Материалы по тегу: бенчмарк
|
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 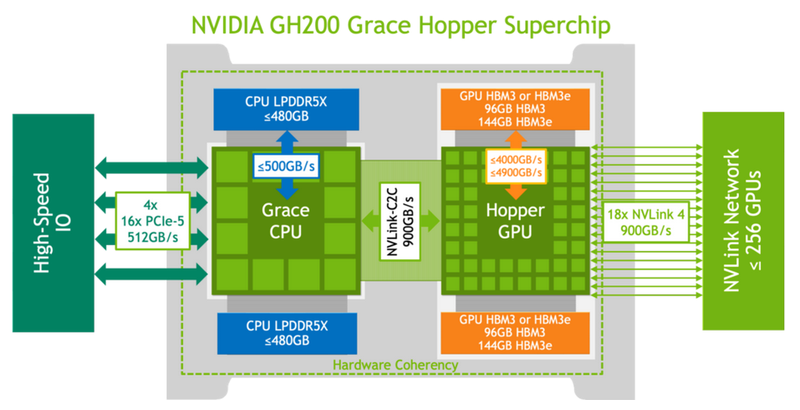
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 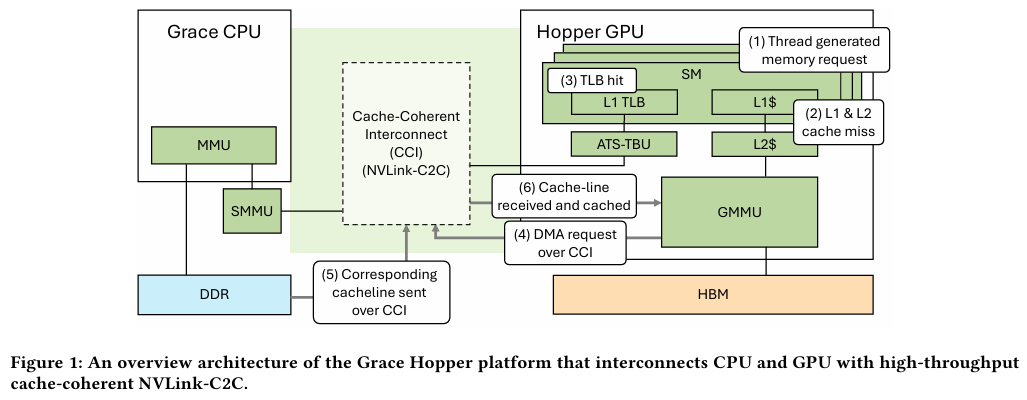
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 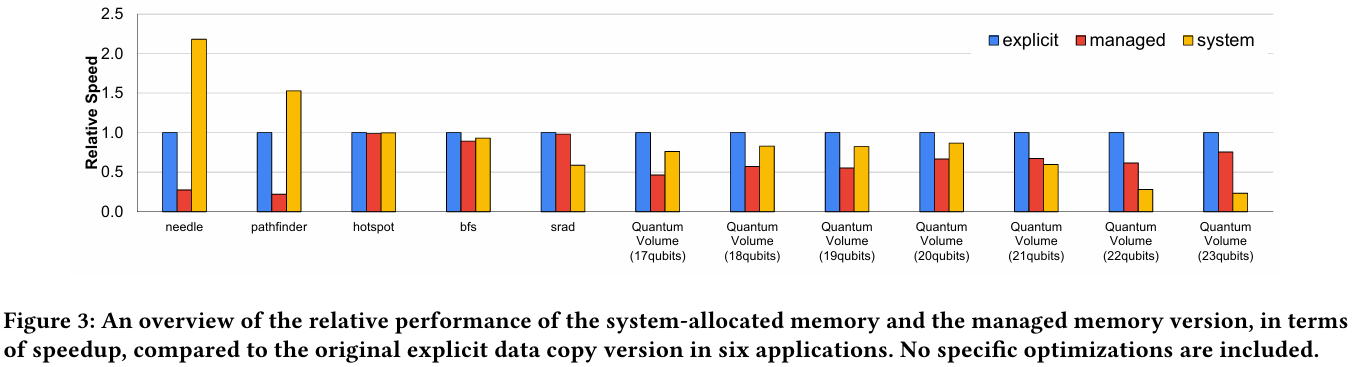
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
25.07.2024 [10:12], Владимир Мироненко
AMD показала превосходство чипов EPYC над Arm-процессорами NVIDIA Grace в серии бенчмарков, но не всё так простоAMD провела серию тестов, чтобы доказать преимущество своих нынешних процессоров AMD EPYC над Arm-процессорами NVIDIA Grace Superchip. Как отметила AMD, в связи с растущей востребованностью ЦОД некоторые компании начали предлагать альтернативные варианты процессоров, «часто обещающие преимущества по сравнению с обычными решениями x86». «Обычно их представляют с большой помпой и заявлениями о значительных преимуществах в производительности и энергоэффективности по сравнению с x86. Слишком часто эти утверждения довольно сложно воплотить в реальные сценарии конкурентной рабочей нагрузки — с использованием устаревших, недостаточно оптимизированных альтернатив или плохо документированных предположений», — отметила AMD. С помощью серии стандартных отраслевых тестов AMD, по её словам, продемонстрировала преимущество EPYC над решениями на базе Arm. «Благодаря проверенной архитектуре x86-64, впервые разработанной AMD, вы можете получить всё это без дорогостоящего портирования или изменений в архитектуре», — подчеркнула компания. Иными словами, тесты AMD могут быть просто попыткой развеять опасения, что архитектура x86 «выдыхается» и что Arm берёт верх. 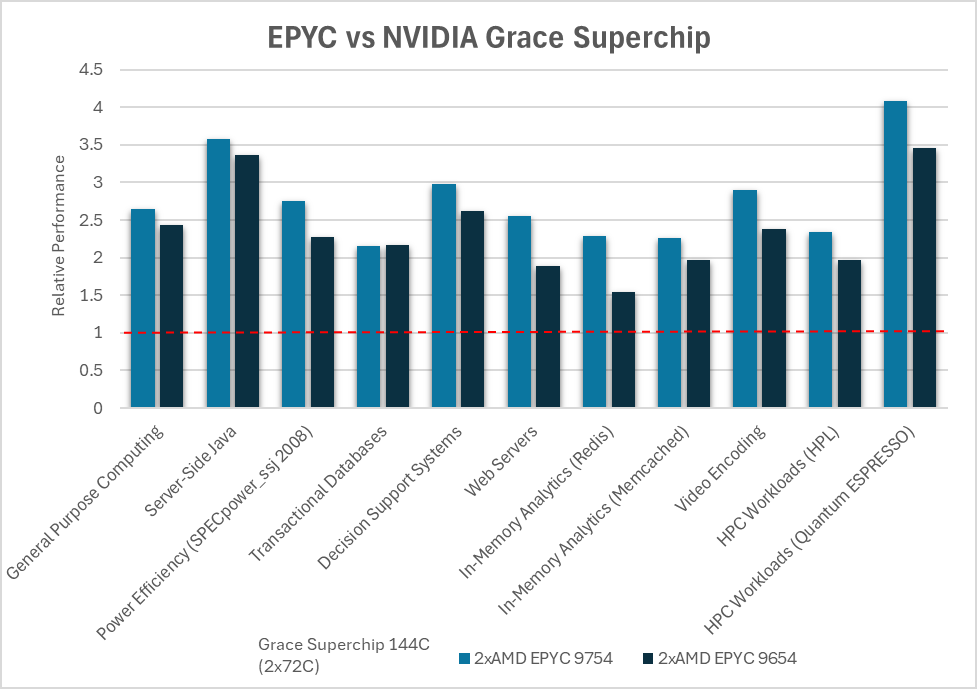
Источник изображений: AMD AMD сравнила производительность AMD EPYC и NVIDIA Grace CPU в десяти ключевых рабочих нагрузках, охватывающих вычисления общего назначения, Java, транзакционные базы данных, системы поддержки принятия решений, веб-серверы, аналитику, кодирование видео и нагрузки HPC. Согласно представленному выше графику, 128-ядерный процессор EPYC 9754 (Bergamo) и 96-ядерный EPYC 9654 (Genoa) более чем вдвое превзошли NVIDIA Grace CPU Superchip по производительности при обработке вышеуказанных нагрузок. Напомним, что Grace CPU Superchip содержит два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2, соединённых шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работает как единый 144-ядерный процессор. В свою очередь, ресурс The Register отметил, что речь идёт о версии с 480 Гбайт памяти LPDDR5x, а не с 960 Гбайт. 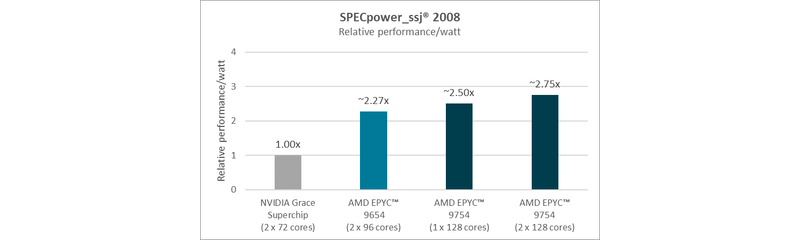 В тесте SPECpower-ssj2008, по данным AMD, одно- и двухсокетные системы на базе AMD EPYC 9754 превосходят систему NVIDIA Grace CPU Superchip по производительности на Вт примерно в 2,50 раза и 2,75 раза соответственно, а двухсокетная система AMD EPYC 9654 — примерно в 2,27 раза. Помимо производительности и эффективности, ещё одним важным фактором для операторов ЦОД является совместимость, сообщила AMD. По оценкам, во всем мире существуют триллионы строк программного кода, большая часть которого написана для архитектуры x86. EPYC основаны на архитектуре x86-64, впервые разработанной AMD, и эта архитектура является наиболее широко используемой и поддерживаемой в индустрии ЦОД, заявила компания, добавив, что изменения в архитектуре сложны, дороги и чреваты риском. AMD также отметила, что экосистема AMD EPYC включает более 250 различных конструкций серверов