Материалы по тегу: ускоритель
|
04.04.2025 [10:10], Сергей Карасёв
Tenstorrent представила ИИ-ускорители Blackhole на архитектуре RISC-VКанадский стартап Tenstorrent анонсировал ИИ-ускорители семейства Blackhole, выполненные в виде двухслотовых карт расширения с интерфейсом PCI Express 5.0 x16. Кроме того, дебютировала рабочая станция TT-QuietBox, оборудованная этими изделиями. Напомним, ранее Tenstorrent выпустила ИИ-ускорители Wormhole с 72 и 128 ядрами Tensix, каждое из которых содержит пять ядер RISC-V. Объём памяти GDDR6 составляет соответственно 12 и 24 Гбайт. Производительность достигает 262 и 466 Тфлопс на операциях FP8. В семейство Blackhole вошли модели p100a и p150a/p150b. Первая располагает 120 ядрами Tensix, 16 «большими» ядрами RISC-V, 180 Мбайт памяти SRAM и 28 Гбайт памяти GDDR6 с пропускной способностью 448 Гбайт/с. Изделия p150a/p150b оснащены 140 ядрами Tensix, 16 «большими» ядрами RISC-V, 210 Мбайт памяти SRAM и 32 Гбайт памяти GDDR6 с пропускной способностью 512 Гбайт/с. 
Источник изображений: Tenstorrent Энергопотребление у всех ускорителей достигает 300 Вт. Тактовая частота ИИ-блока — 1,35 ГГц. Габариты карт составляют 42 × 270 × 111 мм. Модели p100a и p150a наделены активным охлаждением, версия p150b — пассивным. При этом ускорители p150a/p150b оборудованы четырьмя разъёмами QSFP-DD 800G.  Рабочая станция TT-QuietBox несёт на борту четыре карты Blackhole p150. Основой служат материнская плата ASRock Rack SIENAD8-2L2T и процессор AMD EPYC 8124P (Siena) с 16 ядрами (32 потока) с тактовой частотой до 3 ГГц. Объём оперативной памяти DDR5-4800 ECC RDIMM равен 256 Гбайт (8 × 32 Гбайт). Установлен SSD вместимостью 4 Тбайт с интерфейсом PCIe 4.0 x4 (NVMe). Присутствуют по два сетевых порта 10GbE RJ45 (контроллер Intel X710-AT2) и 1GbE RJ45 (Intel i210), четыре порта USB 3.1 Gen1 Type-A (по два спереди и сзади), аналоговый разъём D-Sub.  Ускоритель Blackhole p100 предлагается по цене около $1000, тогда как обе модификации Blackhole p150 оценены в $1300. Рабочая станция TT-QuietBox Blackhole обойдётся в $12 тыс.
02.04.2025 [11:50], Руслан Авдеев
Царь-чипы с интегрированной фотоникой: Cerebras Systems и Ranovus выбраны DARPA для создания вычислительной платформы нового поколенияИИ-стартап Cerebras Systems выбран американским военно-техническим управлением DARPA для разработки высокопроизводительной вычислительной системы нового поколения. Cerebras объединит собственные ИИ-ускорители и фотонные CPO-интерконнекты Ranovus для обеспечения высокой производительности при малом энергопотреблении, сообщает пресс-центр Cerebras. Комбинация технологий двух компаний позволит обеспечить в реальном времени моделирование сложных физических процессов и выполнение масштабных ИИ-задач. С учётом успеха программы DARPA Digital RF Battlespace Emulator (DRBE), в рамках которой Cerebras уже разрабатывает передовой суперкомпьютер для радиочастотной эмуляции, именно Cerebras и Ranovus были выбраны для новой инициативы, позволяющей объединить вычислительные продукты Cerebras с первыми в отрасли фотонными интерконнектами Ranovus. Решение крайне актуальное, поскольку двумя ключевыми вопросами для современных вычислительных систем являются проблемы с памятью и обменом данных между ускорителями и иной серверной инфраструктурой — вычислительные потребности растут быстрее, чем возможности памяти или IO-систем ввода-вывода. Как утверждают в Cerebras, её WSE-чипы имеют в 7 тыс. раз большую пропускную способность, чем классические ускорители, что даёт самый быстрый в мире инференс и самое быстрое моделирование молекулярных процессов. 
Источник изображения: Cerebras В рамках нового плана DARPA стартап Cerebras будет использовать интерконнект Ranovus, что позволит получить производительность, недоступную даже для крупнейших суперкомпьютерных кластеров современности. При этом энергопотребление будет значительно ниже, чем у самых современных решений с использованием коммутаторов. Последние являются одними из самых энергоёмких компонентов в современных ИИ-системах или суперкомпьютерах. Утверждается, что комбинация новых технологий двух компаний позволит искать решения самых сложных задач в реальном времени, будь то ИИ или сложное моделирование физических процессов, на недостижимом сегодня уровне. Подчёркивается, что оставаться впереди конкурентов — насущная необходимость для обороны США, а также местного коммерческого сектора. В частности, это открывает огромные возможности для работы ИИ в режиме реального времени — от обработки данных с сенсоров до симуляции боевых действий и управления боевыми или коммерческими роботами. В Ranovus заявили, что платформа Wafer-Scale Co-Packaged Optics в 100 раз производительнее аналогичных современных решений, что позволяет значительно повысить эффективность ИИ-кластеров, и значительно энергоэффективнее продуктов конкурентов. Партнёрство компаний позволит задать новый стандарт для суперкомпьютерной и ИИ-инфраструктуры, решая задачи роста спроса на передачу и обработку данных и давая возможность реализовать военное и коммерческое моделирование нового поколения. Помимо использования в целях американских военных, гигантские ИИ-чипы Cerebras применяются и оборонными ведомствами других стран. Так, весной 2024 года сообщалось, что продукты компании помогут натренировать ИИ для военных Германии.
31.03.2025 [10:49], Руслан Авдеев
Новые нормы энергоэффективности ИИ-ускорителей угрожают бизнесу NVIDIA в КитаеПекин представил новые нормы энергоэффективности для ИИ-ускорителей. Весьма вероятно, что они помешают китайским компаниям приобретать наиболее востребованные в Китае ускорители NVIDIA, если регуляторы всерьёз возьмутся за контроль их исполнения, сообщает The Financial Times. Национальная комиссия по развитию и реформам (NDRC) настоятельно рекомендует местным игрокам рынка ЦОД использовать ускорители, соответствующие требованиям к энергоэффективности, при строительстве новых дата-центров и расширении уже существующих объектов. Популярный в Китае ИИ-ускоритель NVIDIA H20 менее производителен, чем флагманские модели компании, но его можно официально поставлять в страну. Однако, по данным издания, на сегодняшний день H20 не соответствует новым требованиям комиссии. По информации источников, в последние несколько месяцев китайский регулятор без лишнего шума «отговаривает» местные IT-гиганты, такие как Alibaba, ByteDance и Tencent, от использования H20. Впрочем, пока правила применяются не слишком жёстко, и эти ускорители NVIDIA по-прежнему востребованы на китайском рынке. Последствия для бизнеса NVIDIA могут оказаться серьёзнее, если комиссия решит ужесточить запрет — это поставит под угрозу многомиллиардные доходы компании в Китае. Несмотря на активное строительство дата-центров, американский разработчик рискует потерять заказы, а его место займёт Huawei, чьи продукты лучше соответствуют новым «зелёным» требованиям. В настоящее время NVIDIA ищет способы повысить энергоэффективность своих решений и стремится провести переговоры с руководством NDRC для обсуждения сложившейся ситуации. Однако это приведёт к снижению производительности H20 и, соответственно, конкурентоспособности на китайском рынке. 
Источник изображения: Henry Chen/unsplash.com Поскольку ограничения распространяются главным образом на новые, строящиеся ЦОД, некоторые компании обходят правила, заменяя в уже действующих дата-центрах старые ускорители на H20. В других случаях несоблюдение норм может привести к проверкам и штрафам. Хотя ограничения вступили в силу ещё в прошлом году, до недавнего времени о них не сообщалось — Китай всеми силами стремится к технологическому суверенитету в полупроводниковой сфере и активно содействует отказу местных компаний от продукции NVIDIA. Прямым конкурентом H20 считается Huawei Ascend 910B, на подходе и вариант 910C. NRDC недвусмысленно намекает на будущее отношений Пекина и NVIDIA. После ужесточения экспортных ограничений США в отношении Китая в октябре 2023 года компания специально разработала ослабленную экспортную версию H20. Однако на фоне триумфа китайских ИИ-моделей стартапа DeepSeek в стране разразился настоящий бум ИИ-технологий, и компании вроде Alibaba и Tencent активно закупают H20, особенно с учётом вероятного дальнейшего ужесточения американских санкций, включая возможный запрет на поставки даже ослабленных ускорителей. Китай — четвёртый по величине рынок для NVIDIA в мире: в 2025 фискальном году выручка компании здесь составила $17,1 млрд, или 13 % от всех продаж. Помимо Huawei, конкуренцию NVIDIA на китайском рынке может составить и Intel с её ускорителями HL328 и HL388, однако они также не соответствуют новым китайским требованиям по энергоэффективности. Впрочем, их доля в китайском импорте изначально была незначительной.
