Материалы по тегу: pc
|
19.09.2023 [15:07], Сергей Карасёв
Исследовательская лаборатория ВВС США получила суперкомпьютер Raider мощностью 12 ПфлопсВысокопроизводительный вычислительный комплекс для Исследовательской лаборатории ВВС США (AFRL), по сообщению ресурса Datacenter Dynamics, прибыл на базу Райт-Паттерсон в Огайо. Суперкомпьютер, построенный Penguin Computing, получил название Raider. 
Изображения: AFRL Новая НРС-система имеет производительность приблизительно 12 Пфлопс. Raider является частью более широкой программы модернизации высокопроизводительных вычислений Министерства обороны и будет доступен ВВС, армии и флоту США. Суперкомпьютер примерно в четыре раза мощнее своего предшественника — комплекса Thunder, запущенного в 2015 году: у этой системы производительность составляет 3,1 Пфлопс. Использовать Raider планируется прежде всего для решения сложных задач в области моделирования различных процессов.  В опубликованных в прошлом году документах говорится, что Raider должен был получить 189 тыс. вычислительных ядер. Предполагалось, что система будет включать 356 узлов различного назначения и конфигурации и получит процессоры AMD EPYC 7713 (Milan), 44 Тбайт RAM, 152 ускорителя NVIDIA A100, 200G-интерконнект InfiniBand HDR и 20-Пбайт хранилище. Однако заявленная производительность этой системы составляла 6,11 Пфлопс, так что характеристики суперкомпьютера явно скорректировали. В дополнение к Raider Исследовательская лаборатория ВВС США заказала два других суперкомпьютера — TI-23 Flyer и TI-Raven, которые, как ожидается, будут обеспечивать производительность на уровне 14 Пфлопс. Ввод этих систем в эксплуатацию запланирован на 2024 год.
14.09.2023 [22:40], Руслан Авдеев
NVIDIA и Xanadu построят симулятор квантового компьютера на базе обычного суперкомпьютераКомпания NVIDIA начала сотрудничество с канадской Xanadu Quantum Technologies для того, чтобы запустить крупномасштабную симуляцию квантовых вычислений на суперкомпьютере. Как сообщает Silicon Angle, исследователи используют новейший фреймворк PennyLane компании Xanadu и разработанное NVIDIA ПО cuQuantum для создания квантового симулятора. PennyLane представляет собой фреймворк с открытым кодом, предназначенный для «гибридных квантовых вычислений», а инструменты cuQuantum для разработки программного обеспечения позволяют организовать симулятор квантовых вычислений, используя высокопроизводительные кластеры ускорителей. Вычислительных ресурсов действительно требуется немало, поскольку для воспроизведения работы квантовой модели из около 30 кубитов потребовалось 256 ускорителей NVIDIA A100 в составе суперкомпьютера Perlmutter. 
