Материалы по тегу: mi200
|
23.03.2022 [01:10], Алексей Степин
Анонсирован ускоритель AMD Instinct MI210: половинка MI250 в форм-факторе PCIe-картыAMD продолжает активно осваивать рынок ускорителей и ИИ-сопроцессоров. Вслед за сверхмощными Instinct MI250 и MI250X, анонсированными ещё осенью прошлого года, «красные» представили новинку — ускоритель Instinct MI210. Это менее мощная, одночиповая версия ускорителя с архитектурой CDNA 2, дополняющая семейство MI200 и имеющая более универсальный форм-фактор PCIe-карты. Если Instinct MI250/250X существует только как OAM-модуль, то новый Instinct MI210 имеет вид обычной платы расширения с разъёмом PCI Express 4.0. Это неудивительно, ведь MI250 физически невозможно уложить в тепловые и энергетические рамки, обеспечиваемые таким форм-фактором, поскольку два чипа Aldebaran требуют 560 Вт против привычных для PCIe-плат 300 Вт. Для питания MI210 используется как слот PCIe, так и 8-контактный разъём EPS12V.  Поскольку ускоритель на борту новинки только один, она вдвое уступает MI250/250X по всем параметрам, но всё равно обеспечивает весьма неплохую производительность во всех форматах вычислений. Стоит отметить, что функциональные возможности MI210 не уменьшились. Осталась, например, поддержка Infinity Fabric 3.0 — соответствующие разъёмы расположены в верхней части карты, и она поддерживает работу в кластерном режиме из двух или четырёх ускорителей. 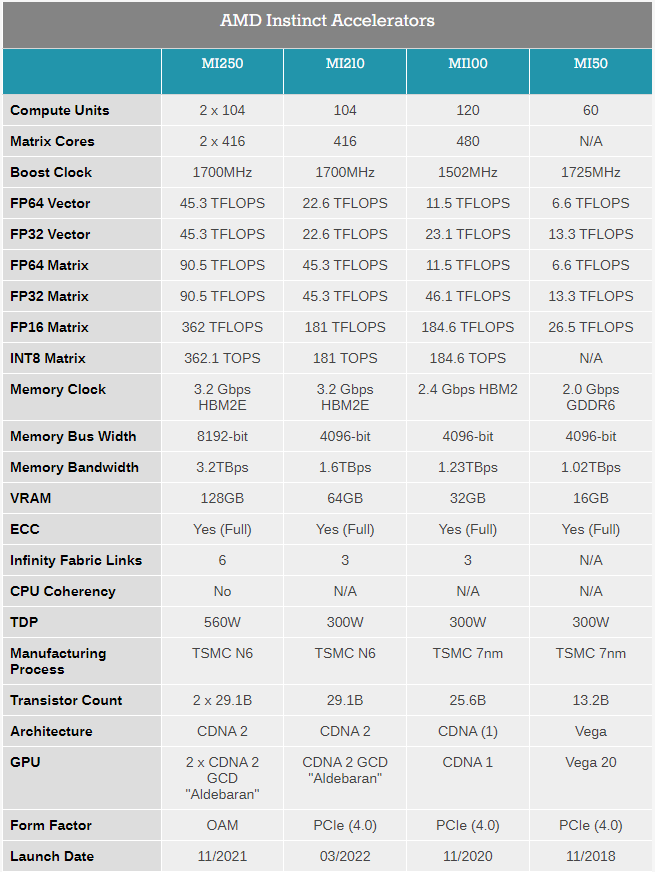
