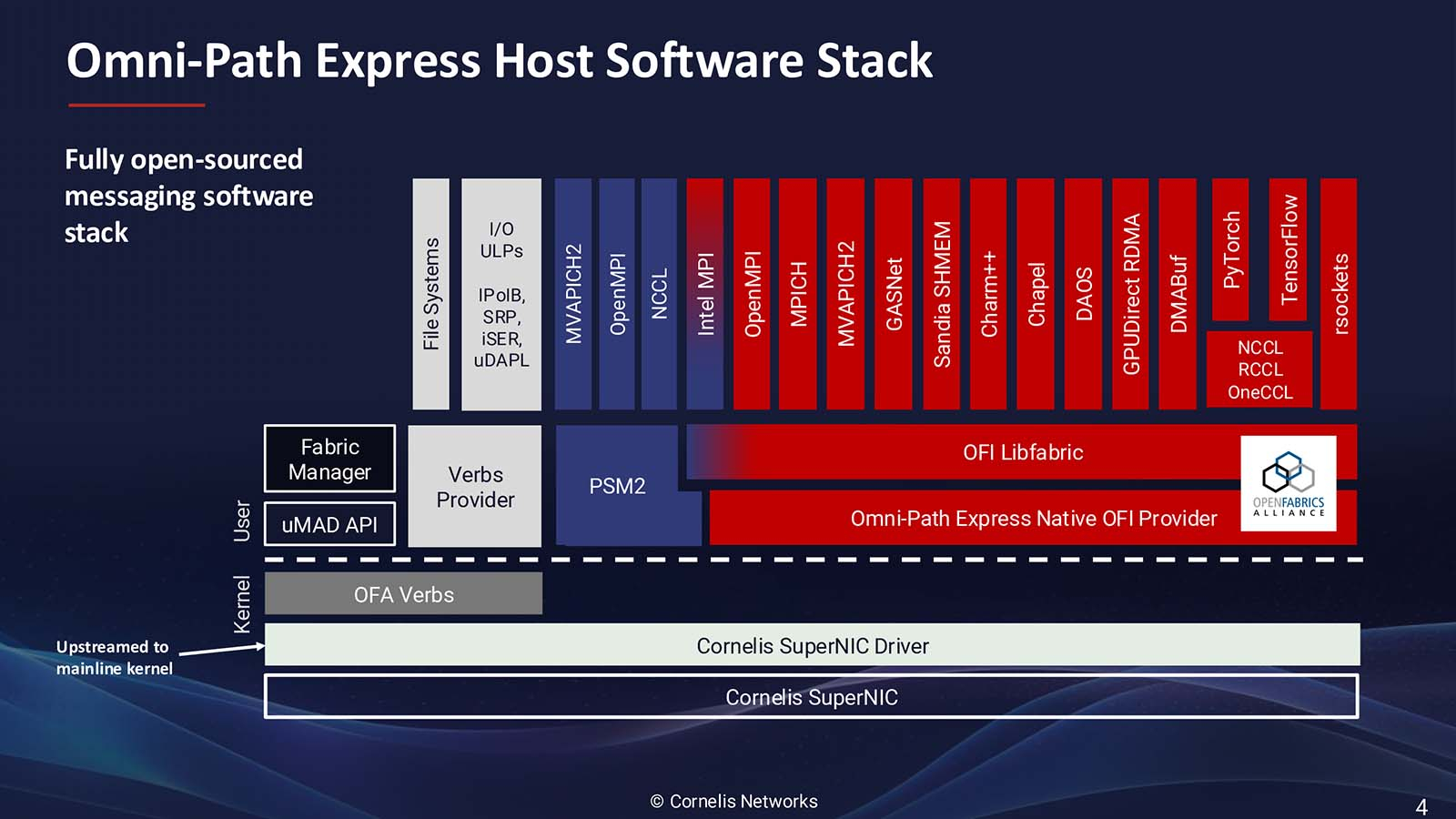 Семейство CN5000 включает:
Как рассказала Спелман, CN5000 представляет собой третий архитектурный подход к высокопроизводительным сетям, отличный от реализаций Ethernet и InfiniBand. Вместо того, чтобы пытаться модернизировать существующие протоколы для рабочих ИИ- и HPC-нагрузок, Cornelis Networks расширила возможности Omni-Path от Intel с учётом конкретных вариантов использования: «Что мы сделали — это исправили архитектуру для рабочих нагрузок».  Архитектура нового решения получила несколько ключевых отличий, разработанных специально для масштабируемых параллельных вычислительных сред. В частности, управление потоком на основе кредитов обеспечивает передачу данных без потерь, в то время как тонкая адаптивная маршрутизация оптимизирует выбор пути в реальном времени. Улучшенные механизмы контроля перегрузки предназначены для поддержания стабильной производительности при высоких нагрузках, что является критически важным требованием для рабочих нагрузок ИИ-обучения, которые могут включать тысячи конечных точек. Всё это позволит улучшить использование GPU и других чипов в ИИ ЦОД, которые традиционно не используются в полной мере из-за неэффективности интерконнекта. Спелман отметила, что отличительной чертой архитектуры Cornelis Networks является то, что при той же пропускной способности можно достичь удвоения скорости передачи сообщений.  «При использовании точно таких же вычислительных ресурсов, просто заменив другую 400G-сеть на CN5000, вы увидите рост производительности приложений на 30 %, — пообещала Спелман. — Обычно для повышения производительности приложений на 30 % вам понадобится новое поколение ЦП». Более эффективное использование чипов позволяет либо работать с более крупными нагрузками на том же «железе», либо добиваться того же результата, используя меньше вычислительного оборудования.  «CN5000 — это сквозная сеть, в которой Super NIC и коммутатор или Director работают вместе», — пояснила Спелман. Платформа CN5000 поддерживает масштабирование до 500 тыс. конечных точек (250 тыс. узлов), что делает её подходящей для крупных установок, типичных для национальных лабораторий и корпоративных программ в области ИИ. Поставки CN5000 клиентам начнутся в июне, а массова она станет доступна с III квартала 2025 года у всех основных OEM-производителей. 