и поддерживает около 900 уникальных облачных инстансов. Также процессоры AMD EPYC установили более 300 мировых рекордов производительности и эффективности в широком спектре тестов. В то же время лишь немногие Arm-решения доказали свою эффективность. В свою очередь, ресурс The Register отметил, что ситуация не так проста, как AMD пытается всех убедить. В феврале сайт The Next Platform сообщил, что исследователи из университетов Стоуни-Брук и Буффало сравнили данные о производительности суперчипа NVIDIA Grace CPU Superchip и нескольких процессоров x86, предоставленные несколькими НИИ и разработчиком облачных решений. 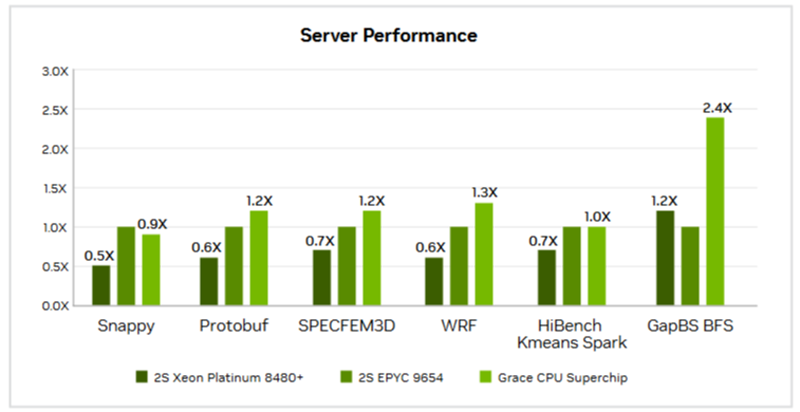
Источник изображений: NVIDIA Большинство этих тестов были ориентированы на HPC, включая Linpack, HPCG, OpenFOAM и Gromacs. И хотя производительность системы Grace сильно различалась в разных тестах, в худшем случае она находилась где-то между Intel Skylake-SP и Ice Lake-SP, превосходя AMD Milan и находясь в пределах досягаемости от показателей Xeon Max. Данные результаты отражают тот факт, что самые мощные процессоры AMD EPYC Genoa и Bergamo могут превзойти первый процессор NVIDIA для ЦОД — при правильно выбранном тесте. 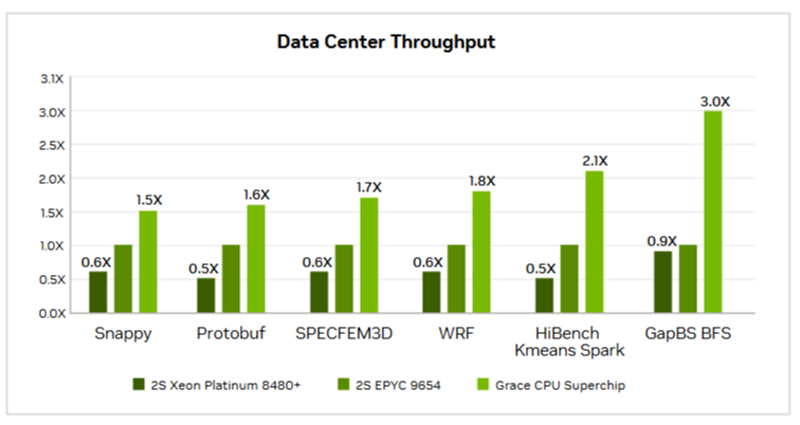 В техническом описании Grace CPU Superchip компания NVIDIA сообщает, что этот чип обеспечивает от 0,9- до 2,4-кратного увеличения производительности по сравнению с двумя 96-ядерными EPYC 9654 и предлагает до трёх раз большую пропускную способность в различных облачных и HPC-сервисах. NVIDIA отмечает, что Superchip предназначен для «обработки массивов для получения интеллектуальных данных с максимальной энергоэффективностью», говоря об ИИ, анализе данных, нагрузках облачных гиперскейлеров и приложениях HPC.
27.06.2024 [09:30], Илья Коваль
Ловкий патч и никакого мошенничества: эмуляция NUMA повышает производительность Raspberry Pi 5 на 18 %Портал Phoronix обратил внимание на необычный патч, заметно повышающий производительность Raspberry Pi 5. Инженеры Igalia в результате экспериментов с эмуляцией NUMA на UMA-системах с чипами ARM64 (AArch64) добились повышения эффективности использования памяти. Так, простой патч для ядра Linux позволил улучшить результаты в Geekbench на 6 % в однопоточном режиме и на целых 18 % — в многопоточном. Авторы патча пишут, что разделение RAM на несколько независимых блоков с последующим попеременными доступом (interleaving) позволяет контроллеру в Broadcom BCM2712 более полно использовать параллелизм на уровне физической организации чипов памяти (parallelism in physical memory chip organisation). Почему так происходит, авторы не уточняют, но, вероятно, это связано с особенностями организации кеша в SoC. 
Источник изображения: Raspberry Pi 16-нм SoC BCM2712 включает четыре ядра Cortex-A76 (2,4 ГГц), каждому из которых полагается по 64 Кбайт кеша для инструкций и данных и 512 Кбайт L2-кеша. Объём общего L3-кеша составляет 2 Мбайт. Встроенный 32-бит контроллер памяти предлагает LPDRR4x-интерфейс, теоретическая пропускная способность которого достигает 17 Гбайт/с. Важно отметить, что этот чип не создавался эксклюзивно для Raspberry Pi — он был выбран среди актуальных массовых решений Broadcom из-за удачного сочетания цены, производительности и доступности. Патч добавляет в Kconfig новую опцию, а для активации эмуляции NUMA (Non-uniform memory access) нужно передать соответствующий параметр при загрузке ядра. Дальнейшая работы осуществляется с помощью стандартной утилиты numactl.
