Материалы по тегу: nvidia
|
29.08.2024 [18:12], Владимир Мироненко
Квартальные результаты NVIDIA и прогноз превысили ожидания Уолл-стрит, но акции упали на 7 %NVIDIA объявила финансовые результаты за II квартал 2025 финансового года, завершившийся 28 июля 2024 года. Рост выручки компании уже четвёртый квартал подряд превышает ожидания аналитиков. В ходе отчёта компания поделилась прогнозом на следующие три месяца, тоже превысившим ожидания Уолл-стрит. Тем не менее в ходе расширенных торгов акции компании упали на 7 %. Выручка NVIDIA составила $30,04 млрд, что выше показателя предыдущего квартала на 15 % и на 122 % год к году. Это также значительно выше консенсус-прогноза аналитиков на уровне $20,75 млрд. NVIDIA повысила ожидания по выручке за III квартал до $32,5 млрд (рост год к году на 80 %), что немного выше консенсусного прогноза в $31,77 млрд. Тем не менее, как сообщила ещё до публикации отчёта ресурсу CNBC Стейси Расгон (Stacy Rasgon), аналитик Bernstein, ожидания инвесторов были ближе к $33–$34 млрд. 
Источник изображения: NVIDIA Подразделение по выпуску продуктов для ЦОД принесло компании в отчётном квартале рекордную выручку в размере $26,3 млрд, превысившую результат предыдущего квартала на 16 % и на 154 % показатель годичной давности. При этом подразделение по выпуску вычислительных компонентов увеличило выручку год к году на 162 % до $22,6 млрд, а продажи сетевых решений повысились на 114 % до $3,7 млрд. Также объявлено, что выручка сегмента профессиональной визуализации увеличилась на 20 % до $454 млн, в автомобильном секторе выручка составила $346 млн (рост 37 %). Чистая прибыль (GAAP) NVIDIA выросла год к году на 168 % до $16,6 млрд или $0,67 на акцию. Чистая прибыль (Non-GAAP) увеличилась на 152 % до $16,9 млрд или $0,68 на акцию. Валовая прибыль составила во II квартале 2025 финансового года 75,1 %, что ниже показателя предыдущего квартала в размере 78,4 %. 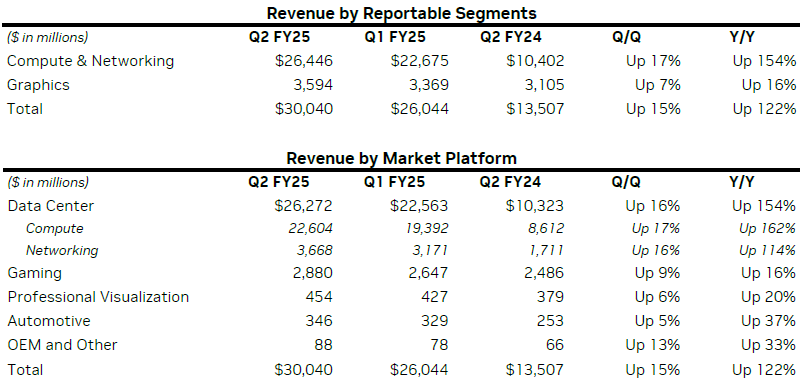
Источник: NVIDIA Как объяснила финансовый директор Колетт Кресс (Colette Kress), снижение связано с изменениями в конструкции ускорителей Blackwell GB200 следующего поколения. Недавно NVIDIA объявила о задержке выхода Blackwell, отметив, что рассчитывает нарастить поставки в IV квартале и получить дополнительно несколько миллиардов долларов дохода. Гендиректор NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что платформа Blackwell будет способствовать росту так называемых «ИИ-фабрики ИИ» для поддержки чрезвычайно интенсивных рабочих нагрузок. Несмотря на впечатляющий рост бизнеса NVIDIA в сегменте ЦОД, старший аналитик Forrester Research Алвин Нгуен (Alvin Nguyen), выразил обеспокоенность по поводу того, что компания, возможно, «кладёт слишком много яиц в одну корзину». «Я всегда беспокоюсь, когда слишком много доходов сосредоточено на слишком малом количестве рынков, — сказал он, добавив: — Это не их вина. Рынок этого хочет». Бурный рост ЦОД сталкивается с недоступностью электроэнергии и воды, что влечёт за собой сопротивление местных властей. «В некоторых районах невозможно построить ЦОД, потому что он отбирает электроэнергию у 20 тыс. домов», — говорит Нгуен. 