Источник изображения: geralt/pixabay.com Как заявляют в Xanadu, комбинация PennyLane и cuQuantum позволяет значительно увеличить число симулированных кубитов — ранее подобных возможностей просто не было. Тесты cuQuantum с одним ускорителем показали повышение производительности симуляции на порядок. Уже к концу текущего года учёные рассчитывают масштабировать технологию до 1 тыс. узлов с использованием 4 тыс. ускорителей, что позволит создать симуляцию более 40 кубитов. 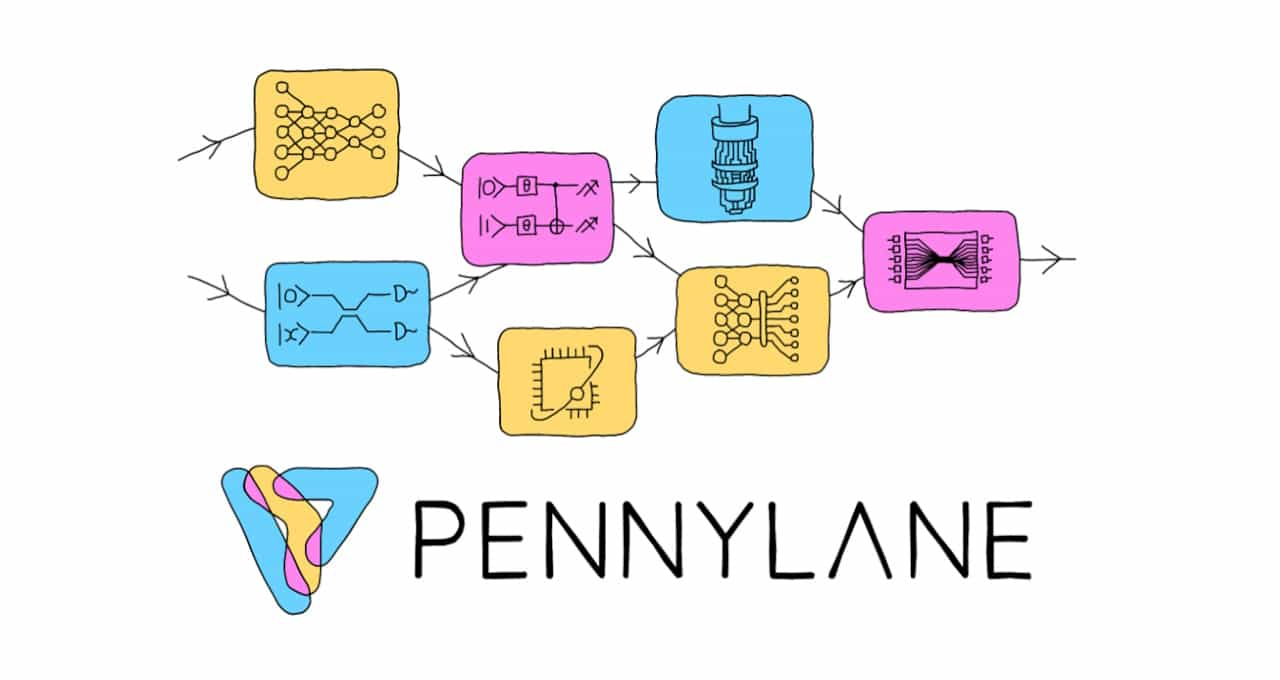
Источник изображения: Xanadu Учёные утверждают, что крупными симуляциями в результате смогут пользоваться даже стажёры. Всего планируется реализация не менее шести проектов с использованием соответствующей технологии для изучения физики высоких энергий, систем машинного обучения, развития материаловедения и химии. Xanadu уже сейчас работает с Rolls-Royce над разработкой квантовых алгоритмов, позволяющих создавать более эффективные двигатели, а также с Volkswagen Group над проектами по созданию эффективных аккумуляторов.
14.09.2023 [18:26], Руслан Авдеев
Британский ИИ-суперкомпьютер Isambard-3 станет одним из самых мощных в ЕвропеВ Великобритании будет реализован новый амбициозный проект в сфере вычислительных технологий. Как сообщает Network World, власти страны объявили о строительстве нового суперкомпьютера, а всего в различные проекты с учётом создания центра по исследованию систем искусственного интеллекта (ИИ) будет вложено £900 млн ($1,1 млрд). Isambard-3 пообещали разместить на площадке в Бристоле в этом году. Машина будет включать тысячи передовых ускорителей и станет одним из самых мощных суперкомпьютеров Европы. Бристоль уже является одним из центров исследований ИИ-систем. На базе Бристольского университета будет создан национальный центр AI Research Resource (AIRR или Isambard-AI) для поддержки исследований в сфере ИИ, в том числего его безопасного использования. 
Источник изображения: franganillo/pixabay.com Суперкомпьютер и AIRR финансируются за счёт средств, выделить которые британское правительство пообещало ещё в марте текущего года. Британские власти ожидают, что центр в Бристоле станет «катализатором» для научных открытий и позволит Великобритании держаться в числе лидеров разработки ИИ, а суперкомпьютер поможет экспертам и исследователям использовать «меняющий правила» потенциал ИИ-систем. Отметим, что ранее Великобритания покинула EuroHPC в связи с Brexit'ом, что несколько затормозило развитие HPC-сферы в стране. Пока не раскрываются технические детали нового суперкомпьютера, хотя первые данные о его спецификациях появились ещё в мае. Правда, тогда речь шла только об использовании Arm-процессоров NVIDIA Grace. Это уже третье поколение HPC-систем на базе Arm, Isambard и Isambard 2 базировались на Cavium ThunderX2 и Fujitsu A64FX соответственно, причём основным поставщиком всех трёх систем является HPE/Cray.
