Материалы по тегу: nvidia
|
13.11.2023 [22:05], Сергей Карасёв
200+ Эфлопс: суперчип NVIDIA Grace Hopper ляжет в основу более 40 ИИ-суперкомпьютеровКомпания NVIDIA сообщила о том, что её суперчип GH200 Grace Hopper ляжет в основу более чем 40 ИИ-суперкомпьютеров по всему миру, которые используются в исследовательских центрах, на облачных площадках и пр. Отмечается, что в скором времени станут доступны десятки новых НРС-систем на базе GH200. Этот суперчип позволяет решать самые сложные научные задачи на базе ИИ, которые требуют обработки терабайт данных. В совокупности вычислительные системы на базе GH200, как сообщается, обеспечат ИИ-производительность около 200 Эфлопс. В частности, HPE объявила, что интегрирует GH200 в суперкомпьютеры HPE Cray. Узлы EX254n оснащаются двумя модулями Quad GH200 с четырьмя суперчипами в каждом, обеспечивая возможность масштабирования до десятков тысяч узлов. Аналогичный подход используется и в платформе Eviden BullSequana XH3000, которую Юлихский исследовательский центр (FZJ) в Германии получит в составе Jupiter — первого европейского суперкомпьютера экзафлопсного класса. 
Источник изображения: NVIDIA Объединённый центр передовых высокопроизводительных вычислений в Японии (JCAHPC) намерен использовать суперчип в своём суперкомпьютере следующего поколения. Техасский центр передовых вычислений при Техасском университете в Остине (США) оборудует суперчипами НРС-систему Vista. Национальный центр суперкомпьютерных приложений при Университете Иллинойса в Урбане-Шампейне будет использовать решения GH200 в составе ИИ-платформы DeltaAI. А Британия получит ИИ-суперкомпьютер Isambard-AI на основе этого суперчипа, который разместится в Бристольском университете. 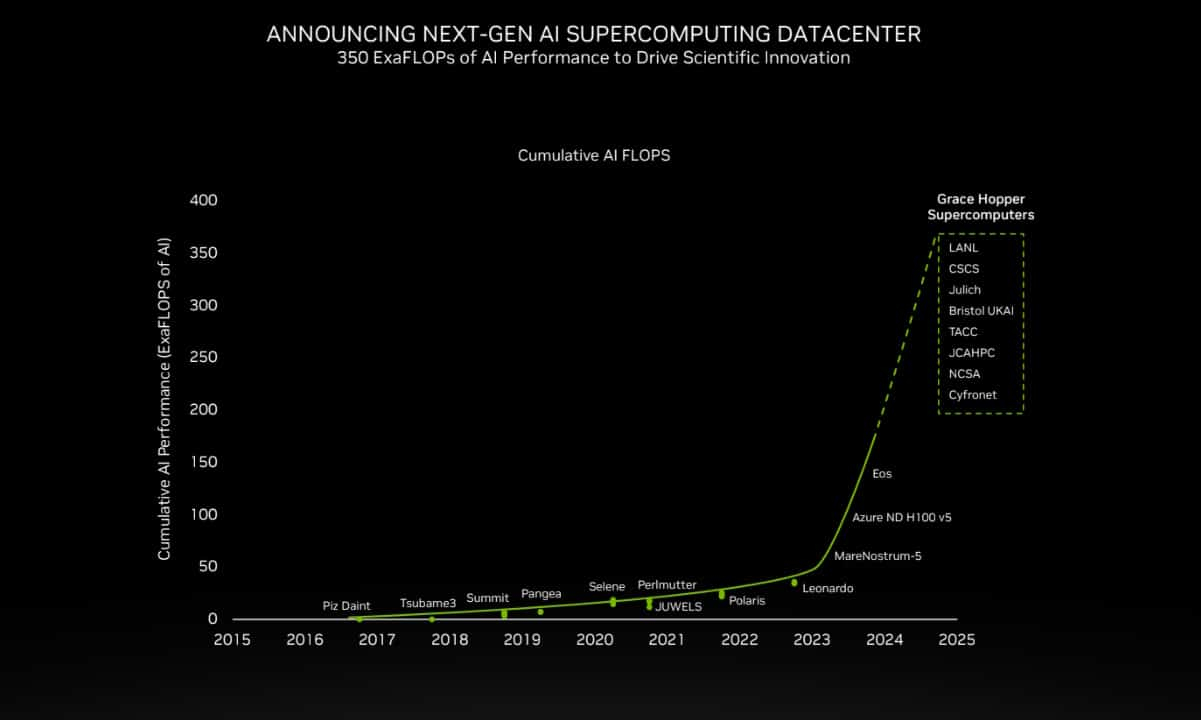
Источник изображения: NVIDIA Все эти системы присоединяются к ранее анонсированным платформам на базе GH200 от Швейцарского национального суперкомпьютерного центра (CSCS) и SoftBank Corp. GH200 уже доступен у некоторых поставщиков облачных услуг, таких как Lambda и Vultr. CoreWeave объявила о планах открыть инстансы GH200 в I квартале 2024 года. Другие производители систем, такие как ASRock Rack, ASUS, Gigabyte и Ingrasys, начнут поставки серверов с этими суперчипами к концу года.