Источник изображения: NVIDIA Тем не менее, гиперскейлеры ищут способы обойти эти барьеры, и именно они могут принести более 45 % доходов ЦОД NVIDIA в течение следующих нескольких лет, говорит Лукас Ке (Lucas Keh), аналитик глобальной исследовательской компании Third Bridge Group Ltd. «Темпы прироста доходов от GPU, как ожидается, сохранятся в течение следующих 12–18 месяцев, — сказал он. — Наши эксперты полагают, что к концу 2025 года 60–70 % обучения (моделей) гипескейлеров будет проводиться на Blackwell». Впрочем, NVIDIA работает над диверсификацией источников доходов. В этом году она запустила десятки NIM-микросервисов, предназначенных для ускорения развёртывания базовых моделей на облачных платформах. NVIDIA также расширила экосистему библиотек CUDA, которые являются строительными блоками для ИИ-приложений. В компании по-прежнему порядка трёх четвертей инженеров занимается именно разработкой ПО. Кроме того, растут доходы компании от сетевых технологий.
29.08.2024 [16:41], Руслан Авдеев
Илон Маск показал ИИ-суперкластер Tesla Cortex из 50 тыс. ускорителей NVIDIAИлон Маск (Elon Musk) продолжает наращивать вычислительные мощности своих компаний. Как сообщает Tom’s Hardware, он поделился сведениями об ИИ-суперкластере Cortex. По данным Tom's Hardware, недавнее дополнение завода Giga Texas компании Tesla будет состоять из 70 тыс. ИИ-серверов, а также потребует 130 МВт энергии на обеспечение вычислений и охлаждения на момент запуска, к 2026 году мощность вырастет до 500 МВт. На опубликованном в социальной сети X видео Илона Маска показан машинный зал: по 16 IT-стоек в ряд, по два ряда на коридор. Каждая стойка вмещает восемь ИИ-серверов, а в середине каждого ряда видны стойки без таковых. В видео можно разглядеть порядка 16–20 рядов, поэтому довольно грубый подсчёт позволяет предположить наличие около 2 тыс. серверов с ускорителями, т.е. менее 3 % от запланированной ёмкости. В ходе июльского финансового отчёта Tesla Илон Маск рассказал, что Cortex будет крупнейшим обучающим кластером Tesla на сегодняшний день и будет состоять из 50 тыс. ускорителей NVIDIA H100 и 20 тыс. ускорителей Tesla D1 собственной разработки. Это меньше, чем Маск прогнозировал раньше, в июне он сообщал, что Cortex будет включать 50 тыс. D1. Правда, сообщалось, что на момент запуска будут применяться только решения NVIDIA, а разработки Tesla появятся позже. 
Источник изображения: Alexander Shatov/unsplash.com Кластер Cortex предназначен в первую очередь для обучения автопилота Full Self Driving (FSD), сервиса Cybertaxi и роботов Optimus, ограниченное производство которых должно начаться в 2025 году для использования на заводах компании. Также Маск анонсировал планы потратить $500 млн на суперкомпьютер Dojo в Буффало (штат Нью-Йорк), также принадлежащий Tesla. Первым же в «коллекции» Маска заработал Memphis Supercluster, принадлежащий xAI и оснащённый 100 тыс. NVIDIA H100. Со временем эта система получит 300 тыс. ускорителей NVIDIA B200, но задержки с их производством заставили отложить реализацию проекта на несколько месяцев.
