Материалы по тегу: ускоритель
|
29.06.2024 [12:52], Сергей Карасёв
ИИ-ускоритель InspireSemi Thunderbird объединяет 6144 ядра RISC-V на карте PCIeКомпания InspireSemi объявила о разработке чипа Thunderbird на открытой архитектуре RISC-V для ИИ-нагрузок. Это изделие легло в основу специализированной карты расширения с интерфейсом PCIe, которая, как утверждается, подходит для решения широкого спектра задач. Чип Thunderbird содержит 1536 кастомизированных 64-битных суперскалярных ядер RISC-V, а также высокопроизводительную память SRAM. Говорится о наличии ячеистой сети с малой задержкой для меж- и внутричиповых соединений. Кроме того, предусмотрены блоки ускорения определённых алгоритмов шифрования. 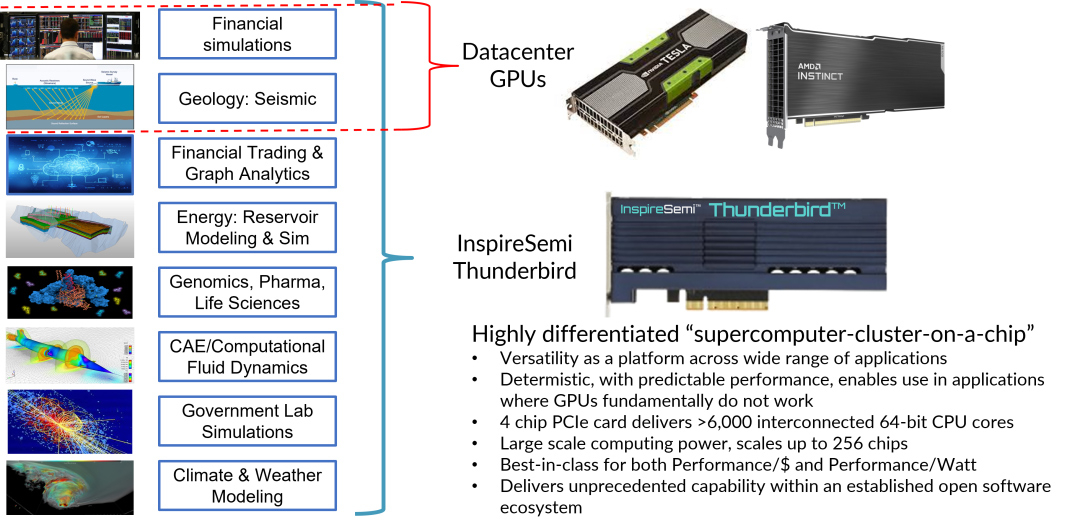
Источник изображения: InspireSemi Идея заключается в том, чтобы объединить универсальность и возможности программирования традиционных CPU с высокой степенью параллелизма GPU. Изделие ориентировано на НРС-приложения, но при этом поддерживает исполнение программ общего назначения. InspireSemi называет новинку «суперкомпьютерным кластером на кристалле». Точно так же назвала свои ИИ-ускорители Esperanto Technologies. Именно её чипы ET-SoC-1, по-видимому, впервые объединили более 1 тыс. ядер RISC-V. Впрочем, сама Esperanto позиционировала их как гибкие и энергоэффективные решения для инференса. В случае Thunderbird четыре могут быть объединены на одной карте PCIe, что в сумме даёт 6144 ядра RISC-V. Более того, заявлена возможность масштабирования до 256 чипов, связанных с помощью высокоскоростных трансиверов. Таким образом, количество ядер может быть доведено до 393 216. Чип обеспечивает производительность до 24 Тфлопс (FP64) при энергетической эффективность 50 Гфлопс/Вт. Для сравнения: NVIDIA A100 обладает быстродействием 19,5 Тфлопс (FP64), а NVIDIA H100 — 67 Тфлопс (FP64). Суперскалярные ядра поддерживают векторные и тензорные операции и форматы данных с плавающей запятой смешанной точности. Однако о совместимости с Linux ничего не говорится. Среди возможных областей применения названы ИИ, НРС, графовый анализ, блокчейн, вычислительная гидродинамика, сложное моделирование в области энергетики, изменений климата и пр.
