Материалы по тегу: бенчмарк
|
27.03.2024 [22:29], Алексей Степин
Новый бенчмарк — новый рекорд: NVIDIA подтвердила лидерские позиции в MLPerf InferenceКомпания NVIDIA опубликовала новые, ещё более впечатляющие результаты в области работы с большими языковыми моделями (LLM) в бенчмарке MLPerf Inference 4.0. За прошедшие полгода и без того высокие результаты, демонстрируемые архитектурой Hopper в инференс-сценариях, удалось улучшить практически втрое. Столь внушительный результат достигнут благодаря как аппаратным улучшениям в ускорителях H200, так и программным оптимизациям. Генеративный ИИ буквально взорвал индустрию: за последние десять лет вычислительная мощность, затрачиваемая на обучение нейросетей, выросла на шесть порядков, а LLM с триллионом параметров уже не являются чем-то необычным. Однако и инференс подобных моделей тоже является непростой задачей, к которой NVIDIA подходит комплексно, используя, по её же собственным словам, «многомерную оптимизацию». 
Источник изображений: NVIDIA Одним из ключевых инструментов является TensorRT-LLM, включающий в себя компилятор и прочие средства разработки, учитывающие архитектуру ускорителей компании. Благодаря ему удалось почти втрое повысить производительность инференса GPT-J на ускорителях H100 всего за полгода. Такой прирост достигнут благодаря оптимизации очередей на лету (inflight sequence batching), применению страничного KV-кеша (paged KV cache), тензорному параллелизма (распределение весов по ускорителям), FP8-квантизации и использованию нового ядра XQA (XQA kernel). 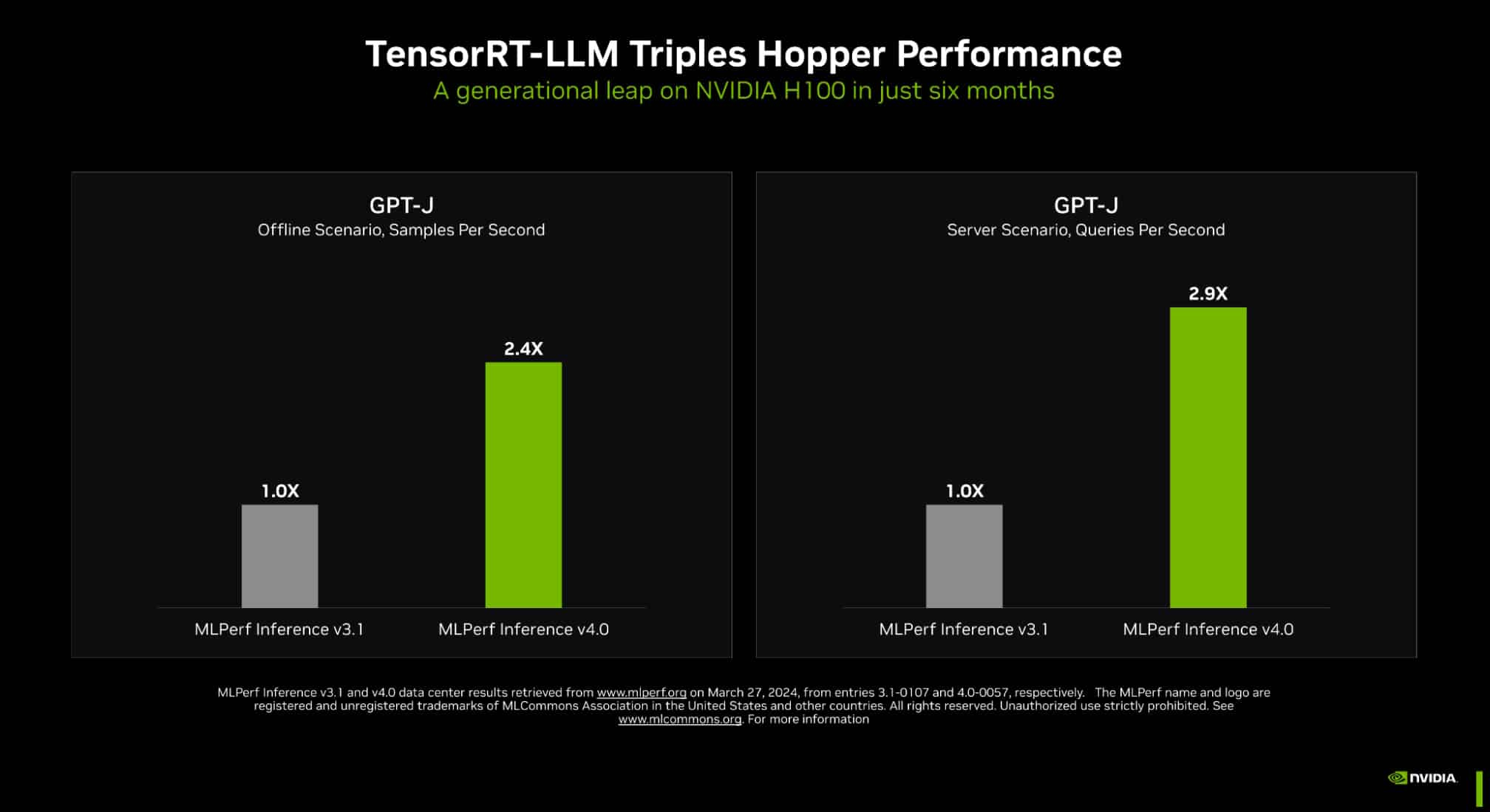 В случае ускорителей H200, использующих ту же архитектуру Hopper, что и H100, важную роль играет память: 141 Гбайт HBM3e (4,8 Тбайт/с) против 80 Гбайт HBM3 (3,35 Тбайт/с). Такой объём позволяет разместить модель уровня Llama 2 70B целиком в локальной памяти. В тесте MLPerf Llama 2 70B ускорители H200 на 28 % производительнее H100 при том же теплопакете 700 Вт, а увеличение теплопакета до 1000 Вт (так делают некоторые вендоры в своих MGX-платформах) даёт ещё 11–14 % прироста, а итоговая разница с H100 в этом тесте может доходить до 45 %. 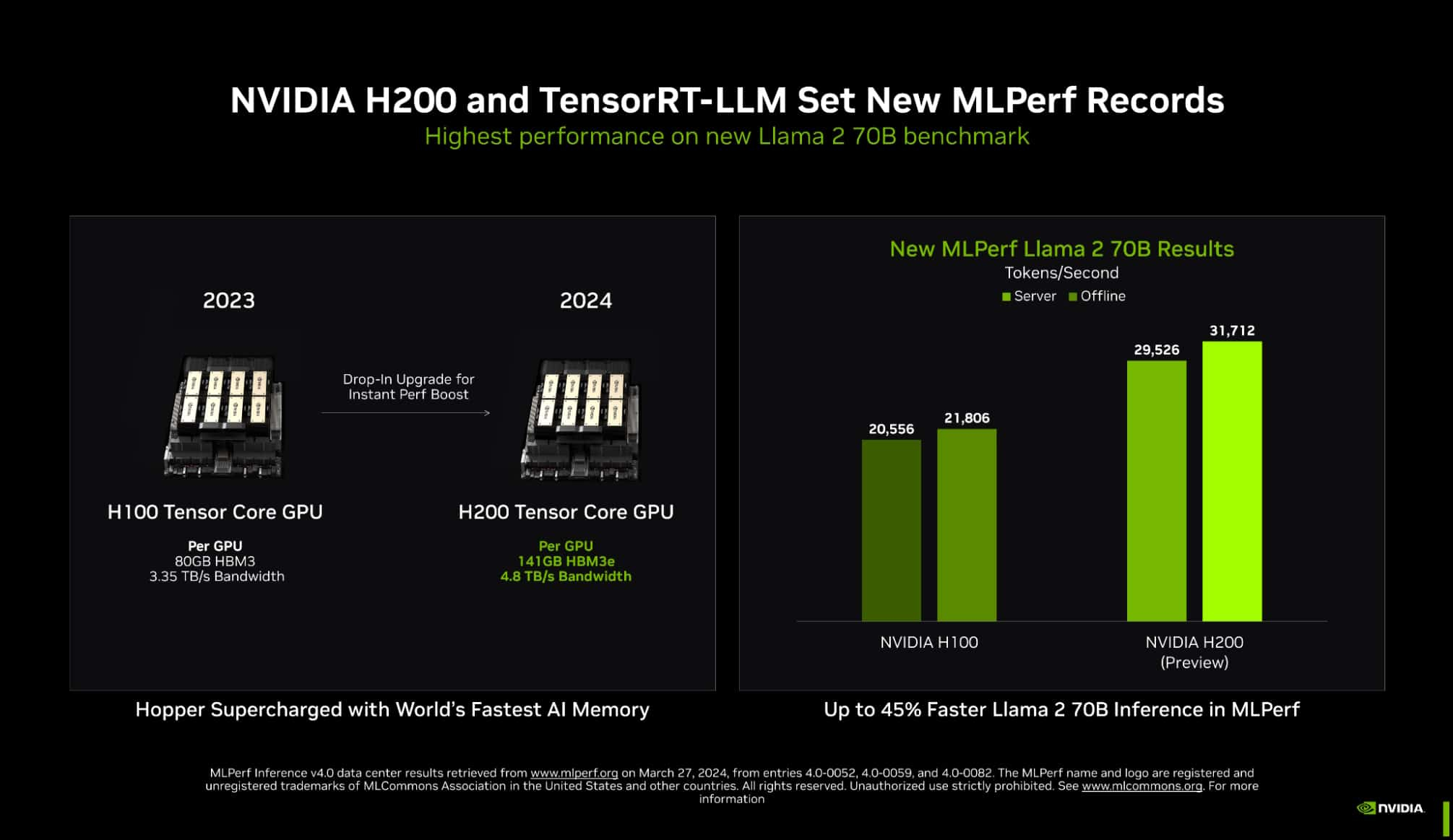 В специальном разделе новой версии MLPerf NVIDIA продемонстрировала несколько любопытных техник дальнейшей оптимизации: «структурированную разреженность» (structured sparsity), позволяющую поднять производительность в тесте Llama 2 на 33 %, «обрезку» (pruning), упрощающую ИИ-модель и позволяющую повысить скорость инференса ещё на 40 %, а также DeepCache, упрощающую вычисления для Stable Diffusion XL и дающую до 74 % прироста производительности. На сегодня платформа на базе модулей H200, по словам NVIDIA, является самой быстрой инференс-платформой среди доступных. Результатами GH200 компания похвасталась ещё в прошлом раунде, а вот показатели ускорителей Blackwell она не предоставила. Впрочем, не все считают результаты MLPerf показательными. Например, Groq принципиально не участвует в этом бенчмарке.
