Материалы по тегу: h200
|
05.04.2025 [10:36], Сергей Карасёв
Европейский суперкомпьютер Discoverer получил обновление в виде NVIDIA DGX H200Европейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о модернизации суперкомпьютера Discoverer, установленного в Софийском технологическом парке в Болгарии. Обновленная НРС-система получила название Discoverer+. Комплекс Discoverer, построенный на платформе BullSequana XH2000, был введён в эксплуатацию в 2021 году. Изначальная конфигурация включала 1128 вычислительных узлов, каждый из которых содержит два 64-ядерных процессора AMD EPYC 7H12 поколения Rome. Производительность (FP64) достигала 4,52 Пфлопс с пиковым значением в 5,94 Пфлопс. С такими показателями система находится на 221-й позиции в ноябрьском рейтинге мощнейших суперкомпьютеров мира TOP500. В рамках модернизации добавлен GPU-раздел на основе четырёх модулей NVIDIA DGX H200. Каждый из них содержит восемь ускорителей H200 и два процессора Intel Xeon Platinum 8480C поколения Sapphire Rapids с 56 ядрами (до 3,8 ГГц). Модули обладают быстродействием до 32 Пфлопс каждый в режиме FP8. Кроме того, обновлённый комплекс получил Lustre-хранилище вместимостью 5,1 Пбайт, систему хранения Weka ёмкостью 273 Тбайт и дополнительную ИБП-систему. 
Источник изображения: EuroHPC JU Как отмечается, Discoverer стал первым суперкомпьютером EuroHPC, прошедшим серьёзную модернизацию с момента своего первоначального запуска. После наращивания мощностей комплекс планируется использовать для крупномасштабных проектов в области ИИ, таких как обучение нейронных сетей, создание цифровых двойников сложных объектов и пр. В декабре 2024 года консорциум EuroHPC выбрал площадки для первых европейских ИИ-фабрик (AI Factory): они расположатся в Финляндии, Германии, Греции, Италии, Люксембурге, Испании и Швеции. Кроме того, такие объекты планируется создать в Австрии, Болгарии, Франции, Германии, Польше и Словении. Эти площадки станут частью высококонкурентной и инновационной экосистемы ИИ в Европе.
18.03.2025 [10:05], Сергей Карасёв
ExxonMobil развернёт суперкомпьютер Discovery 6 с суперчипами NVIDIA GH200Американская ExxonMobil, одна из крупнейших в мире нефтяных компаний, представила проект высокопроизводительного вычислительного комплекса Discovery 6. Этот суперкомпьютер планируется использовать для поддержания работы передовых систем 4D-сейсморазведки. Комплекс создаётся в партнёрстве с НРЕ и NVIDIA. В основу системы ляжет платформа HPE Cray Supercomputing EX4000. Будут задействованы 4032 суперчипа NVIDIA GH200 Grace Hopper. В состав Grace Hopper входят 72-ядерный Arm-процессор NVIDIA Grace, до 480 Гбайт LPDDR5x и ускоритель NVIDIA H100 с 96 или 144 Гбайт HBM3(e). Говорится об использовании интерконнекта HPE Slingshot. Отмечается, что по производительности новый суперкомпьютер примерно в четыре раза превзойдёт предшественника — систему Discovery 5, введённую в эксплуатацию в ноябре 2022 года. Этот комплекс использует платформу HPE Cray EX235n с 32-ядерными процессорами AMD EPYC 7543 и ускорителями NVIDIA A100 SXM4. В ноябрьском рейтинге TOP500 машина Discovery 5 занимала 46-ю позицию с пиковой производительностью 30,99 Пфлопс. Таким образом, быстродействие Discovery 6, как ожидается, будет находиться на уровне 120 Пфлопс. 
Источник изображения: ExxonMobil Для создаваемого суперкомпьютера предусмотрено использование высокоэффективной системы прямого жидкостного охлаждения (DLC). Благодаря запуску Discovery 6 ExxonMobil рассчитывает сократить время обработки сложных сейсмических данных с месяцев до недель. Это поможет повысить эффективность разведки месторождений нефти и газа, что приведёт к увеличению добычи ресурсов с меньшими капиталовложениями. Завершить монтаж Discovery 6 планируется в I половине текущего года.