26.06.2024 [01:00], Игорь Осколков
Etched Sohu — самый быстрый в мире ИИ-ускоритель, но только для трансформеровСтартап Etched, основанный в 2022 году выпускниками Гарварда, анонсировал самый быстрый, по его словам, ИИ-ускоритель Sohu. Секрет высокой производительности очень прост — Sohu представляет собой узкоспециализированный 4-нм ASIC, который умеет работать только с моделями-трансформерами. При этом в длинном анонсе новинки обещана чуть ли не революция в мире ИИ. Etched прямо говорит, что делает ставку на трансформеры, и надеется, что не прогадает. Данная архитектура ИИ-моделей была создана в недрах Google в 2017 году, но сама Google распознать её потенциал, по-видимому, вовремя не смогла. Сейчас же, по словам Etched, практически все массовые ИИ-модели являются именно трансформерами, а стремительно набирать популярность этот подход начал всего полтора года назад с выходом ChatGPT, хотя в Etched «предугадали» важность трансформеров ещё до выхода детища OpenAI. 
Источник изображений: Etched Etched в целом справедливо отмечает, что подавляющее большинство ИИ-ускорителей умышленно создаётся так, чтобы быть достаточно универсальными и уметь работать с различными типами и архитектурами ИИ-моделей. Это ведёт к взрывному росту транзисторного бюджета и уменьшению общей эффективности. Так, по словам Etched, загрузка ускорителя на базе GPU работой на практике составляет около 30 %, а у Sohu она будет на уровне 90 %.  Тут есть некоторое лукавство, потому что Etched в основном говорит о «больших» ускорителях, ориентированных и на обучение тоже, тогда как Sohu предназначен исключительно для инференса. На практике же бывают и гибридные подходы. Например, у AWS есть не только Trainium, но Inferentia. Meta✴ использует чипы NVIDIA для обучения, но для инференса разрабатывает собственные ускорители MTIA. Cerebras практически отказалась от инференса, а Groq — от обучения моделей. Корректнее было бы сравнить именно инференс-ускорители, пусть даже никто из упомянутых Etched конкурентов не ориентирован исключительно на трансформеры.  Также стартап критикует громоздкую программную экосистему для современного генеративного ИИ, к тому же не всегда открытую. Важность оптимизации ПО хороша видна на примере NVIDIA TensorRT-LLM. Но крупным компаниям этого мало, они готовы вкладывать немало средств в глубокую оптимизацию, чтобы ещё чуть-чуть повысить производительность. Дело доходит до выяснения того, у какого регистра задержка меньше при работе с каким тензорным ядром, говорит Etched. Стартап обещает, что его заказчикам не придётся заниматься такими изысканиями — весь программный стек будет open source. Впрочем, на примере AMD ROCm видно, что открытость ещё не означает мгновенный успех у пользователей. 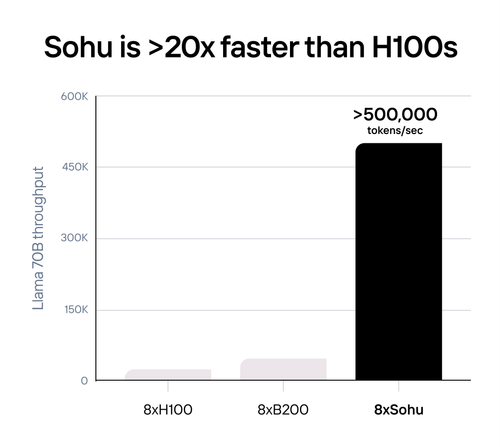 Технические характеристики Sohu не раскрываются. Явно говорится лишь о наличии 144 Гбайт HBM3e. Обещанная производительность сервера с восемью ускорителями Sohu составляет 500 тыс. токенов в секунду для Llama 70B: FP8 без разреженности, параллелизм на уровне модели, 2048 токенов на входе и 128 токенов на выходе. Иными словами, один такой сервер Sohu заменяет сразу 160 ускорителей NVIDA H100, говорит Etched. А вот про масштабируемость своих платформ компания пока ничего не говорит. Зато хвастается, что первые заказчики уже зарезервировали Sohu на десятки миллионов долларов.