29.03.2025 [10:11], Алексей Степин
Bolt Graphics анонсировала универсальную видеокарту со слотами SO-DIMM, которая может потягаться с RTX 5080Все современные графические ускорители предлагаются с жёстко заданным при производстве объёмом видеопамяти, а в наиболее производительных моделях память типа HBM вообще интегрирована на одной с основным кристаллом подложке. Однако требования к объёму памяти в последнее время растут быстрее, а за дополнительный объём вендор просят всё больше. Кардинально иной подход предлагает компания Bolt Graphics, недавно анонсировавшая серию ускорителей Zeus. Несмотря на «ИИ-пандемию», Bolt Graphics в своём анонсе не делает упор на искусственный интеллект, а называет Zeus первым GPU, специально созданным для целей HPC, рендеринга, трассировки лучей и даже компьютерных игр. Что интересно, в основе Zeus лежит не некая закрытая архитектура: скалярная часть нового GPU построена на базе спецификации RISC-V RVA23, векторная представлена FP64 ALU на базе несколько модифицированной RVV 1.0. Прочие функции реализованы путём кастомных расширений и отдельных блоков-ускорителей. Все они пользуются общим кешем объёмом 128 Мбайт. Дополняет картину блок телеметрии и внутренний интерконнект для общения с другими вычислительным блоками. 