13.11.2023 [17:42], Владимир Мироненко
NVIDIA CUDA Quantum позволяет выполнять моделирование процессов, невозможное на обычных компьютерных системахКрупнейшая в мире химическая компания BASF продемонстрировала, как квантовый алгоритм позволяет сделать то, чего не может традиционное моделирование — проверить ключевые свойства перспективного химического соединения FeNTA, с помощью которого можно удалять из городских сточных вод токсичные металлы, такие как железо. Команда BASF смоделировала с помощью ускорителей NVIDIA 24-кубитный квантовый компьютер и продемонстрировала, как он может справиться с новыми задачами. Исследователи BASF полагаются в работе на облако NVIDIA DGX Cloud с ускорителями NVIDIA H100. Вдобавок они уже протестировали первые 60-кубитные симуляции на суперкомпьютере NVIDIA EOS. «Это самая масштабная симуляция квантового алгоритма, которую мы когда-либо запускали», — отметил Майкл Кун (Michael Kuehn) из BASF. 
Изображения: NVIDIA BASF выполняет моделирование посредством NVIDIA CUDA Quantum, открытой платформы для интеграции и программирования CPU, ускорителей вычислений (GPU) и квантовых компьютеров (QPU). Разработчик Давид Водола (Davide Vodola) охарактеризовал платформу как «очень гибкую и удобную в использовании, позволяющую создавать сложную симуляцию квантовой схемы из относительно простых строительных блоков <…> Без CUDA Quantum было бы невозможно запустить это моделирование», — сказал он. В дополнение к работе в области химии команда BASF разрабатывает варианты использования квантовых вычислений в машинном обучении, а также для оптимизации логистики и планирования. Другие компании тоже используют CUDA Quantum в научных исследованиях. Например, в SUNY Stony Brook исследователи используют платформу в области физики высоких энергий для моделирования сложных взаимодействий субатомных частиц. «CUDA Quantum позволяет нам проводить квантовое моделирование, которое в противном случае было бы невозможно», — сказал Дмитрий Харзеев, профессор SUNY и научный сотрудник Брукхейвенской национальной лаборатории.  В свою очередь, Hewlett Packard Labs применяет суперкомпьютер Perlmutter для крупнейших симуляций в области квантовой химии, которую обычными инструментами реализовать очень сложно. «По мере прогресса в практическом применении квантовых компьютеров классическое HPC-моделирование станет ключевым для создания прототипов новых квантовых алгоритмов, — говорит Кирк Брезникер (Kirk Bresniker), главный архитектор Hewlett Packard Labs. — Моделирование и обучение на основе квантовых данных являются перспективными путями использования потенциала квантовых вычислений». Израильский стартап Classiq, чей новый подход к написанию квантовых программ использует более 400 университетов, объявил о создании вместе с NVIDIA исследовательского центра в Тель-Авивском медицинском центре Сураски. Здесь будут обучать экспертов в области естественных наук написанию квантовых программ, которые помогут в диагностике заболеваний и создании новых лекарств. Classiq создал ПО для проектирования, которое автоматизирует низкоуровневые задачи, позволяя разработчикам не вникать в детали функционирования квантового компьютера. Сейчас его софт интегрируют с CUDA Quantum.  Швейцарская Terra Quantum разрабатывает гибридные квантовые приложения для науки о жизни, энергетики и финансов, которые будут работать на CUDA Quantum. Поддержку платформы своим QPU обеспечила и компания IQM из Финляндии. Также известно, что несколько компаний, включая Oxford Quantum Circuits, будут использовать суперчипы NVIDIA Grace Hopper для обеспечения своих гибридных квантовых разработок. Компания Quantum Machines объявила, что Израильский национальный квантовый центр в Тель-Авиве станет первым местом развёртывания NVIDIA DGX Quantum на базе Grace Hopper. Центр будет использовать DGX Quantum в работе квантовых компьютеров от Quantware, ORCA Computing и других компаний. Кроме того, qBraid из Чикаго (США) применяет Grace Hopper в работе над созданием квантового облачного сервиса, а Fermioniq из Амстердама (Нидерланды) — в разработке новых алгоритмов.
