Материалы по тегу: hardware
|
14.11.2023 [18:50], Сергей Карасёв
Запущены суперкомпьютеры Dawn, SuperMUC-NG и Crossroads на базе Intel Data Center GPU Max и Xeon Sapphire Rapids
hardware
hpc
intel
intel max
intel xe
sapphire rapids
sc23
xeon
великобритания
германия
суперкомпьютер
сша
Корпорация Intel на конференции по высокопроизводительным вычислениям SC23 рассказала о новых суперкомпьютерах, попавших в ноябрьский рейтинг TOP500. Речь, в частности, идёт о вычислительных комплексах Dawn (Phase 1), SuperMUC-NG (Phase 2) и Crossroads. Система Dawn, созданная специалистами Intel, Dell Technologies и Кембриджского университета, рассчитана на задачи ИИ. В основу положены серверы Dell PowerEdge XE9640 с жидкостным охлаждением. В общей сложности задействованы 256 узлов, в состав которых входят 512 процессоров Intel Xeon Sapphire Rapids — Platinum 8468 с 48 ядрами (96 потоков; 2,1–3,8 ГГц; 350 Вт). Суперкомпьютер Dawn использует 1024 ускорителя Intel Data Center GPU Max 1550. Общий объём памяти DDR составляет 256 Тбайт, а её пропускная способность достигает 157 Тбайт/с. Кроме того, задействовано 128 Тбайт памяти НВМ с пропускной способностью до 3,3 Пбайт/с. Подсистема хранения данных вместимостью 3 Пбайт обеспечивает скорость до 2 Тбайт/с. Агрегированная пропускная способность сети — до 25,6 Тбайт/с. Заявленная производительность достигает 19,46 Пфлопс (FP64). Это соответствует 41-му месту в ноябрьском рейтинге ТОР500. Пиковое быстродействие — 53,85 Пфлопс. Система установлена в лаборатории Cambridge Open Zettascale Lab (Великобритания). 
Источник изображения: Intel В свою очередь, комплекс SuperMUC-NG (Phase 2) смонтирован в Суперкомпьютерном центре Лейбница Баварской академии наук (Германия). Этот суперкомпьютер базируется на серверах Lenovo ThinkSystem SD650-I V3 Neptune DWC с прямым жидкостным охлаждением. Установлены 240 узлов, в состав которых входят в общей сложности 480 процессоров Intel Xeon Platinum 8480L (56 ядер; 112 потоков; 2,0–3,8 ГГц; 350 Вт) и 960 ускорителей Data Center GPU Max. 
Источник изображения: Intel Комплекс SuperMUC-NG (Phase 2) оперирует 123 Тбайт памяти DDR с пропускной способностью до 147 Тбайт/с. Память НВМ такого же объёма обеспечивает пропускную способность до 3,1 Пбайт/с. Применено хранилище на 1 Пбайт со скоростью 750 Гбайт/с. Пропускная способность сети — до 12 Тбайт/с. Суперкомпьютер обладает производительностью 17,19 Пфлопс (FP64): в списке ТОР500 система располагается на 52-й строке. Наконец, суперкомпьютер Crossroads размещён в Лос-Аламосской национальной лаборатории (LANL) Министерства энергетики США. Система обладает производительностью 30,03 Пфлопс (FP64). Задействованы 2600 чипов Intel Xeon CPU Max 9480 с 56 ядрами и памятью HBM. Система находится на 24-м месте рейтинга ТОР500. Всего же в новой редакци рейтинга есть 20 новых машин на базе Sapphire Rapids, из которых пять используют Max-версию процессоров, а также четыре системы с ускорителями Data Center GPU Max.
14.11.2023 [18:29], Руслан Авдеев
Sitronics Group представила модульный ЦОД для банков, ритейлеров и телеком-операторовВ ходе форума «Финополис» российская Sitronics Group представила модульный ЦОД. Как сообщает пресс-служба компании, серийное производство подобных продуктов запущено ранее в 2023 году в Подмосковье. Решение рассчитано на клиентов разного профиля, от банков до телеком-операторов и ретейлеров. Отмечается, что Sitronics Group способна обеспечить использование в своих ЦОД до 70 % компонентов отечественного производства, а система косвенного адиабатического охлаждения разработана самой Sitronics. Заказчик может получить и платформу виртуализации Sitronics, уже внесённую в реестр российского программного обеспечения, а серверы внесены в реестр Минпромторга страны. 
Источник изображения: Sitronics Group В Sitronics Group сообщают, что среди заказчиков весьма востребована модель сдачи готовых к работе дата-центров. Благодаря подходу, предполагающему создание решения «под ключ», компания может обеспечить повышенные уровни защиты IT-инфраструктуры и надёжности оборудования. В то же время заказчик сократит затраты на строительство и обслуживание благодаря централизации работ при воплощении проектов в жизнь и сокращению необходимости в содержании нескольких команд, ответственных за разные аспекты работы ЦОД. Как подчеркнули в компании, модули подобных ЦОД собираются и испытываются на производстве, что положительно сказывается не только на качестве работ, но и обеспечивает быстрое развёртывание на территории заказчика. Важной продающей характеристикой таких ЦОД является мобильность решения — оно изначально создано с учётом возможности транспортировки в стандартном 40-футовом, что позволяет быстро доставить оборудование в любой регион страны. Данные о начале производства первых модульных ЦОД компанией Sitronics Group появились ещё в мае 2023 года. Сообщалось, что такой дата-центр можно развернуть за небольшое время — в течение нескольких месяцев, а построить его можно практически в любом месте.
14.11.2023 [16:36], Сергей Карасёв
AMD представила встраиваемые процессоры Ryzen Embedded 7000 с графикой RDNA2Компания AMD анонсировала процессоры Ryzen Embedded 7000 на архитектуре Zen 4, предназначенные для использования во встраиваемых системах. О намерении представить продукты на этих чипах сообщили многие известные производители, включая Advantech, ASRock и DFI. Ryzen Embedded 7000 — это первые «встраиваемые» процессоры AMD, при изготовлении которых применяется 5-нм технология. AMD гарантирует, что чипы данной серии будут доступны в течение семи лет. Говорится о совместимости с Windows Server, Windows 10/11, а также Ubuntu Linux. 
