Материалы по тегу: hardware
|
13.11.2023 [13:56], Сергей Карасёв
Synopsys представила ядра ARC-V на архитектуре RISC-VКомпания Synopsys анонсировала процессорные ядра ARC-V на архитектуре RISC-V, которые будут доступны для лицензирования сторонним разработчикам. Заказчики смогут воспользоваться сопутствующими инструментами, включая средства автоматизации проектирования электронных устройств на базе ИИ Synopsys.ai. В семейство Synopsys ARC-V Processor IP вошли модификации с высоким и средним уровнями производительности, а также версия со сверхнизким энергопотреблением. Разработчики смогут воспользоваться платформой Synopsys MetaWare для создания эффективного и высокооптимизированного кода. 
Источник изображения: Synopsys Кроме того, анонсировано ядро Synopsys ARC-V Functional Safety (FS) со встроенными аппаратными функциями безопасности для обнаружения системных ошибок. Говорится об уровнях безопасности ASIL B и ASIL D. Изделие разработано на основе системы управления качеством (QMS) Synopsys, сертифицированной по стандарту ISO 9001. А пакет MetaWare Development Toolkit for Safety поможет разработчикам ускорить написание кода, соответствующего стандарту ISO 26262. 32-битное ядро Synopsys ARC-V RMX для встраиваемых систем станет доступно во II квартале 2024 года. 32-битное ядро реального времени Synopsys ARC-V RHX и 64-битное ядро Synopsys ARC-V RPX IP планируется выпустить во второй половине следующего года. Synopsys также сообщила, что её представитель войдёт в состав совета директоров и технический руководящий комитет некоммерческой организации RISC-V International, которая занимается координацией разработки данной архитектуры.
13.11.2023 [13:40], Сергей Карасёв
IBM представила All-Flash СХД Storage Scale System 6000 с производительностью до 256 Гбайт/с и 13 млн IOPSКорпорация IBM анонсировала СХД Storage Scale System 6000 в форм-факторе 4U. Новинка оптимизирована для хранения полуструктурированных и неструктурированных данных, таких как видеоматериалы, изображения, текст и показания различного оборудования. В состав изделия входят два контроллера на процессорах AMD EPYC Genoa 7642 (48 ядер; 96 потоков; 2,3–3,3 ГГц; 225 Вт), которые функционируют в режиме Active/Active. Объём оперативной памяти может составлять 768 или 1536 Гбайт. Могут быть установлены 24 или 48 SSD (NVMe) вместимостью до 30 Тбайт каждый. В первой половине следующего года станут доступны конфигурации с 24 и 48 модулями IBM FlashCore (FCM) ёмкостью до 114 Тбайт (с учётом компрессии 3:1), которые позволят получить эффективную ёмкость до 5,4 Пбайт. Заявленная производительность достигает 13 млн IOPS, пропускная способность — до 256 Гбайт/с. Говорится о поддержке NVIDIA GPUDirect, Container Native Storage Access (CNSA), CSI, HDFS, NFS v4, SMB, HTTP, S3. 
Источник изображения: IBM Доступны 16 слотов расширения PCIe 5.0. Система может быть оборудована сетевыми адаптерами NVIDIA ConnectX-7: поддерживаются до 16 портов 100 Гбит/с RoCE, InfiniBand 200/400 Гбит/с или их комбинация. В оснащение входят четыре блока питания с возможностью горячей замены. Габариты составляют 175 × 483 × 850 мм. СХД использует платформу Red Hat Enterpise Linux (RHEL) и фирменное ПО IBM Storage Scale for Storage Scale System.
12.11.2023 [18:51], Сергей Карасёв
ORCA Computing предоставит Польше две квантовые вычислительные системыБританский разработчик квантовых систем ORCA Computing выбран Познаньским центром суперкомпьютерных и сетевых технологий (PSNC) в Польше в качестве поставщика двух квантовых компьютеров. Эти системы призваны ускорить решение задач в ряде научных и прикладных областей, включая биологию, химию и машинное обучение. Речь идёт о квантовых фотонных компьютерах ORCA Computing PT-1. Они будут установлены в центре высокопроизводительных вычислений PSNC в Познане в ноябре и декабре нынешнего года и интегрированы в существующую HPC-инфраструктуру. Ситсемы закуплены в рамках проекта EuroHPC-PL. Квантовые компьютеры PT-1 используют источник одиночных фотонов и программируемые сети светоделителей для реализации квантовой памяти. Результаты вычислений представляют собой сложную статистику, где количество фотонов отражает вероятность распределения. Система может быть интегрирована с классическими HPC-платформами. Доступен специализированный комплект для разработки, который поддерживает гибридные квантово-классические алгоритмы с QPU и GPU. 