29.08.2024 [14:55], Руслан Авдеев
CoreWeave развернёт в Швеции крупнейший в Европе ИИ-кластер NVIDIA BlackwellОблачный провайдер CoreWeave намерен арендовать ЦОД у шведского оператора EcoDataCenter. По данным Datacenter Dynamics, партнёры анонсировали сотрудничество для размещения «одного из крупнейших» в Европе кластеров NVIDIA Blackwell. CoreWeave заявила, что разместит тысячи новых ускорителей NVIDIA, чтобы удовлетворить спрос на крупномасштабную ИИ-инфраструктуру ведущих ИИ-лабораторий и компаний. Эти кластеры должны заработать уже в 2025 году. Дополнительные подробности о том, какие объекты будут использоваться и каков реальный масштаб проекта, неизвестны. По словам представителя CoreWeave, сотрудничество с EcoDataCenter стало поворотной точкой для экспансии в Европе. EcoDataCenter была сформирована в 2015 году шведской энергетической компанией Falu Energi & Vatten и оператором ЦОД EcoDC AB. В 2018 году застройщик Areim приобрёл контрольный пакет акций компании, обошедшийся приблизительно в $22 млн, а в 2019 году объединил её со шведским оператором Fortlax. Сейчас шведская компания управляет пятью дата-центрами на трёх площадках. Ранее в этом году она объявила о планах постройки нового 150-МВт кампуса EcoDataCenter 2. Кампус будут строить поэтапно, первый блок на 20 МВт построят уже в 2026 году. 
Источник изображения: EcoDataCenter Основанная в 2017 году компания CoreWeave изначально специализировалась на крипто- и блокчейн-технологиях и активно инвестировала в облачные проекты, обеспечивая доступ клиентам к ускорителям. За последние два года компания привлекла $12 млрд в виде инвестиций и прямых займов и планирует потратить $3,5 млрд на расширение бизнеса в Европе, в том числе в Норвегии и Великобритании. К концу 2024 года компания рассчитывает управлять 28 объектами по всему миру, в прошлом году речь шла всего о 14 ЦОД.
29.08.2024 [01:00], Владимир Мироненко
NVIDIA вновь показала лидирующие результаты в ИИ-бенчмарке MLPerf InferenceNVIDIA сообщила, что её платформы показали самые высокие результаты во всех тестах производительности уровня ЦОД в бенчмарке MLPerf Inference v4.1, где впервые дебютировал ускоритель семейства Blackwell. Ускоритель NVIDIA B200 (SXM, 180 Гбайт HBM) оказался вчетверо производительнее H100 на крупнейшей рабочей нагрузке среди больших языковых моделей (LLM) MLPerf — Llama 2 70B — благодаря использованию механизма Transformer Engine второго поколения и FP4-инференсу на Tensor-ядрах. Впрочем, именно B200 заказчики могут и не дождаться. Ускоритель NVIDIA H200, который стал доступен в облаке CoreWeave, а также в системах ASUS, Dell, HPE, QTC и Supermicro, показал лучшие результаты во всех тестах в категории ЦОД, включая последнее дополнение к бенчмарку, LLM Mixtral 8x7B с общим количеством параметров 46,7 млрд и 12,9 млрд активных параметров на токен, использующую архитектуру Mixture of Experts (MoE, набор экспертов). 
Источник изображения: NVIDIA Как отметила NVIDIA, MoE приобрела популярность как способ привнести большую универсальность в LLM, поскольку позволяет отвечать на широкий спектр вопросов и выполнять более разнообразные задачи в рамках одного развёртывания. Архитектура также более эффективна, поскольку активируются только несколько экспертов на инференс — это означает, что такие модели выдают результаты намного быстрее, чем высокоплотные (Dense) модели аналогичного размера. Также NVIDIA отмечает, что с ростом размера моделей для снижения времени отклика при инференсе объединение нескольких ускорителей становится обязательными. По словам компании, NVLink и NVSwitch уже в поколении NVIDIA Hopper предоставляют значительные преимущества для экономичного инференса LLM в реальном времени. А платформа Blackwell ещё больше расширит возможности NVLink, позволив объединить до 72 ускорителей. 
Источник изображения: NVIDIA Заодно компания в очередной раз напомнила о важности программной экосистемы. Так, в последнем раунде MLPerf Inference все основные платформы NVIDIA продемонстрировали резкий рост производительности. Например, ускорители NVIDIA H200 показали на 27 % большую производительность инференса генеративного ИИ по сравнению с предыдущим раундом. А Triton Inference Server продемонстрировал почти такую же производительность, как и у bare-metal платформ. Наконец, благодаря программным оптимизациям в этом раунде MLPerf платформа NVIDIA Jetson AGX Orin достигла более чем 6,2-кратного улучшения пропускной способности и 2,5-кратного улучшения задержки по сравнению с предыдущим раундом на рабочей нагрузке GPT-J LLM. По словам NVIDIA, Jetson способен локально обрабатывать любую модель-трансформер, включая LLM, модели класса Vision Transformer и, например, Stable Diffusion. А вместо разработки узкоспециализированных моделей теперь можно применять универсальную GPT-J-6B модель для обработки естественного языка на периферии.