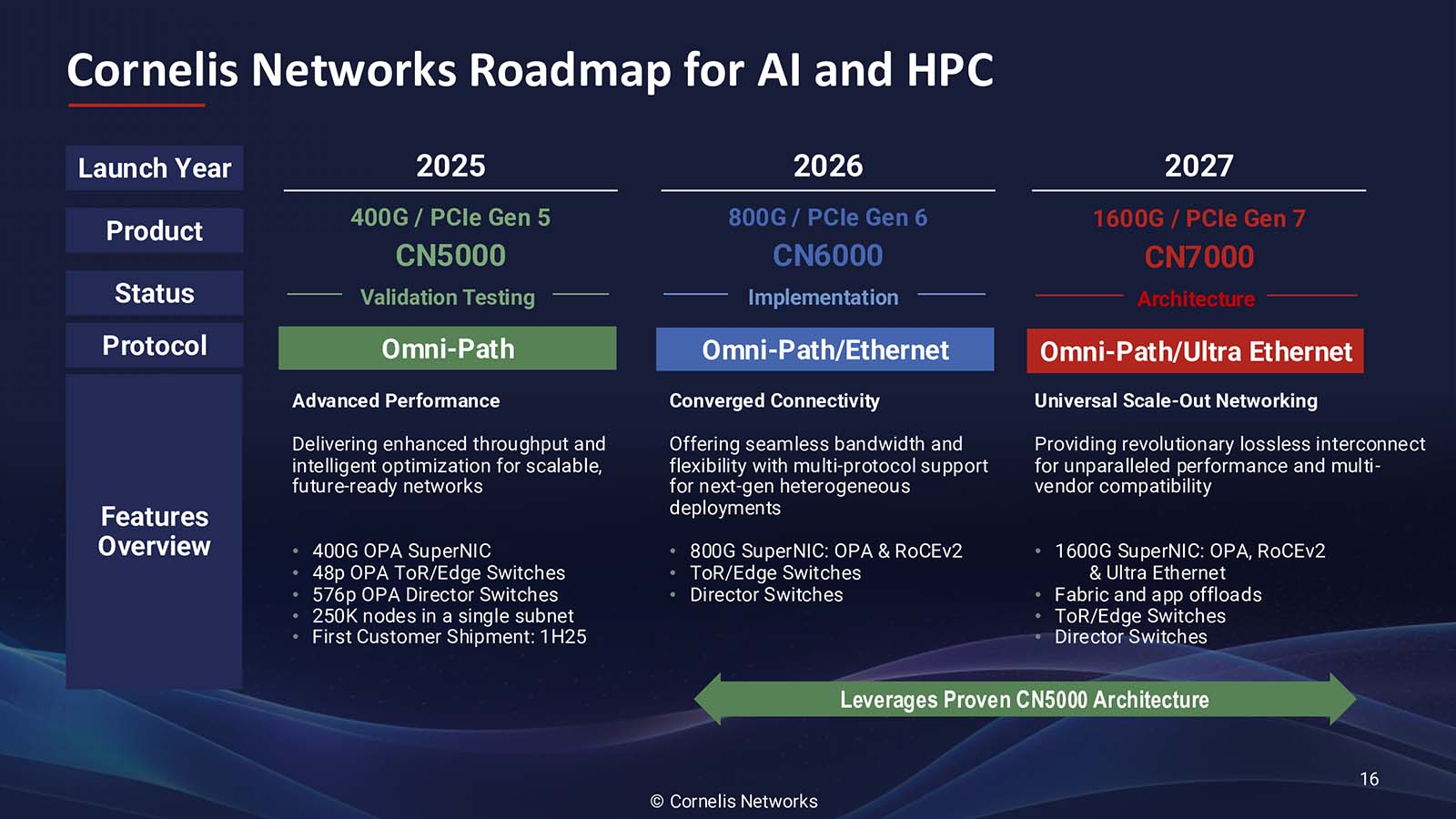 Cornelis Networks видит существенно большие рыночные возможности в следующих поколениях решения. Платформа CN6000 (800 Гбит/с) выйдет в 2026 году и будет включать возможности двухрежимного режима с поддержкой SuperNIC протоколов Ethernet для более широкой совместимости с экосистемой. В 2027 году должна выйти платформа CN7000 (1,6 Тбит/с), которая получит поддержку стандартов Ultra Ethernet на уровне коммутатора. Платформа также будет поддерживать 2 млн узлов и внутрисетевые вычисления. Анонс CN5000 состоялся ещё в конце 2023 года, т.е. у компании ушло довольно много времени на доработку продукта. Вместе с тем буквально вчера были представлены коммутаторы Broadcom Tomahawk 6, которые уже предлагают до 1,6 Тбит/с на порт, интегрированную фотонику (CPO) и поддержку Ultra Ethernet. А весной этого года NVIDIA представила 800G-платформу Ethernet/InfiniBand, причём изначально с CPO. Не осталась в стороне и Eviden (Atos), которая также анонсировала 800G-интерконнект BXI v3.
04.06.2025 [01:00], Владимир Мироненко
Broadcom представила самые быстрые в мире Ethernet-коммутаторы Tomahawk 6: 102,4 Тбит/с на чип и 1,6 Тбит/с на портКомпания Broadcom объявила о старте поставок серии чипов-коммутаторов Tomahawk 6 (BCM78910), первых Ethernet-коммутаторов, обеспечивающий коммутационную способность 102,4 Тбит/с, что вдвое выше возможностей Ethernet-коммутаторов, доступных на рынке. Сообщается, что благодаря невероятной возможности масштабирования, энергоэффективности и оптимизированным для ИИ функциям Tomahawk 6 нацелен на использование в крупных ИИ-кластерах. В случае вертикального масштабирования (scale-up) новинка позволяет объединить до 512 XPU в один кластер. В двухуровневых горизонтально масштабируемых (scale-out) сетях Tomahawk 6 может объединить более 100 тыс. XPU со скоростью 200GbE на каждое подключение. В целом же решение позволяет объединить до 1 млн XPU. Tomahawk 6 предлагает SerDes-блоки 100G/200G PAM с поддержкой «дальнобойных» пассивных медных подключений. Есть и вариант с интегрированными оптическими интерфейсами (CPO), который обеспечивает более высокую энергоэффективность, более низкий уровень задержки, а также повышенную стабильность работы. 