Zeus 1c26-032 (Источник изображений: Bolt Graphics) Используется чиплетный подход. Базовый «строительный блок» Zeus 1c26-032 включает GPU-чиплет, который соединён с 32 Гбайт набортной памяти LPDDR5x (273 Гбайт/с) и контроллером внешней памяти DDR5 (90 Гбайт/с), т.е. при желании можно установить ещё 128 Гбайт RAM (два модуля SO-DIMM). В GPU-чиплет встроены контроллеры DisplayPort 2.1a и HDMI 2.1b, а с внешним миром он общается посредством IO-чиплета, с которым он соединён 256-Гбайт/с каналом. IO-чиплет предлагает необычный набор портов. Помимо сразу двух интерфейсов PCIe 5.0 x16 (64 Гбайт/с каждый) имеется выделенный порт RJ-45 для BMC и 400GbE-порт QSFP-DD. Наконец, есть аппаратный блок видеокодирования, способный справиться с двумя потоками 8K@60 AV1/H.264/H.265.  Заявленный уровень производительности в векторных FP64/FP32/FP16-вычислениях составляет 5/10/20 Тфлопс, а в матричных INT16/INT8 — 307,2/614,4 Топс. Аппаратный блок ускорения лучей (path tracing) выдаёт до 77 гигалучей. Для сравнения: NVIDIA RTX 5090 способна выдавать 32 гигалуча, а FP64-производительность составляет 1,6 Тфлопс. В то же время в расчётах пониженной точности актуальные решения NVIDIA всё равно быстрее Zeus 1c26-032. Однако у новинки есть важное преимущество — её уровень TDP составляет всего 120 Вт. Второй интерфейс PCIe 5.0 x16 можно использовать для прямого объединения двух карт. 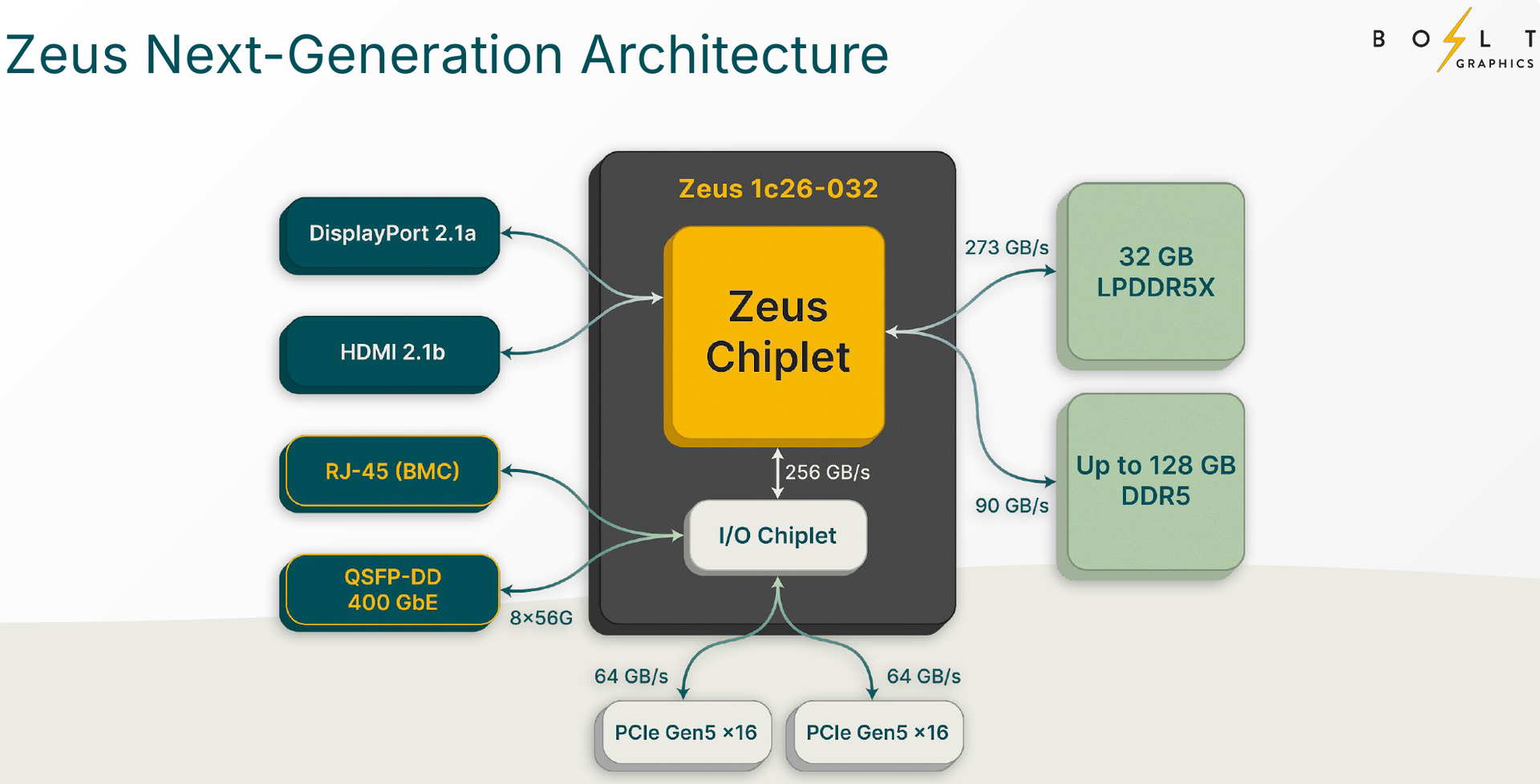 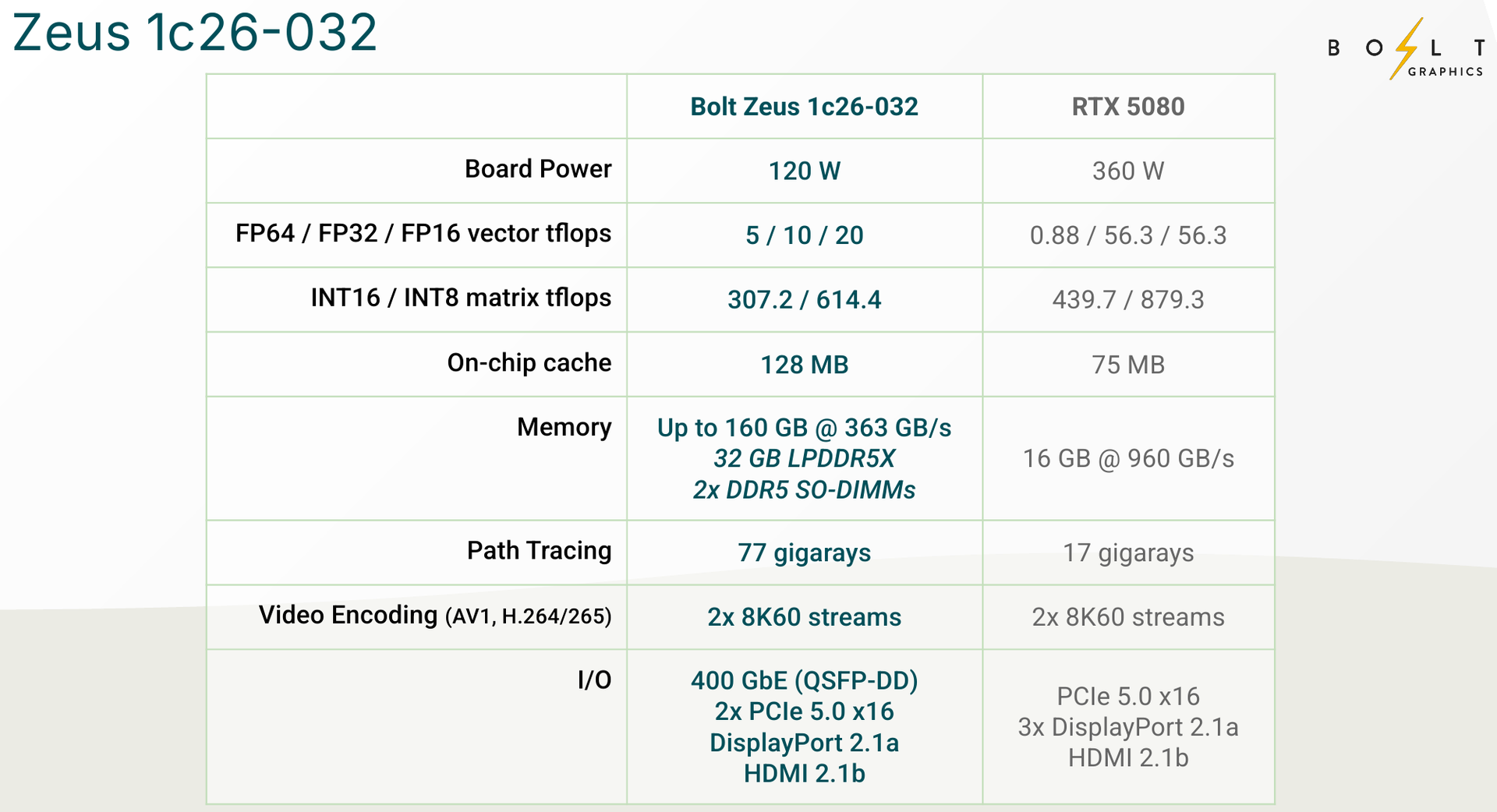 Вариант ускорителя с двумя чиплетами носит название Zeus 2c26-064/128, а с четырьмя — 4c26-256. Последние числа обозначают объём распаянной памяти LPDDR5X. Что касается расширяемой памяти, то количество