Материалы по тегу: h200
|
18.11.2024 [21:30], Сергей Карасёв
Счетверённые H200 NVL и 5,5-кВт GB200 NVL4: NVIDIA представила новые ИИ-ускорителиКомпания NVIDIA анонсировала ускоритель H200 NVL, выполненный в виде двухслотовой карты расширения PCIe. Изделие, как утверждается, ориентировано на гибко конфигурируемые корпоративные системы с воздушным охлаждением для задач ИИ и НРС. Как и SXM-вариант NVIDIA H200, представленный ускоритель получил 141 Гбайт памяти HBM3e с пропускной способностью 4,8 Тбайт/с. При этом максимальный показатель TDP снижен с 700 до 600 Вт. Четыре карты могут быть объединены интерконнкетом NVIDIA NVLink с пропускной способностью до 900 Гбайт/с в расчёте на GPU. При этом к хост-системе ускорители подключаются посредством PCIe 5.0 x16. В один сервер можно установить две такие связки, что в сумме даст восемь ускорителей H200 NVL и 1126 Гбайт памяти HBM3e, что весьма существенно для рабочих нагрузок инференса. Заявленная производительность FP8 у карты H200 NVL достигает 3,34 Пфлопс против примерно 4 Пфлопс у SXM-версии. Быстродействие FP32 и FP64 равно соответственно 60 и 30 Тфлопс. Производительность INT8 — до 3,34 Пфлопс. Вместе с картами в комплект входит лицензия на программную платформа NVIDIA AI Enterprise. 
Источник изображения: NVIDIA Кроме того, NVIDIA анонсировала ускорители GB200 NVL4 с жидкостным охлаждением. Они включает два суперчипа Grace-Backwell, что даёт два 72-ядерных процессора Grace и четыре ускорителя B100. Объём памяти LPDDR5X ECC составляет 960 Гбайт, памяти HBM3e — 768 Гбайт. Задействован интерконнект NVlink-C2C с пропускной способностью до 900 Гбайт/с, при этом всем шесть чипов CPU-GPU находятся в одном домене. 
Источник изображения: NVIDIA Система GB200 NVL4 наделена двумя коннекторами M.2 22110/2280 для SSD с интерфейсом PCIe 5.0, восемью слотами для NVMe-накопителей E1.S (PCIe 5.0), шестью интерфейсами для карт FHFL PCIe 5.0 x16, портом USB, сетевым разъёмом RJ45 (IPMI) и интерфейсом Mini-DisplayPort. Устройство выполнено в форм-факторе 2U с размерами 440 × 88 × 900 мм, а его масса составляет 45 кг. TDP настраиваемый — от 2,75 кВт до 5,5 кВт.
03.11.2024 [12:15], Сергей Карасёв
Google Cloud представила инстансы A3 Ultra с ускорителями NVIDIA H200 и готовится развернуть суперускорители GB200 NVL72Компания Google объявила о том, что в составе её облачной платформы в скором времени станут доступны инстансы A3 Ultra на базе ускорителей NVIDIA H200. Новые виртуальные машины предназначены для ресурсоёмких нагрузок, связанных с ИИ, включая обучение больших языковых моделей (LLM). Напомним, в августе 2023 года Google анонсировала инстансы A3 с ускорителями NVIDIA H100. Позднее дебютировали виртуальные машины A3 Mega с поддержкой конфиденциальных вычислений. А до конца текущего месяца клиенты получат доступ к A3 Ultra со значительно более высокой производительностью. Представленные инстансы построены на серверах с новыми DPU Titanium ML, оптимизированными для высокопроизводительных облачных рабочих нагрузок ИИ. Заявленная пропускная способность RDMA-соединений GPU↔GPU достигает 3,2 Тбит/с (RoCE). Задействована фирменная платформа Google Jupiter с оптической коммутацией. 
Источник изображений: Google По сравнению с A3 Mega виртуальные машины A3 Ultra обеспечивают следующие преимущества:
 Инстансы A3 Ultra будут доступны через Google Kubernetes Engine (GKE). Кроме того, виртуальные машины войдут в состав Hypercompute Cluster — специализированной платформы, объединяющей передовые ИИ-технологии Google Cloud. Отмечается также, что в начале 2025 года Google развернёт системы на базе NVIDIA GB200 NVL72. Ранее Google демонстрировала собственный вариант этого суперускорителя.