28.08.2024 [00:10], Владимир Мироненко
NVIDIA представила шаблоны ИИ-приложений NIM Agent Blueprints для типовых бизнес-задачNVIDIA анонсировала NIM Agent Blueprints, каталог предварительно обученных, настраиваемых программных решений, предоставляющий разработчикам набор инструментов для создания и развёртывания приложений генеративного ИИ для типовых вариантов использования, таких как аватары для обслуживания клиентов, RAG, виртуальный скрининг для разработки лекарственных препаратов и т.д. Предлагая бесплатные шаблоны для частых бизнес-задач, компания помогает разработчикам ускорить создание и вывод на рынок ИИ-приложений. NIM Agent Blueprints включает примеры приложений, созданных с помощью NVIDIA NeMo, NVIDIA NIM и микросервисов партнёров, примеры кода, документацию по настройке и Helm Chart'ы для быстрого развёртывания. Предприятия могут модифицировать NIM Agent Blueprints, используя свои бизнес-данные, и запускать приложения генеративного ИИ в ЦОД и облаках (в том числе в рамках NVIDIA AI Enterprise), постоянно совершенствуя их благодаря обратной связи. На текущий момент NIM Agent Blueprints предлагают готовые рабочие процессы (workflow) для систем обслуживания клиентов, для скрининга с целью автоматизированного поиска необходимых соединений при разработке лекарств и для мультимодального извлечения данных из PDF для RAG, что позволит обрабатывать огромные объёмы бизнес-данных для получения более точных ответов, благодаря чему ИИ-агенты чат-боты службы станут экспертами по темам компании. С примерами можно ознакомиться здесь. 
Источник изображения: NVIDIA Каталог NVIDIA NIM Agent Blueprints вскоре станет доступен у глобальных системных интеграторов и поставщиков технологических решений, включая Accenture, Deloitte, SoftServe и World Wide Technology (WWT). А такие компании как Cisco, Dell, HPE и Lenovo предложат полнофункциональную ИИ-инфраструктуру с ускорителями NVIDIA для развёртывания NIM Agent Blueprints. NVIDIA пообещала, что ежемесячно будут выпускаться дополнительные шаблоны для различных бизнес-кейсов.
23.08.2024 [14:19], Руслан Авдеев
Принадлежащая Indosat индонезийская Lintasarta запустила ИИ-облако Merdeka на базе решений NVIDIAЗанимающаяся IT-услугами индонезийская компания Lintasarta запустила облачный ИИ-сервис GPU Merdeka. По данным Datacenter Dynamics, бизнес принадлежит Indosat и будет предлагать услуги в формате GPU-as-a-Service (GPUaaS). Ранее в этом году было объявлено, что NVIDIA и Indosat построят в Индонезии ИИ ЦОД стоимостью $200 млн в Суракарте (Surakarta). Речь идёт о суверенном ИИ-облаке на основе серверов с восемью NVIDIA H100 (SXM). Сам ЦОД поддерживает до 20 кВт на стойку. Как заявляют в Indosat, благодаря знаковому партнёрству с NVIDIA, компания намерена демократизировать доступ к облачным ИИ-сервисам, сделав соответствующие услуги более доступными в Индонезии и соседних странах. Также компания намерена ускорить рост индонезийской цифровой экономики. 
Источник изображения: Harry Kessell/unsplash.com Облако Merdeka, по словам Lintasarta, является важной вехой на пути превращения в специализирующуюся на ИИ технологическую компанию. Ожидается, что технологии и опыт Lintasarta помогут стране в достижении целей стратегии 2045 Golden Indonesia Vision. IT-система страны нуждается в модернизации. Совсем недавно хакеры заблокировали правительственный ЦОД в стране, потребовав за ключ дешифровки $80 млн, из-за чего нарушилась работа государственных и медицинских учреждений, транспортной инфраструктуры и т.п. Выяснилось, что резервных копий почти никто не делал. В конце концов злоумышленники бесплатно прислали ключ и извинились, но репутация страны в области IT оказалась подпорчена. При этом соседняя Малайзия стремительно наращивает компетенции в области ЦОД и ИИ, намереваясь стать региональным IT-лидером.
