Материалы по тегу: бенчмарк
|
10.02.2024 [14:50], Сергей Карасёв
Более 2000 результатов Intel Xeon в бенчмарке SPEC CPU 2017 поставлены под сомнениеНекоммерческая организация Standard Performance Evaluation Corporation (SPEC), по сообщению ServeTheHome, по сути, аннулировала более 2000 результатов своего бенчмарка SPEC CPU 2017 для процессоров Intel. Причина заключается в специальной оптимизации для целочисленных вычислений, что теперь считается недопустимым. Установлено, что компилятор Intel oneAPI DPC++ фактически «обманывает» стандарты SPEC с помощью целевой оптимизации. Во многих результатах SPEC CPU 2017 в разделе «Примечания для компилятора» появилось уведомление о неточности данных. 
Источник: SPEC «SPEC пришла к выводу, что компилятор, использованный для получения этого результата, выполнял компиляцию, которая искусственно завышает производительность тестов 523.xalancbmk_r/623.xalancbmk_s, используя предварительное знание кода и набора данных», — сказано в сообщении. Отмечается, что SPEC больше не будет публиковать результаты, полученные с использованием указанной оптимизации. В тесте производительности, на который нацелена эта оптимизация компилятора, результат может увеличиться более чем на 50 %. Таким образом, можно добиться повышения общего результата на несколько процентов. С другой стороны, оптимизация имеет узкую применимость: например, 623.xalancbmk_s — это только один из десяти тестов в наборе. Оптимизация влияет на платформу Intel oneAPI версий с 2022.0 по 2023.0, тогда как более новые модификации, в частности, 2023.2.3 проблеме не подвержены. Кроме того, оптимизация не распространяется на процессоры AMD.
14.11.2023 [03:20], Алексей Степин
Intel показала результаты тестов ускорителя Max 1550 и рассказала о будущих чипах Gaudi3 и Falcon ShoresВ рамках SC23 корпорация Intel продемонстрировала ряд любопытных слайдов. На них присутствуют результаты тестирования ускорителя Max 1550 с архитектурой Xe, а также планы относительно следующего поколения ИИ-ускорителей Gaudi. 