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
13.11.2023 [17:00], Сергей Карасёв
Первый в Европе экзафлопсный суперкомпьютер Jupiter получит 24 тыс. гибридных суперчипов NVIDIA Grace HopperКомпания NVIDIA в ходе конференции по высокопроизводительным вычислениям SC23 сообщила о том, что её суперчип GH200 Grace Hopper станет одной из ключевых составляющих НРС-системы Jupiter — первого европейского суперкомпьютера экзафлопсного класса. 
Узел BullSequana XH3000 (Источник здесь и далее: NVIDIA) Jupiter — проект Европейского совместного предприятия по развитию высокопроизводительных вычислений (EuroHPC JU). Комплекс расположится в Юлихском исследовательском центре (FZJ) в Германии. В создании суперкомпьютера участвуют NVIDIA, ParTec, Eviden и SiPearl. Архитектура системы модульная, что позволяет адаптировать её под разные классы задач. В основу одного из основных блоков Jupiter ляжет платформа Eviden BullSequana XH3000 с прямым жидкостным охлаждением, а в состав каждого узла войдут модули Quad GH200. Общее количество суперчипов составит 23752. В качестве интерконнекта будет применяться NVIDIA Quantum-2 InfiniBand. Быстродействие на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность должна достичь 1 Эфлопс. При этом общая потребляемая мощность Jupiter составит всего 18,2 МВт.  Применять систему Jupiter планируется для решения наиболее сложных задач. Среди них — моделирование климата и погоды в высоком разрешении (на базе NVIDIA Earth-2), создание новых лекарственных препаратов (NVIDIA BioNeMo и NVIDIA Clara), исследования в области квантовых вычислений (NVIDIA cuQuantum и CUDA Quantum), промышленное проектирование (NVIDIA Modulus и NVIDIA Omniverse). Ввод Jupiter в эксплуатацию запланирован на 2024 год.
13.11.2023 [16:16], Сергей Карасёв
OSS представила защищённый ИИ-сервер Gen 5 AI Transportable на базе NVIDIA H100Компания One Stop Systems (OSS) на конференции по высокопроизводительным вычислениям SC23 представила сервер Gen 5 AI Transportable, предназначенный для решения задач ИИ и машинного обучения на периферии. Устройство, рассчитанное на монтаж в стойку, выполнено в корпусе уменьшенной глубины. Новинка соответствует американским военным стандартам в плане устойчивости к ударам, вибрации, диапазону рабочих температур и пр. Сервер может применяться в составе мобильных дата-центров, на борту грузовиков, самолётов и подводных лодок. Возможна установка четырёх ускорителей NVIDIA H100 и до 16 NVMe SSD суммарной вместимостью до 1 Пбайт. Говорится о поддержке до 35 одновременных ИИ-нагрузок. Кроме того, могут применяться сетевые решения стандарта 400 Гбит/с. При необходимости можно подключить NAS-хранилище в усиленном исполнении. 
Источник изображения: OSS Для сервера доступны различные варианты охлаждения: воздушное, автономное жидкостное или внешний теплообменник с жидкостным контуром. Поддерживаются различные варианты организации питания с переменным и постоянным током для использования на суше, в воздухе и море. При использовании СЖО ускорители H100, по всей видимости, комплектуются водоблоком EK-Pro NVIDIA H100 GPU WB. Реализована фирменная архитектура Open Split-Flow: она обеспечивает высокую эффективность охлаждения даже при небольшой скорости потока жидкости, что позволяет применять не слишком мощные помпы или помпы, работающие с невысокой скоростью. Микроканалы, фрезерованные на станке с ЧПУ, обладают минимальным гидравлическим сопротивлением потоку. Водоблок имеет однослотовое исполнение. 
Источник изображения: EKWB Предусмотрено проприетарное ПО U-BMC (Unified Baseboard Management Controller) для динамического управления скоростью вентиляторов, мониторинга системы и пр. Сервер подходит для монтажа в большинство 19″ стоек.