31.10.2024 [11:33], Сергей Карасёв
Cisco представила ИИ-сервер UCS C885A M8 на базе NVIDIA H100/H200 или AMD Instinct MI300XКомпания Cisco анонсировала сервер высокой плотности UCS C885A M8, предназначенный для решения задач в области ИИ, таких как обучение больших языковых моделей (LLM), тонкая настройка моделей, инференс, RAG и пр. 
Источник изображения: Cisco Устройство выполнено в форм-факторе 8U. В зависимости от модификации устанавливаются два процессора AMD EPYC 9554 поколения Genoa (64 ядра; 128 потоков; 3,1–3,75 ГГц; 360 Вт) или два чипа EPYC 9575F семейства Turin (64 ядра; 128 потоков; 3,3–5,0 ГГц; 400 Вт). Доступны 24 слота для модулей DDR5-600 суммарным объёмом 2,3 Тбайт. В максимальной конфигурации могут быть задействованы восемь SXM-ускорителей NVIDIA H100, H200 или AMD Instinct MI300X. Каждый ускоритель дополнен сетевым адаптером NVIDIA ConnectX-7 или NVIDIA BlueField-3 SuperNIC. Кроме того, в состав сервера входит DPU BlueField-3. Слоты расширения выполнены по схеме 5 × PCIe 5.0 x16 FHHL плюс 8 × PCIe 5.0 x16 HHHL и 1 × OCP 3.0 PCIe 5.0 x8 (для карты X710-T2L 2x10G RJ45 NIC). 
Источник изображения: Cisco Новинка оборудована загрузочным SSD вместимостью 1 Тбайт (M.2 NVMe), а также 16 накопителями U.2 NVMe SSD на 1,92 Тбайт каждый. Установлены два блока питания мощностью 2700 Вт и шесть блоков на 3000 Вт с возможностью горячей замены. Cisco также представила инфраструктурные стеки AI POD, адаптированные для конкретных вариантов использования ИИ в различных отраслях. Они объединяют вычислительные узлы, сетевые компоненты, средства хранения и управления. Стеки, как утверждается, обеспечивают хорошую масштабируемость и высокую эффективность при решении ИИ-задач.
17.10.2024 [14:36], Руслан Авдеев
Nebius, бывшая Yandex, представила облачную ИИ-платформу с ускорителями NVIDIA H100 и H200ИИ-компания Nebius, сформированная из бывшей Yandex N.V., представила облачную платформу с современными ускорителями NVIDIA. Как уточняет Datacenter Dynamics, речь идёт о моделях NVIDIA H100 и H200, а также L40S. В скором будущем компания рассчитывает добавить и новейшие суперускорители GB200 NVL72. 
Источник изображения: Nebius Облачное хранилище обеспечивает агрегированную скорость чтения до 100 Гбайт/с и 1 млн IOPS. Платформа также предлагает управляемые Apache Spark и MLFlow, а ВМ по умолчанию включают ИИ-библиотеки и драйверы. По словам компании, она прислушалась к запросам клиентов, нуждавшихся в самостоятельном доступе и инфраструктуре, отлично от просто «базовой». Речь идёт о крупномасштабных кластерах с InfiniBand-подключением на базе эталонной архитектуры NVIDIA, но с кастомизированным оборудованием и проприетарной программной облачной платформой. После введения антироссийских санкций Nebius дистанцировалась от «Яндекса», основная часть активов которого была продана группе российских инвесторов. У Nebius остался дата-центр в Финляндии, ёмкость которого она намерена утроить в обозримом будущем. Там разместятся более 60 тыс. ускорителей. В августе сообщалось, что компания увеличила облачную выручку на 60 % год к году во II квартале.
09.10.2024 [11:28], Руслан Авдеев
Nebius, бывшая Yandex, утроит мощность ЦОД в ФинляндииКомпания Nebius, образовавшаяся из Yandex N.V., занимающаяся разработкой ИИ-решений, объявила об увеличении мощности дата-центра в финской общине Мянтсяля (Mäntsälä). По данным Datacenter Dynamics, ёмкость ЦОД вырастет втрое. Nebius увеличит ёмкость дата-центра с 25 до 75 МВт, на объекте разместятся более 60 тыс. ускорителей. Ещё в июле компания сообщала об увеличении площади ЦОД — две секции уже построены, позже будут возведены ещё две, как и планировалось ранее. К середине 2025 года компания намерена инвестировать более $1 млрд в ИИ-инфраструктуру Европы, в том числе «кастомных» ЦОД по индивидуальным заказам, и запустит первый ИИ-кластер во Франции на базе ускорителей NVIDIA H200. Кроме того, на прошлой неделе компания намекнула на строительство ЦОД в США, а в Европе Nebius уже подписала два соглашения о намерениях строительства двух новых ЦОД. 
