Материалы по тегу: ускоритель
|
10.03.2025 [23:17], Владимир Мироненко
ИИ и VMware: хорошие квартальные результаты и оптимистичный прогноз подстегнули рост акций BroadcomАмериканский производитель полупроводниковой продукции и ПО Broadcom объявил результаты I квартала 2025 финансового года, закончившегося 2 февраля 2025 года. Итоги квартала превзошли ожидания Уолл-стрит, что вместе с оптимистичным прогнозом на II финансовый квартал привело к росту акций компании на более чем 12 % после закрытия торгов, пишет ресурс SiliconANGLE. Выручка Broadcom в I финансовом квартале выросла на 25 % до $14,92 млрд с $11,96 млрд годом ранее, превысив прогноз аналитиков, опрошенных LSEG, в размере $14,61 млрд. Скорректированная чистая прибыль (Non-GAAP) тоже оказалась выше прогноза аналитиков от LSEG, составив $1,61 на разводнённую акцию при прогнозе $1,49. Чистая прибыль (GAAP) за I квартал выросла до $5,5 млрд или $1,14 на разводнённую акцию, по сравнению с $1,33 млрд или $0,28 на разводнённую акцию годом ранее. Скорректированный показатель EBITDA увеличился до $10,08 млрд с $7,16 млрд в прошлом году (рост год к году — 41 %), составив 68 % выручки. 
Источник изображений: Broadcom Группа полупроводниковых решений Semiconductor solutions принесла компании выручку в размере $8,21 млрд (рост год к году на 11 %). Разработчики ПО (Infrastructure software), включая VMware, заработали $6,70 млрд (рост 47 %). Выручка от ИИ-решений в I финансовом квартале выросла на 77 % по сравнению с прошлым годом до $4,1 млрд. Компания ожидает дальнейшего роста выручки от ИИ-чипов до $4,4 млрд во II квартале, поскольку партнёры-гиперскейлеры продолжают инвестировать в XPU и коммуникационные решения для ИИ ЦОД.  В декабре прошлого года компания заявила, что разрабатывает кастомные ИИ-чипы для трёх крупных облачных клиентов-гиперскейлеров. В ходе нынешнего квартального отчёта Хок Тан (Hock Tan), президент и генеральный директор Broadcom, отметил, что три крупнейших клиента компании «агрессивно» инвестируют в создание новых мощных ИИ-моделей и стремятся построить кластеры из 1 млн ИИ-ускорителей к концу 2027 года.  Кроме того, Broadcom «тесно взаимодействует» с двумя другими гиперскейлерами и работает над созданием кастомных чипов ещё с четырьмя возможными клиентами. Broadcom уже давно сотрудничает с Google в работе над TPU, а в прошлом году появилась информация о создании серверных ИИ-ускорителей для Apple, ByteDance и OpenAI. Кроме того, будущий процессор Fujitsu MONAKA получит 3.5D-упаковку от Broadcom.  Что примечательно, на вопрос о том, планирует ли Broadcom очередную покупку компания, Тан ответил отрицательно. «Мы слишком заняты ИИ и VMware. Мы не думаем об этом на данный момент», — цитирует его слова The Register. Так что, возможно, сообщения о покупке Broadcom части Intel были всего лишь слухами, сделал вывод ресурс.  В текущем квартале Broadcom ожидает получить выручку в размере $14,9 млрд, что больше год к году на 19 % и выше прогноза Уолл-стрит в $14,76 млрд. В сегменте ПО компания намерена заработать за квартал $6,5 млрд, что больше год к году на 23 %, сообщил Тан. Скорректированный показатель EBITDA, как ожидается, составит 66 % выручки.
07.03.2025 [15:36], Сергей Карасёв
Стартап Axelera AI анонсировал ИИ-ускоритель TitaniaНидерландский стартап Axelera AI B.V., специализирующийся на разработке ИИ-ускорителей, анонсировал решение Titania — высокопроизводительный, энергоэффективный и масштабируемый чиплет для задач инференса. Полностью технические характеристики изделия пока не раскрываются. Известно, что Titania использует проприетарную модель вычислений в памяти Digital In-Memory Computing (D-IMC). Этот подход, как заявляет Axelera AI, обеспечивает ИИ-производительность свыше 50 TOPS на ядро (эквивалентная точность FP32) и энергоэффективность на уровне 15 TOPS на 1 Вт затрачиваемой энергии. Решение Titania базируется на открытой архитектуре RISC-V. Несколько чиплетов могут быть объединены в виде модуля SiP (System-in-Package). Использование D-IMC обеспечивает практически линейную масштабируемость производительности без значительного увеличения затрат на питание и охлаждение. В качестве потенциальных областей применения Titania названы НРС-платформы, корпоративные дата-центры, робототехника, автомобилестроение и пр. 