11.03.2024 [10:02], Сергей Карасёв
Viavi купит Spirent за $1,28 млрдАмериканская компания Viavi Solutions объявила о заключении соглашения по приобретению конкурирующей британской фирмы Spirent Communications. Сумма сделки, осуществить которую планируется за счёт денежных средств, составляет немногим более £1 млрд, или приблизительно $1,277 млрд. Viavi, базирующаяся в Чандлере (Аризона, США), производит оборудование для тестирования и мониторинга сетей. Кроме того, компания специализируется на оптических технологиях для различных сфер применения, включая контроль качества материалов, выявление фальшивых денежных знаков и т.д. В 2023 финансовом году выручка Viavi составила $1,1 млрд, что на 14 % меньше, чем годом ранее. 
Источник изображения: Viavi В свою очередь, Spirent со штаб-квартирой в Кроули (Западный Суссекс, Великобритания) предоставляет продукты и услуги для решения задач в области тестирования, обеспечения качества и автоматизации технологий, в том числе для 5G, SD-WAN, облачных платформ и автономных транспортных средств. По условиям соглашения, акционеры Spirent получат £1,725 (около $2,22) за каждую ценную бумагу. Сделка будет финансироваться за счёт имеющихся у Viavi денежных средств, кредита на семь лет в размере $800 млн от Wells Fargo Bank и инвестиций в $400 млн со стороны Silver Lake. Завершить слияние планируется во II половине 2024 года при условии одобрения акционеров и получения необходимых разрешений со стороны регулирующих органов. Путём совмещения активов стороны намерены укрепить положение в различных отраслях. Объединённая компания намерена вывести на рынок передовые решения, нацеленные на поставщиков облачных услуг, корпоративные сети, IT-инфраструктуры, частные сети 5G/6G и пр.
26.02.2024 [23:34], Владимир Мироненко
Groq LPU способен успешно конкурировать с ускорителями NVIDIA, AMD и IntelСтартап Groq сообщил о значительных достижениях в области инференса с использованием ускорителя LPU, разработанного для запуска больших языковых моделей (LLM), таких как GPT, Llama и Mistral. Groq LPU имеет один массивно-параллельный тензорный процессор TSP, который обеспечивает производительность до 750 TOPS INT8 и до 188 Тфлопс FP16. LPU Groq оснащён локальной SRAM объемом 230 Мбайт с пропускной способностью 80 Тбайт/с. Как сообщает компания, при запуске модели Mixtral 8x7B ускоритель LPU обеспечил скорость инференса 480 токенов в секунду, что является одним из ведущих показателей инференса в отрасли. В таких моделях, как Llama 2 70B с длиной контекста 4096 токенов, Groq может обеспечить скорость инференса 300 токенов/с, тогда как в меньшей модели Llama 2 7B с 2048 токенами контекста скорость инференса составляет 750 токенов/с. 
Изображение: Groq Согласно рейтингу бенчмарка LLMPerf, LPU Groq превосходит результаты систем облачных провайдеров на базе традиционных ИИ-ускорителей в деле запуска LLM Llama в конфигурациях от 7 до 70 млрд параметров. Groq лидирует по скорости инференса и занимает второе место по показателю задержки. 
Источник: The Ray Team Для сравнения, бесплатный чат-бот ChatGPT на базе GPT-3.5 обеспечивает обработку около 40 токенов/с. Текущие LLM с открытым исходным кодом, такие как Mixtral 8x7B, могут превосходить GPT 3.5 в большинстве тестов, и теперь могут работать со скоростью почти 500 токенов/с. 
Источник: The Ray Team Опубликованные данные наглядно подтверждают, что предлагаемый Groq ускоритель LPU Groq значительно превосходит системы для инференса, предлагаемые NVIDIA, AMD и Intel, говорит компания. Groq не раскрывает имена своих заказчиков, но в настоящее время её ИИ-решения используются, например, Аргоннской национальной лабораторией Министерства энергетики США.
10.02.2024 [20:32], Алексей Степин
Опубликованы результаты тестирования рабочей станции на базе NVIDIA GH200Поскольку NVIDIA со своим проектом Grace явно метит в мир высокопроизводительных многоядерных процессоров, результаты тестирования новых чипов представляют существенный интерес для всех, кто интересуется решениями подобного класса. Ресурс Phoronix опубликовал результаты проведённого тестирования NVIDIA GH200, причём в составе рабочей станции. Это, напомним, гибридное решение, включающее в себя 72-ядерный Arm-процессор и ускоритель H100. Сборка также включает в себя 480 Гбайт памяти LPDDR5 для процессорной части, а ускоритель располагает собственной высокоскоростной памятью HBM3e объёмом 96 Гбайт или 144 Гбайт. Связаны CPU и GPU высокоскоростной шиной NVLink-C2C с пропускной способностью 900 Гбайт/с. С периферийными устройствами GH200 может общаться посредством четырёх комплексов PCIe 5.0 по 16 линий каждый, а со стороны ускорителя имеется 18 линий NVLink 4 (900 Гбайт/с совокупно). 
Фото: GPTshop.ai Систему на тестирование предоставил магазин GPTshop.ai, позиционирующий решения на базе GH200 в качестве «настольных суперкомпьютеров». Рабочая станция в башенном корпусе включает в себя модуль GH200 на плате QCT и два блока питания мощностью 2000 Ватт, твердотельные накопители и сетевые карты NVIDIA ConnectX/Bluefield — по желанию заказчика. Стоимость стартует с отметки €47,4 тыс. 