25.06.2024 [13:41], Владимир Мироненко
ByteDance и Broadcom совместно разрабатывают 5-нм ИИ-чипАгентству Reuters стало известно о совместной работе китайской компании ByteDance, владеющей популярным видеосервисом TikTok, и американского производителя чипов Broadcom над созданием усовершенствованного ИИ-ускорителя. По словам источников Reuters, это 5-нм ASIC, на который не будут распространяться экспортные ограничения США. Также сообщается, что производством чипа будет заниматься TSMC. Вероятно, его выпуск начнётся в следующем году. Как сообщил источник, работа над чипом идёт полным ходом, но проектирование ещё не завершено. ByteDance и Broadcom являются партнёрами как минимум с 2022 года. ByteDance покупала у американской компании 5-нм чипы Tomahawk, а также коммутаторы Bailly для ИИ-кластеров, указано в публичных заявлениях Broadcom. Сотрудничество с Broadcom в деле разработки ИИ-ускорителя позволит ByteDance сократить затраты и обеспечить стабильные поставки высокопроизводительных чипов, утверждают источники Reuters. Для ByteDance, владеющей также китайской версией TikTok под названием Douyin, и ещё рядом популярных приложений, включая сервис чат-ботов, похожий на ChatGPT, под названием Doubao с 26 млн пользователей, крайне важно иметь достаточный запас ИИ-ускорителей. 
Источник изображения: Broadcom По словам источника, ByteDance выделила в прошлом году $2 млрд на закупку ИИ-ускорителей. В частности, она успела приобрести неназванные объёмы NVIDIA A100 и H100, которые были доступны до вступления в силу первого раунда санкций США, а также чипы A800 и H800, которые со временем также попали под ограничения. ByteDance также приобретала в прошлом году чипы Huawei Ascend 910B, утверждают информированные источники. Особое внимание Bytedance уделяет набору квалифицированных кадров в сфере ИИ. На веб-сайте компании в настоящее время размещены сотни вакансий, связанных с полупроводниками, в том числе 15 для разработчиков микросхем ASIC. Кроме того, по словам одного из источников, Bytedance переманивает высокопоставленных специалистов у китайских производителей ИИ-чипов.
23.06.2024 [12:35], Сергей Карасёв
Между Microsoft и NVIDIA возникли разногласия по поводу использования ускорителей B200У компаний Microsoft и NVIDIA, по сообщению The Information, возникли разногласия по поводу использования новейших ускорителей B200 на архитектуре Blackwell. NVIDIA настаивает на том, чтобы клиенты приобретали эти изделия в составе полноценных серверных стоек, тогда как Microsoft с этим не согласна. Отмечается, что NVIDIA, удерживающая приблизительно 98 % рынка ускорителей для ЦОД, стремится контролировать использование своих продуктов. В частности, компания накладывает ограничения в отношении дизайна ускорителей, которые партнёры создают на чипах NVIDIA. Во время презентации Blackwell глава NVIDIA Дженсен Хуанг (Jensen Huang) неоднократно указывал на то, что теперь минимальной единицей для развёртывания должен стать суперускоритель GB200 NVL72. То есть NVIDIA призывает клиентов приобретать вместо отдельных ускорителей целые стойки и даже кластеры SuperPOD. По заявлениям компании, это позволит повысить ИИ-производительность благодаря оптимизации всех компонентов и их максимальной совместимости друг с другом. Кроме того, такая бизнес-модель позволит NVIDIA получить дополнительную выручку от распространения серверного оборудования и ещё больше укрепить позиции на стремительно развивающемся рынке ИИ. 
Источник изображения: NVIDIA Однако у Microsoft, которая оперирует огромным количеством разнообразных ускорителей и других систем в составе своей инфраструктуры, возникли возражения в отношении подхода NVIDIA. Сообщается, что вице-президент NVIDIA Эндрю Белл (Andrew Bell) попросил Microsoft приобрести специализированные серверные стойки для ускорителей Blackwell, но редмондский гигант ответил отказом. По заявлениям Microsoft, решения NVIDIA затруднят корпорации внедрение альтернативных ускорителей, таких как AMD Instinct MI300X. 