23.06.2024 [11:45], Сергей Карасёв
AMD отказывается от публичного тестирования ускорителей Instinct MI300X в бенчмарках MLPerfКомпания AMD, по сообщению ресурса Wccftech, отклонила просьбу стартапа Tiny Corp о сравнительном испытании ИИ-ускорителей Instinct MI300X в бенчмарке MLPerf, который предлагает тесты для множества разных сценариев, в том числе для задач машинного зрения, обработки языка, рекомендательных систем и обучения с подкреплением. Tiny Corp является разработчиком фреймворка Tinygrad для нейросетей. Кроме того, стартап проектирует компактные компьютеры Tinybox, ориентированные на выполнение ИИ-задач. В зависимости от типа используемых ускорителей (AMD или NVIDIA) производительность достигает 738 или 991 Тфлопс (FP16). Цена — $15 тыс. и $25 тыс. соответственно. Не так давно Tiny Corp предложила AMD предоставить ускорители Instinct MI300X для нового этапа тестов в MLPerf. Однако разработчик чипов по каким-то причинам отказался это сделать, дав крайне уклончивый ответ. «Наше предложение было отклонено. Они [компания AMD] не говорят чётко "нет", используя вместо этого не несущие смысловой нагрузки слова вроде "партнёрство" и "сотрудничество"», — отмечается в сообщении Tiny Corp. 
Источник изображения: AMD Высказываются предположения, что нежелание AMD участвовать в тестах MLPerf может быть связано с заявлениями компании о превосходстве ускорителей Instinct MI300X над изделиями конкурентов. Фактическая оценка производительности в MLPerf может подорвать эти утверждения. Впрочем, в тестах MLPerf отказываются участвовать и другие игроки рынка, например, Groq. Так или иначе, на сегодняшний день чипы NVIDIA остаются безоговорочными лидерами в бенчмарке MLPerf. Вместе с тем единственным конкурентом для них в этом тесте выступают изделия Intel Gaudi. Изделия Intel не дотягивают по производительности до решений NVIDIA, но компания делает упор на стоимость своих продуктов и даже публично назвала цены на ускорители Gaudi, что для данной индустрии случай крайне редкий.
15.06.2024 [00:25], Алексей Степин
Intel поймала AMD на подтасовке результатов в ИИ-тестах EPYC против XeonНа Computex 2024 AMD анонсировала новое поколение серверных процессоров EPYC Turin на базе архитектуры Zen 5. При этом компания продемонстрировала слайды, из которых следует, что новые решения серьёзно опережают процессоры Intel Xeon. Так, 128-ядерный Turin сравнивается с 64-ядерным Xeon Platinum 8592+ (Emerald Rapids). AMD говорит о 2,5–5,4-кратном превосходстве, однако Intel опровергает полученные результаты и достаточно подробно разбирает вопрос тестирования в своём блоге. Конечно, превосходство AMD в чисто количественных показателях очевидно, но в сложных вычислительных задачах, к которым относятся HPC- и ИИ-сценарии, не меньшую, а то и большую роль может играть оптимизация ПО. Intel отмечает, что AMD не привела в своём анонсе конкретных сведений