09.11.2023 [16:15], Сергей Карасёв
NVIDIA якобы готовит для Китая три новых ускорителя взамен подпавших под санкции: H20, L20 и L2Компания NVIDIA, по сообщению Reuters, планирует выпустить три новых ИИ=ускорителя, модифицированных специально для Китая с учётом дополнительных санкций со стороны США. Изделия фигурируют под обозначениями HGX H20 (SXM), L20 (PCIe) и L2 (PCIe), а их официальная презентация состоится не раньше 16 ноября. Напомним, в середине октября 2023 года США ввели новые ограничения на поставку передовых чипов NVIDIA в Китай: они затронули решения A800 и H800 — модифицированные версии A100 и H100, созданные специально для рынка КНР с учетом ранее действовавших американских ограничений. После этого NVIDIA пришлось искать новые регионы сбыта для «урезанных» ускорителей, предназначавшихся для Поднебесной. Как теперь сообщается, NVIDIA снова нашла возможность поставлять ускорители на китайский рынок, который потенциально может обеспечить значительную выручку. Решения H20, L20 и L2 не подпадают ни под одно из действующих экспортных ограничений. Обратной стороной медали является то, что производительность у них серьёзно снижена (см. характеристики в таблице выше), передаёт SemiAnalysis. 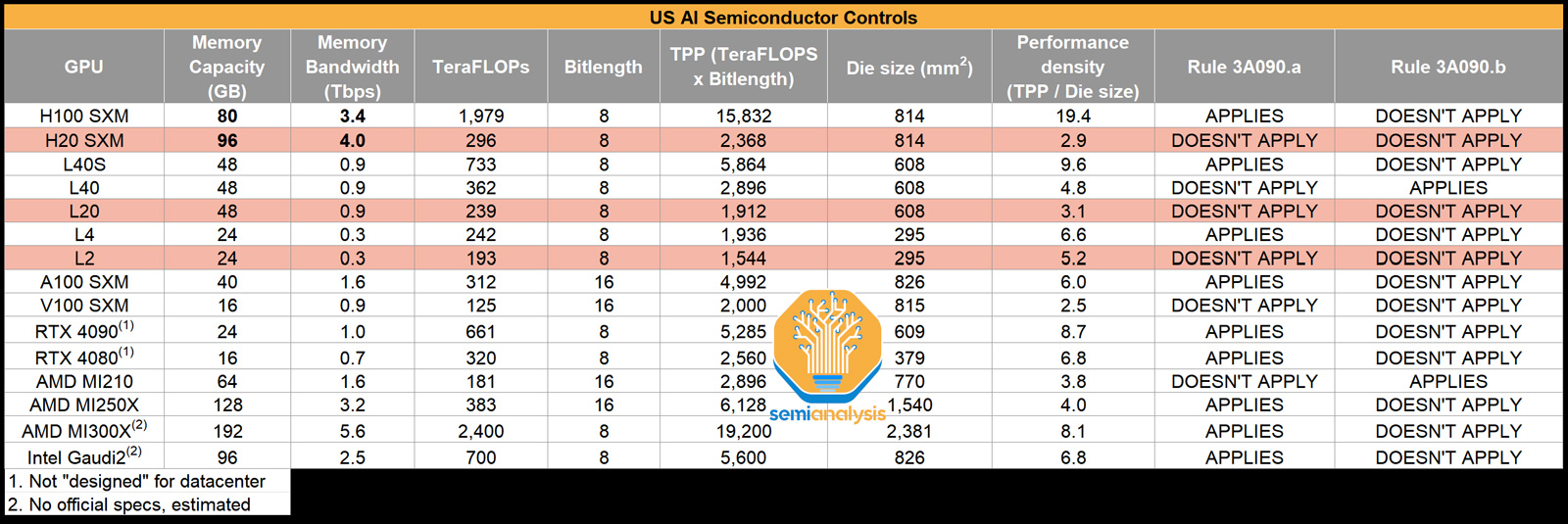
Источник: SemiAnalysis Отмечается, что у NVIDIA уже готовы образцы новых ускорителей для китайского рынка, а их массовое производство будет организовано в течение следующего месяца. Сама компания какие-либо комментарии по поводу обнародованной в интернете информации не даёт.
09.11.2023 [01:35], Руслан Авдеев
Microsoft из-за прожорливости Bing Chat пришлось договориться об аренде ИИ-ускорителей NVIDIA у OracleТочно неизвестно, велик ли спрос на ИИ-сервисы Microsoft или у компании просто недостаточно вычислительных ресурсов, но IT-гиганту пришлось договариваться с Oracle об использовании ИИ-ускорителей в ЦОД последней. Как сообщает The Register, речь идёт о применении оборудования Oracle для «разгрузки» некоторых языковых моделей Microsoft, применяемых в Bing. Во вторник компании анонсировали многолетнее соглашение. Как сообщают в Microsoft, одновременное использование компанией как Oracle Cloud, так и Microsoft Azure расширит возможности клиентов и ускорит работу с поисковыми сервисами. Сотрудничество связано с тем, что Microsoft надо всё больше вычислительных ресурсов для заявляемого «взрывного роста» её ИИ-сервисов, а у Oracle как раз имеются десятки тысяч ускорителей NVIDIA A100 и H100 для аренды. 