доступных разъёмов SO-DIMM также зависит от модели и составляет до восьми, так что во флагманской конфигурации базовые 256 Гбайт LPDDR5x можно дополнить аж 2 Тбайт DDR5. Производительность с увеличением количеств GPU-чиплетов растёт практически пропорционально, но есть некоторые другие нюансы. Так, в Zeus 2c26-064 и Zeus 2c26-128 (оба варианта имеют TDP 250 Вт) есть только один IO-чиплет, а GPU-чиплеты объединены шиной со скоростью 768-Гбайт. 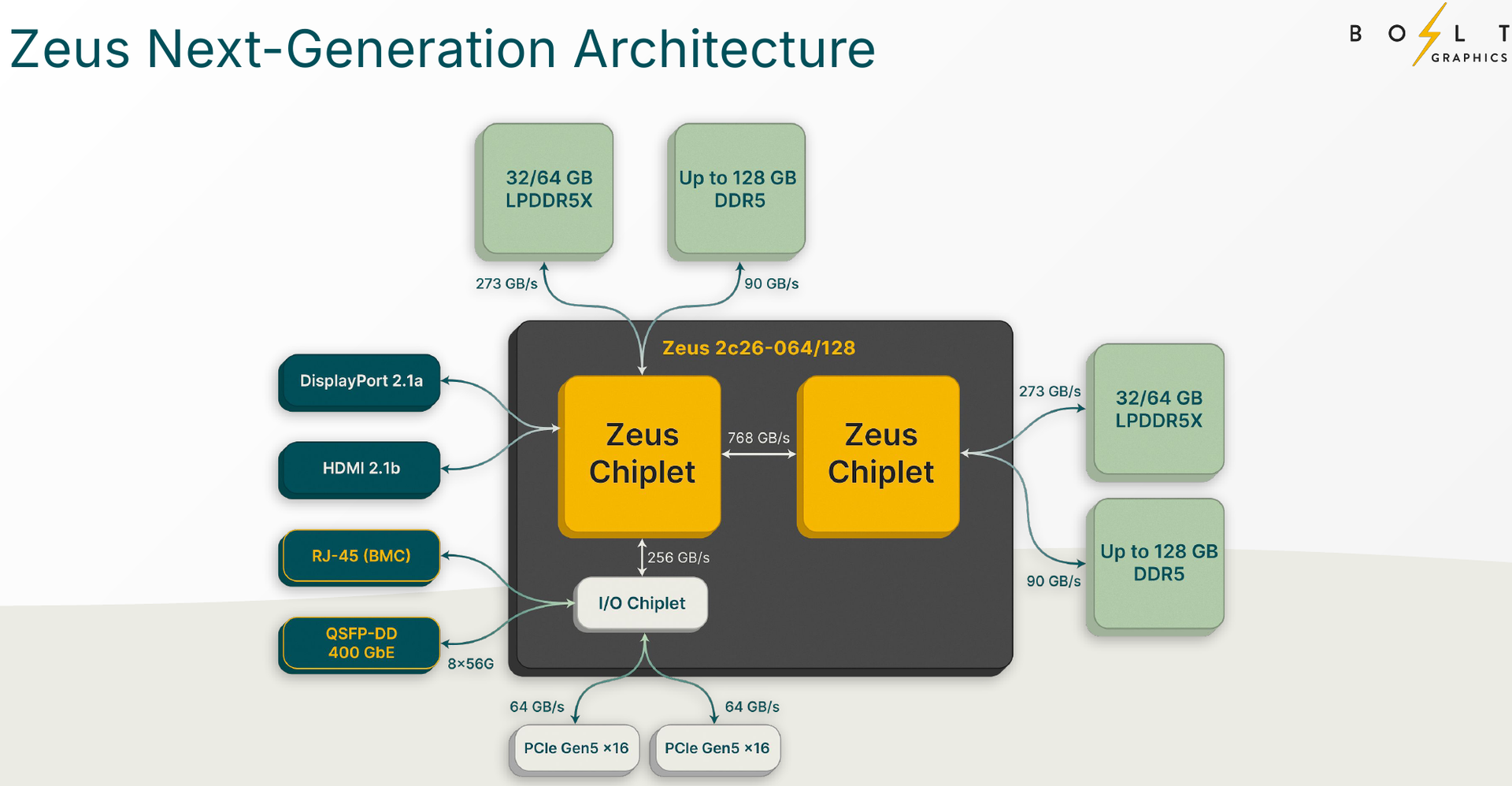  Zeus 4c26-256 имеет сразу четыре I/O чиплета в составе, которые дают восемь контроллеров PCIe 5.0 x4 (один чиплет, совокупно 32 линии) и шесть 800GbE-портов OSFP (три чиплета). Между собой GPU-чиплеты объединены шиной со скоростью 512-Гбайт/с. Каждый из них соединён с собственным IO-чиплетом на скорости 256 Гбайт/с. Теплопакет флагмана составляет 500 Ватт, ускоритель, если верить Bolt Graphnics, развивает 20 Тфлопс в режиме FP64, почти 2500 Топс на вычислениях FP8 и способен обрабатывать до 307 гигалучей. 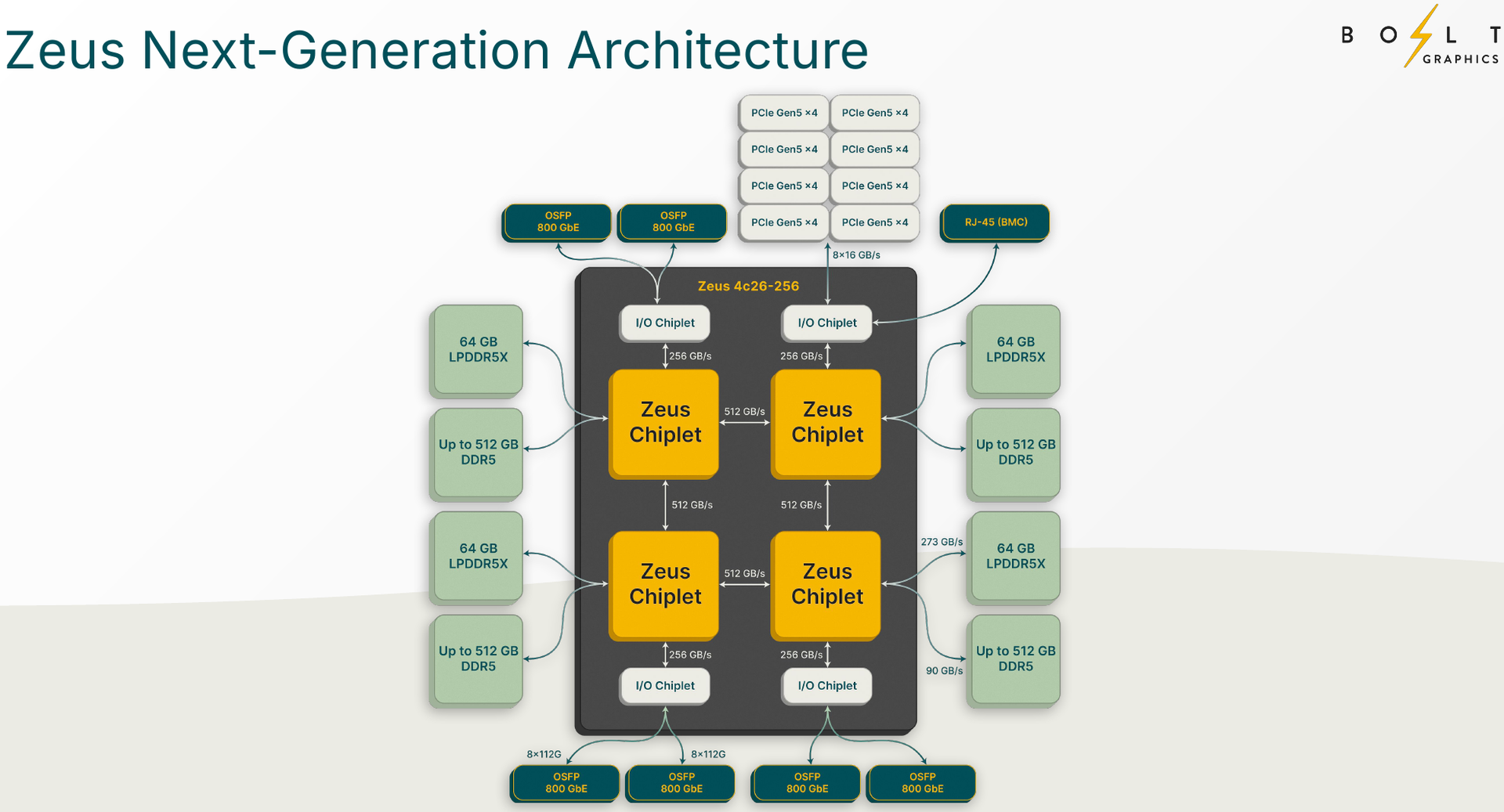 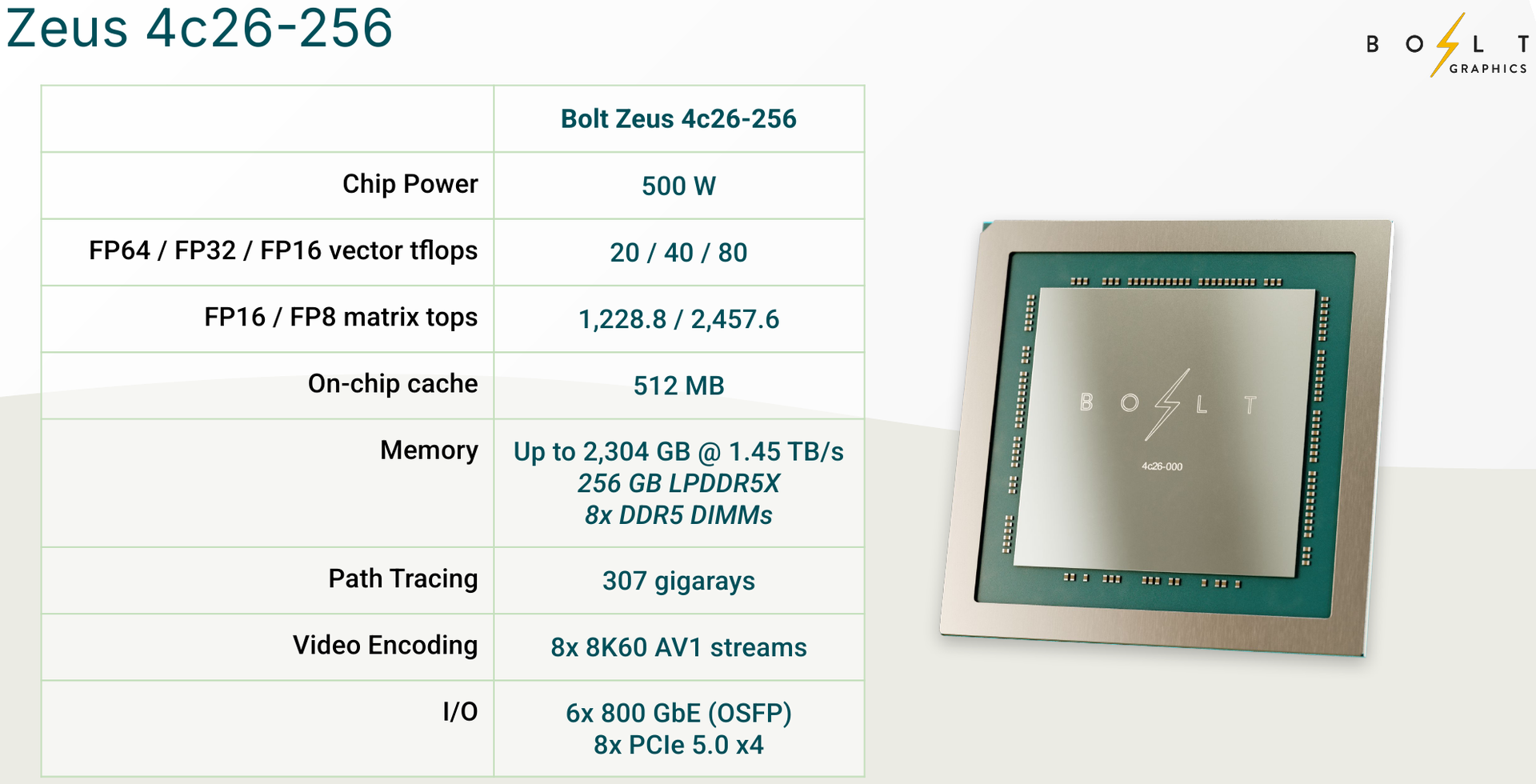 Разработчики явно заложили в своё детище широкие возможности кластеризации, о чём свидетельствует наличие мощной сетевой подсистемы. Поддерживаются как скромные конфигурации из двух GPU, соединённых непосредственно по Ethernet 400GbE, так и масштабные системы уровня стойки, содержащей 80 плат Zeus 4c26-256, соединённых как с коммутатором, так и напрямую друг с другом. Такой кластер