Материалы по тегу: интерконнект
|
22.08.2025 [16:33], Владимир Мироненко
Почти как у самой NVIDIA: NVLink Fusion позволит создавать кастомные ИИ-платформыТехнологии NVIDIA NVLink и NVLink Fusion позволят вывести производительность ИИ-инференса на новый уровень благодаря повышенной масштабируемости, гибкости и возможностям интеграции со сторонними чипами, которые в совокупности отвечает стремительному росту сложности ИИ-моделей, сообщается в блоге NVIDIA. С ростом сложности ИИ-моделей выросло количество их параметров — с миллионов до триллионов, что требует для обеспечения их работы значительных вычислительных ресурсов в виде кластеров ускорителей. Росту требований, предъявляемых к вычислительным ресурсам, также способствует внедрение архитектур со смешанным типом вычислений (MoE) и ИИ-алгоритмов рассуждений с масштабированием (Test-time scaling, TTS). NVIDIA представила интерконнект NVLink в 2016 году. Пятое поколение NVLink, вышедшее в 2024 году, позволяет объединить в одной стойке 72 ускорителя каналами шириной 1800 Гбайт/с (по 900 Гбайт/с в каждую сторону), обеспечивая суммарную пропускную способность 130 Тбайт/с — в 800 раз больше, чем у первого поколения.  Производительность NVLink зависит от аппаратных средств и коммуникационных библиотек, в частности, от библиотеки NVIDIA Collective Communication Library (NCCL) для ускорения взаимодействия между ускорителями в топологиях с одним и несколькими узлами. NCCL поддерживает вертикальное и горизонтальное масштабирование, а также включает в себя автоматическое распознавание топологии и оптимизацию передачи данных. 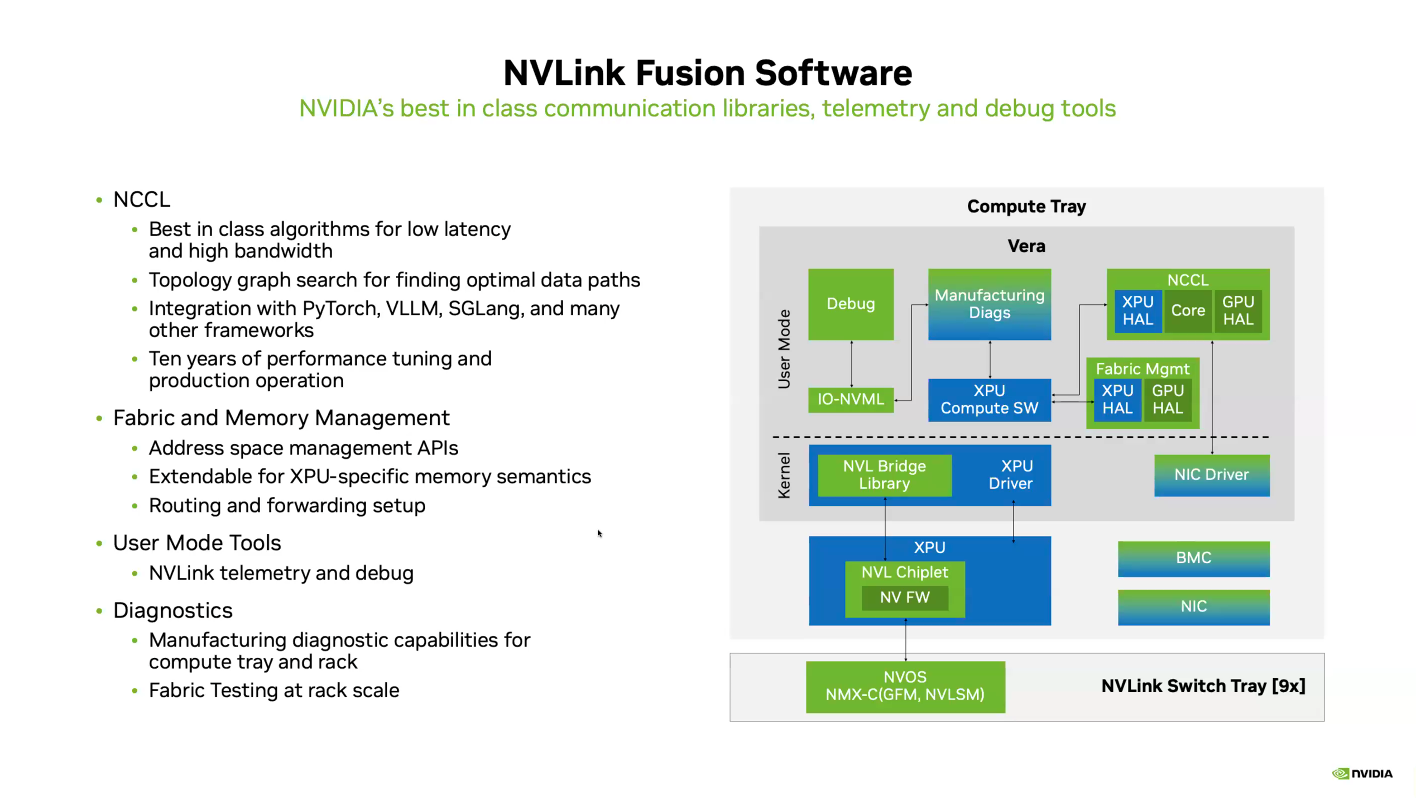 Технология NVLink Fusion призвана обеспечить гиперскейлерам доступ ко всем проверенным в производстве технологиям масштабирования NVLink. Она позволяет интегрировать кастомные микросхемы (CPU и XPU) с технологией вертикального и горизонтального масштабирования NVIDIA NVLink и стоечной архитектурой для развёртывания кастомных ИИ-инфраструктур. 