Материалы по тегу: gigaio
|
05.05.2025 [13:28], Сергей Карасёв
GigaIO и d-Matrix предоставят инференс-платформу для масштабных ИИ-развёртыванийКомпании GigaIO и d-Matrix объявили о стратегическом партнёрстве с целью создания «самого масштабируемого в мире» решения для инференса, ориентированного на крупные предприятия, которые разворачивают ИИ в большом масштабе. Ожидается, что новая платформа поможет устранить узкие места в плане производительности и упростить внедрение крупных ИИ-систем. В рамках сотрудничества осуществлена интеграция ИИ-ускорителей d-Matrix Corsair в состав НРС-платформы GigaIO SuperNODE. Архитектура Corsair основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости около 150 Тбайт/с. По заявлениям d-Matrix, ускоритель обеспечивает непревзойдённую производительность и эффективность инференса для генеративного ИИ. Устройство выполнено в виде карты расширения с интерфейсом PCIe 5.0 х16. Быстродействие достигает 2,4 Пфлопс с (8-бит вычисления). Изделие имеет двухслотовое исполнение, а показатель TDP равен 600 Вт. В свою очередь, SuperNODE использует фирменную архитектуру FabreX на базе PCIe, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE обеспечивает более эффективное использование ресурсов. 
Источник изображения: d-Matrix Новая модификация SuperNODE поддерживает десятки ускорителей Corsair в одном узле. Производительность составляет до 30 тыс. токенов в секунду при времени обработки 2 мс на токен для таких моделей, как Llama3 70B. По сравнению с решениями на базе GPU обещаны трёхкратное повышение энергоэффективности и в три раза более высокое быстродействие при сопоставимой стоимости владения. «Наша система избавляет от необходимости создания сложных многоузловых конфигураций и упрощает развёртывание, позволяя предприятиям быстро адаптироваться к меняющимся рабочим нагрузкам ИИ, при этом значительно улучшая совокупную стоимость владения и операционную эффективность», — говорит Alan Benjamin (Алан Бенджамин), генеральный директор GigaIO.
28.04.2025 [14:48], Сергей Карасёв
ИИ-суперкомпьютер в чемодане — GigaIO Gryf обеспечит производительность до 30 ТфлопсКомпания GigaIO объявила о доступности системы Gryf — так называемого ИИ-суперкомпьютера в чемодане, разработанного в сотрудничестве с SourceCode. Это сравнительно компактное устройство, как утверждается, обеспечивает производительность ЦОД-класса для периферийных развёртываний. Первая информация о Gryf появилась около года назад. Устройство выполнено в корпусе с габаритами 228,6 × 355,6 × 622,3 мм, а масса составляет примерно 25 кг. Система может эксплуатироваться при температурах от +10 до +32 °C. Конструкция предусматривает использование модулей Sled четырёх типов: это вычислительный узел Compute Sled, блок ускорителя Accelerator Sled, узел хранения Storage Sled и сетевой блок Network Sled. Доступны различные конфигурации, но суммарное количество модулей Sled в составе Gryf не превышает шести. Плюс к этому в любой комплектации устанавливается модуль питания с двумя блоками мощностью 2500 Вт. Узел Compute Sled содержит процессор AMD EPYC 7003 Milan с 16, 32 или 64 ядрами, до 512 Гбайт DDR4, системный SSD формата M.2 (NVMe) вместимостью 512 Гбайт и два порта 100GbE QSFP56. Блок Storage Sled объединяет восемь накопителей NVMe SSD E1.L суммарной вместимостью до 492 Тбайт. Модуль Network Sled предоставляет два порта QSFP28 100GbE и шесть портов SFP28 25GbE. За ИИ-производительность отвечает модуль Accelerator Sled, который может нести на борту ускоритель NVIDIA L40S (48 Гбайт), H100 NVL (94 Гбайт) или H200 NVL (141 Гбайт). В максимальной конфигурации быстродействие в режиме FP64 достигает 30 Тфлопс (3,34 Пфлопс FP8), а пропускная способность памяти — 4,8 Тбайт/с. 
