Материалы по тегу: tpu
|
04.09.2025 [14:47], Руслан Авдеев
Google бросила вызов NVIDIA, предложив малым облачным провайдерам собственные ИИ-ускорители TPUПо последним данным, Google обратилась к небольшим облачным провайдерам, обычно сдающим в аренду чипы NVIDIA, с необычным предложением — сдавать в аренду её собственные ИИ-ускорители TPU, ранее доступные только в облаке самой Google, сообщает Trendforce со ссылкой на The Information. Это может привести к прямой конкуренции с NVIDIA. Сообщается, что Google уже заключила соглашение как минимум с одним поставщиком облачных сервисов — лондонской Fluidstack. Предполагается разместить TPU в нью-йоркском дата-центре последней. Fluidstack предложены льготы для расширения бизнеса за счёт TPU. Если компания не сможет покрыть расходы на аренду ЦОД в Нью-Йорке, Google обещает предоставить поддержку в объёме до $3,2 млрд. Как утверждается в отчёте, Google ориентируется на молодые компании, в основном на поставщиков облачных услуг, активных пользователей ускорителей NVIDIA. Сообщается, что она уже пыталась заключить аналогичные договоры с другими поставщиками, в настоящее время отдающими предпочтение NVIDIA — включая такие перспективные компании как Crusoe, которая строит ЦОД для OpenAI. Также возможно сотрудничество с CoreWeave, сдающей оборудование NVIDIA в аренду Microsoft (в основном для OpenAI) и также имеющей прямой контракт с OpenAI. 
Источник изображения: Google Google довольно давно работает над созданием ИИ-ускорителей. По данным источников The Information, компания рассматривала возможности расширения связанного с TPU бизнеса, чтобы увеличить выручку и снизить зависимость от чипов NVIDIA. По оценкам Morningstar, совокупную стоимость бизнеса TPU и подразделения DeepMind составляет приблизительно $900 млрд. Отмечается, что вышедшие в декабре 2024 года TPU Trillium шестого поколения, весьма востребованы, ожидается и рост спроса на седьмое поколение ускорителей — TPU Ironwood. Это первая модель, разработанная для масштабного инференса. Ранее Google в основном применяла TPU для собственных проектов. Однако некоторое время назад доступность TPU для внешних заказчиков в рамках Google Cloud стала намного выше. Эти чипы использует, например, Apple. Впрочем, и она теперь хочет получить ускорители NVIDIA.
27.08.2025 [09:25], Руслан Авдеев
Большому ИИ — большую СЖО: Google рассказала о системе охлаждения TPUЖидкостное охлаждение (СЖО) в ЦОД применяется давно, хотя и не повсеместно. В последнее время оно играет всё более важную роль на фоне роста энергопотребления и тепловыделения ИИ-оборудования. Google рассказала об эволюции охлаждении на уровне дата-центров для своих ИИ-ускорителей TPU, сообщает Chips and Cheese. Google впервые оснастила свои TPU жидкостным охлаждением ещё в 2018 году после ряда экспериментов, и с тех пор совершенствует СЖО. Текущие решения предназначены именно для масштабов ЦОД. Так, стойки с шестью (5+1) блоками распределения жидкости (CDU) обслуживают до восьми стоек с TPU. Применяются гибкие шланги и быстроразъёмные соединения для удобства обслуживания.  Во внутреннем контуре чипы в контуре соединены последовательно, что приводит к прогреву теплоносителя, поэтому расчёт охлаждающей мощности ведётся по самому горячему чипу в конце каждого контура. От CDU через теплообменники тепло передаётся в общую систему водоснабжения объекта без смешения жидкостей (в обоих контурах вода). По данным Google, энергопотребление насосов СЖО составляет менее 5 % от мощности вентиляторов, необходимых для воздушного охлаждения. 
Источник изображения: Chips and Cheese Google применяет водоблок с разделённым потоком жидкости. Для охлаждения TPUv4 применялась система охлаждения открытого кристалла (bare-die). Способ не вполне безопасен, но с случае с TPUv4 такой подход необходим, поскольку такие ускорители потребляют в 1,6 раз больше энергии, чем TPUv3. Кроме того, компании пришлось поработать над проблемами протечек и появления микроорганизмов. 