Фото: GPTshop.ai В качестве ОС может использоваться любой дистрибутив Linux с поддержкой AArch64. В Phoronix использовали Ubuntu 23.10 с ядром версии 6.5 и стоковым компилятором GCC 13. В сравнении приняли участия системы на базе Intel Xeon Emerald Rapids, AMD EPYC и Ampere Altra Max. 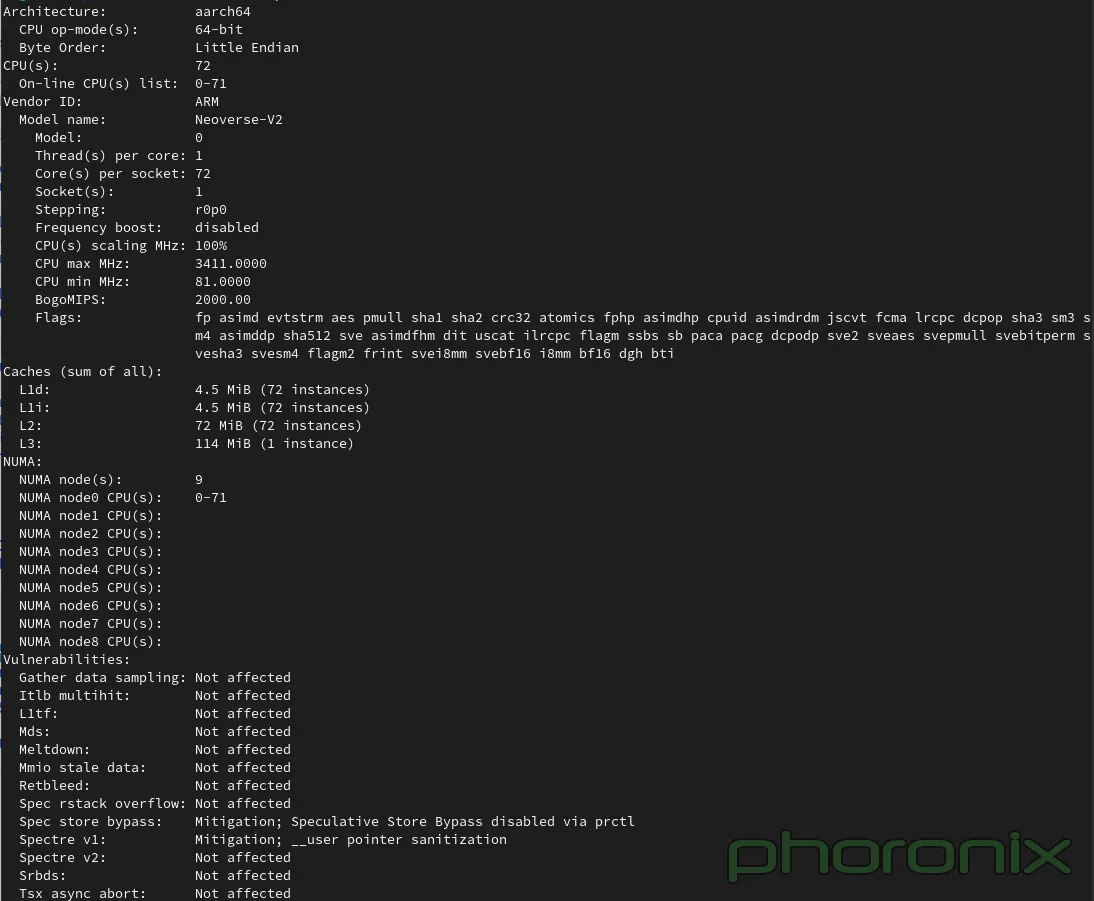
Источник: Phoronix В зависимости от сценария система на базе GH200 выступила с переменным успехом, но в среднем производительность процессорной части оказалась примерно на уровне 64-ядерных x86-процессоров — Xeon Platinum 8592+ или EPYC 9554. А 128-ядерный Altra Max M128-30 решение от NVIDIA уверенно обгоняет за счёт и более совершенной архитектуры, и более производительной подсистемы памяти. 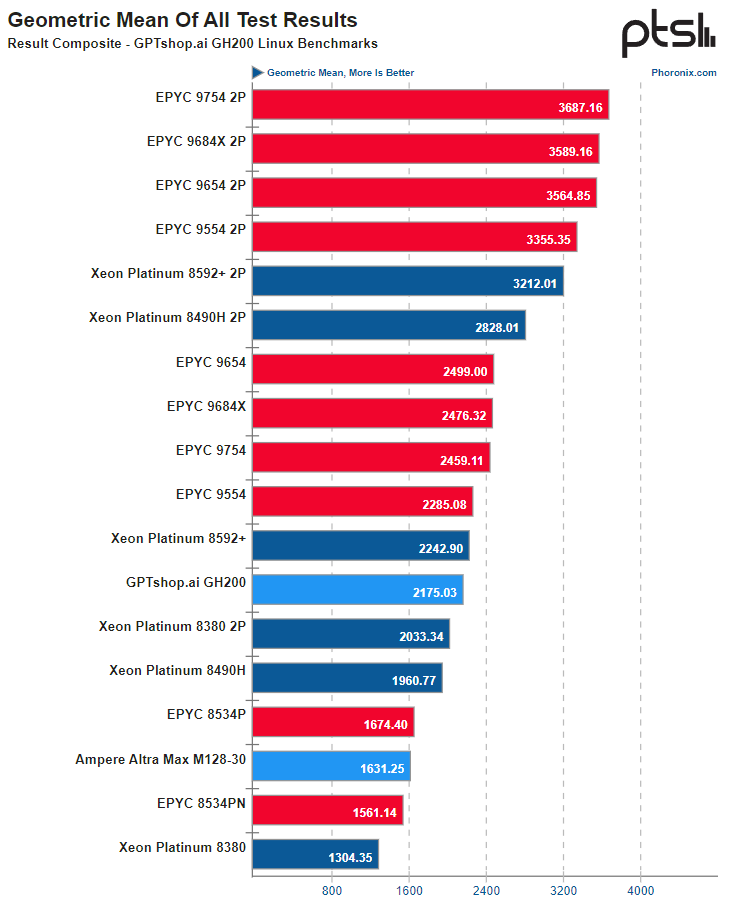
Источник: Phoronix К сожалению, вопрос энергоэффективности пока остался непроясненным, поскольку система не предоставляет интерфейсов RAPL/PowerCap/HWMON в Linux и точных метрик потребления получить невозможно, доступно лишь примерное значение потребления системы в целом через IPMI. Потенциал у GH200, определённо, есть, хотя временами и сказывается недостаточная оптимизация программного обеспечения под архитектуру AArch64. Конкуренции двухпроцессорным решениям Intel или AMD GH200 не составляет, однако в распоряжении NVIDIA имеется и 144-ядерный вариант Grace Superchip. Тестирование такой системы уже значится в планах Phoronix.
10.02.2024 [14:50], Сергей Карасёв
Более 2000 результатов Intel Xeon в бенчмарке SPEC CPU 2017 поставлены под сомнениеНекоммерческая организация Standard Performance Evaluation Corporation (SPEC), по сообщению ServeTheHome, по сути, аннулировала более 2000 результатов своего бенчмарка SPEC CPU 2017 для процессоров Intel. Причина заключается в специальной оптимизации для целочисленных вычислений, что теперь считается недопустимым. Установлено, что компилятор Intel oneAPI DPC++ фактически «обманывает» стандарты SPEC с помощью целевой оптимизации. Во многих результатах SPEC CPU 2017 в разделе «Примечания для компилятора» появилось уведомление о неточности данных. 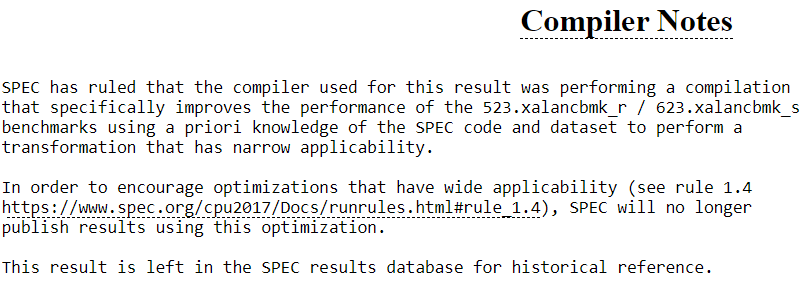
Источник: SPEC «SPEC пришла к выводу, что компилятор, использованный для получения этого результата, выполнял компиляцию, которая искусственно завышает производительность тестов 523.xalancbmk_r/623.xalancbmk_s, используя предварительное знание кода и набора данных», — сказано в сообщении. Отмечается, что SPEC больше не будет публиковать результаты, полученные с использованием указанной оптимизации. В тесте производительности, на который нацелена эта оптимизация компилятора, результат может увеличиться более чем на 50 %. Таким образом, можно добиться повышения общего результата на несколько процентов. С другой стороны, оптимизация имеет узкую применимость: например, 623.xalancbmk_s — это только один из десяти тестов в наборе. Оптимизация влияет на платформу Intel oneAPI версий с 2022.0 по 2023.0, тогда как более новые модификации, в частности, 2023.2.3 проблеме не подвержены. Кроме того, оптимизация не распространяется на процессоры AMD.
14.11.2023 [03:20], Алексей Степин
Intel показала результаты тестов ускорителя Max 1550 и рассказала о будущих чипах Gaudi3 и Falcon ShoresВ рамках SC23 корпорация Intel продемонстрировала ряд любопытных слайдов. На них присутствуют результаты тестирования ускорителя Max 1550 с архитектурой Xe, а также планы относительно следующего поколения ИИ-ускорителей Gaudi. 