Источник изображения: GigaIO Архитектура новинки обеспечивает возможность масштабирования путём объединения в единый комплекс до пяти экземпляров Gryf: в общей сложности можно совместить до 30 модулей Sled в той или иной конфигурации. Заказы на Gryf уже поступили со стороны Министерства обороны США, американских разведывательных структур и пр.
10.05.2024 [11:32], Сергей Карасёв
Суперкомпьютер в стойке GigaIO SuperNODE обзавёлся поддержкой AMD Instinct MI300XКомпания GigaIO анонсировала новую модификацию системы SuperNODE для рабочих нагрузок генеративного ИИ и приложений НРС. Суперкомпьютер в стойке теперь может комплектоваться ускорителями AMD Instinct MI300X, благодаря чему значительно повышается производительность при работе с большими языковыми моделями (LLM). Решение SuperNODE, напомним, использует фирменную архитектуру FabreX на базе PCI Express, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE даёт возможность более эффективно использовать ресурсы. Изначально для SuperNODE предлагались конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100. Новая версия допускает использование 32 изделий Instinct MI300X. Утверждается, что архитектура FabreX в сочетании с технологией интерконнекта AMD Infinity Fabric наделяет систему SuperNODE «лучшими в отрасли» возможностями в плане задержек при передаче данных, пропускной способности и управления перегрузками. Это позволяет эффективно справляться с обучением LLM с большим количеством параметров. 
Источник изображения: GigaIO Отмечается, что SuperNODE значительно упрощает процесс развёртывания и управления инфраструктурой ИИ. Традиционные конфигурации обычно включают в себя сложную сеть и необходимость синхронизации нескольких серверов, что создаёт определённые технических сложности и приводит к дополнительным временным затратам. Конструкция SuperNODE с 32 мощными ускорителями в рамках одной системы позволяет решить указанные проблемы.
08.05.2024 [13:24], Сергей Карасёв
ИИ-суперкомпьютер в чемодане — GigaIO представила платформу GryfКомпания GigaIO совместно с SourceCode анонсировала вычислительную систему Gryf. Это, как утверждается, первый в мире суперкомпьютер для ИИ-нагрузок, выполненный в виде чемодана на колёсиках. Изделие имеет габариты 228,6 × 355,6 × 622,3 мм и весит около 25 кг. Применяется фирменная система интерконнекта FabreX на базе PCI Express. Конфигурация Gryf предусматривает использование модулей (Sled) четырёх типов: это вычислительный узел (Compute Sled), блок ускорителя (Accelerator Sled), узел хранения (Storage Sled) и сетевой блок (Network Sled). Они могут компоноваться в различных сочетаниях, но общее количество модулей в рамках одного экземпляра Gryf не превышает шести. В состав Compute Sled входят процессор AMD EPYC 7313 Milan (16C/32T; 3,0–3,7 ГГц; 155 Вт), 256 Гбайт DDR4-3200, системный накопитель NVMe M.2 SSD вместимостью 256 Гбайт и два 100GbE-порта QSFP56/QSFP28. Может применяться ОС Linux Rocky 8/9 или Ubuntu 20/24. В свою очередь, Accelerator Sled содержит ускоритель NVIDIA L40S (48 Гбайт). Модуль Storage Sled объединяет восемь накопителей NVMe E1.L SSD суммарной вместимостью 246 Гбайт. 
Источник изображения: GigaIO Наконец, Network Sled предоставляет два разъёма QSFP56 100GbE и шесть 25GbE-портов SFP28. Вся система получает питание от двух блоков мощностью 2500 Вт каждый. Применены шесть вентиляторов охлаждения диаметром 60 мм. Диапазон рабочих температур — от 10 до +32 °C. Одно устройство Gryf обеспечивает производительность до 91,6 Тфлопс FP32, до 733 Тфлопс FP16 и до 1466 Тфлопс FP8. При этом в единый комплекс могут быть связаны до пяти экземпляров Gryf, что позволяет масштабировать быстродействие для выполнения тех или иных задач.