Источник изображений: AMD Процессоры получили исполнение AM5. В серию вошли пять моделей (см. таблицу ниже), количество вычислительных ядер у которых в зависимости от модификации равно 6, 8 или 12. Есть SMT. Базовая тактовая частота варьируется от 3,7 до 4,5 ГГц, частота в турбо-режиме — от 5,1 до 5,4 ГГц. Объём кеша L2 равен 1 Мбайт на ядро. Размер кеша L3 составляет 32 или 64 Мбайт. Показатель TDP равен 65 Вт у младших версий и 105 Вт у старших. 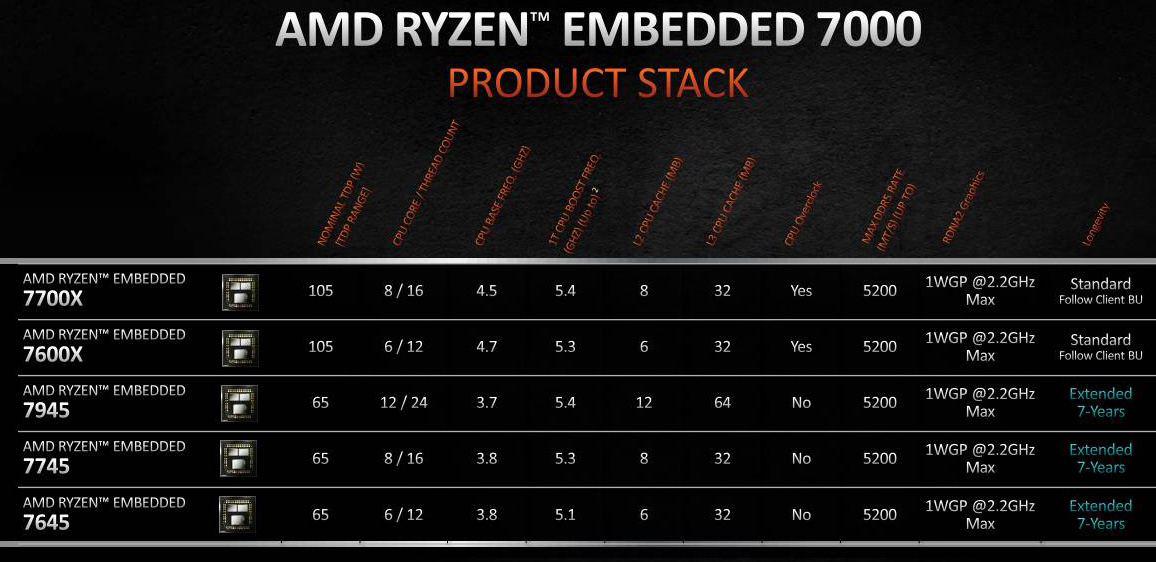 Чипы семейства Ryzen Embedded 7000 получили контроллер оперативной памяти DDR5-5200 ECC и интегрированную графику RDNA2. Обеспечивается поддержка 28 линий PCIe 5.0. Изделия рассчитаны на системы автоматизации, машинного зрения и другие индустриальные применения.
14.11.2023 [15:09], Сергей Карасёв
Lenovo представила рабочую станцию ThinkStation P8 на базе AMD Ryzen Threadripper Pro 7000 WXКомпания Lenovo анонсировала рабочую станцию ThinkStation P8 для решения задач в области ИИ, визуализации данных, обучения больших языковых моделей (LLM) и пр. В основу положены новейшие процессоры AMD Ryzen Threadripper Pro 7000 WX, дебютировавшие в конце октября. Разработчик заявляет, что компьютер обладает гибкими возможностями конфигурирования. Устройство заключено в корпус с габаритами 175 × 508 × 435 мм, а вес может достигать 25,9 кг. Шасси оптимизировано для монтажа в стойку. 
Изображение: Lenovo Используется материнская плата на чипсете AMD WRX90. Максимальная комплектация предусматривает наличие процессора Ryzen Threadripper Pro 7995WX (96 ядер; 192 потока; 2,5–5,1 ГГц). Доступны восемь слотов для модулей DDR5-4800 суммарным объёмом до 2 Тбайт. 
Изображение: Lenovo Рабочая станция может нести на борту до семи SSD формата M.2 (PCIe 4.0) с возможностью формирования массивов RAID 0/1/10/5 или до трёх HDD большой вместимости. Слоты расширения выполнены по схеме 4 × PCIe 5.0 x16, 2 × PCIe 5.0 x8 и 1 × PCIe 4.0 x8. Могут быть установлены до трёх ускорителей NVIDIA RTX 6000 Ada (48 Гбайт), до четырёх карт NVIDIA RTX A4000 (16 Гбайт) или до четырёх ускорителей AMD Radeon Pro W7600 (8 Гбайт). В оснащение входят сетевой контроллер 10GbE, адаптеры Wi-Fi 6E и Bluetooth 5.2, порты USB 3.2 Type-A и Type-C, блок питания мощностью 1000 или 1400 Вт с сертификатом 80 Plus Platinum. Может быть использована платформа Windows 11 Pro или ОС с ядром Linux. В продажу ThinkStation P8 поступит в I квартале 2024 года.
14.11.2023 [08:52], Андрей Крупин
«Росэнергоатом» анонсировал запуск в 2024 году двух новых дата-центровРоссийский энергетический концерн «Росэнергоатом» (входит состав госкорпорации «Росатом») поделился планами строительства новых центров обработки данных. В первом квартале 2024 года компания намерена ввести в эксплуатацию две вычислительные площадки: «Москва-2» мощностью 36 МВт на 3640 стойко-мест уровня Tier IV в Южном административном округе Москвы и «Иннополис» (16 МВт на 2000 стойко-мест уровня Tier III) в особой экономической зоне «Иннополис» под Казанью (Республика Татарстан). Оба ЦОД войдут в состав геораспределённой и катастрофоустойчивой сети дата-центров концерна «Росэнергоатом». 
