Лента новостей
|
26.03.2022 [00:48], Владимир Агапов
Микро-ЦОД вместо котельной — Qarnot предложила отапливать дома б/у серверами«Зелёная» экономика, переход на которую стремится осуществить всё больше стран, требует радикального сокращения вредного воздействия техносферы на окружающую среду. Один из эффективных способов достижения этой задачи связан с включением в полезный оборот побочных продуктов экономической деятельности. В случае дата-центров таким продуктом является тепло. Великобритания, Дания и другие страны направляют тепло от ЦОД в отопительные системы домов, а Норвегия обогревает им омаровые фермы и планирует обязать дата-центры отдавать «мусорное» тепло на общественные нужды. Французская компания Qarnot решила посмотреть на эту задачу под другим углом, разработав в 2017 г. концепцию электрообогревателя для жилых и офисных помещений на процессорах AMD и Intel. 
Изображение: Qarnot (via DataCenterDynamics) В 2018 г. Qarnot продолжила изыскания и выпустила криптообогреватель QC-1. А недавно она порадовала своих заказчиков следующим поколением отопительных устройств QB, которое создано в сотрудничестве с ITRenew. Новые модули используют OCP-серверы, которые ранее работали в дата-центрах гиперскейлеров. Оснащённые водяным охлаждением, они обогревают помещения пользователей и обеспечивают дополнительные мощности для периферийных облачных вычислений. Система отводит 96% тепла, производимого кластером серверов, которое попадает в систему циркуляции воды. IT-часть состоит из процессоров AMD EPYC/Ryzen или Intel Xeon E5 в составе OCP-платформ Leopard, Tioga Pass или Capri с показателем PUE, который, по словам разработчиков, стремится к 1,0. При этом вся система практически бесшумная, поскольку вентиляторы отсутствуют.  В компании заявляют, что с февраля уже развёрнуто 12 000 ядер, и планируется довести их число до 100 000 в течении 2022 года. Среди предыдущих заказчиков систем отопления Qarnot числятся жилищные проекты во Франции и Финляндии, а также банк BNP и клиенты, занимающиеся цифровой обработкой изображений. По словам технического директора Qarnot Клемента Пеллегрини (Clement Pellegrini), QB приносит двойную пользу экологии, используя не только «мусорное» тепло, но и оборудование, которое обычно утилизируется. У ITRenew уже есть очень похожий совместный проект с Blockheating по обогреву теплиц такими же б/у серверами гиперскейлеров.
24.03.2022 [00:23], Владимир Мироненко
IBM подала в суд на LzLabs, предлагающую дешёвую облачную альтернативу её мейнфреймамIBM подала в Окружной суд в Уэйко (штат Техас) на разработчика ПО LzLabs, заявив, что созданная им платформа Software Defined Mainframe (SDM, программно определяемый мейнфрейм) нарушает её патенты. В судебном иске корпорация утверждает, что платформа LzLabs, позволяющая выполнять приложения для мейнфреймов на стандартном оборудовании в облаке, базируется на ПО, основанном на проприетарной технологии IBM. IBM также обвинила LzLabs в том, что та делает ложные заявления о своих продуктах. Кроме того, в иске сообщается, что люди, стоящие за LzLabs, и раньше нарушали патенты IBM. Среди руководителей LzLabs оказался бывший гендиректор стартапа Neon Enterprise Software, который создал ПО zPrime, предлагающее похожую на SDM функциональность. Более того, компания сама подала в 2009 году иск к IBM, обвиняя последнюю в принуждении заказчиков пользоваться дорогими мейнфреймами. В ответном иске IBM обвинили компания в нарушении патентов, и в 2011 году продукт zPrime прекратил существования. 
Изображение: IBM По счастливой случайности в том же году появилась швейцарская компания LzLabs. В 2016 году она представила платформу, которая позволяла выполнять традиционные рабочие нагрузки мейнфреймов, написанные на Cobol или PL/1, на стандартных x86-серверах под управлением Linux как локально, так и в облаке. Впоследствии компания добавила поддержку контейнеров. У LzLabs есть успешные проекты — так, Swisscom перенесла на облачный вариант SDM «все критически важные бизнес-приложения» без перекомпилирования. IBM утверждает, что LzLabs, используя транслятор CPU-инструкций, нарушила два патента на решения, воплощенные в этих инструкциях. Ещё два нарушения связаны с повышением эффективности эмуляции и трансляции. Последний, пятый патент, о нарушении которого сообщила IBM, касается автоматический замены вызываемых приложений на их аналоги для x86-платформ. В своём иске IBM добивается судебного запрета на использование LzLabs интеллектуальной собственности и коммерческих секретов IBM. У IBM есть собственная платформа для разработки, тестирования, демонстрации и изучения приложений мейнфреймов IBM Z Development and Test Environment (ZD&T) на x86-системах, в том числе облачных. А недавно компания представила сервис Wazi aaS для IBM Cloud. В обоих случаях IBM прямо запрещает использовать эти решения для выполнения любых реальных нагрузок, в особенности критически важных.