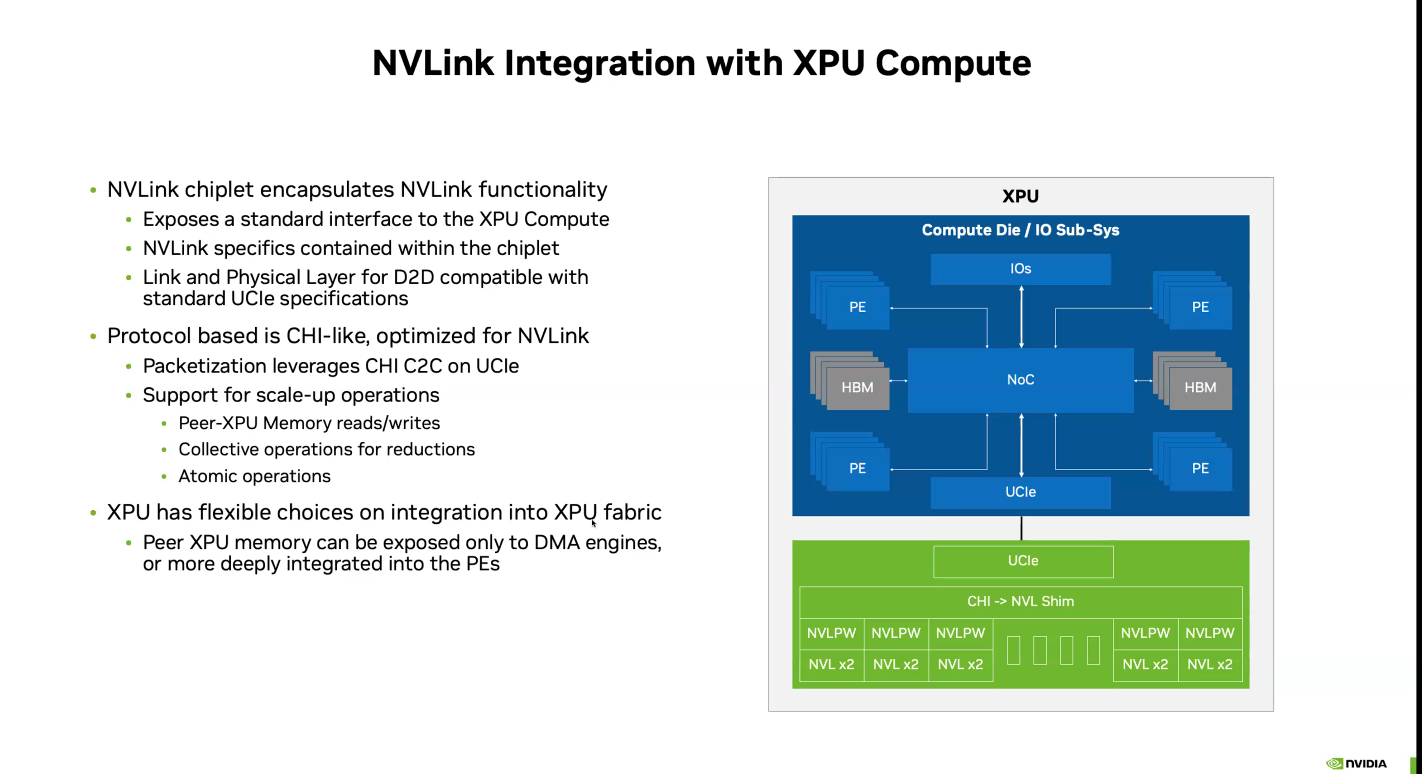 Технология охватывает NVLink SerDes, чиплеты, коммутаторы и стоечную архитектуру, предлагая универсальные решения для конфигураций кастомных CPU, кастомных XPU или комбинированных платформ. Модульное стоечное решение OCP MGX, позволяющее интегрировать NVLink Fusion с любым сетевым адаптером, DPU или коммутатором, обеспечивает заказчикам гибкость в построении необходимых решений, заявляет NVIDIA. 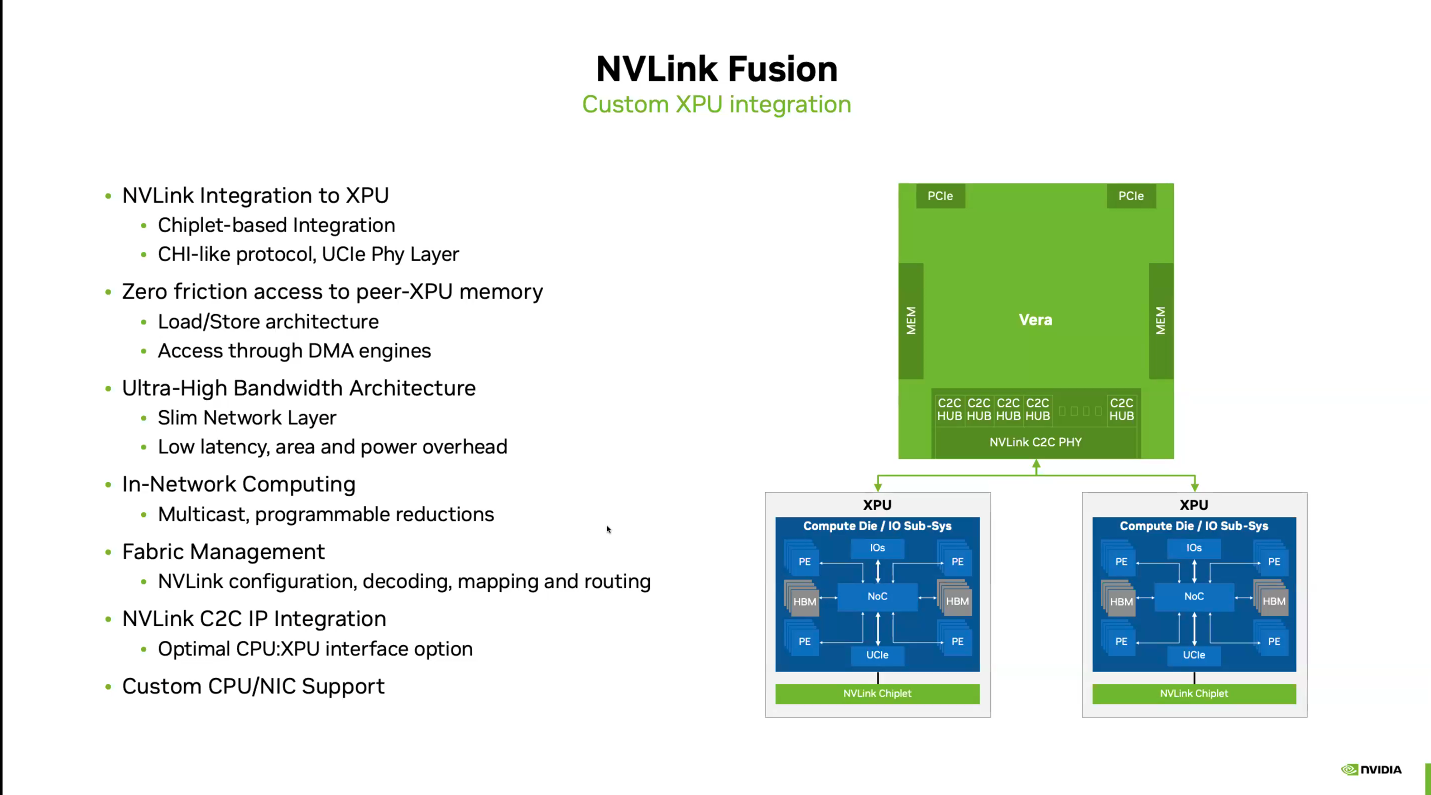 NVLink Fusion поддерживает конфигурации с кастомными CPU и XPU с использованием IP-блоков и интерфейса UCIe, предоставляя заказчикам гибкость в реализации интеграции XPU на разных платформах. Для конфигураций с кастомными CPU рекомендуется интеграция с IP NVLink-C2C для оптимального подключения и производительности GPU. При этом предлагаются различные модели доступа к памяти и DMA. 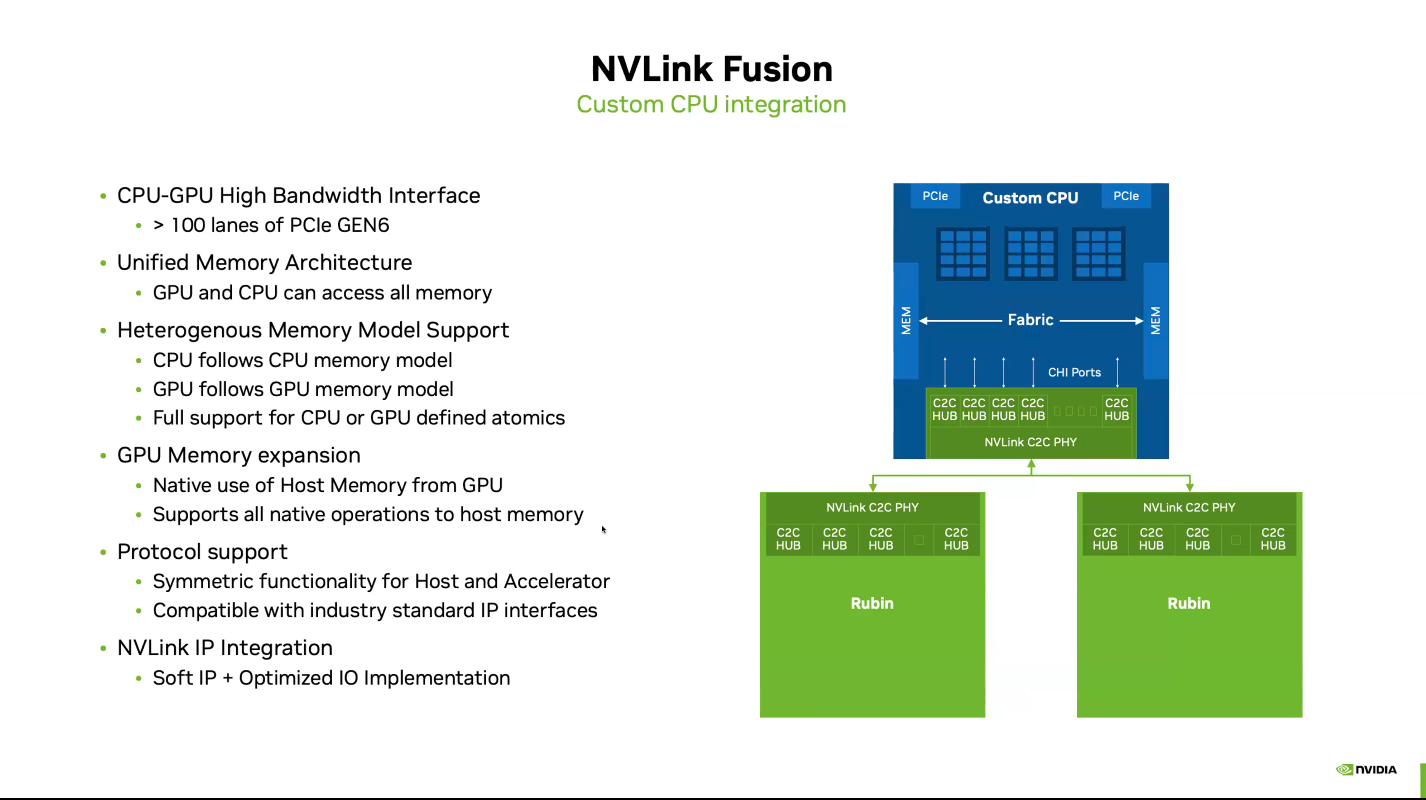 NVLink Fusion использует преимущества обширной экосистемы кремниевых чипов, в том числе от партнёров по разработке кастомных полупроводников, CPU и IP-блоков, что обеспечивает широкую поддержку и быструю разработку новых решений. Основанная на десятилетнем опыте использования технологии NVLink и открытых стандартах архитектуры OCP MGX, платформа NVLink Fusion предоставляет гиперскейлерам исключительную производительность и гибкость при создании ИИ-инфраструктур, подытожила NVIDIA.  При этом основным применением NVLink Fusion с точки зрения NVIDIA, по-видимому, должно стать объединение сторонних чипов с её собственными, а не «чужих» чипов между собой. Более открытой альтернативой NVLink должен стать UALink с дальнейшим масштабированием посредством Ultra Ethernet.