Источник изображений: Broadcom Встроенная технология Cognitive Routing 2.0 автоматически выявляет перегрузки и перенаправляет потоки данных по альтернативным маршрутам, что помогает избежать узких мест в производительности. Cognitive Routing 2.0 в Tomahawk 6 включает расширенную телеметрию, динамический контроль перегрузки, быстрое обнаружение сбоев и обрезку пакетов, что обеспечивает глобальную балансировку нагрузки и адаптивное управление потоком. Эти возможности адаптированы для современных рабочих ИИ-нагрузок, включая MoE-модели, тонкую настройку, обучение с подкреплением и рассуждающие модели.  «Tomahawk 6 — это не просто обновление, это прорыв, — заявил Рам Велага (Ram Velaga), старший вице-президент и генеральный менеджер подразделения Core Switching Group компании Broadcom. — Он знаменует собой поворотный момент в проектировании ИИ-инфраструктуры, объединяя самую высокую пропускную способность, энергоэффективность и адаптивные функции маршрутизации для scale-up и scale-out сетей в одной платформе». Tomahawk 6 поддерживает как стандартные топологии, например, сеть Клоза или тор, так и сети на базе фреймворка Broadcom Scale-Up Ethernet (SUE). 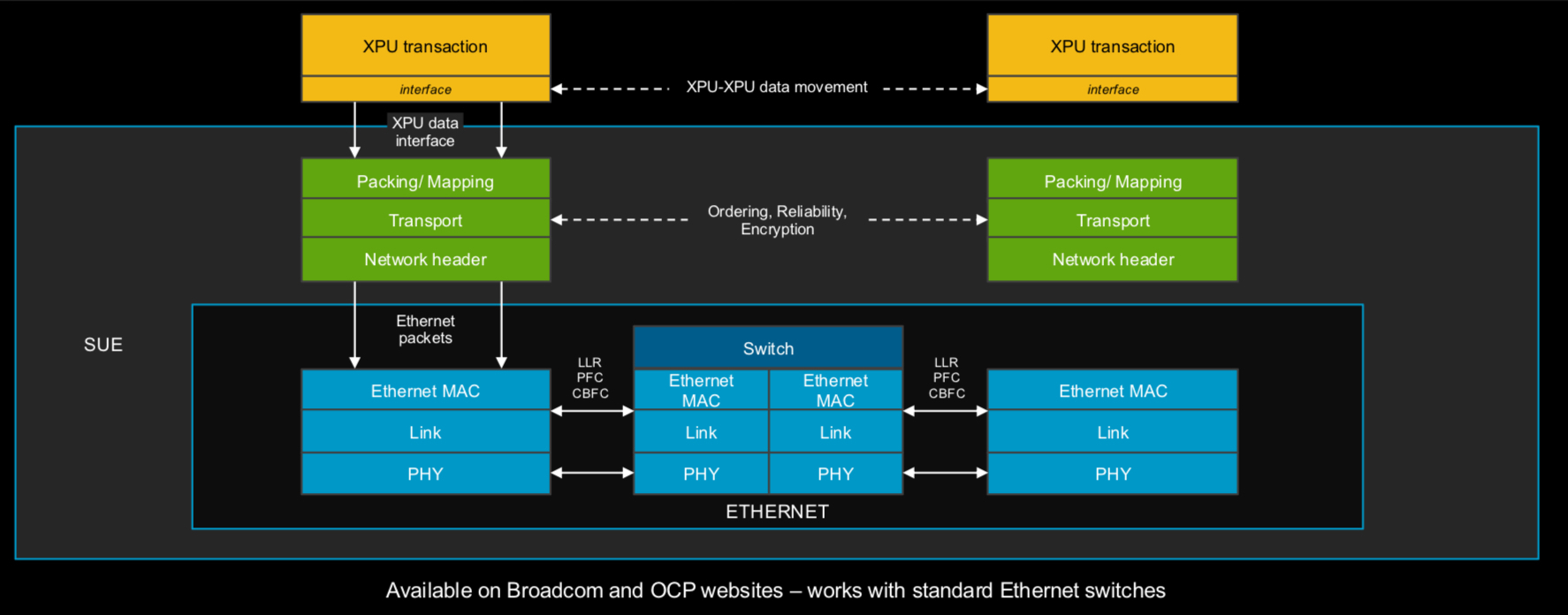 Компания отметила, что благодаря использованию 200G SerDes коммутатор обеспечивает самую большую дальность для пассивного медного соединения, что позволяет проектировать высокоэффективную систему с малой задержкой, высочайшей надежностью и самой низкой совокупной стоимостью владения (TCO). Возможные конфигурации портов: 64 × 1.6TbE, 128 × 800GbE, 256 × 400GbE, 512 × 200GbE. Но Tomahawk 6 предлагает и конфигурацию 1024 × 100GbE, т.е. высокоплотный и экономичный интерконнект на основе Ethernet. А поддержка CPO не просто избавляет от множества трансиверов, но и существенно сокращает связанные с ними перебои, что крайне важно для гиперскейлеров. 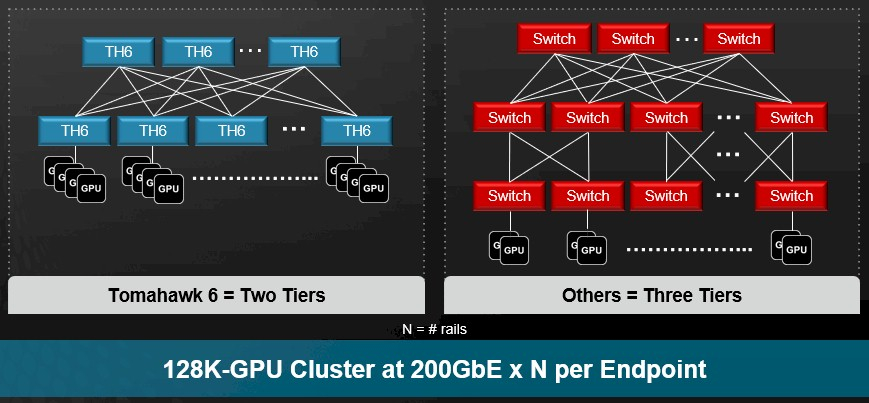 Использование Ethernet предоставляет операторам сетей значительные преимущества, позволяя им использовать единый технологический стек и согласованные инструменты во всей ИИ-инфраструктуре. Это также позволяет использовать взаимозаменяемые интерфейсы, с помощью которых облачные операторы могут динамически формировать кластеры XPU для различных рабочих нагрузок клиентов. Кроме того, Tomahawk 6 также соответствует требованиям Ultra Ethernet Consortium.
19.05.2025 [16:07], Руслан Авдеев
NVLink Fusion: NVIDIA открыла фирменный интерконнект NVLink сторонним разработчикам чиповNVIDIA представила технологию NVLink Fusion, позволяющую применять скоростные интерконнекты NVLink с «полукастомными» ускорителями, включая ASIC-модули. Благодаря этому NVLink можно использовать даже с ускорителями, разработанными сторонними компаниями, сообщает The Register. NVLink 5 поколения сегодня обеспечивает пропускную способность на уровне 1,8 Тбайт/с (900 Гбайт/с в каждом направлении) на каждый ускоритель с возможностью объединения до 72 ускорителей. Ранее поддержка интерконнектов компании ограничивалась ускорителями и процессорами NVIDIA, хотя сообщалось и о сотрудничестве с MediaTek. 