13.09.2023 [13:45], Сергей Карасёв
«Тренировочный» суперкомпьютер Polaris показал высокое быстродействие СХД в тестах MLPerf Storage AIАргоннская национальная лаборатория Министерства энергетики США сообщила о том, что вычислительный комплекс Polaris, предназначенный для решения ИИ-задач, устанавливает высокие стандарты производительности СХД в бенчмарке MLPerf Storage AI. Суперкомпьютер Polaris, разработанный в сотрудничестве с Hewlett Packard Enterprise (HPE), объединяет 560 узлов, соединенных между собой посредством интерконнекта HPE Slingshot. Каждый узел содержит четыре ускорителя NVIDIA A100 и два накопителя NVMe вместимостью 1,6 Тбайт каждый. Задействована платформа хранения HPE ClusterStor E1000, которая предоставляет 100 Пбайт полезной ёмкости на 8480 накопителях. Заявленная скорость передачи данных достигает 659 Гбайт/с. Вычислительный комплекс смонтирован на площадке Argonne Leadership Computing Facility (ALCF). Пиковая производительность составляет около 44 Пфлопс. 
Источник изображения: ALCF Быстродействие Lustre-хранилища оценивалась с использованием двух рабочих нагрузок MLPerf Storage AI — UNet3D и Bert. Данные размещались как в основном хранилище, так и на NVMe-накопителях в составе узлов суперкомпьютера, что позволило эмулировать различные рабочие нагрузки ИИ. В тесте UNet3D с интенсивным вводом-выводом суперкомпьютер достиг пиковой пропускной способности в 200 Гбайт/с для основного хранилища HPE ClusterStor E1000. В случае NVMe-накопителей продемонстрирован результат на уровне 800 Гбайт/с. Менее интенсивная рабочая нагрузка Bert также показала высокие результаты, что говорит о возможности эффективного выполнения современных ИИ-задач.
12.09.2023 [13:42], Сергей Карасёв
Суперкомпьютер Dojo может увеличить рыночную стоимость Tesla на $500 млрдАналитики Morgan Stanley, по сообщению Datacenter Dynamics, полагают, что запуск суперкомпьютера Dojo позволит Tesla увеличить свою рыночную стоимость на $500 млрд. Иными словами, капитализация компании Илона Маска может подняться приблизительно на 60 %. Tesla намерена до конца 2024 года потратить на проект Dojo более $1 млрд. Этот вычислительный комплекс поможет в разработке инновационных технологий для роботизированных автомобилей. В составе системы будут применяться чипы собственной разработки Tesla D1. В перспективе производительность Dojo планируется довести до 100 Эфлопс. По состоянию на сентябрь 2023 года рыночная капитализация Tesla составляет около $778 млрд при стоимости ценных бумаг примерно $248. Отмечается, что цена акций компании в течение нынешнего года уже выросла более чем вдвое после снижения в 2022-м. Morgan Stanley прогнозирует, что после ввода системы Dojo в эксплуатацию стоимость ценных бумаг Tesla поднимется примерно на 60 % — до $400. 
Источник изображения: Tesla «Чем больше мы анализировали проект Dojo, тем больше осознавали потенциальную возможность недооценки акций Tesla», — сказал аналитик Morgan Stanley Адам Джонас (Adam Jonas). Предполагается, что Dojo поможет ускорить развитие технологий автопилотирования, а также усилит позиции Tesla в сегменте облачных сервисов. Ранее генеральный директор Tesla Илон Маск заявлял, что компания разрабатывает систему отчасти из-за того, что не может получить достаточное количество ускорителей на базе GPU для удовлетворения своих потребностей.