Источник изображения: Chips and Cheese Google тщательно проверяет компоненты на герметичность, использует специальные системы оповещения об утечках и проводит плановое обслуживание и фильтрацию. Дополнительно у компании есть набор протоколов реагирования на проблемы и оповещения, что позволяет оперативно устранять угрозы, которые в масштабах ЦОД могут быть весьма существенными. 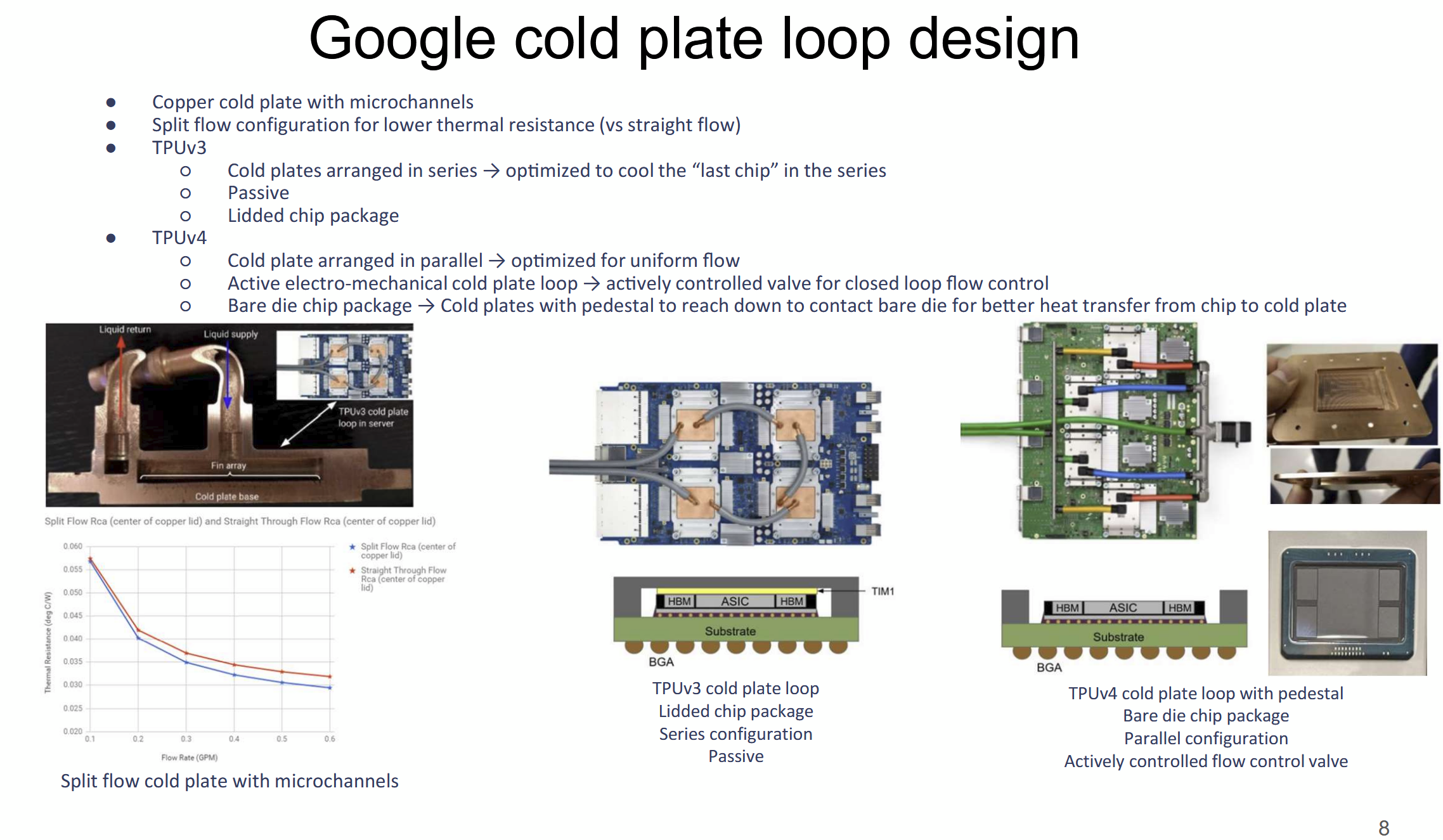
Источник изображения: Chips and Cheese В мае сообщалось, что Google готовит мегаваттные стойки. Строго говоря, компания уже начала использовать 416 В AC на входе в стойки и DC-конвертеры, а также оснащать их встроенными ИБП. Кроме того, она динамически управляет энергопотреблением и производительностью как отдельных TPU, так и стоек в целом.
09.04.2025 [21:55], Владимир Мироненко
Google представила ИИ-ускоритель TPU v7 Ironwood, созданный специально для инференса «размышляющих» моделейКомпания Google Cloud представила тензорный ускоритель TPU седьмого поколения Ironwood, который охарактеризовала как свой самый производительный и масштабируемый настраиваемый ИИ-ускоритель на сегодняшний день и первый среди её чипов, разработанный специально для инференса. Новый чип представляет собой важный поворот в десятилетней стратегии Google по разработке ИИ-чипов, отметил ресурс VentureBeat. В то время как предыдущие поколения TPU были созданы в первую очередь для рабочих нагрузок обучения и инференса, Ironwood — первый чип, специально созданный для инференса. Как пояснила Google, Ironwood знаменует значительный сдвиг в развитии ИИ и инфраструктуры — переход от простых ИИ-моделей, которые просто предоставляют информацию в режиме реального времени, к моделям, которые обеспечивают проактивную генерацию идей и интерпретацию данных. Компания назвала этот период «эпохой инференса», когда ИИ-агенты будут активно извлекать и генерировать данные, чтобы совместно предоставлять информацию и ответы, а не просто «голые» сведения. 