Дата-центр концерна «Росэнергоатом» в Тверской области (источник фото: rosenergoatom.ru) Развитием сети дата-центров «Росэнергоатом» занимается с 2015 года. B настоящий момент инфраструктура ЦОД компании насчитывает три действующих центра обработки данных: «Калининский» (48 МВт на 4800 стойко-мест уровня Tier III) в Тверской области, Xelent (10 МВт на 1476 стойко-мест уровня Tier III) в Санкт-Петербурге и StoreData (1,6 МВт на 170 стойко-мест уровня Tier III) в Москве. Подробнее с реализуемым концерном «Росэнергоатом» проектом строительства глобальной сети дата-центров можно ознакомиться на сайте atomdata.ru.
14.11.2023 [03:20], Алексей Степин
Intel показала результаты тестов ускорителя Max 1550 и рассказала о будущих чипах Gaudi3 и Falcon ShoresВ рамках SC23 корпорация Intel продемонстрировала ряд любопытных слайдов. На них присутствуют результаты тестирования ускорителя Max 1550 с архитектурой Xe, а также планы относительно следующего поколения ИИ-ускорителей Gaudi. 
Изображение: Intel При этом компания применила иной подход, нежели обычно — вместо демонстрации результатов, полученных в стенах самой Intel, слово было предоставлено Аргоннской национальной лаборатории Министерства энергетики США, где летом этого года было завершён монтаж суперкомпьютера экза-класса Aurora, занимающего нынче второе место в TOP500.  