о версиях и настройках ПО, и, вероятнее всего, отказалась от различных расширений. Но, например, Intel Extension for PyTorch (IPEX) позволяет добиться более чем пятикратного прироста производительности по сравнению с «чистой» версией PyTorch. Для системы с двумя Xeon Platinum 8592+ применение IPEX позволяет поднять производительность инференса в режиме INT4 с чат-ботом на базе Llama2-7B со 127 до 686 запросов в секунду при заданной задержке не более 50 мс. Для своей 256-ядерной платформы на базе Turin AMD говорит про 671 запрос — как видно, с оптимизацией результаты получаются вполне сопоставимыми. 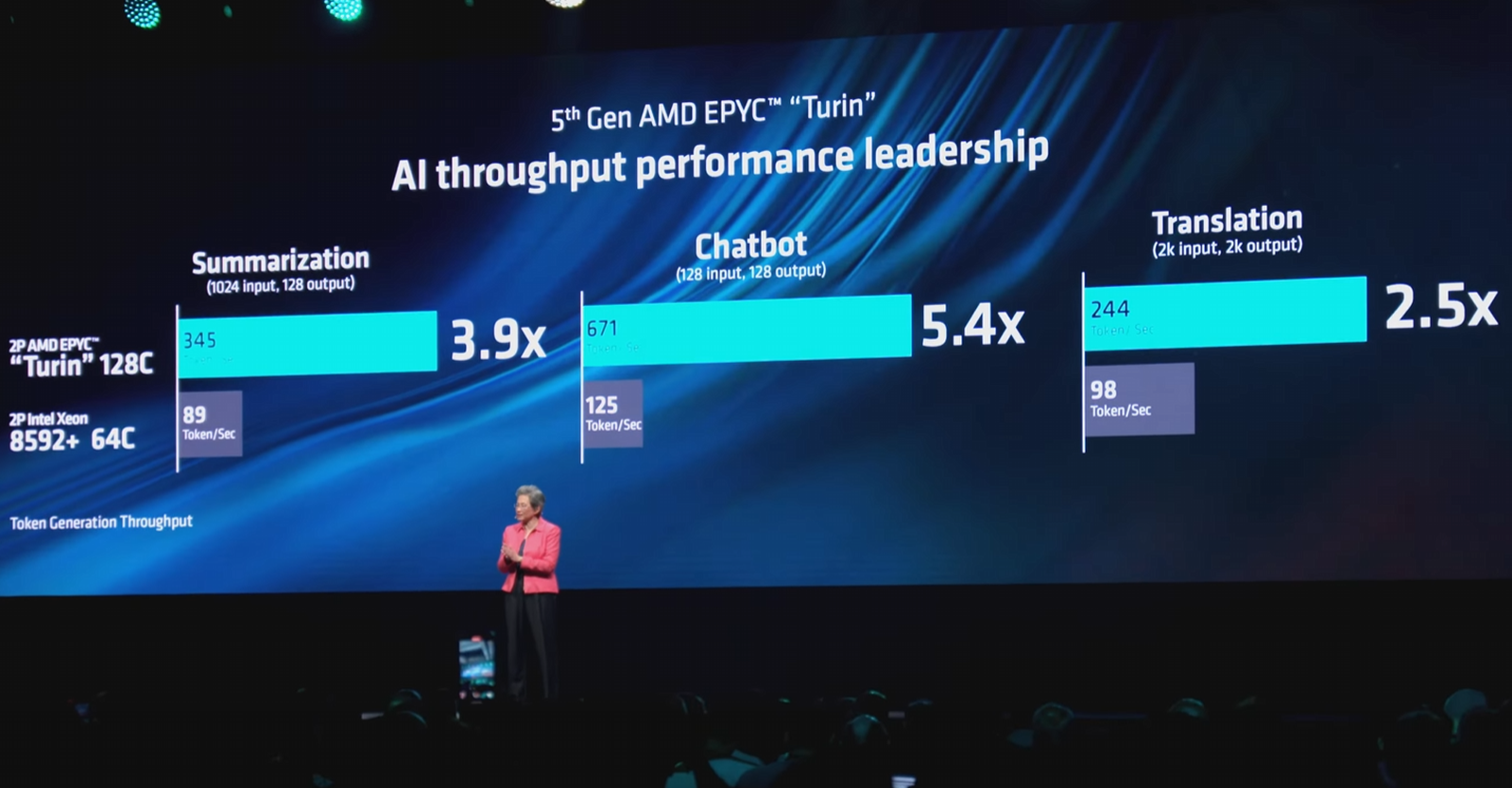
Источник: AMD И потенциал для дальнейшего роста у Xeon есть: Intel сообщает, что при отключении функции Sub-NUMA Clustering результат может достигать 740 запросов. К сожалению, для других тестов компания диаграмм не опубликовала, хотя и там оптимизация позволяет добиться увеличения производительности в 1,2–2,3 раза. Этого уже не хватает, чтобы бороться с платформой Turin, которая, помимо превосходства в числе ядер, использует и более мощную 12-канальную подсистему памяти. 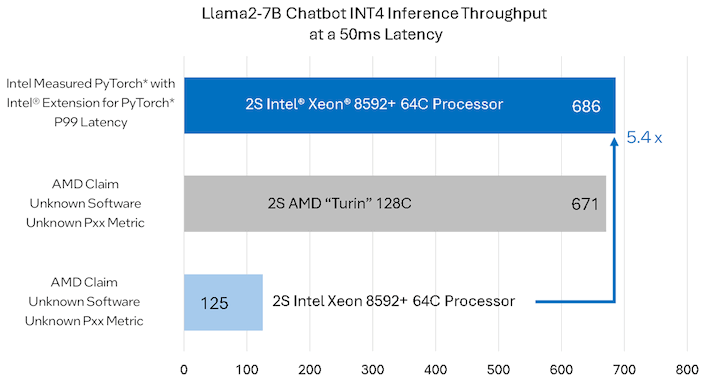
Источник: Intel Следует отметить, что Intel не сказала последнего слова: Xeon Platinum 8592+ уже не нов, а в ближайшем будущем AMD Turin придётся столкнуться с Xeon 6 с большим числом ядер. Пока эти чипы доступны лишь в исполнении с энергоэффективными ядрами, но уже в III квартале появятся и 128-ядерные Granite Rapids с производительными P-ядрами и 12-канальной памятью. 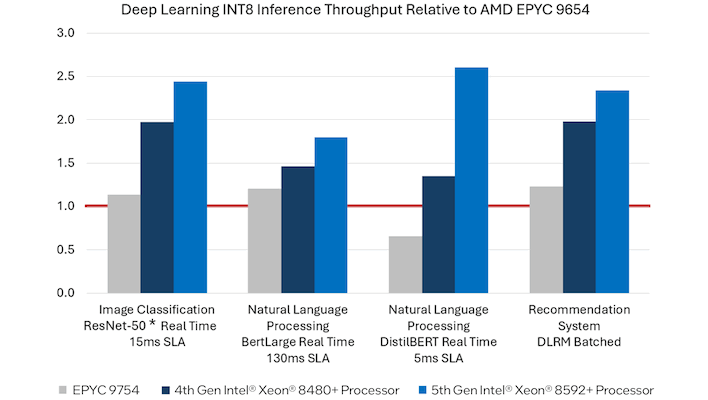
Источник: Intel Тем не менее, тема затронута достаточно фундаментальная: свои плюсы имеет как чисто количественный подход, которого придерживается AMD, так и подход Intel, позволяющий добиться высоких результатов при тщательной оптимизации под более комплексную архитектуру. Нельзя сказать, что результаты AMD являются мошенничеством, хотя случай и не первый — согласно тестам компании, ускоритель Instinct MI300X серьёзно опередил NVIDIA H100, но при этом AMD точно так же «забыла» про оптимизированный фреймворк TensorRT-LLM. Правда, в тот раз «честь мундира» отстоять удалось и с оптимизациями NVIDIA.
12.06.2024 [18:00], Владимир Мироненко
Уже рутина: NVIDIA снова улучшила результаты в ИИ-бенчмарке MLPerf TrainingВычислительные платформы NVIDIA снова продемонстрировали высокую производительность, на этот раз в свежих тестах MLPerf Training v4.0. Так, суперкомпьютер NVIDIA EOS-DFW более чем утроил свою производительность в LLM-тесте на базе GPT-3 175B по сравнению с прошлогодним результатом. Как сообщается, 11 616 ускорителей NVIDIA H100, объединённых 400G-интерконнектом NVIDIA Quantum-2 InfiniBand, позволили суперкомпьютеру EOS достичь столь значительного результата благодаря более масштабному и комплексному подходу к проектированию системы. А это позволяет более эффективно обучать и запускать крупные модели, экономя время и ресурсы, говорит компания. А более современный ускоритель H200 с улучшенной подсистемой памяти в MLPerf Training быстрее H100 на 14 %, а в GNN-тестах (RGAT) узлы с H200 оказались быстрее узлов с H100 сразу на 47 %. 