23.03.2022 [01:10], Алексей Степин
Анонсирован ускоритель AMD Instinct MI210: половинка MI250 в форм-факторе PCIe-картыAMD продолжает активно осваивать рынок ускорителей и ИИ-сопроцессоров. Вслед за сверхмощными Instinct MI250 и MI250X, анонсированными ещё осенью прошлого года, «красные» представили новинку — ускоритель Instinct MI210. Это менее мощная, одночиповая версия ускорителя с архитектурой CDNA 2, дополняющая семейство MI200 и имеющая более универсальный форм-фактор PCIe-карты. Если Instinct MI250/250X существует только как OAM-модуль, то новый Instinct MI210 имеет вид обычной платы расширения с разъёмом PCI Express 4.0. Это неудивительно, ведь MI250 физически невозможно уложить в тепловые и энергетические рамки, обеспечиваемые таким форм-фактором, поскольку два чипа Aldebaran требуют 560 Вт против привычных для PCIe-плат 300 Вт. Для питания MI210 используется как слот PCIe, так и 8-контактный разъём EPS12V.  Поскольку ускоритель на борту новинки только один, она вдвое уступает MI250/250X по всем параметрам, но всё равно обеспечивает весьма неплохую производительность во всех форматах вычислений. Стоит отметить, что функциональные возможности MI210 не уменьшились. Осталась, например, поддержка Infinity Fabric 3.0 — соответствующие разъёмы расположены в верхней части карты, и она поддерживает работу в кластерном режиме из двух или четырёх ускорителей. 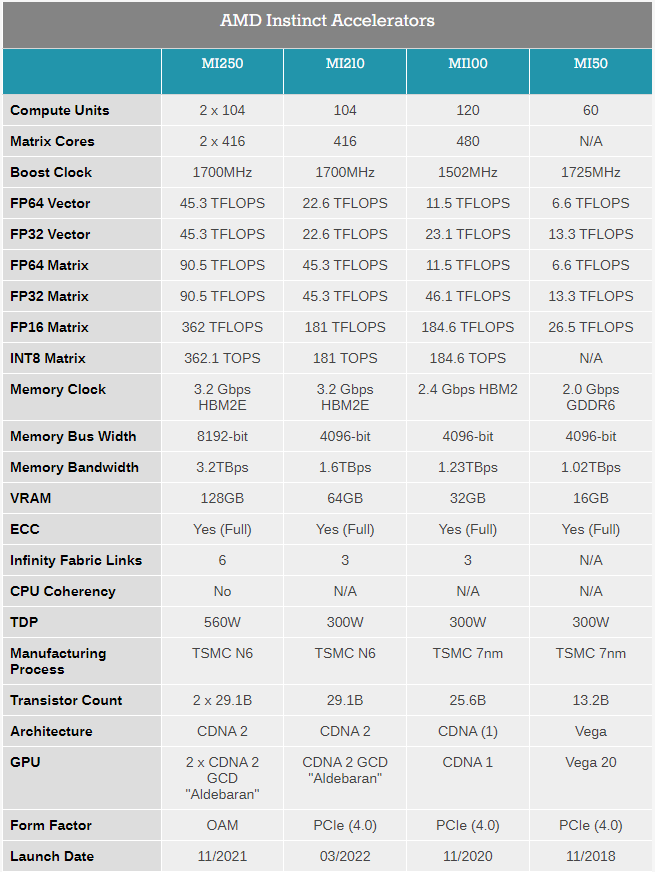
Таблица опубликована AnandTech В MI210 используется более простой вариант Aldebaran с одним кристаллом. Что интересно, по количеству вычислительных блоков этот вариант уступает более старому MI100 (104 CU против 120, 416 матричных ядер против 480). Однако последний использует первую итерацию архитектуры CDNA и работает на меньшей частоте — 1500 против 1700 МГц у новинки. В некоторых форматах вычислений MI100 может быть быстрее, но разница крайне незначительна. 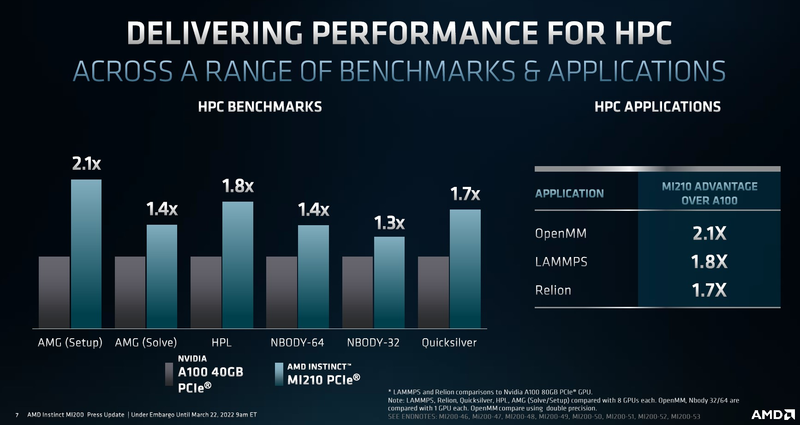
Производительность AMD Instinct MI210 в сравнении с NVIDIA A100 40GB PCIe CDNA2 позволяет использовать уникальные форматы данных, вроде packed FP32, однако это требует поддержки со стороны разработчиков, что несколько затруднит создание универсального ПО, способного полностью задействовать возможности MI210. Но в первую очередь, это ускоритель, не «зажимающий» FP64-производительность: свыше 22 Тфлопс в векторных операциях и 45 Тфлопс — в матричных. Сервер с одним или несколькими MI210 может использоваться в качестве универсальной платформы разработки ПО для суперкомпьютеров на базе более мощных ускорителей AMD Instinct MI250/250X. Новинка уже доступна у традиционных партнёров AMD по выпуску серверов, включая ASUS, Dell, HPE, Supermicro и Lenovo, которые также предлагают более мощные решения на базе MI250/250X.
22.03.2022 [18:48], Игорь Осколков
NVIDIA анонсировала 144-ядерные Arm-процессоры Grace и гибрид Grace HopperГлавным событием GTC 2022 стал анонс новых ускорителей H100 (Hopper), которые станут доступны в III квартале 2022 года. Вслед за ними в первой половине 2023 года появятся давно обещанные CPU Grace и гибридная система Grace Hopper, сочетающие, как понятно из названия, процессоры Grace (ARMv9) и ускорители Hopper. Как и было сказано ранее, для связи всех компонентов между собой будет использоваться mesh-сеть на базе всё той же шины NVLink 4.0 (900 Гбайт/с) с кеш-когерентностью. А сочетание LPDDR5X (с ECC, конечно) и HBM даст суммарный объём памяти до 600 Гбайт с общей полосой пропускания порядка 2 Тбайт/с. Для Grace Hopper компания подготовит полный стек ПО, благо портированием на Arm она начала заниматься ещё 3 года назад. 
