Материалы по тегу: инференс
|
21.11.2024 [00:26], Владимир Мироненко
Intel случайно раскрыла, что готовит ИИ-ускоритель Jaguar Shores вслед за Falcon ShoresIntel сообщила о новом ИИ-ускорителе Jaguar Shores, готовящемся в качестве преемника Falcon Shores, упомянув его в презентации во время технического семинара на конференции SC24. Презентация была посвящена чипам Gaudi, сообщает ресурс HPCwire. По мнению источника, упоминание чипа следующего поколения в презентации могло быть случайным. Ожидается, что Falcon Shores поступит в серийное производство в 2025 году. Также в следующем году в массовую продажу поступит ИИ-ускоритель Gaudi 3, представленный ещё в феврале 2023 года. В остальном Intel предпочитает не раскрывать подробностей о своих планах по выпуску ИИ-чипов. Для сравнения, NVIDIA и AMD уже анонсировали планы по выпуску чипов вплоть до 2026–2027 гг. В августе прошлого года Intel сообщила ресурсу HPCwire о работе над чипом Falcon Shores 2, который планируется к выпуску в 2026 году. «У нас упрощённая дорожная карта, поскольку мы объединяем наши GPU и ускорители в единое предложение», — пояснил тогда генеральный директор Патрик Гелсингер (Pat Gelsinger). С тех пор финансовое положение Intel значительно ухудшилось, однако компания продолжает разработку новых ИИ-ускорителей. Пока неясно, будет ли Jaguar Shores GPU или ASIC, но логика именования чипов Intel позволяет предположить, что речь идёт именно о GPU следующего поколения. 
Источник изображения: Intel На данный момент Intel уступила рынок ИИ-обучения компаниям NVIDIA и AMD, сосредоточив свои усилия на инференсе с использованием ИИ-ускорителей Gaudi. Вероятно, Jaguar Shores также будет ориентирован на задачи инференса, который Гелсингер определил как более крупный и перспективный рынок. Однако чтобы догнать ушедших вперёд конкурентов NVIDIA и AMD, Jaguar Shores должен стать действительно прорывным продуктом, полагает HPCwire. «Наши инвестиции в ИИ будут дополнять и использовать наши решения на базе x86, с акцентом на корпоративный, экономически эффективный вывод данных. Наша дорожная карта для Falcon Shores остаётся неизменной», — заявил представитель Intel ресурсу HPCwire несколько месяцев назад.
02.11.2024 [13:06], Владимир Мироненко
Microsoft не хватает ресурсов для обслуживания ИИ, но компания готова и далее вкладываться в ЦОД, хотя инвесторам это не по нравуMicrosoft сообщила о результатах работы в I квартале 2025 финансового года, завершившемся 30 сентября. Показатели компании превысили прогнозы аналитиков, но её ожидания и планы вызвали опасения инвесторов, так что акции упали в четверг на 6 %. До этого акции компании падали столь значительно 26 октября 2022 года — на 7,7 %, за месяц до публичного релиза ChatGPT, после которого начался бум на ИИ. В этот раз инвесторов не устроили планы компании по увеличению расходов на искусственный интеллект (ИИ) в текущем квартале и ожидаемое