Источник изображения: Axelera AI Одновременно с анонсом Titania стартап Axelera AI объявил о привлечении до €61,6 млн от EuroHPC JU в рамках проекта Digital Autonomy with RISC-V for Europe (DARE). Компания Axelera AI будет поддерживать EuroHPC в области разработки суперкомпьютерной экосистемы мирового класса в Европе. В частности, стартап планирует расширять свои научно-исследовательские и опытно-конструкторские подразделения в Нидерландах, Италии и Бельгии. Отмечается также, что основанная в 2021 году компания Axelera AI за три года существования получила инвестиции на общую сумму более $200 млн.
03.03.2025 [13:45], Сергей Карасёв
Разработчик аналоговых ИИ-чипов EnCharge AI привлёк на развитие $100 млнСтартап EnCharge AI, занимающийся разработкой аналоговых ИИ-ускорителей, объявил о проведении раунда финансирования Series B, в ходе которого на развитие привлечено более $100 млн. Полученные средства будут направлены на коммерциализацию технологии, а первые ИИ-ускорители нового поколения, как ожидается, выйдут в текущем году. Компания EnCharge AI, отделившаяся от Принстонского университета (США), основана в 2022 году. Она занимается созданием первых в своём роде аналоговых ИИ-чипов для вычислений в оперативной памяти. Утверждается, что такие изделия по сравнению с современными ускорителями обеспечат в 20 раз более высокую энергоэффективность (TOPS/Вт) и в 9 раз более высокую плотность вычислений (TOPS/мм2), а также 10-кратное снижение совокупной стоимости владения (инференс или токены в расчёте на $1) и 100-кратное сокращение выбросов углекислого газа (по сравнению с облаками). 
Источник изображения: EnCharge AI EnCharge AI отмечает, что в настоящее время основная часть нагрузок, связанных с ИИ-инференсом, выполняется в крупных дата-центрах, оборудованных огромными кластерами ускорителей на базе GPU. Но такой подход является экологически и экономически невыгодным. Аналоговые чипы EnCharge позволят переместить нагрузки из облака на локальные устройства, обеспечив совершенно новые ИИ-возможности при одновременном улучшении безопасности и снижении задержки. Концепция вычислений в оперативной памяти поможет значительно поднять эффективность и сократить потребность в перемещение данных. EnCharge AI заявляет, что смогла преодолеть ограничения, присущие обычным аналоговым изделиям. Выпускать новые чипы планируется в разных форматах — от SoC и М.2 до ASIC и карт PCIe. Раунд финансирования Series B возглавила инвестиционная компания Tiger Global. В нём также приняли участие Maverick Silicon, Capital TEN, SIP Global Partners, Zero Infinity Partners, CTBC VC, Вандербильтский университет, Morgan Creek Digital, RTX Ventures, Anzu Partners, Scout Ventures, AlleyCorp, ACVC и S5V. Плюс к этому средства предоставили Samsung Ventures — корпоративное венчурное подразделение Samsung и HH-CTBC — партнёрство между Hon Hai Technology Group (Foxconn) и CTBC VC.
26.02.2025 [17:18], Руслан Авдеев
ИИ-ускорители Ascend впервые стали приносить Huawei прибыльHuawei поступательно улучшает качество своих чипов. По последним данным, уже 40 % экземпляров новейших ускорителей Ascend пригодны к эксплуатации, а их производство впервые стало для компании прибыльным, говорят отраслевые эксперты. Компания намерена повысить показатель годности до 60 % в соответствии со стандартами индустрии, сообщает The Financial Times. Год назад речь шла якобы лишь о 20 %. Это чрезвычайно важно для компании, поскольку Ascend 910C значительно производительнее 910B. Это очередной шаг на пути Китая к строительству независимой вычислительной инфраструктуры, не подверженной санкциям. Местную полупроводниковую отрасль активно поддерживает государство. Пекин постоянно призывает китайские компании покупать местные альтернативы продуктов NVIDIA, которая до сих пор остаётся лидером рынка ускорителей в КНР. По данным отраслевых источников, в этом году Huawei намерена выпустить 100 тыс. чипов 910C и 300 тыс. 910B. В 2024 году последних выпустили 200 тыс. экземпляров, а массовый впуск 910С ещё не был налажен. Впрочем, компании придётся постараться, чтобы убедить потенциальных покупателей отказаться от продукции NVIDIA. Отмечается, что программная экосистема NVIDIA CUDA намного удобнее и производительнее ПО Huawei. Кроме того, бизнес и сама Huawei признают, Ascend 910B недостаточно хороши для обучения больших моделей. Эту проблему компания попыталась решить в модели 910C. 