NVIDIA Grace (Изображения: NVIDIA) Двухчиповый процессор Grace Superchip для ИИ- и HPC-нагрузок имеет 144 ядра, результат которых в SPECrate2017_int_base составляет 740, что, по словам компании, в полтора раза выше, чему у пары AMD EPYC, использующихся в DGX A100. И это, честно говоря, не такой уж и впечатляющий результат.  Но NVIDIA утверждает, что новые CPU вдвое лучше по отношению производительности к энергопотреблению, чем «традиционные серверы» — использование LPDDR5X позволяет добиться пропускной способности памяти в 1 Тбайт/с, а вся сборка CPU+RAM будет потреблять менее 500 Вт. 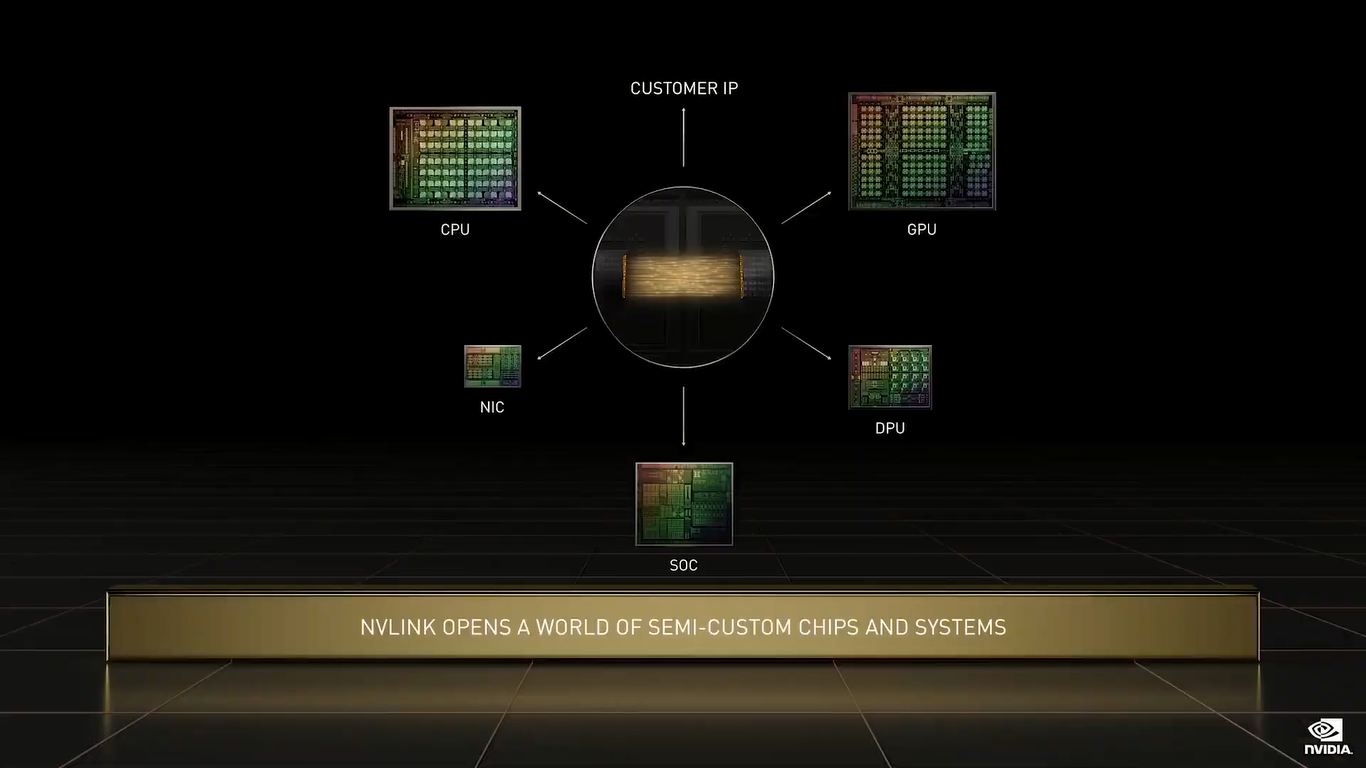 Чипы (или чиплеты, если хотите) в Grace Superchip тоже объединены посредством NVLink, только в данном случае этот интерконнект называется NVLink-C2C (Chip-to-Chip). И его NVIDIA предлагает использовать другим компаниям для создания кастомных сборок, объединяющих необходимые кристаллы, да и сама готова масштабировать и адаптировать свои решения под нужды заказчика. 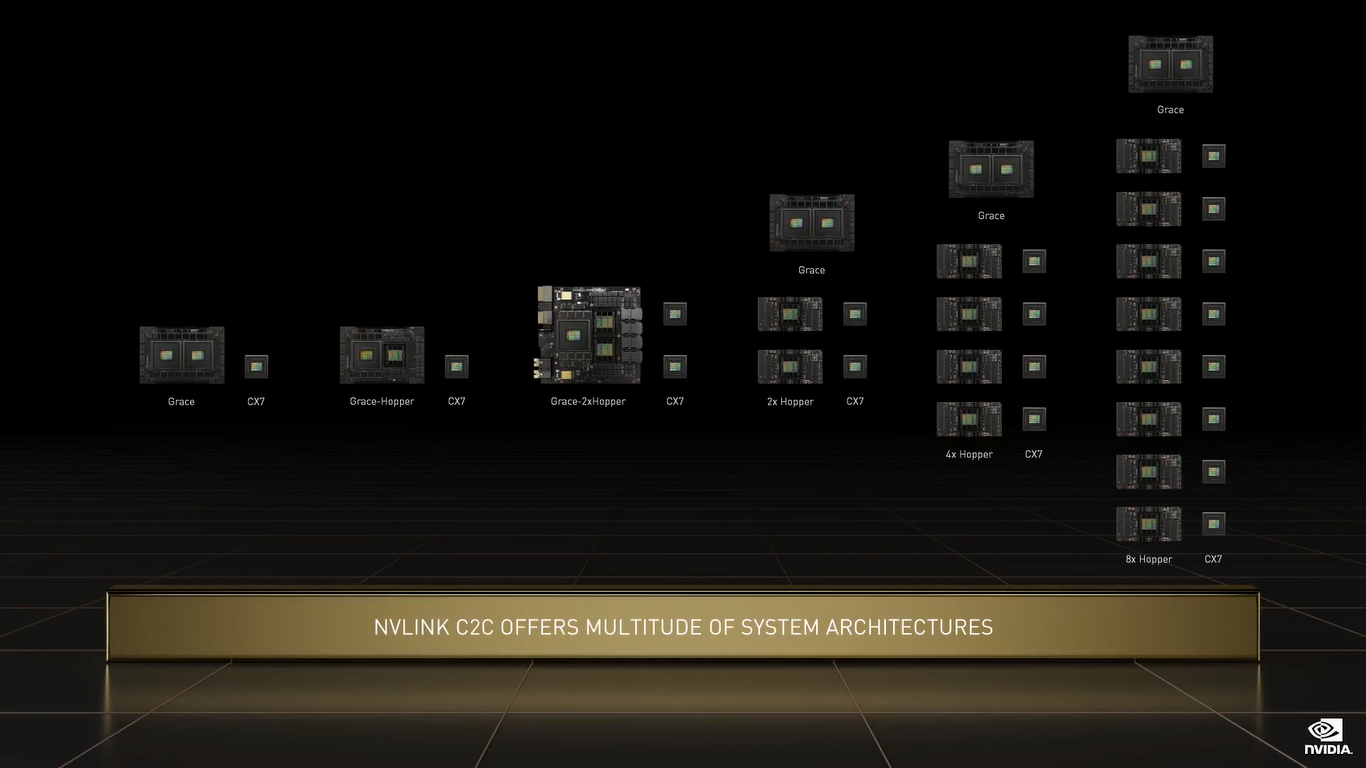 По словам NVIDIA, NVLink-C2C в 25 раз энергоэффективнее PCIe 5.0, а для его реализации нужна в 90 раз меньшая площадь кремния. Шина предлагает высокую скорость (да-да, всё те же 900 Гбайт/с), низкий уровень задержек, поддержку атомарных операций и совместимость с Arm AMBA CHI, CXL и UCIe.