Ещё один вариант OCP-стойки с СЖО (Источник изображения: Microsoft) Дело в том, что форм-факторы стоек NVIDIA и стоек Microsoft различаются на несколько дюймов. Из-за этого могут возникнуть сложности с изменением конфигурации и модернизацией, предусматривающей использование конкурирующих компонентов. Так, Microsoft использует единую базовую платформу и для ускорителей NVIDIA, и для ускорителей AMD. Microsoft эксплуатирует вариант стоек OCP и старается максимально унифицировать инфраструктуру своих многочисленных дата-центров. NVIDIA, в конце концов, согласилась с доводами Microsoft и пошла на уступки, но это, похоже, не последнее подобное разногласие между компаниями.
14.06.2024 [23:15], Владимир Мироненко
Южнокорейские ИИ-стартапы Sapeon и Rebellions объединятся, чтобы вместе противостоять NVIDIASapeon и Rebellions, два южнокорейский участника альянса AI Platform Alliance, сформированного в прошлом году с целью ускорения внедрения передовых решений в области ИИ, объявили о планах по объединению усилий, чтобы ускорить работу и добиться больших масштабов бизнеса. Компания Sapeon предлагает чип X330, предназначенный для инференса и обслуживания больших языковых моделей (LLM), а также основанные на этом чипе серверы. В свою очередь, Rebellions разработала NPU ATOM для систем компьютерного зрения и использования с чат-ботами на базе ИИ. Оба производителя участвуют в программе по импортозамещению ИИ-ускорителей, CPU и иных чипов. Сейчас Южная Корея стремится добиться технологической независимости от зарубежных поставщиков оборудования и ПО. Речь, в первую очередь, об NVIDIA. Ускорители последней в своё время не достались местному IT-гиганту Naver, который временно был вынужден заменить их процессорами Intel Xeon, а впоследствии вместе с Samsung создал собственные ИИ-чипы Mach-1. 
Источник изображения: Rebellions Инициатором слияния Sapeon и Rebellions выступила SK hynix, которая вместе с SK Telecom является акционером Sapeon. В своём заявлении она отметила, эти компании согласились на слияние, поскольку, по их мнению, это позволит создать компанию, способную оказать конкуренцию другим участникам глобального рынка ИИ. Как отметил The Register, время сейчас имеет решающее значение для Sapeon и Rebellions, поскольку следующие два или три года воспринимаются как «золотое время» для создания компаний, способных стать крупными игроками в области ИИ. Поэтому предполагается провести слияние в кратчайшие сроки с завершением сделки в III квартале и запуском объединённой компании до конца 2024 года. 
Источник изображения: Sapeon В свою очередь, SK hynix планирует оказать помощь объединенной компании в разработке ИИ-полупроводников. Sapeon была выделена SK Telecom в отдельную компанию в 2016 году. Rebellions была создана всего четыре года назад при поддержке прямого конкурента SK Telecom в лице KT Corp., но уже договорилась с Samsung о поставке ей ИИ-чипов, которые будут производиться компанией Chaebol с использованием 4-нм процесса с интеграцией HBM3e.