Изображение: Intel При этом компания применила иной подход, нежели обычно — вместо демонстрации результатов, полученных в стенах самой Intel, слово было предоставлено Аргоннской национальной лаборатории Министерства энергетики США, где летом этого года было завершён монтаж суперкомпьютера экза-класса Aurora, занимающего нынче второе место в TOP500.  В этом HPC-кластере применены OAM-модули Max 1550 (Ponte Vecchio) с теплопакетом 600 Вт. Они содержат в своём составе 128 ядер Xe и 128 Гбайт памяти HBM2E. Интерфейс Xe Link позволяет общаться напрямую восьми таким модулям, что обеспечивает более эффективную масштабируемость. 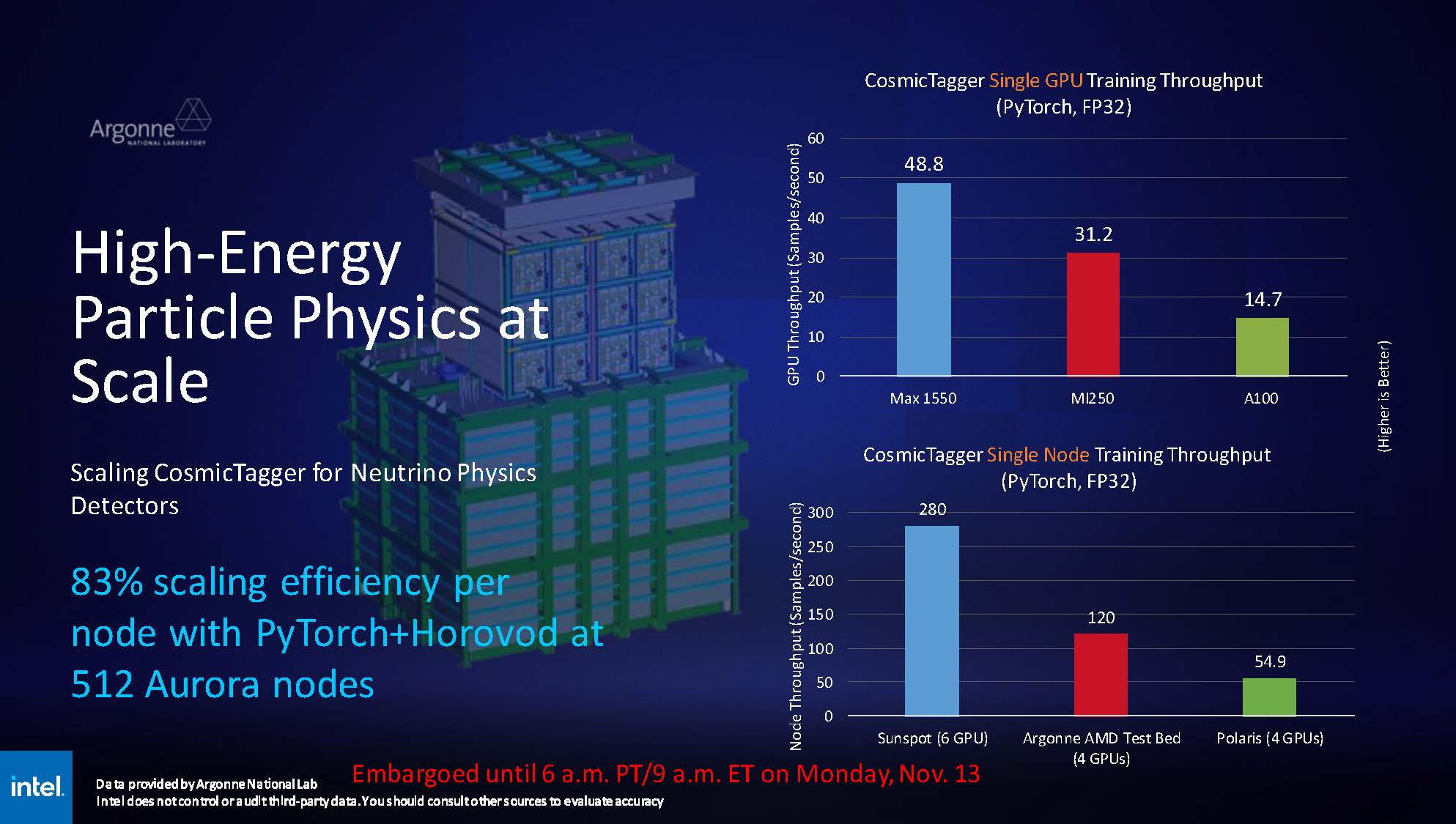
Источник изображений здесь и далее: Intel via ServeTheHome Хотя настройка вычислительного комплекса Aurora ещё продолжается, уже имеются данные о производительности Max 1550 в сравнении с AMD Instinct MI250 и NVIDIA A100. В тесте физики высоких частиц, использующих сочетание PyTorch+Horovod (точность вычислений FP32), ускорители Intel уверенно заняли первое место, а также показали 83% эффективность масштабирования на 512 узлах Aurora.  В тесте, симулирующем поведение комплекса кремниевых наночастиц, ускорители Max 1550, также оказались первыми как в абсолютном выражении, так и в пересчёте на 128-узловой тест в сравнении с системами Polaris (четыре A100 на узел) и Frontier (четыре MI250 на узел). Написанный с использованием Fortran и OpenMP код доказал работоспособность и при масштабировании до более чем 500 вычислительных узлов Aurora. 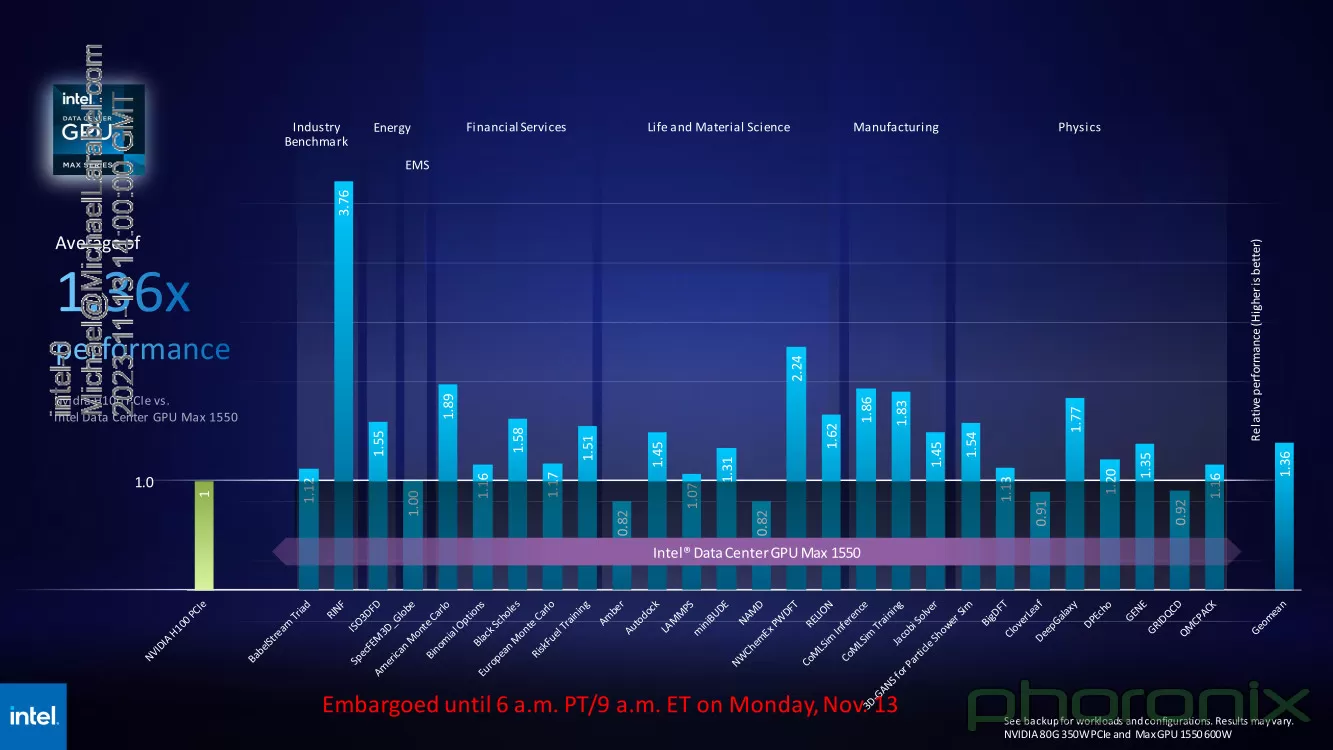
Источник изображения: Intel via Phoronix В целом, ускорители Intel Max 1550 демонстрируют хорошие результаты и не уступают NVIDIA H100: в некоторых задачах их относительная эффективность составляет не менее 0,82, но в большинстве других тестов этот показатель варьируется от 1,0 до 3,76. Очевидно, что у H100 появился достойный соперник, который, к тому же, имеет меньшую стоимость и большую доступность. Но сама NVIDIA уже представила чипы (G)H200, а AMD готовит Instinct MI300.  