Изображение: Intel При этом компания применила иной подход, нежели обычно — вместо демонстрации результатов, полученных в стенах самой Intel, слово было предоставлено Аргоннской национальной лаборатории Министерства энергетики США, где летом этого года было завершён монтаж суперкомпьютера экза-класса Aurora, занимающего нынче второе место в TOP500.  В этом HPC-кластере применены OAM-модули Max 1550 (Ponte Vecchio) с теплопакетом 600 Вт. Они содержат в своём составе 128 ядер Xe и 128 Гбайт памяти HBM2E. Интерфейс Xe Link позволяет общаться напрямую восьми таким модулям, что обеспечивает более эффективную масштабируемость. 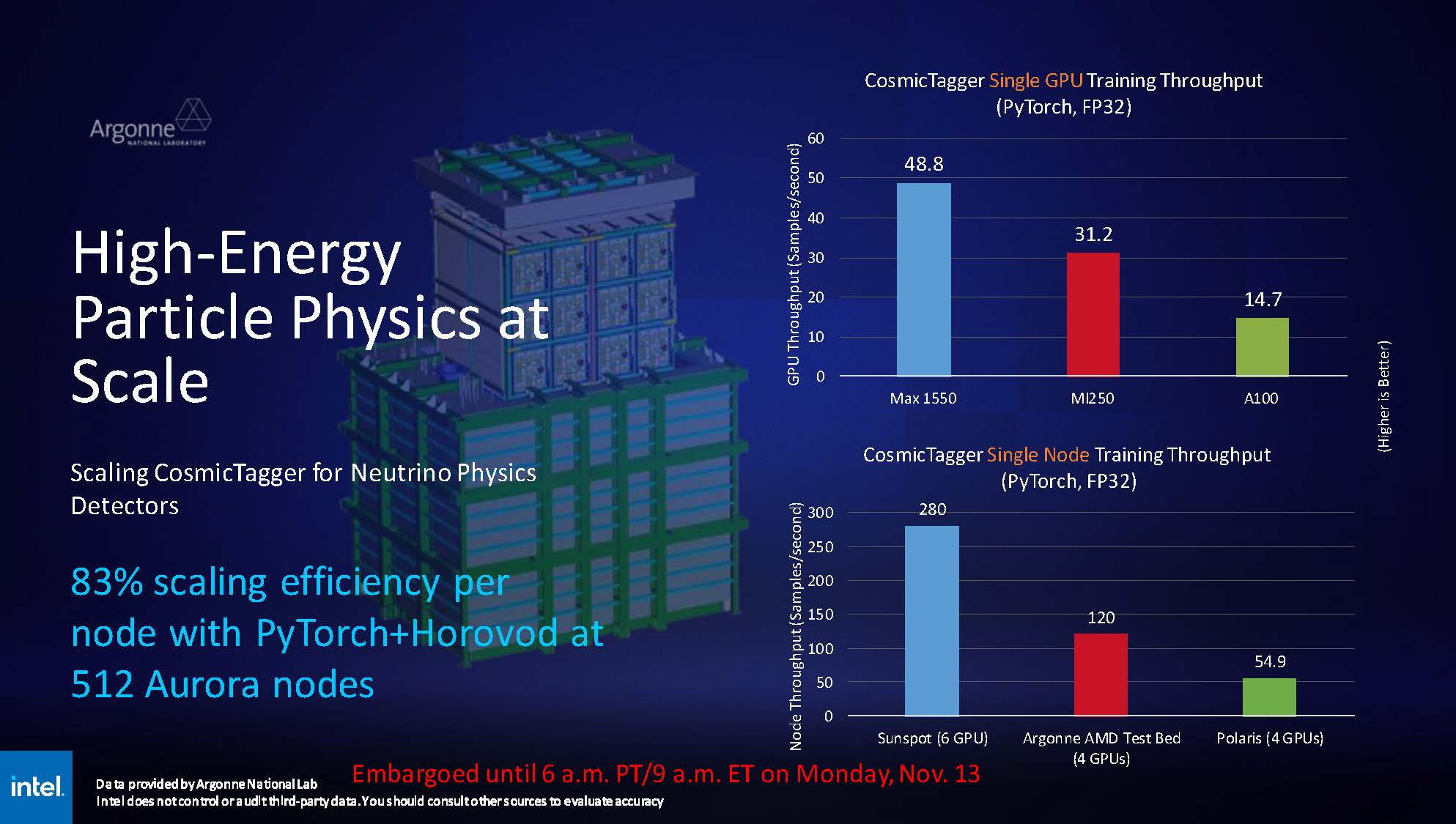
Источник изображений здесь и далее: Intel via ServeTheHome Хотя настройка вычислительного комплекса Aurora ещё продолжается, уже имеются данные о производительности Max 1550 в сравнении с AMD Instinct MI250 и NVIDIA A100. В тесте физики высоких частиц, использующих сочетание PyTorch+Horovod (точность вычислений FP32), ускорители Intel уверенно заняли первое место, а также показали 83% эффективность масштабирования на 512 узлах Aurora.  В тесте, симулирующем поведение комплекса кремниевых наночастиц, ускорители Max 1550, также оказались первыми как в абсолютном выражении, так и в пересчёте на 128-узловой тест в сравнении с системами Polaris (четыре A100 на узел) и Frontier (четыре MI250 на узел). Написанный с использованием Fortran и OpenMP код доказал работоспособность и при масштабировании до более чем 500 вычислительных узлов Aurora. 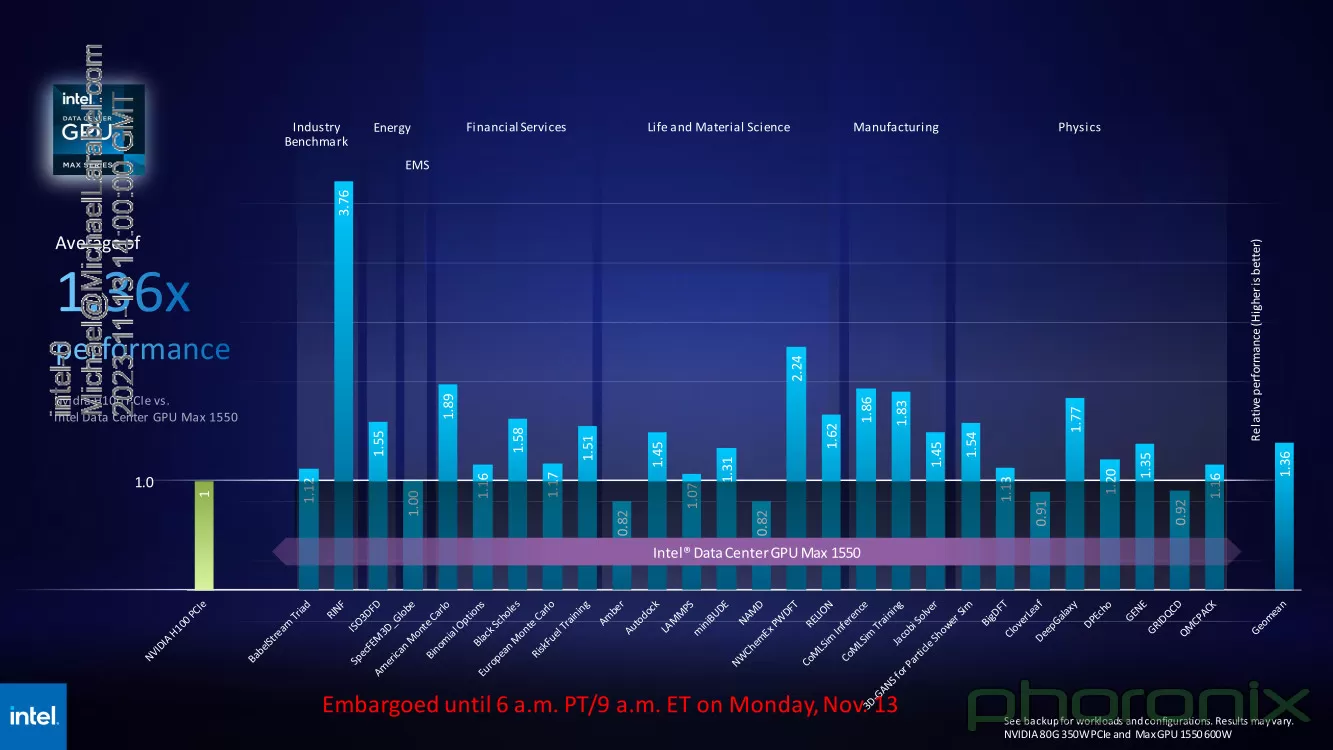
Источник изображения: Intel via Phoronix В целом, ускорители Intel Max 1550 демонстрируют хорошие результаты и не уступают NVIDIA H100: в некоторых задачах их относительная эффективность составляет не менее 0,82, но в большинстве других тестов этот показатель варьируется от 1,0 до 3,76. Очевидно, что у H100 появился достойный соперник, который, к тому же, имеет меньшую стоимость и большую доступность. Но сама NVIDIA уже представила чипы (G)H200, а AMD готовит Instinct MI300.  