Материалы по тегу: инференс
|
01.02.2025 [15:23], Сергей Карасёв
Самый быстрый инференс DeepSeek R1 в мире: ИИ-платформа Cerebras снова поставила рекорд производительностиАмериканский стартап Cerebras Systems объявил о том, что его инференс-платформа позволила установить мировой рекорд производительности при использовании «рассуждающей» ИИ-модели DeepSeek R1 в модификации с 70 млрд параметров (DeepSeek-R1-Distill-Llama-70B). DeepSeek R1 может содержать до 671 млрд параметров. Однако, как отмечает Cerebras, развёртывание модели со способностью к рассуждению столь большого масштаба представляет значительные проблемы. Версия с 70 млрд параметров позволяет совместить возможности рассуждений более крупной модели с MoE с широко поддерживаемой архитектурой Meta✴ Llama. 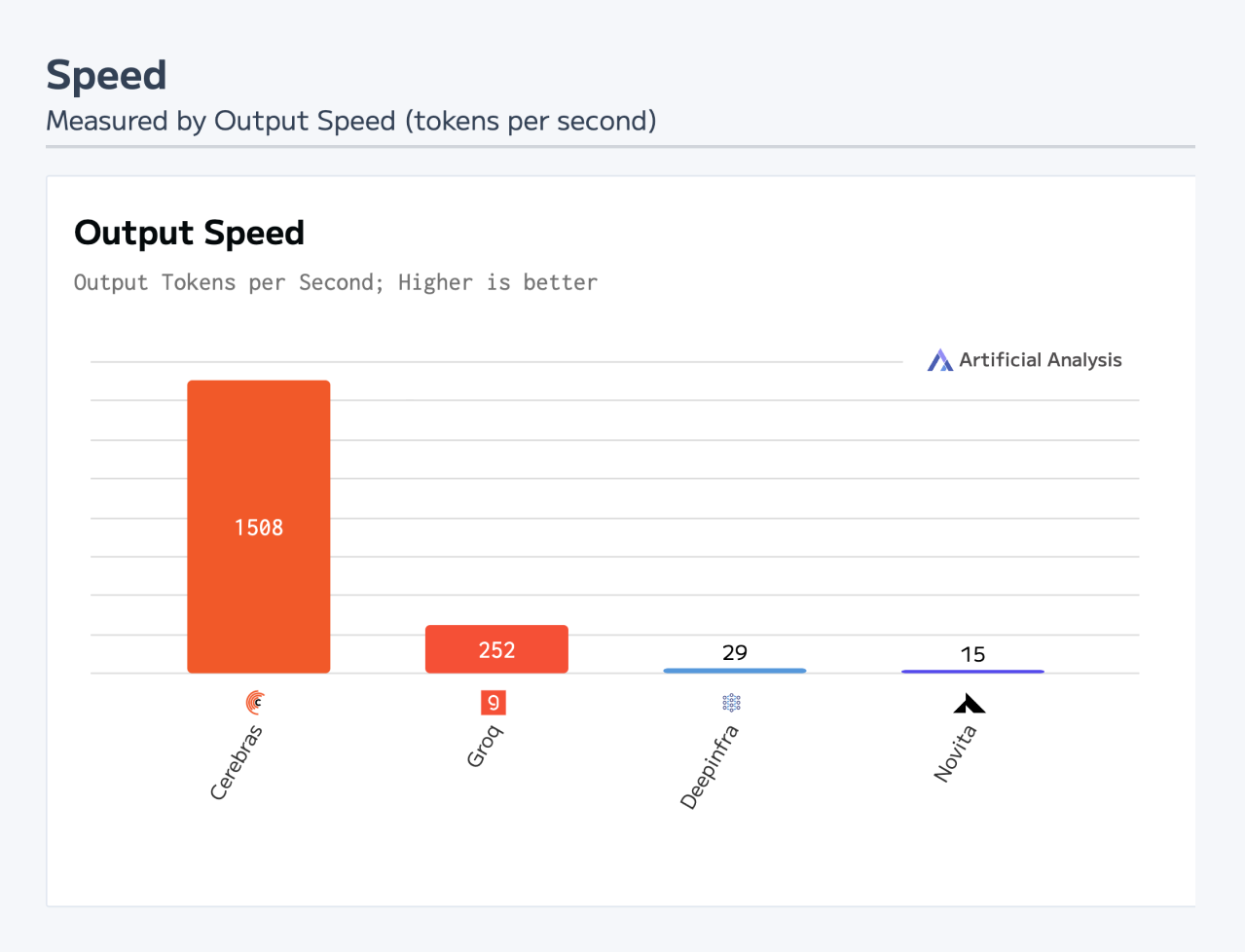
Источник изображений: Cerebras Основой платформы Cerebras являются царь-ускорители собственной разработки WSE (Wafer Scale Engine). Производительность DeepSeek R1 при работе на инфраструктуре Cerebras достигает 1508 токенов в секунду — это значительно быстрее по сравнению с конкурирующими решениями. В частности, в случае Groq показатель составляет 252 токена в секунду. Стандартный запрос на генерацию кода, который, как утверждает компания, занимает 22 секунды на конкурирующих платформах, в случае Cerebras завершается всего за 1,5 секунды, что соответствует 15-кратному повышению производительности. Cerebras подчёркивает, что DeepSeek-R1-Distill-Llama-70B превосходит как GPT-4o, так и o1-mini в сложных математических задачах и генерации кода. 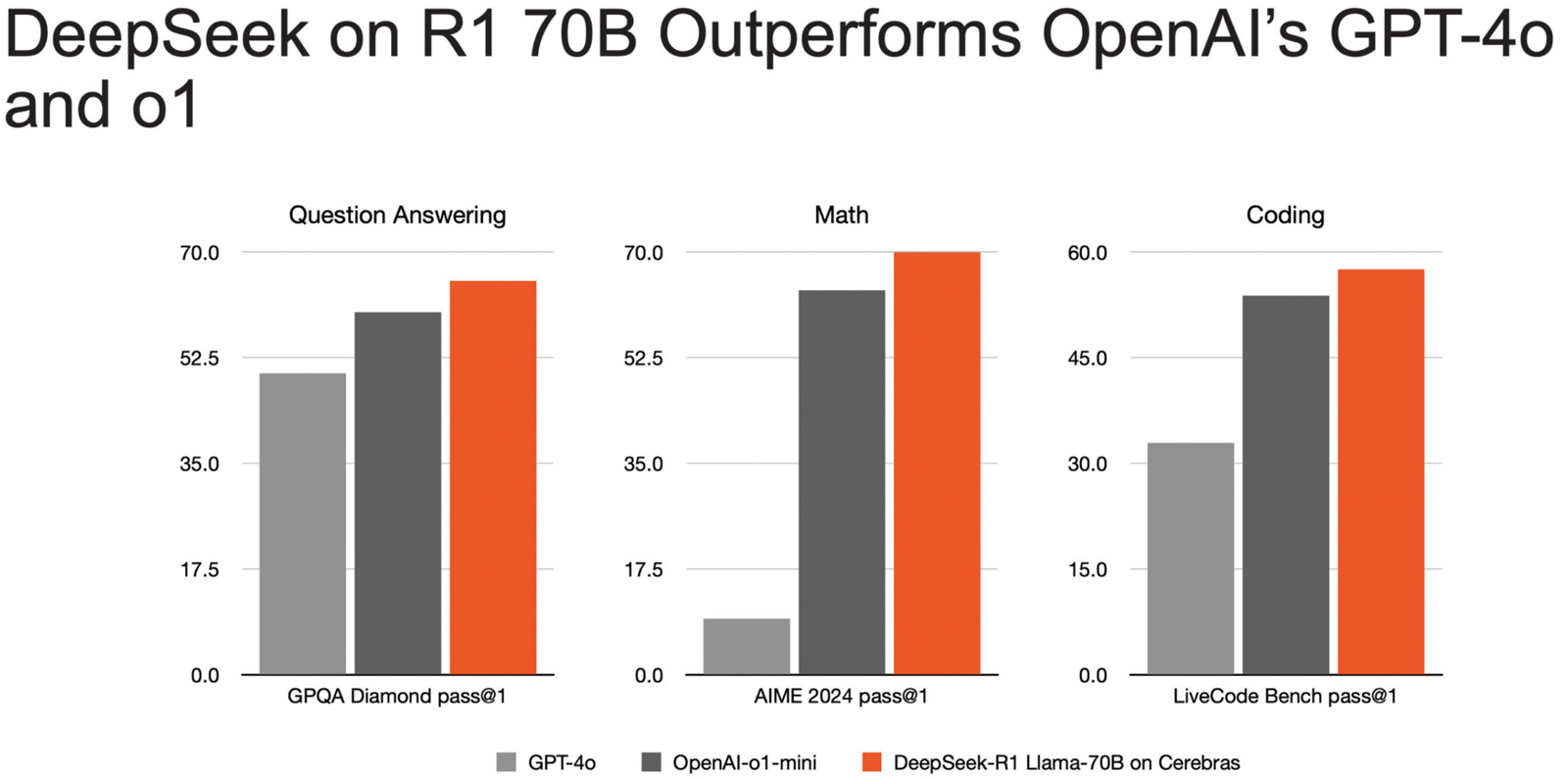 Cerebras также отмечает, что все вычисления осуществляются на базе ИИ-инфраструктуры в США, развёрнутой в собственных дата-центрах компании. При этом никакие данные не сохраняются, что гарантирует полную безопасность для клиентов. Кроме того, модель DeepSeek R1 может быть развёрнута локально в ЦОД заказчика для обеспечения максимального контроля.
31.01.2025 [19:44], Руслан Авдеев
Blackstone внимательно следит за успехами DeepSeek, но отказываться от крупных инвестиций в ЦОД не собираетсяИнвестиционная компания Blackstone не намерена отказываться от своих вложений в дата-центры даже после того, как китайская DeepSeek произвела настоящий фурор на рынке ИИ, выпустив недорогие и эффективные модели, обученные с минимумом ресурсов. В ходе последнего отчёта о доходах она объявила о продолжении инвестиций в сектор, сообщает Datacenter Dynamics. В октябре компания сообщала, что располагает портфолио в соответствующем секторе на $70 млрд и готова увеличить его ещё на $100 млрд. После того, как Morgan Stanley задала вопрос о вероятных проблемах расширения инфраструктуры, связанных с успехом DeepSeek, поскольку многие усомнились в целесообразности строительства новых ИИ ЦОД для обучения всё более крупных моделей — вроде проекта Stargate. Представитель Blackstone заявил, что компания потратила немало времени на изучения феномена китайского успеха, но пока не видит для себя проблем, поскольку многие из крупнейших компаний заключили долгосрочные контракты на аренду дата-центров, а BlackStone не строит ЦОД «спекулятивно». Blackstone через QTS и другие свои активы намерена продолжить тратить большие средства на строительство новых объектов с учётом спроса со стороны арендаторов. В компании уверены, что рынок ЦОД по-прежнему остаётся важным сегментом и Blackstone внимательно следит за тем, что на нём происходит. 