Системы на базе Intel Max доступны в различном виде: как в облаке Intel Developer Cloud, так и в составе OEM-решений. Supermicro предлагает сервер с восемью модулями OAM, а Dell и Lenovo — решения с четырьями ускорителями в этом же формате. PCIe-вариант Max 1100 доступен от вышеуказанных производителей, а также у HPE. 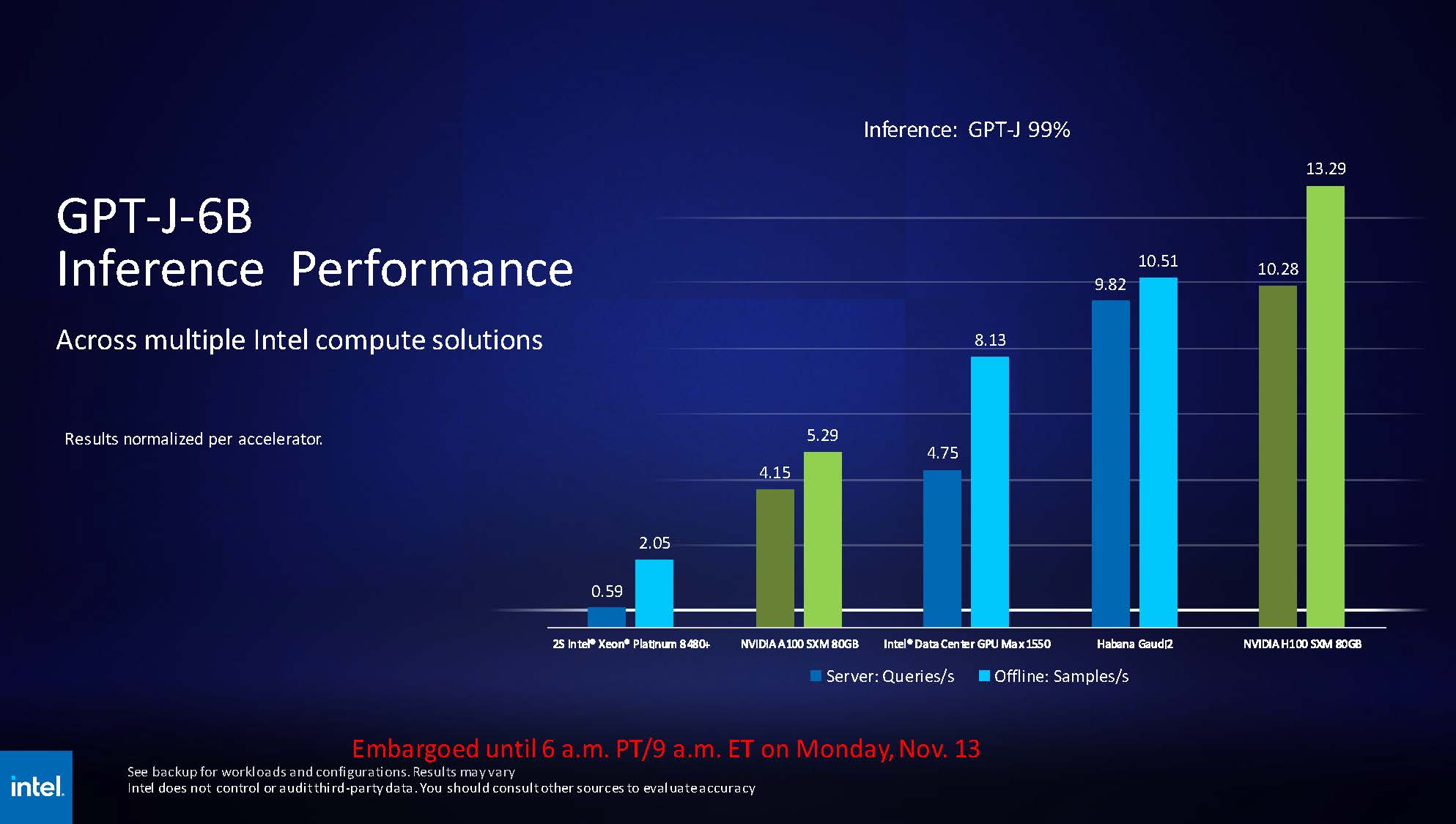 Помимо ускорителей Max, Intel привела и новые данные о производительности ИИ-сопроцессоров Gaudi2. Компания продолжает активно совершенствовать и оптимизировать программную экосистему Gaudi. В результате, в инференс-системе на базе модели GPT-J-6B результаты ускорителей Gaudi2 уже сопоставимы с NVIDIA H100 (SXM 80 Гбайт), а A100 существенно уступает как Gaudi2, так и Max 1550.  Но самое интересное — это сведения о планах относительно следующего поколения Gaudi. Теперь известно, что Gaudi3 будет производиться с использованием 5-нм техпроцесса. Новый чип будет в четыре раза быстрее в вычислениях BF16, а также получит вдвое более мощную подсистему памяти и в 1,5 раза больше памяти HBM. Увидеть свет он должен в 2024 году. 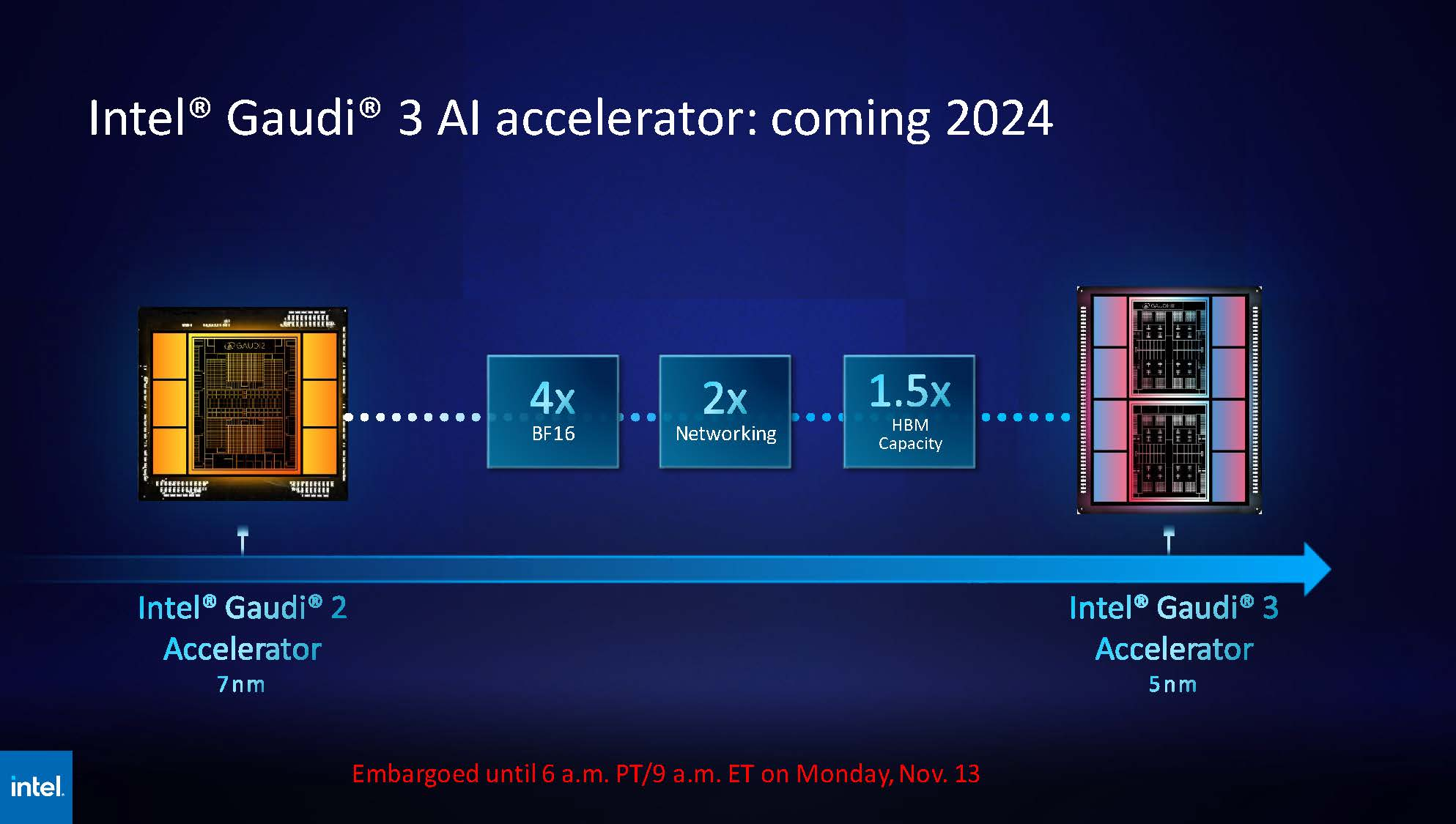 Заодно компания напомнила, что процессоры Xeon Emerald Rapids будут представлены ровно через месяц, а Granite Rapids появятся в 2024 году. В 2025 появится чип Falcon Shores, который теперь должен по задумке Intel сочетать в себе GPU и ИИ-сопроцессор. Он объединит архитектуры Habana и Xe в единое решение с тайловой компоновкой, памятью HBM3 и полной поддержкой CXL. 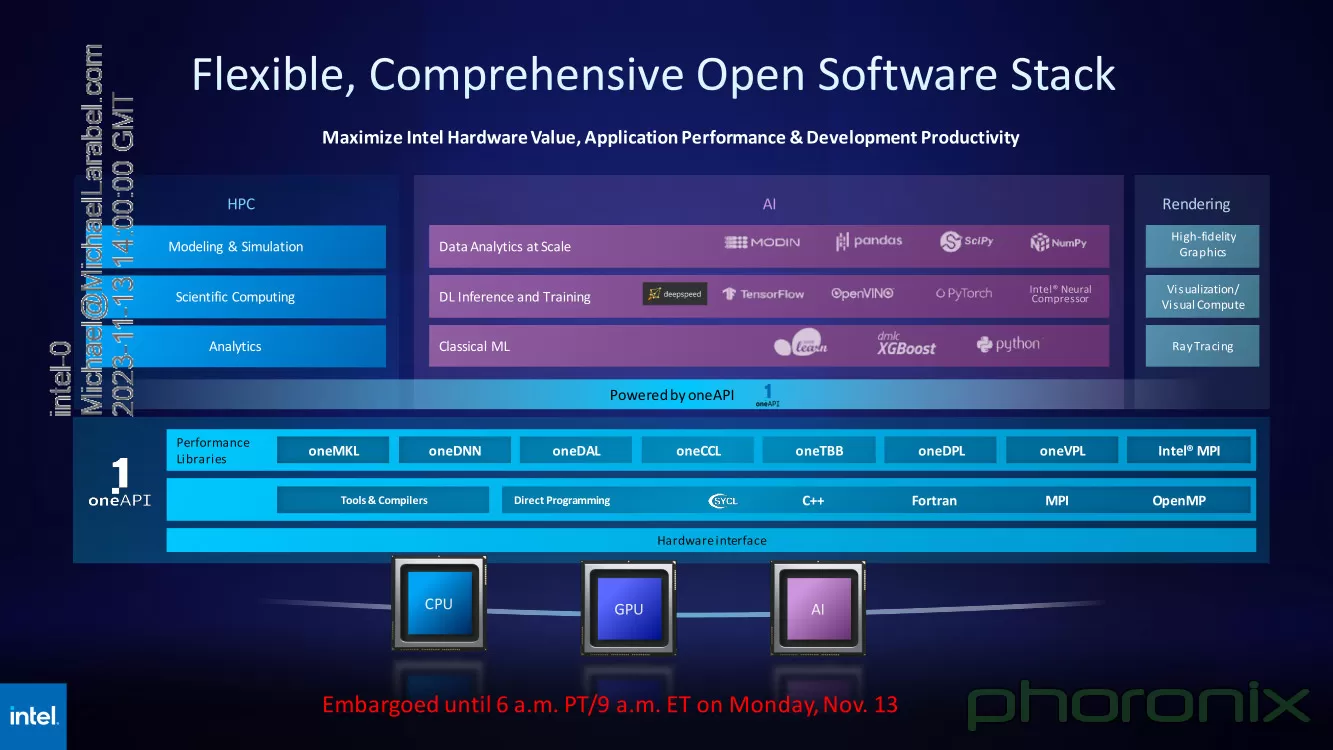
Источник изображения: Intel via Phoronix Следует отметить, что такая унификация вполне реальна: Intel весьма активно развивает универсальный, гибкий и открытый стек технологий в рамках проекта oneAPI. В него входят все необходимые инструменты — от компиляторов и системных библиотек до средств интеграции с популярными движками аналитики данных, моделями и библиотеками искусственного интеллекта.