20.08.2025 [09:34], Владимир Мироненко
Lightmatter «упаковала» 16 длин волн в одномодовое волокноLightmatter объявила о новом достижении в области оптической связи: двунаправленном оптическом канале связи Lightmatter Passage 3D CPO с 16 λ и DWDM, работающем на одном одномодовом оптоволокне. Как сообщает компания, решение, основанное на интерконнекте Lightmatter Passage и лазерной технологии Lightmatter Guide, устраняет прежние ограничения по плотности полосы пропускания волокна и использованию спектра, устанавливая новый стандарт для высокопроизводительных и отказоустойчивых интерконнектов в ЦОД. Lightmatter отметила, что с ростом числа сложности MoE-моделей с триллионами параметров масштабирование ИИ-нагрузок будет ограничено количеством портов и их пропускной способности. Lightmatter Passage 3D обеспечивает «беспрецедентную» двунаправленную пропускную способность 800 Гбит/с (по 400 Гбит/с для передачи и для приёма) для одномодового оптоволокна на расстоянии до 1 км. Это восьмикратный скачок пропускной способности на волокно по сравнению с традиционными решениями, говорится в блоге Lightmatter. При этом не требуется более дорогостоящее волокно с поддержкой поляризации (PM). 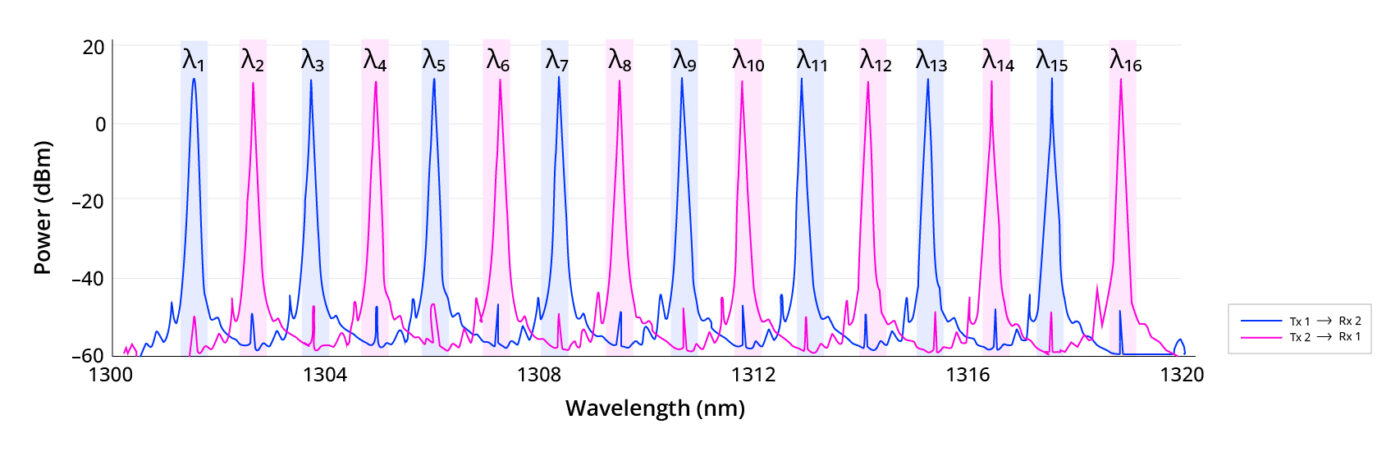
Источник изображений: Lightmatter Как и прежде, решение Lightmatter относится к системам интегрированной фотоники (CPO). Оно объединяет восемь сверхэффективных кольцевых микромодуляторов (MRM), фотодетекторы и аналоговые схемы на одном монолитном кремниевом кристалле с запатентованной системой термической стабилизации. Замкнутая система цифровой стабилизации активно компенсирует любой тепловой дрейф, обеспечивая непрерывную передачу данных с низким уровнем ошибок даже при заметных колебаниях температуры кристалла. В решении компании чередуются нечётные и чётные длины волн в диапазоне 1310 нм: восемь нечётных каналов передают в одном направлении, а восемь чётных — в противоположном. Каждый канал работает со скоростью 50 Гбит/с с интервалом 200 ГГц между соседними каналами передачи/приёма и 400 ГГц между каналами, передающими данные в одном направлении. 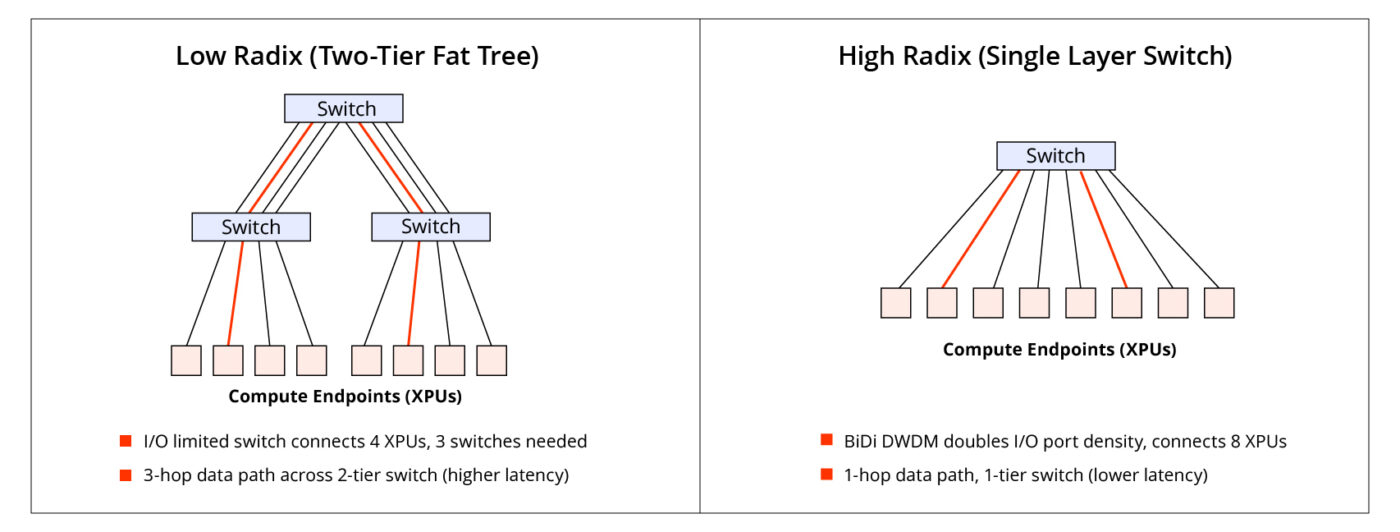 Удваивая количество I/O-портов на коммутатор или XPU, технология сокращает количество сетевых переходов, снижает задержку и энергопотребление, а также минимизирует затраты в крупных ИИ-кластерах. В крупных MoE-моделях интерконнект с большим радиксом обеспечивают взаимодействие «экспертов» с высокой пропускной способностью, что позволяет избежать узких мест при масштабировании и сократить время обучения. Lightmatter позиционирует новое решение как естественную эволюцию технологии CPO для создания ИИ-суперкомпьютеров следующего поколения. Развитием направления CPO также активно занимаются ведущие разработчики ИИ-ускорителей. AMD недавно приобрела стартап Enosemi, который специализируется на разработке фотонных чипов. NVIDIA в марте нынешнего года анонсировала 800G-коммутаторы Spectrum-X и Quantum-X, в которых применены новые ASIC, объединяющие на одной подложке чип-коммутатор и фотонные модули.