19.08.2024 [10:10], Сергей Карасёв
Gigabyte представила ИИ-серверы с ускорителями NVIDIA H200 и процессорами AMD и IntelКомпания Gigabyte анонсировала HGX-серверы G593-SD1-AAX3 и G593-ZD1-AAX3, предназначенные для задач ИИ и НРС. Устройства, выполненные в форм-факторе 5U, включают до восьми ускорителей NVIDIA H200. При этом используется воздушное охлаждение. 
Источник изображений: Gigabyte Модель G593-SD1-AAX3 рассчитана на два процессора Intel Xeon Emerald Rapids с показателем TDP до 350 Вт, а версия G593-ZD1-AAX3 располагает двумя сокетами для чипов AMD EPYC Genoa с TDP до 300 Вт. Доступны соответственно 32 и 24 слота для модулей оперативной памяти DDR5.  Серверы наделены восемью фронтальными отсеками для SFF-накопителей NVMe/SATA/SAS-4, двумя сетевыми портами 10GbE на основе разъёмов RJ-45 (выведены на лицевую панель) и выделенным портом управления 1GbE (находится сзади). Есть четыре слота FHHL PCIe 5.0 x16 и восемь разъёмов LP PCIe 5.0 x16. Модель на платформе AMD дополнительно располагает двумя коннекторами М.2 для SSD с интерфейсом PCIe 3.0 x4 и x1.  Питание у обоих серверов обеспечивают шесть блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. Габариты новинок составляют 447 × 219,7 × 945 мм. Диапазон рабочих температур — от +10 до +35 °C. Есть два порта USB 3.2 Gen1 и разъём D-Sub. Массовое производство серверов Gigabyte серии G593 запланировано на II половину 2024 года. Эти системы станут временной заменой (G)B200-серверов, выпуск которых задерживается.
15.08.2024 [14:57], Руслан Авдеев
Выходцы из Google DeepMind запустили ИИ-облако FoundryНа рынке ИИ-облаков появился очередной провайдер. The Register сообщает, что стартап Foundry Cloud Platform (FCP) объявил о доступности своей платформы, но пока только для избранных. Компания основана в 2022 году бывшим экспертом Google DeepMind Джаредом Куинси Дэвисом (Jared Quincy Davis) и ей придётся конкурировать с Lambda Labs и CoreWeave, которые уже получили миллиарды инвестиций. Стартап намерен сделать клиентам более интересное предложение, чем просто аренда ИИ-ускорителей в облаке. Так, клиент, зарезервировавший 1000 ускорителей на X часов, получит именно столько ресурсов, сколько заказал. Задача на самом деле не очень простая, поскольку временные отказы вычислительного оборудования возникают довольно часто, а время простоя всё равно оплачивается. В Foudry намерены решить проблему, поддерживая в готовности пул зарезервированных узлов на случай возникновения сбоев основного оборудования. 
Источник изображения: Foundry Cloud Platform При этом резервные мощности будут использоваться даже во время «дежурства» для выполнения более мелких задач, соответствующие ресурсы будут предлагаться клиентам по ценам в 12–20 раз ниже рыночных. При этом пользователь таких spot-инстансов должен быть готов к тому, что их в любой момент могут отобрать. При этом состояние текущей нагрузки будет сохранено, чтобы её можно было перезапустить. А если прямо сейчас мощный инстанс не нужен, то его можно «перепродать» другим пользователям. Также можно задать порог стоимости покупаемых ресурсов, чтобы воспользоваться ими, когда цена на них упадёт ниже заданной. Foundry вообще делает упор именно на гибкость и доступность вычислений, ведь далеко не всем задачам нужны самый быстрые ускорители или самый быстрый отклик. Компания умышленно дистанцируется от традиционных контрактов сроком на год и более. Уже сейчас минимальный срок разовой аренды составляет всего три часа, что для индустрии совершенно нетипично. 