Системы на базе Intel Max доступны в различном виде: как в облаке Intel Developer Cloud, так и в составе OEM-решений. Supermicro предлагает сервер с восемью модулями OAM, а Dell и Lenovo — решения с четырьями ускорителями в этом же формате. PCIe-вариант Max 1100 доступен от вышеуказанных производителей, а также у HPE. 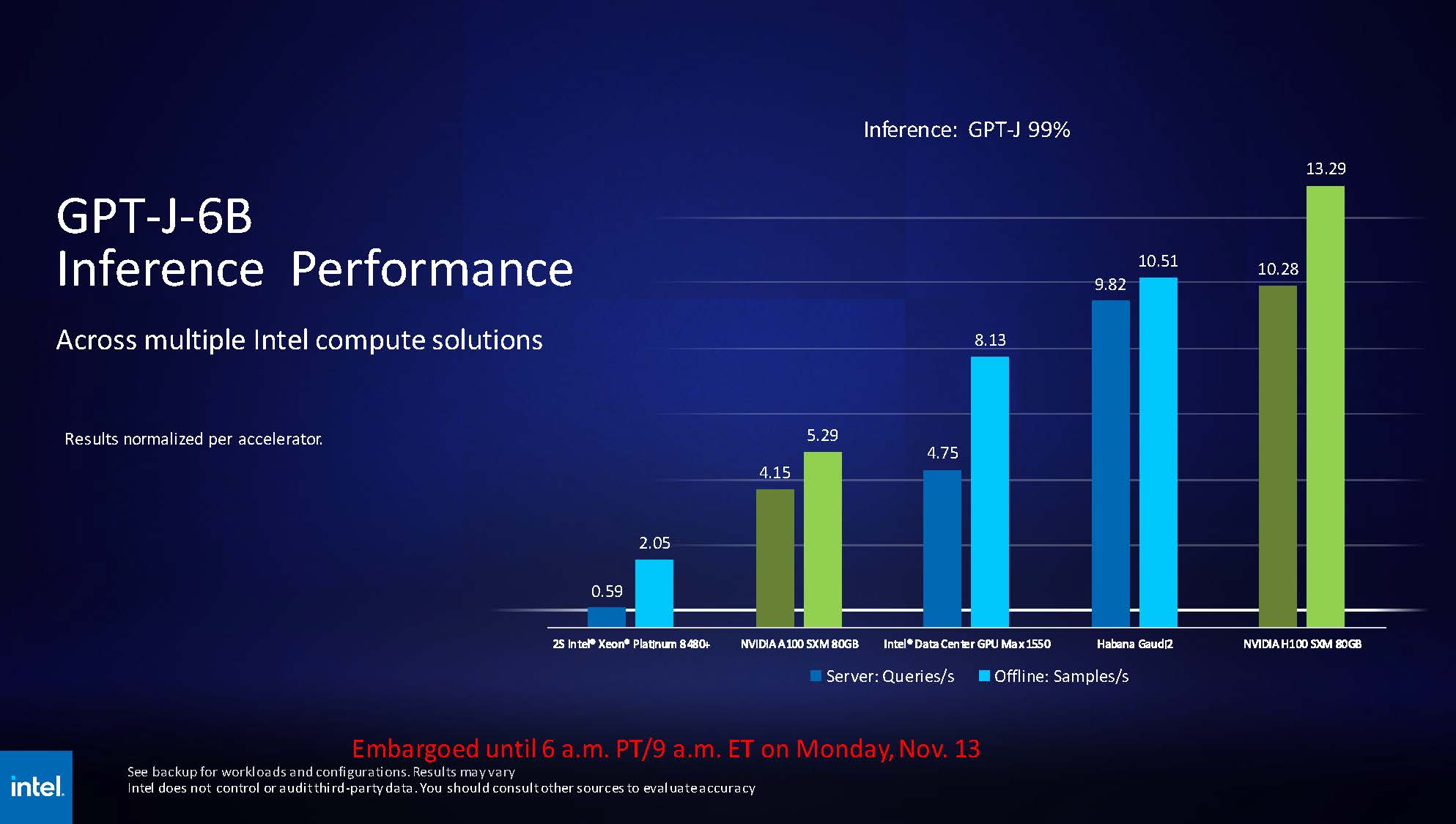 Помимо ускорителей Max, Intel привела и новые данные о производительности ИИ-сопроцессоров Gaudi2. Компания продолжает активно совершенствовать и оптимизировать программную экосистему Gaudi. В результате, в инференс-системе на базе модели GPT-J-6B результаты ускорителей Gaudi2 уже сопоставимы с NVIDIA H100 (SXM 80 Гбайт), а A100 существенно уступает как Gaudi2, так и Max 1550.  Но самое интересное — это сведения о планах относительно следующего поколения Gaudi. Теперь известно, что Gaudi3 будет производиться с использованием 5-нм техпроцесса. Новый чип будет в четыре раза быстрее в вычислениях BF16, а также получит вдвое более мощную подсистему памяти и в 1,5 раза больше памяти HBM. Увидеть свет он должен в 2024 году. 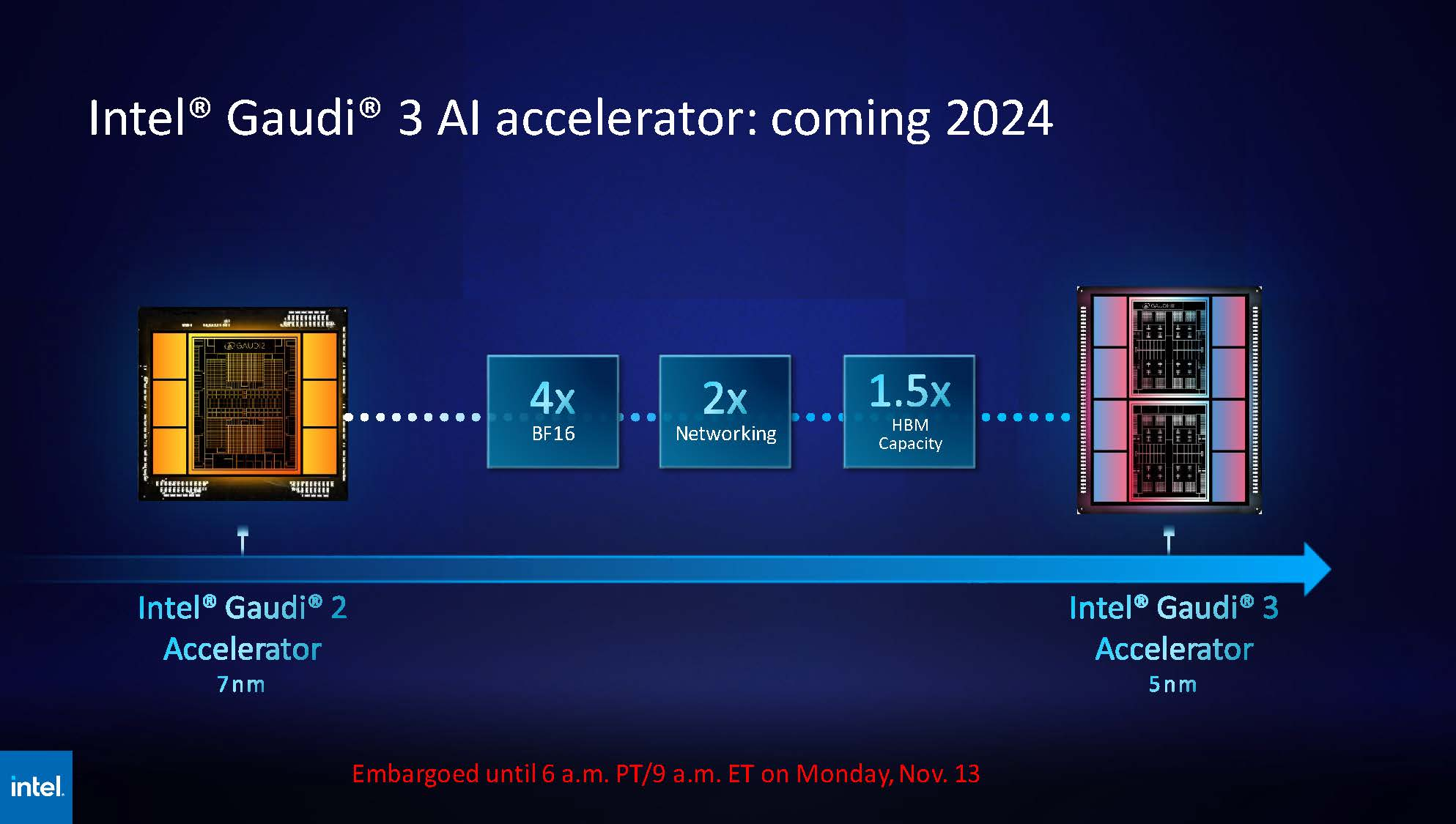 Заодно компания напомнила, что процессоры Xeon Emerald Rapids будут представлены ровно через месяц, а Granite Rapids появятся в 2024 году. В 2025 появится чип Falcon Shores, который теперь должен по задумке Intel сочетать в себе GPU и ИИ-сопроцессор. Он объединит архитектуры Habana и Xe в единое решение с тайловой компоновкой, памятью HBM3 и полной поддержкой CXL. 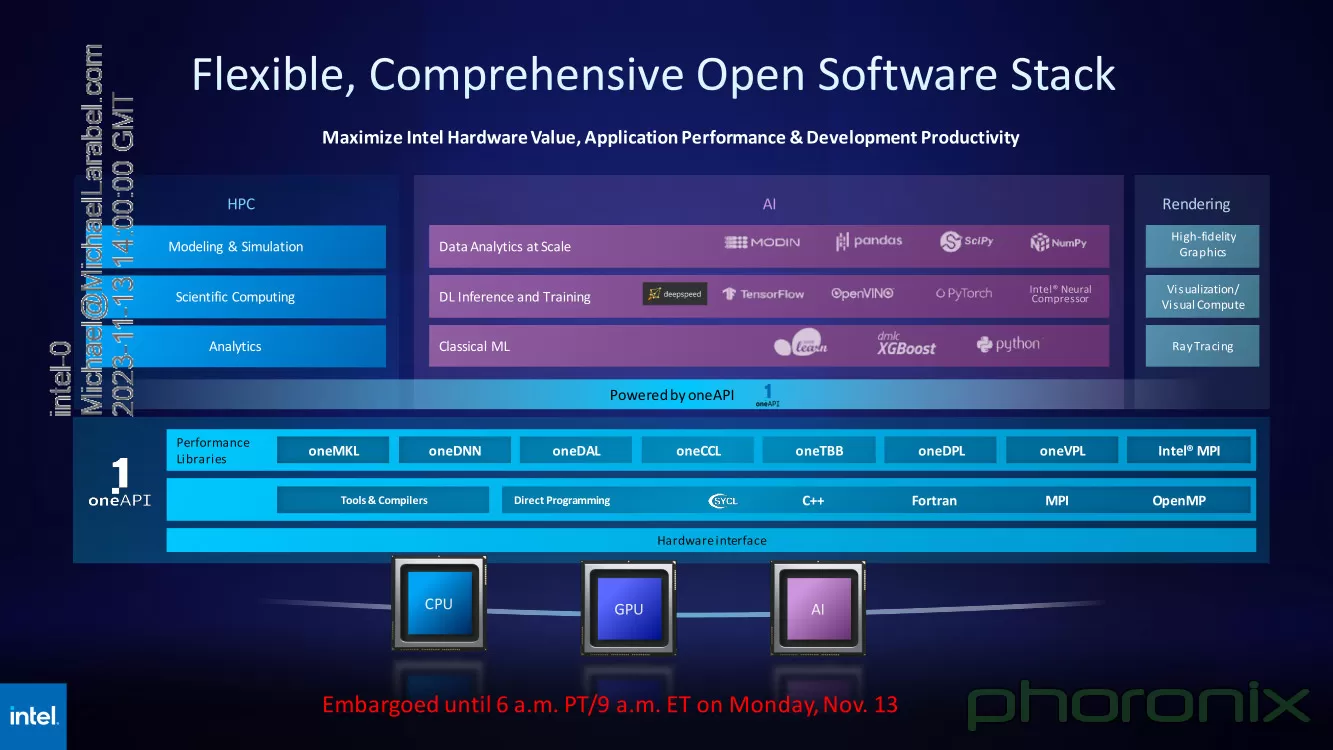
Источник изображения: Intel via Phoronix Следует отметить, что такая унификация вполне реальна: Intel весьма активно развивает универсальный, гибкий и открытый стек технологий в рамках проекта oneAPI. В него входят все необходимые инструменты — от компиляторов и системных библиотек до средств интеграции с популярными движками аналитики данных, моделями и библиотеками искусственного интеллекта.