09.08.2025 [13:22], Сергей Карасёв
До 64 ГТ/с: обнародована спецификация UCIe 3.0 для объединения чиплетовКонсорциум Universal Chiplet Interconnect Express (UCIe) объявил о выпуске спецификации UCIe 3.0 для соединения чиплетов в составе высокопроизводительных систем, таких как платформы аналитики данных, HPC и ИИ. Напомним, консорциум UCIe был сформирован в 2022 году с целью создания стандартного интерконнекта, позволяющего объединять в одном корпусе чиплеты разных производителей, обладающие различными функциями и изготовленные на разных предприятиях. В состав консорциума вошли Intel, AMD, Qualcomm и TSMC, а также ведущие гиперскейлеры, включая Google Cloud, Meta✴ и Microsoft. 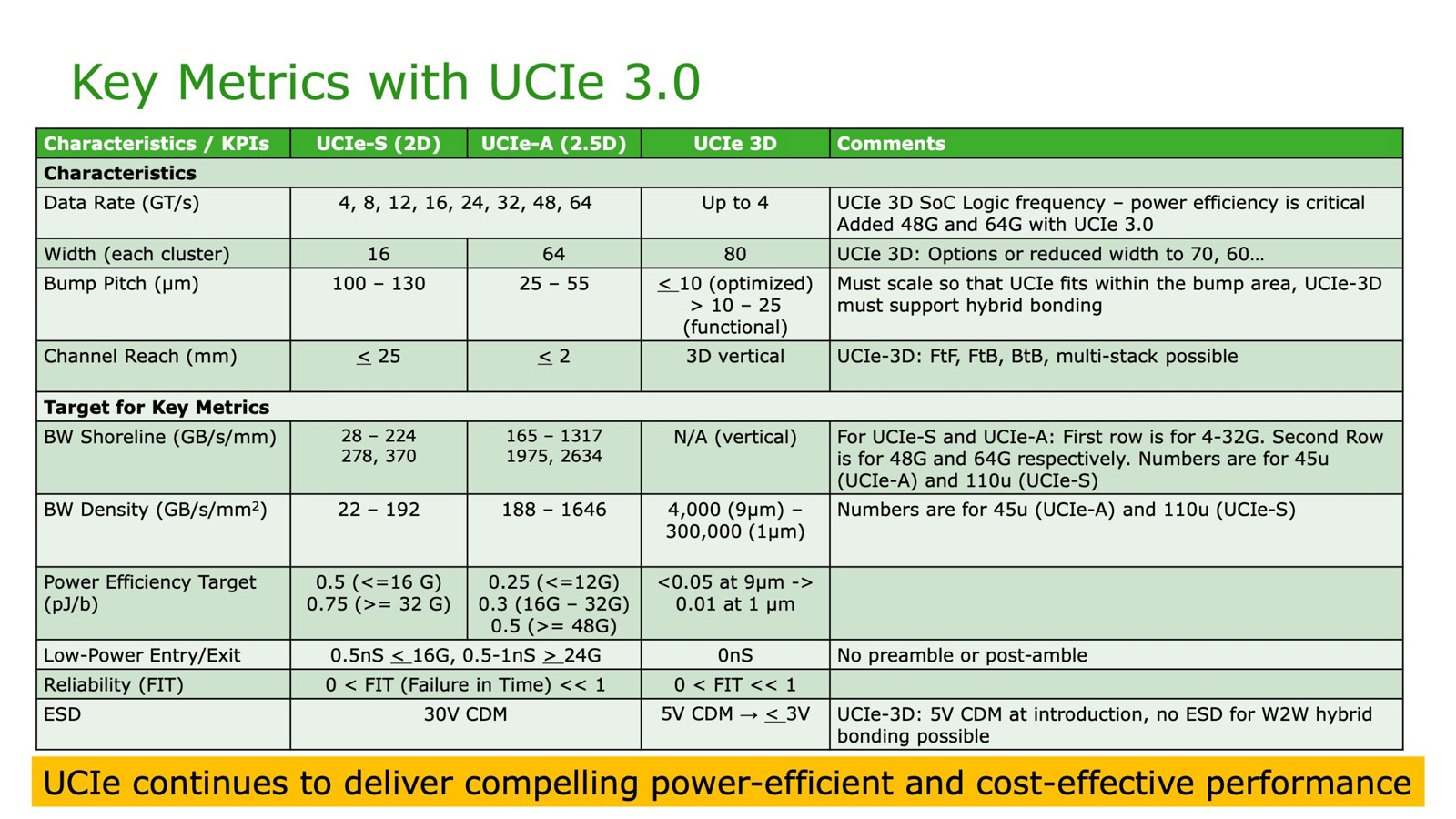
Обнародованная спецификация UCIe 3.0 предусматривает удвоение скорости по сравнению со стандартом предыдущего поколения — до 48 и 64 ГТ/с для вариантов UCIe-S (стандартная упаковка 2D) и UCIe-A (передовая упаковка 2.5D). Таким образом, достигается более высокая пропускная способность в расчёте на соединение, что имеет большое значение, когда для обмена данными между кристаллами может быть задействовано строго ограниченное количество соединений. В случае UCIe 3D скорость ограничивается 4 ГТ/с.
Для UCIe 3.0 заявлена обратная совместимость со спецификациями предыдущих поколений. Упомянута улучшенная перекалибровка во время выполнения, обеспечивающая снижение энергопотребления каналов передачи данных и чиплетов. Предусмотрены и другие усовершенствования, ориентированные на повышение плотности полосы пропускания, энергоэффективности и управляемости на системном уровне. В целом, спецификация UCIe 3.0 обеспечивает более высокую масштабируемость, гибкость и совместимость, что, как считают участники консорциума, поможет ускорить инновации в области модульной полупроводниковой архитектуры. Вместе с тем некоммерческая организация Open Compute Project Foundation (OCP) выпустила новую спецификацию Universal D2D Transaction и Link-Layer, которая охватывает в том числе UCIe.
05.08.2025 [18:00], Сергей Карасёв
Спецификации PCIe 8.0 будут утверждены к 2028 году: до 1 Тбайт/с в двустороннем режиме x16Организация PCI Special Interest Group (PCI-SIG) объявила о том, что спецификация PCI Express (PCIe) 8.0 будет готова к 2028 году. Интерфейс нового поколения обеспечит удвоение пропускной способности по сравнению с предыдущей версией стандарта, а также привнесёт ряд других изменений. Напомним, финальная спецификация PCIe 7.0 была опубликована в июне нынешнего года. «Сырая» скорость достигает 128 ГТ/с на линию, а пропускная способность в двустороннем режиме в конфигурации x16 составляет 512 Гбайт/с. Реализованы кодирование