21.07.2023 [15:35], Сергей Карасёв
NVIDIA, подвинься: Cerebras представила 4-Эфлопс ИИ-суперкомпьютер Condor Galaxy 1 и намерена построить ещё восемь таких жеКомпания Cerebras Systems анонсировала суперкомпьютер Condor Galaxy 1 (CG-1), предназначенный для решения ресурсоёмких задач с применением ИИ. Это одна из первых действительно крупных машин на базе уникальных чипов Cerebras. В проекте стоимостью $100 млн приняла участие холдинговая группа G42 из ОАЭ, которая занимается технологиями ИИ и облачными вычислениями. G42 является основным заказчиком комплекса. В текущем виде комплекс CG-1, расположенный в Санта-Кларе (Калифорния, США), объединяет 32 системы Cerebras CS-2 и обеспечивает производительность на уровне 2 Эфлопс (FP16). В IV квартале ткущего года будут добавлены ещё 32 системы Cerebras CS-2, что позволит довести быстродействие до 4 Эфлопс (FP16). Ожидаемый уровень энергопотребления составит порядка 1,5 МВт или более. 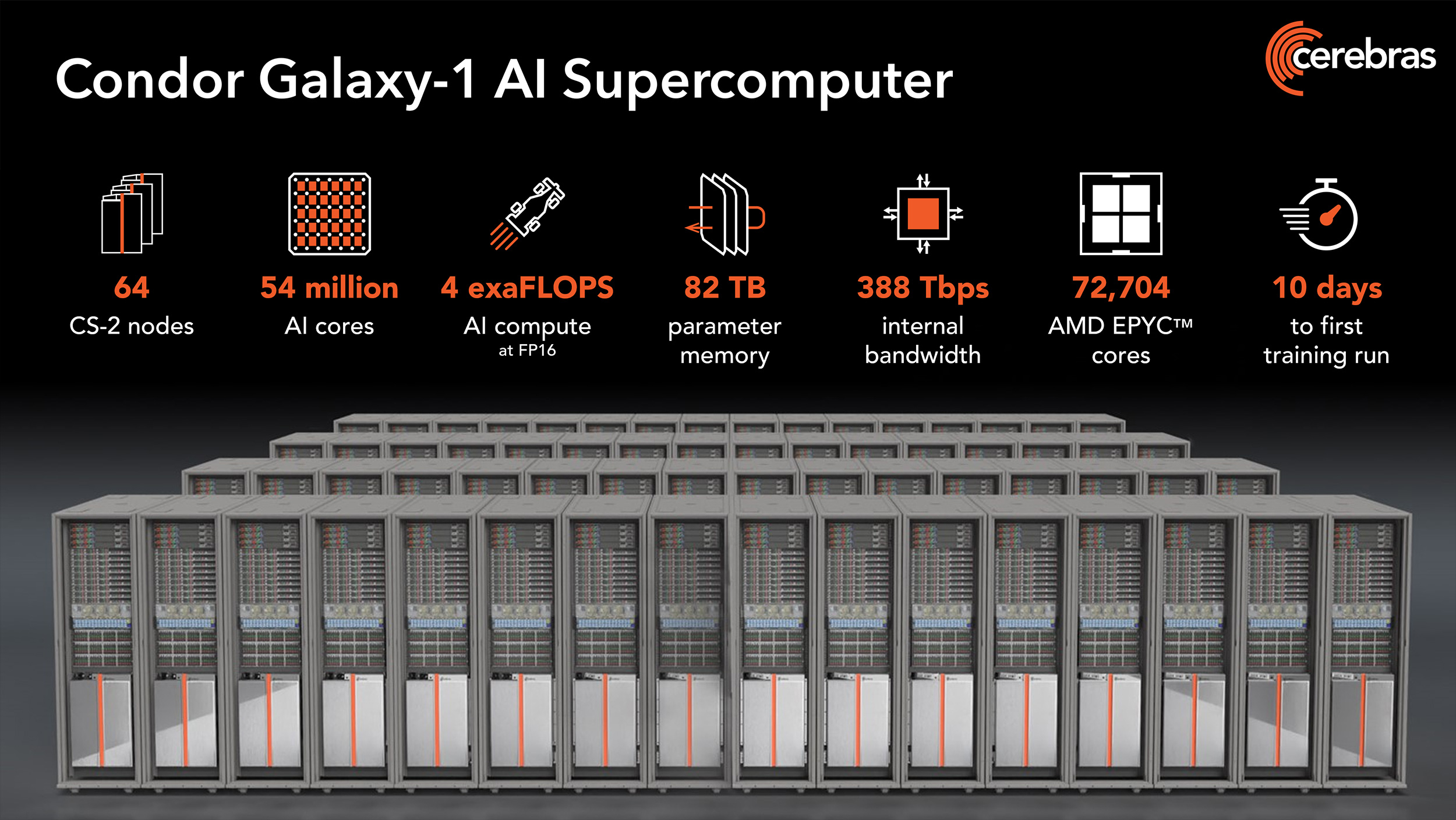
Источник изображений: Cerebras (via ServeTheHome) В системах Cerebras CS-2 применяются гигантские чипы Wafer-Scale Engine 2 (WSE-2), насчитывающие 2,6 трлн транзисторов. Такие чипы имеют 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Системы выполнены в формате 15 RU и укомплектованы шестью блоками питания мощностью 4 кВт каждый. Задействована технология жидкостного охлаждения. Отдельно отмечается, что программный стек позволит без проблем и существенных модификаций кода работать с ИИ-моделями.  После ввода в строй второй очереди комплекс CG-1 суммарно получит 54,4 млн ИИ-ядер, 2,56 Тбайт SRAM и внутренний интерконнект со скоростью 388 Тбит/с. Их дополнят 72 704 ядра AMD EPYC Milan и 82 Тбайт памяти для хранения параметров. По словам создателей, мощностей суперкомпьютера хватит для обучения модели с 600 млрд параметров и на очередях длиной до 50 тыс. токенов. При этом производительность масштабируется практически линейно.  Cerebras и G42 будут предоставлять доступ к CG-1 по облачной схеме, что позволит заказчикам использовать ресурсы ИИ-суперкомпьютера без необходимости управлять моделями или распределять их по узлам и ускорителям. CG-1 — первый из трёх ИИ-суперкомпьютеров нового поколения. В I полугодии 2024 года будут построены комплексы CG-2 и CG-3, полностью аналогичные CG-1, которые будут объединены в распределённый ИИ-кластер. А к концу следующего года у Cerebras будет уже девять систем CG.  Для Cerebras это означает, что компания более не является стартапом, поскольку в её решения заказчики поверили и без участия в индустриальных тестах вроде MLPerf. Кроме того, теперь компания является не просто очередным производителем «железа», а предоставляет услуги, которые и помогут ей заработать в будущем.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения.