Источник изображения: Becca Tapert/unsplash.com Эксперты считают, что успех DeepSeek стал частью более широкой тенденции, в рамках которой существенно снижается стоимость разработки ИИ-моделей. Тем не менее это, вероятно, не приведёт к сокращению рынка ИИ ЦОД. Если на обучение будут тратить меньше ресурсов, то масштабы инференса, наоборот, будут только расти. Другими словами, потребность в дата-центрах никуда не делась и по-прежнему острая, может измениться лишь формат их использования. Совсем недавно в Fortune опровергли опасения относительно того, что успех DeepSeek в долгосрочной перспективе негативно скажется на IT-рынке. Приводится т. н. «парадокс Джевонса», предполагающий рост потребления ресурса в случае, если его использование становится более эффективным и доступным. Другими словами, ожидается, что рынок будет только расширяться.
28.01.2025 [18:40], Владимир Мироненко
«Рынки ошибаются»: DeepSeek не угрожает NVIDIA и другим американским IT-гигантам
deepseek
fortune
hardware
nvidia
анализ рынка
ии
инференс
китай
прогноз
санкции
сша
ускоритель
финансы
Рост популярности ИИ-технологий способствовал росту рыночной стоимости NVIDIA выше $3 трлн. Однако её акции обрушились в понедельник на 17 %, вызвав падение рыночной стоимости компании почти на $600 млрд, после анонса китайским стартапом DeepSeek ИИ-моделей V3 и R1, способных соперничать с лучшими моделями любой американской компании, хотя и были обучены за малую часть стоимости на менее продвинутых чипах NVIDIA H800 и A100, пишет Fortune. Также в начале недели приложение AI Assistant стартапа DeepSeek вышло на первое место в рейтинге самых популярных бесплатных приложений в интернет-магазине в Apple App Store в США, опередив ИИ-чат-бот ChatGPT от OpenAI. Более того, модель DeepSeek R1, призванная бросить вызов модели «рассуждений» OpenAI o1, можно запустить на рабочей станции, а не в ЦОД. Поскольку мощные ускорители NVIDIA являются одной из самых больших статей расходов на разработку самых передовых моделей ИИ, инвесторы начали пересматривать свои представления относительно вложений в ИИ-бизнес. Да, DeepSeek явно потряс рынок ИИ, однако разговоры о крахе NVIDIA могут быть преждевременными, равно как и заявления о том, что успех DeepSeek означает, что США следует отказаться от политики, направленной на ограничение доступа Китая к самым передовым ИИ-чипам, предупреждают аналитики Fortune. DeepSeek утверждает, что использует 10 тыс. ускорителей NVIDIA A100, а также чипы H800, что на порядок меньше, чем используют американские компании для обучения своих самых передовых ИИ-моделей. Например, Xai Илона Маска (Elon Musk) построила вычислительный кластер Colossus в Теннесси на базе 100 тыс. ускорителей NVIDIA H100, его планирует расширить до 1 млн чипов. 