11.11.2023 [15:23], Сергей Карасёв
MLPerf: Intel улучшила производительность Gaudi2, но лидером остаётся NVIDIA H100Консорциум MLCommons обнародовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training 3.1, который оценивает производительность на ИИ-операциях. Отмечается, что корпорация Intel смогла существенно увеличить быстродействие своего ускорителя Habana Gaudi2, но безоговорочным лидером остаётся NVIDIA H100. Тесты проводились на платформе Xeon Sapphire Rapids. Отмечается, что для некоторых задач Intel реализовала поддержку FP8-вычислений, благодаря чему производительность поднялась в два раза по сравнению с показателями, которые этот же ускоритель демонстрировал ранее. Согласно результатам тестов, в бенчмарке GPT-3 ускоритель Gaudi2 ровно в два раза проигрывает решению NVIDIA H100. То же самое касается теста Stable Diffusion: при этом нужно отметить, что Gaudi2 использовал формат BF16, а H100 — FP16. В ResNet эти ускорители демонстрируют сопоставимую производительность. В тесте BERT чип H100 при использовании FP8-вычислений показал значительное преимущество перед Gaudi2, который использовал формат BF16. 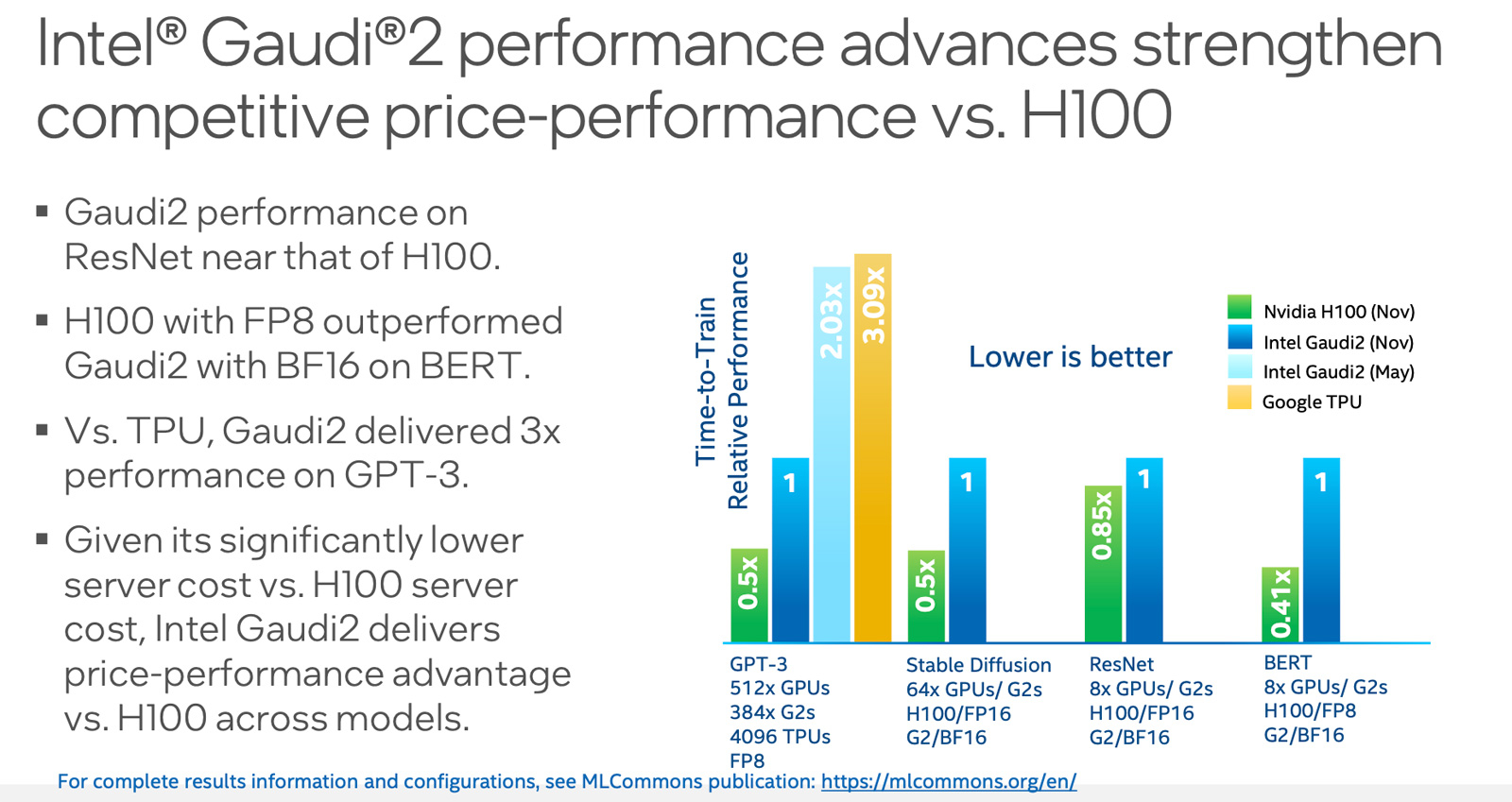
Источник изображения: MLCommons Сама Intel отмечает, что с внедрением поддержки FP8 система с 384 ускорителями Gaudi2 способна завершить обучение GPT-3 за 153,58 мин. При использовании 64 чипов Gaudi2 тест Stable Diffusion может быть завершён за 20,2 мин (BF16). Для тестов BERT и ResNet-50 на восьми ускорителях Gaudi2 (BF16) результат составляет 13,27 и 15,92 мин соответственно. Вместе с тем стоимость и доступность ускорителей Intel, как считается, существенно лучше, чем у решений NVIDIA.