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки). 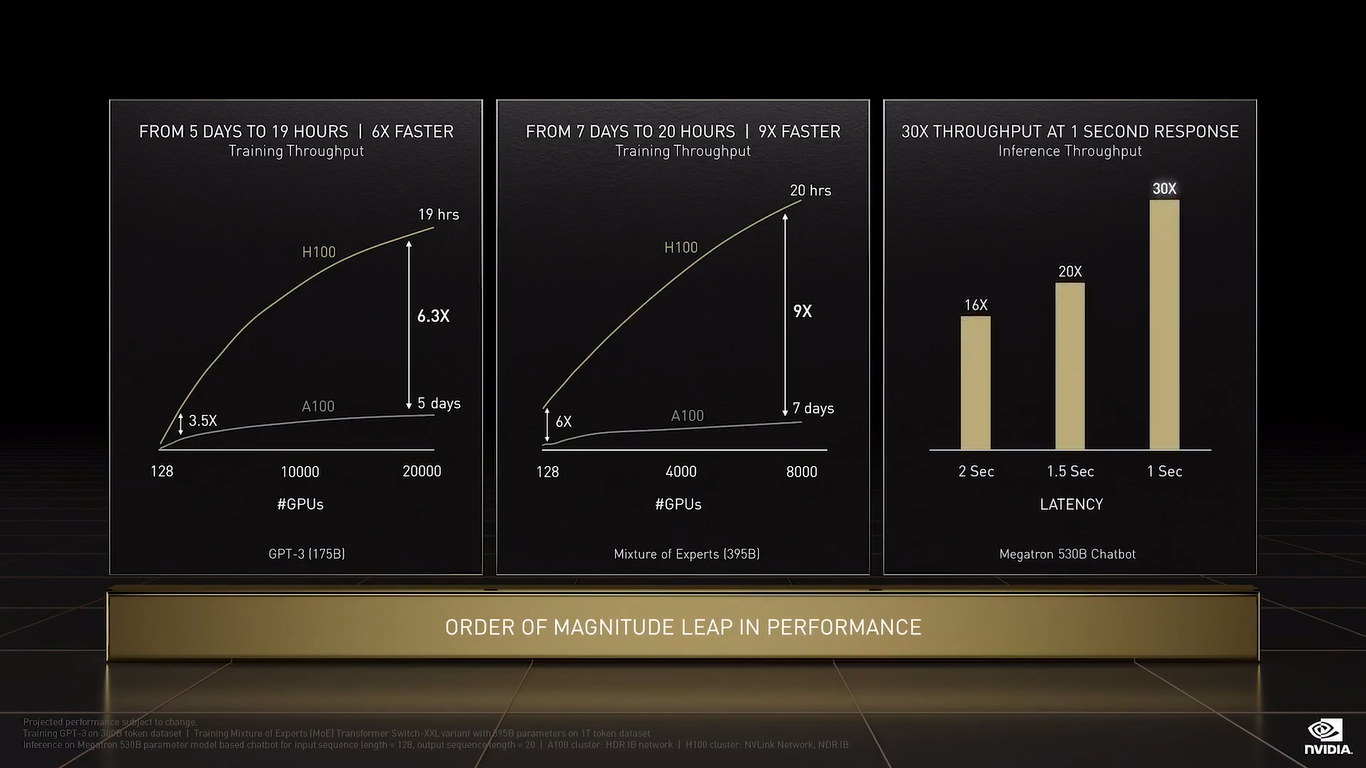 Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4.
11.03.2022 [18:28], Владимир Мироненко
ENOG, евразийская группа сетевых операторов RIPE NCC, похоже, фактически расформированаЕвразийская группа сетевых операторов (ENOG), основанная RIPE NCC (некоммерческая ассоциация, выполняющая функции регионального Интернет-реестра [RIR]), оказалась фактически расформированной после того, как её руководство покинуло посты. ENOG поддерживает развитие Сети в азербайджанском, армянском, белорусском, русском, украинском и других, преимущественно постсоветских региональных сообществах. Председатель Программного комитета ENOG Артём Гавриченков в своё посте на форуме RIPE указал, что сообщество ENOG практически распалось: «Настоящим я при всем уважении прошу, чтобы Исполнительный совет RIPE официально распустил ENOG и отменил все возможные будущие встречи на неопределённый срок», — написал Гавриченков. Он отметил, что при нормальных обстоятельствах такое решение должно было быть вынесено на голосование, но в существующих условиях, когда ряд членов Программного комитета фактически не может выполнять свои функции в привычном режиме, организовывать голосование по этому поводу нельзя назвать разумным действием. После этого заявления Артём Гавриченков объявил, что покидает пост. 