Источник изображения: Foundry Cloud Platform Foundry предлагает ускорители NVIDIA H100, A100, A40 и A5000 с 3,2-Тбит/с InfiniBand-фабрикой, размещённые в ЦОД уровня Tier III/IV. Облако соответствует уровню защиты SOC2 Type II и предлагает HIPAA-совместимые опции. При этом пока не ясны объёмы кластеров, предлагаемых Foundry. Возможно, именно поэтому компания сейчас очень тщательно отбирает клиентов. Другими словами, стартапу ещё рано тягаться с CoreWeave или Lambda, даже при наличии передовых и нестандартных технических решений. Преимуществом для таких «новых облаков» стала относительная простота получения необходимого финансирования для создания больших кластеров ИИ-ускорителей. Помимо привлечения средств в ходе традиционных раундов инвестирования, компании стали занимать новые средства под залог самих ускорителей. В своё время CoreWeave удалось таким способом получить $7,5 млрд. Пока многие компании ещё не выяснили, как оценить финансовую отдачу от внедрения ИИ. Тем не менее, поставщики инфраструктуры этот вопрос, похоже, уже решили. Ранее портал The Next Platform подсчитал, что кластер из 16 тыс. H100 обойдётся примерно в $1,5 млрд и принесёт $5,27 млрд в течение четырёх лет, если ИИ-бум не пойдёт на спад.
12.08.2024 [17:26], Руслан Авдеев
AMD сначала разрешила, а потом запретила доступ к коду проекта ZLUDA по запуску CUDA-приложений на своих ускорителяхПохоже, команда юристов AMD намерена получить полный контроль над значительной частью базы ПО, созданной в рамках открытого проекта ZLUDA. По данным The Register, ранее в этом году компания прекратила финансовую поддержку инициативы, позволяющей использовать CUDA-код на сторонних ускорителях. Теперь, похоже, AMD ужесточает политику. Изначально проект ZLUDA создавался для запуска CUDA-приложений без каких-либо модификаций на GPU Intel при поддержке со стороны самой Intel. Позже автор проекта Анджей Яник (Andrzej Janik) подписал с AMD контракт, в рамках которого предполагалось создание аналогичного инструмента для ускорителей AMD. В начале 2022 года проект стал закрытым, но уже в начале 2024 года Яник снова сделал проект открытым по соглашению сторон, поскольку AMD решила прекратить финансирование и дальнейшее развитие ZLUDA. 
Источник изображения: Mapbox/unsplash.com Однако позже AMD изменила своё решение. Именно по её запросу соответствующее ПО стало недоступным. По словам Яника, юристы AMD заявили, что предыдущее письмо с разрешением на публикацию кода не является юридически значимым документом. Яник после консультации с юристом пришёл к выводу, что законность писем не имеет значения, поскольку потенциальная судебная тяжба с AMD отняла бы у него слишком много ресурсов, а её результат трудно предсказать. Проще и быстрее переписать проект на базе старых наработок, хотя часть функций, вероятно, воссоздать не выйдет. Почему в AMD решили попытаться «похоронить» ZLUDA, достоверно неизвестно. Первой и самой очевидной причиной может быть желание AMD дистанцироваться от проекта, возможно, нарушающего права NVIDIA на интеллектуальную собственность. NVIDIA уже запретила использовать CUDA-код на других аппаратных платформах, создавая «слои трансляции CUDA», и прибегать к декомпиляции всего, что создано с помощью CUDA SDK, для адаптации ПО для запуска на других GPU. Кроме того, в AMD могли посчитать, что само существование ZLUDA могло бы помешать внедрению собственного ПО. Собственный инструментарий AMD предполагает именно портирование и рекомпиляцию исходного кода CUDA вместо запуска уже готовых программ. Кроме того, мог возникнуть конфликт относительного того, какой код, созданный в рамках ZLUDA, можно выпускать, а какой нет.