Таблица опубликована AnandTech В MI210 используется более простой вариант Aldebaran с одним кристаллом. Что интересно, по количеству вычислительных блоков этот вариант уступает более старому MI100 (104 CU против 120, 416 матричных ядер против 480). Однако последний использует первую итерацию архитектуры CDNA и работает на меньшей частоте — 1500 против 1700 МГц у новинки. В некоторых форматах вычислений MI100 может быть быстрее, но разница крайне незначительна. 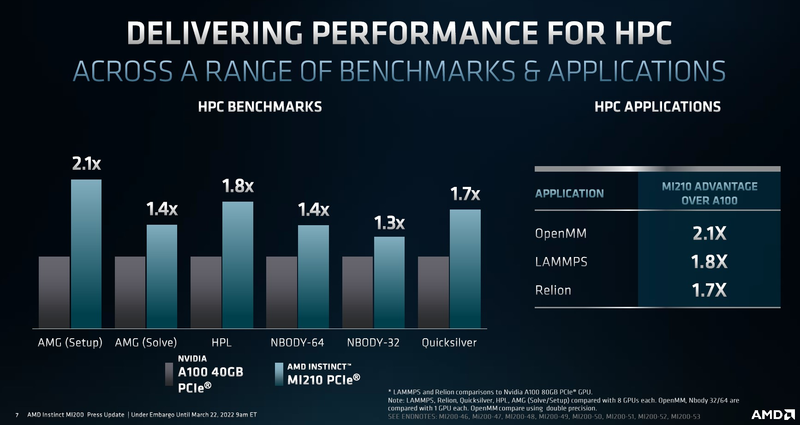
Производительность AMD Instinct MI210 в сравнении с NVIDIA A100 40GB PCIe CDNA2 позволяет использовать уникальные форматы данных, вроде packed FP32, однако это требует поддержки со стороны разработчиков, что несколько затруднит создание универсального ПО, способного полностью задействовать возможности MI210. Но в первую очередь, это ускоритель, не «зажимающий» FP64-производительность: свыше 22 Тфлопс в векторных операциях и 45 Тфлопс — в матричных. Сервер с одним или несколькими MI210 может использоваться в качестве универсальной платформы разработки ПО для суперкомпьютеров на базе более мощных ускорителей AMD Instinct