Источник изображения: Miikka Luotio/unsplash.com Объект в Финляндии будет использовать ускорители NVIDIA H200, доступ к которым клиенты NVIDIA должны получить с ноября 2024 года. В этом случае Nebius станет одним из первых операторов в Европе, представивших решения на базе этой платформы на рынке. ЦОД в Финляндии использует фрикулинг и отдаёт тепло для отопления местных жилых помещений. Сегодня речь идёт о ежегодной «рекуперации» около 20 ГВт∙ч. После расширения возможности компании только увеличатся. Конструкция ЦОД позволяет работать при температурах до +40 °C, благодаря этому экономится ещё 15 % энергии. По словам представителя Nebius Андрея Короленко, утроение мощности стало важным этапом на пути построения лучшей в своём классе инфраструктуры ИИ в Европе, демонстрирующим возможности Nebius. Базирующая в Амстердаме Nebius, оставшаяся в Европе после раскола «Яндекса», сохранила финский ЦОД компании и подразделение Nebius AI, а также подразделение Toloka AI для обработки данных, поставщика образовательных технологий TripleTen и компанию Avdrive, занимающуюся системами автономного вождения. ЦОД в Мянтсяля был одним из пяти дата-центров «Яндекса» и сегодня является крупнейшим налогоплательщиком местного муниципалитета.
07.10.2024 [12:19], Сергей Карасёв
В облаке Microsoft Azure появились инстансы ND H200 v5 на базе NVIDIA H200В августе 2023 года Microsoft развернула в своём облаке Azure инстансы ND H100 v5 на базе NVIDIA H100 для HPC-вычислений и нагрузок ИИ. А теперь запущены машины ND H200 v5 с ускорителями NVIDIA H200, оптимизированные для инференса и обучения больших языковых моделей (LLM). Новые инстансы объединяют восемь ускорителей NVIDIA H200, каждый из которых содержит 141 Гбайт памяти HBM3e с пропускной способностью 4,8 Тбайт/с. По сравнению с NVIDIA H100 объём памяти увеличился на 76 %, пропускная способность — на 43 %. Для ND H200 v5 предусмотрена возможность масштабирования до тысяч ускорителей при помощи интерконнекта на базе NVIDIA Quantum-2 CX7 InfiniBand с пропускной способностью до 400 Гбит/с в расчёте на ускоритель (до 3,2 Тбит/с на виртуальную машину). В составе инстансов задействованы чипы Intel Xeon поколения Sapphire Rapids: каждая виртуальная машина насчитывает 96 vCPU. Объём памяти составляет 1850 Гбайт, вместимость локального хранилища — 28 000 Гбайт. Обеспечивается доступ к 16 облачным накопителям. Кроме того, используются восемь сетевых адаптеров (суммарно до 80 Гбит/c). 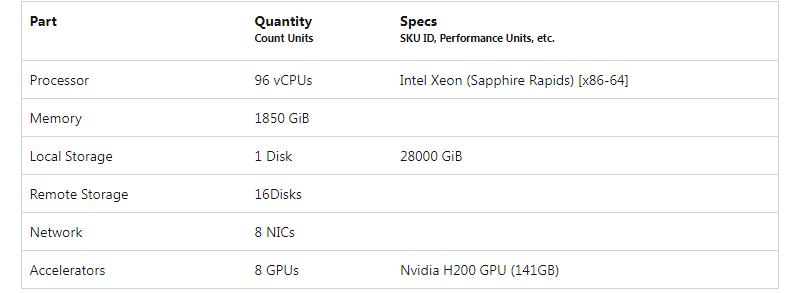
Источник изображения: Microsoft Виртуальные машины ND H200 v5 имеют предварительную интеграцию с Azure Batch, Azure Kubernetes Service, Azure OpenAI Service и Azure Machine Learning. Говорится, что инстансы обеспечивают высокую производительность при решении различных задач, связанных с ИИ, машинным обучением и аналитикой данных.