потребляет 44 кВт, но зато способен обеспечивать запуск крупных физических симуляций или обучение ИИ моделей за счёт огромного массива общей памяти, составляющего 160 Тбайт. Вычислительная производительность такого кластера достигает 1,6 Пфлопс в режиме FP64 и 196 Попс в режиме FP8. 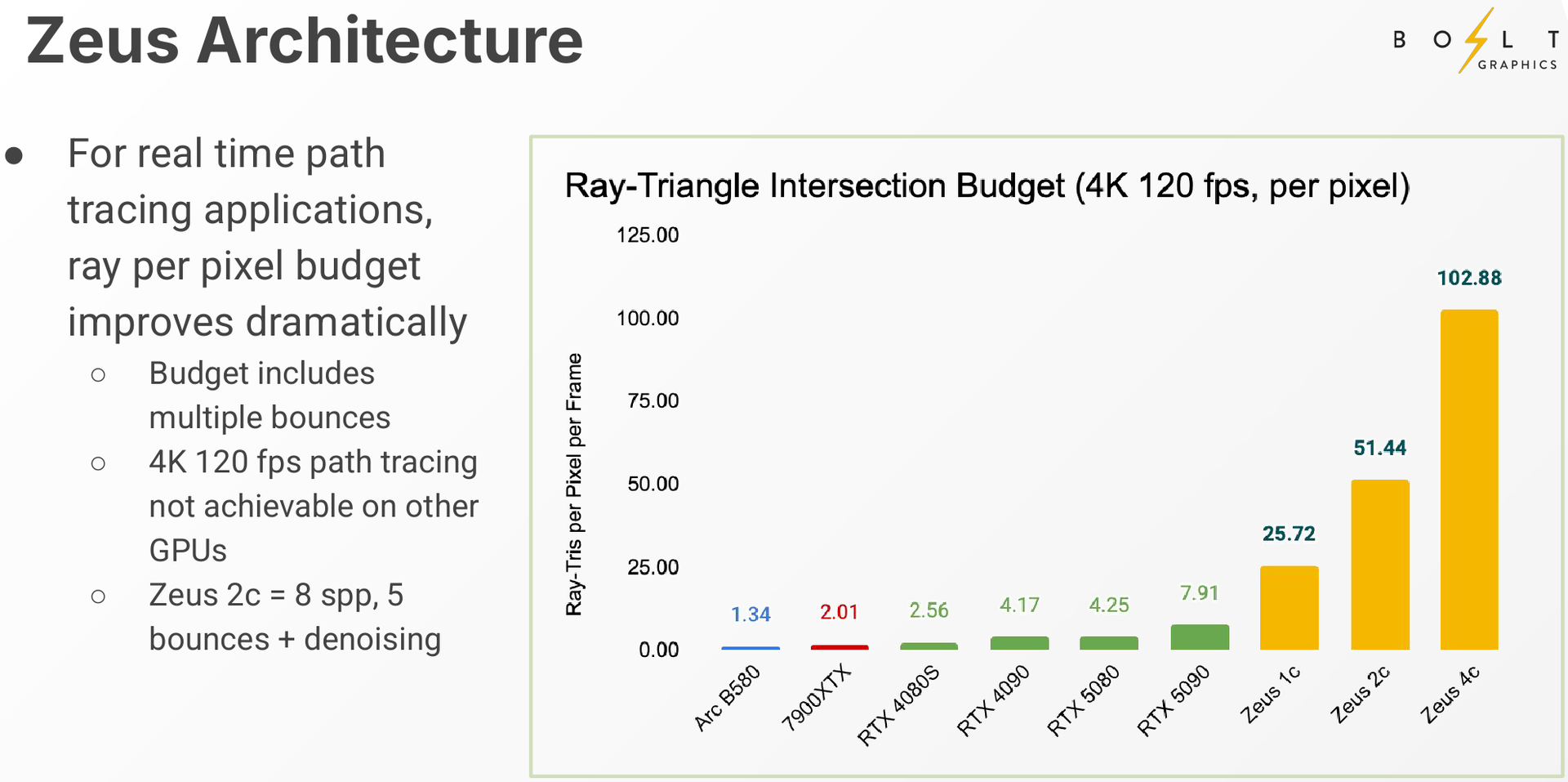  Одной из особенностей новинок является трассировщик лучей Glowstick, способный работать в режиме реального времени практически во всех современных пакетах 3D-моделирования или видеоредактирования, таких как Maya, 3ds Max, Blender, SketchUp, Houdini и Nuke. Он будет дополнен фирменной библиотекой Bolt MaterialX, содержащей более 5000 текстур высокого качества. А благодаря поддержке стандарта OpenUSD он сможет легко интегрироваться в любую цепочку рендеринга и пост-обработки. Также запланирован электромагнитный симулятор Bolt Apollo. Обещаны фирменные драйверы Vulkan/DirectX и SDK с использованием LLVM. 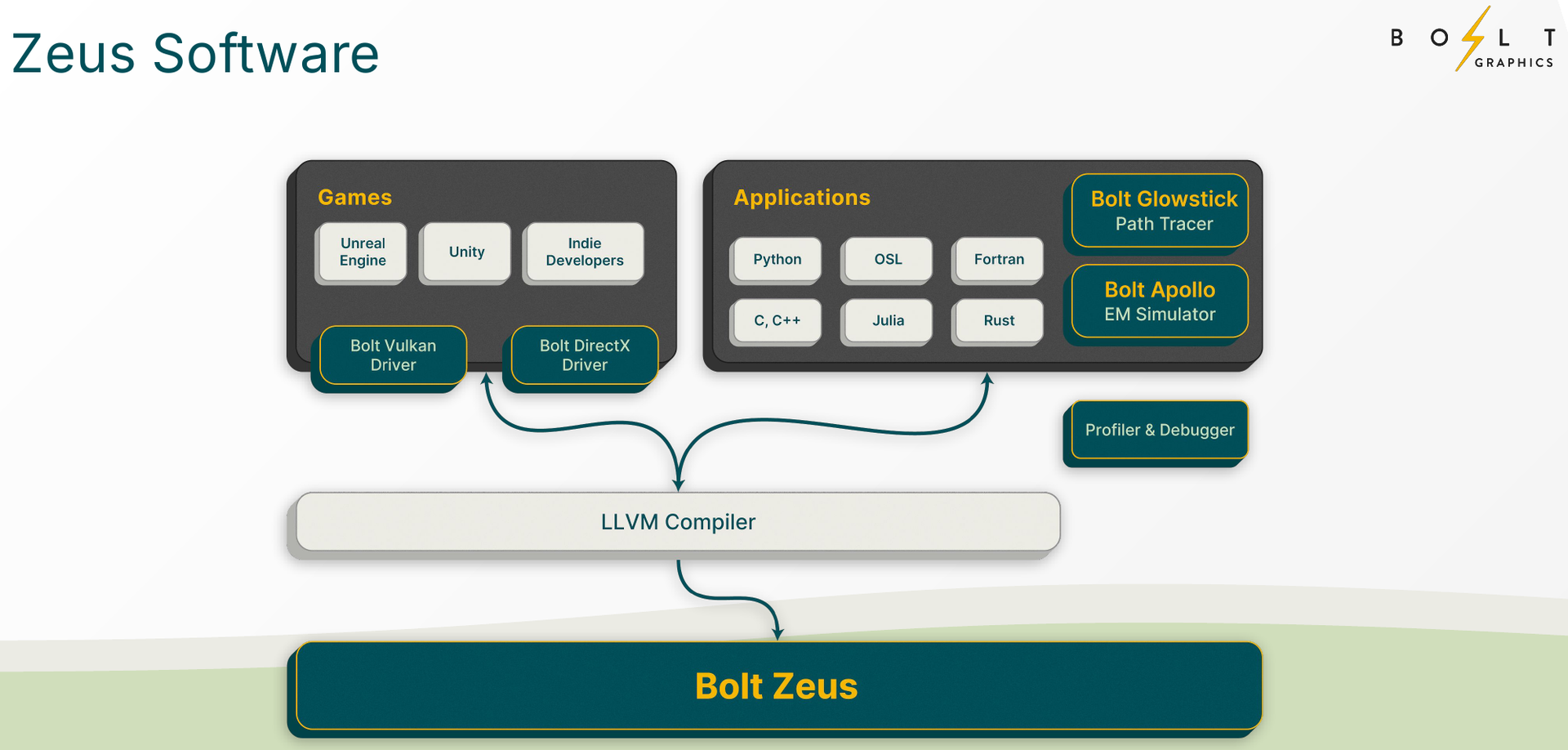 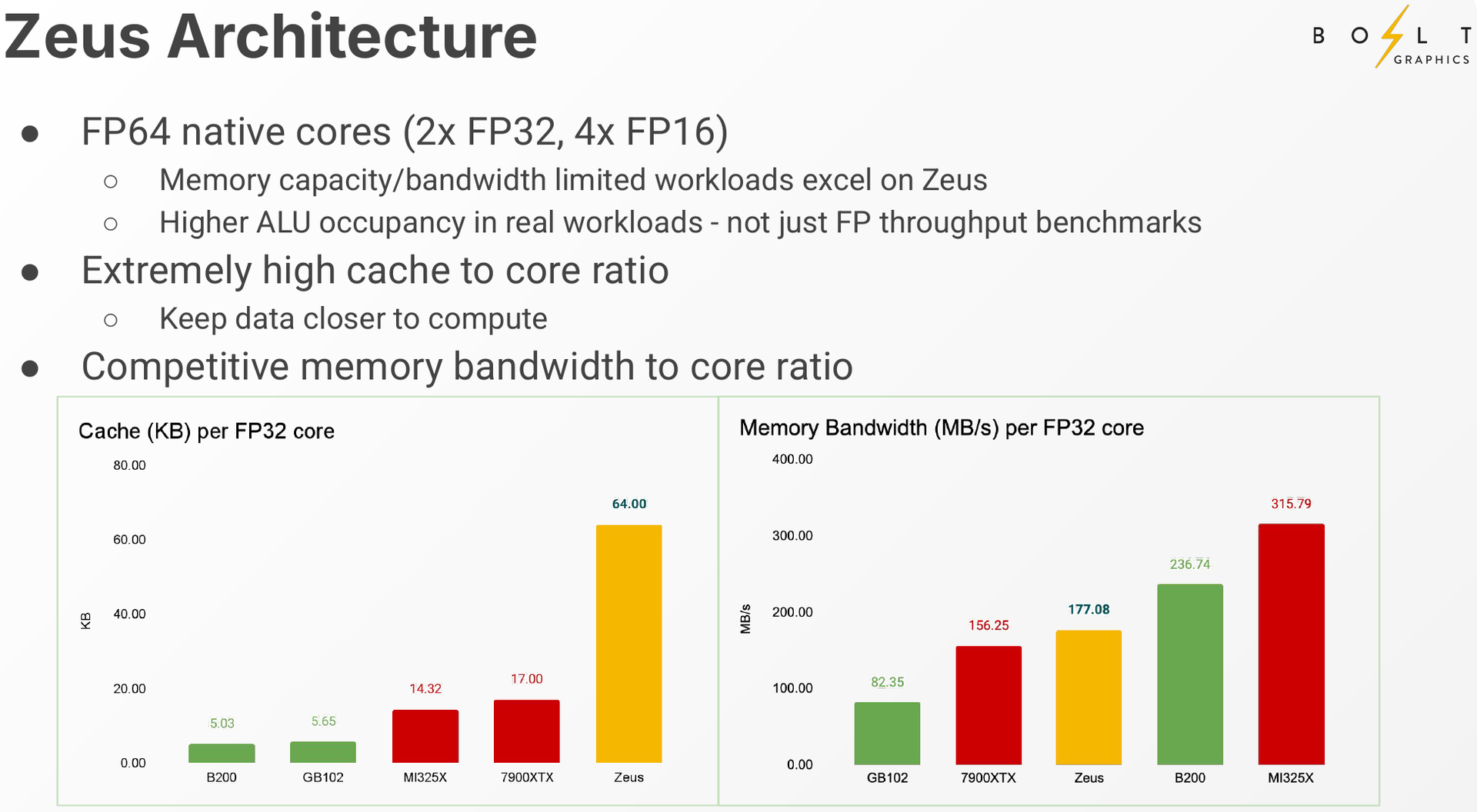 Ранний доступ к комплектам разработчика Bolt Graphics наметила на IV квартал текущего года. В III квартале 2026 года должны появиться 2U-серверы на базе Zeus, а массовые поставки серверов и PCIe-карт начнутся не ранее IV квартала того же года. Пока сложно сказать, насколько хорошо новая архитектура себя проявит, но если верить предварительным тестам Zeus, выигрыш в сравнении с существующими ускорителями существенен, особенно в энергопотреблении.