MI250/250X. Новинка уже доступна у традиционных партнёров AMD по выпуску серверов, включая ASUS, Dell, HPE, Supermicro и Lenovo, которые также предлагают более мощные решения на базе MI250/250X.
08.11.2021 [20:00], Игорь Осколков
AMD анонсировала Instinct MI200, самые быстрые в мире ускорители вычислений на базе CDNA 2В прошлом году AMD окончательно развела ускорители для графики и вычислений, представив Instinct MI100, первый продукт на базе архитектуры CDNA, который позволил компании противостоять NVIDIA. Теперь же AMD подготовила новую версию архитектуры CDNA 2 и ускорители MI200 на неё основе. Новинки, согласно внутренним тестам, в ряде задач на голову выше того, что сейчас может предложить NVIDIA. 
AMD Instinct MI200 в OAM-варианте (Здесь и ниже изображения AMD) Циркулировавшие ранее слухи оказались верны — MI200 являются двухчиповыми решениями с 2.5D-упаковкой кристаллов (GCD) самих ускорителей, четырёх линий Infinity Fabric между ними и восьми стеков памяти HBM2e (8192 бит, 1600 МГц, 128 Гбайт, 3,2 Тбайт/c). В данном случае используется мостик EFB (Elevated Fanout Bridge), который позволяет задействовать стандартные подложки, что удешевляет и упрощает производство и тестирование ускорителей, не потеряв при этом в производительности и, что важнее, без существенного увеличения задержек в обмене данными. 