Источник изображения: Huawei В 2020 году США буквально заставили тайваньскую TSMC прекратить производство для Huawei ускорителей Ascend и чипсетов для смартфонов компании. Выпуском ускорителей Huawei занимается китайская SMIC, которая тоже находится под американскими санкциями. Компания использует техпроцесс N+2, позволяющий выпускать высокопроизводительные чипы без EUV-литографии. В Китай запрещено продавать соответствующее оборудование нидерландской ASML. Так или иначе, Huawei является единственным конкурентом, способным состязаться с NVIDIA при производстве чипов для инференса. Правда, как отмечают многие китайские заказчики, компания не может обеспечить действительно масштабных поставок для всех желающих, отдавая приоритет крупным облачным провайдерам, за которыми стоит государство, например, China Mobile. По мнению экспертов, на Huawei сегодня приходится более ¾ общего производства ИИ-чипов в Китае, мелким соперникам трудно конкурировать с техногигантом из-за того, что тот имеет доступ к самым передовым технологическим процессам SMIC. Предполагается, что NVIDIA всё равно будет продавать больше ускорителей в Китае, чем Huawei, несмотря на то что американской компании разрешено поставлять только урезанные модели H20. По оценкам SemiAnalysis, выручка NVIDIA за продажу только в 2024 году в Китай 1 млн ускорителей составила $12 млрд. Триумф ИИ-моделей DeepSeek только подстегнул спрос на чипы NVIDIA H20 в Китае.
16.02.2025 [00:22], Сергей Карасёв
HBF вместо HBM: SanDisk предлагает увеличить объём памяти ИИ-ускорителей в 16 раз, заменив DRAM на сверхбыструю флеш-памятьКомпания SanDisk, которая вскоре станет независимой, отделившись от Western Digital, предложила способ многократного увеличения объёма памяти ИИ-ускорителей. Как сообщает ресурс ComputerBase.de, речь идёт о замене HBM (High Bandwidth Memory) на флеш-чипы с высокой пропускной способностью HBF (High Bandwidth Flash). На первый