11.11.2023 [15:23], Сергей Карасёв
MLPerf: Intel улучшила производительность Gaudi2, но лидером остаётся NVIDIA H100Консорциум MLCommons обнародовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training 3.1, который оценивает производительность на ИИ-операциях. Отмечается, что корпорация Intel смогла существенно увеличить быстродействие своего ускорителя Habana Gaudi2, но безоговорочным лидером остаётся NVIDIA H100. Тесты проводились на платформе Xeon Sapphire Rapids. Отмечается, что для некоторых задач Intel реализовала поддержку FP8-вычислений, благодаря чему производительность поднялась в два раза по сравнению с показателями, которые этот же ускоритель демонстрировал ранее. Согласно результатам тестов, в бенчмарке GPT-3 ускоритель Gaudi2 ровно в два раза проигрывает решению NVIDIA H100. То же самое касается теста Stable Diffusion: при этом нужно отметить, что Gaudi2 использовал формат BF16, а H100 — FP16. В ResNet эти ускорители демонстрируют сопоставимую производительность. В тесте BERT чип H100 при использовании FP8-вычислений показал значительное преимущество перед Gaudi2, который использовал формат BF16. 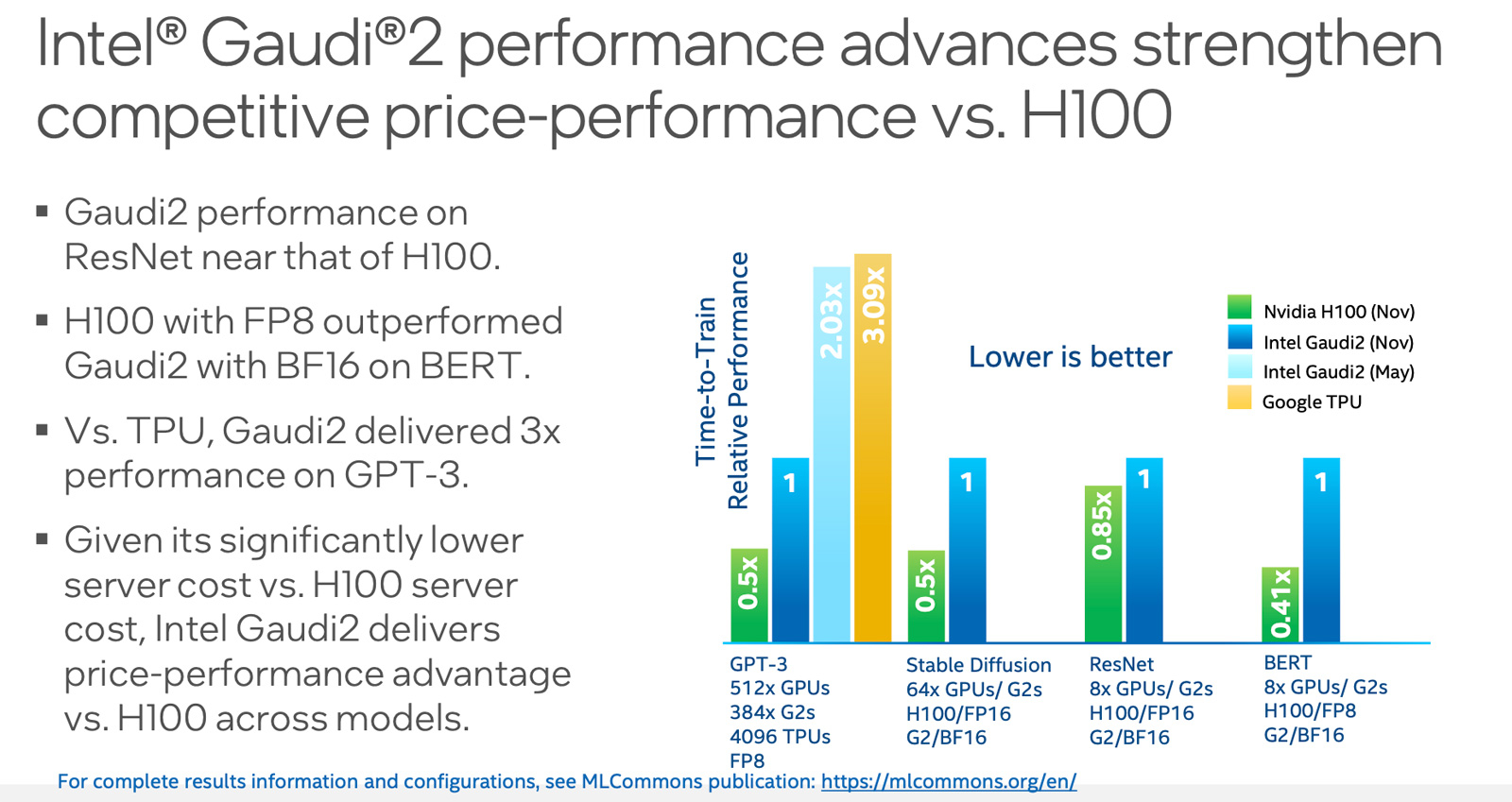
Источник изображения: MLCommons Сама Intel отмечает, что с внедрением поддержки FP8 система с 384 ускорителями Gaudi2 способна завершить обучение GPT-3 за 153,58 мин. При использовании 64 чипов Gaudi2 тест Stable Diffusion может быть завершён за 20,2 мин (BF16). Для тестов BERT и ResNet-50 на восьми ускорителях Gaudi2 (BF16) результат составляет 13,27 и 15,92 мин соответственно. Вместе с тем стоимость и доступность ускорителей Intel, как считается, существенно лучше, чем у решений NVIDIA.
08.11.2023 [20:00], Игорь Осколков
Счёт на секунды: ИИ-суперкомпьютер NVIDIA EOS с 11 тыс. ускорителей H100 поставил рекорды в бенчмарках MLPerf TrainingВместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег. 