В этом HPC-кластере применены OAM-модули Max 1550 (Ponte Vecchio) с теплопакетом 600 Вт. Они содержат в своём составе 128 ядер Xe и 128 Гбайт памяти HBM2E. Интерфейс Xe Link позволяет общаться напрямую восьми таким модулям, что обеспечивает более эффективную масштабируемость. 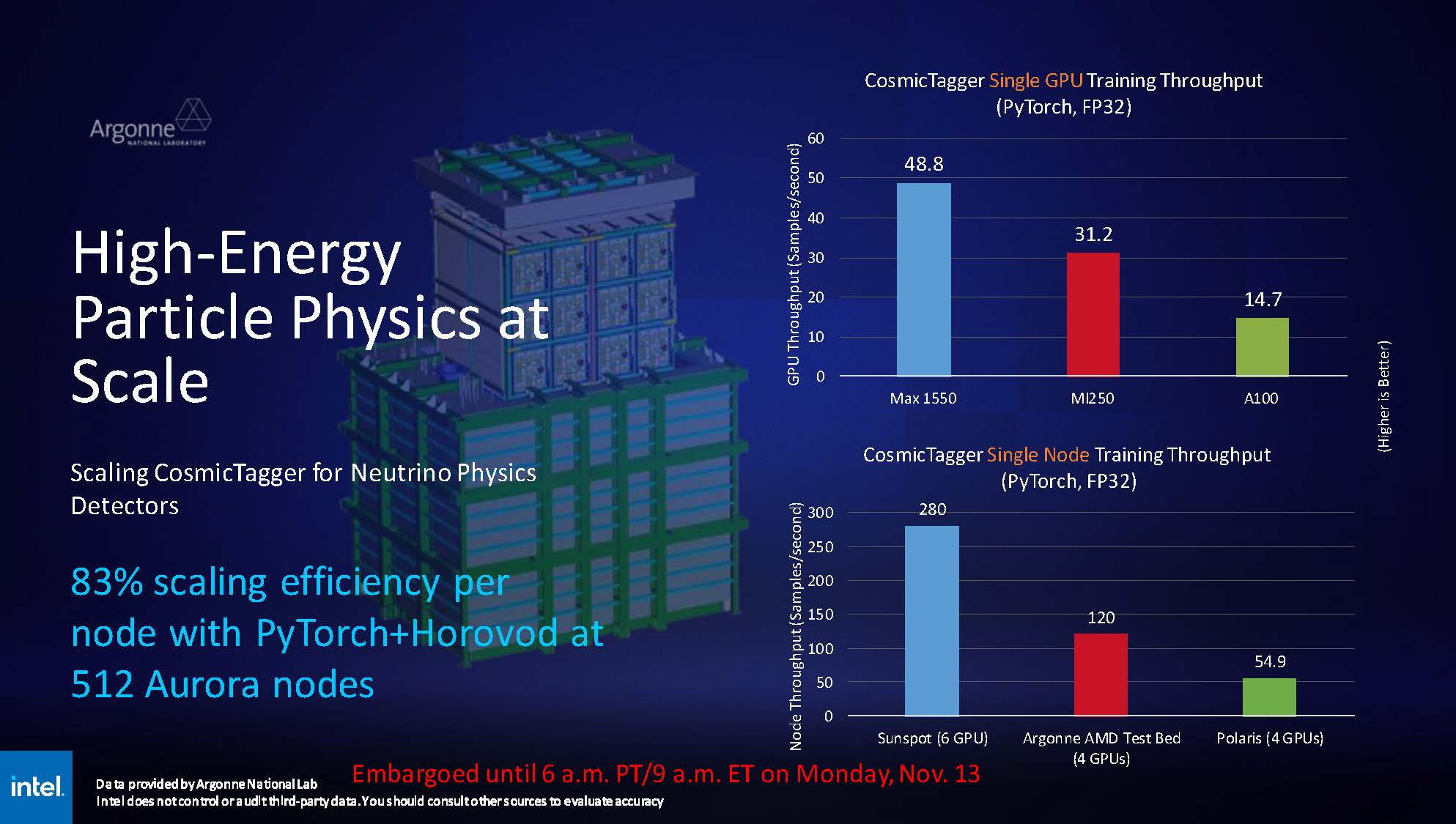
Источник изображений здесь и далее: Intel via ServeTheHome Хотя настройка вычислительного комплекса Aurora ещё продолжается, уже имеются данные о производительности Max 1550 в сравнении с AMD Instinct MI250 и NVIDIA A100. В тесте физики высоких частиц, использующих сочетание PyTorch+Horovod (точность вычислений FP32), ускорители Intel уверенно заняли первое место, а также показали 83% эффективность масштабирования на 512 узлах Aurora.  В тесте, симулирующем поведение комплекса кремниевых наночастиц, ускорители Max 1550, также оказались первыми как в абсолютном выражении, так и в пересчёте на 128-узловой тест в сравнении с системами Polaris (четыре A100 на узел) и Frontier (четыре MI250 на узел). Написанный с использованием Fortran и OpenMP код доказал работоспособность и при масштабировании до более чем 500 вычислительных узлов Aurora. 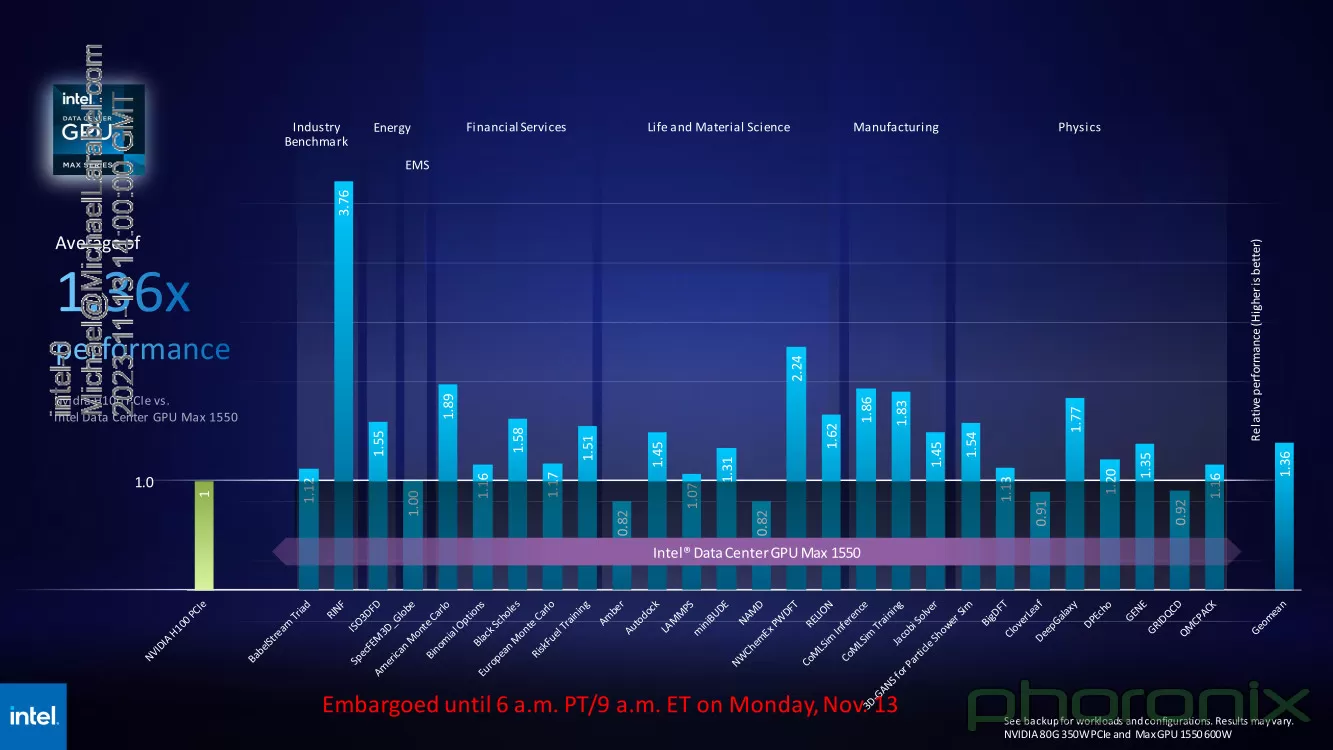