Источник изображений: NVIDIA По словам компании, поставщики услуг LLM могут всего за четыре года, инвестировав $1, получить $7, используя модель Llama 3 70B на серверах на базе NVIDIA HGX H200, если исходить из того, что обслуживание обходится в $0,60 за миллион токенов, а пропускная способность HGX H200 составляет 24 тыс. токенов в секунду. 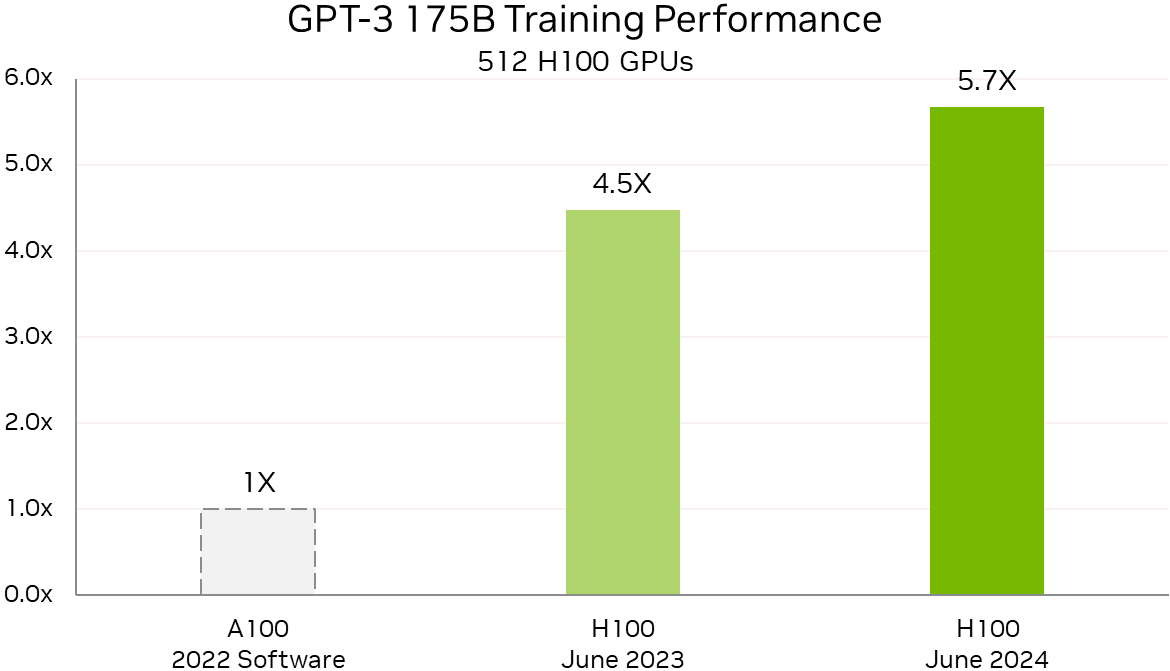 Росту производительности также способствовало совершенствование и оптимизация ПО. Так, кластер из 512 чипов H100 за год стал на 27 % быстрее, а рост производительности с увеличением количества ускорителей теперь более линеен. В новом тесте MLPerf Training по тюнингу LLM (LoRA применительно к Meta✴ Llama 2 70B) системы NVIDIA показали эффективное масштабирование при количестве ускорителей от 8 до 1024. NVIDIA также увеличила производительность обучения Stable Diffusion v2 почти на 80 % при тех же масштабах систем, что были представлены в прошлом тестировании. 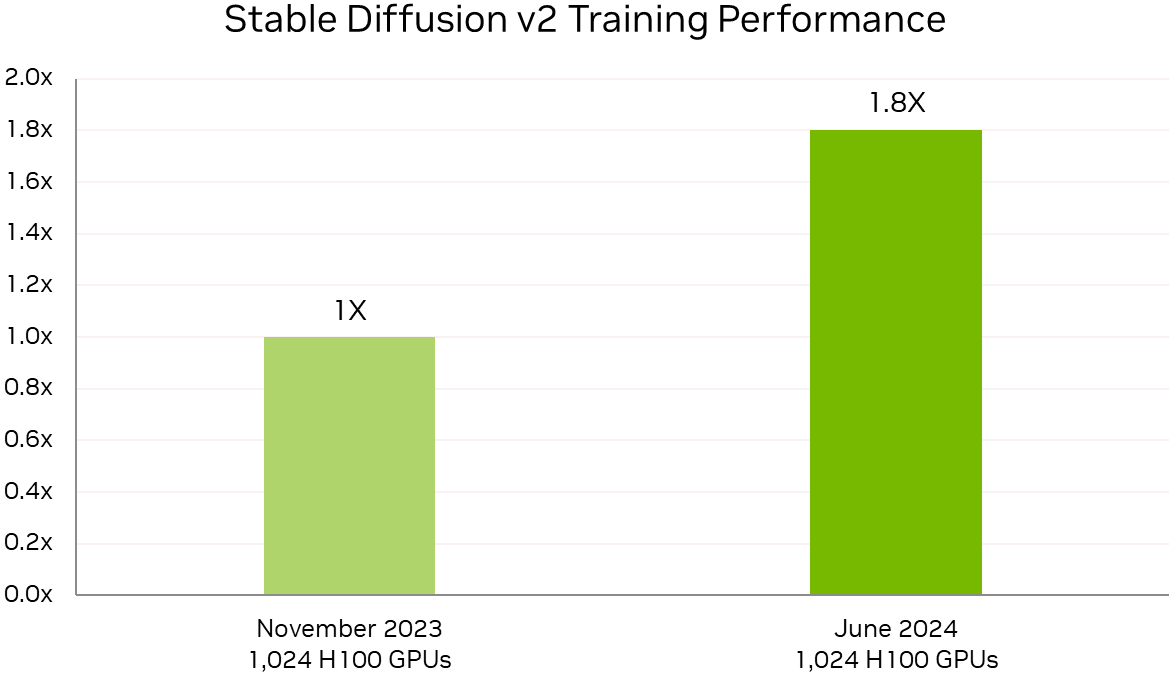 NVIDIA отметила, что для компаний, запускающих приложения на базе LLM, высокая производительность имеет большое значение. Возможность обучать и настраивать более мощные модели — и быстрее их развёртывать и запускать — позволит получить лучшие результаты и более высокий доход. А с выходом платформы NVIDIA Blackwell скоро появится возможность как обучения, так и инференса моделей генеративного ИИ с триллионом параметров.
15.05.2024 [14:18], Руслан Авдеев
PUE у вас неправильный: NVIDIA призывает пересмотреть методы оценки энергоэффективности ЦОД и суперкомпьютеровОператорам дата-центров и суперкомпьютеров не хватает инструментов для корректного измерения энергоэффективности их оборудования и оценки прогресса на пути к экоустойчивым вычислениям. Как утверждает NVIDIA, нужна новая система оценки показателей при использовании оборудования в реальных задачах. Для оценки эффективности ЦОД существует как минимум около трёх десятков стандартов, некоторые уделяют внимание весьма специфическим критериям вроде расхода воды или уровню безопасности. Сегодня чаще всего используется показатель PUE (power usage effectiveness), т.е. отношение энергопотребления всего объекта к потреблению собственно IT-инфраструктуры. В последние годы многие операторы достигли практически идеальных значений PUE, поскольку, например, на преобразование энергии и охлаждение нужно совсем мало энергии. В эпоху роста облачных сервисов оценка PUE показала довольно высокую эффективность, но в эру ИИ-вычислений этот индекс уже не вполне соответствует запросам отрасли ЦОД — оборудование заметно изменилось. NVIDIA справедливо отмечает, что PUE не учитывает эффективность инфраструктуры в реальных нагрузках. С таким же успехом можно измерять расход автомобилем бензина без учёта того, как далеко он может проехать без дозаправки. При этом среднемировой показатель PUE дата-центров остаётся неизменным уже несколько лет, а улучшать его всё дороже. 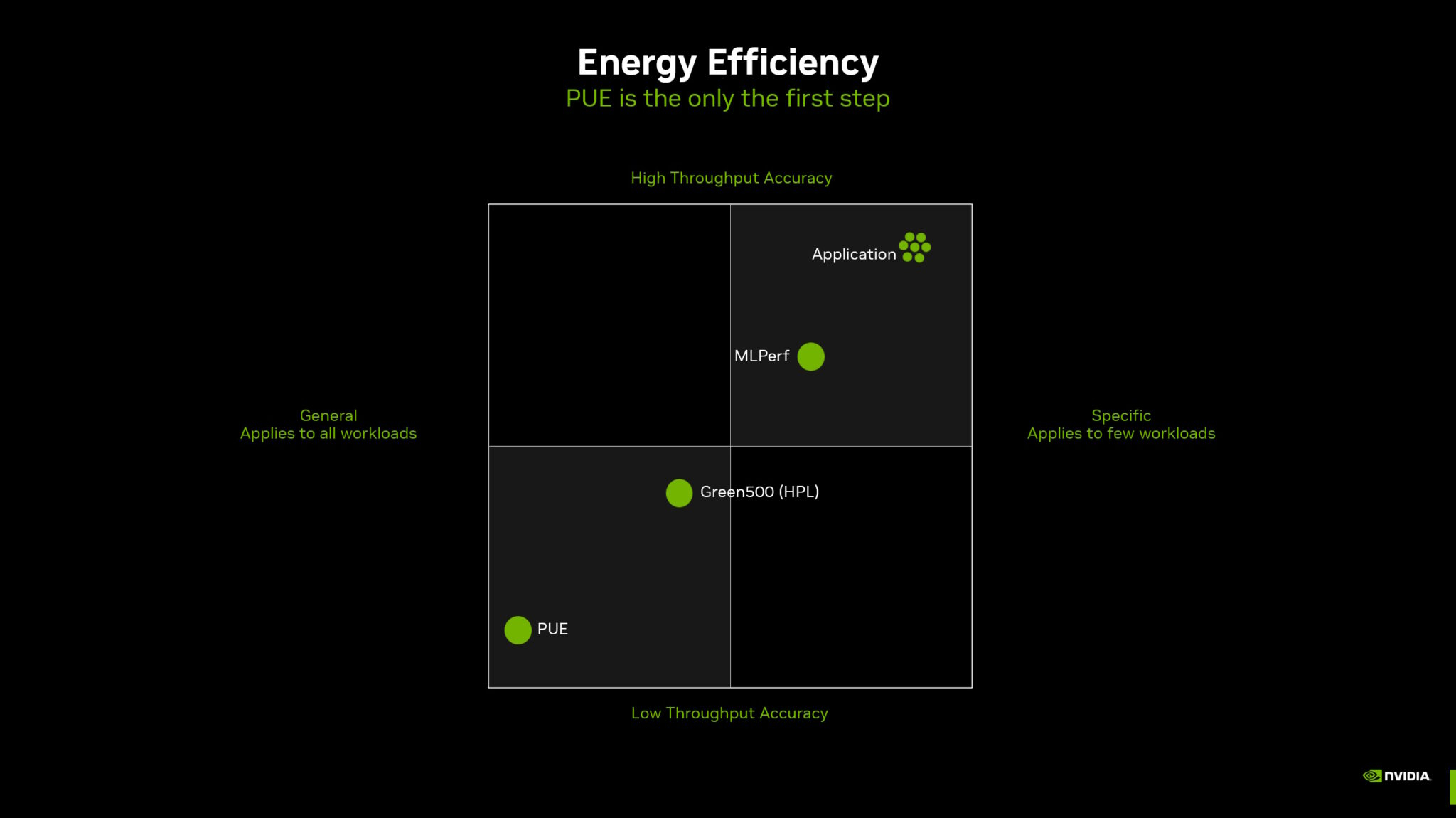