Источник изображений: NVIDIA Как сообщают в NVIDIA, технологию будут предлагать в двух конфигурациях — первая предназначена для связи кастомных CPU с ускорителями NVIDIA (CPU-to-GPU), в 14 раз быстрее в сравнении с PCIe 5.0 (128 Гбайт/с). Второй, более необычный вариант предусматривает связь CPU Crace и Vera с ускорителями, разработанными не NVIDIA. Этого можно добиться, используя либо IP-блок NVLink, либо отдельный чиплет. 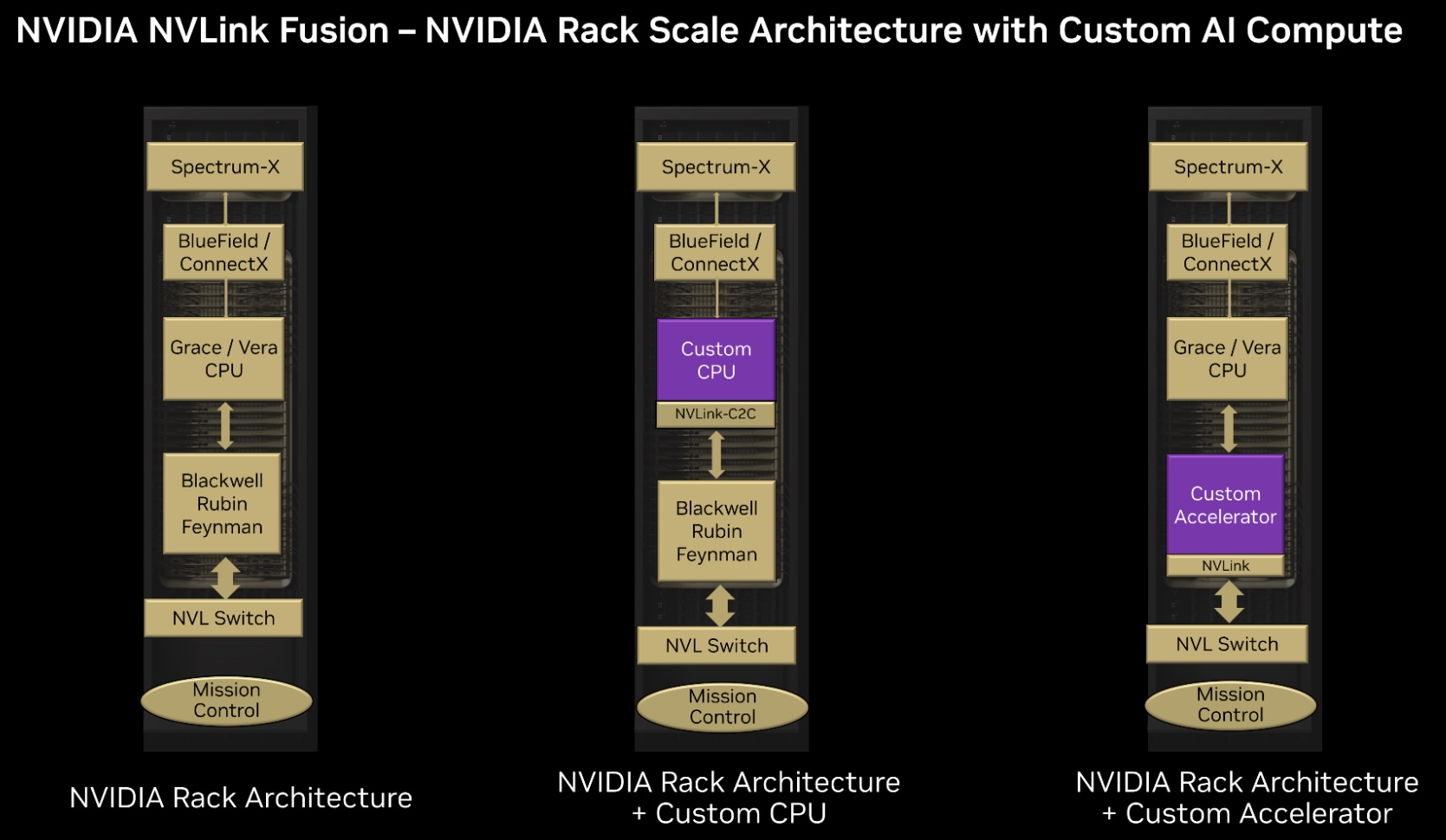 В теории это откроет возможность создания кластеров-«суперчипов» с любыми комбинациями CPU и GPU NVIDIA, AMD, Intel и др., но только с участием продуктов NVIDIA. Другими словами, объединить, например, только процессоры и ускорители Intel с помощью NVLink Fusion не выйдет. Кроме того, NVIDIA не открывает свой стандарт полностью. Как сообщает пресс-служба NVIDIA, поддержку интерконнекта уже обещали добавить MediaTek, Marvell, AIchip, Astera Labs, Synopsys и Cadence, а Fujitsu и Qualcomm планируют добавить объединить свои CPU с ускорителями NVIDIA посредством NVLink Fuison. При этом ни AMD, ни Intel в списке партнёров пока нет и, возможно, они там не появятся. Обе компании сделали ставку на Ultra Accelerator Link — открытую альтернативу NVLink. UALink первой версии предлагает всего лишь 200 Гбит/с на линию (до 800 Гбит/с на ускоритель), но позволяет объединить до 1024 ускорителей. Стандарт во много основан на AMD Infinity Fabric. Год назад AMD также приоткрыла Infinity Fabric, но в PCIe-версии, представив AFL (Accelerated Fabric Link). Intel же изначально сделала ставку на Ethernet для связи ускорителей внутри и вне узла.
19.05.2025 [11:24], Сергей Карасёв
Broadcom представила оптический CPO-интерконнект третьего поколения со скоростью 200G на линиюКомпания Broadcom анонсировала платформу CPO (Co-Packaged Optics — интегрированная оптика) третьего поколения для создания оптического интерконнекта с высокой пропускной способностью. Решение ориентировано на инфраструктуры ИИ с большой нагрузкой и возможностью масштабирования. Broadcom начала активное развитие направления CPO в 2021 году, анонсировав чипсет первого поколения Tomahawk 4-Humboldt. Затем последовало решение второго поколения Tomahawk 5-Bailly (TH5-Bailly) со скоростью передачи данных 100 Гбит/с на линию. В настоящее время организовано массовое производство таких продуктов. Они, как утверждается, обеспечивают бесшовную интеграцию оптических и электрических компонентов для повышения производительности при снижении энергопотребления. Решения Broadcom CPO третьего поколения поддерживают оптические соединения с пропускной способностью 200 Гбит/с на линию. Интерконнект может применяться в инфраструктурах, насчитывающих более 512 узлов, которые предназначены для обучения крупных моделей ИИ и инференса. Технология, как отмечается, призвана решить проблемы пропускной способности, мощности и задержки, возникающие на фоне увеличения количества параметров ИИ-моделей. 
Источник изображения: Broadcom В число партнёров Broadcom по экосистеме CPO входят Corning Incorporated, Delta Electronics, Foxconn Interconnect Technology, Micas Networks и Twinstar Technologies. В частности, Delta Electronics организовала производство коммутаторов Ethernet TH5-Bailly 51.2T CPO в форм-факторе 3RU, которые доступны в конфигурациях с воздушным и жидкостным охлаждением. А Micas Networks предлагает сетевую коммутационную систему TH5-Bailly, обеспечивающую экономию электроэнергии более чем на 30 % по сравнению с решениями с традиционными подключаемыми модулями. Вместе с тем Broadcom уже разрабатывает решения CPO четвёртого поколения, которые обеспечат пропускную способность до 400 Гбит/с на линию.