взгляд, идея может показаться абсурдной, поскольку флеш-память NAND значительно медленнее DRAM, которая служит основой HBM. Но, по заявлениям SanDisk, архитектура HBF позволяет обойти ограничения, присущие традиционным NAND-изделиям, что сделает память нового типа пригодной для применения в ИИ-ускорителях. При этом HBF планируется использовать прежде всего для задач инференса, а не обучения моделей ИИ. С каждым новым поколением HBM растёт объём памяти, которым оснащаются ИИ-карты: у современных ускорителей AMD и NVIDIA он достигает 192 Гбайт. Благодаря внедрению HBF компания SanDisk рассчитывает увеличить показатель в 8 или даже 16 раз при сопоставимой цене. Компания предлагает две схемы использования флеш-памяти с высокой пропускной способностью: одна предусматривает полную замену HBM на HBF, а другая — совмещение этих двух технологий. 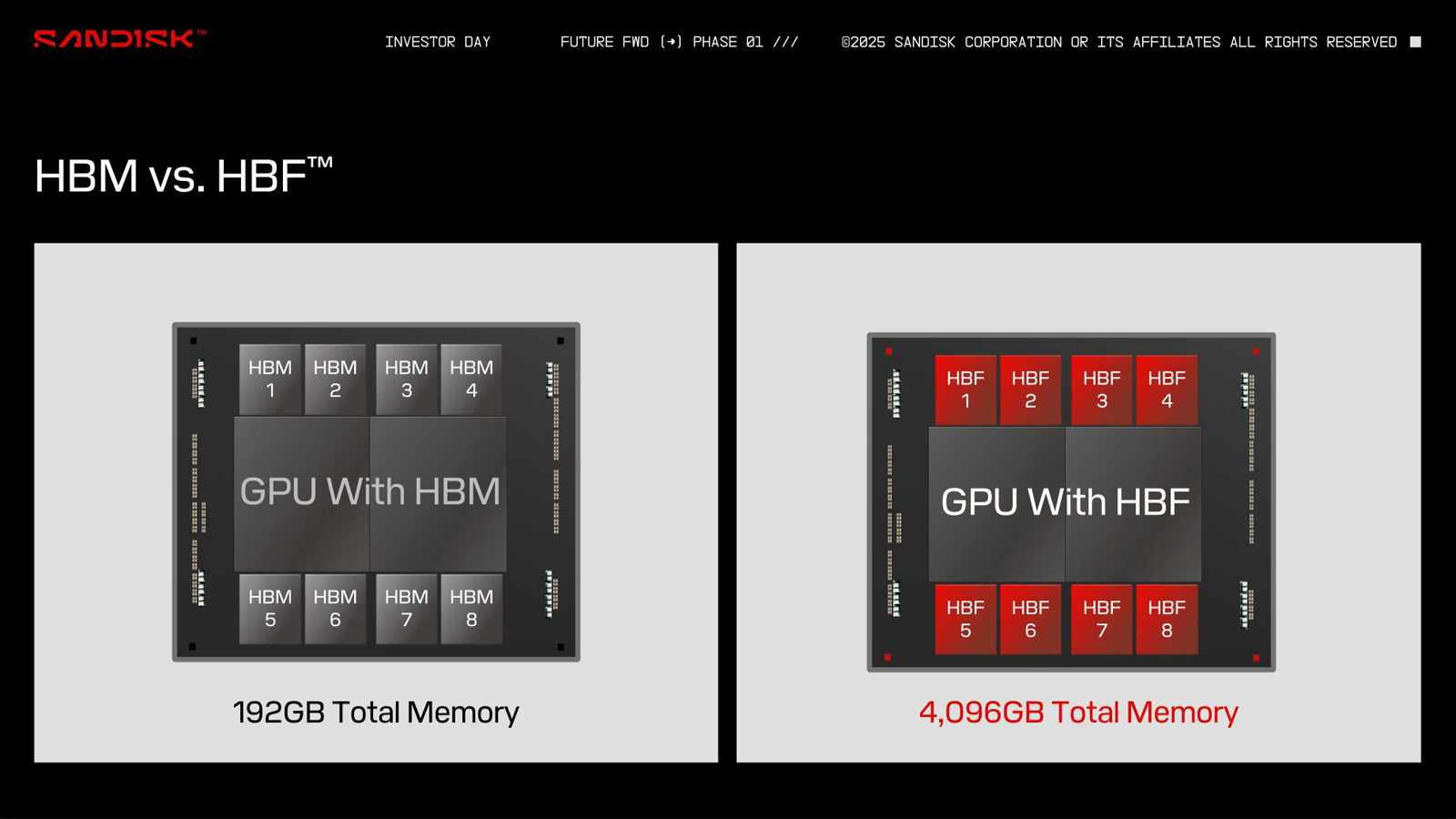
Источник изображений: ComputerBase.de В качестве примера SanDisk приводит GPU со 192 Гбайт памяти HBM, которая разделена на восемь стеков по 24 Гбайт. В случае HBF каждый такой стек сможет иметь ёмкость 512 Гбайт. Таким образом, при полной замене HBM ускоритель сможет нести на борту 4 Тбайт памяти: это позволит полностью загрузить большую языковую модель Frontier с 1,8 трлн параметров размером 3,6 Тбайт. В гибридной конфигурации можно, например, использовать связку стеков 2 × HBM плюс 6 × HBF, что в сумме даст 3120 Гбайт памяти. 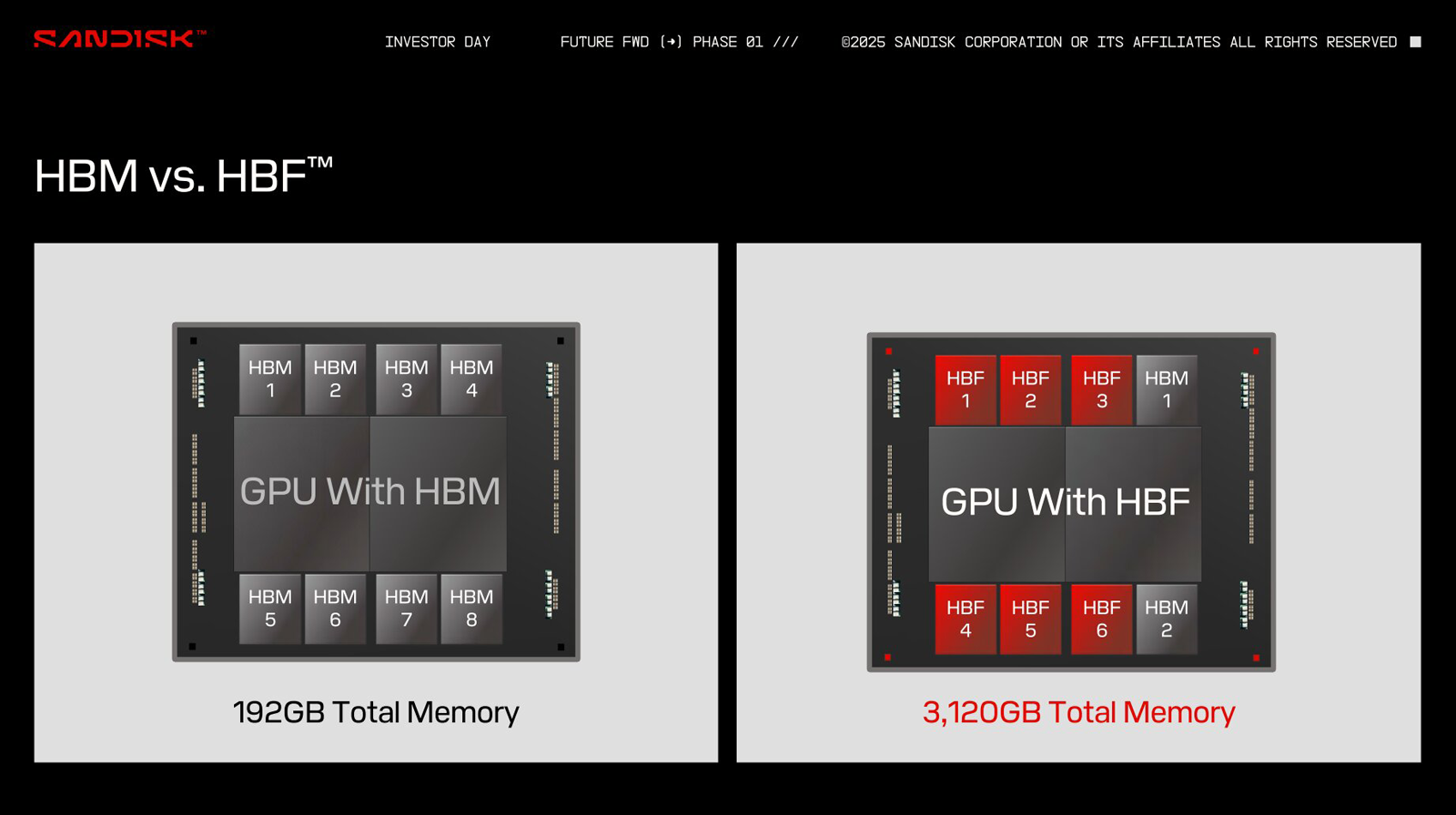 Архитектура HBF предполагает монтаж кристаллов NAND друг над другом поверх логического кристалла. Вся эта связка располагается на интерпозере рядом с GPU, CPU, TPU или SoC — в зависимости от предназначения конечного изделия. Обычная флеш-память NAND приближается к DRAM по пропускной способности, но не может сравниться с ней по времени доступа. SanDisk предлагает решить проблему путём разделения HBF на массив областей с большим количеством линий данных: это позволит многократно увеличить скорость доступа.  