08.11.2023 [20:00], Игорь Осколков
Счёт на секунды: ИИ-суперкомпьютер NVIDIA EOS с 11 тыс. ускорителей H100 поставил рекорды в бенчмарках MLPerf TrainingВместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег. 
Изображения: NVIDIA Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.   В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов. 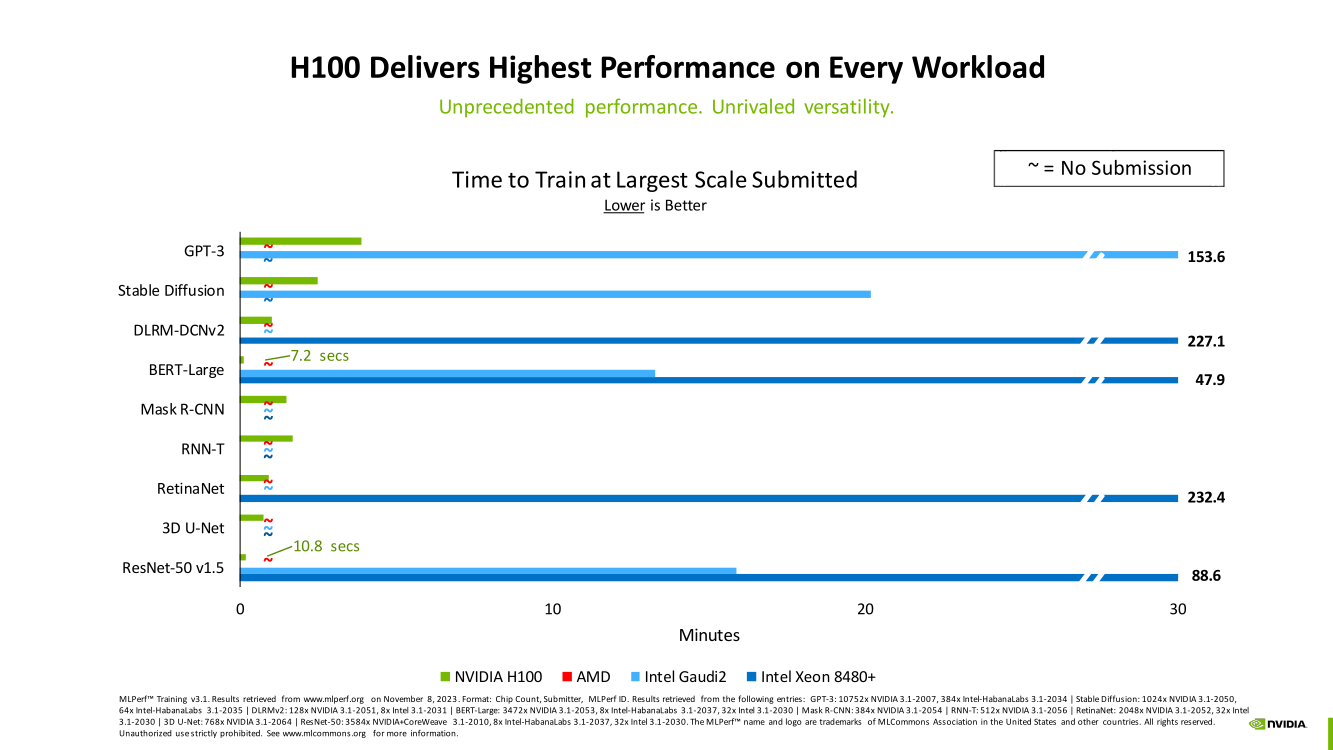 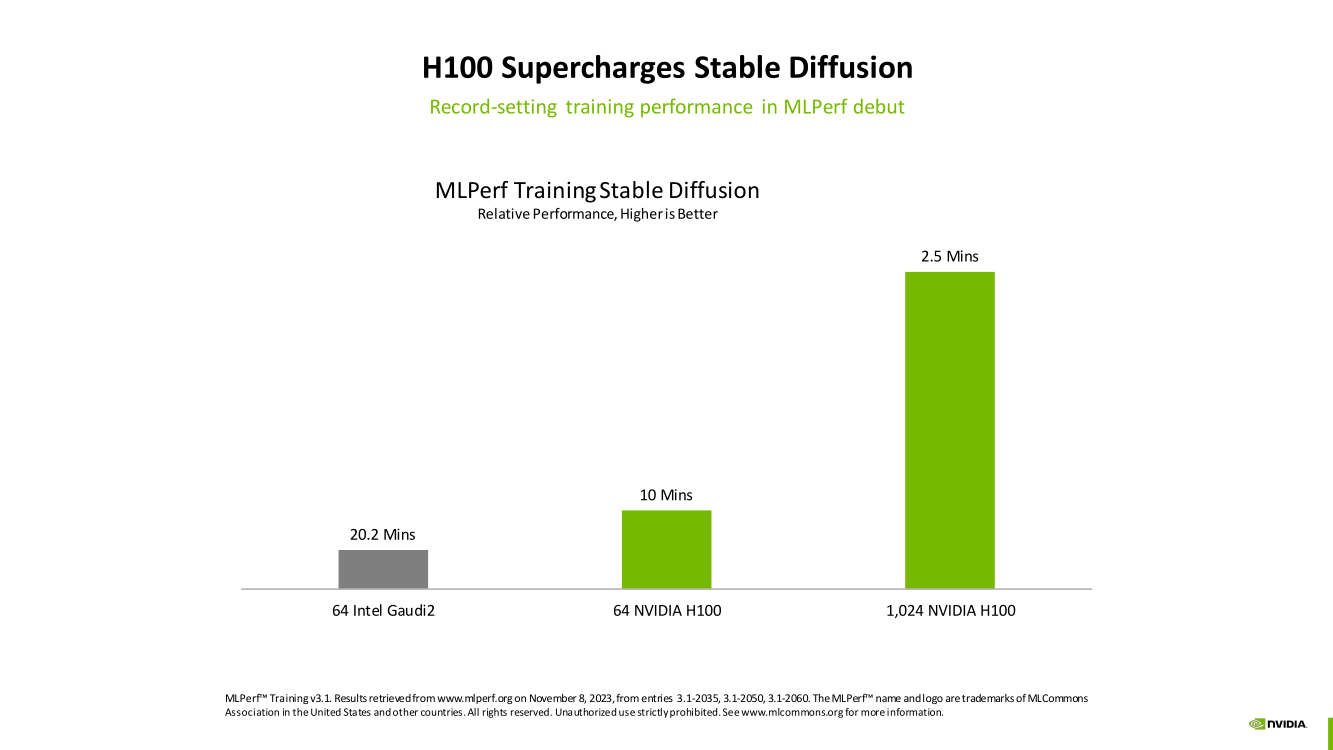 NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд. 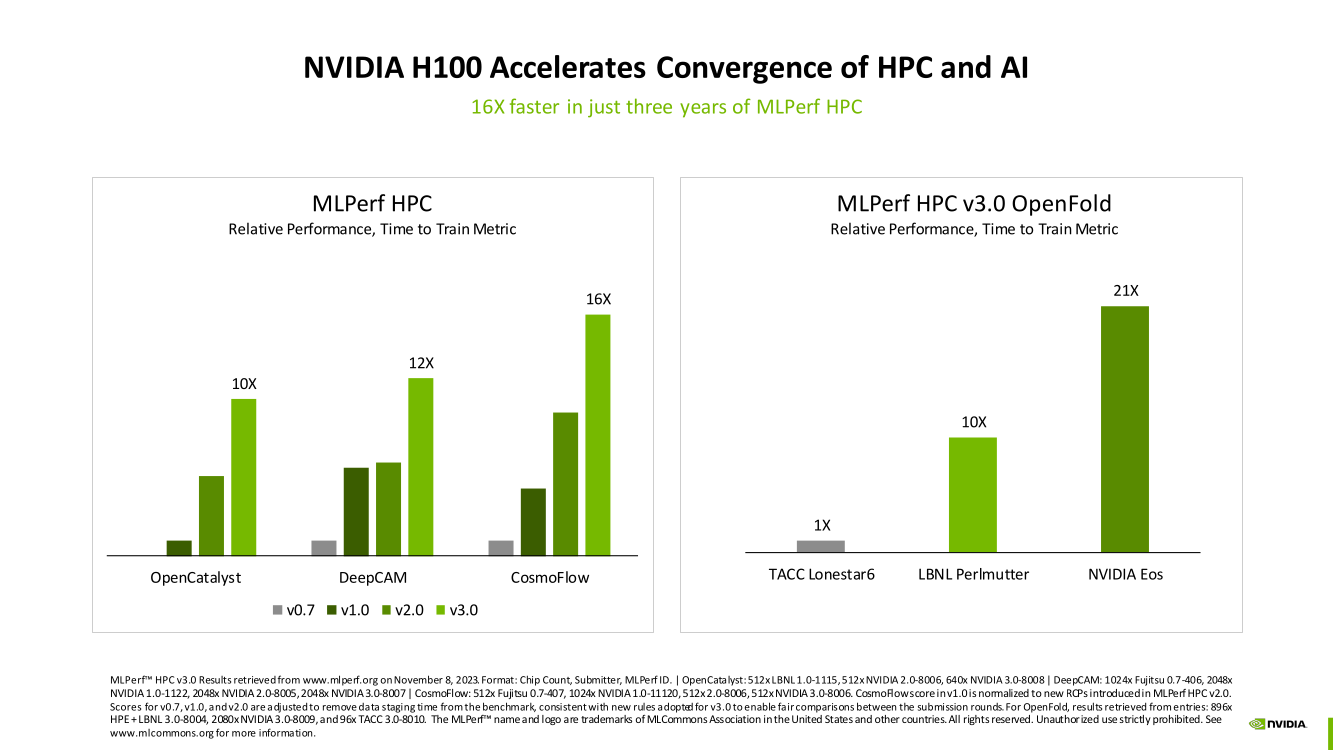
13.07.2022 [16:13], Алексей Степин
128-ядерный Arm-процессор Alibaba T-Head Yitian 710 показал отличные результаты в SPEC CPU2017Не секрет, что китайские гиганты, такие, как Huawei и Alibaba Cloud, разрабатывают собственные серверные процессоры на базе архитектуры Arm. Однако информации об этих чипах, как правило, не очень много и пользоваться общепринятыми на западе тестами и рейтингами разработчики не спешат, что, к слову, характерно и для китайских суперкомпьютеров. Alibaba Cloud представила чип Yitian 710 ещё осенью прошлого года. Этот процессор построен на базе архитектуры Armv9 и максимально может иметь 128 ядер с частотой до 3,2 ГГц. Однако результаты проверки чипа в популярном тесте SPEC CPU2017 были опубликованы только сейчас. 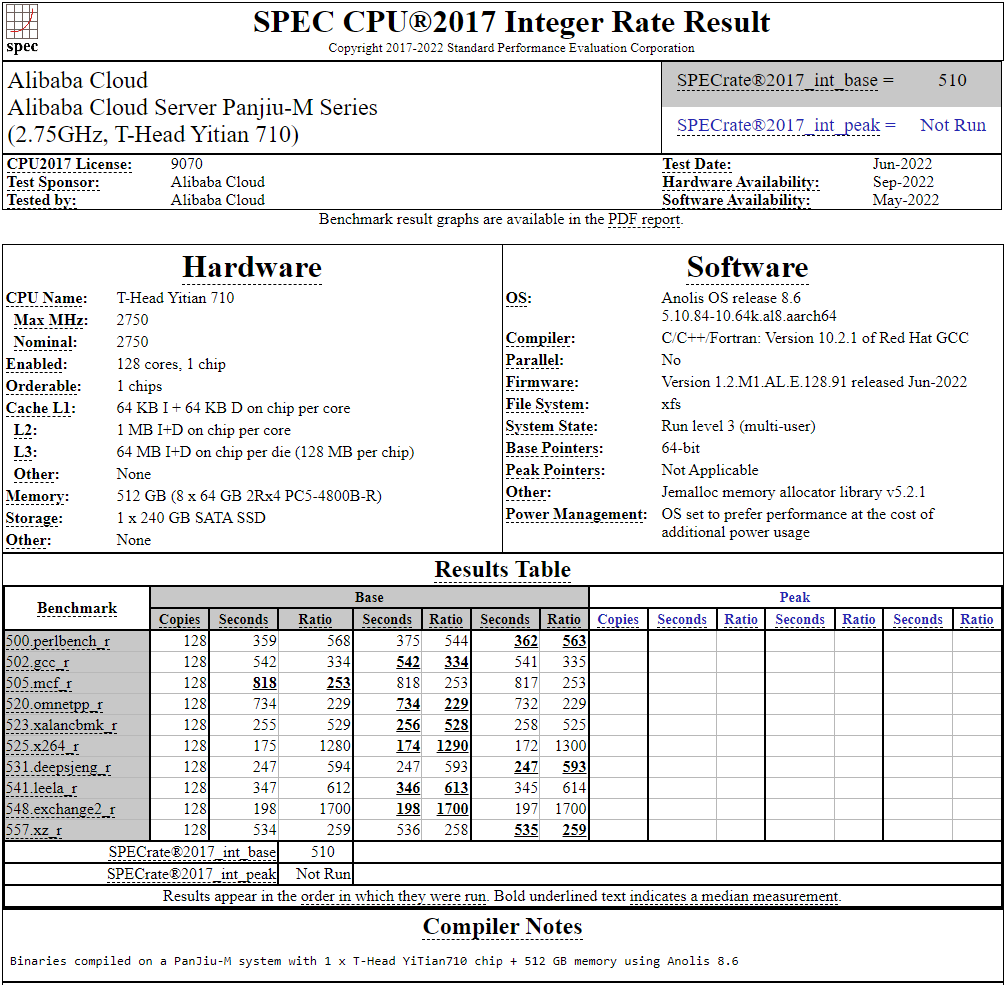 Процессор тестировался в составе референс-сервера Panjiu. Применялась 128-ядерная версия с частотой 2,75 ГГц, 1 Мбайт кеша L2 на ядро и 64 Мбайт кеша L3 на кристалл (128 Мбайт на сборку). Последнее позволяет говорить о том, что Alibaba также использует в своих процессорах чиплетную компоновку. 