26.09.2024 [10:39], Сергей Карасёв
Nebius, бывшая структура Яндекса, запустила первый ИИ-кластер во Франции на базе NVIDIA H200Nebius, бывшая материнская компания «Яндекса», объявила о развёртывании своего первого вычислительного ИИ-кластера во Франции. Комплекс, предназначенный для нагрузок ИИ, сформирован на базе дата-центра Equinix PA10 в Сен-Дени — в 9 км к северу от центра Парижа. Новый кластер станет первым объектом Nebius, на котором используются исключительно серверы и стойки собственной разработки. Такие системы проектируются специально с прицелом на применение мощных ускорителей на базе GPU. Благодаря этому, в частности, ускоряется ввод в эксплуатацию. Настройка оборудования и ввод систем в эксплуатацию на площадке Equinix PA10 займут всего два месяца. ЦОД начнёт обрабатывать клиентские рабочие нагрузки в ноябре 2024 года. Известно, что в составе кластера Nebius задействованы ускорители NVIDIA H200. Тепло, вырабатываемое серверами Nebius, будет использоваться для обогрева городской фермы, раскинувшейся на крыше дата-центра Equinix PA10. Она включает теплицу, в которой выращиваются сезонные фрукты и овощи, и сад. 
Источник изображений: Nebius Говорится, что запуск парижской площадки является частью стратегии Nebius по созданию крупномасштабной сети ИИ-кластеров по всему миру. Они будут предоставлять клиентам ресурсы для решения задач, связанных с ИИ. В частности, к середине 2025 года Nebius намерена инвестировать более $1 млрд в инфраструктуру ИИ в Европе. Со следующего года компания начнёт внедрение систем на базе ускорителей NVIDIA Blackwell.  «Мы работаем в новой отрасли, которая требует как передовых технологий, так и значительного капитала. Запуск кластера в Париже — это следующий шаг в рамках нашей программы по расширению возможностей ИИ в Европе», — сказал Аркадий Волож, основатель и генеральный директор Nebius.
17.09.2024 [23:07], Игорь Осколков
Швейцария ввела в эксплуатацию гибридный суперкомпьютер Alps: 11 тыс. NVIDIA GH200, 2 тыс. AMD EPYC Rome и щепотка A100, MI250X и MI300AШвейцарская высшая техническая школа Цюриха (ETH Zurich) провела церемонию официального запуска суперкомпьютера Alps в Швейцарском национальном суперкомпьютерном центре (CSCS) в Лугано. Система, построенная HPE, уже заняла шестую строчку в последнем рейтинге TOP500 и имеет устоявшеюся FP64-производительность 270 Пфлопс (теоретический пик — 354 Пфлопс). К ноябрю будут введены в строй остальные модули машины, и её максимальная производительность составит порядка 500 Пфлопс. 
Источник изображений: CSCS В июньском рейтинге TOP500 участвовал раздел из 2688 узлов HPE Cray EX254n с «фантастической четвёркой» NVIDIA Quad GH200. Если точнее, это всё же «старый» вариант ускорителя с H100 (96 Гбайт HBM3), 72-ядерным Arm-процессором Grace и 128 Гбайт LPDDR5x — суммарно 10 752 Grace Hopper. Данный раздел потребляет 5,2 МВт и в Green500 находится на 14 месте. Узлы, конечно же, используют СЖО. Это основной, но не единственный раздел суперкомпьютера. Ещё в 2020 году HPE развернула 1024 двухпроцессорных узла с 64-ядерными AMD EPYC 7742 (Rome) и 256/512 Гбайт RAM. Его производительность составляет 4,7 Пфлопс. Кроме того, в состав Alps входят 144 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя NVIDIA A100 (80 или 96 Гбайт HBM2e).  Наконец, машина получит 24 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя AMD Instinct MI250X (128 Гбайт HBM2e) и 128 узлов с четырьмя гибридными ускорителями AMD Instinct MI300A. Большая часть узлов будет объединена интерконнектом HPE Slingshot-11: 200G-подключение на узел или ускоритель. Более точную конфигурацию системы раскроют в ноябре. Lustre-хранилище для будущей машины обновили ещё в прошлом году. Основной СХД является Cray ClusterStor E1000 с подключением Slingshot-11. Так, было добавлено 100 Пбайт полезной HDD-ёмкости (8480 × 16 Тбайт) с пропускной способностью 1 Тбайт/с (300 тыс. IOPS на запись, 1,5 млн IOPS на чтение) и 5 Пбайт SSD, а также резервные ёмкости. За архивное хранение отвечают две ленточные библиотеки объёмом 130 Пбайт каждая.  Особенностью системы является её геораспределённость (фактически узлы размещены в четырёх местах) и облачная модель использования. Так, метеослужба страны MeteoSwiss получила в своё распоряжение выделенный виртуальный кластер, что уже позволило перейти на использование метеомодели более высокого разрешения, которая лучше отражает сложный рельеф Швейцарии. Кроме того, для подстраховки часть узлов Alps размещена на территории Федеральной политехнической школы Лозанны (EPFL). Alps приходит на смену суперкомпьютеру Piz Daint (Cray XC50/40, 21,2 Пфлопс), о завершении жизненного цикла которого было объявлено в конце июля 2024 года. В CSCS пока останутся машины Arolla + Tsa (для нужд MeteoSwiss) и Blue Brain 5 (решает задачи реконструкции и симуляции мозга). Alps же помимо традиционных HPC-нагрузок, будет использоваться для разработки ИИ-решений.