SanDisk разработала архитектуру HBF в 2024 году под «влиянием ключевых игроков в области ИИ». В дальнейшие планы входят формирование технического консультативного совета, включающего партнёров и лидеров отрасли, и создание открытого стандарта. Впрочем, есть и другие методы увеличения объёма памяти ускорителей. Один из них — использование CXL-пулов.
13.02.2025 [01:05], Владимир Мироненко
Meta✴ намерена купить разработчика ИИ-ускорителей FuriosaAI, и не одна онаMeta✴ ведет переговоры о приобретении южнокорейского стартапа FuriosaAI, разработчика ИИ-ускорителей, базирующегося в Сеуле (Южная Корея) и Санта-Кларе (США), что позволит ей выпускать собственные кастомные чипы на фоне нехватки ускорителей NVIDIA, сообщил Forbes со ссылкой на информированные источники. По словам одного из источников, сделка может быть заключена уже в этом месяце. Другой источник утверждает, что ещё несколько компаний ведут переговоры о приобретении FuriosaAI. Компанию основал в 2017 году Джун Пайк (June Paik), ранее работавший в Samsung Electronics и AMD и занимающий сейчас пост гендиректора. FuriosaAI привлекла в общей сложности около ₩170 млн (около $115 млн) венчурного финансирования. Среди первых инвесторов были южнокорейский интернет-гигант Naver и базирующаяся в Сеуле DSC Investment. В последнем раунде финансирования, прошедшем на прошлой неделе, FuriosaAI получила ₩2 млрд (около $1,4 млн) от южнокорейской CRIT Ventures. В августе прошлого года FuriosaAI представила энергоэффективный ИИ-ускоритель RNGD, который был разработан в партнёрстве с тайваньским производителем микросхем Global Unichip Corp. По словам компании, RNGD является идеальным выбором для крупномасштабного развёртывания продвинутых моделей генеративного ИИ, таких как Llama 2 и Llama 3, поскольку не уступает передовым ускорителям по производительности, отличаясь при этом низким TDP в пределах 150 Вт. 