Источник изображения: Heather Wilde / Unsplash Это дало повод некоторым экспертам утверждать, что введение ограничений США подстегнуло инновации в Китае. В Fortune считают такие умозаключения недальновидными и утверждают, что влияние DeepSeek может, как это ни парадоксально звучит на первый взгляд, увеличить спрос на передовые чипы ИИ — как NVIDIA, так и её конкурентов. Причина отчасти заключена в феномене, известном как парадокс Джевонса (Jevons Paradox). Парадокс Джевонса, также известный как эффект отскока, назван в честь британского экономиста XIX века Уильяма Стэнли Джевонса (William Stanley Jevons), который заметил: когда технический прогресс делает использование ресурса более эффективным, общее потребление этого ресурса имеет тенденцию к увеличению. Это имеет смысл, если спрос на что-либо относительно эластичен — снижающаяся из-за повышения эффективности цена создаёт ещё больший спрос на продукт. Одной из причин слабого внедрения ИИ-моделей в крупных организациях была их дороговизна. Это особенно касалось новых «рассуждающих» моделей, таких как o1 от OpenAI. Модели DeepSeek гораздо дешевле конкурентов в эксплуатации, так что теперь компании могут позволить себе развёртывать их для многих сценариев использования. В масштабах отрасли это может привести к резкому росту спроса на вычислительную мощность. В понедельник гендиректор Microsoft Сатья Наделла (Satya Nadella) и бывший гендиректор Intel Пэт Гелсингер (Pat Gelsinger) указали на это в сообщениях в социальных сетях. Наделла напрямую сослался на парадокс Джевонса, в то время как Гелсингер сказал, что «вычисления подчиняются» тому, что он назвал «законом газа». «Если сделать его значительно дешевле, рынок для него расширится… это сделает ИИ гораздо более широко распространенным, — написал он. — Рынки ошибаются». 
Источник изображения: Mark Daynes / Unsplash В Fortune задались вопросом: «Какая именно вычислительная мощность потребуется?». Топовые ускорители NVIDIA оптимизированы для обучения крупнейших больших языковых моделей (LLM), таких как GPT-4 от OpenAI или Claude 3-Opus от Anthropic. Для инференса чипы NVIDIA меньше подходят, чем изделия конкурентов, включая AMD и, например, Groq, чипы которых позволяют исполнять ИИ-нагрузки быстрее и намного эффективнее. Google и Amazon также создают свои собственные чипы ИИ, некоторые из которых оптимизированы для инференса. NVIDIA сейчас занимает более 80 % рынка ИИ-вычислений на базе ЦОД (если исключить кастомные ASIC облачных провайдеров, её доля может составить до 98 %) и вряд ли утратит доминирование быстро или полностью, отметили в Fortune. Ёе ускорители также могут использоваться для инференса, а программная платформа CUDA имеет большое и лояльное сообщество разработчиков, которое вряд ли откажется от него в одночасье. Если общий спрос на ИИ-чипы увеличится из-за парадокса Джевонса, общие доходы NVIDIA всё равно смогут вырасти даже при падении доли на рынке из-за увеличившегося рынка. Ещё одна причина, по которой спрос на передовые ИИ-чипы, вероятно, продолжит рост, связана с особенностями работы моделей рассуждений, таких как R1. В то время как способности предыдущих типов LLM росли по мере увеличения доступной вычислительной мощности во время обучения, то модели рассуждений зависят от вычислительных ресурсов во время инференса — чем их больше, тем лучше ответы. 
Источник изображения: Kayla Kozlowski / Unsplash Запустив R1 на ноутбуке, можно получить хороший ответ на сложный математический вопрос, скажем, через час, в то время как при использовании ускорителей в облаке на тот же ответ уйдут считанные секунды. Для многих бизнес-приложений задержка или время, необходимое модели для ответа, имеет большое значение. И чтобы сократить время выполнения задачи, по-прежнему будут нужны передовые ИИ-ускорители. Кроме того, многие эксперты сомневаются в правдивости заявления DeepSeek о том, что её модель V3 была обучена примерно на 2048 урезанных ускорителях NVIDIA H800 или что её модель R1 была обучена на столь малом количестве чипов. Александр Ван (Alexandr Wang), генеральный директор Scale AI, сообщил в интервью CNBC, что, по его данным, DeepSeek тайно получила доступ к кластеру из 50 тыс. ускорителей H100. Также известно, что хедж-фонд HighFlyer, которому принадлежит DeepSeek, успел закупить до введения санкций значительное количество менее производительных ускорителей NVIDIA. Так что вполне возможно, что NVIDIA находится в лучшем положении, чем предполагают паникующие инвесторы, и что проблема с экспортным контролем США заключается не в политике, а в её реализации, подытожили аналитики Fortune.
24.01.2025 [14:33], Сергей Карасёв
Бывший гендиректор Intel Пэт Гелсингер инвестировал средства в ИИ-стартап FractileЭкс-гендиректор Intel Пэт Гелсингер, по сообщению TrendForce, стал инвестором британского стартапа Fractile.ai, который специализируется на разработках в области ИИ. Сумма, которую предоставил бывший глава Intel на развитие этой компании, не раскрывается. Fractile.ai основана в 2022 году Уолтером Гудвином (Walter Goodwin) — специалистом, получившим докторскую степень в области искусственного интеллекта и робототехники в Оксфордском университете. Стартап разрабатывает специализированные ИИ-чипы, использующие метод вычислений в оперативной памяти. Такой подход может существенно повысить скорость инференса и выполнения других задач, связанных с интенсивными вычислениями. Утверждается, что по сравнению с традиционными ИИ-ускорителями на базе GPU решения Fractile.ai обеспечат ряд значительных преимуществ. В частности, говорится, что новые чипы позволят поднять производительность больших языковых моделей (LLM) в 100 раз при одновременном 10-кратном снижении затрат по сравнению с решениями NVIDIA. При этом чипы Fractile.ai обеспечат в 20 раз более высокую производительность в расчёте на 1 Вт затрачиваемой энергии по сравнению с любым другим оборудованием ИИ, представленным в настоящее время на рынке. 
Источник изображения: Intel Однако пока Fractile.ai не изготовила тестовые образцы изделий, а оценка их характеристик и возможностей проводится путём компьютерного моделирования. Тем не менее, Гелсингер говорит, что ни один подход в отношении ИИ-вычислений не воодушевляет его больше, чем тот, который предлагает Fractile.ai. По его словам, для дальнейшего масштабирования ИИ большое значение имеет снижение как энергопотребления, так и стоимости вычислений. Отмечается также, что стартап Fractile.ai ранее привлек в общей сложности $17,5 млн финансирования. В число инвесторов входят Kindred Capital, NATO Innovation Fund, Oxford Science Enterprises и несколько бизнес-ангелов.
23.01.2025 [13:29], Руслан Авдеев
В Nebius AI Studio появились открытые ИИ-модели для преобразования текста в изображениеИИ-компания Nebius B.V. (бывшая Yandex N.V.) анонсировала обновление платформы «инференс как услуга» для разработчиков. В частности, добавлены новые open source модели, предназначенные для преобразования текста в изображение, сообщает Silicon Angle. В скором времени в сервисе появятся модели для преобразования текста в видео. Nebius AI Studio представляет собой гибкую, удобную для пользователей среду для разработчиков, решивших заняться созданием ИИ-приложений, говорит компания. Помимо обеспечения доступа к обширному набору больших языковых моделей (LLM), решение является одним из самых доступных с точки зрения стоимости. Поскольку компания управляет своей собственной облачной инфраструктурой, она может обеспечить одну из самых низких цен за токен на рынке, подчёркивает Nebius. Кроме того, предлагается гибкая ценовая модель — чем больше ресурсов потребляется, тем они дешевле. 