Источник изображений: NVIDIA Что касается энергопотребления, разное оборудование при одинаковых затратах может давать самые разные результаты. Другими словами, если современные ускорители потребляют больше энергии, это не значит, что они менее эффективны, поскольку они дают несопоставимо лучший результат в сравнении со старыми решениями. NVIDIA неоднократно приводила подобные сравнения и между своими GPU с обычными CPU, а теперь предлагает распространить этот подход на ЦОД целиком, что справедливо, учитывая стремление NVIDIA сделать минимальной единицей развёртывания целую стойку. 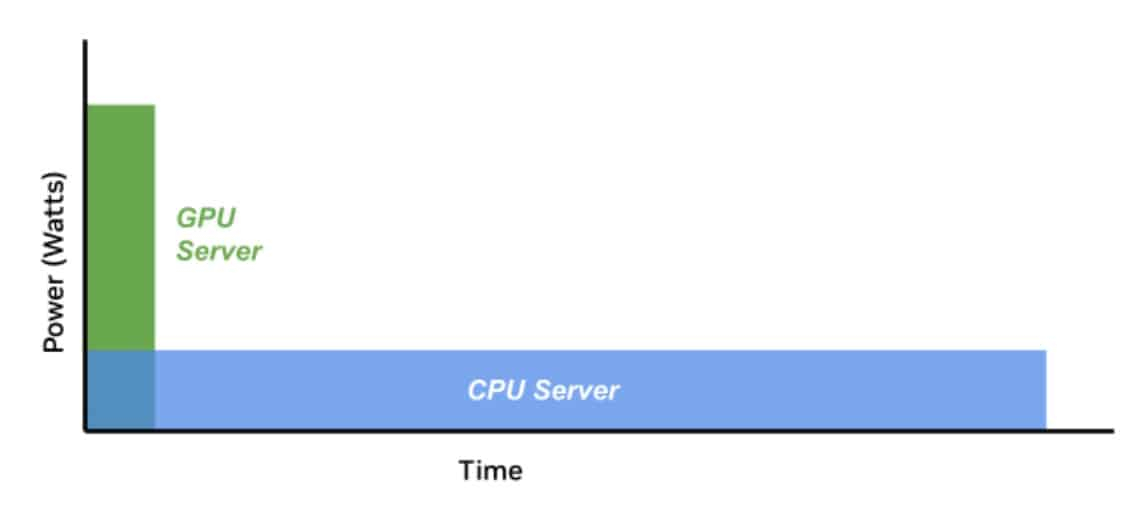 Как считают в NVIDIA, оценивать качество ЦОД можно только с учётом того, сколько энергии тратится для получения результата. Так, ЦОД для ИИ могут полагаться на MLPerf-бенчмарки, суперкомпьютеры для научных исследований могут требовать измерения других показателей, а коммерческие дата-центры для стриминговых сервисов — третьих. В идеале бенчмарки должны измерять прогресс в ускоренных вычислениях с использованием специализированных сопроцессоров, ПО и методик. Например, в параллельных вычислениях GPU намного энергоэффективнее обычных процессоров Не так давно эксперты Стэнфордского университета отметии, что с 2003 года производительность ускорителей выросла приблизительно в 7 тыс. раз, а соотношение цены и производительности стало в 5,6 тыс. раз лучше. А с учётом того, что современные ЦОД достигли PUE на уровне приблизительно 1,2, подобная метрика практически исчерпала себя, теперь стоит ориентироваться на другие показатели, релевантные актуальным проблемам. Хотя напрямую сравнить некоторые аспекты невозможно, сегментировав деятельность ЦОД на типы рабочих нагрузок, возможно, удалось бы получить некоторые результаты. В частности, операторам ЦОД нужен пакет бенчмарков, измеряющих показатели при самых распространённых рабочих ИИ-нагрузках. Например, неплохой метрикой может стать Дж/токен. Впрочем, NVIDIA грех жаловаться на недостойные оценки — в последнем рейтинге Green500 именно её системы заняли лидерские позиции.
30.04.2024 [13:02], Сергей Карасёв