Источник изображения: cliff1126/pixabay.com Служба Oracle Interconnect обеспечивает взаимодействие с облаком Microsoft Azure, что позволяет работающим в Azure сервисам взаимодействовать с ресурсами Oracle Cloud Infrastructure (OCI). Раньше такое решение уже применялось, но для сторонних клиентов двух компаний. Теперь Microsoft применяет Interconnect наряду с Azure Kubernetes Service для организации работы ИИ-узлов в облаке Oracle на благо Bing Chat. Microsoft ещё в феврале интегрировала чат-бота Bing Chat в свой поисковый сервис и свой браузер. Не так давно добавилась и возможность, например, генерировать изображения прямо в процессе диалога. При этом использование больших языковых моделей требует огромного числа ускорителей для их тренировки, но для инференса необходимы ещё большие вычислительные мощности. 
Фото: Microsoft В Oracle утверждают, что облачные суперкластеры компании, которые, вероятно, будет использовать Microsoft, могут масштабироваться до 32 768 ИИ-ускорителей A100 или 16 384 ускорителей H100 с использованием RDMA-сети с ультранизкой задержкой. Дополнением является хранилище петабайтного класса. В самой Microsoft избегают говорить, сколько именно узлов Oracle нужно компании, причём, похоже, не намерены делать этого и в будущем. Конкуренты сотрудничают уже не в первый раз. В сентябре Oracle сообщала о намерении размещать системы с базами данных в ЦОД Azure. Более того, ещё в мае 2023 года Microsoft и Oracle изучали возможность аренды ИИ-серверов друг у друга на случай, если у них вдруг не будет хватать вычислительных мощностей для крупных облачных клиентов. Ранее ходили слухи, что похожие соглашения Microsoft подписала с CoreWeave и Lambda Labs, к которым NVIDIA более благосклонна в вопросах поставки ускорителей. Попутно Microsoft ищет более экономичные альтернативы языковым моделям OpenAI.
08.11.2023 [20:00], Игорь Осколков
Счёт на секунды: ИИ-суперкомпьютер NVIDIA EOS с 11 тыс. ускорителей H100 поставил рекорды в бенчмарках MLPerf TrainingВместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег. 
Изображения: NVIDIA Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.   В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов. 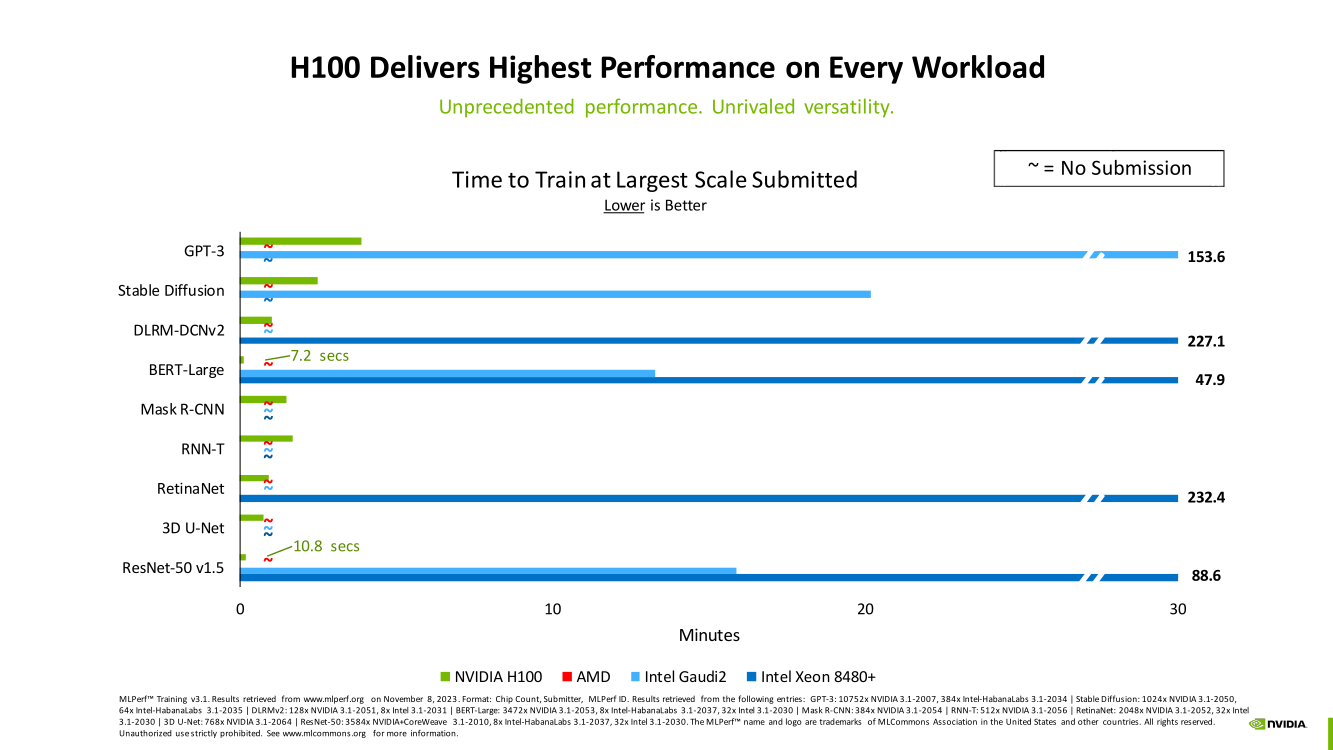 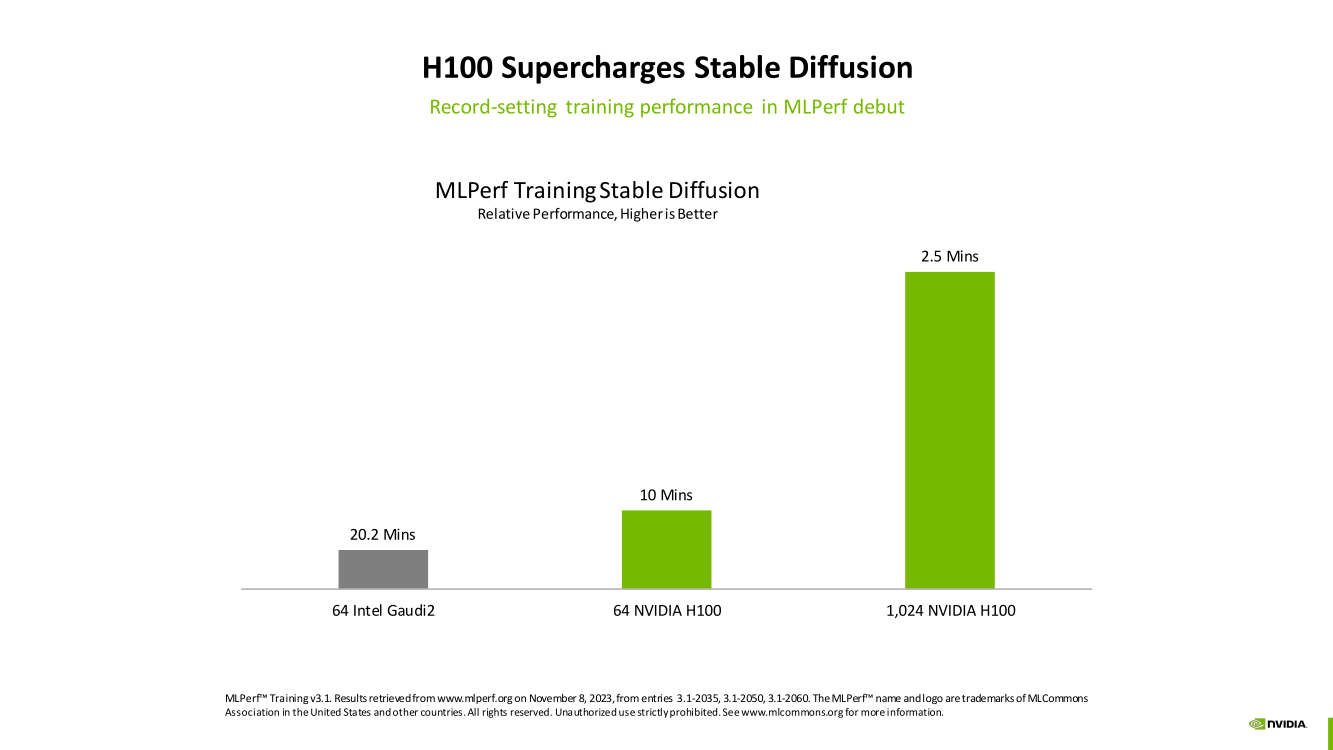 NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд. 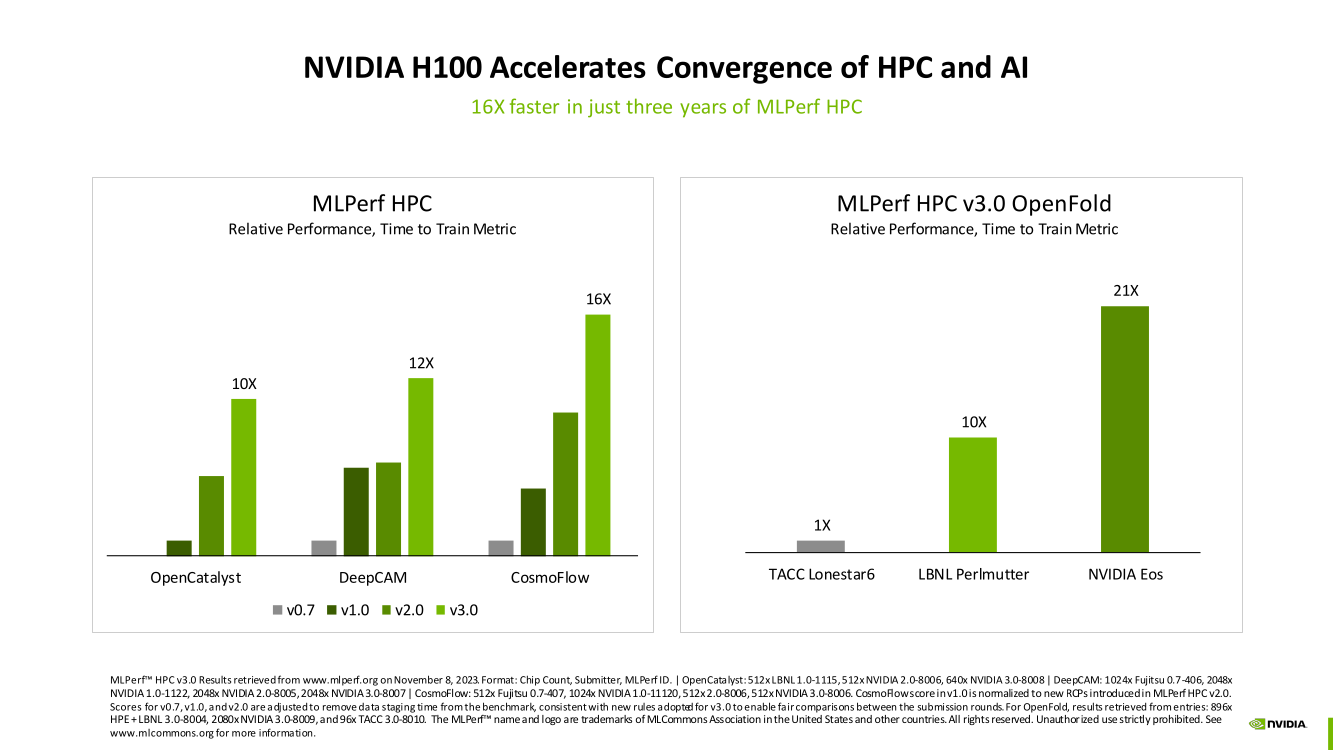
06.11.2023 [23:56], Владимир Мироненко