Источник изображения: Intel via Phoronix В целом, ускорители Intel Max 1550 демонстрируют хорошие результаты и не уступают NVIDIA H100: в некоторых задачах их относительная эффективность составляет не менее 0,82, но в большинстве других тестов этот показатель варьируется от 1,0 до 3,76. Очевидно, что у H100 появился достойный соперник, который, к тому же, имеет меньшую стоимость и большую доступность. Но сама NVIDIA уже представила чипы (G)H200, а AMD готовит Instinct MI300.  Системы на базе Intel Max доступны в различном виде: как в облаке Intel Developer Cloud, так и в составе OEM-решений. Supermicro предлагает сервер с восемью модулями OAM, а Dell и Lenovo — решения с четырьями ускорителями в этом же формате. PCIe-вариант Max 1100 доступен от вышеуказанных производителей, а также у HPE. 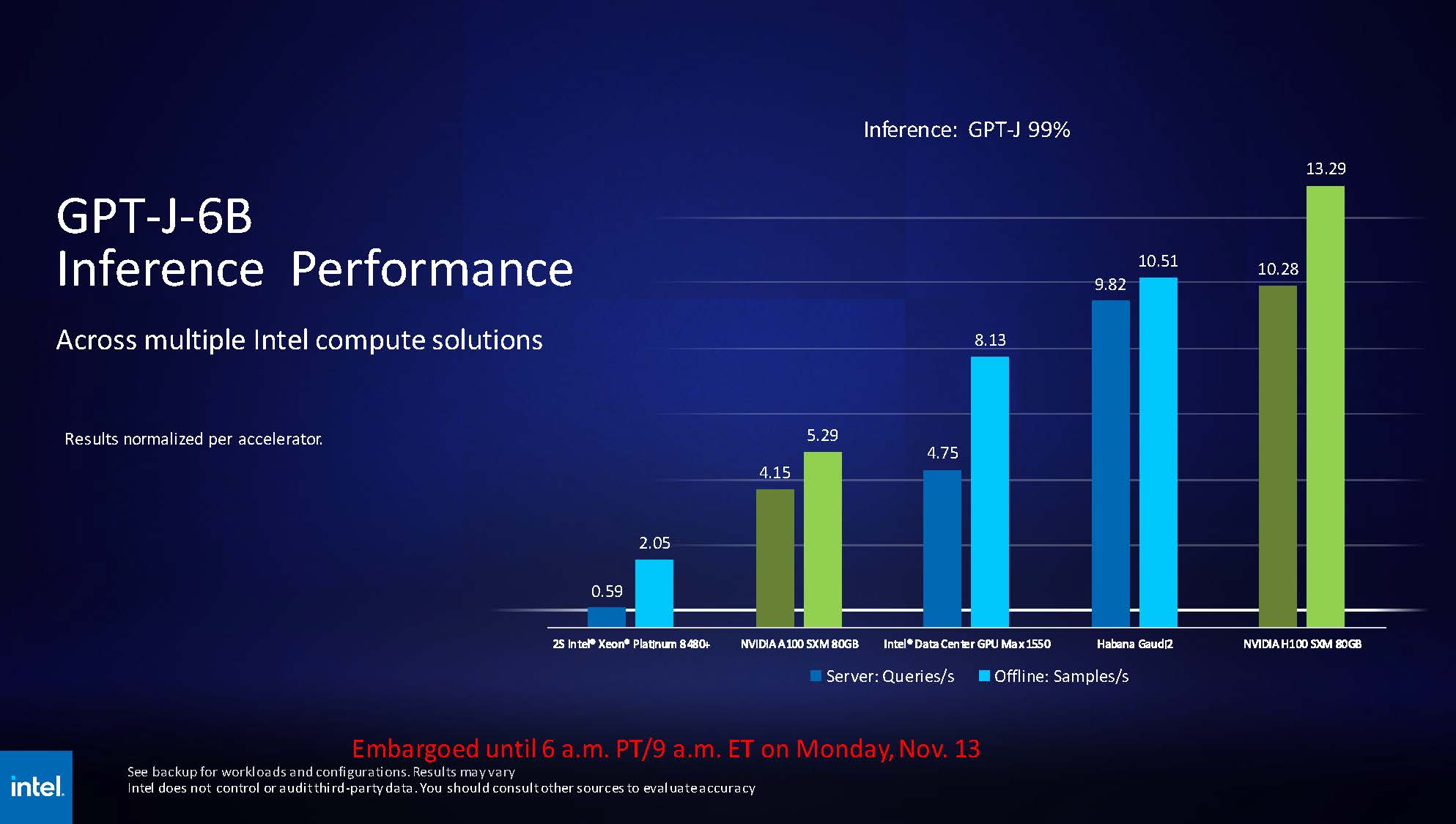 Помимо ускорителей Max, Intel привела и новые данные о производительности ИИ-сопроцессоров Gaudi2. Компания продолжает активно совершенствовать и оптимизировать программную экосистему Gaudi. В результате, в инференс-системе на базе модели GPT-J-6B результаты ускорителей Gaudi2 уже сопоставимы с NVIDIA H100 (SXM 80 Гбайт), а A100 существенно уступает как Gaudi2, так и Max 1550.  