Изображения: NVIDIA Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.   В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов. 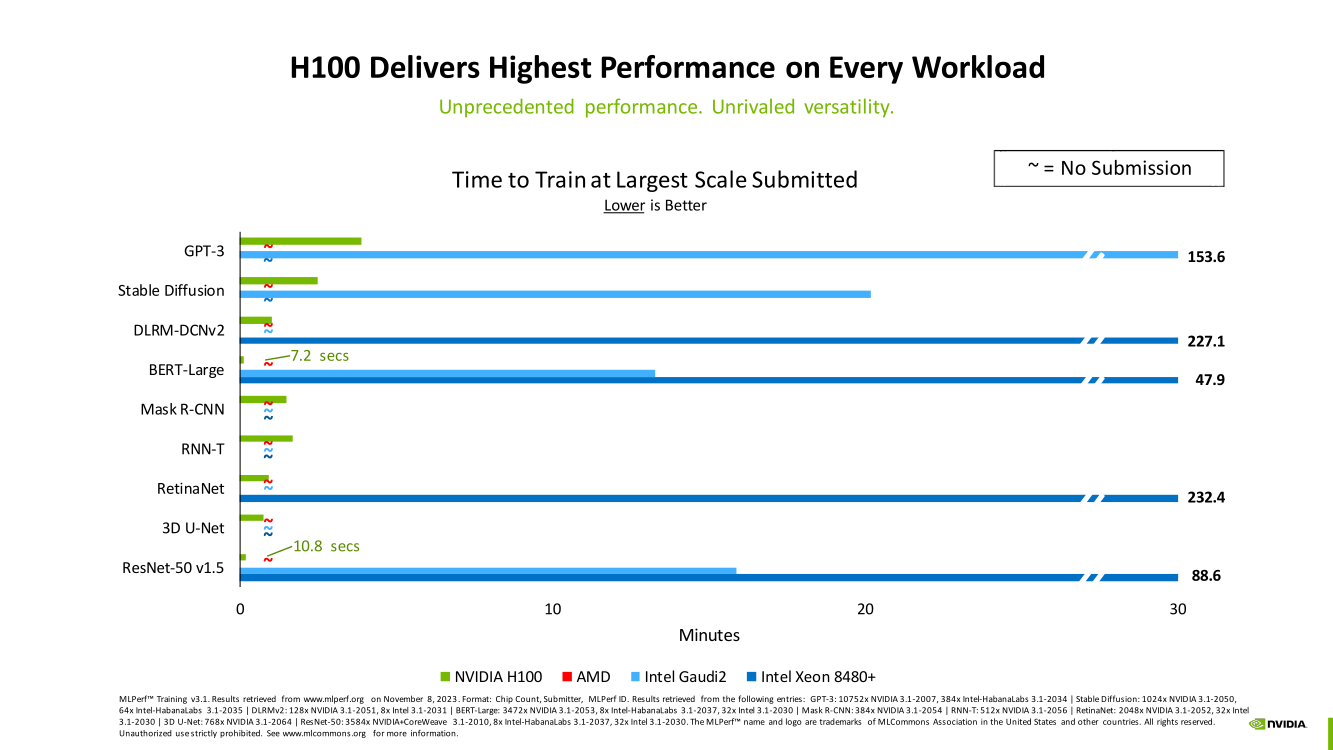 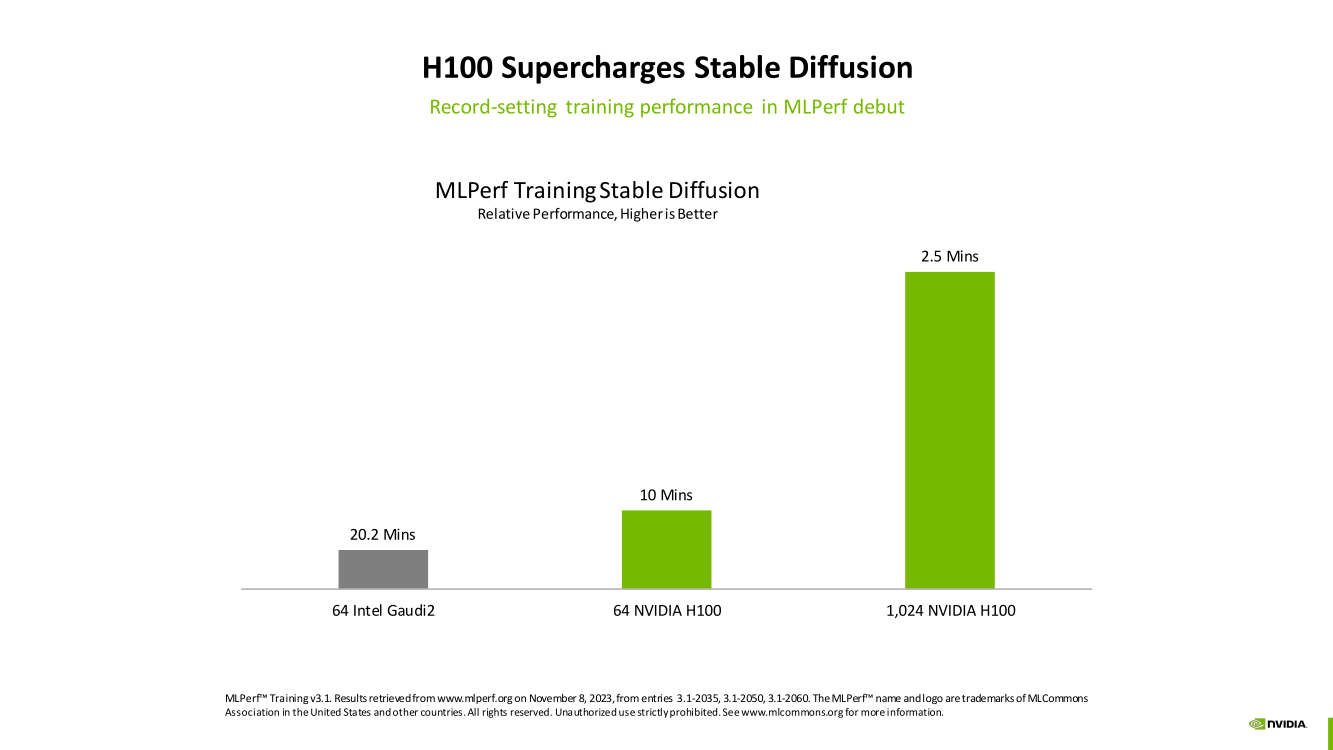 NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд. 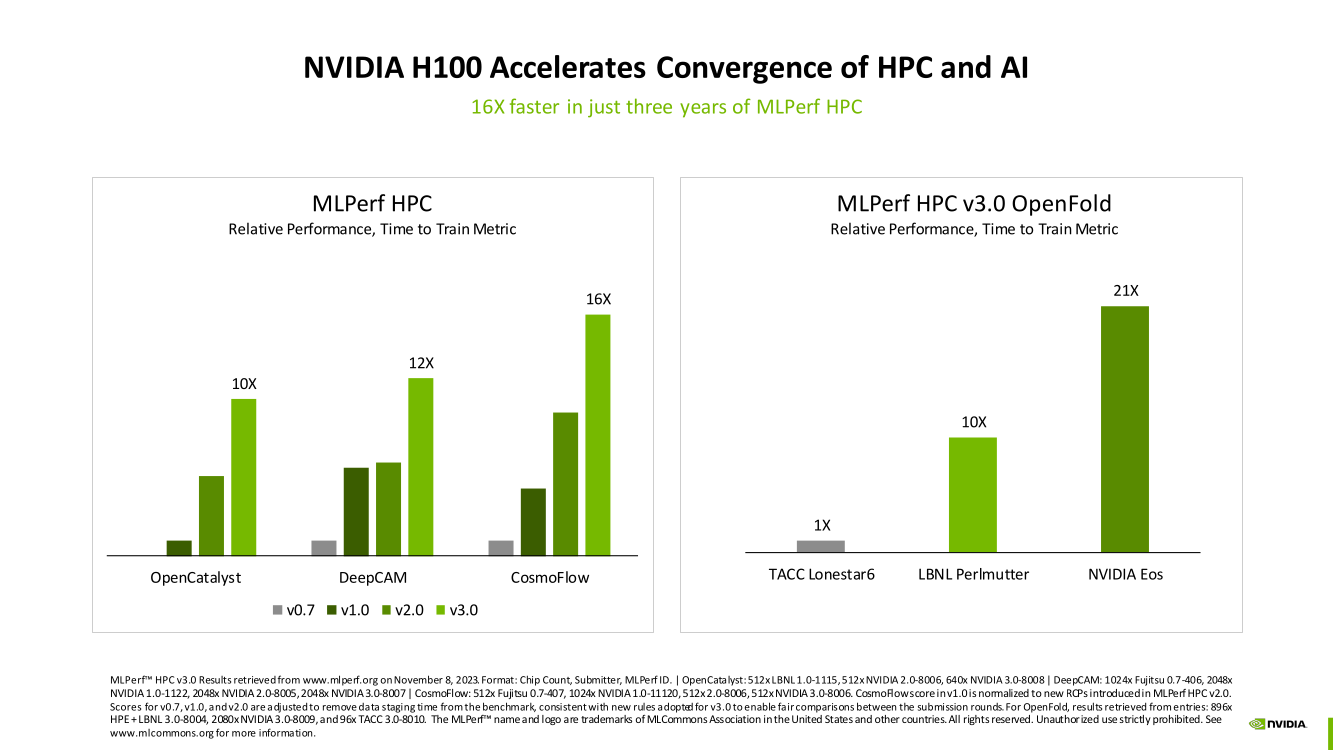
13.10.2023 [23:30], Алексей Степин
AMD EPYC Siena так же быстры, как Intel Xeon Sapphire Rapids, но более экономичныНе столь давно AMD придала семейству процессоров EPYC законченный вид, анонсировав вариант для периферийных вычислений под кодовым названием Siena. А на днях исследователи с сайта Phoronix опубликовали результаты сводного тестирования EPYC 8324P/PN, сравнив производительность новых процессоров с Intel Xeon Gold 6421N. Как известно, AMD EPYC Siena — упрощённая и удешевлённая версия Bergamo, использующая те же ядра Zen4c и оптимизированные по количеству транзисторов площади кристалла, но имеющая лишь шестиканальную подсистему памяти, а также не поддерживающая конфигурации с двумя процессорами.  Исследователи выбрали для сравнительного анализа 32-ядерные версии процессоров как AMD, так и Intel. Со стороны «красных» выступили EPYC 8324P (2,65–3,0 ГГц) и EPYC 8324PN (2,05–3,0 ГГц), а честь «синих» был призван отстаивать Xeon Gold 6421N (1,8–3,6 ГГц) поколения Sapphire Rapids. 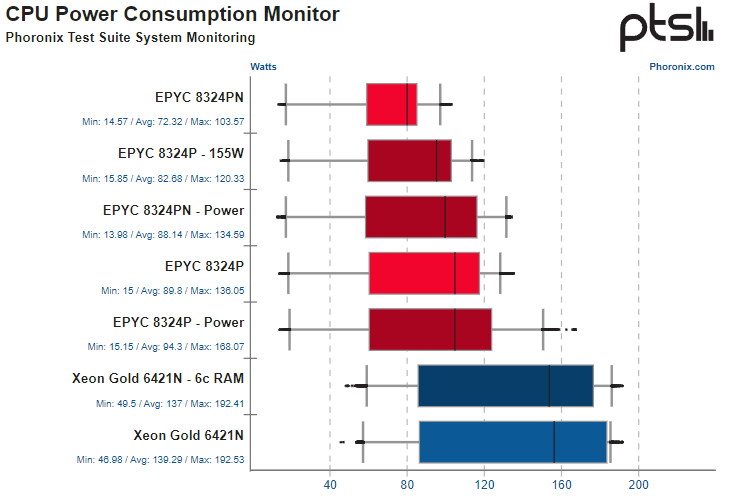 Тестирование показало весьма любопытные результаты. Хотя архитектура Intel Golden Cove явно сложнее AMD Zen 4c и предусматривает полноценную поддержку AVX-512 и AMX, в большинстве тестов это не стало преимуществом для решения Intel. Процессоры AMD практически везде показали сопоставимый уровень производительности при существенно меньшем уровне энергопотребления. 