22.04.2025 [08:45], Владимир Мироненко
Google настаивает на скорейшем переходе к 448G SerDes и готова отказаться от OSFP ради дальнейшего масштабирования ИИ-кластеровВ ходе семинара OIF 448Gbps Signaling for AI Workshop, инженер по оптическому оборудованию для систем машинного обучения Google Тэд Хофмайстер (Tad Hofmeister) привёл доводы в пользу скорейшего согласования отраслью технологий SerDes следующего поколения. Об этом пишет ресурс Converge Digest. В связи со стремительным масштабированием ИИ-нагрузок, стимулирующим беспрецедентный спрос на более высокие скорости передачи данных, Хофмайстер подчеркнул необходимость выхода за пределы возможностей 224G SerDes и начала развёртывания 448G в ИИ-системах, причём как в вертикально масштабируемых архитектурах, так и в горизонтально масштабируемых системах. Google призывает всю индустрию сфокусироваться на развитии 448G SerDes, поскольку уже сейчас возможностей 224G едва хватает — контактов на чипах скоро будет слишком мало, чтобы передавать данные. 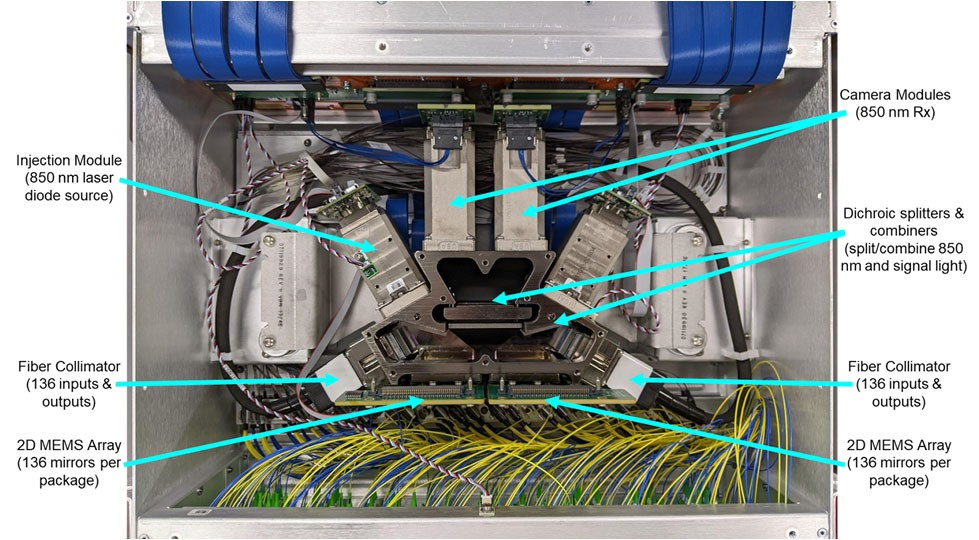
Источник изображения: Google Он отметил, что последнее поколение TPU Ironwood и суперускорителей NVIDIA GB200 расширяют требования к производительности и пропускной способности интерконнекта. И хотя медные соединения по-прежнему пригодны для топологий внутри стойки с коротким радиусом действия, оптические соединения необходимы для масштабирования ИИ-кластеров. Использование Google собственного протокола ICI для интерконнекта TPU с оптическими коммутаторами Apollo между модулями, способные объединить до 9126 ускорителей, подчеркивает важность гибких сетевых архитектур с высокой пропускной способностью. Хофмайстер также коснулся проблем, связанных с конструкцией разъёмов, целостностью сигнала и питанием. Он предположил, что отрасли, возможно, придётся отказаться от обратной совместимости с OSFP, а также объединиться для работы над модуляциями более высокого порядка — PAM6 или PAM8 вместо PAM4. Интегрированная оптика (co-packaged optics) и высокоскоростные flyover-кабели для подключения компонентов внутри узла рассматриваются как необходимые средства для обхода ограничений печатных плат и сохранения целостности сигнала 448G.