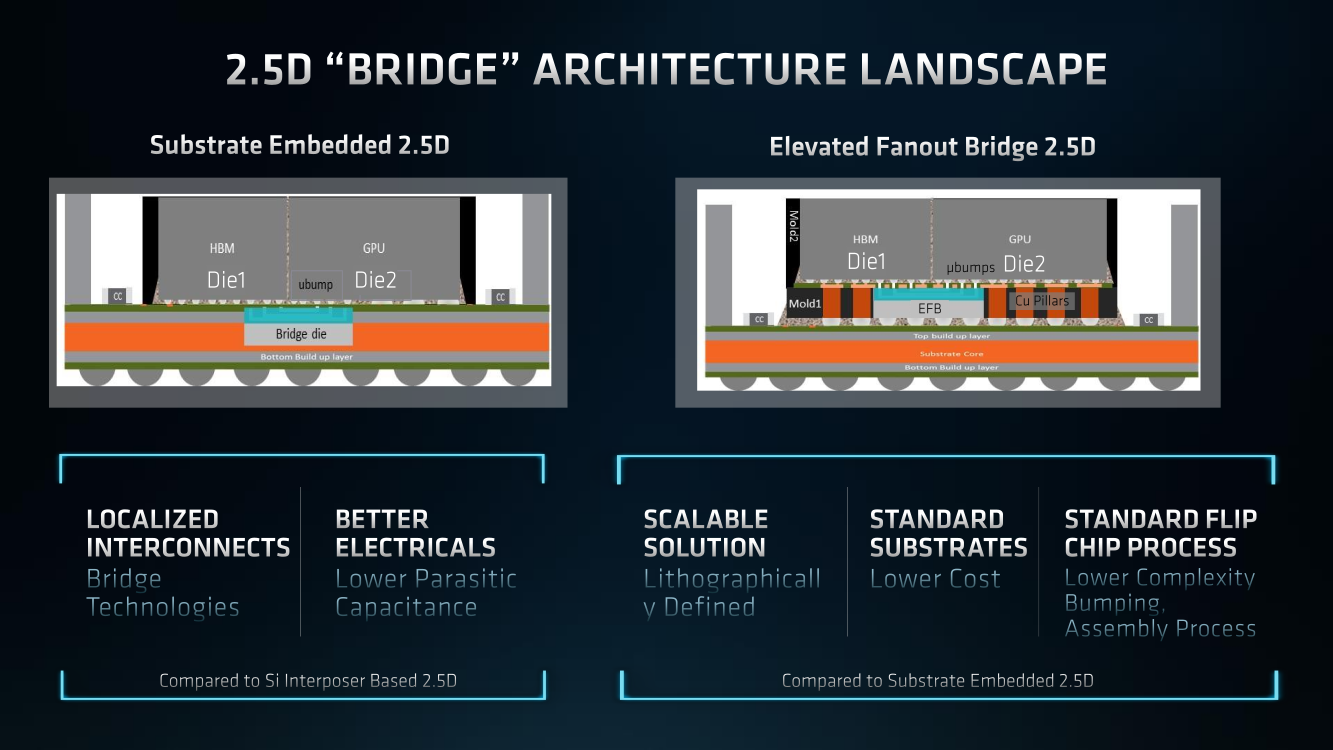 Несмотря на то, что в составе ускорителя два GCD, системе они представляются как единое целое с общей же памятью. Каждый GCD в случае CDNA 2 включает 112 CU (Compute Unit), но в конечных продуктах они задействованы не все. CU разбиты на четыре группы (с индивидуальным планировщиком) с общим L2-кешем объёмом 8 Мбайт и пропускной способностью 6,96 Тбайт/с, который поделён на 32 отдельных блока. А сами блоки имеют индивидуальные подключения к контроллерам памяти в GCD.  Важное отличие CDNA 2 заключается в «подтягивании» производительности векторных FP64- и FP32-вычислений — они исполняются с одинаковой скоростью в отличие от CDNA первого поколения. Кроме того, появилась поддержка сжатых (packed) инструкций для операций FMA/FADD/FMUL для FP32-векторов. Второй крупный апдейт касается матричных вычислений. Для них теперь тоже есть отдельная поддержка FP64, и с той же производительностью, что и для FP32. Новые инструкции рассчитаны на блоки 16×16×4 и 4×4×4. 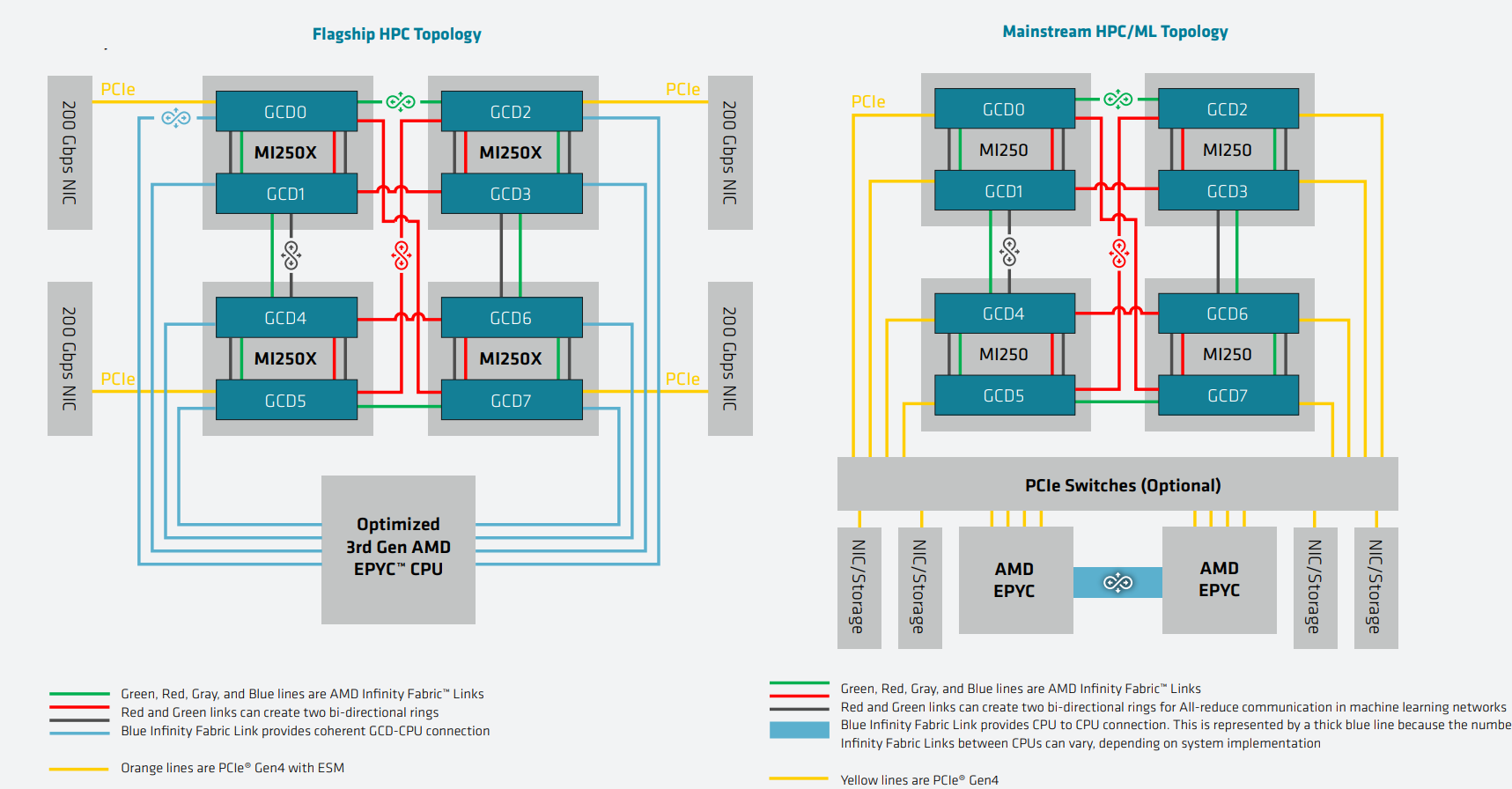 Поддержка FP16/BF16 в матричных ядрах, конечно, тоже есть, что позволяет задействовать их и для ИИ-задач, а не только HPC. Подспорьем для них в некоторых задачах будут два блока VCN (Video Codec Next) в