08.08.2024 [00:48], Сергей Карасёв
NVIDIA задержит выпуск ускорителей GB200, отложит B100/B200, а на замену предложит B200AКомпания NVIDIA, по сообщению ресурса The Information, вынуждена повременить с началом массового выпуска ИИ-ускорителей следующего поколения на архитектуре Blackwell, сохранив высокие темпы производства Hopper. Проблема, как утверждается, связана с технологией упаковки Chip on Wafer on Substrate (CoWoS) от TSMC. Отмечается, что NVIDIA недавно проинформировала Microsoft о задержках, затрагивающих наиболее продвинутые решения семейства Blackwell. Речь, в частности, идёт об изделиях Blackwell B200. Серийное производство этих ускорителей может быть отложено как минимум на три месяца — в лучшем случае до I квартала 2025 года. Это может повлиять на планы Microsoft, Meta✴ и других операторов дата-центров по расширению мощностей для задач ИИ и НРС. По данным исследовательской фирмы SemiAnalysis, задержка связана с физическим дизайном изделий Blackwell. Это первые массовые ускорители, в которых используется технология упаковки TSMC CoWoS-L. Это сложная и высокоточная методика, предусматривающая применение органического интерпозера — лимит возможностей технологии предыдущего поколения CoWoS-S был достигнут в AMD Instinct MI300X. Кремниевый интерпорзер, подходящий для B200, оказался бы слишком хрупок. Однако органический интерпозер имеет не лучшие электрические характеристики, поэтому для связи используются кремниевые мостики. В используемых материалах как раз и кроется основная проблема — из-за разности коэффициента теплового расширения различных компонентов появляются изгибы, которые разрушают контакты и сами чиплеты. При этом точность и аккуратность соединений крайне важна для работы внутреннего интерконнекта NV-HBI, который объединяет два вычислительных тайла на скорости 10 Тбайт/с. Поэтому сейчас NVIDIA с TSMC заняты переработкой мостиков и, по слухам, нескольких слоёв металлизации самих тайлов.  Вместе с тем у TSMC наблюдается нехватка мощностей по упаковке CoWoS. Компания в течение последних двух лет наращивала мощности CoWoS-S, в основном для удовлетворения потребностей NVIDIA, но теперь последняя переводит свои продукты на CoWoS-L. Поэтому TSMC строит фабрику AP6 под новую технологию упаковки, а также переведёт уже имеющиеся мощности AP3 на CoWoS-L. При этом конкуренты TSMC не могут и вряд ли смогут в ближайшее время предоставить хоть какую-то альтернативную технологию упаковки, которая подойдёт NVIDIA. Таким образом, как сообщается, NVIDIA предстоит определиться с тем, как использовать доступные производственные мощности TSMC. По мнению SemiAnalysis, компания почти полностью сосредоточена на стоечных суперускорителях GB200 NVL36/72, которые достанутся гиперскейлерам и небольшому числу других игроков, тогда как HGX-решения B100 и B200 «сейчас фактически отменяются», хотя малые партии последних всё же должны попасть на рынок. Однако у NVIDIA есть и запасной план. План заключается в выпуске упрощённых монолитных чипов B200A на базе одного кристалла B102, который также станет основой для ускорителя B20, ориентированного на Китай. B200A получит всего четыре стека HBM3e (144 Гбайт, 4 Тбайт/с), а его TDP составит 700 или 1000 Вт. Важным преимуществом в данном случае является возможность использования упаковки CoWoS-S. Чипы B200A как раз и попадут в массовые HGX-системы вместо изначально планировавшихся B100/B200.  На смену B200A придут B200A Ultra, у которых производительность повысится, но вот апгрейда памяти не будет. Они тоже попадут в HGX-платформы, но главное не это. На их основе NVIDIA предложит компромиссные суперускорители MGX GB200A Ultra NVL36. Они получат восемь 2U-узлов, в каждом из которых будет по одному процессору Grace и четыре 700-Вт B200A Ultra. Ускорители по-прежнему будут полноценно объединены шиной NVLink5 (одночиповые 1U-коммутаторы), но вот внутри узла всё общение с CPU будет завязано на PCIe-коммутаторы в двух адаптерах ConnectX-8. Главным преимуществом GX GB200A Ultra NVL36 станет воздушное охлаждение из-за относительно невысокой мощности — всего 40 кВт на стойку. Это немало, но всё равно позволит разместить новинки во многих ЦОД без их кардинального переоборудования пусть и ценой потери плотности размещения (например, пропуская ряды). По мнению SemiAnalysis, эти суперускорители в случае нехватки «полноценных» GB200 NVL72/36 будут покупать и гиперскейлеры. |
|