Источник изображения: FuriosaAI RNGD предназначен для инференса и оснащён HBM3-памятью SK hynix. FuriosaAI сообщила, что RNGD показывает в три раза большую производительность в расчёте на 1 Вт, чем ускорители NVIDIA H100 при запуске продвинутых больших языковых моделей (LLM). Как ожидается, массовое производство RNGD начнётся во II половине 2025 года. При этом сама Meta✴ разработала уже два поколения собственных ИИ-ускорителей для инференса. И если от MTIA v1 в итоге было решено отказаться в пользу в первую очередь продуктов NVIDIA, то MTIA v2, судя по всему, активно внедряются, но их всё ещё не хватает для удовлетворения потребностей компании. 
Источник изображения: Meta✴ По данным Forbes, заинтересованность в RNGD также продемонстрировали исследовательская ИИ-лаборатория LG и Saudi Aramco. В сентябре последняя подписала меморандум о взаимопонимании с FuriosaAI и Cerebras Systems, ещё одним производителем ИИ-ускорителей, для «изучения сотрудничества в области суперкомпьютеров и ИИ». Переговоры проходят спустя несколько месяцев после того, как ещё один южнокорейский стартап в сфере ИИ Rebellions, завершил слияние с поддерживаемой SK hynix компанией Sapeon. Объединённая компания, которая осуществляет деятельность под брендом Rebellions, является первым в Южной Корее единорогом в области производства чипов ИИ.
11.02.2025 [11:39], Сергей Карасёв
OpenAI близка к завершению разработки своего первого ИИ-чипаКомпания OpenAI, по сообщению Reuters, в течение нескольких месяцев намерена завершить разработку своего первого чипа для ресурсоёмких ИИ-задач. Появление этого изделия, как ожидается, поможет снизить зависимость от NVIDIA, которая контролирует более 80 % мирового рынка ИИ-ускорителей. Информация о том, что OpenAI намерена заняться созданием фирменных ИИ-чипов, появилась в октябре 2023 года. Год спустя стало известно, что партнёром в рамках данного проекта выступает Broadcom, а организовать производство изделий планируется на мощностях TSMC. 
Источник изображения: unsplash.com / Zac Wolff По данным Reuters, ИИ-ускоритель разрабатывается внутренней командой в составе примерно 40 специалистов под руководством Ричарда Хо (Richard Ho), который более года назад перешёл в OpenAI из Google, где также курировал программу по созданию ИИ-чипов. По оценкам аналитиков, стоимость разработки одной версии нового ИИ-продукта может составлять около $500 млн. Эта сумма удваивается с учётом создания сопутствующего ПО и необходимых периферийных компонентов. Ожидается, что решение OpenAI будет изготавливаться по 3-нм технологии на предприятии TSMC. На текущий год запланирована фаза Tape-out — заключительный этап проектирования интегральных схем или печатных плат перед их отправкой в производство: этот процесс предполагает перенос цифрового макета чипа на фотошаблон для последующего изготовления. Массовый выпуск изделия намечен на 2026 год. Говорится, что чип OpenAI проектируется с прицелом как на обучение, так и на запуск моделей ИИ. Однако на начальном этапе его применение в вычислительной инфраструктуре компании будет ограничено. Очевидно, это связано с необходимостью оценки эффективности и целесообразности применения новинки в большом масштабе.
06.02.2025 [19:27], Руслан Авдеев
Грамм на экзафлоп — Google ввела новую метрику CCI для оценки углеродных выбросов ИИ-ускорителейGoogle опубликовала результаты внутреннего исследования, показавшие прогресс в повышении углеродной эффективности своих ИИ-ускорителей TPU. По словам компании, за два поколения — от TPU v4 до Trillium (v6) — усовершенствование аппаратной оборудования привело к трёхкратному повышению экологичности выполняемых ИИ-нагрузок. Оценка всего жизненного цикла (LCA) ускорителей позволяет подробно проанализировать статистику выбросов, связанных с ИИ-ускорителями Google, используя полный набор данных — от добычи сырья и производства чипов до потребления электричества во время работы. Компания даже ввела новую метрику Compute Carbon Intensity (CCI), позволяющую оценить углеродные выбросы относительно производительности. CCI показывает, сколько граммов выбросов CO2 приходится на каждый экзафлоп проделанной работы. Чем ниже CCI, тем ниже выброс оборудования для заданной рабочей нагрузки. Для оценки прогресса Google сравнила пять моделей TPU в течение всего их жизненного цикла и пришла к выводу, что TPU новых поколений стали значительно экологичнее, поскольку CCI за четыре года улучшился втрое. TPU Trillium, очевидно, показали наилучшие результаты. 