каждом GCD. Они поддерживают декодирование H.264/AVC, H.265/HEVC, VP9 и JPEG, а также кодирование H.264/H.265, что потенциально позволит более эффективно работать ИИ-алгоритмам с изображениями и/или видео. 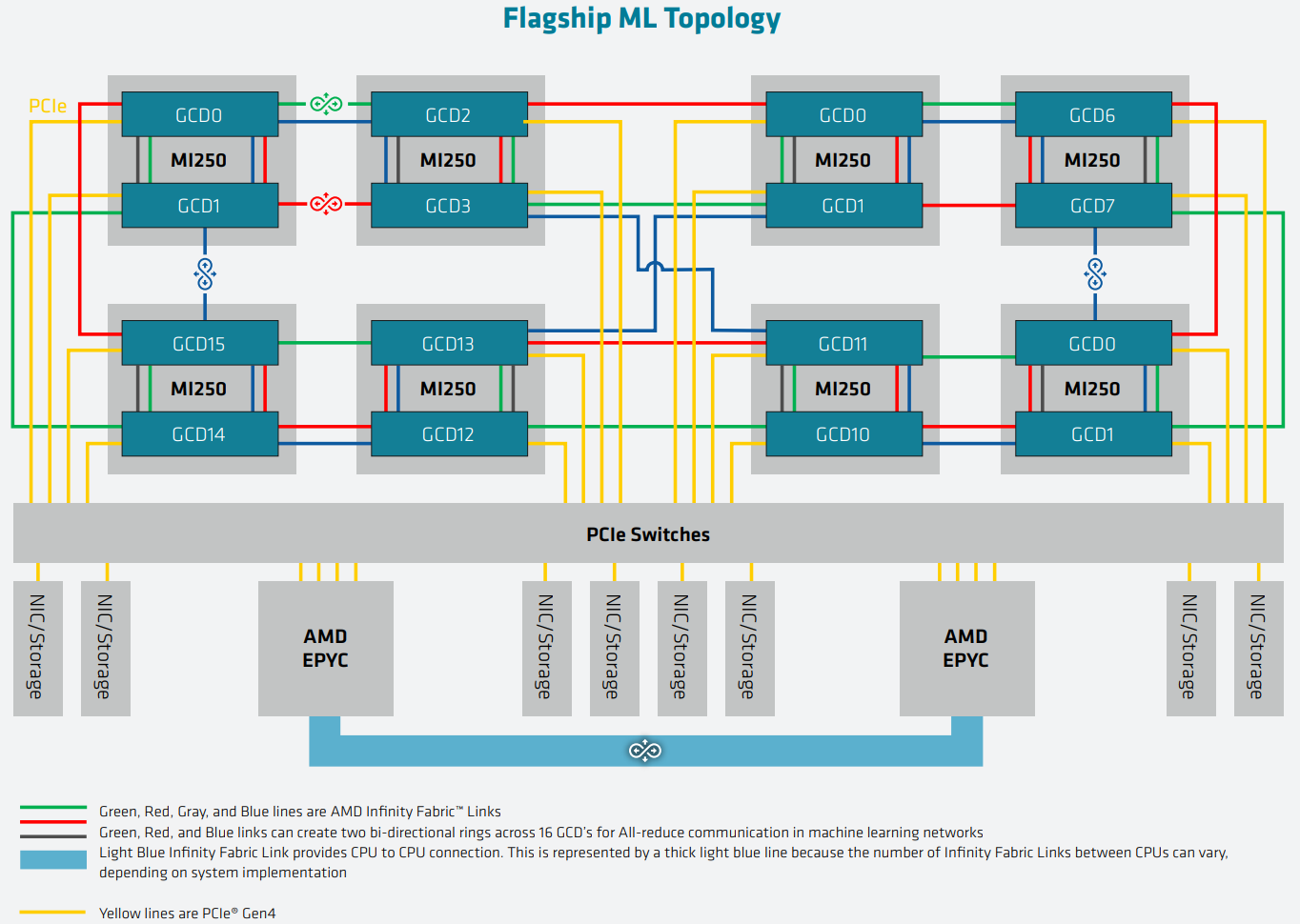 Для обмена данными между ускорителями и CPU используется единая шина Infinity Fabric (IF) с поддержкой кеш-когерентности. Всего на ускоритель приходится до восьми внешних линий IF, а суммарная скорость обмена данными может достигать 800 Гбайт/c. В наиболее плотной компоновке из четырёх MI200 и одного EPYC каждый ускоритель имеет по две линии для связи с CPU и со своим соседом. Причём внутренние и внешние IF-линии образуют два двунаправленных кольца между ускорителями. Каждая IF-линия опирается на x16-подключение PCIe 4.0, но в данном случае есть ряд оптимизаций конкретно под HPC-системы HPE Cray.  Дополнительно у каждого ускорителя есть собственный root-комплекс, что позволяет напрямую подключить сетевой адаптер класса 200G. И это явный намёк на возможность непосредственного RDMA-соединения с внешними хранилищами, поскольку в такой схеме на локальные NVMe-накопители линий попросту не остаётся. Более простые топологии уже предполагают использование половины линий IF в качестве обычного PCIe-подключения и задействуют коммутатор(-ы) для связи с CPU и NIC. В этом случае IF-подключение остаётся только между процессорами. Зато в одной системе можно объединить восемь MI200.  