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
16.05.2023 [09:23], Сергей Карасёв
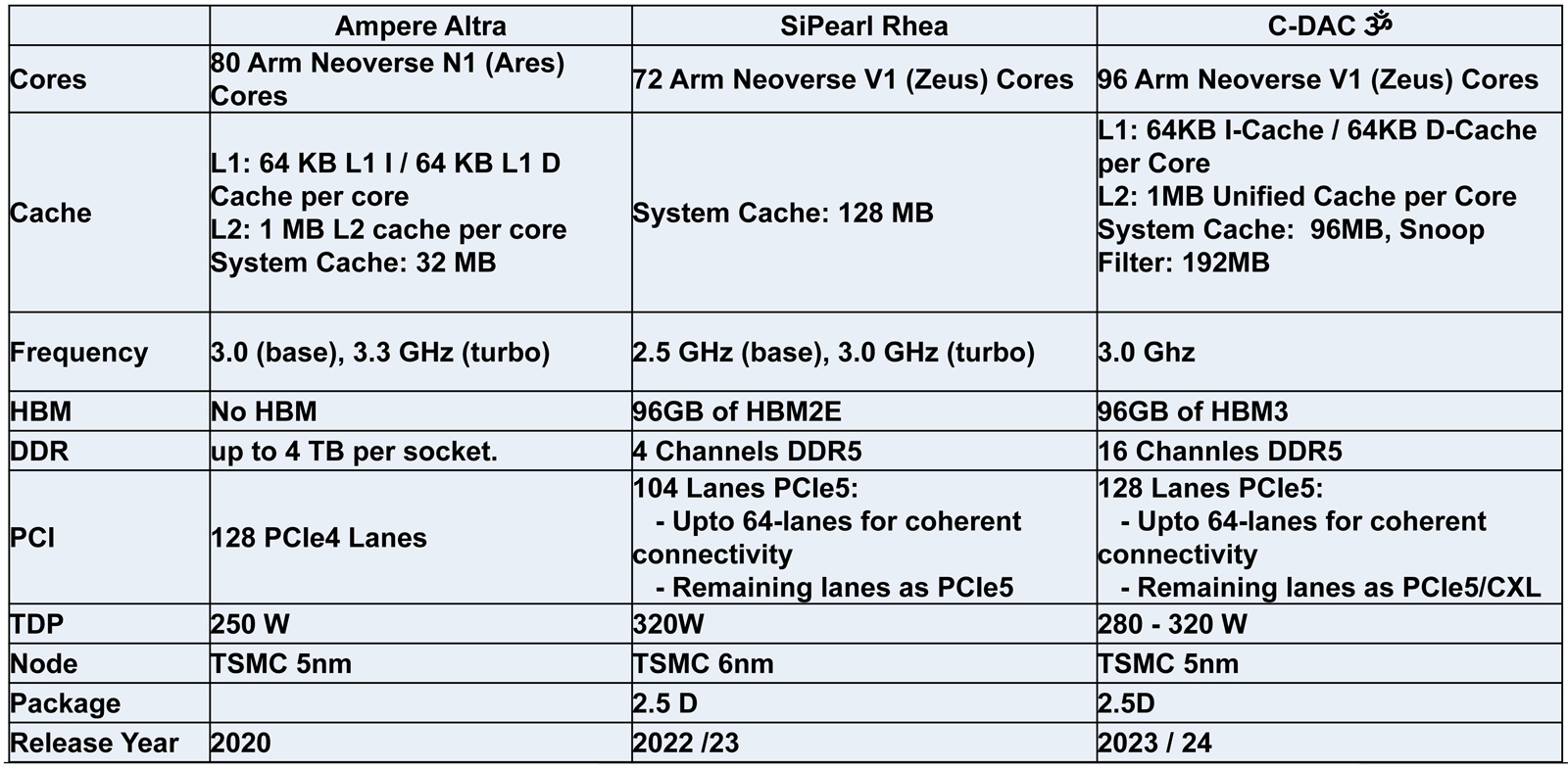
Индия представила свой первый серверный процессор AUM: 96 ядер и 96 Гбайт памяти HBM3Центр развития передовых вычислений (C-DAC) Департамента электроники и информационных технологий Министерства коммуникаций и информационных технологий Индии представил первый в стране