замедление роста облачного бизнеса Azure, что свидетельствует о том, что крупных инвестиций в ИИ было недостаточно, чтобы справиться с ограничениями мощности ЦОД компании — Microsoft попросту не хватает ресурсов для обслуживания заказчиков. Выручка Microsoft выросла год к году на 16 % до $65,6 млрд, что выше средней оценки аналитиков в $64,5 млрд, которых опросила LSEG. Чистая прибыль увеличилась на 11 % до $24,67 млрд, в то время как аналитики прогнозировали $23,15 млрд. Чистая прибыль на акцию составила $3,30 при прогнозе Уолл-стрит в рамзере $3,10. Сегмент Intelligent Cloud компании Microsoft, который охватывает облачные сервисы Azure, а также Windows Server, SQL Server, GitHub, Nuance, Visual Studio и корпоративные сервисы, показал рост выручки на 20 % в годовом исчислении до $24,1 млрд. Azure и другие облачные сервисы увеличили выручку на 33 %. При этом ИИ внес 12 п.п. в рост выручки Azure в отчётном квартале по сравнению с 11 п.п. в предыдущем трёхмесячном периоде. 
Источник изображений: Microsoft Большинство направлений бизнеса Microsoft показали значительный рост: LinkedIn — 10 %; продукты Dynamics и облачные сервисы — 14 %, в том числе Dynamics 365 — 18 %; серверные продукты и облачные сервисы — 23 %. Выручка Microsoft 365 Commercial Cloud выросла на 15 %, а потребительского Microsoft 365 и сопутствующих облачных сервисов — на 5 %. 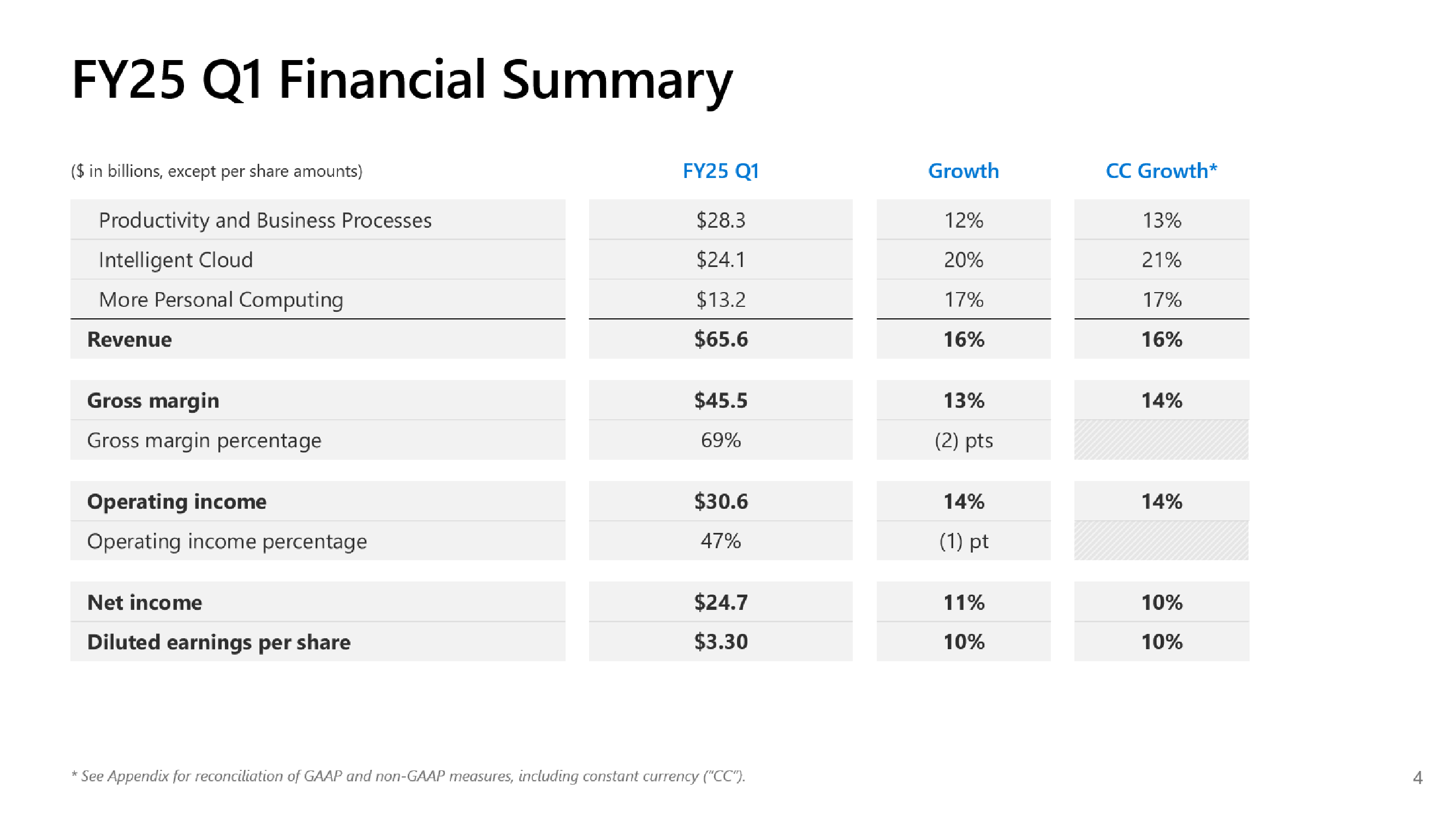 Вместе с тем внешние поставщики запаздывают с поставкой инфраструктуры ЦОД для Microsoft, что означает, что компания не сможет удовлетворить спрос во II финансовом квартале. Бретт Иверсен (Brett Iversen), вице-президент Microsoft по связям с инвесторами, подтвердил, что Microsoft не сможет решить проблему ограничений мощности ИИ до II половины финансового года. 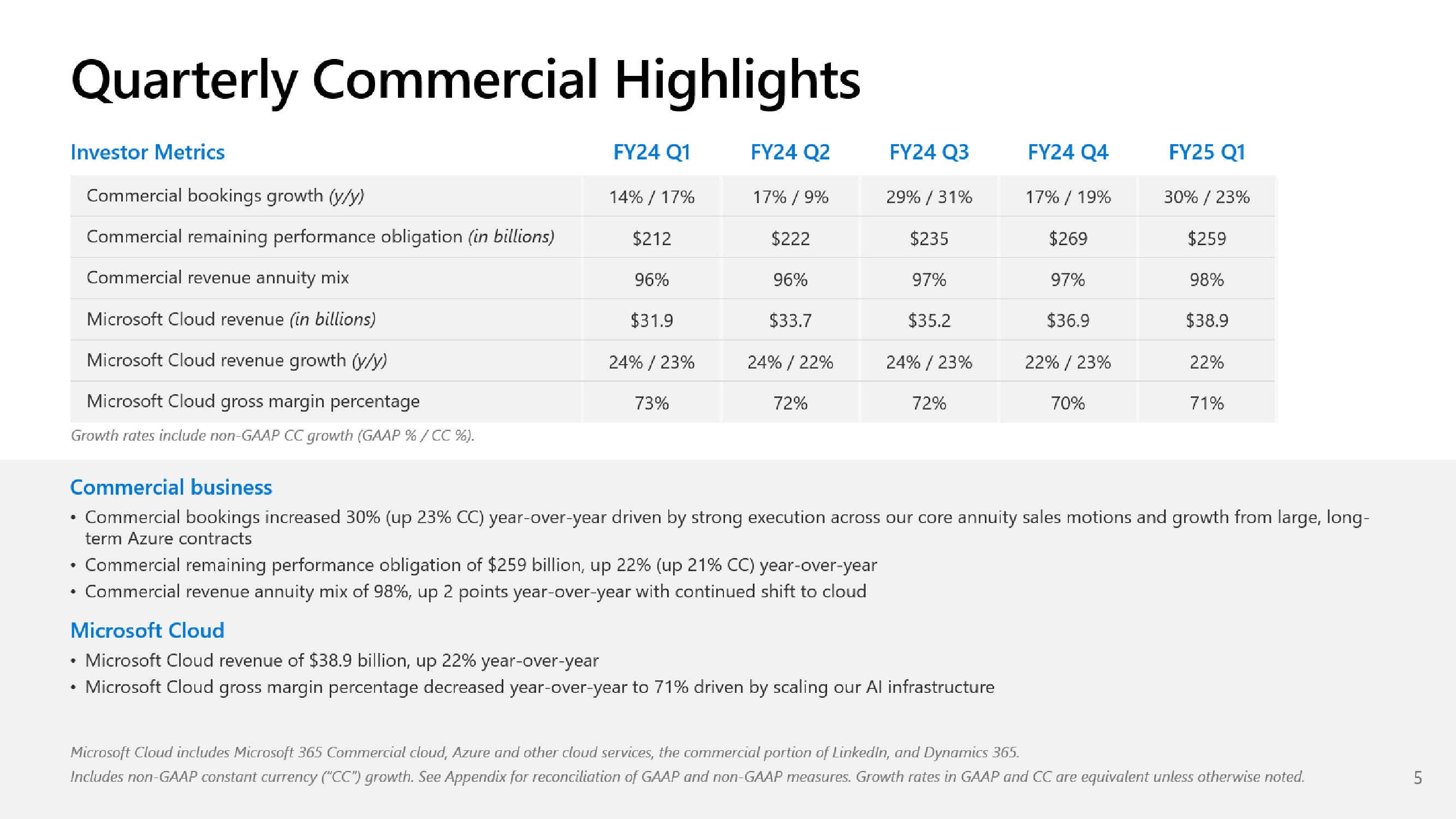 Microsoft прогнозирует замедление роста выручки Azure во II финансовом квартале до 31–32 %, что отстает от среднего роста в 32,25 %, ожидаемого аналитиками, согласно Visible Alpha. Наряду с замедлением роста выручки Azure у инвесторов вызывает обеспокоенность и то, что Microsoft вкладывает огромные средства в создание инфраструктуры ИИ и расширение ЦОД. Microsoft заявила, что за квартал капитальные затраты выросли на 5,3 % до $20 млрд по сравнению с $19 млрд в предыдущем квартале. Это выше оценки Visible Alpha в размере $19,23 млрд. Сообщается, что в основном средства пошли на расширение ЦОД.  Всего за 2025 финансовый год, начавшийся в июле, по оценкам аналитиков Visible Alpha, компания потратит более $80 млрд, что на $30 млрд больше, чем в предыдущем финансовом году. Компания считается лидером среди крупных технологических компаний в гонке ИИ благодаря своему эксклюзивному партнёрству с OpenAI, разработчиком ИИ-чат-бота ChatGPT. Доход Microsoft от бизнеса ИИ пока невелик, хотя компания прогнозирует, что он станет более существенным. В текущем квартале компания планирует достичь выручки в размере $10 млрд в годовом исчислении. 