PAM4, поддержка Flit-режима и обратная совместимость с предыдущими версиями PCIe. В случае PCIe 8.0 «сырая» скорость увеличится до 256 ГТ/с на линию, тогда как пропускная способность в двустороннем режиме x16 поднимется до 1 Тбайт/с. Как и прежде, планируется обеспечение обратной совместимости с более ранними поколениями PCIe. Для повышения скорости передачи данных подвергнется доработкам протокол. Кроме того, будет уделяться внимание дальнейшему улучшению энергетической эффективности, обеспечению целевых показателей надёжности и задержки. Упомянуто кодирование PAM4. 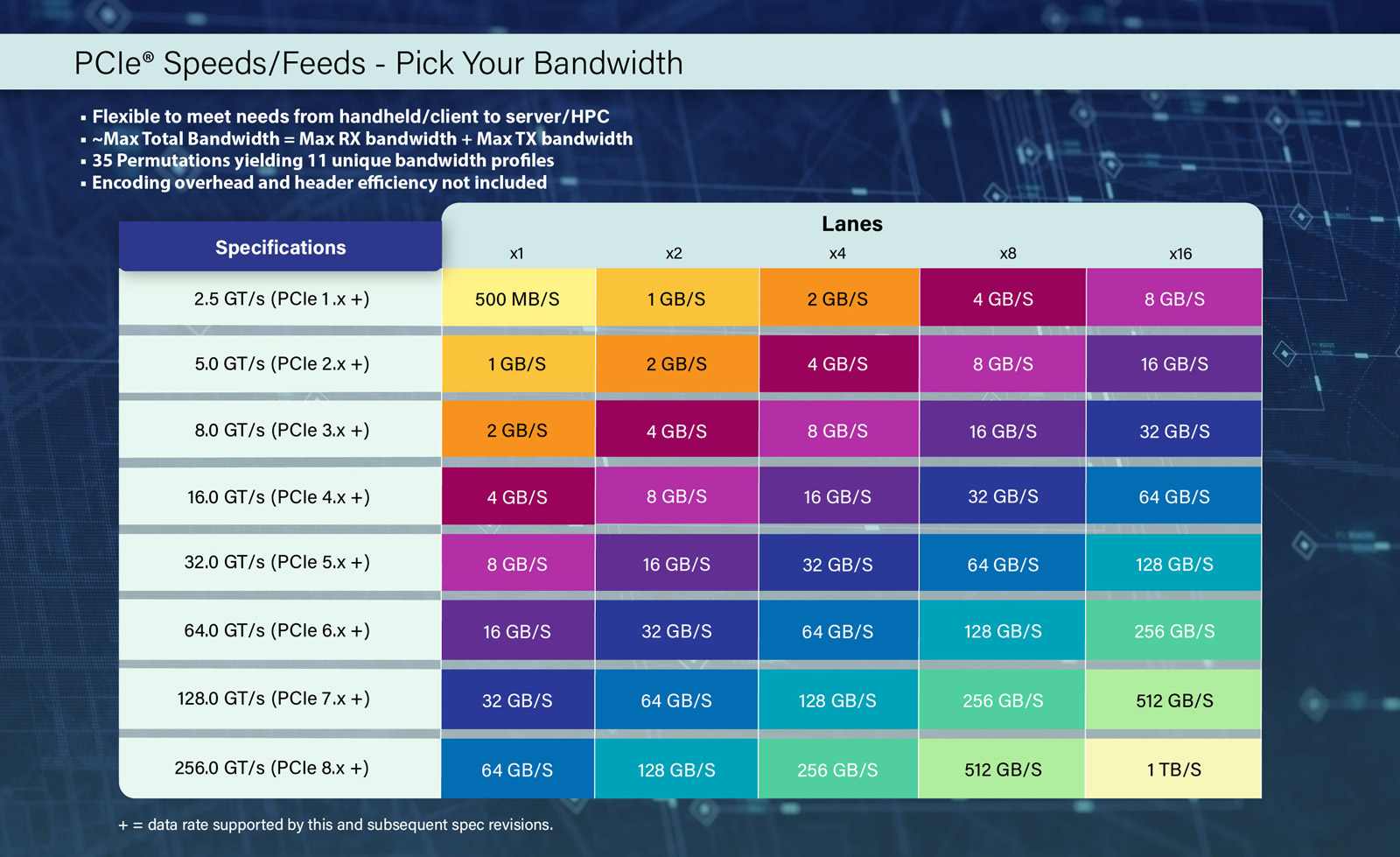
Источник изображений: PCI-SIG Одновременно продолжится работа над совершенствованием кабелей CopprLink для PCIe. Весной 2024 года PCI-SIG обнародовала спецификации электрических кабелей и разъёмов CopprLink для внешних и внутренних подключений PCIe 5.0 и PCIe 6.0: скорость достигает 32 и 64 ГТ/с соответственно. Максимальная длина соединения в пределах одной системы составляет 1 м, между стойками — 2 м. Но, как отмечается, для высокопроизводительных систем требуются соединения большей протяжённости. 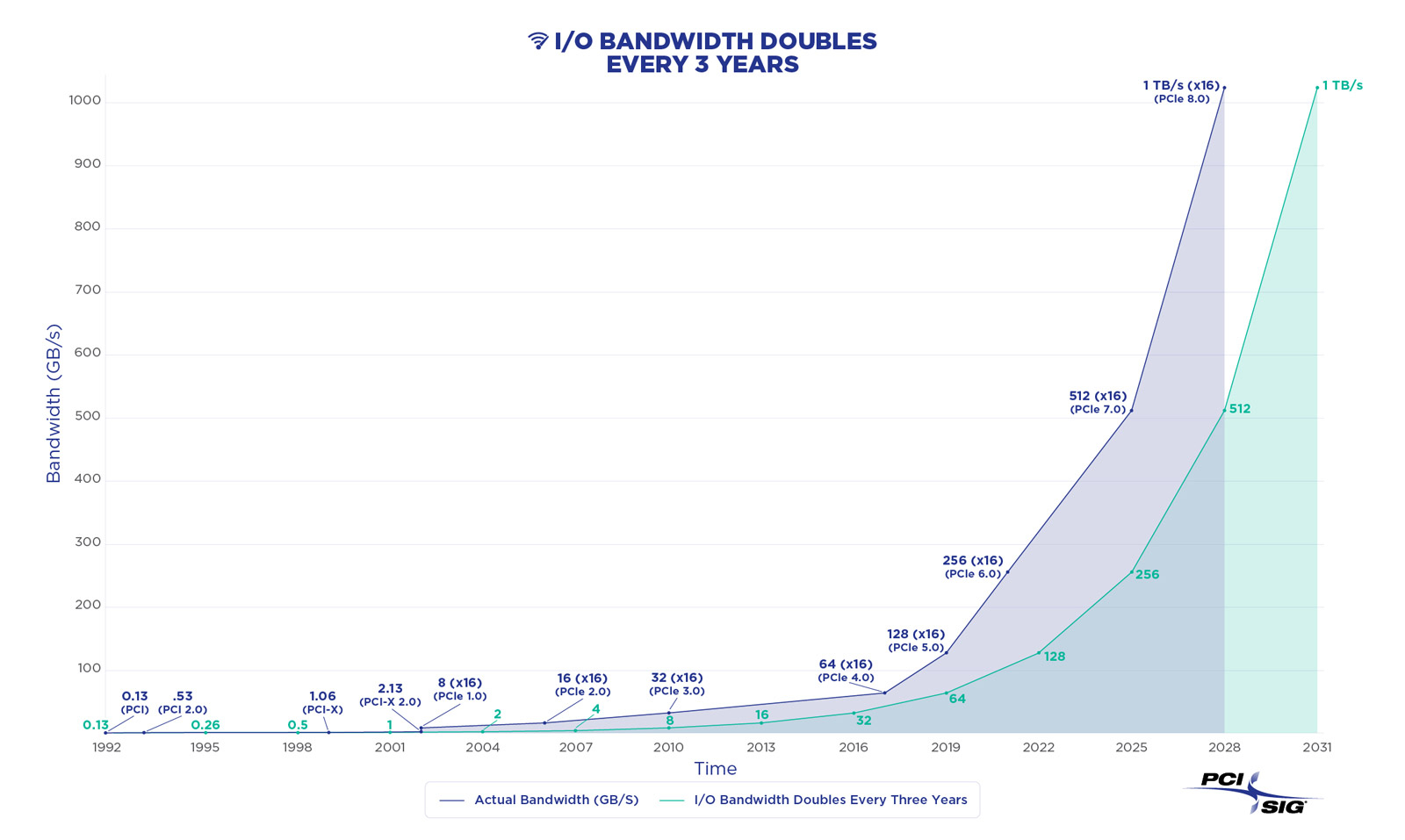 В целом, спецификация PCIe 8.0 нацелена на создание высокоскоростного интерфейса для таких сфер применения, как ИИ и машинное обучение, периферийные и квантовые вычисления, а также приложения с интенсивным использованием данных, включая дата-центры гиперскейлеров, НРС-задачи, автомобильные и аэрокосмические платформы и пр.
05.08.2025 [10:39], Сергей Карасёв
HyperPort на 3,2 Тбит/с: Broadcom выпустила чип-коммутатор Jericho4 для распределённой ИИ-инфраструктурыКомпания Broadcom объявила о начале поставок коммутационного чипа Jericho4, специально разработанного для распределённой инфраструктуры ИИ. Изделие, как утверждается, позволяет объединять более миллиона ускорителей (GPU, TPU) в географически разнесённых дата-центрах, преодолевая традиционные ограничения масштабирования. Отмечается, что по мере роста размера и сложности моделей ИИ требования к инфраструктуре ЦОД повышаются: создаётся необходимость в объединении ресурсов нескольких площадок, каждая из которых обеспечивает мощность в десятки или сотни мегаватт. Для этого требуется оборудование нового поколения, оптимизированное для сверхширокополосной и безопасной передачи данных на значительные расстояния. Новинка позволяет решить проблему. Jericho4 обладает коммутационной способностью 51,2 Тбит/с. Благодаря глубокой буферизации и интеллектуальному управлению перегрузкой изделие обеспечивает поддержку RoCE без потерь на расстоянии более 100 км, что позволяет формировать распределённую инфраструктуру ИИ, говорит Broadcom. 