09.04.2025 [00:49], Алексей Степин
Все против NVIDIA: представлена открытая альтернатива NVLink — интерконнект UALink 200G 1.0Консорциум UALink, в состав которой входят AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft, опубликовала первые спецификации на разрабатываемую в рамках альянса более доступную альтернативу проприетарным решениям NVIDIA. Интерконнект UALink призван заменить в первую очередь NVLink и во многом опирается на AMD Infinity Fabric, хотя пока что по скоростям составляет конкуренцию скорее Ethernet и InfiniBand. Консорциум Ultra Accelerator Link был сформирован в конце прошлого года с целью создания высокоскоростного интерконнекта с низкими задержками, базирующегося на открытых технологиях. Речь здесь не только о приверженности открытым стандартам, но и о солидном потенциальном куске рынка — только за прошедший финансовый год сетевое подразделение NVIDIA выручило $13 млрд. 
Источник здесь и далее: UALink Появление более доступной и открытой альтернативы теоретически должно пошатнуть позиции последней в этом секторе, а также позволить разработчикам HPC-систем и ИИ-кластеров избежать жёсткой привязки к одному вендору. В том числе речь идёт о возможности организации сети UALink, включающей в себя GPU и ускорители разных поставщиков. Упор в первой версии стандарта сделан на общий доступ к памяти ускорителей с высокой скоростью, низкими задержками и простыми атомарными операциями 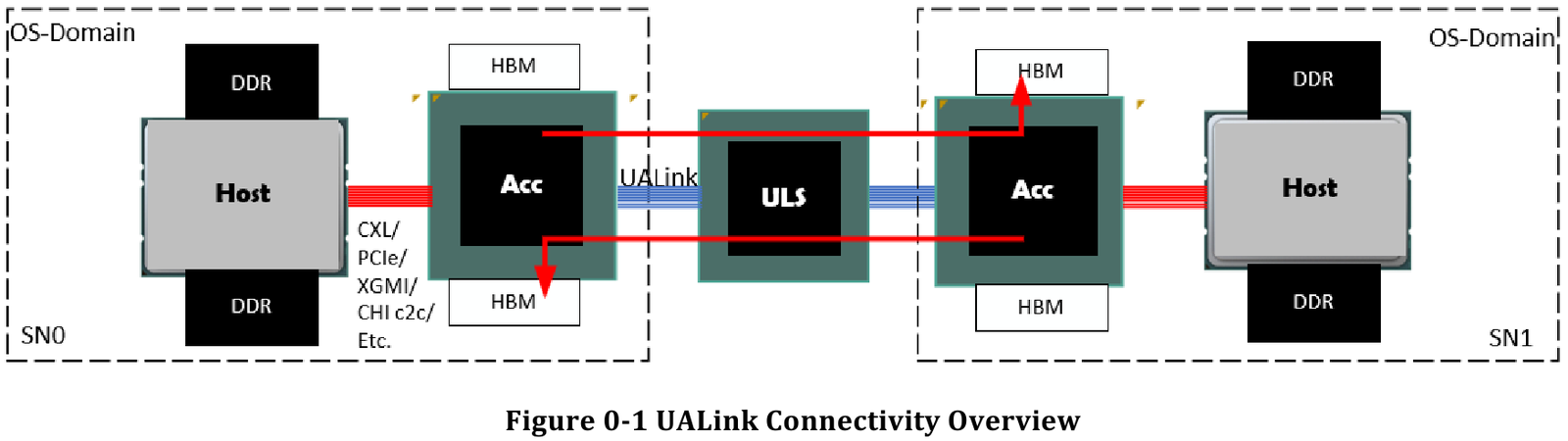 Впервые опубликованные спецификации описывают стандарт UALink 200G 1.0. В основе лежит коммутируемая сеть с пропускной способностью 200 Гбит/с на каждую линию, во многом наследующая AMD Infinity Fabric, но дополненная разработками других участников альянса. Максимальное количество линий на один ускоритель может достигать четырёх, что позволяет поднять пропускную способность до 800 Гбит/с. Поддерживается бифуркация. 