Источник изображений здесь и далее: Phoronix С настройками теплопакета по умолчанию EPYC 8324P опередил Xeon Gold 6421N на 2,7 %, в режиме максимальной производительности отрыв составил 5 %, а при ограничении TDP до уровня 155 Вт отставание составило всего 2,5 %. Имеющий более скромную частотную формулу EPYC 8324PN отстал от Xeon на 11,8 %, но перевод процессора в режим производительности позволил вырваться вперед на 4,8 %. По части энергопотребления в среднем показатель решений AMD оставался на уровне 89 или 94 Вт (в зависимости от режима), в то время как для Intel Xeon аналогичный параметр составил 139 Вт. Таким образом, процессоры Siena доказали не только свою способность тягаться на равных с Sapphire Rapids, но и подтвердили свою ориентацию на сектор энергоэффективных, но достаточно производительных систем, например, платформ периферийных вычислений и RAN-оборудования. Впрочем, по части программной поддержки в последнем случае пока лидирует Intel.
15.09.2023 [11:29], Сергей Карасёв
СХД DDN AI400X2 показала быстродействие до 16,2 Гбайт/с в ИИ-тесте MLPerf Storage v0.5Компания DataDirect Networks (DDN), специализирующаяся на платформах хранения данных для НРС-систем, сообщила о том, что её массив AI400X2 NVMe показал высокие результаты в ИИ-бенчмарке MLPerf Storage v0.5 при выполнении задач сегментации изображений и обработки естественного языка. Платформа AI400X2 совмещает параллельную файловую систему с новым алгоритмом сжатием данных на стороне клиента. Утверждается, что по сравнению с альтернативными решениями достигается увеличение производительности до 10 раз. В частности, в тесте MLPerf Storage v0.5 при использовании одного узла AI400X2 продемонстрирована пропускная способность на уровне 16,2 Гбайт/с. Утверждается, что этого достаточно для обслуживания 40 высокопроизводительных ИИ-ускорителей. В многоузловой конфигурации скорость передачи данных достигает 61,6 Гбайт/с, что позволяет поддерживать работу до 160 ускорителей ИИ. 
Источник изображения: DDN DDN заявляет, что продемонстрированные в бенмарке MLPerf Storage v0.5 показатели говорят о повышении эффективности СХД приблизительно на 700 % в расчёте на каждый узел по сравнению с конкурирующими локальными решениями. Отмечается, что возможность поддерживать ИИ-нагрузки и большие языковые модели с высоким уровнем эффективности и масштабируемости, одновременно минимизируя энергопотребление и занимаемую площадь ЦОД, имеет решающее значение при внедрении передовых приложений и сервисов.
14.09.2023 [16:55], Сергей Карасёв
Конкуренцию NVIDIA H100 в MLPerf пока может составить только Intel Habana Gaudi2Корпорация Intel обнародовала результаты тестирования ускорителя Habana Gaudi2 в бенчмарке GPT-J (входит в MLPerf Inference v3.1), основанном на большой языковой модели (LLM) с 6 млрд параметров. Полученные данные говорят о том, что это изделие может стать альтернативой решению NVIDIA H100 на ИИ-рынке. В частности, в тесте GPT-J ускоритель H100 демонстрирует сравнительно небольшое преимущество в плане производительности по сравнению с Gaudi2 — ×1,09 в серверном режиме и ×1,28 в оффлайн-режиме. При этом Gaudi2 превосходит ускоритель NVIDIA A100 в 2,4 раза в режиме server и в 2 раза в оффлайн-режиме. Кроме того, решение Intel опережает H100 на моделях BridgeTower. Этот тест обучен на 4 млн изображений. Говорится, что точность Visual Question Answering (VQAv2) достигает 78,73 %. При масштабировании модель имеет ещё более высокую точность — 81,15 %, превосходя модели, обученные на гораздо более крупных наборах данных. 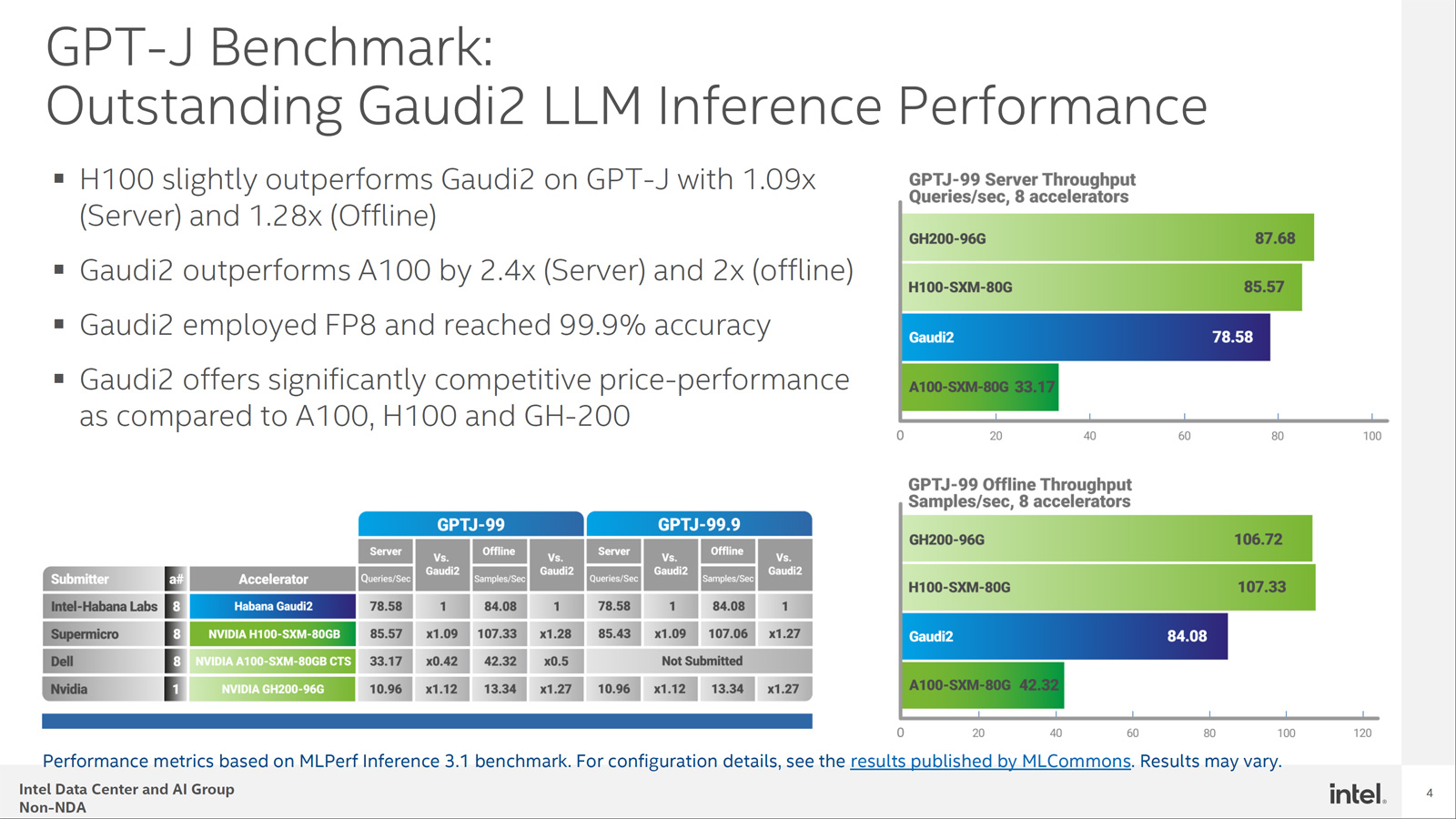
Источник изображений: Intel Тест GPT-J говорит о конкурентоспособности Habana Gaudi2. При онлайн-обработке запросов этот ускоритель достигает производительности 78,58 выборки в секунду, а в автономном режиме — 84,08 выборки в секунду. Для сравнения: у NVIDIA H100 эти показатели равны соответственно 85,57 и 107,33 выборки в секунду.  В дальнейшем Intel планирует повышать производительность и расширять охват моделей в тестах MLPerf посредством регулярных обновлений программного обеспечения. Но Intel всё равно остаётся в догоняющих — NVIDIA подготовила открытый и бесплатный инструмент TensorRT-LLM, который не только вдвое ускоряет исполнение LLM на H100, но и даёт некоторый прирост производительности и на старых ускорителях.