Но самое интересное — это сведения о планах относительно следующего поколения Gaudi. Теперь известно, что Gaudi3 будет производиться с использованием 5-нм техпроцесса. Новый чип будет в четыре раза быстрее в вычислениях BF16, а также получит вдвое более мощную подсистему памяти и в 1,5 раза больше памяти HBM. Увидеть свет он должен в 2024 году. 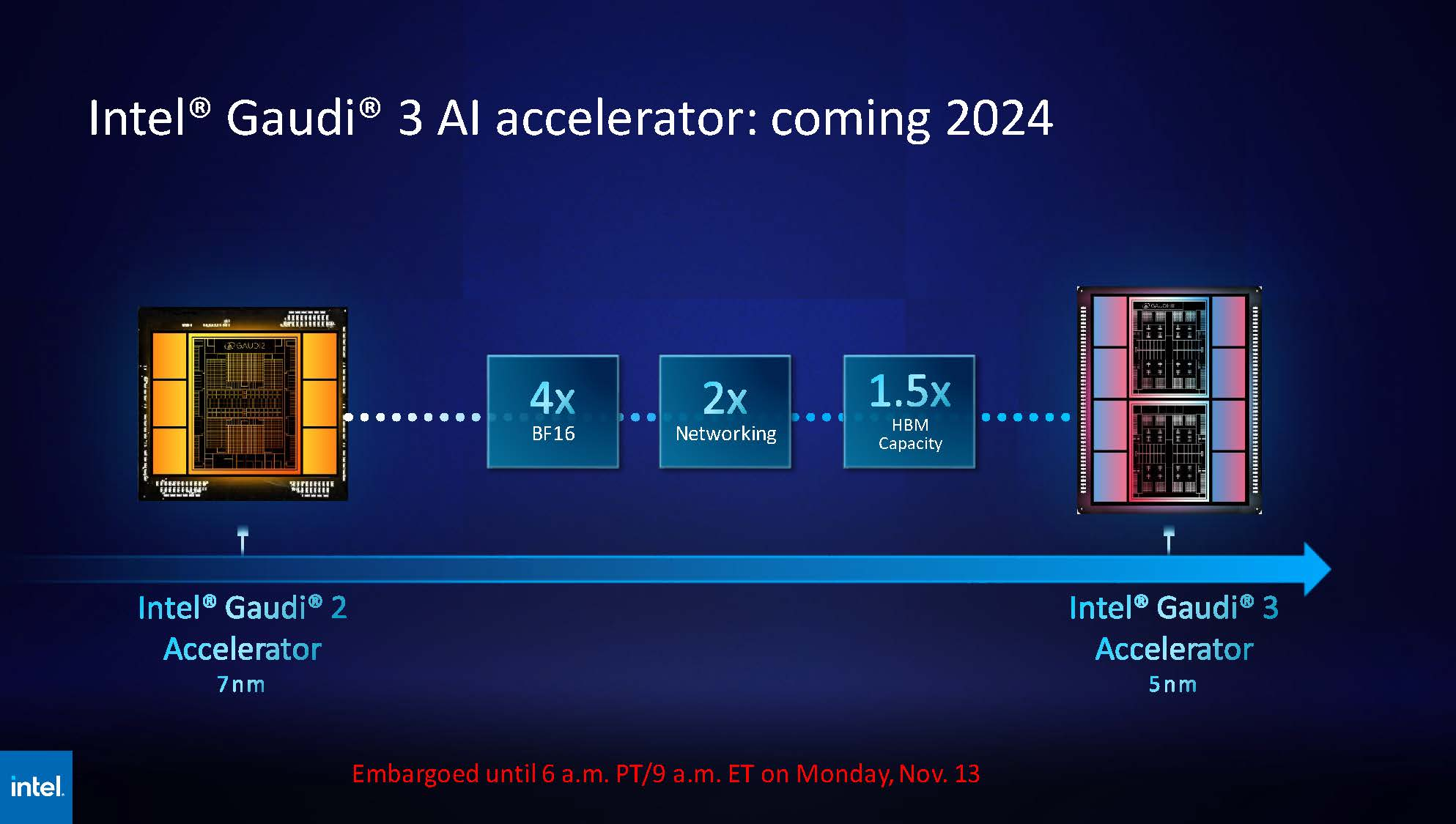 Заодно компания напомнила, что процессоры Xeon Emerald Rapids будут представлены ровно через месяц, а Granite Rapids появятся в 2024 году. В 2025 появится чип Falcon Shores, который теперь должен по задумке Intel сочетать в себе GPU и ИИ-сопроцессор. Он объединит архитектуры Habana и Xe в единое решение с тайловой компоновкой, памятью HBM3 и полной поддержкой CXL. 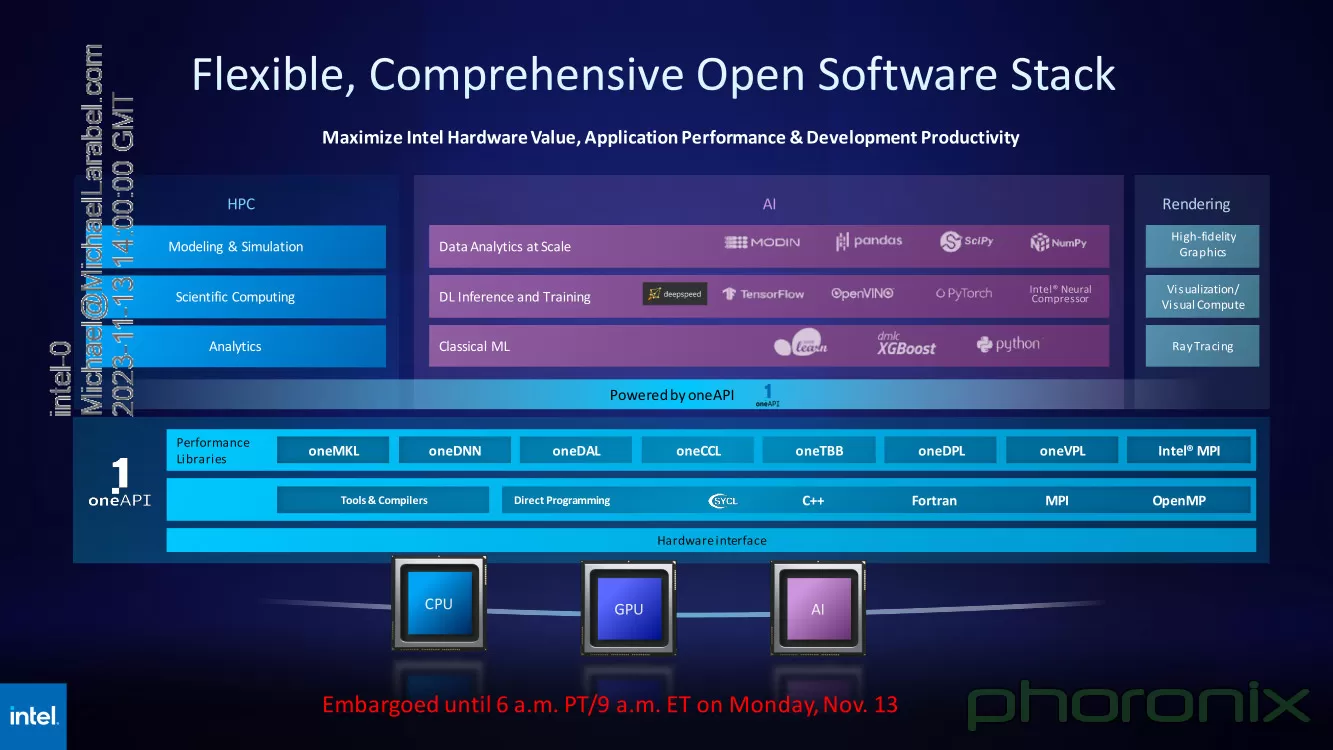
Источник изображения: Intel via Phoronix Следует отметить, что такая унификация вполне реальна: Intel весьма активно развивает универсальный, гибкий и открытый стек технологий в рамках проекта oneAPI. В него входят все необходимые инструменты — от компиляторов и системных библиотек до средств интеграции с популярными движками аналитики данных, моделями и библиотеками искусственного интеллекта.