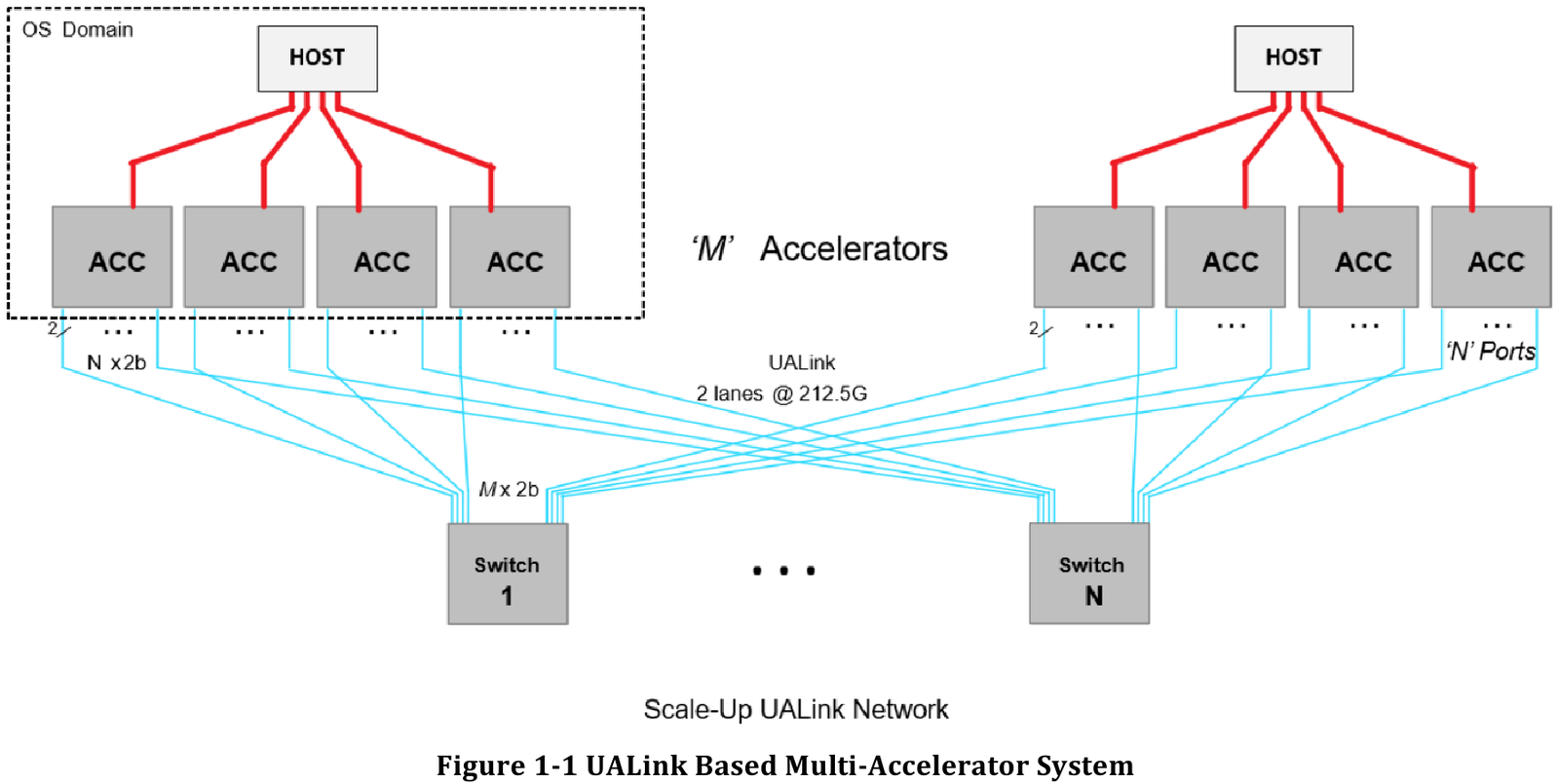 Размер кластера в данной версии стандарта UALink ограничен 1024 узлами, не считая коммутаторов. При этом гарантируются линейные скорости на уровне соответствующих версий Ethernet, но c энергопотреблением от трети до половины от аналогичного показателя последних, при времени отклика на уровне коммутируемых вариантов PCI Express. Задержка от порта к порту должна составить менее 100 нс, на уровне коммутаторов UASwitch — 100–150 нс. Для сравнения: NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене со скоростью до 0,9–1,8 Тбайт/с на ускоритель.  Также предусмотрена совместная работа с Ethernet в составе GPU-кластера, где хост-процессоры общаются между собой посредством традиционной сети (в том числе Ultra Ethernet), а ускорители могут использовать либо прямое, либо коммутируемое подключение UALink. 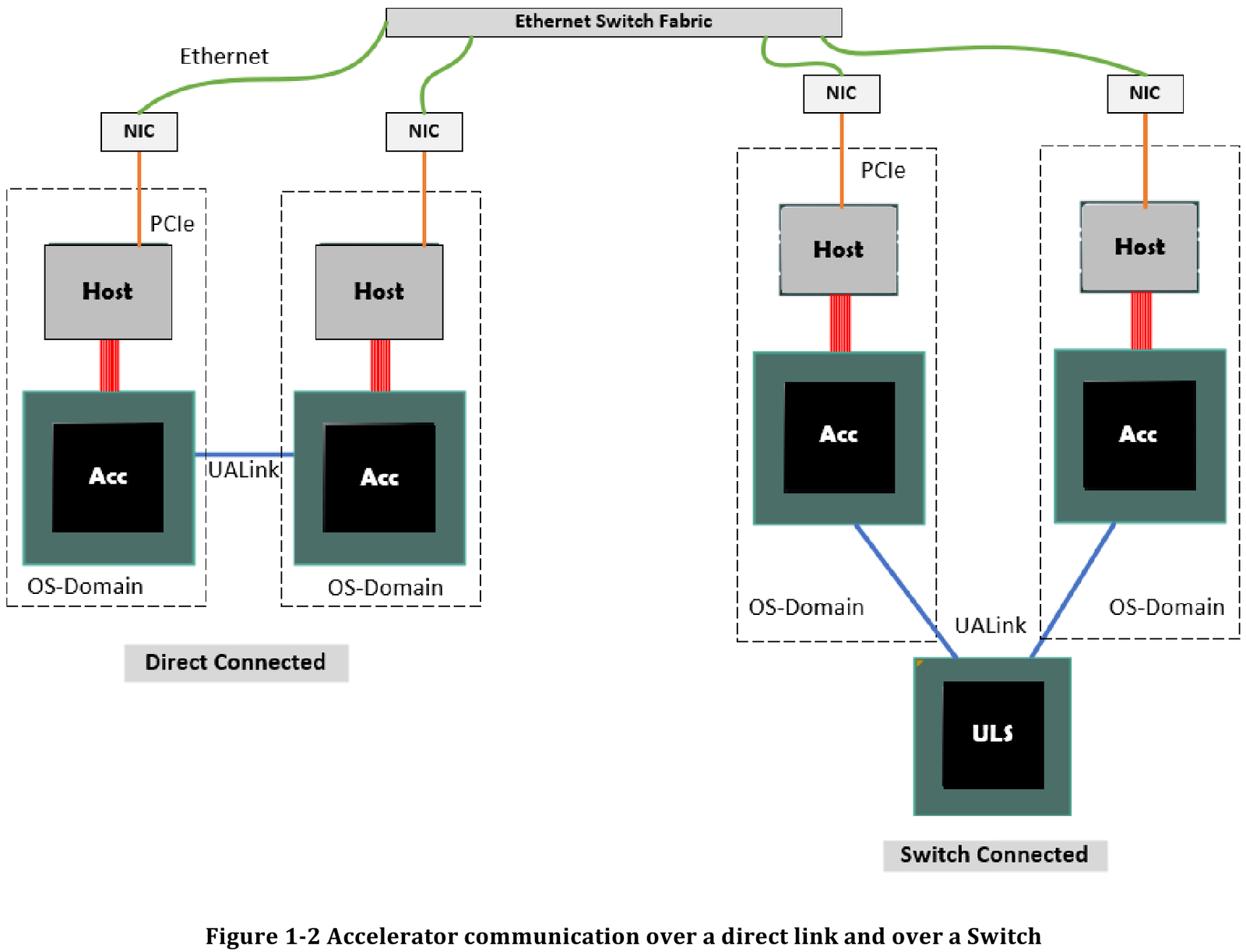 Передача данных осуществляется словами длиной 680 байт: 640-байт флит-пакеты + 40 байт накладных расходов на упреждающую коррекцию ошибок (FEC) и кодирование 256B/257B. Реализованы механизмы доступа к удалённой памяти, но когерентность на аппаратном уровне не поддерживается, также имеются различия на подуровне PCS (Physical coding sublayer). На физическом уровне используется стандарт IEEE 802.3dj: 200GBASE-KR1/CR1, 400GBASE-KR2/CR2 и 800GBASE-KR4/CR4. Имеющиеся ретаймеры для Ethernet также совместимы с UALink. 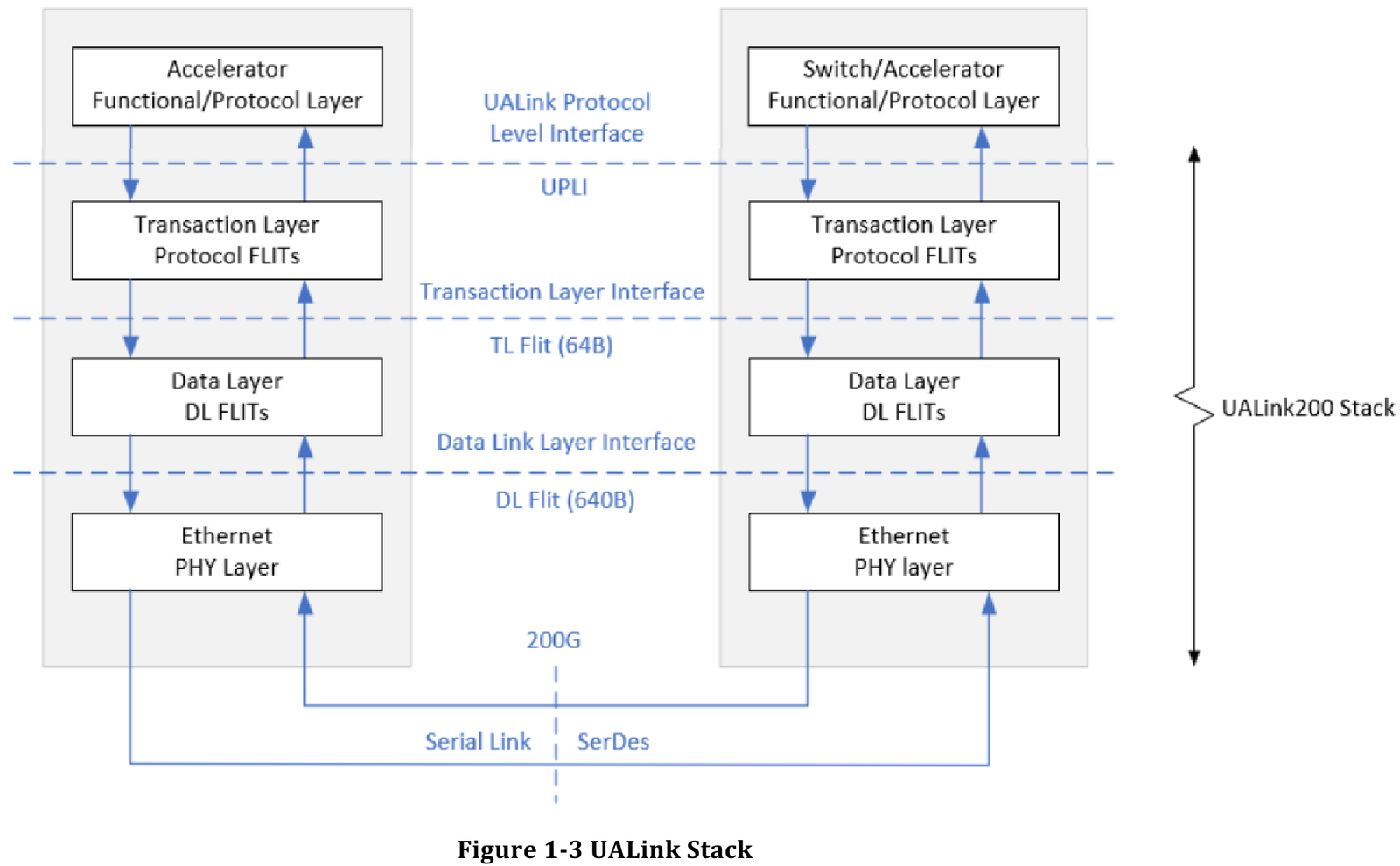 Спецификации UALink 200G 1.0 доступны на сайте проекта. Глава консорциума UALink, Кёртис Боумен (Kurtis Bowman) настроен оптимистично и говорит примерно о 18 месяцах до появления первых аппаратных решений, что на полгода быстрее типичных сценариев воплощения спецификаций «в железо». Тем временем, альянс уже начал работу над второй версией UALink, использующей стек технологий 400G.