Источник изображения: ORCA Computing Технология ORCA Computing предусматривает использование одиночных фотонов в качестве носителя. Это не только позволяет системе естественным образом взаимодействовать с оптическими сетями, но также обеспечивает модульность и гибкость архитектуры с возможностью последующего обновления. Задействована проприетарная технология мультиплексирования для управления синхронизацией, частотой и маршрутизацией одиночных фотонов: данная методика позволяет достигать высокой плотности данных, что даёт возможность осуществлять полномасштабные квантовые вычисления с гораздо меньшим количеством компонентов.
12.11.2023 [16:53], Сергей Карасёв
Dell представила объектное All-Flash хранилище ObjectScale XF960 для генеративного ИИКорпорация Dell анонсировала программно определяемую объектную систему хранения данных ObjectScale XF960. Новинка, ставшая первым представителем семейства ObjectScale X Series, ориентирована на задачи генеративного ИИ и аналитику в реальном времени. В состав системы входят серверы PowerEdge, коммутаторы, необходимое стоечное оборудование и кабели. Применена программная платформа ObjectScale v1.3. В зависимости от конфигурации ObjectScale XF960 объединяет от 4 до 16 узлов. Каждый из них несёт на борту два 32-ядерных процессора Intel Xeon Sapphire Rapids и 256 Гбайт оперативной памяти. Предусмотрены два загрузочных накопителя с зеркалированием для обеспечения надёжности. Сетевая подсистема включает по два порта 100 GbE (back-end) и 25 GbE (front-end). Система относится к классу All-Flash. В оснащение каждого из 2U-узлов входят 24 накопителя NVMe на основе флеш-памяти TLC вместимостью 30,72 Тбайт. Таким образом, суммарная «сырая» ёмкость составляет 737,3 Тбайт. В максимальной конфигурации с 16 узлами общая вместимость достигает 11,8 Пбайт. 
Источник изображения: Dell Dell заявляет, что ObjectScale XF960 — это полностью интегрированная система «под ключ» и самая мощная в мире объектная платформа хранения данных, созданная специально для Kubernetes. Система способна обеспечить скорость чтения до 5,7 Гбайт/с и скорость записи до 5,0 Гбайт/с на каждый узел.
11.11.2023 [23:59], Алексей Степин
СуперДупер: GigaIO SuperDuperNODE позволяет объединить посредством PCIe сразу 64 ускорителяКомпания GigaIO, чьей главной разработкой является система распределённого интерконнекта на базе PCI Express под названием FabreX, поставила новый рекорд — в новой платформе разработчикам удалось удвоить количество одновременно подключаемых PCIe-устройств, увеличив его с 32 до 64. О разработках GigaIO мы рассказывали читателям неоднократно. Во многом они действительно уникальны, поскольку созданная компанией композитная инфраструктура позволяет подключать к одному или нескольким серверам существенно больше различных ускорителей, нежели это возможно в классическом варианте, но при этом сохраняет высокий уровень утилизации этих ускорителей. 
GigaIO SuperNODE. Источник изображений здесь и далее: GigaIO В начале года компания уже демонстрировала систему с 16 ускорителями NVIDIA A100, а летом GigaIO представила мини-кластер SuperNODE. В различных конфигурациях система могла содержать 32 ускорителя AMD Instinct MI210 или 24 ускорителя NVIDIA A100, дополненных СХД ёмкостью 1 Пбайт. При этом система в силу особенностей FabreX не требовала какой-либо специфической настройки перед работой. 