Источник изображения: Google Google отмечает, что за весь жизненный цикл TPU 70 % выбросов относятся к эксплуатационным, т.е. связаны с потреблением электричества. Это подчёркивает важность повышения энергоэффективности чипов и снижения выбросов углерода, связанных с энергообеспечением. Однако доля выбросов, связанных с производством, по-прежнему весьма заметна. Более того, со временем она может даже увеличиться, поскольку к 2030 году Google намерена добиться использования полностью безуглеродной энергии в каждой энергосети, питающей её оборудование. Если компания захочет и далее повышать экологичность своих решений, ей придётся вмешаться в цепочки поставок. Кроме того, постоянная оптимизация ИИ-моделей позволит сократить объёмы необходимых вычислений (при прочих равных). Впрочем, повышение эффективности моделей, скорее всего, приведёт к ещё большему использованию ИИ. В будущем Google намерена анализировать углеродные выбросы отдельных ИИ-моделей и влияние на их оптимизации ПО. А пока что выбросы парниковых газов Google из-за ИИ только растут — +48 % за пять лет.
03.02.2025 [15:21], Сергей Карасёв
Реальные затраты DeepSeek на создание ИИ-моделей на порядки выше заявленных, но достижений компании это не умаляетКитайский стартап DeepSeek наделал много шума в Кремниевой долине, анонсировав «рассуждающую» ИИ-модель DeepSeek R1 c 671 млрд параметров. Утверждается, что при её обучении были задействованы только 2048 ИИ-ускорителей NVIDIA H800, а затраты на данные работы составили около $6 млн. Это бросило вызов многим западным конкурентам, таким как OpenAI, а акции ряда крупных ИИ-компаний начали падать в цене. Однако, как сообщает ресурс SemiAnalysis, фактические расходы DeepSeek на создание ИИ-инфраструктуры и обучение нейросетей могут быть гораздо выше. Стартап DeepSeek берёт начало от китайского хедж-фонда High-Flyer. В 2021 году, ещё до введения каких-либо экспортных ограничений, эта структура приобрела 10 тыс. ускорителей NVIDIA A100. В мае 2023 года с целью дальнейшего развития направления ИИ из High-Flyer была выделена компания DeepSeek. После этого стартап начал более активное расширение вычислительной ИИ-инфраструктуры. По данным SemiAnalysis, на сегодняшний день DeepSeek имеет доступ примерно к 10 тыс. изделий NVIDIA H800 и 10 тыс. NVIDIA H100. Кроме того, говорится о наличии около 30 тыс. ускорителей NVIDIA H20, которые совместно используются High-Flyer и DeepSeek для обучения ИИ, научных исследований и финансового моделирования. Таким образом, в общей сложности DeepSeek может использовать до 50 тыс. ускорителей NVIDIA при работе с ИИ, что в разы больше заявленной цифры в 2048 ускорителей. 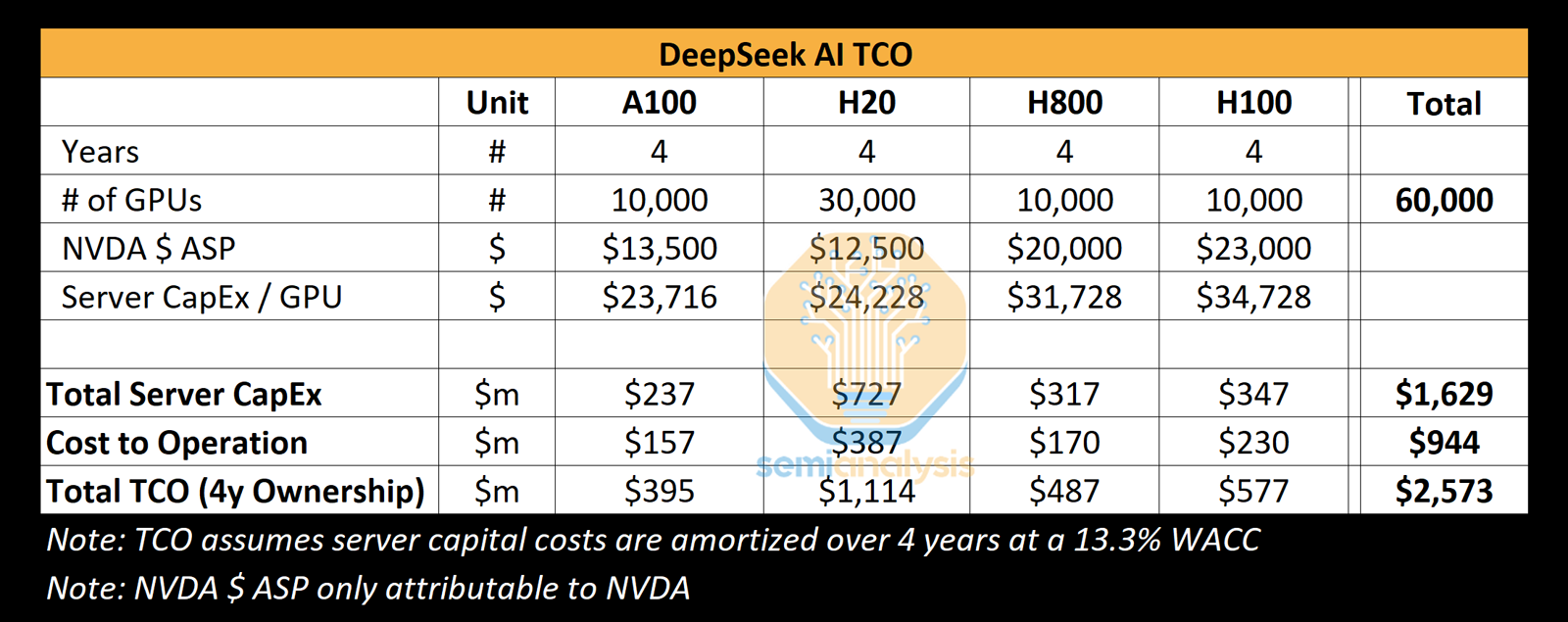