29.03.2024 [13:39], Сергей Карасёв
GigaIO представила оптические кабели PCIe 5.0 для развёртывания масштабных ИИ-кластеровКомпания GigaIO, разрабатывающая систему распределённого интерконнекта на базе PCI Express под названием FabreX, представила первые в отрасли оптические кабели QSFP-DD с поддержкой PCIe 5.0. Отмечается, что оптические кабели обеспечивают ряд преимуществ перед традиционными медными соединениями. Это, в частности, повышенная пропускная способность. Кроме того, длина оптических линий может превышать 3 м, что является ограничением для медных кабелей. Представленные кабели используют конфигурацию PCIe 5.0 x8 с возможностью агрегации 16 линий. Благодаря этим изделиям упрощается развёртывание высокопроизводительных систем GigaIO SuperNODE, которые позволяют связать воедино до 32 ускорителей посредством упомянутой платформы FabreX. 
Фото: LinkedIn/GigaIO Отмечается, что оптические кабели способны обеспечить передачу данных с высокой скоростью на десятки метров. Таким образом, несколько систем SuperNODE или SuperDuperNODE могут быть объединены в единый кластер для решения наиболее ресурсоёмких задач ИИ. Медные соединения обычно ограничивают размер кластеров двумя–тремя стойками. В случае оптических кабелей предоставляется гораздо большая гибкость в плане конфигурации оборудования. В результате системы SuperNODE могут быть развёрнуты даже в тех дата-центрах, в которых существуют жёсткие ограничения по мощности и охлаждению в расчёте на стойку. Оптические кабели QSFP-DD с поддержкой PCIe 5.0 станут доступны предстоящим летом.
07.12.2023 [16:54], Сергей Карасёв
GigaIO создаст уникальное ИИ-облако с тысячами ускорителей AMD Instinct MI300XКомпания GigaIO объявила о заключении соглашения по созданию инфраструктуры для специализированного ИИ-облака TensorNODE, которое создаётся провайдером TensorWave. В составе платформы будут применяться ускорители AMD Instinct MI300X, оснащённые 192 Гбайт памяти HBM3. Основой TensorNODE послужат мини-кластеры SuperNODE, дебютировавшие летом уходящего года. Особенность этого решения заключается в том, что оно позволяет связать воедино 32 и даже 64 ускорителя посредством распределённого интерконнекта на базе PCI Express. TensorWave будет использовать FabreX для формирования пулов памяти петабайтного масштаба. На первом этапе в начале 2024 года платформа TensorNODE объединит до 5760 ускорителей Instinct MI300X в одном домене. Таким образом, при решении сложных задач можно будет получить доступ более чем к 1 Пбайт памяти с любого узла. Это, как отмечается, позволит обрабатывать даже самые ресурсоёмкие нагрузки в рекордно короткие сроки. 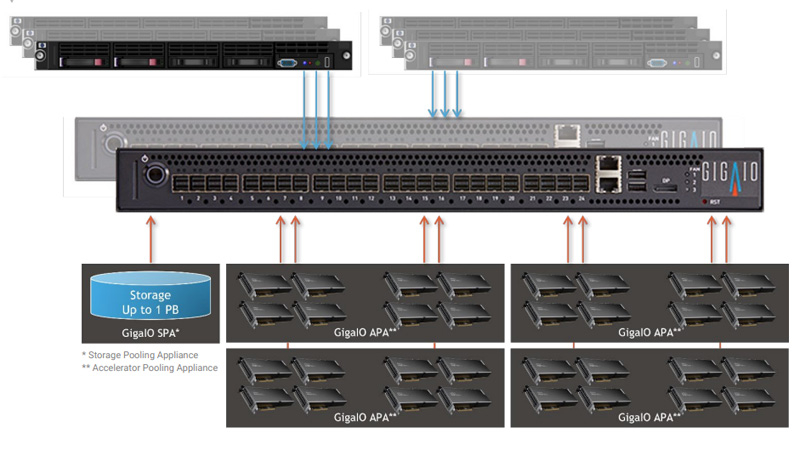
Источник изображения: GigaIO В течение следующего года планируется развернуть несколько систем TensorNODE. Архитектура GigaIO обеспечит улучшенную гибкость по сравнению с традиционными решениями: инфраструктуру можно будет оптимизировать «на лету» для удовлетворения как текущих, так и будущих потребностей в области ИИ и больших языковых моделей (LLM). Отмечается, что TensorNODE полностью базируется на ключевых компонентах AMD. Помимо ускорителей Instinct MI300X, это процессоры EPYC Genoa. Облако TensorWave обеспечит снижение энергозатрат и общей стоимости владения благодаря исключению из конфигурации избыточных серверов и связанного с ними сетевого оборудования.