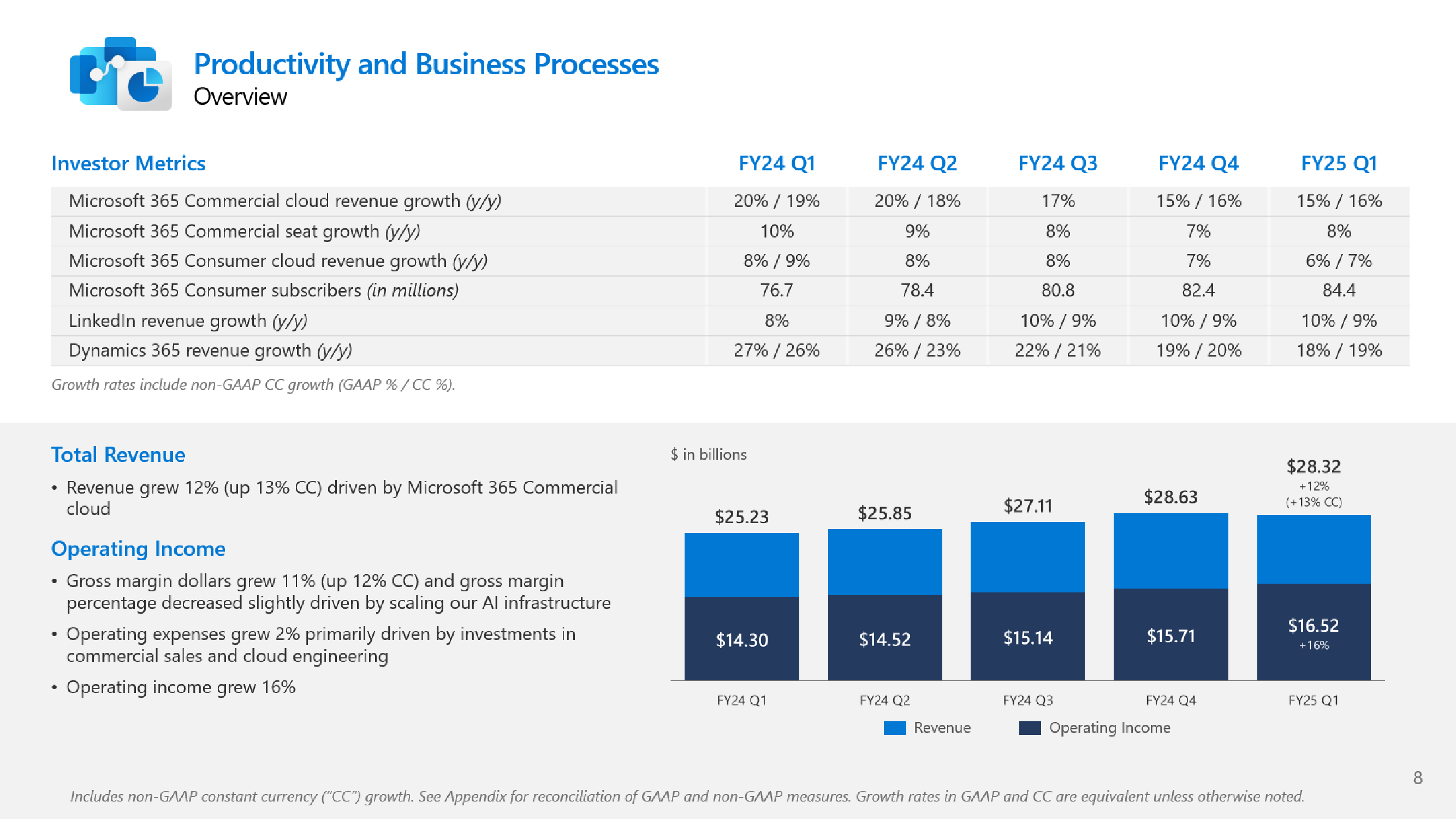 Также Microsoft сообщила об отказе от предоставления клиентам в аренду ускорителей для обучения новых моделей ИИ, сделав приоритетным инференс. «На самом деле мы не продаем другим просто GPU для обучения [ИИ-моделей], — сказал Сатья Наделла (Satya Nadella). — Это своего рода бизнес, от которого мы отказываемся, потому что у нас очень большой спрос на инференс» для поддержки различных Copilot и других услуг ИИ. 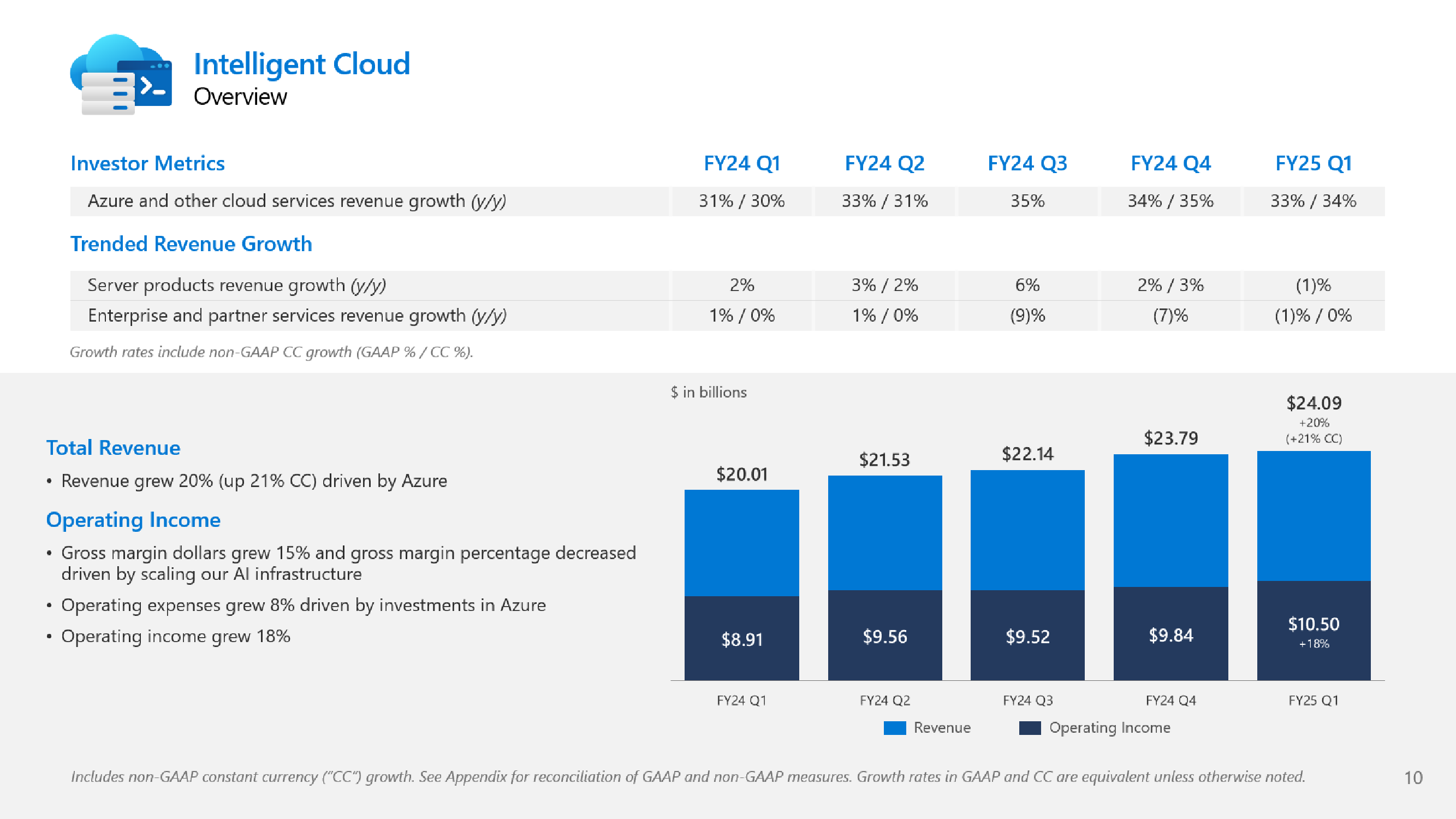 Как сообщает The Register, финансовый директор Эми Худ (Amy Hood), в свою очередь заявила, что Microsoft рассматривает доход, полученный от инференса, как источник средств для оплаты будущих инициатив по обучению ИИ-моделей. Сейчас компания стремительно наращивает закупки суперускорителей NVIDIA GB200 NVL72, стремясь получить их до того, как они станут доступны другим игрокам. Кроме того, Azure станет посредником в процессе расширения ИИ-инфраструктуры OpenAI.
30.10.2024 [11:49], Сергей Карасёв
OpenAI разрабатывает собственные ИИ-чипы совместно с Broadcom и TSMC, а пока задействует AMD Instinct MI300XКомпания OpenAI, по информации Reuters, разрабатывает собственные чипы для обработки ИИ-задач. Партнёром в рамках данного проекта выступает Broadcom, а организовать производство изделий планируется на мощностях TSMC ориентировочно в 2026 году. Слухи о том, что OpenAI обсуждает с Broadcom возможность создания собственного ИИ-ускорителя, появились минувшим летом. Тогда говорилось, что эта инициатива является частью более масштабной программы OpenAI по увеличению вычислительных мощностей компании для разработки ИИ, преодолению дефицита ускорителей и снижению зависимости от NVIDIA. Как теперь стало известно, OpenAI уже несколько месяцев работает с Broadcom над своим первым чипом ИИ, ориентированным на задачи инференса. Соответствующая команда разработчиков насчитывает около 20 человек, включая специалистов, которые ранее принимали участие в проектировании ускорителей TPU в Google, в том числе Томаса Норри (Thomas Norrie) и Ричарда Хо (Richard Ho). Подробности о проекте не раскрываются. Reuters, ссылаясь на собственные источники, также сообщает, что OpenAI в дополнение к ИИ-ускорителям NVIDIA намерена взять на вооружение решения AMD, что позволит диверсифицировать поставки оборудования. Речь идёт о применении изделий Instinct MI300X, ресурсы которых будут использоваться через облачную платформу Microsoft Azure. 
Источник изображения: Unsplash Это позволит увеличить вычислительные мощности: компания OpenAI только в 2024 году намерена потратить на обучение ИИ-моделей и задачи инференса около $7 млрд. Вместе с тем, как отмечается, OpenAI пока отказалась от амбициозных планов по созданию собственного производства ИИ-чипов. Связано это с большими финансовыми и временными затратами, необходимыми для строительства предприятий.