Источник изображений: Broadcom Могут быть задействованы интерфейсы 50GbE, 100GbE, 200GbE, 400GbE, 800GbE и 1.6TbE. Реализована технология HyperPort, которая объединяет четыре порта 800GbE в один канал с пропускной способность 3,2 Тбит/с, что упрощает проектирование и управление сетью. Единая инфраструктура на базе Jericho4 может масштабироваться до 36 тыс. портов HyperPort, каждый из которых работает со скоростью 3,2 Тбит/с. Jericho4 поддерживает шифрование MACsec на каждом порту на полной скорости для защиты передаваемой между ЦОД информации без ущерба для производительности — даже при самых высоких нагрузках. Новинка полностью соответствует спецификациям, разработанным консорциумом Ultra Ethernet (UEC): благодаря этому достигается бесшовная интеграция с широкой экосистемой сетевых карт, коммутаторов и программных стеков. 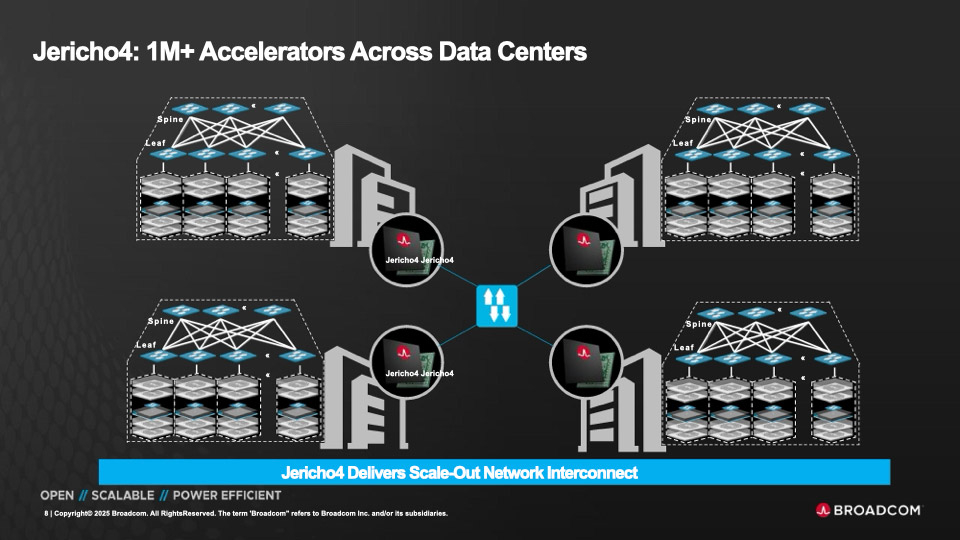 Чип Jericho4 производится по 3-нм технологии. Он оснащён модулями Broadcom PAM4 SerDes 200G. Это устраняет необходимость в дополнительных компонентах, таких как ретаймеры, что способствует снижению энергопотребления и повышению надёжности системы в целом. В частности, энергозатраты уменьшены на 40 % в расчёте на бит по сравнению с решениями предыдущего поколения. Это помогает организациям снижать эксплуатационные расходы и достигать целей устойчивого развития, говорит Broadcom.
03.08.2025 [12:14], Сергей Карасёв
Enfabrica представила технологию EMFASYS для расширения памяти ИИ-системКомпания Enfabrica анонсировала технологию EMFASYS, которая объединяет Ethernet RDMA и CXL для создания пулов памяти, предназначенных для работы с серверными ИИ-стойками на базе GPU. Решение позволяет снизить нагрузку на HBM-память ИИ-ускорителей и тем самым повысить эффективность работы всей системы в целом. Enfabrica основана в 2019 году. Стартап предлагает CXL-платформу ACF на базе ASIC собственной разработки, которая позволяет напрямую подключать друг к другу любую комбинацию GPU, CPU, DDR5 CXL и SSD, а также предоставляет 800GbE-интерконнект. Компания создала чип ACF SuperNIC (ACF-S) для построения высокоскоростного интерконнекта в составе кластеров ИИ на основе GPU. В рамках платформы EMFASYS специализированный пул памяти подключается к GPU-серверам через чип-коммутатор ACF-S с пропускной способностью 3,2 Тбит/с, который объединяет PCIe/CXL и Ethernet. Поддерживаются интерфейсы 100/400/800GbE, 32 сетевых порта и 160 линий PCIe. Могут быть задействованы до 144 линий CXL 2.0, что позволяет использовать до 18 Тбайт памяти DDR5 (в перспективе — до 28 Тбайт). Вместо копирования и перемещения данных между несколькими чипами на плате Enfabrica использует один SuperNIC, который позволяет представлять память в качестве целевого RDMA-устройства для приложений ИИ. 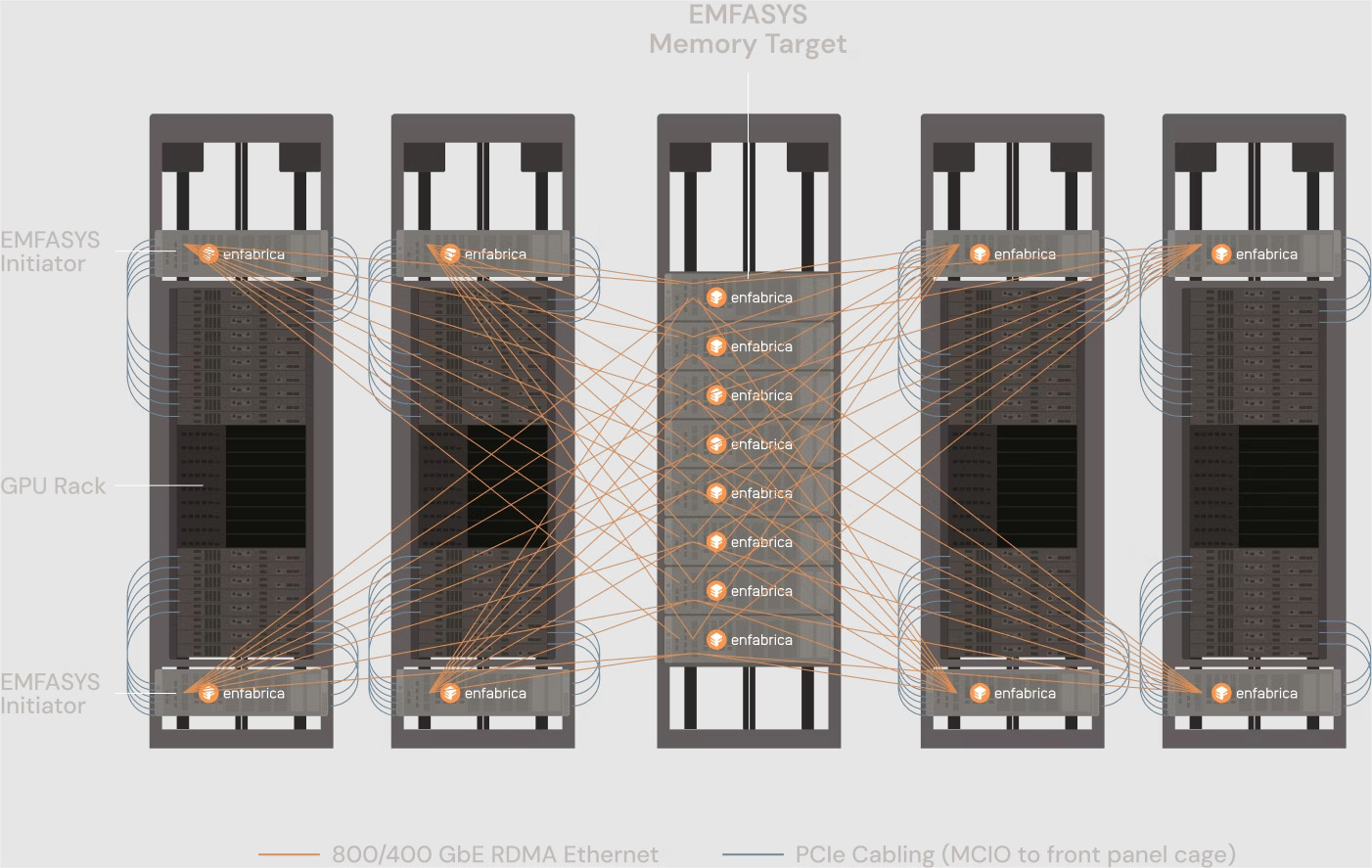
Источник изображений: Enfabrica Высокая пропускная способность памяти достигается за счёт распределения операций более чем по 18 каналам на систему. Время доступа при чтении измеряется в микросекундах. Программный стек на базе InfiniBand Verbs обеспечивает массовую параллельную передачу данных с агрегированной полосой пропускания между GPU-серверами и памятью DRAM через группы сетевых портов 400/800GbE. 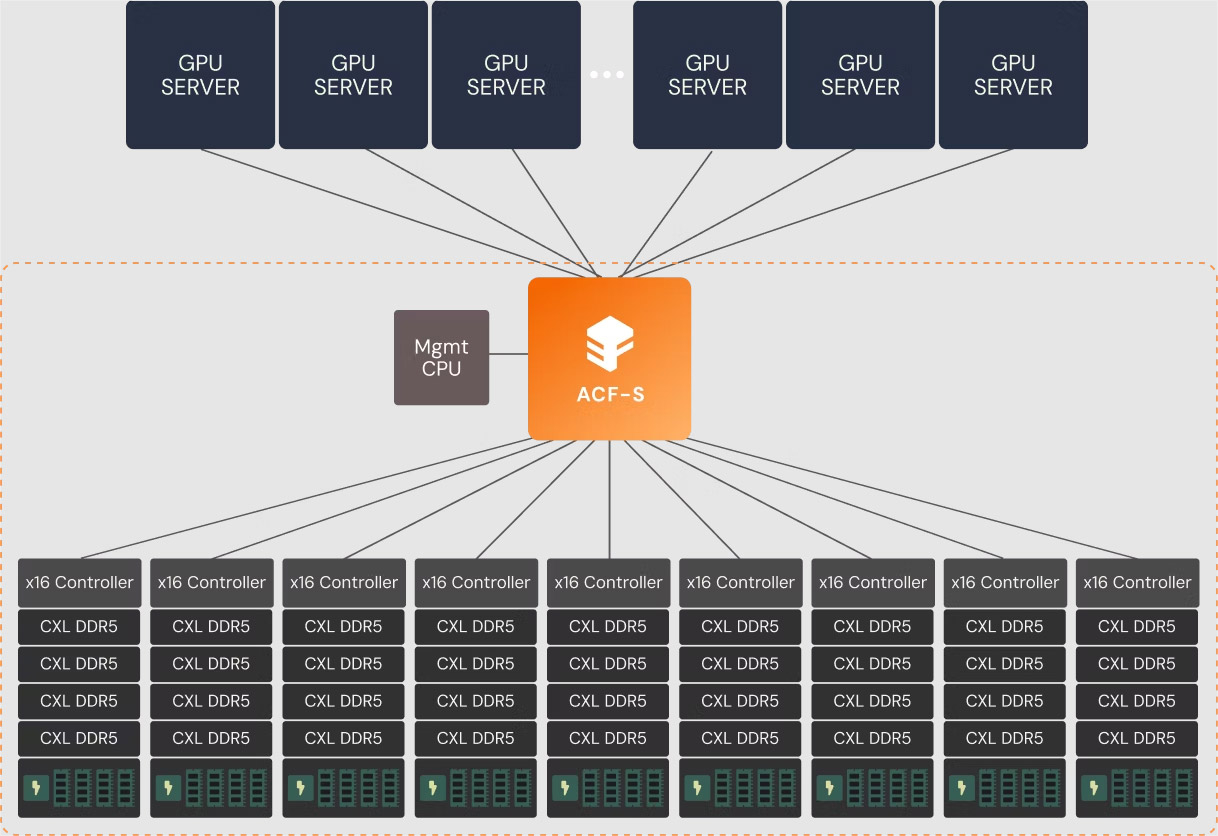 Enfabrica отмечает, что рабочие нагрузки генеративного, агентного и рассуждающего ИИ растут экспоненциально. Во многих случаях таким приложениям требуется в 10–100 раз больше вычислительной мощности на запрос, чем большим языковым моделям (LLM) предыдущего поколения. Если память HBM постоянно загружена, дорогостоящие ускорители простаивают. Технология EMFASYS позволяет решить проблему посредством расширения памяти: в этом случае ресурсы GPU используются более полно, а заявленная экономия достигает 50 % в расчёте на токен на одного пользователя.
31.07.2025 [12:12], Сергей Карасёв
Разработчик оптического интерконнекта Teramount привлёк на развитие $50 млнИзраильская компания Teramount, специализирующаяся на разработке оптического интерконнекта, объявила о проведении раунда финансирования Series A, в ходе которого на развитие привлечено $50 млн. Инвестиционную программу возглавила венчурная фирма Koch Disruptive Technologies (KDT). Teramount основана в 2013 году Хешамом Тахой (Hesham Taha), который занимает пост генерального директора, и Ави Израилем (Avi Israel), исполняющим обязанности технического директора. Компания разрабатывает решения в области оптической связи для ИИ-платформ, дата-центров и НРС-систем. 