Источник изображения: Nebius Ранее компания называлась Yandex N.V. — это была родительская структура российского «Яндекса». Позже она продала поисковый и некоторые другие бизнесы, но сохранила ЦОД за пределами России (и даже намерена строить новые) и, наконец, превратилась в облачный инфраструктурный ИИ-сервис. На этой инфраструктуре и работает Nebius AI Studio. Обновление добавило модели Flux Schnell и Flux Dev, разработанные ИИ-стартапом Black Forest Labs Inc. — позиционирующим себя как одного из конкурентов OpenAI. Разработчики, создающие ИИ-приложения в Nebius AI Studio, смогут напрямую интегрировать в них новые модели. В компании утверждают, что она обеспечивает одну из самых высоких скоростей рендеринга — изображения создаются за секунды. Приложения, создаваемые с использованием Nebius AI Studio, могут поддерживать обработку до 100 млн токенов в минуту, сообщает пресс-служба компании.
22.01.2025 [08:08], Руслан Авдеев
Ускорители Ascend не готовы состязаться с чипами NVIDIA в деле обучения ИИ, но за эффективность инференса Huawei будет бороться всеми силамиХотя на китайском рынке ИИ-ускорителей по-прежнему доминирует NVIDIA, Huawei намерена отнять у неё значительную его долю. Для этого китайский разработчик намерен помочь китайским ИИ-компаниям внедрять чипы собственного производства для инференса, сообщает The Financial Times. Для обучения ИИ-моделей китайские производители в массе своей применяют чипы NVIDIA. Huawei пока не готова заменить продукты NVIDIA в этом деле из-за ряда технических проблем, в том числе из-за проблем с интерконнектом ускорителей при работе с крупными моделями. Предполагается, что в будущем именно инференс станет пользоваться большим спросом, если темпы обучения ИИ-моделей замедлятся, а приложения вроде чат-ботов будут распространены повсеместно. Если инференс нужен постоянно, то к обучению ИИ-моделей прибегают лишь время от времени. По словам сотрудников и клиентов Ascend, компания сосредоточена на менее сложном, но, возможно, более прибыльном пути. Но поскольку ускорители NVIDIA и Huawei используют разные программные экосистемы, последняя предлагает бизнесам ПО для обеспечения совместимости. Продукция Huawei продвигается при поддержке китайского правительства, внутри страны именно эта компания считается наиболее серьёзным конкурентом NVIDIA. И хотя китайские компании всё более ограничены в доступе к аппаратным решениям NVIDIA из-за санкций, они охотно покупают даже урезанные чипы H20, которые всё равно считают более предпочтительным вариантом, чем китайские альтернативы. 
Источник изображения: Huawei Задача Huawei — убедить разработчиков отказаться от платформы CUDA, во многом благодаря которой NVIDIA и смогла добиться успеха на рынке. От проблем с ПО страдает и AMD — по словам экспертов, именно оно не позволяет раскрыть потенциал ускорителей Instinct MI300X. Впрочем, готовящаяся к релизу версия Huawei Ascend 910C должна решить эти проблемы, поскольку новое поколение ускорителей получит ПО, упрощающее работу разработчиков. Тем временем китайские Baidu и Cambricon добились определённых успехов в разработке собственных ИИ-ускорителей, а ByteDance обратилась за помощью к Broadcom. По оценкам SemiAnalysis, в прошлом году NVIDIA заработала $12 млрд на продажах своей продукции в Китае, поставив 1 млн ускорителей H20, т.е. вдвое больше, чем Ascend 910B. Впрочем, отрыв, по словам экспертов, быстро сокращается, поскольку Huawei наращивает производство. Отмечается, что рост доли Huawei на рынке ИИ-ускорителей отчасти сдерживается лишь недостаточным предложением её продукции. По мнению экспертов, наращивать производство будет трудно, поскольку Китайское вынужден использовать устаревшее оборудование из-за санкций США. Специализация на инференсе может свидетельствовать и об особом векторе развития китайских ИИ-систем, отличающемся от американского. Китайские компании не участвуют в гонке Meta✴, xAI и OpenAI по созданию мегакластеров на базе решений NVIDIA. Зато большей эффективности в задачах инференса можно добиться даже с более слабыми чипами. Снизив стоимость работы ИИ-моделей, можно будет сохранять конкурентоспособность даже в таких условиях. В прошлом месяце китайский стартап DeepSeek представил ИИ-модель V3, обеспечивающую низкие затраты на обучение и инференс в сравнении с сопоставимыми по возможностям моделями из США. DeepSeek утверждает, что Huawei успешно адаптировала V3 к Ascend. Ранее сообщалось, что Huawei охотно направляет к клиентам специалистов для помощи с переходом с NVIDIA на Ascend.
20.01.2025 [07:53], Владимир Мироненко
SRAM, да и только: d-Matrix готовит ИИ-ускоритель CorsairСтартап d-Matrix создал ИИ-ускоритель Corsair, оптимизированный для быстрого пакетного инференса больших языковых моделей (LLM). Архитектура ускорителя основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости порядка 150 Тбайт/с. Новинка, по словам компании, отличается производительностью и энергоэффективностью, пишет EE Times. Массовое производство Corsair начнётся во II квартале. Среди инвесторов d-Matrix — Microsoft, Nautilus Venture Partners, Entrada Ventures и SK hynix. d-Matrix фокусируется на пакетном инференсе с низкой задержкой. В случае Llama3-8B сервер d-Matrix (16 четырёхчиплетных ускорителей в составе восьми карт) может производить 60 тыс. токенов/с с задержкой 1 мс/токен. Для Llama3-70B стойка d-Matrix (128 чипов) может производить 30 тыс. токенов в секунду с задержкой 2 мс/токен. Клиенты d-Matrix могут рассчитывать на достижение этих показателей для размеров пакетов порядка 48–64 (в зависимости от длины контекста), сообщила EE Times руководитель отдела продуктов d-Matrix Шри Ганесан (Sree Ganesan). 