Чипы ускорителей MI250X изготовлены по 6-нм техпроцессу FinFet, содержат 58 млрд транзисторов и предлагают 220 CU, включающих 880 ядер для матричных вычислений и 14080 шейдерных ядер второго поколения. У MI250 их 208, 832 и 13312 соответственно. Для обеих моделей уровень TDP составляет 500 или 560 Вт, поэтому поддерживается как воздушное, так и жидкостное охлаждение. В дополнение к OAM-версиям MI250(X) чуть позже появится и более традиционная PCIe-модель MI210.  Для сравнения — у NVIDIA A100 объём и пропускная способность памяти (тоже HBM2e) составляют до 80 Гбайт и 2 Тбайт/с соответственно. Шина же NVLink 3.0 имеет пропускную способность 600 Гбайт/c, а коммутатор NVSwitch для связи между восемью ускорителями — 1,8 Тбайт/с. Потребление SXM3-версии составляет 400 Вт. Стоит также отметить, что первая версия A100 появилась ещё весной 2020 года, и скоро ожидается анонс следующего поколения ускорителей на базе архитектуры Hopper. На носу и выход ускорителей Intel Xe Ponte Vecchio.  И если про первые мы пока ничего толком не знаем, то вторые, похоже, уже проиграли MI250X в «голой» производительности как минимум по одной позиции (FP32). AMD говорит, что создавала Instinct MI200 как серию универсальных ускорителей, пригодных и для «классических» HPC-задач, и для ИИ. Отсюда и практически пятикратная разница в пиковой FP64-производительности с NVIDIA A100. 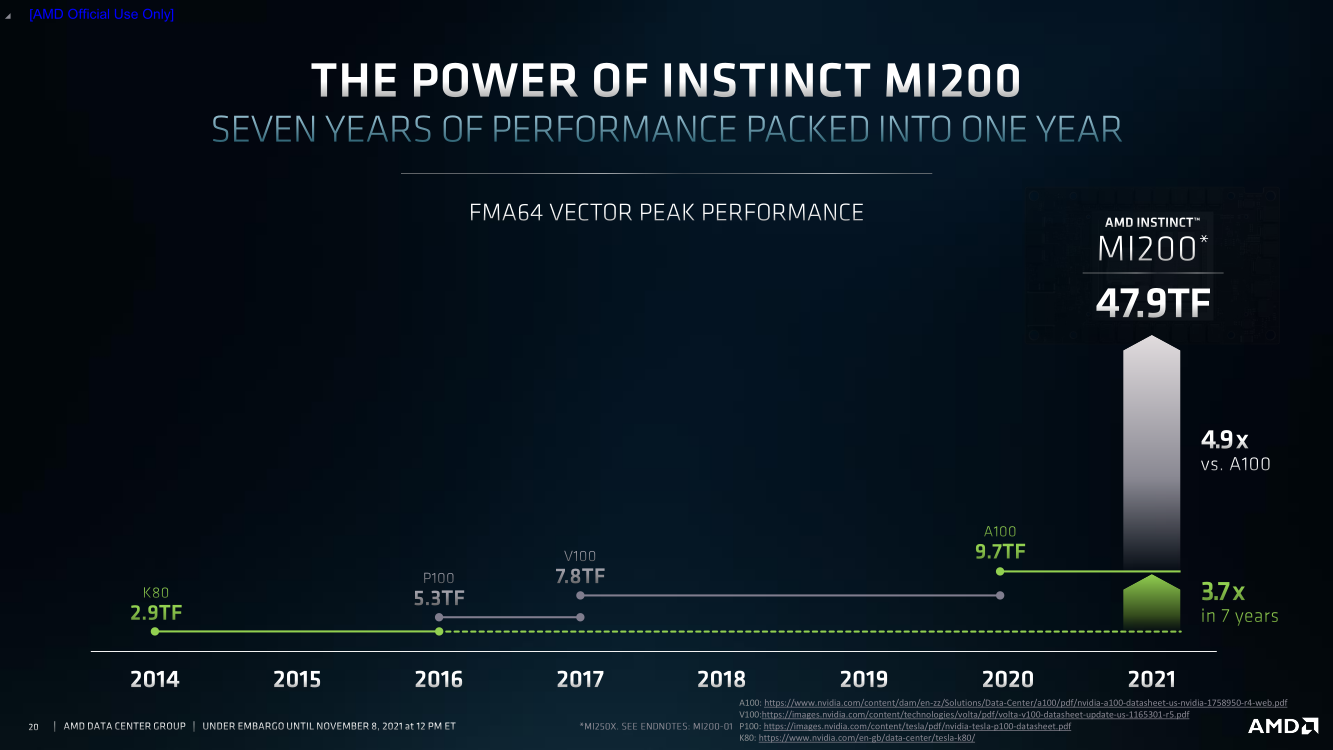 Но вот с нейронками всё не так однозначно. Предпочтительным форматом для обучения у NVIDIA является собственный TF32, поддержка которого есть в Tensor-ядрах Ampere. Ядра для матричных вычислений в CDNA2 про него ничего не знают, поэтому сравнить производительность в лоб нельзя. Разница в BF16/FP16 между MI250X и A100 уже не так велика, так что AMD говорит о приросте в 1,2 раза для обучения со смешанной точностью. 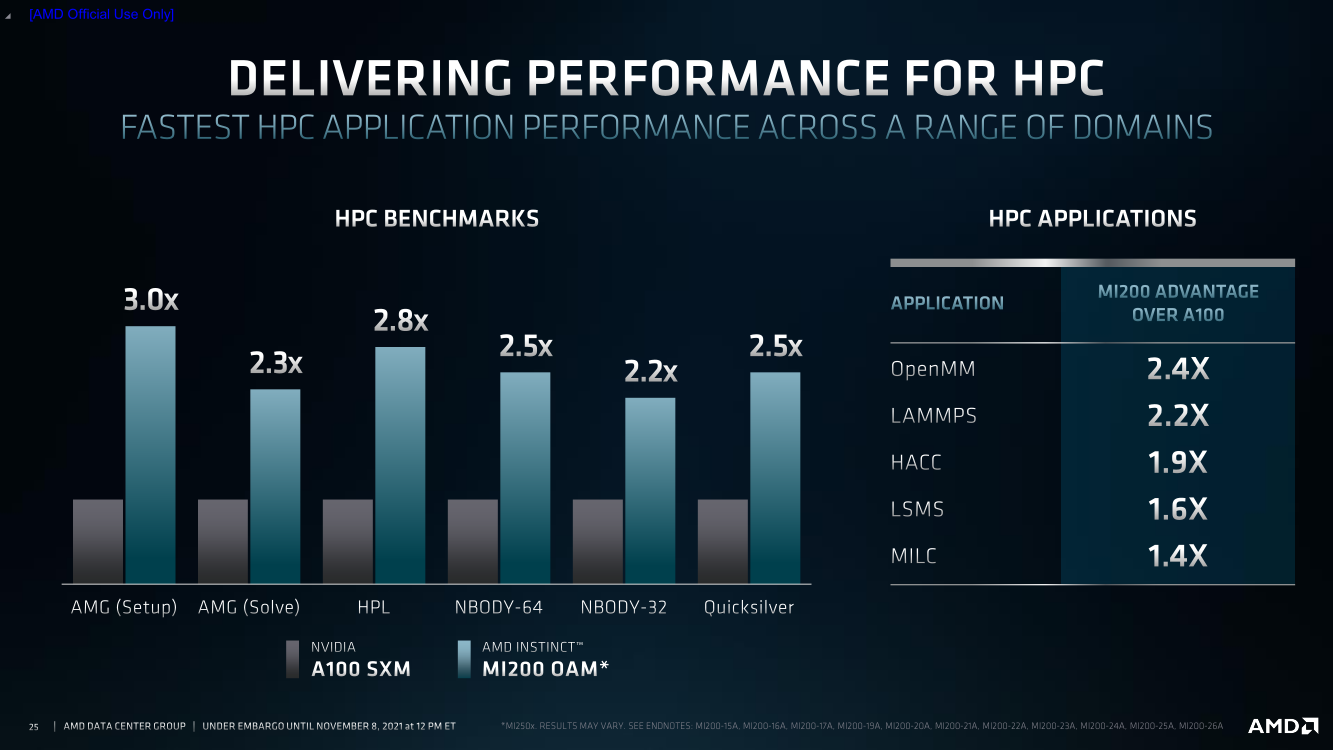 Данные по INT8 и INT4 в презентацию не вынесены, что неудивительно. Пиковый показатель для обоих форматов у MI250X составляет 383 Топс, тогда как тензорные ядра NVIDIA A100 выдают 624 и 1248 Топс соответственно. В данном случае больший объём памяти сыграл бы на руку MI200 в задачах инференса для крупных моделей. Наконец, у A100 есть ещё одно преимущество — поддержка MIG (Multi-Instance GPU), которая позволяет более эффективно задействовать имеющиеся ресурсы, особенно в облачных системах.  