13.09.2023 [13:45], Сергей Карасёв
«Тренировочный» суперкомпьютер Polaris показал высокое быстродействие СХД в тестах MLPerf Storage AIАргоннская национальная лаборатория Министерства энергетики США сообщила о том, что вычислительный комплекс Polaris, предназначенный для решения ИИ-задач, устанавливает высокие стандарты производительности СХД в бенчмарке MLPerf Storage AI. Суперкомпьютер Polaris, разработанный в сотрудничестве с Hewlett Packard Enterprise (HPE), объединяет 560 узлов, соединенных между собой посредством интерконнекта HPE Slingshot. Каждый узел содержит четыре ускорителя NVIDIA A100 и два накопителя NVMe вместимостью 1,6 Тбайт каждый. Задействована платформа хранения HPE ClusterStor E1000, которая предоставляет 100 Пбайт полезной ёмкости на 8480 накопителях. Заявленная скорость передачи данных достигает 659 Гбайт/с. Вычислительный комплекс смонтирован на площадке Argonne Leadership Computing Facility (ALCF). Пиковая производительность составляет около 44 Пфлопс. 
Источник изображения: ALCF Быстродействие Lustre-хранилища оценивалась с использованием двух рабочих нагрузок MLPerf Storage AI — UNet3D и Bert. Данные размещались как в основном хранилище, так и на NVMe-накопителях в составе узлов суперкомпьютера, что позволило эмулировать различные рабочие нагрузки ИИ. В тесте UNet3D с интенсивным вводом-выводом суперкомпьютер достиг пиковой пропускной способности в 200 Гбайт/с для основного хранилища HPE ClusterStor E1000. В случае NVMe-накопителей продемонстрирован результат на уровне 800 Гбайт/с. Менее интенсивная рабочая нагрузка Bert также показала высокие результаты, что говорит о возможности эффективного выполнения современных ИИ-задач.
11.09.2023 [19:00], Сергей Карасёв
Много памяти, быстрая шина и правильное питание: гибридный суперчип GH200 Grace Hopper обогнал H100 в ИИ-бенчмарке MLPerf InferenceКомпания NVIDIA сообщила о том, что суперчип NVIDIA GH200 Grace Hopper и ускоритель H100 лидируют во всех тестах производительности ЦОД в бенчмарке MLPerf Inference v3.1 для генеративного ИИ, который включает инференс-задачи в области компьютерного зрения, распознавания речи, обработки медицинских изображений, а также работу с большими языковыми моделями (LLM). Ранее NVIDIA уже объявляла о рекордах H100 в новом бенчмарке MLPerf. Теперь говорится, что суперчип GH200 Grace Hopper впервые прошёл все тесты MLPerf. Вместе с тем системы, оснащенные восемью ускорителями H100, обеспечили самую высокую пропускную способность в каждом тесте MLPerf Inference. Решения NVIDIA прошли обновленное тестирование в области рекомендательных систем (DLRM-DCNv2), а также выполнили первый эталонный тест GPT-J — LLM с 6 млрд параметров. Примечательно, что GH200 оказался до 17 % быстрее H100, хотя чип самого ускорителя в обоих продуктах один и тот же. NVIDIA объясняет это несколько факторами. Во-первых, у GH200 больше набортной памяти — 96 Гбайт против 80 Гбайт. Во-вторых, ПСП составляет 4 Тбайт/с, а сам чип является гибридным, так что для передачи данных между LPDDR5x и HBM3 не используется PCIe. В-третьих, GH200 при низкой нагрузке на CPU умеет отдавать часть энергии ускорителю, оставаясь в заданных рамках энергопотребления. Правда, в тестах GH200 работал на полную мощность, т.е. с TDP на уровне 1 кВт (UPD: NVIDIA уточнила, что реально потребление GH200 под полной нагрузкой составляет 750–800 Вт). 
Источник изображений: NVIDIA Отдельно внимание уделено оптимизации ПО — на днях NVIDIA анонсировала открый программный инструмент TensorRT-LLM, предназначенный для ускорения исполнения LLM на продуках NVIDIA. Этот софт даёт возможность вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B (входит в состав MLPerf Inference v3.1). NVIDIA отмечает, что улучшение ПО позволяет клиентам с течением времени повышать производительность ИИ-систем без дополнительных затрат. 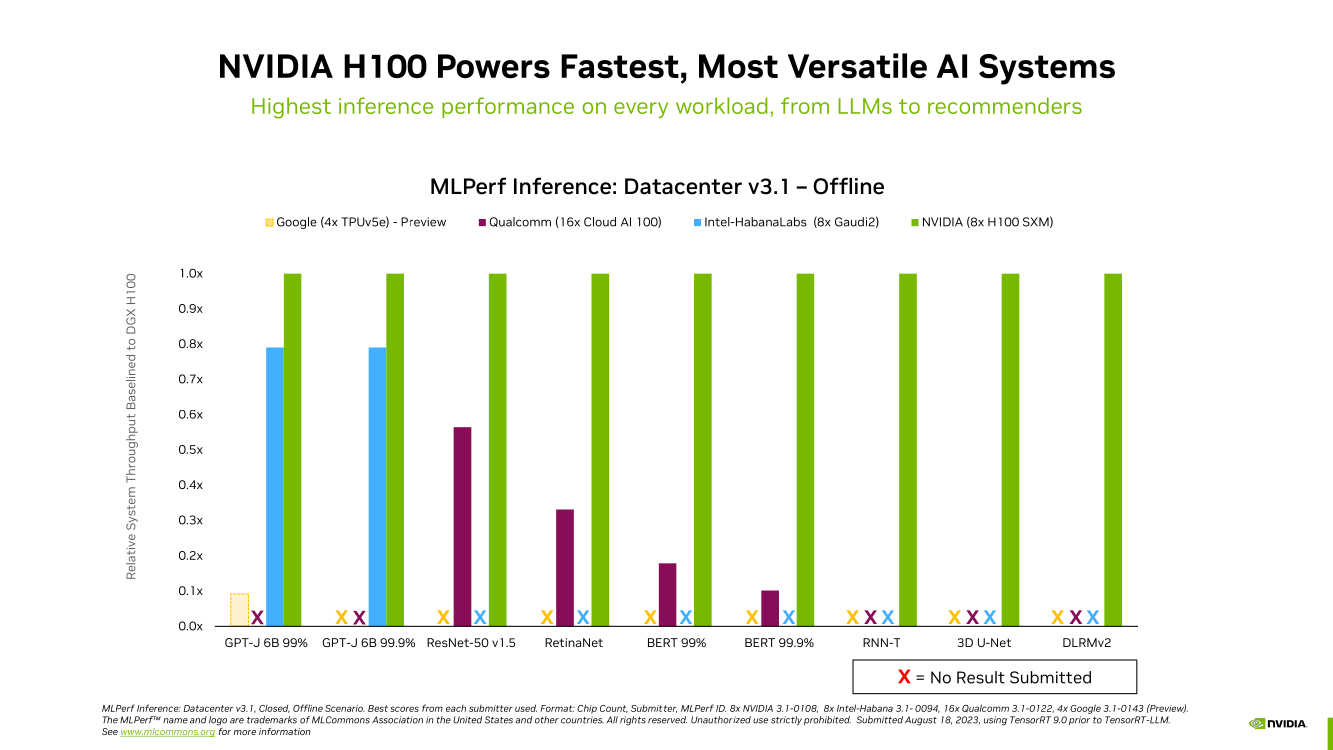 Также отмечается, что модули NVIDIA Jetson Orin благодаря новому ПО показали прирост производительности до 84 % на задачах обнаружения объектов по сравнению с предыдущим раундом тестирования MLPerf. Ускорение произошло благодаря задействованию Programmable Vision Accelerator (PVA), отдельного движка для обработки изображений и алгоритмов компьютерного зрения работающего независимо от CPU и GPU.  Сообщается также, что ускоритель NVIDIA L4 в последних тестах MLPerf выполнил весь спектр рабочих нагрузок, показав отличную производительность. Так, в составе адаптера с энергопотреблением 72 Вт этот ускоритель демонстрирует в шесть раз более высокое быстродействие, нежели CPU, у которых показатель TDP почти в пять раз больше. Кроме того, NVIDIA применила новую технологию сжатия модели, что позволило продемонстрировать повышение производительности в 4,4 раза при использовании BERT LLM на ускорителе L4. Ожидается, что этот метод найдёт применение во всех рабочих нагрузках ИИ. В число партнёров при проведении тестирования MLPerf вошли поставщики облачных услуг Microsoft Azure и Oracle Cloud Infrastructure, а также ASUS, Connect Tech, Dell Technologies, Fujitsu, Gigabyte, Hewlett Packard Enterprise, Lenovo, QCT и Supermicro. В целом, MLPerf поддерживается более чем 70 компаниями и организациями, включая Alibaba, Arm, Cisco, Google, Гарвардский университет, Intel, Meta✴, Microsoft и Университет Торонто.