Источник изображений: d-Matrix Производительность оптимизирована для исполнения моделей в расчёте до 100 млрд параметров на одну стойку. По словам Ганесан, это реалистичный сценарий использования LLM. В таких сценариях решение d-Matrix обеспечивает 10-кратное преимущество в интерактивности (время до получения токена) по сравнению с решениями на базе традиционных ускорителей, таких как NVIDIA H100. Corsair ориентирован на модели размером менее 70 млрд параметров, подходящих для генерации кода, интерактивной генерации видео или агентского ИИ, которые требуют высокой интерактивности в сочетании с пропускной способностью, энергоэффективностью и низкой стоимостью.  Ранние версии архитектуры d-Matrix использовали MAC-блоки на базе SRAM-ячеек, дополненных большим количеством транзисторов для операций умножения. Сложение же выполнялось в аналоговом виде с использованием разрядных линий, измерения тока и аналого-цифрового преобразования. В 2020 году компания выпустила чиплетную платформу Nighthawk на основе этой архитектуры. «[Nighthawk] продемонстрировал, что мы можем значительно повысить точность по сравнению с традиционными аналоговыми решениями, но мы всё ещё отстаем на пару процентных пунктов от традиционных решений типа GPU», — сказал EE Times генеральный директор d-Matrix Сид Шет (Sid Sheth). 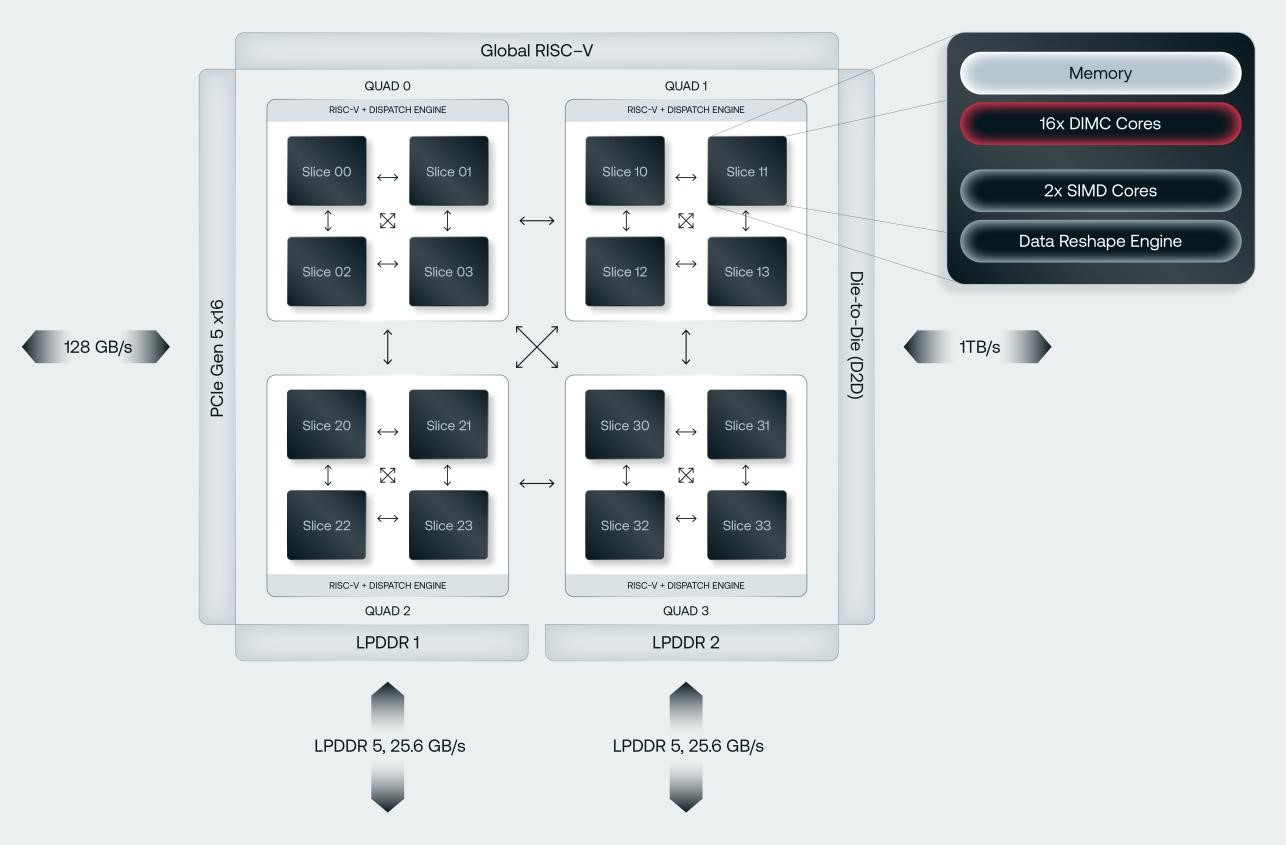 Однако потенциальным клиентам не понравилось, что при таком подходе возможно снижение точности, так что в Corsair компания вынужденно сделала выбор в пользу полностью цифрового сумматора. ASIC d-Matrix включает четыре чиплета, каждый из которых содержит по четыре вычислительных блока, объединённых посредством DMX Link по схеме каждый-с-каждым, и по одному планировщику и RISC-V ядру. Внутри каждого вычислительного блока есть 16 DIMC-ядер, состоящих из наборов SRAM-ячеек (64×64), а также два SIMD-ядра и движок преобразования данных. Суммарно доступен 1 Гбайт SRAM с пропускной способностью 150 Тбайт/с. 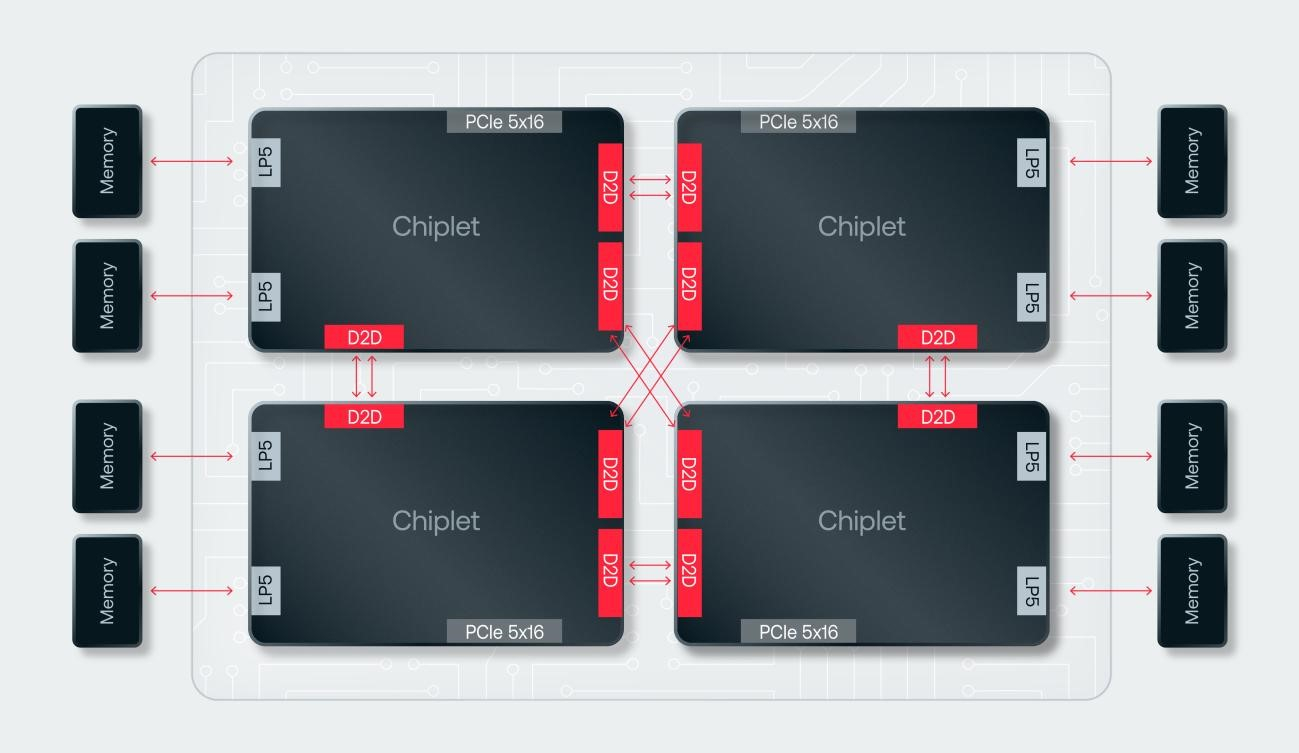 ASIC объединён со 128 Гбайт LPDDR5 (до 400 Гбайт/с) посредством органической подложки (без дорогостоящего кремниевого интерпозера). Хотя текущее поколение ASIC включает только четыре чиплета именно из-за ограничений подложки, в будущем их количество увеличится. Внешние интерфейсы ASIC представлены стандартным PCIe 5.0 x16 (128 Гбайт/с) и фирменным интерконнектом DMX Link (1 Тбайт/с) для объединения чиплетов. 