28.10.2024 [11:48], Сергей Карасёв
Cerebras втрое повысила производительность своей инференс-платформыАмериканский стартап Cerebras Systems, специализирующийся на разработке ИИ-ускорителей, объявил о самом масштабном обновлении ИИ-платформы Cerebras Inference с момента её запуска. Производительность системы поднялась примерно в три раза. Первый релиз Cerebras Inference состоялся в августе 2024 года. Основой облачной платформы являются ускорители собственной разработки WSE-3. На момент запуска быстродействие составляло до 1800 токенов в секунду на пользователя для ИИ-модели Llama3.1 8B и до 450 токенов в секунду для Llama3.1 70B (FP16). Разработчик заявлял, что Cerebras Inference — это «самая мощная в мире» ИИ-платформа для инференса. 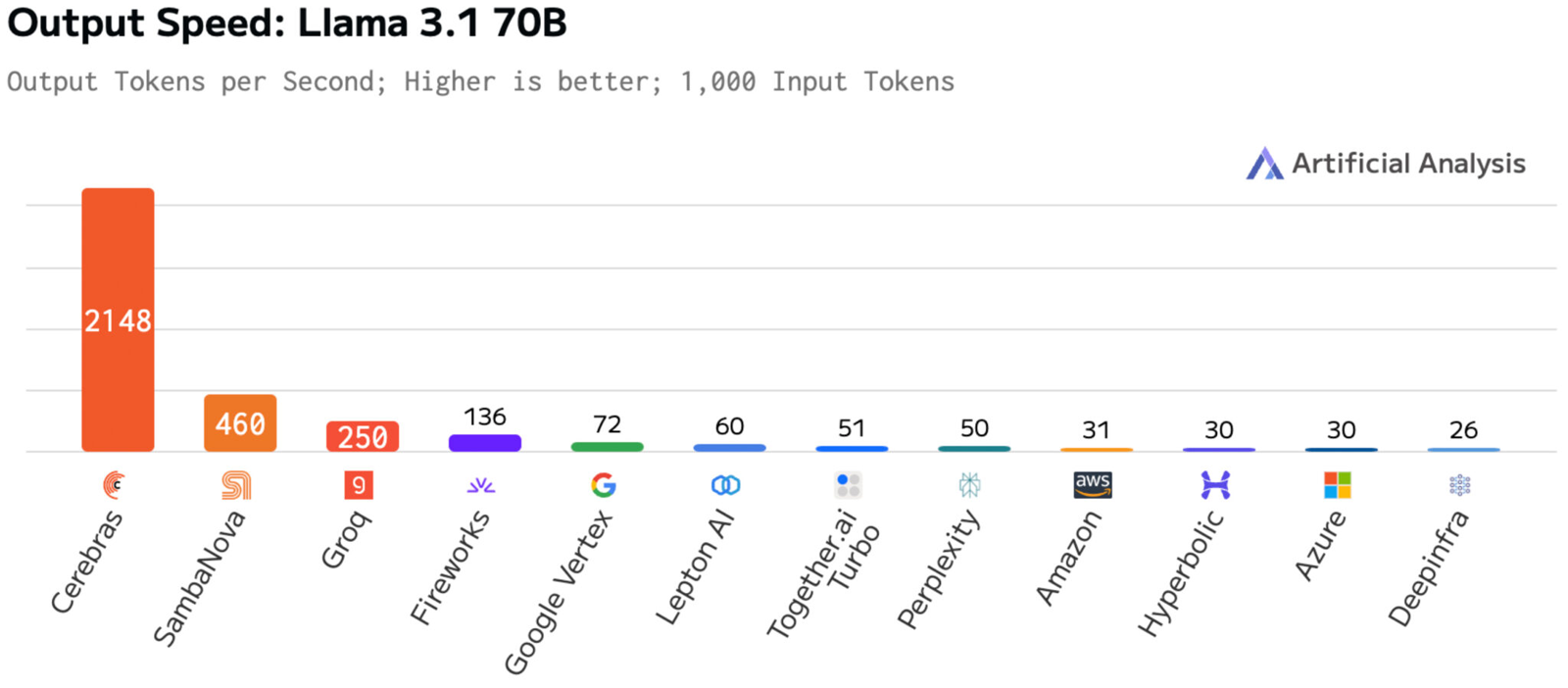
Источник изображений: Cerebras Systems Однако в сентябре нынешнего года у Cerebras Inference появился серьёзный конкурент. Компания SambaNova Systems запустила облачный сервис SambaNova Cloud, также назвав его «самой быстрой в мире платформой для ИИ-инференса». Система на основе чипов собственной разработки SN40L демонстрирует быстродействие до 461 токена в секунду при использовании Llama 3.1 70B. В ответ Cerebras Systems усовершенствовала своё решение путём «многочисленных улучшений программного обеспечения, оборудования и алгоритмов». 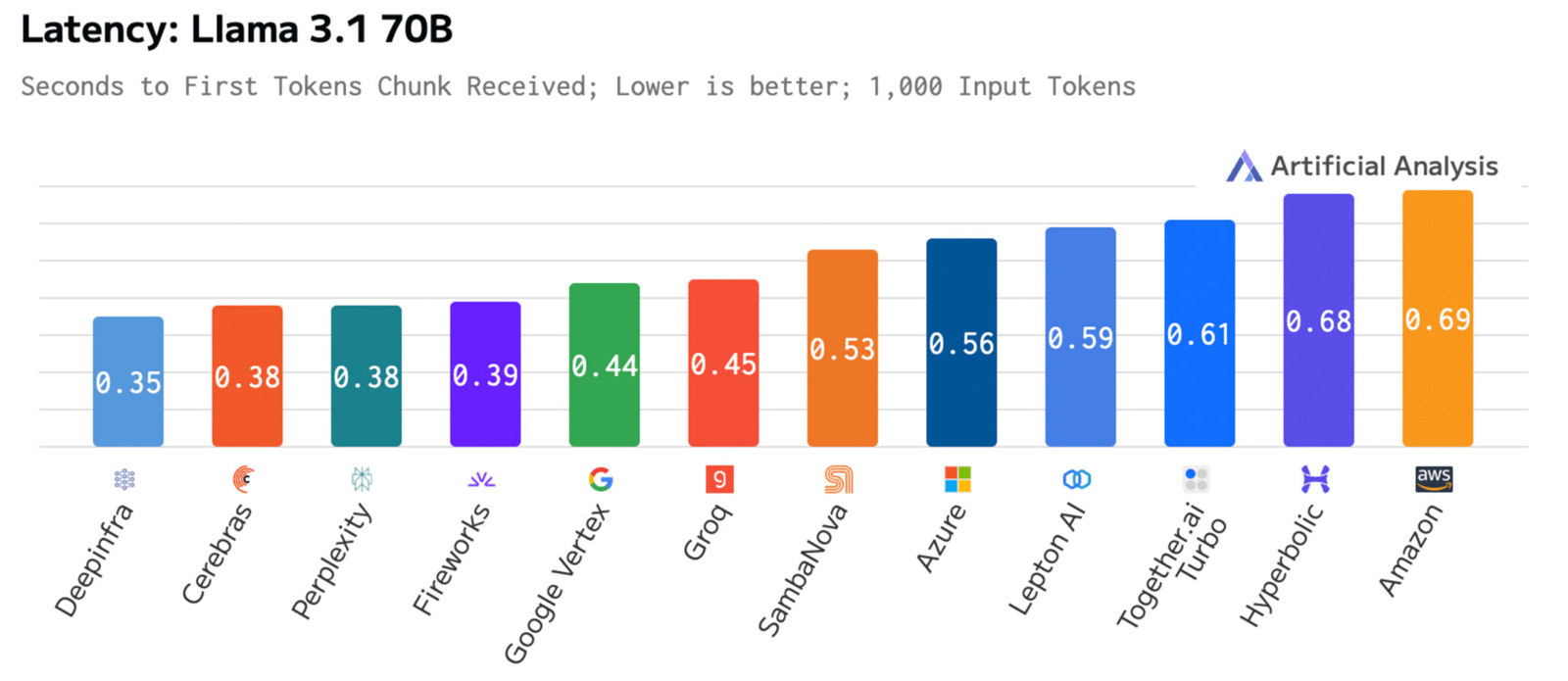 Утверждается, что обновлённая платформа Cerebras Inference при обслуживании Llama3.1 70B обеспечивает быстродействие 2148 токенов в секунду. Для сравнения: у AWS — лидера мирового облачного рынка — этот показатель равен 31 токену в секунду. А у Groq значение находится на уровне 250 токенов в секунду. Данные получены по результатам тестов Artificial Analysis. 