Источник изображений: Google Ironwood разработан в соответствии со сложными вычислительными и коммуникационными требованиями «моделей мышления», которые охватывают большие языковые модели (LLM), смешанные экспертные модели (MoE) и сложные задачи для рассуждения. Эти модели требуют массивной параллельной обработки и эффективного доступа к памяти. В частности, Ironwood разработан для минимизации перемещения данных и задержек на чипе при выполнении массивных тензорных манипуляций. Требования размышляющих моделей к вычислительным мощностям выходят далеко за рамки возможностей любого отдельного чипа.  Google Cloud Ironwood будет поставляться в двух конфигурациях: с 256 или с 9216 чипами. Один чип может похвастаться пиковой вычислительной мощностью 4614 Тфлопс (FP8), а кластер из 9216 чипов мощностью порядка 10 МВт выдаёт в общей сложности 42,5 Эфлопс. Ironwood оснащён усовершенствованным блоком SparseCore, предназначенным для ускорения работы с ИИ-моделями, которые используются в системах ранжирования и рекомендаций. Расширенная реализация SparseCore в Ironwood позволяет ускорить более широкий спектр рабочих нагрузок, выйдя за рамки традиционной области ИИ в финансовые и научные сферы.  Каждый чип оснащен 192 Гбайт памяти HBM, что в шесть раз больше, чем у TPU v6 Trillium. Пропускная способность памяти достигает 7,2 Тбайт/с на чип, что в 4,5 раза больше, чем у Trillium. Также используется межчиповый интерконнект Inter-Chip Interconnect (ICI) с пропускной способностью 1,2 Тбайт/с в дуплексе, что в 1,5 раза больше, чем у Trillium. Наконец, самое важное в эпоху ограниченных по мощности ЦОД — Ironwood обеспечивает вдвое большую производительность на Вт по сравнению с Trillium, а в сравнении с самым первым TPU от 2018 года он почти в 30 энергоэффективнее. Для Ironwood используется СЖО. 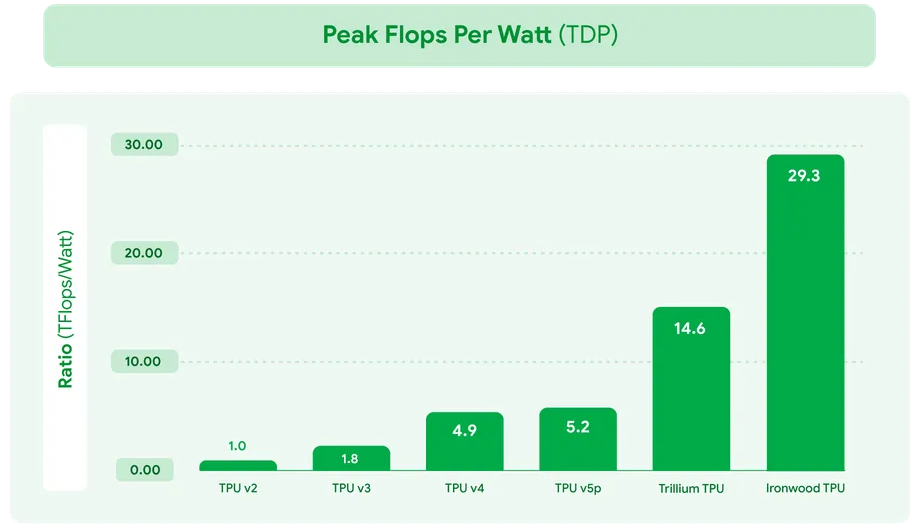 С Ironwood разработчики также могут задействовать программный стек Pathways от Google DeepMind, чтобы использовать объединённую вычислительную мощность десятков тысяч TPU Ironwood. Как сообщается, Ironwood будет доступен клиентам Google и её собственным разработчикам в конце 2025 года.  Google зафиксировала 10-кратный рост спроса на ИИ-вычисления за последние восемь лет. Как отметил ресурс VentureBeat, перенос Google фокуса на оптимизацию инференса имеет смысл. Обучение производится редко, а операции инференса — миллиарды раз в день. Экономика ИИ всё больше связана с затратами на инференс, особенно по мере того, как модели становятся всё более сложными и требующими больших вычислительных ресурсов.
03.04.2025 [16:47], Руслан Авдеев
Google готовится к аренде ИИ-серверов с ускорителями NVIDIA Blackwell у CoreWeaveКомпания Google близка к тому, чтобы согласиться на сделку с CoreWeave. Предполагается, что гиперскейлер будет арендовать у последней серверы, оснащённые ускорителями серии NVIDIA Blackwell, сообщает The Information. Сделка находится на «поздних стадиях» согласования. Благодаря ей Google сможет получить доступ к большему количеству новейших ИИ-ускорителей. Об этом издание сообщает со ссылкой на два анонимных источника, знакомых с вопросом. Ещё два источника добавили, что Google уже пыталась договориться с конкурентами CoreWeave о доступе к свободным ускорителям — судя по всему, компании не хватает доступных вычислительных мощностей. Возможные партнёры пока не комментируют ситуацию. По информации Seeking Alpha, на момент закрытия торгов в среду акции CoreWeave выросли на 16 %, колебания курсов акций Google и NVIDIA оказались незначительными. По данным The Information, отдельно Google и CoreWeave ведут переговоры об аренде площадей в дата-центрах последней — там Google сможет разместить тензорные ускорители (TPU) собственной разработки, которые компания довольно успешно внедряет наряду с решениями NVIDIA. 
Источник изображения: Microsoft Edge/unsplash.com Потенциальное соглашение косвенно свидетельствует о проблемах компаний, желающих пользоваться ускорителями NVIDIA, но не имеющих возможности удовлетворить спрос в полной мере. Уникальные отношения CoreWeave и NVIDIA и возможности оператора ЦОД предоставлять в распоряжение новые ИИ-мощности привлекают крупные облачные сервисы и ключевых ИИ-разработчиков вроде OpenAI и Meta✴. По данным Investing.com, за последние несколько дней крупные ИИ-структуры вроде xAI и OpenAI публично озвучивали необходимость увеличения доступных вычислительных ресурсов. Буквально на днях CoreWeave вышла на IPO — правда, планы развития компании могут оказаться под вопросом, поскольку средств привлечено меньше, чем ожидалось, а капитализация её оказалась значительно меньше, чем рассчитывалось. UPD 29.06.2025: Google действительно арендует ускорители у CoreWeave, но только для того, чтобы сдать их OpenAI. Вероятно, это часть более крупной сделки, в рамках которой OpenAI, по слухам, также начнёт использовать фирменные ускорители Google TPU.