14.11.2023 [02:35], Игорь Осколков
Ноябрьский TOP500: запоздалый рассвет IntelСвежая, 62-ая по счёту редакция рейтинга TOP500 самых производительных суперкомпьютеров мира среди тех, кто пожелал в нём участвовать (это снова отсылка к Китаю) принесла не очень много изменений, но зато интересных. Первое место по-прежнему удерживает AMD-система Frontier с показателем 1,194 Эфлопс и всё такой же приличной энергоэффективностью на уровне 52,59 Гфлопс/Вт, которая с лета обновлений не получала. А вот второе место… Второе место, наконец-то, досталось суперкомпьютеру Aurora, с анонса которого прошло восемь лет, а архитектура и заявленная производительность неоднократно пересматривались. Формально машина, использующая процессоры Intel Xeon Max с HBM-памятью и ускорители Data Center GPU Max (Ponte Vecchio), объединённых интерконнектом HPE Slingshot 11 (как у Frontier), была смонтирована ещё летом этого года, но процесс ввода в эксплуатацию этой уникальной системы завершится только в 2024 году. К тому моменту Aurora должна достичь заявленной производительности 2 Эфлопс. Столько же предложит AMD-система El Capitan. 
Фото: Intel Но для Intel и Аргоннской национальной лаборатории (ANL) попадание в лидеры TOP500, похоже, стало делом принципа — за потраченные деньги (суммарно $500 млн) и время надо отчитаться. Поэтому в тесте участвовала лишь половина машины, которая добралась до отметки 585,34 Пфлопс. При этом разница между фактической и теоретической пиковой производительностью составляет почти два раза, а сама система уже потребляет больше Frontier и в Green500 находится в конце третьего десятка с показателем 23,71 Гфлопс/Вт. Так что простор для оптимизаций ещё есть. В целом, в свежем рейтинге сразу два десятка из полсотни новичков рейтинга используют Sapphire Rapids, причём пять систем ещё и Xeon Max, но ускорителями Intel Xe обзавелось лишь четыре системы. У AMD же сейчас есть десяток систем с Instinct MI250X (и ещё одна с MI210) и пять систем EPYC Genoa. Всего на EPYC’ах разных поколений базируется 140 систем против 331 на базе Xeon. Ускорителями NVIDIA оснащено 166 машин в списке, из которых только десять имеют новые H100, причём одна в необычной конфигурации. Без акселераторов обходятся 314 машин. 
Фото: Microsoft Третье место заняла облачная система, которые в TOP500 встречаются всё чаще, а в будущем и вовсе станут неизбежны. Эта Microsoft Azure Eagle на базе инстансов NDv5 (Intel Xeon Platinum 8480C + NVIDIA H100 + Infiniband NDR400) набрала 561,2 Пфлопс. Впрочем, технически классические и облачные HPC-системы становятся всё ближе — суперкомпьютер NVIDIA EOS, который построен на ровно тех же компонентах, что Eagle, и который в TOP500 занял девятое место (121,4 Пфлопс), фактически тоже использует облачную архитектуру. А на примере MLPerf обе компании показали эффективность масштабирования нагрузок. Пятое место досталось финской системе LUMI, которая после очередного апгрейда набрала 379,7 Пфлопс. Наконец, на восьмом месте с показателем 138,2 Пфлопс закрепился европейский суперкомпьютер MareNostrum 5 с непростой судьбой. Точнее, его GPU-часть (ACC), поскольку CPU-часть (GPP) набрала 40,1 Пфлопс. ACC использует узлы Eviden BullSequana XH3000 с Intel Xeon Platinum 8460Y+ и ускорителями NVIDIA H100, но с 64 Гбайт памяти. GPP базируется на узлах Lenovo ThinkSystem SD650 v3 с Intel Xeon Platinum 8480+. Объединяет всю систему интерконнект Infiniband NDR200. 
Изображение: NVIDIA Fugaku, некогда самая мощная машина, да ещё и на Arm, опустилась на четвёртую строчку рейтинга. Правда, в HPCG ей равных всё равно нет (16 Пфлопс), а второе и третье места достались Frontier (14,05 Пфлопс) и LUMI (4,59 Пфлопс). В Green500 семь машин из первой десятки представлены опять-таки связками AMD EPYC + Instinct, хотя лидерство всё ещё за Henri (Intel Xeon Ice Lake-SP + NVIDIA H100). Результаты HPL-MxP (ранее HPL-AI) с июня не обновлялись, так что в тройку лидеров входят Frontier (9,95 Эфлопс), LUMI (2,35 Эфлопс) и Fugaku (2 Эфлопс). Тройка лидеров среди производителей по количеству машин включает Lenovo (169 шт.), HPE (103 шт.) и Eviden (48 шт.), но по производительности с большим отрывом лидирует HPE (34,9 %), а за ней уже идут Eviden (9,8 %) и Lenovo (8,6 %). Впрочем, Китай, где как раз много однотипных машин Lenovo, направляет всё меньше заявок на включение в рейтинг, а США — всё больше. По суммарной производительности суперкомпьютеров Штаты тоже лидируют — 53 % от всего списка.
13.11.2023 [22:05], Сергей Карасёв
200+ Эфлопс: суперчип NVIDIA Grace Hopper ляжет в основу более 40 ИИ-суперкомпьютеровКомпания NVIDIA сообщила о том, что её суперчип GH200 Grace Hopper ляжет в основу более чем 40 ИИ-суперкомпьютеров по всему миру, которые используются в исследовательских центрах, на облачных площадках и пр. Отмечается, что в скором времени станут доступны десятки новых НРС-систем на базе GH200. Этот суперчип позволяет решать самые сложные научные задачи на базе ИИ, которые требуют обработки терабайт данных. В совокупности вычислительные системы на базе GH200, как сообщается, обеспечат ИИ-производительность около 200 Эфлопс. В частности, HPE объявила, что интегрирует GH200 в суперкомпьютеры HPE Cray. Узлы EX254n оснащаются двумя модулями Quad GH200 с четырьмя суперчипами в каждом, обеспечивая возможность масштабирования до десятков тысяч узлов. Аналогичный подход используется и в платформе Eviden BullSequana XH3000, которую Юлихский исследовательский центр (FZJ) в Германии получит в составе Jupiter — первого европейского суперкомпьютера экзафлопсного класса. 