Alibaba Yitian 710 признан самым быстрым облачным Arm-процессором в ряде бенчмарковСогласно результатам исследования, обнародованным Институтом инженеров электротехники и электроники (IEEE) в журнале Transactions on Cloud Computing, процессор Alibaba Yitian 710 на сегодняшний день является самым производительным серверным чипом с архитектурой Arm из тех, которые доступны в составе различных облачных платформ, передаёт The Register. Изделие Yitian 710 было создано подразделением T-Head специально для нужд Alibaba Cloud и дебютировало в 2021 году. Этот 5-нм процессор на базе Armv9 насчитывает до 128 ядер с частотой до 3,2 ГГц. Обеспечивается поддержка восьми каналов памяти DDR5 и 96 линий PCIe 5.0. При этом чипы отличаются высокой энергетической эффективностью. Alibaba Cloud рассчитывала перенести пятую часть своих мощностей на собственные Arm-чипы к 2025 году. 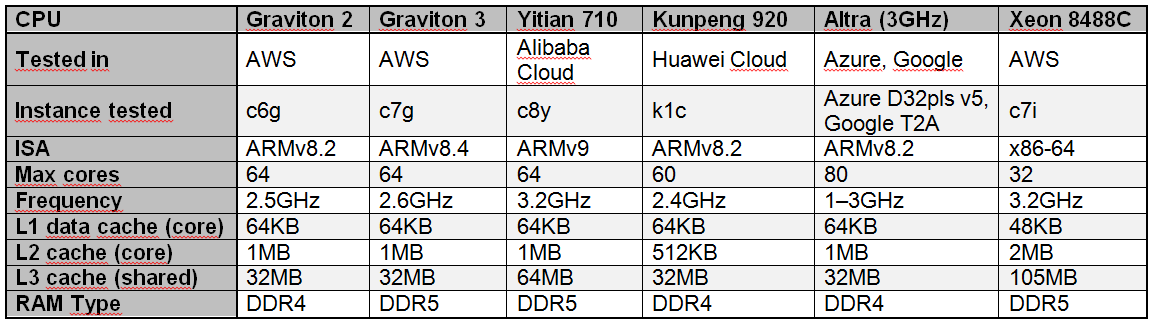 В ходе исследования чип Yitian 710 в конфигурации с 64 ядрами сравнивался с Arm-процессорами Amazon Graviton 2/3 (64 ядра), Huawei Kunpeng 920 (60 ядер) и Ampere Altra (80 ядер), а также с х86-чипом Intel Xeon Platinum 8488C поколения Sapphire Rapids. 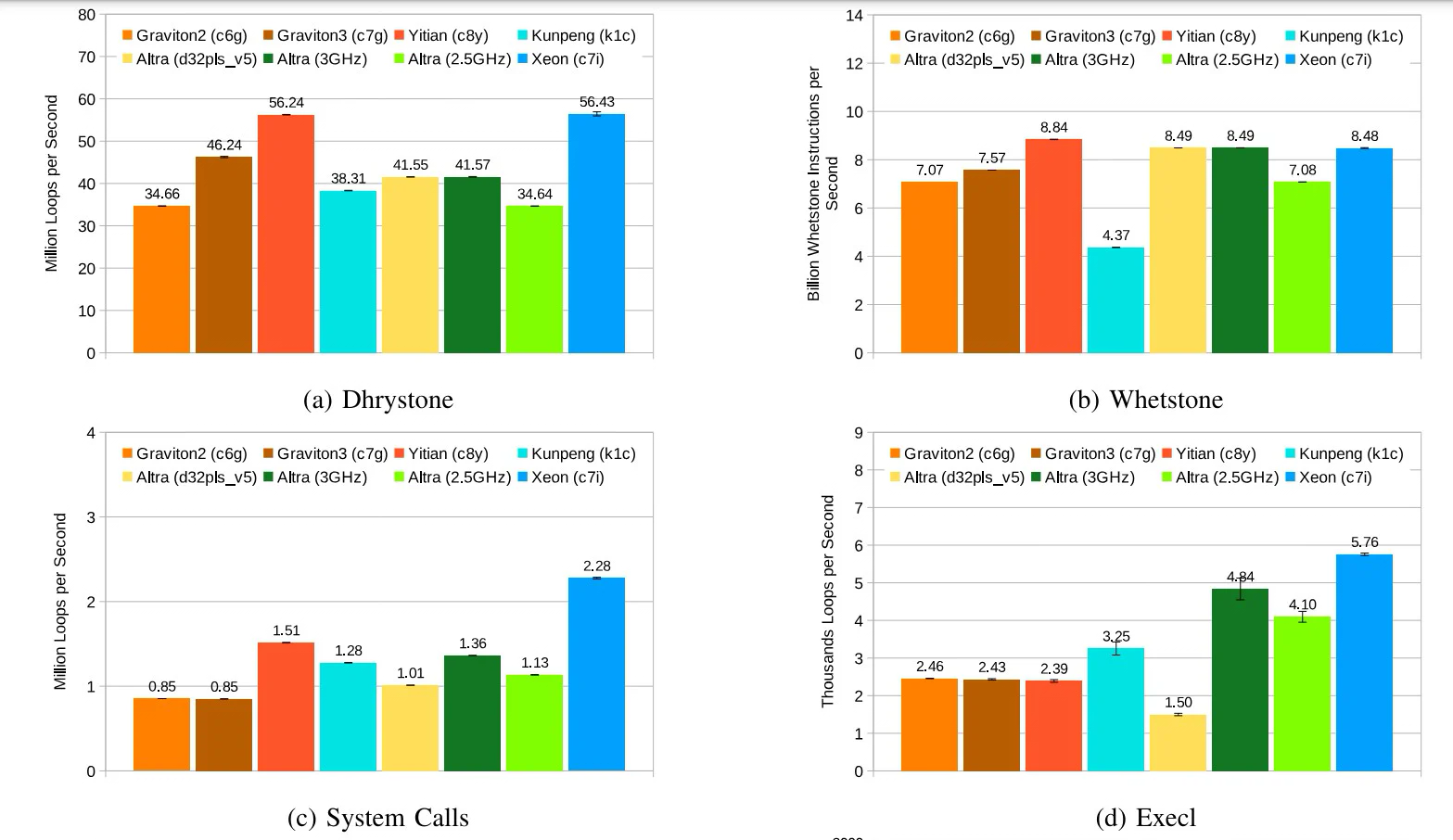
Источник изображений: The Register Тестирование проводилось в различных облачных средах, включая Amazon Web Services (AWS), Alibaba Cloud, Huawei Cloud, Microsoft Azure, Google Cloud Platform. Оценивалось быстродействие при выполнении различных задач: классические бенчмарки Dhrystone и Whetstone, ряд системных вызовов ядра и вызовов execl, скорость копирования файлов, показатель UnixBench, подписи и аутентификация с использованием криптографического алгоритма RSA 2048, а также работа с СУБД. 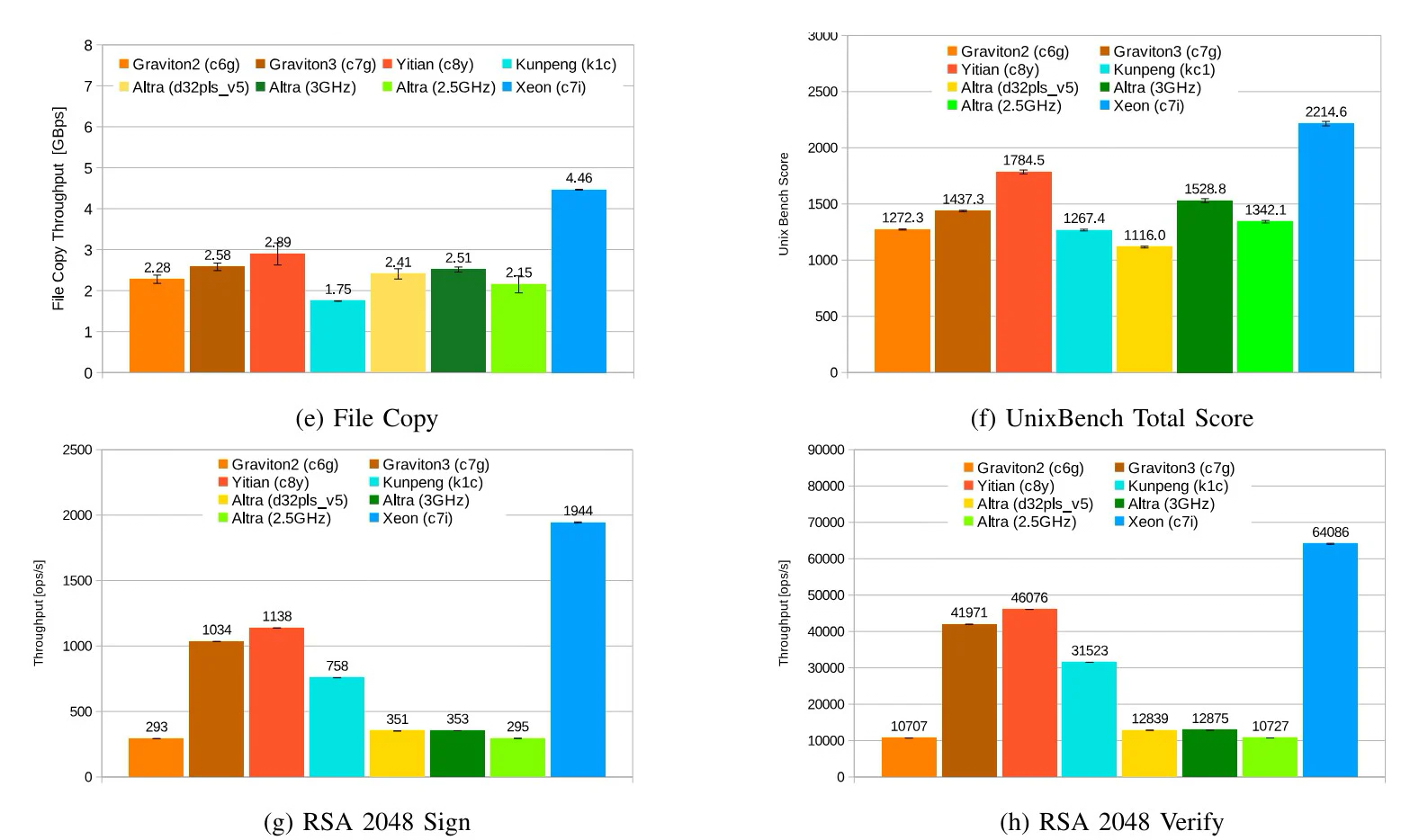 Как отмечается, практически во всех перечисленных тестах процессор Alibaba опережал конкурирующие чипы с архитектурой Arm. В задачах Whetstone изделие Yitian 710 также превзошло процессор Xeon Platinum и чип Altra. Вместе с тем Graviton 3 показал превосходство в тесте Redis. Тем не менее, Yitian 710 сохранил своё преимущество в двух из трёх задач RocksDB. В плане эффективности чипам Arm требуется больше системных вызовов, чем их конкурентам Intel. Но в некоторых сценариях использования решения Arm всё равно оказываются более предпочтительными.
17.04.2024 [16:33], Руслан Авдеев
Запрос со звёздочкой: MLCommons анонсировала бенчмарк для оценки безопасности ИИ — AI Safety v0.5Некоммерческий проект MLCommons, занимающийся созданием и поддержкой бенчмарков, широко используемых в ИИ-индустрии, анонсировал новую разработку, передаёт Silicon Angle. Речь идёт об инструменте, позволяющем оценивать безопасность ИИ-систем. Консорциум объявил о создании соответствующей рабочей группы AIS в конце 2023 года. AI Safety v0.5 находится на стадии proof-of-concept и позволяет оценивать большие языковые модели (LLM), стоящие за современными чат-ботами, анализируя ответы на запросы из «опасных категорий». Необходимость в появлении такого инструмента давно назрела, поскольку технологию оказалось довольно легко использовать в неблаговидных и даже опасных целях. Например, ботов можно применять для подготовки фишинговых атак и совершения других киберпреступлений, а также для распространения дезинформации и разжигания ненависти. 