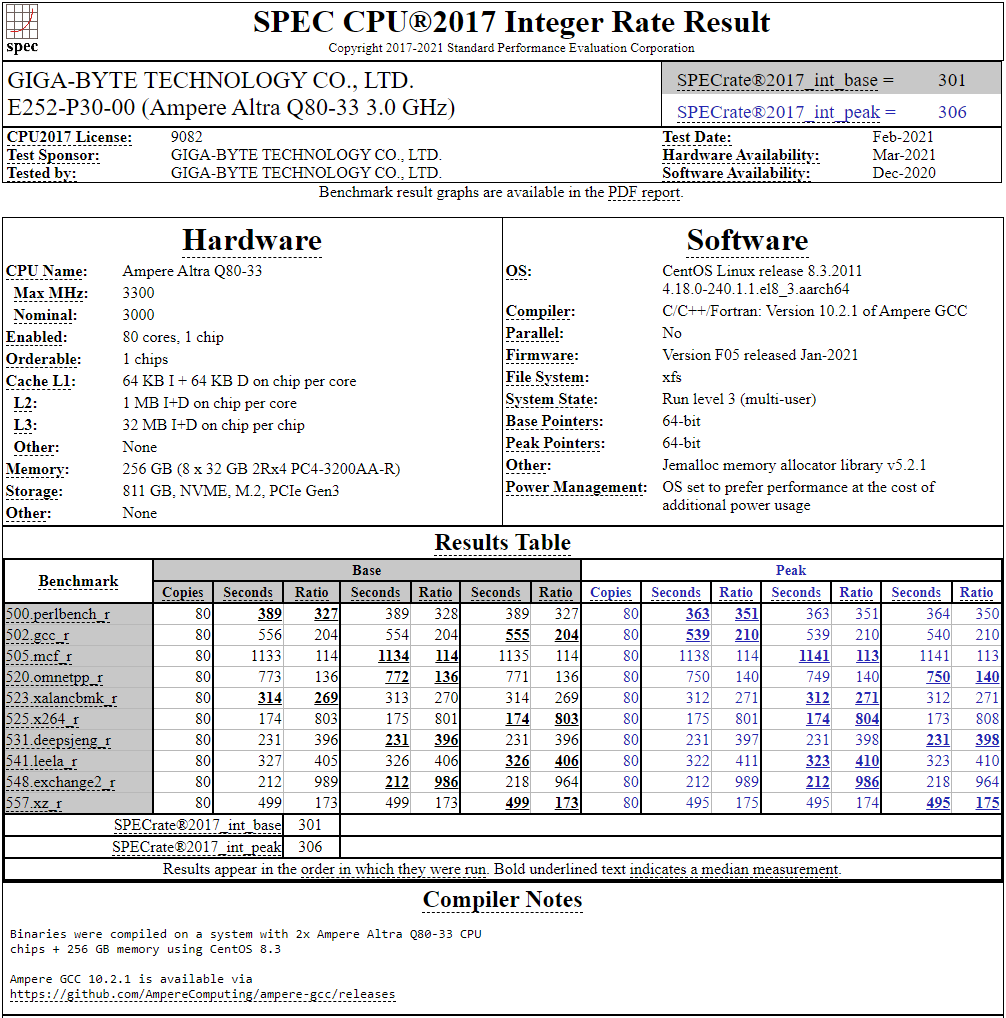 Результаты оказались существенно более высокими, нежели у Ampere Altra Q80-33; правда, стоит сделать скидку на то, что у Ampere использовалась 80-ядерная версия, а не более новая 128-ядерая Altra Max. Но в аутсайдерах оказался также и AMD EPYC 7773X (64 ядер/128 потоков, 2,2-3,5 ГГц, 768 Мбайт L3), показавший 440 очков против 510 у Yitian 710. Увеличенный объём кеша не слишком помог детищу «красных». 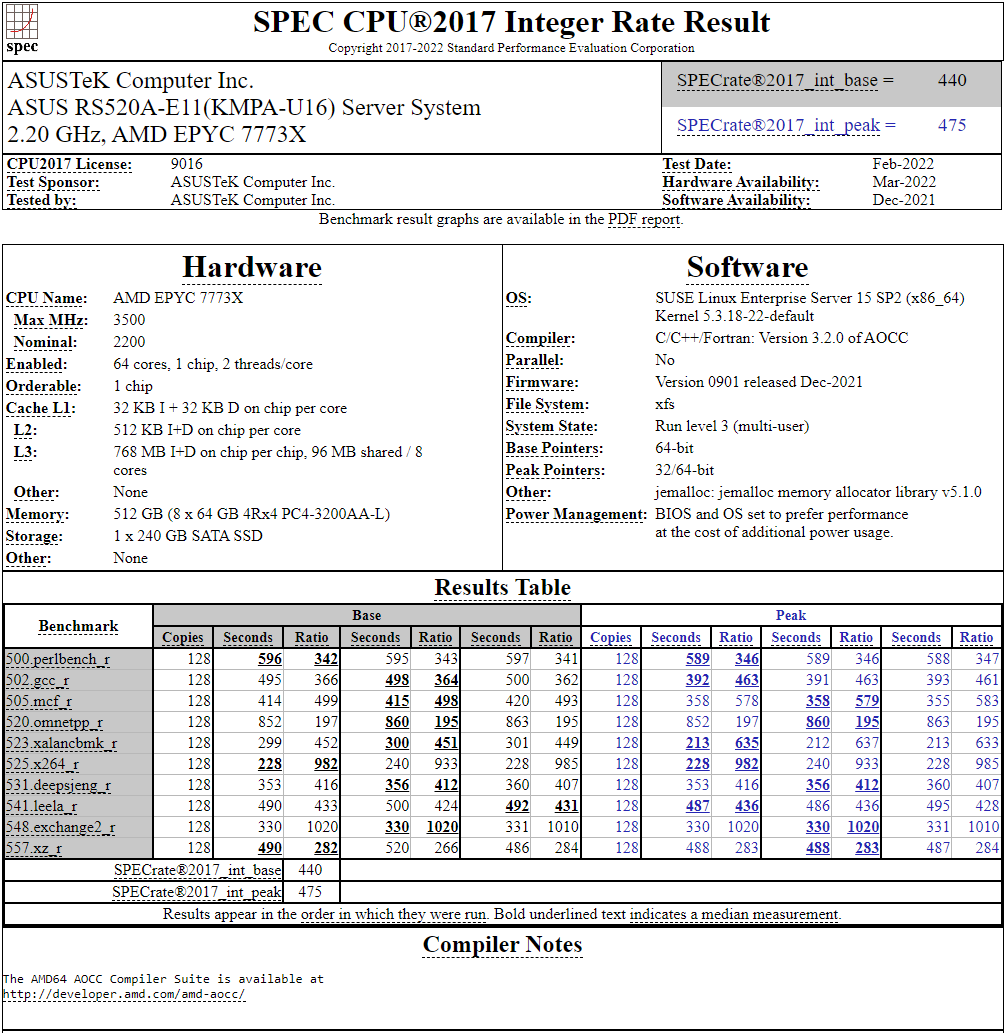 Таким образом, процессор на базе архитектуры Armv9 занял первое место там, где традиционно господствовали решения с архитектурой x86 — достаточно взглянуть на Топ-20 в рейтинге CPU2017 Integer. Можно сказать, что 128-ядерный процессор не вполне корректно сравнивать с 64-ядерным с поддержкой SMT, однако если технологии и архитектура позволяют разместить вдвое больше полноценных ядер в сопоставимом по размеру с AMD EPYC корпусе, так ли это важно? 
Текущий Tоп-20 целочисленной производительности в SPEC CPU2017 К сожалению, пока речь идёт только о целочисленных вычислениях. По неизвестной причине, Alibaba Cloud не опубликовала результаты CPU2017 Floating Point, где сравнение вышло бы существенно интереснее. В любом случае, монополия AMD на первые места пошатнулась; что же касается Intel, то в классе однопроцессорных систем самым мощным вариантом является 36-ядерный Xeon Platinum 8351N, который заведомо проиграет 64-128 ядерным монстрам AMD, Ampere, а теперь уже и Alibaba Cloud. |
|