06.02.2025 [19:27], Руслан Авдеев
Грамм на экзафлоп — Google ввела новую метрику CCI для оценки углеродных выбросов ИИ-ускорителейGoogle опубликовала результаты внутреннего исследования, показавшие прогресс в повышении углеродной эффективности своих ИИ-ускорителей TPU. По словам компании, за два поколения — от TPU v4 до Trillium (v6) — усовершенствование аппаратной оборудования привело к трёхкратному повышению экологичности выполняемых ИИ-нагрузок. Оценка всего жизненного цикла (LCA) ускорителей позволяет подробно проанализировать статистику выбросов, связанных с ИИ-ускорителями Google, используя полный набор данных — от добычи сырья и производства чипов до потребления электричества во время работы. Компания даже ввела новую метрику Compute Carbon Intensity (CCI), позволяющую оценить углеродные выбросы относительно производительности. CCI показывает, сколько граммов выбросов CO2 приходится на каждый экзафлоп проделанной работы. Чем ниже CCI, тем ниже выброс оборудования для заданной рабочей нагрузки. Для оценки прогресса Google сравнила пять моделей TPU в течение всего их жизненного цикла и пришла к выводу, что TPU новых поколений стали значительно экологичнее, поскольку CCI за четыре года улучшился втрое. TPU Trillium, очевидно, показали наилучшие результаты. 
Источник изображения: Google Google отмечает, что за весь жизненный цикл TPU 70 % выбросов относятся к эксплуатационным, т.е. связаны с потреблением электричества. Это подчёркивает важность повышения энергоэффективности чипов и снижения выбросов углерода, связанных с энергообеспечением. Однако доля выбросов, связанных с производством, по-прежнему весьма заметна. Более того, со временем она может даже увеличиться, поскольку к 2030 году Google намерена добиться использования полностью безуглеродной энергии в каждой энергосети, питающей её оборудование. Если компания захочет и далее повышать экологичность своих решений, ей придётся вмешаться в цепочки поставок. Кроме того, постоянная оптимизация ИИ-моделей позволит сократить объёмы необходимых вычислений (при прочих равных). Впрочем, повышение эффективности моделей, скорее всего, приведёт к ещё большему использованию ИИ. В будущем Google намерена анализировать углеродные выбросы отдельных ИИ-моделей и влияние на их оптимизации ПО. А пока что выбросы парниковых газов Google из-за ИИ только растут — +48 % за пять лет.
26.12.2024 [18:17], Руслан Авдеев
Omdia: быстрый рост спроса на TPU Google ставит под вопрос доминирование NVIDIA на рынке ИИ-ускорителейНовейшее исследование Omdia показывает, что быстрый рост спроса на кастомные ИИ-ускорители Google (TPU) формирует особый тренд. Не исключено, что он станет достаточно сильным для того, чтобы начать процесс, способный прекратить доминирование NVIDIA на рынке ускорителей, сообщает Omdia. Результаты III квартала компании Broadcom, чьё подразделение Semiconductor Solutions выполняет аутсорс-заказы Google, Meta✴ и некоторых других IT-гигантов, дают по-новому взглянуть на рынок ускорителей. В частности, они позволяют оценить покупательские тенденции и косвенно получить информацию, которая обычно скрывается. Например, как много кастомных процессоров покупает Google. Глава Broadcom Хок Тан (Hock Tan) неоднократно пересматривал планы выручки от ИИ-полупроводников, в этом году компания намерена заработать $12 млрд. Исходя из этого ожидается, что на TPU Google придётся от $6 млрд (близко к текущим оценкам Omdia) до $9 млрд, в зависимости от распределения выручки между вычислительными и сетевыми решениями. В сумму целиком входит и выручка от чипов Meta✴ MTIA. В следующем году у Broadcom, вероятно, появится и загадочный третий заказчик. Им может стать Apple, которая сейчас активно использует для обучения моделей именно TPU. 
Источник изобраджения: Google По словам экспертов Omdia, даже с учётом того, что соотношение выручки от вычислительных и сетевых устройств точно не определено, поставки TPU даже «по нижней границе» в $6 млрд свидетельствуют о росте достаточно быстром, чтобы впервые отвоевать часть доли рынка у NVIDIA. По оценкам TechInsights, в 2023 году поставки TPU достигли 2 млн шт., а ускорителей NVIDIA для ЦОД — 3,8 млн шт. Стоит отметить, что выручка бизнеса Google Cloud Platform продолжает расти как часть выручки Google, при этом растёт и рентабельность подразделения. Это может свидетельствовать о том, что инстансы на основе TPU выступают драйверами роста Google Cloud и являются высокоприбыльными продуктами. В середине ноября Google и NVIDIA показали первые результаты TPU v6 и B200 в ИИ-бенчмарке MLPerf Training, где ускорители продемонстрировали неоднозначные результаты в разных сравнениях.
14.11.2024 [23:07], Владимир Мироненко
Google и NVIDIA показали первые результаты TPU v6 и B200 в ИИ-бенчмарке MLPerf TrainingУскорители Blackwell компании NVIDIA опередили в бенчмарках MLPerf Training 4.1 чипы H100 более чем в 2,2 раза, сообщил The Register. По словам NVIDIA, более высокая пропускная способность памяти в Blackwell также сыграла свою роль. Тесты были проведены с использование собственного суперкомпьютера NVIDIA Nyx на базе DGX B200. Новые ускорители имеют примерно в 2,27 раза более высокую пиковую производительность в вычисления FP8, FP16, BF16 и TF32, чем системы H100 последнего поколения. B200 показал в 2,2 раза более высокую производительность при тюнинге модели Llama 2 70B и в два раза большую производительность при предварительном обучении (Pre-training) модели GPT-3 175B. Для рекомендательных систем и генерации изображений прирост составил 64 % и 62 % соответственно. Компания также отметила преимущества используемой в B200 памяти HBM3e, благодаря которой бенчмарк GPT-3 успешно отработал всего на 64 ускорителях Blackwell без ущерба для производительности каждого GPU, тогда как для достижения такого же результата понадобилось бы 256 ускорителей H100. Впрочем, про Hopper компания тоже не забывает — в новом раунде компания смогла масштабировать тест GPT-3 175B до 11 616 ускорителей H100. 