Источник изображения: Teramount Запатентованные компанией Teramount технологии PhotonicPlug и PhotonicBump обеспечивают бесшовную интеграцию оптоволокна с кремниевыми чипами. Кроме того, Teramount разработала разъёмное оптоволоконное соединение TeraVerse. Решения компании позволяют интегрировать фотонику с традиционной электроникой, благодаря чему повышается скорость передачи данных. В раунде финансирования, помимо KDT, приняли участие AMD Ventures, Hitachi Ventures, Samsung Catalyst Fund и Wistron, а также существующий инвестор Grove Ventures. Программа включает $41 млн новых средств и дополнительные $9 млн из предыдущего раунда SAFE (Simple Agreement for Future Equity), проведённого в 2024 году теми же инвесторами. Полученные деньги помогут Teramount расширить команду специалистов и наладить массовое производство продукции. Отметим, что разработкой фотонных решений для ИИ-систем и дата-центров занимаются и многие другие компании. В их число входят DustPhotonics, Oriole Networks, Lightmatter, Celestial AI, Xscape Photonics, Ayar Labs и пр.
26.07.2025 [15:54], Сергей Карасёв
OCP запустила проект OCS по развитию оптической коммутации в ИИ ЦОДНекоммерческая организация Open Compute Project Foundation (OCP) анонсировала проект Optical Circuit Switching (OCS), направленный на ускорение внедрения технологий фотонной (оптической) коммутации в ИИ ЦОД. Цель инициативы — повышение пропускной способности, снижение задержек и улучшение энергоэффективности инфраструктур с интенсивным обменом данными. Проект возглавляют iPronics и Lumentum, а в число его участников входят Coherent, Google, Lumotive, Microsoft, nEye, NVIDIA, Oriole Networks и Polatis (Huber+Suhner). Нужно отметить, что разработкой фотонных решений для высоконагруженных платформ ИИ и дата-центров занимаются многие компании. В их число входят DustPhotonics, Oriole Networks, Lightmatter, Celestial AI, Xscape Photonics, Ayar Labs и пр. 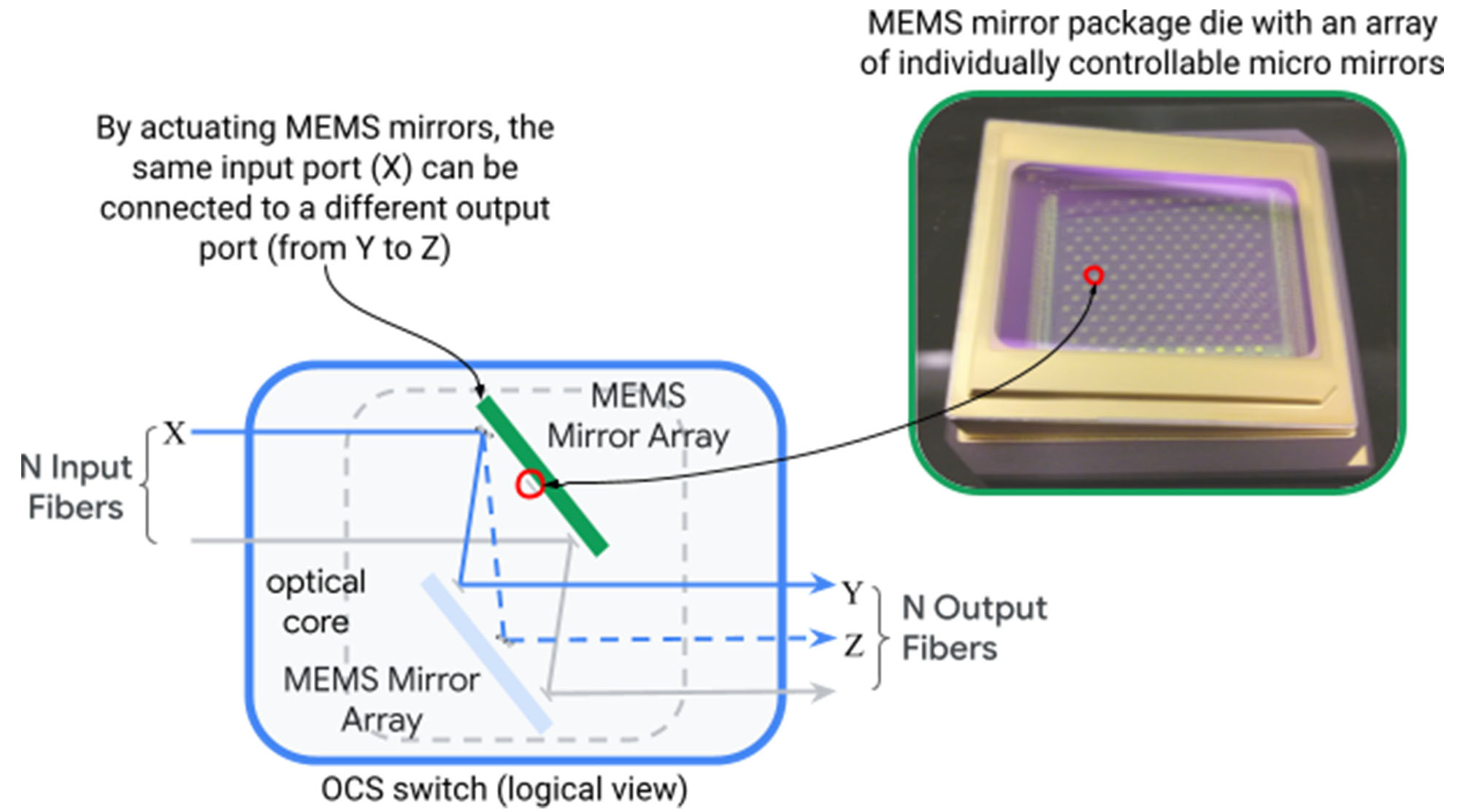
Источник изображений: Google В отличие от традиционной электрической коммутации, решение OCS базируется на оптической маршрутизации данных. Новый интерконнект планируется использовать в кластерах ИИ, поддерживающих ресурсоёмкие нагрузки, включая генеративные сервисы и большие языковые модели (LLM). Предполагается, что проект OCS позволит создать масштабируемое и надёжное решение для обработки больших объёмов данных, поддерживающее бесшовную интеграцию с различными сетевыми протоколами. Упомянута совместимость с такими программными фреймворками, как gNMI, gNOI, gNSI и OpenConfig. 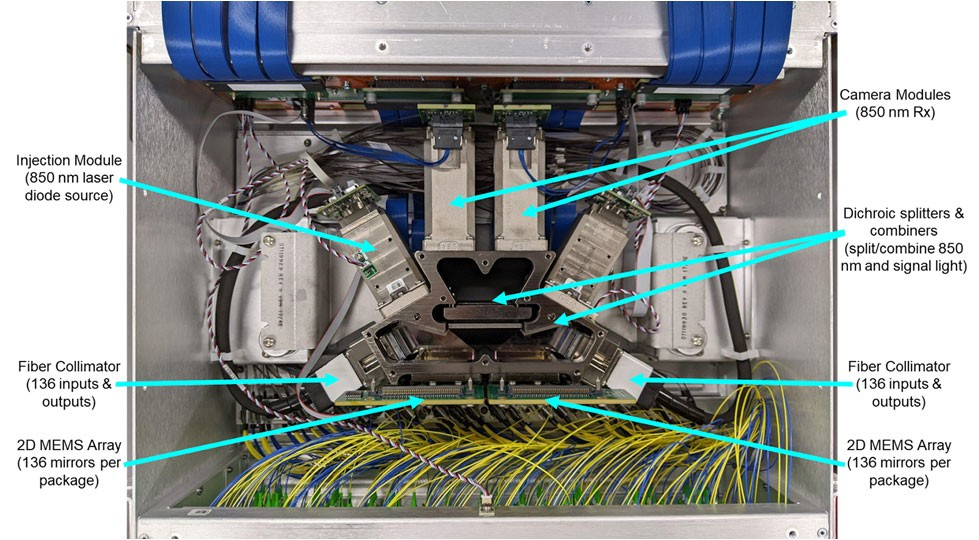 В заявлении OCP говорится, что инициатива OCS будет способствовать сотрудничеству между ведущими игроками отрасли, гиперскейлерами и поставщиками для создания совместимых открытых продуктов, которые помогут стимулировать инновации в области оптических сетей. В частности, планируется выпуск компактных и гибко настраиваемых оптических коммутаторов для ИИ ЦОД. На практике оптическую коммутацию массово использует, по-видимому, только Google. В 2022 году компания рассказала об OCS Apollo, которые используют MEMS-переключатели для перенаправления лучей света. Эти коммутаторы обслуживают кластеры TPU.
16.07.2025 [11:44], Сергей Карасёв
Broadcom представила 51,2-Тбит/с чип-коммутатор Tomahawk Ultra — альтернативу NVIDIA InfiniBand и NVLinkКомпания Broadcom анонсировала чип-коммутатор Tomahawk Ultra, специально разработанный для кластеров НРС и платформ ИИ. Новинка, как ожидается, составит конкуренцию InfiniBand в традиционных суперкомпьютерах, NVLink в стоечных решениях вроде NVIDIA GB200 NVL72, а также Ultra Accelerator Link (UALink) в масштабируемых системах ИИ в дата-центрах. Решение Tomahawk Ultra разработано в рамках инициативы Broadcom Scaling Up Ethernet (SUE). Утверждается, что эта технология будет поддерживать масштабируемые системы с не менее чем 1024 ускорителями ИИ. Для сравнения, NVIDIA заявляет, что её коммутационная система NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене. Broadcom подчёркивает, что чип Tomahawk Ultra разработан с нуля специально для удовлетворения потребностей высоконагруженных НРС-сред и ИИ-кластеров. Новинка обеспечивает коммутационную способность 51,2 Тбит/с при размере пакетов 64 байта. Задержка составляет 250 нс, что значительно меньше, чем у коммутаторов с более высокой пропускной способностью. А общая задержка при общении XPU между собой составляет не более 400 нс. Поддерживается обработка до 77 млрд пакетов в секунду. 