Источник изображения: ENOG Алексей Семеняка, директор по внешним связям RIPE NCC выразил согласие с тем, что сообщество больше не существует и заявил об уходе с поста заместителя председателя Программного комитета ENOG. Отставки вызвали неоднозначную реакцию сообщества. Один из участников раскритиковал это решение, назвав его эскалацией и добавив, что может быть, целесообразнее было бы передать управление кому-то другому. RIPE отказалась от комментариев по этому поводу. Группа ранее отклонила просьбу украинского правительства помочь отключить Россию, что в основном получило поддержку сообщества. ENOG планировала провести следующую региональную встречу RIPE NCC в июне этого года в Москве. В ENOG входят участники из Ростелекома, Scaleway, СВК-Телеком, Яндекса, DE-CIX, Servers.com, Megalink и т. д.
05.03.2022 [01:28], Алексей Степин
Graphcore анонсировала ИИ-ускорители BOW IPU с 3D-упаковкой кристаллов WoWРазработка специализированных ускорителей для задач и алгоритмов машинного обучения в последние несколько лет чрезвычайно популярна. Ещё в 2020 году британская компания Graphcore объявила о создании нового класса ускорителей, которые она назвала IPU: Intelligence Processing Unit. Их архитектура оказалась очень любопытной. Основной единицей IPU является не ядро, а «тайл» — область кристалла, содержащая как вычислительную логику, так и некоторое количество быстрой памяти с пропускной способностью в районе 45 Тбайт/с (7,8 Тбайт/с между тайлами). В первой итерации чип Graphcore получил 1216 таких тайлов c 300 Мбайт памяти, а сейчас компания анонсировала следующее поколение своих IPU. 
Изображения: Graphcore Новый чип, получивший название BOW, можно условно отнести к «поколению 2,5». Он использует кристалл второго поколения Colossus Mk2: 892 Мбайт SRAM в 1472 тайлах, способных выполнять одновременно 8832 потока. Этот кристалл по-прежнему производится с использованием 7-нм техпроцесса TSMC, но теперь Graphcore перешла на использование более продвинутой упаковки типа 3D Wafer-on-Wafer (3D WoW). Новый IPU стал первым в индустрии чипом высокой сложности, использующем новый тип упаковки, причём технология 3D WoW была совместно разработана Graphcore и TSMC с целью оптимизации подсистем питания. Процессоры такой сложности отличаются крайней прожорливостью, а «накормить» их при этом не просто. В итоге обычная упаковка не позволяет добиться от чипа уровня Colossus Mk2 максимальной производительности — слишком велики потери и паразитный нагрев. 