11.06.2024 [15:22], Сергей Карасёв
3,76 млн ускорителей в 2023 году: NVIDIA захватила 98 % рынка GPU для ЦОДПо оценкам аналитической фирмы Tech Insights, которые приводит ресурс HPC Wire, компания NVIDIA в 2023 году отгрузила приблизительно 3,76 млн ускорителей на базе GPU, ориентированных на ЦОД. Это более чем на 1 млн штук превосходит результат 2022 года, когда поставки таких изделий оценивались в 2,64 млн единиц. С учётом решений AMD и Intel общий объём поставок GPU-ускорителей для ЦОД в 2023 году составил 3,85 млн единиц против примерно 2,67 млн штук в 2022 году. Правда, столь малая доля отгрузок решений AMD и Intel вызывает некоторые сомнения. Как отмечает аналитик Tech Insights Джеймс Сандерс (James Sanders), в настоящее время на рынке не хватает аппаратных ресурсов для удовлетворения всех ИИ-потребностей. А поэтому будет расти спрос на ускорители и специализированные чипы разработчиков, конкурирующих с NVIDIA. Согласно подсчётам TechInsights, по итогам 2023-го NVIDIA контролировала около 98 % мирового рынка ускорителей на базе GPU для дата-центров. Схожий результат компания продемонстрировала и годом ранее. Такой рост связан со стремительным развитием ИИ-приложений и увеличением спроса на НРС-системы. При этом на NVIDIA приходится и 98 % выручки от реализации таких ускорителей: в 2023 году они принесли компании $36,2 млрд, что более чем в три раза превышает прошлогодний показатель в $10,9 млрд.  По данным TechInsights, в 2023 году AMD поставила около 50 тыс. ускорителей для ЦОД, а Intel — примерно 40 тыс. единиц (в оригинальном материале HPCWire указаны на порядок более высокие значения; корректировка сделана в соответствии с оставшейся долей в 2 % рынка). В 2024-м, как полагают эксперты, спрос на такие продукты в глобальном масштабе поднимется. Речь, в частности, идёт об ускорителях серии Instinct MI300, разработанных AMD. При этом AMD заявляет, что намерена выпускать новые решения ежегодно: ускоритель MI325X запланирован на 2024 год, MI350 — на 2025-й, а MI400 — на 2026-й. В свою очередь, Intel продвигает изделия Gaudi3. Специализированные ИИ-чипы проектируют и ведущие гиперскейлеры. Так, AWS в конце прошлого года представила ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Google анонсировала изделия Cloud TPU v5p, а Microsoft — Maia 100. Meta✴ намерена активно внедрять собственные ИИ-ускорители Artemis.
07.06.2024 [13:35], Руслан Авдеев
Новый трюк КНР: китайские компании пытаются использовать запрещённые к экспорту чипы на территории самих СШАКитайские компании, лишённые доступа к передовым ИИ-чипам из-за введённых США санкций, освоили новую схему обхода ограничений. По данным The Register, теперь они покупают доступ к подсанкционному оборудованию непосредственно на территории Соединённых Штатов. О возможности подобной схемы эксперты предупреждали уже давно. По слухам, Alibaba и Tencent вели переговоры с NVIDIA о получении тем или иным способом доступа к ускорителям, продажа которых в Китай ограничена — бизнесы из КНР рассматривали возможность использовать их в ЦОД на территории США. China Telecom, как считается, тоже вела переговоры с облачными провайдерами о получении доступа к высокопроизводительному ИИ-оборудованию. Другими словами, китайский бизнес намерен обходить американские санкции, покупая или арендуя оборудование под боком у Вашингтона. Владелец TikTok — компания ByteDance, похоже, тоже участвует в подобных схемах со своим партнёром Oracle, у которого она арендует доступ к передовым ускорителям NVIDIA. 
Источник изображения: Mark Daynes/unsplash.com В NVIDIA ответили на запросы журналистов, сообщив, что поддерживают новые дата-центры в США, расширяя вычислительные экосистемы и создавая рабочие места. В компании подчеркнули, что все клиенты американских ЦОД должны соблюдать местные законы, включая правила экспортного контроля и прочие ограничения. США уже годами вовлечены в «полупроводниковую войну» и применили в отношении Китая несколько пакетов санкций, призванных ограничить доступ Китаю к данным о передовых архитектурах чипов и современному оборудованию для их производства. Конечно, КНР ищет пути для обхода ограничений — например, компании вроде Huawei неоднократно ловили на попытках так или иначе обмануть американскую санкционную машину. В то же время США пытаются наладить производство чипов на территории страны — сегодня большинство передовых полупроводников выпускается на Тайване. Это только усилит желание КНР получить доступ к самым современным технологиям и подстегнёт не только инвестиции в полупроводниковую отрасль, но и поиск новых путей обхода санкций. Правда, пока не известно, могут ли считаться китайские компании, пытающиеся организовать вычисления на территории США, нарушителями законов или они просто ловко нашли пробел в американском законодательстве.