04.03.2025 [11:10], Сергей Карасёв
SoftBank, ZutaCore и Foxconn представили стоечную систему с ИИ-серверами на базе NVIDIA H200 и двухфазной СЖОКомпании ZutaCore, Hon Hai Technology Group (Foxconn) и SoftBank объявили о внедрении двухфазной технологии прямого жидкостного охлаждения (DLC) в ИИ-сервер с ускорителями NVIDIA H200. Утверждается, что это первая подобная реализация на рынке. Двухфазная DLC-система ZutaCore служит для отвода тепла от CPU, GPU, микросхем памяти и других критичных компонентов в серверах. Данное решение по сравнению с традиционными средствами охлаждения позволяет снизить энергопотребление дата-центра и повысить общую эффективность. В результате сокращаются выбросы вредных газов в атмосферу. Система ZutaCore использует специальную охлаждающую пластину, которая находится в контакте с CPU, GPU и другими элементами сервера с большим тепловыделением. Применяется диэлектрическая жидкость с низкой температурой кипения: при нагреве происходит фазовый переход из жидкого в газообразное состояние. Эффективное охлаждение достигается благодаря многократному испарению и конденсации. 
Источник изображений: ZutaCore При этом температура жидкости может поддерживаться на более высоком уровне, чем в обычных системах с водяным охлаждением, что повышает эффективность отвода тепла, говорится в пресс-релизе. Кроме того, снижается нагрузка на насос, что способствует сокращению энергопотребления. Использование диэлектрического состава предотвращает серьезные повреждения сервера в случае протечки.  В рамках партнёрства Foxconn разработала ИИ-сервер на базе NVIDIA H200 с двухфазной DLC-системой ZutaCore. В свою очередь, SoftBank создала серверную стойку, предназначенную для максимально эффективного охлаждения оборудования посредством двухфазной DLC-технологии. Эта ORv3-стойка совместима с 21″ и 19″ серверами. Источники питания и основная проводка сосредоточены в задней части для обеспечения безопасности эксплуатации и повышения удобства обслуживания.
27.02.2025 [12:33], Сергей Карасёв
Cisco представила MGX-сервер UCS C845A M8 на базе AMD EPYC 9005 Turin с поддержкой восьми PCIe-ускорителей NVIDIAКомпания Cisco анонсировала сервер UCS C845A M8 для рабочих нагрузок ИИ, построенный на модульной архитектуре NVIDIA MGX. Устройство поддерживает установку от двух до восьми ускорителей NVIDIA H200 NVL, H100 NVL и L40S), а также адаптеров NVIDIA BlueField-3 SuperNIC и ConnectX-7. Новинка выполнена в форм-факторе 4U с применением аппаратной платформы AMD EPYC 9005 Turin: максимальная конфигурация включает два 96-ядерных процессора EPYC 9655. Доступны 32 слота для модулей DDR5-4400/5200. Система может нести на борту два загрузочных SSD формата M.2 с интерфейсом SATA вместимостью 960 Гбайт каждый, а также до 20 накопителей E1.S NVMe. Предусмотрены пять слотов PCIe 5.0 x16 для сетевых 400G-адаптеров типоразмера FHHL: один для внешней сети, четыре для внутренней сети кластера. Задействовано воздушное охлаждение. За питание отвечают четыре блока мощностью 3200 Вт с возможностью горячей замены. Имеется слот OCP 3.0 под сетевую карту Intel X710-DA2 с двумя портами 10GbE для управления. По заявлениям Cisco, при разработке модели UCS C845A M8 особое внимание было уделено конструкции системы: говорится об улучшенной прокладке кабелей для оптимального воздушного потока и упрощении обслуживания, включая замену компонентов. 