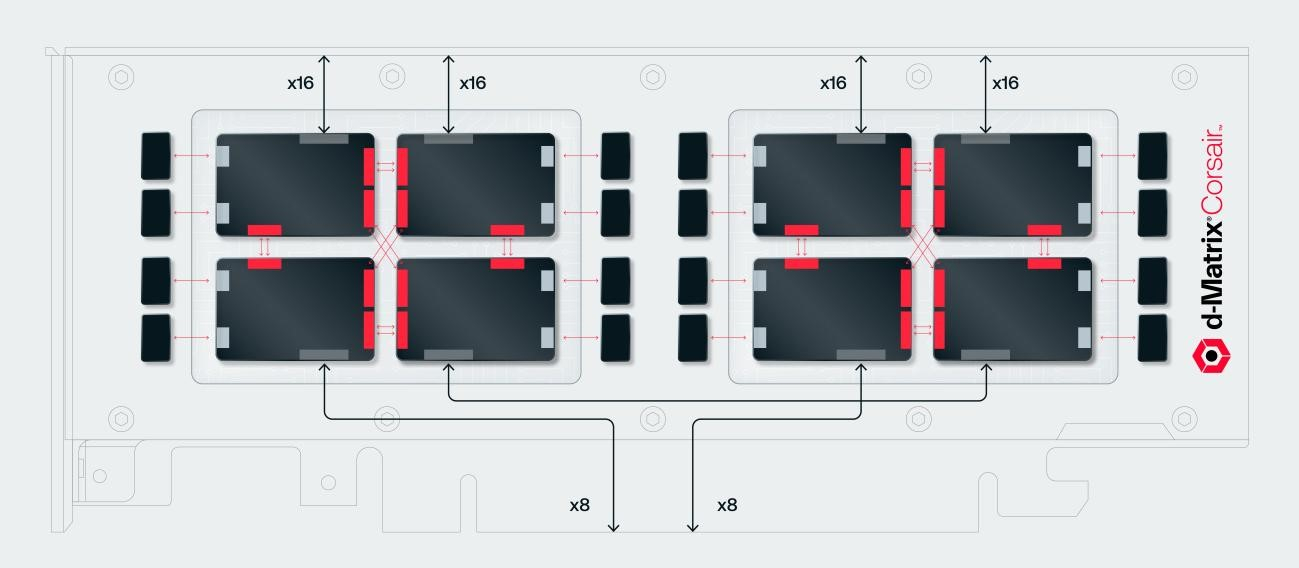 FHFL-карта Corsair включает два ASIC d-Matrix (т.е. всего восемь чиплетов) и имеет TDP на уровне 600 Вт. Ускоритель работает с форматами данных OCP MX (Microscaling Formats) и обеспечивает до 2400 Тфлопс в MXINT8-вычислениях или 9600 Тфолпс в случае MXINT4. Две карты Corsair можно объединить посредством 512-Гбайт/с мостика DMX Bridge. Их, по словам компании, достаточно для задействования тензорного параллелизма. Дальнейшее масштабирование возможно посредством PCIe-коммутации. Именно поэтому d-Matrix работает с GigaIO и Liqid. В одно шасси можно поместить восемь карт Corsair, а в стойку, которая будет потреблять порядка 6–7 кВт — 64 карты. 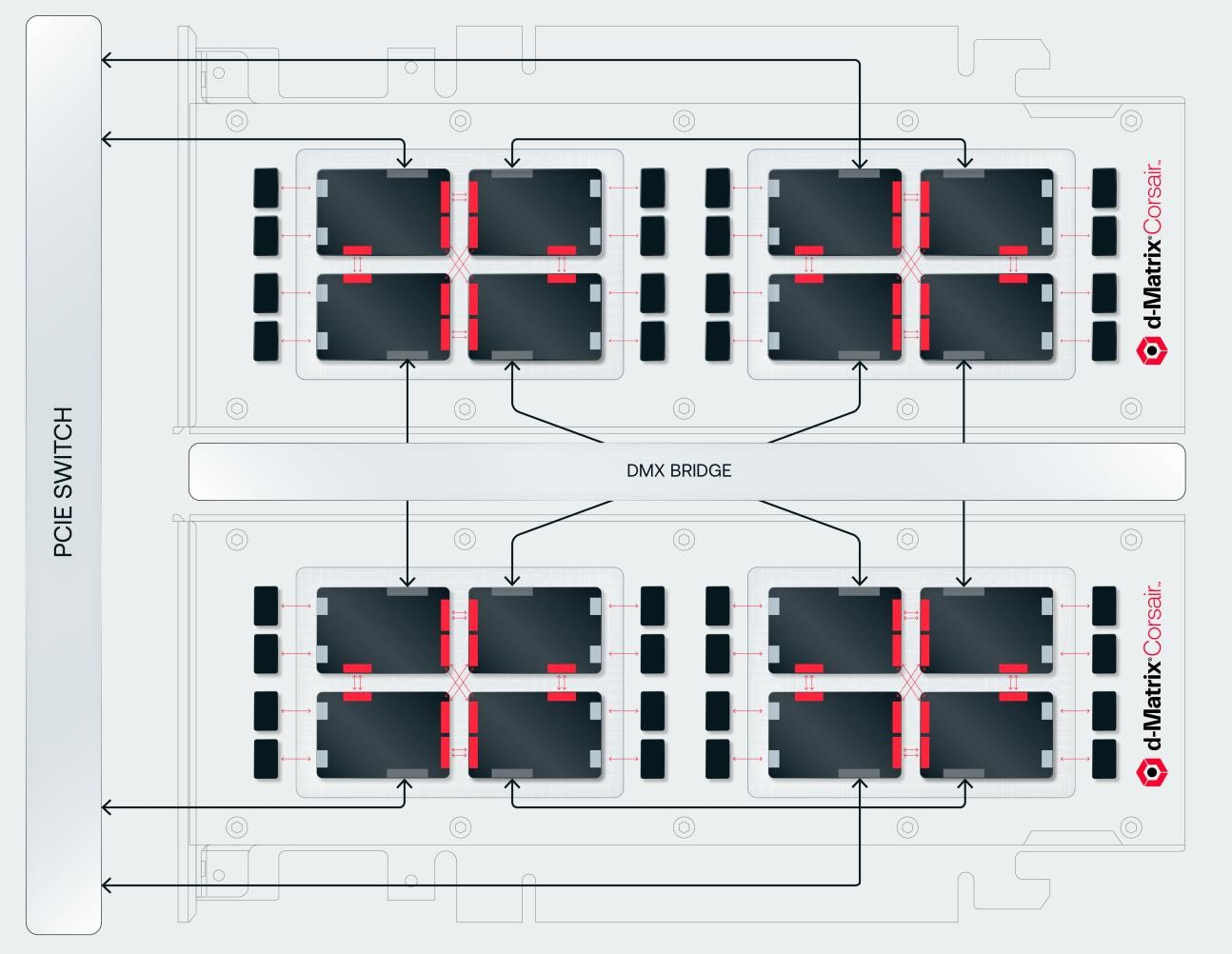 d-Matrix уже разрабатывает ASIC следующего поколения Raptor, который должен выйти в 2026 году. Raptor будет ориентирован на «думающие» модели и получит ещё больше памяти за счёт размещения DRAM непосредственно поверх вычислительных чиплетов. SRAM-чиплеты Raptor также перейдут с 6-нм техпроцесса TSMC, который используется при изготовлении Corsair, к 4 нм без существенных изменений микроархитектуры. По словам компании, она потратила два года на работу с TSMC, чтобы создать 3D-упаковку для нового поколения ASIC. 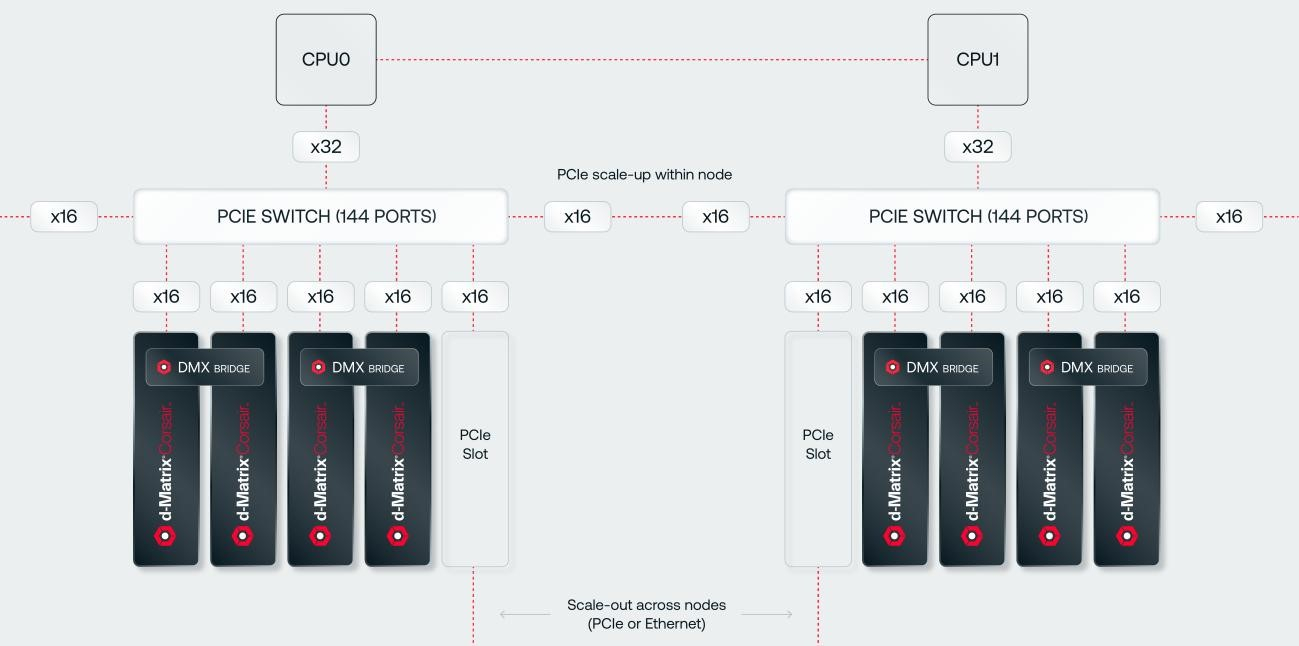 Как отмечает EETimes, команда разработчиков ПО d-Matrix в два раза больше команды разработчиков оборудования (120 против 60). Стратегия компании в области ПО заключается в максимальном использовании open source экосистемы, включая PyTorch, OpenAI Triton, MLIR, OpenBMC и т.д. Вместе они образуют программный стек Aviator, который отвечает за конвертацию моделей в числовые форматы d-Matrix, применяет к ним фирменные методы разрежения, компилирует их, распределяет нагрузку по картам и серверам, а также управляет исполнением моделей, включая обслуживание большого количества запросов.
06.01.2025 [19:00], Владимир Мироненко