Источник изображений: NVIDIA Компания отметила, что платформа NVIDIA Blackwell обеспечивает значительный скачок производительности по сравнению с платформой Hopper, особенно при работе с LLM. В то же время чипы поколения Hopper по-прежнему остаются актуальными благодаря непрерывным оптимизациям ПО, порой кратно повышающим производительность в некоторых задач. Интрига в том, что в этот раз NVIDIA решила не показывать результаты GB200, хотя такие системы есть и у неё, и у партнёров. 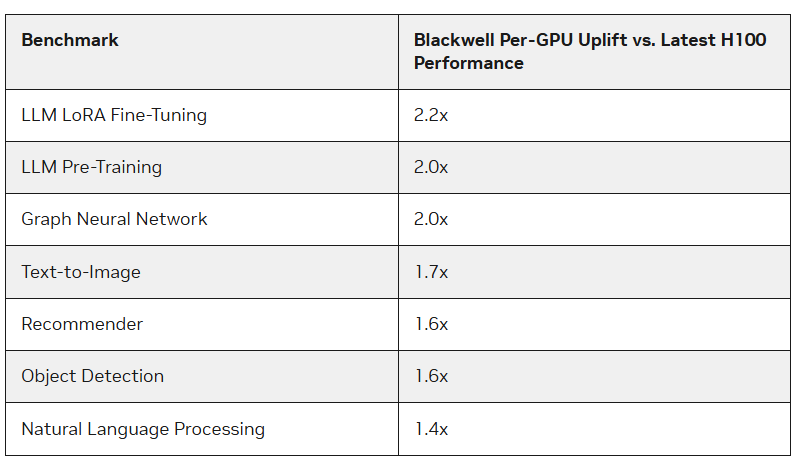 В свою очередь, Google представила первые результаты тестирования 6-го поколения TPU под названием Trillium, о доступности которого было объявлено в прошлом месяце, и второй раунд результатов ускорителей 5-го поколения TPU v5p. Ранее Google тестировала только TPU v5e. По сравнению с последним вариантом, Trillium обеспечивает прирост производительности в 3,8 раза в задаче обучения GPT-3, отмечает IEEE Spectrum.  Если же сравнивать результаты с показателями NVIDIA, то всё выглядит не так оптимистично. Система из 6144 TPU v5p достигла контрольной точки обучения GPT-3 за 11,77 мин, отстав от системы с 11 616 H100, которая выполнила задачу примерно за 3,44 мин. При одинаковом же количестве ускорителей решения Google почти вдвое отстают от решений NVIDIA, а разница между v5p и v6e составляет менее 10 %. 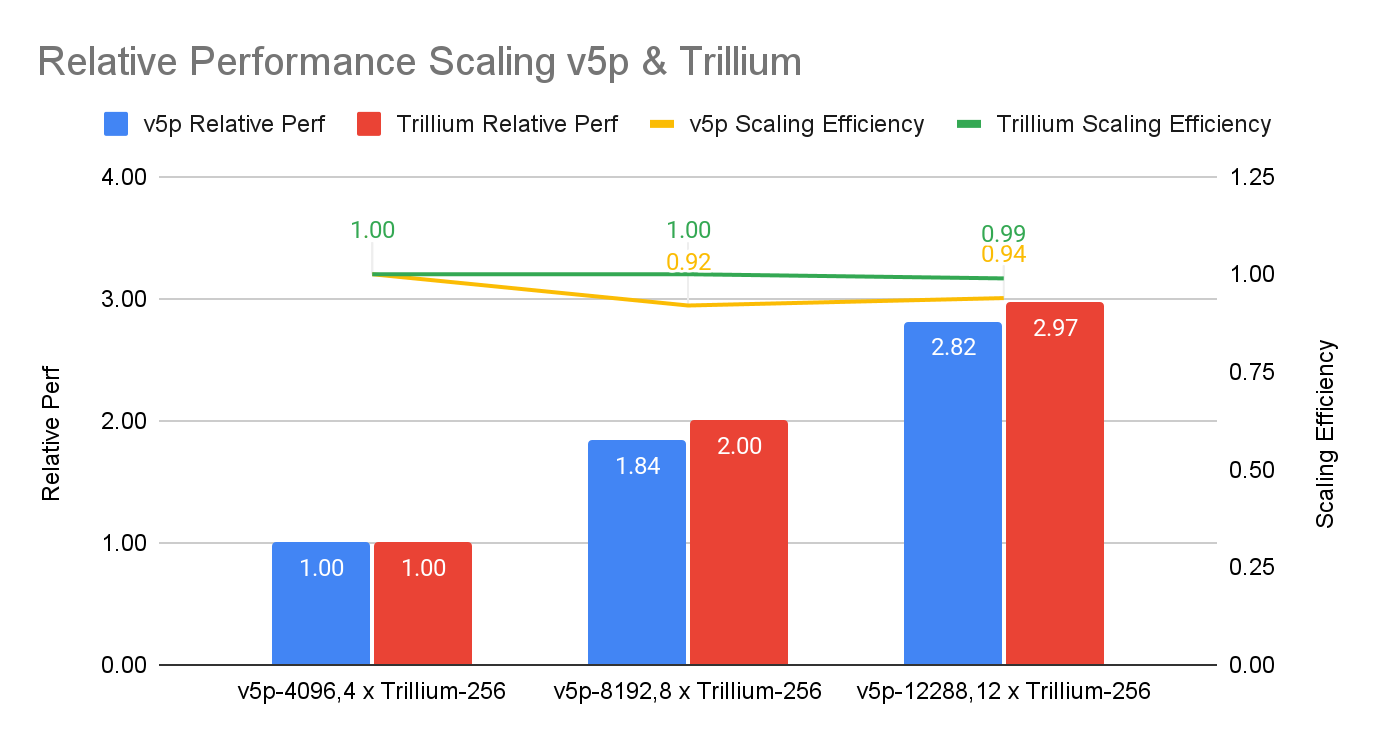
Источник изображения: Google В тесте Stable Diffusion система из 1024 TPU v5p заняла второе место, завершив работу за 2,44 мин, тогда как система того же размера на основе NVIDIA H100 справилась с задачей за 1,37 мин. В остальных тестах на кластерах меньшего масштаба разрыв остаётся примерно полуторакратным. Впрочем, Google упирает на масштабируемость и лучшее соотношение цены и производительности в сравнении как с решениями конкурентов, так и с собственными ускорителями прошлых поколений. Также в новом раунде MLPerf появился единственный результат измерения энергопотребления во время проведения бенчмарка. Система из восьми серверов Dell XE9680, каждый из которых включал восемь ускорителей NVIDIA H100 и два процессора Intel Xeon Platinum 8480+ (Sapphire Rapids), в задаче тюнинга Llama2 70B потребила 16,38 мДж энергии, потратив на работу 5,05 мин. — средняя мощность составила 54,07 кВт.