FabreX позволяет физически объединить все типы ресурсов на базе существующего стека технологий PCI Express На этой неделе GigaIO анонсировала новый вариант своей HPC-системы, получившей незамысловатое название SuperDuperNODE. В ней она смогла удвоить количество ускорителей с 32 до 64. Как и прежде, система предназначена, в первую очередь, для использования в сценариях генеративного ИИ, но также интересна она и с точки зрения ряда HPC-задач, в частности, вычислительной гидродинамики (CFD). Система SuperNODE смогла завершить самую сложную в мире CFD-симуляцию всего за 33 часа. В ней имитировался полёт 62-метрового авиалайнера Конкорд. Хотя протяжённость модели составляет всего 1 сек, она очень сложна, поскольку требуется обсчёт поведения 40 млрд ячеек объёмом 12,4 мм3 на протяжении 67268 временных отрезков. 29 часов у системы ушло на обсчёт полёта, и ещё 4 часа было затрачено на рендеринг 3000 4К-изображений. С учётом отличной масштабируемости при использовании SuperDuperNODE время расчёта удалось сократить практически вдвое. Как уже упоминалось, FabreX позволяет малой кровью наращивать число ускорителей и иных мощных PCIe-устройств на процессорный узел при практически идеальном масштабировании. Обновлённая платформа не подвела и в этот раз: в тесте HPL-MxP пиковый показатель утилизации составил 99,7 % от теоретического максимума, а в тестах HPL и HPCG — 95,2 % и 88 % соответственно. Компания-разработчик сообщает о том, что программное обеспечение FabreX обрело завершённый вид и без каких-либо проблем обеспечивает переключение режимов SuperNODE между Beast (система видна как один большой узел), Swarm (множество узлов для множества нагрузок) и Freestyle Mode (каждой нагрузке выделен свой узел с заданным количеством ускорителей). Начало поставок SuperDuperNODE запланировано на конец года. Партнёрами, как и в случае с SuperNODE, выступят Dell и Supermicro.
11.11.2023 [22:13], Руслан Авдеев
Историческое общество попросило Google не строить посадочную станцию для интернет-кабеля Nuvem на месте мемориала Второй мировой войныИсторическое общество острова Сент-Дэвид на Бермудах обратилось к Google с просьбой не строить посадочную станцию для подводного интернет-кабеля Nuvem в парке «Бухта Энни». Как сообщает Datacenter Dynamics, здесь находится военный мемориал, посвящённый событиям Второй мировой войны. Именно на острове Сент-Дэвид, как ожидается, будет размещена одна из посадочных станций кабеля, который со временем свяжет Португалию, Бермуды и США. Местный регулятор выделил два места для таких станций, которые уже используются пятью кабельными системами: Сент-Дэвид и Девоншир. Однако для Nuvem требуется новая, намного более крупная станция. Представитель Google заявляет, что место для возведения объекта всё ещё обсуждается, хотя Сент-Дэвид является ключевой зоной интересов компании. 
Фото: Mona Jain / Unsplash Принадлежащая местным властям компания Bermuda Land Development Corporation предложила план строительства, предполагающий сохранение парка «Бухта Энни», но президент исторического общества считает, что такая концепция несовместима с возведением станции для кабеля. Он заявляет, что сейчас ведутся работы по расширению парка «Бухта Энни», благодаря чему посетителям должны открыться новые потрясающие виды, которые были недоступны жителям с 1941 года. Мемориалы различного рода нередко становятся препятствием при строительстве инфраструктуры. В июне на Гуаме недалеко от места строительства посадочной станции и ЦОД обнаружили древние захоронения местных жителей, а в декабре прошлого года в центре скандала оказалась Microsoft, построившая дата-центр на месте исторического кладбища. UPD 15.11.2023: Google сообщила, что не собирается ничего строить в «Бухте Энни», сославшись на недопонимание. Кабель по подземным коллекторам будет протянут вглубь острова. Компания уже присмотрело место, где можно было бы возвести посадочную станцию площадью 4645 м2.