20.03.2025 [01:10], Владимир Мироненко
Анонсированы суперускорители на Rubin и Rubin Ultra, в которых NVIDIA не будет ошибаться в подсчётахNVIDIA анонсировала ИИ-ускорители следующего поколения Rubin, которые придут на смену Blackwell Ultra во II половине 2026 года. Выход Rubin Ultra запланирован на II половину 2027 года. Компанию им составят Arm-процессоры Vera. Серия названа в честь астронома Веры Купер Рубин (Vera Florence Cooper Rubin), известной своими исследованиями тёмной материи. NVIDIA отметила, что в названии предыдущих ускорителей была «допущена ошибка». В Blackwell каждый чип состоит из двух GPU, но, например, в названии GB200/GB300 NVL72 упоминается только 72 GPU, хотя речь фактически идёт о 144 GPU. Поэтому, начиная с Rubin компания будет использовать новую схему наименований, которая больше не учитывает количество чипов, а относится исключительно к количеству GPU. Таким образом, следующее поколение суперускорителей, упакованных в ту же стойку Oberon, что используется для Grace Blackwell, получило название Vera Rubin NVL144. Rubin во многом повторяет дизайн Blackwell, поскольку R200 всё так же включает два кристалла GPU (в составе SXM7), способных выдавать до 50 Пфлопс в вычислениях FP4 (без разреженности), и 288 Гбайт памяти в восьми стеках 12-Hi, но на этот раз уже HBM4 с общей пропускную способностью 13 Тбайт/с (2048-бит шина). Кристаллы GPU будут изготовлены по техпроцессу TSMC N3P, а компанию им составят два IO-чиплета, отвечающие за все внешние коммуникации, пишет SemiAnalysis. Всё вместе будет упаковано посредством CoWoS-L. TDP новинок не указывается. 
Источник изображений: NVIDIA Чипы перейдут на интерконнект NVLink 6 со скоростью 1,8 Тбайт/с в каждую сторону (3,6 Тбайт/с в дуплексе), что вдвое выше, чем у текущего поколения NVLink 5. Аналогичным образом вырастет и коммутационная способность NVSwitch, а также NVLink C2C. Впрочем, при сохранении прежней схемы, когда один CPU обслуживает два модуля GPU, каждому из последних, по-видимому, достанется половина пропускной способности шины. Собственно процессор Vera получит 88 кастомных (а не Neoverse CSS в случае Grace) 3-нм Arm-ядра, причём с SMT, что даст 176 потоков. Каждый CPU получит порядка 1 Тбайт LPDDR-памяти и будет вдвое быстрее Grace при теплопакете в районе 50 Вт.  По словам NVIDIA, VR200 NVL144 будет в 3,3 раза быстрее: 3,6 Эфлопс в FP4-вычислениях для инференса и 1,2 Эфлопс в FP8 для обучения. Суммарный объём HBM-памяти составит более 20,7 Тбайт, системной памяти — 75 Тбайт. Внешняя сеть будет представлена адаптерами ConnectX-9 SuperNIC со скоростью 1,6 Тбит/с на порт, что вдвое больше, чем у ConnectX-8, обслуживающих GB300.  Во II половине 2027 года появится ускоритель Rubin Ultra (R300) с FP4-производительностью более 100 Пфлопс (без разреженности), объединяющий сразу четыре GPU, два IO-чиплета и 16 стеков HBM4e-памяти 16-Hi общим объёмом 1 Тбайт (32 Тбайт/с) в упаковке SXM8. Более того, ускорители, по-видимому, получат ещё и LPDDR-память. Процессор Vera перекочует в новую платформу без изменений, один CPU будет приходиться на четыре GPU. Внутренней шиной станет NVLink 7, которая сохранит скорость NVLink 6, зато получит вчетверо более производительные коммутатор NVSwitch. А вот внешнее подключение по-прежнему будут обслуживать адаптеры ConnectX-9.  Новая стойка Kyber полностью поменяет компоновку. Узлы теперь напоминают вертикальные блейд-серверы, используемые в суперкомпьютерах. Каждый узел (VR300) будет включать один процессор Vera и один ускоритель Rubin Ultra. Всего таких узлов будет 144, что в сумме даёт 144 CPU, 576 GPU и 144 Тбайт HBM4e. Суперускоритель Rubin Ultra NVL576 будет потреблять 600 кВт и обеспечит быстродействие в 15 Эфлопс для инференса (FP4) и 5 Эфлопс для обучения (FP8). При этом упоминается, что объём быстрой (fast) памяти составит 365 Тбайт, но сколько из них достанется CPU, не уточняется. Дальнейшие планы NVIDIA включают выход во II половине 2028 года первого ускорителя на новой архитектуре Feynman, названной в честь физика-теоретика Ричарда Филлипса Фейнмана (Richard Phillips Feynman). Сообщается, что Feynman будет полагаться на память HBM «следующего поколения» и, вероятно, на CPU Vera. Это поколение также получит коммутаторы NVSwitch 8 (NVL-Next), сетевые коммутаторы Spectrum7 и адаптеры ConnectX-10.
19.03.2025 [08:28], Сергей Карасёв
NVIDIA представила ускоритель RTX Pro 6000 Blackwell Server Edition с 96 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 6000 Blackwell Server Edition для требовательных приложений ИИ и рендеринга высококачественной графики. Ожидается, что новинка будет востребована среди заказчиков из различных отраслей, включая архитектуру, автомобилестроение, облачные платформы, финансовые услуги, здравоохранение, производство, игры и развлечения, розничную торговлю и пр. Как отражено в названии, в основу решения положена архитектура Blackwell. Задействован чип GB202: конфигурация включает 24 064 ядра CUDA, 752 тензорных ядра пятого поколения и 188 ядер RT четвёртого поколения. Устройство несёт на борту 96 Гбайт памяти GDDR7 (ECC) с пропускной способностью до 1,6 Тбайт/с. Ускоритель RTX Pro 6000 Blackwell Server Edition использует интерфейс PCIe 5.0 x16. Энергопотребление может настраиваться в диапазоне от 400 до 600 Вт. Реализована поддержка DisplayPort 2.1 с возможностью вывода изображения в форматах 8K / 240 Гц и 16K / 60 Гц. Аппаратный движок NVIDIA NVENC девятого поколения значительно повышает скорость кодирования видео (упомянута поддержка 4:2:2 H.264 и HEVC). Всего доступно по четыре движка NVENC/NVDEC. 
Источник изображения: NVIDIA По заявлениям NVIDIA, по сравнению с ускорителем предыдущего поколения L40S Ada Lovelace модель RTX PRO 6000 Blackwell Server Edition обеспечивает многократное увеличение производительности в широком спектре рабочих нагрузок. В частности, скорость инференса больших языковых моделей (LLM) повышается в пять раз для приложений агентного ИИ. Геномное секвенирование ускоряется практически в семь раз, а быстродействие в задачах генерации видео на основе текстового описания увеличивается в 3,3 раза. Достигается также двукратный прирост скорости рендеринга и примерно такое же повышение скорости инференса рекомендательных систем. Ускоритель RTX PRO 6000 Blackwell Server Edition может использоваться в качестве четырёх полностью изолированных экземпляров (MIG) с 24 Гбайт памяти GDDR7 каждый. Это обеспечивает возможность одновременного запуска различных рабочих нагрузок — например, ИИ-задач и обработки графики. Упомянута поддержка TEE.
17.03.2025 [22:20], Владимир Мироненко
Новый гендиректор Intel предупредил сотрудников, что придётся принимать «жёсткие решения»С 18 марта к обязанностям гендиректора Intel приступит Лип-Бу Тан (Lip-Bu Tan). Как сообщает Reuters со ссылкой на информированные источники, в числе первоочередных мер по возрождению потенциала компании новый гендиректор наметил реструктуризацию подхода компании к ИИ и сокращение персонала, в частности, «раздутого», по его мнению, среднего управленческого звена. По словам источников, одним из основных приоритетов Тана является модернизация производственных операций компании, которая когда-то производила только чипы для своих нужд, но была перепрофилирована на производство полупроводников для внешних клиентов. На прошедшем после назначения собрании Тан предупредил сотрудников, что компании придётся принимать «жёсткие решения». В ближайшей перспективе Тан планирует повысить доходы подразделения Intel Foundry, которое производит чипы для других компаний, путём агрессивного привлечения новых клиентов, говорят источники Reuters. Изменения коснутся и производства чипов для ИИ-серверов. Также подлежит пересмотру работа в таких сферах, как ПО, робототехника и разработка базовых ИИ-моделей. По словам источников, Тан был ярым внутренним критиком действий Пэта Гелсингера (Patrick Gelsinger), который после назначения гендиректором Intel в 2021 году занялся её преобразованием в контрактного производителя чипов. Гелсингер выделил десятки миллиардов долларов на строительство заводов в США и Европе для производства чипов, но компания не смогла обеспечить надлежащий уровень обслуживания клиентов и технической поддержки, как у конкурента TSMC, что привело к задержкам с выходом новых чипов, проблемам в их работе, а также неудовлетворительным тестам, говорят источники Reuters из числа бывших топ-менеджеров. 