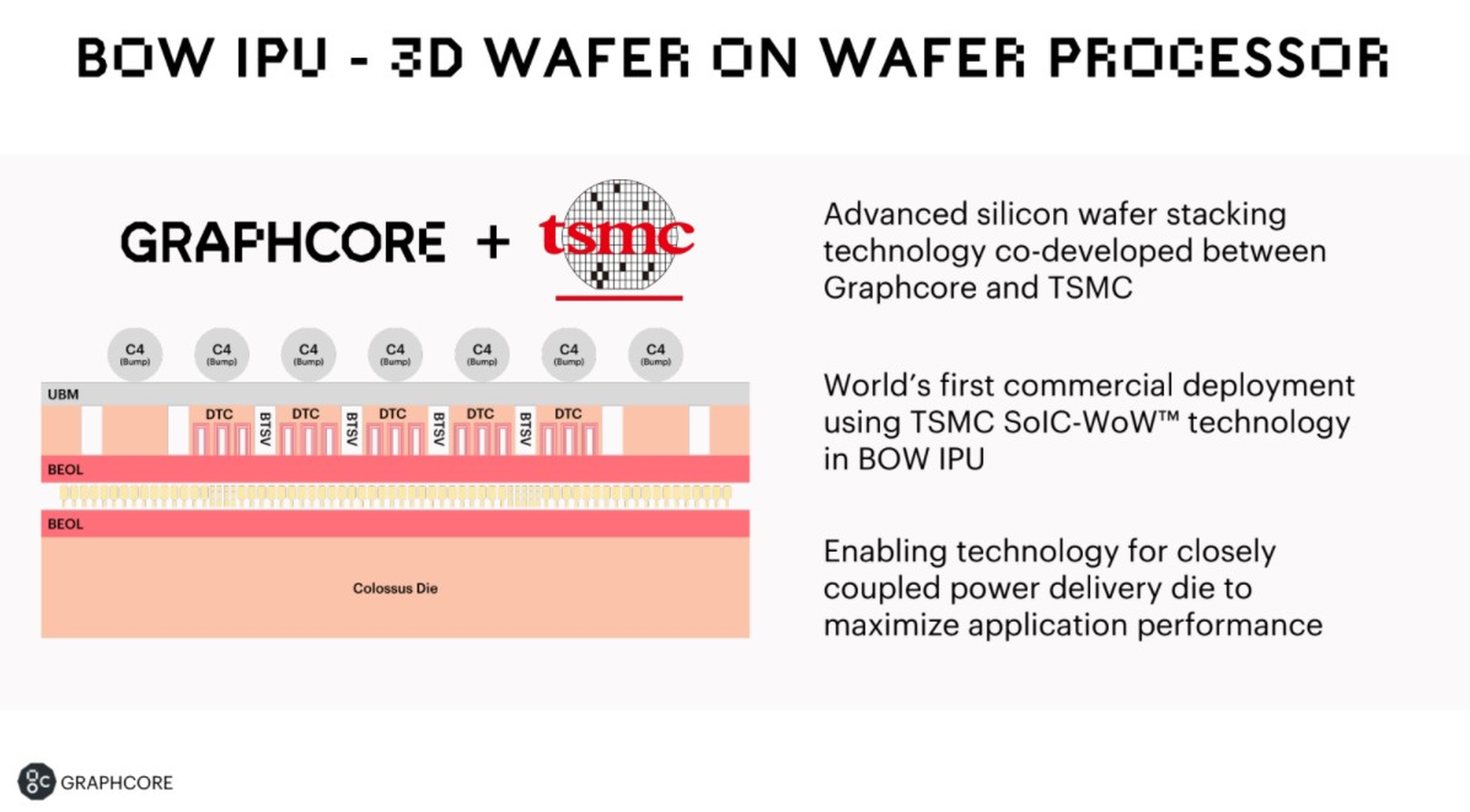 Реализована 3D WoW во многом аналогично технологии, применённой AMD в серверных чипах Milan-X. Упрощённо говоря, медные структуры-стержни пронизывают кристалл и позволяют соединить его напрямую с другим кристаллом, причём «склеиваются» они друг с другом благодаря. В случае с BOW роль нижнего кристалла отводится распределителю питания с системой стабилизирующих конденсаторов, который питает верхний кристалл Colossus Mk2. За счёт перехода с плоских структур на объёмные можно как увеличить подводимый ток, так и сделать путь его протекания более короткими. В итоге компании удалось дополнительно поднять частоту и производительность BOW, не прибегая к переделке основного процессора или переводу его на более тонкий и дорогой техпроцесс. Если у оригинального IPU второго поколения максимальная производительность составляла 250 Тфлопс, то сейчас речь идёт уже о 350 Тфлопс — для системы BOW-2000 с четырьмя чипами заявлено 1,4 Пфлопс совокупной производительности. И это хороший выигрыш, полученный без критических затрат. 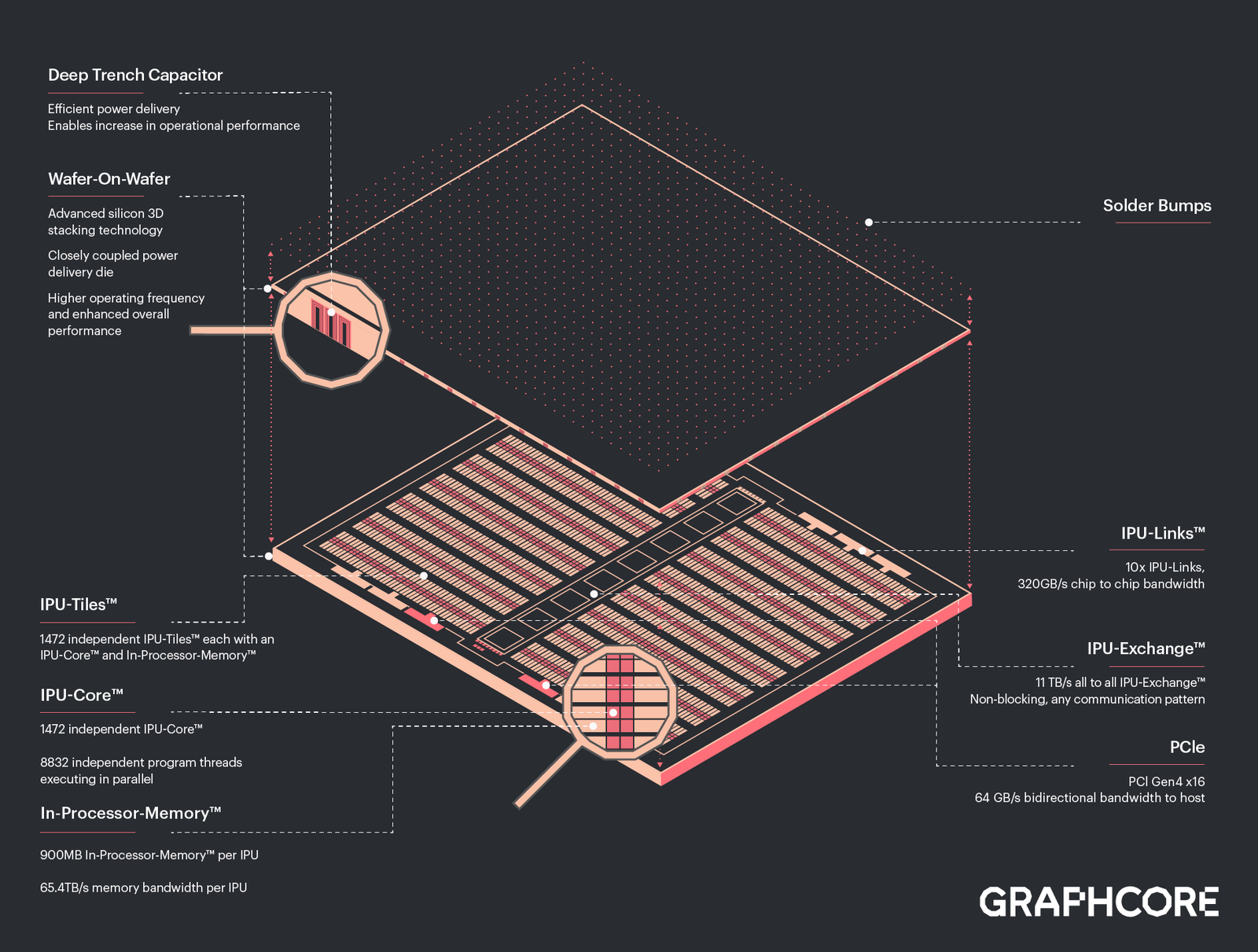 С внешним миром IPU общается по-прежнему посредством 10 каналов IPU-Link (320 Гбайт/с). Внутренней памяти в такой системе уже почти 4 Гбайт, причём работает она на скорости 260 Тбайт/с — критически важный параметр для некоторых задач машинного обучения, которые требуют всё большие по объёму наборов данных. Ёмкость набортной памяти далека от предлагаемой NVIDIA и AMD, но выигрыш в скорости даёт детищу Graphcore серьёзное преимущество. Узлы BOW-2000 совместимы с узлами предыдущей версии. Четыре таких узла (BOW POD16) с управляющим сервером — всё в 5U-шасси — имеют производительность до 5,6 Пфлопс. А полная стойка с 16 узлами BOW-2000 (BOW POD64) даёт уже 22,4 Пфлопс. По словам компании, производительность новой версии возросла на 30–40 %, а прирост энергоэффективности составляет от 10 % до 16 %. 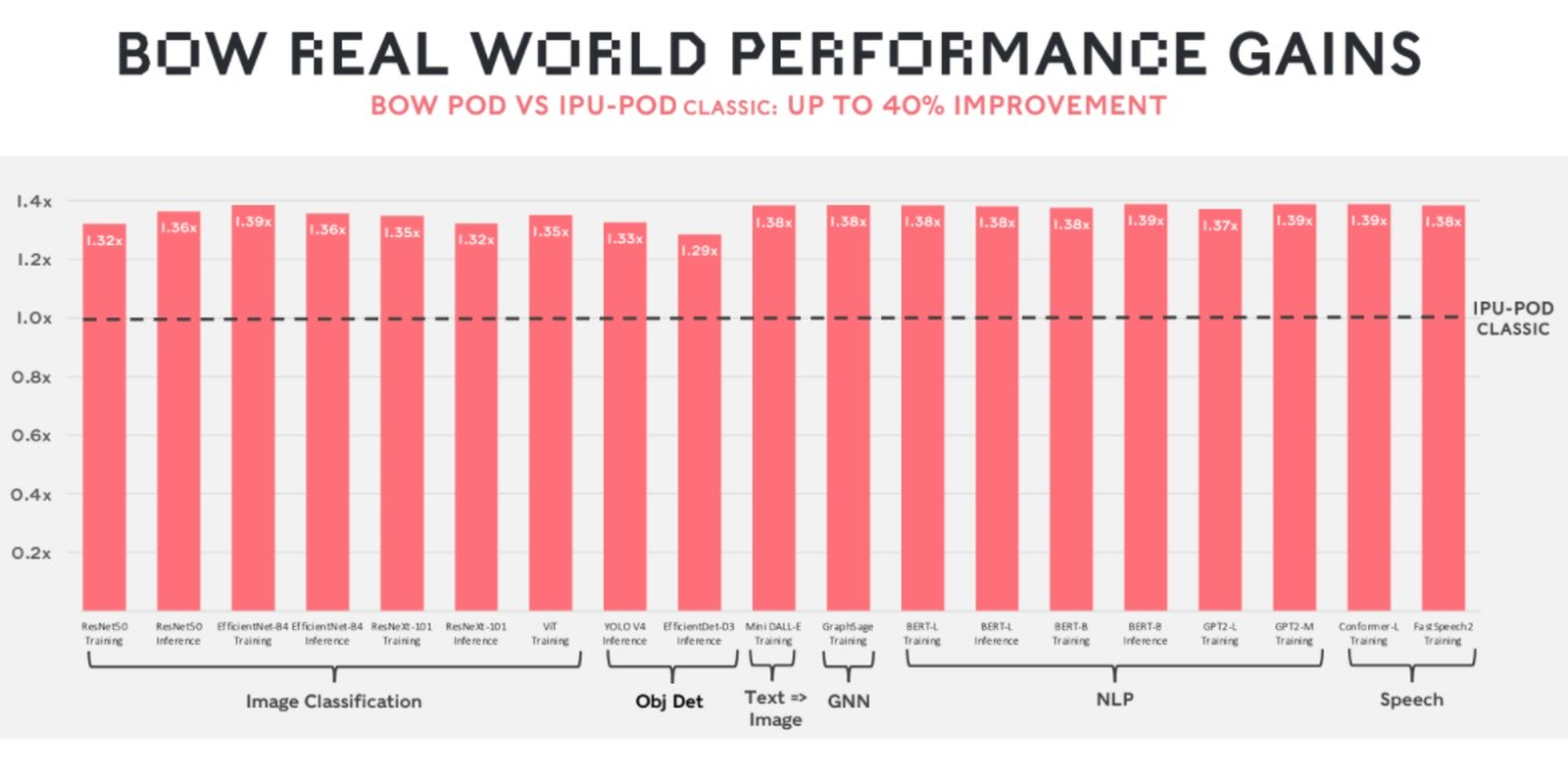 Graphcore говорит о десятикратном превосходстве BOW POD16 над NVIDIA DGX-A100 в полной стоимости владения (TCO). Cтоит BOW POD16 вдвое дешевле DGX-A100. К сожалению, говорить о завоевании рынка машинного обучения Graphcore рано: клиентов у компании уже довольно много, но среди них нет таких гигантов, как Google или Baidu. В долгосрочной перспективе ситуация для Graphcore далеко не безоблачна, но компания уже готовит третье поколение IPU на базе 3-нм техпроцесса.
04.03.2022 [20:20], Руслан Авдеев