Источник изображения: NVIDIA Объединённый центр передовых высокопроизводительных вычислений в Японии (JCAHPC) намерен использовать суперчип в своём суперкомпьютере следующего поколения. Техасский центр передовых вычислений при Техасском университете в Остине (США) оборудует суперчипами НРС-систему Vista. Национальный центр суперкомпьютерных приложений при Университете Иллинойса в Урбане-Шампейне будет использовать решения GH200 в составе ИИ-платформы DeltaAI. А Британия получит ИИ-суперкомпьютер Isambard-AI на основе этого суперчипа, который разместится в Бристольском университете. 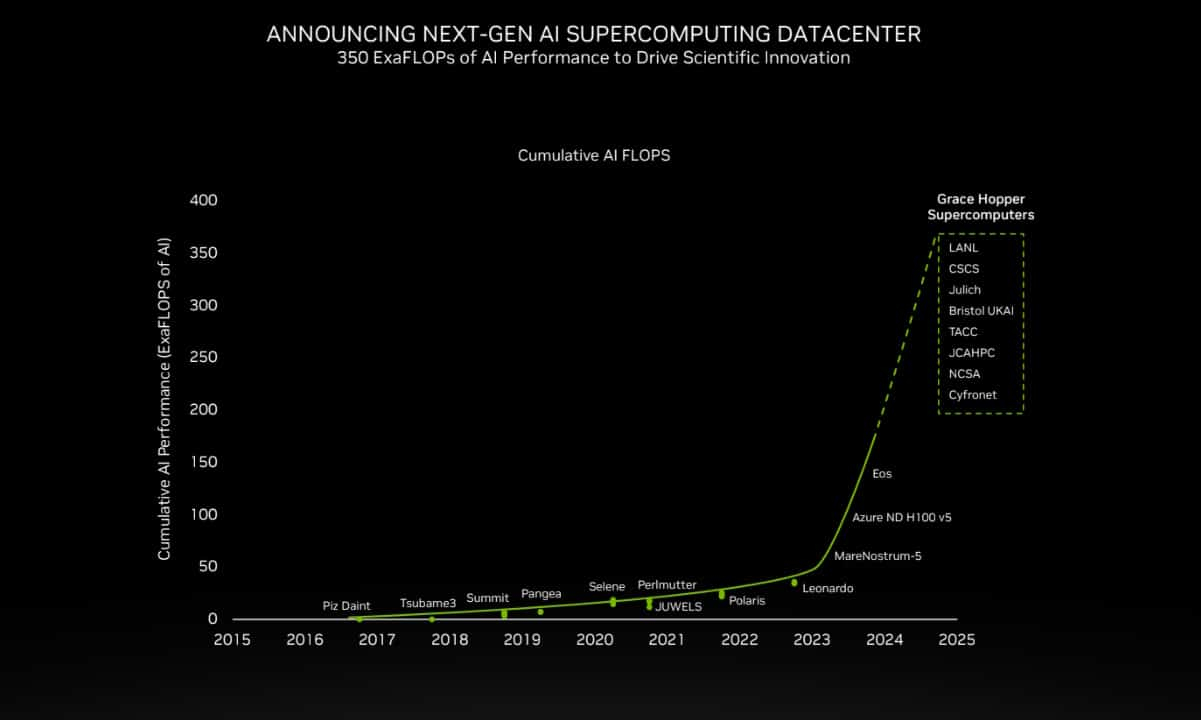
Источник изображения: NVIDIA Все эти системы присоединяются к ранее анонсированным платформам на базе GH200 от Швейцарского национального суперкомпьютерного центра (CSCS) и SoftBank Corp. GH200 уже доступен у некоторых поставщиков облачных услуг, таких как Lambda и Vultr. CoreWeave объявила о планах открыть инстансы GH200 в I квартале 2024 года. Другие производители систем, такие как ASRock Rack, ASUS, Gigabyte и Ingrasys, начнут поставки серверов с этими суперчипами к концу года.
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
13.11.2023 [17:00], Сергей Карасёв
Первый в Европе экзафлопсный суперкомпьютер Jupiter получит 24 тыс. гибридных суперчипов NVIDIA Grace HopperКомпания NVIDIA в ходе конференции по высокопроизводительным вычислениям SC23 сообщила о том, что её суперчип GH200 Grace Hopper станет одной из ключевых составляющих НРС-системы Jupiter — первого европейского суперкомпьютера экзафлопсного класса. 
Узел BullSequana XH3000 (Источник здесь и далее: NVIDIA) Jupiter — проект Европейского совместного предприятия по развитию высокопроизводительных вычислений (EuroHPC JU). Комплекс расположится в Юлихском исследовательском центре (FZJ) в Германии. В создании суперкомпьютера участвуют NVIDIA, ParTec, Eviden и SiPearl. Архитектура системы модульная, что позволяет адаптировать её под разные классы задач. В основу одного из основных блоков Jupiter ляжет платформа Eviden BullSequana XH3000 с прямым жидкостным охлаждением, а в состав каждого узла войдут модули Quad GH200. Общее количество суперчипов составит 23752. В качестве интерконнекта будет применяться NVIDIA Quantum-2 InfiniBand. Быстродействие на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность должна достичь 1 Эфлопс. При этом общая потребляемая мощность Jupiter составит всего 18,2 МВт.  Применять систему Jupiter планируется для решения наиболее сложных задач. Среди них — моделирование климата и погоды в высоком разрешении (на базе NVIDIA Earth-2), создание новых лекарственных препаратов (NVIDIA BioNeMo и NVIDIA Clara), исследования в области квантовых вычислений (NVIDIA cuQuantum и CUDA Quantum), промышленное проектирование (NVIDIA Modulus и NVIDIA Omniverse). Ввод Jupiter в эксплуатацию запланирован на 2024 год. |
|