03.11.2024 [13:15], Сергей Карасёв
Google объявила о доступности ИИ-ускорителей TPU v6 TrilliumКомпания Google сообщила о том, что её новейшие ИИ-ускорители TPU v6 с кодовым именем Trillium доступны клиентам для ознакомления в составе облачной платформы GCP. Утверждается, что на сегодняшний день новинка является самым эффективным решением Google по соотношению цена/производительность. Официальная презентация Trillium состоялась в мае нынешнего года. Изделие оснащено 32 Гбайт памяти HBM с пропускной способностью 1,6 Тбайт/с, а межчиповый интерконнект ICI обеспечивает возможность передачи данных со скоростью до 3,58 Тбит/с (по четыре порта на чип). Задействованы блоки SparseCore третьего поколения, предназначенные для ускорения работы с ИИ-моделями, которые используются в системах ранжирования и рекомендаций. 
Источник изображений: Google Google выделяет ряд существенных преимуществ Trillium (TPU v6e) перед ускорителями TPU v5e:
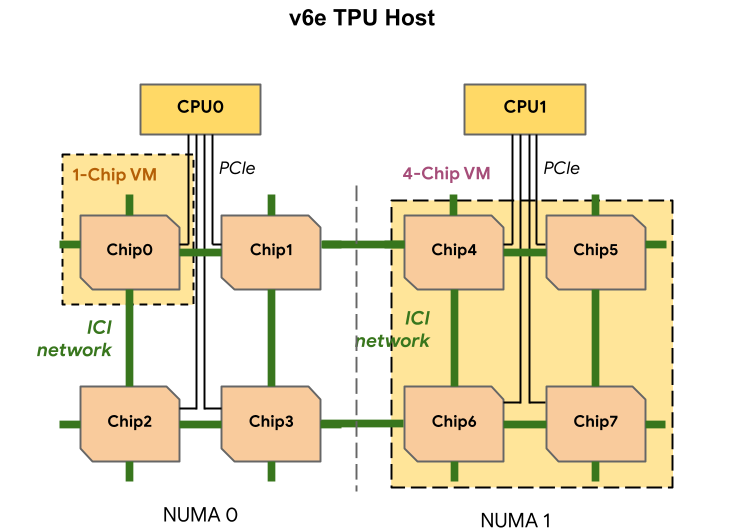 Один узел включает восемь ускорителей TPU v6e (в двух NUMA-доменах), два неназванных процессора (суммарно 180 vCPU), 1,44 Тбайт RAM и четыре 200G-адаптера (по два на CPU) для связи с внешним миром. Отмечается, что посредством ICI напрямую могут быть объединены до 256 изделий Trillium, а агрегированная скорость сетевого подключение такого кластера (Pod) составляет 25,6 Тбит/с. Десятки тысяч ускорителей могут быть связаны в масштабный ИИ-кластер благодаря платформе Google Jupiter с оптической коммутацией, совокупная пропускная способность которой достигает 13 Пбит/с. Trillium доступны в составе интегрированной ИИ-платформы AI Hypercomputer. 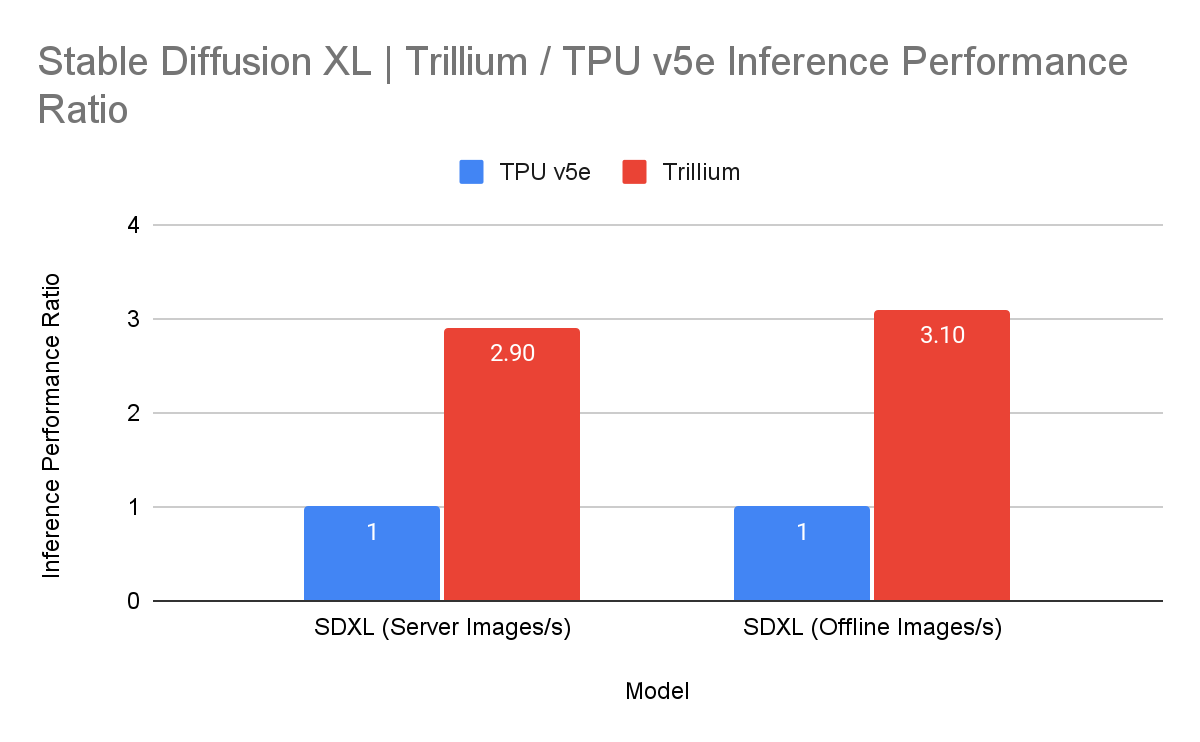 Заявляется, что благодаря ПО Multislice Trillium обеспечивается практически линейное масштабирование производительности для рабочих нагрузок, связанных с обучением ИИ. Производительность кластеров на базе Trillium может достигать 91 Эфлопс на ИИ-операциях: это в четыре раза больше по сравнению с самыми крупными развёртываниями систем на основе TPU v5p. BF16-производительность одного чипа TPU v6e составляет 918 Тфлопс, а INT8 — 1836 Топс. 