Источник изображений: Broadcom Основная часть трафика, передаваемого через коммутаторы Ethernet, состоит из пакетов большего размера. Поэтому при проектировании сетевого оборудования внимание уделяется прежде всего увеличению размера пакетов для оптимизации пропускной способности. Вместе с тем обмен пакетами небольшого размера широко распространен в платформах НРС/ИИ: представленная новинка Broadcom нацелена именно на такие среды.
Чип-коммутатор Tomahawk Ultra (семейство BCM78920) поддерживают 64 порта 800GbE, 128 портов 400GbE или 256 портов 200GbE. Изделие использует блоки Peregrine 106.25G PAM4 SerDes. Решение совместимо по выводам с Broadcom Tomahawk 5 (TH5). Поддерживаются функции, предназначенные для масштабируемых нагрузок ИИ и HPC, включая Link Layer Retry (LLR), Credit-based Flow Control (CBFC) и AI Fabric Headers (AFH). Кроме того, непосредственно в ASIC реализована поддержка коллективных операций вроде AllReduce and AllGather. Используются измененные заголовки Ethernet, размер которых уменьшен с 46 до 10 байт: это позволяет оптимизировать общее соотношение размера заголовка к полезной нагрузке. Упомянута совместимость с современными топологиями сетей HPC, такими как Mesh, Torus и Dragonfly. Кроме того, заявлена совместимость с Ultra Ethernet (UEC). Поставки Tomahawk Ultra уже начались.
12.07.2025 [15:13], Сергей Карасёв
От 100GbE до 800GbE, недорого: стартап TORmem обещает трансформировать рынок ЦОД-коммутаторовСтартап TORmem, специализирующийся на решениях для дезагрегации памяти в дата-центрах, обнародовал планы по выпуску коммутаторов для сетей с высокой пропускной способностью. В семейство войдут модели с поддержкой стандартов от 100GbE до 800GbE. По утверждениям TORmem, она потратила четыре года на разработку «революционной технологии дезагрегации», которая позволяет реализовывать концепцию вычислений в оперативной памяти (IMC) в масштабах ЦОД. Полученный опыт стартап намерен использовать для решения другой проблемы современных дата-центров — высокой стоимости корпоративной сетевой инфраструктуры. TORmem обещает трансформировать сегмент коммутаторов корпоративного класса, выпустив высокопроизводительные устройства по цене в два раза меньше по сравнению с аналогичными решениями, уже представленными на рынке. В частности, TORmem предлагает для заказа модель стандарта 100GbE (S6500-32X) с 32 портами на основе ASIC Marvell: устройство стоит $7 тыс. против $14 тыс. или более у «стандартных продуктов», говорит компания. 
Источник изображений: TORmem В конце текущего года стартап намерен подготовиться к началу производства коммутаторов 200GbE/400GbE, которые, как ожидается, также окажутся на 50 % дешевле конкурирующих изделий: их цена составит от $12 тыс. до $20 тыс. против $25–$40 тыс., которые, как утверждается, будут просить конкуренты. Кроме того, в разработке находятся модели класса 800GbE.  На сайте Unipoe.net удалось обнаружить описание коммутатора RZ-S6500-32X. Он располагает 32 портами 40/100GbE QSFP28, а коммутируемая ёмкость достигает 6,4 Тбит/с. Устройство выполнено в форм-факторе 1U с габаритами 440 × 470 × 43 мм. Предусмотрены сетевой порт управления, консольный порт и разъём USB 2.0. В оснащение входят два блока питания и пять модульных вентиляторов с возможностью горячей замены. Максимальное энергопотребление составляет менее 650 Вт. Диапазон рабочих температур — от 0 до +40 °C. Упомянута поддержка протоколов RIP, IS-IS, RIPng, OSPFv3, BGP4+ и пр. Отраслевые аналитики прогнозируют, что объём глобального рынка высокоскоростных коммутаторов увеличится с примерно $8 млрд в 2025 году до более чем $15 млрд в 2027-м. Основным драйвером отрасли называется внедрение решений стандарта 200GbE и выше. |
|