Источник изображения: SemiAnalysis Кроме того, SemiAnalysis сообщает, что общие капитальные затраты на ИИ-серверы для DeepSeek составили около $1,6 млрд, тогда как операционные расходы могут достигать $944 млн. Это подрывает заявления о том, что DeepSeek заново изобрела процесс обучения ИИ и инференса с существенно меньшими инвестициями, чем лидеры отрасли. Цифра в $6 млн не учитывает затраты на исследования, тюнинг модели, обработку данных и пр. На самом деле, как подчёркивается, DeepSeek потратила более $500 млн на разработки с момента своего создания. И всё же DeepSeek имеет ряд преимуществ перед другими участниками глобального ИИ-рынка. В то время как многие ИИ-стартапы полагаются на внешних поставщиков облачных услуг, DeepSeek эксплуатирует собственные дата-центры, что позволяет быстрее внедрять инновации и полностью контролировать разработку, оптимизируя расходы. Кроме того, DeepSeek остаётся самофинансируемой компанией, что обеспечивает гибкость и позволяет более оперативно принимать решения. Плюс к этому DeepSeek нанимает специалистов исключительно из Китая, уделяя особое внимание не формальным записям в аттестатах, а практическим навыкам работы и способностям эффективно выполнять поставленные задачи. Некоторые ИИ-исследователи в DeepSeek зарабатывают более $1,3 млн в год, что говорит об их высочайшей квалификации.
31.01.2025 [06:24], Сергей Карасёв
Intel решила не поставлять ускорители Falcon Shores на рынокСо-генеральный директор Intel Мишель Джонстон Холтхаус (Michelle Johnston Holthaus) дала комментарии по поводу ускорителей Falcon Shores, которые должны были поступить в продажу в 2025 году. По её словам, эти изделия не появятся на коммерческом рынке. Ожидалось, что Falcon Shores выйдут после ускорителей Rialto Bridge, которые должны были прийти на смену Ponte Vecchio. Но в марте 2023 года Intel отменила выпуск Rialto Bridge. Тогда же сообщалось, что дебют Falcon Shores откладывается. После того, как гендиректор Intel Пэт Гелсингер (Pat Gelsinger) подал в отставку, будущее Falcon Shores оказалось под вопросом. Пытаясь прояснить ситуацию, Intel заявила, что планы по выпуску этих решений сохраняются — их планировалось поставлять в качестве GPU, а не гибридных ускорителей, как говорилось изначально. Однако в конце 2024 года появилась информация, что Intel рассматривает Falcon Shores как тестовый продукт. 
Источник изображения: Intel Как теперь заявила Холтхаус, Intel действительно использует Falcon Shores «в качестве внутреннего тестового чипа» — без планов по его выводу на коммерческий рынок. По её словам, основное внимание будет уделено ускорителям Jaguar Shores, которые, как предполагается, помогут разработать «системное решение в масштабе стойки» для укрепления позиций в области дата-центров, ориентированных на задачи ИИ. «ИИ ЦОД являются привлекательным рынком для нас. Но мы пока не закрепились в данном сегменте должным образом. Поэтому мы упрощаем дорожную карту и концентрируем ресурсы», — сказала Холтхаус. Она также добавила, что заказчики хотят получить полномасштабное стоечное решение, а не просто чипы. Ожидается, что проект Falcon Shores поможет в создании комплексной платформы, охватывающей системные компоненты, сеть и память. Вероятно, речь идёт об аналоге суперускорителей NVIDIA GB200 NVL72. В целом, Intel пытается скорректировать план дальнейшей работы после ряда неудач. Корпорация катастрофически отстала от NVIDIA и AMD по продажам ИИ-ускорителей — так, объём реализации Gaudi не достиг даже $500 млн. На этом фоне Intel приходится в спешном порядке менять стратегию. |
|