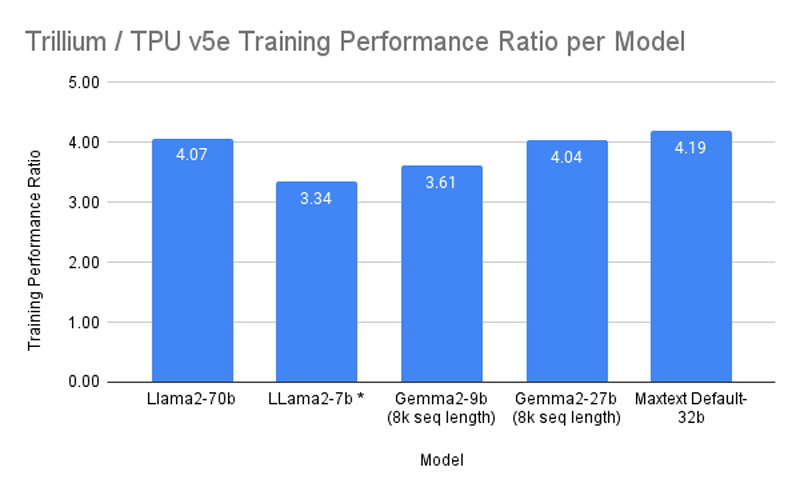 В бенчмарках Trillium по сравнению с TPU v5e показал более чем четырёхкратное увеличение производительности при обучении моделей Gemma 2-27b, MaxText Default-32b и Llama2-70B, а также более чем трёхкратный прирост для LLama2-7b и Gemma2-9b. Кроме того, Trillium обеспечивает трёхкратное увеличение производительности инференса для Stable Diffusion XL (по отношению к TPU v5e). По соотношению цена/производительность TPU v6e демонстрирует 1,8-кратный рост по сравнению с TPU v5e и примерно двукратный рост по сравнению с TPU v5p. Появится ли более производительная модификация TPU v6p, не уточняется.
31.10.2024 [14:56], Владимир Мироненко
DIGITIMES Research: в 2024 году Google увеличит долю на рынке кастомных ИИ ASIC до 74 %Согласно отчету DIGITIMES Research, в 2024 году глобальные поставки ИИ ASIC собственной разработки для ЦОД, как ожидается, достигнут 3,45 млн единиц, а доля рынка Google вырастет до 74 %. Как сообщают аналитики Research, до конца года Google начнёт массовое производство нового поколения ИИ-ускорителей TPU v6 (Trillium), что ещё больше увеличит её присутствие на рынке. В 2023 году доля Google на рынке ИИ ASIC собственной разработки для ЦОД оценивалась в 71 %. В отчёте отмечено, что помимо самой высокой доли рынка, Google также является первым из трёх крупнейших сервис-провайдеров в мире, кто разработал собственные ИИ-ускорители. Первый TPU компания представила в 2016 году. Ожидается, что TPU v6 будет изготавливаться с применением 5-нм процесса TSMC, в основном с использованием 8-слойных чипов памяти HBM3 от Samsung. Также в отчёте сообщается, что Google интегрировала собственную архитектуру оптического интерконнекта в кластеры TPU v6, позиционируя себя в качестве лидера среди конкурирующих провайдеров облачных сервисов с точки зрения внедрения технологий и масштаба развёртывания. Google заменила традиционные spine-коммутаторы на полностью оптические коммутаторы Jupiter собственной разработки, которые позволяют значительно снизить энергопотребление и стоимость обслуживания ИИ-кластеров TPU POD по сравнению с решениями Broadcom или Mellanox. 