11.11.2023 [15:23], Сергей Карасёв
MLPerf: Intel улучшила производительность Gaudi2, но лидером остаётся NVIDIA H100Консорциум MLCommons обнародовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training 3.1, который оценивает производительность на ИИ-операциях. Отмечается, что корпорация Intel смогла существенно увеличить быстродействие своего ускорителя Habana Gaudi2, но безоговорочным лидером остаётся NVIDIA H100. Тесты проводились на платформе Xeon Sapphire Rapids. Отмечается, что для некоторых задач Intel реализовала поддержку FP8-вычислений, благодаря чему производительность поднялась в два раза по сравнению с показателями, которые этот же ускоритель демонстрировал ранее. Согласно результатам тестов, в бенчмарке GPT-3 ускоритель Gaudi2 ровно в два раза проигрывает решению NVIDIA H100. То же самое касается теста Stable Diffusion: при этом нужно отметить, что Gaudi2 использовал формат BF16, а H100 — FP16. В ResNet эти ускорители демонстрируют сопоставимую производительность. В тесте BERT чип H100 при использовании FP8-вычислений показал значительное преимущество перед Gaudi2, который использовал формат BF16. 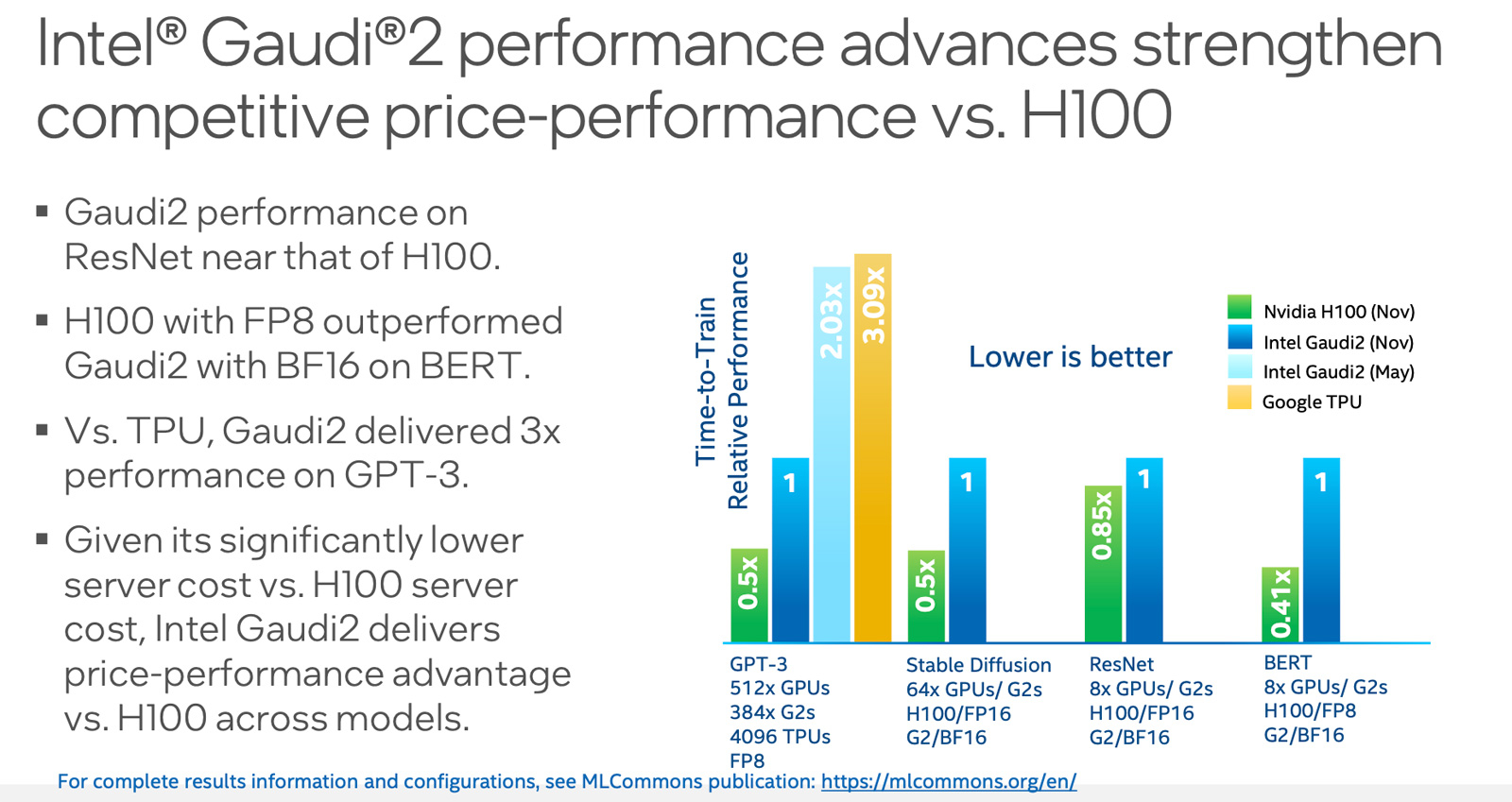
Источник изображения: MLCommons Сама Intel отмечает, что с внедрением поддержки FP8 система с 384 ускорителями Gaudi2 способна завершить обучение GPT-3 за 153,58 мин. При использовании 64 чипов Gaudi2 тест Stable Diffusion может быть завершён за 20,2 мин (BF16). Для тестов BERT и ResNet-50 на восьми ускорителях Gaudi2 (BF16) результат составляет 13,27 и 15,92 мин соответственно. Вместе с тем стоимость и доступность ускорителей Intel, как считается, существенно лучше, чем у решений NVIDIA.