10.09.2024 [14:55], Сергей Карасёв
TACC ввёл в эксплуатацию Arm-суперкомпьютер Vista на базе NVIDIA GH200 для ИИ-задачТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) объявил о том, что мощности нового НРС-комплекса Vista полностью доступны открытому научному сообществу. Суперкомпьютер предназначен для решения ресурсоёмких задач, связанных с ИИ. Формальный анонс машины Vista состоялся в ноябре 2023 года. Тогда говорилось, что Vista станет связующим звеном между существующим суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Vista состоит из двух ключевых частей. Одна из них — кластер из 600 узлов на гибридных суперчипах NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель H100/H200. Обеспечивается производительность на уровне 20,4 Пфлопс (FP64) и 40,8 Пфлопс на тензорных ядрах. Каждый узел содержит локальный накопитель вместимостью 512 Гбайт, 96 Гбайт памяти HBM3 и 120 Гбайт памяти LPDDR5. Интероконнект — Quantum 2 InfiniBand (400G). Второй раздел суперкомпьютера объединяет 256 узлов с процессорами NVIDIA Grace CPU Superchip, содержащими два кристалла Grace в одном модуле (144 ядра). Узлы укомплектованы 240 Гбайт памяти LPDDR5 и накопителем на 512 Гбайт. Интерконнект — Quantum 2 InfiniBand (200G). Узлы произведены Gigabyte, а за интеграцию всей системы отвечала Dell. 
Источник изображения: TACC Общее CPU-быстродействие Vista находится на отметке 4,1 Пфлопс. В состав комплекса входит NFS-хранилише VAST Data вместимостью 30 Пбайт. Суперкомпьютер будет использоваться для разработки и применения решений на основе генеративного ИИ в различных секторах, включая биологические науки и здравоохранение.
09.09.2024 [11:08], Сергей Карасёв
Gigabyte представила серверы с ускорителями NVIDIA HGX H200 и СЖО
amd
coolit systems
emerald rapids
epyc
genoa
gigabyte
h200
hardware
intel
nvidia
sapphire rapids
xeon
сервер
Компания Giga Computing, подразделение Gigabyte, анонсировала серверы G593-ZD1-LAX3 и G593-SD1-LAX3, предназначенные для ресурсоёмких нагрузок, связанных с ИИ. Устройства, оснащённые системой прямого жидкостного охлаждения (DLC) от CoolIT, могут нести на борту до восьми ускорителей NVIDIA HGX H200. 
Источник изображений: Gigabyte Модель G593-ZD1-LAX3 выполнена в форм-факторе 5U. Допускается установка двух процессоров AMD EPYC 9004 поколения Genoa с показателем TDP до 400 Вт. Предусмотрены 24 слота для модулей оперативной памяти DDR5-4800. Во фронтальной части расположены отсеки для восьми SFF-накопителей (NVMe/SATA/SAS-4). Есть два коннектора М.2 для SSD типоразмера 2280/22110 с интерфейсом PCIe 3.0 x4 и PCIe 3.0 x1.  Доступны восемь слотов PCIe 5.0 x16 для низкопрофильных карт расширения и четыре разъёма PCIe 5.0 x16 для карт FHHL. В оснащение входят два порта 10GbE (Intel X710-AT2), два выделенных сетевых порта управления 1GbE, два разъёма USB 3.2 Gen1. В свою очередь, сервер G593-SD1-LAX3 рассчитан на два процессора Intel Xeon Emerald Rapids или Sapphire Rapids, величина TDP которых может достигать 350 Вт. Для модулей ОЗУ DDR5-4800/5600 предусмотрены 32 слота. Прочие характеристики (за исключением разъёмов М.2) аналогичны модели на платформе AMD.  Новые серверы укомплектованы шестью блоками питания мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Присутствует контроллер Aspeed AST2600. Диапазон рабочих температур — от 10 до +35 °C. Система DLC предназначена для отвода тепла от ускорителей NVIDIA HGX H200. При этом в области материнской платы и слотов PCIe установлены вентиляторы охлаждения. |
|