процессор для серверов и НРС-систем. Изделие под названием AUM выйдет на коммерческий рынок в текущем или следующем году. Решение имеет чиплетную компоновку на базе двух модулей A48Z, каждый из которых насчитывает 48 вычислительных ядер Zeus с архитектурой Arm. Таким образом, суммарное количество ядер достигает 96. Тактовая частота составляет 3,0 ГГц (до 3,5 ГГц в турбо-режиме); показатель TDP варьируется от 280 до 320 Вт. 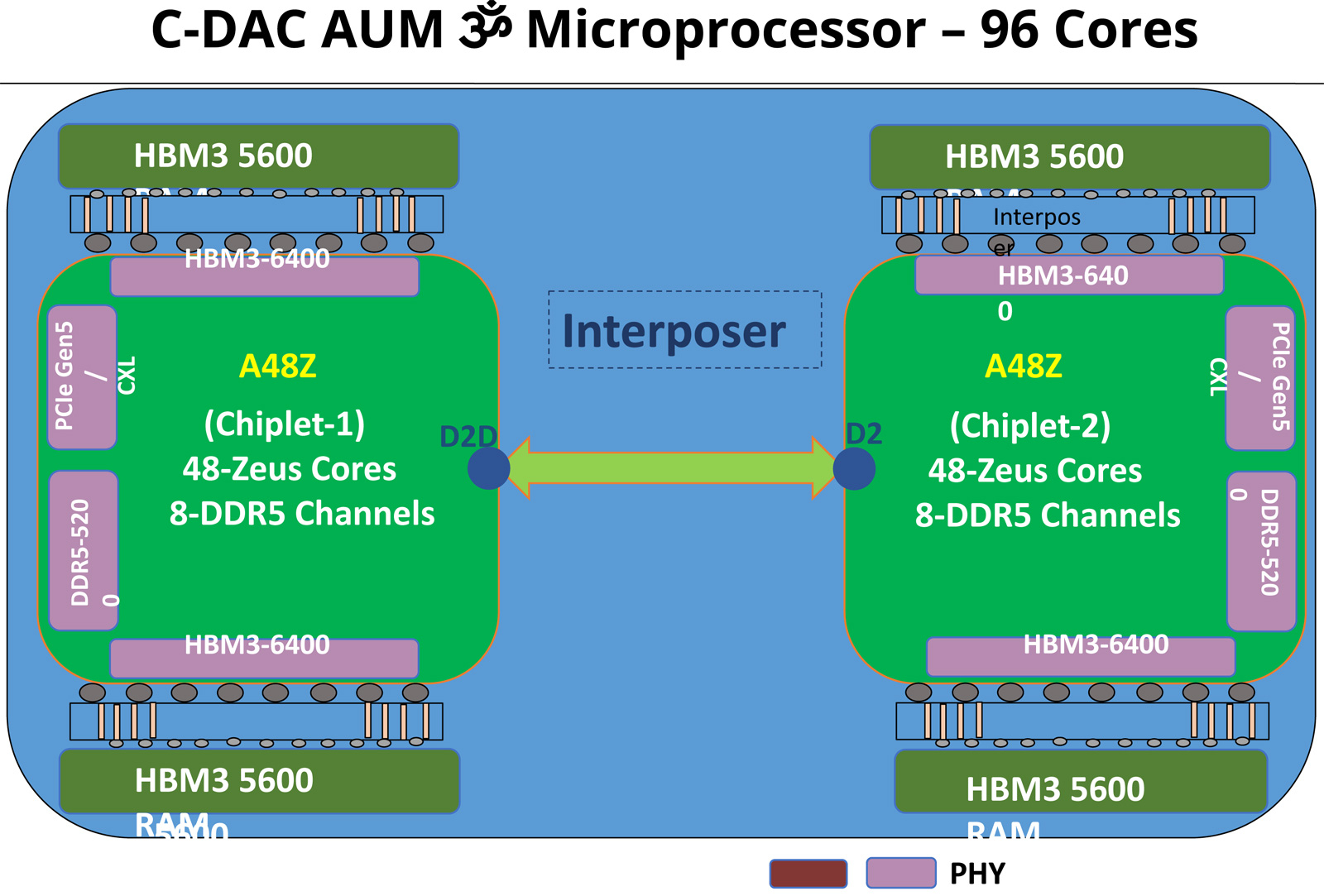
Источник изображений: C-DACC-DAC Новинка будет изготавливаться на предприятии TSMC по 5-нм технологии. Чип содержит 96 Мбайт кеша L2 и 96 Мбайт системного кеша. Изделие получило 96 Гбайт памяти HBM3 и 8-канальный контроллер DDR5-5200; кроме того, имеется доступ к 64 Гбайт памяти HBM3-5600. Таким образом, задействована трёхуровневая