Источник изображения: Cisco В зависимости от количества установленных GPU и объема памяти сервер подходит для решения таких задач, как обучение и тонкая настройка ИИ-моделей, аналитика и визуализация данных, приложения НРС, проектирование и моделирование, обработка естественного языка, разговорный ИИ, рендеринг, облачные приложения и пр. В качестве потенциальных покупателей названы крупные предприятия, научно-исследовательские институты, государственные учреждения и облачные провайдеры.
05.12.2024 [13:37], Сергей Карасёв
AWS представила инстансы EC2 P5en на базе NVIDIA H200 и кастомизированных чипов Intel XeonОблачная платформа AWS объявила о доступности инстансов EC2 P5en, рассчитанных на такие нагрузки, как глубокое обучение, генеративный ИИ, обработка данных в реальном времени и приложения HPC. В основу новых экземпляров положены аппаратные компоненты Intel и NVIDIA. В частности, задействованы кастомизированные процессоры Xeon Sapphire Rapids. У них все ядра могут одновременно работать на турбо-частоте 3,2 ГГц, а максимальная частота отдельных ядер достигает 3,8 ГГц. Кроме того, применяются ИИ-ускорители NVIDIA H200 и адаптеры AWS Elastic Fabric Adapter (EFA) v3 с пропускной способностью до 3,2 Тбит/с. Конфигурация инстансов EC2 P5en включает 192 vCPU, 2048 ГиБ памяти, восемь ускорителей H200 и восемь SSD вместимостью 3,84 Тбайт каждый. Пропускная способность EBS составляет 100 Гбит/с. Отмечается, что экземпляры P5en демонстрируют увеличение производительности локального хранилища до двух раз и пропускной способности EBS до 25 % по сравнению с инстансами P5 на базе NVIDIA H100. 
Источник изображения: NVIDIA На сегодняшний день инстансы EC2 P5en доступны в американских регионах AWS US East (Огайо) и US West (Орегон), а также в Азиатско-Тихоокеанском регионе в Токио. Предлагаются различные тарифные опции, включая оплату по мере использования. Ранее были представлены инстансы EC2 P5e с процессорами AMD EPYC Milan, 2 ТиБ памяти, восемью ускорителями NVIDIA H200 и восемью NVMe SSD на 3,84 Тбайт каждый. У этих экземпляров пропускная способность EBS равна 80 Гбит/с.
02.12.2024 [11:39], Сергей Карасёв
Один из модулей будущего европейского экзафлопсного суперкомпьютера JUPITER вошёл в двадцатку самых мощных систем мираЮлихский исследовательский центр (FZJ) в Германии объявил о достижении важного рубежа в рамках проекта JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) по созданию европейского экзафлопсного суперкомпьютера. Введён в эксплуатацию JETI — второй модуль этого НРС-комплекса. Напомним, контракт на создание JUPITER заключён между Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU) и консорциумом, в который входят Eviden (подразделение Atos) и ParTec. Суперкомпьютер JUPITER создаётся на базе модульного дата-центра, за строительство которого отвечает Eviden. Система JUPITER получит, в частности, энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea1 с HBM. Кроме того, в состав машины входят узлы с NVIDIA Quad GH200, а общее количество суперчипов GH200 Grace Hopper составит почти 24 тыс. Узлы объединены интерконнектом NVIDIA Mellanox InfiniBand. Запущенный модуль JETI (JUPITER Exascale Transition Instrument) обладает FP64-производительностью 83,14 Пфлопс, тогда как пиковый теоретический показатель достигает 95 Пфлопс. С такими результатами эта машина попала на 18-ю строку нынешнего рейтинга мощнейших суперкомпьютеров мира TOP500. В составе JETI задействованы в общей сложности 391 680 ядер. Энергопотребление модуля равно 1,31 МВт. Отмечается, что JETI обеспечивает примерно одну двенадцатую от общей расчётной производительности машины JUPITER. Попутно JETI занял шестое место в рейтинге энергоэффективных систем Green500. 