06.06.2024 [13:23], Руслан Авдеев
Маск подтвердил передачу ИИ-стартапу xAI 12 тыс. ускорителей H100, предназначавшихся TeslaГлава Tesla и других компаний Илон Маск (Elon Musk) подтвердил передачу ускорителей NVIDIA H100, ранее заказанных Tesla, социальной сети X и ИИ-стартапу xAI. Слухи об этом, напоминает The Register, появились в СМИ — в распоряжение журналистов попала внутренняя документация и электронная переписка с NVIDIA. В частности, в одной из записок за декабрь прошлого года прямо указывалось, что Илон отдаёт приоритет внедрению 12 тыс. ускорителей в X вместо Tesla. Общая стоимость такого количества H100 превышает $500 млн. Вместо этого заказанные для X экземпляры H100 позже будут переданы Tesla (поставки ожидались в январе и июне 2024 года). Кроме того, есть проблемы и с созданием ИИ-суперкомпьютера Dojo на базе собственных чипов, который должен улучшить положение Tesla. Приоритетным для Маска, вероятно, является кластер H100, создаваемый X и тесно связанным с сетью стартапом xAI. Компании совместно работают над большими языковыми моделями, стоящими за чат-ботом Grok, уже доступным премиум-подписчикам X. По данным утечки из NVIDIA, 100 тыс. H100 приказано передать к концу года в xAI для создания «крупнейшего в мире» кластера ускорителей, который разместится в Северной Дакоте. 
Источник изображения: Alexander Shatov/unsplash.com Хотя на уровне компаний комментариев не поступало, сам Маск подтвердил, что у Tesla просто не было места для чипов NVIDIA, поэтому они хранились на складе. При этом ещё не так давно Маск уверял инвесторов Tesla, как важны HPC-системы и ИИ для компании. Более того, ещё в апреле появилась новость о том, что автопроизводитель только в течение одного квартала вложил в ИИ $1 млрд. Также миллиардер сообщал, что один из заводов Tesla в Техасе вместит 50 тыс. H100 для обучения систем автономного вождения, в общей сложности число ускорителей достигло бы 85 тыс. Пока нет точных данных об обстоятельствах передачи ускорителей между Tesla и X или xAI. Нет даже информации о том, заплатила ли уже Tesla за «железо» и получила ли за него какую-то компенсацию. Условия передачи H100 могут иметь большое значение с учётом того, что Маск не является единоличным владельцем Tesla. Если выяснится, что Маск злоупотребил властью, к нему могут возникнуть вопросы как у инвесторов, так и у регуляторов. Впрочем, Tesla не впервые приходится делиться активами с X. Вскоре после покупки Twitter более 50 сотрудников автопроизводителя якобы отправили на «усиление» социальной соцсети. Есть данные, что сотрудников Tesla привлекают к работам и в других компаниях Маска, причём без дополнительной платы. Время для новостей не особенно удачное — на следующей неделе акционеры Tesla будут голосовать по ряду предложений, главным из которых является официальный перенос штаб-квартиры в Техас. Также речь пойдёт о переизбрании брата Кимбала, брата Илона Маска (Kimbal Musk), в совет директоров и других ключевых для бизнесмена вопросах. Тем временем в Tesla падают продажи со II половины 2022 года, увольняют сотрудников и, главное, стоимость акций компании падает критическими темпами. Приказ передать H100 станет дополнительным козырем в руках критиков миллиардера, которые утверждают, что его активное участие в других проектах мешает ему сконцентрироваться на автобизнесе и эффективно выполнять обязанности главы Tesla.
05.06.2024 [14:07], Руслан Авдеев
Против всех правил: Intel публично раскрыла стоимость ИИ-ускорителей GaudiХотя производители легко раскрывают рекомендованные цены на классические процессоры, в случае с ИИ-ускорителями ситуация обстоит иначе. Как сообщает портал CRN, Intel публично объявила стоимость новейшей платформы Gaudi3. Фактически компания нарушила негласно принятые в отрасли нормы секретности, сообщив в ходе выставки Computex, что UBB-плата с восемью OAM-модулями Gaudi3 будет стоить $125 тыс. для производителей серверов, намеренных поддержать платформу в момент выпуска в III квартале 2024 года. Intel раскрыла цены после того, как конкуренты в лице NVIDIA и AMD пообещали представлять всё более мощные чипы ежегодно — это станет серьёзной угрозой как для Intel, так и для менее крупных игроков. 