Источник изображения: Intel Лип-Бу Тан вошёл в совет директоров Intel в 2022 году, а в октябре 2023 года получил от него расширенные полномочия. Среди прочего на него был возложен контроль за производством. По словам источников Reuters, Тан высказывал разочарование культурой компании, утверждая, что она утратила принцип «выживают только параноики», введённый основателем и бывшим гендиректором Intel Эндрю Гроувом (Andrew Grove). Он также пришел к выводу, что принятие решений серьёзно замедляется из-за раздутого штата. В итоге Тан ушёл в отставку из-за разногласий с советом директоров, отказавшимся реализовать его предложения. Тан сообщил в новом меморандуме, что он планирует сохранить контроль над заводами, которые остаются финансово и операционно отделёнными от конструкторского бизнеса, и восстановить положение Intel как «контрактного производителя мирового класса». Контрактное производство Intel будет успешным, если компания сможет привлечь по крайней мере двух крупных клиентов, что позволит обеспечить выпуск большого объёма чипов, считают отраслевые аналитики и топ-менеджеры Intel. Привлечению крупных клиентов будет способствовать улучшение процесса производства чипов. За последние недели Intel продемонстрировала улучшения в своих производственных процессах, что привклекло NVIDIA и Broadcom, которые начали ранние тесты чипов, пишет Reuters. По данным издания, AMD также сейчас оценивает производство Intel. Ожидается, что Tan будет работать над улучшением выхода годной продукции, поскольку компания в этом году переходит к массовому производству первого собственного чипа с использованием техпроцесса 18A. Цель состоит в том, чтобы перейти к графику выпуска ИИ-чипов, подобного NVIDIA, ежегодно обновляющей свой ассортимент, но на это понадобятся годы. По словам трёх отраслевых источников Reuters и ещё одного собеседника, осведомлённого о прогрессе Intel в разработке, компания сможет разработать эффективную архитектуру для первого ИИ-чипа не ранее 2027 года.
13.03.2025 [23:30], Владимир Мироненко
Бывший глава Google предупредил об опасности стремления США к доминированию в области ИИ
software
безопасность
ии
информационная безопасность
китай
прогноз
разработка
санкции
сша
ускоритель
цод
Бывший глава Google Эрик Шмидт (Eric Schmidt) опубликовал статью «Стратегия сверхразума» (Superintelligence Strategy), написанную в соавторстве с Дэном Хендриксом (Dan Hendrycks), директором Центра безопасности ИИ, и Александром Вангом (Alexandr Wang), основателем и генеральным директором Scale AI, в которой высказывается мнение о том, что США следует воздержаться от реализации аналога «Манхэттенского проекта» для достижения превосходства в области ИИ, поскольку это спровоцирует упреждающие киберответы со стороны, например, Китая, пишет The Register. Авторы статьи утверждают, что любое государство, которое создаст супер-ИИ, будет представлять прямую угрозу для других стран, и они, стремясь обеспечить собственное выживание, будут вынуждены саботировать такие проекты ИИ. Любая «агрессивная попытка одностороннего доминирования в области ИИ приведёт к превентивному саботажу со стороны конкурентов», который может быть реализован в виде шпионажа, кибератак, тайных операций по деградации обучения моделей и даже прямого физического удара по ИИ ЦОД. Авторы считают, что в области ИИ мы уже близки к доктрине взаимного гарантированного уничтожения (Mutual Assured Destruction, MAD) времён Холодной войны. Авторы дали нынешнему положению название «гарантированное взаимное несрабатывание ИИ» (Mutual Assured AI Malfunction, MAIM), при котором проекты ИИ, разрабатываемые государствами, ограничены взаимными угрозами саботажа. 
Источник изображения: Igor Omilaev/unsplash.com Вместе с тем ИИ, как и ядерные программы в своё время, может принести пользу человечеству во многих областях, от прорывов в разработке лекарств до автоматизации процессов производства, использование ИИ важно для экономического роста и прогресса в современном мире. Согласно статье, государства могут выбрать одну из трех стратегий.
Комментируя предложение Комиссии по обзору экономики и безопасности США и Китая (USCC) о госфинансирования США своего рода «Манхэттенского проекта» по созданию суперинтеллекта в какому-нибудь укромном уголке страны, авторы статьи предупредили, что Китай отреагирует на этот шаг, что приведёт лишь к длительному дисбалансу сил и постоянной нестабильности. 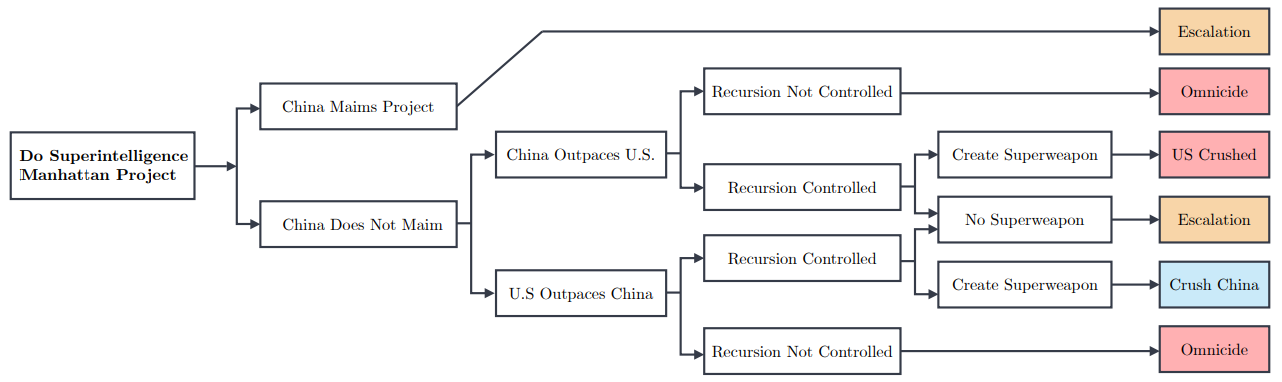
Источник: Superintelligence Strategy: Expert Version Авторы статьи считают, что государства должны отдавать приоритет доктрине сдерживания, а не победе в гонке за искусственный сверхразум. MAIM подразумевает, что попытки любого государства достичь стратегической монополии в области ИИ столкнутся с ответными мерами со стороны других стран, а также приведут к соглашениям, направленным на ограничение поставок ИИ-чипов и open source моделей, которые по смыслу будут аналогичны соглашениям о контроле над ядерным оружием. Чтобы обезопасить себя от атак на государственном уровне с целью замедлить развитие ИИ, в статье предлагается строить ЦОД в удалённых местах, чтобы минимизировать возможный ущерб, пишет Data Center Dynamics. Тот, кто хочет нанести ущерб работе других стран в сфере ИИ, может начать с кибератак: «Государства могут “отравить” данные, испортить веса и градиенты моделей, нарушить работу ПО, которое обрабатывают ошибки ускорителей и управляет питанием и охлаждением…». 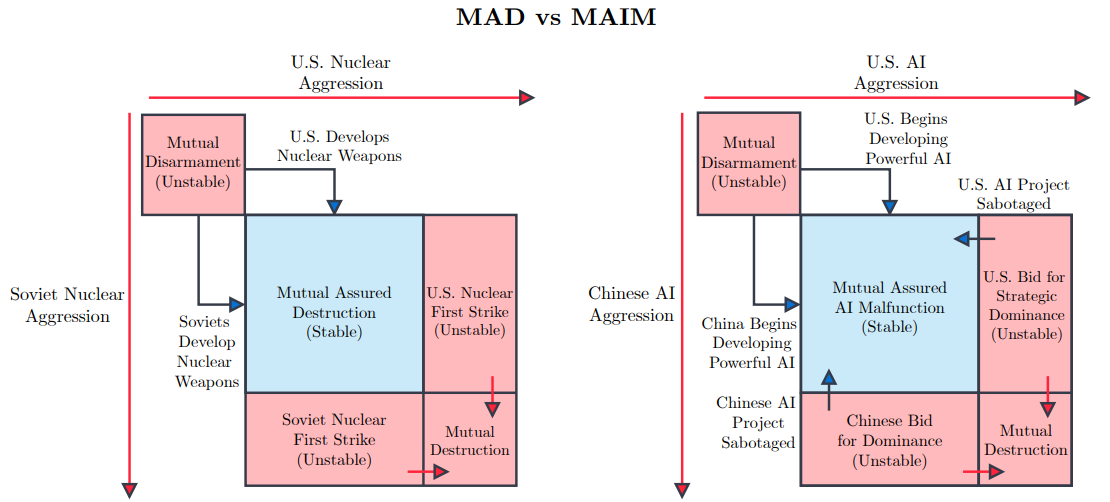
Источник: Superintelligence Strategy: Expert Version Снизить вероятность атак поможет и прозрачность разработок. ИИ можно использовать для оценки безопасности других ИИ-проектов, что позволит избежать атак на «гражданские» ЦОД. Вместе с тем не помешает и прозрачность цепочек поставок. Поскольку ИИ-ускорители существуют в реальном, а не виртуальном мире, отследить их перемещение не так уж трудно. Таким образом, даже устаревшие или признанные негодными чипы не смогут попасть на чёрный рынок — их предлагается утилизировать с той же степенью ответственности, что и химические или ядерные материалы. Впрочем, соблюдение всех этих рекомендаций не устранит главную проблему — зависимость от Тайваня в плане производства передовых чипов, которая является критической для США, говорят авторы статьи. Поэтому западным странам следует разработать гарантированные цепочки поставок ИИ-чипов. Для этого потребуются значительные инвестиции, но это необходимо для обеспечения конкурентоспособности.