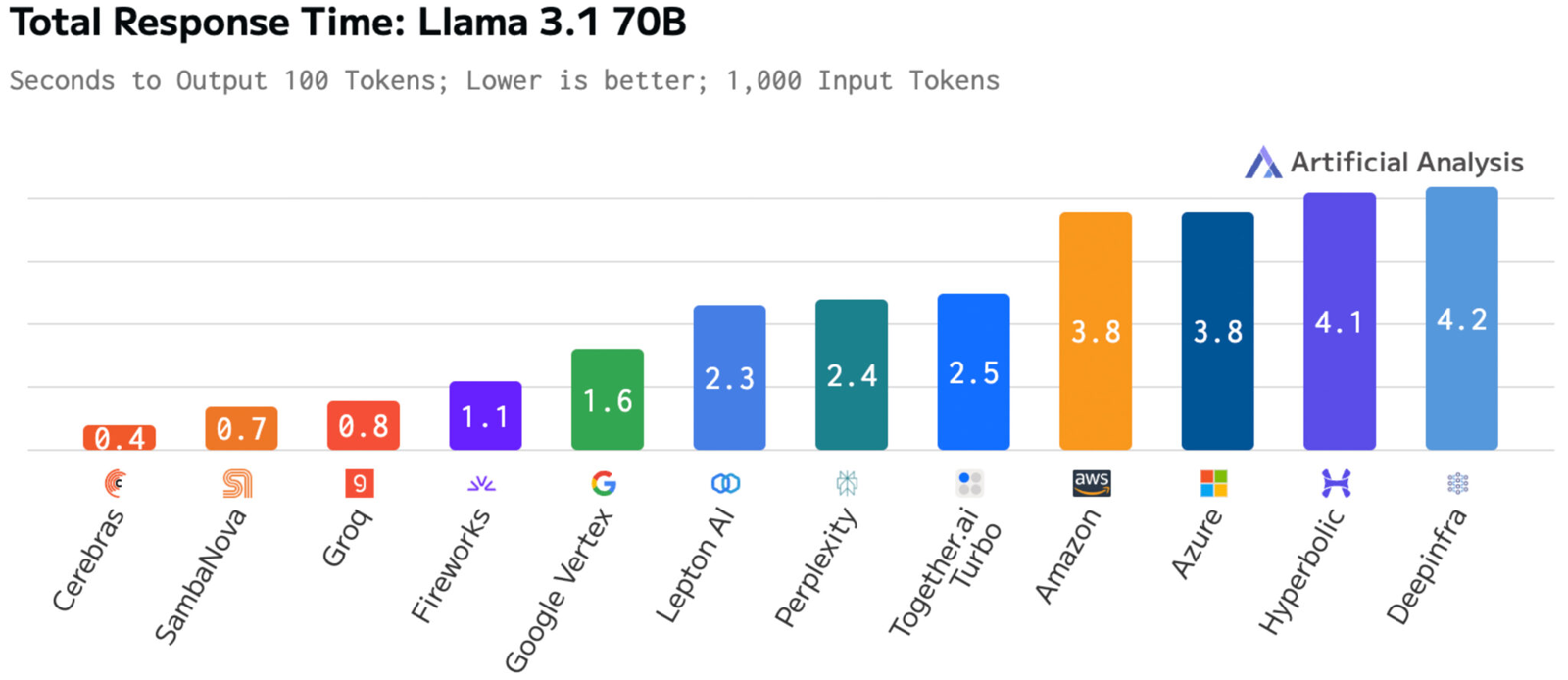 Время до получения первого токена имеет решающее значение для приложений реального времени. Cerebras находится на втором месте с показателем 0,38 с, уступая только Deep Infra (0,35 с). Вместе с тем Cerebras лидирует по общему времени отклика для 100 токенов на выходе с показателем 0,4 с против 0,7 с у SambaNova, которая находится на втором месте. В целом, как отмечается, платформа Cerebras Inference при работе с Llama3.1 70B опережает сервисы конкурентов на основе GPU, обрабатывающие модель Llama3.1 3B, которая в 23 раза меньше. 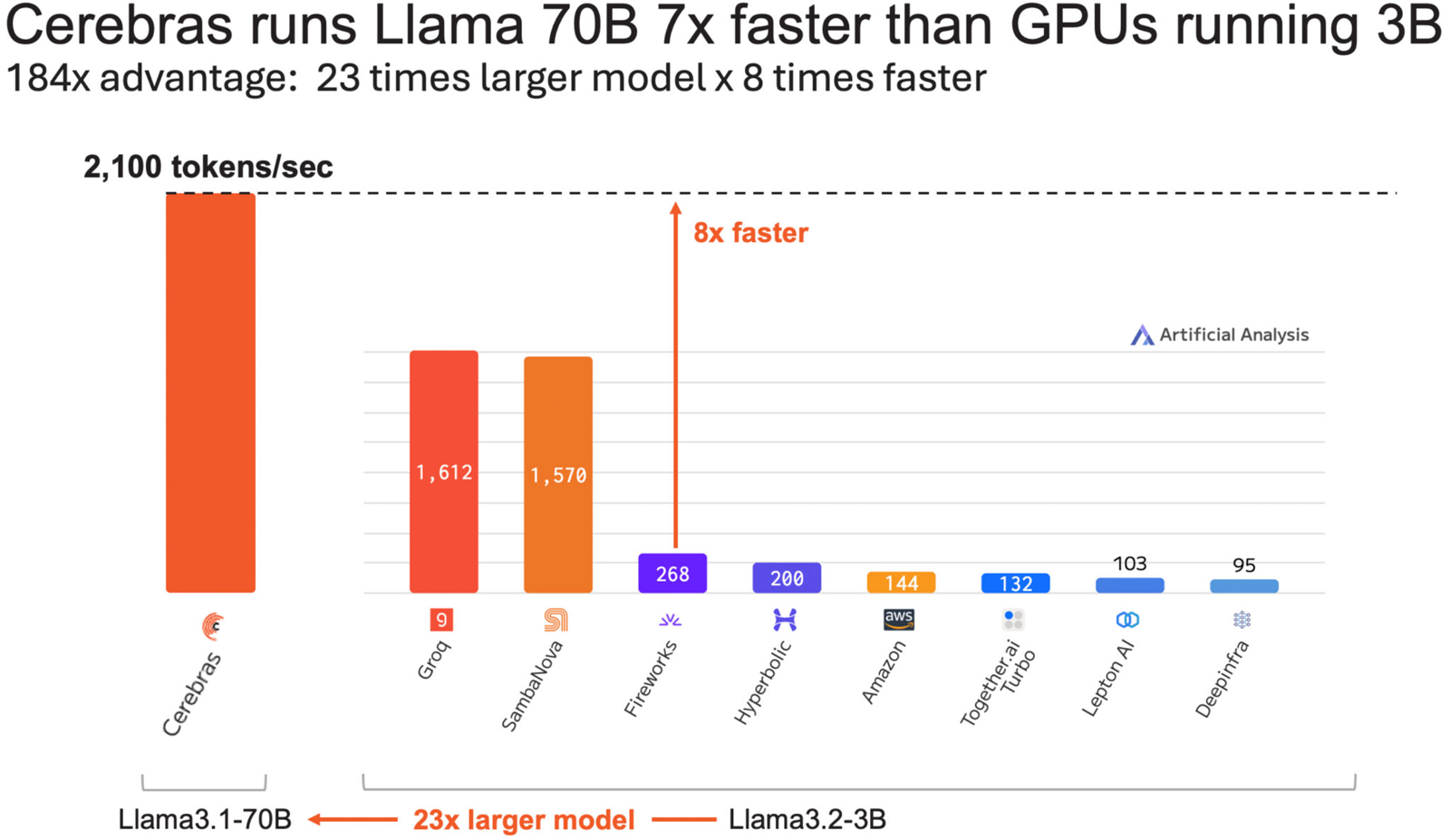
05.10.2024 [15:55], Сергей Карасёв
Qualcomm готовит «урезанные» ИИ-ускорители Cloud AI 80Qualcomm, по сообщению Phoronix, планирует выпустить ускорители Cloud AI 80 (AIC080) для ИИ-задач. Информация о них появилась на сайте самого разработчика, а также в драйверах Linux. Речь идёт об «урезанных» версиях изделий Cloud AI 100, уже доступных на рынке. Базовая версия Cloud AI 100 Standard выполнена в виде HHHL-карты (68,9 × 169,5 мм) с интерфейсом PCIe 4.0 х8 и пассивным охлаждением. Объём памяти LPDDR4x-2133 с пропускной способностью 137 Гбайт/с составляет 16 Гбайт. Есть также 126 Мбайт памяти SRAM. TDP равен 75 Вт. Заявленное быстродействие достигает 350 TOPS на операциях INT8 и 175 Тфлопс при вычислениях FP16. От них в своё время отказалась Meta✴, сославшись на сырость программной экосистемы и предпочтя разработать собственные ИИ-ускорители MTIA. 