11.11.2023 [14:51], Сергей Карасёв
Квартальная выручка Supermicro увеличилась, но чистая прибыль упалаКомпания Supermicro обнародовала показатели деятельности в I четверти 2024 финансового года, которая была закрыта 30 сентября. Известный американский производитель серверов, СХД, сетевого оборудования и комплексных систем показал смешанные результаты. Выручка за трёхмесячный период составила $2,12 млрд против $1,85 млрд годом ранее. Таким образом, по данному показателю зафиксирован рост около 15 %. Вместе с тем в IV квартале 2023 финансового года выручка была несколько выше — $2,18 млрд. 
Источник изображения: Supermicro Чистая прибыль Supermicro в I четверти 2024 финансового года зафиксирована на уровне $157 млн. Для сравнения: годом ранее компания заработала $184 млн. То есть, отмечено падение на 15%. Прибыль в пересчёте на одну ценную бумагу за год сократилась с $3,35 до $2,75. По состоянию на 30 сентября 2023 года общая сумма денежных средств и их эквивалентов составляла $543 млн, а общая банковская задолженность — $146 млн. Supermicro прогнозирует, что во II квартале 2024 финансового года, который закончится 31 декабря, выручка составит от $2,7 млрд до $2,9 млрд, а чистая прибыль — от $3,75 до $4,24 на акцию. На 2024 финансовый год в целом, заканчивающийся 30 июня 2024-го, компания сохраняет прогноз по выручке в диапазоне от $10 млрд до $11 млрд. Вместе с тем Supermicro объявила о расширении глобального объёма производства до 5000 полностью протестированных стоек НРС, ИИ и решений на основе СЖО в месяц. Заводы по выпуску продукции компании располагаются в США, на Тайване, в Нидерландах и Малайзии. В целом, компания нацелена на существенный рост бизнеса в ближайшие годы.
10.11.2023 [16:24], Сергей Карасёв
Представлен одноплатный компьютер Firefly ROC-RK3588-RT с одним 2.5GbE и двумя 1GbE-портамиКоманда Firefly, по сообщению ресурса CNX-Software, начала продажи одноплатного компьютера ROC-RK3588-RT, подходящего для создания различных сетевых устройств — маршрутизаторов, брандмауэров и пр. Новинка доступна для заказа по цене $229. Изделие имеет габариты 108,48 × 74,98 мм. Применён процессор Rockchip RK3588 (4 × Cortex-A76 @ 2,4 ГГц, 4 × Cortex-A55 @ 1,8 ГГц, Arm Mali-G610 MP4) частотой до 2,4 ГГц. В состав чипа входит нейропроцессорный блок (NPU) с производительностью до 6 TOPS. Есть возможность декодирование видео 8K@60p H.265/VP9/AVS2. Индустриальная версия платы использует модификацию RK3588J с частотой до 2,2 ГГц. 