12.03.2025 [20:37], Владимир Мироненко
Евросоюз потратит €240 млн на создание трёх RISC-V чиплетов для суперкомпьютеров в рамках проекта DARE
eurohpc
hardware
hpc
risc-v
европа
ии
импортозамещение
инвестиции
суперкомпьютер
ускоритель
финансы
чиплеты
Digital Autonomy with RISC-V in Europe (DARE), крупнейший проект по разработке чипов из когда-либо финансируемых Европейским союзом, созданный с целью укрепления технологического суверенитета Европы в области высокопроизводительных вычислений (HPC) и искусственного интеллекта (ИИ), официально начал первый этап DARE SGA1, на реализацию которого выделено €240 млн ($262 млн), сообщается на сайте проекта. Европа и Китай делают ставку на RISC-V. Финансирование инициативы обеспечат 38 участников, включая ИТ-компании, исследовательские институты и университеты по всей Европе. Проект поддерживается EuroHPC JU и координируется Барселонским суперкомпьютерным центром (BSC-CNS). Последний имеет богатый опыт разработки чипов RISC-V и суперкомпьютерных систем. Половина инвестиций в проект DARE будет предоставлена Европейской комиссией через EuroHPC, а другая половина поступит напрямую от европейских партнёров, включая €34 млн от Министерства науки, инноваций и университетов Испании. Рассчитанный на три года DARE SGA1 является первым этапом шестилетней инициативы DARE. Цель — создание полноценного независимого европейского суперкомпьютерного программно-аппаратного стека для HPC и ИИ, включая чипы, системы на основе чиплетов и ПО. Инициатива направлена на удовлетворение стратегической потребности Европы в цифровом суверенитете и получения полного контроля над критической вычислительной инфраструктурой. 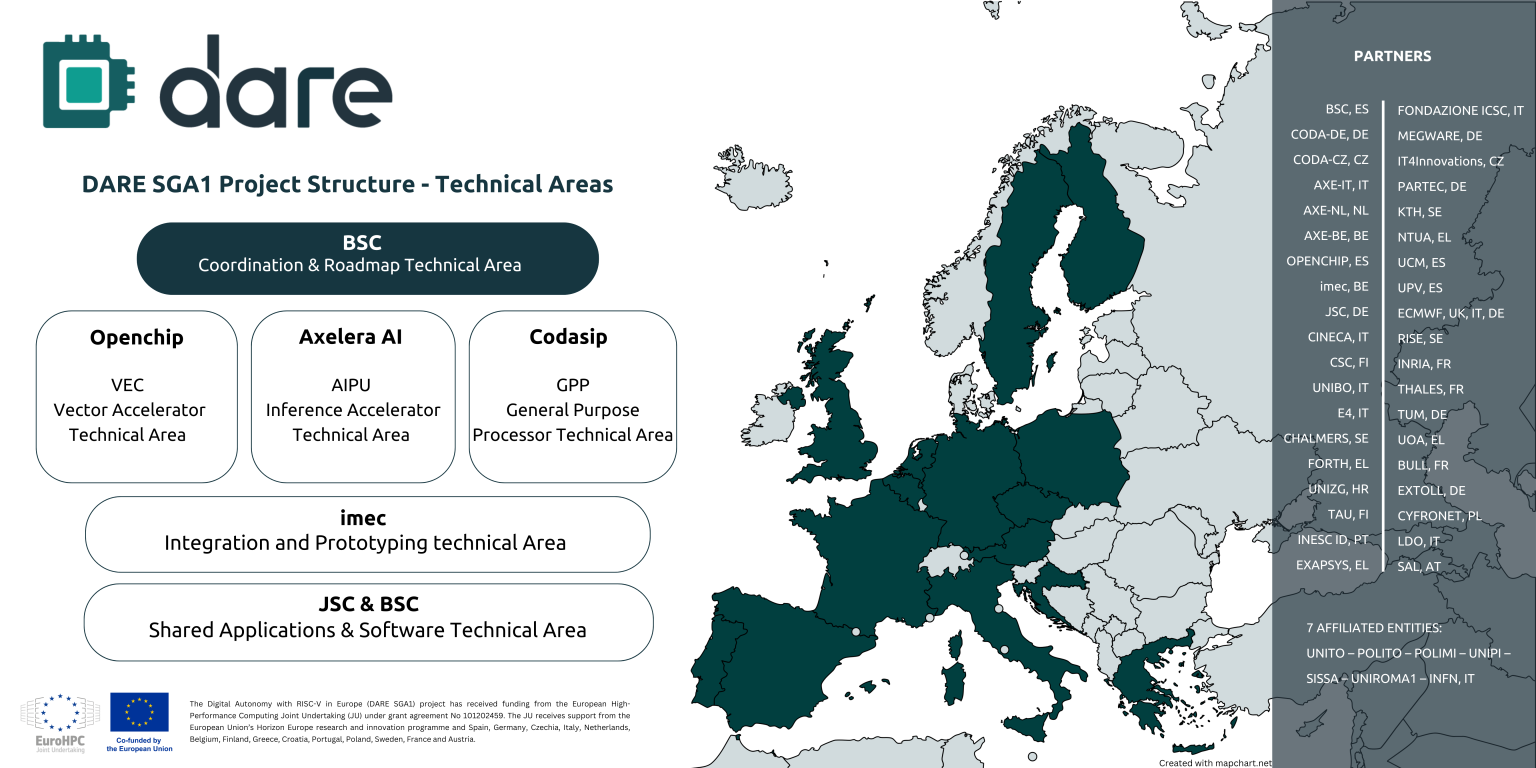
Источник изображения: DARE Проектом DARE SGA1 предусмотрена разработка трёх чиплетов на основе архитектуры RISC-V, каждый из которых будет выполнять критически важную функцию в вычислениях HPC и ИИ:
В дополнение к указанным компаниям в качестве технических лидеров названы imec и Юлихский исследовательский центр (JÜLICH Supercomputing centre, JSC), которые будут продвигать ключевые инновации в рамках проекта. Помимо координации усилий, BSC также возглавит разработку планов и будет участвовать в разработке программных и аппаратных решений. Изготавливаться чиплеты будут по технологии CMOS с использованием современных техпроцессов. Axelera получит на разработку до €61 млн при условии выполнения различных задач в течение следующих трёх лет, рассказал ресурсу EE Times генеральный директор Axelera Фабрицио дель Маффео (Fabrizio del Maffeo). Хотя нынешний чип Axelera Metis AIPU предназначен для периферийных систем, дель Маффео сказал, что разрабатываемый в рамках DARE продукт на основе чиплетов не несёт кардинальные изменения, речь скорее о масштабировании. Codasip в прошлом году анонсировала 64-бит чип X730 на базе RISC-V с архитектурной защитой CHERI. По данным The Next Platform, за последнее десятилетие компания привлекла $34,6 млн общего финансирования, включая средства в рамках различных инициатив ЕС, а также посевной раунд в размере $2,5 млн в 2016 году и раунд A в размере $10 млн в 2018 году.
12.03.2025 [00:25], Владимир Мироненко
Meta✴ начала тестирование собственного ускорителя для обучения ИИ-моделейMeta✴ Platforms приступила к тестированию ИИ-ускорителя собственной разработки, который, в случае успеха, позволит ей снизить зависимость от поставок чипов NVIDIA, пишет Reuters со ссылкой на информированные источники. По словам одного из источников, новый чип Meta✴ представляет собой специализированный ускоритель, то есть ASIC, предназначенный для обработки только ИИ-нагрузок. Небольшую пробную партию чипов Meta✴ изготовила тайваньская TSMC. По словам собеседника Reuters, тестирование началось после завершения фазы Tape-out — это заключительный этап разработки чипов перед началом производства, что является значительным маркером успеха в их разработке, отметило Reuters. Обычно этап Tape-out занимает от трёх до шести месяцев, причём без гарантии, что всё пройдёт успешно, и обходится в десятки миллионов долларов. В случае неудачи Meta✴ потребуется диагностировать проблему и начать всё заново. Этот чип представляет собой новое поколение ИИ-ускорителей, разработанных в рамках программы Meta✴ Training and Inference Accelerator (MTIA). Разработка продвигается с переменным успехом уже много лет. В прошлом году Meta✴ добилась определённых успехов — второе поколение ИИ-ускорителей Meta✴ MTIA оказалось втрое быстрее первого. В прошлом году Meta✴ начала использовать MTIAv2 для инференса рекомендательных систем Facebook✴ и Instagram✴. 
Источник изображения: Meta✴ Meta✴ сообщила, что планирует к 2026 году начать использовать собственные ИИ-чипы для обучения моделей. Как и в случае с чипом для инференса, новый ИИ-ускоритель сначала пройдёт проверку в работе с рекомендательными системами, после чего его задействуют для приложений генеративного ИИ, таких как чат-бот Meta✴ AI, заявили в Meta✴. Крис Кокс (Chris Cox), директор по продуктам Meta✴, сообщил, что разработка чипов идёт с переменным успехом, отметив, что руководство компании посчитала ИИ-ускоритель для инференса первого поколения «большим успехом». Однако тестовые испытания он провалил, так что в 2022 году компания стала заказывать ускорители NVIDIA. С тех она остаётся крупным клиентом NVIDIA, используя её чипы как для обучения своих моделей, так и для инференса. Meta✴ прогнозирует общие расходы в 2025 году в размере от $114 до $119 млрд, в том числе до $65 млрд капитальных затрат, в основном связанных с расширением ИИ-инфраструктуры. Использование собственных чипов позволит компании значительно снизить затраты на это направление. |
|