Источник изображений: Qualcomm Кроме того, существует решение Cloud AI 100 Ultra в виде карты FH3/4L (111,2 × 237,9 мм). Для обмена данными служит интерфейс PCIe 4.0 х16; значение TDP равно 150 Вт. В оснащение входят 128 Гбайт памяти LPDDR4x, пропускная способность которой достигает 548 Гбайт/с. Объём памяти SRAM — 576 Мбайт. INT8-производительность составляет до 870 TOPS, FP16 — до 288 Тфлопс.  Сообщается, что к выпуску готовятся «урезанные» ускорители Cloud AI 80 Standard и Cloud AI 80 Ultra. Их характеристики в точности соответствуют таковым у Cloud AI 100 Standard и Cloud AI 100 Ultra. Отличия заключаются исключительно в пониженном быстродействии. Так, у Cloud AI 80 Standard производительность INT8 находится на уровне 190 TOPS, FP16 — 86 Тфлопс. У Cloud AI 80 Ultra значения равны 618 TOPS и 222 Тфлопс.  Нужно отметить, что в старшее семейство также входит модель Cloud AI 100 Pro в формате карты HHHL с интерфейсом PCIe 4.0 х8 и TDP 75 Вт. Она несёт на борту 32 Гбайт памяти LPDDR4x (137 Гбайт/с) и 144 Мбайт памяти SRAM. Производительность INT8 составляет до 400 TOPS, FP16 — до 200 Тфлопс. Появится ли подобная модификация в серии Cloud AI 80, пока не ясно.
12.09.2024 [21:46], Сергей Карасёв
SiMa.ai представила чипы Modalix для мультимодальных рабочих нагрузок ИИ на периферииСтартап SiMa.ai анонсировал специализированные изделия Modalix — «системы на чипе» с функциями машинного обучения (MLSoC), спроектированные для обработки ИИ-задач на периферии. Эти решения предназначены для дронов, робототехники, умных камер видеонаблюдения, медицинского диагностического оборудования, edge-серверов и пр. В семейство Modalix входя четыре модификации — М25, М50, М100 и М200 с ИИ-производительностью 25, 50, 100 и 200 TOPS соответственно (BF16, INT8/16). Изделия наделены процессором общего назначения с восемью ядрами Arm Cortex-A65, работающими на частоте 1,5 ГГц. Кроме того, присутствует процессор обработки сигналов изображения (ISP) на базе Arm Mali-C71 с частотой 1,2 ГГц. В оснащение входят 8 Мбайт набортной памяти. Изделия производятся по 6-нм технологии TSMC и имеют упаковку FCBGA с размерами 25 × 25 мм. 
Источник изображения: SiMa.ai Чипы Modalix располагают узлом компьютерного зрения Synopsys ARC EV-74 с частотой 1 ГГц. Говорится о возможности декодирования видеоматериалов H.264/265/AV1 в формате 4K со скоростью 60 к/с и кодировании H.264 в формате 4K со скоростью 30 к/с. Реализована поддержка восьми линий PCIe 5.0, четырёх портов 10GbE, четырёх интерфейсов MIPI CSI-2 (по четыре линии 2.5Gb), восьми каналов памяти LPDDR4/4X/5-6400 (до 102 Гбайт/с). Таким образом, по словам SiMa.ai, Modalix покрывает практически весь цикл работы с данными, не ограничиваясь только ускорением ИИ-задач. 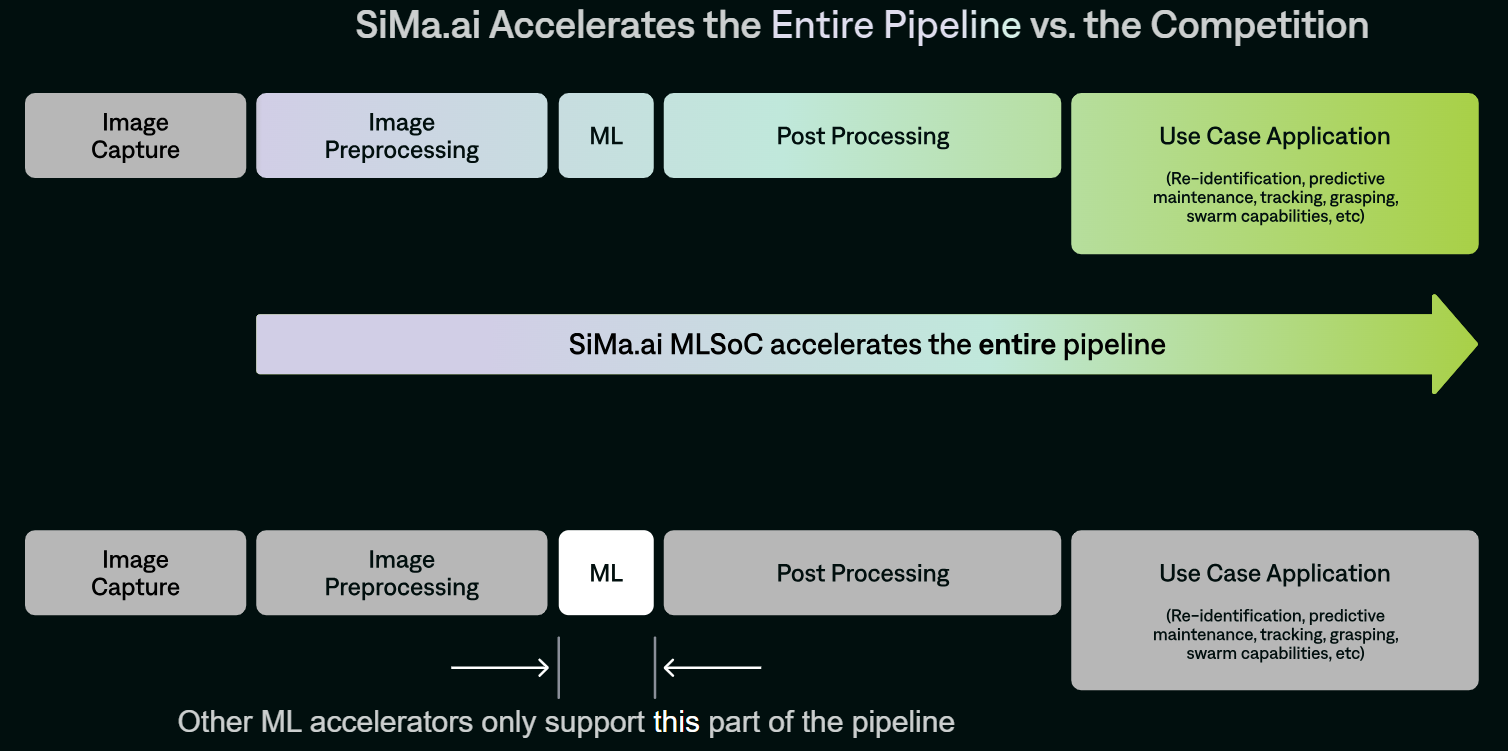
Источник изображения: SiMa.ai По заявлениям SiMa.ai, чипы Modalix можно применять для работы с большими языковыми моделями (LLM), генеративным ИИ, трансформерами, свёрточными нейронными сетями и мультимодальными приложениями. Среди возможных вариантов использования названы медицинская визуализация и роботизированная хирургия, интеллектуальные приложения для розничной торговли, автономные транспортные средства, беспилотники для инспекции зданий и пр. Есть поддержка популярных фреймворков PyTorch, ONNX, Keras, TensorFlow и т.д. Также предоставляется специализированный набор инструментов под названием Pallet, упрощающий создание ПО для новых процессоров.