Источник изображения: Firefly Компьютер может нести на борту от 4 до 32 Гбайт оперативной памяти LPDDR4/LPDDR4x/LPDDR5. Можно установить модуль eMMC вместимостью от 32 до 128 Гбайт, а также SSD формата M.2 2242 с интерфейсом SATA или PCIe. Доступен слот для карты microSD. 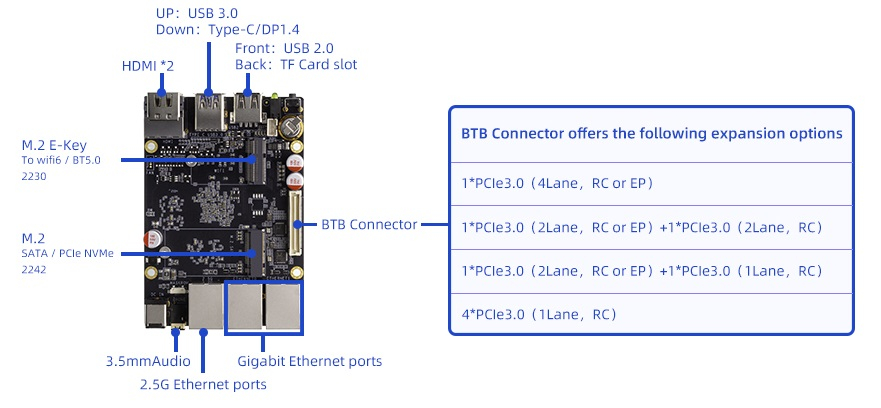
Источник изображения: Firefly Предусмотрены интерфейсы HDMI 2.1 (до 8Kp60), HDMI 2.0 (до 4Kp60) и USB-C с поддержкой DisplayPort 1.4 (до 8Kp30), порты USB 3.0 и USB 2.0, аудиогнездо на 3,5 мм. За сетевые подключения отвечают два порта 1GbE и один порт 2.5GbE: любой из них может работать в режиме WAN/LAN. Опционально можно добавить комбинированный модуль Wi-Fi/Bluetooth (M.2 E-Key 2230). В оснащение также входит 60-контактная колодка ВТВ (2 × PCIe 3.0 (4 линии), 2 × UART, 1 × USB 2.0, 1 × CAN bus, 1 × SARADC, GPIO). Одноплатный компьютер предлагается в коммерческой и индустриальной версиях: в первом случае диапазон рабочих температур простирается от -20 до +60 °C, во втором — от -40 до +85 °C. Питание 12 В подаётся через коннектор 5,5/2,1 мм. По умолчанию на компьютере применяется ОС Android 12.
10.11.2023 [16:11], Сергей Карасёв
ИИ-стартап Anthropic задействует чипы Google TPU v5e для обучения моделейСтартап Anthropic, специализирующийся на технологиях генеративного ИИ, по информации Datacenter Dynamics, намерен использовать ускорители Google TPU для обучения своих систем, включая большую языковую модель Claude. Многие компании вынуждены искать альтернативы дефицитным чипам NVIDIA, хотя это и требует дополнительных затрат для адаптации ПО. Речь идёт о чипах Google TPU v5e, которые были анонсированы в августе нынешнего года. Это специализированные решения, предназначенные для обучения нейросетей или инференс-систем среднего и большого классов. Ускоритель содержит четыре блока матричных вычислений, по одному блоку для скалярных и векторных расчётов, а также HBM2-память. 
Источник изображения: pixabay.com Google и Anthropic уже связывают партнёрские отношения. В частности, в конце 2022-го Google приобрела в этом ИИ-стартапе долю в размере 10 % за $300 млн. В октябре 2023-го стало известно, что Google предоставит Anthropic дополнительно $500 млн, а позднее — ещё $1,5 млрд. Google уже добавила в своё облако ИИ-модели Anthropic, а стартап, в свою очередь, развернул один из самых крупных кластеров Google Kubernetes Engine (GKE) для ИИ. Между тем интерес к Anthropic проявляют и другие компании. Так, в августе нынешнего года SK Telecom вложила $100 млн в этот ИИ-стартап. А в сентябре Amazon объявила о намерении инвестировать в Anthropic до $4 млрд. По условиям соглашения, Anthropic будет использовать облачные ресурсы AWS; кроме того, стороны займутся разработкой чипов Trainium и Inferentia нового поколения. |
|