Вместе с Instinct MI200 была анонсирована и новая версия открытой (open source) платформы ROCm 5.0, которая обзавелась поддержкой и различными оптимизациями не только для этих ускорителей, но и, например, Radeon Pro W6800. В этом релизе компания уделит особое внимание расширению программной экосистемы и адаптации большего числа приложений. Кроме того, будет развиваться и новый портал Infinity Hub, где будет представлено больше готовых к использованию контейнеров с популярным ПО с рекомендациями по настройке и запуску.  AMD Instinct MI200 появятся в I квартале 2022 года. Новинки, в первую очередь MI210, будут доступны у крупных OEM/ODM-производителей: ASUS, Atos (X410-A5 2U1N2S), Dell Technologies, Gigabyte (G262-ZO0), HPE, Lenovo и Supermicro. Ускорители Instinct MI250X пока остаются эксклюзивом для систем HPE Cray Ex. Именно они вместе с «избранными» процессорами AMD EPYC (без уточнения, будут ли это Milan-X) станут основой для самого мощного в США суперкомпьютера Frontier.  Окончательный ввод в эксплуатацию этого комплекса запланирован на будущий год. Ожидается, что его пиковая производительность превысит 1,5 Эфлопс. При этом он должен стать самой энергоэффективной системой подобного класса. А адаптация ПО под него позволит несколько потеснить NVIDIA CUDA в некоторых областях. И это для AMD сейчас, пожалуй, гораздо важнее, чем победа по флопсам. |
|