11.09.2024 [18:07], Сергей Карасёв
SambaNova запустила «самую быструю в мире» облачную платформу для ИИ-инференсаКомпания SambaNova Systems объявила о запуске облачного сервиса SambaNova Cloud: утверждается, что на сегодняшний день это самая быстрая в мире платформа для ИИ-инференса. Она ориентирована на работу с большими языковыми моделями Llama 3.1 405B и Llama 3.1 70B, насчитывающими соответственно 405 и 70 млрд параметров. В основу сервиса положены ИИ-чипы собственной разработки SN40L. Эти изделия состоят из двух крупных чиплетов, оперирующих 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной памяти HBM3. Утверждается, что восьмипроцессорная система на базе SN40L способна запускать и обслуживать ИИ-модели с 5 трлн параметров и глубиной запроса более 256к. 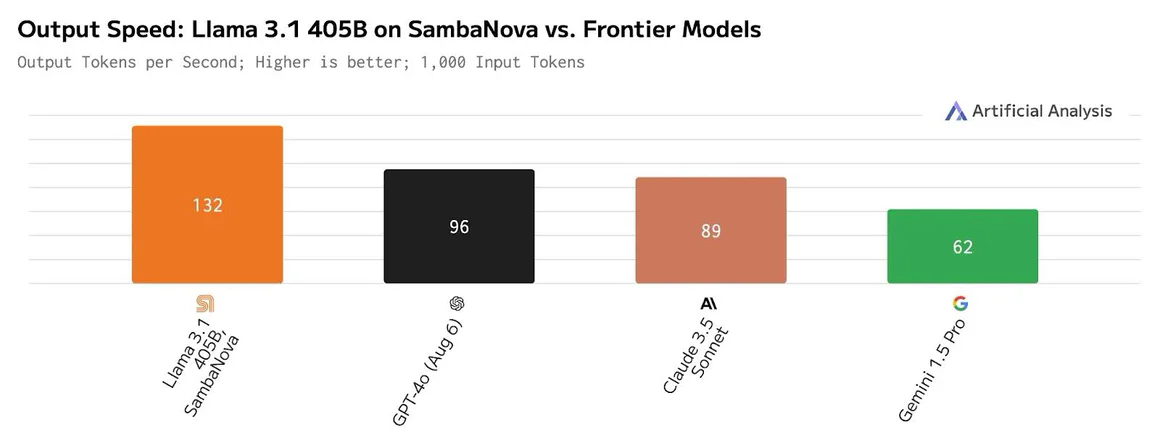
Источник изображения: SambaNova Платформа SambaNova Cloud, по заявлениям разработчиков, демонстрирует производительность до 132 токенов в секунду при работе с Llama 3.1 405B и до 461 токена в секунду при использовании Llama 3.1 70B. Для сравнения, по оценкам Artificial Analysis, даже самые мощные системы на базе GPU могут обслуживать модель Llama 3.1 405B только со скоростью 72 токена в секунду, а большинство из них намного медленнее. Подчёркивается, что SambaNova Cloud демонстрирует рекордную скорость при сохранении полной 16-битной точности. Однако без компромиссов всё же не обошлось: модель работает не в полном контекстном окне в 128k, а при 8k. Доступ к SambaNova Cloud предоставляется по трём схемам — Free, Developer и Enterprise. Первая предусматривает бесплатное базовое использование через API. Схема для разработчиков Developer (появится к концу 2024 года) позволяет работать с моделями Llama 3.1 8B, 70B и 405B с более высокими лимитами. Наконец, план Enterprise предлагает корпоративным клиентам возможность масштабирования для поддержки ресурсоёмких рабочих нагрузок. Ранее Cerebras Systems тоже объявила о запуске «самой мощной в мире» ИИ-платформы для инференса, а Groq ещё в прошлом году говорила о преимуществах своих решений и тоже переключилась на создание облачных сервисов. Впрочем, в бенчмарках MLPerf Inference по-прежнему бессменно лидируют решения NVIDIA.
31.08.2024 [14:12], Сергей Карасёв
Cerebras Systems запустила «самую мощную в мире» ИИ-платформу для инференсаАмериканский стартап Cerebras Systems, занимающийся разработкой чипов для систем машинного обучения и других ресурсоёмких задач, объявил о запуске, как утверждается, самой производительной в мире ИИ-платформы для инференса — Cerebras Inference. Ожидается, что она составит серьёзную конкуренцию решениям на основе ускорителей NVIDIA. В основу облачной системы Cerebras Inference положены ускорители WSE-3. Эти гигантские изделия, выполненные с применением 5-нм техпроцесса TSMC, содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. Для сравнения: один чип HBM3e в составе NVIDIA H200 может похвастаться пропускной способностью «только» 4,8 Тбайт/с. 
Источник изображений: Cerebras По заявлениям Cerebras, новая инференс-платформа обеспечивает до 20 раз более высокую производительность по сравнению с сопоставимыми по классу решениями на чипах NVIDIA в сервисах гиперскейлеров. В частности, быстродействие составляет до 1800 токенов в секунду на пользователя для ИИ-модели Llama3.1 8B и до 450 токенов в секунду для Llama3.1 70B. Для сравнения, у AWS эти значения равны соответственно 93 и 50. Речь идёт об FP16-операциях. Cerebras заявляет, что лучший результат для кластеров на основе NVIDIA H100 в случае Llama3.1 70B составляет 128 токенов в секунду. 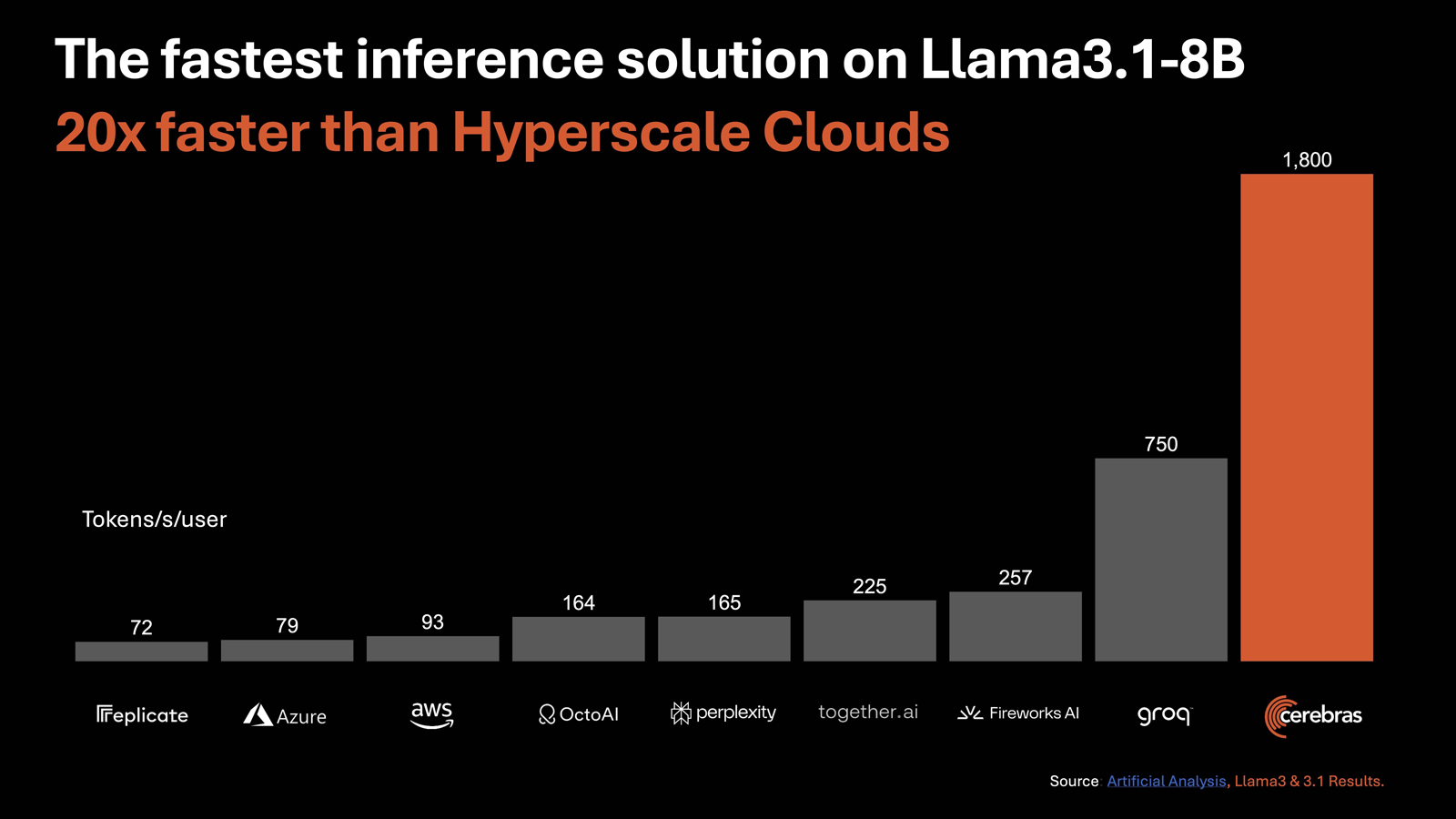 «В отличие от альтернативных подходов, которые жертвуют точностью ради быстродействия, Cerebras предлагает самую высокую производительность, сохраняя при этом точность на уровне 16 бит для всего процесса инференса», — заявляет компания. При этом услуги Cerebras Inference стоят в несколько раз меньше по сравнению с конкурирующими предложениями: $0,1 за 1 млн токенов для Llama 3.1 8B и $0,6 за 1 млн токенов для Llama 3.1 70B. Оплата взимается по мере использования. Cerebras планирует предоставлять инференс-услуги через API, совместимый с OpenAI. Преимущество такого подхода заключается в том, что разработчикам, которые уже создали приложения на основе GPT-4, Claude, Mistral или других облачных ИИ-моделей, не придётся полностью менять код для переноса нагрузок на платформу Cerebras Inference. 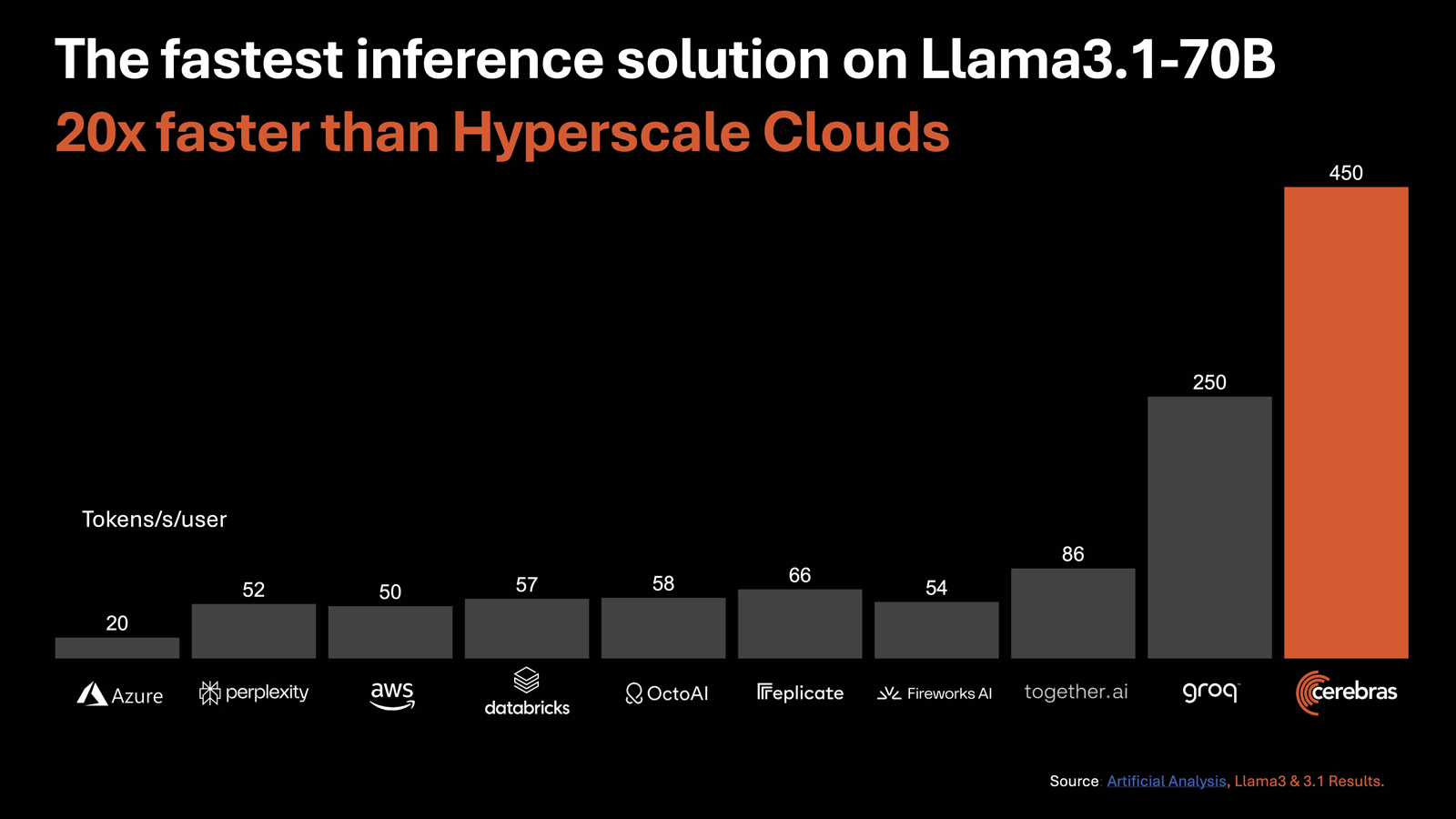 Для крупных предприятий предлагается план обслуживания Enterprise Tier, который предусматривает тонко настроенные модели, индивидуальные условия и специализированную поддержку. Стандартный пакет Developer Tier предполагает подписку по цене от $0,1 за 1 млн токенов. Кроме того, имеется бесплатный доступ начального уровня Free Tier с ограничениями. Cerebras говорит, что запуск платформы откроет качественно новые возможности для внедрения генеративного ИИ в различных сферах.