Опубликован доклад о пожаре в ЦОД OVHcloud: деревянные потолки, отсутствие системы автоматического пожаротушения и единого «электрорубильника»Через год после пожара в дата-центре OVHcloud в Страсбурге, наконец, опубликован официальный отчёт, согласно которому сгоревший объект не соответствовал многим требованиям к безопасности подобного типа помещений. Здание дата-центра SBG2 вспыхнуло 10 марта 2021 года, но пострадал и соседний ЦОД SBG1, который было решено не восстанавливать. По данным местных экспертов, которые приводит DataCenter Dynamics со ссылкой на Le Journal Du Net (JDN), SBG2 не имел автоматической системы пожаротушения, деревянные потолки помещения способны были противостоять огню не более часа, а система вентиляции создавала условия, благодаря которым огонь распространялся гораздо быстрее, чем мог бы. Более того, пожарные встретили в горящем здании электрические дуги протяжённостью более метра, вспыхивавшие на пути в энергоотсек. 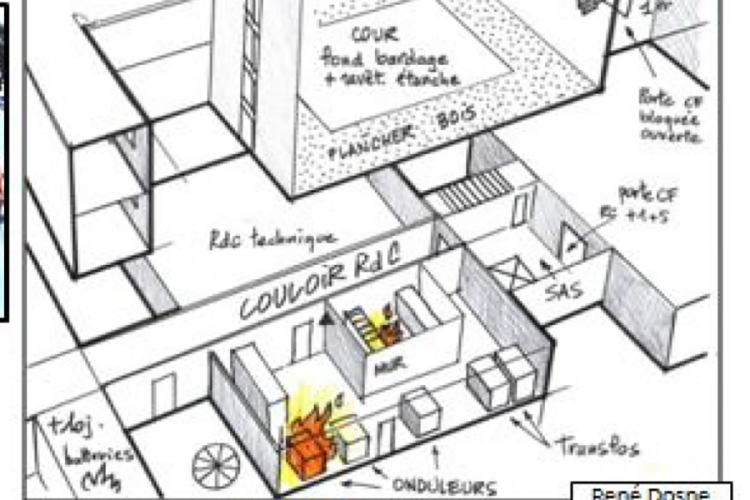
Источник изображения: Bas-Rhin Fire Service (via DataCenter Dynamics) На полное отключение электропитания ушло три часа, поскольку единой точки изоляции от энергосети у ЦОД не было. Так что некоторые клиенты всё ещё пользовались серверами после начала возгорания. После того, как огонь вырвался из энергоотсека, он стал быстро распространяться по помещениям из-за неудачной конструкции системы вентиляции, обеспечивающей приток свежего воздуха для охлаждения серверов. 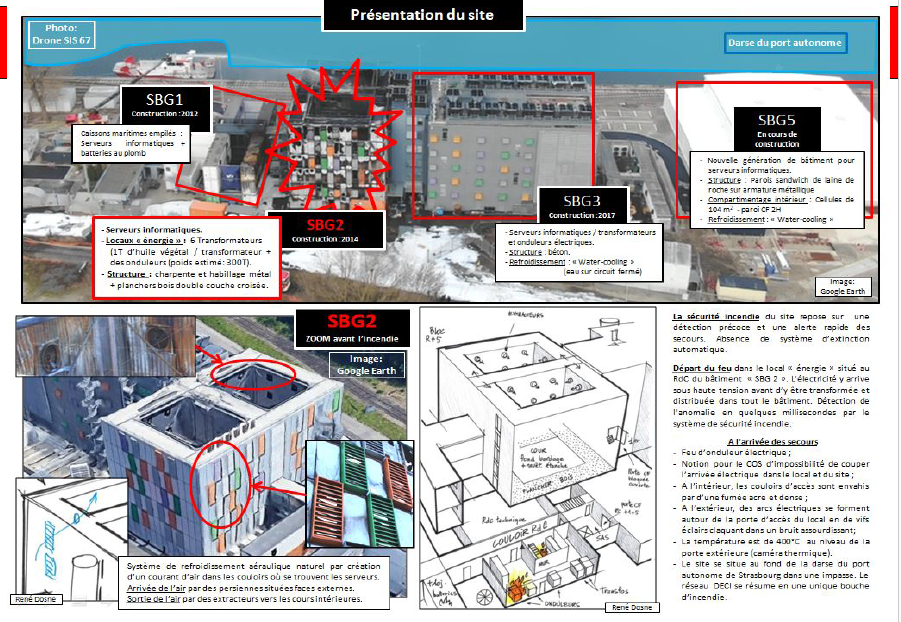
Источник изображения: Bas-Rhin Fire Service (via DataCenter Dynamics) Отчёт может повлиять на грядущие судебные разбирательства и капитализацию компании, которая недавно вышла на биржу — бывшие клиенты подали к OVHcloud коллективный иск, обвиняя её в том, что она не справилась со своими обязанностями и, кроме того, не предоставила адекватную компенсацию пострадавшим. Ранее сообщалось, что к иску присоединились 103 клиента, ещё 4 крупных игрока решили выступить в суде самостоятельно.
03.03.2022 [19:00], Алексей Степин
Intel анонсировала новую версию платформы vPro, в том числе для ChromeOSВместе с расширением двенадцатого поколения процессоров Core (Alder Lake) компания Intel представила и новую версию бизнес-платформы vPro, обеспечивающую улучшенные возможности в области удалённого управления и информационной безопасности. Сама платформа vPro насчитывает уже более 15 лет, но сегодня некогда достаточно простой набор технологий разросся до полноценного портфолио, покрывающего потребности бизнес-клиентов в любых масштабах. 
Изображения: Intel Обновлённое портфолио включает следующие разновидности Intel vPro:
 В рамках новой версии vPro, по словам Intel, представлен полный спектр систем и решений, подходящий для любой задачи любой компании любого размера. Помимо всех тех особенностей, что предлагает архитектура Alder Lake (два вида ядер, DDR5 и т.д.), платформа vPro также включает ряд других программных и аппаратных компонентов:
 На момент анонса партнёрами Intel представлено более 150 различных дизайнов вычислительных платформ, во всех форм-факторах. Все они должны быть доступны уже в этом году. Не забыта и сфера IoT, где процессоры Intel двенадцатого поколения в сочетании с vPro обеспечат высокую производительность и удобство удалённого управления. Новинки этого типа отлично впишутся в современную розничную торговлю, образование медицину, производственные и банковские процессы, экосистемы «умных городов» и т.д.  С точки зрения Cisco, одного из крупнейших производителей сетевого оборудования, в новой платформе очень важна поддержка Wi-Fi 6E, не просто обеспечивающая настоящий «гигабит по воздуху», но и позволяющая без проблем подключать больше беспроводных устройств к точкам доступа, большую надёжность, и предсказуемость поведения Wi-Fi в сценариях класса mission critical. Компания считает очень удачным сочетание систем Intel с поддержкой Wi-Fi 6E c новыми точками доступа Cisco Catalyst и Meraki.
27.02.2022 [01:01], Владимир Мироненко
Облако ждёт: к 2030 году Fujitsu откажется от мейнфреймов и UNIX-системFujitsu подтвердила, что выпуску её мейнфреймов и серверных систем c Unix подходит конец. Согласно новым планам компании, она прекратит производство и продажу мейнфреймов к 2030 году, а выпуск серверных систем UNIX — к концу 2029 года. Сопровождение обоих продуктов продлится в течение ещё пяти лет и закончится в 2035 году и в 2034 году соответственно. Как надеется компания, к тому времени пользователи подобных систем окончательно перейдут в облако. 
Источник изображений: Fujitsu Тем не менее, Fujitsu по-прежнему планирует выпустить в 2024 году новую модель в серии мейнфреймов GS21. Также планируется обновление семейства UNIX-серверов Fujitsu SPARC M12 в конце этого года и в 2026 году. Впрочем, это пока предварительные планы. Компания уже составила график перехода с мейнфреймов и UNIX-серверов в облако в рамках нового бизнес-бренда Fujitsu Uvance. Теперь у пользователей мейнфреймов Fujitsu есть чётко обозначенный срок, к которому они должны перенести свои приложения на другую платформу или воспользоваться возможностью создать их с нуля в рамках более современной инфраструктуры.  Сомнительной альтернативой может быть уход на платформу IBM z. Филип Доусон (Philip Dawson), вице-президент Gartner Research сообщил The Register, что отказ от UNIX пройдёт менее болезненно, так как рабочие нагрузки могут быть относительно легко перенесены на Linux: «По сути, Linux заменил UNIX. Но такой замены нет для мейнфреймов. Когда аппаратное обеспечение исчезнет, что вы будете делать с приложениями?». Фактически Fujitsu в наследство достались две разные серии мейнфреймов от Amdahl Corporation (GS21) и Siemens (BS2000), если не считать старые решения ICL. |
|