Источник изображения: Eviden Ожидается, что после завершения строительства суммарное быстродействие JUPITER на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность превысит 1 Эфлопс. Затраты на создание комплекса оцениваются в €273 млн, включая доставку, установку и обслуживание НРС-системы.
22.11.2024 [10:15], Сергей Карасёв
Oracle объявила о доступности облачного ИИ-суперкомпьютера из 65 тыс. NVIDIA H200Корпорация Oracle сообщила о доступности облачного суперкластера с ускорителями NVIDIA H200, предназначенного для ресурсоёмких ИИ-нагрузок, включая обучение больших языковых моделей (LLM). Арендовать мощности системы можно по цене от $10 в час в расчёте на GPU. Кластер масштабируется до 65 536 ускорителей. В максимальной конфигурации теоретическое пиковое быстродействие достигает 260 Эфлопс на операциях FP8, что более чем в четыре раза превышает показатели систем предыдущего поколения. Утверждается, что на сегодняшний день это самый высокопроизводительный облачный ИИ-суперкомпьютер, доступный в облаке. Сейчас компания готовится к созданию облачного кластера из 131 тыс. NVIDIA B200. Новые инстансы получили обозначение BM.GPU.H200.8. Каждая виртуальная машина типа Bare Metal (без гипервизора) содержит восемь изделий NVIDIA H200 (141 Гбайт памяти HBM3e), объединённых посредством NVIDIA NVLink. Задействованы два процессора Intel Xeon Platinum 8480+ поколения Sapphire Rapids (56C/112T; до 3,8 ГГц; 350 Вт). Объём системной памяти DDR5 составляет 3 Тбайт. В состав локального хранилища входят восемь NVMe SSD вместимостью 3,84 Тбайт каждый. 
Источник изображения: NVIDIA Кластер использует кастомную RoCE-сеть на базе NVIDIA ConnectX-7 с суммарной пропускной способностью 3200 Гбит/с (восемь каналов по 400 Гбит/с) на узел. Инстансы включают frontend-сеть с пропускной способностью 200 Гбит/с. По данным Oracle, каждый инстанс в суперкластере содержит на 76 % больше памяти HBM по сравнению с виртуальными машинами на основе NVIDIA H100, а пропускная способность памяти увеличена на 40 %. Таким образом, производительность инференса выросла в 1,9 раза.
20.11.2024 [12:11], Сергей Карасёв
Dell представила ИИ-серверы PowerEdge XE9685L и XE7740Компания Dell анонсировала серверы PowerEdge XE9685L и PowerEdge XE7740, предназначенные для НРС и ресурсоёмких рабочих нагрузок ИИ. Устройства могут монтироваться в 19″ стойку высокой плотности Dell Integrated Rack 5000 (IR5000), что позволяет экономить место в дата-центрах. 
Источник изображений: Dell Модель PowerEdge XE9685L в форм-факторе 4U рассчитана на установку двух процессоров AMD EPYC Turin. Применяется жидкостное охлаждение. Доступны 12 слотов для карт расширения PCIe 5.0. Говорится о возможности использования ускорителей NVIDIA HGX H200 или B200. По заявлениям Dell, система PowerEdge XE9685L предлагает самую высокую в отрасли плотность GPU с поддержкой до 96 ускорителей NVIDIA в расчёте на стойку. Новинка подходит для организаций, решающих масштабные вычислительные задачи, такие как создание крупных моделей ИИ, запуск сложных симуляций или выполнение геномного секвенирования. Конструкция сервера обеспечивает оптимальные тепловые характеристики при высоких рабочих нагрузках, а наличие СЖО повышает энергоэффективность.  Вторая модель, PowerEdge XE7740, также имеет типоразмер 4U, но использует воздушное охлаждение. Допускается установка двух процессоров Intel Xeon 6 на базе производительных ядер P-core (Granite Rapids). Заказчики смогут выбирать конфигурации с восемью ИИ-ускорителями двойной ширины, включая Intel Gaudi 3 и NVIDIA H200 NVL, а также с 16 ускорителями одинарной ширины, такими как NVIDIA L4.  Сервер подходит для различных вариантов использования, например, для тонкой настройки генеративных моделей ИИ, инференса, аналитики данных и пр. Конструкция машины позволяет эффективно сбалансировать стоимость, производительность и масштабируемость. Dell также готовит к выпуску новый сервер PowerEdge XE на базе NVIDIA GB200 NVL4. Говорится о поддержке до 144 GPU на стойку формата 50OU (Dell IR7000).