Источник изображения: cloud.google.com Кроме того, трансиверы Google получил ряд усовершенствований, значительно нарастив пропускную способность. Если в 2017 году речь шла о полнодуплексном 200G-решении, то в этом году речь идёт уже о 800G-решениях с возможностью модернизации до 1,6T. Скорость одного канала также существенно выросла — с 50G PAM4 в 2017 году до 200G PAM4 в 2024 году.
28.08.2024 [09:14], Владимир Мироненко
Google поделилась подробностями истории создания ИИ-ускорителей TPUВ огромной лаборатории в штаб-квартире Google в Маунтин-Вью (Калифорния, США) установлены сотни серверных стоек с ИИ-ускорителями TPU (Tensor Processing Unit) собственной разработки, с помощью которых производится обучение больших языковых моделей, пишет ресурс CNBC, корреспонденту которого компания устроила небольшую экскурсию. Первое поколение Google TPU, созданное ещё в 2015 году, и представляет собой ASIC для обработки ИИ-нагрузок. Сейчас компания использует такие, хотя и более современные ускорители для обучения и работы собственного чат-бота Gemini. С 2018 года TPU Google доступны облачным клиентам компании. В июле этого года Apple объявила, что использует их для обучения моделей ИИ, лежащих в основе платформы Apple Intelligence. 
TPU v1 (Источник изображений здесь и далее: Google) «В мире есть фундаментальное убеждение, что весь ИИ, большие языковые модели, обучаются на (чипах) NVIDIA, и, конечно, на решения NVIDIA приходится львиная доля объёма обучения. Но Google пошла по собственному пути», — отметил гендиректор Futurum Group Дэниел Ньюман (Daniel Newman). Благодаря расширению использованию ИИ подразделение Google Cloud увеличило доход, и в последнем квартальном отчёте холдинг Alphabet сообщил, что выручка от облачных вычислений выросла на 29 %, впервые превысив $10 млрд за квартал. Google была первым провайдером облачных вычислений, создавшим кастомные ИИ-чипы. Лишь спустя три года Amazon Web Services анонсировала свой первый ИИ-ускоритель Inferentia, Microsoft представила ИИ-ускоритель Azure Maia 100 в ноябре 2023 года, а в мае того же года Meta✴ рассказала об семействе MTIA. Однако лидирует на рынке генеративного ИИ компания OpenAI, обученная на ускорителях NVIDIA, тогда как нейросеть Gemini была представлена Google спустя год после презентации ChatGPT.  В Google рассказали, что впервые задумались о создании собственного чипа в 2014 году, когда в руководстве решили обсудить, насколько большими вычислительными возможностями нужно обладать, чтобы дать возможность всем пользователям поговорить с поиском Google в течение хотя бы 30 с каждый день. По оценкам, для этого потребовалось бы удвоить количество серверов в дата-центрах. «Мы поняли, что можем создать специальное аппаратное обеспечение, <…> в данном случае тензорные процессоры, для обслуживания [этой задачи] гораздо, гораздо более эффективно. Фактически в 100 раз эффективнее, чем было бы в противном случае», — отметил представитель Google. С выходом второго поколения TPU в 2018 году Google расширила круг выполняемых чипом задач, добавив к инференсу обучение ИИ-моделей. Процесс создания ИИ-ускорителя не только отличается высокой сложностью, но и требует больших затрат. Так что реализация таких проектов в одиночку не по силам даже крупным гиперскейлерам. Поэтому с момента создания первого TPU Google сотрудничает с разработчиком чипов Broadcom, который также помогает её конкуренту Meta✴ в создании собственных ASIC. Broadcom утверждает, что потратила более $3 млрд в рамках реализации совместных проектов.  В рамках сотрудничества Google отвечает за собственно вычислительные блоки, а Broadcom занимается разработкой I/O-блоков, SerDes и иных вспомогательных компонентов, а также упаковкой. Самы чипы выпускаются на TSMC. С 2018 года в Google трудятся ещё одни кастомные чипы — Video Coding Unit (VCU) Argos, предназначенной для обработки видео. Что касается TPU, то в этом году клиентам Google будет доступно шестое поколение TPU Trillium. Более того, им станут доступны и первые Arm-процессоры Axion собственной разработки. Google выходит на этот рынок с большим отставанием от конкурентов. Amazon выпустила первый собственный процессор Graviton в 2018 году, Alibaba Yitian 710 появились в 2021 году, а Microsoft анонсировала Azure Cobalt 100 в ноябре. Все эти чипы основаны на архитектуре Arm — более гибкой и энергоэффективной альтернативе x86. Энергоэффективность имеет решающее значение. Согласно последнему экологический отчёту Google, с 2019 по 2023 год выбросы компании выросли почти на 50 %, отчасти из-за увеличения количества ЦОД для ИИ-нагрузок. Для охлаждения ИИ-серверов требуется огромное количество воды. Именно поэтому начиная с третьего поколения TPU компания использует прямое жидкостное охлаждение, которое только теперь становится практически обязательным для современных ИИ-ускорителей вроде NVIDIA Blackwell. |
|