Источник изображения: Intel По оценкам Intel, $125 тыс. — это всего ⅔ стоимости платформы NVIDIA с восемью ускорителями H100, лежащих в основе системы NVIDIA DGX и серверов стороннего производства. Хотя в самой NVIDIA цены своих ускорителей или платформ не раскрывают, если верить расчётам Intel, платформа HGX H100 обходится приблизительно в $187 тыс. Цена может меняться в зависимости от объёмов закупок и конфигурации серверов. При этом ускорители Blackwell B200 будут стоить уже $30-$40 тыс./шт. 
Источник изображения: Intel (via ServeTheHome) В Intel утверждают, что по соотношению цена/производительность чипы Gaudi3 в сравнении с H100 в 2,3 раза эффективнее при инференсе и на 90 % — при обучении. UBB-плата с восемью ускорителями Gaudi2 стоит всего $65 тыс., это приблизительно треть от стоимости платформы NVIDIA HGX H100. При этом в публичных бенчмарках MLPerf только Gaudi2 смогли составить конкуренцию H100 как в обучении, так и в инференсе. Цены на отдельные чипы Gaudi 3 пока не называются. 
Источник изображения: Intel Есть и ещё один важный момент — ускорители Gaudi используют встроенные Ethernet-контроллеры как для связи между собой, так и для общения с внешним миром, тогда как решениям NVIDIA требуется отдельный адаптер InfiniBand/Ethernet на каждый ускоритель, что увеличивает итоговую стоимость платформы. В Intel уверены, что клиенты всё больше уделяют внимания показателю токен/$, на который большое влияние оказывает стоимость инфраструктуры. В компании пояснили, что раскрытие цен на Gaudi2 и Gaudi3 поможет клиентам более эффективно планировать инвестиции в ИИ-проекты. Например, стартапы часто не имеют точных сведений об экосистеме, ценах и процессе закупок, так что теперь им будет легче рассчитать, чего можно ожидать от предлагаемого оборудования. Открытость Intel нашла поддержку у крупных производителей IT-оборудования.
05.06.2024 [12:15], Сергей Карасёв
Комплект Raspberry Pi AI Kit с ИИ-ускорителем Hailo расширит возможности Raspberry Pi 5Команда Raspberry Pi анонсировала комплект Raspberry Pi AI Kit, который позволяет наделить ИИ-возможностями одноплатный компьютер Raspberry Pi 5, дебютировавший в сентябре 2023 года. Модуль расширения уже доступен для заказа по ориентировочной цене $70. В основу Raspberry Pi AI Kit положен ИИ-чип Hailo-8L, созданный Hailo Technologies. Это изделие ориентировано на приложения, которым не требуется слишком высокое ИИ-быстродействие. Заявленное быстродействие достигает 13 TOPS, а стандартное энергопотребление составляет 1,5 Вт. 
Источник изображений: Raspberry Pi В случае Raspberry Pi AI Kit чип Hailo-8L установлен на модуль типоразмера M.2 2242, который подключается к соответствующему коннектору на плате расширения M.2 HAT+. Эта плата, в свою очередь, обменивается данными с Raspberry Pi 5 посредством интерфейса PCIe 2.0. Габариты M.2 HAT+ составляют 65 × 56,5 × 5,6 мм. Заявленный диапазон рабочих температур простирается от 0 до +50 °C. Новинка может быть смонтирована поверх одноплатного компьютера.  Отмечается, что при использовании обновлённой версии Raspberry Pi OS распознавание чипа Hailo-8L происходит автоматически, после чего ускоритель становится доступен для обработки ИИ-нагрузок. Говорится о полной интеграции с программным стеком Raspberry Pi Camera, что позволяет реализовывать различные приложения на основе машинного зрения. |
|