11.11.2023 [23:59], Алексей Степин
СуперДупер: GigaIO SuperDuperNODE позволяет объединить посредством PCIe сразу 64 ускорителяКомпания GigaIO, чьей главной разработкой является система распределённого интерконнекта на базе PCI Express под названием FabreX, поставила новый рекорд — в новой платформе разработчикам удалось удвоить количество одновременно подключаемых PCIe-устройств, увеличив его с 32 до 64. О разработках GigaIO мы рассказывали читателям неоднократно. Во многом они действительно уникальны, поскольку созданная компанией композитная инфраструктура позволяет подключать к одному или нескольким серверам существенно больше различных ускорителей, нежели это возможно в классическом варианте, но при этом сохраняет высокий уровень утилизации этих ускорителей. 
GigaIO SuperNODE. Источник изображений здесь и далее: GigaIO В начале года компания уже демонстрировала систему с 16 ускорителями NVIDIA A100, а летом GigaIO представила мини-кластер SuperNODE. В различных конфигурациях система могла содержать 32 ускорителя AMD Instinct MI210 или 24 ускорителя NVIDIA A100, дополненных СХД ёмкостью 1 Пбайт. При этом система в силу особенностей FabreX не требовала какой-либо специфической настройки перед работой. 
FabreX позволяет физически объединить все типы ресурсов на базе существующего стека технологий PCI Express На этой неделе GigaIO анонсировала новый вариант своей HPC-системы, получившей незамысловатое название SuperDuperNODE. В ней она смогла удвоить количество ускорителей с 32 до 64. Как и прежде, система предназначена, в первую очередь, для использования в сценариях генеративного ИИ, но также интересна она и с точки зрения ряда HPC-задач, в частности, вычислительной гидродинамики (CFD). Система SuperNODE смогла завершить самую сложную в мире CFD-симуляцию всего за 33 часа. В ней имитировался полёт 62-метрового авиалайнера Конкорд. Хотя протяжённость модели составляет всего 1 сек, она очень сложна, поскольку требуется обсчёт поведения 40 млрд ячеек объёмом 12,4 мм3 на протяжении 67268 временных отрезков. 29 часов у системы ушло на обсчёт полёта, и ещё 4 часа было затрачено на рендеринг 3000 4К-изображений. С учётом отличной масштабируемости при использовании SuperDuperNODE время расчёта удалось сократить практически вдвое. Как уже упоминалось, FabreX позволяет малой кровью наращивать число ускорителей и иных мощных PCIe-устройств на процессорный узел при практически идеальном масштабировании. Обновлённая платформа не подвела и в этот раз: в тесте HPL-MxP пиковый показатель утилизации составил 99,7 % от теоретического максимума, а в тестах HPL и HPCG — 95,2 % и 88 % соответственно. Компания-разработчик сообщает о том, что программное обеспечение FabreX обрело завершённый вид и без каких-либо проблем обеспечивает переключение режимов SuperNODE между Beast (система видна как один большой узел), Swarm (множество узлов для множества нагрузок) и Freestyle Mode (каждой нагрузке выделен свой узел с заданным количеством ускорителей). Начало поставок SuperDuperNODE запланировано на конец года. Партнёрами, как и в случае с SuperNODE, выступят Dell и Supermicro. |
|