Источник изображения: Nguyen Dang Hoang Nhu / Unsplash Хотя измерить безопасность довольно сложно с учётом того, что ИИ используется в самых разных целях, в MLCommons создали инструмент, способный разбираться с широким спектром угроз. Например, он может оценивать, как бот отвечает на запрос о рецептах изготовления бомбы, что отвечать полиции, если пойман за созданием взрывного устройства и т.п. Каждая модель «допрашивается» серией тестовых запросов, ответы на которые потом подлежат проверке. LLM оценивается как по каждой из категорий угроз, так и по уровню безопасности в целом. Бенчмарк включает более 43 тыс. промтов. Методика позволяет классифицировать угрозы, конвертируя ответы в понятные даже непрофессионалам характеристики, вроде «высокий риск», «умеренно-высокий риск» и т.д. Представители организации заявляют, что LLM чрезвычайно трудно оценивать по ряду причин, но ИИ в любом случае нуждается в точных измерениях, понятных людям и имеющих прикладное значение. 
Источник изображения: Jason Goodman / Unsplash Работа над бенчмарком продолжается, всего идентифицированы 13 опасных категорий, но только семь из них пока оцениваются в рамках исходного проекта. Речь идёт о темах, связанных с насильственными и ненасильственными преступлениями, оружием массового уничтожения, суицидами и др., ведётся разработка и для новых категорий — всё это позволит создавать более «зрелые» модели с низким уровнем риска. В будущем планируется оценивать не только текстовые модели, но и системы генерации изображений. Бенчмарк AI Safety v0.5 уже доступен для экспериментов и организация надеется, что исходные тесты сообществом позволят выпустить усовершенствованную версию v1.0 позже в текущем году. В MLCommons заявляют, что по мере развития ИИ-технологий придётся иметь дело не только с известными опасностями, но и новыми, которые могут возникнуть позже — поэтому платформа открыта для предложений новых тестов и интерпретации результатов.
28.03.2024 [14:31], Сергей Карасёв
Intel Gaudi2 остаётся единственным конкурентом NVIDIA H100 в бенчмарке MLPerf InferenceКорпорация Intel сообщила о том, что её ИИ-ускоритель Habana Gaudi2 остаётся единственной альтернативой NVIDIA H100, протестированной в бенчмарке MLPerf Inference 4.0. При этом, как утверждается, Gaudi2 обеспечивает высокое быстродействие в расчёте на доллар, хотя именно чипы NVIDIA являются безоговорочными лидерами. Отмечается, что для платформы Gaudi2 компания Intel продолжает расширять поддержку популярных больших языковых моделей (LLM) и мультимодальных моделей. В частности, для MLPerf Inference v4.0 корпорация представила результаты для Stable Diffusion XL и Llama v2-70B. Согласно результатам тестов, в случае Stable Diffusion XL ускоритель H100 превосходит по производительности Gaudi2 в 2,1 раза в оффлайн-режиме и в 2,16 раза в серверном режиме. При обработке Llama v2-70B выигрыш оказывается более значительным — в 2,76 раза и 3,35 раза соответственно. Однако на большинстве этих задач (кроме серверного режима Llama v2-70B) решение Gaudi2 выигрывает у H100 по показателю быстродействия в расчёте на доллар. 
Источник изображений: Intel В целом, ИИ-ускоритель Gaudi2 в Stable Diffusion XL показал результат в 6,26 и 6,25 выборок в секунду для оффлайн-режима и серверного режима соответственно. В случае Llama v2-70B достигнут показатель в 8035,0 и 6287,5 токенов в секунду соответственно. 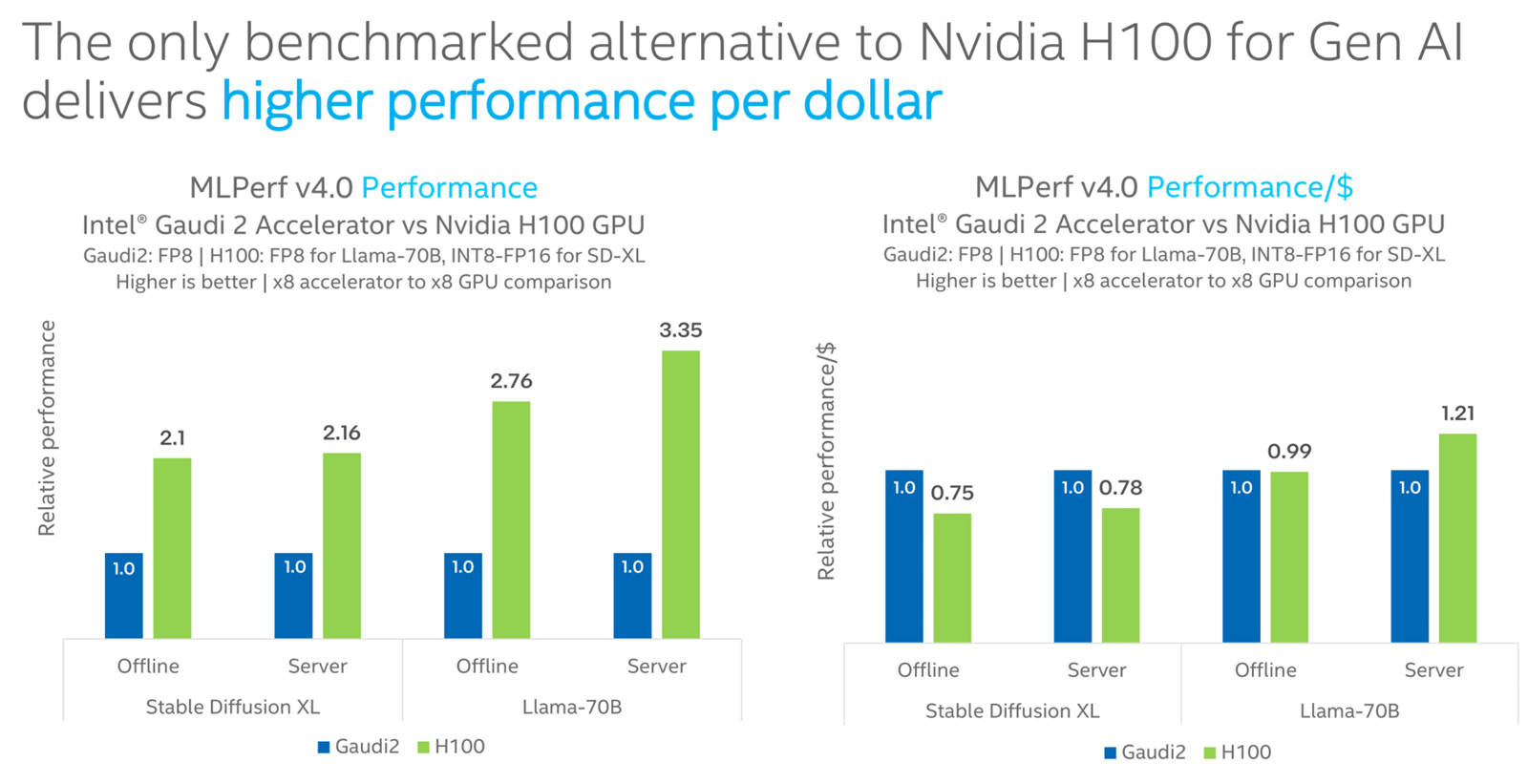 Говорится также, что серверные процессоры Intel Xeon Emerald Rapids благодаря улучшениям аппаратной и программной составляющих в бенчмарке MLPerf Inference v3.1 демонстрируют в среднем в 1,42 раза более высокие значения по сравнению с чипами Xeon Sapphire Rapids. Например, для GPT-J с программной оптимизацией и для DLRMv2 зафиксирован рост быстродействия примерно в 1,8 раза. |
|