NVIDIA определилась, куда поставлять предназначавшиеся для Китая ускорители A800В связи с введением новых экспортных ограничений США на поставку в Китай современых технологий компания NVIDIA начала перераспределять в другие регионы поставки ускорителей A800, изначально созданных для Поднебесной взамен NVIDIA А100 (40 Гбайт) с учётом предыдущих ограничений по производительности и пропускной способности интерконнекта, установленных в октябре 2022 года. Как сообщает ресурс CRN, на прошлой неделе американский производитель электроники PNY Technologies и системный интегратор Colfax International начали продвигать на рынке ускоритель NVIDIA A800 Active PCIe 40GB, который чип-мейкер охарактеризовал на своём сайте как «идеальную платформу для рабочих станций для ИИ, анализа данных и высокопроизводительных вычислений». 
Источник изображения: Acro Представитель PNY сообщил CRN, что компания с прошлого понедельника начала продажи нового ускорителя через партнёров в Северной Америке, Латинской Америке, Европе, Африке и Индии. Исключение составляют подсанкционные государства: Китай, Россия и большинство стран Ближнего Востока. В числе партнёров NVIDIA, которые также занимаются продвижением NVIDIA A800 Active PCIe 40GB, есть японские компании ASK Corp. и Elsa, а также индийская Acro. 