Qualcomm представила энергоэффективные ИИ-микросерверы AI On-Prem Appliance SolutionQualcomm Technologies анонсировала Qualcomm AI On-Prem Appliance Solution — компактное энергоэффективное аппаратное решение для локальной обработки рабочих нагрузок инференса и компьютерного зрения. Также компания представила готовый к использованию набор ИИ-приложений, библиотек, моделей и агентов Qualcomm Cloud AI Inference Suite, способный работать и на периферии, в облаках. Согласно пресс-релизу, сочетание новых продуктов позволяет малым и средним предприятиям и промышленным организациям запускать кастомные и готовые приложения ИИ на своих объектах, включая рабочие нагрузки генеративного ИИ. Qualcomm отметила, что инференс на собственных мощностях позволит значительно снизить эксплуатационные расходы и общую совокупную стоимость владения (TCO) по сравнению с арендой сторонней ИИ-инфраструктуры. 
Источник изображений: Qualcomm С помощью AI On-Prem Appliance Solution совместно с AI Inference Suite клиенты смогут использовать генеративный ИИ на базе собственных данных, точно настроенные модели и технологическую инфраструктуру для автоматизации процессов и приложений практически в любой среде, например, в розничных магазинах, ресторанах, торговых точках, дилерских центрах, больницах, на заводах и в цехах, где рабочие процессы хорошо отлажены, повторяемы и готовы к автоматизации.  «Решения AI On-Prem Appliance Solution и Cloud AI Inference Suite меняют TCO ИИ, позволяя обрабатывать рабочие нагрузки генеративного ИИ не в облаке, а локально», — заявила компания, подчеркнув, что AI On-Prem Appliance Solution позволяет значительно снизить эксплуатационные расходы на приложения ИИ для корпоративных и промышленных нужд в самых разных областях. Кроме того, локальное развёртывание обеспечивает защиту от утечек чувствительных данных.  Платформа Qualcomm AI On-Prem Appliance Solution работает на базе семейства ускорителей Qualcomm Cloud AI. Сообщается, что новинка поддерживает широкий спектр возможностей, в том числе:
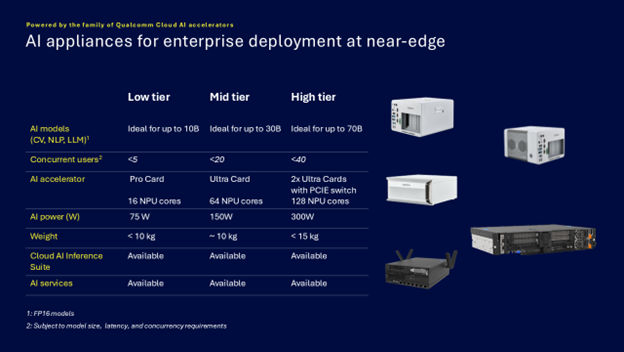 В свою очередь Qualcomm Cloud AI Inference Suite предлагает полный набор инструментов и библиотек для разработки или переноса приложений генеративного ИИ на AI On-Prem Appliance Solution или другие платформы на базе ускорителей Qualcomm Cloud AI. Набор предлагая множество API для управления пользователями и администрирования, для работы чатов, для генерации изображений, аудио и видео. Заявлена совместимость с API OpenAI и поддержка RAG. Кроме того, доступна интеграция с популярными моделями генеративного ИИ и фреймворками. Возможно развёртывание с использованием Kubernetes и bare metal.