20.11.2024 [10:59], Сергей Карасёв
Nebius, бывшая Yandex, развернёт в США своей первый ИИ-кластер на базе NVIDIA H200Nebius, бывшая материнская компания «Яндекса», объявила о создании своего первого вычислительного ИИ-кластера на территории США. Система будет развёрнута на базе дата-центра Patmos в Канзас-Сити (штат Миссури), а её ввод в эксплуатацию запланирован на I квартал 2025 года. На начальном этапе в составе кластера Nebius будут использоваться ИИ-ускорители NVIDIA H200. В следующем году планируется добавить решения поколения NVIDIA Blackwell. Мощность площадки может быть увеличена с первоначальных 5 МВт до 40 МВт: это позволит задействовать до 35 тыс. GPU. По заявлениям Nebius, фирма Patmos была выбрана в качестве партнёра в связи с гибкостью и опытом в поэтапном строительстве ЦОД. Первая фаза проекта включает развёртывание необходимой инфраструктуры, в том числе установку резервных узлов, таких как генераторы. Новая зона доступности, как ожидается, позволит Nebius более полно удовлетворять потребности американских клиентов, занимающихся разработками и исследованиями в области ИИ. 
Источник изображения: Nebius Говорится, что Nebius активно наращивает присутствие в США в рамках стратегии по формированию ведущего поставщика инфраструктуры для ИИ-задач. На 2025 год намечено создание второго — более масштабного — кластера GPU в США. Кроме того, компания открыла два центра по работе с клиентами — в Сан-Франциско и Далласе, а третий офис до конца текущего года заработает в Нью-Йорке. Напомним, что ранее Nebius запустила первый ИИ-кластер во Франции на базе NVIDIA H200. У компании также есть площадка в Финляндии. К середине 2025 года Nebius намерена инвестировать более $1 млрд в инфраструктуру ИИ в Европе. А около месяца назад компания представила облачную ИИ-платформу с ускорителями NVIDIA H100 и H200.
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 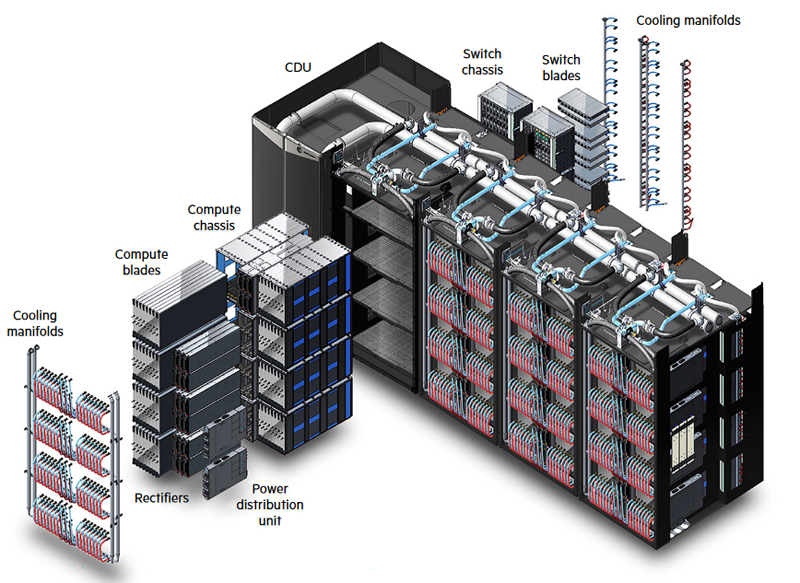 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin. |
|