подсистема памяти. Упомянуты до 128 линий PCIe 5.0 с поддержкой CXL. 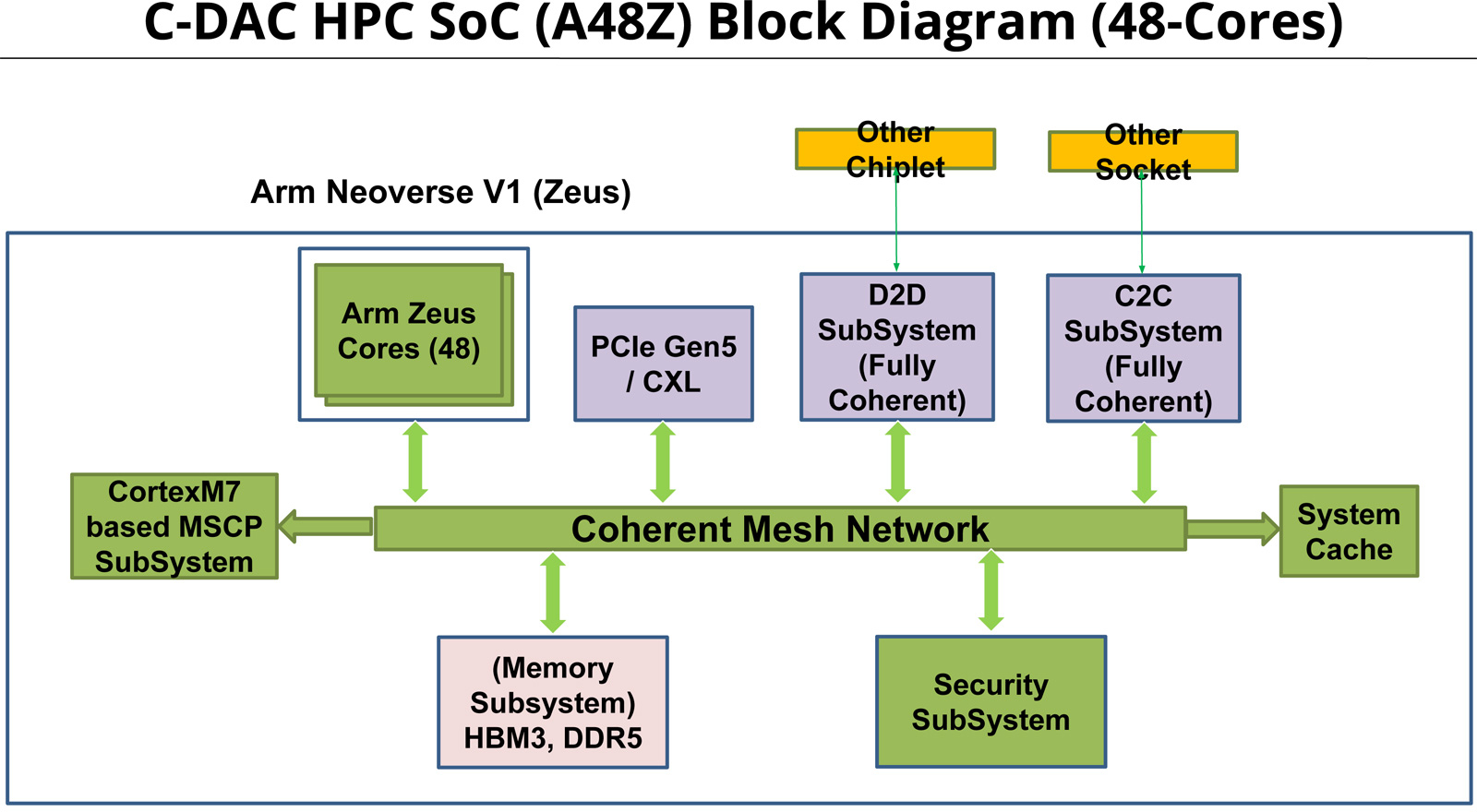 Процессор AUM может применяться в двухсокетных серверах. Заявленная производительность превышает 4,6 Тфлопс в расчёте на разъём. Реализованы различные средства обеспечения безопасности, в том числе функция Secure Boot и криптографические алгоритмы. 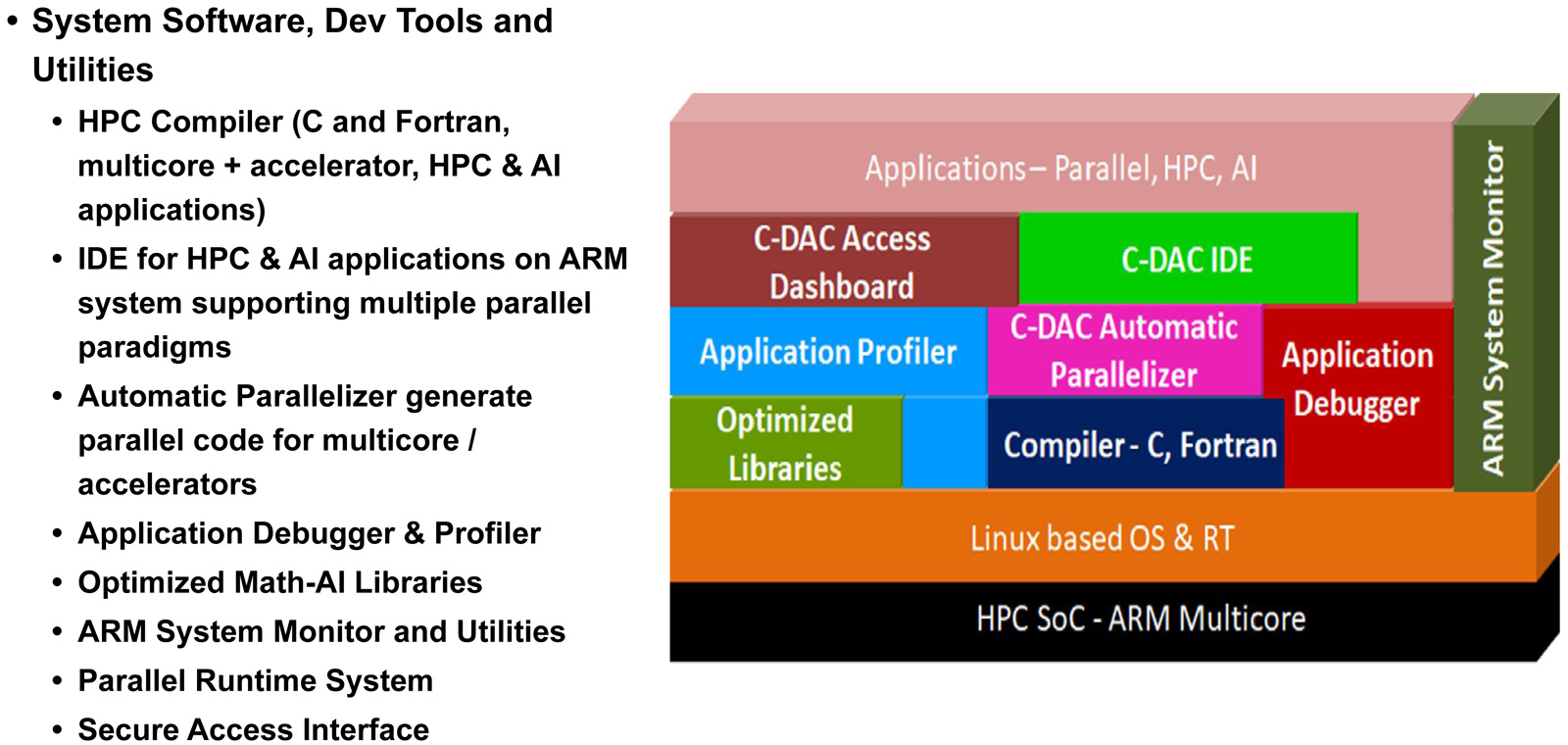
 |
|