28.12.2024 [01:55], Владимир Мироненко
Дороже, но втрое эффективнее: NVIDIA готовит ускорители GB300 с 288 Гбайт HBM3E и TDP 1,4 кВтNVIDIA выпустила новые ускорители GB300 и B300 всего через шесть месяцев после выхода GB200 и B200. И это не минорное обновление, как может показаться на первый взгляд — появление (G)B300 приведёт к серьёзной трансформации отрасли, особенно с учётом значительных улучшений в инференсе «размышляющих» моделей и обучении, пишет SemiAnalysis. При этом с переходом на B300 вся цепочка поставок меняется, и от этого кто-то выиграет, а кто-то проиграет. Конструкция вычислительного кристалла B300 (ранее известного как Blackwell Ultra), изготавливаемого с использованием кастомного техпроцесса TSMC 4NP. Благодаря этому он обеспечивает на 50 % больше Флопс (FP4) по сравнению с B200 на уровне продукта в целом. Часть прироста производительности будет получена за счёт увеличения TDP, достигающим 1,4 кВт и 1,2 кВт для GB300 и B300 HGX соответственно (по сравнению с 1,2 кВт и 1 кВт для GB200 и B200). Остальное повышение производительности связано с архитектурными улучшениями и оптимизациями на уровне системы, такими как динамическое распределение мощности между CPU и GPU. Кроме того, в B300 применяется память HBM3E 12-Hi, а не 8-Hi, ёмкость которой выросла до 288 Гбайт. Однако скорость на контакт осталась прежней, так что суммарная пропускная способность памяти (ПСП) по-прежнему составляет 8 Тбайт/с. В качестве системной памяти будут применяться модули LPCAMM. Разница в производительности и экономичности из-за увеличения объёма HBM намного больше, чем кажется. Усовершенствования памяти имеют решающее значение для обучения и инференса больших языковых моделей (LLM) в стиле OpenAI O3, поскольку более длинные последовательности токенов негативно влияют на скорость обработки и задержку. 
Источник изображения: NVIDIA На примере обновления H100 до H200 хорошо видно, как память влияет на производительность ускорителя. Более высокая ПСП (H200 — 4,8 Тбайт/с, H100 — 3,35 Тбайт/с) в целом улучшила интерактивность в инференсе на 43 %. А большая ёмкость памяти снизила объём перемещаемых данных и увеличила допустимый размер KVCache, что увеличило количество генерируемых токенов в секунду втрое. Это положительно сказывается на пользовательском опыте, что особенно важно для всё более сложных и «умных» моделей, которые могут приносить больше дохода с каждого ускорителя. Валовая прибыль от использования передовых моделей превышает 70 %, тогда как для отстающих моделей в конкурентной open source среде она составляет менее 20 %. 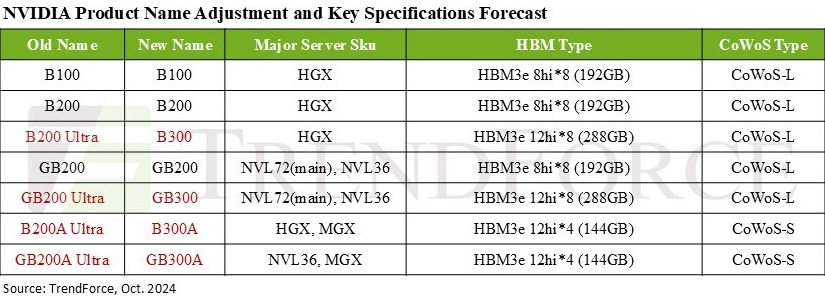
Источник изображения: TrendForce Однако одного наращивания скорости и памяти, как это делает AMD в Instinct MI300X (192 Гбайт), MI325X и MI355X (256 Гбайт и 288 Гбайт соответственно), мало. И дело не в том, что забагованное ПО компании не позволяет раскрыть потенциал ускорителей, а в особенности общения ускорителей между собой. Только NVIDIA может предложить коммутируемое соединение «все ко всем» посредством NVLink. В GB200 NVL72 все 72 ускорителя могут совместно работать над одной и той же задачей, что повышает интерактивность, снижая задержку для каждой цепочки размышлений и в то же время увеличивая их максимальную длину. На практике NVL72 — единственный способ увеличить длину инференса до более чем 100 тыс. токенов и при этом экономически эффективный, говорит SemiAnalysis. По оценкам, GB300 NVL72 обойдётся заказчиками минимум в $7,5 млн, тогда как GB200 NVL72 стоил порядка $3 млн.
16.12.2024 [16:08], Руслан Авдеев
Южнокорейская FuriosaAI включается в ИИ-гонку с собственным ускорителем RNGDСеульский стартап FuriosaAI, основанный в 2017 году, анонсировал в августе 2024 года ИИ-ускорители RNGD для гиперскейлеров и других корпоративных клиентов. Недавно компания начала тестирование новинки и рассылку образцов некоторым потенциальным клиентам, включая LG AI Research и Aramco, сообщает DigiTimes. RNGD позиционируется как решение, способное бросить вызов продуктам NVIDIA. По словам создателей, новинка на 40 % энергоэффективнее NVIDIA H100 при сопоставимых вычислительных характеристиках. Представитель компании недавно сообщил журналистам, что изначально компания сконцентрировалась исключительно на разработке, отложив производство до получения значительных инвестиций. Чип первого поколения был разработан ещё в 2021 году. Несмотря на скромный бюджет в $6 млн, компании удалось добиться результатов, достаточных для того, чтобы в раунде финансирования серии B компания получила $60 млн, что и позволило разработать модель RNGD. 
Источник изображения: FuriosaAI RNGD создан совместно с Global Unichip Corporation (GUC) и TSMC и рассчитан на работу с большими языковыми моделями (LLM). Ускоритель использует память HBM3 и выполнен по 5-нм техпроцессу. Компания разрабатывала его с прицелом на инференс моделей уровня GPT-3 и новее. Соблюдению баланса производительности и энергопотребления способствовала проприетарная архитектура Tensor Construction Processor. В августе 2024 года LG AI Research начала интегрировать RNGD в свою ИИ-инфраструктуру, чтобы снизить зависимость от NVIDIA и способствовать развитию южнокорейского полупроводникового бизнеса. При этом FuriosaAI прилагает все усилия для программной поддержки своего продукта. В стартапе уверены, что рынок ИИ достаточно велик, чтобы места хватило и игрокам помельче NVIDIA. В компании сравнивают амбиции FuriosaAI с усилиями создателей первых электромобилей, которые в итоге произвели революцию во всей индустрии. Стартап укрепляет международные связи для экспансии в США, Азии и других регионах. В сентябре был подписан меморандум о взаимопонимании с арабской Aramco. Дополнительно ведутся переговоры с потенциальными партнёрами в Японии и Индии. Первые коммерческие поставки RNGD ожидаются в I квартале 2025 года. Подчёркивается и важность Тайваня для экосистемы FuriosaAI — в качестве хаба для передового производства остров играет ключевую роль. Потенциально рассматривается открытие офиса на Тайване для укрепления сотрудничества. |
|