31.08.2024 [00:39], Алексей Степин
Новые мейнфреймы IBM z получат ИИ-ускорители SpyreВместе с процессорами Telum II для систем z17 компания IBM представила и собственные ускорители Spyre, ещё больше расширяющие возможности будущих мейнфреймов в области обработки ИИ-нагрузок. Они станут дополнением к встроенным в Telum ИИ-блокам. 
Источник изображений: IBM Spyre представляет собой плату расширения с интерфейсом PCIe 5.0 x16 и теплопакетом 75 Вт. Помимо самого нейропроцессора IBM на ней установлено 128 Гбайт памяти LPDDR5, а производительность в ИИ-задачах оценивается производителем в более чем 300 Топс, т.е. новинки подходят для инференса крупных моделей. Сам чип приозводится с использованием 5-нм техпроцесса Samsung 5LPE и содержит 26 млрд транзисторов, а площадь его кристалла составляет 330 мм2.  Spyre включает 32 ядра, каждое из которых дополнено 2 Мбайт быстрой скрэтч-памяти. Отдельно отмечено, что последняя не является кешем. При этом заявлена эффективность использования доступных вычислительных ресурсов — свыше 55 % на ядро. Каждое ядро содержит 78 матричных блоков и раздельные FP16-аккумуляторы, по восемь на «вход» и «выход». Интересно, что ядра Spyre и скрэтч-память используют отдельные кольцевые двунаправленные шины разной разрядности (32 и 128 бит соответственно), причём с оперативной памятью на скорости 200 Гбайт/с соединена именно вторая.  Каждый узел (drawer) на базе Telum II способен вместить восемь плат Spyre, которые формируют логический кластер, располагающий 1 Тбайт памяти с совокупной ПСП 1,6 Тбайт/с, но, разумеется, каждая плата будет ограничена 128 Гбайт/с из-за интерфейса PCIe 5.0 x16. Spyre создан с упором на предиктивный и генеративный ИИ, благо в полной комплектации новые мейнфреймы могут нести 96 таких ускорителей и развивать до 30 ПОпс (Петаопс).  Новинки рассчитаны на работу в средах zCX или Linux on Z, сопровождаются оптимизированным набором библиотек и совместимы с популярными фреймворками Pytoch, TensorFlow и ONNX. Они станут частью программных платформ IBM watsonx и Red Hat OpenShift. Новые мейнфреймы IBM z17 должны дебютировать на рынке в 2025 году. А в собственном облаке IBM будет также полагаться и на Intel Gaudi 3.
30.08.2024 [13:11], Руслан Авдеев
ИИ-ускорители Intel Gaudi 3 дебютируют в облаке IBM CloudКомпании Intel и IBM намерены активно сотрудничать в сфере облачных ИИ-решений. По данным HPC Wire, доступ к ускорителям Intel Gaudi 3 будет предоставляться в облаке IBM Cloud с начала 2025 года. Сотрудничество обеспечит и поддержку Gaudi 3 ИИ-платформой IBM Watsonx. IBM Cloud станет первым поставщиком облачных услуг, принявшим на вооружение Gaudi 3 как для гибридных, так и для локальных сред. Взаимодействие компаний позволит внедрять и масштабировать современные ИИ-решения, а комбинированное использование Gaudi 3 с процессорами Xeon Emerald Rapids откроет перед пользователями дополнительные возможности в облаках IBM. Gaudi 3 будут применяться и в задачах инференса на платформе Watsonx — клиенты смогут оптимизировать исполнение таких нагрузок с учётом соотношения цены и производительности. Для помощи клиентам в различных отраслях, в том числе тех, деятельность которых жёстко регулируется, компании предложат возможности IBM Cloud для гибкого масштабирования нагрузок, а интеграция Gaudi 3 в среду IBM Cloud Virtual Servers for VPC позволит компаниям, использующим аппаратную базу x86, быстрее и безопаснее использовать свои решения, чем до интеграции. 
Источник изображения: Intel Ранее сообщалось, что модель Gaudi 3 готова бросить вызов ускорителям NVIDIA. В своё время Intel выступила с заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при значительно меньшей стоимости. Позже Intel публично раскрыла стоимость новых ускорителей, нарушив негласные правила рынка. |
|