Источник изображения: NVIDIA Введение ограничений власти США объясняют намерением помешать Китаю получить доступ к новейшим технологиям для укрепления своих вооружённых сил. Ограничения коснулись и недавно выпущенного ускорителя NVIDIA L40S, который в ряде задач является неплохой альтернативой A100, а также чипов Intel и AMD. Ранее газета The Wall Street Journal сообщила, что из-за санкций NVIDIA пришлось отменить заказы на поставку ускорителей китайским фирмам в следующем году на сумму более $5 млрд. 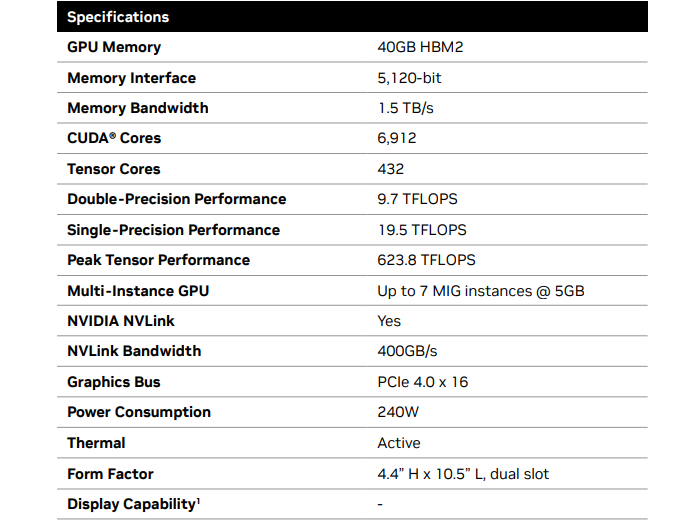
Источник: NVIDIA Следует уточнить, что NVIDIA A800 40 GB Active представляет собой двухслотовую PCIe-карту с активным охлаждением, но ускоритель A800 также предлагался в форм-факторе SXM. Ускоритель имеет 40 Гбайт памяти HBM2 с ПСП на уровне 1,5 Тбайт/с, а также поддерживает объединение двух карт посредством мостика NVLink, пропускная способность которого в угоду санкциям была урезана с 600 до 400 Гбайт/с. TDP составляет 240 Вт.
02.11.2023 [21:49], Руслан Авдеев
Британия получит 200-Пфлопс ИИ-суперкомпьютер Isambard-AI на гибридных Arm-чипах NVIDIA GH200Правительство Великобритании о выделении £225 млн ($273 млн) на строительство самого мощного в стране суперкомпьютера Isambard производительностью более 200 Пфлопс в FP64-вычислениях и более 21 Эфлопс в ИИ-задачах. Как сообщает The Register, новая машина на базе тысяч гибридных Arm-суперчипов NVIDIA Grace Hopper (GH200) разместится в Бристольском университете и будет построена HPE. Ожидается, что машина будет введена в эксплуатацию в следующем году и поможет в выполнении самых разных задач, от автоматизированной разработки лекарств до анализа климатических изменений, от изучения и внедрения нейросетей в робототехнике до задач, связанных с обеспечением национальной безопасности и обработкой больших данных. Isambard-AI войдёт в десятку самых быстрых суперкомпьютеров мира. Пока что самый быстрый суперкомпьютер Великобритании — это 20-Пфлопс система Archer2, занимающая 30-ю позицию в рейтинге TOP500 и введённая в строй всего пару лет назад. Isambard-AI получит 5448 гибридных чипов NVIDIA GH200 GraceHopper с 96/144 Гбайт HBM-памяти. Используется платформа HPE Cray EX с интерконнектом Slingshot 11 и СЖО. 25-Пбайт хранилище использует СХД Cray ClusterStor E1000. Система будет размещена в ЦОД с автономным охлаждением, а система утилизации избыточного тепла позволит обогревать близлежащие здания. Первыми выгодоприобретателями проекта Isambard-AI станут команды Frontier AI Task Force и AI Safety Institute, намеренные смягчить угрозу со стороны ИИ национальной безопасности Великобритании. 
Изображение: HPE Компанию Isambard-AI составит ранее анонсированный Arm-суперкомпьютер Isambard-3, который также построит HPE. Эту машину введут в эксплуатацию следующей весной, она обеспечит британским учёным ранний доступ к вычислительным мощностям на первом этапе реализации проекта Isambard-AI. Isambard-3 получит 384 суперчипа NVIDIA Grace, а его пиковое быстродействие в FP64-вычислениях составит 2,7 Пфлопс. Всего в различные ИИ-проекты британские власти вложат порядка £900 млн ($1,1 млрд). В частности, вместе с Isambard-AI был объявлен и суперкомпьютер Dawn, который разместится в Кембридже. Хотя ранее NVIDIA описывала Isambard-AI как самый быстрый в стране, создатели Dawn утверждают, что быстрейшим будет именно он. Система будет полагаться на серверы Dell PowerEdge XE9640 с процессорами Sapphire Rapids и ускорителями Max. |
|