03.04.2025 [16:42], Владимир Мироненко
Ayar Labs анонсировала фотонный UCIe-чиплет TeraPHY с пропускной способностью 8 Тбит/сКомпания Ayar Labs, занимающаяся разработкой интерконнекта на базе кремниевой фотоники, анонсировала чиплет оптического I/O TeraPHY, способный обеспечить пропускную способность 8 Тбит/с и использующий оптический источник света SuperNova с поддержкой 16 длин волн. Чиплет поддерживает интерфейс Universal Chiplet Interconnect Express (UCIe), что означает возможность объединения в одном решении чиплетов от разных поставщиков. Ayar Labs отметила, что совместимость со стандартом UCIe позволяет создать более доступную и экономичную экосистему, которая упрощает внедрение передовых оптических технологий, необходимых для масштабирования рабочих ИИ-нагрузок и преодоления ограничений традиционных медных соединений. 
Источник изображений: Ayar Labs Ayar Labs сообщила, что объединила кремниевую фотонику с производственными процессами CMOS, чтобы обеспечить использование оптических соединений в форм-факторе чиплета в многочиповых корпусах. Это позволяет GPU и другим ускорителям взаимодействовать на широком диапазоне расстояний, от миллиметров до километров, при этом эффективно функционируя как единый гигантский ускоритель. Ранее компания совместно с Fujitsu показал концепт процессора A64FXс UCIe-чиплетом TeraPHY.  Марк Уэйд (Mark Wade), генеральный директор и соучредитель Ayar Labs заявил, что в компании давно увидели потенциал совместно упакованной оптики (CPO), и поэтому занялись внедрением оптических решений в ИИ-приложениях. «Продолжая расширять границы оптических технологий, мы объединяем цепочку поставок, производство, а также процессы тестирования и проверки, необходимые клиентам для масштабного развёртывания этих решений», — подчеркнул он. Среди партнёров Ayar Labs крупнейшие компании отрасли, включая AMD, Intel, NVIDIA и TSMC. В последнем раунде финансирования, прошедшем в декабре прошлого года, компания привлекла $155 млн. Рыночная стоимость Ayar Labs, по оценкам, составляет $1 млрд.
02.04.2025 [20:32], Владимир Мироненко
Lightmatter анонсировала оптический интерконнект CPO Passage L200 и фотонный 3D-суперчип Passage M1000Lightmatter анонсировала оптический интерконнект 3D co-packaged optics (CPO) Passage L200, разработанный для интеграции с новейшими дизайнами GPU и XPU, а также коммутаторами, предназначенный для обеспечения значительного увеличения скорости обработки ИИ-нагрузок в огромных кластерах из тысяч ускорителей, благодаря устранению узких мест в полосе пропускания интерконнекта. Семейство L200 3D CPO включает версии на 32 Тбит/с (L200) и 64 Тбит/с (L200X), что в 5–10 раз превышает возможности существующих решений. L200 позволяет размещать несколько GPU в одной упаковке, обеспечивая более 200 Тбит/с общей полосы пропускания I/O, что позволяет ускорить обучение и инференс ИИ-моделей до восьми раз. 
Источник изображений: Lightmatter В обычных ЦОД ускорители соединены между собой с помощью массива сетевых коммутаторов, которые образуют многоуровневую иерархию. Эта архитектура создает слишком большую задержку, поскольку для того, чтобы один ускоритель мог взаимодействовать с другим, сигнал должен пройти через несколько коммутаторов. Как сообщил ранее в интервью ресурсу SiliconANGLE генеральный директор Lightmatter Ник Харрис (Nick Harris), Passage решает проблему громоздких сетевых соединений, интегрируя свою сверхплотную оптоволоконную технологию в чипы, чтобы улучшить пропускную способность в 100 раз по сравнению с лучшими решениями, используемыми сегодня. «Таким образом, вместо шести или семи слоев коммутации у вас есть два, и каждый GPU может подключаться к тысячам других», — пояснил он. Lightmatter назвала свою архитектуру интерконнекта «I/O без границ» (edgeless I/O) и заявила, что она может масштабировать пропускную способность по всей площади кристалла на GPU, в то время как традиционные кристаллы могут подключаться к другим кристаллам только на краю (shoreline). Интеграция Passage 3D позволяет размещать SerDes-блоки в любом месте кристалла, а не ограничиваться его краями, обеспечивая пропускную способность эквивалентную 40 подключаемых оптических трансиверов. Сообщается, что модульное решение 3D CPO использует стандартный совместимый интерфейс UCIe die-to-die (D2D) и упрощает масштабируемую архитектуру на основе чиплетов для бесшовной интеграции с XPU и коммутаторами следующего поколения. Компания заявила, что грядущий L200 CPO разработан для крупносерийного производства, и она тесно сотрудничает для его подготовки с партнёрами по производству полупроводников, такими как Global Foundries, ASE и Amkor, а также передовыми производителями CMOS. В серийное производство Lightmatter L200 и L200X поступят в следующем году. Lightmatter также анонсировала референсную платформу Passage M1000 — фотонный 3D-суперчип (3D Photonic Superchip), разработанный для XPU и коммутаторов следующего поколения. Passage M1000 обеспечивает рекордную общую оптическую пропускную способность на уровне 114 Тбит/с для самых требовательных приложений ИИ-инфраструктуры.  M1000 площадью более 4000 мм² представляет собой многосетчатый активный фотонный интерпозер, который позволяет клиентам создавать свои собственные кастомные соединения с использованием кремниевой фотоники, обеспечивая подключение к множеству GPU в одной 3D-упаковке. Как сообщается, Passage M1000 позволяет преодолеть ограничение по подключению по краям, обеспечивая I/O практически в любом месте на своей поверхности для комплекса кристаллов, размещённых сверху. Интерпозере оснащён обширной и реконфигурируемой сетью волноводов, которая передает WDM-сигналы по всему M1000. Благодаря полностью интегрированному соединению с поддержкой 256 волокон с пропускной способностью 448 Гбит/с на волокно, M1000 обеспечивает на порядок более высокую пропускную способность в меньшем размере корпуса по сравнению с обычными структурами Co-Packaged Optics (CPO) и аналогичными предложениями. Поставки Passage M1000 начнутся этим летом. Среди инвесторов Lightmatter крупные технологические компании, такие как Alphabet и HPE. В последнем раунде финансирования, прошедшем в октябре 2024 года, Lightmatter привлекла $400 млн инвестиций, в результате чего сумма привлечённых компанией средств достигла $850 млн, а её рыночная стоимость теперь оценивается в $4,4 млрд. |
|