06.09.2023 [19:20], Алексей Степин
Первые бенчмарки NVIDIA Grace Superchip: не хуже EPYC и быстрее Xeon, а по энергоэффективности намного лучше AMD и Intel144-ядерный Arm-процессор NVIDIA Grace Superchip был продемонстрирован публике ещё весной этого года на конференции GTC 2023. Несмотря на то, что технические характеристики этого решения известны уже давно, первые результаты тестирования компания решила опубликовать только сейчас, вероятно, с подачи Arm, которая готовится к IPO. Производство Grace Superchip уже запущено, а появления ОЕМ-систем на его базе следует ожидать уже во II квартале 2024 года. Напомним, Grace Superchip представляет собой сборку из двух чипов Grace, каждый из которых включает 72 ядра Arm Neoverse V2 (Arm v9) с поддержкой векторных расширений SVE2. Процессор умеет работать с форматами BF16/INT8 и развивает до 7,1 Тфлопс в режиме FP64. С точки зрения системы сборка представляется единым 144-ядерным процессором. 
Сборка Grace Superchip. Источник изображения: NVIDIA В качестве соперников Grace Superchip были избраны платформы на базе AMD EPYC Genoa 9654 (2 процессора, 192 ядра) и Intel Xeon Sapphire Rapids 8480+ (также 2 процессора, 112 ядер). Итог довольно любопытен: несмотря на заметное отставание в количестве ядер от системы AMD, решение NVIDIA сумело достичь паритета в подавляющем большинстве тестов, а в сценарии аналитики графов даже продемонстрировало 1,4-кратное превосходство. 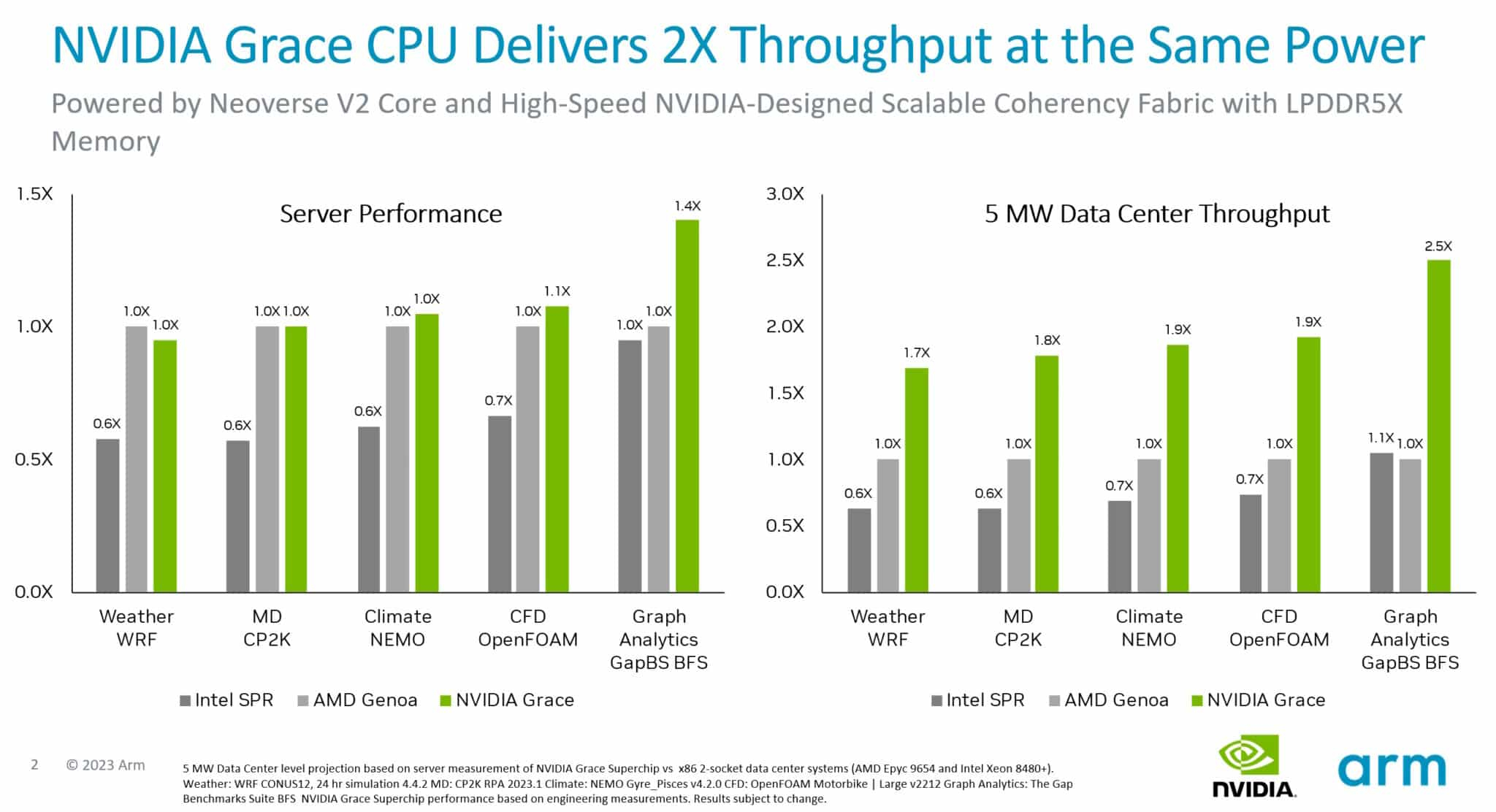
Источник изображения: NVIDIA Возможно, тут новинке помогла мощная подсистема памяти: Grace Superchip оснащается набором чипов LPDDR5x объёмом 960 Гбайт с совокупной ПСП 1 Тбайт/с. Но куда интереснее результаты, приведённые к уровню энергопотребления — сборка Grace Superchip буквально разгромила решения на базе x86-64. Выигрыш в этом случае составил от 70 % до 150 %! Полученные результаты достаточно неплохо согласуются с официальными данными об энергопотреблении систем-участниц тестирования — это 720 и 700 Вт у решений AMD и Intel соответственно против 500 Вт у NVIDIA Grace Superchip. Если опубликованные сегодня результаты будут подтверждены независимыми тестами, можно говорить о появлении у серверных решений x86 серьёзнейшего конкурента. Впрочем, ценовая политика NVIDIA в отношении Grace Superchip пока остаётся тайной. |
|